
WHAT YOU WILL LEARN IN THIS CHAPTER:
Defining a new class in terms of an existing one
How to use the
protectedkeyword to define a new access specification for class membersHow a class can be a friend to another class
How to use virtual functions
Pure virtual functions
Abstract classes
When to use virtual destructors
In this chapter, you're going to look into a topic that lies at the heart of object-oriented programming (OOP): class inheritance. Simply put, inheritance is the means by which you can define a new class in terms of one you already have. This is fundamental to programming in C++, so it's important that you understand how inheritance works.
As you have seen, a class is a data type that you define to suit your own application requirements. Classes in OOP also define the objects to which your program relates. You program the solution to a problem in terms of the objects that are specific to the problem, using operations that work directly with those objects. You can define a class to represent something abstract, such as a complex number, which is a mathematical concept, or a truck, which is decidedly physical (especially if you run into one on the highway). So, as well as being a data type, a class can also be a definition of a set of real-world objects of a particular kind, at least to the degree necessary to solve a given problem.
You can think of a class as defining the characteristics of a particular group of things that are specified by a common set of parameters and share a common set of operations that may be performed on them. The operations that you can apply to objects of a given class type are defined by the class interface, which corresponds to the functions contained in the public section of the class definition. The CBox class that you used in the previous chapter is a good example — it defined a box in terms of its dimensions plus a set of public functions that you could apply to CBox objects to solve a problem.
Of course, there are many different kinds of boxes in the real world: there are cartons, coffins, candy boxes, and cereal boxes, to name but a few, and you will certainly be able to come up with many others. You can differentiate boxes by the kinds of things they hold, the materials from which they are made, and in a multitude of other ways, but even though there are many different kinds of boxes, they share some common characteristics — the essence of boxiness, perhaps. Therefore, you can still visualize all kinds of boxes as actually being related to one another, even though they have many differentiating features. You could define a particular kind of box as having the generic characteristics of all boxes — perhaps just a length, a width, and a height. You could then add some additional characteristics to the basic box type to differentiate a particular kind of box from the rest. You may also find that there are new things you can do with your specific kind of box that you can't do with other boxes.
It's also possible that some objects may be the result of combining a particular kind of box with some other type of object: a box of candy or a crate of beer, for example. To accommodate this, you could define one kind of box as a generic box with basic "boxiness" characteristics and then specify another sort of box as a further specialization of that. Figure 9-1 illustrates an example of the kinds of relationships you might define between different sorts of boxes.
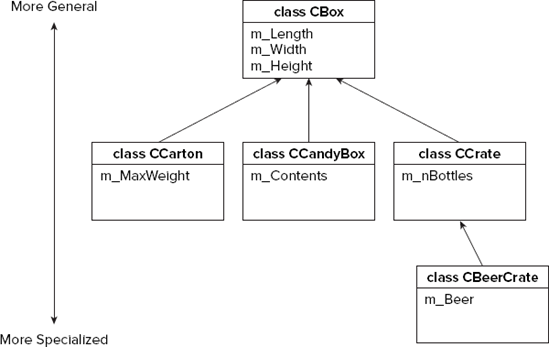
The boxes become more specialized as you move down the diagram, and the arrows run from a given box type to the one on which it is based. Figure 9-1 defines three different kinds of boxes based on the generic type, CBox. It also defines beer crates as a further refinement of crates designed to hold bottles.
Thus, a good way to approximate the real world relatively well using classes in C++ is through the ability to define classes that are interrelated. A candy box can be considered to be a box with all the characteristics of a basic box, plus a few characteristics of its own. This precisely illustrates the relationship between classes in C++ when one class is defined based on another. A more specialized class has all the characteristics of the class on which it is based, plus a few characteristics of its own that identify what makes it special. Let's look at how this works in practice.
When you define one class based on an existing class, the new class is referred to as a derived class. A derived class automatically contains all the data members of the class that you used to define it and, with some restrictions, the function members as well. The class is said to inherit the data members and function members of the class on which it is based.
The only members of a base class that are not inherited by a derived class are the destructor, the constructors, and any member functions overloading the assignment operator. All other function members, together with all the data members of a base class, are inherited by a derived class. Of course, the reason for certain base members not being inherited is that a derived class always has its own constructors and destructor. If the base class has an assignment operator, the derived class provides its own version. When I say these functions are not inherited, I mean that they don't exist as members of a derived class object. However, they still exist for the base class part of an object, as you will see.
A base class is any class that you use as a basis for defining another class. For example, if you define a class, B, directly in terms of a class, A, A is said to be a direct base class of B. In Figure 9-1, the CCrate class is a direct base class of CBeerCrate. When a class such as CBeerCrate is defined in terms of another class, CCrate, CBeerCrate is said to be derived from CCrate. Because CCrate is itself defined in terms of the class CBox, CBox is said to be an indirect base class of CBeerCrate. You'll see how this is expressed in the class definition in a moment. Figure 9-2 illustrates the way in which base class members are inherited in a derived class.
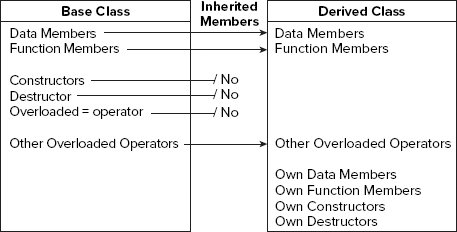
Just because member functions are inherited doesn't mean that you won't want to replace them in the derived class with new versions, and, of course, you can do that when necessary.
Let's go back to the original CBox class with public data members that you saw at the beginning of the previous chapter:
// Header file Box.h in project Ex9_01
#pragma once
class CBox
{
public:
double m_Length;
double m_Width;
double m_Height;
CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0):
m_Length(lv), m_Width(wv), m_Height(hv){}
};Create a new empty WIN32 console project with the name Ex9_01 and save this code in a new header file in the project with the name Box.h. The #pragma once directive ensures the definition of CBox appears only once in a build. There's a constructor in the class so that you can initialize objects when you declare them. Suppose you now need another class of objects, CCandyBox, that are the same as CBox objects but also have another data member — a pointer to a text string — that identifies the contents of the box.
You can define CCandyBox as a derived class with the CBox class as the base class, as follows:
// Header file CandyBox.h in project Ex9_01
#pragma once
#include "Box.h"
class CCandyBox: CBox
{
public:
char* m_Contents;
CCandyBox(char* str = "Candy") // Constructor
{
m_Contents = new char[ strlen(str) + 1 ];
strcpy_s(m_Contents, strlen(str) + 1, str);
}
~CCandyBox() // Destructor
{ delete[] m_Contents; };
};Add this header file to the project Ex9_01. You need the #include directive for the Box.h header file because you refer to the CBox class in the code. If you were to leave this directive out, CBox would be unknown to the compiler, so the code would not compile. The base class name, CBox, appears after the name of the derived class, CCandyBox, and is separated from it by a colon. In all other respects, it looks like a normal class definition. You have added the new member, m_Contents, and, because it is a pointer to a string, you need a constructor to initialize it and a destructor to release the memory for the string. You have also put a default value for the string describing the contents of a CCandyBox object in the constructor. Objects of the CCandyBox class type contain all the members of the base class, CBox, plus the additional data member, m_Contents.
Note the use of the strcpy_s() function that you first saw in Chapter 6. Here, there are three arguments — the destination for the copy operation, the length of the destination buffer, and the source. If both arrays were static — that is, not allocated on the heap — you could omit the second argument and just supply the destination and source pointers. This is possible because the strcpy_s() function is also available as a template function that can infer the length of the destination string automatically. You can therefore call the function just with the destination and source strings as arguments when you are working with static strings.
TRY IT OUT: Using a Derived Class
Now, you'll see how the derived class works in an example. Add the following code to the Ex9_01 project as the source file Ex9_01.cpp:
// Ex9_01.cpp
// Using a derived class
#include <iostream> // For stream I/O
#include <cstring> // For strlen() and strcpy()
#include "CandyBox.h" // For CBox and CCandyBox
using std::cout;
using std::endl;
int main()
{
CBox myBox(4.0, 3.0, 2.0); // Create CBox object
CCandyBox myCandyBox;
CCandyBox myMintBox("Wafer Thin Mints"); // Create CCandyBox object
cout << endl
<< "myBox occupies " << sizeof myBox // Show how much memory
<< " bytes" << endl // the objects require
<< "myCandyBox occupies " << sizeof myCandyBox
<< " bytes" << endl
<< "myMintBox occupies " << sizeof myMintBox
<< " bytes";
cout << endl
<< "myBox length is " << myBox.m_Length;
myBox.m_Length = 10.0;
// myCandyBox.m_Length = 10.0; // uncomment this for an errorcout << endl; return 0; }
The access to inherited members in a derived class needs to be looked at more closely. Consider the status of the private members of a base class in a derived class.
There was a good reason to choose the version of the class CBox with public data members in the previous example, rather than the later, more secure version with private data members. The reason was that although private data members of a base class are also members of a derived class, they remain private to the base class in the derived class, so member functions added to the derived class cannot access them. They are only accessible in the derived class through function members of the base class that are not in the private section of the base class. You can demonstrate this very easily by changing all the CBox class data members to private and putting a Volume() function in the derived class CCandyBox, so that the class definition is as follows:
// Version of the classes that will not compile
class CBox
{
public:
CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0):
m_Length(lv), m_Width(wv), m_Height(hv){}
private:
double m_Length;
double m_Width;double m_Height;
};
class CCandyBox: public CBox
{
public:
char* m_Contents;
// Function to calculate the volume of a CCandyBox object
double Volume() const // Error - members not accessible
{ return m_Length*m_Width*m_Height; }
CCandyBox(char* str = "Candy") // Constructor
{
m_Contents = new char[ strlen(str) + 1 ];
strcpy_s(m_Contents, strlen(str) + 1, str);
}
~CCandyBox() // Destructor
{ delete[] m_Contents; }
};A program using these classes does not compile. The function Volume() in the class CCandyBox attempts to access the private members of the base class, which is not legal, so the compiler will flag each instance with error number C2248.
The Ex9_02.cpp file in the project contains:
// Ex9_02.cpp// Using a function inherited from a base class#include <iostream> // For stream I/O #include <cstring> // For strlen() and strcpy() #include "CandyBox.h" // For CBox and CCandyBox using std::cout; using std::endl; int main() { CBox myBox(4.0,3.0,2.0); // Create CBox object CCandyBox myCandyBox; CCandyBox myMintBox("Wafer Thin Mints"); // Create CCandyBox object cout << endl << "myBox occupies " << sizeof myBox // Show how much memory << " bytes" << endl // the objects require << "myCandyBox occupies " << sizeof myCandyBox << " bytes" << endl << "myMintBox occupies " << sizeof myMintBox << " bytes";cout << endl<< "myMintBox volume is " << myMintBox.Volume(); // Get volume of a// CCandyBox objectcout << endl; return 0; }
This example produces the following output:
myBox occupies 24 bytes myCandyBox occupies 32 bytes
myMintBox occupies 32 bytes myMintBox volume is 1
Although I said the base class constructors are not inherited in a derived class, they still exist in the base class and are used for creating the base part of a derived class object. This is because creating the base class part of a derived class object is really the business of a base class constructor, not the derived class constructor. After all, you have seen that private members of a base class are inaccessible in a derived class object, even though they are inherited, so responsibility for these has to lie with the base class constructors.
The default base class constructor was called automatically in the last example to create the base part of the derived class object, but this doesn't have to be the case. You can arrange to call a particular base class constructor from the derived class constructor. This enables you to initialize the base class data members with a constructor other than the default, or, indeed, to choose to call a particular class constructor, depending on the data supplied to the derived class constructor.
The CandyBox.h header file should contain:
// CandyBox.h in Ex9_03#pragma once#include <iostream>#include "Box.h"using std::cout;using std::endl;class CCandyBox: public CBox { public: char* m_Contents;// Constructor to set dimensions and contents// with explicit call of CBox constructorCCandyBox(double lv, double wv, double hv, char* str = "Candy"):CBox(lv, wv, hv){cout << endl <<"CCandyBox constructor2 called";m_Contents = new char[ strlen(str) + 1 ];strcpy_s(m_Contents, strlen(str) + 1, str);}// Constructor to set contents// calls default CBox constructor automaticallyCCandyBox(char* str = "Candy"){cout << endl << "CCandyBox constructor1 called";m_Contents = new char[ strlen(str) + 1 ];strcpy_s(m_Contents, strlen(str) + 1, str);}~CCandyBox() // Destructor { delete[] m_Contents; } };
The #include directive for the <iostream> header and the two using declarations are not strictly necessary here because Box.h contains the same code, but it does no harm to put them in. On the contrary, putting these statements in here also means that if you were to remove this code from Box.h because it was no longer required there, CandyBox.h would still compile.
The contents of Ex9_03.cpp are:
// Ex9_03.cpp// Calling a base constructor from a derived class constructor#include <iostream> // For stream I/O #include <cstring> // For strlen() and strcpy() #include "CandyBox.h" // For CBox and CCandyBox using std::cout; using std::endl; int main() { CBox myBox(4.0, 3.0, 2.0); CCandyBox myCandyBox;CCandyBox myMintBox(1.0, 2.0, 3.0, "Wafer Thin Mints");cout << endl << "myBox occupies " << sizeof myBox // Show how much memory << " bytes" << endl // the objects require << "myCandyBox occupies " << sizeof myCandyBox << " bytes" << endl << "myMintBox occupies " << sizeof myMintBox << " bytes"; cout << endl << "myMintBox volume is " // Get volume of a << myMintBox.Volume(); // CCandyBox object cout << endl; return 0; }
In addition to the public and private access specifiers for members of a class, you can also declare members of a class as protected. Within the class, the protected keyword has the same effect as the private keyword: members of a class that are protected can only be accessed by member functions of the class, and by friend functions of the class (also by member functions of a class that is declared as a friend of the class — you will learn about friend classes later in this chapter). Using the protected keyword, you could redefine the CBox class as follows:
// Box.h in Ex9_04#pragma once #include <iostream> using std::cout; using std::endl; class CBox { public: // Base class constructor CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0): m_Length(lv), m_Width(wv), m_Height(hv) { cout << endl << "CBox constructor called"; }// CBox destructor - just to track calls∼CBox(){ cout << "CBox destructor called" << endl; }protected:double m_Length; double m_Width; double m_Height; };
Now, the data members are still effectively private, in that they can't be accessed by ordinary global functions, but they'll still be accessible to member functions of a derived class.
