
CHAPTER 14
DATABASES AND THE INTERNET
One of the fascinating things about successful new technologies is that, after they've been around for a while, it's hard to imagine how we ever did without them! Automobiles and airplanes have always been a part of the lives of anyone reading this book. Computers are almost too obvious in this regard. What about photocopiers, as an example? How did we ever get along without photocopiers, which we used to routinely call “Xerox machines?” But even they have been in substantial use for well over forty years at this point. Then, there is the Internet. How did we ever get along without the Internet? The Internet has become such a huge part of our lives so quickly that it's easy to forget that its widespread commercial use began only in the mid-1990s. Do you remember when there was no Amazon.com? It seems as if it was always there! The question for us in this chapter is: how does the Internet relate to database management?
OBJECTIVES
- List the four differences between the Internet database environment and the standard database environment.
- Describe the database connectivity issues in the Internet environment.
- Describe the expanded set of data types found in the Internet environment.
- Describe such database control issues as performance, availability, scalability, and security and privacy in the Internet environment.
- Describe the significance of data extraction into XML in the Internet environment.
CHAPTER OUTLINE
Introduction
Database Connectivity Issues
Expanded Set of Data Types
Database Control Issues
- Performance
- Availability
- Scalability
- Security and Privacy
Data Extraction into XML
Summary
INTRODUCTION
Aside from email and file transfers, we associate the Internet with that most exciting of applications, electronic commerce. It's amazing how we as individuals can shop online, bank online, get our news online, get all sorts of entertainment online, and search for every kind of information imaginable, all within the broad scope of e-commerce. Companies have found new ways of selling to one another, forming alliances with one another, disposing of excess inventory, and generally speaking turning the world into a global marketplace. And, the essence of all of this e-commerce activity is data stored in databases. When you look through a company's product selections, the data comes from a database. When you place an order with a company, the order goes into a database. When you check your bank account balance, you're querying a database. Even reading newspapers online involves retrieving data from specialized text databases.
The question for us in this chapter is: what makes the Internet database environment different from a database environment that does not specifically involve the Internet? Well, first of all, what's not different? The fact is that most (but not all) e-commerce databases are relational databases and many are transactional in nature. The concepts of relational databases and the rules for designing relational databases are the same for transactional e-commerce applications as for any other transactional applications. SQL and other standard query tools can be and are used in the e-commerce environment, too. Yet, there are some differences between the Internet database environment and the non-Internet environment. So, what's different? We will organize the answer to this question into four categories that will form the major headings in this chapter:
- Database Connectivity Issues
- Expanded Set of Data Types
- Database Control Issues
- Data Extraction into XML
CONCEPTS IN ACTION
14-A STATE OF TENNESSEE–DEPARTMENT OF SAFETY
Tennessee, with 5.7 million people and an area of over 42,000 square miles, is the 16th largest U.S. state in population and the 36th largest in area. It became the 16th state of the U.S. in 1796. Its principal cities are Memphis, Nashville (the capital), Knoxville, and Chattanooga. Its leading industries include printing, publishing, chemicals, fabricated metals, and automobile manufacturing. Almost one-half of the state's land is dedicated to 80,000 farms, with the major products being cattle, hardwood lumber, dairy products, and cotton. Centrally located in the U.S., the state is also known as a major distribution center. As in all states, the Tennessee state government is responsible for a wide variety of public services, including the collection and management of state taxes, the management and maintenance of state parks, and the management of various social services for its citizens. The state's Department of Safety is responsible for services such as the licensing of motor vehicles and drivers and the enforcement of laws covering the operation of motor vehicles.
The Department of Safety maintains a Driver's License System database application that tracks the state's driver's licenses. Implemented in 1978, the database stores basic name and address data as well as data specifying the type of license and any restrictions such as corrective lenses. In 1996, an extension to the application was implemented that captures and stores both a photograph of the driver and the driver's signature in a digital format or “image.” All of this data, including the photo and signature, are incorporated into the actual physical driver's license. The images are captured at each driver's licensing location and transmitted online to the database for storage. All the data, including the images, can be queried and retrieved online using canned queries.
Running on an IBM OS/390 mainframe computer located in Nashville, the database application is an interesting hybrid of two different types of databases and DBMSs. The original 1978 application that stores the name and address and license type data is implemented in IBM's IMS DBMS. The 1996 extension that stores the photos and signatures is implemented in IBM's DB2 relational DBMS. The relational database currently holds approximately 7 million photo and signature images, including driver photos taken for previous license renewals.

