
As long as I held the Divine Spear, I had to accept debugging as my primary duty. | ||
| --Tatsuya Hamazaki, .hack//AI Buster 2 | ||
In Chapter 4, we looked at the operating system's role as a development tool for applications that required parallel programming. We provided a brief overview of the part that the operating system plays in process management and thread management. We introduced the reader to the notion of operating system Application Program Interfaces (APIs) and System Program Interfaces (SPIs), and in particular we introduced the POSIX API. In this chapter we are going to take a closer look at:
Where the process fits in with C++ programming and multicore computers
The POSIX API for process management
Process scheduling and priorities
Building C++ interface components that can be used to simplify part of the POSIX API for process management
Basically, a program can be divided into processes and/or threads in order to achieve concurrency and take advantage of multicore processors. In this chapter, we cover how the operating system identifies processes and how an application can utilize multiple processes.
Keep in mind that the name multicore is a popular substitution for single chip multiprocessor or CMP. Multiprocessors are computers that have more than two or more CPUs or processors. Although multiprocessor computers have been around for some time now, the wide availability and low cost of the CMP has brought multiprocessor capabilities within the reach of virtually all software developers. This raises a series of questions: How do single applications take advantage of CMPs? How do single user versus multiple user applications take advantage of CMPs? Using C++ how do you take advantage of the operating system's multiprocessing and multiprogramming capabilities? Once you have a software design that includes a requirement for some tasks to execute concurrently, how do you map those tasks to the multiple processors available in your multicore computers?
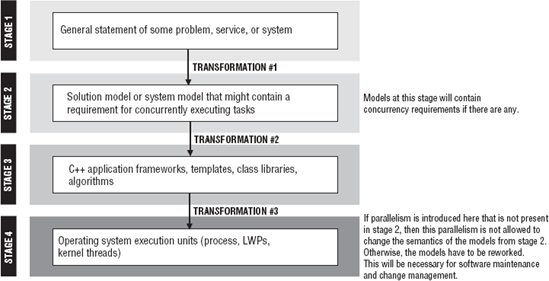
Recall from Chapter 4 that the operating system schedules execution units that it can understand. If your software design consists of some tasks that can be executed in parallel, you will have to find a way to relate those tasks to execution units the operating system can understand. Association of your tasks with operating system execution units is part of a four-stage process involving three transformations.
Each transformation in Figure 5-1 changes the view of the model, but the meaning of the model should remain intact. That is, the implementation of the application frameworks, class libraries, and templates as processes and threads should not change the meaning or semantics of what those components are doing. The execution units in stage four are what the operating system deals with directly. The execution units shown in stage four of Figure 5-1 are the only things that can be assigned directly to the cores. From the operating system's viewpoint your application is a collection of one or more processes. Concurrency in a C++ application is ultimately accomplished by factoring your program into either multiple processes or multiple threads. While there are variations on how the logic for a C++ program can be organized (for example, within objects, predicates, functions, or generic templates), the options for parallelization (with the exception of instruction level) are accounted for through the use of multiple processes and threads.
This chapter focuses on the notion of a process and how C++ applications and programs can be divided into multiple processes using the POSIX API process management services.
A process is a unit of work created by the operating system. It is important to note that processes and programs are not necessarily equivalent. A program may consist of multiple tasks, and each task can be associated with one or more processes. Processes are artifacts of the operating system, and programs are artifacts of the developer. Current operating systems are capable of managing hundreds even thousands of concurrently loaded processes. In order for a unit of work to be called a process, it must have an address space assigned to it by the operating system. It must have a process id. It must have a state and an entry in the process table. According to the POSIX standard, it must have one or more flows of controls executing within that address space and the required system resources for those flows of control. A process has a set of executing instructions that resides in the address space of that process. Space is allocated for the instructions, any data that belongs to the process, and stacks for functions calls and local variables. One of the important differences between a process and a thread is the fact that each process has its own address space, whereas threads share the address space of the processes that created them. A program can be broken down into one or more processes.
When you are mapping C++ tasks to execution units that the operating system can understand, threads turn out to be easier to program. This is because threads share the same address space. This makes communication and synchronization between threads much easier. It takes the operating system less work to create a thread or to terminate a thread than it takes for processes. In general, you can create more threads within the context of a single computer than processes. The starting and stopping of threads is typically faster than processes.
So why use processes at all? First, processes have their own address space. This is important because separate address spaces provide a certain amount security and isolation from rogue or poorly designed processes. Second, the number of open files that threads may use is limited to how many open files a single process can have. Dividing your C++ application up into multiple processes instead of or in conjunction with multithreading provides access to more open file resources. For multiuser applications, you want each user's process to be isolated. If one user's process fails, the other users can continue to perform work. If you use some threading approach for multiuser applications, a single errant thread can disrupt all the users. Operating system resources are assigned primarily to processes and then shared by threads. So, in general, threads are limited to the number of resources that a single process can have. Thus, when isolation security, address space isolation, and maximum number of resources that concurrently executing tasks may have are major concerns, it is better to use processes than threads. Communication between processes and startup time are the primary tradeoffs.
The functions listed in Table 5-1 are declared in spawn.h. This header contains the POSIX functions used to spawn and manage processes.
Table 5.1. Table 5-1
POSIX Functions | |
|---|---|
posix_spawn() posix_spawnp() | |
posix_spawnattr_init() | |
posix_spawnattr_destroy() | |
Setting and retrieving attribute values |
posix_spawnattr_setsigdefault() posix_spawnattr_getsigdefault() posix_spawnattr_setsigmask() posix_spawnattr_getsigmask() posix_spawnattr_setflags() posix_spawnattr_getflags() posix_spawnattr_setpgroup() posix_spawnattr_getpgroup() |
Process scheduling |
posix_spawnattr_setschedparam() posix_spawnattr_setschedpolicy() posix_spawnattr_getschedparam() posix_spawnattr_getschedpolicy() sched_setscheduler() sched_setparm() |
posix_spawn_file_actions_addclose() posix_spawn_file_actions_adddup2() posix_spawn_file_actions_addopen() posix_spawn_file_actions_destroy() posix_spawn_file_actions_init() |
Similarly to the fork-exec() and system() methods of process creation, the posix_spawn() functions create new child processes from specified process images. But the posix_spawn() functions create child processes with more fine-grained control during creation. While the POSIX API also supports the fork-exec() class of functions, we focus on the posix_spawn functions for process creation to achieve greater cross-platform compatibility. Some platforms may have trouble implementing fork(), so the posix_spawn() functions can be used as substitution. These functions control the attributes that the child process inherits from the parent process, including:
They also control whether signals ignored by the parent are ignored by the child or reset to some default action. Controlling file descriptors allow the child process independent access to the data stream opened by the parent. Being able to set the child's process group id affects how the child's job control relates to that of the parent. The child's scheduling policy can be set to be different from the scheduling policy of the parent.
Synopsis
#include <spawn.h>
int posix_spawn(pid_t *restrict pid, const char *restrict path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict],
char *const envp[restrict]);
int posix_spawnp(pid_t *restrict pid, const char *restrict file,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict],
char *const envp[restrict]);The difference between these two functions is that posix_spawn() has a path parameter and posix_spawnp() has a file parameter. The path parameter in the posix_spawn() function is the absolute or relative pathname to the executable program file. file in posix_spawnp() is the name of the executable program. If the parameter contains a slash, then file is used as a pathname. If not, the path to the executable is determined by PATH environment variable.
The file_actions parameter is a pointer to a posix_spawn_file_actions_t structure:
struct posix_spawn_file_actions_t{
{
int __allocated;
int __used;
struct __spawn_action *actions;
int __pad[16];
};posix_spawn_file_actions_t is a data structure that contains information about the actions to be performed in the new process with respect to file descriptors. file_actions is used to modify the parent's set of open file descriptors to a set file descriptors for the spawned child process. This structure can contain several file action operations to be performed in the sequence in which they were added to the spawn file action object. These file action operations are performed on the open file descriptors of the parent process. These operations can duplicate, duplicate and reset, add, delete, or close a specified file descriptor on behalf of the child process even before it's spawned. If file_actions is a null pointer, then the file descriptors opened by the parent process remain open for the child process without any modifications. Table 5-2 lists the functions used to add file actions to the posix_spawn_file_actions object.
Table 5.2. Table 5-2
Descriptions | |
|---|---|
int posix_spawn_file_actions_addclose (posix_spawn_file_actions_t *file_actions, int fildes); | Adds a |
int posix_spawn_file_actions_addopen (posix_spawn_file_actions_t *file_actions, int fildes, const char *restrict path, int oflag, mode_t mode); | Adds an |
int posix_spawn_file_actions_adddup2 (posix_spawn_file_actions_t *file_actions, int fildes, int newfildes); | Adds a |
int posix_spawn_file_actions_destroy (posix_spawn_file_actions_t *file_actions); | Destroys the specified |
int posix_spawn_file_actions_init (posix_spawn_file_actions_t *file_actions); | Initializes the specified |
The attrp parameter points to a posix_spawnattr_t structure:
struct posix_spawnattr_t
{
short int __flags;
pid_t __pgrp;
sigset_t __sd;
sigset_t __ss;
struct sched_param __sp;
int __policy;
int __pad[16];
}This structure contains information about the scheduling policy, process group, signals, and flags for the new process. The description of individual attributes is as follows:
__Flags:Used to indicate which process attributes are to be modified in the spawned process. They are bitwise-inclusive OR of 0 or more of the following:POSIX_SPAWN_RESETIDSPOSIX_SPAWN_SETPGROUPPOSIX_SPAWN_SETSIGDEFPOSIX_SPAWN_SETSIGMASKPOSIX_SPAWN_SETSCHEDPARAMPOSIX_SPAWN_SETSCHEDULER
__pgrp:The id of the process group to be joined by the new process.__sd:Represents the set of signals to be forced to use default signal handling by the new process.__ss:Represents the signal mask to be used by the new process.__sp:Represents the scheduling parameter to be assigned to the new process.__policy:Represents the scheduling policy to be used by the new process.