TRY IT OUT: Using Protected Members
You can demonstrate the use of protected data members by using this version of the class CBox to derive a new version of the class CCandyBox, which accesses the members of the base class through its own member function, Volume():
// CandyBox.h in Ex9_04#pragma once #include "Box.h" #include <iostream> using std::cout; using std::endl; class CCandyBox: public CBox { public: char* m_Contents;// Derived class function to calculate volumedouble Volume() const{ return m_Length*m_Width*m_Height; }// Constructor to set dimensions and contents // with explicit call of CBox constructor CCandyBox(double lv, double wv, double hv, char* str = "Candy") :CBox(lv, wv, hv) // Constructor { cout << endl <<"CCandyBox constructor2 called"; m_Contents = new char[ strlen(str) + 1 ]; strcpy_s(m_Contents, strlen(str) + 1, str); } // Constructor to set contents // calls default CBox constructor automatically CCandyBox(char* str = "Candy") // Constructor { cout << endl << "CCandyBox constructor1 called"; m_Contents = new char[ strlen(str) + 1 ]; strcpy_s(m_Contents, strlen(str) + 1, str); } ~CCandyBox() // Destructor {cout << "CCandyBox destructor called" << endl;delete[] m_Contents; } };
The code for main() in Ex9_04.cpp is:
// Ex9_04.cpp// Using the protected access specifier#include <iostream> // For stream I/O #include <cstring> // For strlen() and strcpy() #include "CandyBox.h" // For CBox and CCandyBox using std::cout; using std::endl;int main(){CCandyBox myCandyBox;
CCandyBox myToffeeBox(2, 3, 4, "Stickjaw Toffee");cout << endl<< "myCandyBox volume is " << myCandyBox.Volume()<< endl<< "myToffeeBox volume is " << myToffeeBox.Volume();// cout << endl << myToffeeBox.m_Length; // Uncomment this for an errorcout << endl;return 0;}
In this example, you calculate the volumes of the two CCandyBox objects by invoking the Volume() function that is a member of the derived class. This function accesses the inherited members m_Length, m_Width, and m_Height to produce the result. The members are declared as protected in the base class and remain protected in the derived class. The program produces the output shown as follows:
CBox constructor called CCandyBox constructor1 called CBox constructor called CCandyBox constructor2 called myCandyBox volume is 1 myToffeeBox volume is 24 CCandyBox destructor called CBox destructor called CCandyBox destructor called CBox destructor called
The output shows that the volume is being calculated properly for both CCandyBox objects. The first object has the default dimensions produced by calling the default CBox constructor, so the volume is 1, and the second object has the dimensions defined as initial values in its declaration.
The output also shows the sequence of constructor and destructor calls, and you can see how each derived class object is destroyed in two steps.
Destructors for a derived class object are called in the reverse order of the constructors for the object. This is a general rule that always applies. Constructors are invoked starting with the base class constructor and then the derived class constructor, whereas the destructor for the derived class is called first when an object is destroyed, followed by the base class destructor.
You can demonstrate that the protected members of the base class remain protected in the derived class by uncommenting the statement preceding the return statement in the function main(). If you do this, you get the following error message from the compiler,
error C2248: 'm_Length': cannot access protected member declared in class 'CBox'
which indicates quite clearly that the member m_Length is inaccessible.
You know that if you have no access specifier for the base class in the definition of a derived class, the default specification is private. This has the effect of causing the inherited public and protected members of the base class to become private in the derived class. The private members of the base class remain private to the base and, therefore, inaccessible to member functions of the derived class. In fact, they remain private to the base class regardless of how the base class is specified in the derived class definition.
You have also used public as the specifier for a base class. This leaves the members of the base class with the same access level in the derived class as they had in the base, so public members remain public and protected members remain protected.
The last possibility is that you declare a base class as protected. This has the effect of making the inherited public members of the base protected in the derived class. The protected (and private) inherited members retain their original access level in the derived class. This is summarized in Figure 9-3.
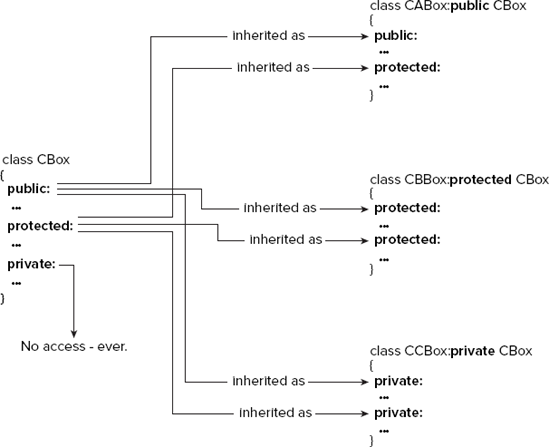
This may look a little complicated, but you can reduce it to the following three points about the inherited members of a derived class:
Members of a base class that are declared as
privateare never accessible in a derived class.Defining a base class as
publicdoesn't change the access level of its members in the derived class.Defining a base class as
protectedchanges itspublicmembers toprotectedin the derived class.
Being able to change the access level of inherited members in a derived class gives you a degree of flexibility, but don't forget that you cannot relax the level specified in the base class; you can only make the access level more stringent. This suggests that your base classes need to have public members if you want to be able to vary the access level in derived classes. This may seem to run contrary to the idea of encapsulating data in a class in order to protect it from unauthorized access, but, as you'll see, it is often the case that you define base classes in such a manner that their only purpose is to act as a base for other classes, and they aren't intended to be used for instantiating objects in their own right.
Remember that the copy constructor is called automatically when you declare an object that is initialized with an object of the same class. Look at these statements:
CBox myBox(2.0, 3.0, 4.0); // Calls constructor CBox copyBox(myBox); // Calls copy constructor
The first statement calls the constructor that accepts three arguments of type double, and the second calls the copy constructor. If you don't supply your own copy constructor, the compiler supplies one that copies the initializing object, member by member, to the corresponding members of the new object. So that you can see what is going on during execution, you can add your own version of a copy constructor to the class CBox. You can then use this class as a base for defining the CCandyBox class:
// Box.h in Ex9_05#pragma once #include <iostream> using std::cout; using std::endl; class CBox // Base class definition { public: // Base class constructor CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0): m_Length(lv), m_Width(wv), m_Height(hv) { cout << endl << "CBox constructor called"; }// Copy constructorCBox(const CBox& initB){
cout << endl << "CBox copy constructor called";m_Length = initB.m_Length;m_Width = initB.m_Width;m_Height = initB.m_Height;}// CBox destructor - just to track calls ~CBox() { cout << "CBox destructor called" << endl; } protected: double m_Length; double m_Width; double m_Height; };
Also recall that the copy constructor must have its parameter specified as a reference to avoid an infinite number of calls to itself, which would otherwise result from the need to copy an argument that is transferred by value. When the copy constructor in our example is invoked, it outputs a message to the screen, so you'll be able to see from the output when this is happening. All you need now is to add a copy constructor to the CCandyBox class.
You can now run this new version (Ex9_05) of the last example with the following function main() to see how the new copy constructor works:
int main()
{
CCandyBox chocBox(2.0, 3.0, 4.0, "Chockies"); // Declare and initialize
CCandyBox chocolateBox(chocBox); // Use copy constructor
cout << endl
<< "Volume of chocBox is " << chocBox.Volume()
<< endl
<< "Volume of chocolateBox is " << chocolateBox.Volume()<< endl; return 0; }
How It Works
When you run this example, it produces the following output:
CBox constructor called CCandyBox constructor2 called CBox constructor called CCandyBox copy constructor called Volume of chocBox is 24 Volume of chocolateBox is 1 CCandyBox destructor called CBox destructor called CCandyBox destructor called CBox destructor called
Although, at first sight, this looks okay, there is something wrong. The third line of output shows that the default constructor for the CBox part of the object chocolateBox is called, rather than the copy constructor. As a consequence, the object has the default dimensions rather than the dimensions of the initializing object, so the volume is incorrect. The reason for this is that when you write a constructor for an object of a derived class, you are responsible for ensuring that the members of the derived class object are properly initialized. This includes the inherited members.
The fix for this is to call the copy constructor for the base part of the class in the initialization list for the copy constructor for the CCandyBox class. The copy constructor then becomes:
// Derived class copy constructor
CCandyBox(const CCandyBox& initCB): CBox(initCB)
{
cout << endl << "CCandyBox copy constructor called";
// Get new memory
m_Contents = new char[ strlen(initCB.m_Contents) + 1 ];
// Copy string
strcpy_s(m_Contents, strlen(initCB.m_Contents) + 1, initCB.m_Contents);
}Now, the CBox class copy constructor is called with the initCB object. Only the base part of the object is passed to it, so everything works out. If you modify the last example by adding the base copy constructor call, the output is as follows:
CBox constructor called CCandyBox constructor2 called CBox copy constructor called CCandyBox copy constructor called Volume of chocBox is 24 Volume of chocolateBox is 24
CCandyBox destructor called CBox destructor called CCandyBox destructor called CBox destructor called
The output shows that all the constructors and destructors are called in the correct sequence, and the copy constructor for the CBox part of chocolateBox is called before the CCandyBox copy constructor. The volume of the object chocolateBox of the derived class is now the same as that of its initializing object, which is as it should be.
You have, therefore, another golden rule to remember:
Note
If you write any kind of constructor for a derived class, you are responsible for the initialization of all members of the derived class object, including all its inherited members.
Of course, as you saw in the previous chapter, if you want to make a class that allocates memory on the heap as efficient as possible, you should overload the copy constructor with a version that uses an rvalue reference parameter. You could add the following to the CCandyBox class to take care of this:
// Move constructor
CCandyBox(CCandyBox&& initCB): CBox(initCB)
{
cout << endl << "CCandyBox move constructor called";
m_Contents = initCB.m_Contents;
initCB.m_Contents = 0;
}You still have to call the base class copy constructor to get the base members initialized.
You saw in Chapter 7 how a function can be declared as a friend of a class. This gives the friend function the privilege of free access to any of the class members. Of course, there is no reason why a friend function cannot be a member of another class.
Suppose you define a CBottle class to represent a bottle:
#pragma once
class CBottle
{
public:
CBottle(double height, double diameter)
{
m_Height = height;
m_Diameter = diameter;
}
private:double m_Height; // Bottle height
double m_Diameter; // Bottle diameter
};You now need a class to represent the packaging for a dozen bottles that automatically has custom dimensions to accommodate a particular kind of bottle. You could define this as:
#pragma once
class CBottle; // Forward declaration
class CCarton
{
public:
CCarton(const CBottle& aBottle)
{
m_Height = aBottle.m_Height; // Bottle height
m_Length = 4.0*aBottle.m_Diameter; // Four rows of ...
m_Width = 3.0*aBottle.m_Diameter; // ...three bottles
}
private:
double m_Length; // Carton length
double m_Width; // Carton width
double m_Height; // Carton height
};The constructor here sets the height to be the same as that of the bottle it is to accommodate, and the length and width are set based on the diameter of the bottle so that 12 fit in the box. The forward declaration for the CBottle class is necessary because the constructor refers to CBottle. As you know by now, this won't work. The data members of the CBottle class are private, so the CCarton constructor cannot access them. As you also know, a friend declaration in the CBottle class fixes it:
#pragma once;class CCarton; // Forward declarationclass CBottle { public: CBottle(double height, double diameter) { m_Height = height; m_Diameter = diameter; } private: double m_Height; // Bottle height double m_Diameter; // Bottle diameter// Let the carton constructor infriend CCarton::CCarton(const CBottle& aBottle);};
The only difference between the friend declaration here and what you saw in Chapter 7 is that you must put the class name and the scope resolution operator with the friend function name to identify it. You have a forward declaration for the CCarton class because the fried function refers to it.
You might think that this will compile correctly, but there is a problem. The CCarton class definition refers to the CBottle class, and the CBottle class with the friend function added refers to the CCarton class, so we have a cyclic dependency here. You can put a forward declaration of the CCarton class in the CBottle class, and vice versa, but this still won't allow the classes to compile. The problem is with the CCarton class constructor. This appears within the CCarton class definition and the compiler cannot compile this function without having first compiled the CBottle class. On the other hand, it can't compile the CBottle class without having compiled the CCarton class. The only way to resolve this is to put the CCarton constructor definition in a .cpp file. The header file holding the CCarton class definition will be:
#pragma once
class CBottle; // Forward declaration
class CCarton
{
public:
CCarton(const CBottle& aBottle);
private:
double m_Length; // Carton length
double m_Width; // Carton width
double m_Height; // Carton height
};The contents of the carton.cpp file will be:
#include "carton.h"
#include "bottle.h"
CCarton::CCarton(const CBottle& aBottle)
{
m_Height = aBottle.m_Height; // Bottle height
m_Length = 4.0*aBottle.m_Diameter; // Four rows of ...
m_Width = 3.0*aBottle.m_Diameter; // ...three bottles
}Now, the compiler is able to compile both class definitions and the carton.cpp file.
You can also allow all the function members of one class to have access to all the data members of another by declaring it as a friend class. You could define the CCarton class as a friend of the CBottle class by adding a friend declaration within the CBottle class definition:
friend CCarton;
With this declaration in the CBottle class, all function members of the CCarton class now have free access to all the data members of the CBottle class.
Class friendship is not reciprocated. Making the CCarton class a friend of the CBottle class does not mean that the CBottle class is a friend of the CCarton class. If you want this to be so, you must add a friend declaration for the CBottle class to the CCarton class.
Class friendship is also not inherited. If you define another class with CBottle as a base, members of the CCarton class will not have access to its data members, not even those inherited from CBottle.
Let's look more closely at the behavior of inherited member functions and their relationship with derived class member functions. You could add a function to the CBox class to output the volume of a CBox object. The simplified class then becomes:
// Box.h in Ex9_06
#pragma once
#include <iostream>
using std::cout;
using std::endl;
class CBox // Base class
{
public:
// Function to show the volume of an object
void ShowVolume() const
{
cout << endl
<< "CBox usable volume is " << Volume();
}
// Function to calculate the volume of a CBox object
double Volume() const
{ return m_Length*m_Width*m_Height; }
// Constructor
CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0)
:m_Length(lv), m_Width(wv), m_Height(hv) {}
protected:
double m_Length;
double m_Width;
double m_Height;
};Now, you can output the usable volume of a CBox object just by calling the ShowVolume() function for any object for which you require it. The constructor sets the data member values in the initialization list, so no statements are necessary in the body of the function. The data members are as before and are specified as protected, so they are accessible to the member functions of any derived class.
Suppose you want to derive a class for a different kind of box called CGlassBox, to hold glassware. The contents are fragile, and because packing material is added to protect them, the capacity of the box is less than the capacity of a basic CBox object. You therefore need a different Volume() function to account for this, so you add it to the derived class:
// GlassBox.h in Ex9_06
#pragma once
#include "Box.h"
class CGlassBox: public CBox // Derived class
{
public:
// Function to calculate volume of a CGlassBox
// allowing 15% for packing
double Volume() const
{ return 0.85*m_Length*m_Width*m_Height; }
// Constructor
CGlassBox(double lv, double wv, double hv): CBox(lv, wv, hv){}
};There could conceivably be other additional members of the derived class, but we'll keep it simple and concentrate on how the inherited functions work, for the moment. The constructor for the derived class objects just calls the base class constructor in its initialization list to set the data member values. No statements are necessary in its body. You have included a new version of the Volume() function to replace the version from the base class, the idea being that you can get the inherited function ShowVolume() to call the derived class version of the member function Volume() when you call it for an object of the class CGlassBox.
TRY IT OUT: Using an Inherited Function
Now, see how your derived class works in practice. You can try this out very simply by creating an object of the base class and an object of the derived class with the same dimensions and then verifying that the correct volumes are being calculated. The main() function to do this is as follows:
// Ex9_06.cpp
// Behavior of inherited functions in a derived class
#include <iostream>
#include "GlassBox.h" // For CBox and CGlassBox
using std::cout;
using std::endl;
int main()
{
CBox myBox(2.0, 3.0, 4.0); // Declare a base box
CGlassBox myGlassBox(2.0, 3.0, 4.0); // Declare derived box - same size
myBox.ShowVolume(); // Display volume of base boxmyGlassBox.ShowVolume(); // Display volume of derived box cout << endl; return 0; }
If you run this example, it produces the following output:
CBox usable volume is 24 CBox usable volume is 24
This isn't only dull and repetitive, but it's also disastrous. It isn't working the way you want at all, and the only interesting thing about it is why. Evidently, the fact that the second call is for an object of the derived class CGlassBox is not being taken into account. You can see this from the incorrect result for the volume in the output. The volume of a CGlassBox object should definitely be less than that of a basic CBox with the same dimensions.
