
4
Introducing Transact-SQL Language
In the early days of relational databases, a number of industry-wide efforts were made to unify different, proprietary query languages. IBM had established an early standard called Structured English Query Language. This name was condensed to literally spell the word SEQUEL. Another effort resulted in a language called Select Query Language (SQL) that included commands allowing data to be read only for reporting and record look-up. This became a popular, product-independent standard to which the “Sequel” acronym was still applied by members of the database community. Eventually, additional commands were added, enabling records to be added, deleted, and modified. This created a quandary. They had worked so hard to create a standard language with a cute name that no longer fit. The word Select was finally replaced with the word Structured… and the universe was once again brought back to a state of balance. Of course, the purists will insist that SQL is pronounced ESS CUE EHL, rather than “SEQUEL.” So, how should you pronounce it? Any way you want. Disagree if you like, but I save one syllable and say “SEQUEL.”
For the SQL language to survive outside of a specific product or company, the standard was published and held by an independent standards organization. The SQL standard was originally registered with the American National Standards Institute and officially called the ANSI SQL standard, established in 1986. This standard has been revised a few times, resulting in revisions known as the following:
 ANSI SQL-86
ANSI SQL-86- ANSI SQL-89
- ANSI SQL-92
- ANSI SQL-99
- ANSI SQL-2003
The concept seems quite simple but there is a little more to this story. The ANSI SQL standard is actually no longer held exclusively by the American National Standards Institute. This is a common tale of American-born standards that are later implemented internationally. In 1987, SQL became an international standard and was registered with the International Standards Organization using its previously copyrighted title, ANSI SQL. This means that the 1992 revision of the SQL standard is actually known as ISO ANSI SQL-92. Even though the standard was updated in 1999 and 2003, most SQL-based database products had been established on the ANSI SQL-92 standard and they have not been revised to fully conform to the ANSI SQL-99 or 2003 specifications. Like most of its competition, Transact-SQL does not fully conform to the ANSI SQL-99 or ANSI SQL-2003 standards but does implement selected features.
Finally, the ANSI SQL standard actually defines three conformance levels: Entry, Intermediate, and Full. Most products, including SQL Server, conform entirely to the entry-level standard and partially to the higher levels.
The Nature of SQL
Most folks who work with Transact-SQL have had some experience with other languages. If you've never done any programming, please don't close the book at this point and give up. This is certainly not a prerequisite for writing SQL, but is a reference point for many who have worked with computer systems in other capacities.
Comparing Transact-SQL to a procedural or object-oriented programming language (such as Java, C, C++, C#, or Visual Basic) is like comparing apples to pomegranates. It's not better than or worse than, but quite different than, a true programming language—even though you may see some similarities in the syntax and structure of certain statements. For different types of operations, Transact-SQL may be far superior or much worse than these languages, simply because of what it is designed to accomplish. One of the challenges in making broad statements about the capabilities of different languages is that as they continue to grow and evolve, version after version, additional capabilities are added. The problem with industry standards is that everyone is out to protect and enhance their own product. Over time, the capabilities of each technology (or language, in this case) begin to overlap, leaving us with a number of different options to perform the same tasks.
Is it possible to perform data access or data manipulation (to insert, modify, or delete values in a database) with a procedural programming language without using SQL? Yes, but it's cumbersome and usually inefficient. Can you perform complex mathematical operations, looping, string parsing, or multidimensional array management in Transact-SQL? Probably, but it likely won't be a very good experience. Chapter 1 mentioned that SQL Server 2005 gives programmers the capability of writing stored procedures and user-defined functions entirely in object-oriented program code, rather than SQL. This doesn't make Transact-SQL any less capable as SQL Server's native query language. It simply gives programmers another option.
Transact-SQL is designed primarily to work with relational data. No big surprise here. Secondarily, Transact-SQL also has a number of useful capabilities for working with scalar (single value) data, logical operations, mathematics, decision structures, text string parsing, and looping mechanisms. However, compared with most programming languages, SQL is not as powerful or as capable as a true programming language. If your needs call for advanced functionality that may be outside the realm of SQL's native capabilities, you may need to carefully consider using a different approach, such as a custom, extended, stored procedure, application programming interface (API), .NET assembly, or other programming solution. This is why SQL Server's Data Transformation Services (Data Integration Services in SQL Server 2005) can utilize both programming code and Transact-SQL. With that settled, what can you do with Transact-SQL? Quite a lot.
Transact-SQL is the language used to talk to SQL Server, and query expressions are essentially used to ask the server to do things. It's important to know what you can ask for—and what SQL Server can do. Query operations are divided into three different categories. I'll briefly describe them and then take some time to look at specific examples. Like everything else in the technical world, these categories are best known by three-letter abbreviations (that's TLA, for short.) Locally, these fall in the order I've listed here:
- Data Definition Language (DDL) — Commands are used to create and manage the objects in a database. DDL statements can be used to create, modify, and drop databases, tables, indexes, views, stored procedures, and other objects.
- Data Control Language (DCL) —Statements control the security permissions for users and database objects. Some objects have different permission sets. You can grant or deny these permissions to a specific user or users who belong to a database role or Windows user group.
- Data Manipulation Language (DML) — Contains the statements used to work with data. This includes statements to retrieve data, insert rows into a table, modify values, and delete rows.
Where to Begin
Where should we begin? This is one of those chicken and egg questions. Before you can query data, you have to have it stored somewhere. I think it would be a bit distracting to start from the very beginning and step through the entire process to create a new database. For simplicity's sake, I'd like to start out working with data stored in an existing database so we don't get too far off topic. I'll cover DDL and DCL statements, used primarily for database construction and administration, at the end of this chapter.
You'll be working with the Adventure Works Cycles sample database. The versions of this database that Microsoft includes with SQL Server 2000 and SQL Server 2005 are quite different. The SQL Server 2005 version includes some complexity that I felt was unnecessary for this book. This is why the AdventureWorks2000 for both versions of SQL Server is used for the examples. Please double-check that you have this database available to you and, if not, refer to the instructions in Chapter 2.