Table 5-3 lists the functions used to set and retrieve the individual attributes contained in the posix_spawnattr_t structure.
Table 5.3. Table 5-3
Spawn Process Attributes Functions | Descriptions |
|---|---|
int posix_spawnattr_getflags (const posix_spawnattr_t *restrict attr, short *restrict flags); | Returns the value of the |
int posix_spawnattr_setflags (posix_spawnattr_t *attr, short flags); | Sets the value of the |
int posix_spawnattr_getpgroup (const posix_spawnattr_t *restrict attr, pid_t *restrict pgroup); | Returns the value of the |
int posix_spawnattr_setpgroup (posix_spawnattr_t *attr, pid_t pgroup); | Sets the value of the |
int posix_spawnattr_getschedparam (const posix_spawnattr_t *restrict attr, struct sched_param *restrict schedparam); | Returns the value of the |
int posix_spawnattr_setschedparam (posix_spawnattr_t *attr, const struct sched_param *restrict schedparam); | Sets the value of the |
int posix_spawnattr_getpschedpolicy (const posix_spawnattr_t *restrict attr, int *restrict schedpolicy); | Returns the value of the |
int posix_spawnattr_setpschedpolicy (posix_spawnattr_t *attr, int schedpolicy); | Sets the value of the |
int posix_spawnattr_getsigdefault (const posix_spawnattr_t *restrict attr, sigset_t *restrict sigdefault); | Returns the value of the |
int posix_spawnattr_setsigdefault (posix_spawnattr_t *attr, const sigset_t *restrict sigdefault); | Sets the value of the |
int posix_spawnattr_getsigmask (const posix_spawnattr_t *restrict attr, sigset_t *restrict sigmask); | Returns the value of the |
int posix_spawnattr_setsigmask (posix_spawnattr_t *restrict attr, const sigset_t *restrict sigmask); | Sets the value of the |
int posix_spawnattr_destroy (posix_spawnattr_t *attr); | Destroys the specified |
int posix_spawnattr_init (posix_spawnattr_t *attr); | Initializes the specified |
Example 5-1 shows how the posix_spawn() function can be used to create a process.
Example 5.1. Example 5-1
// Example 5-1 Spawns a process, using the posix_spawn()
// function that calls the ps utility.
#include <spawn.h>
#include <stdio.h>
#include <errno.h>
#include <iostream>
{
//...
posix_spawnattr_t X;
posix_spawn_file_actions_t Y;
pid_t Pid;
char * argv[] = {"/bin/ps","-lf",NULL};
char * envp[] = {"PROCESSES=2"};
posix_spawnattr_init(&X);
posix_spawn_file_actions_init(&Y);
posix_spawn(&Pid,"/bin/ps",&Y,&X,argv,envp);
perror("posix_spawn");
cout << "spawned PID: " << Pid << endl;
//...
return(0);
}In Example 5-1, posix_spawnattr_t and posix_spawn_file_actions_t objects are initialized. posix_spawn() is called with the arguments PID; path; Y; X; argv, which contains the command as the first element and the argument as the second; and envp, the environment list. If posix_spawn() is successful, then the value stored in Pid will be the PID of the spawned process. perror displayed:
posix_spawn: Success
and the Pid is sent to output. The spawned process, in this case, executes:
/bin/ps -lf
These functions return the process id of the child process to the parent process in the pid parameter and return 0 as the return value. If the function is unsuccessful, no child process is created; thus, no pid is returned, and an error value is returned as the return value of the function. Errors can occur on three levels when using the spawn functions.
An error can occur if the
file_actionsorattrobjects are invalid. If this occurs after the function has successfully returned (the child process was spawned), then the child process may have an exit status of 127.If the spawn attribute functions cause an error, then the error produced for that particular function (listed in Tables 5-2 and 5-3) is returned. If the spawn function has already successfully returned, then the child process may have an exit status of 127.
Errors can also occur when you are attempting to spawn the child process. These errors would be the same errors produced by
fork()orexec()functions. If they occur, they will be the return values for the spawn functions.
If the child process produces an error, it is not returned to the parent process. For the parent process to be aware that the child has produced an error, you have to use other mechanisms since the error will not be stored in the child's exit status. You can use Interprocess Communication, or the child can set some flag visible to the parent.
Listing 5-1 recalls the "guess the mystery code" program from Chapter 4, Listing 4-1, that spawned two child processes.
Example 5.1. Listing 5-1
// Listing 5-1 Program used to launch ofind_code.
1 using namespace std;
2 #include <iostream>
3 #include <string>
4 #include <spawn.h>
5 #include <sys/wait.h>
6
7 int main(int argc,char *argv[],char *envp[])
8 {
9
10 pid_t ChildProcess;
11 pid_t ChildProcess2;
12 int RetCode1;
13 int RetCode2;
14 int Value;
15 RetCode1 = posix_spawn(&ChildProcess,"find_code",NULL,
16 NULL,argv,envp);
17 RetCode2 = posix_spawn(&ChildProcess2,"find_code",NULL,
18 NULL,argv,envp);
19 wait(&Value);
20 wait(&Value);
21 return(0);
22 }In Example 5-1, we used posix_spawn to launch the ps shell utility. Here in Listing 5-1, we use posix_spawn to launch the ofind_code program. This illustrates an important feature of posix_spawn(); it is used to launch programs external to the calling program. Any programs that are located on the local computer can be easily launched with posix_spawn(). The posix_spawn() calls in Listing 5-1, lines 15 and 16 have a terse interface. In Chapter 4, we introduced the notion of interface classes, which can start you on the road to a more declarative style multicore programming. Interface classes are easy to implement. Listing 5-2 shows a simple interface class that you can use to encapsulate the basics of the posix_spawn() functions.
Example 5.2. Listing 5-2
//Listing 5-2 An initial interface class for a posix process.
1 #ifndef __POSIX_PROCESS_H
2 #define __POSIX_PROCESS_H
3 using namespace std;
4
5 #include <spawn.h>
6 #include <errno.h>
7 #include <iostream>
8 #include <string>
9
10
11 class posix_process{
12 protected:
13 pid_t Pid;
14 posix_spawnattr_t SpawnAttr;
15 posix_spawn_file_actions_t FileActions;
16 char **argv;
17 char **envp;
18 string ProgramPath;
19 public:
20 posix_process(string Path,char **av,char **env);
21 posix_process(string Path,char **av,char **env, posix_spawnattr_t X,
posix_spawn_file_actions_t Y);
22 void run(void);
23 void pwait(int &X);
24 };
25
26
27 #endif
28This simple interface class can be used to add a more object-oriented approach to process management. It makes it easier to move from models shown in Stage 2 in Figure 5-1 to the execution units in Stage 4. It also makes the OS API calls transparent to the user. For example, the guess_it program shown in Listing 5-1 can be restated as shown in Listing 5-3.
Example 5.4. Listing 5-3
//Listing 5-3 Our guess_it program using an interface class for the posix_spawn
capability.
1 #include "posix_process.h"
2
3 int main(int argc,char *argv[],char *envp[])
4 {
5 int Value;
6 posix_process Child1("ofind_code",argv,envp);
7 posix_process Child2("ofind_code",argv,envp);
8 Child1.run();
9 Child2.run();
10 Child1.pwait(&Value);
11 Child2.pwait(&Value);
12 return(0);
13 }
14Recall from Chapter 4 that the guess_it program spawns two child processes. Each child process in turn spawns two threads. The resulting four threads are used to search files. The value of the interface class as a tool for converting procedural paradigms into Object-Oriented declarative approaches cannot be overstated. Once you have a posix_process class, it can be used like a datatype with the container classes. This means that you can have:
vector<posix_process> list<posix_process> multiset<posix_process> etc...
thinking about processes and threads as objects as opposed to sequences of actions, which is a big step in the direction of the declarative models of parallel programming. Listing 5-4 shows the initial method definitions for the posix_process interface class.
Example 5.4. Listing 5-4
// Listing 5-4 The initial method definitions for the posix_process interface class.