The reason for the incorrect output is that the call of the Volume() function in the function ShowVolume() is being set once and for all by the compiler as the version defined in the base class. ShowVolume() is a base class function, and when CBox is compiled, the call to Volume() is resolved at that time to the base class Volume() function; the compiler has no knowledge of any other Volume() function. This is called static resolution of the function call since the function call is fixed before the program is executed. This is also sometimes called early binding because the particular Volume() function chosen is bound to the call from the function ShowVolume() during the compilation of the program.
What we were hoping for in this example was that the question of which Volume() function call to use in any given instance would be resolved when the program was executed. This sort of operation is referred to as dynamic linkage, or late binding. We want the actual version of the function Volume() called by ShowVolume() to be determined by the kind of object being processed, and not arbitrarily fixed by the compiler before the program is executed.
No doubt, you'll be less than astonished that C++ does, in fact, provide you with a way to do this, because this whole discussion would have been futile otherwise! You need to use something called a virtual function.
A virtual function is a function in a base class that is declared using the keyword virtual. If you specify a function in a base class as virtual and there is another definition of the function in a derived class, it signals to the compiler that you don't want static linkage for this function. What you do want is the selection of the function to be called at any given point in the program to be based on the kind of object for which it is called.
Using pointers with objects of a base class and of a derived class is an important technique. You can use a pointer to a base class type to store the address of a derived class object as well as that of a base class object. You can thus use a pointer of the type "pointer to base" to obtain different behavior with virtual functions, depending on what kind of object the pointer is pointing to. You'll see more clearly how this works by looking at an example.
TRY IT OUT: Pointers to Base and Derived Classes
You'll use the same classes as in the previous example, but make a small modification to the function main() so that it uses a pointer to a base class object. Create the Ex9_08 project with Box.h and GlassBox.h header files the same as in the previous example. You can copy the Box.h and Glassbox.h files from the Ex9_07 project to this project folder. Adding an existing file to a project is quite easy; you right-click Ex9_08 in the Solution Explorer tab, select Add
// Ex9_08.cpp// Using a base class pointer to call a virtual function#include <iostream> #include "GlassBox.h" // For CBox and CGlassBox using std::cout; using std::endl; int main() { CBox myBox(2.0, 3.0, 4.0); // Declare a base box CGlassBox myGlassBox(2.0, 3.0, 4.0); // Declare derived box of same sizeCBox* pBox(nullptr); // Declare a pointer to base class objectspBox = &myBox; // Set pointer to address of base objectpBox->ShowVolume(); // Display volume of base boxpBox = &myGlassBox; // Set pointer to derived class objectpBox->ShowVolume(); // Display volume of derived boxcout << endl; return 0; }
How It Works
The classes are the same as in example Ex9_07.cpp, but the function main() has been altered to use a pointer to call the function ShowVolume(). Because you are using a pointer, you use the indirect member selection operator, ->, to call the function. The function ShowVolume() is called twice, and both calls use the same pointer to base class objects, pBox. On the first occasion, the pointer contains the address of the base object, myBox, and on the occasion of the second call, it contains the address of the derived class object, myGlassBox.
The output produced is as follows:
CBox usable volume is 24 CBox usable volume is 20.4
This is exactly the same as that from the previous example, where you used explicit objects in the function call.
You can conclude from this example that the virtual function mechanism works just as well through a pointer to a base class, with the specific function being selected based on the type of object being pointed to. This is illustrated in Figure 9-4.
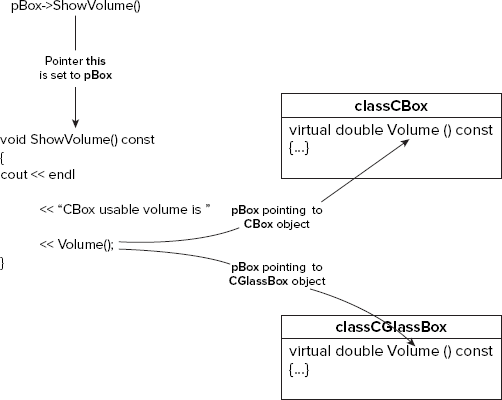
This means that, even when you don't know the precise type of the object pointed to by a base class pointer in a program (when a pointer is passed to a function as an argument, for example), the virtual function mechanism ensures that the correct function is called. This is an extraordinarily powerful capability, so make sure you understand it. Polymorphism is a fundamental mechanism in C++ that you will find yourself using again and again.
If you define a function with a reference to a base class as a parameter, you can pass an object of a derived class to it as an argument. When your function executes, the appropriate virtual function for the object passed is selected automatically. We could see this happening by modifying the function main() in the last example to call a function that has a reference as a parameter.
TRY IT OUT: Using References with Virtual Functions
Let's move the call to ShowVolume() into a separate function and call that separate function from main():
// Ex9_09.cpp// Using a reference to call a virtual function#include <iostream> #include "GlassBox.h" // For CBox and CGlassBox using std::cout; using std::endl;void Output(const CBox& aBox); // Prototype of functionint main() { CBox myBox(2.0, 3.0, 4.0); // Declare a base box CGlassBox myGlassBox(2.0, 3.0, 4.0); // Declare derived box of same sizeOutput(myBox); // Output volume of base class objectOutput(myGlassBox); // Output volume of derived class objectcout << endl; return 0; }void Output(const CBox& aBox){aBox.ShowVolume();}
Box.h and GlassBox.h for this example have the same contents as for the previous example.
How It Works
The function main() now basically consists of two calls of the function Output(), the first with an object of the base class as an argument and the second with an object of the derived class. Because the parameter is a reference to the base class, Output() accepts objects of either class as an argument, and the appropriate version of the virtual function Volume() is called, depending on the object that is initializing the reference.
The program produces exactly the same output as the previous example, demonstrating that the virtual function mechanism does indeed work through a reference parameter.
At the beginning of the previous example, you have the prototype declaration for the Output() function. To process this declaration, the compiler needs to have access to the definition of the CBox class because the parameter is of type CBox&. In this case, the definition of the CBox class is available at this point because you have a #include directive for GlassBox.h that has its own #include directive for Box.h.
However, there may be situations where you have such a declaration and the class definition cannot be included in this way, in which case, you would need some other way to at least identify that the name CBox refers to a class type. In this situation, you could provide an incomplete definition of the class CBox preceding the prototype of the output function. The statement that provides an incomplete definition of the CBox class is simply:
class CBox;
The statement just identifies that the name CBox refers to a class that is not defined at this point, but this is sufficient for the compiler to know that CBox is the name of a class, and this allows it to process the prototype of the function Output(). Without some indication that CBox is a class, the prototype causes an error message to be generated.
It's possible that you'd want to include a virtual function in a base class so that it may be redefined in a derived class to suit the objects of that class, but that there is no meaningful definition you could give for the function in the base class.
For example, you could conceivably have a class CContainer, which could be used as a base for defining the CBox class, or a CBottle class, or even a CTeapot class. The CContainer class wouldn't have data members, but you might want to provide a virtual member function Volume() to allow it to be called polymorphically for any derived classes. Because the CContainer class has no data members and, therefore, no dimensions, there is no sensible definition that you can write for the Volume() function. You can still define the class, however, including the member function Volume(), as follows:
// Container.h for Ex9_10
#pragma once
#include <iostream>
using std::cout;
using std::endl;
class CContainer // Generic base class for specific containers
{
public:
// Function for calculating a volume - no content
// This is defined as a 'pure' virtual function, signified by '= 0'
virtual double Volume() const = 0;
// Function to display a volume
virtual void ShowVolume() const
{
cout << endl
<< "Volume is " << Volume();
}
};The statement for the virtual function Volume() defines it as having no content by placing the equals sign and zero in the function header. This is called a pure virtual function. Any class derived from this class must either define the Volume() function or redefine it as a pure virtual function. Because you have declared Volume() as const, its implementation in any derived class must also be const. Remember that const and non-const varieties of a function with the same name and parameter list are different functions. In other words, a const version of a function is an overload of a non-const version.
The class also contains the function ShowVolume(), which displays the volume of objects of derived classes. Because this is declared as virtual, it can be replaced in a derived class, but if it isn't, the base class version that you see here is called.
A class containing a pure virtual function is called an abstract class. It's called abstract because you can't define objects of a class containing a pure virtual function. It exists only for the purpose of defining classes that are derived from it. If a class derived from an abstract class still defines a pure virtual function of the base as pure, it, too, is an abstract class.
You should not conclude, from the previous example of the CContainer class, that an abstract class can't have data members. An abstract class can have both data members and function members. The presence of a pure virtual function is the only condition that determines that a given class is abstract. In the same vein, an abstract class can have more than one pure virtual function. In this case, a derived class must have definitions for every pure virtual function in its base; otherwise, it, too, will be an abstract class. If you forget to make the derived class version of the Volume() function const, the derived class will still be abstract because it contains the pure virtual Volume() member function that is const, as well as the non-const Volume() function that you have defined.
TRY IT OUT: An Abstract Class
You could implement a CCan class, representing beer or cola cans, perhaps, together with the original CBox class, and derive both from the CContainer class that you defined in the previous section. The definition of the CBox class as a subclass of CContainer is as follows:
// Box.h for Ex9_10#pragma once#include "Container.h" // For CContainer definition#include <iostream> using std::cout; using std::endl;class CBox: public CContainer // Derived class{ public: // Function to show the volume of an object virtual void ShowVolume() const { cout << endl << "CBox usable volume is " << Volume(); } // Function to calculate the volume of a CBox object virtual double Volume() const
{ return m_Length*m_Width*m_Height; }
// Constructor
CBox(double lv = 1.0, double wv = 1.0, double hv = 1.0)
:m_Length(lv), m_Width(wv), m_Height(hv){}
protected:
double m_Length;
double m_Width;
double m_Height;
};The unshaded lines are the same as in the previous version of the CBox class. The CBox class is essentially as we had it in the previous example, except this time, you have specified that it is derived from the CContainer class. The Volume() function is fully defined within this class (as it must be if this class is to be used to define objects). The only other option would be to specify it as a pure virtual function, since it is pure in the base class, but then we couldn't create CBox objects.
You could define the CCan class in the Can.h header file like this:
// Can.h for Ex9_10
#pragma once
#include "Container.h" // For CContainer definition
extern const double PI; // PI is defined elsewhere
class CCan: public CContainer
{
public:
// Function to calculate the volume of a can
virtual double Volume() const
{ return 0.25*PI*m_Diameter*m_Diameter*m_Height; }
// Constructor
CCan(double hv = 4.0, double dv = 2.0): m_Height(hv), m_Diameter(dv){}
protected:
double m_Height;
double m_Diameter;
};The CCan class also defines a Volume() function based on the formula hπr2 where h is the height of a can and r is the radius of the cross-section of a can. The volume is calculated as the height multiplied by the area of the base. The expression in the function definition assumes a global constant PI is defined, so we have the extern statement indicating that PI is a global variable of type const double that is defined elsewhere — in this program, it is defined in the Ex9_10.cpp file. Also notice that we redefined the ShowVolume() function in the CBox class, but not in the CCan class. You can see what effect this has when we get some program output.
You can exercise these classes with the following source file containing the main() function:
// Ex9_10.cpp // Using an abstract class #include "Box.h" // For CBox and CContainer #include "Can.h" // For CCan (and CContainer)
#include <iostream> // For stream I/O
using std::cout;
using std::endl;
const double PI= 3.14159265; // Global definition for PI
int main(void)
{
// Pointer to abstract base class
// initialized with address of CBox object
CContainer* pC1 = new CBox(2.0, 3.0, 4.0);
// Pointer to abstract base class
// initialized with address of CCan object
CContainer* pC2 = new CCan(6.5, 3.0);
pC1->ShowVolume(); // Output the volumes of the two
pC2->ShowVolume(); // objects pointed to
cout << endl;
delete pC1; // Now clean up the free store
delete pC2; // ...
return 0;
} 
How It Works
In this program, you declare two pointers to the base class, CContainer. Although you can't define CContainer objects (because CContainer is an abstract class), you can still define a pointer to a CContainer, which you can then use to store the address of a derived class object; in fact, you can use it to store the address of any object whose type is a direct or indirect subclass of CContainer. The pointer pC1 is assigned the address of a CBox object created in the free store by the operator new. The second pointer is assigned the address of a CCan object in a similar manner.
Of course, because the derived class objects were created dynamically, you must use the delete operator to clean up the free store when you have finished with them. You learned about the delete operator back in Chapter 4.
The output produced by this example is as follows:
CBox usable volume is 24 Volume is 45.9458
Because you have defined ShowVolume() in the CBox class, the derived class version of the function is called for the CBox object. You did not define this function in the CCan class, so the base class version that the CCan class inherits is invoked for the CCan object. Because Volume() is a virtual function implemented in both derived classes (necessarily, because it is a pure virtual function in the base class), the call to it is resolved when the program is executed by selecting the version belonging to the class of the object being pointed to. Thus, for the pointer pC1, the version from the class CBox is called and, for the pointer pC2, the version in the class CCan is called. In each case, therefore, you obtain the correct result.
You could equally well have used just one pointer and assigned the address of the CCan object to it (after calling the Volume() function for the CBox object). A base class pointer can contain the address of any derived class object, even when several different classes are derived from the same base class, and so you can have automatic selection of the appropriate virtual function across a whole range of derived classes. Impressive stuff, isn't it?
At the beginning of this chapter, I said that a base class for a subclass could, in turn, be derived from another, "more" base class. A small extension of the last example provides you with an illustration of this, as well as demonstrating the use of a virtual function across a second level of inheritance.
TRY IT OUT: More Than One Level of Inheritance
All you need to do is add the class CGlassBox to the classes you have from the previous example. The relationship between the classes you now have is illustrated in Figure 9-5.

The class CGlassBox is derived from the CBox class exactly as before, but we omit the derived class version of ShowVolume() to show that the base class version still propagates through the derived classes. With the class hierarchy shown above, the class CContainer is an indirect base of the class CGlassBox, and a direct base of the classes CBox and CCan.
The GlassBox.h header file for the example contains:
// GlassBox.h for Ex9_11
#pragma once
#include "Box.h" // For CBox
class CGlassBox: public CBox // Derived class
{
public:
// Function to calculate volume of a CGlassBox
// allowing 15% for packing
virtual double Volume() const
{ return 0.85*m_Length*m_Width*m_Height; }
// Constructor
CGlassBox(double lv, double wv, double hv): CBox(lv, wv, hv){}
};The Container.h, Can.h, and Box.h header files contain the same code as those in the previous example, Ex9_10.
The source file for the new example, with an updated function main() to use the additional class in the hierarchy, is as follows:
// Ex9_11.cpp// Using an abstract class with multiple levels of inheritance#include "Box.h" // For CBox and CContainer #include "Can.h" // For CCan (and CContainer)#include "GlassBox.h" // For CGlassBox (and CBox and CContainer)#include <iostream> // For stream I/O using std::cout; using std::endl; const double PI = 3.14159265; // Global definition for PIint main(){// Pointer to abstract base class initialized with CBox object addressCContainer* pC1 = new CBox(2.0, 3.0, 4.0);CCan myCan(6.5, 3.0); // Define CCan objectCGlassBox myGlassBox(2.0, 3.0, 4.0); // Define CGlassBox objectpC1->ShowVolume(); // Output the volume of CBoxdelete pC1; // Now clean up the free store// initialized with address of CCan objectpC1 = &myCan; // Put myCan address in pointerpC1->ShowVolume(); // Output the volume of CCanpC1 = &myGlassBox; // Put myGlassBox address in pointerpC1->ShowVolume(); // Output the volume of CGlassBox
cout << endl;return 0;}
You have the three-level class hierarchy shown in Figure 9-5 with CContainer as an abstract base class because it contains the pure virtual function, Volume(). The main() function now calls the ShowVolume() function three times using the same pointer to the base class, but with the pointer containing the address of an object of a different class type each time. Because ShowVolume() is not defined in either CCan or CGlassBox, the inherited version is called in each instance. A separate branch from the base CContainer defines the derived class CCan so CCan inherits ShowVolume() from CContainer and CGlassBox inherits the function from CBox.
