
Chapter4
Network Models
WHAT’S IN A NETWORK?
In this chapter, I am concerned with representations that have more structure than those discussed in chapters 2 and 3. These representations all have some kind of network structure. A network consists of nodes and links; for example, an airline may create a network to illustrate the routes it flies and the distances between cities it flies to. A network representation of this type is shown in Figure 4.1. The nodes in this diagram represent cities the airline flies to; each node is labeled with the name of the city it represents. The links represent flights that the airline makes; each link is labeled with the distance of the flight. This kind of network can be used to determine routes between cities and the total flying distance required to travel from one city to another: A trip from Los Angeles to New York requires only a single flight of 2,451 miles. On this airline, a trip from San Francisco to Washington, D.C. requires at least three flights. Flying from San Francisco to Chicago to New York to Washington, D.C., requires 2,776 miles of air travel.
In the network in Figure 4.1, the links are undirected. Undirected links are used when the relation represented by the link is symmetric. In this example, if there is a direct flight from one city to another, the airline also has a direct flight from the second city back to the first. It would seem odd for an airline to fly directly from one city to a second (e.g., from Chicago to New York), but not to fly the return trip directly. Network models, however, can also be used when the relation between two nodes is asymmetric. When the relation between nodes is asymmetric, then the links are directed. Directed links are usually drawn on network diagrams with arrows, which indicate that the relation holds in the direction an arrow points, but not in the reverse direction.1
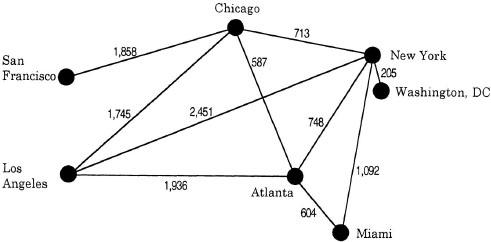
FIG. 4.1. Network diagram showing airline routes for a fictitious company. The nodes represent cities and are labeled with the city name. The links represent flights the company makes and are labeled with the flying distances between cities.
The node and link structure of the networks and the labels on the nodes and links are critical aspects of the representing worlds of these networks. Other aspects of the diagram in Figure 4.1 are not essential. This diagram was drawn to vaguely resemble a map (much like the map constructed from flying distances in Figure 2.2), but the spatial layout of the nodes and the physical distances between nodes and links are not part of the representing world of network models. Only the set of connections and the labels are used by the processes that operate on semantic networks.
In this chapter, I focus on three aspects of networks with nodes and links. First is a semantic network. Early semantic network models consisted of networks with nodes, links, and labels. Processing in these networks often involved passing markers across the links between nodes to model text comprehension and access to words in the lexicon. After describing these initial models, I discuss extensions to this initial proposal focusing on the automatic spread of activation through a network. Finally, I examine parallel constraint satisfaction networks, which also use nodes, links, and spreading activation. Parallel constraint satisfaction models are related to the connectionist models described in chapter 2.
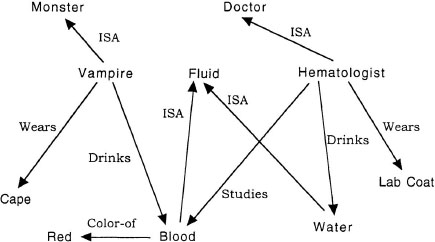
FIG. 4.2. Sample semantic network with nodes related to Vampire, and Hematologist.
SEMANTIC NETWORKS
An important class of representations in cognitive science is semantic networks, which have nodes that are labeled and links that are both labeled and directed (Quillian, 1968). Nodes in the network correspond to concepts, in which the labels specify the concept denoted by the node just as the labels specified the city represented by the node in Figure 4.1. Figure 4.2 shows a sample semantic network surrounding the concept vampire. Each node has a unique label that distinguishes one from another, and the links also have labels. The label on the link specifies a relation between the nodes connected by the link. For example, the vampire and monster nodes are linked by a class inclusion relation with a link labeled ISA (e.g., “A vampire ISA monster”). Class inclusion is a relation stating that one category is a subset of another. Any relation that can hold between a pair of nodes can be used as a label for a link. The label drinks specifies that an object specified by one node drinks a substance specified by a second node (as in the drinks link between vampire and blood in Figure 4.2). Finally, these links are directed. As discussed previously, the direction of the link is specified by the arrow on the link and represents the fact that this relation is asymmetric. The ISA link from vampire to monster points from vampire to monster in accordance with the fact that all vampires are monsters, but all monsters are not vampires.
An early motivation for using semantic network models was storage efficiency. To illustrate, consider assessing the truth of the following two sentences:
![]()
and
![]()
Sentence 4.1 seems to be a fact about dogs. It may seem reasonable to have a link in a semantic network between the dog node and the fur node to specify that dogs are covered with fur. In contrast, there need not be a direct link between dogs and air to specify that dogs breathe air. This fact is true, but the connection is indirect.
These indirect connections can be established in semantic networks through inheritance. In particular, some categories (like dog) are members of more general categories (like mammal). One can connect the knowledge of some facts to general categories rather than to specific ones. Thus, if mammals breathe air and dogs are a subcategory of mammals, dogs can inherit the property of breathing air from animals. Class inclusion relations (i.e., ISA relations) support the inheritance of properties. Properties can be inherited from any more general category of which a given category is a member. Poodles breathe air, because all mammals breathe air and poodles are mammals. The same object may inherit properties from categories at many different levels of abstraction. For example, one can determine that dogs breathe air because they are mammals and that they are composed of molecules because they are physical objects.
The ability to inherit properties means that the storage of properties in a semantic network can be efficient. One need only link a given property to the node for the most general category about which it is true. Any more specific category for which the property is true inherits the property by virtue of being connected to the more general category by ISA links. In this way, one can avoid constructing links between a property and every category it is related to.
The notion of storage efficiency deserves more attention. The idea that objects inherit properties because of their membership in more general categories allows one to learn facts about one object and then infer these facts for other objects about which they were not explicitly stated. One need not learn directly that all dogs breathe air and all cats breathe air and all moles breathe air and all sloths breathe air. Simply finding out that all mammals breathe air and that a particular animal is a mammal is enough to determine that it breathes air. Nevertheless, there is no reason to believe that the human cognitive system is maximally efficient (Collins & Loftus, 1975). Early semantic network models (e.g., Quillian, 1968) suggested that the fact that people know many things forces them to be reasonably efficient in the use of memory, and so people often store properties at the most general level at which they are true and then allow all subcategories to inherit the property from a supercategory.2 For properties that are usually true, one may store the property at a general level and store the exceptions specially. For example, one can store the fact that all birds have feathers by allowing the property “has feathers” to be inherited by all subcategories of bird. One can store strongly characteristic properties like “flies” with birds, whereas properties like “does not fly” are stored with exceptions like penguins.