1 #include "posix_process.h"
2 #include <sys/wait.h>
3
4
5 posix_process::posix_process(string Path,char **av,char **env)
6 {
7
8 argv = av;
9 envp = env;
10 ProgramPath = Path;
11 posix_spawnattr_init(&SpawnAttr);
12 posix_spawn_file_actions_init(&FileActions);
13
1415 }
16
17 posix_process::posix_process(string Path,char **av,char **env,
posix_spawnattr_t X, posix_spawn_file_actions_t Y)
18 {
19 argv = av;
20 envp = env;
21 ProgramPath = Path;
22 SpawnAttr = X;
23 FileActions = Y;
24 posix_spawnattr_init(&SpawnAttr);
25 posix_spawn_file_actions_init(&FileActions);
26
27
28
29 }
30
31 void posix_process::run(void)
32 {
33
34 posix_spawn(&Pid,ProgramPath.c_str(),&FileActions,
&SpawnAttr,argv,envp);
35
36
37 }
38
39 void posix_process::pwait(int &X)
40 {
41
42 wait(&X);
43 }The run() method defined on Line 31 in Listing 5-4 adapts the interface to the posix_spawn() function. You can build on these declarations by adding methods that adapt the interface of all of the functions listed in Table 5-2 and Table 5-3. Once completed, you can add process building blocks to your object-oriented toolkit.
There are two functions that return the process id (PID) of the process and parent process:
These functions are always successful; therefore no errors are defined.
Synopsis
#include <unistd.h> pid_t getpid(void); pid_t getppid(void);
When a process executes, the operating system assigns the process to a processor. The process executes its instructions for a quantum. The process is preempted, so another process can be assigned the processor. The operating system scheduler switches between the code of one process, user, or system to the code of another process, giving each process a chance to execute its instructions. There are system and user processes.
Processes that execute system code are called system processes, also sometimes referred to as kernel processes. System processes administer the whole system. They perform housekeeping tasks such as allocating memory, swapping pages of memory between internal and secondary storage, checking devices, and so on. They also perform tasks on behalf of the user processes such as filling I/O requests, allocating memory, and so forth.
User processes execute their own code, and sometimes they make system function calls. When a user process executes its own code, it is in user mode. In user mode, the process cannot execute certain privileged machine instructions. When a user process makes a system function call (for example,
read(), write(), oropen()), it is executing operating system instructions. What occurs is the user process is put on hold until the system call has completed. The processor is given to the kernel to complete the system call. At that time the user process is said to be in kernel mode and cannot be preempted by any user processes.
Processes have characteristics that identify them and determine their behavior during execution. The kernel maintains data structures and provides system functions that allow the user to have access to this information. Some information is stored in the process control block (PCB). The information stored in the PCB describes the process to the operating system. This PCB is part of the heavy weight of the process. This information is needed for the operating system to manage each process. When the operating system switches between a process utilizing the CPU to another process, it saves the current state of the executing process and its context to the PCB save area in order to restart the process the next time it is assigned to the CPU. The PCB is read and changed by various modules of the operating system. Modules concerned with the monitoring the operating system's performance, scheduling, allocation of resources, and interrupt processing all will access and/or modify the PCB. The PCB is what makes the process visible to the operating system and entities like user threads invisible to the operating system.
PCB information includes:
Current state and priority of the process
Process, parent, and child identifiers
Pointers to allocated resources
Pointers to location of the process's memory
Pointer to the process's parent and child processes
Processor utilized by process
Control and status registers
Stack pointers
The information stored in the PCB can be organized as follows:
Information concerned with process control, such as the current state and priority of the process, pointers to parent/child PCB's, allocated resources, and memory. This also includes any scheduling related information, process privileges, flags, messages, and signals that have to do with communication between processes (IPC — Interprocess Communication). The process control information is required by the operating system in order to coordinate the concurrently active processes.
The content of user, control, and status registers and stack pointers are all types of information concerned with the state of the processor. When a process is running, information is placed in the registers of the CPU. Once the operating system decides to switch to another process, all the information in those registers has to be saved. When the process gains the use of the CPU again, this information can be restored.
Other information has to do with process identification. This is the process id, PID, and the parent process id, PPID. These identification numbers are unique for each process. They are positive, nonzero integers.
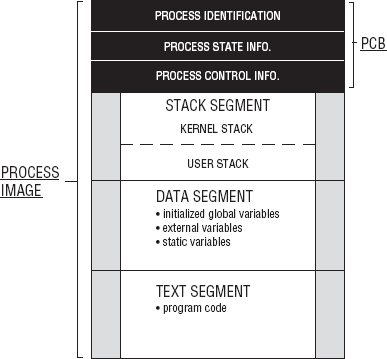
The address space of a process is divided into three logical segments: text (program code), data, and stack segments. Figure 5-2 shows the logical layout of a process. The text segment is at the bottom of the address space. The text segment contains the instructions to be executed called the program code. The data segment above it contains the initialized global, external, and static variables for the process. The stack segment contains locally allocated variables and parameters passed to functions. Because a process can make system function calls as well as user-defined function calls, two stacks are maintained in the stack segment, the user stack and the kernel stack. When a function call is made, a stack-frame is constructed and pushed onto either the user or kernel stack, depending on whether the process is in user or kernel mode. The stack segment grows downward toward the data segment. The stack frame is popped from the stack when the function returns. The text, data, and stack segments and the process control block are part of what forms the process image.
The address space of a process is virtual. Virtual storage dissociates the addresses referenced in an executing process from the addresses actually available in internal memory. This allows the addressing of storage space much larger than what is available. The segments of the process's virtual address space are contiguous blocks of memory. Each segment and physical address space are broken up into chunks called pages. Each page has a unique page frame number. The virtual page frame number (VPFN) is used as an index into the process's page tables. The page tables entries contain a physical page frame number (PFN), thus mapping the virtual page frames to physical page frames. This is depicted in Figure 5-3. As illustrated, virtual address space is contiguous but it is mapped to physical pages in any order.

Even though the virtual address space of each process is protected to prevent another process from accessing it, the text segment of a process can be shared among several processes. Figure 5-3 also shows how two processes can share the same program code. The same physical page frame number is stored in the page table entries of both processes' page tables. As illustrated in Figure 5-3, process A's virtual page frame 0 is mapped to physical page frame 5, as is process B's virtual page frame 2.
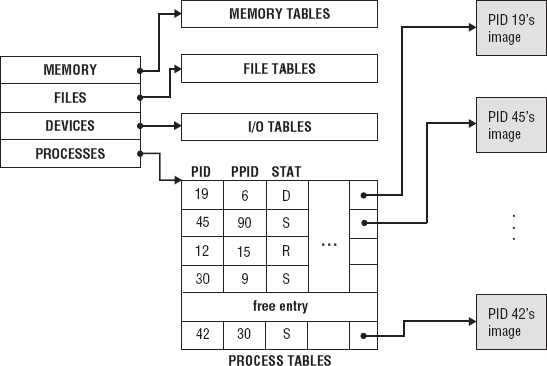
For the operating system to manage all the processes stored in internal memory, it creates and maintains process tables. Actually, the operating system has a table for all of the entities that it manages. Keep in mind that the operating system manages not only processes but all the resources of the computer including devices, memory, and files. Some of the memory, devices, and files are managed on the behalf of the user processes. This information is referenced in the PCB as resources allocated to the process. The process table has an entry for each process image in memory. This is depicted in Figure 5-4. Each entry contains the process and parent process id; the real and effective user id and group id; a list of pending signals; the location of the text, data, and stack segments; and the current state of the process. When the operating system needs to access a process, the process is looked up in the process table, and then the process image is located in memory.
During a process's execution, it changes its state. The state of the process is the current condition or status of the process. In a POSIX-compliant environment, a process can be in the following states:
The current condition of the process depends upon the circumstances created by the process or by the operating system. When certain circumstances exist, the process will change its state. State transition is the circumstance that causes the process to change its state. Figure 5-5 is the state diagram for the processes. The state diagram has nodes and directed edges between the nodes. Each node represents the state of the process. The directed edges between the nodes are state transitions. Table 5-4 lists the state transitions with a brief description. As Figure 5-5 and Table 5-4 show, only certain transitions are allowed between states. For example, there is a transition, an edge, between ready and running, but there is no transition, no edge, between sleeping and running. Meaning, there are circumstances that causes a process to move from the ready state to the running state, but there are no circumstances that cause a process to move from the sleeping state to a running state.
