
Those are places that can't be accessed from a Chaos Gate. If you try to enter, you show up, see a warning indicator, and then you're warped back to town. | ||
| --Miu Kawasaki, .hack// Another Birth | ||
In Chapter 8, we introduced the Predicate Breakdown Structure (PBS) of an application and the Parallel Application Design Layers (PADL) analysis model. These are top-down approaches to producing declarative architectures for applications that have a concurrency or parallel programming requirements. One of the ultimate goals of PBS and PADL is to establish a chain of possession or audit trail for the application concurrency requirements that lead from the solution model to threads or processes at the operating system level. In this chapter, we connect the PBS and PADL analysis to application software testing and exception handling. The PBS and PADL tell you what you should be testing for and what constitutes an error or an exception. You can use exception handling to provide a kind of logical fault-tolerance for declarative architectures. That is, if your application for unknown and uncontrollable reasons violates statements, assertions, rules, predicates, or constraints from the PBS, you want to throw an exception and gracefully exit because once the predicates have been violated, then the correctness, reliability, and meaning of the application has been compromised.
In this chapter, we also introduce the various types of testing that should be part of any Software Development Life Cycle (SDLC), especially ones where parallel programming will be deployed. We explain exception handling, the differences between error handling and exception handling, some of the issues for multithreading and parallel programming. We also briefly introduce the notion of model checking, the relevance of possible-world semantics to the declarative interpretation of parallel programming, and how they are used for testing and exception handling.
Specifically, in this chapter we will cover the following:
Connecting the PBS and PADL analysis to application software testing and exception handling
Explaining the various types of testing that should be part of any SDLC
Defining exception handling and what the differences are between error handling and exception handling
Introducing to the notion of model checking and the relevance of possible-world semantics to the declarative interpretation of parallel programming
The goal of testing software is to make sure that the software does what you want and you want what is does. An application is often requested as a list of desired features. This list can be represented as a formal specification consisting of hundreds of pages or can be as simple as verbal request from an employer detailing a dozen or so requirements. Regardless of how the list of requirements for a piece of software is generated, the testing process must make sure that the software meets those requirements and that the requirements meet the user's expectations. In many cases where parallel computers or multiprocessors are involved, the user's expectations include performance speed up or a certain level of high performance throughput. The kinds of software errors increase when multithreading or multiprocessing is added in attempt to meet the user's expectation. When the software does not perform according to the specifications, the software is in error, even if the specification violation is that the system performs too slowly. Software that requires parallel programming can be notoriously difficult to test and debug. Testing and debugging are among the top 10 challenges to parallel programming discussed in Chapter 3. Some of the main issues that are unique to testing and debugging multithreaded or multiprocessing programs are:
Simulating minimum-to-maximum volume loads
Duplicating the exact flow of control during debugging
Duplicating race condition errors during debugging
Duplicating systemwide process and thread contention
Finding hidden unsafe thread functions
Testing and debugging nondeterministic algorithms
Proving there are no possibilities for deadlock or data race in the software
Simulating boundary and average workload mixes
Checking intermediate results when 100s or 1000s of threads and processes are in execution
Identifying the right number of threads or processes that will generate acceptable performance
The PADL and PBS analysis covered in Chapter 8 create the primary concurrency infrastructure and implementation models that testing phases validate and verify. Declarative and predicate-based approaches lend themselves to more automated forms of model checking and testing. Declarative designs lead to declarative implementations. Declarative implementations bring the testing complexity of medium to large-scale parallel programs within reach of the software developer. Regardless of the complexity of the testing or debugging process, the goal is to deploy software that is error free and fault tolerant. The testing process must find each error and software defect and remove it.
Some of the concurrency challenges in Chapter 3 have to be checked for in the testing phase and accounted for in exception handlers. These challenges are:
Incorrect/inadequate communication between two or more tasks that are executing in parallel
Data corruption as a result of unsafe updating of data by two or more instructions or tasks
Resource contention when there is a many-to-one ratio between tasks and a resource
An unacceptable number of units that need to execute in parallel
Missing/incomplete documentation for communicating a software design that contains multiprocessing and multithreading
In Chapter 7, we discussed the mechanisms that are used to enable and synchronize communication and data or device access between concurrently executing threads or processes. For instance, mutexes and semaphores are used to control and prevent errors that would occur from Challenge 2 in the preceding list. Timed mutexes can be used to control and prevent errors that would result from the problems that could occur from Challenge 3 in the preceding list. Documentation in so many cases receives the least amount of attention and dedicated resources, but it is one of the most important components of a software deployment. As with everything else with parallel programming and multithreading, documentation is even more critical for these classes of application. The testing process should verify and validate that the design documentation and the postproduction documentation match! Table 10-1 shows which mechanisms discussed in Chapter 7 can be used to prevent control and prevent some of the five challenges shown in the preceding list.
Table 10.1. Table 10-1
Description | |
|---|---|
Mutex semaphores | Mechanism used to implement mutual exclusion in a critical section of code. |
Read-write locks | Mechanism used to implement read-write access policy between tasks. |
Condition variables | Mechanism used to broadcast a signal between tasks that an event has taken place. When a task locks an event mutex, it blocks until it receives the broadcast. |
Multiple condition variable | Same as an event mutex but includes multiple events or conditions. |
The mechanisms listed in Table 10-1 are low-level mechanisms. Fortunately, using features of higher-level component libraries, such as Threading Building Blocks (TBB) or the standard C++ concurrent programming library, can take some of tedium away during the testing process. These issues are meant to be dealt with in Layer 2 and 3 of the PADL analysis model discussed in Chapter 8.