The assumption of maximal efficiency is too strong to be correct. The focus on efficiency was due in part to the tools available at the time these models were developed. When semantic networks were developed as computer models in the late 1960s, computers were large and slow and had very little storage capacity. Under these circumstances, efficiency was paramount, because storing redundant information was wasteful of precious space. In contrast, computers are now small and fast and have vast online and long-term storage facilities. As anyone who has loaded a new version of a computer program can attest, there is no longer a premium on efficient storage of information in computer programs. Because computer technology has often been used as a metaphor for the processing capacities of the mind, it seems no more imperative to assume that humans are efficient in their storage of knowledge than computers are.
Even though redundancy in cognitive systems no longer seems like a technological problem, there are still barriers to creating links between every property and every category about which it is true. The problem is that making inferences takes some amount of time and effort. If a semantic network has many objects organized into class-inclusion hierarchies, the addition of new facts to the network creates a vast array of other new facts that are suddenly known to be true. For example, suppose one knows about 100 different birds and learns that birds have hollow bones. Moving down the ISA hierarchy, one can attach the fact “has hollow bones” to all 100 subcategories of birds (and to all subtypes of these subcategories, and so on). This possibility is called forward chaining inference, because one makes inferences at the time that the information is added. The advantage of forward chaining inference is that retrieving a new fact is fast in the future: If I exhaustively make the inference that all subclasses of birds (and all subclasses of these subclasses) have hollow bones, I can quickly retrieve this fact about any bird. The cost, of course, is that it may take a long time to attach this fact to every subclass of birds, and each time I learn that a new object is a bird, I must add many new facts to its representation.3
If the cost of forward chaining inference is too great, the cognitive system could delay inferring a particular fact until it is needed. In this situation, if someone asks whether robins have hollow bones, the system must first check to see whether the fact is known directly. If not, ISA links can be followed, checking at each supercategory to see whether this fact can be inherited. The process stops when the fact of interest is found, or when the top of the hierarchy is eventually reached. This type of inference is called backward chaining inference. The advantage of backward chaining inference is that there is very little cost to learning a new fact, but later processing may take a long time, because much information about objects must be derived rather than being stored directly with the objects for which it is true. Many artificial intelligence (AI) proposals for large knowledge bases use some combination of forward chaining and backward chaining inference (Lenat & Guha, 1990).
Processing in Semantic Networks
To this point, I have talked primarily about the structure of semantic networks without regard to how information is processed in them. In early proposals about semantic networks, the central form of processing involved finding intersections between concepts in the network. Intersections can be found by using a marker-passing algorithm. A marker-passing algorithm is like sending scouts through new terrain, where each scout places a distinctive tag (called a marker or an activation tag) at each place he or she visits. These scouts begin at the nodes for the concepts in the sentence being processed. At each processing cycle, the scout at a given node visits every node connected to the node where he or she is, places a marker at each node, and checks to see whether a scout for another concept has placed a marker there already. On subsequent cycles, markers are passed recursively to more distant nodes through the links from the nodes reached on the first pass. The search is halted when a node receives markers from both initial concepts (i.e., when the scout reaches a node that already has a marker from the other concept) or after some specified time elapses (i.e., the scouts get tired and want to return home). The path between the nodes is used to describe the relationship between the concepts.
For example, imagine that someone with the semantic network in Figure 4.2 was processing the sentence “A vampire is like a hematologist.” Processing this sentence requires figuring out how a vampire is like a hematologist. Initially, the vampire and hematologist nodes are activated, and each sends activation to nodes to which it is connected. Vampire sends activation to Cape, Blood, and Monster. The fact that each of these nodes is connected to Vampire with a different link does not matter. Likewise, Hematologist sends an activation tag to Doctor, Lab Coat, Water, and Blood. The intersection of activation tags for Vampire and Hematologist at Blood leads the program to analyze the links to the intersected concept. A system using this network would conclude that a vampire is like a hematologist in that the former drinks blood and the latter studies blood. Semantic network models assume that the process of finding intersections through passing markers is a central mechanism in sentence comprehension.
Sending an activation tag across a link is thought to take some amount of time (Collins & Quillian, 1972). It generally takes longer to search along a long path than to search along a short path. The amount of time needed to traverse a link is not assumed to be constant for all links, however, and in some cases it may be possible to traverse a long path with links that transmit information more quickly than to traverse a short path with links that transmit information slowly. In particular, links that are important or criterial for a concept are assumed to allow shorter traversal times than do links that are less important or less criterial. Sending an activation marker across a link is assumed to facilitate subsequent processing along that link and other links with the same label. That is, activating an ISA link is assumed to facilitate processing of class-inclusion relations, even those between different concepts from the ones processed initially.
Semantic networks have been used as the basis of models for explaining priming effects in semantic memory. Priming occurs when processing of one concept affects the processing of a subsequently presented concept. Priming generally involves a facilitation of processing, although under some circumstances, it can actually involve an inhibition (e.g., Neely, 1976). A common finding in psychological experiments is that a brief presentation of a word facilitates the recognition of a word with a related meaning. One commonly used technique for demonstrating priming of concepts is lexical decision, in which a subject is shown a prime and then a string of letters and is asked to say whether the string of letters is a word. In this task, people shown the word “nurse” are faster to verify that the string DOCTOR is a word than are people given a neutral prime like a string of asterisks (Meyer & Schvaneveldt, 1971; Meyer, Schvaneveldt, & Ruddy, 1975). Another common finding is that processing a particular aspect of one stimulus can faciliate processing that same aspect for another stimulus. For example, processing the sentence “Fire engines are red” can facilitate later processing of the sentence “Grass is green.” This facilitation may reflect activation of the “color of” link in a semantic network (Collins & Loftus, 1975).
In a semantic network, priming has a straightforward explanation. On an experimental trial, a subject may briefly see the word “nurse”. At the presentation of the word “nurse,” the concept node for nurse is activated in the semantic network. Activation tags are then sent to the nodes connected to nurse, and tags are sent from those nodes to the nodes to which they are connected. As discussed previously, the speed of transmission of the tags depends on the strength of the connection. This spread of activation continues until the second target string of letters (e.g., DOCTOR) is presented. It is assumed that if the concept node for doctor has been activated through its connection to the concept nurse (either directly through an associative link or indirectly through a connection to common nodes), then the string DOCTOR is recognized more quickly than if the node was not activated. Presumably, a neutral prime (like a string of asterisks) does not pass an activation tag to doctor. Thus, the semantic network model predicts that recognition of the word doctor is faster following a semantically related prime than following a neutral prime.
Testing the Basic Proposal
Early proposals about semantic networks spawned a flurry of research in cognitive psychology to test their psychological plausibility. This empirical work focused on several central aspects of these models. As discussed earlier, semantic networks were originally posited as knowledge representation systems suitable for explaining phenomena in text comprehension. Because text comprehension is a difficult business, many experimental studies focused on narrower assumptions of the model. Studies focused on the basic claim that activation spreads through a network and thereby facilitates the processing of related concepts. In addition, many studies have examined the claim that activation takes more time to spread over longer paths than over shorter paths. Research has also focused on the assumption of efficiency and has examined the extent to which information is stored redundantly in a semantic network. I review some of this evidence in this section.