The example produces this output:
CBox usable volume is 24 Volume is 45.9458 CBox usable volume is 20.4
The output shows that one of the three different versions of the function Volume() is selected for execution according to the type of object involved.
Note that you must delete the CBox object from the free store before you assign another address value to the pointer. If you don't do this, you won't be able to clean up the free store, because you would have no record of the address of the original object. This is an easy mistake to make when reassigning pointers and using the free store.
One problem that arises when dealing with objects of derived classes using a pointer to the base class is that the correct destructor may not be called. You can see this effect by modifying the last example.
TRY IT OUT: Calling the Wrong Destructor
You just need to add a public destructor to each of the classes in the example that outputs a message so that you can track which destructor is called when the objects are destroyed. The destructor for the CContainer class in the Container.h file for this example is:
// Destructor
~CContainer()
{ cout << "CContainer destructor called" << endl; }The destructor for the CCan class in Can.h in the example is:
// Destructor
~CCan()
{ cout << "CCan destructor called" << endl; }The CBox class destructor in Box.h should be:
// Destructor
~CBox()
{ cout << "CBox destructor called" << endl; }The CGlassBox destructor in the GlassBox.h header file should be:
// Destructor
~CGlassBox()
{ cout << "CGlassBox destructor called" << endl; }Finally, the source file Ex9_12.cpp for the program should be as follows:
// Ex9_12.cpp// Destructor calls with derived classes// using objects via a base class pointer#include "Box.h" // For CBox and CContainer #include "Can.h" // For CCan (and CContainer) #include "GlassBox.h" // For CGlassBox (and CBox and CContainer) #include <iostream> // For stream I/O using std::cout; using std::endl; const double PI = 3.14159265; // Global definition for PI int main() { // Pointer to abstract base class initialized with CBox object address CContainer* pC1 = new CBox(2.0, 3.0, 4.0); CCan myCan(6.5, 3.0); // Define CCan object CGlassBox myGlassBox(2.0, 3.0, 4.0); // Define CGlassBox object pC1->ShowVolume(); // Output the volume of CBoxcout << endl << "Delete CBox" << endl;delete pC1; // Now clean up the free storepC1 = new CGlassBox(4.0, 5.0, 6.0); // Create CGlassBox dynamicallypC1->ShowVolume(); // ...output its volume...cout << endl << "Delete CGlassBox" << endl;delete pC1; // ...and delete itpC1 = &myCan; // Get myCan address in pointer pC1->ShowVolume(); // Output the volume of CCan pC1 = &myGlassBox; // Get myGlassBox address in pointer
pC1->ShowVolume(); // Output the volume of CGlassBox cout << endl; return 0; }
How It Works
Apart from adding a destructor to each class that outputs a message to the effect that it was called, the only other change is a couple of additions to the function main(). There are additional statements to create a CGlassBox object dynamically, output its volume, and then delete it. There is also a message displayed to indicate when the dynamically created CBox object is deleted. The output generated by this example is shown as follows:
CBox usable volume is 24 Delete CBox CContainer destructor called CBox usable volume is 102 Delete CGlassBox CContainer destructor called Volume is 45.9458 CBox usable volume is 20.4 CGlassBox destructor called CBox destructor called CContainer destructor called CCan destructor called CContainer destructor called
You can see from this that when you delete the CBox object pointed to by pC1, the destructor for the base class CContainer is called, but there is no call of the CBox destructor recorded. Similarly, when the CGlassBox object that you added is deleted, again, the destructor for the base class CContainer is called but not the CGlassBox or CBox destructors. For the other objects, the correct destructor calls occur with the derived class destructor being called first, followed by the base class destructor. For the first CGlassBox object created in a declaration, three destructors are called: first, the destructor for the derived class, followed by the direct base destructor, and, finally, the indirect base destructor.
All the problems are with objects created in the free store. In both cases, the wrong destructor is called. The reason for this is that the linkage to the destructors is resolved statically, at compile time. For the automatic objects, there is no problem — the compiler knows what they are and arranges for the correct destructors to be called. With objects created dynamically and accessed through a pointer, things are different. The only information that the compiler has when the delete operation is executed is that the pointer type is a pointer to the base class. The type of object the pointer is actually pointing to is unknown to the compiler because this is determined when the program executes. The compiler, therefore, simply ensures that the delete operation is set up to call the base class destructor. In a real application, this can cause a lot of problems, with bits of objects left strewn around the free store and possibly more serious problems, depending on the nature of the objects involved.
The solution is simple. You need the calls to be resolved dynamically — as the program is executed. You can organize this by using virtual destructors in your classes. As I said when I first discussed virtual functions, it's sufficient to declare a base class function as virtual to ensure that all functions in any derived classes with the same name, parameter list, and return type are virtual as well. This applies to destructors just as it does to ordinary member functions. You need to add the keyword virtual to the definition of the destructor in the class CContainer in Container.h so that the class definition is as follows:
class CContainer // Generic base class for containers
{
public:
// Destructor
virtual ∼CContainer()
{ cout << "CContainer destructor called" << endl; }
// Rest of the class as before
};Now, the destructors in all the derived classes are automatically virtual, even though you don't explicitly specify them as such. Of course, you're free to specify them as virtual if you want the code to be absolutely clear.
If you rerun the example with this modification, it produces the following output:
CBox usable volume is 24 Delete CBox CBox destructor called CContainer destructor called CBox usable volume is 102 Delete CGlassBox CGlassBox destructor called CBox destructor called CContainer destructor called Volume is 45.9458 CBox usable volume is 20.4 CGlassBox destructor called CBox destructor called CContainer destructor called CCan destructor called CContainer destructor called
As you can see, all the objects are now destroyed with a proper sequence of destructor calls. Destroying the dynamic objects produces the same sequence of destructor calls as the automatic objects of the same type in the program.
The question may arise in your mind at this point, can constructors be declared as virtual? The answer is no — only destructors and other member functions.
Note
It's a good idea always to declare your base class destructor as virtual as a matter of course when using inheritance. There is a small overhead in the execution of the class destructors, but you won't notice it in the majority of circumstances. Using virtual destructors ensures that your objects will be properly destroyed and avoids potential program crashes that might otherwise occur.
You have seen how you can store the address of a derived class object in a variable that is a pointer to a base class type, so a variable of type CContainer* can store the address of a CBox object, for example. So, if you have an address stored in a pointer of type CContainer*, can you cast it to type CBox*? Indeed, you can, and the dynamic_cast operator is specifically intended for this kind of operation. Here's how it works:
CContainer* pContainer = new CGlassBox(2.0, 3.0, 4.0); CBox* pBox = dynamic_cast<CBox*>( pContainer); CGlassBox* pGlassBox = dynamic_cast<CGlassBox*>( pContainer);
The first statement stores the address of the CGlassBox object created on the heap in a base class pointer of type CContainer*. The second statement casts pContainer up the class hierarchy to type CBox*. The third statement casts the address in pContainer to its actual type, CGlassBox*.
You can apply the dynamic_cast operator to references as well as pointers. The difference between dynamic_cast and static_cast is that the dynamic_cast operator checks the validity of a cast at runtime, whereas the static_cast operator does not. If a dynamic_cast operation is not valid, the result is null. The compiler relies on the programmer for the validity of a static_cast operation, so you should always use dynamic_cast for casting up and down a class hierarchy and check for a null result if you want to avoid abrupt termination of your program as a result of using a null pointer.
You can put the definition of one class inside the definition of another, in which case, you have defined a nested class. A nested class has the appearance of being a static member of the class that encloses it and is subject to the member access specifiers, just like any other member of the class. If you place the definition of a nested class in the private section of the class, the class can only be referenced from within the scope of the enclosing class. If you specify a nested class as public, the class is accessible from outside the enclosing class, but the nested class name must be qualified by the outer class name in such circumstances.
A nested class has free access to all the static members of the enclosing class. All the instance members can be accessed through an object of the enclosing class type, or a pointer or reference to an object. The enclosing class can only access the public members of the nested class, but in a nested class that is private in the enclosing class, the members are frequently declared as public to provide free access to the entire nested class from functions in the enclosing class.
A nested class is particularly useful when you want to define a type that is only to be used within another type, whereupon the nested class can be declared as private. Here's an example of that:
// A push-down stack to store Box objects
class CStack
{
private:
// Defines items to store in the stack
struct CItem
{
CBox* pBox; // Pointer to the object in this node
CItem* pNext; // Pointer to next item in the stack or null
// Constructor
CItem(CBox* pB, CItem* pN): pBox(pB), pNext(pN){}
};
CItem* pTop; // Pointer to item that is at the top
public:
// Constructor
CStack():pTop(nullptr){}
// Push a Box object onto the stack
void Push(CBox* pBox)
{
pTop = new CItem(pBox, pTop); // Create new item and make it the top
}
// Pop an object off the stack
CBox* Pop()
{
if(!pTop) // If the stack is empty
return nullptr; // return null
CBox* pBox = pTop->pBox; // Get box from item
CItem* pTemp = pTop; // Save address of the top item
pTop = pTop->pNext; // Make next item the top
delete pTemp; // Delete old top item from the heap
return pBox;
}
// Destructor
~CStack()
{
CItem* pTemp(nullptr);
while(pTop) // While pTop not null
{
pTemp = pTop;
pTop = pTop->pNext;
delete pTemp;
}
}
};The CStack class defines a push-down stack for storing CBox objects. To be absolutely precise, it stores pointers to CBox objects so the objects pointed to are still the responsibility of the code making use of the Stack class. The nested struct, CItem, defines the items that are held in the stack. I chose to define CItem as a nested struct rather than a nested class because members of a struct are public by default. You could define CItem as a class and then specify the members as public so they can be accessed from the functions in the CStack class. The stack is implemented as a set of CItem objects, where each CItem object stores a pointer to a CBox object plus the address of the next CItem object down in the stack. The Push() function in the CStack class pushes a CBox object onto the top of the stack, and the Pop() function pops an object off the top of the stack.
Pushing an object onto the stack involves creating a new CItem object that stores the address of the object to be stored plus the address of the previous item that was on the top of the stack — this is null the first time you push an object onto the stack. Popping an object off the stack returns the address of the object in the item, pTop. The top item is deleted and the next item becomes the item at the top of the stack.
Because a CStack object creates CItem objects on the heap, we need a destructor to make sure any remaining CItem objects are deleted when a CStack object is destroyed. The process is to work down through the stack, deleting the top item after the address of the next item has been saved in pTop. Let's see if it works.
TRY IT OUT: Using a Nested Class
This example uses CContainer, CBox, and CGlassBox classes from Ex9_12, so create an empty WIN32 console project, Ex9_13, and add the header files containing those class definitions to it. Then add Stack.h to the project containing the definition of the CStack class from the previous section, and add Ex9_13.cpp to the project with the following contents:
// Ex9_13.cpp
// Using a nested class to define a stack
#include "Box.h" // For CBox and CContainer
#include "GlassBox.h" // For CGlassBox (and CBox and CContainer)
#include "Stack.h" // For the stack class with nested struct Item
#include <iostream> // For stream I/O
using std::cout;
using std::endl;
int main()
{
CBox* pBoxes[] = { new CBox(2.0, 3.0, 4.0),
new CGlassBox(2.0, 3.0, 4.0),
new CBox(4.0, 5.0, 6.0),
new CGlassBox(4.0, 5.0, 6.0)
};
int nBoxes = sizeof pBoxes/sizeof pBoxes[0];
cout << "The array of boxes have the following volumes:";
for (int i = 0 ; i<nBoxes ; i++)
pBoxes[i]->ShowVolume(); // Output the volume of a box
cout << endl << endl<< "Now pushing the boxes on the stack..."
<< endl;
CStack* pStack = new CStack; // Create the stack
for (int i = 0 ; i<nBoxes ; i++)
pStack->Push(pBoxes[i]);
cout << "Popping the boxes off the stack presents them in reverse order:";
CBox* pTemp(nullptr);
while(pTemp = pStack->Pop())
pTemp->ShowVolume();
cout << endl;
delete pStack;
for(int i = 0 ; i<nBoxes ; ++i)
delete pBoxes[i];
return 0;
} 
The output from this example is:
The array of boxes have the following volumes: CBox usable volume is 24 CBox usable volume is 20.4 CBox usable volume is 120 CBox usable volume is 102 Now pushing the boxes on the stack... Popping the boxes off the stack presents them in reverse order: CBox usable volume is 102 CBox usable volume is 120 CBox usable volume is 20.4 CBox usable volume is 24
How It Works
You create an array of pointers to CBox objects so each element in the array can store the address of a CBox object or an address of any type that is derived from CBox. The array is initialized with the addresses of four objects created on the heap:
CBox* pBoxes[] = { new CBox(2.0, 3.0, 4.0),
new CGlassBox(2.0, 3.0, 4.0),
new CBox(4.0, 5.0, 6.0),
new CGlassBox(4.0, 5.0, 6.0)
};The objects are two CBox objects and two CGlassBox objects with the same dimensions as the CBox objects.
After calculating the number of elements in the pBoxes array and listing the volumes of the four objects, you create a CStack object and push the objects onto the stack in a for loop:
CStack* pStack = new CStack; // Create the stack for (int i = 0 ; i<nBoxes ; i++) pStack->Push(pBoxes[i]);
Each element in the pBoxes array is pushed onto the stack by passing the array element as the argument to the Push() function for the CStack object. This results in the first element from the array being at the bottom of the stack, and the last element at the top.
You pop the objects off the stack in a while loop:
CBox* pTemp(nullptr); while(pTemp = pStack->Pop()) pTemp->ShowVolume();
The Pop() function returns the address of the element at the top of the stack, and you use this to call the ShowVolume() function for the object. The loop ends when the Pop() function returns null. Because the last element was at the top of the stack, the loop lists the volumes of the objects in reverse order. From the output, you can see that the CStack class does, indeed, implement a stack using a nested struct to define the items to be stored in the stack.
All C++/CLI classes, including classes that you define, are derived classes by default. This is because both value classes and reference classes have a standard class, System::Object, as a base class. This means that both value classes and reference classes inherit from the System::Object class and, therefore, have the capabilities of the System::Object class in common. Because the ToString() function is defined as a virtual function in System::Object, you can override it in your own classes and have the function called polymorphically when required. This is what you have been doing in previous chapters when you defined the ToString() function in a class.
Because System::Object is a base class for all C++/CLI classes, the handle type System::Object^ fulfils a similar role to the void* type in native C++, in that it can be used to reference any type of object.