However, first, we need to establish some definitions. There are several words that are used in discussions on testing, error handling, and fault tolerance that are often used incorrectly or too loosely. Table 10-2 contains the basic definitions for the terms that we will use in this chapter.
Table 10.2. Table 10-2
Since some of the terms in Table 10-2 such as error, failure, and fault are commonly used in many different ways, we have provided simple definitions for how they are used in this chapter. The extent to which software is able to minimize the effects of failure is a measure of its fault tolerance. Achieving fault tolerant software is one of the primary goals of any software engineering effort. However, the distinction between fault-tolerant software and well-tested software is often misunderstood and blurred. Sometimes the responsibilities and activities of software verification, software validation, and exception handling are erroneously interchanged. To work toward the goal of using the C++ exception-handling mechanism to help achieve logical fault-tolerant software, you must first be clear where exception handling fits in the scheme of things.
Failures occur at runtime during software operation. Failures are the result of a defect in hardware, software, or human operation. If the software is not running, then it cannot encounter defects. Although this is an obvious statement it is important in understanding some of the distinctions between the responsibilities and activities of the testing phase versus those of the exception handler. Ideally defects in the software are removed during the testing stages. The same would be true for hardware. As for defects in human operation, we would like to remove those defects through training and experience, but this is easier said than done. To keep matters simple, we focus our discussion on defects in software.
Table 10-3 describes the eight basic types of testing that should be performed on a piece of software prior to its being put into operation.
Table 10.3. Table 10-3
Types of Testing | Description |
|---|---|
Requires that the software be tested one component or unit at a time. A unit might be a software module, a collection of modules, a function, a procedure, an object, an algorithm, or in some instances a computer program. | |
Designed to push a component or a system up to and sometimes beyond its limits. Stress testing includes testing boundary conditions. When boundary conditions are tested, it helps in determining what happens at the boundaries the software component or system contains. | |
Used to test the assembly of components. The components are combined into logical groups, and each group is tested as a unit. The group can be subjected to the same type of tests to which units are subjected. As each component is added to the assembly, the number of elements that must be tested grows combinatorially. | |
Used to retest modules that have changed. Regression tests ensure that the changes to the component do not cause it to lose any functionality. | |
Used to test the system in its full operation. This test puts the software component in a live environment to be tested under a complete system load. The tests that the component undergoes during unit, integration, and stress testing usually serve as operational tests as well. The operational tests also serve to determine how the component will behave in a totally foreign environment. | |
Specification testing | Used as part of the software verification process. The component is audited against the original specification. This specification dictates what components are involved in a system and what the relationships are between those components. |
Used by the end user of the module, component, or system to determine performance. Acceptance testing is part of the software validation process. |
As you perform the type of tests in Table 10-3 on a piece of software, you find defects and remove them from the software. The more defects you find and remove during testing, the fewer defects your software encounters during runtime. Defects encountered during runtime lead to failures in the software. Failures in the software produce exceptional conditions for the software to operate under. The exceptional conditions require exception handlers. So, the balancing act is between:
Defect removal during the testing stages
Defect survival during exception handling
Although you can choose to favor defect survival over defect removal, the problem is that exception-handling code can become so complex that it introduces defects into the software. So, instead of providing a mechanism to help achieve fault tolerance, the exception handler becomes a source of failure. Choosing defect survival over defect removal reduces the software's chance to operate properly. Extensive and thorough testing removes defects, which reduces the strain on the exception handlers. It is also important to note that exception handlers do not occur as freestanding pieces of code. They occur within the context of the overall software architecture. The journey toward fault tolerance in our software begins by recognizing that:
No amount of exception handling can rescue a flawed or inappropriate software architecture.
The fault tolerance of a piece of software is directly related to the quality of its architecture.
The exception-handling architecture cannot replace the testing stages.
To make this discussion about exception handling clear and meaningful, it is important to understand that the exception-handling architecture occurs within the context of the software architecture as a whole. This means that exceptions are identified by the PBS and PADL analysis. The solution model has a PBS. When you have an unavoidable, uncontrollable, unexplainable deviation from the application architecture's PBS, then you have an exception. So, the exception is defined by clearly articulated architectures. If the software architecture is inappropriate, incomplete, or poorly thought out, then any attempt at after-the-fact exception handling is highly questionable. Further, if shortcuts have been taken during the testing stages (that is, incomplete stress testing, incomplete integration testing, incomplete glass box testing, and so on), then the exception-handling code has to be perpetually added to and becomes increasingly complex, ultimately detracting from the software's fault tolerance and the declarative architecture of the application. On the other hand, if the software architecture is sound and the exception-handling architecture is compatible and consistent with the PBS and Layers 3, 4, and 5 of the PADL analysis, then a high degree of fault tolerance can be achieved for parallel programs. If you approach the goal of context failure resilience with an understanding of the roles that software application architecture and testing play, then it is obvious that you need to choose defect removal over defect survival. Defect removal takes place during testing.
First, we should point out that testing should accompany every major activity in the SDLC from requirements gathering activities to software maintenance activities. However, programs that involve multithreading or multiprocessing require even more effort during the testing phase. So, you make use of PADL analysis and PBS breakdown during you test plan. You break up the testing goals of parallel programs into answering three fundamental questions:
Do the design models and PBS correctly and completely represent the solution model (assuming that the solution model solves the original problem)?