Printed by permission of State of Tennessee—Department of Safety
DATABASE CONNECTIVITY ISSUES
In a simple database environment, the application program, the database management system, and even the data (during execution) are all contained and run within the hardware of a single computer. Figure 14.1 illustrates this arrangement when the computer is a stand-alone PC, but the situation is certainly similar for a much larger computer with multiple simultaneous users.

FIGURE 14.1 A stand-alone PC
In Chapter 12, we talked about client/server systems. In the simplest client/server systems, there are two classes of computers, as shown in Figure 14.2. The client computers are end-user PCs that are all connected to a server computer on a local-area network. The server contains the application programs, the database management system, and the database that all of the clients share. When an end-user wants to run an application or retrieve data from the shared database, the client computers handle the initial processing of the request. This is the “presentation” or “graphical user interface” aspect. Then the data is sent on to the server for processing by the application code, including data retrieval from the shared database as necessary. The server then returns the results to the client PC, where the client is again responsible for formatting the screen display.
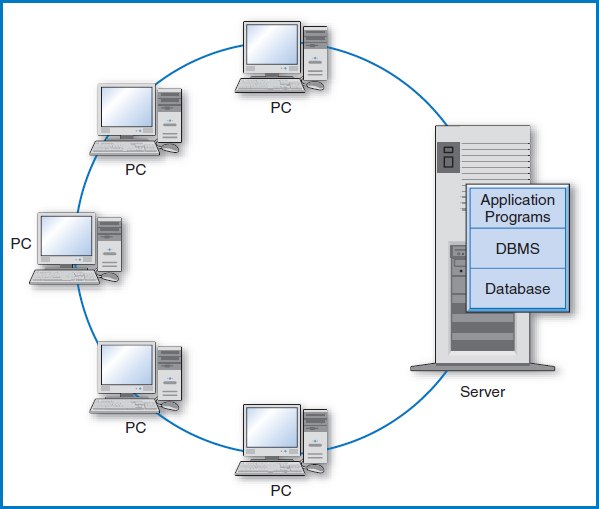
FIGURE 14.2 Basic Client/server system
While we usually associate the term “client/server system” with a system built on a local-area network, in a broad sense the World Wide Web can be considered a massive client/server system built on the Internet, Figure 14.3. The clients are the PCs that individuals and companies use to connect to the Internet. The browsers in the PCs, such as Microsoft's Internet Explorer and Google Chrome, constitute the software that handles the “client-side” screen presentation duties. The servers are the company Web servers with which people at their PCs communicate as they participate in the world of e-commerce. With this expansion of the idea of a client/server system, the World Wide Web, built on the Internet, certainly qualifies as the world's largest client/server system!
But there is more to it than that, which really shouldn't be surprising considering the much larger scale of a company's Web site and Web server than the server on a typical LAN. Let's talk about the hardware first, then the software. In the discussion in Chapter 12 on client/server database systems, we suggested the possibility of having a “database server” as a separate computer from the “application server,” Figure 12.4. This is a common arrangement in larger Web sites. Figure 14.4 shows the hardware components of the Web, including the disks containing the databases. There are three levels of computers in this arrangement: the client PCs, the Web server, and the database server. How does all of this connect together? Let's use an example and talk about this at two levels of detail, first at a high level and then at a somewhat more detailed level that will introduce some of the specialized software developed for the Web environment. Remember, this book is about database management systems and so our goal in this discussion is to connect the ultimate user into the database.