The System::Object base class for all value class types is also responsible for enabling the boxing and unboxing of values of the fundamental types. Boxing a value type instance converts it to an object on the garbage-collected heap, so it will carry full type information along with the basic value. Unboxing is the reverse of boxing. The boxing/unboxing capability means that values of the fundamental types can behave as objects, but can participate in numerical operations without carrying the overhead of being objects. Values of the fundamental types are stored on the stack just as values for the purposes of normal operations and are only converted to an object on the heap that is referenced by a handle of type System::Object^ when they need to behave as objects. For example, if you pass an unboxed value to a function with a parameter that is an appropriate value class type, the compiler will arrange for the value to be converted to an object on the heap; this is achieved by creating a new object on the heap containing the value. Thus, you get implicit boxing and the argument value will be boxed automatically.
Of course, explicit boxing is also possible. You can force a value to be boxed by assigning it to a variable of type Object^. For example:
double value = 3.14159265; Object^ boxedValue = value;
The second statement forces the boxing of value, and the boxed representation is referenced by the handle boxedValue.
You can also force boxing of a value using gcnew to create a boxed value on the garbage-collected heap, for example:
long^ number = gcnew long(999999L);
This statement implicitly boxes the value 999999L and stores it on the heap in a location referenced by the handle number.
You can unbox a value type using the dereference operator, for example:
Console::WriteLine(*number);
The value pointed to by the handle number is unboxed and then passed as a value to the WriteLine() function.
Finally, you can unbox a boxed value using safe_cast:
long n = safe_cast<long>(number);
This statement unboxes number and stores the value in n. Note that without the safe_cast, this statement will not compile because there is no implicit conversion in this situation.
Although value classes always have the System::Object class as a base, you cannot derive a value class from an existing class. To put it another way, when you define a value class, you are not allowed to specify a base class. This implies that polymorphism in value classes is limited to the functions that are defined as virtual in the System::Object class. These are the virtual functions that all value classes inherit from System::Object:
DESCRIPTION | |
|---|---|
| Returns a |
| Compares the current object to |
| Returns an integer that is a hash code for the current object. Hash codes are used as keys to store objects in a collection that stores |
Of course, because System::Object is also a base class for reference classes, you may want to override these functions in reference classes, too. Note that if you override the Equals() function in a class, you must also implement the operator==() function in the class so that it returns the same result as the Equals() function.
You can derive a reference class from an existing reference class in the same way as you define a derived class in native C++. Let's re-implement Ex9_12 as a C++/CLI program as this also demonstrates nested classes in a CLR program. We can start by defining the Container class:
// Container.h for Ex9_14
#pragma once
using namespace System;
// Abstract base class for specific containers
ref class Container abstract
{
public:
// Function for calculating a volume - no content
// This is defined as an "abstract" virtual function,
// indicated by the "abstract" keyword
virtual double Volume() abstract;
// Function to display a volume
virtual void ShowVolume()
{
Console::WriteLine(L"Volume is {0}", Volume());
}
};The first thing to note is the abstract keyword following the class name. If a C++/CLI class contains the equivalent of a native C++ pure virtual function, you must specify the class as abstract. You can, however, also specify a class as abstract that does not contain any abstract functions, which prevents you from creating objects of that class type. The abstract keyword also appears at the end of the Volume() function member declaration to indicate that it is not defined for this class. You could also add the " = 0" to the end of the member declaration for Volume() as you would for a native C++ member, but it is not required.
Both the Volume() and ShowVolume() functions are virtual here, so they can be called polymorphically for objects of class types that are derived from Container.
You can define the Box class like this:
// Box.h for Ex9_14
#pragma once
#include "Container.h" // For Container definition
ref class Box : Container // Derived class
{
public:
// Function to show the volume of an object
virtual void ShowVolume() override
{
Console::WriteLine(L"Box usable volume is {0}", Volume());
}
// Function to calculate the volume of a Box object
virtual double Volume() override
{ return m_Length*m_Width*m_Height; }
// Constructor
Box() : m_Length(1.0), m_Width(1.0), m_Height(1.0){}
// Constructor
Box(double lv, double wv, double hv)
: m_Length(lv), m_Width(wv), m_Height(hv){}
protected:
double m_Length;
double m_Width;
double m_Height;
};A base class for a ref class is always public and the public keyword is assumed by default. You can specify the base class explicitly as public, but it is not necessary to do so. A base class to a ref class cannot be specified as anything other than public. Because you cannot supply default values for parameters as in the native C++ version of the class, you define the no-arg constructor so that it initializes all three fields to 1.0. The Box class defines the Volume() function as an override to the inherited base class version. You must always specify the override keyword when you want to override a function in the base class. If the Box class did not implement the Volume() function, it would be abstract, and you would need to specify it as such to compile the class successfully.
Here's how the GlassBox class definition looks:
// GlassBox.h for Ex9_14
#pragma once
#include "Box.h" // For Box
ref class GlassBox : Box // Derived class
{
public:
// Function to calculate volume of a GlassBox
// allowing 15% for packing
virtual double Volume() override
{ return 0.85*m_Length*m_Width*m_Height; }
// Constructor
GlassBox(double lv, double wv, double hv): Box(lv, wv, hv){}
};The base class is Box, which is public by default. The rest of the class is essentially the same as the original.
Here's the Stack class definition:
// Stack.h for Ex9_14
// A push-down stack to store objects of any ref class type
#pragma once
ref class Stack
{
private:
// Defines items to store in the stack
ref struct Item
{
Object^ Obj; // Handle for the object in this item
Item^ Next; // Handle for next item in the stack or nullptr
// Constructor
Item(Object^ obj, Item^ next): Obj(obj), Next(next){}
};
Item^ Top; // Handle for item that is at the top
public:
// Push an object onto the stack
void Push(Object^ obj)
{
Top = gcnew Item(obj, Top); // Create new item and make it the top
}
// Pop an object off the stack
Object^ Pop()
{if(Top == nullptr) // If the stack is empty
return nullptr; // return nullptr
Object^ obj = Top->Obj; // Get object from item
Top = Top->Next; // Make next item the top
return obj;
}
};The first difference to notice is that the function parameters and fields are now handles, because you are dealing with ref class objects. The inner struct, Item, now stores a handle of type Object^, which allows objects of any CLR class type to be stored in the stack; this means either value class or ref class objects can be accommodated, which is a significant improvement over the native C++ CStack class. You don't need to worry about deleting Item objects when the Pop() function is called or when a Stack object is destroyed, because the garbage collector takes care of that.
Here's a summary of the differences from native C++ that these classes have demonstrated:
A base class for a derived ref class is always
public.A function that has no definition for a ref class is an abstract function and must be declared using the
abstractkeyword.A class that contains one or more abstract functions must be explicitly specified as abstract by placing the
abstractkeyword following the class name.A class that does not contain abstract functions can be specified as
abstract, in which case, instances of the class cannot be defined.You must explicitly use the
overridekeyword when specifying a function that overrides a function inherited from the base class.
All you need to try out these classes is a CLR console project with a definition of main(), so let's do it.
TRY IT OUT: Using Derived Reference Classes
Create a CLR console program with the name Ex9_14 and add the classes in the previous section to the project; then add the following contents to Ex9_14.cpp:
// Ex9_14.cpp : main project file.// Using a nested class to define a stack#include "stdafx.h"#include "Box.h" // For Box and Container#include "GlassBox.h" // For GlassBox (and Box and Container)#include "Stack.h" // For the stack class with nested struct Itemusing namespace System; int main(array<System::String ^> ^args) {
array<Box^>^ boxes = { gcnew Box(2.0, 3.0, 4.0),gcnew GlassBox(2.0, 3.0, 4.0), gcnew Box(4.0, 5.0, 6.0), gcnew GlassBox(4.0, 5.0, 6.0) };Console::WriteLine(L"The array of boxes have the following volumes:");for each(Box^ box in boxes)box->ShowVolume(); // Output the volume of a boxConsole::WriteLine(L" Now pushing the boxes on the stack...");Stack^ stack = gcnew Stack; // Create the stackfor each(Box^ box in boxes)stack->Push(box);Console::WriteLine(L"Popping the boxes off the stack presents them in reverse order:");Object^ item;while((item = stack->Pop()) != nullptr)safe_cast<Container^>(item)->ShowVolume();Console::WriteLine(L" Now pushing integers onto the stack:");for(int i = 2 ; i<=12 ; i += 2){Console::Write(L"{0,5}",i);stack->Push(i);}Console::WriteLine(L" Popping integers off the stack produces:");while((item = stack->Pop()) != nullptr)Console::Write(L"{0,5}",item);Console::WriteLine();return 0; }
The output from this example is:
The array of boxes have the following volumes: Box usable volume is 24 Box usable volume is 20.4 Box usable volume is 120 Box usable volume is 102 Now pushing the boxes on the stack... Popping the boxes off the stack presents them in reverse order: Box usable volume is 102 Box usable volume is 120 Box usable volume is 20.4 Box usable volume is 24
Now pushing integers onto the stack:
2 4 6 8 10 12
Popping integers off the stack produces:
12 10 8 6 4 2You first create an array of handles to Box objects:
array<Box^>^ boxes = { gcnew Box(2.0, 3.0, 4.0),
gcnew GlassBox(2.0, 3.0, 4.0),
gcnew Box(4.0, 5.0, 6.0),
gcnew GlassBox(4.0, 5.0, 6.0)
};Because Box and GlassBox are ref classes, you create the objects on the CLR heap using gcnew. The addresses of the objects initialize the elements of the boxes array.
You then create a Stack object and push the boxes onto the stack:
Stack^ stack = gcnew Stack; // Create the stack for each(Box^ box in boxes) stack->Push(box);
The parameter to the Push() function is of type Object^, so the function accepts an object of any class type as the argument. The for each loop pushes each of the elements in the boxes array onto the stack.
Popping the elements off the stack occurs in a while loop:
Object^ item; while((item = stack->Pop()) != nullptr) safe_cast<Container^>(item)->ShowVolume();
The loop condition stores the value returned from the Pop() function for the stack object in item, and compares it with nullptr. As long as item has not been set to nullptr, the statement that is the body of the while loop is executed. Within the loop, you cast the handle stored in item to type Container^. The item variable is of type Object^, and because the Object class does not define the ShowVolume() function, you cannot call the ShowVolume() function using a handle of this type; to call a function polymorphically, you must use a handle of a base class type that declares the function to be a virtual member. By casting the handle to type Container^, you are able to call the ShowVolume() function polymorphically, so the function is selected for the ultimate class type of the object that the handle references. In this case, you could have achieved the same result by casting item to type Box^. You use safe_cast here because you are casting up the class hierarchy, and it's just as well to use a checked cast operation in such circumstances. The safe_cast operator checks the cast for validity and, if the conversion fails, the operator throws an exception of type System::InvalidCastException. You could use dynamic_cast, but it is better to use safe_cast in CLR programs.
Finally, you push integers onto the stack and pop them off the stack again. You can see that the same Stack object can contain objects that are value types as well as reference types.
The definition of an interface class looks quite similar to the definition of a ref class, but it is quite a different concept. An interface is a class that specifies a set of functions that are to be implemented by other classes to provide a standardized way of providing some specific functionality. Both value classes and ref classes can implement interfaces. An interface does not define any of its function members — these are defined by each class that implements the interface.
You have already met the System::IComparable interface in the context of generic functions where you specified the IComparable interface as a constraint. The IComparable interface specifies the CompareTo() function for comparing objects, so all classes that implement this interface have the same mechanism for comparing objects. You specify an interface that a class implements in the same way as a base class. For example, here's how you could make the Box class from the previous example implement the System::IComparable interface:
ref class Box : Container, IComparable // Derived class{ public:// The function specified by IComparable interfacevirtual int CompareTo(Object^ obj){if(Volume() < safe_cast<Box^>(obj)->Volume())return −1;else if(Volume() > safe_cast<Box^>(obj)->Volume())return 1;elsereturn 0;}// Rest of the class as before...};
The name of the interface follows the name of the base class, Container. If there were no base class, the interface name alone would appear here. A ref class can only have one base class, but it can implement as many interfaces as you want. The class must define every function specified by each of the interfaces that it claims to implement. The IComparable interface only specifies one function, but there can be as many functions in an interface as you want. The Box class now defines the CompareTo() function with the same signature as the IComparable interface specifies for the function. Because the parameter to the CompareTo() function is of type Object^, you have to cast it to type Box^ before you can access members of the Box object it references.
You define an interface class using either of the keywords interface class or interface struct. Regardless of whether you use the interface class or the interface struct keyword to define an interface, all the members of an interface are always public by default, and you cannot specify them to be otherwise. The members of an interface can be functions, including operator functions, properties, static fields, and events, all of which you'll learn about later in this chapter. An interface can also specify a static constructor and can contain a nested class definition of any kind. In spite of all that potential diversity of members, most interfaces are relatively simple. Note that you can derive one interface from another in basically the same way as you use to derive one ref class from another. For example:
interface class IController : ITelevison, IRecorder
{
// Members of IController...
};The IController interface contains its own members, and it also inherits the members of the ITelevision and IRecorder interfaces. A class that implements the IController interface has to define the member functions from IController, ITelevision, and IRecorder.
You could use an interface instead of the Container base class in Ex9_14. Here's how the definition of this interface would look:
// IContainer.h for Ex9_15
#pragma once
interface class IContainer
{
double Volume(); // Function for calculating a volume
void ShowVolume(); // Function to display a volume
};By convention, the names of interfaces start with I in C++/CLI, so the interface name is IContainer. It has two members: the Volume() function and the ShowVolume() function, which are public because members of an interface are always public. Both functions are effectively abstract because an interface never includes function definitions — indeed, you could add the abstract keyword to both here, but it is not required. Instance functions in an interface definition can be specified as virtual and abstract, but it is not necessary to do so as they are anyway.
Any class that implements the IContainer interface must implement both functions if the class is not to be abstract. Let's see how the Box class looks:
// Box.h for Ex9_15#pragma once#include "IContainer.h" // For interface definitionusing namespace System;ref class Box : IContainer{ public: // Function to show the volume of an objectvirtual void ShowVolume()
{
Console::WriteLine(L"Box usable volume is {0}", Volume());
}
// Function to calculate the volume of a Box object
virtual double Volume()
{ return m_Length*m_Width*m_Height; }
// Constructor
Box() : m_Length(1.0), m_Width(1.0), m_Height(1.0){}
// Constructor
Box(double lv, double wv, double hv)
: m_Length(lv), m_Width(wv), m_Height(hv){}
protected:
double m_Length;
double m_Width;
double m_Height;
};The name of the interface goes after the colon in the first line of the class definition, just as if it were a base class. Of course, there could also be a base class, in which case, the interface name would follow the base class name, separated from it by a comma. A class can implement multiple interfaces, in which case, the names of the interfaces are separated by commas.
The Box class must implement both function members of the IContainer interface class; otherwise, it would be an abstract class and would need to be declared as such. The definitions for these functions in the Box class do not have the override keyword appended because you are not overriding existing function definitions here; you are implementing them for the first time.
The GlassBox class is derived from the Box class and, therefore, inherits the implementation of IContainer. The GlassBox class definition needs no changes at all to accommodate the introduction of the IContainer interface class.
The IContainer interface class has the same role as a base class in polymorphism. You can use a handle of type IContainer to store the address of an object of any class type that implements the interface. Thus, a handle of type IContainer can be used to reference objects of type Box or type GlassBox and obtain polymorphic behavior when calling the functions that are members of the interface class. Let's try it.