Does the implementation model map correctly to the design models (Layer 4 and 5 from PADL) and the PBS?
Have all of the challenges to concurrency in the implementation model been addressed?
Traditionally, most of the effort in testing parallel programs goes into answering the third question. This is what typically happens in an imperative bottom-up approach to parallel programming. However, in a declarative approach you answer Question 1 first. This is the most important test. If this test fails, there is no reason to perform any further testing. We have presented simple versions of these models in Chapter 8, but in release code these models would contain a considerable amount of detail. If the design models are sufficiently detailed and accurate, the PBS is complete, and they both accurately map to the original solution problem, then you are in good shape. Opportunities for scalability or evolution of a software application are determined by its application architecture and concurrency infrastructure. We test the quality of both during the process of answering the first question. If the answer to the second question is yes, then you have a solid application. So, answering Question 3, which has typically been thought of as the most important, becomes secondary to answering Question 1 and Question 2. Standard software engineering testing techniques are used to answer these questions. We simply use PADL and PBS to formulate the three fundamental questions. Testing will verify that our application meets PADL and PBS.
To get some idea how this works, you can take a look at the flow of process that precedes the standard testing phases.
Recall from Chapter 8 the refinement of the game scenario: My trusted assistant has handed me a six-character code. The code can contain any character more than once. However, the code can only contain any characters from the numbers 0-9, or characters a-z. Your job is to guess what code the trusted assistant has handed me. In the game the buzzer is set to go off after 2 minutes. If you guess what I'm thinking in 2 minutes, you win. If my trusted assistant determines that you have made more than N incorrect guesses within a 15-second interval, my assistant hands me a new code guaranteed to be among the guesses that you have already made.
From the problem statement you devised the following simple strategy: You just happened to have all 4,496,388 possible codes to choose from in a file. You could simply perform an exhaustive search on the file presenting each code as a guess. But since you are given a time constraint of 2 minutes, you aren't sure if you'll have enough time. So, your strategy is to find a way to search through multiple portions of the file simultaneously. You decide to divide the original file into eight and have it searched concurrently. Therefore, you should be able to guess correctly in the time that it takes to search one-eighth of the file. But you also make one other provision. If you are able to search all 8 files, you still did not guess correctly, and you are not out of time, you will divide the files into 64 and try again. If you fail and still have time, you will divide the file into 128, try again, and so on.
Since you have determined that parallelism is useful in your solution model, you now include PADL analysis as part of your SDLC. Layer 5 in PADL involves identifying an appropriate application architecture for the problem and solution model. On first take, it appears that a multiagent architecture best fits the solution model. So, you refine the solution model in the context of a multiagent application architecture.
You can easily see from the statement of the problem that you are initially dealing with three agents. If you recast the game in terms of agents you have: Agent A gives the code to Agent B. Agent C tries to guess Agent B's code. If Agent C comes up with too many guesses in a 15-second interval, Agent A gives Agent B a new code that is guaranteed to be a code that Agent C has already presented. If Agent C is able to go through all of the possibilities and is still not declared the winner and if Agent C has more time left, Agent C will make the same guesses only faster. Agent C realizes that generating enough guesses to guarantee success within the given time limit requires help. So, Agent C recruits a team of agents to help come up with guesses. For each pass through the total possibilities Agent C recruits a bigger team of agents to help with the guesses.
From the revised agent model, you have identified that the concurrency models that you need to use are the boss-worker model, peer-to-peer, Single Program Multiple Data (SPMD), Single Instruction Multiple Data (SIMD), and Exclusive Read Exclusive Write (EREW). You use SPMD/SIMD here because the agents use the same search techniques over different data sets. EREW covers the agents' communication with the boss. The boss-worker model covers the relationship between guesser agent and its helpers. The peer-to-peer model covers the relationship between the code owner and the trusted assistant.
Breakdown 1: You've won the game if your guess is correct and in time.
Breakdown 2: Your guess is correct if it consists of a six-character code that contains only combinations of the characters (a–z, 0–9), considering that duplication is allowed and that code is the one my agent has handed me.
Breakdown 3: Your guess is in time if it is correct and it occurs within 2 minutes.
Breakdown 4: A brute force search through the codes will be successful if there are enough agents searching.
Breakdown 5: N agents are enough find the correct code from a sample of 4 million codes in 2 minutes.
Breakdown 6: 4 times N agents are required to find the correct code from a sample of 4 million codes in 2 minutes if the code is being changed every 15 seconds.
Listing 10-1 follows the declarative semantics of the PBS.
Example 10.1. Listing 10-1
// Listing 10-1 A declarative implementation of the guess_it program.
1 #include "posix_process.h"
2 #include "posix_queue.h"
3 #include "valid_code.h"
4
5
6 char **av;
7 char **env;
8
9
10 int main(int argc,char *argv[],char *envp[])
11 {
12
13 valid_code ValidCode;
14 ValidCode.determination("ofind_code");
15 cout << (ValidCode() ? "you win": "you lose)";
16 }So, you have a declaration of a ValidCode predicate in Line 13 and 14. This predicate is used to represent the statement:
This is the code the trusted agent handed you.
On Line 14 you test this statement by invoking the predicate ValidCode(). The ValidCode() predicate spawns four processes which in turn create two threads each. So, in fact the ValidCode predicate is implemented using parallel programming. However, its implementation is encapsulated. Listing 10-2 shows the declaration of the valid_code predicate class.