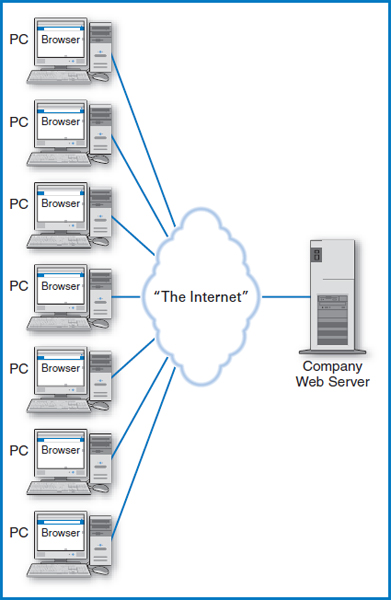
FIGURE 14.3 The World Wide Web as a client/server system
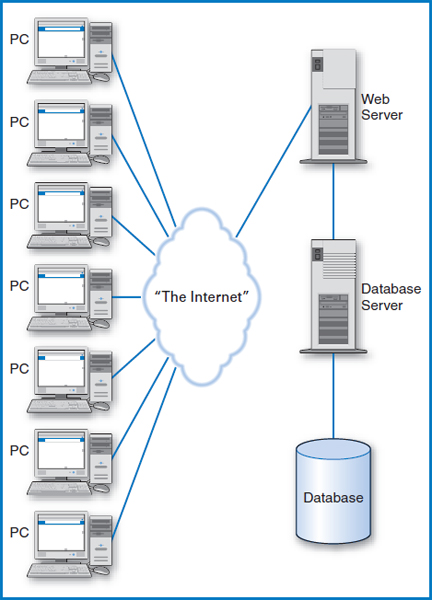
FIGURE 14.4 Basic hardware components of the Web to database connection
Suppose that Good Reading Bookstores has developed a Web site to sell books to consumers online and that you are about to become one of its customers. Follow along in Figure 14.4. You sit down at your PC, establish contact with your Internet Service Provider (ISP) (such as America Online or Microsoft's MSN), and enter the URL or Web address www.GoodReadingBookstores.com. The browser software in your PC sends a message to Good Reading's Web server and establishes a “session” or connection with it. The Web server sends your browser Good Reading's “home page,” which your browser displays on your monitor. Suppose you are shopping for a particular book. On the home page is a space for you to fill in the book's name. So, from the information systems point of view, what you are really trying to do at this point, is to search the BOOK table in Good Reading's database (repeated here as Figure 14.5) to see if Good Reading carries this particular book. You type the book's name in the space on the home page display and press the Enter key. The book name is transmitted on the Internet to the application running in Good Reading's Web server. This application sends a command to the relational DBMS in Good Reading's database server, ordering it to perform the look-up operation in the database. This could very well be done with an SQL command embedded in the application running in the Web server. Then, everything flows in reverse. The relational DBMS retrieves the data from the database and sends it to the application in the Web server, which then sends it back over the Internet to the browser in your PC. The browser displays it for you, either showing information about the book or stating that Good Reading doesn't carry it. If the book is in stock and you want to buy it, the transaction continues with message traffic passing back and forth between you and your browser on the “client side” and the Web server on the “server side”. Every time the database must be accessed, the application in the Web server passes a command to the database server, which queries the database and returns the result.
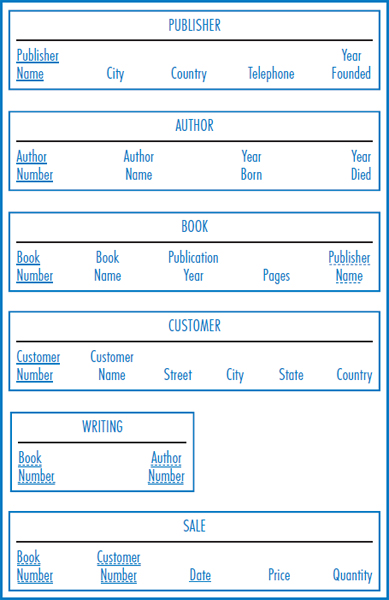
FIGURE 14.5 The Good Reading Bookstores relational database
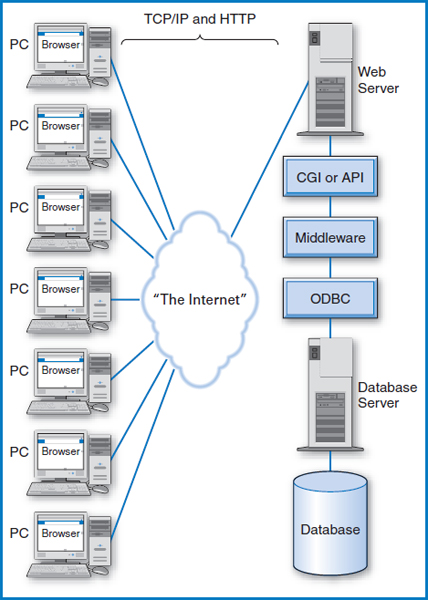
FIGURE 14.6 Basic software components of the web to database connection
Now, using Figure 14.6, let's take a bit more of a detailed look at the same Good Reading Bookstores scenario, introducing some of the specialized Web software that we have met. When your browser sends a message to the Web server (and vice versa),the message follows the rules of the Transmission Control Protocol/Internet Protocol (TCP/IP), which all Internet traffic (including, e.g., email) must follow, and the Hypertext Transfer Protocol (HTTP), which is an additional protocol layer for World Wide Web traffic on the Internet. TCP specifies how the message is broken up into smaller “packets” for transmission. IP deals with the address of the computer to which the message is being sent. At the Web level, HTTP indicates the type of browser in the client and other information needed to format Web pages. But what happens once the message reaches the Web server and, in particular, how is access to the database accomplished?