TRY IT OUT: Implementing an Interface Class
Create the CLR console project Ex9_15 and add the IContainer.h and Box.h header files with the contents from the previous section. You should also add copies of the Stack.h and GlassBox.h header files from Ex9_14 to the project. Finally, modify the contents of Ex9_15.cpp to the following:
// Ex9_15.cpp : main project file. // Implementing an interface class #include "stdafx.h" #include "Box.h" // For Box and IContainer #include "GlassBox.h" // For GlassBox (and Box and IContainer) #include "Stack.h" // For the stack class with nested struct Item
using namespace System;
int main(array<System::String ^> ^args)
{
array<IContainer^>^ containers = { gcnew Box(2.0, 3.0, 4.0),
gcnew GlassBox(2.0, 3.0, 4.0),
gcnew Box(4.0, 5.0, 6.0),
gcnew GlassBox(4.0, 5.0, 6.0)
};
Console::WriteLine(L"The array of containers have the following volumes:");
for each(IContainer^ container in containers)
container->ShowVolume(); // Output the volume of a box
Console::WriteLine(L"
Now pushing the containers on the stack...");
Stack^ stack = gcnew Stack; // Create the stack
for each(IContainer^ container in containers)
stack->Push(container);
Console::WriteLine(
L"Popping the containers off the stack presents them in reverse order:");
Object^ item;
while((item = stack->Pop()) != nullptr)
safe_cast<IContainer^>(item)->ShowVolume();
Console::WriteLine();
return 0;
} 
This example produces the following output:
The array of containers have the following volumes: CBox usable volume is 24 CBox usable volume is 20.4 CBox usable volume is 120 CBox usable volume is 102 Now pushing the containers on the stack... Popping the containers off the stack presents them in reverse order: CBox usable volume is 102 CBox usable volume is 120 CBox usable volume is 20.4 CBox usable volume is 24
How It Works
You create an array of elements of type IContainer^ and initialize the elements with the addresses of Box and GlassBox objects:
array<IContainer^>^ containers = { gcnew Box(2.0, 3.0, 4.0),gcnew GlassBox(2.0, 3.0, 4.0),
gcnew Box(4.0, 5.0, 6.0),
gcnew GlassBox(4.0, 5.0, 6.0)
};The Box and GlassBox classes implement the IContainer interface, so you can store addresses of objects of these types in variables of type handle to IContainer. The advantage of doing this is that you'll be able to call the function members of the IContainer interface class polymorphically.
You list the volumes of the Box and GlassBox objects in a for each loop:
for each(IContainer^ container in containers) container->ShowVolume(); // Output the volume of a box
The loop body shows polymorphism in action; the ShowVolume() function for the specific type of object referenced by container is called, as you can see from the output.
You push the elements of the containers array onto the stack in essentially the same way as the previous example. Popping the elements off the stack is also similar to the previous example:
Object^ item; while((item = stack->Pop()) != nullptr) safe_cast<IContainer^>(item)->ShowVolume();
The loop body shows that you can cast a handle to an interface type using safe_cast in exactly the same way as you would cast to a ref class type. You are then able to use the handle to call the ShowVolume() function polymorphically.
Using interface classes is not only a useful way of defining sets of functions that represent standard class interfaces, but also a powerful mechanism for applying polymorphism in your programs.
A C++/CLI application always resides in one or more assemblies, so C++/CLI classes always reside in an assembly. The classes we have defined for each example up to now have all been contained in a single simple assembly that is the executable, but you can create assemblies that contain your own library classes. C++/CLI adds visibility specifiers for classes that determine whether a given class is accessible from outside the assembly in which it resides, which is referred to as its parent assembly. In addition to the public, private, and protected member access specifiers that you have in native C++, C++/CLI has additional access specifiers for class members that determine from where they may be accessed in different assemblies.
You can specify the visibility of a non-nested class, interface, or enum as private or public. A public class is visible and accessible outside the assembly in which it resides, whereas a private class is only accessible within its parent assembly. Classes, interfaces, and enum classes are private by default and, therefore, only visible within their parent assembly. To specify a class as public, you just use the public keyword, like this:
public interface class IContainer
{
// Details of the interface...
};The IContainer interface here is visible in an external assembly because you have defined it as public. If you omit the public keyword, the interface would be private by default and only usable within its parent assembly. You can specify a class, enum, or interface explicitly as private if you want, but it is not necessary.
C++/CLI adds three more access specifiers for class members: internal, public protected, and private protected. The effects of these are described in the comments in the class definition:
public ref class MyClass // Class visible outside assembly
{
public:
// Members accessible from classes inside and outside the parent assembly
internal:
// Members accessible from classes inside the parent assembly
public protected:
// Members accessible in types derived from MyClass outside the parent assembly
// and in any classes inside the parent assembly
private protected:
// Members accessible in types derived from MyClass inside the parent assembly
};Obviously, the class must be public for the member access specifiers to allow access from outside the parent assembly. Where the access specifier involves two keywords, such as private protected, the less restrictive keyword applies inside the assembly and the more restrictive keyword applies outside the assembly. You can reverse the sequence of the keyword pairs, so protected private has the same meaning as private protected.
To use some of these, you need to create an application that consists of more than one assembly, so let's recreate Ex9_15 as a class library assembly plus an application assembly that uses the class library.
The IContainer interface class, the Box class, and the Stack class are now in this library. The changes to the original definitions for these classes are shaded. Each class is now public, which makes them accessible from an external assembly. The fields in the Box class are public protected, which means that they are inherited in a derived class as protected fields but are public so far as classes within the parent assembly are concerned. You don't actually refer to these fields from other classes within the parent assembly, so you could have left the fields in the Box class as protected in this case.
When you have built this project successfully, the assembly containing the class library is in a file Ex9_16lib.dll that is in the debug subdirectory to the project directory if you built a debug version of the project, or in a release subdirectory if you built the release version. The .dll extension means that this is a dynamic link library, or DLL. You now need another project that uses your class library.
TRY IT OUT: Using a Class Library
Add a new CLR console project with the name Ex9_16 in its own solution as always. You can then modify Ex9_16.cpp as follows:
// Ex9_16.cpp : main project file.// Using a class library in a separate assembly#include "stdafx.h"#include "GlassBox.h" #using <Ex9_16lib.dll>using namespace System;using namespace Ex9_16lib;int main(array<System::String ^> ^args) {array<IContainer^>^ containers = { gcnew Box(2.0, 3.0, 4.0), gcnew GlassBox(2.0, 3.0, 4.0), gcnew Box(4.0, 5.0, 6.0), gcnew GlassBox(4.0, 5.0, 6.0) }; Console::WriteLine(L"The array of containers have the following volumes:"); for each(IContainer^ container in containers) container->ShowVolume(); // Output the volume of a box Console::WriteLine(L" Now pushing the containers on the stack..."); Stack^ stack = gcnew Stack; // Create the stack for each(IContainer^ container in containers) stack->Push(container); Console::WriteLine( L"Popping the containers off the stack presents them in reverse order:"); Object^ item;while((item = stack->Pop()) != nullptr)
safe_cast<IContainer^>(item)->ShowVolume(); Console::WriteLine();return 0; }
You also need to add the GlassBox.h header to the project with the same code as in Ex9_15, so you can copy the file to this project directory and then add it to the project by right-clicking Header Files in the Solution Explorer tab and selecting Add
#using <Ex9_16lib.dll>
You should also remove the the #include directive for Box.h.
The Box class name is defined within the Ex9_16lib namespace, so you also need to add a using statement for that following the #using directive:
using namespace Ex9_16lib;
The Ex9_16lib.dll file must be available to build the project, so copy the file from the Ex9_16lib project to the subdirectory of the Ex9_16 project that contains the source files. Once the build is successful, you can move Ex9_16lib.dll to the directory that contains the Ex9_16.exe file so that the executable can find it when you run it. You could specify the full path to the assembly in the #using directive, but it is more usual to put any class libraries that a project uses in the directory that contains the executable for an application.
It's easy to get the directories muddled here. The Ex9_16lib.dll file is in the debug subdirectory of the Ex9_16lib solution directory, not the debug subdirectory of the Ex9_16lib project directory. You are copying the library file to the debug subdirectory of the Ex9_16 solution directory. Make sure you copy the .dll file to the correct directory, or the library won't be found.
Because the classes in the external assembly are in their own namespace, you have a using directive for the Ex9_16lib namespace name. Without this, you would have to qualify the IContainer, Box, and Stack names with the namespace name, so you would write Ex9_16lib::Box instead of just Box, for example.
The remainder of the code is exactly the same as in the main() function for Ex9_15; no changes are necessary because you are now using classes from an external assembly. If you execute the program, you'll see the output is the same as that from Ex9_15.
You have seen how you use the override keyword to override a function in a base class. You can also specify a function in a derived class as new, in which case, it hides the function in the base class that has the same signature, and the new function does not participate in polymorphic behavior. To define the Volume() function as new in a class NewBox that is derived from Box, you code it like this:
ref class NewBox : Box // Derived class
{
public:
// New function to calculate the volume of a NewBox object
virtual double Volume() new
{ return 0.5*m_Length*m_Width*m_Height; }
// Constructor
NewBox(double lv, double wv, double hv): Box(lv, wv, hv){}
};This version of the function hides the version of the Volume() function that is defined in Box, so if you call the Volume() function using a handle of type NewBox^, the new version is called. For example:
NewBox^ newBox = gcnew NewBox(2.0, 3.0, 4.0); Console::WriteLine(newBox->Volume()); // Output is 12
The result is 12 because the new Volume() function hides the polymorphic version that the NextBox class inherits from Box.
The new Volume() function is not a polymorphic function, so for polymorphic calls using a handle to a base class type, the new version is not called. For example:
Box^ newBox = gcnew NewBox(2.0, 3.0,4.0); Console::WriteLine(newBox->Volume()); // Output is 24
The only polymorphic Volume() function in the NewBox class is the one that is inherited from the Box class, so that is the function that is called in this case.
An event is a member of a class that enables an object to signal when a particular event has occurred, and the signaling process for an event involves a delegate that provides the mechanism for responding to the event in some way. A mouse click is a typical example of an event, and the object that originated the mouse-click event would signal that the event has occurred by calling one or more functions that are responsible for dealing with the event; a delegate would provide the means to access the function that is to respond to the event. Let's look at delegates first and return to events a little later in this chapter.
The idea of a delegate is very simple — it's an object that can encapsulate one or more pointers to functions that have a given parameter list and return type. A function that a delegate points to will deal with a particular kind of event. Thus, a delegate provides a similar facility in C++/CLI to a function pointer in native C++. Although the idea of a delegate is simple, however, the details of creating and using delegates can get a little confusing, so it's time to concentrate.
The declaration for a delegate looks like a function prototype preceded by the delegate keyword, but, in reality, it defines two things: the reference type name for a delegate object, and the parameter list and return type of the functions that can be associated with the delegate. A delegate reference type has the System::Delegate class as a base class, so a delegate type always inherits the members of this class. Here's an example of a declaration for a delegate:
public delegate void Handler(int value); // Delegate declaration
This defines a delegate reference type Handler, where the Handler type is derived from System::Delegate. An object of type Handler can contain pointers to one or more functions that have a single parameter of type int and a return type that is void. The functions pointed to by a delegate can be instance functions or static functions.
Having defined a delegate type, you can now create delegate objects of this type. You have a choice of two constructors for a delegate: one that accepts a single argument, and another that accepts two arguments.
The argument to the delegate constructor that accepts one argument must be a static function member of a class or a global function. The function you specify as the argument must have the same return type and parameter list as you specified in the delegate declaration. Suppose you define a class with the name HandlerClass like this:
public ref class HandlerClass
{
public:
static void Fun1(int m)
{ Console::WriteLine(L"Function1 called with value {0}", m); }
static void Fun2(int m)
{ Console::WriteLine(L"Function2 called with value {0}", m); }
void Fun3(int m)
{ Console::WriteLine(L"Function3 called with value {0}", m+value); }
void Fun4(int m)
{ Console::WriteLine(L"Function4 called with value {0}", m+value); }
HandlerClass():value(1){}
HandlerClass(int m):value(m){}
protected:
int value;
};The class has four functions, with a parameter of type int and a return type of void. Two of these are static functions, and two are instance functions. It also has two constructors, including a no-arg constructor. This class doesn't do much except produce output where you'll be able to determine which function was called and, for instance functions, what the object was.
You could create a delegate of the type Handler that we defined earlier like this:
Handler^ handler = gcnew Handler(HandlerClass::Fun1); // Delegate object
The handler object contains the address of the static function, Fun1, in the HandlerClass class. If you call the delegate, the HandlerClass::Fun1() function is called, with the argument the same as you pass in the delegate call. You can write the delegate call like this:
handler->Invoke(90);
This calls all the functions in the invocation list for the handler delegate. In this case, there is just one function in the invocation list, HandlerClass::Fun1(), so the output is:
Function1 called with value 90
You could also call the delegate with the following statement:
handler(90);
This is shorthand for the previous statement that explicitly called the Invoke() function, and this is the form of delegate call you see generally.
The + operator is overloaded for delegate types to combine the invocation lists for two delegates into a new delegate object. For example, you could apparently modify the invocation list for the handler delegate with this statement:
handler += gcnew Handler(HandlerClass::Fun2);
The handler variable now references a delegate object with an invocation list containing two functions: Fun1 and Fun2. However, this statement creates a new delegate object. The invocation list for a delegate cannot be changed, so the + operator works in a similar way to the way it works with String objects — you always get a new object created. You could invoke the delegate again with this statement:
handler(80);
Now, you get the output:
Function1 called with value 80 Function2 called with value 80
Both functions in the invocation list are called, and they are called in the sequence in which they were added to the delegate object.
You can effectively remove an entry from the invocation list for a delegate by using the subtraction operator:
handler -= gcnew Handler(HandlerClass::Fun1);
This creates a new delegate object that contains just HandlerClass::Fun2() in its invocation list. The effect of using the -= operator is to remove the functions that are in the invocation list on the right side (HandlerClass::Fun1) from the list for the handler, and create a new object pointing to the functions that remain.
Note
The invocation list for a delegate must contain at least one function pointer. If you remove all the function pointers using the subtraction operator, then the result will be nullptr.
When you use the delegate constructor that has two parameters, the first argument is a reference to an object on the CLR heap, and the second object is the address of an instance function for that object's type. Thus, this constructor creates a delegate that contains a pointer to the instance function specified by the second argument for the object specified by the first argument. Here's how you can create such a delegate:
HandlerClass^ obj = gcnew HandlerClass; Handler^ handler2 = gcnew Handler (obj, &HandlerClass::Fun3);
The first statement creates an object of type HandlerClass, and the second statement creates a delegate of type Handler pointing to the Fun3() function for the HandlerClass object obj. The delegate expects an argument of type int, so you can invoke it with the statement:
handler2(70);
This results in Fun3() for obj being called with an argument value of 70, so the output is:
Function3 called with value 71
The value stored in the value field for obj is 1 because you create the object using the default constructor. The statement in the body of Fun3() adds the value field to the function argument — hence the 71 in the output.
Because they are both of the same type, you could combine the invocation list for handler with the list for the handler2 delegate:
Handler^ handler = gcnew Handler(HandlerClass::Fun1); // Delegate object handler += gcnew Handler(HandlerClass::Fun2); HandlerClass^ obj = gcnew HandlerClass; Handler^ handler2 = gcnew Handler (obj, &HandlerClass::Fun3); handler += handler2;
Here, you recreate handler to reference a delegate that contains pointers to the static Fun1() and Fun2() functions. You then create a new delegate referenced by handler that contains the static functions plus the Fun3() instance function for obj. You can now invoke the delegate with the statement:
handler(50);
This results in the following output:
Function1 called with value 50 Function2 called with value 50 Function3 called with value 51
As you see, invoking the delegate calls the two static functions plus the Fun3() member of obj, so you can combine static and non-static functions with a single invocation list for a delegate.