Example 10.2. Listing 10-2
//Listing 10-2 Declaration of the valid_code predicate class.
1 #ifndef __VALID_CODE_H
2 #define __VALID_CODE_H
3 using namespace std;
4
5 #include <string>
6 class valid_code{
7 private:
8 string Code;
9 float TimeFrame;
10 string Determination;
11 bool InTime;
12 public:
13 bool operator()(void);
14 void determination(string X);
15 };
16
17 #endifIn C++ predicates are classes that have an operator() method that returns a boolean value. You use the C++ predicate to approximate the notion of predicates from the PBS. Since a predicate is a C++ class, it can be used in conjunction with containers and algorithms. Listing 10-3 shows the definition of the predicate class.
Example 10.3. Listing 10-3
// Listing 10-3 Definition of the valid_code predicate.
1 #include "valid_code.h"
2 #include "posix_process.h"
3 #include "posix_queue.h"
4
5 extern char **av;
6 extern char **env;
7
8
9 bool valid_code::operator()(void)
10 {
11 int Status;
12 int N;
13 string Result;
14 posix_process Child[4];
15 for(N = 0; N < 2; N++)
16 {
17 Child[N].binary(Determination);
18 Child[N].arguments(av);
19 Child[N].environment(env);
20 Child[N].run();
21 Child[N].pwait(Status);
22 }23 posix_queue PosixQueue("queue_name");
24 PosixQueue.receive(Result);
25 if((Result == Code) && InTime){
26 return(true);
27 }
28 return(false);
29 }
30
31
32 void valid_code::determination(string X)
33 {
34 Determination = X;
35 }Here is Program Profile 10-1 for Listings 10-1, 10-2, 10-3, and 10-4, which appears later in the chapter.
This program is a "guess it" game. You win the game if your guess is correct in 2 minutes. Your guess is correct if it consists of a six-character code that contains only combinations of the characters a-z, 0-9, considering duplication is allowed.
The declaration of a ValidCode predicate is used to represent the statement:
This is the code the trusted agent handed you.
This statement is tested by invoking the predicate ValidCode(). The ValidCode() predicate spawns four processes, which in turn create two threads each. Its implementation is encapsulated.
pguess_it.cc (Listing 10-1), posix_process.cc (Listing 10-4), valid_code.cc (Listing 10-3), posix_queue.cc
Please note that because of its length
posix_queue.ccis not listed in its entirety in the book. However, you can download the fullposix_queue.cc, along with the rest of the sample code from the book, fromwww.wrox.com.
posix_process.h (Listing 5-3), valid_code.h (Listing 10-2), posix_queue.h (Listing 7-3).
c++ -o pguess_it pguess_it.cc valid_code.cc posix_process.cc posix_queue.cc -lrt
You use standard software engineering testing techniques but within the context of PADL, PBS and those three fundamental questions mentioned earlier in the chapter. To answer this question, you see how far you can get through standard software engineering tests with the PBS as the basic measuring stick of success.
As we have previously noted, there are many types of software tests: tests done during the software design as well as those done during implementation phases, installation and operational tests, usability tests, and even acceptance tests done that determine whether a customer is satisfied with a delivered system. Because of the complexity of today's software systems, and their economic and social value, software testing has become a highly specialized field. The Institute of Electrical and Electronics Engineers (IEEE) publishes standards for the complete set of testing activities. IEEE, a nonprofit organization, is the world's leading professional association for the advancement of technology. Two important testing standards documents published by the IEEE are:
Every software development group should have these documents readily available. If you do not have them, they can be downloaded from
www.standards.ieee.org.
This chapter provides a brief overview of some of the issues covered in Std 1008 and Std 1012. Because testing is one of the fundamental activities in any SDLC, Std 1008 and 1012 should be part of every SDLC. If they are adhered to, the guidelines and recommendations presented in these standards considerably enhance the quality of the software that is ultimately delivered to the user. The requirements and the specifications you can glean from Std 1008 and Std 1012 help you answer two questions:
Am I building the correct software?
Am I building the software correctly?
The answers to these two questions deal with issues of software verification and validation.
Software verification and validation perform are concerned with removing defects during each of the types of testing mentioned in Table 10-3. When you engage in software validation, you are answering the first question whereas verification answers the second question. Validation is an audit of the software features against the software specification. According to IEEE Std 1012:
Software verification and validation (V&V) is a technical discipline of systems engineering. The purpose of software V&V is to help the development organization build quality into the software during the software life cycle. The software V&V processes determine if development products of a given activity conform to the requirements of that activity, and if the software satisfies the intended use and user needs. The determination includes assessment, analysis, evaluation, review, inspection, and testing of software products and processes. The software V&V is performed in parallel with the software development, not at the conclusion of the software development.
During the requirements and analysis activities of the SDLC, software specifications are generated. For the purpose of the multicore application design that we are discussing in this book, the specifications come from the design models and implementation models of the PADL analysis and the PBS. When you perform software verification, you are examining whether the software meets these specifications. When you engage in the process of determining whether the software actually performs the work the user wants, you are answering the second question. Verification is implementing the software right and validation is implementing the right software. Much of the software-testing process can be described as a verification or validation process. Ultimately, all of the types of testing in Table 10-3 have to be performed during the SDLC.
