
Although while, until, and for loops are a core part of the Ruby
language, it is probably more common to write loops using special
methods known as iterators. Iterators are one of
the most noteworthy features of Ruby, and examples such as the following
are common in introductory Ruby tutorials:
3.times { puts "thank you!" } # Express gratitude three times
data.each {|x| puts x } # Print each element x of data
[1,2,3].map {|x| x*x } # Compute squares of array elements
factorial = 1 # Compute the factorial of n
2.upto(n) {|x| factorial *= x }
The times, each, map,
and upto methods are all iterators, and they interact with the
block of code that follows them. The complex
control structure behind this is yield. The yield statement temporarily returns control
from the iterator method to the method that invoked the iterator.
Specifically, control flow goes from the iterator to the block of code
associated with the invocation of the iterator. When the end of the
block is reached, the iterator method regains control and execution
resumes at the first statement following the yield. In order to implement some kind of
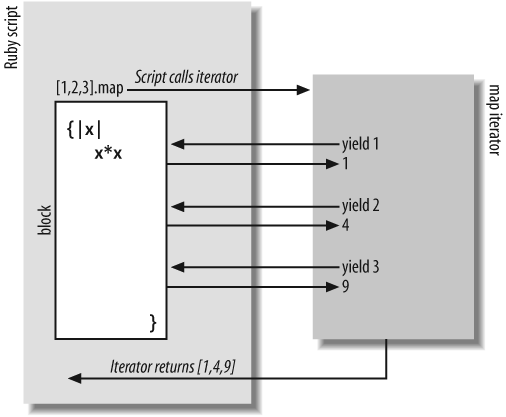
looping construct, an iterator method will typically invoke the yield statement multiple times. Figure 5-1 illustrates
this complex flow of control. Blocks and yield are described in detail in Blocks below; for now, we focus on the iteration itself
rather than the control structure that enables it.
As you can see from the previous examples, blocks may be
parameterized. Vertical bars at the start of a block are like
parentheses in a method definition—they hold a list of parameter names.
The yield statement is like a method
invocation; it is followed by zero or more expressions whose values are
assigned to the block parameters.
The core Ruby API provides a number of standard iterators. The
Kernel method loop behaves like an infinite loop, running its associated block
repeatedly until the block executes a return, break, or other statement that exits from
the loop.
The Integer class defines three commonly used iterators. The
upto method invokes its associated block once for each integer
between the integer on which it is invoked and the integer which is
passed as an argument. For example:
4.upto(6) {|x| print x} # => prints "456"
As you can see, upto yields
each integer to the associated block, and it includes both the
starting point and the end point in the iteration. In general,
n.upto(m) runs its block m-n+1 times.
The downto method is just like upto
but iterates from a larger number down to a smaller number.
When the Integer.times method
is invoked on the integer n, it
invokes its block n times, passing
values 0 through n-1 on successive iterations. For
example:
3.times {|x| print x } # => prints "012"
In general, n.times is
equivalent to 0.upto(n-1).
If you want to do a numeric iteration using floating-point
numbers, you can use the more complex step method defined by the Numeric class. The following iterator, for example, starts at 0 and iterates in steps of 0.1 until it reaches Math::PI:
0.step(Math::PI, 0.1) {|x| puts Math.sin(x) }
Array, Hash, Range, and a number of other classes define an each iterator that passes each element of
the collection to the associated block. This is perhaps the most
commonly used iterator in Ruby; as we saw earlier, the for loop only works for iterating over
objects that have each methods.
