
CHAPTER 8 Identity and Access Management
Overview
In this chapter, we will look at some of the most popular mechanisms for identifying users and managing their privileges in enterprise systems. The systems we will discuss share many features in common, but each system has been developed to respond to the unique needs of a popular context. By the end of this chapter, you should know:
- The differences between identity management and access management
- The phases in identity and access management models
- The three categories of user credentials
- The relative strengths and weaknesses of the major authentication technologies
Identity management
Identity management is the processes of identifying individuals and collating all necessary data to grant or revoke privileges for these users to resources. The username and password system you use on your laptop is an example of an identity management system. In larger organizations, formal processes become necessary to manage the churn of users through the system. Using the example of a typical state university, on any given day, hundreds of events such as students joining the university, leaving the university, obtaining on-campus employment, changing on-campus employment occur, each of which affects what information these users are allowed to access. The simple processes that work at a home computer need to be replaced by formal systems to ensure that everyone has timely information in this dynamic environment, without compromising information to which they should not have access. Identity management systems perform the necessary functions to accomplish these goals.
Information about users is stored in a system of record. Based on the US Privacy Act of 1974,1 we define a System of Record (SoR) as records from which information is retrieved by the name, identifying number, symbol, or other identifying particular assigned to the individual. A system of record does not have to be very elaborate. The users panel in your Windows laptop is an example of an SoR. The HR and payroll database would also be considered an SoR. At a large organization, this database may be part of an ERP system, whereas at a small company, it may just be an Excel spreadsheet.
Similarly, your university's Student Information System is an example of an SoR for student data. As a general rule, a System of Record is established to store data for a particular purpose or about a particular group of people. For example, information about a student who is employed at her University will be found in both the student and employee SoRs. Thus, it is common for an individual person to have identities in multiple Systems of Record at the same time.
Within the SoR, an identity is a distinct record stored in a System of Record. Thus, what we traditionally call a computer user is called an “identity” in the information security world. An identifier is a string of digits which uniquely identifies an identity in an SoR.
Identity management systems handle the complexities associated with synchronizing identities across SoRs. They operate in three stages (Figure 8.1) to gather all the information necessary to manage identities – identity discovery, identity reconciliation, and identity enrichment. At the end of the process, we get a person registry with actionable information about users in the organization.
Phase I: identity discovery
Identity management begins with a discovery phase, where all new and updated identities throughout the organization are located. In this phase, the identity management system collects all the new or updated identifiers in each SoR. Name changes, role updates, and corrections to date of birth or identifiers are all common occurrences, and need to be discovered. The complexity of this phase varies greatly depending on the size of the organization. For small organizations with minimal employee turnover, this process can be completely manual – when an employee is hired or terminated, his or her data is updated in the Human Resources database and manually entered into the identity management system. In larger organizations, however, this may involve multiple automated systems collecting thousands of pieces of data from a dozen or more systems several times per day. Regardless of the method, at the end of the identity discovery phase, we obtain a list of new or updated identifiers from all of the organization's Systems of Record. This list is the input data for the next phase of the identity management process – identity reconciliation.
Phase 2: identity reconciliation
Once the list of new or updated identifiers has been compiled, we can perform identity reconciliation. Identity reconciliation is the process of comparing each discovered identity to a master record of all individuals in the organization. To demonstrate why reconciliation is necessary, suppose that Sunshine University hires a new faculty member. The following data is entered into the university's Human Resources database:

![]()
After a few years, Dr. Jones decides to take a class in his free time and enrolls in a class in the Biology department. The following data is entered into the Student Information System:
![]()
Without an identity reconciliation process in place, when the identifiers from the various Systems of Record are collected into one place, it is not clear if there are two people with the name Henry Jones, one faculty and one student, or one person with multiple roles:

With an identity reconciliation process in place, we can determine that both these records refer to the same Henry Jones, as follows:
![]()
Person Registry
As you can see in the example above, Henry Jones was issued an identifier in addition to the Student and Employee identifiers issued by their respective Systems of Record. This third identifier is for the identity management system itself. At the heart of most identity management systems is a database known as the Person Registry. The Person Registry is the central hub that connects identifiers from all Systems of Records into a single “master” identity and makes the correlation and translation of identity data (such as Student ID to Employee ID) possible.
What makes up the Person Registry? The registry itself is just a simple database. It issues a unique identifier for each new person that is created. Notice that these identifiers are issued “per person” and not “per identity” as with the Systems of Record. As we've seen in the example above, a single person can have multiple identities in the Systems of Record, but the goal of the Person Registry is to issue a single identifier for each person. The Person Registry stores all the identifiers from the different Systems of Record and a few other important pieces of identity data (name, date of birth, etc.) for each individual in the organization.
Identity reconciliation functions
The identity reconciliation process is itself characterized by three main functions – identity creation, identity matching, and identity merges. In fact, identity reconciliation is sometimes referred to in the industry as the “match/merge” process. Identity matching is the process of searching the existing Person Registry for one or more records that match a given set of identity data. Once a matching person record has been found, the identity merge function combines the new or updated record with data associated with the existing person record. If a suitable match is not found in the Person Registry, the supplied data is assumed to represent a new person. In this situation, we invoke identity creation, which is the function that creates a new person record and identifier in the Person Registry. If the given identity data matches multiple identities, an identity conflict occurs. To resolve an identity conflict, an administrator must evaluate the identity data supplied by the SoR and decide if this is a new identity or manually match it with one of the existing identities. A flow chart of the match/merge process is included in Figure 8.2.
Again, depending on the organization size and the number of Systems of Record, the identity reconciliation phase varies greatly in complexity. In the simplest case – an organization with only one System of Record – reconciliation and the Person Registry are not needed. In any case, after identities are reconciled, we move to the next phase of the identity management process – identity enrichment.
Why not use social security numbers as identifiers everywhere?
A very natural question at this point would be – why not just use social security numbers everywhere? After all, they are issued per person, and not per identity. This would largely eliminate the need for identity reconciliation.
One of the most important reasons for not using social security numbers extensively is that using social security numbers in this manner would create an additional burden upon the organization to maintain the security of these numbers.
Phase 3: identity enrichment
Up to this point in the identity management process, the only data that has been collected from Systems of Record has been related to identifying an individual and distinguishing them from all other individuals in the organization. The identity enrichment phase collects data about each individual's relationship to the organization. In our Sunshine State University example, during the identity discovery phase, we collected the identifiers for Henry Jones from the student and Human Resources databases, but not any information about his relationship to the university. During the identity enrichment phase, we would also record that Henry Jones is a faculty member in the Archaeology department and is taking a class in the Biology department. After identity enrichment, Dr. Jones' Person Registry entry would look like this:

An individual's relationship to the organization is referred to as their role or affiliation. Individuals can have multiple roles within an organization, and may have roles with multiple organizations concurrently. For instance, the director of Marketing at a company holds both the roles of director in terms of the Marketing organization, and employee in terms of the company as a whole. Because of this, in most organizations it is necessary to determine a primary role for each individual. This is accomplished by applying a priority value to each role as part of the identity enrichment process. Once a list of all roles of an individual have been compiled, the list can be sorted by priority value and the primary role selected. In the preceding example, the role of director would receive a higher priority value than employee, so this user's primary role would be recorded as “director.” Similarly, Henry Jones would have a primary role of “faculty.”

