
There is only one constant, one universal. It is the only real truth; causality. Action, reaction. Cause and effect. | ||
| --Merovingian, Matrix Reloaded | ||
In Chapter 6, we discussed the similarities and differences between processes and threads. The most significant difference between threads and processes is that each process has its own address space and threads are contained in the address space of their process. We discussed how threads and processes have an id, a set of registers, a state, and a priority, and adhere to a scheduling policy. We explained how threads are created and managed. We also created a thread class.
In this chapter, we take the next step and discuss communication and cooperation between threads and processes. We cover among other topics:
In Chapter 3, we discussed the challenges of coordinating the execution of concurrent tasks. The example used was software-automated painters who were to paint the house before guests arrived for the holidays. A number of issues were outlined while decomposing of the problem and solution for the purpose of determining what would be the best approach to painting the house. Some of those issues had to deal with communication and the synchronization resource usage.
Did the painters have to communicate with each other?
Should the painters communicate when they had completed a task or when they required some resource like a brush or paint?
Should painters communicate directly with each other or should there be a central painter through which all communications are routed?
Would it be better if only painters in one room communicated or if painters of different rooms communicated?
As far as sharing resources, can multiple painters share a resource or will usage have to be serialized?
These issues are concerned with coordinating communication and synchronization between these concurrent tasks. If communication between dependent tasks is not appropriately designed, then data race conditions can occur. Determining the proper coordination of communication and synchronization between tasks requires matching the appropriate concurrency models during problem and solution decomposition. Concurrency models dictate how and when communication occurs and the manner in which work is executed. For example, for our software-automated painters a boss-worker model (which we discuss later in this chapter) could be used. A single boss painter can delegate work or direct painters as to which rooms to paint at a particular time. The boss painter can also manage the use of resources. All painters then communicate what resources they need in order to complete their tasks to the boss who then determines when resources are delegated to painters. Dependency relationships can be used to examine which tasks are dependent on other tasks for communication or cooperation.
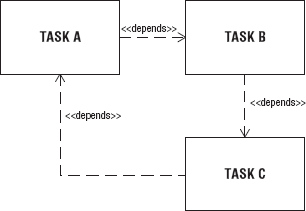
When processes or threads require communication or cooperation among each other to accomplish a common goal, they have a dependency relationship. Task A depends on Task B to supply a value for a calculation, to give the name of the file to be processed, or to release a resource. Task A may depend on Task B, but Task B may not have a dependency on Task A. Given any two tasks, there are exactly four dependency relationships that can exist between them:
In the first and second cases the dependency is a one-way unidirectional dependency. In the third case, there is a two-way bidirectional dependency; A and B are mutually dependent on each other. In the fourth case, there is a NULL dependency between Task A and B; no dependency exists.
When Task A requires data from Task B in order for it to execute its work, then there is a dependency relationship between Task A and Task B. A software-automated painter can be designated to fill all buckets running low on paint with paint at the behest of the boss painter. That would mean all painters (that are actually painting) would have to communicate with the boss painter that they were low on paint. The boss painter would then inform the refill painter that there were buckets of paint to be filled. This would mean that the worker painters have a communication dependency with the boss painter. The refill painter also had a communication dependency with the boss painter.
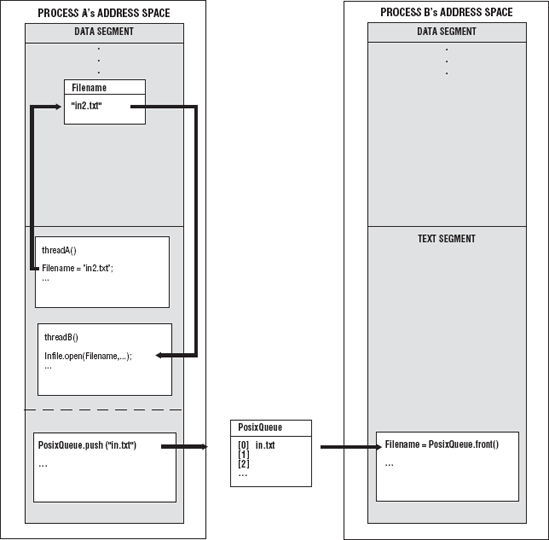
In Chapter 5, a posix_queue object was used to communicate between processes. The posix_queue is an interface to the POSIX message queue, a linked list of strings. The posix_queue object contains the names of the files that the worker processes are to search to find the code. A worker process can read the name of the file from posix_queue. posix_queue is a data structure that resides outside the address space of all processes. On the other hand, threads can also communicate with other threads within the address space of their process by using global variables and data structures. If two threads wanted to pass data between them, thread A would write the name of the file to a global variable, and thread B would simply read that variable. These are examples of unidirectional communication dependencies where only one task depends on another task. Figure 7-1 shows two examples of unidirectional communication dependencies: the posix_queue used by processes and the global variables used to hold the name of a file for threads A and B.
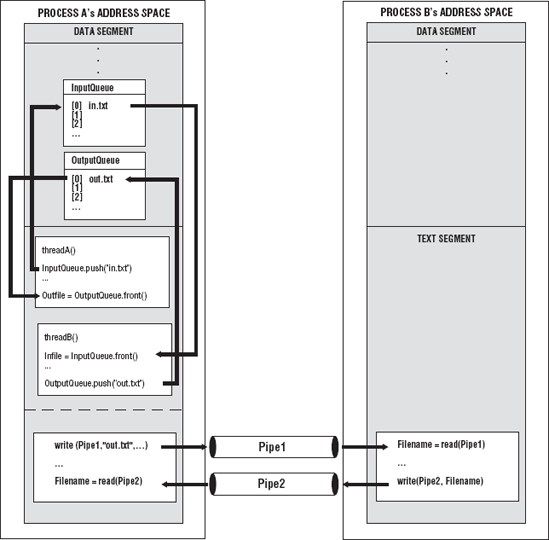
An example of a bidirectional dependency is two First-In, First-Out (FIFO) pipes. A pipe is a data structure that forms a communication channel between two processes. Process A will use pipe 1's input end to send the name of the file that process B has to process. Process B will read the name of the file from the output end of pipe 1. After it has processed the contents of the file, the result is written to a new file. The name of the new file will be written to the input end of pipe 2. Process A will read the name of the file from the output end of pipe 2. This is bidirectional communication dependency. Process B depends on process A to communicate the name of the file, and process A depends on process B to communicate the name of the new file. Thread A and thread B can use two global data structures like queues; one would contain the names of source files, and the other would be used to contain the names of resultant files. Figure 7-2 shows two examples of bidirectional communication dependencies between processes A and B and threads A and B.
When Task A requires a resource that Task B owns and Task B must release the resource before Task A can use it, this is a cooperation dependency. When two tasks are executing concurrently, and both are attempting to utilize the same resource, cooperation is required before either can successfully use the resource. Assume that there are multiple software-automated painters in a single room, and they are sharing a single paint bucket. They all try to access the paint bucket at the same time. Considering that the bucket cannot be accessed simultaneously by painters (it's not thread safe to do so), access has to be synchronized, and this requires cooperation.
Another example of cooperation dependency is write access to the posix_queue. If multiple processes were to write the names of the files where the code was located to the posix_queue, this would require that only one process at a time be able write to the posix_queue. Write access would have to be synchronized.
You can understand the overall task relationships between the threads or processes in an application by enumerating the number of possible dependencies that exist. Once you have enumerated the possible dependencies and then their relationships, you can determine which threads you must code for communication and synchronization. This is similar to truth tables used to determine possible branches of decision in a program or application. Once the dependency relationships among threads are enumerated, the overall thread structure of the process is available.
For example, if there are three threads A, B, and C (three threads from one process or one thread from three processes), you can examine the possible dependencies that exist among the threads. If there are two threads involved in a dependency, use combination to calculate the possible threads involved in the dependency from the three threads: C(n,k) where n is the number of threads and k is the number of threads involved in the dependency. So, for the example C(3,2), the answer is 3; there are three possible combinations of threads: A and B, A and C, B and C.
Now if you consider each combination as a graph (with two nodes and one edge between them), a simple graph, meaning that there are no self-loops and no parallel edges (no two edges will have the same endpoints), then the number of edges in a graph is n(n- 1)/2. So, for the two-node simple graph, there are 2(2 - 1)/2, which is 1. There is one edge for each graph. Now each edge can have a possible four possible dependency relationships as discussed earlier:
A → B: Task A depends on Task B.
A ← B: Task B depends on Task A.
A
B: Task A depends on Task B, and Task B depends on Task A.
A NULL B: There are no dependencies between Task A and Task B.
So, each individual graph has four possible relationships. If you count the number of possible dependency relationships among three threads in which two are involved in the relationship, there are 12 possible relationships.
An adjacency matrix can be used to enumerate the actual dependency relationships for two-thread combinations. An adjacency matrix is a graph G = (V,E) in which V is the set of vertices or nodes of the graph and E is the set of edges such that:
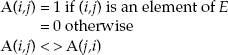
where i denotes a row and j denotes a column. The size of the matrix is n x n, where n is the total number of threads. Figure 7-3(A) shows the adjacency matrix for three threads. The 0 indicates that there is no dependency, and the 1 indicates that there is a dependency. An adjacency matrix can be used to demarcate all of the dependency relationships between any two threads. On a diagonal, there are all 0s because there are no self-dependencies.
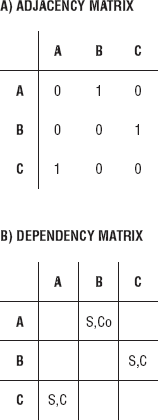
A dependency graph is useful for documenting the type of dependency relationship, for example, C for communication or Co for cooperation. S is for synchronization if the communication or cooperation dependency requires synchronization. The dependency graph can be used during the design or testing phase of the Software Development Life Cycle (SDLC). To construct the dependency graph, the adjacency matrix is used. Where there is a 1 in a row column position, it is replaced by the type of relationship. Figure 7-3(B) shows the dependency graph for the three threads. The 0s and 1s have been replaced by C or Co. Where there was a 0, no relationship exists; the space is left blank. For A(1,2), A depends on B for synchronized cooperation, A(2,3) B depends on C for synchronized communication, and A(3,2) C depends on A for synchronized communication. Bidirectional relationships like A
These tools and approaches are very useful. Knowing the number of possible relationships and identifying what those relationships are helps in establishing the overall thread structure of processes and the application. We have used them for small numbers of threads. The matrix is only useful when two threads are involved in the dependency. For large numbers of threads, the matrix approach cannot be used (unless it is multidimensional.) But having to enumerate each relationship for even a moderate number of threads would be unwieldy. This is why the declarative approach is very useful.
Processes have their own address space. Data that is declared in one process is not available in another process. Events that happen in one process are not known to another process. If process A and process B are working together to perform a task such as filtering out special characters in a file or searching files for a code, there must be methods for communicating and coordinating events between the two processes. In Chapter 5, the layout of a process was described. A process has a text, data, and stack segment. Processes may also have other memory allocated in the free store. The data that the process owns is generally in the stack and data segments or is dynamically allocated in memory protected from other processes. For one process to be made aware of another process's data or events, you use operating system Application Program Interfaces (APIs) to create a means of communication. When a process sends data to another process or makes another process aware of an event by means of operating system APIs, this is called Interprocess Communication (IPC). IPC deals with the techniques and mechanisms that facilitate communication between processes. The operating system's kernel acts as the communication channel between the processes. The posix_queue is an example of IPC. Files can also be used to communicate between related or unrelated processes.
The process resides in user mode or space. IPC mechanisms can reside in kernel or user space. Files used for communication reside in the filesystem outside of both user and kernel space. Processes sharing information by utilizing files have to go through the kernel using system calls such as read, write, and lseek or by using iostreams. Some type of synchronization is required when the file is being updated by two processes simultaneously. Shared information between processes resides in kernel space. The operations used to access the shared information will involve a system call into the kernel. An IPC mechanism that does reside in user space is shared memory. Shared memory is a region of memory that each process can reference. With shared memory, processes can access the data in this shared region without making calls to the kernel. This also requires synchronization.
The persistence of an object refers to the existence of an object during or beyond the execution of the program, process, or thread that created it. A storage class specifies how long an object exists during the execution of a program. An object can have a declared storage class of automatic, static, or dynamic.
Automatic objects exist during the invocation of a block of code. The space and values an object is given exist only within the block. When the flow of control leaves the block, the object goes out of existence and cannot be referred to without an error.
A static object exists and retains values throughout the execution of the program.
An object that was dynamically allocated can have no more than static storage but can have less than automatic storage. Programmers determine when an object is dynamically declared during runtime, and that object will exist for the entire execution of the program.
Persistence of an object is not necessarily synonymous with the storage of the object on a storage device. For example, automatic or static objects may be stored in external storage that is used as virtual memory during program execution, but the object will be destroyed after the program is over.
IPC entities reside in the filesystem, in kernel space, or in user space, and persistence is also defined the same way: filesystem, kernel, and process persistence.
An IPC object with filesystem persistence exists until the object is deleted explicitly. If the kernel is rebooted, the object will keep its value.
Kernel persistence defines IPC objects that remain in existence until the kernel is rebooted or the object is deleted explicitly.
An IPC object with process persistence exists until the process that created the object closes it.
There are several types of IPCs, and they are listed in Table 7-1. Most of the IPCs work with related processes — child and parent processes. For processes that are not related and require Interprocess Communication, the IPC object has a name associated with it so that the server process that created it and the client processes can refer to the same object. Pipes are not named; therefore, they are used only between related processes. FIFO or named pipes can be used between unrelated processes. A pathname in the filesystem is used as the identifier for a FIFO IPC mechanism. A name space is the set of all possible names for a specified type of IPC mechanism. For IPCs that require a POSIX IPC name, that name must begin with a slash and contain no other slashes. To create the IPC, one must have write permissions for the directory.
Table 7.1. Table 7-1
Name space | Persistence | Process | |
|---|---|---|---|
Pipe | unnamed | process | Related |
FIFO | pathname | process | Both |
Mutex | unnamed | process | Related |
Condition variable | unnamed | process | Related |
Read-write locks | unnamed | process | Related |
Message queue | Posix IPC name | kernel | Both |
Semaphore (memory-based) | unnamed | process | Related |
Semaphore (named) | Posix IPC name | kernel | Both |
Shared memory | Posix IPC name | kernel | Both |
Table 7-1 also shows that each type of IPC (FIFO and pipes) has process persistence. Message queues and shared memory mst have kernel persistence, but may also use filesystem persistence. When message queues and shared memory utilize filesystem persistence, they are implemented by using a mapping a file to internal memory. This is called mapped files or memory mapped files. Once the file is mapped to memory that is shared between processes, the contents of the files are modified and read by using a memory location.