I have already mentioned that primes can facilitate the recognition of semantically related words. The relations between the words that prime each other can be rather broad: Pairs like doctor and nurse are associates. Priming is also obtained for concepts on a taxonomic hierarchy: Robin primes bird. The link between a category and its parent taxonomic category is typically stronger than is the link between the parent and its child. Thus, robin primes bird more than the reverse (Collins & Quillian, 1972). The relation between prime and target need not be semantic to get facilitation: Words that sound alike can also prime each other (phonological priming) as can words with letters in common (orthographic priming). To capture these latter results, a semantic network model must be extended to incorporate aspects of the words themselves in addition to relations between concepts.
Studies of sentence verification have made clear the need for links that vary in their strength. Imagine a network that is strictly hierarchically organized. A simple network of terms connected by ISA links is shown in Figure 4.3. Here, robin, sparrow, chicken, and penguin are all instances of birds, and all are connected to the bird node through ISA links. If all links have the same strength, it should take the same amount of time to pass an activation tag from the ISA links connecting each instance of bird to the bird node, without any difference in speed to verify that various instances of birds are in fact birds. In contrast to this prediction, category verification studies have often found a relationship between the typicality of an instance and the speed with which it is verified as being a member of a category (Rips et al., 1973). For example, robin (a typical bird) is verified as an instance of the bird category faster than is chicken (an atypical bird). For these data to be explained by a network model, it is important to assume that links have different strengths.
Studies of sentence verification also make clear that networks are not designed for optimal conservation of storage space. Again, consider the sample network in Figure 4.3. All instances of birds are connected directly to the bird node and indirectly to the animal node through its connection to bird. All instances of mammals are connected to the mammal node directly and to the animal node indirectly through its connection to mammal. With this strict hierarchy, it should take less time to verify that an instance of the category mammal is a mammal than to verify that it is an animal and less time to verify that an instance of the category bird is a bird than to verify that it is an animal. In contrast to this prediction, Rips and colleagues (1973) found that it actually takes more time to verify that most instances are members of the category mammal than to verify that they are instances of the category animal (see also E. E. Smith et al. [1974]; Collins & Quillian [1972]).4
To account for these findings with a model that uses a semantic network, assumptions about minimal storage must be relaxed. One possible account is to connect concepts to more than one more general (i.e., superordinate) category by using ISA links, rather than connecting them only to the category immediately more general. For example, the bear node could be connected by an ISA link to the mammal node and by a second ISA link to the animal node. A second possibility is to adopt a solution similar to the one posited by the featural model of E. E. Smith et al. (1974) described in chapter 3. In that model, objects were described as sets of features, and the category verification process consisted of a comparison of the features of object pairs, in which the initial comparison involved all features and later comparisons involved only core features. In a semantic network, concepts have links to many nodes corresponding to features true of those concepts. Initially, when activation spreads through this network of features, related concepts become highly activated and potentially yield fast responses. If the activation falls in an intermediate range, the search can be restricted to ISA links, similar to focusing on core features. In this respect, the feature model and a semantic network model are nearly indistinguishable (see Collins & Loftus [1975] for a similar discussion).
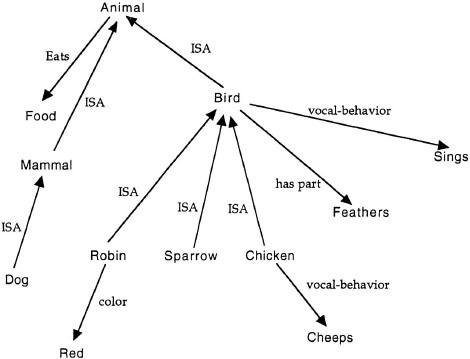
FIG. 4.3. Sample semantic network with knowledge about birds and animals.
Finally, some findings seem less compatible with the assumptions of semantic networks discussed so far. These findings involve the damping of activation to a concept, also called inhibition. In one classic study, Neely (1976) found that if the prime was semantically unrelated to the target and the interval between the presentation of the stimulus and the presentation of the target letter string was long, the time to respond that the string was a word in a lexical decision task was actually longer than is observed for a neutral prime. Presenting the prime hockey could inhibit responses to the string DOCTOR in a lexical decision task. This finding suggests that semantically unrelated concepts are actually driven below their resting level of activation. Explaining findings of inhibition requires additional mechanisms beyond those discussed so far. In particular, there must be some way to decrease the activation of a node.
As for the initial goal of language comprehension, it is unclear how a spreading activation model can account for concept access in online language comprehension. A classic study by Swinney and Hakes (1976) provided a useful illustration. In this study, researchers read aloud to participants a passage in which there was an ambiguous word but the passage strongly biased one reading of the word. For example, the passage might read: “Rumor had it that for years, the government building had been plagued with problems. The man was not surprised when he found several spiders, roaches and other bugs in the corner of the room.” When the ambiguous word (bugs) was heard, a string of letters was presented for a lexical decision task. The letter string was either related to the contextually biased meaning (e.g., ant), related to another meaning of the ambiguous word (e.g., spy), or unrelated to the ambiguous word (e.g., sew). When the lexical decision task occurred immediately after the ambiguous word, both words related to the contextually biased meaning and to the other meaning of the ambiguous word were facilitated relative to the unrelated word. In contrast, when the lexical decision task was presented three syllables after the ambiguous word, only the contextually related meaning of the ambiguous word was primed. Thus, selection of the correct word sense also seems to inhibit the spread of activation through the semantic network for unrelated concepts. Accounting for online language comprehension data like these is also likely to involve mechanisms that inhibit all meanings of a word except the one selected.
To summarize, the initial formulation of semantic networks was used as the basis of models of text comprehension. In these models, it was assumed that finding intersections among concepts in the network could be used to determine the meaning of a sentence. Of course, sentence meaning involves more than just finding intersections between known concepts. In many cases, language is used to provide new information about a situation, and the sentence constructs new knowledge, rather than just stating relations among known concepts. Additional processing mechanisms are required to allow semantic networks to model this situation.
One place in which semantic networks have been used successfully is in models of the activation of concepts by language. Many studies have demonstrated that one concept can facilitate the access to a related concept. Semantic network models use the process of spreading activation to model the way that one concept can activate another. Although the simple use of markers to pass activation from one node to another has had some success modeling lexical priming, additional mechanisms are needed to model the fine details of processing. I turn to some extensions of the basic processing assumptions in semantic networks in the next section.