Let's put some of the fragments together in an example to make sure it really does work.
TRY IT OUT: Creating and Calling Delegates
Here's a potpourri of what you have seen so far about delegates:
// Ex9_17.cpp : main project file.// Creating and calling delegates#include "stdafx.h" using namespace System;public ref class HandlerClass { public: static void Fun1(int m) { Console::WriteLine(L"Function1 called with value {0}", m); } static void Fun2(int m) { Console::WriteLine(L"Function2 called with value {0}", m); } void Fun3(int m) { Console::WriteLine(L"Function3 called with value {0}", m+value); } void Fun4(int m) { Console::WriteLine(L"Function4 called with value {0}", m+value); } HandlerClass():value(1){} HandlerClass(int m):value(m){} protected: int value; }; public delegate void Handler(int value); // Delegate declarationint main(array<System::String ^> ^args) {
Handler^ handler = gcnew Handler(HandlerClass::Fun1); // Delegate object Console::WriteLine(L"Delegate with one pointer to a static function:"); handler->Invoke(90); handler += gcnew Handler(HandlerClass::Fun2); Console::WriteLine(L" Delegate with two pointers to static functions:"); handler->Invoke(80); HandlerClass^ obj = gcnew HandlerClass; Handler^ handler2 = gcnew Handler (obj, &HandlerClass::Fun3); handler += handler2; Console::WriteLine(L" Delegate with three pointers to functions:"); handler(70); Console::WriteLine(L" Shortening the invocation list..."); handler -= gcnew Handler(HandlerClass::Fun1); Console::WriteLine (L" Delegate with pointers to one static and one instance function:"); handler(60);return 0; }
This example produces the following output:
Delegate with one pointer to a static function: Function1 called with value 90 Delegate with two pointers to static functions: Function1 called with value 80 Function2 called with value 80 Delegate with three pointers to functions: Function1 called with value 70 Function2 called with value 70 Function3 called with value 71 Shortening the invocation list... Delegate with pointers to one static and one instance function: Function2 called with value 60 Function3 called with value 61
The delegates you have seen up to now have been examples of bound delegates. They are called bound delegates because they each have a fixed set of functions in their invocation list. You can also create unbound delegates; an unbound delegate points to an instance function with a given parameter list and return type for a given type of object. Thus, the same delegate can invoke the instance function for any object of the specified type. Here's an example of declaring an unbound delegate:
public delegate void UBHandler(ThisClass^, int value);
The first argument specifies the type of the this pointer for which a delegate of type UBHandler can call an instance function; the function must have a single parameter of type int and a return type of void. Thus, a delegate of type UBHandler can only call a function for an object of type ThisClass, but for any object of that type. This may sound a bit restrictive but turns out to be quite useful; you could use the delegate to call a function for each element of type ThisClass^ in an array, for example.
You can create an unbound delegate of type UBHandler like this:
UBHandler^ ubh = gcnew UBHandler(&ThisClass::Sum);
The argument to the constructor is the address of a function in the ThisClass class that has the required parameter list and return type.
Here's a definition for ThisClass:
public ref class ThisClass
{
public:
void Sum(int n)
{ Console::WriteLine(L"Sum result = {0}", value + n); }
void Product(int n)
{ Console::WriteLine(L"Product result = {0}", value*n); }
ThisClass(double v) : value(v){}
private:
double value;
};The Sum() function is a public instance member of the ThisClass class, so invoking the ubh delegate can call the Sum() function for any given object of this class type.
When you call an unbound delegate, the first argument is the object for which the functions in the invocation list are to be called, and the subsequent arguments are the arguments to those functions. Here's how you might call the ubh delegate:
ThisClass^ obj = gcnew ThisClass(99.0); ubh(obj, 5);
The first argument is a handle to a ThisClass object that you created on the CLR heap by passing the value 99.0 to the class constructor. The second argument to the ubh call is 5, so it results in the Sum() function being called with an argument of 5 for the object referenced by obj.
You can combine unbound delegates using the + operator to create a delegate that calls multiple functions. Of course, all the functions must be compatible with the delegate, so for ubh, they must be instance functions in the ThisClass class that have one parameter of type int and a void return type. Here's an example:
ubh += gcnew UBHandler(&ThisClass::Product);
Invoking the new delegate referenced by ubh calls both the Sum() and Product() functions for an object of type ThisClass. Let's see it in action.
TRY IT OUT: Using an Unbound Delegate
This example uses the code fragments from the previous section to demonstrate the operation of an unbound delegate:
// Ex9_18.cpp : main project file.// Using an unbound delegate#include "stdafx.h" using namespace System;public ref class ThisClass { public: void Sum(int n) { Console::WriteLine(L"Sum result = {0} ", value+n); } void Product(int n) { Console::WriteLine(L"product result = {0} ", value*n); } ThisClass(double v) : value(v){} private: double value; };
public delegate void UBHandler(ThisClass^, int value); int main(array<System::String ^> ^args) { array<ThisClass^>^ things = { gcnew ThisClass(5.0),gcnew ThisClass(10.0), gcnew ThisClass(15.0),gcnew ThisClass(20.0), gcnew ThisClass(25.0) }; UBHandler^ ubh = gcnew UBHandler(&ThisClass::Sum); // Create a delegate object // Call the delegate for each things array element for each(ThisClass^ thing in things) ubh(thing, 3); ubh += gcnew UBHandler(&ThisClass::Product); // Add a function to the delegate // Call the new delegate for each things array element for each(ThisClass^ thing in things) ubh(thing, 2);return 0; }
This example produces the following output:
Sum result = 8 Sum result = 13 Sum result = 18 Sum result = 23 Sum result = 28 Sum result = 7 product result = 10 Sum result = 12 product result = 20 Sum result = 17 product result = 30 Sum result = 22 product result = 40 Sum result = 27 product result = 50
As I said earlier, the signaling of an event involves a delegate, and the delegate contains pointers to the functions that are to be called when the event occurs. Most of the events you work with in your programs are events associated with controls such as buttons or menu items, and these events arise from user interactions with your program, but you can also define and trigger events in your own program code.
An event is a member of a reference class that you define using the event keyword and a delegate class name:
public delegate void DoorHandler(String^ str);
// Class with an event member
public ref class Door
{
public:
// An event that will call functions associated
// with an DoorHandler delegate object
event DoorHandler^ Knock;
// Function to trigger events
void TriggerEvents()
{
Knock("Fred");
Knock("Jane");
}
};The Door class has an event member with the name Knock that corresponds to a delegate of type DoorHandler. Knock is an instance member of the class here, but you can specify an event as a static class member using the static keyword. You can also declare an event to be virtual. When a Knock event is triggered, it can call functions with the parameter list and return type that are specified by the DoorHandler delegate.
The Door class also has a public function, TriggerEvents(), that triggers two Knock events, each with different arguments. The arguments are passed to the functions that have been registered to receive notification of the Knock event. As you see, triggering an event is essentially the same as calling a delegate.
You could define a class that might handle Knock events like this:
public ref class AnswerDoor
{
public:
void ImIn(String^ name)
{
Console::WriteLine(L"Come in {0}, it's open.",name);
}
void ImOut(String^ name)
{
Console::WriteLine(L"Go away {0}, I'm out.",name);
}
};The AnswerDoor class has two public function members that potentially could handle a Knock event, because they both have the parameter list and return type identified in the declaration of the DoorHandler delegate.
Before you can register functions that are to receive notifications of Knock events, you need to create a Door object. You can create a Door object like this:
Door^ door = gcnew Door;
Now, you can register a function to receive notification of the Knock event in the door object like this:
AnswerDoor^ answer = gcnew AnswerDoor; door->Knock += gcnew DoorHandler(answer, &AnswerDoor::ImIn);
The first statement creates an object of type AnswerDoor — you need this because the ImIn() and ImOut() functions are not static class members. You then add an instance of the DoorHandler delegate type to the Knock member of class Door. This exactly parallels the process of adding function pointers to a delegate, and you could add further handler functions to be called when a Knock event is triggered in the same way. We can see it operating in an example.
TRY IT OUT: Handling Events
This example uses the classes from the preceding section to define, trigger, and handle events:
// Ex9_19.cpp : main project file.
// Defining, triggering and handling events.
#include "stdafx.h"
using namespace System;
public delegate void DoorHandler(String^ str);
// Class with an event member
public ref class Door
{
public:
// An event that will call functions associated
// with a DoorHandler delegate object
event DoorHandler^ Knock;
// Function to trigger events
void TriggerEvents()
{
Knock(L"Fred");
Knock(L"Jane");
}
};
// Class defining handler functions for Knock events
public ref class AnswerDoor{ public: void ImIn(String^ name) { Console::WriteLine(L"Come in {0}, it's open.",name); } void ImOut(String^ name) { Console::WriteLine(L"Go away {0}, I'm out.",name); } };int main(array<System::String ^> ^args) {Door^ door = gcnew Door; AnswerDoor^ answer = gcnew AnswerDoor; // Add handler for Knock event member of door door->Knock += gcnew DoorHandler(answer, &AnswerDoor::ImIn); door->TriggerEvents(); // Trigger Knock events // Change the way a knock is dealt with door->Knock -= gcnew DoorHandler(answer, &AnswerDoor::ImIn); door->Knock += gcnew DoorHandler(answer, &AnswerDoor::ImOut); door->TriggerEvents(); // Trigger Knock eventsreturn 0; }
Executing this example results in the following output:
Come in Fred, it's open. Come in Jane, it's open. Go away Fred, I'm out. Go away Jane, I'm out.
You can define a destructor for a reference class in the same way as you define a destructor for a native C++ class. The destructor for a reference class is called when the handle goes out of scope or the object is part of another object that is being destroyed. You can also apply the delete operator to a handle for a reference class object, and that results in the destructor being called. The primary reason for implementing a destructor for a native C++ class is to deal with data members allocated on the heap, but obviously, that doesn't apply to reference classes, so there is less need to define a destructor in a ref class. You might do this when objects of the class are using other resources that are not managed by the garbage collector, such as files that need to be closed in an orderly fashion when an object is destroyed. You can also clean up such resources in another kind of class member called a finalizer.
A finalizer is a special kind of function member of a reference class that is called automatically by the garbage collector when destroying an object. The purpose of a finalizer is to deal with unmanaged resources used by a reference class object that will not be dealt with by the garbage collector. Note that the finalizer is not called for a class object if the destructor was called explicitly, or was called as a result of applying the delete operator to the object. In a derived class, finalizers are called in the same sequence as destructor calls would be, so the finalizer for the most derived class is called first, followed by the finalizers for successive parent classes in the hierarchy, with the finalizer for the most base class being called last.
You define a finalizer in a class like this:
public ref class MyClass
{
// Finalizer definition
!MyClass()
{
// Code to clean-up when an object is destroyed...
}
// Rest of the class definition...
};You define a finalizer function in a class in a similar way to a destructor, but with ! instead of the ~ that you use preceding the class name for a destructor. Similar to a destructor, you must not supply a return type for a finalizer, and the access specifier for a finalizer will be ignored. You can see how destructors and finalizers operate with a little example.
TRY IT OUT: Finalizers and Destructors
This example shows when destructors and finalizers get called in an application:
// Ex9_20.cpp : main project file.// Finalizers and destructors#include "stdafx.h" using namespace System;ref class MyClass { public: // Constructor MyClass(int n) : value(n){} // Destructor ~MyClass() { Console::WriteLine("MyClass object({0}) destructor called.", value); } // Finalizer !MyClass() { Console::WriteLine("MyClass object({0}) finalizer called.", value); } private: int value; };int main(array<System::String ^> ^args) {MyClass^ obj1 = gcnew MyClass(1);
MyClass^ obj2 = gcnew MyClass(2); MyClass^ obj3 = gcnew MyClass(3); delete obj1; obj2->~MyClass(); Console::WriteLine(L"End Program");return 0; }
The output from this example is:
MyClass object(1) destructor called. MyClass object(2) destructor called. End Program MyClass object(3) finalizer called.
C++/CLI provides you with the capability for defining generic classes where a specific class is instantiated from the generic class type at runtime. You can define generic value classes, generic reference classes, generic interface classes, and generic delegates. You define a generic class using one or more type parameters in a similar way to generic functions that you saw in Chapter 6.
For example, here's how you could define a generic version of the Stack class you saw in Ex9_14:
// Stack.h for Ex9_21
// A generic pushdown stack
generic<typename T> ref class Stack
{
private:
// Defines items to store in the stack
ref struct Item
{
T Obj; // Handle for the object in this item
Item^ Next; // Handle for next item in the stack or nullptr
// Constructor
Item(T obj, Item^ next): Obj(obj), Next(next){}
};
Item^ Top; // Handle for item that is at the top
public:
// Push an object onto the stack
void Push(T obj)
{
Top = gcnew Item(obj, Top); // Create new item and make it the top
}
// Pop an object off the stack
T Pop()
{
if(!Top) // If the stack is empty
return T(); // return null equivalent
T obj = Top->Obj; // Get object from item
Top = Top->Next; // Make next item the top
return obj;
}
};The generic version of the class now has a type parameter, T. Note that you could use the class keyword instead of the typename keyword when specifying the parameter — there is no difference between them in this context. A type argument replaces T when the generic class type is used; T is replaced by the type argument through the definition of the class, so a major advantage over the original version is that the generic class type is much safer without losing any of its flexibility. The Push() member of the original class accepts any handle, so you could happily push a mix of objects of type MyClass^, String^, or, indeed, any handle type onto the same stack, whereas an instance of the generic type accepts only objects of the type specified as the type argument or objects of a type that have the type argument as a base.
Look at the implementation of the Pop() function. The original version returned nullptr if the top item in the stack was null, but you can't return nullptr for a type parameter because the type argument could be a value type. The solution is to return T(), which is a no-arg constructor call for type T. This results in the equivalent of 0 for a value type and nullptr for a handle.
Note
You can specify constraints on a generic class type parameter using the where keyword in the same way as you did for generic functions in Chapter 6.
You could create a stack from the Stack<> generic type that stores handles to Box objects like this:
Stack<Box^>^ stack = gcnew Stack<Box^>;
The type argument Box^ goes between the angled brackets and the statement creates a Stack<Box^> object on the CLR heap. This object allows handles of type Box^ to be pushed onto the stack as well as handles of any type that have Box as a direct or indirect base class. You can try this out with a revised version of Ex9_14.
TRY IT OUT: Using a Generic Class Type
Create a new CLR console program with the name Ex9_21 and then copy the header files Container.h, Box.h, and GlassBox.h from Ex9_14 to the directory for this project. Add these headers to the project by right-clicking Header Files in the Solution Explorer tab and selecting Add
// Ex9_21.cpp : main project file.