In the kind of self-contained computer and database environment illustrated in Figure 14.1, all of the hardware and software are designed to work together from beginning to end. The problem to be addressed in the Web database environment is that there can be different kinds of hardware even merely between the Web server and the database server, different kinds of application software languages, different browsers on the client side, and a variety of different kinds of data, not just data in relational databases. In order to tie all these variable and assorted pieces together and make them work in concert we need specialized interfaces and specialized software known as middleware.
Consider again the application program that manages Good Reading's online sales process running in the Web server and follow the diagram in Figure 14.6. First, in order for the application software running in the Web server to connect with software outside the Web server, there must be agreed upon interfaces, and indeed there are. The original such interface is called the Common Gateway Interface (CGI). Later, another such interface with certain performance advantages was developed, known as the Application Program Interface (API). These interfaces have associated software “scripts” that let them exchange data between the application in the server and the databases controlled by the database server. The connection to the databases could be made directly at this point, but again, with the prospect of different database management systems and different kinds of data involved, it made sense to create another level of standards to smooth out the differences and have one standard way of accessing the data. The most common set of such standards is called Open Database Connectivity (ODBC), which is designed as an interface to relational databases. Another, with its own set of features, is called Java Database Connectivity (JDBC). Other standards exist for various kinds of non-relational data.
Because of the importance of connecting the applications in the Web server with the databases in the database server, various companies have developed specialized middleware with a variety of broad features, capabilities, and connectivity options. Among the products of this type on the market are Cold Fusion, Oracle Application Server, Microsoft Active Server Pages (ASP), and others.
EXPANDED SET OF DATA TYPES
Most of the data in traditional transactional databases are of two basic “types”: numeric and character. These data types are all we generally need for accounting data, inventory data, marketing data, production data, and so forth. Indeed, all of the database examples in this book have used only numeric and character data. But there are other kinds of data, as brought up once before in discussing object-oriented databases (see Figure 9.10). There can be large text blocks (e.g. newspaper stories or descriptions of entities of any kind),graphic images (e.g. industrial design images or maps), photographs, video clips (or entire movies), and audio clips(or recordings). Specialized applications have focused on these special data types. For example, newspaper composition deals with large text blocks and photos, and geographic information systems (GIS) are based on maps as graphic images.
But the Internet and its World Wide Web have created a new emphasis on this assortment of data types in a way that no previous information systems environment ever did. Think of the Web sites you have visited. The displays coming to you as Web pages don't exactly look like reams of accounting data! Certainly they contain numbers and short character strings, but they also contain photographs, graphic images, animated graphic images, large text blocks (in online newspapers, magazines, etc.), video clips, and audio clips. The point for us is that databases supporting Web sites must be capable of storing, searching, and retrieving this wide variety of data.
Relational DBMS vendors have added features to their products that support these various text and multimedia data types. Oracle has a category of data types known as the large object (LOB) category that includes data types:
- Binary LOB (BLOB)—Up to four gigabytes of unstructured binary data, suitable for graphic images, photographs, video clips, and audio clips.
- Binary File (BFILE)—A pointer to up to four gigabytes of “read-only” unstructured binary data stored in a file external to the database.
- Character LOB (CLOB)—Up to four gigabytes of character data suitable for large text files or documents.
- National Character LOB (NCLOB)—Up to four gigabytes of data suitable for large text files or documents in languages based on pictographs or non-Latin characters.
An older category of data types used for multimedia data and known as RAW, including the data types RAW and LONG RAW, is no longer recommended.
The object/relational DBMS Informix Universal Server provides another style of handling multimedia and large text data using “data blades.” Among these are:
- The data type IMAGE, which can be used as a general-purpose image data type. Alternatively, a data type may be defined for each of the common image formats, including JPEG, GIF, TIFF, and others.
- The data type DOC, which is used for storing large text blocks.
- A set of data types, including point, line, polygon, path, and circle, which can be used for storing a variety of graphic images.