Because you've already learned the basics of using the Query Analyzer for SQL Server 2000 and the Query Editor in the SQL Server 2005 Management Studio, I'm not going to be giving you specific instructions regarding the use of these tools. The purpose here is to focus on the language. If you need to, review these instructions in Chapter 2. To begin, open Query Analyzer or the SQL Server Management Studio Query Editor and connect to your database server.
Data Manipulation Language (DML)
The basic statements of DML are introduced in this chapter with elaboration to follow in later chapters.
You can do only four things with data. You can Create records, Read them, Update record values, and you can Delete records. That spells CRUD… we do CRUD with data. When SQL was devised, they chose to use different words for these four operations: Insert, Select, Update, and Delete. Somehow, ISUD isn't quite as easy to remember as CRUD. If you can master these four types of statements, you will be able to do just about anything with data using SQL. Here's the catch: Inserts, Updates, and Deletes are a piece of cake. On the surface, the Select command can also appear simple.
Queries Have Layers
In the movie Shrek, Mike Myers' character Shrek the Ogre explains to his friend Donkey that “Ogres are like onions—they have layers.” To some degree, the SELECT statement is like an Ogre, or rather it's like an onion —it has layers. On the surface, there isn't that much to it. However, when you start peeling back the layers, there's quite a lot to it. You've likely discovered this fact on your own. Here's the important point: it's not complicated. It's really just layers upon simple layers. The fundamentals are quite simple. I call this principle compounded simplicity.
Before I can effectively introduce the next topic, I need to jump the gun a little bit and briefly discuss the SELECT statement. This statement is covered thoroughly in Chapter 5. For now, it's important to understand that to return data from tables in SQL Server, you will use the SELECT statement. In relational databases, information gets transformed into data, typically by storing it in multiple tables. It would stand to reason, then, that to turn data back into useful information it must be retrieved from multiple tables. This is accomplished by using a handful of techniques: joins, subqueries, and unions. You learn more about these topics in future chapters. For now, know that these represent the bulk of the work you will do as you create and use queries.
Here's a simple example. When the following query runs, the query processor parses the query and breaks it down into individual steps.
SELECT TOP 10 Product.Name ,SalesOrderDetail.LineTotal FROM Product INNER JOIN SalesOrderDetail ON Product.Productid = SalesOrderDetail.ProductID WHERE SalesOrderDetail.SpecialOfferID = 1 ORDER BY SalesOrderDetail.LineTotal DESC
Figure 4-1 shows the execution plan for the preceding query. Reading from right-to-left, the query optimizer chooses to implement each operational step based on available resources and statistical information about the data. The first two steps (at the beginning point of the two branches) show you that clustered index scans were used to initially retrieve data from both of the tables referenced in this query. Subsequent steps are chosen and analyzed for efficiency as the data is handled through the query process.

Figure 4-1
The low-level instructions used to process these steps are compiled into executable instruction code and cached in-memory so that subsequent executions don't require the same degree of preparation and resource overhead. Depending on whether this query is part of an ad-hoc SQL statement or a saved database object, the compiled instructions may also be saved to permanent storage, improving efficiency in the long term.
Set-Based Operations
When SQL Server processes a SELECT command, it builds a structure in memory to return a result set. This structure, essentially a two-dimensional array of rows and columns, is known as a cursor. The word cursor is an acronym for CURrent Set Of Records. As such, it represents the entire set of rows returned from a table or query. SQL Server's query-processing engine is built on a foundation of cursor processing and is optimized to work with data as a set of records, rather than individual rows.
Row-Based Operations
A technique more popular in other database products is to populate a cursor type variable from a SELECT query and then step through each row. You can do this in SQL Server but it often works against the query-processing engine. Whenever possible, it is advisable to work with this set-based result paradigm rather than trying to process individual rows.
Row-level cursor operations have their place. This technique is discussed in Chapter 10.
Query Syntax Basics
A query is like a sentence; it must to be a complete statement with at least a noun and a verb. The semantic rules of SQL define a simple structure. You start with a clause that states what you intend to do: Select, Insert, Update, or Delete—these are the verbs. You also must define the columns or values to be returned. Usually, you will indicate the table or other database object you want to work with—this is the subject or noun. Depending on the type of operation, there are connecting words such as From and Into.