In addition to the seven types of software testing in Table 10-3, there are also six important types of errors that you must keep in mind that relate to parallel programming. Table 10-4 lists the common parallel programming errors and their descriptions.
Table 10.4. Table 10-4
Common Parallel Programming Errors | Description |
|---|---|
Deadlock | A task is waiting for an event that will not occur |
Occurs when a lower-priority task blocks the execution of a higher-priority task when synchronization variables are being used or when they are competing for resources | |
Occurs when a system's performance lowers or degrades in terms of responsiveness, execution time, calculation of results, and so on | |
Occurs when a system indefinitely delays the scheduling of tasks while other tasks receive the attention and the allocation of resources | |
Occurs when a system has reached its maximum number of mutexes that can be created | |
Occurs when a system has reached its maximum number of threads that can be allocated |
For example, after performing the most basic unit tests, say you discover that the program from Listing 10-1 fails the unit tests. The program doesn't work. What does it mean for the program not work? This program fails because it does not meet the specifications of the PBS. This means that the program causes one or more of the statements in the PBS to be false. Since the PBS is meant to capture the meaning of the concurrency infrastructure, you know that the parallelism in this program will fail at some point because it does not correctly implement the assertions, statements, and predicates in the PBS. In particular PBS #6 states:
Breakdown 6: 4 times N agents are required to find the correct code from a sample of 4 million codes in 2 minutes if the code is being changed every 15 seconds.
Recall the user-defined predicate valid_code() referenced on Lines 13-15 in Listing 10-1. It states whether the search was successful or not. But in order for the search to be successful all of the assertions in the PBS must be maintained. If you look a little closer at the definition of the predicate operator() for valid_code in Lines 9-30 in Listing 10-3, you can see that it spawns four posix_processes. Listing 10-4 shows the definition for the user-defined process_interface class.
Example 10.4. Listing 10-4
// Listing 10-4 Definitions for user-defined posix_process interface class.
1 #include "posix_process.h"
2 #include <sys/wait.h>
3
4
5 posix_process::posix_process(string Path,char **av,char **env)
6 {
7
8 argv = av;
9 envp = env;
10 ProgramPath = Path;
11 posix_spawnattr_init(&SpawnAttr);
12 posix_spawn_file_actions_init(&FileActions);
13
14
15 }
16
17 posix_process::posix_process(string Path,char **av,char **env,
posix_spawnattr_t X,
posix_spawn_file_actions_t Y)
18 {
19 argv = av;
20 envp = env;
21 ProgramPath = Path;
22 SpawnAttr = X;
23 FileActions = Y;
24 posix_spawnattr_init(&SpawnAttr);
25 posix_spawn_file_actions_init(&FileActions);
26
27
28
29 }30
31 void posix_process::run(void)
32 {
33
34 posix_spawn(&Pid,ProgramPath.c_str(),&FileActions,
&SpawnAttr,argv,envp);
35
36
37 }
38
39 void posix_process::pwait(int &X)
40 {
41
42 wait(&X);
43 }The class in Listing 10-4 is an interface class that adapts the interface for the POSIX API posix_spawn(). The posix_process class is used to spawn two copies of ofind_code. ofind_code in turn spawns two threads. The problem is that you end up with only eight consecutive agents working (four processes * two threads). So, the PBS #6 requirement that you quadruple the number of agents if the code is being changed is not addressed by the valid_code predicate. In this case, you have a simple mapping of one agent per thread. You should not get past unit tests if the predicates in the application are not consistent with the PBS.
This matching of the PBS with C++ predicates is part of the fundamental shift to a declarative style of parallel programming. This is a subtle but very powerful idea. You apply software verification and validation (V&V) to the mapping of the PBS, and the C++ predicates extend the declarative style of parallel programming to the V&V. Some of the other important objectives of V&V are:
Facilitate early detection and correction of software errors
Enhance management insight into process and product risk
Support the software life cycle processes to ensure compliance with program performance, schedule, and budget requirements
If you audit the predicates against the PBS, you can find the concurrency problems early and before the software is deployed. In fact, one of the primary objectives of PADL and PBS is to deal with the full complexity of the concurrency requirements prior to writing any code.
One of the consequences of the PADL and PBS is that they support declarative models of testing such as model checking and possible-worlds analysis (which are briefly discussed later in the chapter). These models can be deployed early in the SDLC. The complexity and integrity of multithreaded and multiprocessing programs have to be managed at the beginning of the software development effort. The testing process must mirror this. Consider the following from IEEE Std 1012:
Planning the V&V process, software integrity levels are generally assigned early in the development process, preferably during the system requirements, analysis, and architecture design activities. The software integrity level can be assigned to software requirements, functions, group of functions or software components and subsystems. The assigned software integrity levels may vary as the software evolves. Design, coding, procedural, and technology implementation features selected by the development organization can raise or lower the software criticality and the associated software integrity levels assigned to the software.
The V&V at the unit test level is surprisingly effective (when used), as the example of the ValidCode() predicate failing at the unit test level demonstrates. The unit testing process is composed of three phases that are partitioned into a total of eight basic activities:
Perform the test planning
Plan the general approach, resources, and schedule
Determine features to be tested
Refine the general plan
Acquire the test set
Design the set of tests
Implement the refined plan and design
Measure the test unit
Execute the test procedures
Check for termination
Evaluate the test effort and unit
We suggest that you start to integrate these basic activities at end of the Layer 4 analysis from the PADL model and after the PBS has been done. Other common types of errors that should be located in the testing phase of your Layer 4 analysis are shown in Table 10-5.