DATABASE CONTROL ISSUES
Managing an Internet database environment presents several unique challenges in comparison to a database environment in a system that is specifically not connected to the Internet. Having said that, we must recognize that today most systems are either directly connected to the Internet or are connected to other systems that are. Thus, in the Internet database environment, the general public potentially has access (planned or unplanned access, as by hackers) to the company's databases. Furthermore, the public response to the applications that involve the Internet is often unpredictable, meaning that the load on the system and on access to the databases can change rapidly. These and other challenges require a special emphasis on:
- Performance
- Availability
- Scalability
- Security and Privacy
Performance
We have all experienced widely different performance levels when interacting with Web sites on the Internet. Response time, the elapsed time from pressing the Enter key or clicking on a “Go” icon to displaying the Web server's response as a new Web page on your monitor, can vary greatly. In business-to-consumer electronic commerce, for example, a consumer's lack of tolerance for poor performance at one Web site can easily cause him to click over to a competitor's site. The complexity of the Internet and Web environment provides many potential reasons for poor performance, including whether your connection to the Internet is through a 56K modem or a broadband connection, the level of hardware at your Internet service provider, the speed of the Web server you are interacting with, associated facilities at the Web site, and so forth.
From the point of view of the company and its Web site, there is another major factor, too: the amount of traffic coming in from the Internet. Internet traffic to a Web site, the number of people or companies trying to access it simultaneously, can vary greatly because of a variety of factors:
- The time of day (which must be considered on a worldwide basis).
- The season of the year (e.g. the Christmas shopping season).
- The rapidly growing popularity of a Web site.
- A major new product introduction.
- A major event (e.g. the Victoria's Secret annual fashion show, which has overwhelmed its Web site).
These spikes, some of them huge, in Internet traffic require serious predictive capacity planning. The trick is that the companies want to be able to maintain reasonable response time during the spikes without spending lots of money to buy lots of extra computer equipment that will sit idle much of the time. Accomplishing this takes some serious planning and significant expertise.
Of course, system performance is also affected by software design and, in particular for our interest here, in database design. Thus, Chapter 8 on physical database design is of particular interest in the Internet database environment. The various performance-boosting physical design techniques that we discussed, including denormalization, are applicable at least for relatively static database tables such as product lists in some industries.
In addition, we mention two performance-boosting techniques that are of particular interest in the Web database environment. For the first one, take another look at Figure 14.4. When a query comes in from a PC and is passed from the Web server to the database server to the database, it is often the case that the retrieved data will be used again by the same or a different end user fairly soon. If a copy of that data can be held somewhere outside the database on a temporary basis for the next time it is requested, then two benefits can be gained: not only can the response time for future retrievals of that data be improved, but the amount of traffic between the Web server and the database server can be decreased, which helps to improve the performance of other accesses to the database. This concept of database persistence can be accomplished with a query cache, a special dedicated memory associated with the Web server or a proxy server attached to it, to hold a copy of the retrieved data temporarily. A second performance-boosting technique is used in situations where company employees can write SQL queries to access data over the Internet (or over an internal Intranet): frequently run queries can be stored or “canned” and then called when needed. This avoids having the system spend time going through query optimization to come up with an efficient access path every time the query is run, a concept that was discussed in general in Chapter 4.
Availability
A company's Web site and the databases it accesses should be available to the public at all times. This is especially true if the company is expecting traffic to the site on a worldwide basis, which, after all, is one of the hallmarks of e-commerce. Three o'clock in the morning in one part of the world is the middle of the day in another, and so the system really has to be up all of the time. There are several reasons that an information system can be unavailable.
- Because of some kind of system or telecommunications failure.
- Because of the failure of a support system, such as an electrical outage.
- Because of a planned down period for system maintenance.
- Because of excessive traffic that clogs the system.
Here again, the challenge is to make the information systems and their databases available 24/7 without going overboard in terms of cost. Regarding system failure, electrical outages, and planned maintenance time, redundant computer hardware and such accessories as electrical generators and batteries will do the job. The trick is to accomplish this at a reasonable cost. Excessive traffic is another story. Legitimate traffic spikes, as discussed above, can certainly reduce availability. But computer viruses that reproduce many copies of themselves and automated “robots” searching Web sites for information can clog systems, too. Either these must be prevented or the system must be constantly monitored by software that watches for such conditions.
One technique used to improve availability is known as clustering. A cluster of several servers is built, each with its own replicated copy of the database. As queries come in over the Web, sophisticated software checks the activity on each of the servers and their databases and performs “load balancing,” sending each particular query to a server that is relatively idle at that moment.
Scalability
Some electronic commerce efforts, in both “pure” e-commerce start-up companies and established companies, have experienced rapid growth. In one case, the growth rate in traffic to a Web site was estimated at 1000-4000 % per year in the early years. This is certainly good news for the company that experiences it! But the information system that supports this Web site and its traffic growth must be scalable; that is, it must be capable of growing without adversely affecting the operations of the site. It is thus imperative to choose that hardware and software that is capable of rapid and major expansion.