At the completion of the identity enrichment phase, the identity management process is complete. The identity management system has compiled enough information in the Person Registry to be reasonably certain that each individual in the organization is uniquely identified and enough information has been extracted to make intelligent decisions about the access and privileges this individual should receive. The identity is now ready to be used by the access management system, which handles these access decisions and the resulting actions.
Access management
The identity management process established who the individuals are in the organization. We now need to determine what each of these individuals is allowed to do. The access management system encompasses all of the policies, procedures and applications which take the data from the Person Registry and the Systems of Record to make decisions on granting access to resources.
Role-based access control
Before granting access to any resources, security administrators and the organization's leadership need to develop policies to govern how access is granted. In most large organizations, these policies use a role-based access control (RBAC) approach to granting access. In an RBAC system, the permissions needed to perform a set of related operations are grouped together as a system role. These system roles are mapped to specific job functions or positions within the organization. The RBAC system grants individuals in specified job roles the access privileges associated with the corresponding system role. For example, someone who is employed as a purchasing agent in an organization may be allowed to enter a new purchase order, but not approve payment. The ability to approve payment would be given to a role connected to an individual in a different position, such as in accounting. A constraint where more than one person is required to complete a task is known as separation of duties. Separation of duties is a common feature of business systems, especially when monetary transactions are involved.
The goal of an RBAC security system is to make the security policies of an organization mirror the actual business processes in the organization. Each individual in the organization should only be granted the roles that are absolutely necessary to complete their work successfully and each role should only contain the permissions needed to perform its specific tasks. Since the RBAC framework maps directly to the real-world functions of the individuals in an organization, security administrators can work directly with system users and business-process owners to develop policies that will be put in place. This is important because the system users are the subject-area experts; they know what system permissions are needed for a particular job function and what job functions are performed by which position.
Access Registry
The core of the access management process is the Access Registry database. The access registry provides security administrators with a single view of an individual's accounts and permissions across the entire organization. Each IT system connected to the access management system is audited on a regular basis for permission and account changes and the data is updated in the access registry. In addition, the access registry includes applications that run periodic access audits. Access audits determine what access each individual should have based on the data provided by the Person Registry and the current security policies. By comparing the access audit results with the access data stored in the access registry, security administrators can easily determine what access should be added or removed to ensure the system is in compliance with security policies.
The final step in the access management process is to act on the access changes required by sending/provisioning actions to each affected service or system. Provisioning actions include creating accounts or adding permissions that an individual is lacking or deleting (de-provisioning) accounts or permissions that are no longer needed.
Provisioning standards
The applications used to send provisioning actions have historically been highly specialized and generally have to be written to target a single application or service. However, given its importance, there has been some work to create standard frameworks for sending provisioning data, such as the Service Provisioning Markup Language (SPML)2 and the System for Cross-Domain Identity Management (SCIM).3 The specification for SPML was approved in 2007, but it has only seen limited use, mainly in very large enterprises, because of its complexity. SCIM, on the other hand, is relatively new (version 1.0 was released in December 2011) and strives for simplicity. It is still too early to tell if SCIM will become a widely used standard, but it does appear to have broad support from the major cloud service providers.
Once the system administrator has completed the identity management and access management processes, the system is ready to serve the users. The system needs to provide a way for users to prove their identities so that appropriate privileges may be provided. Authentication mechanisms enable users to prove their identities.
Authentication
In computer networks, authentication is the process that a user goes through to prove that he or she is the owner of the identity that is being used. When a user enters his username (also known as a security principal), he or she is attempting to use an identity to access the system. To authenticate the user, i.e., verify that the user is indeed the owner of the identity, the most common next step is to ask for credentials. Credentials are the piece (or pieces) of information used to verify the user's identity. The most commonly used credentials fall into three broad categories:
- Something you know
- Something you have
- Something you are
Something you know – passwords
A password is the oldest and simplest form of credential. A password is a secret series of characters that only the owner of the identity knows and uses it to authenticate identity. If the person attempting to access the account provides the correct password, it is assumed that they are the owner of the identity and are granted access. You are no doubt familiar with the use of passwords already. They are widely used because they are simple and don't require advanced hardware or software to implement. Although passwords are currently the most widely used form of credential, we have seen earlier that there are many issues with their security, including weak passwords. Also, attackers use two common techniques for guessing passwords:4
- Dictionary attacks – trying thousands of passwords from massive dictionaries of common passwords and words from multiple languages
- Brute-force attacks – trying random character combinations until the password is guessed or every possible combination has been tried
Dictionary attacks can guess common passwords very quickly, but are not very effective against passwords containing multiple numbers and symbols in addition to letters. A brute-force attack, on the other hand, will guess any password given enough time. To combat this weakness, most organizations enact password policies to enforce “strong” passwords. Some of the typical rules in use are as follows:
- Passwords must be eight or more characters long.
- Passwords must contain a number, upper- and lowercase letter, and a special character.
- Passwords must not contain a dictionary word.
Password entropy
Unfortunately, these rules generate passwords that are hard to remember, but do not necessarily result in a strong password. In 2006, the National Institute of Standard and Technology (NIST) issued the Special Publication 800-63,5 which presents a mathematic definition of password strength based on the entropy6 of the password. The entropy calculation allows you to estimate how long it would take an attacker to guess a given password using a brute-force attack. For example, a password that meets all of the rules above and would be considered strong: !d3nT1ty was calculated to have 25 bits of entropy, which represents 225 possible (33 million) passwords. On average, an attacker would have to try over 16 million passwords (half the total number) to guess the correct value. At 1000 attempts per second, it would only take the attacker about 4 hours to guess the password. However, if instead of a single word, you use 3–4 common words together as a passphrase, such as “rock paper scissors” you raise the entropy to 241–it would increase the amount of time required to guess it to over 8 years.
As you can see, a password with a higher entropy is much more resistant to brute-force attacks.7
Something you have – tokens
Instead of basing authentication on a secret that the user knows and could share (intentionally or otherwise) with someone else, tokens are physical objects (or in the case of software tokens, stored on a physical object) that must be presented to prove the user's identity. In nearly all cases, the token must be accompanied with a password (“something you have” and “something you know”), creating a two-factor authentication system. Two-factor authentication is a relatively simple way to establish a high degree of confidence in the identity of the individual accessing the system. Financial institutions have used two-factor authentication (ATM card and PIN) for decades, as have large corporations. However, the rise in phishing and other password-based attacks in recent years have motivated many more organizations to add a second factor to their existing authentication scheme.
Smart cards are credit-card sized hardware tokens that either store an ID number, which uniquely identifies the card, or include a small amount of memory to store a digital certificate which identifies the user themself. Smart cards are used in a wide range of applications, from the SIM cards inside every mobile telephone to the access cards used for physical access to secure areas in government and military installations. An alternative approach to certificate-based authentication is to load the certificate directly on a USB storage device (Figure 8.3). In addition to eliminating the need for a smart card reader, some USB-based authentication tokens also use the certificate and password to secure the onboard storage.
A drawback of the smart card and USB-based authentication tokens is that the user must have physical access to a computer's USB ports or a previously connected card reader. This is not always possible, especially when using a mobile device or logging in from an open-use computer lab or Internet Café. In these environments, a token that does not need to connect directly to a computer is required. Key-chain size hardware tokens from companies like RSA and Vasco deal with this by generating a string of numbers that is displayed on a small LCD screen on the front of the token. This string is then entered by the user as a one-time password (OTP), a password that can only be used one time and is usually only valid for a limited time. Such hardware tokens (Figure 8.4) have been popular for many years in corporate and government sectors because they are relatively easy to implement, do not require special readers or other accessories to be connected to each computer in the organization and can be used easily in a desktop or mobile environment.