Parent processes share their resources with child processes. By using posix_spawn, or the exec functions, the parent process can create the child process with exact copies of its environment variables or initialize them with new values. Environment variables store system-dependent information such as paths to directories that contain commands, libraries, functions, and procedures used by a process. They can be used to transmit useful user-defined information between the parent and the child processes. They provide a mechanism to pass specific information to a related process without having it hardcoded in the program code. System environment variables are common and predefined to all shells and processes in that system. The variables are initialized by startup files.
The common environment variables are listed in Chapter 5.
Environment variables and command-line argument can also be passed to newly initialized processes.
int posix_spawn(pid_t *restrict pid, const char *restrict path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict], char *const envp[restrict]);argv[] and envp[] are used to pass a list of command-line argument and environment variables to the new process. This is one-way, one-time communication. Once the child process has been created, any changes to those variables by the child will not be reflected in the parent's data, and the parent cannot make any changes to the variables that are seen by its child processes.
Using files to transfer data between processes is one of the simplest and most flexible means of transferring or sharing data. Files can be used to transfer data between processes that are related or unrelated. They can allow processes that were not designed to work together to do so. Of course, files have filesystem persistence; in this case, the persistence can survive a system reboot.
When you use files to communicate between processes, you follow seven basic steps in the file-transferring process:
The name of the file has to be communicated.
You must verify the existence of the file.
Be sure that the correct permission are granted to access to the file.
Synchronize access to the file.
While reading/writing to the file, check to see if the stream is good and that it's not at the end of the file.
Close the file.
First, the name of the file has to be communicated between the processes. You might recall from Chapters 4 and 5 that files stored the work that had to be processed by the workers. Each file contained over a million strings. The posix_queue contained the names of the files. Filenames can also be passed to child processes by means of other IPC-like pipes.
When the process is accessing the file, if more than one process can also access the same file, you need synchronization. You might recall in Chapter 4 in Listing 4-2, that a file was broken up into smaller files, and each process had exclusive access to the file. However, if there was just one file, the access to the file would have to be synchronized. One process at a time would have exclusive read capability and would read a string from the file, advancing the read pointer. We discuss read/write locks and other types of synchronization later in the chapter.
Leaving the file open can lead to data corruption and can prevent other processes from accessing the file. The processes that read or write to or from the file should know the file's file format in order to correctly process the file. The file's format refers to the file type and the file's organization. The file's type also implies the type of data in the file. Is it a text file or a binary file? The processes should also know the file layout or how the data is organized in the file.
File descriptors are unsigned integers used by a process to identify an open file. They are shared between parent and child processes. They are indexes to the file descriptor table, a block maintained by the kernel for each process. When a child process is created, the descriptor table is copied for the child process, which allows the child process to have equal access to the files used by the parent. The number of file descriptors that can be allocated to a process is governed by a resource limit. The limit can be changed by setrlimit(). The file descriptor is returned by the open(). File descriptors are frequently used by other IPCs.
A block of shared memory can be used to transfer information between processes. The block of memory does not belong to any of the processes that are sharing the memory. Each process has its own address space; the block of memory is separate from the address space of the processes. A process gains access to the shared memory by temporarily connecting the shared memory block to its own memory block. Once the piece of memory is attached, it can be used like any other pointer to a block of memory. Like other data transfer mechanisms, shared memory is also set up with the appropriate access permission. It is almost as flexible as using a file to transfer data. If Processes A, B, and C were using a shared memory block, any modifications by any of the processes are visible to all the other processes. This is not a one-time, one-way communication mechanism.
Pipes require that at least two processes be connected before they can be used; shared memory can be written to and read by a single process and held open by that process. Other processes can attach to and detach from the shared memory as needed. This allows much larger blocks of data to be transferred faster than when you use pipes and FIFOs. However, it is important to consider how much memory to allocate to the shared region.
When you are accessing the data contained in the shared memory, synchronization is required. In the same way that file locking is necessary for multiple processes to attempt read/write access for the same file at the same time, access to shared memory must be regulated. Semaphores are the standard technique used for controlling access to shared memory. Controlled access is necessary because a data race can occur when two processes attempt to update the same piece of memory (or file for that matter) at the same time.
The shared memory maps:
a file
internal memory
to the shared memory region:
Synopsis
#include <sys/mman.h> void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset); int mumap(void *addr, size_t len);
The function maps len bytes starting at offset offset from the file or other object specified by the file descriptor fd into memory, preferably at address addr, which is usually specified as 0. The actual place where the object is mapped in memory is returned and is never 0. It is a void *. prot describes the desired memory protection. It must not conflict with the open mode of the file. flags specifies the type of mapped object. It can also specify mapping options and whether modifications made to the mapped copy of the page are private to the process or are to be shared with other references. Table 7-2 shows the possible values for prot and flags with a brief description. To remove the memory mapping from the address space of a process, use mumap().
Table 7.2. Table 7-2
Flag Arguments for mmap | Description |
|---|---|
prot | Describes the protection of the memory-based region. |
| Data can be read. |
| Data can be written. |
| Data can be executed. |
| Data is inaccessible. |
flags | Describes how the data can be used. |
| Changes are shared. |
| Changes are private. |
|
|
To create a shared memory, open a file and store the file descriptor; then call mmap() with the appropriate arguments and store the returning void *. Use a semaphore when accessing the variable. The void * may have to be type cast. depending on the data you are trying to manipulate:
fd = open(file_name,O_RDWR); ptr =casting<type>(mmap(NULL,sizeof(type),PROT_READ,MAP_SHARED,fd,0));
This is an example of memory mapping with a file. When using shared memory with internal memory, a function that creates a shared memory object is used instead of a function that opens a file:
Synopsis
#include <sys/mman.h> int shm_open(const char *name, int oflag, mode_t mode); int shm_unlink(const char *name);
The shm_open() creates and opens a new or opens an existing POSIX shared memory object. The function is very similar to open(). name specifies the shared memory object created and/or opened. To ensure the portability of name use an initial slash (/) and don't use embedded slashes. oflag is a bit mask created by ORing together one of these flags: O_RDONLY or O_RDWR and any of the other flags listed in Table 7-3, along with the possible values for mode with a brief description. shm_open() returns a new file descriptor referring to the shared memory object. The file descriptor is used in the function call to mmap().
fd = sh_open(memory_name,O_RDWR, MODE); ptr =casting<type>(mmap(NULL,sizeof(type),PROT_READ,MAP_SHARED,fd,0));
Now ptr can be used like any other pointer to data. Be sure to use semaphores between processes:
sem_wait(sem); ... *ptr; sem_post(sem);
Table 7.3. Table 7-3
Shared Memory Arguments | Description |
|---|---|
oflag | Describes how the shared memory will be opened. |
| Opens the object for read or write access. |
| Opens the object for read-only access. |
| Creates the shared memory if it does not exist. |
| Checks for the existence and creation of the object. If |
| If the shared memory object exists, then truncates it to zero bytes. |
mode | Specifies the permission. |
| User has read permission. |
| User has write permission. |
| Group has read permission. |
| Group has write permission. |
| Others have read permission. |
| Others have write permission. |
Pipes are communication channels used to transfer data between processes. Whereas data transfer using files generally does not require the sending and receiving of data to be active at the same time, data transfer using pipes includes processes that are active at the same time. Although there are exceptions, the general rule is that pipes are used between two or more active processes. One process (the writer) opens or creates the pipe and then blocks until another process (the reader) opens the same pipe for reading and writing.
There are two kinds of pipes:
Anonymous
Named (also called FIFO)
Anonymous pipes are used to transfer data between related processes (child and parent). Named pipes are used for communication between related or unrelated processes. Related processes created using fork() can use the anonymous pipes. Processes created using posix_spawn() use named pipes. Unrelated processes are created separately by programs. Unrelated processes can be logically related and work together to perform some task, but they are still unrelated. Named pipes are used by unrelated processes and related processes that refer to the pipe by the name associated with it. Named pipes are kernel objects. So, they reside in kernel space with kernel persistence (as far as the data), but the file structure has filesystem persistence until it is explicitly removed from the filesystem.
Pipes are created from one process, but they are rarely used in a single process. A pipe is a communication channel to a different process that is related or unrelated. Pipes create a flow of data from one end in one process (input end) to the other end that is in another process (output end). The data becomes a stream of bytes that flows in one direction through the pipe. Two pipes can be used to create bidirectional flow of communication between the processes. Figure 7-5 shows the various uses of pipes from a single process, from to two processes using a single pipe with a one direction flow of data from Process A to Process B, and then with a bidirectional flow of data between two processes that use two pipes.
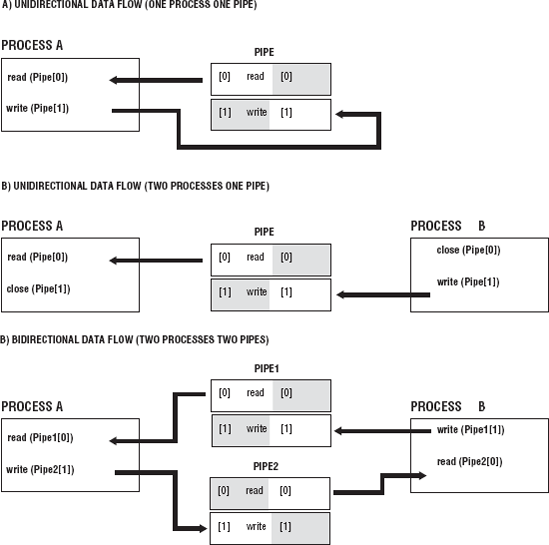
Two pipes are used to create a bidirectional flow of data because of the way that pipes are set up. Each pipe has two ends, and each pipe has a one-way flow of data. So, one process uses the pipe as an input end (write data to pipe), and the other process uses the same pipe but uses the output end (read data from the pipe). Each process closes the end of the process it does not access, as shown in Figure 7-5.
Anonymous pipes are temporary and exist only while the process that created them has not terminated. Named pipes are special types of files and exist in the filesystem. They can remain after the process that created it has terminated unless the process explicitly removes them from the filesystem. A program that creates a named pipe can finish executing and leave the named pipe in the filesystem, but the data that was placed in the pipe will not be present. Future programs and processes can then access the named pipe later, writing new data to the pipe. In this way, a named pipe can be set up as a kind of permanent channel of communication. Named pipes have file permission settings associated with them, and anonymous pipes do not.
Names pipes are created with mkfifo():
Synposis
#include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *pathname, mode_t mode); int unlink(const char *pathname);
mkfifo() creates a named pipe using pathname as the name of the FIFO with permission specified by mode. mode comprises the file permission bits. They are as listed previously in Table 7-3.
mkfifo() is created with O_CREAT | O_EXCL flags, which means it creates a new named pipe with the name specified if it does not exist. If is does exist, an error EEXIST is returned. So, if you want to open an already existing named pipe, call the function, and check for this error. If the error occurs then use open() instead of mkfifo().
The unlink() removes the filename pathname from the filesystem. The program in Listing 7-1 creates a named pipe with mkfifo.
Listings 7-1 and 7-2 are listings of programs that demonstrate how a named pipe can be used the transfer data from one process to another unrelated process. Listing 7-1 contains the program of the writer, and Listing 7-2 contains the program for the reader.
Example 7.1. Listing 7-1
// Listing 7-1 A program that creates a named pipe with mkfifo(). 1 using namespace std; 2 #include <iostream> 3 #include <fstream> 4 #include <sys/wait.h> 5 #include <sys/types.h> 6 #include <sys/stat.h> 7
8 int main(int argc,char *argv[],char *envp[])
9 {
10
11 fstream Pipe;
12
13 if(mkfifo("Channel-one",S_IRUSR | S_IWUSR
14 | S_IRGRP
15 | S_IWGRP) == −1){
16 cerr << "could not make fifo" << endl;
17 }
18
19 Pipe.open("Channel-one",ios::out);
20 if(Pipe.bad()){
21 cerr << "could not open fifo" << endl;
22 }
23 else{
24 Pipe << "2 3 4 5 6 7 " << endl;
25
26 }
27
28 return(0);
29 }The program in Listing 7-1 creates a named pipe with the mkfifo() system call. The program then opens the pipe with an fstream object called Pipe in Line 19. Notice that Pipe has been opened for output using the ios::out flag. If the Pipe is not in a bad() state after the call to open, then the Pipe is ready for writing data to Channel-one. Although Pipe is ready for input, it blocks (waits) until another process has opened Channel-one for reading. When using the iostreams with pipes, it is important to remember that either the writer or reader must be opened for both input and output using ios::in | ios::out. Opening either the reader or the writer in this manner will prevent deadlock. In this case, we open the reader (Listing 7-2) for both. The program in this listing is called a reader because it reads the information from the pipe. The writer then writes a line of input to Pipe.
Example 7.2. Listing 7-2
// Listing 7-2 A program that reads from a named pipe.
1 using namespace std;
2 #include <iostream>
3 #include <fstream>
4 #include <string>
5 #include <sys/wait.h>
6 #include <sys/types.h>
7 #include <sys/stat.h>
8
9
10 int main(int argc, char *argv[])
11 {
12 int type;
13 fstream NamedPipe;
14 string Input;
15
16 NamedPipe.open("Channel-one",ios::in | ios::out);17
18 if(NamedPipe.bad()){
19 cerr << "could not open Channel-one" << endl;
20 }
21
22 while(!NamedPipe.eof() && NamedPipe.good()){
23
24 getline(NamedPipe,Input);
25 cout << Input << endl;
26 }
27 NamedPipe.close();
28 unlink("Channel-one");
29 return(0);
30
31 }The program in Listing 7-1 uses the << operator to write data into the pipe. Here the reader also has to open the pipe by using an fstream open, using the name of the named pipe Channel-one, and opening the pipe for input and output in Line 16. If the NamedPipe is not in a bad state after opening, then the data is read from the NamedPipe while NamedPipe is not eof() and is still good. The data is read from the pipe and stored in a string Input that is sent to cout. NamedPiped is then closed and the pipe is unlinked. These are unrelated processes. To run, each is launched separately.
Here is Program Profile 7-1 for Listings 7-1 and 7-2.
Listing 7-1 creates a pipe and opens the pipe with a fstream object. Before it writes a string to the pipe, it waits until another process opens the pipe for reading (Listing 7-2). Once the reader process opens the pipe for reading, the writer program writes a string to the pipe, closes the pipe, and then exits. The reader pipe reads the string from the pipe and displays the string to standard out. Run the reader and then the writer.
Run each program in separate terminals.