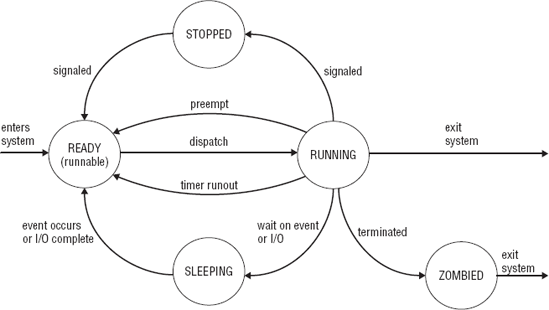
Table 5.4. Table 5-4
State Transitions | Descriptions |
|---|---|
READY->RUNNING (dispatch) | The process is assigned to the processor. |
RUNNING->READY(timer runout) | The time slice the process assigned to the processor has run out. The process is placed back in the ready queue. |
RUNNING->READY(preempt) | The process has been preempted before the time slice ran out. This can occur if a process with a higher priority is runnable. The process is placed back in the ready queue. |
The process gives up the processor before the time slice has run out. The process may need to wait for an event or has made a system call, for example, a request for I/O. The process is placed in a queue with other sleeping processes. | |
SLEEPING->READY (unblock) | The event the process was waiting for has occurred, or the system call has completed. For example, the I/O request is filled. The process is placed back in the ready queue. |
The process gives up the processor because it has received a signal to stop. | |
STOPPED->READY | The process has received the signal to continue and is placed back in the ready queue. |
The process has been terminated and awaits the parent to retrieve its exit status from the process table. | |
ZOMBIED->EXIT | The parent process has retrieved the exit status, and the process exits the system. |
RUNNING->EXIT | The process has terminated, the parent has retrieved the exit status, and the process exits the system. |
When a process is created, it is ready to execute its instructions but must first wait until the processor is available. Each process is allowed to use the processor only for a discrete interval called a time slice. Processes waiting to use the processor are placed in ready queues. Only processes in the ready queues are selected (by the scheduler) to use the processor. Processes in the ready queues are runnable. When the processor is available, a runnable process is assigned the processor by the dispatcher. When the time slice has expired, the process is removed from the processor, whether it has finished executing all its instructions or not. The process is placed back in the ready queue to wait for its next turn to use the processor. A new process is selected from a ready queue and is given its time slice to execute. System processes are not preempted. When they are given the processor, they run until completion. If the time slice has not expired, a process may voluntarily give up the processor if it cannot continue to execute because it must wait for an event to occur. The process may have made a request to access an I/O device by making a system call, or it may need to wait on a synchronization variable to be released. Processes that cannot continue to execute because they are waiting for an event to occur are in a sleeping state. They are placed in a queue with other sleeping processes. They are removed from that queue and placed back in the ready queue when the event has occurred. The processor may be taken away from a process before its time slice has run out. This may occur if a process with a higher priority, like a system process, is runnable. The preempted process is still runnable and, therefore, is placed back in the ready queue.
A running process can receive a signal to stop. The stopped state is different from a sleeping state. The process's time slice has not expired nor has the process made any request of the system. The process may receive a signal to stop because it is being debugged or some situation has occurred in the system. The process has made a transition from running to stopped state. Later the process may be awakened, or it may be destroyed.
When a process has executed all its instructions, it exits the system. The process is removed from the process table, the PCB is destroyed, and all of its resources are deallocated and returned to the system pool of available resources. A process that is unable to continue executing but cannot exit the system is in a zombied state. A zombied process does not use any system resources, but it still maintains an entry in the process table. When the process table contains too many zombied processes, this can affect the performance of the system, possibly causing the system to reboot.
When a ready queue contains several processes, the scheduler must determine which process should be assigned to a processor first. The scheduler maintains data structures that allow it to schedule the processes in an efficient manner. Each process is given a priority class and placed in a priority queue with other runnable processes with the same priority class. There are multiple priority queues, each representing a different priority class used by the system. These priority queues are stratified and placed in a dispatch array called the multilevel priority queue. Figure 5-6 depicts the multilevel priority queue. Each element in the array points to a priority queue. The scheduler assigns the process at the head of the nonempty highest priority queue to the processor.
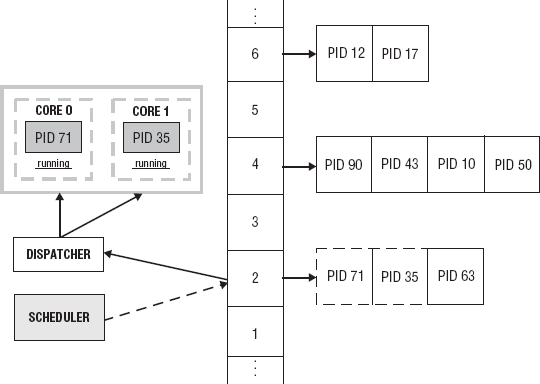
Priorities can be dynamic or static. Once a static priority of a process is set, it cannot be changed. Dynamic priorities can be changed. Processes with the highest priority can monopolize the use of the processor. If the priority of a process is dynamic, the initial priority can be adjusted to a more appropriate value. The process is placed in a priority queue that has a higher priority. A process monopolizing the processor can also be given a lower priority, or other processes can be given a higher priority than that process has. When you are assigning priority to a user process, consider what the process spends most of its time doing. Some processes are CPU-intensive. CPU-intensive processes use the processor for the whole time slice. Some processes spend most of its time waiting for I/O or some other event to occur. When such a process is ready to use the processor, it should be given the processor immediately so it can make its next request for I/O. Processes that are interactive may require a high priority to assure good response time. System processes have a higher priority than user processes.
The processes are placed in a priority queue according to a scheduling policy. Two of the primary scheduling policies used in the POSIX API are the First-In, First-Out (FIFO) and round robin (RR) policies.
Figure 5-7 (a) shows the FIFO scheduling policy. With a FIFO scheduling policy, processes are assigned the processor according to the arrival time in the queue. When a running process time slice has expired, it is placed at the head of its priority queue. When a sleeping process becomes runnable, the process is placed at the end of its priority queue. A process can make a system call and give up the processor to another process with the same priority level. The process is then placed at the end of its priority queue.
In round robin scheduling policy, all processes are considered equal. Figure 5-7 (b) depicts the RR scheduling policy. RR scheduling is the same as FIFO scheduling with one exception: When the time slice expires, the process is placed at the back of the queue and the next process in the queue is assigned the processor.
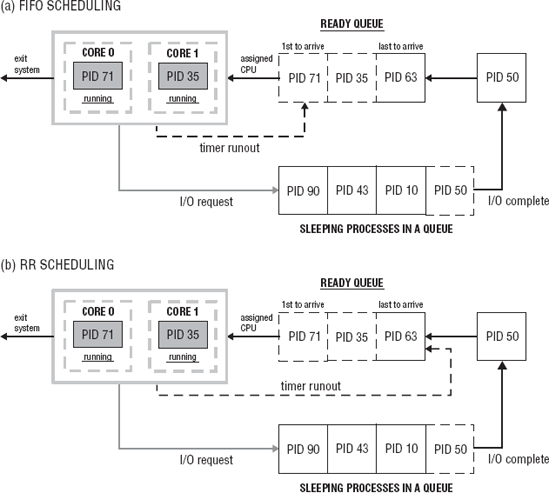
Figure 5-7 shows the behavior of the FIFO and RR scheduling policies. The FIFO scheduling policy assigns processes to the processor according to its arrival time in the queue. The process runs until completion. RR scheduling policy assigns processes using FIFO scheduling, but when the time slice runs out, the process is placed at the back of the ready queue.
The ps utility generates a report that summarizes execution statistics for the current processes. This information can be used to monitor the status of current processes. Table 5-5 lists the common headers and the meaning of the output for the ps utility for the Solaris/Linux environments.
Table 5.5. Table 5-5
Description | Headers | Description | |
|---|---|---|---|
Username of process owner | Process's controlling terminal | ||
Process ID Parent process ID |
| Current state of the process | |
| ID of process group leader ID of session leader |
| Total CPU time used by the process (HH:MM:SS) |
Percentage of CPU time used by the process in the last minute | Time or date the process started | ||
Amount of real RAM currently used by the process in k |
| Nice value of the process | |
Percentage of real RAM used by the process in the last minute |
| Priority of the process | |
Size of virtual memory of the process's data and stack in k or pages |
| Short term CPU-use factor used by scheduler to compute PRI | |
| Memory address of a process | ||
Command name and arguments | ID of the lwp (thread) The number of lwps |
In a multiprocessor environment, the ps utility is useful to monitor the state, CPU and memory usage, processor utilized, priority, and start time of the current processes executing. Command options control which processes are listed and what information is displayed about each process. In the Solaris environment, by default (meaning no command options are used), information about processes with the same effective user id and controlling terminal of the calling invoker is displayed. In the Linux environment, by default, the processes with the same user id as the invoker are displayed. In both environments, the only information that is displayed is PID, TTY, TIME, and COMMAND. These are some of the options that control which processes are displayed:
-t term:List the processes associated with the terminal specified byterm-e:All current processes-a:(Linux) All processes with tty terminal except the session leaders(Solaris) Most frequently requested processes except group leaders and processes not associated with a terminal
-d:All current processes except session leadersT:(Linux) All processes in this terminala:(Linux) All processes including those of other usersr:(Linux) Only running processes
Synopsis
(Linux) ps -[Unix98 options] [BSD-style options] --[GNU-style long options (Solaris) ps [-aAdeflcjLPy][-o format][-t termlist][-u userlist] [-G grouplist][-p proclist][-g pgrplist][-s sidlist]
The following lists some of the command options used to control the information displayed about the processes:
-f:Full listings-l:Long format-j:Jobs format
This is an example of using the ps utility in Solaris/Linux environments:
ps -f
This displays information about the default processes in each environment. Figure 5-8 shows the output in the Solaris environment. The command options can also be used in tandem. Figure 5-8 also shows the output of using -l and -f together in the Solaris environment:
ps -lf
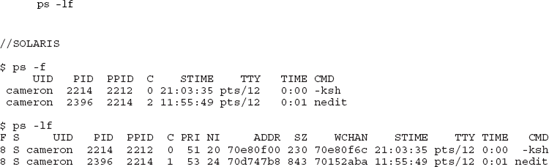
The -l command option shows the additional headers F, S, PRI, NI, ADDR, SZ, and WCHAN.
The P command option displays the PSR header. Under this header is the number of the processor to which the process is assigned or bound.