You'll learn about each of these statements in greater detail later but, for now, some simple examples follow. If you want to retrieve all of the column values from all rows in the Product table, you would execute the following query:
SELECT * From Product
If you need to raise the cost of all product records by ten percent, this statement would work:
UPDATE Product SET StandardCost = StandardCost * 1.1
The Transact-SQL language is very forgiving when it comes to formatting statements. The SQL Server query-processing engine doesn't care about whether commands are in upper- or lowercase. It doesn't care about spaces, tabs, and carriage returns as long as they don't interfere with the name of a command or value. This means that you can format your script for readability just about any way you like. For example, the following query returns product sales information for a range of dates, sorted by product category and subcategory. The query could be written like this:
SELECT ProductCategory.Name AS Category, ProductSubCategory.Name AS SubCategory, Product.Name AS ProductName, SalesOrderHeader.OrderDate, SalesOrderDetail.OrderQty, SalesOrderDetail.UnitPrice FROM SalesOrderHeader INNER JOIN SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID INNER JOIN Product ON SalesOrderDetail.ProductID = Product.ProductID INNER JOIN ProductSubCategory ON Product.ProductSubCategoryID = ProductSubCategory.ProductSubCategoryID INNER JOIN ProductCategory ON ProductSubCategory.ProductCategoryID = ProductCategory.ProductCategoryID WHERE SalesOrderHeader.OrderDate BETWEEN ‘1/1/2003’ AND ‘12/31/2003’ ORDER BY ProductCategory.Name, ProductSubCategory.Name, Product.Name
Or, it could be written like this:
SELECT ProductCategory.Name AS Category
, ProductSubCategory.Name AS SubCategory
, Product.Name AS ProductName
, SalesOrderHeader.OrderDate
, SalesOrderDetail.OrderQty
, SalesOrderDetail.UnitPrice
FROM SalesOrderHeader
INNER JOIN SalesOrderDetail
ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID
INNER JOIN Product
ON SalesOrderDetail.ProductID = Product.ProductID
INNER JOIN ProductSubCategory
ON Product.ProductSubCategoryID =
ProductSubCategory.ProductSubCategoryID
INNER JOIN ProductCategory
ON ProductSubCategory.ProductCategoryID =
ProductCategory.ProductCategoryID
WHERE SalesOrderHeader.OrderDate BETWEEN ‘1/1/2003’ AND ‘12/31/2003’
ORDER BY ProductCategory.Name, ProductSubCategory.Name, Product.Name
Obviously, the second query is easier to read and would be much easier for someone to look at and figure out what's going on. Because both uppercase and lowercase statements are acceptable, a query could be written as follows:
select name, standardcost from product
Although the preceding statement would execute just fine, it's not quite as easy to read as the following:
SELECT Name, StandardCost FROM Product
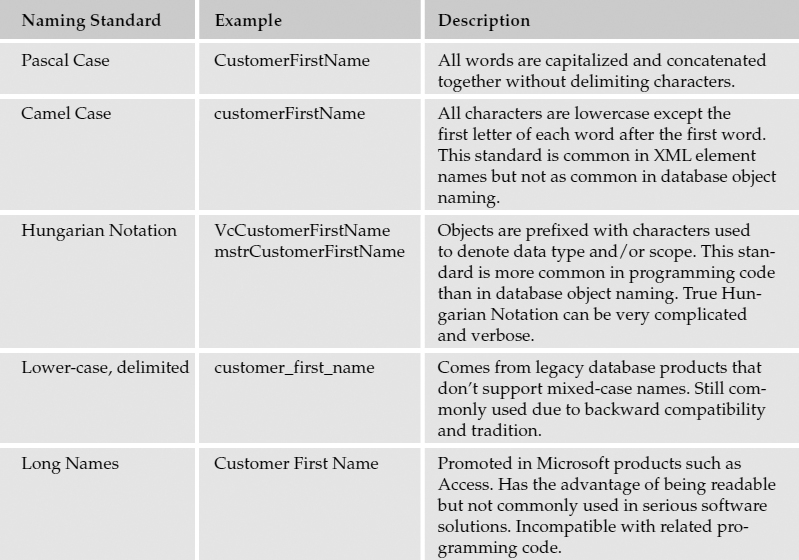
Naming Conventions
There seems to be a universal concept that anything that can be very simple and uncomplicated must become confusing and overly complicated. When a database is created, objects should be named according to some kind of sensible naming convention. There is no industry-wide standard, and people have different ideas about appropriate naming conventions. Most folks perceive this as a simple matter of common sense, so they don't put much effort into it. The problem with common sense is that it's not very common and everyone seems to have their own idea about what is sensible.
It would be very convenient to have one simple standard to follow, and if things were that simple, I'd tell you exactly what to do. Most of it is quite easy, but object naming is a bit of an art. There are many considerations. For example, it's a good idea to use names that are descriptive and complete, describing the purpose of each object. On the other hand, you should keep names short and simple so users don't have to do a lot of extra typing. These are conflicting directions.
Be cautious about using any names that duplicate the name of a command or other reserved word. Before deciding upon a table, field, or other object name, review the list of data types, SQL clauses, and function names. Although it is possible to use some of these names, it's never a good idea. Once you have established a name, don't reuse it for something else. For example, the Product table shouldn't contain a Product column. SQL Server will not complain if you do this, but it will be very confusing to someone trying to write queries or read your SQL script.
Some older database products don't support mixed-case names or names containing spaces. For this reason, many database administrators continue to use all lowercase names with words separated by underscores. Personally, I find mixed-case names a little easier on the eyes.
Trends come and go. With Windows 95, Microsoft promoted the use of long file names. Microsoft Access, which was developed at about the same time, also promoted the use of long database object names. From a certain perspective, it makes sense to use friendly, sentence-like, descriptive names. The fact is that SQL Server will have no problem with names containing spaces, but other components of a solution may have issues with this. As values are handled at different levels of an application, they may move from the controls in the user interface to variables in the program code, then to the method parameters or properties of a class. Eventually, these values are passed into a stored procedure as parameters or as field names in a SQL statement. The point is that it is much easier on everyone involved if these items all have the same, or very similar, names. Figure 4-2 shows an example of the data flow through a sample application.
You could argue that there would be no harm in using space-filled field names in the database and similar names, sans spaces, elsewhere—and you'd probably be right. The general belief among database professionals is that spaces don't belong in object names. Frankly, this is probably more of an issue of perception, rather than technical feasibility.
I've done a lot of one-man solution development where I create the database, write the software components, design and develop the user interfaces, and write all the program code to glue the pieces together. Even in these applications, it's easy to get lost if related object names aren't the same. I have always insisted that they be consistent throughout the entire solution. I've also worked on some fairly large, complex projects where the database was designed by someone else long ago. If the names aren't clear and concise in the beginning, I'm faced with a quandary: change the names in my program code to something easier to understand (accepting that they don't match the table and field names), or consistently apply the same cryptic and confusing names throughout the entire solution.
It's not uncommon for a database designer to model and create tables, applying his or her own naming standards to table and field names. After this person has moved on to a different job, another database expert comes in and adds stored procedures. He might disagree with the names applied by the original designer, so he names the procedures and input parameters differently than the fields in the table. Along comes an outside consultant developing software components and he uses abbreviated names for the related class properties that correspond to the fields and parameters. Later, a junior-level software developer is assigned to create a user application for the data. He takes a class or reads a book about appropriate object naming standards and decides to fix the problem by applying his own names in spite of those that already exist. Coincidentally, I just finished modifying some report queries today. I had designed the tables these reports used. In testing, I discovered that performance wasn't ideal and decided to build another table with pre-aggregated data. Another database designer stepped in to help and named some of the columns differently than mine. For example, I have a column named FiscalMonthYearNumber and his was FiscalMonthNum. Is this a big deal? Not really, but it does require that I fix the queries for all of my reports.