These types of tokens create the one-time passwords by using either time-based or sequence-based methods.
- Time-based tokens generate a new password on a set time interval, usually 30 or 60 seconds.
- Sequence-based tokens use complex algorithms to generate a series of passwords that cannot be guessed based on previous passwords in the series.
Regardless of which type is used, the hardware token is registered with the authentication server before being given to the user, establishing an initial value to start the sequence-based algorithm or synchronizing the internal clock for time-based ones.
In addition to hardware tokens, security vendors such as RSA also offer software tokens, mobile phone applications that function in the same manner as a hardware token but don't require the user to carry a separate device. Since they don't involve delivering a physical device, these tokens have the added benefit of quick, simple deployment – just installing an application. Once the application is installed, the software token functions exactly like the hardware variety – the application generates a one-time password which then can be combined with their password to authenticate to the system. The Google Authenticator is a software token available for iOS and Android smartphones which provides two-factor authentication for Google accounts.8
In addition to software token applications, the unique capabilities of modern mobile phones have increased the number of options available for two-factor authentication. SMS text messaging is a simple way to provide a second factor for authentication. During account setup, users register their mobile phone numbers with the authentication service. From that point on, when the user attempts to authenticate, a short passcode is sent in a text message to their phone number. The user then enters the code to prove they are still in possession of the registered phone. One drawback of using SMS as an authentication credential is that many cellular phone companies charge per-message fees.
tiQR (http://tiqr.org) provides an example of another novel approach to authentication that takes advantage of the hardware features found in smartphones. When logging into a site protected by tiQR, the user is presented with a challenge-phrase encoded as a Quick Response (QR) code. The user then takes a picture of the QR code using the tiQR application (as of this writing, Android and iOS versions are available) on their smartphone. The user then enters their password into the tiQR application and submits it to the authentication server along with the decode challenge-phrase. The authentication server validates the user's password and challenge-phrase to verify the user's identity.
Something you are – biometrics
Hardware and software tokens are a great way to add a second factor and increase security, but like any physical object, tokens can be lost or stolen and used by attackers to impersonate users. How can we ensure that the person accessing a system is definitely the owner of the identity? Biometric devices analyze the minute differences in certain physical traits or behaviors, such as fingerprints or the pattern of blood vessels in an eye, to identify an individual. In general, biometric devices work by comparing the biometric data captured from the subject against a copy of the person's biometric data previously captured during an enrollment process. If the person accessing the system's biometric data matches the saved data, he or she is assumed to be the same person and authentication is successful.
Observable physical differences among people are called biometric markers. There are many markers that could be used, but the suitability of a particular marker is determined by several factors, including:9
- Universality – every person should have the trait or characteristic
- Uniqueness – no two people should be the same in terms of the trait
- Permanence – the trait should not change over time
- Collectability – the trait should be measurable quantitatively
- Performance – resource requirements for accurate measurement should be reasonable
- Acceptability – users' willingness to accept the measurement of the trait
- Circumvention – difficulty of imitating traits of another person10
Fingerprints
By far, the most widely known and used biometric marker is the fingerprint. Fingerprints that are made up of the unique pattern of ridges on the fingers or palm of the human hand are truly unique – in over 100 years of crime-scene investigation and millions of prints, no two people have ever been found to have matching fingerprints.
Once common only in highly secure applications, the price and complexity of scanning technology has lowered to the point that fingerprint scanners are commonly included as standard equipment in PC laptops designed for business users. Fingerprint scanners use either optical sensors that are tiny cameras which take a digital image of the finger, or capacitive scanners that generate an image of the user's finger using electrical current. Instead of comparing the entire print, the scanning software compares the shape and location of dozens of uniquely shaped features (minutiae) (Figure 8.5). By matching up multiple minutiae between the two fingerprints, the software can compute the probability that the two prints are a match. This type of probabilistic matching prevents environment factors (lighting, smudges on the camera, etc.) from affecting the outcome of a fingerprint match. However, it also introduces a weakness in biometric authentication. An attacker doesn't need to get an exact match of a fingerprint to impersonate a target; he only needs to duplicate enough of the minutiae to convince the scanner that he is “probably” the correct person. Although successful attacks against fingerprint scanners have been published,11 the technology is generally secure and will continue to be the most used form of biometric identification for years to come.
Iris and retinal scanning
Retinal scanners record the unique pattern of blood vessels located in the back of your eye. In addition to the retina, the eye contains another uniquely identifying trait: the iris. The iris is the thin, circular structure that surrounds the pupil and gives the eye its color. Like fingerprints, these structures are unique to each individual and can be used for authentication. Retinal and iris scans have long been the stuff of spy movies – in order to enter the secret base, a security system scans the agent's eye and verifies his or her identity. In real life, these systems are used to protect areas as secure as the Pentagon and as mundane as your local gym.
Retinal scanners have been used in the highest security areas for many years. To the user, a retinal scan is much like a test that would be done at an Optometrist's office. He or she looks into a eyepiece and focuses on a point of light for several seconds while the scanner captures an image of the retina and processes the data. Retinal scans are highly accurate, but they are not considered acceptable for general use because they are much more invasive that other technologies and are generally slower than the alternatives.

Unlike retinal scanners, iris scanning is quick and painless. An iris scanner is basically a standard digital camera (video or still) fitted with an infrared (IR) filter which allows it to capture an enhanced image of the iris. Although not quite as accurate as a retinal scan, iris scanners are used in many more applications because they are much easier to use. An iris scan is very similar to taking a photograph and does not require the user to be in close proximity to the scanner (up to a few meters away) or to hold still for an extended period of time as the images are captured instantaneously.
In 2001, the United Arab Emirates Ministry of the Interior began a program of scanning all foreign nationals entering the country, looking for people who have been previously ejected from the country for work permit violations (Figure 8.6). The system contains millions of identities and runs billions of searches per day. To date, the system has caught over 10,000 people with fraudulent travel documents attempting to re-enter the country.12