Security and Privacy
In Chapter 11 we discussed data security at some length. Now, consider the Internet database environment in which all of the traditional data security concerns are still present but in addition, the information system is exposed to the whole world through its Web site! And that is not an exaggeration. In the business-to-consumer e-commerce environment, the company wants as many people as possible to visit its Web site and buy its products. But that also means that hackers, data thieves, virus writers, and anyone else with mischief on their minds has an openly published entry point into the company's information system. Obviously, this requires heavy-duty security, such as:
- Separating the different parts of the information system so that they run on different computers. Thus, the Web server and the database server should be different computers, as shown in Figure 14.4. Furthermore, these should be separated from the rest of the company's information system by being on a different LAN.
- Making major use of firewalls. As we discussed earlier, firewalls can be separate “proxy” computers that extract data from incoming messages and pass the data on in a different format to the Web server. Figure 14.7 is a redrawing of the hardware arrangement in Figure 14.4 with the inclusion of a firewall computer. Firewalls can also be software-based, checking incoming messages for viruses and other suspicious code. And additional firewalls, including additional middleware (see Figure 14.6), can be placed between the Web server and the database server to catch any malicious code that gets through the initial firewall. Firewalls can also be placed between the Web server and the rest of the company' sinformation systems.
Closely related to the issue of security is the issue of privacy. Companies have long held in their databases personal data about their customers. What is different in the Internet database environment is first, that the companies are communicating digitally with their customers through their Web sites over the Internet, including passing their personal data. This requires the use of encryption so that the data cannot be intercepted and read while in transit over the Internet. Second, the collected personal data in the company's database makes a tempting target for someone out to steal such data. And again, the database is potentially accessible through the company's public Web site, which brings us back to the discussion about firewalls and such above.
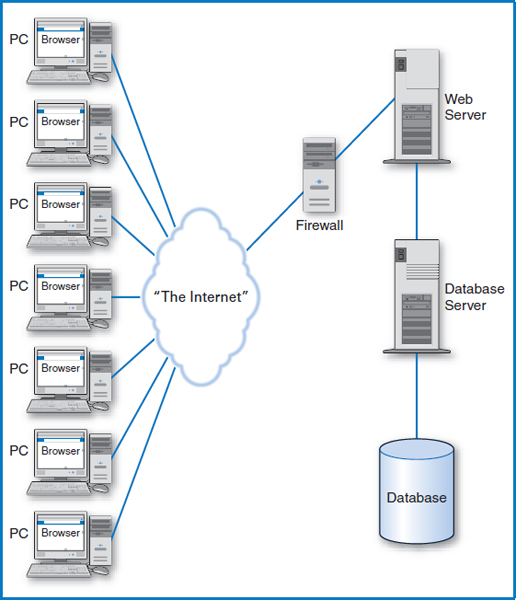
FIGURE 14.7 A firewall between the Internet and the Web server
YOUR TURN
14.1 UNIVERSITY DATA ACCESS OVER THE INTERNET
Consider a university information systems environment that includes both tables with current data and historic data in a data warehouse.
QUESTION:
Describe the kinds of data that a university might want to store and access that would be in an expanded set of data types as described in this chapter. What uses would the university have for this data and who would want access to it? What circumstances could occur in a university environment that would bring up Internet database issues of performance, availability, scalability, security, and privacy?
CONCEPTS IN ACTION
14-B BAPTIST MEMORIAL HEALTH CARE
Baptist Memorial Health Care Corp., headquartered in Memphis, TN, operates a total of 17 hospitals in Arkansas, Mississippi, and Tennessee. Its flagship hospital, Baptist Memorial Hospital-Memphis, is a 706-bed tertiary care teaching hospital, closely affiliated with University of Tennessee Medical School. Baptist Memphis annually has more than 28,000 admissions, 53,000 emergency department visits, 25,000 surgeries, and 125,000 outpatient visits. Located on the same campus are the Baptist Heart Institute and the Baptist Memorial Hospital for Women.
Baptist Memphis has a state-of-the-art relational database application, “Baptist MD,” that was originally implemented in 2000. Supporting approximately 1,400 physicians and physician staff employees, the central feature of Baptist MD is a Web site on which a wide variety of patient data can be stored. This includes patient history, pathology reports, blood tests, and radiology results. The site can also store and display x-ray and MRI images. A special site feature is real-time fetal monitoring by which a physician can remotely check on the condition of the fetus via the Web site while the mother is in labor. The system provides each physician with a “My Patient” list, from which the physician can select one of their current patients to check their condition. The physician's office staff also has access to the Web site for record keeping purposes. Since the system is Web based, physicians can check on their patients anywhere they can log onto the Internet. In one critical case, a physician who was out of state on vacation was contacted by the hospital and was able to access the Web site and make a decision about a patient.