The use of fstream simplifies the IPC making the named pipe easier to access. All of the functionality of streams comes into play for this example:
mkfifo("Channel-one",...);
vector<int> X( 2,3,4,5,6,7);
ofstream OPipe("Channel-one",ios::out);
ostream_iterator<int> Optr(OPipe,"
");
copy(X.begin(),X.end(),Optr);Here a vector is used to hold all the data. An ofstream object is used this time instead of an fstream object to open the named pipe. An ostream iterator is declared and points to the named pipe (Channel-one). Now instead of successive insertion in a loop, the copy algorithm can copy all the data to the pipe. This is a convenience if have hundreds, thousands, or even more numbers to write to the pipe.
Besides simplifying the use of IPC mechanisms by using iostreams, iterators, and algorithm, you can also simplify use by encapsulating the FIFO into an FIFO interface class. Remember that in doing so you are modeling a FIFO structure. The FIFO class is a model for the communication between two or more processes. It transmits some form of information between them. The information is translated into a sequence of data, inserted into the pipe, and then retrieved by a process on the other side of the pipe. The data is then reassembled by the retrieving process. There must be somewhere for the data to be stored while it is in transit from process A to process B. This storage area for the data is called a buffer. Insertion and extraction operations are used to place the data into or extract the data from this buffer. Before performing insertions or extractions into or from the data buffer, the data buffer must exist. Once communication has been completed, the data buffer is no longer needed. So, your model must be able to remove the data buffer when it is no longer necessary. As indicated, a pipe has two ends, one end for inserting data and the other end for extracting data, and these ends can be accessed from different processes. Therefore the model should also include an input port and an output port that can be connected to separate processes. Here are the basic components of the FIFO model:
Input/output port
Insertion and extraction operation
Creation/initialization operation
Buffer creation, insertion, extraction, destruction
For this example, there are only two processes involved in communication. But if there are multiple processes that can read/write to/ from the named pipe stream, synchronization is required. So, this class also requires a mutex object. Example 7-1 shows the beginnings of the FIFO class:
Example 7.1. Example 7-1
// Example 7-1 Declaration of fifo class.
class fifo{
mutex Mutex;
//...
protected:
string Name;
public:
fifo &operator<<(fifo &In, int X);
fifo &operator<<(fifo &In, char X);
fifo &operator>>(fifo &Out, float X);
//...
};Using this technique, you can easily create fifos in the constructor. You can pass them easily as parameters and return values. You can use them in conjunction with the standard container classes and so on. The construction of such a component greatly reduces the amount of code needed to use FIFOs, provides opportunities for type safety, and generally allows the programmer to work at a higher level.
A message queue is a linked list of strings or messages. This IPC mechanism allows processes with the adequate permissions to the queue to write or remove messages. The sender of the message assigns a priority to it. Message queues do not require more than one process to be used. With a FIFO, the writer process blocks and cannot write to the pipe until there is a process that opens it for reading. With a message queue, a writer process can write to the message queue and then terminate. The data is retained in the queue. Some other process later can read or write to it. The message queue has kernel persistence. When reading a message from the queue, the oldest message with the highest priority is returned. Each message in the queue has these attributes:
A priority
The length of the message
The message or data
With a linked list the head of the list has the maximum number of messages allowed in the queue and the maximum size allowed for a message.
The message queue is created with mq_open():
Synopsis
#include <mqueue.h>
mqd_t mq_open(const char *name, int oflag,mode_t mode,
struct mq_attr *attr);
int mq_close(mqd_t mqdes);
int mq_unlink(const char *name);mq_open() creates a message queue with the specified name. The message queue uses oflag with these possible values to specify the access modes:
O_RDONLY: Open to receive messagesO_WRONLY: Open to send messagesO_RDWR: Open to send or received messages
These flags can be ORred with the following:
O_CREAT: Create a message queue.O_EXCL: If ORred with previous flag, function fails if the pathname already exists.O_NONBLOCK: Determines if queue waits for resources or messages that are not currently available.
The function returns a message queue descriptor of type mq_dt.
The last parameter is a struct mq_attr *attr. This is an attribute structure that describes the properties of the message queue:
struct mq_attr {
long mq_flags; //flags
long mq_maxmsg; //maximum number of messages allowed
long mq_msgsize; //maximum size of message
long mq_curmsgs; //number of messages currently in queue
}mq_close() closes the message queue, but the message queue still exists in the kernel. However, the calling function can no longer use the descriptor. If the process terminates, all message queues associated with the process also close. The data is still retained in the queue.
unlink() removes the message queue specified by name from the system. The number of references to the message queue is tracked, but the queue name can still be removed from the system even if the count is greater than 0. The queue is not destroyed until all processes that utilized the queue have closed or called mq_close().
There are two functions to set and return the attribute object, as shown in the following code synopsis:
Synopsis
#include <mqueue.h> int mq_getattr(mqd_t mqdes,struct mq_attr *attr); int mq_setattr(mqd_t mqdes,struct mq_attr *attr,struct mq_attr *oattr);
When you are setting the attribute with mq_setattr, only the mq_flags are set in the attr structure. Other attributes are not affected. mq_maxmsg and mq_msgsize are set when the message queue is created. mq_curmsg can be returned and not set. oattr contains the previous values for the attributes.
To send or write a message to the queue, use these functions:
Synopsis
#include <mqueue.h>
int mq_send(mqd_t mqdes, const char *ptr, size_t len,
unsigned int prio);
ssize_t mq_receive(mqd_t mqdes, const char *ptr, size_t len,
unsigned int priop);For mq_receive(), the len must be at least the maximum size of the message. The returned message is stored in *ptr.
posix_queue is a simple class that models some of the functionality of a message queue. It encapsulates the basic functions and the message queue attributes. Listing 7-3 shows the declaration of the posix_queue class.
Example 7.3. Listing 7-3
// Listing 7-3 Declaration of the posix_queue class. 1 #ifndef __POSIX_QUEUE 2 #define __POSIX_QUEUE 3 using namespace std; 4 #include <string> 5 #include <mqueue.h> 6 #include <errno.h> 7 #include <iostream> 8 #include <sstream>
9 #include <sys/stat.h>
10
11
12 class posix_queue{
13 protected:
14 mqd_t PosixQueue;
15 mode_t OMode;
16 int QueueFlags;
17 string QueueName;
18 struct mq_attr QueueAttr;
19 int QueuePriority;
20 int MaximumNoMessages;
21 int MessageSize;
22 int ReceivedBytes;
23 void setQueueAttr(void);
24 public:
25 posix_queue(void);
26 posix_queue(string QName);
27 posix_queue(string QName,int MaxMsg, int MsgSize);
28 ~posix_queue(void);
29
30 mode_t openMode(void);
31 void openMode(mode_t OPmode);
32
33 int queueFlags(void);
34 void queueFlags(int X);
35
36 int queuePriority(void);
37 void queuePriority(int X);
38
39 int maxMessages(void);
40 void maxMessages(int X);
41 int messageSize(void);
42 void messageSize(int X);
43
44 void queueName(string X);
45 string queueName(void);
46
47 bool open(void);
48 int send(string Msg);
49 int receive(string &Msg);
50 int remove(void);
51 int close(void);
52
53
54 };
55
#endifThe basic functions performed by a message queue are encapsulated in the posix_queue class:
47 bool open(void); 48 int send(string Msg); 49 int receive(string &Msg); 50 int remove(void); 51 int close(void);
We have discussed what each these functions does already. Examples 7-2 through 7-6 show the definitions of these methods. Example 7-2 is the definition of open():
Example 7.2. Example 7-2
// Example 7-2 The definition of open().
122 bool posix_queue::open(void)
123 {
124 bool Success = true;
125 int RetCode;
126 PosixQueue = mq_open(QueueName.c_str(),QueueFlags,OMode,&QueueAttr);
127 if(errno == EACCES){
128 cerr << "Permission denied to created " << QueueName << endl;
129 Success = false;
130 }
131 RetCode = mq_getattr(PosixQueue,&QueueAttr);
132 if(errno == EBADF){
133 cerr << "PosixQueue is not a valid message descriptor" << endl;
134 Success = false;
135 close();
136
137 }
138 if(RetCode == −1){
139 cerr << "unknown error in mq_getattr() " << endl;
140 Success = false;
141 close();
142 }
143 return(Success);
144 }After the call to mq_open() is made in Line #126, errno is checked to see if message queue failed to open because a message queue by the name QueueName.c_str() already exists. If it does, then the call is not successful. bool Success is returned with a value of false.
In Line 131, the queue attribute structure is returned by mq_getattr(). To ensure that the message queue was opened and successfully initialized its attribute, errno is checked again in Line 132. EBADF means the descriptor was not a valid message queue descriptor. The return code is checked in Line 138.
Example 7-3 is the definition of send().
Example 7.3. Example 7-3
// Example 7-3 The definition of send().
146 int posix_queue::send(string Msg)
147 {
148
149 int StatusCode = 0;
150 if(Msg.size() > QueueAttr.mq_msgsize){
151 cerr << "message to be sent is larger than max queue
message size " << endl;
152 StatusCode = −1;
153 }
154 StatusCode = mq_send(PosixQueue,Msg.c_str(),Msg.size(),0);
155 if(errno == EAGAIN){
156 StatusCode = errno;
157 cerr << "O_NONBLOCK not set and the queue is full " << endl;
158 }
159 if(errno == EBADF){
160 StatusCode = errno;
161 cerr << "PosixQueue is not a valid descriptor open for
writing" << endl;
162 }
163 if(errno == EINVAL){
164 StatusCode = errno;
165 cerr << "msgprio is out side of the priority range for the
message queue or " << endl;
166 cerr << "Thread my block causing a timing conflict with
time out" << endl;
167 }
168
169 if(errno == EMSGSIZE){
170 StatusCode = errno;
171 cerr << "message size exceeds maximum size of message
parameter on message queue" << endl;
172
173 }
174 if(errno == ETIMEDOUT){
175 StatusCode = errno;
176 cerr << "The O_NONBlock flag was not set, but the time expired
before the message " << endl;
177 cerr << "could be added to the queue " << endl;
178 }
179 if(StatusCode == −1){
180 cerr << "unknown error in mq_send() " << endl;
181 }
182 return(StatusCode);
183
184 }In Line 150, the message is checked to ensure that its size does not exceed the allowable size for a message. In Line 154 the call to mq_send() is made. All other code checks for errors.
Example 7-4 is the definition of receive().
Example 7.4. Example 7-4
//Example 7-4 The definition of receive().
187 int posix_queue::receive(string &Msg)
188 {
189
190 int StatusCode = 0;
191 char QueueBuffer[QueueAttr.mq_msgsize];
192 ReceivedBytes = mq_receive(PosixQueue,QueueBuffer,
QueueAttr.mq_msgsize,NULL);
193 if(errno == EAGAIN){
194 StatusCode = errno;
195 cerr << "O_NONBLOCK not set and the queue is full " << endl;
196
197 }
198 if(errno == EBADF){
199 StatusCode = errno;
200 cerr << "PosixQueue is not a valid descriptor open for writing"
<< endl;
201 }
202 if(errno == EINVAL){
203 StatusCode = errno;
204 cerr << "msgprio is out side of the priority range for the message
queue or " << endl;
205 cerr << "Thread my block causing a timing conflict with time out"
<< endl;
206 }
207 if(errno == EMSGSIZE){
208 StatusCode = errno;
209 cerr << "message size exceeds maximum size of message parameter on
message queue" << endl;
210 }
211 if (errno == ETIMEDOUT){
212 StatusCode = errno;
213 cerr << "The O_NONBlock flag was not set, but the time expired
before the message " << endl;
214 cerr << "could be added to the queue " << endl;
215 }
216 string XMessage(QueueBuffer,QueueAttr.mq_msgsize);
217 Msg = XMessage;
218 return(StatusCode);
219
220 }In Line 191, a buffer QueueBuffer with the maximum size of a message is created. mq_receive() is called. The message returned is stored in QueueBuffer, and the number of bytes is returned and stored in ReceivedBytes. In Line 216, the message is extracted from QueueBuffer and assigned to the string in Line 217.
In Example 7-5 is the definition for remove().
Example 7.5. Example 7-5
//Example 7-5 The definition for remove().
221 int posix_queue::remove(void)
222 {
223 int StatusCode = 0;
224 StatusCode = mq_unlink(QueueName.c_str());
225 if(StatusCode != 0){
226 cerr << "Did not unlink " << QueueName << endl;
227 }
228 return(StatusCode);
229 }
230In Line 224, mq_unlink() is called to remove the message queue from the system.
Example 7-6 provides the definition for close().
Example 7.6. Example 7-6
//Example 7-6 The definition for close().
231 int posix_queue::close(void)
232 {
233
234 int StatusCode = 0;
235 StatusCode = mq_close(PosixQueue);
236 if(errno == EBADF){
237 StatusCode = errno;
238 cerr << "PosixQueue is not a valid descriptor open for
writing" << endl;
239 }
240 if(StatusCode == −1){
241 cerr << "unknown error in mq_close() " << endl;
242 }
243 return(StatusCode);
244
245 }In Line 235, mq_close() is called to close the message queue.
Return briefly to Listing 7-3, notice that the bolded methods from Examples 7-2 through 7-6 encapsulate the message queue's attributes to set and return the properties of the message queue:
33 int queueFlags(void); 34 void queueFlags(int X); 35 36 int queuePriority(void); 37 void queuePriority(int X); 38
39 int maxMessages(void); 40 void maxMessages(int X); 41 int messageSize(void); 42 void messageSize(int X);
Some of these attributes are can also be set in the constructor. There are three constructors in Listing 7-3:
25 posix_queue(void); 26 posix_queue(string QName); 27 posix_queue(string QName,int MaxMsg, int MsgSize);
At Line 25 is the default constructor. Example 7-7 shows the definition.
Example 7.7. Example 7-7
// Example 7-7 The definition of the default constructor.
4 posix_queue::posix_queue(void)
5 {
6
7
8 QueueFlags = O_RDWR | O_CREAT | O_EXCL;
9 OMode = S_IRUSR | S_IWUSR;
10 QueueName.assign("none");
11 QueuePriority = 0;
12 MaximumNoMessages = 10;
13 MessageSize = 8192;
14 ReceivedBytes = 0;
15 setQueueAttr();
16
17
18 }This posix_queue class is a simple model of the message queue. All functionality has not been included here, but you can see a message queue class makes the message queue easier to use. The posix_queue class performs error checking for all of the major functions of the IPC mechanism. What should be added is the mq_notify function. With notification signaling, a process is signaled when the empty message queue has a message. This class does not have synchronization capabilities. If multiple processes want to use the posix_queue to write to it, a built-in mutex should be implemented and used when messages are sent or received.
We have discussed the different mechanisms defined by POSIX to perform communication between processes, related and unrelated. We have discussed where those IPC reside and their persistence. Because threads reside in the address space of their process, it is safe and logical to assume that communication between threads would not be difficult or require the use of special mechanisms just for communication. That is true. The most important issue that has to be dealt with when peer threads require communication with each other is synchronization. Data races and indefinite postponement are likely when performing Interthread Communication (ITC).