Extending Network Assumptions: Activation and Activation Tags
Collins and Loftus (1975) made many changes in the basic assumptions of the network model that laid the groundwork for significant work to follow. In particular, they assumed that activation was spread through the network in a manner similar to the connectionist models described in chapter 2. On this view, activation is a continuous value possessed by a node rather than a marker indicating that the node has been activated. Activation from one node is passed to neighboring nodes via links. The links retain a criterial weight as Collins and Quillian (1972) assumed, but now an activated node raises the activation level of nodes to which it is connected as a function of both the activation of the initial node as well as of the strength of the links between nodes. It is further assumed that the activation of a node decreases over time, so that if the source of activation of a node is removed, the node’s activation gradually decreases to a baseline level.
An example of the spread of activation in a network with continuous levels of activation is shown in Figure 4.4. Here, the ovals are nodes, and the arrows are links. The thicker the arrows, the stronger the connection between nodes. Activation at a given node is shown by the darkness of the oval. Figure 4.4A depicts the state of a network presented with the sentence “A vampire is like a hematologist.” The nodes for vampire and hematologist have activation, but the other nodes in the network do not. At the next time step, shown in Figure 4.4B, activation has spread from the active nodes to those it is connected to. Because the ISA links in this figure are assumed to be stronger connections than are the other links, the monster and doctor nodes are more strongly activated than are the lab coat, water, and cape nodes. The node representing blood is strongly activated because it is connected to both the vampire and hematologist nodes and thus receives activation from both sources. If this example were carried further, the fluid node would also begin to get activation from both the water and blood nodes. In addition, the activation levels of each node would begin to decay. In this way, only nodes that receive activation from many sources tend to remain active. The other nodes get a brief boost of activation and then decay to their resting state (shown in white in Figure 4.4).
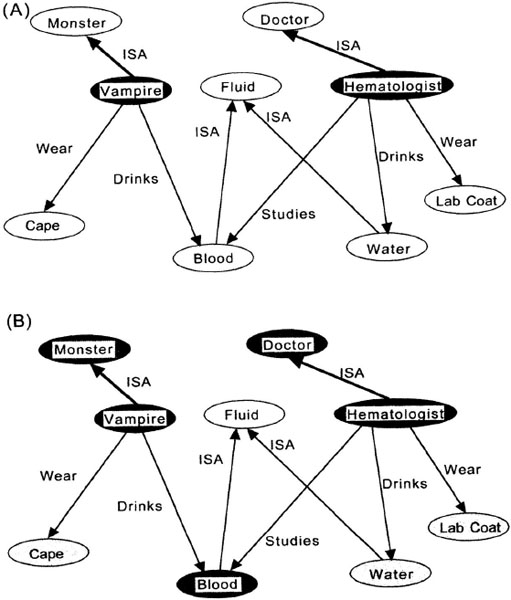
FIG. 4.4. Example of the spread of activation through a semantic network with continuous levels of activation. The strength of connection is shown by the thickness of the arrows. The degree of activation of a node is shown by the darkness of the node. A: The state of the network just after exposure to the sentence “A vampire is like a hematologist.” B: The state of the network as activation begins to spread through it.
This network model emphasizes the activation of nodes and the strength of connections between nodes. Although there are still labels on the links between nodes, they are less important to the model than they were under the earlier assumptions. This change reflects a shift in the emphasis of these models from models of text comprehension to models of priming in semantic memory. For this model, it is assumed that the greater the degree of activation of a node, the easier to access the concept conveyed by that node in the future. Facilitatory priming reflects that the activation of a node is greater following some priming stimulus than following some neutral prime.
J. R. Anderson (1983b) also adopted a network model in which nodes have a level of activation measured on a continuous scale. Like the proposal by Collins and Loftus, Anderson’s model assumed that activation spreads across links to other nodes and that the links have different connection strengths. Anderson explicitly thought of this network as the long-term memory structure of an individual, so that short-term or working memory consisted of those units with positive activation. Short-term memory is the set of concepts that are active at any moment and are available to be used by cognitive processes that are currently operating.
Because the activation level of each element decays over time in the absence of continued activation from other units, there is a limited amount of activation in the network at any given time. Thus, working memory has a limited capacity. More recent work has assumed a limit to the amount of activation that can be provided by active sources in memory, and thus a limit to the capacity of working memory (J. R. Anderson, 1993; J. R. Anderson, Reder, & Lebiere, 1996). J. R. Anderson (1983a) clearly maintained that working memory should not be confused with the amount of information reported in short-term memory tests. In his classic paper, Miller (1956) found that people can report only about seven independent bits of information in short-term memory tasks. Anderson suggested that the amount of information reported is a function of both the active information in working memory as well as the interaction of the information with processes that report it.
The continuous activation version of semantic networks makes a number of predictions that can be tested. One particularly interesting prediction is the fan effect. Fan is defined as the number of nodes connected to a given node in memory. The more that activation from a single node must be spread out (i.e., fanned out) among other nodes, the less of an impact this node has in activating other nodes. In empirical studies, fan is typically varied by varying the number of facts that people learn about different items. For example, if I learn one fact about John Doe (say, that John Doe eats ice cream) and two facts about Richard Roe (say, that Richard Roe likes the New York Giants and that Richard Roe owns a dog), the fan for John Doe is lower than the fan for Richard Roe. Anderson suggested that the fan of an element affects the element by dividing the activation flowing from the unit among the various links that emanate from it. Thus, if a node with fan one sends an amount of activation A down its link, a node with fan two sends activation A/2 down each link. More generally, the amount of activation going down the links coming from a node is A/f, where f is the fan of that node. Thus, the higher the fan of a node, the less activation it passes to nodes to which it is connected and the longer it takes to retrieve and use these nodes in subsequent processing.
Consistent with these predictions, a variety of findings have suggested that high fan items take longer to respond to than do low fan items. J. R. Anderson (1983a) described an experiment in which participants studied a set of subject–verb–object sentences (e.g., “The cat ate the pizza”). The objects in the sentences always had a fan of one (i.e., they were unique), whereas the subjects and verbs differed in their fan (i.e., they could appear in many sentences). The only constraints on the stimulus materials were that a particular subject and verb appeared together only once and the subject and verb in a sentence had the same fan. Participants were then given two tests. In the recognition test, they saw a sentence and were asked whether it appeared in the memory set. In the recall test, participants were given the subject and verb and were asked to produce the object. The data are shown in Table 4.1. In both tasks, the latency to respond increased with the fan of the subject and verb. This effect was much stronger in the recall task, for which participants could rely only on the subject and verb, than it was for the recognition task, for which participants could focus on the unique object. These data provide clear support for the predicted fan effect.
As many examples in this chapter demonstrate, the assumptions of semantic network models have often been tested with response time tasks that probe the amount of time needed to respond to questions. Theories of working memory must also account for the way people perform in complex situations. Such studies have often been carried out using a dual-task paradigm in which people are asked to carry out two tasks at the same time and the difficulty of one or both tasks is varied. Subjects’ performance on both tasks is examined as a function of the difficulty of the tasks.
