
Chapter 9. Parsing XML for Legacy Services
Sometimes an application must integrate with legacy services whose design is out of your control. It is common for these services to use XML formats such as SOAP, XML-RPC, or RESTful XML. This chapter covers some of the tools for parsing and working with XML-based services.
XML
Many older (and some newer) services use XML as their serialization format. While JSON is quickly becoming the preferred method of serialization due to its ease of use and simplicity, client libraries must occasionally work with XML. Libraries for parsing XML in Ruby include REXML, Nokogiri, Hpricot, LibXml Ruby, and SimpleXML.
The focus of this section is on parsing responses using REXML and Nokogiri. The reason for the choice of these two libraries is simple. REXML is included with Ruby, and Nokogiri currently has the best performance and is actively being developed and supported. While the other XML libraries are usable, for libraries outside the standard REXML, Nokogiri is currently the leading option.
The services written so far in this book have been JSON based, so this section explores an example outside the services created in previous chapters. The Amazon EC2 Query API provides a real-world instance where parsing and requesting XML-based services is useful. The next sections look at methods for parsing XML for one of the EC2 requests.
Amazon describes in the EC2 API documentation some common XML data types. These data types include multiple elements, which can be found in the API reference (http://docs.amazonwebservices.com/AWSEC2/latest/APIReference/). The examples for working with XML step through parsing the call to “describe instances.” This response gives information about virtual computer instances running in Amazon’s Elastic Compute Cloud:



The entire response is wrapped in the DescribeInstanceResponse XML element. Within that element is a reservationSet that contains the information for instance reservations. Each instance reservation is contained within item elements. These elements map together instances and their security groups.
The client library should parse out the reservation sets, each of which contains a reservation ID, an owner ID, a security group, and the collection of instances. Each of the instances contains an instance ID, an image ID, an instance state, a private DNS name, a DNS name, a key name, an instance type, and an availability zone. The parsing code should be able to pull out each of these elements.
The following examples don’t bother to parse every single element from the XML. In fact, to maintain a clear and usable API, the client should extract and expose only the data that is necessary.
REXML
Ruby versions 1.8 and newer include REXML (http://www.germane-software.com/software/rexml/) as part of the standard library. It is a fully featured XML parsing library written in pure Ruby, with full support for XPath. XPath is a language for addressing elements within an XML document (see http://www.w3.org/TR/xpath). REXML also includes a simple API for traversing elements in a document. This example shows use of the basic REXML API.
The code for parsing the EC2 DescribeInstancesResponse can be broken down into three classes: one class for the entire response, another class for a reservation set, and another class to store information about specific EC2 instances. The following code example shows the class for parsing the response to a describe instances request:

The DescribeInstancesResponse class acts as the wrapper for the entire response from EC2. The data that this class contains can be determined quickly by looking at the top of the class and noticing the attribute reader for reservation_sets. Other than the initialization, this class contains only one method: a class method for parsing an XML string into an instance of this class.
The parse method first creates a REXML document. It then sets up the reservation sets by looping through the items in the reservationSet element. Each item element is passed to a new class called ReservationSet, which is covered in a moment. Once the reservation sets are built, a new instance of the DescribeInstancesResponse class is returned from the parse method.
Having a separate class for the reservation set makes the code simpler to read and keep organized. Generally, it’s a good idea to create a class for each logical grouping of data that you parse. This is usually a collection of XML elements that are the children of a common ancestor. The class for wrapping reservation sets continues the building of objects that represent the response, shown here:

As with the class for parsing the describe instances response, this class shows the data that is exposed through the attribute readers and the initialization method. The security group, the reservation ID, and the instances that represent the set are accessible through this class.
The from_xml method takes an XML node. The use of the name from_xml rather than parse is intentional, as this method expects an already parsed XML node object. The method loops through the item elements in the instancesSet within this node. Each of those nodes is passed to the Instance.from_xml method to create an instance of Instance.
Finally, a new instance of ReservationSet is created. The constructor is passed the instances previously built and the extracted text from the appropriate elements for the security group and the reservation ID.
The class for each instance is the last part of code necessary to parse all of the elements required from the describe instances response:

The Instance class holds most of the important data for the call to describe instances. The attributes of the instance are all contained within this class. The attribute readers and constructor continue the examples for the previous two classes, showing clearly what data the Instance class holds.
The from_xml method takes an XML node. It calls the constructor and pulls out the required data from the elements within the passed-in node. One thing to notice about all three of these classes is that the XML parsing logic is all contained within a single public method. This makes it easier to get an immediate sense for where parsing occurs.
The constructors of all three classes expect attribute hashes. This is useful when creating test version of these objects later. It is much easier to pass in an attribute hash than sample XML.
Nokogiri
Nokogiri is an HTML and XML parser backed by the libxml and libxslt C libraries. It is compatible with versions of Ruby including 1.8, 1.9, JRuby, and Rubinius. Because of its use of underlying C libraries, Nokogiri is very fast. The results of benchmarks have varied, but Nokogiri has been shown to be consistently faster than other parsers, particularly REXML. Hpricot and LibXml-Ruby have parsing speeds that are either on par, a little faster, or sometimes slower. Your mileage may vary with each benchmark setup.
However, speed isn’t the only reason to use Nokogiri, as it also includes support for powerful CSS3 selectors. Selectors are patterns that match against elements in an HTML or XML document tree. In addition to CSS selectors, Nokogiri has built-in support for XPath and a few other methods for traversing the document tree.
To install Nokogiri, you must have the libxml2, libxml2-dev, libxslt, and libxslt-dev packages installed. Once these prerequisites have been set up, installation is as simple as the following command:
gem install nokogiri
The following example using Nokogiri looks very similar to the REXML example:
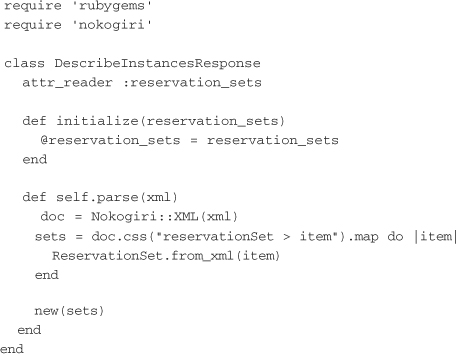
Because all parsing logic is contained within a single method in each class, those methods are the only ones that must be modified. The object interface looks identical whether you use Nokogiri or REXML. The start of the DescribeInstansesResponse class is the same as for the REXML example. The attribute readers and constructor show what data this class stores. The parse method contains the real changes.
First, there is a call to create a Nokogiri document from the XML string. The reservation sets are then extracted from the document. This is an example of a CSS selector. In this case, the selector is looking for item elements that are direct children of the reservationSet element. The selector returns a NodeSet that can be iterated through. This makes for a slightly cleaner notation because of the use of map instead of each, as in the REXML example. Each of the nodes is passed to the from_xml method on the reservation set:

The ReservationSet class keeps the same structure as in the previous example. The from_xml method contains the updates to this class.
First, the Instance objects are created by looping through the XML nodes with a CSS selector. This selector looks for nodes named item that are direct children of the instancesSet element. These nodes are then passed to the Instance constructor. When the instances have been built, the security group and reservation ID are passed out and handed to the reservation set constructor:

The Instance class is no different from the three others. The attribute readers and constructor look the same as before, while the changes in parsing are in the from_xml method.
The XML parsing logic consists of single calls with various CSS selectors. Each of the attributes can be parsed with this simple logic. With regard to parsing the individual attributes, the CSS selectors don’t provide any particular advantage or disadvantage over the XPath-based selectors.
When you use Nokogiri for parsing, the choice of whether to use XPath or CSS is mainly one of familiarity. While the XPath selectors have been shown to be slightly faster than CSS, both are still faster than using REXML. You should use whatever you’re most comfortable with.
SOAP
Simple Object Access Protocol (SOAP) is a specification for implementing web services using XML. Full coverage of SOAP is beyond the scope of this book. However, this section goes over a few basics and shows examples for working with SOAP-based services. There are multiple libraries for working with SOAP in Ruby. The most popular libraries are soap4r (http://dev.ctor.org/soap4r), Savon (http://github.com/rubiii/savon), and Handsoap (http://github.com/unwire/handsoap). The examples in this chapter focus on using Savon because of its popularity and ease of use. soap4r is the oldest of the bunch, but it is slower and difficult to use; Handsoap is a framework for writing SOAP clients.
Exploring Web Services with a WSDL File
SOAP services expose their interface through a Web Services Description Language (WSDL) file. This is an XML file that describes the interface for a web service. The easiest method for exploring the interface of a SOAP service is to take a look at its WSDL file. Amazon’s Product Advertising API (http://docs.amazonwebservices.com/AWSECommerceService/latest/DG/) is a useful real-world example. The WSDL file, found at http://webservices.amazon.com/AWSECommerceService/AWSECommerceService.wsdl, describes the API methods and the arguments they take.
Savon includes methods for loading a WSDL file and looking at the output:

In this example, the client is pointed to the API WSDL file. Then the client’s wsdl object is output, and the SOAP endpoint and namespace URI are output. (These two will be useful later, when you create a client that doesn’t need to use the WSDL file.) Finally, the actions are output.
The Savon WSDL class doesn’t expose the arguments that the operations take or the results that the API calls return. For this information, the best resource is either the API documentation or the WSDL file itself. It is a fairly readable XML file. For example, the following snippet shows the XML for making a search request for items in the Amazon store:

In the Amazon API, each operation consists of the request and response complex types. This example shows only a subset of the possible arguments for the ItemSearch operation. Each of the elements has a type associated with it. The response contains many nested and complex types. Here is a snippet of the associated XML:


At the top is ItemSearchResponse. This is the basic object that contains the results. Below ItemSearchResponse is the Items object. This represents a collection of items and includes the number of results, number of pages, and 0 or more occurrences of the Item object. Next is a part of the Item object. It contains some of the metadata about the returned results, such as their sales rank, a URI for their web page, images, and the item attributes.
Making Requests
After exploring the WSDL file of a SOAP service, the next thing to do is make requests against the API. The easiest way to get going is by loading up the WSDL file and making requests from there.
The following example makes a request to the Amazon API to complete a search for products:


This example contains a file for making requests to the Amazon Product Advertising API. The class takes the Amazon access key ID and the shared secret key. The timestamp_and_signature method does the HMAC signing of the operation. The important parts of the SOAP request are all contained inside the search method.
The operation is the API method that will get called, namely ItemSearch. That is passed to the method to get a timestamp and an HMAC signature. The request is then made with the @client.item_search block. Within that block, the body of the SOAP request must be set. Amazon requires the access key, timestamp, and signature. The SearchIndex and Keywords options are arguments made to the ItemSearch method. The Savon::Result object is returned from that method.
While the WSDL method of using the API is slightly easier, it isn’t suitable for production use. This is because it actually has to request the WSDL file and parse options. A more efficient method is to point the client directly to the SOAP endpoint. Remember that this was an output from the first WSDL code example. The following changes make the same SOAP request without using the WSDL file:

This example shows two modifications from the previous WSDL example. First, the Savon::Client initialization points directly to the SOAP endpoint. Second, the search method must provide the client with a little more information. The method call on the client object is ItemSearch! instead of the WSDL example item_search. The reason is that when the WSDL file is used, Savon knows how to modify that method call into its SOAP equivalent. Without the WSDL file, the method call must have exactly the same casing as in SOAP.
There are two additions inside the code block passed to the ItemSearch call. First, the namespace must be set on the SOAP object. This was pulled earlier, using the WSDL file. Second, the input must be set to the ItemSearch operation. Now the search method can make calls without downloading and parsing the WSDL file.
Sometimes constructing requests without the WSDL file can be a little tricky. A useful troubleshooting method is to write a WSDL-based version of the request and keep the Savon logging on. Both of the previous examples disable logging by using the line Savon::Request.log = false. The debug output shows the XML that is being sent in the request. You can run the WSDL version and the regular version and compare the XML. This will help you determine which additional parameters must be set on the SOAP object.
Conclusion
Parsing service responses can range from an easy task to a difficult task, depending on how much data is returned. While there are multiple options for parsing XML in Ruby, Nokogiri is currently the leading option in terms of speed and ease of use. When writing classes to parse service responses, there are a some key points to follow in designing classes:
• Keep parsing logic separate from object logic, preferably within a single method.
• Use multiple classes for data. Don’t try to put everything into a single class.
• Make object constructors that take standard Ruby objects and not unparsed strings.
Following these guidelines when designing classes to wrap service responses results it more readable and maintainable code. These guidelines also apply to writing classes that make SOAP calls. Parsing, request, and SOAP logic should be handled within the class. Data objects should be returned from the class that show through a clear API what data a response contains.