// Using a nested class to define a stack
#include "stdafx.h"
#include "Box.h" // For Box and Container
#include "GlassBox.h" // For GlassBox (and Box and Container)
#include "Stack.h" // For the generic stack class
using namespace System;
int main(array<System::String ^> ^args){ array<Box^>^ boxes = { gcnew Box(2.0, 3.0, 4.0), gcnew GlassBox(2.0, 3.0, 4.0), gcnew Box(4.0, 5.0, 6.0), gcnew GlassBox(4.0, 5.0, 6.0) }; Console::WriteLine(L"The array of boxes have the following volumes:"); for each(Box^ box in boxes) box->ShowVolume(); // Output the volume of a box Console::WriteLine(L" Now pushing the boxes on the stack..."); Stack<Box^>^ stack = gcnew Stack<Box^>; // Create the stack for each(Box^ box in boxes) stack->Push(box); Console::WriteLine( L"Popping the boxes off the stack presents them in reverse order:"); Box^ item; while((item = stack->Pop()) != nullptr) safe_cast<Container^>(item)->ShowVolume(); // Try the generic Stack type storing integers Stack<int>^ numbers = gcnew Stack<int>; // Create the stack Console::WriteLine(L" Now pushing integers onto the stack:"); for(int i = 2 ; i<=12 ; i += 2) { Console::Write(L"{0,5}",i); numbers->Push(i); } int number; Console::WriteLine(L" Popping integers off the stack produces:"); while((number = numbers->Pop()) != 0) Console::Write(L"{0,5}",number); Console::WriteLine();return 0; }
This example produces the following output:
The array of boxes have the following volumes: CBox usable volume is 24 CBox usable volume is 20.4 CBox usable volume is 120 CBox usable volume is 102 Now pushing the boxes on the stack... Popping the boxes off the stack presents them in reverse order:
CBox usable volume is 102
CBox usable volume is 120
CBox usable volume is 20.4
CBox usable volume is 24
Now pushing integers onto the stack:
2 4 6 8 10 12
Popping integers off the stack produces:
12 10 8 6 4 2You can define generic interfaces in the same way as you define generic reference classes, and a generic reference class can be defined in terms of a generic interface. To show how this works, you can define a generic interface that can be implemented by the generic class, Stack<>. Here's a definition for a generic interface:
// Interface for stack operations
generic<typename T> public interface class IStack
{
void Push(T obj); // Push an item onto the stack
T Pop();
};This interface has two functions identifying the push and pop operations for a stack.
The definition of the generic Stack<> class that implements the IStack<> generic interface is:
generic<typename T> ref class Stack : IStack<T>{ private: // Defines items to store in the stack ref struct Item { T Obj; // Handle for the object in this item Item^ Next; // Handle for next item in the stack or nullptr // Constructor Item(T obj, Item^ next): Obj(obj), Next(next){} }; Item^ Top; // Handle for item that is at the top public: // Push an object onto the stackvirtual void Push(T obj){ Top = gcnew Item(obj, Top); // Create new item and make it the top } // Pop an object off the stackvirtual T Pop(){ if(!Top) // If the stack is empty return T(); // return null equivalent T obj = Top->Obj; // Get object from item Top = Top->Next; // Make next item the top return obj; } };
The changes from the previous generic Stack<> class definition are shaded. In the first line of the generic class definition, the type parameter, T, is used as the type argument to the interface IStack, so the type argument used for the Stack<> class instance also applies to the interface. The Push() and Pop() functions in the class now have to be specified as virtual because the functions are virtual in the interface. You could add a header file containing the IStack interface to the previous example, and amend the generic Stack<> class definition to the example, and recompile the program to see it operating with a generic interface.
A collection class is a class that organizes and stores objects in a particular way; a linked list and a stack are typical examples of collection classes. The System::Collections::Generic namespace contains a wide range of generic collection classes that implement strongly typed collections. The generic collection classes available include the following:
TYPE | DESCRIPTION |
|---|---|
| Stores items of type T in a simple list that can grow in size automatically when necessary |
| Stores items of type T in a doubly linked list |
| Stores item of type T in a stack, which is a first-in last-out storage mechanism |
| Stores items of type T in a queue, which is a first-in first-out storage mechanism |
| Stores key/value pairs where the keys are of type K and the values are of type V |
I won't go into details of all these, but I'll mention briefly just three that you are most likely to want to use in your programs. I'll use examples that store value types for simplicity, but of course, the collection classes work just as well with reference types. The code fragments that follow assume a using directive for the System::Collections::Generic namespace is in effect.
List<T> defines a generic list that automatically increases in size when necessary. You can add items to a list using the Add() function and you can access items stored in a List<T> using an index, just like an array. Here's how you define a list to store values of type int:
List<int>^ numbers = gcnew List<int>;
This has a default capacity, but you could specify the capacity you require. Here's a definition of a list with a capacity of 500:
List<int>^ numbers = gcnew List<int>(500);
You can add objects to the list using the Add() functions:
for(int i = 0 ; i<1000 ; i++) numbers->Add( 2*i+1);
This adds 1000 integers to the numbers list. The list grows automatically if its capacity is less than 1000. When you want to insert an item in an existing list, you can use the Insert() function to insert the item specified by the second argument at the index position specified by the first argument. Items in a list are indexed from zero, like an array.
You could sum the contents of the list like this:
int sum = 0; for(int i = 0 ; i<numbers->Count ; i++) sum += numbers[i];
Count is a property that returns the current number of items in the list. The items in the list may be accessed through the default indexed property, and you can get and set values in this way. Note that you cannot increase the capacity of a list using the default indexed property. If you use an index outside the current range of items in the list, an exception is thrown.
You could also sum the items in the list like this:
for each(int n in numbers)
sum +=n;You have a wide range of other functions you can apply to a list, including functions for removing elements, and sorting and searching the contents of the list.
LinkedList<T> defines a linked list with forward and backward pointers so you can iterate through the list in either direction. You could define a linked list that stores floating-point values like this:
LinkedList<double>^ values = gcnew LinkedList<double>;
You could add values to the list like this:
for(int i = 0 ; i<1000 ; i++)
values->AddLast(2.5*i);The AddLast() function adds an item to the end of the list. You can add items to the beginning of the list by using the AddFirst() function. The Find() function returns a handle of type LinkedListNode<T>^ to a node in the list containing the value you pass as the argument to Find(). You could use this handle to insert a new value before or after the node that you found. For example:
LinkedListNode<double>^ node = values->Find(20.0); // Find node containing 20.0 if(node) values->AddBefore(node, 19.9); // Insert 19.9 before node
The first statement finds the node containing the value 20.0. If it does not exist, the Find() function returns nullptr. The last statement that is executed if node is not nullptr adds a new value of 19.9 before node. You could use the AddAfter() function to add a new value after a given node. Searching a linked list is relatively slow because it is necessary to iterate through the elements sequentially.
You could sum the items in the list like this:
double sumd = 0;
for each(double v in values)
sumd += v;The for each loop iterates through all the items in the list and accumulates the total in sum.
The Count property returns the number of items in the linked list, and the First and Last properties return the values of the first and last items.
The generic Dictionary<> collection class requires two type arguments; the first is the type for the key, and the second is the type for the value associated with the key. A dictionary is especially useful when you have pairs of objects that you want to store, where one object is a key to accessing the other object. A name and a phone number are an example of a key value pair that you might want to store in a dictionary, because you would typically want to retrieve a phone number using a name as the key. Suppose you have defined Name and PhoneNumber classes to encapsulate names and phone numbers, respectively. You can define a dictionary to store name/number pairs like this:
Dictionary<Name^, PhoneNumber^>^ phonebook = gcnew Dictionary<Name^, PhoneNumber^>;
The two type arguments are Name^ and PhoneNumber^, so the key is a handle for a name and the value is a handle for a phone number.
You can add an entry in the phonebook dictionary like this:
Name^ name = gcnew Name("Jim", "Jones");
PhoneNumber^ number = gcnew PhoneNumber(914, 316, 2233);
phonebook->Add(name, number); // Add name/number pair to dictionaryTo retrieve an entry in a dictionary, you can use the default indexed property — for example:
try
{
PhoneNumber^ theNumber = phonebook[name];
}
catch(KeyNotFoundException^ knfe)
{
Console::WriteLine(knfe);
}You supply the key as the index value for the default indexed property, which, in this case, is a handle to a Name object. The value is returned if the key is present, or an exception of type KeyNotFoundException is thrown if the key is not found in the collection; therefore, whenever you are accessing a value for a key that may not be present, the code should be in a try block.
A Dictionary<> object has a Keys property that returns a collection containing the keys in the dictionary, as well as a Values property that returns a collection containing the values. The Count property returns the number of key/value pairs in the dictionary.
Let's try some of these in a working example.
TRY IT OUT: Using Generic Collection Classes
This example exercises the three collection classes you have seen:
// Ex9_22.cpp : main project file.
// Using generic collection classes
#include "stdafx.h"
using namespace System;using namespace System::Collections::Generic; // For generic collections // Class encapsulating a name ref class Name { public: Name(String^ name1, String^ name2) : First(name1),Second(name2){} virtual String^ ToString() override{ return First + L" " + Second;} private: String^ First; String^ Second; }; // Class encapsulating a phone number ref class PhoneNumber { public: PhoneNumber(int area, int local, int number): Area(area),Local(local), Number(number){} virtual String^ ToString() override { return Area + L" " + Local + L" " + Number; } private: int Area; int Local; int Number; };int main(array<System::String ^> ^args) {// Using List<T> Console::WriteLine(L"Creating a List<T> of integers:"); List<int>^ numbers = gcnew List<int>; for(int i = 0 ; i<1000 ; i++) numbers->Add(2*i+1); // Sum the contents of the list int sum = 0; for(int i = 0 ; i<numbers->Count ; i++) sum += numbers[i]; Console::WriteLine(L"Total = {0}", sum); // Using LinkedList<T> Console::WriteLine(L" Creating a LinkedList<T> of double values:"); LinkedList<double>^ values = gcnew LinkedList<double>; for(int i = 0 ; i<1000 ; i++) values->AddLast(2.5*i); double sumd = 0.0; for each(double v in values) sumd += v; Console::WriteLine(L"Total = {0}", sumd); LinkedListNode<double>^ node = values->Find(20.0); // Find node containing 20.0
values->AddBefore(node, 19.9); values->AddAfter(values->Find(30.0), 30.1); // Sum the contents of the linked list again sumd = 0.0; for each(double v in values) sumd += v; Console::WriteLine(L"Total after adding values = {0}", sumd); // Using Dictionary<K,V> Console::WriteLine(L" Creating a Dictionary<K,V> of name/number pairs:"); Dictionary<Name^, PhoneNumber^>^ phonebook = gcnew Dictionary<Name^, PhoneNumber^>; // Add name/number pairs to dictionary Name^ name = gcnew Name("Jim", "Jones"); PhoneNumber^ number = gcnew PhoneNumber(914, 316, 2233); phonebook->Add(name, number); phonebook->Add(gcnew Name("Fred","Fong"), gcnew PhoneNumber(123,234,3456)); phonebook->Add(gcnew Name("Janet","Smith"), gcnew PhoneNumber(515,224,6864)); // List all numbers Console::WriteLine(L"List all the numbers:"); for each(PhoneNumber^ number in phonebook->Values) Console::WriteLine(number); // List names and numbers Console::WriteLine(L"Access the keys to list all name/number pairs:"); for each(Name^ name in phonebook->Keys) Console::WriteLine(L"{0} : {1}", name, phonebook[name]);return 0; }
The output from this example should be as follows:
Creating a List<T> of integers: Total = 1000000 Creating a LinkedList<T> of double values: Total = 1248750 Total after adding values = 1248800 Creating a Dictionary<K,V> of name/number pairs: List all the numbers: 914 316 2233 123 234 3456 515 224 6864 Access the keys to list all name/number pairs: Jim Jones : 914 316 2233 Fred Fong : 123 234 3456 Janet Smith : 515 224 6864
This chapter covered the principal ideas involved in using inheritance for native C++ classes and C++/CLI classes.
You have now gone through all of the important language features of ISO/ANSI C++ and C++/CLI. It's important that you feel comfortable with the mechanisms for defining and deriving classes and the process of inheritance in both language versions. Windows programming with Visual C++ 2010 involves extensive use of all these concepts.
Exercises
You can download the source code for the examples in the book and the solutions to the following exercises from www.wrox.com.
What's wrong with the following code?
class CBadClass { private: int len; char* p; public: CBadClass(const char* str): p(str), len(strlen(p)) {} CBadClass(){} };Suppose you have a class
CBird, as follows, that you want to use as a base class for deriving a hierarchy of bird classes:class CBird { protected: int wingSpan; int eggSize; int airSpeed; int altitude; public: virtual void fly() { altitude = 100; } };Is it reasonable to create a
CHawkby deriving fromCBird? How about aCOstrich? Justify your answers. Derive an avian hierarchy that can cope with both of these birds.Given the following class,
class CBase { protected: int m_anInt; public: CBase(int n): m_anInt(n) { cout << "Base constructor "; } virtual void Print() const = 0; };what sort of class is
CBaseand why? Derive a class fromCBasethat sets its inherited integer value,m_anInt, when constructed, and prints it on request. Write a test program to verify that your class is correct.A binary tree is a structure made up of nodes, where each node contains a pointer to a "left" node and a pointer to a "right" node plus a data item, as shown in Figure 9-6.
The tree starts with a root node, and this is the starting point for accessing the nodes in the tree. Either or both pointers in a node can be null. Figure 9-6 shows an ordered binary tree, which is a tree organized so that the value of each node is always greater than or equal to the value of the left node and less than or equal to the value of the right node.
Define a native C++ class to define an ordered binary tree that stores integer values. You also need to define a
Nodeclass, but that can be an inner class to theBinaryTreeclass. Write a program to test the operation of yourBinaryTreeclass by storing an arbitrary sequence of integers in it and retrieving and outputting them in ascending sequence.Hint: Don't be afraid to use recursion.
Implement Exercise 4 as a CLR program. If you did not manage to complete Exercise 4, look at the solution in the download and use that as a guide to doing this exercise.
Define a generic
BinaryTreeclass for any type that implements theIComparableinterface class, and demonstrate its operation by using instances of the generic class to store and retrieve first a number of random integers, and then the elements of the following array:array<String^>^ words = {L"Success", L"is", L"the", L"ability", L"to", L"go", L"from", L"one", L"failure", L"to", L"another", L"with", L"no", L"loss", L"of", L"enthusiasm"};Write the values retrieved from the binary tree to the command line.
WHAT YOU LEARNED IN THIS CHAPTER
TOPIC | CONCEPT |
|---|---|
Inherited members of a class | A derived class inherits all the members of a base class except for constructors, the destructor, and the overloaded assignment operator. |
Accessibility of inherited members of a class | Members of a base class declared as |
Access specifiers for a base class | A base class can be specified for a derived class with the keyword |
Constructors in derived classes | If you write a derived class constructor, you must arrange for data members of the base class to be initialized properly, as well as those of the derived class. |
Virtual functions | A function in a base class may be declared as |
Virtual destructors | You should declare the destructor in a native C++ base class that contains a virtual function as |
| A native C++ class may be designated as a |
Pure virtual functions | A virtual function in a native C++ base class can be specified as pure by placing |
Derived classes in C++/CLI | A C++/CLI reference class can be derived from another reference class. Value classes cannot be derived classes. |
Interface classes | An interface class declares a set of public functions that represent a specific capability that can be implemented by a reference class or value class. An interface class can contain public functions, events, and properties. An interface can also define static data members, functions, events, and properties, and these are inherited in a class that implements the interface. |
Derived interface classes | An interface class can be derived from another interface class, and the derived interface contains the members of both interfaces. |
Delegates | A delegate is an object that encapsulates one or more pointers to functions that have the same return type and parameter list. Invoking a delegate calls all the functions pointed to by the delegate. |
Event members of a class | An event member of a class can signal when the event occurs by calling one or more handler functions that have been registered with the event. |
Generic C++/CLI classes | A generic class is a parameterized type that is instantiated at runtime. The arguments you supply for type parameters when you instantiate a generic type can be value class types or reference class types. |
Collection classes | The |
C++/CLI class libraries | You can create a C++/CLI class library in a separate assembly, and the class library resides in a |