J. R. Anderson and colleagues (1996) used a dual-task paradigm to test the proposal that working memory is limited by a cap on the amount of activation that can spread through a network at any time. In their study, one task involved solving simple algebra problems, and the other task involved remembering a set of digits. The idea was that making the algebra problems more difficult to solve and increasing the working memory load (by asking participants to remember more digits) would adversely affect people’s performance on the algebra problems. Subjects’ data would then be compared to the performance of a computational model (described later).
TABLE 4.1
Demonstration of the Fan Effect

Note. Fan refers to the fan of subjects and verbs in the sentences. From J. R. Anderson (1983a). Copyright © 1983 by Harvard University Press. Reprinted with permission.
In the study, the easy problems required only one transformation, as in solving the equation:
![]()
for x. The difficult problems required two transformations, as in solving the equation:
![]()
for x. Subjects were asked to solve these problems while remembering a set of digits. On each trial, the subject was asked to remember either two, four, or six different digits. People were able to remember the shorter (two- and four-digit) strings of numbers correctly with high accuracy, although their accuracy on these strings was higher when they were solving easy problems than when they were solving hard ones. There was a sharp drop in recall performance for the long (six-digit strings). In the equation-solving task, subjects accurately solved the easy problems regardless of the length of the string they were supposed to remember. For the hard problems, solution accuracy was uniformly worse than for the easy problems, and subjects had particular difficulty solving the hard problems when they had to remember long strings of numbers.
J. R. Anderson et al. were able to fit these data by using a version of the ACT-R model. The ACT-R model has two components. One is a semantic network that spreads activation between nodes connected by links, with a strict limit on the amount of activation that can arise from elements that are attended to. That is, working memory is limited by placing a cap on the amount of activation that can flow through the network. The second part is a production system, which allows the model to carry out steps in solving a problem by following rules. (I discuss production systems in more detail in chap. 5.) The purpose of the production system is to carry out the steps needed to solve algebra word problems and to access and output the set of numbers for the recall task. Anderson et al. were able to model subjects’ data in this task by using ACT-R, a result suggesting that working memory can be conceptualized as the activation in a semantic network and that the limit on working memory is a limit on the amount of activation that can flow through the network.
There are two reasons that both a spreading activation mechanism and a rule-following mechanism are required in ACT-R. The spreading activation mechanism provides an efficient mechanism for searching through an established conceptual structure, but a complete reasoning system needs to be able to construct new knowledge. In addition, it needs to be able to carry out complex processes like solving algebra problems. Both processes require that behavior be guided by the information that is active. (In chap. 5, there is an extended discussion of production systems making clear that the rule carried out at any given moment is a function of what is currently active in memory.)
Some Critiques of Semantic Networks
I have discussed semantic networks that can be characterized as networks consisting of nodes and links. The nodes are labeled with the concepts they represent, and the links have labels representing relations that hold among concepts.5 I have focused attention on simple modes of processing in these networks in which activation is spread through the network. This spread of activation can be used to search for paths connecting concepts, or it can be used to model the activation of concepts during language comprehension. I have also assumed that complex processes (like production rules) can be added to a semantic network, but these processes go beyond the scope of my focus in this chapter.
One criticism of semantic networks formulated in this way is that the links are used inconsistently in the network (Woods, 1975). For example, in Figure 4.2, some links represent class inclusion relations. Others represent actions that an agent participates in (e.g., a vampire drinks blood). Yet other links represent adjectival relations (e.g., the color of blood is red). It is true that each of these is a relation and that the links play the role of relating pairs of nodes, but the links are not uniform in the types of relations that they represent. Thus, a semantic network representation seems to gloss over distinctions among types of relations that a representational system may want to make.
Another criticism of semantic networks is that they are primarily concerned with relations among elements in the representing world rather than the connection between the representing world and the represented world (Johnson-Laird, Hermann, & Chaffin, 1984). A key characteristic of semantic networks is that processing uses existing elements in a network that is often assumed to contain what is stored in long-term memory. This assumption is problematic, because many aspects of meaning depend on understanding the outside world. For example, Medin and Shoben (1988) showed that people often use their knowledge of the world when interpreting combinations of concepts. Many people thought a wooden spoon was large, even though spoons are not typically thought of as large, and wooden things are not typically thought of as large. Instead, people seemed to think of specific instances of spoons made of wood and to determine that they are large (relative to other spoons). A semantic network would have difficulty with conceptual combinations like this, because it has extensive information about the relations among concepts in the network but it has no mechanisms for processing information about the represented world. Thus, in cases where there are emergent properties of combinations (like large for wooden spoons), a semantic network is likely to run into problems.
Finally, as discussed earlier, semantic networks tend to be static; they are taken to be the set of concepts already possessed. Most of the effort in developing processes that act on semantic networks has focused on ways of using the networks to access information or to process paths between concepts. Much less work has focused on ways of constructing new semantic knowledge during language comprehension. This gap is unfortunate, because much of what people do when they comprehend language is to construct new connections between concepts. They read things to learn new information and not simply to verify facts that they already know. It is important to note that processes that construct semantic networks are not incompatible with the idea of semantic networks as a type of representing world, but these constructive processes have typically not been studied in the context of semantic networks.
It must also be emphasized that many limitations of semantic networks are real if one assumes that the primary processing mechanisms operating on them involve a spread of activation and an analysis of paths between nodes. In fact, the basic assumptions described in this chapter can be augmented in many ways (see Johnson-Laird et al., 1984, for a discussion of some modifications). These extensions turn semantic networks into the kinds of structured representations I discuss in chapters 5 to 7.
INTERACTIVE ACTIVATION AND PARALLEL CONSTRAINT SATISFACTION MODELS
Researchers have also applied the spreading activation mechanism used in semantic network models in models of other processes ranging from letter recognition to analogy to person perception to theory change in the history of science. These models can be grouped under the heading of interactive activation models, using the moniker established by McClelland and Rumelhart (1981) in their influential model of letter recognition. These models derive their power from using spreading activation to satisfy several simultaneous constraints on a problem at once. Hence, they have also been called parallel constraint satisfaction models.
Such models are one type of localist connectionist model. In chapter 2, I discussed distributed connectionist models in which the representations consist of patterns of activation across a set of units and no individual unit can be identified as a representation of a specific element in the representing world. In a localist connectionist model, the individual nodes in the network do represent specific things in the represented world. The links between nodes are set up to enforce constraints believed to hold in the domain of the model.
The semantic networks described in the previous section were developed as computer models of language comprehension (Collins & Quillian, 1972; Quillian, 1968). As a result, the terminology for describing these networks was borrowed from computer science and mathematics (e.g., nodes in a network connected by links). Localist connectionist models owe some of their heritage to semantic networks, but they also are tied to neuroscience. Thus, these models borrow terminology from both camps. Links between nodes with a positive weight are often called excitatory connections. Parallel constraint satisfaction networks take an additional type of link from neuroscience—the inhibitory connection. An inhibitory connection between nodes has a negative weight so that high levels of activation of one node strongly inhibit (or decrease) the activation of a second node. In the rest of this chapter, I discuss the basic properties of interactive activation models and describe a few representative models as examples of the strengths and weaknesses of this approach.