Communication between threads is used to:
Share data
Send a message
Multiple threads share data in order to streamline processing performed concurrently. Each thread can perform different processing or the same processing on data streams. The data can be modified, or new data can be created as a result, which in turn is shared. Messages can also be communicated. For example, if an event happens in one thread, this could trigger another event in another thread. Threads may communicate a signal to other peer threads, or the main thread may signal the worker threads.
When two processes need to communicate, they use a structure that is external to both processes. When two threads communicate, they typically use structures that are part of the same process to which they both or all belong. Threads cannot communicate with threads outside their process unless you are referring to primary threads of processes. In that case, you refer to them as two processes. Threads within a process can pass values from the data segment of the process or stack segments of each thread.
In most cases, the cost of Interprocess Communication is higher than Interthread Communication. The external structures that must be created by the operating system during IPC require more system processing than the structures involved in ITC. The efficiency of ITC mechanisms makes threads a more attractive alternative in many, but not all programming scenarios that require concurrency.
We discussed some of the issues and drawbacks of using threads as compared to processes in Chapter 5.
Table 7-4 lists the basic Interthread Communications with a brief description.
Table 7.4. Table 7-4
Types of ITC | Description |
|---|---|
Declared outside of the main function or have global scope. Any modifications to the data are instantly accessible to all peer threads. | |
Parameters | Parameters passed to threads during creation. The generic pointer can be converted any data type. |
File handles | Files shared between threads. These threads share the same read-write pointer and offset of the file. |
An important advantage that threads have over processes is that threads can share global data, variables, and data structures. All threads in the process can access them equally. If any thread changes the data, the change is instantly available to all peer threads. For example, take three threads, ThreadA, ThreadB, and ThreadC. ThreadA makes a calculation and stores the results in a global variable Answer. ThreadB reads Answer, performs its calculation on it, and then stores its results in Answer. Then Thread C does the same thing. The final answer is to be displayed by the main thread. This example is shown in Listings 7-4, 7-5, and 7-6.
Example 7.4. Listing 7-4
// Listing 7-4 thread_tasks.h. 1 2 void *task1(void *X); 3 void *task2(void *X); 4 void *task3(void *X); 5
Example 7.5. Listing 7-5
// Listing 7-5 thread_tasks.cc.
1 extern int Answer;
2
3 void *task1(void *X)
4 {
5 Answer = Answer * 32;
6 }
7
8 void *task2(void *X)
9 {
10 Answer = Answer / 2;
11 }
12
13 void *task3(void *X)
14 {
15 Answer = Answer + 5;
16 }Example 7.6. Listing 7-6
// Listing 7-6 main thread.
1 using namespace std;
2 #include <iostream>
3 #include <pthread.h>
4 #include "thread_tasks.h"
5
6 int Answer = 10;
7
8
9 int main(int argc, char *argv[])
10 {
11
12 pthread_t ThreadA, ThreadB, ThreadC;
13
14 cout << "Answer = " << Answer << endl;
15
16 pthread_create(&ThreadA,NULL,task1,NULL);
17 pthread_create(&ThreadB,NULL,task2,NULL);
18 pthread_create(&ThreadC,NULL,task3,NULL);
1920 pthread_join(ThreadA,NULL); 21 pthread_join(ThreadB,NULL); 22 pthread_join(ThreadC,NULL); 23 24 cout << "Answer = " << Answer << endl; 25 26 return(0); 27 28 }
In these listings, the tasks that the threads will execute are defined in a separate file. Answer is the global data declared in the main line in the file program7-6.cc. It is out of scope for use by the tasks that are in defined in thread_tasks.cc. It is declared as extern, so it can have global scope. If the threads are to process the data in the way described earlier — ThreadA, ThreadB, and then ThreadC perform their calculations — it requires synchronization. It is not guaranteed that the correct answer, 165, will be returned if ThreadA and ThreadB have other work they have to do first. The threads are transferring data from one thread to another. With, say, two multicores, ThreadA and ThreadB can be executing. ThreadA works for a time slice, and then ThreadC is given the processor. When ThreadA is preempted, it may still not execute its calculation on Answer. If ThreadC finished when it was preempted, the value of Answer would be 15. Then ThreadB finishes; the Answer is 7. Then ThreadA does its calculation; Answer is 224 not 165. Although a pipeline model of data communication is what was desired, there is no synchronization in place for it to be executed.
Threads can also share data structures in the same way that the variable was used. IPC supports only a limited set of data structures that can be used (for example, a message queue); in contrast, any type of global set, map, or so forth or any other collection or container class can be used to accomplish ITC. For example, threads can share a set. With a set, membership, intersection, union, and so forth, operations can be performed by different threads using Multiple Instruction Single Data (MISD) or Single Instruction Single Data (SISD) memory access models. The coding that it would take to implement a set container that could be used as an IPC mechanism is prohibitive.
Here is Program Profile 7-2 for Listings 7-4, 7-5, and 7-6.
For this program, there is a global variable Answer declared in the main line in the file program7-6.cc. It is declared as extern, so it can have global scope in thread_tasks.cc. Answer is to be processed by ThreadA, ThreadB, and then ThreadC. They are to perform their calculations, which requires synchronization. The correct answer is 165. Although a pipeline model of data communication is what was desired, there is no synchronization in place for it to be executed.
Parameters to threads can be used for communication between threads or between the primary thread and peer threads. The thread creation API supports thread parameters. The parameter is in the form of a void pointer:
int pthread_create(pthread_t *threadID,const pthread_attr_t *attr,
void *(*start_routine)(void*),
void *restrict parameter);The void pointer in C++ is a generic pointer and can be used to point to any data type. The value of parameter passes values as simple as a char * or a complex as a pointer to a container or user-defined object. In the program in Listing 7-7 and Listing 7-8, we use two queues of strings as global data structures. One thread uses the queue as an output queue, and another thread uses that same queue as a data stream for input and then writes to the second global queue of strings.
Example 7.7. Listing 7-7
// Listing 7-7 Thread tasks that use two global data structures. 1 using namespace std; 2 #include <queue> 3 #include <string> 4 #include <iostream> 5 6 extern queue<string> SourceText; 7 extern queue<string> FilteredText; 8 9 void *task1(void *X)
10 {
11 char Token = '?';
12
13 queue<string> *Input;
14
15
16 Input = static_cast<queue<string> *>(X);
17 string Str;
18 string FilteredString;
19 string::iterator NewEnd;
20
21 for(int Count = 0;Count < 16;Count++)
22 {
23 Str = Input->front();
24 Input->pop();
25 NewEnd = remove(Str.begin(),Str.end(),Token);
26 FilteredString.assign(Str.begin(),NewEnd);
27 SourceText.push(FilteredString);
28
29 }
30
31
32 }
33
34
35 void *task2(void *X)
36 {
37 char Token = '.';
38
39 string Str;
40 string FilteredString;
41 string::iterator NewEnd;
42
43 for(int Count = 0;Count < 16;Count++)
44 {
45 Str = SourceText.front();
46 SourceText.pop();
47 NewEnd = remove(Str.begin(),Str.end(),Token);
48 FilteredString.assign(Str.begin(),NewEnd);
49 FilteredText.push(FilteredString);
50
51
52 }
53
54 }These tasks filter a string of text. task1 removes the (?) from a string and task2 removes a (.) from a string. task1 accepts a queue that serves as the container of strings to be filtered. The void * is type cast to a pointer to a queue of strings in Line #16. task2 does not require a queue for input. It uses the global queue SourceText that is populated by task1. Inside their loops, a string is removed from the queue, the token is removed, and the new string is pushed onto the global queues. For task1 the queue string is SourceText and for task2, the queue string is FilteredText. Both queues are declared extern in Lines 6 and 7.
Example 7.8. Listing 7-8
// Listing 7-8 Main thread declares two global data structures.
1 using namespace std;
2 #include <iostream>
3 #include <pthread.h>
4 #include "thread_tasks.h"
5 #include <queue>
6 #include <fstream>
7 #include <string>
8
9
10
11
12 queue<string> FilteredText;
13 queue<string> SourceText;
14
15 int main(int argc, char *argv[])
16 {
17
18 ifstream Infile;
19 queue<string> QText;
20 string Str;
21 int Size = 0;
22
23
24 pthread_t ThreadA, ThreadB;
25
26 Infile.open("book_text.txt");
27 for(int Count = 0;Count < 16;Count++)
28 {
29 getline(Infile,Str);
30 QText.push(Str);
31
32 }
33
34 pthread_create(&ThreadA,NULL,task1,&QText);
35 pthread_join(ThreadA,NULL);
36
37 pthread_create(&ThreadB,NULL,task2,NULL);
38 pthread_join(ThreadB,NULL);
39
40 Size = FilteredText.size();
41
42 for(int Count = 0;Count < Size;Count++)
43 {
44 cout << FilteredText.front() << endl;
45 FilteredText.pop();
46
47 }
48
49 Infile.close();50 51 return(0); 52 53 }
The program in Listing 7-8 shows the code for the main thread. It declares the two global queues on Line 12 and Line 13. The strings are read in from a file into string queue QText. This is the data source queue for ThreadA in Line 34. The main thread then calls a join on ThreadA and waits for it to return. When ThreadA returns, ThreadB uses the global queue SourceText just populated by task1. When ThreadB returns, the strings in the global queue FilteredText are sent to cout by the main thread. By the main thread calling join in this way these threads are not executed concurrently. The main thread does not create ThreadB until ThreadA returns. If the threads were created one after the other, they would be executed concurrently. The threat of a core dump looms. If ThreadB starts its execution before ThreadA populates its source queue, then ThreadB attempts to pop an empty queue. The size of the queue could be checked before attempting to read it. But you want to take advantage of the multicore in doing this processing. Here you have a few strings in a queue and all you want to do is remove a single token. But if you scale this problem to thousands of string and many tokens to be removed, you realize that another approach has to exist. Again, you do not want to go to a serial solution. Access to the queue can be synchronized but filtering all the strings at once can also be parallelized. We will revisit the problem and present a better solution later in this chapter.
Here is Program Profile 7-3 for Listings 7-7 and 7-8.
The program in Listing 7-8 shows the code for the main thread. It declares the two global queues used for input and output. The strings are read in from a file into string queue QText, the data source queue for ThreadA. The main thread then calls a join on ThreadA and waits for it to return. When ThreadA returns, ThreadB uses the global queue SourceText just populated by ThreadA. When ThreadB returns, the strings in the global queue FilteredText are sent to cout by the main thread.
None
With processes, command-line arguments are passed by using the exec family of functions or posix_spawn, as discussed in Chapter 5. The command-line arguments are restricted to simple data types such as numbers and characters. The parameters passed to processes are one-way communication. The child process simply copies the parameter values. Any modifications made to the data will not be reflected in the parent. With threads, the parameter is not a copy but an address to some data location. Any modification made by the thread to that data can be seen by any thread that uses it.
But this type of transparency may not be what you desire. A thread can keep its own copy of data passed to it. It can copy it to its stack, but what's on its stack will come and go. A thread can be called several times performing the same task over and over again. By using thread-specific data, data can be associated with a thread and made private and persistent.
Sharing files between multiple threads as a form of ITC requires the same caution as using global variables. If Thread A moves the file pointer, then Thread B accesses the file at that location. What if one thread closes the files and another thread attempts to write to the file — what happens? Can a thread read from the file while another thread writes to it? Can multiple threads write to the file? Care must be taken to serialize or synchronize access to files within a multithreaded environment. Since threads can share actual read-write pointers, cooperation techniques must be used.
In any computer system, the resources are limited. There is only so much memory, and there are only so many I/O devices and ports, hardware interrupts, and, yes, even processors cores to go around. The number of I/O devices is usually restricted by the number of I/O ports and the hardware interrupts that a system has. In an environment of limited hardware resources, an application consisting of multiple processes and threads must compete for memory locations, peripheral devices, and processor time. Some threads and processes will be working together intimately using the system's limited sharable resources to perform a task and achieve a goal while other threads and processes work asynchronously and independently competing for those same sharable resources. It is the operating system's job to determine when the process or thread utilizes system resources and for how long. With preemptive scheduling, the operating system can interrupt the process or thread in order to accommodate all the processes and threads competing for the system resources. There are software resources and hardware resources. An example of software resources is a shared library that provides a common set of services or functions to processes and threads. Other sharable software resources are:
To share software resources requires only one copy of the program(s) code to be brought into memory. Data resources are objects, system data files (for example, environment variables), globally defined variables, and data structures. In the last section, we discussed data resources that are used for data communication. It is possible for processes and threads to have their own copy of shared data resources. In other cases, it is desirable, and maybe necessary, that data is shared. Sharing data can be tricky and may lead to race conditions (modifying data simultaneously) or data not being where it should when it is needed. Even attempting to synchronize access to resources can cause problems if this is not properly executed or if the wrong IPC or ITC mechanism is used. This can cause indefinite postponement or deadlock. Synchronization allows multiple threads and processes to be active at the same time while sharing resources without interfering with each other's operation. The synchronization process temporarily serializes (in some cases) execution of the multiple tasks to prevent problems. Serialization occurs if one-at-a-time access has to be granted to hardware or software resources. But too much serialization defeats the advantages of concurrency and parallelism. Then cores sit idle. Serialization is used as the last approach if nothing else can be done. Coordination is the key.
We talked about the resources of the system that are shared, hardware and software resources. These are the entities in a system that require synchronization. What also should be included are tasks, which should also be synchronized. You saw evidence of this in the program in Listing 7-7 and 7-8. task1 had to execute and complete before task2 could begin. Therefore, there are three major categories of synchronization:
Data
Hardware
Task
Table 7-5 summarizes each type of synchronization.
Table 7.5. Table 7-5
Types of synchronization | Description |
|---|---|
Data | Necessary to prevent race conditions. It allows concurrent threads/processes to access a block of memory safely. |
Hardware | Necessary when several hardware devices are needed to perform a task or group of tasks. It requires communication between tasks and tight control over real-time performance and priority settings. |
Task | Necessary to prevent race conditions. It enforces preconditions and postconditions of logical processes. |
In this chapter thus far, we have discussed IPC and ITC. As we have discussed, the difference between data shared between processes and data shared between threads is that threads share the same address space and processes have separate address spaces. IPC exists outside the address space of the processes involved in the communication, in the kernel space or in the filesystem. Shared memory maps a structure to a block of memory that is accessible to the processes. ITC are global variables and data structures. It is the IPC and ITC mechanisms that require synchronization. Figure 7-6 shows where the IPC and ITC mechanisms exist in the layout of a process.