Figure 5-9 shows the output of the ps utility using the Tux command options in the Linux environment.

The %CPU, %MEM, and STAT information is displayed for the processes. In a multiprocessor environment, this information can be used to monitor which processes are dominating CPU and memory usage. The STAT header shows the state or status of the process. Table 5-6 lists how the status is encoded and their meanings.
The STAT header can reveal additional information about the status of the process:
D:(BSD) Disk waitP:(BSD) Page waitX:(System V) Growing: waiting for memoryW:(BSD) Swapped outK:(AIX) Available kernel processN:(BSD) Niced: execution priority lowered>:(BSD) Niced: execution priority artificially raised<:(Linux) High-priority processL:(Linux) Pages are locked in memory
These codes precede the status codes. If an N precedes the status, this means that the process is running at a lower priority level. If a process has a status S<W, this means the process is sleeping, swapped out, and has a high priority level.
The priority level of a process can be changed by using the nice() function. Each process has a nice value that is used to calculate the priority level of the calling process. A process inherits the priority of the process that created it. But the priority of a process can be lowered by raising its nice value. Only superuser and kernel processes can raise priority levels.
Synopsis
#include <unistd.h> int nice(int incr);
A low nice value raises the priority level of the process. The incr parameter is the value added to the current nice value of the calling process. The incr can be negative or positive. The nice value is a non-negative number. A positive incr value raises the nice value, thus lowering the priority level. A negative incr value lowers the nice value, thus raising the priority level. If the incr value raises the nice value above or below its limits, the nice value of the process is set to the highest or lowest limit accordingly. If successful, the nice() function returns the new nice value of the process. If unsuccessful, the function returns −1, and the nice value is not changed.
Synopsis
#include <sys/resource.h> int getpriority(int which, id_t who); int setpriority(int which, id_t who, int value);
setpriority() sets the nice value for a process, process group, or user. getpriority() returns the priority of a process, process group, or user. Example 5-2 shows the syntax for the functions setpriority() and getpriority() to set and return the nice value of the current process.
Example 5.2. Example 5-2
//Example 5-2 shows how setpriority() and getpriority() can be used.
#include <sys/resource.h>
//...
id_t pid = 0;
int which = PRIO_PROCESS;
int value = 10;
int nice_value;
int ret;
nice_value = getpriority(which,pid);
if(nice_value < value){
ret = setpriority(which,pid,value);
}
//...In Example 5-2, the priority of the calling process is being returned and set. If the calling process's nice value is < 10, the nice value of the process is set to 10. The target process is determined by the values stored in the which and who parameters. The which parameter can specify a process, process group, or a user. It can have the following values:
Depending on the value of which, the who parameter is the id number of a process, process group, or effective user. In Example 5-2, which is assigned PRIO_PROCESS. A 0 value for who indicates the current process, process group, or user. In Example 5-2, who is set to 0, indicating that the current process value for setpriority() will be the new nice value for the specified process, process group, or user.
The range of nice value in the Linux environment is −20 to 19. In Example 5-2, the value of nice is set to 10 if the current nice value is less than 10. In contrast to how things worked with the function nice(), the value passed to setpriority() is the actual value of nice, not an offset to be added to the current nice value. In a process with multiple threads, the modification of the priority affects the priority of all the threads in that process. If successful, getpriority() returns the nice value of the specified process. If successful, setpriority() returns 0. If unsuccessful, both functions return −1. The return value −1 is a legitimate nice value for a process. To determine if an error has occurred, check the external variable errno.
A context switch occurs when the use of the processor is switched from one process to another process. When a context switch occurs, the system saves the context of the current running process and restores the context of the next process selected to use the processor. The PCB of the preempted process is updated. The process state field is changed from the running to the appropriate state (runnable, blocked, zombied, or so forth). The contents of the processor's registers, state of the stack, user and process identification and privileges, and scheduling and accounting information are saved and updated.
The system must keep track of the status of the process's I/O and other resources, and any memory management data structures. The preempted process is placed in the appropriate queue.
A context switch occurs when a:
Process is preempted
Process voluntarily gives up the processor
Process makes an I/O request or needs to wait for an event
Process switches from user mode to kernel mode
When the preempted process is selected to use the processor again, its context is restored, and execution continues where it left off.
To run any program, the operating system must first create a process. When a new process is created, a new entry is placed in the main process table. A new PCB is created and initialized. The process identification portion of the PCB contains a unique process id number and the parent process id. The program counter is set to point to the program entry point, and the system stack pointers are set to define the stack boundaries for the process. The process is initialized with any of the attributes requested. If the process is not given a priority value, it is given the lowest-priority value by default. The process initially does not own any resources unless there is an explicit request for resources or they have been inherited from the creator process. The state of the process is runnable, and it is placed in the runnable or ready queue. Address space is allocated for the process. How much space to be set aside can be determined by default, based on the type of process. The size can also be set as a request by the creator of the process. The creator process can pass the size of the address space to the system at the time the process is created.
In addition to posix_spawn(), for creating processes the POSIX API also supports the fork/exec functions. These functions are available in all Unix/Linux derivatives. The fork() call creates a new process that is a duplication of the calling process, the parent. The fork() returns two values if it succeeds, one to the parent and one to the child process. It returns 0 to the child process and returns the PID of the child to the parent process. The parent and child processes continue to execute from the instruction immediately following the fork() call. If not successful, meaning that no child process was created, −1 is returned to the parent process.
Synopsis
#include <unistd.h> pid_t fork(void);
The fork() fails if the system does not have the resources to create another process. If there is a limit to the number of child processes the parent can spawn or the number of systemwide executing processes and that limit has been exceeded, the fork() fails. In that case, errno is set to indicate the error.
The exec family of functions replaces the calling process image with a new process image. The fork() call creates a new process that is a duplication of the parent process, whereas the exec function replaces the duplicate process image with a new one. The new process image is a regular executable file and is immediately executed. The executable can be specified as a path or a filename. These functions can pass command-line arguments to the new process. Environment variables can also be specified. There is no return value if the function is not successful, because the process image that contained the call to the exec is overwritten. If the function is unsuccessful, −1 is returned to the calling process.
All of the exec() functions can fail under these conditions:
Permissions are denied.
Search permission is denied for the executable's file directory.
Execution permission is denied for the executable file.
Files do not exist.
Executable file does not exist.
Directory does not exist.
File is not executable.
File is not executable because it is open for writing by another process.
File is not an executable file.
The exec functions are used with the fork(). The fork() creates and initializes the child process with the duplicate of the parent. The child process then replaces its process image by calling an exec(). Example 5-3 shows an example of the fork-exec usage.
Example 5.3. Example 5-3
// Example 5-3 Using the fork-exec system calls.
//...
RtValue = fork();
if(RtValue == 0){
execl("/home/user/direct","direct",".");
}In Example 5-3, the fork() function is called and the return value is stored in RtValue. If RtValue is 0, then it is the child process. The execl() function is called. The first parameter is the path to the executable module, the second parameter is the execution statement, and the third parameter is the argument. direct is a utility that lists all the directories and subdirectories from a given directory, which, in this case, is the current directory. There are six versions of the exec functions, each having different calling conventions and uses; those are discussed in the next sections.
The execl(), execle(), and execlp() functions pass the command-line arguments as a list. The number of command-line arguments should be known at compile time in order for these functions to be useful.
int execl(const char *path,const char *arg0,.../*,(char *)0 */);
The
pathparameter is the pathname to the program executable. It can be specified as an absolute pathname or a relative pathname from the current directory. The next arguments are the list of command-line arguments, fromarg0toargn. There can be n number of arguments. The list is to be followed by a NULL pointer.int execle(const char *path,const char *arg0,.../*,(char *)0 *, char *const envp[]*/);
This function is identical to
execl()except that it has an additional parameter,envp[]. This parameter contains the new environment for the new process.envp[]is a pointer to a null-terminated array of null-terminated strings. Each string has the form:name=value
where
nameis the name of the environment variable, and value is the string to be stored.envp[]can be assigned in this manner:char *const envp[] = {"PATH=/opt/kde5:/sbin", "HOME=/home",NULL};int execlp(const char *file,const char *arg0,.../*,(char *)0 */);
fileis the name of the program executable. It uses thePATHenvironment variable to locate the executables. The remaining arguments are the list of command-line arguments as explained forexecl()function.
These are examples of the syntax of the execl() functions using these arguments:
char *const args[] = {"direct",".",NULL};
char *const envp[] = {"files=50",NULL};
execl("/home/tracey/direct","direct",".",NULL);
execle("/home/tracey/direct","direct",".",NULL,envp);
execlp("direct","direct",".",NULL);Each shows the syntax of how the execl() function creates a process that executes the direct program.