The Interactive Activation Model of Letter Perception
The ability to recognize letters is a key perceptual ability underlying the capacity to read. Intuitively, letter recognition may seem simply a function of combining low-level features of letters into larger groups that allow one letter to be distinguished from another. For example, as shown in Figure 4.5, one can think of the letter P as one set of features, the letter B as another set of features, and the letter R as yet another set of features. These features may overlap to some degree, but the task of identifying a letter is simply to find the right mapping between the features in the stimulus and the letters.
Unfortunately, data from psychological studies have shown that letter recognition is not that simple: Many phenomena do not fit neatly into such a simple featural view. One critical finding is the word superiority effect, which demonstrates that letters are identified more quickly in the context of words than out of context. Thus, although words may seem to increase the processing load and make letter recognition more difficult, it is actually easier to recognize a letter when it is embedded in a word than to recognize it in isolation. This advantage extends to pronounceable nonwords, strings of letters that could be words but are not, like blick or frin.
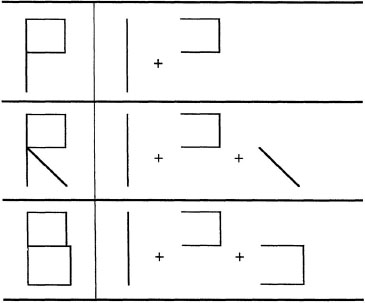
FIG. 4.5. Stick figure letters similar to those used in McClelland and Rumelhart’s (1981) interactive activation model.
To account for data like these, McClelland and Rumelhart (1981) proposed an interactive activation model that uses many of the mechanisms of spreading activation discussed in this chapter. The model, which is illustrated in Figure 4.6, consists of a network of nodes organized into three layers: features, letters, and words. Thus, each layer has nodes that represent properties of the same type. The feature layer consists of nodes representing features of letters. There are separate sets of features for each letter in a given position in a word. The original model recognized four-letter words and so had four sets of feature nodes. The letter layer consists of the 26 letters of the English alphabet. Again, there are four sets of letters, one for each position in the word. Finally, the word layer consists of a lexicon of four-letter words. The original model had 1,179 four-letter English words in its lexicon.
Just as in the semantic network models described earlier, the nodes in the interactive activation network are connected via links that allow activation to be passed from one node to another. The feature nodes are given connections with positive weights (excitatory connections) to letters that contain the feature, and connections with negative weights (inhibitory connections) to letters that do not contain the feature. Thus, the presence of a feature promotes the recognition of letters that contain the feature, and inhibits the recognition of letters that do not contain it. For example, in Figure 4.6, there are excitatory connections between the feature horizontal line on the top and the letters A, T, G, and S, and an inhibitory connection between that feature and the letter N.

FIG. 4.6. Interactive activation model. Arrows represent excitatory connections between nodes, and circles represent inhibitory connections between nodes. From J. L. McClelland and D. E. Rumelhart (1981). Copyright © 1981 by American Psychological Association. Reprinted with permission.
In the letter layer, there are inhibitory connections between the letters at the same position of the word. These inhibitory connections reflect that letters are mutually exclusive at each position in a word. If the first letter is determined to be an A, it has also been determined not to be a G. The letter nodes are also connected to the word nodes. There are excitatory connections between each letter node and nodes for words in the lexicon with the letter at that position. There are inhibitory connections between each letter node and nodes for words in the lexicon without the letter in that position. For example, the node for an initial letter A has an excitatory connection to the node for the word ABLE, but an inhibitory connection to the word TRAP. In the word layer, nodes for each word have inhibitory connections to other words. For the letter layer, this pattern reflects that a string of letters corresponds to only a single word. Finally, of critical importance to this model is the fact that the connections between nodes can pass activation in both directions (i.e., they are two-way connections). Thus, letters pass activation to words to assist in the recognition of words, but words also pass activation back to letters and thereby assist in the recognition of letters.
Processing in the model begins by activating the features of a presented word and then continues in time slices that update the activation of nodes in the network. At each step, the activation of a node consists of any external activation that the node receives (which only happens for feature nodes) as well as the inputs to the node from other nodes in the network. These inputs are determined by summing the activation of nodes connected to each node, modified by the weight of the connection between nodes. In this way, processing begins by passing activation from the features presented to the letter layer. At subsequent time slices, activation is passed from the letter layer to the word layer (as well as back to the feature layer). Once word nodes are activated, they begin to spread activation back to the letter layer, and thereby each layer of the network can affect processing in other layers. At some point, a letter reaches a level of activation high enough to cause it to be recognized. The amount of time that the network processes a particular situation is assumed to be related to the number of cycles in which the weights on nodes are updated.
The interaction between nodes allows the model to explain data from studies of letter recognition. Because the letter layer receives input from both the feature layer and the word layer, letter recognition is a function of both the features presented as well as the words that the model knows. Even strings of letters that are not actual words but are close to actual words receive some extra activation from the word layer, as a function of the activation of words that are close to the string of letters provided. The model is also able to deal with degraded initial input. If ink spilled on a page and caused some features to be obscured, the missing features can be “filled in” by allowing the model to guess the word spelled by the string of letters and then to feed activation back to the letter layer and from there to the feature layer.
The performance of this model allows several constraints on letter recognition to be used simultaneously. The data from studies have suggested that letter recognition is influenced by both the perceptual features of the word presented and the known words in the lexicon. Letter recognition is facilitated by having features consistent with the letter in the visual input (hence the excitatory connection between the feature nodes and letter nodes for letters containing the feature) and by the presence of words that contain the letter (hence the excitatory connection between word nodes and the nodes for letters contained in the word). Finally, it is assumed that both letter recognition and word recognition are competitive, and so there are inhibitory connections between elements in a level.
The network itself is an instantiation of a theory of letter and word recognition, not a theory by itself. That is, the constraints on letter and word recognition were determined in advance by theorists, and then the network was constructed in accordance with the proposed constraints. As an instantiation of this theory, the connection weights in the network are positive when the influence is assumed to be positive and negative when the influence is assumed to be negative. There are no mechanisms for fine control over the constraints as they operate. A constraint that is assumed to be strong can be given a large connection weight, and a constraint that is assumed to be weak can be given a small connection weight, but there is very little temporal control over when particular constraints become active. The only sequencing of constraints in the interactive activation model is that activation starts in the feature nodes, and it takes a few time slices before activation in the word layer can feed back to the letter layer. In general, however, constraints do not become active only in specific circumstances. Rather, all constraints are mixed together, and activation is allowed to pass through the network.