Examples of each iterators:
[1,2,3].each {|x| print x } # => prints "123"
(1..3).each {|x| print x } # => prints "123" Same as 1.upto(3)
The each iterator is not only
for traditional “data structure” classes. Ruby’s IO class defines an each iterator that yields lines of text read
from the Input/Output object. Thus,
you can process the lines of a file in Ruby with code like
this:
File.open(filename) do |f| # Open named file, pass as f
f.each {|line| print line } # Print each line in f
end # End block and close file
Most classes that define an each method also include the Enumerable module, which defines a number of
more specialized iterators that are implemented on top of the each method. One such useful iterator is
each_with_index, which allows us to
add line numbering to the previous example:
File.open(filename) do |f|
f.each_with_index do |line,number|
print "#{number}: #{line}"
end
end
Some of the most commonly used Enumerable iterators are the
rhyming methods collect, select, reject, and inject. The collect method (also known as map) executes its associated block for each
element of the enumerable object, and collects the return values of
the blocks into an array:
squares = [1,2,3].collect {|x| x*x} # => [1,4,9]
The select method invokes the
associated block for each element in the enumerable object, and
returns an array of elements for which the block returns a value other
than false or nil. For example:
evens = (1..10).select {|x| x%2 == 0} # => [2,4,6,8,10]
The reject method is simply
the opposite of select; it returns
an array of elements for which the block returns nil or false. For example:
odds = (1..10).reject {|x| x%2 == 0} # => [1,3,5,7,9]
The inject method is a little
more complicated than the others. It invokes the associated block with
two arguments. The first argument is an accumulated value of some sort
from previous iterations. The second argument is the next element of
the enumerable object. The return value of the block becomes the first
block argument for the next iteration, or becomes the return value of
the iterator after the last iteration. The initial value of the
accumulator variable is either the argument to inject, if there is one, or the first
element of the enumerable object. (In this case, the block is invoked
just once for the first two elements.) Examples make inject more clear:
data = [2, 5, 3, 4]
sum = data.inject {|sum, x| sum + x } # => 14 (2+5+3+4)
floatprod = data.inject(1.0) {|p,x| p*x } # => 120.0 (1.0*2*5*3*4)
max = data.inject {|m,x| m>x ? m : x } # => 5 (largest element)
See Enumerable Objects for further details on the
Enumerable module and its
iterators.
The defining feature of an iterator method is that it invokes a
block of code associated with the method invocation. You do this with
the yield statement. The following method is a trivial iterator that just
invokes its block twice:
def twice yield yield end
To pass argument values to the block, follow the yield statement with a comma-separated list of expressions. As with
method invocation, the argument values may optionally be enclosed in
parentheses. The following simple iterator shows a use of yield:
# This method expects a block. It generates n values of the form
# m*i + c, for i from 0..n-1, and yields them, one at a time,
# to the associated block.
def sequence(n, m, c)
i = 0
while(i < n) # Loop n times
yield m*i + c # Invoke the block, and pass a value to it
i += 1 # Increment i each time
end
end
# Here is an invocation of that method, with a block.
# It prints the values 1, 6, and 11
sequence(3, 5, 1) {|y| puts y }
Here is another example of a Ruby iterator; it passes two arguments to its block. It is worth noticing that the implementation of this iterator uses another iterator internally:
# Generate n points evenly spaced around the circumference of a
# circle of radius r centered at (0,0). Yield the x and y coordinates
# of each point to the associated block.
def circle(r,n)
n.times do |i| # Notice that this method is implemented with a block
angle = Math::PI * 2 * i / n
yield r*Math.cos(angle), r*Math.sin(angle)
end
end
# This invocation of the iterator prints:
# (1.00, 0.00) (0.00, 1.00) (-1.00, 0.00) (-0.00, -1.00)
circle(1,4) {|x,y| printf "(%.2f, %.2f) ", x, y }
Using the yield keyword
really is a lot like invoking a method. (See Chapter 6 for complete details on method invocation.)
Parentheses around the arguments are optional. You can use * to expand an array into individual
arguments. yield even allows you to
pass a hash literal without the curly braces around it. Unlike a
method invocation, however, a
yield expression may not be
followed by a block. You cannot pass a block to a block.
If a method is invoked without a block, it is an error for that
method to yield, because there is
nothing to yield to. Sometimes you want to write a method that yields
to a block if one is provided but takes some default action (other
than raising an error) if invoked with no block. To do this, use
block_given? to determine whether
there is a block associated with the invocation. block_given?, and its synonym iterator?, are Kernel methods, so they act like global
functions. Here is an example:
# Return an array with n elements of the form m*i+c
# If a block is given, also yield each element to the block
def sequence(n, m, c)
i, s = 0, [] # Initialize variables
while(i < n) # Loop n times
y = m*i + c # Compute value
yield y if block_given? # Yield, if block
s << y # Store the value
i += 1
end
s # Return the array of values
end
An enumerator is an Enumerable object
whose purpose is to enumerate some other object. To use enumerators in
Ruby 1.8, you must require
'enumerator'. In Ruby 1.9 (and also 1.8.7), enumerators are
built-in and no require is
necessary. (As we’ll see later, the built-in enumerators have
substantially more functionality than that provided by the enumerator library.)