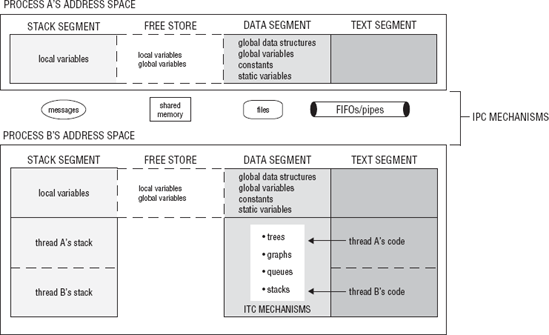
Data synchronization is needed in order to control race conditions and allow concurrent threads or processes to safely access a block of memory. Data synchronization controls when a block of memory can be read or modified. Concurrent access to shared memory, global variables, and files must be synchronized in a multithreaded environment. Data synchronization is needed at the location in a task's code when it attempts to access the block of memory, global variable, or file shared with other concurrently executing processes or threads. This is called the critical section. The critical section can be any block of code that changes the writes or reads to/from a file, closes a file, reads or writes global variables or data structures.
Critical sections are an area or block of code that accesses a shared resource that must be controlled because the resource is being shared by multiple concurrent tasks. Critical sections are marked by an entry point and an exit point. The actual code in the critical section can be one line of code where the thread/process is reading or writing to memory or a file. It can also be several lines of code where processing and calls to other methods involve the shared data. The entry point marks your entering the critical section and an exit point marks your leaving the critical section.
entry point(synchronization starts here) - - - -critical section - - - -access file, variable or other resource- - - -critical section - - - -exit point(synchronization ends here)
In order to solve the problems caused by multiple concurrent tasks sharing a resource, three conditions should be met:
If a task is in its critical section, other tasks sharing the resource cannot be executing in their critical section. They are blocked. This is called mutual exclusion.
If no tasks are in their critical section, then any blocked tasks can now enter their critical section. This is called progress.
There should be a bounded wait as to the number of times that a task is allowed to reenter its critical sections. A task that keeps entering its critical sections may prevent other tasks from attempting to enter theirs. A task cannot reenter its critical sections if other tasks are waiting in a queue.
These synchronization techniques are what are used to manage critical sections. It is important to determine the how these concurrently executing tasks are using the shared data. Are they writing to the data while others are reading? Are all reading from it? Are all writing to it? How they are sharing the shared data helps determine what type of synchronization is needed and how it should be implemented. Remember applying synchronization incorrectly can also cause problems like deadlock, data race conditions, and so forth.
The Parallel Random-Access Machine (PRAM) is a simplified theoretical model in which there are N processors labeled P1, P2, P3, ... PN that share one global memory. All the processors have simultaneous read and write access to shared global memory. Each of these theoretical processors can access the global shared memory in one uninterruptible unit of time. The PRAM model has four algorithms that can be used to access the shared global memory, concurrent read and write algorithms, and exclusive read and write algorithms that work like this:
Concurrent read algorithms are allowed to read the same piece of memory simultaneously with no data corruption.
Concurrent write algorithms allow multiple processors to write to the shared memory.
Exclusive read algorithms are used to ensure that no two processors ever read the same memory location at the same time.
Exclusive write ensures that no two processors write to the same memory at the same time.
Now this PRAM model can be used to characterize concurrent access to shared memory by multiple tasks.
The concurrent and exclusive read-write algorithms can be combined into the following types of algorithm combinations that are possible for read-write access:
These algorithms can be viewed as access policies implemented by the tasks sharing the data. Figure 7-7 shows these access policies. EREW means access to the shared memory is serialized where only one task at a time is given access to the shared memory whether it is access to write or to read. An example of EREW access policy is the producer-consumer. The program in Chapter 5 in Listing 5-7 has an EREW access policy with the shared posix_queue between processes. One process writes the name of a file another process is to search for the code in. Access to the queue that contained the filenames was restricted to exclusive write by the producer and exclusive read by the consumer. Only one task was allowed access to the queue at any given time.
CREW access policy allows multiple reads of the shared memory and exclusive writes. There are no restrictions on how many tasks can read the shared memory concurrently, but only one task can write to the shared memory. Concurrent reads can occur while an exclusive write is taking place. With this access policy, each reading task may read a different value while other task is writing. The next task that reads the shared memory will see different data than some other task. This may be intended, but it also may not. ERCW access policy is direct reverse of CREW. Only one task can read the shared data, but concurrent writes are allowed. CRCW access policy allows concurrent reads and concurrent writes.
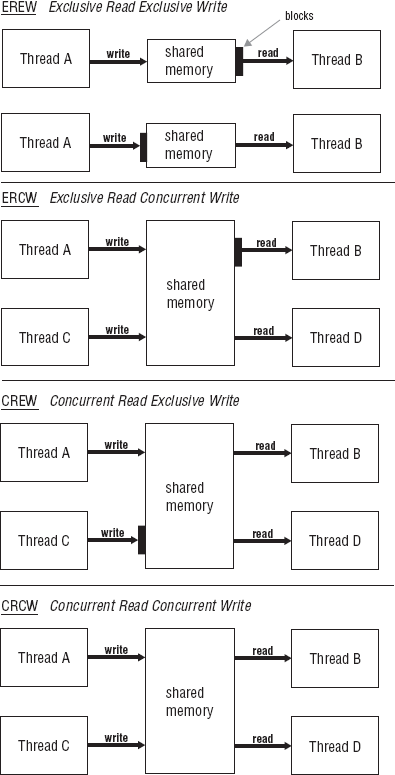
Each of these four algorithm types requires different levels and types of synchronization. They can be analyzed on a continuum with the access policy that requires the least amount of synchronization to implement on one end and the access policy that requires the most amount of synchronization at the other end. EREW is the policy that is the simplest to implement because EREW essentially forces sequential processing. You may think that CRCW is the simplest, but it presents the most challenges. It may appear that memory can be accessed without restriction. But this is the most difficult to implement and requires the most synchronization in order to meet the goal to implement a synchronization process that maintains data integrity and satisfactory system performance.
Synchronization is also needed to coordinate the order of execution of concurrent tasks. Order of execution was important in the program in Listings 7-5 and 7-6. If the tasks were executed out of order, the final value for Answer would be wrong. In the program in Listings 7-7 and 7-8, if task1 did not complete, task2 would attempt to read from an empty queue. Synchronization is required to coordinate these tasks so that work can progress or so that the correct results can be produced. Data synchronization (access synchronization) and task synchronization (sequence synchronization) are two types of synchronization required when executing multiple concurrent tasks. Task synchronization enforces preconditions and postconditions of logical processes.
There are four basic synchronization relationships between any two tasks in a single process or between any two processes within a single application:
Start-to-start (SS)
Finish-to-start (FS)
Start-to-finish (SF)
Finish-to-finish (FF)
These four basic relationships characterize the coordination of work between threads and processes. Figure 7-8 shows activity diagrams for each synchronization relationship.
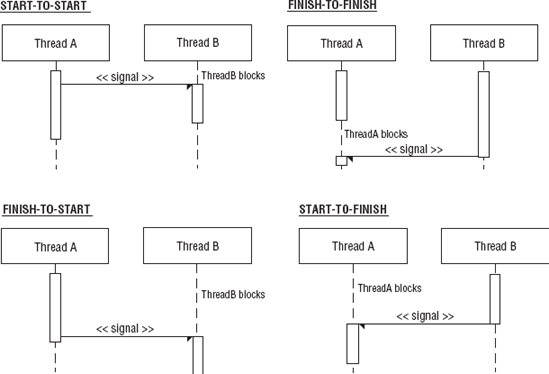
In a start-to-start synchronization, one task cannot start until another task starts. One task may start before the other but never after. For example, say that you have a program that implements an Embedded Conversational Agent (ECA). The ECA is a computer-generated talking head, which provides a kind of personality for software. The program that implements the ECA has several threads. Here, the focus is on the threads that controls the animation of the eyes (ECA does not have a mouth, the eyes animate) and the thread that controls the sound or voice. You want to give the illusion that the sound and eyes animation are synchronized. Ideally, they should execute at precisely the same moment. With multiple processor cores, both threads may start simultaneously. The threads have a start-to-start relationship. Because of timing conditions, the thread that produces the audio (Thread A) is allowed to start slightly before the thread that starts the animation (Thread B), but not much before for the illusion's sake. It takes a little longer for the audio to initialize, so it can start a bit early. Graphics load much faster. Figure 7-9 shows images of our ECA.

In a finish-to-start synchronization, Task A cannot finish until Task B starts. This type of relationship is common with parent-child processes. The parent process cannot complete execution of some operation until it spawns a child process or it receives a communication from the child process that it has started its operation. The child process continues to execute once it has signaled the parent or supplied the needed information. The parent process is then free to complete its operation.
A start-to-finish synchronization relationship is the reverse of the finish-to-start relationship. In a start-to-finish synchronization relationship, one task cannot start until another task finishes. Task A cannot start execution until Task B finishes executing or completes a certain operation. The program in Listing 7-7 and 7-8 had a start-to-finish synchronization. task2 could not start until task1 completed. The main thread used a join for synchronization. The main thread blocked until task1 returned then it created a thread that executed task2.
If process A is reading from a pipe connected to process B, process B must first write to the pipe before process A reads from it. Process B must complete at least one operation — write a single element to the pipe — before process A starts. With the pipe, there is limited synchronization built in by using blocking. But if there are multiple readers and writers, then more elaborate synchronization is required.
A finish-to-finish synchronization relationship means one task cannot finish until another task finishes. Task A cannot finish until Task B finishes. This again can describe the relationship between parent and child processes. The parent process must wait until all its child processes have terminated before it is allowed to terminate. If the parent process terminates before its child processes, those terminated child processes become zombied. The parent process calls a wait() for each of its child processes (like join for threads) or waits for a mutex or condition variable that is broadcast by child threads.
Another example of a finish-to-finish relationship is the boss-worker concurrency model. It is the boss's job to delegate work to the workers. It would be undesirable for the boss to terminate before the worker. New requests to the system would not be processed, existing threads would have no work to perform, and no new threads would be created. If the boss were a primary thread and it terminated, the process would terminate along with all the worker threads. In a peer-to-peer model, if thread A dynamically allocates an object passed to thread B and thread A terminates, the object is destroyed along with thread A. If this is done before thread B has a chance to use it, a segmentation fault or data access violation occurs. In order to prevent these kinds of errors with threads, termination of threads is synchronized by using the pthread_join(). This creates a finish-to-finish synchronization.
The synchronization mechanisms we discuss in this section cover mechanisms for both processes and threads. These mechanisms can be used to prevent race conditions and deadlocks between multiple tasks by implementing the synchronization access policies we have mentioned and managing critical sections of tasks. In this section, we introduce:
Semaphores and mutexes
Read-write locks
Condition variables
A semaphore is a synchronization mechanism that is used to manage synchronization relationships and implement access policies. A semaphore is a special kind of variable that can be accessed only by very specific operations. It helps threads and processes synchronize access to shared modifiable memory or manage access to a device or other resource. The semaphore is like a key that grants access the resource. This key can be owned by only one process or thread at a time. Whichever task owns the key or semaphore locks the resource for its exclusive use. Locking the resource causes any other task that wishes to access the resource to wait until the resource has been unlocked. When the semaphore is unlocked, the next task waiting in the queue for the semaphore is given it, thus accessing the resource. The next task is determined by the scheduling policy used by the thread or process. Figure 7-10 shows the basic concept of a semaphore as described.
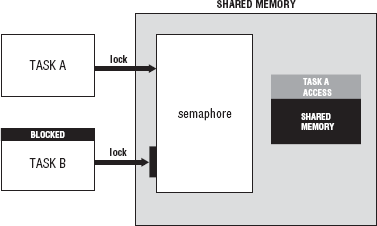
A semaphore can be accessed only by specific operations. There are two operations that can be performed on a semaphore: P() and V() operations. The P() operation decrements the semaphore and the V() operation increments the semaphore:
P(Mutex)if(Mutex > 0){ Mutex — ; } else { Block on Mutex; }V(Mutex)if(Blocked on Mutex N processes){ pass on Mutex; } else{ Mutex++; }
Here Mutex is the semaphore. The actual implementation will be system dependent. These operations are indivisible. This means that once the operation is in progress, it cannot be preempted. If several tasks attempt to make a call to the P() operation, only one task is allowed to proceed. If Mutex has already been decremented, then the task blocks and is placed in a queue. The V() operation is called by the task that owns Mutex. If there are other tasks waiting on Mutex, it is given to the next task in the queue according the scheduling policy. If no tasks are waiting, then Mutex is incremented.
Semaphore operations can go by other names such as:
P() operationlock() wait() own()V() operationunlock() post() unown()
The value of the semaphore depends on the type of semaphore it is. There are several types of semaphores. For example:
A binary semaphore has the value 0 or 1. The semaphore is available when its value is 1 and not available when it is 0. When a process or thread obtains the binary semaphore, the value is decremented to 0. So, if another process or thread tests its value, it will not be available. Once the process or thread is done, the semaphore is incremented.
A counting semaphore has some non-negative integer value. Its initial value represents the number of resources available.
The POSIX standard defines several types of semaphores. Some of these semaphores are used by threads only, and others can be used by processes or threads. Any operating system that is compliant with the Single Unix Specification or POSIX standard can supply an implementation of these semaphores. They are apart of the libpthread library, and the functions are declared in the pthread.h header.
The POSIX semaphore defines a named binary semaphore. The name corresponds to a pathname in the filesystem. Table 7-6 lists the basic functions for using a semaphore along with a brief description.
Table 7.6. Table 7-6
Basic Semaphore Operations | Description |
|---|---|
Initialization | Allocates memory required to hold the semaphore and give memory initial values. Also determines whether the semaphore is private, sharable, owned, or unowned. |
Request ownership | Makes a request to own the semaphore. If the semaphore is owned by a thread, then the thread blocks. |
Releases the semaphore so it is accessible to blocked threads. | |
Try ownership | Tests the ownership of the semaphore. If the semaphore is owned, the requester does not block but continues executing. Can wait for a period of time before continuing. |
Destruction | Frees the memory associated with the mutex. The memory cannot be destroyed or closed if it is owned or others are still waiting. |
Listing 7-9 shows how semaphores can be used between multiple processes.
Example 7.9. Listing 7-9
// Listing 7-9 A process using a semaphore on an output file.