Other Parallel Constraint Satisfaction Models
This general parallel constraint satisfaction approach has been applied to a number of different problems in psychology. In this section, I illustrate the use of these models with two additional examples. One is a model of explanatory coherence (Thagard, 1989), and the second is a model of person perception based on the principles of the explanatory coherence model (Read & Marcus-Newhall, 1993). These two examples are designed to highlight both the strengths and the weaknesses of the parallel constraint satisfaction approach. (See Holyoak & Thagard [1995] for a description of several other parallel constraint satisfaction models.)
Explanatory Coherence. Philosophers and psychologists have speculated about the factors that make a particular explanation a good one. In the context of the history of science, Thagard (1989) proposed seven principles of coherence which he incorporated into a parallel constraint satisfaction model of causal explanation. The principles he proposed are symmetry, explanation, analogy, data priority, contradiction, acceptability, and system coherence. Symmetry means that if one statement is consistent with another, the second is consistent with the first. Likewise, if one statement is inconsistent with a second, the second is inconsistent with the first. Explanation implies that the set of propositions in an explanation must all be mutually coherent and that fewer explanatory postulates are better than many. Analogy asserts that analogies are useful for generating explanations. Data priority requires that descriptions of data be treated more strongly than are explanatory postulates. Contradiction means that explanatory postulates should not contradict the things being explained. Acceptability asserts that explanations explaining a broad range of facts are better than explanations explaining a narrow range of facts. Finally, system coherence suggests that the coherence of an explanation arises from the coherence of its parts rather than as an emergent property of the explanation as a whole. Clearly, these constraints need not all point in the same direction. One explanation may be broader than another, but the second may involve fewer postulates than the first.
To model the simultaneous influence of multiple constraints, Thagard implemented this view of explanatory coherence in a computer model, ECHO, which sets up a constraint satisfaction network. The network used by the model consists of facts to be explained and explanatory hypotheses that do the explaining. For example, Thagard (1989) described a network that was given some facts known when the oxygen and phlogiston theories were being debated as well as propositions that described the two theories. The network was created with nodes corresponding to each piece of evidence; these nodes were sources of activation in the network (as the feature nodes in the interactive activation model described earlier were sources of activation). Facts were sources of activation, because the explanatory coherence model assumes that facts are of paramount importance in explanation. The postulates of the oxygen theory were given excitatory connections to the facts they explained, because a theory should explain facts. In addition, excitatory connections were placed between all the postulates of the oxygen theory, because postulates of a single explanation should be mutually supportive. For the same reasons, the postulates of the phlogiston theory were given excitatory connections to the facts they explained and to each other. In addition, inhibitory connections were placed between postulates of the phlogiston theory which contradicted known facts, because a good explanation should not contradict known facts. Finally, inhibitory connections were placed between postulates of the oxygen theory and postulates of the phlogiston theory, because explanation is essentially a competition among competing hypotheses.
The network was constructed so that the oxygen theory explained more facts than did the phlogiston theory and only the phlogiston theory contradicted known facts, but the phlogiston theory involved fewer postulates. Thus, the constraints on explanatory coherence were not all satisfied best by the same explanation. In the ECHO model, the amount of activation emanating from a node representing part of an explanation is divided by the number of hypotheses involved in the explanation to implement a preference for explanations with fewer postulates. In the simulation, activation is divided in fewer ways across the postulates of the simpler phlogiston theory than across the postulates of the more complex oxygen theory. When activation is allowed to spread through the network until it settles, the postulates of oxygen theory have high activation levels, and the postulates of phlogiston theory have low activation levels. This result is consistent with the historical fact that the oxygen theory was accepted as a better explanation of the available data than was the phlogiston theory. This run of the simulation demonstrated that a large broad theory consistent with the available data and not contradicting any of them was preferred to a smaller, narrower theory that did contradict some available data.
This example demonstrates that a constraint satisfaction network can be used to implement multiple constraints being satisfied in parallel, but it is not clear that ECHO can be taken as a psychological model of explanation. The particular set of facts described here is unlikely to be a representation that any individual scientist was likely to have had. Rather, these facts are ones that the scientific community at the time had available. Furthermore, explanation (particularly in science) is an active process in which new facts are searched for precisely because of the explanation being constructed. In contrast, a parallel constraint satisfaction model is given full information and has no capacity to search for new information. Thagard’s model of explanatory coherence is probably best viewed as a description of the forces that lead a particular explanation to be taken as coherent, rather than as a model of the psychological processes that an individual goes through when deciding on an explanation to accept.
Person Perception. Although the ECHO model falls somewhere between psychology and philosophy of science, the style of model embodied in ECHO, as well as some of its specific proposals, have been used in psychological models. In particular, they have formed the basis of a research program on how people evaluate new individuals that they meet. Much research in social psychology has focused on how people determine the personality characteristics or traits of new people. Such dispositional inferences are considered helpful for deciding how to interact with an individual, for explaining past behavior, and for predicting behavior in new situations. One model of the process of making dispositional inferences draws heavily on Thagard’s work on explanatory coherence (Read & Marcus-Newhall, 1993; Read & Miller, 1993).
According to this view, dispositional inferences are made in order to provide a coherent explanation of a person’s behavior. Read and Marcus-Newhall (1993) condensed Thagard’s seven constraints into four central constraints on coherence in social inference: breadth, simplicity, recursive explanation, and competition. Breadth suggests that explanations accounting for many facts are better than explanations accounting for few facts. Simplicity implies that the fewer assumptions required to construct an explanation, the more it should be preferred. Recursive explanation states that an explanation is better if its assumptions also have explanations than if its assumptions are unsupported. Finally, competition suggests that explanations compete and that the presence of a good explanation weakens the support for other explanations of the same set of facts.
One reason that parallel constraint satisfaction models are popular in social psychology is that they provide a mechanism for implementing classic theories. For example, Heider (1958) suggested that forces in social relations are resolved to achieve a balanced state in which there is no pressure for change. Heider described a scenario that gives an example of an imbalance:
Bob thinks Jim [is] very stupid and a first class bore. One day, Bob reads some poetry he likes so well that he takes the trouble to track down the author in order to shake his hand. He finds that Jim wrote the poems. (p. 176)
(4.3)
In this situation, opposing forces are at work. On the one hand, Bob thinks Jim is a bore, but on the other hand, he has just discovered that Jim is the author of poetry that he likes. Somehow, he must resolve this discrepancy to bring his opinions into “balance.” Subjects given a passage like this typically either change the value of the poetry (e.g., it wasn’t so good after all), or they change Bob’s opinion of Jim (e.g., he wasn’t so boring after all). The intuition underlying balance theory is strong. There does seem to be an opposition of forces in this example. Nevertheless, balance theory (and other consistency theories; see Read & Miller, 1993) fell out of favor with psychologists, because they lacked good mechanisms for describing how forces were balanced. One appeal of parallel constraint satisfaction models is that they provide a mechanism for implementing models with a strong kinship to these classic theories.