Synopsis
#include <unistd.h>
int execl(const char *path,const char *arg0,.../*,(char *)0 */);
int execle(const char *path,const char *arg0,.../*,
(char *)0 *,char *const envp[]*/);
int execv(const char *path,char *const arg[]);
int execlp(const char *file,const char *arg0,.../*,(char *)0 */);
int execve(const char *path,char *const arg[],
char *const envp[]);
int execvp(const char *file,char *const arg[]);The execv(), execve(), and execvp() functions pass the command-line arguments in a vector of pointers to null-terminated strings. The number of command-line arguments should be known at compile time in order for these functions to be useful. argv[0] is usually the execution statement.
int execv(const char *path,char *const arg[]);
The
pathparameter is the pathname to the program executable. It can be specified as an absolute pathname or relative pathname to the current directory. The next argument is the null-terminated vector that contains the command-line arguments as null-terminated strings. There can be n number of arguments. The vector is to be followed by a NULL pointer.arg[]can be assigned in this manner:char *const arg[] = {"traverse",".", ">","1000",NULL};This is an example of a function call:
execv("traverse",arg);In this case, the
traverseutility lists all files in the current directory larger than 1000 bytes.int execve(const char *path,char *const arg[],char *const envp[]);
This function is identical to
execv()except that it has the additional parameterenvp[]described earlier.int execvp(const char *file,char *const arg[]);
fileis the name of the program executable. The next argument is the null-terminated vector that contains the command-line arguments as null-terminated strings. There can be n number of arguments. The vector is to be followed by a NULL pointer.
These are examples of the syntax of the execv() functions using these arguments:
char *const arg[] = {"traverse",".", ">","1000",NULL};
char *const envp[] = {"files=50",NULL};
execv("/home/tracey/traverse",arg);
execve("/home/tracey/traverse",arg,envp);
execvp("traverse",arg);Each shows the syntax of how each execv() function creates a process that executes the traverse program.
There is a limit on the size that argv[] and envp[] can be when passed to the exec() functions. The sysconf() can be used to determine the maximum size of the command-line arguments plus the size of environment variables for the functions that accept envp[], which can be passed to the exec() functions. To return the size, name should have the value _SC_ARG_MAX.
Synopsis
#include <unistd.h> long sysconf(int name);
Another restriction when you are using exec() and the other functions used to create processes is the maximum number of simultaneous processes allowed per user id. To return this number, name should have the value _SC_CHILD_MAX.
Environment variables are null-terminated strings that store system-dependent information such as paths to directories that contain commands, libraries, functions, and procedures used by a process. They can also be used to transmit any useful user-defined information between the parent and the child processes. They are a mechanism for providing specific information to a process without having it hardcoded in the program code. System environment variables are predefined and common to all shells and processes in that system. The variables are initialized by startup files. These are the common system variables:
They can be stored in a file or in an environment list. The environment list contains pointers to null-terminated strings. The variable:
extern char **environ
points to the environment list when the process begins to execute. These strings have the form:
name=value
as explained earlier. Processes initialized with the functions execl(), execlp(), execv(), and execvp() inherit the environment of the parent process. Processes initialized with the functions execve() and execle() set the environment for the new process.
There are functions and utilities that can be called to examine, add, or modify environment variables. getenv() is used to determine whether a specific variable has been set. The parameter name is the environment variable in question. The function returns NULL if the specified variable has not been set. If the variable has been set, the function returns a pointer to a string containing the value.
Synopsis
#include <stdlib.h> char *getenv(const char *name); int setenv(const char *name, const char *value, int overwrite); void unsetenv(const char *name);
string Path;
Path = getenv("PATH");the string Path is assigned the value contained in the predefined environment PATH.
setenv()is used to change or add an environment variable. The parameter name contains the name of the environment variable added with the value stored in value. If the name variable already exists, then the value is changed to value if the overwrite parameter is non-zero. If overwrite is 0, the content of the specified environment variable is not modified. setenv() returns 0 if it is successful and −1 if it is unsuccessful. The unsetenv() removes the environment variable specified by name.
system() is another function that is used to execute a command or executable program. system() causes the execution of fork(), exec(), and a shell. The system() function executes a fork(), and the child process calls an exec() with a shell that executes the given command or program.
Synopsis
#include <stdlib.h> int system(const char *string);
The string parameter can be a system command or the name of an executable file. If successful, the function returns the termination status of the command or return value (if any) of the program. Errors can happen at several levels; the fork() or exec() may fail, or the shell may not be able to execute the command or program.
The function returns a value to the parent process. The function returns 127 if the exec() fails and −1 if some other error occurs. The return code of the command is returned if the function succeeds. This function does not affect the wait status of any of the child processes.
When a process is terminated, the PCB is erased, and the address space and resources used by the terminated process are deallocated. An exit code is placed in its entry in the main process table. The entry is removed once the parent has accepted the exit code. The termination of the process can occur under several conditions:
All instructions have executed. The process makes an explicit return or makes a system call that terminates the process. The child processes may automatically terminate when the parent has terminated.
The parent sends a signal to terminate its child processes.
Abnormal termination of a process can occur when the process itself does something that it shouldn't:
The process requires more memory than the system can provide it.
The process attempts to access resources it is not allowed to access. The process attempts to perform an invalid instruction or a prohibited computation.
The termination of a process can also be initiated by a user when the process is interactive.
The parent process is responsible for the termination/deallocation of its children. The parent process should wait until all its child processes have terminated. When a parent process retrieves a child process's exit code, the child process exits the system normally. The process is in a zombied state until the parent accepts the signal. If the parent never accepts the signal because it has already terminated and exited the system or because it is not waiting for the child process, the child remains in the zombied state until the init process (the original system process) accepts its exit code. Many zombied processes can negatively affect the performance of the system.
There are two functions a process can call for self-termination, exit() and abort(). The exit() function causes a normal termination of the calling process. All open file descriptors associated with the process will be closed. The function flushes all open streams that contain unwritten buffered data then the open streams are closed. The status parameter is the process's exit status. It is returned to the waiting parent process that is then restarted. The value of status may be 0, EXIT_FAILURE, or EXIT_SUCCESS. The 0 value means that the process has terminated successfully. The waiting parent process only has access to the lower 8 bits of status. If the parent process is not waiting for the process to terminate, the zombied process is adopted by the init process. The abort() function causes an abnormal termination of the calling process. An abnormal termination of the process causes the same effect as fclose() on all open streams. A waiting parent process receives a signal that the child process aborted. A process should only abort when it encounters an error that it cannot deal with programmatically.
Synopsis
#include <stdlib.h> void exit(int status); void abort(void);
The kill() function can be used to cause the termination of another process. The kill() function sends a signal to the process or processes specified or indicated by the parameter pid. The parameter sig is the signal to be sent to the specified process. The signals are listed in the header <signal.h>. To kill a process, sig has the value SIGKILL. The calling process must have the appropriate privileges to send a signal to the process, or it has to have a real or an effective user id that matches the real or saved set-user-ID of the process that receives the signal. The calling process may have permission to send only certain signals to processes and not others. If the function successfully sends the signal, 0 is returned to the calling process. If it fails, b-1 is returned.
The calling process can send the signal to one or several processes under these conditions:
pid > 0:The signal is sent to the process whose PID is equal to thepid.pid = 0:The signal is sent to all the processes whose process group id is the same as the calling process.pid = b-1:The signal is sent to all processes for which the calling process has permission to send that signal.pid < b-1:The signal is sent to all processes whose process id group is equal to the absolute value ofpidand for which the calling process has permission to send that signal.
Synopsis
#include <signal.h> int kill(pid_t pid, int sig);
In order for a process to perform whatever task it is instructed to perform, it may need to write data to a file, send data to a printer, or display data to the screen. A process may need input from the user via the keyboard or input from a file. Processes can also use other processes such as a subroutine as a resource. Subroutines, files, semaphores, mutexes, keyboards, and display screens are all examples of resources that can be utilized by a process. A resource is anything used by the process at any given time as a source of data, as a means to process or compute, or as the means by which the data or information is displayed.
For a process to access a resource, it must first make a request to the operating system. If the resource is available, the operating system allows the process to use the resource. The process uses the resource then releases it so that it will be available to other processes. If the resource is not available, the request is denied, and the process must wait. When the resource becomes available, the process is awakened. This is the basic format of resource allocation. Figure 5-10 shows a resource allocation graph. The resource allocation graph shows which processes hold resources and which processes are requesting resources. In Figure 5-10, Process B makes a request for resource 2, which is held by Process C. Process C makes a request for resource 3, which is held by Process D.
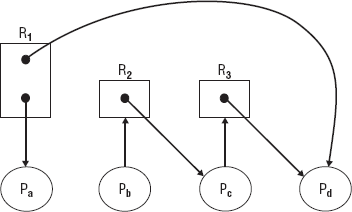
When more than one request to access a resource is granted, the resource is sharable. This is shown in Figure 5-10 as well. Process A shares resource 1 with Process D. A resource may allow many processes concurrent access or may allow one process only limited time before allowing another process access. An example of this type of shared resource is the processor. A process is assigned a processor for a short interval and then another process is assigned the processor. When only one request to access a resource is granted at a time and that occurs after the resource has been released by another process, the resource is unshared, and the process has exclusive access to the resource. In a multiprocessor environment, it is important to know whether a shared resource can be accessed simultaneously or only by one process at a time, in order to avoid some of the pitfalls inherent in concurrency.
Some resources can be changed or modified by a process. Other resources do not allow a process to change it. The behavior of shared modifiable or unmodifiable resources is determined by the resource type.
There are three basic types of resources:
Hardware resources are physical devices connected to the computer. Examples of hardware resources are processors, main memory, and all other I/O devices including printers; hard disk, tape, and zip drives; monitors; keyboards; sound, network, and graphic cards; and modems. All these devices can be shared by several processes.