Iris scanning has also begun to move from large government organizations into business applications. For example, Equinox Fitness Clubs has equipped 15 of their locations with iris scanners instead of the traditional card scanners used in other fitness clubs. The scanners allow their VIP members to access exclusive services without having to carry cards or remember a PIN.13
Biometric system issues
Biometric systems provide a highly secure form of second-factor authentication and can provide a high degree of certainty in the user's identity, however their permanence is actually a drawback. If an attacker steals a user's password or hardware security token, the threat is eliminated once a new password or token is issued. That is not possible when dealing with biometric data. By their nature, biometric markers are permanent – we can't issue someone new fingerprints if their fingerprint data is compromised. That marker can no longer be used as a reliable authentication factor. Either the fingerprint system must be upgraded to remove the flaw that allowed an attacker to imitate a valid user or the entire system must be replaced using a different biometric marker.
Biometrics may seem new, but they're the oldest form of identification. Tigers recognize each other's scent; penguins recognize calls. Humans recognize each other by sight from across the room, voices on the phone, signatures on contracts, and photographs on driver's licenses. Fingerprints have been used to identify people at crime scenes for more than 100 years.
What is new about biometrics is that computers are now doing the recognizing: thumbprints, retinal scans, voiceprints, and typing patterns.14
Single sign-on
Once the user's identity has been established, access is granted to a system or application. If this authentication is for a local account, such as logging into Windows when you start up your computer, the authentication process is complete. The operating system informs all programs on your computer about your identity and there is no need to authenticate again. However, what if the application you need to access is on another system? How would you identify yourself to the remote application? An example would be accessing course information from a learning management system such as Blackboard.
You could repeat the authentication process and supply your username and password plus any other factor (token, biometric, etc.) that is required in your environment. This would work, but quickly becomes tedious, particularly if you are accessing many systems. What is needed is a way to login once to a system and gain access to all connected applications without being prompted for credentials again. This system is referred to as single sign-on (SSO) and can be accomplished in a number of ways. Single sign-on (SSO) refers to technology that allows a user to authenticate once and then access all the resources the user is authorized to use.
Generally, the system administrator in a single sign-on environment creates unique and strong user passwords for each resource the user is authorized to access and changes each of these individual resource passwords regularly, as specified by the organization's password policy. The end user is not aware of any of these individual resource passwords. Instead, the user is provided one single password that the user enters when trying to access a resource controlled by the single sign-on technology.
The implementation of single sign-on technology typically uses one central repository for password-based authentication. Once the user authenticates to this repository, the system looks up the resources which the user is authorized to access. When the user tries to access any of these resources, the SSO system provides the resource password on the user's behalf. Single sign-on is becoming increasingly popular in large organizations such as universities and banks.
SSO benefits and concerns
Before looking at the different SSO technologies, let's look at the advantages and disadvantages of deploying SSO in a system. There are several major benefits that SSO provides immediately to users and the system administrators:
- Better user experience – no one likes entering credentials multiple times.
- Credentials are kept secret – only the user and the SSO server have access to the user's credentials. This eliminates the possibility of an attacker accessing passwords through a compromised service.
- Easier implementation of two-factor authentication – instead of updated all of the services to support token or biometric authentication, only the SSO system needs to be updated.
- Less confusion – users don't have to remember multiple accounts with differing usernames and passwords.
- Fewer help desk calls – users are more likely to remember their password.
- Stronger passwords – since users only need to remember one password, that password can be more complex.
- Centralized auditing – all authentication is logged and can be monitored in one place.
In general, implementing an SSO technology improves the security and user experience, but there are drawbacks as well:
- Compromised credentials are a bigger threat. A single compromised account can access multiple systems or applications.
- Phishing attacks – Having a single login page creates an attractive target for phishers. They can copy the HTML of your login page exactly, making it easier for users to fall for their deception.
- Your SSO system becomes a single point of failure. If it is unavailable, no one can authenticate to any system. A failure of this repository will compromise not only the confidentiality and integrity of all passwords in the repository but also the availability of any system controlled by this repository.
- Adding any type of SSO increases the complexity of the system as a whole. The more complex a solution is, the more things that could go wrong.
Password synchronization
In addition to SSO, some organizations employ a password synchronization authentication scheme. Password synchronization ensures that the user has the same username and password in all systems. However unlike SSO, in password synchronization, the user is required to enter the credentials when accessing each system. Password changes on one system are propagated to other resources. This reduces user confusion and may reduce help desk calls for password resets.
Unlike SSO, there is no central repository of passwords in password synchronization. Instead, each synchronized system stores a copy of the user's password and the user authenticates to each system directly. The benefit to the user is that there is only one password to remember. Password synchronization is commonly used when integrating several different types of systems together, for instance the user must be able to access a web-based application, an application running on a mainframe, and a database account using the same credentials.
Since password synchronization has fewer components to implement, it is generally less expensive than SSO. However, password synchronization has its own problems. Since the same password is known to be used on many resources, a compromise of any one of these resources compromises all other resources synchronized with this resource. If password synchronization is used with resources with different security requirements, attackers can compromise less secure resources to gain access to higher security resources, which are likely to be more valuable.
Active directory and Kerberos
In Microsoft Windows networks, Active Directory serves as the single sign-on architecture. Active Directory integrates various network services including DNS and LDAP with Kerberos. Kerberos is an authentication protocol that allows nodes in an insecure network to securely identify themselves to each other using tokens. Kerberos is a very popular authentication protocol, and serves as the basis for many other authentication technologies. The Kerberos project was developed in the 1980s by researchers at MIT and released to the public in 1993.15 Kerberos provides a very high degree of confidence in the identity provided to the protected application by building a trusted relationship based on shared encryption keys between the authentication server, the protected application, and the client.
In a typical Kerberos situation, an actor wishes to use a remote service, such as a printer or file server. Authentication using the Kerberos protocol requires one additional participant, a key distribution center, and requires that all three actors be members of the same Kerberos “realm” (domain in Active Directory):
- A client that is initiating the authentication.
- A Key Distribution Center (KDC), which has two components:
- Authentication service,
- Ticket-granting service.
- The service that the client wishes to access.
With this setup, the operation of Kerberos is shown in Figure 8.7.
Before a client can access a “kerberized” service, they must authenticate to the KDC. Client and services first announce their presence on the network by providing their credentials and requesting a Ticket-Granting-Ticket (TGT) (1). The KDC then issues a TGT encrypted with a secret key known only to the KDC and a session key that future responses from the KDC will be encrypted with (2). The TGT and session key have a lifetime of 10 hours by default and can be renewed by the client at any time.
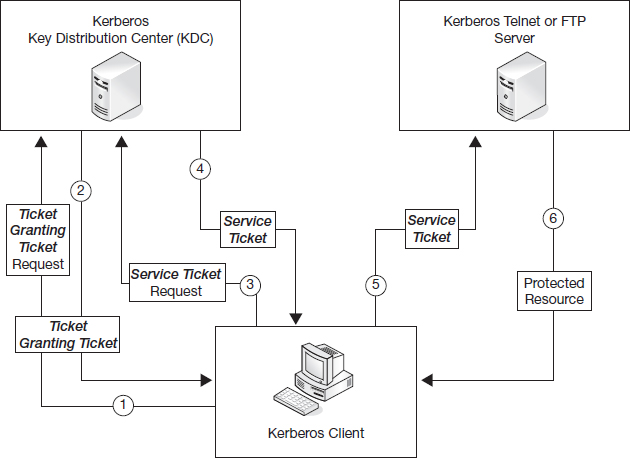
When the client needs a service, it requests a Service Ticket for the particular service by presenting the TGT to the KDC (3). If the KDC can successfully decrypt the TGT, it issues a new service ticket for both the client and the requested service (4). The client decrypts its portion using the session key sent earlier by the KDC and then sends the other portion to the requested service (5). The service then verifies the ticket using its own long-term session key generated by the KDC and grants access to the user (6).
Kerberos is by far the most popular SSO technology for desktop use. Most large organizations are using Windows desktops and Active Directory to manage user accounts. The Kerberos authentication included with Active Directory allows users to login to their desktop once and mount remote drives and printers or access remote applications without providing their username or password. However, Kerberos and Active Directory are geared towards corporate use – they work when all users are accessing the system on trusted (usually company owned and maintained) computers. Kerberos is not a good fit for applications that are targeted at web users who are accessing the system on their personal computers. In these cases, it is not possible to assume that retailers and consumers would be willing to enter into a trusting relationship with each other to exchange service tickets. The techniques discussed below are designed to work in these wider environments.