The model developed by Read and his colleagues is meant to be taken as a model of the psychology of social explanation. The facts in this domain consist of behaviors exhibited by individuals. The explanatory postulates are possible personality traits that may define the people being observed as well as their motivations and goals. In the network model, observed behaviors as well as goals, motivations, and personality traits are represented as nodes in a constraint satisfaction network. Traits, goals, and motivations are given excitatory connections to observed behaviors that they explain and inhibitory connections to observed behaviors that they contradict. Possible behaviors can also be added to the network by using background knowledge about the relationship between traits and observed behaviors. Elements of competing explanations are linked via inhibitory connections. Finally, a preference for simpler explanations is implemented in the network by dividing the activation of a node that forms part of an explanation by the number of elements (e.g., traits, goals, and motivations) involved in the explanation.
As an example, I can create a network to resolve the imbalance in Example 4.5. This network is shown in Figure 4.7. The basic facts that were in conflict were that Bob thought Jim was boring yet Jim wrote good poetry. These facts are connected by an inhibitory link, because they are inconsistent. There are (at least) two possible inferences that can help resolve this dispute. One is that Jim’s poetry is not so good, and the other is that Jim is not boring. Each of these inferences is consistent with one fact and inconsistent with another. The two inferences are mutually inconsistent, and so they get an inhibitory connection. Finally, people may have causal beliefs about social interactions. One such belief shown in the figure is that poetry is a good indicator of the sensitivity of an individual. This belief may be consistent with the inference that Jim is not boring and inconsistent with the inference that Jim’s poetry is not good. If the two known facts (at the bottom of Figure 4.7) are given activation and this activation spreads through the network, the inference that Jim is not boring after all becomes active and inhibits the inference that Jim’s poetry is not good. In this way, an imbalance of social forces is resolved. The parallel constraint satisfaction network provides a way to implement this balancing of forces.
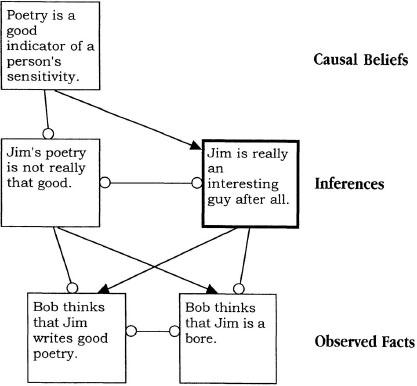
FIG. 4.7. Parallel constraint satisfaction network for making dispositional inferences about a story. Arrows represent excitatory connections, and circles represent inhibitory connections.
This model is assumed to be a description of the process people go through to make dispositional inferences and to make predictions about behaviors that may be observed in the future. There are, however, two parts to the process of making these inferences. First, there is some process that sets up a network like the one in Figure 4.7. This process must have some knowledge about the behaviors that are consistent with different explanations. It must also be able to determine which explanations are mutually consistent and which are mutually inconsistent. Once this process constructs a constraint satisfaction network, activation runs through it until it settles. There is no mechanism for directing the flow of activation through the network; thus, this model assumes that dispositional inferences are made automatically. To the extent that dispositional inference involves some controlled or rule-governed processes (beyond those needed to build the network), additional mechanisms must be added to the model in much the same way as the assumptions about spreading activation were coupled to a production system in Anderson’s model of working memory and problem solving described earlier in this chapter.
In addition to spelling out the processes that construct the constraint satisfaction network, other information needs to be considered in models of dispositional inference as well. Chronically accessible personality traits and personality traits activated by recent processing seem to be important determinants of dispositional inferences in similar tasks (Bargh, Lombardi, & Higgins, 1988). In addition, dispositional inferences are often based on characteristics of significant others who are similar to the new person in some way (Andersen & Cole, 1990). These factors have a clear impact on person perception, and the mechanisms that underlie these influences must be reconciled with the constraint satisfaction approach. Constraint satisfaction models may often have to be combined with other mechanisms to achieve an explanation of psychological phenomena.
SUMMARY
Many models in psychology involve the assumption that information is organized into a network consisting of nodes representing concepts and links representing relations between concepts. Semantic network models use these networks as a proposal for the structure of long-term memory. Memory is searched automatically by passing activation across the links. This structure allows the activation of one concept to activate many other concepts as well. A more general formulation of network models assumes that nodes represent concepts of interest to some psychological model and that connections reflect the constraints operating among these concepts. If a constraint operates to promote a pair of concepts, the connection is excitatory; if a constraint operates to promote one concept at the expense of another, the connection is inhibitory. Once the network is set up in accord with the constraints assumed to control a domain, activation is allowed to pass through it in much the same way as activation passes through semantic networks.
Both of these models focus on automatic processing. The spread of activation is assumed to take place without conscious awareness and without conscious control. Models of phenomena that are assumed to involve both automatic and controlled processes generally require a combination of mechanisms. Models like J. R. Anderson’s (1983a, 1993; Anderson et al., 1996) ACT combine a semantic network with a rule-based production system to carry out complex problem-solving tasks. Models like Thagard’s (1989) ECHO use rule-based processes to set up a constraint satisfaction network that models the simultaneous satisfaction of multiple constraints by passing activation through the network.
Finally, I have focused on the spread of activation through networks and the analysis of intersections between nodes. The combination of a semantic network with a rule-based system like ACT-R makes this representational system equivalent to the structured representations I discuss in the next three chapters.6 These structured representations require complex processes that are sensitive to the way elements are related. For this reason, I have treated spreading activation separately from other processes. Because network models lend themselves to the spread of activation, it is natural to include such mechanisms in network models.
1The terms directed and undirected are borrowed from graph theory in mathematics. The networks that have been used in psychology and artificial intelligence are all types of graphs, and the mathematics of graph theory has been used to develop procedures for processing information using networks.
2Quillian’s theory, particularly as elaborated by Collins and Quillian (1972) and later by Collins and Loftus (1975), made it clear that the networks were not supposed to be maximally efficient, but that they allowed some redundant information to be stored.
3Another problem with rampant forward chaining inference is that it increases the amount of processing that must be done when a false belief is discovered. For example, if a forward chaining inference system is told that all birds need trace amounts of uranium to survive, the system adds this fact to all known subclasses of birds. If this fact is later retracted (or shown to be false), some process must remove the appropriate link connecting bird to uranium and also the links between all subclasses of birds and uranium.
4A developmental perspective on semantic networks suggests that this finding is not so surprising. Most children are exposed to the category animal before they are exposed to the category mammal. There is no reason to think that learning a category intermediate in abstraction between two other categories causes the direct links between the first two categories to be removed. Thus, learning about mammals need not remove the direct ISA link between instances of animals (i.e., dogs and cats) and the node for animal.
5In fact, it is possible to construct semantic networks in which only the links are labeled. See Johnson-Laird, Hermann, and Chaffin (1984) for a discussion of this issue.
6Semantic networks can even be constructed to permit the representation of quantified statements like “Some dogs live in houses.” (I discuss methods for representing quantified statements in chapter 5.)