Enumerators are of class Enumerable::Enumerator. Although this class
can be instantiated directly with new, this is not how enumerators are
typically created. Instead, use to_enum or its synonym enum_for, which are methods of Object. With no arguments, to_enum returns an enumerator whose each method simply calls the each method of the target object. Suppose
you have an array and a method that expects an enumerable object. You
don’t want to pass the array object itself, because it is mutable, and
you don’t trust the method not to modify it. Instead of making a
defensive deep copy of the array, just call to_enum on it, and pass the resulting
enumerator instead of the array itself. In effect, you’re creating an
enumerable but immutable proxy object for your array:
# Call this method with an Enumerator instead of a mutable array. # This is a useful defensive strategy to avoid bugs. process(data.to_enum) # Instead of just process(data)
You can also pass arguments to to_enum, although the enum_for synonym seems more natural in this
case. The first argument should be a symbol that identifies an
iterator method. The each method of
the resulting Enumerator will
invoke the named method of the original object. Any remaining
arguments to enum_for will be
passed to that named method. In Ruby 1.9, the String class is not Enumerable, but it defines three iterator
methods: each_char, each_byte, and each_line. Suppose we want to use an
Enumerable method, such as map, and we want it to be based on the
each_char iterator. We do this by
creating an enumerator:
s = "hello"
s.enum_for(:each_char).map {|c| c.succ } # => ["i", "f", "m", "m", "p"]
In Ruby 1.9 (and 1.8.7), it is usually not even necessary to use
to_enum or enum_for explicitly as we did in the
previous examples. This is because the built-in iterator methods of
Ruby 1.9 (which include the numeric iterators times, upto, downto, and step, as well as each and related methods of Enumerable) automatically return an
enumerator when invoked with no block. So, to pass an array enumerator
to a method rather than the array itself, you can simply call the
each method:
process(data.each_char) # Instead of just process(data)
This syntax is even more natural if we use the chars alias in place of each_char. To map the characters of a string
to an array of characters, for example, just use .chars.map:
"hello".chars.map {|c| c.succ } # => ["i", "f", "m", "m", "p"]
Here are some other examples that rely on enumerator objects
returned by iterator methods. Note that it is not just iterator
methods defined by Enumerable that
can return enumerator objects; numeric iterators like times and upto do the same:
enumerator = 3.times # An enumerator object
enumerator.each {|x| print x } # Prints "012"
# downto returns an enumerator with a select method
10.downto(1).select {|x| x%2==0} # => [10,8,6,4,2]
# each_byte iterator returns an enumerator with a to_a method
"hello".each_byte.to_a # => [104, 101, 108, 108, 111]
You can duplicate this behavior in your own iterator methods by
returning self.to_enum when no
block is supplied. Here, for example, is a version of the twice iterator shown earlier that can return
an enumerator if no block is provided:
def twice
if block_given?
yield
yield
else
self.to_enum(:twice)
end
end
In Ruby 1.9, enumerator objects define a with_index method that is not available in the Ruby 1.8 enumerator
module. with_index simply returns a
new enumerator that adds an index parameter to the iteration. For
example, the following returns an enumerator that yields the
characters of a string and their index within the string:
enumerator = s.each_char.with_index
Finally, keep in mind that enumerators, in both Ruby 1.8 and
1.9, are Enumerable objects that can be used with the
for loop. For example:
for line, number in text.each_line.with_index
print "#{number+1}: #{line}"
end
Our discussion of enumerators has focused on their use as Enumerable proxy objects. In Ruby 1.9, (and
1.8.7, though the implementation is not as efficient) however,
enumerators have another very important use: they are
external iterators. You can use an enumerator to
loop through the elements of a collection by repeatedly calling the
next method. When there are no more
elements, this method raises a StopIteration exception:
iterator = 9.downto(1) # An enumerator as external iterator begin # So we can use rescue below print iterator.next while true # Call the next method repeatedly rescue StopIteration # When there are no more values puts "...blastoff!" # An expected, nonexceptional condition end
External iterators are quite simple to use: just call next each time you want another element.
When there are no more elements left, next will raise a StopIteration exception. This may seem
unusual—an exception is raised for an expected termination condition
rather than an unexpected and exceptional event. (StopIteration is a descendant of StandardError and IndexError; note that it is one of the only
exception classes that does not have the word “error” in its name.)
Ruby follows Python in this external iteration technique. By treating
loop termination as an exception, it makes your looping logic
extremely simple; there is no need to check the return value of
next for a special end-of-iteration
value, and there is no need to call some kind of next? predicate before calling next.
To simplify looping with external iterators, the Kernel.loop method
includes (in Ruby 1.9) an implicit rescue clause and exits cleanly when
StopIteration is raised. Thus, the
countdown code shown earlier could more easily be written like
this:
iterator = 9.downto(1) loop do # Loop until StopIteration is raised print iterator.next # Print next item end puts "...blastoff!"
Many external iterators can be restarted by calling the rewind method. Note, however, that rewind is not effective for all enumerators.
If an enumerator is based on an object like a File which reads lines sequentially, calling
rewind will not restart the
iteration from the beginning. In general, if new invocations of
each on the underlying Enumerable object do
not restart the iteration from the beginning, then calling rewind will not restart it either.