Figure 4-2
There is no easy solution to this common problem. Ideally, the person who designs the database should carefully consider the impact of the names he chooses and document them thoroughly. This sets the standard for all those who follow—and all names should remain consistent. I typically use mixed-case names, capitalizing each word and concatenating them together. In programming circles, this is often referred to as Pascal Case, named after the Pascal programming language. The following table shows a few common naming standards with some of the history and pros and cons regarding each.
Commenting Script
When you write SQL script, it will inevitably be easy to read and understand—at the time you write it. Programming is something we do in a certain context. When I work on a project, my head is in that project and most everything makes perfect sense at the time. I once developed a database application for a consulting client. A few different people had been involved in writing queries and program code over a few months. They asked me to come back in to create some new reports. As I opened the project, reading through the code, I found it difficult to understand the logic. In my frustration, I said, “I don't understand what is going on in this code. Who wrote this?” My customer replied to my dismay, “Paul, that's your code. You wrote it last year.” Needless to say, I was embarrassed as well as frustrated.
I learned a valuable lesson: comment everything. No matter how plain the logic seems. No matter how much sense it makes at the time, it probably won't make so much sense to the next person who reads it, especially months or years later. If nothing else reminds you of this simple lesson, just remember this: Every one of us leaves a legacy. Other query designers and programmers will remember you for what you leave behind for them to maintain. They will most likely either remember you for making their job difficult or for making their job easier.
Comments typically are made in two forms that include header blocks and in-line comments. A header block is a formal block of text that precedes every scripted object, such as a stored procedure or user-defined function. It should conform to a standard format and should contain information such as the following:
- The name of the scripted object
- The name of the designer or programmer
- Contact information
- Creation date
- Revision dates and notes
- Information about what the object does and how it's called
- Validation testing and approval notes
Comments in Transact-SQL can be either in block format or on a single line. Block comments begin with a forward slash and at least one asterisk (/*) and end with an asterisk and a forward slash (*/). Everything in between is treated as a comment and ignored by the query parser. A header block doesn't need to be complicated. It should just be consistent. Here's an example of a simple header block preceding the script for a stored procedure used to insert product records:
/*******************************************************************
spInsProduct - Inserts product records
Accepts ProductName, StandardPrice, QtylnStock, CategorylD
Returns new ProductID, Int
6-12-04 by Paul Turley ([email protected])
Revisions:
7-10-04 - PT - Added MarkupPercent parameter
7-12-04 - PT - Changed data type from Int to Decimal
********************************************************************/
In-line comments are placed in the body of the script to document the process and flow along with the actual script. Comments are preceded by two hyphens (--). The query parser ignores the remainder of the line. In-line comments can be placed after executable script on the same line or can be written on a separate line, as you can see in the following example:
CREATE PROCEDURE spGetCustomer
-- Define City parameter, set default to Null if parameter not passed
@City VarChar(25) = NULL
AS
IF @City IS Null -- Check for Null (parameter not passed)
BEGIN
-- Return all Store records
SELECT Store.Name AS StoreName, Address.City
FROM Store
INNER JOIN Customer
ON Store.CustomerID = Customer.CustomerID
INNER JOIN CustomerAddress
ON Customer.CustomerID = Address.CustomerID
INNER JOIN Address
ON CustomerAddress.AddressID = Address.AddressID
END
ELSE
BEGIN
-- Return Store records only for matching City
SELECT Store.Name AS StoreName, Address.City
FROM Store INNER JOIN Customer
ON Store.CustomerID = Customer.CustomerID
INNER JOIN CustomerAddress
ON Customer.CustomerID = CustomerAddress.CustomerID
INNER JOIN Address
ON CustomerAddress.AddressID = Address.AddressID
WHERE Address.City = @City
END
If in doubt, add a comment. If not in doubt, add one anyway. Don't worry about overdoing it. Granted, some of your script will make sense without commenting and may be somewhat self-documenting, but don't take a chance. Don't listen to yourself when that little voice says “Don't worry about commenting your code now. You can do it later.” Maybe you're more disciplined than I am, but if I don't write comments when I'm writing code, it won't get done.
Another important application of in-line comments is temporary development notes to myself and others. Inevitably, on the first pass through my script, I'm most concerned about getting core functionality working. Exceptions to basic logic, problem workarounds, error-handling, and less-common conditions are usually secondary to just getting the code to work once under ideal conditions. As I consider all of these secondary factors, I make notes to myself that may include to-do items and reminders to go back and add clean-up code and polished features.
Using Templates
Query Analyzer contains a very useful, and often underutilized, feature. Templates provide a starting place for a variety of database object scripts. Several templates come with SQL Server and adding your own is an easy task. In Chapter 3 you learned how to use the script template features in Query Analyzer and the SQL Server Management Studio. In reality, a template is just a text file containing SQL commands and placeholders for object names. Using a template can save considerable time and effort, especially when writing script that you may not use very often. For example, I don't write an Instead Of Trigger very often, so I may not be able to remember the syntax off the top of my head. Rather than scouring Books Online or searching the web for help, I'll simply open this template in a new script window:
-- =============================================
-- Create basic Instead Of Trigger
-- =============================================
IF EXISTS (SELECT name
FROM sysobjects
WHERE name = N‘<trigger_name, sysname, trig_test>’
AND type = ‘TR’)
DROP TRIGGER <trigger_name, sysname, trig_test>
GO
CREATE TRIGGER <trigger_name, sysname, trig_test>
ON <table_or_view_name, sysname, pubs.dbo.sales>
INSTEAD OF INSERT
AS
BEGIN
RAISERROR (50009, 16, 10)
EXEC sp_who
END
GO
This script provides a basic pattern to get you started. If you'd like to create your own templates, this is very easy to do. Simply write the script in a new query window and then use the File ![]() Save As menu to save it to a Template SQL file. In Query Analyzer, templates are saved with a tql extension, but in the SQL Management Studio templates are saved with a sql extension, like other script files.