1 using namespace std;
2 #include <semaphore.h>
3 #include <iostream>
4 #include <fstream>
5
6
7 int main(int argc, char *argv[])
8 {
9
10 int Loop, PN;
11 sem_t *Sem;
12 const char *Name;
13 ofstream Outfile("out_text.txt",ios::app);
14
15 PN = atoi(argv[1]);
16 Loop = atoi(argv[2]);
17 Name = argv[3];
18
19 Sem = sem_open(Name,O_CREAT,O_RDWR,1);
20 sem_unlink(Name);
21
22
23 for (int Count = 1; Count < Loop; ++Count) {
24 sem_wait(Sem);
25 Outfile << "Process:" << PN << " counting " << Count << endl;
26 sem_post(Sem);
27
28 }
29 Outfile.close();
30
31 exit(0);
32
33
34
35 }The program in Listing 7-9 opens a semaphore of type sem_t in Line 11. The named semaphore Sem is opened with Name typed in as the third argument on the command line. O_CREATE and O_RDWR are flags that specify how the semaphore is opened. In this case, the semaphore is opened only if is does not exist. With the O_RDWR flag set, the semaphore is opened with read and write permissions. Sem is initialized with a value of 1. The sem_wait and sem_post operations encapsulate the access to Outfile. During the execution of Line 25, no other processes should access the file. All processes that use this file for input or output should use the same semaphore. In Listing 7-10, a process that reads the file also uses the semaphore.
Example 7.10. Listing 7-10
// Listing 7-10 A process using a semaphore on an input file.
1 using namespace std;
2 #include <semaphore.h>
3 #include <iostream>
4 #include <fstream>
5 #include <string>
6
7
8 int main(int argc, char *argv[])
9 {
10
11 string Str;
12 const char *Name;
13 sem_t *Sem;
14 ifstream Infile("out_text.txt");
15
16 if(Infile.is_open()){
17 Name = argv[1];
18 Sem = sem_open(Name,O_CREAT,O_RDWR,1);
19 sem_unlink(Name);
20
21 while(!Infile.eof() && Infile.good()){
22 sem_wait(Sem);
23 getline(Infile,Str);
24 cout << Str << endl;
25 sem_post(Sem);
26
27 }
28 cout << " - - - - - - - - - - - - - - - - " << endl;
29
30 Infile.close();
31
32 }
33
34 exit(0);
35
36
37
38 }The program in Listing 7-10 the named semaphore Sem is opened with Name typed in as the first argument on the command line. O_CREATE and O_RDWR are flags that specify how the semaphore is opened, as in Listing 7-9. The sem_wait and sem_post operations encapsulate the access to Infile. During the execution of Line 23, the process in Listing 7-9 cannot write to the file.
Here is Program Profile 7-4 for Listings 7-9 and 7-10.
The program7-9 in Listing 7-9 opens a semaphore of type sem_t named semaphore Sem. It is opened with Name typed in as the third argument on the command line. Sem is initialized with a value of 1. The sem_wait and sem_post operations encapsulate the access to Outfile. During the execution no other processes should access the file. All processes that use this file for input or output should use the same semaphore. In Listing 7-10, a process that reads the file also uses the semaphore. From the command line the program looks for the process number, a loop invariant, and the name of the semaphore. The program writes process, process number, and the loop iteration number to the file.
In program7-10 in Listing 7-10 the named semaphore Sem is opened with Name typed in as the first argument on the command line. It should have the same name as the semaphore in program7-9 in order to coordinate access to out_text.txt. The sem_wait and sem_post operations encapsulate the access to Infile. During the execution program7-9 cannot write to the file. The program requires the name of the semaphore as a command-line argument. It uses the named semaphore. It opens the file out_text.txt and writes its contents to stout.
c++ -o program7-9 program7-9.cc -lrt c++ -o program7-10 program7-10.cc -lrt
These programs require command-line arguments. For program7-9, the first argument is the process number, the second argument is the loop invariant, and the third argument is the name of the semaphore. program7-10 requires the name of the semaphore.
./program7-9 3 4 /sugi & ./program7-10 /sugi
Make sure that the name of the semaphore contains a "/". These programs are to execute at the same time.
The POSIX standard defines a mutex semaphore of type pthread_mutex_t that can be used by threads and processes. Mutex means mutual exclusion. A mutex is a type semaphore, but there is a difference between them. A mutex must always be unlocked by the thread that locked it. With a semaphore, a post (or unlock) can be performed by a thread other than the thread that performed the wait (or unlock). So, one thread or process can call wait() and another process/thread can call post() on the same semaphore.
pthread_mutex_t provides the basic operations necessary to make it a practical synchronization mechanism:
Initialization
Request ownership
Release ownership
Try ownership
Destruction
Table 7-7 lists the pthread_mutex_t functions that are used to perform these basic operations. The initialization allocates memory required to hold the mutex semaphore and to give the memory some initial values. A binary semaphore has an initial value of 0 or 1. A counting semaphore has a value that represents the number of resources the semaphore is to track. It can represent the request limit a program is capable of processing in a single session. In contrast to regular variables, there is no guarantee that the initialization operation of a mutex will occur. Be sure to take precautions to ensure that the mutex was initialized by checking the return value or checking the errno value. The system fails to create the mutex if the space set aside for mutexes has been used, the number of allowable semaphores has been exceeded, the named semaphore already exists, or there is some other memory allocation problem.
Table 7.7. Table 7-7
Function Prototypes/Macros | |
|---|---|
Initialization |
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; |
Request ownership |
<time.h >int pthread_mutex_lock(pthread_mutex_t *mutex); int pthread_mutex_timedlock(pthread_mutex_t *restrict mutex, const struct timespec *restrict abs_timeout); |
Release ownership |
int pthread_mutex_unlock (pthread_mutex_t *mutex); |
Try ownership |
int pthread_mutex_trylock(pthread_mutex_t *mutex); |
Destruction |
int pthread_mutex_destroy(pthread_mutex_t *mutex); |
The pthread mutex has an attribute object that encapsulates all the attributes of the mutex. This attribute object is used similarly to the attribute object for a thread. This difference is that whereas the attribute object of a thread is set, the attribute for a mutex has no set group of properties associated with it. We will discuss this later in the chapter. What is important to understand for now is that the attribute object can be passed to the initialization function creating a mutex with attributes of those set in the object. If no attribute object is used, the mutex is initialized with default values. The pthread_mutex_t is initially unlocked and private. A private mutex is shared between threads of the same process, whereas a shared mutex is shared between threads of multiple processes. If default attributes are to be used, the mutex can be initialized statically by using the macro:
pthread_mutext Mutex = PTHREAD_MUTEX_INITIALIZER;
This creates a statically allocated mutex object. This method uses less overhead but performs no error checking.
The request ownership operation grants ownership of the mutex to the calling process or thread. The mutex is either owned or unowned. Once owned, the thread or process owning it has exclusive access to the resource. If there is any attempt to own the mutex (by calling this operation) by any other processes or threads, they are blocked until the mutex is made available. When the mutex is released, this causes the next process or thread that has blocked to unblock and obtain ownership of the mutex. With the pthread_mutex_lock() the thread granted ownership of a given mutex is the only thread that can release the mutex.
The try ownership operation tests the mutex to see if it is already owned. The function returns some value if it is owned. The advantage of this operation is the thread or process does not block. It can continue executing code. If the mutex is not owned, then ownership is granted.
The destruction operation frees the memory associated with the mutex. The memory cannot be destroyed or closed if it is owned or a thread or process is waiting for the mutex.
The pthread_mutex_t has an attribute object used in a similar way as the thread attribute. As previously indicated, the attribute object encapsulates the attributes of a mutex object. Once initialized, it can be used by multiple mutex objects when passed to pthread_mutex_init(). Also, as previously indicated, in contrast to the thread attribute function, there are no mandatory attributes associated with the object. The functions that can be used to set the mutex attributes have to do with the following:
Priority ceiling
Protocol
Shared
Type
These functions are listed in Table 7-8 with a brief description.
Table 7.8. Table 7-8
To use a phtread mutex between threads of different processes requires the shared attribute. This attribute determines if the mutex is private or shared. Private mutexes are shared only among threads of the same process. They can be declared as global or a handle can be passed between threads. Shared mutexes, however, are used by any thread that has access to the mutex memory, and this includes threads of different processes. To do this, use pthread_mutexattr_setshared() and set the attribute to PTHREAD_PROCESS_SHARED as follows:
pthread_mutexattr_setpshared(&MutexAttr,PTHREAD_PROCESS_SHARED);
This allows Mutex to be shared by threads of different processes.
Figure 7-11 contrasts the idea of private and shared mutexes. If threads of different processes are to share a mutex, that mutex must be allocated in memory shared between processes. We discussed shared memory earlier in this chapter. Mutexes between processes can be used to protect critical sections that access files, pipes, shared memory, and devices.
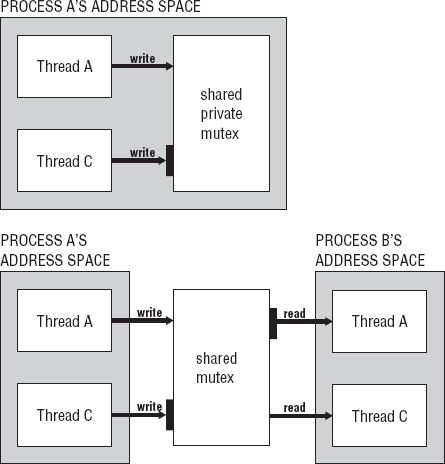
Mutexes can be used to manage critical sections of processes and threads in order to control race conditions. Mutexes avoid race conditions by serializing access to the critical section. Example 7-8 shows code for the new tasks defined in Listing 7-5. Mutexes are used to protect their critical sections.
Example 7.8. Example 7-8
// Example 7-8 New code for tasks in Listing 7-5.
3 void *task1(void *X)
4 {
5 pthread_mutex_lock(&Mutex);
6 Answer = Answer * 32; //critical section
7 pthread_mutex_unlock(&Mutex);
8 cout << "thread A Answer = " << Answer << endl;
9
10 }In Example 7-8, task1 now uses a mutex when it modifies the global variable Answer. In Line 8 the task sends the new value of Answer to cout. This is the critical section for the task. Now you can have each task execute the same code except each task sends to stout its thread name. So, now this is the output:
Before threads Answer = 10 thread 1 Answer = 320 thread 2 Answer = 160 thread 3 Answer = 165 After threads Answer = 165
Mutex semaphores serialize the critical section. Only threads or processes that use the shared data are permitted to enter the critical section. With read-write locks, multiple threads are allowed to enter the critical section if they are to read the shared memory only. Therefore, any number of threads can own a read-write lock for reading, but if multiple threads are to write or modify the shared memory, only one thread is given access. No other threads are allowed to enter the critical section if one thread is given write access to the shared memory. If the application has multiple threads, mutex exclusion can be extreme. The performance of the application can benefit by allowing multiple reads. The POSIX standard defines a read-write lock of type pthread_rwlock_t. Similar to mutex semaphores, the read-write locks have the same operations. Table 7-9 lists the read-write lock operations.
Table 7.9. Table 7-9
Function Prototypes #include <pthread.h> | |
|---|---|
Initialization |
int pthread_rwlock_init(pthread_rwlock_t *restrictrwlock, const pthread_rwlockattr_t *restrict attr); |
Request ownership |
#include <time.h> int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); int pthread_rwlock_timedrdlock(pthread_rwlock_t *restrict rwlock, const struct timespec *restrict abs_timeout); int pthread_rwlock_timedwrlock(pthread_rwlock_t *restrict rwlock, const struct timespec *restrict abs_timeout); |
Release ownership |
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock); |
Try ownership |
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock); |
Destruction |
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); |
The difference between regular mutexes and read-write mutexes is their locking request operations. Instead of one locking operation there are two:
pthread_rwlock_rdlock() pthread_rwlock_wrlock()
pthread_rwlock_rdlock() obtains a read-lock and pthread_rwlock_wrlock() obtains a write lock. If a thread requests a read-lock, it is granted the lock as long as there are no threads that hold a write lock. If so, the calling thread is blocked. If a thread requests a write lock, it is granted as long as there are no threads that hold a read lock or a write lock. If so, the calling thread is blocked.
The read-write lock is of type pthread_rwlock_t. This type also has an attribute object that encapsulates its attributes. The attribute functions are listed in Table 7-10.
Table 7.10. Table 7-10
The pthread_rwlock_t can be private between threads or shared between threads of different processes.
Read-write locks can be used to implement a CREW access policy. Several tasks can be granted concurrent reads, but only one task is granted write access. Using read-write locks can keep concurrent reads from occurring with the exclusive write. Example 7-9 contains tasks using read-write locks to protect critical sections.
Example 7.9. Example 7-9
// Example 7-9 Threads using read-write locks.
//...
pthread_t ThreadA,ThreadB,ThreadC,ThreadD;
pthread_rwlock_t RWLock;
void producer1(void *X)
{
pthread_rwlock_wrlock(&RWLock);//critical sectionpthread_rwlock_unlock(&RWLock); } void producer2(void *X) { pthread_rwlock_wrlock(&RWLock);//critical sectionpthread_rwlock_unlock(&RWLock); } void consumer1(void *X) { pthread_rwlock_rdlock(&RWLock);//critical sectionpthread_rwlock_unlock(&RWLock); } void consumer2(void *X) { pthread_rwlock_rdlock(&RWLock);//critical sectionpthread_rwlock_unlock(&RWLock); } int main(void) { pthread_rwlock_init(&RWLock,NULL); //set mutex attributes pthread_create(&ThreadA,NULL,producer1,NULL); pthread_create(&ThreadB,NULL,consumer1,NULL); pthread_create(&ThreadC,NULL,producer2,NULL); pthread_create(&ThreadD,NULL,consumer2,NULL); //... return(0); }
In Example 7-9 four threads are created. Two threads are producers, ThreadA and ThreadC, and two threads are consumers, ThreadB and ThreadD. All the threads have a critical section protected by the read-write lock, RWLock. ThreadB and ThreadD can enter their critical sections concurrently or serially, but neither thread can enter its critical section if either ThreadA or ThreadC is in its. ThreadA and ThreadC cannot enter their critical sections concurrently. Table 7-11 shows part of the decision table for this program.
Listing 7-11 is the declaration of an object-oriented mutex class.
Example 7.11. Listing 7-11
// Listing 7-11 Declaration of an object-oriented mutex class.
1 #ifndef _PERMIT_H
2 #define_PERMIT_H
3 #include <pthread.h>
4 #include <time.h>
5 class permit{
6 protected:
7 pthread_mutex_t Permit;
8 pthread_mutexattr_t PermitAttr;
9 public:
10 permit(void);
11 bool available(void);
12 bool not_in_use(void);
13 bool checkAvailability(void);
14 bool availableFor(int secs,int nanosecs);
15 };
16
17
18 #endif/* _PERMIT_H */The permit class provides the basic operations for a mutex class. Listing 7-12 contains the definition of the permit class.
Example 7.12. Listing 7-12
// Listing 7-12 Definition of the permit class.