Web single sign-on
Kerberos was designed in the 1980s, well before the creation of the World Wide Web. Although the protocol has been updated in the years since, it has never been integrated easily with web-based applications. There are two reasons for this: the first is the requirement that all clients and servers be members of a Kerberos realm; that is not feasible with general web applications. The other reason is browser support – the major web browsers did not support Kerberos authentication until relatively recently and some still require extensive configuration to enable support. Web single sign-on (WebSSO) systems allow users to authenticate to a single web application and access other web applications without entering their username and password again. There are many different types of WebSSO in use. We will look at the broad outlines of authentication technologies used for web single sign-on and then focus on a particular WebSSO protocol that is widely used in education and commercial networks.
Token-based authentication
The simplest form of Web single sign-on is the use of a shared authentication token. An authentication token is a unique identifier or cryptographic hash that proves the identity of the user in possession of the token. When a user attempts to access one of the protected web applications for the first time, they are redirected to a token provider service that validates their username and password (and any other required authentication factors) and generates the authentication token (Figure 8.8).
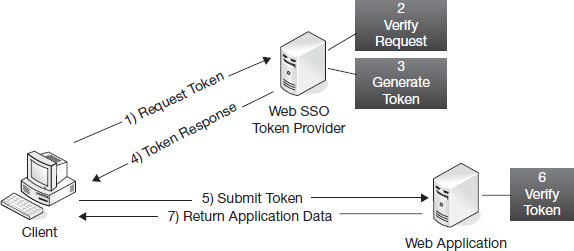
Depending on the specific implementation of the token provider, the authentication token may be generated in a number of different ways. Most commonly, the token is the result of a cryptographic process such as passing the username through a secure hashing algorithm (HMAC-MD5) or secret-key encryption algorithm (AES). Once the token is generated, the user is redirected to the requested service and the token is added to the HTTP request parameters. An alternative to this is to save the token into the user's browser as a session cookie before redirecting the user to the requested service. Session cookies are stored in temporary memory only and are deleted whenever the user closes their browser. In addition to authentication data, applications may store other data such as stored items in a shopping cart or site preferences for the user in the session cookie.
Sharing authentication tokens in a session cookie is a simple way to enable SSO between multiple web applications, but a major limitation is that web browsers do not allow cookies to be shared between multiple domains. A session cookie saved for sunshine.edu can only be used by applications on sub-domains of sunshine.edu such as www.sunshine.edu and mail.sunshine.edu, but not on www.example.com. If SSO is needed between applications on two different domains, session cookies cannot be used.
At the web application, the process to validate an authentication token depends on the method that was used to generate it. In the simplest case, if a symmetric-key algorithm were used, the requested web application would input the token and its copy of the cryptographic key to a decryption algorithm. The resulting data would include at least the username of the person authenticating it, but could also include other data about the person, such as name, or the authentication event, such as timestamp or IP address.
Single sign-on using token-based authentication is relatively easy to implement and, when done correctly and using a strong cryptographic key, is secure. However, there are some drawbacks. The first is that there are no standard protocols or frameworks for authentication tokens, so each organization implements their authentication system differently. This isn't a problem if all of the applications that will be using SSO are written in-house, but can be a major issue when trying to integrate external applications. Another problem is that cryptographic key management is hard to deal with. If you generate a unique key for each application using SSO, you'll potentially have hundreds of keys to manage. On the other hand if you use a single key for all services, and the key is compromised, all of the services are vulnerable.
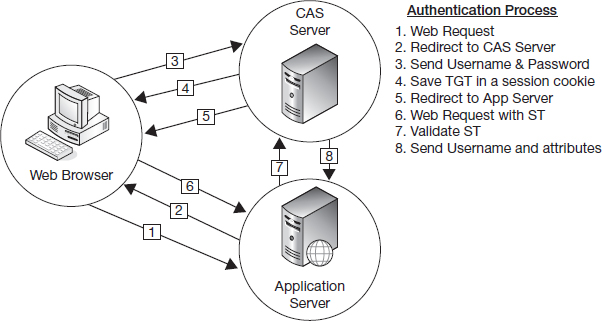
Central Authentication Service (CAS)
The Central Authentication Service (CAS) protocol is one of the leading open-source single sign-on technologies, especially in higher education. It was first developed at Yale University in 2001. The CAS protocol combines aspects of token-based authentication with concepts gleaned from Kerberos to develop a Web SSO that is both secure and easy to integrate with most web applications (Figure 8.9). In 2004, ownership of the project was transferred to the Java Architectures Special Interest Group (Jasig), a consortium of education institutions dedicated to developing software primarily for higher education.
Like token-based authentication, when a user attempts to access a web application protected by CAS, they are redirected to an authentication service on the CAS server. Like a Kerberos KDC, this service accepts and validates the user's credentials and then issues a Ticket-Granting-Ticket (TGT). The unique thing about CAS is that this ticket is saved into the user's browser in a session cookie that only the CAS server has access to. On subsequent visits to the authentication service during the CAS login session (2 hours by default), the browser presents the TGT for authentication instead of prompting the user to enter their credentials.
Continuing with the similarity to Kerberos, the browser requests the CAS server to issue a Service Ticket (ST) for the protected web application. A CAS Service Ticket is a random value that is used only as a unique identifier; no user data is stored in the service ticket. Service Tickets are of single use; they can only be verified once and then they are deleted from the CAS server. Also, they are only valid for the URL that the ticket was requested for and are valid for a very short period of time (10 seconds by default). Once the ST is generated, the user is redirected to the application they had originally requested with the ST appended to the HTTP request parameters, similar to the process used by token-based authentication.
Instead of being validating by the web application itself like an authentication token would be, the Service Ticket is submitted back to the CAS server for validation. If the service's URL matches the one the ST was generated for and the ticket has not expired, the CAS server responds with an XML document which contains the authenticated username. Later versions of the CAS server added the ability to return attributes such as name or email address in addition to the username.
The key factors in the success of the CAS server have been its simplicity and flexibility. CAS support can be easily added to virtually any web application, either by using one of the available clients16 or developing your own client. Unlike token authentication, which requires cryptographic algorithms that can sometimes be difficult to work with, the only requirements to interact with the CAS server are the ability to make a HTTPS connection and parse the CAS server response XML. Every major programming language in use today easily meets both of these criteria, so developing a custom CAS client is not difficult. The CAS server itself is also easy to extend and is designed for flexibility. It supports many different types of user credentials such as LDAP username/password and x.509 certificates. It can even be configured to accept Kerberos tickets, creating a complete SSO solution – users login when their computer starts up in the morning and do not have to re-enter their password, even when accessing web applications.
Federation
Kerberos and some form of Web SSO provide all of the necessary controls for securing applications within an organization, but what if your users need to access applications outside of your organization (such as Google Apps or Office 365) or users from other organizations need to access to some of your applications? The traditional answer was to generate accounts for your users in the external systems and “guest” accounts in your system for all of the external users. Imagine that faculty members at Sunshine State University are collaborating with researchers from a local biotech firm. The only way to give access to the research data to both groups of researchers, all of the biotech personnel would need university credentials and the faculty members would need credentials from the biotech.
Ultimately, this process is unsupportable for a number of reasons; the first of which is it introduces a second set of credentials; eliminating all of the advantages gained by SSO. The most important issue from a security standpoint, however, is that there is no way to know when to revoke privileges from an external user. Access for individuals inside the organization can be revoked as soon as a change in their affiliation (termination, position change, etc.) has been detected by the identity management system. However, this type of information would generally not be available for individuals outside the organization, which makes access control difficult. In addition to the security implications, creating accounts in external organizations normally requires the release of personal data (such as name and email address) for your users, which may introduce serious privacy concerns.
A federation bridges the gap between the authentication systems in separate organizations. Federation is typically implemented by providing a method for an internal application (service provider or SP) to trust the information about an individual (assertion) sent by a external source (identity provider or IdP). In the Sunshine State example above, instead of creating accounts for all of the biotech researchers, the system containing the research data on the Sunshine State campus would verify the identity of the user with the biotech companies' IdP and request enough information about the user to make a decision on whether to grant access. If the authentication succeeds and the information provided by the IdP meets the application's requirements, access would be granted. This information request and access decision is done each time the user attempts to authenticate, allowing Sunshine State to deny access to a user who no longer meets the criteria as soon as the biotech IdP has the information.
Allowing users from more than one identity provider to access a service introduces an interesting challenge. How can the service know which identity providers can authenticate users? The answer is to ask the user which organization they are affiliated with. A discovery service provides the user with a list of the trusted organizations that they can choose from to authenticate. Figure 8.10 is an example of the discovery service in one of the popular federation systems – InCommon.
Security Assertion Markup Language (SAML)
The most common federation protocol used in enterprise software is the Security Assertion Markup Language (SAML). SAML is an XML-based protocol that was first developed in 2001 by the OASIS Security Services Technical Committee.17 The protocol has gone through several revisions, the latest (SAML 2.0) being released in 2005. SAML incorporates several other XML standards for message security, including encryption and signing. Message security is important in the protocol because instead of sending data directly from the IdP to the SP, the parties in a SAML-based transaction communicate by relaying messages through the user's browser in HTML forms. This simplifies the configuration of SAML federations, as network controls don't need to be updated to allow a new IdP or SP to connect to the other members of the federation. However, since the message is passing through an untrusted third party (the user's browser), the XML messages must be cryptographically signed and encrypted to ensure their security and integrity.