Save As menu to save it to a Template SQL file. In Query Analyzer, templates are saved with a tql extension, but in the SQL Management Studio templates are saved with a sql extension, like other script files.
Template files saved to the standard template folders will be added to the available templates for Query Analyzer and the SQL Management Studio. SQL Server 2000 assigns the extension .TQL to template files. SQL Server 2005 uses the standard .SQL extension. In a default SQL Server installation, these folders are found in the following locations:
| Version | Templates Folder Path |
| SQL Server 2000 | C:Program FilesMicrosoft SQL Server80ToolsTemplates |
| SQL Server 2005 | C:Program FilesMicrosoft SQL Server90ToolsBinnVSShellCommon7IDEsqlworkbenchnewitemsSql |
Generating Script
The term script simply refers to a bunch of SQL statements typically used together to perform some useful purpose. This could vary from a simple SQL query to a group of several queries and commands used to create an entire database. The SQL Server client and administrative tools (Enterprise Manager, Query Analyzer, Workbench, and Visual Studio) have the ability to generate script for just about any object or combination of objects. You can even generate the script to re-create an entire database. Script is usually saved to a file with a sql extension and is simply plain text. You could easily create or edit a script file with Notepad or any other text editor.
Managing Script
I suggest that you have a designated folder for your script files. I usually create a folder for each database project or application I'm working on. I will also make it a point to back up and archive the script files in these folders. Just like program source code, my scripts are treated like gold. Especially for the programming objects in your database (views, functions, and stored procedures), these objects should be scripted and saved on a CD or protected network folder. This practice will be invaluable in case (make that when) something goes wrong.
To keep you and your co-workers on their toes, you may find it helpful to stage a routine fire drill of sorts. On a bi-weekly basis, designate a hard disk or folder as corrupted or deleted and then go in and take inventory of your losses. You can use this exercise to let other team members know how well your recovery plan is working and how it can be improved.
Version Control
One of the greatest challenges in managing scripts is how to keep track of multiple versions of the same file. The natural order of application development involves prototyping a feature, working through iterations of design, testing, and debugging until the feature is stable. At this point, it is important to keep a copy of the working SQL script and program source code before any changes are made. Adding features and capabilities to a query or programming object nearly always has adverse effects, at least in the short term. The secret to success is to script and save your queries and objects to script files after you get them working.
On many occasions, I have been asked to make some minor change or enhancement to a project. It may involve adding a column to a table or just adding a calculation to a query. I do a quick test and then implement the change on the production server the night before flying out to a training engagement. Almost inevitably, the change will have some unforeseen impact. Perhaps my customer calls in a panic to inform me that she's getting an error, it's the end of the month, and they can't print invoices.
Making this minor change often seems like a good idea at the time. Fortunately, if objects were scripted before making changes, it's usually a simple task to either review the original script and make corrections, or to run the original script, returning the query to its previous, working state. Script version management is not complicated, but without having a system in place and making a deliberate effort to follow it, it's easy to lose track of your changes.
A few simple approaches to version control exist. Version control software, such as Microsoft Visual SourceSafe, automates this task by storing files in a central database. As files are checked out and checked in, a separate copy is time-stamped and stored in the SourceSafe database. Any version of the file can then be retrieved at any time. SourceSafe is the best bet if a group of people will be sharing script files and working on different, networked development computers. SQL Server 2000 has no built-in integration with Visual SourceSafe, but SourceSafe is easy enough to use at the file system level. The SQL Server 2005 Workbench does integrate with Visual SourceSafe. Much like Visual Studio, files can be checked out, checked in, and managed from within the Workbench design environment.
A less-sophisticated approach is to simply append file names with the date they are created and the initials of the person creating them. Keep these files in project-related folders and back them up regularly. The following are examples of the script files for a stored procedure called spGetCustomerAccountDetail:
- Create spGetCustomerAccountDetail - 7-02-04 PT.sql
- Create spGetCustomerAccountDetail - 7-09-04 PT.sql
- Create spGetCustomerAccountDetail - 7-11-04 PT.sql
- Create spGetCustomerAccountDetail - 7-15-04 PT.sql
- Create spGetCustomerAccountDetail - 8-03-04 PT.sql
Data Definition Language
If you have used Enterprise Manager, Visual Studio, Access, or any other tools to create and design SQL Server databases, you have used Data Definition Language (DDL)—perhaps not directly but by using these user interface tools to manage database objects. Nearly all database maintenance operations are scripted and then that script is executed. This is one reason why there are so many scripting options in the SQL Server management tools. The scripting engine has been there for years in one form or another.
This is a simple topic because you can do only three things with any database object: create it, modify it, or delete it. Subsequently, the corresponding DDL statements are as follows:
| Statement | Description |
| CREATE | Used to create a new object. This applies to many common database objects including Database, Table, View, Procedure, Trigger, and Function. |
| ALTER | Used to modify the structure of an existing object. The syntax for each of these objects will vary depending on its purpose. |
| DROP | Used to delete an existing object. Some objects cannot be dropped because they are schema-bound. This means that you may not be able to drop a table if it contains data participating in a relationship or if another object depends on the object you intend to drop. |
The syntax of DDL statements is quite simple. A quick tour through each of the common database objects and an example for each follows. Because this isn't a database programming book, it won't be exploring the nuances and uses for these objects, but the syntax used to manage them.
Creating a Table
In its simplest form, to add a new table to the current database, you specify the table name and then list the table's new columns in parentheses, followed by their data type. Here's an example:
CREATE TABLE Appointment
( AppointmentID Int
, Description VarChar(50)
, StartDateTime DateTime
, EndDateTime DateTime
, Resource VarChar(50) Null
)
You can specify several options for each column definition. Briefly, this might include options such as auto-sequencing identity, default values, constraints, and whether the column value may be set to Null. For a complete list of options, check the SQL Server Books Online documentation.