Table 10.5. Table 10-5
Using the declarative architecture of the application in conjunction with mapping the PBS and PADL early on in the unit testing phase will deal with the most significant challenges of a parallel programming development effort. This technique is then supported by the application using C++ exception handling and what we call logical fault tolerance.
You can use the C++ exception handling facilities and the exception classes to enforce the semantics of the PADL and PBS. By extending the exception and error classes through inheritance you aid the testing process in catching non sequiturs that occur in the C++ predicate implementation of the application PBS. We call this process adding logical fault tolerance to an application.
How the basics of the C++ exception-handling facility are used has at least two important implications for the software architecture:
The flow of control in the software architecture can be altered by the throw mechanism.
The exception classes used introduce new types and each type has its own semantics.
It is the transfer of control from the problem area to someplace that knows how to bring the system into a consistent state and knows the semantics of the exception thrown that enables you to start to reach for the goal of logical fault tolerance. The semantics of the exception thrown describes what the exceptional condition is and suggests what should be done. The transfer of control takes you to code that implements your exception strategy. The exception strategy is designed to make the software resilient to defects and system failures. In C++, the catch() mechanism either implements the exception strategy directly or creates objects and calls functions that implement the exception strategy:
catch(some_exception){
//Execute exceptions strategy
}The catch{} block is called the exception handler. A C++ program can contain multiple exception handlers. Each exception handler is associated with one or more types (depending on the class hierarchy of the exception). Three of the basic functions of an exception handler are:
Register the type of exception(s) that it can handle
Record or in some way log what exception has occurred (sometimes this requires notification)
Execute an appropriate exception-handling strategy
Exception-handling strategies come in many shapes and sizes. The primary purpose of the exception-handling strategy in the termination model is to bring the software back to a consistent state so that the software can continue to function at some acceptable level. Table 10-6 contains some of the commonly used exception strategies.
Table 10.6. Table 10-6
Exception Strategies | Description |
|---|---|
Resource reallocation and deallocation | Attempt to:
|
Undoing steps of an incomplete transaction, rolling the data back to a check point where the data was valid | |
Retrying an operation:
| |
Turning over processing to other threads or that are operating in parallel with the current process | |
Notification for outside assistance | Requesting assistance from other software agents, human users, or other systems |
The exception-handling strategy(ies) that are used will greatly impact the software architecture. This means that the exception-handling strategy has to be included in the software design phase. In the approach toward declarative interpretations of parallel programming, you are moving toward logical models. Ultimately, you want nonlogical models or irrational program behavior to be considered an exception. So the exception-handling strategy flows from Layer 5 of the PADL and the PBS. It is a fundamental part of the software architecture. If the overall software architecture is brittle, the exception-handling strategy is doomed.
The semantics of the exception thrown is tied to the exception strategy implemented. Defining and understanding the semantics of an exception in the context of the software architecture is as important as deciding where to transfer control during the exception-handling process. The C++ standard defines several built-in exception classes with their own semantics. Figure 10-1 shows the class relationship diagram for the C++ exception classes.
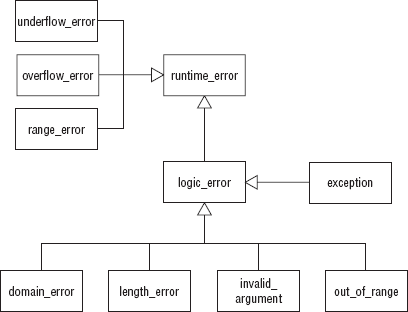
These exception classes can be extended through inheritance. C++ also supports user-defined exception classes.
The standard C++ class library has nine exception classes divided into two basic groups: the runtime error group and the logic error group. The runtime error group represents errors that are somewhat difficult to prevent, whereas the logic error group represents errors that are theoretically preventable.
The runtime_error family of classes is derived from the exception class. Three classes are derived from runtime_error: range_error, overflow_error, and underflow_error. The runtime_error classes report internal computation or arithmetic errors. The runtime_error classes get their primary functionality from the exception class ancestor. The what() method, assignment operator=(), and the constructors for the exception-handling class provide the capability of the runtime_error classes. The runtime_error classes provide an exception framework and architectural blueprint to build upon.
The logic_error family of classes is derived from the exception class. In fact, most of the functionality of the logic_error family of classes is also inherited from the exception class. The exception class contains the what() method, used to report to the user a description for the error being thrown. Each class in the logic_error family contains a constructor used to tailor a message specific to that class.
Like the runtime_error classes, these classes are really designed to be specialized. Unless the user adds some functionality to these classes, they cannot do anything other than report the error and the type. So, the nine generic exception classes provide no corrective action or error handling. Take a look at how the basic exception classes work with no specialization. Example 10-1 shows how an exception object and a logic_error object can be thrown.
Example 10.1. Example 10-1
// Example 10-1 Throwing an exception object and a logic_error object.
try{
exception X;
throw(X);
}
catch(const exception &X)
{
cout << X.what() << endl;
}
try{
logic_error Logic("Logic Mistake");
throw(Logic);
}
catch(const exception &X)
{
cout << X.what() << endl;
}The basic exception classes have only construction, destruction, assignment, copy, and simple reporting capabilities. They do not contain the capability to correct a fault that has occurred. The error message returned by the what() method of the exception classes will be determined by the string passed to the constructor for the logic_error object. In Example 10-1, the string "Logic Mistake" passed to the constructor is returned by the what() message in the catch block().