Once an external iteration has started (i.e., after next has been called for the first time), an
enumerator cannot be cloned or duplicated. It is typically possible to
clone an enumerator before next is
called, or after StopIteration has
been raised or rewind is
called.
Normally, enumerators with next methods are created from Enumerable objects that have an each method. If, for some reason, you define
a class that provides a next method
for external iteration instead of an each method for internal iteration, you can
easily implement each in terms of
next. In fact, turning an
externally iterable class that implements next into an Enumerable class is as simple as mixing in
(with include—see Modules) a module like this:
module Iterable
include Enumerable # Define iterators on top of each
def each # And define each on top of next
loop { yield self.next }
end
end
Another way to use an external iterator is to pass it to an internal iterator method like this one:
def iterate(iterator)
loop { yield iterator.next }
end
iterate(9.downto(1)) {|x| print x }
The earlier quote from Design Patterns
alluded to one of the key features of external iterators: they solve
the parallel iteration problem. Suppose you have two Enumerable collections
and need to iterate their elements in pairs: the first elements of
each collection, then the second elements, and so on. Without an
external iterator, you must convert one of the collections to an array
(with the to_a method defined by
Enumerable) so
that you can access its elements while iterating the other collection
with each.
Example 5-1 shows the
implementation of three iterator methods. All three accept an
arbitrary number of Enumerable
objects and iterate them in different ways. One is a simple sequential
iteration using only internal iterators; the other two are parallel
iterations and can only be done
using the external iteration features of Ruby 1.9.
Example 5-1. Parallel iteration with external iterators
# Call the each method of each collection in turn.
# This is not a parallel iteration and does not require enumerators.
def sequence(*enumerables, &block)
enumerables.each do |enumerable|
enumerable.each(&block)
end
end
# Iterate the specified collections, interleaving their elements.
# This can't be done efficiently without external iterators.
# Note the use of the uncommon else clause in begin/rescue.
def interleave(*enumerables)
# Convert enumerable collections to an array of enumerators.
enumerators = enumerables.map {|e| e.to_enum }
# Loop until we don't have any more enumerators.
until enumerators.empty?
begin
e = enumerators.shift # Take the first enumerator
yield e.next # Get its next and pass to the block
rescue StopIteration # If no more elements, do nothing
else # If no exception occurred
enumerators << e # Put the enumerator back
end
end
end
# Iterate the specified collections, yielding tuples of values,
# one value from each of the collections. See also Enumerable.zip.
def bundle(*enumerables)
enumerators = enumerables.map {|e| e.to_enum }
loop { yield enumerators.map {|e| e.next} }
end
# Examples of how these iterator methods work
a,b,c = [1,2,3], 4..6, 'a'..'e'
sequence(a,b,c) {|x| print x} # prints "123456abcde"
interleave(a,b,c) {|x| print x} # prints "14a25b36cde"
bundle(a,b,c) {|x| print x} # '[1, 4, "a"][2, 5, "b"][3, 6, "c"]'
The bundle method of Example 5-1 is similar to the Enumerable.zip method. In Ruby 1.8, zip must first convert its Enumerable arguments to arrays and then use
those arrays while iterating through the Enumerable object it is
called on. In Ruby 1.9, however, the zip method can use external iterators. This
makes it (typically) more efficient in space and time, and also allows
it to work with unbounded collections that could not be converted into
an array of finite size.
In general, Ruby’s core collection of classes iterate over
live objects rather than private copies or “snapshots” of those
objects, and they make no attempt to detect or prevent concurrent
modification to the collection while it is being iterated. If you call
the each method of an array, for
example, and the block associated with that invocation calls the
shift method of the same array, the
results of the iteration may be surprising:
a = [1,2,3,4,5]
a.each {|x| puts "#{x},#{a.shift}" } # prints "1,1
3,2
5,3"
You may see similarly surprising behavior if one thread modifies
a collection while another thread is iterating it. One way to avoid
this is to make a defensive copy of the collection before iterating
it. The following code, for example, adds a method each_in_snapshot to the Enumerable module:
module Enumerable
def each_in_snapshot &block
snapshot = self.dup # Make a private copy of the Enumerable object
snapshot.each &block # And iterate on the copy
end
end
[*] Within the Japanese Ruby community, the term “iterator” has fallen out of use because it implies an iteration that is not actually required. A phrase like “method that expects an associated block” is verbose but more precise.
[*] Design Patterns: Elements of Reusable Object-Oriented Software, by Gamma, Helm, Johnson, and Vlissides (Addison-Wesley).