Creating a View
A view is similar to a table in that users can select from a view like a table. Views are stored in the database but they don't really store data. A view is really just a SQL SELECT query that gets optimized to make it execute more efficiently than if you were to make up the query every time you wanted to select data. However, views can do some very interesting things that we're not going to get into (like actually storing data.). They can be indexed and they can be used with other programming objects to make SQL Server do some very powerful things. Enough for now. The finer points of views are discussed in Chapter 10.
When you create a view, you're really just naming a SQL SELECT statement. The syntax looks like this:
CREATE VIEW vwProductOrderDetails AS SELECT CustomerID , OrderDate , OrderQty , UnitPrice , Product.Name AS Product FROM SalesOrderHeader INNER JOIN SalesOrderDetail ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID INNER JOIN Product ON SalesOrderDetail.ProductID = Product.ProductID
Creating a Stored Procedure
Stored procedures can perform a wide range of actions and business functionality. For example, a stored procedure can insert, update, or delete records in a table. By passing parameter values, it can make decisions and either select data or perform other operations accordingly. Because stored procedures can be used in so many unique ways, it's hard to exemplify a “typical” stored procedure. The syntax for creating a stored procedure is similar to that of a view. Note the input parameters defined just before the word AS:
/******************************************************
Checks for existing Product record
If exists, updates the record. If not,
inserts new record
******************************************************/
CREATE PROCEDURE spInsertOrUpdateProduct
-- Input parameters --
@ProductName nVarChar(50),
@ProductNumber nVarChar(25),
@StdCost Money
AS
IF EXISTS(SELECT * From Product Where ProductNumber = @ProductNumber)
UPDATE Product SET NAME = @ProductName, StandardCost = @StdCost
WHERE ProductNumber = @ProductNumber
ELSE
INSERT INTO Product (Name, ProductNumber, StandardCost)
SELECT @ProductName, @ProductNumber, @StdCost
Creating a Trigger
Creating a trigger is similar to a stored procedure. Actually, a trigger is a special type of stored procedure that gets executed when specific operations are performed on the records in a table (such as an Insert, Update, or Delete). Business logic similar to that of a standard stored procedure may be performed within a trigger, but it is typically used to apply specialized business rules to ensure data integrity. Some of the unique characteristics of triggers include their assignment to a DML operation (Insert, Update, and/or Delete), implicit transaction control, and virtual table references that are used to represent the record or records involved in the transaction that caused the trigger to fire.
In the following example, note the reference to a virtual table called Deleted. This “table” is actually a virtual set of rows that are in the process of being deleted as the trigger is automatically executed. There is no script to explicitly begin processing a transaction because the trigger execution is the result of a transaction in progress. The Rollback Transaction script affects this inherent transaction and prevents the delete operation from being completed.
/******************************************************
Checks for existing sales orders using
the product being deleted.
Prevents deletion if orders exist.
******************************************************/
CREATE TRIGGER tr_DelProduct
ON Product
FOR DELETE
AS
IF (SELECT Count(*) FROM SalesOrderDetail
INNER JOIN Deleted ON SalesOrderDetail.ProductID = Deleted.ProductID) > 0
BEGIN
RAISERROR 50009 ‘Cannot delete a product with sales orders’
ROLLBACK TRANSACTION
RETURN
END
Creating a User-Defined Function
User-defined functions are used to apply custom business logic such as performing calculations, parsing values, and making value comparisons. Functions are often called within views and stored procedures to reduce code redundancy and to encapsulate functionality. The script used to create a new user-defined function is similar to that of a stored procedure. The function is defined on the first executable line of the script (preceded in this example by a comment block). Immediately following the CREATE command, the function name references one or more parameters followed by a data type, in parentheses. The text following the Returns keyword indicates the data type that the function will return. This is a simple scalar (single value) function that returns a DateTime type value. In Chapter 10 you also learn how user-defined functions can return complex, multi-value results and table-type result sets; similar to a view or stored procedure. This function utilizes local variables and system functions to perform its internal logic.
/********************************************************** Returns a date representing the last date of any given month. **********************************************************/ CREATE Function dbo.fn_LastOfMonth(@TheDate DateTime) Returns DateTime AS BEGIN DECLARE @FirstOfMonth DateTime DECLARE @DaysInMonth Int DECLARE @RetDate DateTime SET @FirstOfMonth = DATEADD(mm, DATEDIFF(mm,0,@TheDate), 0) SET @DaysInMonth = DATEDIFF(d, @FirstOfMonth, DATEADD(m, 1, @FirstOfMonth)) RETURN DATEADD(d, @DaysInMonth - 1, @FirstOfMonth) END
Scripting Practices
When scripting objects, a common practice is to check for the existence of the object before creating it. Although this isn't necessary when you know the object isn't already in the database, if you generate script using Enterprise Manager, Query Analyzer, or SQL Server Management Studio, logic is typically included to remove the object if it exists and then re-create it. Keep in mind that dropping and re-creating an object will remove any security privileges that have been granted to users. If you simply need to modify an object to add capabilities, it may be advisable to use the ALTER command rather than DROP followed by the CREATE command. A number of different scripting options can be used to customize auto-generated script, and many of the non-default options may be unnecessary.
Every SQL Server 2000 database contains a number of standard system tables. Generally, you need not be concerned with these tables and really ought to leave them alone. However, you can get a lot of useful information about your database from these tables. The following script searches the sysobjects system table to find out if the Product table exists in the current database. If it does exist, the DROP statement is conditionally executed to delete the table. This script will also work on a SQL Server 2005 instance, but sysobjects isn't a table in SQL Server 2005, it is a view. There is no direct access to system tables in SQL Server 2005.