The exception classes can be used as is, that is, they can be used simply to report an error message describing the error that has occurred. However, this is virtually useless as an exception-handling technique. Simply knowing what the exception was doesn't do much to increase software reliability. The real value of the exception class hierarchy is the architectural road map that it provides for the designer and the developer. The exception classes provided basic error types that the developer can specialize. Many of the exceptions that occur in a runtime environment can be placed into either the logic_error or runtime_error family of classes. To see how to specialize an exception class, you can consider the runtime_error class as an example. As already noted, the runtime_error class is a descendant of the exception class. You can specialize the runtime_error class through inheritance. For example:
class concurrent_ file_access_exception: public runtime_error{
protected:
//...
int ErrorNumber;
string DetailedExplanation;
string FileName;
//...
public:
virtual int takeCorrectiveAction(void)
string detailedExplanation(void);
//...
};Here, the concurrent_file_access_exception inherits runtime_error and specializes it by adding a number of data members and member functions. Specifically, the takeCorrectiveAction() method is added. This method can be used to help the exception handler perform its recovery and correction work. This file_access_exception object knows how to identify deadlock and how to break deadlock. Recall that deadlock is one of the major challenges for parallel programming. It also has specialized logic for dealing with viruses that can damage files. It also has specialized knowledge for dealing with file transfers that get unexpectedly interrupted. Each of these situations can introduce runtime exceptions. You can use the concurrent_file_access_exception objects with the throw, catch, and try facilities of C++. For example:
try{
//...
fileProcessingOperation();
//...
}
catch(concurrent_file_access_exception &E)
{
cerr << E.what() << endl;
cerr << E.detailedExplanation() << endl;E.takeCorrectiveAction();
// Handler Take Additional Corrective Action
//...
}The exception objects are thrown when some software component encounters a software or hardware anomaly. But note, the exception objects themselves do not throw exceptions. This has many implications. Special care should be taken when designing handlers in multithreaded or multiprocessing environments. If the processing of the exception is complex enough to potentially cause another exception to be generated, then the exception processing should be redesigned and simplified where possible. The exception-handling mechanism is unnecessarily complicated when exception-handling code can generate exceptions. Therefore, most of the methods in the exception classes contain the empty throw() specification.
// Class declaration for exception class
class exception {
public:
exception() throw() {}
exception(const exception&) throw() {}
exception& operator=(const exception&) throw() {return *this;}
virtual ~exception() throw() {}
virtual const char* what() const throw();
};Note the throw() declarations with empty arguments. The empty argument shows that the method cannot throw an exception. If the method attempts to throw an exception, a compile-time error message is generated. If the base class cannot throw an exception, then the corresponding method in any derived class cannot throw an exception.
In its simplest form, the implementation model creates a C++ predicate for each of the predicates in the PBS structure of the application. At that time, a predicate exception class (possibly derived from logic_error) is created for each predicate. If for some unknown and uncontrollable reason assumptions, assertions, or propositions concerning a predicate are contradicted, then that predicate's exception class is thrown. In most cases this means that the application will exit gracefully. It should exit at this point because once one or more of the predicates from the PBS are contradicted; therefore, the application doesn't have the same meaning. The integrity of the concurrency infrastructure has been violated. The predicate exception class acts as a logic-based invariant that guards the consistency of the PBS for the application. Obviously, the predicate exception handler will know what to do when its exception is thrown.
For example, if the guess_it program determines that it does not have enough agents to generate enough guesses in time to win, should it throw a valid_code exception? Or is the lack of enough agents a normal software error, which, therefore, should be taken care of by error handling as opposed to exception handling? The answer is a lack of enough agents in this case is not a normal software error because the fundamental operation of the software is to acquire enough agents to guess the code in time. If it cannot acquire enough agents, then it will fail its mission. The unit testing process should expose this, and the predicate exception handlers are used to aid the quality of unit testing. So, logical fault tolerance serves two important roles in this example:
It brings the application to a graceful exit (or other acceptable state). For multiagent and blackboard architectures this includes:
Dismissing or retiring agents and knowledge sources
Returning blackboard resources and communication lines
Releasing reservations on any shared data, synchronization, or communication components
It prevents the application from carrying on in an irrational state and thereby prevents the application from committing further fallacies.
In particular, the second role logical fault tolerance plays here helps to build and enforce a declarative-based architecture.
Typically, the exception-handling mechanism is used to keep the program from simply crashing. The C++ exception-handling mechanism supports the termination model. A graceful exit is what is called for in the termination model. However, you usually terminate an application when something catastrophic has happened. Although it may be possible for a multithreaded or multiprocessing application to continue if the PBS is not strictly adhered to, you should classify any departure from the PBS as catastrophic because the logical consequence (or the meaning) of the application is the sum of is its predicates, propositions, axioms, and statements. These predicates form the application's logical argument. If one of the assertions or predicates turns out to be false, then the application is irrational at that point. You want to discover any irrational behavior during the testing phase, and you use logical fault tolerance semantics to help you do this. This use of C++ predicates in conjunction with predicate exceptions is an important part of achieving a declarative approach to parallel programming. While the goal is to find all of the defects in the testing phases, it is not always possible. So, you add to the typical uses for the C++ exception handling that of logical fault tolerance. The goal of logical fault tolerance is to not allow the program to have any other consequences than the consequences that are present in the PBS.