Baptist MD is based on the Microsoft SQL Server DBMS, running on a Compaq server. It relies on XML to deal with all the different kinds of data in its Web site presentations. The system by its very nature is oriented around queries. These are menu driven with menu selections triggering SQL queries. The relational database's main tables are a physician table with physician qualifications and patient admitting authority, a patient table that contains about 45,000 records (including a 90-day history), a results table that typically has 10?20 test results and so forth per patient, and a users table with additional information about the physicians and the physician office staff employees who have access to the database.

Photo Courtesy of Baptist Memorial Health Care
DATA EXTRACTION INTO XML
As the final topic on Internet databases, we will briefly touch on the Extensible Markup Language, “XML,” and how it relates to database management. First, some background. You are probably aware that when a Web server sends a Web page to your PC, the text and data in the page is formatted in HyperText Markup Language (HTML). Embedded HTML “tags” literally “mark up” the text and data, instructing your PC's browser on how to display the page on your monitor. In the Good Reading Bookstores example, if the place on the Web page at which you are to enter the book title you're searching for is labeled “Book Title” and this label is to appear in boldface type on your monitor, it will come from the server looking like:
<h1><b>Book Title</b></h1>
which instructs your browser to display it in boldface type (the “b” in “<b>”). OK, but what does this have to do with database management? We're getting there.
HTML is derived from a broader markup language called the Standard Generalized Markup Language (SGML). As you can see from HTML, SGML is capable of handling the formatting of displayed text and data. But, SGML is also capable of indicating the meaning of data. It is this capability that XML, which is also derived from SGML, focuses on. Figure 14.8 shows how the attributes in the BOOK table in Good Reading's database, Figure 14.5, would be represented in an XML “document type definition” (DTD). Figure 14.9 shows some actual BOOK table data described by XML based on the DTD of Figure14.8. Notice that each actual attribute in Figure 14.9, each piece of data, is accompanied by tags indicating its meaning. This XML ability to handle different kinds of data is put to good use by Baptist MD, as noted earlier, and is indeed important in the Web database environment. But beyond this ability of XML to represent data in a generalized way that incorporates the meaning of the data with the data itself, what does XML have to do with database management?
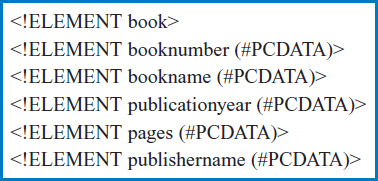
FIGURE 14.8 XML Document Type Definition (DTD) for Good Reading Bookstores' BOOK data

FIGURE 14.9 XML for a Good Reading Bookstores' book
Finally, the answer to this question goes straight to the heart of e-commerce and the countless databases that support it. Modern companies are interconnected in automated “supply-chains” in which their information systems applications send data to each other over telecommunications networks. This is not a new concept. For many years this activity has been accomplished with “electronic data interchange” (EDI). For example, an automobile manufacturer's parts inventory management system might recognize that it is starting to run short of tires on the assembly line. When the number of tires falls below a pre-set “reorder point” it automatically sends a message to an application in the tire manufacturer's computer ordering more tires. This type of process could also apply to Good Reading Bookstores and the publishers or book wholesalers that supply its stores. But a classic problem in EDI has been the different data formats in the supply-chain partners' databases. In order to automatically exchange data in an EDI arrangement, two companies have to go to a lot of trouble to match up attribute names, types, lengths, and so forth, with each other. Furthermore, a particular company has to go through this with each of its supply-chain partners. It can be done and it is done, but it is a grueling, time-consuming process.
The beauty of XML in this regard is that it provides an independent layer of data definition that is separate from the particular formatting of each company's data in its databases. Again, consider Good Reading Bookstores, but broaden the view and realize that there are many bookstores and bookstore chains, and many publishers and book wholesalers. Assume that every one of these companies agrees to use a single standard XML description of books. Further, each company will arrange to have software convert their stored book data to the standard XML format. Then, they can all freely exchange book data with one another, Figure 14.10. For example, if Good Reading has to order books from Publisher A, its software converts the book data in its database needed for the order to the XML standard. When Publisher A receives Good Reading's order in the XML standard, its software converts the data from the XML standard to its own format and go on to process the order. And, of course, this works in both directions. So, as long as Good Reading can convert its data to the XML standard, it can assume that every publisher it deals with can go on to convert the XML standard data to that publisher's data format, and vice versa from the publishers to the bookstores.