In federations of more than a few identity and service providers, the maintenance of the federation becomes so complex it can be separated into its own organization. The federation provider is responsible for all of the administrative tasks related to the running of the federation, such as membership management, creating and enforcing federation policies and managing the Public Key Infrastructure (PKI) needed for cryptographic operations. The federation provider also publishes the federation metadata, which is an XML document containing a comprehensive list of all federation members and important data, such as organization and contact information, for each identity service provider. The federation provider is the central point in the network of trust that makes up the federation. The participants of the federation trust the provider to vet new members and uphold a certain level of quality in their identity management processes. In turn, the participants fund the federation provider through membership fees.
Figure 8.11 describes the process of authenticating a user in an SAML federation. When a user attempts to authenticate to an SAML-protected service provider (1), the SP first checks that the requested resource requires authentication (access check). If authentication is required, the SP returns a HTML form (2) that contains an AuthnRequest XML document that will be presented (3) to the SSO service on the identity provider. The IdP then requests the user's credentials (4) and validates them (5). If the authentication is successful, the IdP gathers all of the data about this user that should be released to this service provider and generates an SAML response. To protect the data contained in the response, the IdP encrypts the XML with the service provider's public key (retrieved from the federation provider) and signs the document with its own private key. The IdP then sends a HTML form that contains the response data to the user (6). The form is automatically submitted to the service provider (7), which decrypts the XML document and verifies the message signature. Now that the user has been authenticated, the service provider supplies the requested resource to the user (8).

Unlike some of the other SSO protocols that we have covered in this chapter, SAML was not written as part of a server application. The SAML standard defined the details of how the protocol worked, but the actual implantation of those details were left up to application developers. Because of this, there are many different authentication systems that support the SAML protocol both from major commercial software vendors, such as Oracle and Microsoft, and freely available open-source implementations.
Microsoft's implementation of SAML is a portion of their Active Directory Federation Services (ADFS) product. ADFS is a service that extends the Active Directory system to support federated access to local and external resources using SAML and related protocols. ADFS is at the heart of many of Microsoft's newest products as they begin to introduce more Software-as-a-service model for software delivery. For instance, using ADFS for federated access to Office 365 allows an organization to use their local credentials (with single sign-on to their desktop computers) to access their cloud-based email and calendar. ADFS' compliance to the SAML standard also allows the organization to federate with non-Microsoft products such as Salesforce.com or Google Apps for business.
Shibboleth is the most popular of the open-source SAML-based authentication server implementations. Shibboleth is an open-source identity management and federated access control infrastructure based on Security Assertion Markup Language (SAML). It was developed for web single sign-on by an Internet2 group consisting of developers from several major universities and research organizations. Faculty and researchers from the various organizations needed a way to access shared resources on the various member campuses, each of which used their own unique authentication system. The initial version (1.0) of Shibboleth was released in 2003, with major version upgrades in 2005 (version 1.3) and 2008 (version 2.0) and many smaller point releases have been released since then. Shibboleth is now the most popular authentication system for educational institutions, especially large research universities, and is the basis for many national and international federations.
Shibboleth?
The Merriam-Webster Dictionary defines Shibboleth as “a custom or usage regarded as distinguishing one group from others.”18 The term comes from the Hebrew Bible (Judges 12:5–6) in which correct pronunciation of this word was used to distinguish the Gileadites (who pronounced it correctly) from the Ephraimites (who pronounced it as “Sibboleth”).
Around the same time the first versions of Shibboleth were being developed, the foundation that runs the networking infrastructure for all Swiss universities, SWITCH, was dealing with the same issues that the members of the Internet2 group working on Shibboleth were facing. In 2003 SWITCH announced a new federation, SWITCHaai19 that would link all of the universities in Switzerland and all of their research or commercial partners, allowing Swiss students and faculty to access all of the educational resources in the country with a single set of credentials. As of November 2012, SWITCHaai had over 50 educational institutions with identity providers and nearly 100 public sector and corporate partners as service providers.
After the success that SWITCH had with running a large-scale federation, educational networks around the world started to develop their own plans for federation. In 2004, Internet2 announced a national federation, InCommon, to link American universities with government research institutions and corporate partners. InCommon started off with just a handful of members and grew slowly at first, but with the addition of major corporate partners like Microsoft and the release of Shibboleth 2.0 in 2008, membership exploded. By the end of 2012, InCommon included over 300 educational institutions, representing almost 6 million users, and over 150 research and commercial partners.20 SWITCH and Internet2's counterpart in the United Kingdom, JISC, announced the UK Federation in 2005,21 which has become one of the largest federations in the world with nearly 1000 participants and hundreds of service providers.
OpenID
SAML-based federations are an excellent solution for enterprise security, such as authenticating employees or business partners, but it requires planning and forethought before adding new federation resources. Each identity and service provider must be registered with the federation before being used for authentication. The registration must be performed by the identity provider's system administrators and, depending on the service provider's requirements, may require configuration changes to the IdP system. In an enterprise situation, this is fine. When a new federated service is identified by employees or other members of the organization, the requirements are reviewed and must be approved before any configuration changes are made. This also means that SAML has distinct disadvantages when applications whose user base includes the general public. Imagine the amount of work required to maintain a federation that contained the millions of services and identity providers that exist on the Internet with hundreds or thousands of new providers created daily. To handle sites with massive user populations from all over the globe, like Twitter and Facebook, a new type of federation is required.
OpenID was originally developed in 2005 for the LiveJournal.com blogging platform. Instead of requiring identity providers (referred to as OpenID Providers) to register with a central federation provider, OpenID uses a distributed model for authentication. The only requirements to becoming an OpenID Provider are having an Internet connection that allows other computers to reach you and a web server running an OpenID-compliant server application. These low barriers for entry meant that extremely security and privacy conscious users could even run their own OpenID Provider, allowing them to set the strength requirements and type of credentials they use to authenticate themselves. The reason that the protocol succeeded, however, was the benefit to the service providers (Relying Party in the OpenID protocol). The promise of “web applications” was just beginning to appear with sites like Gmail, Flickr, and Facebook, all launching in 2004. Startups were launching new applications all the time and users were frustrated at having to juggle multiple accounts and passwords. Adding OpenID support was relatively easy for the application developers and major email providers such as AOL, Google, and Yahoo were soon on board as OpenID Providers. Thanks to providers such as these, OpenID is in use in thousands of sites and over one billion OpenID URLs are in use on the web.
To authenticate using the OpenID 1.0 protocol, users supply their OpenID URL to the Relying Party instead of a username (1). The OpenID URL is unique to each user and is normally a subdomain of the organization that hosts the OpenID provider, for example, http://jsmith.sunshine.edu. The Relying Party then requests the URL and is redirected to the OpenID provider (2). The OpenID provider responds with a shared secret that will be used to validate the authentication response (3). The Relying Party then redirects the user's browser to the OpenID provider to authenticate. Once the user has supplied their credentials (4) and the OpenID provider verifies that they are valid (5), it generates an authentication response and returns it, along with the shared secret, back to the Relying Party (6). Once the user is authenticated, the OpenID URL is associated with a local account at the Relying Party application and user details necessary for the service (name, email address, etc.) are requested from the user. The process is shown in Figure 8.12.
The final specification for OpenID 2.022 was released in late 2007, bringing with it the ability to release attributes about the user in addition to the authentication response (OpenID Attribute Exchange23). OpenID 2.0 also added support for “directed identities” which allows users to enter the domain name of their OpenID provider (yahoo.com, for example) or select the provider from a list and a central discovery service at that provider would return the correct OpenID URL for the user. Figure 8.13 shows a typical provider selection screen for an OpenID 2.0 Relying Party. Attribute release was an important feature; it allowed users to bypass forms requesting basic user info such as name and email address by having their OpenID provider assert that information for them. Because the signup and login process was easier for users, Relying Parties saw marked increases in registrations and service usage when using OpenID authentication.24 The attribute release system in OpenID 2.0 can also be seen as a gain for user's privacy. Before releasing any data to a Relying Party, the OpenID provider seeks the user's permission and allows them to terminate the transaction if they do not wish to release the requested data.