You might recall from the guess_it game that the agent with the code would change the code only if the number of guesses within a certain interval had been reached. In this scenario, the agent that attempted to guess the code faced two possible worlds: one world in which the code had not been changed and one where it had. The PBS had the following breakdowns for these situations:
Breakdown 5: N agents are enough find the correct code from a sample of 4 million codes in 2 minutes.
Breakdown 6: 4 times N agents are required to find the correct code from a sample of 4 million codes in 2 minutes if the code is being changed every 15 seconds.
The ValidCode() predicate failed the unit test because it did not provide for Breakdown 6. It is important to note that if you were in a situation where the agent luckily guessed the code before the 15 seconds were up, it would appear that the program was in good working order. But when you are evaluating the application against the PBS, you have to have a test case for each predicate in the PBS. Each predicate introduces one or more possible worlds. The notion of possible worlds is taken from field of logic. A possible world is used to express what is necessarily true, possibly true, or contingently true. The intuitive idea behind the possible-worlds model is that besides the true (or current) state of affairs, there are a number of other possible states of affairs, or "worlds" [Fagin et al., 1995]. Possible worlds are outcomes that an agent considers possible, in this case, the possibility of the code being changed (world 1) or not changed (world 2). The PBS of an application clearly defines what the possible worlds an agent or knowledge source will operate within. For every world that is possible for the agent, there is a set of acceptable code that the agent or knowledge source can execute. On the other hand, for worlds that are not possible (as far as the agent is concerned), there is no acceptable code that the agent can execute. Impossible worlds generate predicate exceptions!
The predicates in the PBS introduce what possible worlds there are for an application or its agents to live in. The predicate exception class represents scenarios where impossible worlds are encountered. For example, the world where the code is changed every 15 seconds but no new agents are added to accommodate that is an impossible world in the example PBS. It is exactly this problem that caused the ValidCode() predicate to fail. You can use a form of model checking during your unit tests to uncover these kinds of software defects in a parallel program.
Although a discussion of model checking is beyond the scope of this book, we introduce it here so that once you're ready to deal with validation and verification of large and potentially complex parallel programs or massively multithreaded applications, you have some idea of what tools are used. In this book, we present a brief introduction to some of the more challenging issues with multicore and multithreaded programming. But this book is just an introduction. We present declarative parallel programming techniques that move in the direction of logical models of parallelism. Logical models will ultimately help developers cope with massively parallel multicore computers. Model-checking techniques can be used to automate some of the testing multithreaded or parallel programs that have declarative architectures. Model checking is a technique for verifying finite-state concurrent systems [Huth, Ryan, 2004]. Model checking is used to determine whether the model that is presented is the model that is expected. The PBS approach used as an example in this chapter presents a logical model of the application that can be formalized and used with model checking tools. You might be interested to know that Kripke Structures are used in a formal presentation of possible worlds and model checking [Meyer, Van der Hoek, 2004].
The goal of testing software is to make sure that the software does what you want, and that you want what is does. An application is often requested as a list of desired features, and regardless to how the list of requirements for a piece of software is generated, the testing process must make sure that the software meets those requirements and that the requirements meet the user's expectations.
In many cases where parallel computers or multiprocessors are involved, the user's expectations include performance speedup or a certain level of high-performance throughput, and often the kinds of software errors you encounter increase when multithreading or multiprocessing is added in attempt to achieve the user's expectation. When the software does not perform according to the specifications, the software is in error, even if the specification violation is that the system performs too slowly.
In this chapter, we discussed using exception handling to provide a kind of logical fault tolerance for declarative architectures. That is, if an application for unknown and uncontrollable reasons violates statements, assertions, rules, predicates, or constraints from the PBS, you want to throw an exception and gracefully exit because once your predicates have been violated, then the correctness, reliability, and meaning of the application has been compromised. The journey toward fault tolerance in your software begins by recognizing that:
No amount of exception handling can rescue a flawed or an inappropriate software architecture.
The fault tolerance of a piece of software is directly related to the quality of its architecture.
The exception-handling architecture cannot replace the testing stages.
In this approach toward declarative interpretations of parallel programming, we are moving you more toward logical models. Ultimately, you want nonlogical models or irrational program behavior to be considered an exception. So, the exception-handling strategy needs to flow from Layer 5 of the PADL and the PBS and become a fundamental part of the software architecture. User-defined C++ predicates form the application's logical argument. If one of the assertions or predicates turns out to be false, then the application is irrational at that point. The PBS of an application clearly defines what the possible worlds an agent or knowledge source will operate within. For every world that is possible for the agent, there is a piece of acceptable code that the agent or knowledge source can execute.
Software that requires parallel programming can be notoriously difficult to test and debug, which is why testing and debugging represent key challenges for software that has a concurrency requirement. Ideally, this chapter has given you a good foundation for how to approach some of those testing and debugging challenges in your own parallel programming, just as this book has grounded you in the everyday fundamentals of programming for multiprocessor and multithreaded architectures, the very kind of application design and development that is now a mainstream concern. We wish you the best of luck with your future multicore programming projects.
Note
Finally, we want to leave you with a reiteration of a point we made toward the beginning of this chapter: As software developers, we produce applications in the fields of medicine, manufacturing, homeland security, transportation, finance, education, scientific research, and all areas of business, we have an ethical and moral responsibility to produce software that is safe, correct, reliable, and fault tolerant. Anything less is malpractice.