IF EXISTS ( SELECT * FROM sysobjects WHERE Name = ‘Product’ ) DROP TABLE Product GO
A line of script may fail for a variety of reasons. Due to referential constraints and other dependencies, tables must be dropped in the right order. In case the table isn't successfully dropped, it may be a good idea to check again for the existence of the table before attempting to create it. This is performed in the following script fragment (shortened for simplicity):
IF NOT EXISTS (
SELECT * FROM sysobjects WHERE Name = ‘Product’
)
BEGIN
CREATE TABLE Product
(
ProductID Int Identity
, Name nVarChar(50) Not Null
, ProductNumber nVarChar(25) Null
, DiscontinuedDate DateTime Null
…
System tables were not designed for ease of use or readability, so they can be somewhat cryptic. Another problem if you use system tables is that there are no guarantees that they won't change in later versions of SQL Server, possibly breaking your code if you were to upgrade and migrate your database. This is the case if you plan to upgrade from SQL Server 2000 to SQL Server 2005. As previously mentioned, there is no direct access to system tables. Microsoft created a number of system views in SQL Server 2005 to replace the system tables from SQL Server 2000. The new views have the same name as the old tables so scripts created on a SQL Server 2000 instance should still work. However, Microsoft has been recommending not querying system tables directly for years and there is no guarantee that SQL Server 2000 scripts that ran against system objects will continue to work. In lieu of directly querying system tables, a set of views is provided with both SQL Server 2000 and 2005 to simplify the structure and data in the system tables and the new system views. These Information Schema views are stored in the Master database and can be used in any database on the server. Each view is prefixed with the name INFORMATION_SCHEMA, followed by a period and a general object type. In place of the script in the previous example, which selects from the sysobjects table, similar script may be used with the INFORMATION_SCHEMA.TABLES view, such as in the following:
IF EXISTS (
SELECT * FROM Information_Schema.Tables WHERE Table_Name = ‘Product’
)
DROP TABLE Product
GO
Altering Objects
The script used to modify some existing objects is very similar to the syntax used to create objects, using the ALTER command in place of CREATE. This is the case for objects that contain SQL expressions such as views, stored procedures, and user-defined functions. The following script is very similar to the example used to demonstrate how to create a stored procedure. An additional input parameter and a line to handle error conditions have been added.
/******************************************************
Checks for existing Product record
If exists, updates the record. If not,
inserts new record
Revised: 4-12-06 PT
******************************************************/
ALTER PROCEDURE spInsertOrUpdateProduct
-- Input parameters --
@ProductName nVarChar(50),
@ProductNumber nVarChar(25),
@StdCost Money,
@ListPrice Money
AS
IF EXISTS (SELECT * FROM Product WHERE ProductNumber = @ProductNumber)
UPDATE Product
SET Name = @ProductName
, StandardCost = @StdCost
, ListPrice = @ListPrice
WHERE ProductNumber = @ProductNumber
ELSE
INSERT INTO Product (Name, ProductNumber, StandardCost, ListPrice)
SELECT @ProductName, @ProductNumber, @StdCost, @ListPrice
IF @@Error <> 0
RAISERROR (‘spInsertUpdateProduct execution failed’, 15, 1)
After the ALTER statement has been executed, the object retains all of its previous properties and security access privileges or restrictions, but its definition is updated with any of the script changes. This includes the comment block before the ALTER statement line.
Some objects require different syntax used to alter their definition than the language used to create them. For example, when creating a table, columns are defined within parentheses after the table name. To alter the design of a table and change the columns, you would use the ADD or DROP keyword before each column definition. Any existing columns that are not addressed in the Alter Table script remain in the table's definition.
Each column or constraint change must be performed in a separate ALTER TABLE statement. For example, if my goal was to add the LeadTime column and to drop the Resource column, this can be performed using the previous and next statements but can't be done in a single statement.
ALTER TABLE Appointment DROP COLUMN Resource
Dropping Objects
Why is it that the most dangerous commands are the easiest to perform? Dropping an object removes it from the database catalog (from the system tables), completely deleting it from the database. Tables containing data and their related indexes are de-allocated, freeing the storage space for other data. To quote a well-known former president of the United States, “let me make one thing perfectly clear”… There is no Undo command in SQL Server. If you have dropped an object or deleted data, it's gone. However, the storage space occupied by dropped or truncated objects is not actually wiped clean and made available to the operating system unless the database is set to AutoShrink.
The syntax for dropping all objects is the same: DROP objecttype objectname. Here are a few examples of script used to drop the objects I previously created:
DROP TABLE Appointment DROP VIEW vwProductOrderDetails DROP PROCEDURE spInsertOrUpdateProduct DROP TRIGGER TR_Del_Product DROP FUNCTION dbo.fn_LastOfMonth
Some objects cannot be dropped if there are dependent objects that would be affected if they no longer existed. Examples are tables with foreign key constraints, user-defined types, and rules. This safety feature is called schema binding. Some objects don't enforce schema binding by default but it can be created to explicitly enforce this rule. Views, stored procedures, and user-defined functions can optionally be created with schema binding and prevent orphaned dependencies. This feature is discussed in greater detail in Chapter 10.
Data Control Language
This is by far the simplest subset of the SQL language. The goal of Data Control Language (DCL) is to manage users' access to database objects. After the database has been designed and objects are created using DDL, a security plan should be implemented to provide users and applications with an appropriate level of access to data and database functionality, while protecting the system from intrusion. Access privileges can be controlled at the server or database level and groups of privileges can be assigned to individual users and to groups of users who are assigned role membership. Although database security involves simple concepts, it is not a task to be approached in a haphazard manner. It's important to devise a comprehensive plan and to consider all of the business requirements and the organization's security standards when devising a database security plan.
SQL Server recognizes two separate security models. These include SQL Server Security, where roles and users are managed entirely within the database server, and Integrated Windows Security, which maps privileges to groups and users managed in a Windows-based network system. This topic is discussed in greater detail in Chapter 10, but some of the basic principles are explained in this section.