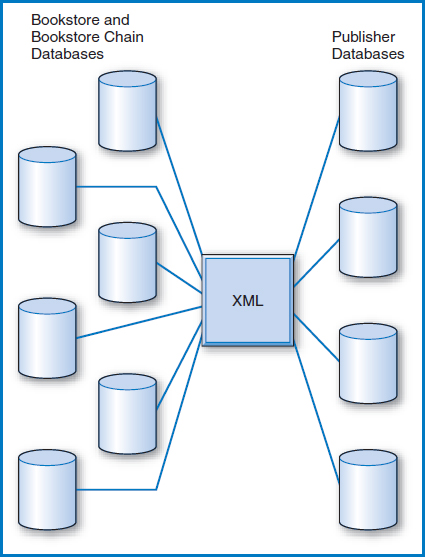
FIGURE 14.10 XML as an independent layer of data definition
SUMMARY
The Internet and its associated application, electronic commerce, have greatly increased the activity of access to databases. This has brought up several issues, one of which is modes of connectivity to the databases. Also, with the desire for access to music, movies, and other media over the Internet, dealing with an expanded set of data types has gained new importance. Access to databases over the Internet has brought increased focus on several database control issues including performance, availability, scalability, and security and privacy. Finally, data extraction into XML provides an important means of data conversion for companies transacting business over the Internet.
KEY TERMS
Audio clip
Availability
Binary file (BFILE)
Binary large object (BLOB)
Browser
Character large object (CLOB)
Client side
Clustering
Data type
Database connectivity
Database persistence
Electronic data interchange (EDI)
Home page
HyperText Markup Language(HTML)
Electronic commerce
Graphic image
Internet
Java Database Connectivity (JDBC)
Load balancing
Middleware
National character large object (NCLOB)
Open Database Connectivity (ODBC)
Query cache
Scalability
Server side
Standard Generalized Markup Language(SGML)
Supply chain
Video clip
World Wide Web(WWW)
XML
QUESTIONS
- Explain why the World Wide Web is like a giant client/server system.
- One of the principles of client/server systems is that the processing functions are divided among different computers in the system. Describe and explain this “division of labor” in the World Wide Web.
- Describe the arrangement of computers and disks at a Web site.
- Describe the various software components needed to reach a database within a Web site.
- Why is it important to have standardized software interfaces between the various Web site components?
- List three multimedia data types that might be required for a Web site.
- What is a BLOB? What is a CLOB? What are they used for?
- List some factors that can affect response time in e-commerce.
- List some factors that can cause large variations in the number of people trying to access a Web site simultaneously.
- What can a company do to handle spikes in traffic to its Web site?
- What does “availability” mean? Why is it important in the e-commerce environment?
- What factors or events can affect a Web site's availability?
- What does “scalability” mean? Why is it important in the e-commerce environment?
- What is different about data security concerns in the Internet environment vs. the non-Internet environment?
- What techniques or equipment can be employed for data security in the Internet environment?
- Why is data privacy a concern in the e-commerce environment?
- What is XML and why is it useful regarding database in the e-commerce environment?
EXERCISES
- Consider Lucky Rent-A-Car's Web site, which contains its database, as described in Figure 5.18. Describe, in detail, the steps taken in both hardware and software to reach the database when a customer is making a reservation for a rental car over the Web.
- Consider the World Music Association's Web site, which contains its database, as described in Figure 5.17. Describe, in detail, the steps taken in both hardware and software to reach the database when a customer is searching for information about recordings of Beethoven's Fifth Symphony.
- Describe three different uses for non-traditional data types in the Web sites of:
- Good Reading Bookstores.
- World Music Association.
- Lucky Rent-A-Car.
MINICASES
- Happy Cruise Lines.
- Consider Happy Cruise Lines' Web site, which contains its database, as described in Minicase 5.1. Describe, in detail, the steps taken in both hardware and software to reach the database when an employee is gathering statistics about a particular cruise, such as the total revenue (the sum of the fares paid) for the cruise.
- Describe three different uses for non-traditional data types in the Happy Cruise Lines Web site.
- Super Baseball League.
- Consider the Super Baseball League's Web site, which contains its database, as described in Minicase 5.2. Describe, in detail, the steps taken in both hardware and software to reach the database to produce a list of the work experiences of a particular coach on a particular team.
- Describe three different uses for non-traditional data types in the Super Baseball League Web site.