Some hardware resources are preempted to allow different processes access. For example, a processor is preempted to allow different processes time to run. RAM is another example of a shared preemptible resource. When a process is not in use, some of the physical page frames it occupies may be swapped out to secondary storage in order for another process to be swapped in to occupy those now available page frames. A range of memory can be occupied only by the page frames of one process at any given time. An example of a nonpreemptible shared resource is a printer. When a printer is shared, the jobs sent to the printer by each process are stored in a queue. Each job is printed to completion before another job starts. The printer is not preempted by any waiting printer jobs unless the current job is canceled.
Data resources such as objects; system data such as environment variables, files, and handles; globally defined variables such as semaphores; and mutexes are all resources shared and modified by processes. Regular files and files associated with physical devices such as the printer can be opened, restricting the type of access processes has to that file. Processes may be granted only read or write access, or read/write access. For processes with parent-child relationships, the child process inherits the parent process's resources and access rights to those resources existing at the time of the child's creation. The child process can advance the file pointer or close, modify, or overwrite the contents of a file opened by the parent. Shared memory and files with write permission require their access to be synchronized. Shared data such as semaphores or mutexes can be used to synchronize access to other shared data resources.
Shared libraries are examples of software resources. Shared libraries provide a common set of services or functions to processes. Processes can also share applications, programs, and utilities. In such a case, only one copy of the program(s) code is brought into memory. However, there are separate copies of the data, one for each user (process). Program code that is not changed (also called reentrant) can be accessed by several processes simultaneously.
POSIX defines functions that restrict a process's ability to use certain resources. The operating system sets limitations on a process's ability to utilize system resources. These resource limits affect the following:
The operating system sets a hard limit on resource usage by a process. The process can set or change the soft limit of its resources. Its value should not exceed the hard limit set by the operating system. A process can lower its hard limit. This value should be greater than or equal to the soft limit. When a process lowers its hard limit, it is irreversible. Only processes with special privileges can raise their hard limit.
Synopsis
#include <sys/resource.h> int setrlimit(int resource, const struct rlimit *rlp); int getrlimit(int resource, struct rlimit *rlp); int getrusage(int who, struct rusage *r_usage);
The setrlimit() function is used to set limits on the consumption of specified resources. This function can set both hard and soft limits. The parameter resource represents the resource type. Table 5-7 lists the values for resource with a brief description. The soft and hard limits of the specified resource are represented by the rlp paramater. The rlp parameter points to a struct rlimit that contains two objects of type rlim_t:
struct rlimit
{
rlim_t rlim_cur;
rlim_t rlim_max;
}rlim_t is an unsigned integer type. rlim_cur contains the current or soft limit. rlim_max contains the maximum or hard limit. rlim_cur and rlim_max can be assigned any value. They can also be assigned these symbolic constants defined in the header <sys/resource.h>:
The soft or hard limit can be set to RLIM_INFINITY, which means that the resource is unlimited.
Table 5.7. Table 5-7
Descriptions | |
|---|---|
Maximum size of a core file in bytes that may be created by a process | |
Maximum amount of CPU time in seconds that may be used by a process | |
Maximum size of a process's data segment in bytes | |
Maximum size of a file in bytes that may be created by a process | |
A number one greater than the maximum value that the system may assign to newly created file descriptor | |
Maximum size of a process's stack in bytes | |
Maximum size of a process's total available memory in bytes |
The getrlimit() returns the soft and hard limit of the specified resource in the rlp object. Both the getrlimit() and setrlimit() functions return 0 if successful and −1 if unsuccessful. Example 5-4 contains an example of a process setting the soft limit for file size in bytes.
Example 5.4. Example 5-4
//Example 5-4 Using setrlimit() to set the soft limit for file size. #include <sys/resource.h> //... struct rlimit R_limit; struct rlimit R_limit_values; //... R_limit.rlim_cur = 2000; R_limit.rlim_max = RLIM_SAVED_MAX; setrlimit(RLIMIT_FSIZE,&R_limit); getrlimit(RLIMIT_FSIZE,&R_limit_values); cout << "file size soft limit: " << R_limit_values.rlim_cur << endl; //...
In Example 5-4, the file size soft limit is set to 2000 bytes, and the hard limit is set to hard limit maximum. R_limit and RLIMIT_FSIZE are passed to setrlimit(). getrlimit() is passed RLIMIT_FSIZE and R_limit_values. The soft value is sent to cout.
getrusage() returns information about the measures of resources used by the calling process. It also returns information about the terminated child process the calling process is waiting for. The parameter who can have these values:
If the value for who is RUSAGE_SELF, then the information returned pertains to the calling process. If the value for who is RUSAGE_CHILDREN, then the information returned is pertaining to the calling process's children. If the calling process did not wait for its children, then the information pertaining to the children processes is discarded. The information is returned in r_usage. r_usage points to a struct rusage that contains information listed and described in Table 5-8. If the function is successful, it returns 0; if unsuccessful, it returns −1.
Table 5.8. Table 5-8
| Description |
|---|---|
| User time used System time used |
| Maximum resident set size Shared memory size Unshared data size Unshared stack size |
| Number of page claims Number of page faults |
| Number of page swaps |
| Block input operations Block output operations |
| Number of messages sent Number of messages received |
| Number of signals received |
| Number of voluntary context switches Number of involuntary context switches |
Asynchronous processes execute independent of each other. Process A runs until completion without any regard to process B. Asynchronous processes may or may not have a parent-child relationship. If process A creates process B, they can both execute independently, but at some point the parent retrieves the exit status of the child. If the processes do not have a parent-child relationship, they may share the same parent.
Asynchronous processes may execute serially or simultaneously or their execution may overlap. These scenarios are depicted in Figure 5-11.
In Case 1, process A runs until completion, then process B runs until completion, and then process C runs until completion. This is serial execution of these processes.
Case 2 depicts simultaneous execution of processes. Process A and B are active processes. While process A is running, process B is sleeping. At some point both processes are sleeping. Process B awakens before process A. Then process A awakens, and now both processes are running at the same time. This shows that asynchronous processes may execute simultaneously only during certain intervals of their execution.
In Case 3, the execution of process A and the execution of process B overlap.
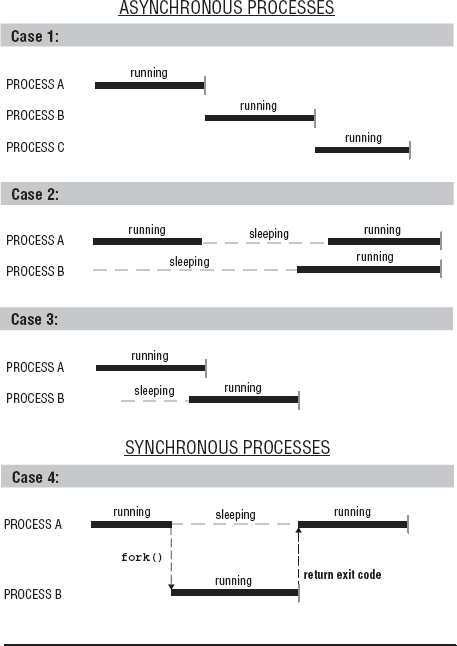
Asynchronous processes may share resources like a file or memory. This may or may not require synchronization or cooperation of the use of the resource. If the processes are executing serially (Case 1), then they will not require any synchronization. For example, all three processes, A, B, and C, may share a global variable. Process A writes to the variable before it terminates. Then, when process B runs, it reads the data stored in the variable, and before it terminates it writes to the variable. When Process C runs, it reads data from the variable. But in Case 2 and 3, the processes may attempt to modify the variable at the same time, thus requiring synchronization of its use.
For our purposes, we define synchronous processes as processes with interleaved execution; one process suspends its execution until another process finishes. For example, process A, the parent process, executes and creates process B, the child process. Process A suspends its execution until process B runs to completion. When process B terminates, its exit code is placed in the process table. Process A is informed process B has terminated. Process A can resume additional processing and then terminate, or it can immediately terminate. Process A and process B are synchronous processes. Figure 5-11 contrasts synchronous and asynchronous execution of processes A and B.
Processes created by the fork(), fork-exec(), and posix_spawn() functions create asynchronous processes. When you are using fork(), the parent process image is duplicated. Once the child process has been created, the function returns to the parent both the child's PID and a return value of 0, indicating process creation was successful. The parent does not suspend execution; both processes continue to execute independently from the statement immediately preceding the fork().
Child processes created using the fork-exec() combination initialize the child's process image with a new process image. The exec() functions do not return to the parent process unless the initialization was not successful.
The posix_spawn() functions create the child process image and initialize it within one function call. The PID is returned to the posix_spawn() as well as a return value, indicating if the process was spawned successfully. After posix_spawn() returns, both processes are executing at the same time.
Processes created by the system() function create synchronous processes. A shell is created that executes the system command or executable file. The parent process is suspended until the child process terminates and the system() call returns.