1 #include "permit.h"
2
3
4 permit:: permit(void)
5 {
6 int AValue,MValue;
7 AValue = pthread_mutexattr_init(&PermitAttr);
8 MValue = pthread_mutex_init(&Permit,&PermitAttr);
9 }
10 bool permit::available(void)
11 {
12 int RC;
13 RC = pthread_mutex_lock(&Permit);
14 return(true);
15
16 }
17 bool permit::not_in_use(void)
18 {
19 int RC;
20 RC = pthread_mutex_unlock(&Permit);
21 return(true);
22
23 }
24 bool permit::checkAvailability(void)
25 {
26 int RC;
27 RC = pthread_mutex_trylock(&Permit);
28 return(true);
29 }
30 bool permit::availableFor(int secs,int nanosecs)
31 {
32 //...
33 struct timespec Time;
34 return(true);
35
36 }Listing 7-12 shows only the basic operations. For the class to be a fully viable mutex class, error checking would have to be added, as was the case in the posix_queue class in Example 7-3 earlier in the chapter.
Here is Program Profile 7-5 for Listings 7-11 and 7-12.
Listing 7-11 contains the header for permit.h, and Listing 7-12 contains permit.cc.
A mutex allows tasks to synchronize by controlling access to the shared data. A condition variable allows tasks to synchronize on the value of the data. Condition variables are semaphores that signal when an event has occurred. There can be multiple processes or threads waiting for the signal once the event has taken place. Condition variables are typically used to synchronize the sequence of operations.
The condition variable is of type pthread_cond_t. These are the types of operations it can perform:
Initialize
Destroy
Wait
Timed wait
Signal
Broadcast
The initialize and destroy operations work in a similar manner to the other mutexes. The wait and timed wait operations suspend the caller until another process/thread signals on the condition variable. The timed wait allows you to specify a period of time the thread waits. If the condition is not signaled within the specified time, the thread is released. Condition variables are used with mutexes. If a thread or process attempts to lock a mutex, you know that it blocks until the mutex is released. Once unblocked, it obtains the mutex and then continues. If a condition variable is used, it must be associated with a mutex. A task waits for the signal, and another task signals or broadcasts that the signal has happened. Table 7-12 lists the basic operations defined for a condition variable.
Table 7.12. Table 7-12
Function Prototypes/Macros#include <pthread.h> | |
|---|---|
Initialization |
int pthread_cond_init(pthread_cond_t *restrictcond, const pthread_condattr_t *restrict attr); pthread_cond_t cond = PTHREAD_COND_INITIALIZER; |
Signaling |
int pthread_cond_signal(pthread_cond_t *cond); int pthread_cond_broadcast(pthread_cond_t *cond); |
Destruction |
int pthread_cond_destroy(pthread_cond_t *cond); |
A task attempts to lock a mutex. If the mutex is already locked, then the task blocks. Once unblocked, the task releases the mutex while it waits on the signal for the condition variable. If the mutex is not locked, it releases the mutex and waits, indefinitely. With a timed wait, the task waits only for a specified period of time. If the time expires before the task is signaled, the function returns an error. It then acquires the mutex.
The signaling operation causes a task to signal to another thread or process that an event has occurred. If a task is waiting for a condition variable, it is unblocked and given the mutex. If there are several tasks waiting for the condition variable, only one is unblocked. The tasks wait in a queue and unblock according to the scheduling policy. The broadcast operation signals all the tasks waiting for the condition variable. If multiple tasks are unblocked, the tasks compete for the ownership of the mutex according to a scheduling policy. In contrast to the waiting operation, the signaling task is not required to own the mutex, although it is recommended.
The condition variable also has an attribute object. Table 7-13 lists the functions of the attribute object with a brief description.
Table 7.13. Table 7-13
The condition variable and the mutex can be used to implement the synchronization relationships mentioned earlier in the chapter:
Start-to-start (SS)
finish-to-start (FS)
Start-to-finish (SF)
Finish-to-finish (FF)
These relationships can exist between threads of the same processes or different processes. Listing 7-13 contains a program demonstrating how to implement SF synchronization relationship. There are two mutexes used in each example. One mutex is used to synchronize access to the shared data, and the other mutex is used with the condition variable.
Example 7.13. Listing 7-13
// Listing 7-13 SF synchronization relationship implemented with
// condition variables and mutexes.
1 using namespace std;
2 #include <iostream>
3 #include <pthread.h>
4
5 int Number;
6 pthread_t ThreadA,ThreadB;
7 pthread_mutex_t Mutex,EventMutex;
8 pthread_cond_t Event;
9
10 void *worker1(void *X)
11 {
12 for(int Count = 1;Count < 10;Count++){
13 pthread_mutex_lock(&Mutex);
14 Number++;
15 pthread_mutex_unlock(&Mutex);
16 cout << "worker1: Number = " << Number << endl;
17 if(Number == 7){
18 pthread_cond_signal(&Event);
19 }
20 }
21
22 return(0);
23 }
24
25 void *worker2(void *X)
26 {
27 pthread_mutex_lock(&EventMutex);
28 pthread_cond_wait(&Event,&EventMutex);
29 pthread_mutex_unlock(&EventMutex);
30 for(int Count = 1;Count < 10;Count++){
31 pthread_mutex_lock(&Mutex);
32 Number = Number + 20;
33 cout << "worker2: Number = " << Number << endl;
34 pthread_mutex_unlock(&Mutex);
35
36 }
37
38 return(0);
39 }
40
41
42 int main(int argc, char *argv[])
43 {
44 pthread_mutex_init(&Mutex,NULL);45 pthread_mutex_init(&EventMutex,NULL); 46 pthread_cond_init(&Event,NULL); 47 pthread_create(&ThreadA,NULL,worker1,NULL); 48 pthread_create(&ThreadB,NULL,worker2,NULL); 49 50 pthread_join(ThreadA,NULL); 51 pthread_join(ThreadB,NULL); 52 53 return (0); 54 }
In Listing 7-13, the SF synchronization relationship is implemented. ThreadB cannot start until ThreadA finishes. ThreadA signals to ThreadB once Number has a value of 7. It can then continue execution until finished. ThreadB cannot start its computation until it gets a signal from ThreadA. Both use the EventMutex with the condition variable Event. Mutex is used to synchronize write access to the shared data Number. A task can use several mutexes to synchronize different critical sections and synchronize different events. These techniques can easily be used to synchronize order of execution between processes.
Here is Program Profile 7-6 for Listing 7-13.
program7-13.cc (Listing 7-13) has a SF synchronization relationship. ThreadB cannot start until ThreadA finishes. ThreadA signals to ThreadB once Number has a value of 7. It can then continue execution until finished. ThreadB cannot start its computation until it gets a signal from ThreadA. Both use the EventMutex with the condition variable Event. Mutex is used to synchronize write access to the shared data Number. ThreadA and ThreadB send Number to stout. ThreadA adds 1 to the value of Number and ThreadB adds 20 to Number at each iteration through the loop.
The thread strategies determine the approach that can be employed when threading your application. The approach determines how the threaded application delegates its works to the tasks and how communication is performed. A strategy supplies a structure and approach to threading and helps in determining the access policies.
The purpose of a thread is to perform work on behalf of the process. If a process has multiple threads, each thread performs some subtask as part of what the application is to do. Threads are given work according to a specific strategy or approach. If the application models some procedure or entity, then the approach selected should reflect that model.
The common models are as follows:
Delegation (boss-worker)
Peer-to-peer
Pipeline
Producer-consumer
Each model has its own Work Breakdown Structure (WBS). WBS determines which piece of software does what, for example, who is responsible for thread creation and under what conditions threads are created.
WBS is discussed in more detail in Chapter 3.
With a centralized approach there is a single process/thread that creates other processes/threads and delegates work to each. An assembly line approach performs work at different stages on the same data. Once these processes/threads are created, they can perform the same task on different data sets, different tasks on the same data set, or different tasks on different data sets. Threads can be categorized to perform only certain types of tasks. There can be a group of threads that only perform computations while others perform process input or produce output.
It is also important to remember that what is to be modeled may not be homogeneous throughout the application or the process. Therefore, it may be necessary to mix models. One model may be embedded in another model. With the pipeline model, a thread or process may create other threads or processes and utilize a delegation model locally in order to process the data at that stage.
In the delegation model, a single thread (boss) creates other threads (workers) and assigns each a task. It may be necessary for the boss thread to wait until each worker thread completes its task before it can continue its executing its code. Its code may be based on the results of the worker thread. The boss thread delegates the task each worker thread is to perform by specifying a function. As each worker is assigned its task, it is the responsibility of each worker thread to perform that task and produce output or synchronize with the boss or other thread to produce output.
The boss thread can create threads as a result of requests made to the system. The processing of each type of request can be delegated to a thread worker. The boss thread executes an event loop. As events occur, thread workers are created and assigned their duties. A new thread is created for every new request that enters the system. Using this approach may cause the process to exceed its resources or thread limits. A different approach is to have a boss thread create a pool of threads that are reassigned new requests. The boss thread creates a number of threads during initialization, and then each thread is suspended until a request is added to their queue. As requests are placed in the queue, the boss thread signals a worker thread to process the request. When the thread completes, it dequeues the next request. If none are available, the thread suspends itself until the boss signals to the thread more work is available in the queue. If all the worker threads are to share a single queue, then the threads process only certain types of request. The results from each thread are placed in another queue. The primary purpose of the boss thread is to:
Create all the threads
Place work in the queue
Awaken worker threads when work is available
The worker threads:
Check the request in the queue
Perform the assigned task
Suspend itself if no work is available
All the workers and the boss are executing concurrently. Example 7-10 contains pseudocode for the event loop for the delegation model for this approach.
Example 7.10. Example 7-10
// Example 7-10 Skeleton program for delegation model where boss creates a
// pool of threads.
pthread_t Thread[N]
// boss thread
{
pthread_create(&(Thread[1]...taskX...);
pthread_create(&(Thread[2]...taskY...);
pthread_create(&(Thread[3]...taskZ...);
//...
pthread_create(&(Thread[N]...?...);
loop while(Request Queue is not empty
get request
classify request
switch(request type)
{
case X:
enqueue request to XQueue
broadcast to thread XQueue request available
case Y:
enqueue request to YQueue
broadcast to thread YQueue request available
case Z:
enqueue request to ZQueue
broadcast to thread ZQueue request available
//...
}
end loop
}
void *taskX(void *X)
{
loop
waiting for signal
when signaled
loop while XQueue is not empty
lock mutex
dequeue request
release mutex
process request
set mutex
enqueue results
release queue
end loop
until done
}void *taskY(void *X)
{
loop
waiting for signal
when signaled
loop while YQueue is not empty
lock mutex
dequeue request
release mutex
process request
set mutex
enqueue results
release queue
end loop
until done
}
void *taskZ(void *X)
{
loop
waiting for signal
when signaled
loop while ZQueue is not empty
lock mutex
dequeue request
release mutex
process request
set mutex
enqueue results
release queue
end loop
until done
}
//...In Example 7-10, the boss thread creates N number of threads. Each task is associated with processing a request type denoted by taskX, taskY, and taskZ. In the event loop, the boss thread dequeues a request from the request queue, determines the request type, and then enqueues the request to the appropriate request queue. It broadcasts to the threads a request is available in a particular queue. The functions also contain an event loop. The thread is suspended until it receives a signal from the boss that there is a request in its queue. Once awakened, in the inner loop, the thread processes all the requests in the queue until it is empty. It removes a request from the queue, processes it, and then places the results in the result queue. A mutex is used for the input and output queues.
Whereas the delegation model has a boss thread that delegates tasks to worker threads, in the peer-to-peer model all the threads have an equal working status. There is a single thread that initially creates all the threads needed to perform all the tasks, but that thread is still considered a worker thread. It does no delegation of work. The worker (peers) threads have more local responsibility. The peer threads can process requests from a single input stream shared by all the threads, or each thread may have its own input stream for which it is responsible. The input can also be stored in a file or database. The peer threads may have to communicate and share resources. Example 7-11 contains the pseudocode for the peer-to-peer model.
Example 7.11. Example 7-11
// Example 7-11 Skeleton program using the peer-to-peer model.
//...
pthread_t Thread[N]
// initial thread
{
pthread_create(&(Thread[1]...taskX...);
pthread_create(&(Thread[2]...taskY...);
pthread_create(&(Thread[3]...taskZ...);
//...
pthread_create(&(Thread[N]...?...);
}
void *taskX(void *X)
{
loop while (Type XRequests are available)
set mutex
extract Request
unlock mutex
process request
lock mutex
enqueue results
unlock mutex
end loop
return(NULL)
}
//...In the producer-consumer model, there is a producer thread that produces data to be consumed by the consumer thread. The data is stored in a block of memory shared between the producer and consumer threads. The producer thread must produce data; then the consumer threads retrieve it. If the producer thread deposits data at a much faster rate than the consumer thread consumes it, then the producer thread may at several times overwrite previous results before the consumer thread retrieves it. On the other hand, if the consumer thread retrieves data at a much faster rate than the producer deposits data then the consumer thread may retrieve identical data or attempt to retrieve data not yet deposited. This process, like the others, requires synchronization. We discussed read-write locks earlier in this chapter and included an example of producers that write and consumers that read. Example 7-12 contains the pseudocode for the producer-consumer model. The producer-consumer model is also called the client-server model for large-scale programs and applications.
Example 7.12. Example 7-12
// Example 7-12 Skeleton program using the producer-consumer model.
/...
// initial thread
{
pthread_create(&(Thread[1]...producer...);
pthread_create(&(Thread[2]...consumer...);
//...
}
void *producer(void *X)
{
loop
perform work
lock mutex
enqueue data
unlock mutex
signal consumer
//...
until done
}
void *consumer(void *X)
{
loop
suspend until signaled
loop while(Data Queue not empty)
lock mutex
dequeue data
unlock mutex
perform work
lock mutex
enqueue results
unlock mutex
end loop
until done
}The pipeline model is characterized by an assembly-line approach in which a stream of items is processed in stages. At each stage, work is performed on a unit of input by a thread. When the unit has been through all the stages in the pipeline, then the processing of the input has been completed and exits the system. This approach allows multiple inputs to be processed simultaneously. Once data has been processed at a certain stage, it is ready to process the next data in the stream. Each thread is responsible for producing its interim results or output and making them available to the next stage in the pipeline. The last stage or thread produces the result of the pipeline.
As the input moves down the pipeline, it may be necessary to buffer units of input at certain stages as threads process previous input. This may cause a slowdown in the pipeline if a particular stage's processing is slower than other stages. This may cause a backlog. To prevent backlog, it may be necessary for that stage to create additional threads to process incoming input. This is a case of mixed models. At this stage in the pipeline, the thread may create a delegation model to process its input and prevent backlogs.
The stages of work in a pipeline should be balanced so that one stage does not take more time than the other stages. Work should be evenly distributed throughout the pipeline. More stages and therefore more threads may also be added to the pipeline. This also prevents backlog. Example 7-13 contains the pseudocode for the pipeline model.