The easiest way to think about permissions is in layers. Because users can have memberships to multiple roles, they may have a mixed set of privileges for different database objects. Like placing multiple locks on a door, a user can only gain access to an object if all restrictive permissions are removed and they have been granted access through at least one role membership. Using the lock analogy, if you had a key to one of three locks, you would not be able to open the door. Likewise, if a user is a member of three roles, two of which are denied access to an object, access won't be allowed even if it is explicitly granted. The user must be either removed from the restrictive roles or these permissions must be revoked.
In short, DCL consists of three commands that are used to manage security privileges for users or roles on specific database objects:
- The GRANT command gives permission set to a user or role.
- The DENY command explicitly restricts a permission set.
- The REVOKE command is used to remove a permission set on an object.
Revoking permissions removes an explicit permission (GRANT or DENY) on an object so that permissions that may have been applied at a less-specific level are used. Before permissions can be applied to objects, users and roles are defined. SQL Server provides a set of standard roles for both the database server and for each database. You learn how to manage permissions for roles and users in Chapter 10.
Following are some examples. This statement grants SELECT permission to the user Paul on the Product table:
GRANT SELECT ON Product TO Paul
Tables and views have permissions to allow or restrict the use of the four DML statements: Select, Insert, Update, and Delete. Stored procedures and functions recognize the EXECUTE permission. On tables, views, and functions, permissions can also be given or restricted on a user's ability to implement referential integrity, using the DRI permission.
This example grants EXECUTE permission to members of the db_datawriter built-in role but denies this permission to a user named Martha:
GRANT EXECUTE ON spAddProduct TO db_datawriter DENY EXECUTE ON spAddProduct TO Martha
Multiple permissions can be applied on an object by placing permissions in a comma-delimited list, as in the following:
GRANT SELECT, INSERT, UPDATE ON Product TO Paul
An important aspect to remember about SQL Server security is that SQL Server does not enforce logical combinations of permissions. For example, assume that user Paul is a member of a security role called Authors and the following DCL scripts are executed:
Because Paul is a member of the Authors role he inherits the UPDATE permission granted to that role. He was also specifically denied the SELECT permission on the table PublishedBooks. The logical assumption would be that Paul could not update the PublishedBooks table, but this assumption would be wrong. Paul cannot update any specific rows due to this permission combination so the following command would fail:
UPDATE PublishedBooks SET Author = ‘Paul Turley’ WHERE BookID = 222
However this command would succeed:
UPDATE PublishedBooks SET Author = ‘Paul Turley’
Because the WHERE expression is in essence a select command that is processed prior to the update, Paul is prevented from making the change. Unfortunately, Paul is a savvy SQL user and he knows that by updating all the rows in the table he circumvents the denied select permission and changes all the published book records to show that he is the author. The moral to this story is to use care and planning when applying permissions.
This short discourse should have provided a cursory introduction to the concepts and practices of DCL. As previously mentioned, like database design, security is a matter that should be carefully planned and implemented in a uniform and standard approach. It's usually best to have a small number of database administrators charged with the task of security to keep tight reigns over how privileges are applied for users of a database.
Summary
By now you should have a good understanding about what the Transact-SQL language is used for and how it is implemented with Microsoft SQL Server. You learned that Transact-SQL is a dialect of the Structured Query Language, based on the industry-wide ANSI SQL standard.
Three categories of statements within SQL are used to define and manage a database and the objects contained therein, to control access to data and database functionality, and to manage the data in a database. Data Definition Language (DDL) encompasses the CREATE and ALTER statements, used to define database objects. Data Control Language (DCL) is used to manage security access and user privileges to data and database objects. Finally, Data Manipulation Language (DML) is the subset of SQL you will typically use most often. DML contains the SELECT, INSERT, UPDATE, and DELETE statements and several variations of these statements that you will use to populate tables with records, modify, remove, and read data values. The SELECT statement has several modifiers and additional commands and clauses you will use to do useful things with, and make sense of, the data stored in a database.
The SQL Server database engine uses intelligent logic to process queries as efficiently as possible. The query parser and optimizer translate a SQL query into distinct operations, which are then compiled into low-level machine instructions. This compiled execution plan is cached in memory and can be stored permanently within the database with database programming objects to run more efficiently.
You also learned about the proper way to write SQL script, using comments and naming standards. Script can be saved in script files for safekeeping and templates can be used to save time and effort when writing new queries.
This chapter, along with the first three chapters, is the foundation upon which more specific topics are based. As you move forward, you will be using the scripting techniques discussed here and the tools you learned to use in Chapter 2. The rest of the book focuses on specific types of queries and objects.
Exercises
Exercise 1
Use Query Analyzer or SQL Server Management Studio to create and execute a new query, and view the results:
- Open a connection to your local or remote test server.
- Indicate that you want to run queries against the AdventureWorks2000 database.
Execute the following SQL statement:
SELECT * FROM Contact
- Check the status bar for the numbers of rows returned by the query.
- Check the results with the solution.
Exercise 2
Insert a row using generated SQL script:
- Using Query Analyzer or SQL Server Management Studio, expand the AdventureWorks2000 database in the object browser. Right-click the ProductCategory table and select Script Object to New Window As Insert.
- In the new query editor window, remove the references to the ProductCategoryID column on both lines. On the top line, delete all text from and including the first open square bracket, [, to the first end square bracket, ], and the following comma. On the second line, remove all text from and including the first open angled bracket, <, to the first close angled bracket, >, and the following comma.
- One the second line, replace the placeholders (angled brackets and all text between them) for each of the columns as follows: Replace the Name with ‘Widget’ (including the single quotes). Replace the ModifiedDate and rowguid with the word DEFAULT (no quotes).
- Select the AdventureWorks2000 database from the database selection drop-down list on the toolbar and execute the query.
Enter the following query to view the contents of the ProductCategory table:
SELECT * FROM ProductCategory.
- Highlight this statement and execute this query.
- Verify that a new row was added to the results. Check the modified SQL expression that you generated with the solution.