Asynchronous processes can suspend execution until a child process terminates by executing wait() system call. After the child process terminates, a waiting parent process collects the child's exit status that prevents zombied processes. The wait() function obtains the exit status from the process table. The status parameter points to a location that contains the exit status of the child process. If the parent process has more than one child process and several of them have terminated, the wait() function retrieves the exit status for only one child process from the process table. If the status information is available before the execution of the wait() function, the function returns immediately. If the parent process does not have any children, the function returns with an error code. The wait() function can also be called when the calling process is to wait until a signal is delivered and then perform some signal-handling action.
Synopsis
#include <sys/wait.h> pid_t wait(int *status); pid_t waitpid(pid_t pid, int *status, int options);
The waitpid() function is the same as wait(), except that it takes an additional parameter, pid. The pid parameter specifies a set of child processes for which the exit status is retrieved. Which processes are in the set is determined by the value of pid:
pid > 0:A single child processpid = 0:Any child process whose group id is the same as the calling processpid < −1:Any child processes whose group id is equal to the absolute value ofpidpid = −1:Any child processes
The options parameter determines how the wait should behave and can have the value of the following constants defined in the header <sys/wait.h>:
WCONTINUED:Reports the exit status of any continued child process (specified bypid) whose status has not been reported since it continued.WUNTRACED:Reports the exit status of any child process (specified bypid) that has stopped whose status has not been reported since it stopped.WNOHANG:The calling process is not suspended if the exit status for the specified child process is not available.
These constants can be logically ORRED and passed as the options parameter (for example: WCONTINUED | WUNTRACED).
Both the wait() and waitpid() functions return the PID of the child process whose exit status was obtained. If the value stored in status is 0, then the child process has terminated under these conditions:
The process returned 0 from the function
main().The process called some version of
exit()with a 0 argument.The process was terminated because the last thread of the process terminated.
Table 5-9 lists the macros in which the value of the exit status can be evaluated.
Table 5.9. Table 5-9
Description | |
|---|---|
Evaluates to nonzero if status was returned by a normally terminated child process. | |
If | |
Evaluates to nonzero if | |
If | |
Evaluates to nonzero if | |
If WIFSTOPPED is nonzero, this evaluates to the number of the signal that caused the child process to stop. | |
Evaluates to nonzero if |
Recall that a predicate in C++ is a function object that returns a bool [Stroustrup, 1997]. One thing that's often overlooked in this definition is the word object. A predicate is not simply a function. It has object semantics. Predicates give a declarative interpretation to a sequence of actions. A predicate is a statement that can be evaluated to true or false. In a shift toward a more declarative approach to parallelism, you will find that is sometimes convenient to encapsulate a process or a thread as a C++ predicate. Enapsulating the process or thread within a predicate allows you to thread them as objects for use with containers and algorithms. This subtle use of the notion of a predicate in C++ allows you to take a big step away from the procedural approach to parallelism and toward a declarative approach.
Take, for example, the guess_it program from Listing 5-3 earlier in the chapter. Although we used an interface class to provide a more declarative interface for the posix_spawn function, we can do better. In other words, Listing 5-3 is a more declarative version of the guess_it program from Chapter 4, and now Listing 5-5 is a more declarative form of the program in Listing 5-3.
Example 5.9. Listing 5-5
// Listing 5-5 A restatement of the guess_it program from Chapter 4.
1 #include "posix_process.h"
2 #include "posix_queue.h"
3 #include "valid_code.h"
4
5
6 char **av;
7 char **env;
8
9
10 int main(int argc,char *argv[],char *envp[])
11 {
12
13 valid_code ValidCode;
14 ValidCode.determination("ofind_code");
15 cout << (ValidCode() ? "you win": "you lose");
16 return(0);
17 }Here, we have decided to model the code from our game as a C++ class named valid_code. We have decided to encapsulate the invocation of the posix_process.run() method within a C++ predicate. Line 15 of Listing 5-5 contains the ValidCode() predicate. If the predicate ValidCode() is true, then the user has guessed the right six-character code within the 5-minute time constraint. The program in Listing 5-5 spawns two processes using the posix_process class and four threads using the user_thread class from Chapter 4. Both the posix_process class and the user_thread class are interface classes that adapt the interface to posix_spawn() and pthread_create().
The program oguess_it is a more declarative form of the program in Listing 5-3. The invocation of posix_process.run() method is encapsulated within a C++ predicate. If the predicate ValidCode() is true, then the user has guessed the right six-character code within the 5-minute time constraint. The program spawns two processes using the posix_process class and four threads using the user_thread.
None
We take the declarative interpretation further by encapsulating the Process.run() invocation as a C++ predicate. Listing 5-6 is a declaration of the valid_code predicate class.
Example 5.6. Listing 5-6
//Listing 5-6 Declaration of our valid_code predicate class.
1 #ifndef __VALID_CODE_H
2 #define __VALID_CODE_H
3 using namespace std;
4
5 #include <string>
6 class valid_code{
7 private:
8 string Code;
9 float TimeFrame;
10 string Determination;
11 bool InTime;
12 public:
13 bool operator()(void);
14 void determination(string X);
15 };
16
17 #endifWe designate this as a predicate class because we have overloaded the operator() on Line 13. Notice that operator() returns a bool. This is what distinguishes the predicate from the function object. Because valid_code is a class, it has the declarative semantics that we need to build on. Because valid_code is a class, it can be used with container classes and algorithms. This use of the predicate notion for processes and threads opens up new ways of thinking about parallel programming. Listing 5-7 contains the definitions for the valid_code class.
Example 5.11. Listing 5-7
//Listing 5-7 Definition of our valid_code predicate class.
1 #include "valid_code.h"
2 #include "posix_process.h"
3 #include "posix_queue.h"
4
5 extern char **av;
6 extern char **env;
7
8
9 bool valid_code::operator()(void)
10 {
11 int Status;
12 int N;
13 string Result;
14 posix_process Child[2];
15 for(N = 0; N < 2; N++)
16 {
17 Child[N].binary(Determination);
18 Child[N].arguments(av);
19 Child[N].environment(env);
20 Child[N].run();
21 Child[N].pwait(Status);
22 }
23 posix_queue PosixQueue("queue_name");
24 PosixQueue.receive(Result);
25 if((Result == Code) && InTime){
26 return(true);
27 }
28 return(false);
29 }
30
31
32 void valid_code::determination(string X)
33 {
34 Determination = X;
35 }
36The definition of the predicate defined by the operator() begins on Line 9 of Listing 5-7. Notice on Line 25 that if the Result is correct and Intime, then this predicate returns true; otherwise, it returns false. Lines 16-21 cause two processes to be spawned. Line 14 from Listing 5-5 has the determination that is the name of the binary (ofind_code) that is associated with the two processes that have been spawned. In this case, each instance of ofind_code creates two threads to perform the search, causing us to have a total of four threads. But all of this talk of processes and threads is totally transparent to the program in Listing 5-5. The program in Listing 5-5 is concerned with something called ValidCode and only concerned whether the ValidCode() predicate is true or false.
You can extend the number of processes and threads without changing the declarative interpretation of the parallelism. We stress declarative semantics here because as you scale to more cores on a CMP, it gets increasingly challenging to think procedurally. You can use declarative models to help you cope with the complexity of parallel programming. Using C++ interface classes in conjunction with C++ predicates to encapsulate processes, threads, and POSIX APIs is a step in the right direction.
The bulk of this chapter has dealt with processes and how you can leverage them to aid your multicore programming. Some of the key points covered include:
Concurrency in a C++ program is accomplished by factoring your program into either multiple processes or multiple threads. When isolation, security, address space, and maximum number of resources that concurrently executing tasks may have are major concerns, it is better to use processes than threads. Communication between processes and startup time are two of the primary tradeoffs when you decide to use processes rather than threads.
The primary characteristics and attributes of a process are stored in the process control block (PCB) used by the operating system to identify the process. This information is needed by the operating system to manage each process. The PCB is one of the structures that makes processes heavier or more expense to use than threads.
Processes that create other processes have a parent-child relationship with the created process. The creator of the process is the parent, and the created process is the child process. Child processes inherit many attributes from the parent. The parent's key responsibility is to wait for the child process so the parent can exit the system.
There are several system calls that can be used to create processes:
fork(), fork-exec(), system(), andposix_spawn(). Thefork(), fork-exec(), andposix_spawn()functions create processes that are asynchronous to the parent process, whereassystem()creates a child process that is synchronous to the parent process. Some platforms may have trouble implementingfork(), so theposix_spawn()functions can be used instead.Use interface classes, such as the
posix_processclass from this chapter, to build declarative interfaces for POSIX API functions that are used for processes management. If you build interface classes for processes as well as threads, then you can begin to implement your current tasks from the Object-Oriented point of view rather than the procedural viewpoint.In the shift toward a more declarative approach to parallelism, you can also find it sometimes useful to encapsulate a process or a thread as a C++ predicate. Encapsulating the process or thread within a predicate allows you to thread them as objects for use with containers and algorithms. This subtle use of the notion of a predicate in C++ allows you to take a big step away from the procedural approach to parallelism and toward a declarative approach.
In the next chapter, we discuss multithreading. A thread is a sequence of executable code within a process that is scheduled for execution by the operating system on a processor or core. The use of threads for parallel programming on multicore processors has a number of advantages over multiple processes. In the next chapter, we discuss those advantages and some of the pitfalls. We discuss POSIX APIs functions for creating and managing threads and show how that functionality can be encapsulated in a thread class first introduced in Chapter 4.