Example 7.13. Example 7-13
// Example 7-13 Skeleton program using the pipeline model.
//...
pthread_t Thread[N]
Queues[N]
// initial thread
{
place all input into stage1's queue
pthread_create(&(Thread[1]...stage1...);
pthread_create(&(Thread[2]...stage2...);
pthread_create(&(Thread[3]...stage3...);
//...
}
void *stageX(void *X)
{
loop
suspend until input unit is in queue
loop while XQueue is not empty
lock mutex
dequeue input unit
unlock mutex
perform stage X processing
enqueue input unit into next stage's queue
end loop
until done
return(NULL)
}
//...In concurrency models, the threads may be performing the same task over and over again on different data sets or may be assigned different tasks to be performed on different data sets. Figure 7-12 shows the different models of parallelism. Concurrency models utilize Single Instruction Multiple Data (SIMD) or Multiple Programs Multiple Data (MPMD). These are two models of parallelism that classify programs by instruction and data streams. They can be used to describe the type of work that the thread models are implementing in parallel. For purposes of this discussion, MPMD is better defined as Multiple Threads Multiple Data (MTMD). This model describes a system that executes different threads processing different sets of data or data streams. In Figure 7-12 (a) you can see that thread 1 processes dataset 1, and thread 2 processes dataset 2. Likewise, SIMD (also known as Single Program Multiple Data or SIMD) for purposes of this discussion is better redefined as Single Thread Multiple Data (STMD). This model describes a system that executes a single thread that processes different sets of data or data streams. In Figure 7-12 (b), thread 1 executes routine A and processes dataset 1 and thread 2 also executes routine A but processes dataset 2. This means several identical threads executing the same routine are given different sets of data to process. Multiple Threads Single Data (MTSD) describes a system where different instructions are applied to the same dataset. In Figure 7-12 (c), thread 1, which executes routine A, and thread 2, which executes routine B, both process the same dataset, dataset 1. Single Instruction Single Data (SISD) describes a system in which a single instruction processes a single dataset. In Figure 7-12 (d), thread 1 executes routine A, which sequentially processes datasets.
The delegation and peer-to-peer models can both use STMD or MTMD models of parallelism. As described, the pool of threads can execute different routines processing different sets of data. This approach utilizes the MTMD model. The pool of threads can also be given the same routine to execute. The requests or jobs submitted to the system could be different sets of data instead of different tasks. In this case, there would be a set of threads implementing the same instructions but on different sets of data, thus utilizing STMD. The peer-to-peer model can be threads executing the same or different tasks. Each thread can have its own data stream or several files of data that each thread is to process. The pipeline model uses the MTMD model of parallelism. At each stage, different processing is performed, so multiple input units are at different stages of completion. The pipeline metaphor would be useless if at each stage the same processing was performed.
Now we have discussed communication and cooperation between concurrently executing tasks, whether they are processes or threads. We have discussed communication relationships and the mechanisms of communication with IPC and ITC. We have also covered task cooperation, memory access models, and synchronization relationships. Data and communication synchronization was also covered along with the many techniques that can be used to avoid race conditions. Concurrency models can be used to layout an approach for communication and delegation of work. Now we want to use these techniques and models to do some work.
We have a multitude of text files that requires filtering. The text files have to be filtered in order to be used in our Natural Language Processing (NLP) system. We want to remove a specified group of tokens or characters from multiple text files, characters such as [, . ? ! ], and we want this done in real time.
The objects that can be immediately identified are:
Text files
The characters to be removed
The resulting filtered files
We have over 70 files to process. Each file can contains hundreds or thousands of lines of text. To simplify this, we have a set of characters we want to remove. We want to be able specify the name of the file, have the program filter out all the unwanted characters, have it create the new filtered file, and then be able to give the program the next file. With the guess_it example we used earlier in the book, an approach to break down the problem into smaller tasks was used. The task was to search a file for a code. The file was very large with over four million codes to search. So the file was broken down into smaller files and the search was performed on the smaller files. Since there was a time constraint, the searches had to be performed in parallel.
Here with this problem the filtered files have to be the same as the original files with the unwanted characters removed. The text cannot be altered in anyway. Although deconstructing the files into smaller files can be done, reconstructing them is not something we want to do. So what approach should we take? Keep in mind these are the goals:
Removing all the unwanted characters has to be performed
Having the work done in real-time
Keeping the integrity of the contents of each file
We can remove characters from the whole file or remove characters from each line at a time. Here are the possibilities:
Approach 1: Search the file for a character. When it is, found remove it, and then search for the next occurrence of the character. When all of those characters have been removed, search the file again for the next unwanted character. Repeat this for each file. The postcondition is met because we are working on the original file and removing the unwanted characters from it.
Approach 2: Remove all occurrences of a single character from each file then repeat this process for each unwanted character. The postcondition is met in the same way as in Approach 1.
Approach 3: Read in a single line of text, remove an unwanted character. Go through the same line of text and remove the next unwanted character, and so on. When all characters have been removed from the line of text, write the filtered line of text to the new file. This is done for each file. The postcondition is met because we are restructuring a new file as we go. As a line is processed, it is written to the new file.
Approach 4: Same as Approach 3, but we remove only a single unwanted character from a line of text and then write it to a file or container. Once the whole file has been processed, it is reprocessed for the next character. When the last character has been removed, the file has been filtered. If the text is in a container, it can now be written to a file. This is repeated for each file. The container becomes important in restructuring the file.
When considering each approach, we see there are a number of passes through a file or through a single line of text. This is what has to be looked at to see how it affects performance. This filtering has to be done in real time. For Approaches 1 and 2, the file is reentered for every occurrence of the character. There is a pass through the file for each unwanted character. There are four unwanted characters. An interim result is a whole file in which a single character has been removed, then two, and so on. With Approaches 3 and 4, a single line of text is filtered. So, the interim results are a single line of text. In Approach 3, a single line of text can be completed quickly. Depending of what type of processing is to be performed, a single line of text may be useful or it may not be. Waiting for a whole file is a longer wait. What is also obvious in each approach is that, whether it is a file or a single line of text you are dealing with, they are not dependent tasks; a file can be processed independently from other files. This is also true for a single line of text. But with a single line of text (remembering that the integrity of the file has to be maintained), it has to be performed in the order in which the line appears in the file. So, the lines of text have to be filtered in order: line 1, line 2, line 3, and so forth.
We will use Approach 3. Based on the observations stated, we have concluded that this approach will give us results more quickly, even for large sets of data, and produce interim results. Now we can consider the concurrency model. The model helps determine the communication and type of cooperation to be used to solve this problem. A single line should start being processed before another line is attempted. This suggests a pipeline model. At each stage, the same single line of text and a single unwanted character are to be removed. At the end of the stages, a single line of text is completely filtered. It can then be written to a file. This is to be done very quickly, and the file keeps its integrity. Queues should be used because they have First-In, First-Out access. This ensures that the lines of text stay in order.
Each stage has an input queue and an output queue. The input queue is the output queue of the previous stage. Once the text has been processed, it is written to a queue, and the next stage retrieves the line of text from the queue. Of course, this requires synchronization. A task retrieves the text from the queue after the previous stage has placed the text in the queue. Since there are only two tasks involved in sharing any queue, a mutex (mutual exclusion) works fine. We can use the permit class from Listing 7-10 and Listing 7-11.
What are the communication and cooperation requirements in this solution:
Queues require synchronization.
EREW access policy is needed.
Main agent populates the first queue and then creates the threads (one for each stage).
The input and output queues and a mutex are passed to the stages.
We can discuss the solution of this problem as an agent model. Each stage is going to be managed by an agent. The queues are lists that contain lines of text from a file. For each list, the agent is given a permit to access the list. The new objects in this solution are now agents, lists, and permits. Figure 7-13 shows the class relationship diagram for this solution.
Example 7-14 is the main line for the simple agent solution.
Example 7.14. Example 7-14
//Example 7-14 The main line for character removal agent.
1 #include "clear_text.h"
2 #include <iostrema>
3
4
5 int main(int argc, char** argv) {
6
7 if(argc != 2){
8 cerr << "usage: characters_removed FileName:" << endl;
9 exit(0);
10 }
11 clear_text CharactersRemoved(argv[1]);
12 if(CharactersRemoved()){
13 CharactersRemoved.changesSaved();
14 return (1);
15 }
16 return(0);
17 }
18The CharactersRemoved object of type clear_text is the main agent. It manages the pipeline. The name of the file to be filtered is the second command-line argument. CharactersRemoved() executes the pipeline. If it returns false, this means that one of the agents failed, and the unwanted character that was to be removed by the agent may not have been removed from the file or some of the lines of text. changesSaved() gets the results from the last lists (which contains all the filtered lines of text) and writes them to a file.
Example 7-15 contains the operator() method.
Example 7.15. Example 7-15
//Example 7-15 The pipeline method for the clear_text object.
1 bool clear_text::operator()(void)
2 {
3 bool Sound = true;
4 char_assertion CharacterRemoved[4];
5 CharacterRemoved[0].setUnWantedChar(','),
6 CharacterRemoved[1].setUnWantedChar('.'),
7 CharacterRemoved[2].setUnWantedChar('?'),
8 CharacterRemoved[3].setUnWantedChar('''),
9
10 for(int N = 0; N < 3;N++)
11 {
12 CharacterRemoved[N].getInList(TextQ[N],Permit[N]);
13 CharacterRemoved[N].getOutList(TextQ[N+1],Permit[N+1]);
14 }
1516 for(int N = 0; N < 4; N++)
17 {
18 CharacterRemoved[N]();
19 }
20
21 CharacterRemoved[3].wait();
22 CharacterRemoved[0].wait();
23 CharacterRemoved[1].wait();
24 CharacterRemoved[2].wait();
25
26 for(int N = 0; N < 4;N++)
27 {
28 Sound = Sound * CharacterRemoved[N].sound();
29 }
30 return(Sound);
31
32 }In Example 7-15, in Line #4 four char_assertion agents are declared. Each is passed the unwanted character it is to remove from the file. In Lines 10-14, the for loop passes to each agent the source list and its permit and the output list with its permit. The for loop in Lines 16-19 actually starts the agents working.
operator() is defined in the base class assertion as well as wait() and sound(). Example 7-16 contains operator(), wait(), and sound() as defined in the assertion class.
Example 7.16. Example 7-16
//Example 7-16 The methods defined in the base class assertion.
1 bool assertion::operator()(void)
2 {
3 pthread_create(&Tid,NULL,some_assertion,this);
4 return(Sound);
5 }
6
7 void assertion::wait(void)
8 {
9 pthread_join(Tid,NULL);
10 }
11
12
13 bool assertion::sound(void)
14 {
15 return(Sound);
16 }In Example 7-16, you see that the assertion class creates the threads for the char_assertion agents in Line 3. The threads/agents are to execute the some_assertion function. The assertion class is an improved version of the user_thread class in Chapter 6 and some_assertion is the do_something method.
Example 7-17 contains the some_assertion method from the assertion class and Example 7-18 contains the assert method from the char_assertion class.
Example 7.17. Example 7-17
//Example 7-17 The some_assertion method defined in the base class assertion.
1 void * some_assertion (void * X)
2 {
3
4 assertion *Assertion;
5 Assertion = static_cast<assertion *>(X);
6 if(Assertion->assert()){
7 Assertion->Sound = true;
8 }
9 else{
10 Assertion->Sound = false;
11 }
12 return(NULL);
13
14
15 }Example 7.18. Example 7-18
//Example 7-18 The assert method defined in the class char_assertion.
1 bool char_assertion::assert(void)
2 {
3
4
5 if(PermitIn.available()){
6 TokenString = ListIn.front();
7 ListIn.pop();
8 remove(TokenString.begin(),TokenString.end(),RemovedCharacter);
9 PermitIn.not_in_use();
10 }
11 if(PermitOut.available()){
12 ListOut.push(TokenString);
13 PermitOut.not_in_use();
14 }
15
16 return(true);
17 }In Example 7-17, on Line 6, assert() is called. This method is where the agent does the work of its stage in the pipeline. Example 7-18 contains the definition for assert(), the work of the agent. If PermitIn is available for ListIn list, which is the source of strings of text, the string is popped, the unwanted character is removed in Line 8, and PermitIn is released. Now the new string is to be pushed on ListOut if PermitOut is available.
This example shows the use of a concurrency model (namely a pipeline) utilizing a MTSD. A single string of text is processed at each stage of the pipeline where a single unwanted character is removed from the string. Each thread at a stage can be assigned to its own processor core. This is a simple process, removing a single character from a string, but the process described (from determining the problem, decomposition of the problem, and determining an approach) can be used to solve problems on a larger scale. But we can do better. Here we have described a task-oriented software decomposition to multicore programming. In Chapter 9, we discuss a declarative and predicate-oriented decomposition for problems on a larger scale with massive cores to manage.
In this chapter, we discussed managing synchronized communication between concurrent tasks as well as synchronizing access to global data, resources, and task execution. We also discussed concurrency models that can be used to delegate the work and communication between concurrently executing tasks running on multiple processor cores. This chapter discussed the following points:
Dependency relationships can be used to examine which tasks are dependent on other tasks for communication or cooperation. Dependency relationships are concerned with coordinating communication and synchronization between these concurrent tasks. If communication between dependent tasks is not appropriately designed, then data race conditions can occur.
Interprocess Communications (IPC) are techniques and mechanisms that facilitate communication between processes. When a process sends data to another process or makes another process aware of an event by means of operating system APIs, it requires IPC. The POSIX queue, shared memory, pipes, mutexes/semaphores, and condition variables are examples of IPC.
Interthread Communications (ITC) are techniques that facilitate communication between threads that reside in the same address space of their process, The most important issues that have to be dealt with concerning ITC are data races and indefinite postponement.
You can synchronize access to data and resources and task execution. Task synchronization is required when a thread is in its critical sections. Critical sections can be managed by PRAM models such as EREW and CREW. There are four basic synchronization relationships between any two tasks in a single process or between any two processes within a single application.
Synchronization mechanisms are used for both processes and threads. These mechanisms can be used to prevent race conditions and deadlocks between multiple tasks by implementing the synchronization access policies using semaphores and mutexes, read-write locks, and condition variables.
The thread strategies determine the approach that can be employed when threading your application. The approach determines how the threaded application delegates its work to the tasks and how communication is performed. A strategy supplies a structure and approach to threading and helps in determining the access policies.
In the next chapter, we discuss the Parallel Application Design Layers (PADL). PADL is a five-layer analysis model used in the design of software that requires some parallel programming. It is used to help organize the software decomposition effort. PADL is meant to be used during the requirements analysis and software design activities of the Software Development Life Cycle (SDLC), which is also covered in Chapter 8.