OAuth
The OpenID protocols were designed to fill the typical use case of a web application – a human being sitting in front of a web browser is accessing the service. However, two new use cases appeared shortly after the development of OpenID: web mashups and mobile applications. A web mashup is a web page or application that combines data from one or more web-based APIs into a new service. For example, BigHugeLabs (http://bighugelabs.com) uses the image APIs from Flickr to create posters, mosaics, and many other types of new images. There are literally thousands of mashups using the Google Maps API (https://developers.google.com/maps), from finding a Winery tour anywhere in the United States (http://winesandtimes.com) to seeing the current Twitter trends by location (http://trendsmap.com) (Figure 8.14). The APIs used by mashups can't be protected by OpenID because they are not being accessed by a person who can authenticate to the OpenID provider. They are being accessed by the web application combining the data and creating the mashup.
Similarly, applications on mobile devices such as smartphones and tablets access the web-based APIs to retrieve and manipulate data for the user to enhance their native capabilities. A game on a smartphone may allow you to update your status on Twitter or Facebook with your high score, but you would not want to give full access (to update your friend list, for instance) to the game's developer. A protocol was needed that would allow a user to grant an application or service access to specific resources for a limited amount of time without giving out their credentials. The OAuth (open authorization) protocol was developed to meet this need. According to the OAuth technology home page,25 OAuth is a mechanism that allows a user to grant access to private resources on one site (the service provider) to another site (the consumer). Figure 8.15 is an overview of the protocol.
The first thing that you must know about the OAuth protocol is that it is not an authentication protocol, although many people mistakenly refer to it as one. OAuth deals strictly with authorization, it provides a web application (OAuth client) with a way to request access to one or more resources (scope) from a user (resource owner) through an OAuth authorization server and be able to reuse that authorization for an extended period of time and allow the user to revoke access at any time.
FIGURE 8.14 http://trendsmap.com
Before a client can send requests to an authorization server, the application must register an identifier with the server and receive client credentials, usually in the form of a password or shared secret. When a client needs to access a resource for the first time, it redirects the resource owner's user agent (browser or mobile application) to the authorization server along with the scope of the request and the client identifier (1a & 1b). The Authorization Server authenticates the user (2 & 3) (it may request their credentials directly or, more likely, be part of a federation/SSO network) and presents them with a list of the requested resources and gives them a chance to accept or deny the request.
If the resource owner grants access, the user agent is redirected back to the OAuth client along with an authorization code (4a & 4b). The OAuth client then sends the authorization code and the client credentials previously established with the authorization server (5). The authorization server verifies the client credentials and request and then issues an access token (6) that the client can use to access the protected resource (7). The OAuth client can continue using this access token until it expires or access is revoked by the resource owner.
Most of the major social networking sites including Facebook, Twitter, Foursquare, and Google+ provide access to an OAuth authorization server. If you've ever allowed another application to post to your Facebook timeline or update post to your Twitter account, you've been the resource owner in an OAuth transaction. The major problem with OAuth is that the user authentication is left up to the authorization server, meaning that if a user has clients accessing three different services that use OAuth for authorization, they will likely have to authenticate three separate times. Many developers consider OAuth “good enough” as an authentication system because they feel that if the authorization server issues an authorization code for an OpenID request, the user's identity has been verified and the authentication can be trusted. If an OAuth access token is used for authentication and authorization, there is the possibility, however, that a rogue or compromised client could misuse the token and impersonate the user at any other site that uses the same authorization service. In most applications that OAuth is in use for today the risk of this type of attack is minimal, as the resources protected by OAuth (social networking, blogs, etc.) aren't particularly valuable. As banking and other financial institutions begin to implement OAuth however, the target becomes much more valuable and more likely to be exploited. A newly proposed protocol, OpenID Connect, combines OAuth for authorization, OpenID for authentication, and elements of the SAML protocol for message security into a single standard.26 The design of OpenID Connect is still very much in flux and is several years from approaching the popularity of OAuth, but as the successor to OpenID 2.0 it is worth mentioning.

A simple way to see how OAuth is used in practice may be seen by creating a simple MVC 4 application with the Internet template in Visual Studio 2012. MVC 4 introduces the SimpleMembershipProvider mechanism to authenticate users and includes OAuth as one of its features. To implement OAuth, MVC 4 uses a table called webpages_OAuthMembership, whose structure may be seen in Figure 8.16. The Userid column in the table is the primary key to the user's record in the local application. Through the webpages_OAuthMembership table, SimpleMembership associates the local user id to the user's identification information on a remote provider such as Facebook or Twitter. Once the association is made, the user can provide their credentials at the remote provider. The local application will verify it with the remote provider and, if confirmed by the third party, allows the user access into the local application.
The user, not the application, makes the association between the local user id and the id at the third party. The application merely allows the user to make such as association.
Example case–Markus Hess
Cliff Stoll, an astronomer and amateur IT system administrator used his keen sense of observation to track down a young German intruder, Markus Hess, who successfully entered many US military establishments over a 1 year period during 1986–1987. The intruder sold many of the files he downloaded to the KGB. Apart from the intruder's persistence and skill, in most cases, he was able to enter computers by exploiting weak passwords. The intruder's connection path is shown in Figure 8.17.
Monitoring detailed printouts of the intruder's activity, it turned out that he attempted to enter about 450 computers, using common account names like roof, guest, system, or field and default or common passwords. Using simple utilities such as who or finger that list currently logged users, he could find valid user account names. In about 5% of the machines attempted, default account names and passwords were valid, though the machines were expected to be secure. These default credentials often gave system-manager privileges as well. In other cases, once he entered into a system, he could exploit well-known software vulnerabilities to escalate his privileges to become system manager. In other cases, he took advantage of well-publicized problems in several operating systems, to obtain root or system-manager privileges.
The intruder also cracked encrypted passwords. In those days, the UNIX operating system stored passwords in encrypted form, but in publicly readable locations. Traffic logs showed that he was downloading encrypted password files from compromised systems to his own computer and within about a week, reconnecting to the same computers and logging into existing accounts with correct passwords. Upon investigation, it turned out that the successfully guessed passwords were English words, common names, or place-names, suggesting a dictionary attack where he would successively encrypt dictionary words and compare the results to the downloaded passwords.

This experience helped investigators appreciate the weaknesses of password security in some versions of UNIX and its implications. These versions of Unix at the time lacked password aging, expiration, and exclusion of dictionary words as passwords. Also, allowing anyone to read passwords, trusting the security of the encryption scheme was improper. The Lawrence Berkeley lab guidelines did not bother to promote good password selection with the result that almost 20% of its users' passwords could be guessed using dictionary words.
REFERENCES
Stoll, C. “Stalking the wily hacker,” Communications of the ACM, May 1988, 31(5): 484 – 497
Stoll, C. “The Cuckoo's egg,” Doubleday, http://en.wikipedia.org/wiki/The_Cuckoo's_Egg
SUMMARY
In this chapter, we looked at identity and access management processes, from the start of a user's identity in a System of Record to the mechanics of authentication and authorization. We introduced the phases of identity management – identity discovery, identity reconciliation, and identity enrichment – and how role-based access control policies are used for access management.
Authentication is the process used to validate the identity of an account holder. It requires at least two pieces of information: a principal (username) and a credential. Credentials can be broken up into three broad categories: passwords, tokens, and biometrics. Multifactor authentication requires two or more different types of credentials used together to validate an identity.
Single sign-on systems allow users to access applications on multiple computer systems within a single organization while only authenticating once. Some SSO protocols such as Kerberos are designed for desktop use, while others, like CAS and token-based authentication, are meant to be used by web applications. Federation protocols such as Shibboleth and OpenID allow users from multiple organizations to access shared resources and extend the single sign-on experience outside of a single organization.
CHAPTER REVIEW QUESTIONS
- What is identity management?
- Briefly describe the phases of the identity management model.
- What is a System of Record?
- Would a person's name be a good identifier for a System of Record? Why or why not?
- What role does the Person Registry play in the identity management process?
- What is a role?
- What is separation of duties?
- Give an example of role-based access control policy.
- What do access audits do?
- What is a credential?
- What are the three categories of credentials?
- What is the oldest and simplest form of credential?
- What is the difference between a dictionary and brute-force password attack?
- Name one advantage and disadvantage for each of these types of credentials:
- What are the seven factors that should be considered when determining the suitability of a biometric marker?
- Name and briefly describe three advantages and disadvantages to single sign-on.
- What is the name of Microsoft's single sign-on architecture?
- What is an authentication token?
- Name at least one advantage and disadvantage to using:
- Shared tokens
- CAS
- Shibboleth
- OpenID
- OAuth
- Name at least one similarity in design that CAS and Kerberos share.
- What is the purpose of a federation?
- Where was the first of the major SAML federations established? What was it called?
- Name and briefly describe the four roles in an SAML federation.
- Describe two ways that the OpenID 2.0 differs from the OpenID 1.0 specification.
- What is a web mashup? Why are they reliant on OAuth for functionality?
EXAMPLE CASE QUESTIONS
- What are some of the activities that the Lawrence Berkeley labs are currently engaged in?
- What in your opinion may be the most valuable items of information an attacker may gain from improperly accessing computers at these labs?
- What are the steps currently being taken by the labs to reduce the likelihood of such compromises? (you should be able to find this information online)
- What is the operating system you use the most?
- How do you view all user accounts and their properties on this operating system?
- Do you see any default user accounts on your system (guest, administrator, etc.)?
- If there are any such accounts, do you see any potential vulnerabilities on your computer as a result of these accounts?
- If you answer yes to the above, what can you do to fix these vulnerabilities?
HANDS-ON ACTIVITY–IDENTITY MATCH AND MERGE
This activity will demonstrate the identity match and merge process used by a Person Registry during the identity reconciliation phase of the identity management process. You will compare the data from two different Sunshine State University Systems of Record and create a single data file.
- Download the spreadsheet (human_resources.xls) containing the employee identity data from the Human Resources system from the textbook companion website.
- Download the spreadsheet (student_system.xls) containing the student identity data from the textbook companion website.
- Download the Person Registry spreadsheet (person_registry.xls) from the textbook companion website.
- Using the flow chart in Figure 8.2, apply the Match/Merge process to data in the Human Resources and Student spreadsheets.
- Record the results of the Match/Merge process in the Person Registry spreadsheet.
Deliverable: Submit the contents of the Person Registry spreadsheet to your instructor.
Human Resources data:

Student data:

Resulting Person Registry data:

Two-factor authentication
The next activity will demonstrate the use of two-factor authentication. You will build and install the Google Authenticator authentication module on the Linux virtual machine included with this text. The Google Authenticator is a time-based onetime password (TOTP) application that runs on iOS and Android mobile devices. Although it was originally developed to provide two-factor authentication for web applications written by Google, it can also be used when logging into a Linux system.
To install the Google Authenticator module, open a terminal window and “su” to the root account:
[alice@sunshine ~]$ su - Password: thisisasecret
Copy the Google Authenticator install files to a temporary directory, extract the files and build the authentication module.
[root@sunshine ~]# cp /opt/book/chptr8/ packages/libpam-google-authenticator- 1.0-source.tar /tmp/.
[root@sunshine ~]# cd /tmp [root@sunshine /tmp]# tar xvf libpam- google-authenticator-1.0-source.tar [root@sunshine /tmp]# cd libpam-google-authenticator-1.0-source [root@sunshine libpam…]# make
The make command compiles the module's source code into binary instructions.
Next, run the automated testing suite:
[root@sunshine libpam…]# make test
and install the module:
[root@sunshine libpam…]# make install
To enable the module, modify /etc/pam.d/sshd to match the following:
#%PAM-1.0 auth required pam_sepermit.so auth required pam_google_authenticator .so nullok auth include password-auth account required pam_nologin.so account include password-auth password include password-auth # pam_selinux.so close should be the first session rule session required pam_selinux.so close session required pam_loginuid.so # pam_selinux.so open should only be fol- lowed by sessions to be executed in the user context session required pam_selinux.so open env_params session optional pam_keyinit.so force revoke session include password-auth
Restart SSHD:
[root@sunshine libpam…]# service sshd restart
Open a new terminal window and use SSH to access another account to insure that users who have not yet configured a Google Authenticator token are not required to enter an authentication code. To test this, we'll login to the bob@ sunshine account using SSH:
[alice@sunshine Desktop]$ ssh bob@sunshine The authenticity of host 'sunshine (127.0.0.1)' can't be established. RSA key fingerprint is 5c:40:15:b8:b7:f4: eb:08:14:cd:1b:c7:d0:4c:76:74. Are you sure you want to continue con- necting (yes/no)? yes Warning: Permanently added'sunshine’ (RSA) to the list of known hosts. Password: bisforbanana Last login: Sun May 12 20:23:01 2013 from sunshine.edu [bob@sunshine ~]$
Now, let's configure a Google Authenticator for the bob@sunshine account:
[bob@sunshine ~]$ google-authenticator Do you want authentication tokens to be time-based (y/n) y https://www.google.com/chart?chs=200x200 &chld=M|0&cht=qr&chl=otpauth://totp/bob@ sunshine.edu%3Fsecret%3DXPE7E73HKJ7S4XB3 Your new secret key is: XPE7E73HKJ7S4XB3 Your verification code is 424105 Your emergency scratch codes are: 85632437 55053127 44712977 12900353 82868046
Save the URL returned in the response from google-authenticator. You will need it when configuring your mobile device.
Do you want me to update your “/home/ bob/.google_authenticator” file (y/n) y Do you want to disallow multiple uses of the same authentication token? This restricts you to one login about every 30s, but it increases your chances to notice or even prevent man-in-the-middle attacks (y/n) y By default, tokens are good for 30 sec- onds and in order to compensate for possible time-skew between the client and the server, we allow an extra token before and after the current time. If you experience problems with poor time synchronization, you can increase the window from its default size of 1:30min to about 4min. Do you want to do so (y/n) n If the computer that you are logging into isn't hardened against brute-force login attempts, you can enable rate- limiting for the authentication module. By default, this limits attackers to no more than 3 login attempts every 30s. Do you want to enable rate-limiting (y/n) y
The Google Authenticator module is now configured for the bob@sunshine account when logging into the server with SSH. Before testing the module, you'll need to configure the Google Authenticator app for iOS or Android mobile devices or use one of the “emergency scratch codes” provided by google-authenticator. The Google Authenticator mobile application uses an innovative configuration method; a QR code contains all of the information required to configure the device. Before configuring your device, open the link returned from google-authenticator configuration app in your desktop's browser to view the configuration QR code.
Configuring Google Authenticator on an iOS device
To use the Google Authenticator app, you must have an iPhone 3G or newer running iOS 5 or later.
- Visit the Apple App Store
- Search for Google Authenticator
- Download and install the application
- Open the application
- Tap the plus icon
- Tap the “Scan Barcode” button and point your camera at the QR code on your screen (Figure 8.18).
Configuring Google Authenticator on an Android device
To use the Google Authenticator app, you must be running Android 2.1 (Éclair) or later.
- Visit the Google Play app store
- Search for Google Authenticator
- Download and install the application
- Tap the “Add an Account” button
- Select “Scan account barcode”
- If the app cannot locate a barcode scanner app on your device, you will be prompted to install one. Press the “Install” button and go through the installation process.
- Point your camera at the QR code on your screen

Using Google Authenticator with your mobile device
Now that you have configured your device, you can now log into the bob@sunshine account using both a password and the Google Authenticator token using SSH. Open the Google Authenticator app again. The application will present you with a new authentication code every 30 seconds. You can see how much time has elapsed for the current code by watching the circle in the top-left corner.
[alice@sunshine Desktop]$ ssh bob@sunshine Validation Code: <enter Google Authenticator code> Password: bisforbanana Last login: Sun May 12 22:11:03 2013 from sunshine.edu [bob@sunshine ~]$
As you can see, the login using both the password and code from the Google Authenticator app was successful. All SSH login attempts for the bob@sunshine account will receive the Validation Code prompt from now on. If you wish to stop using two-factor authentication with an account, just remove the .google_authenticator file from the home directory.
Using Google Authenticator without a mobile device
What if you lose your mobile device or you're not able to open the Google Authenticator app (dead battery, broken device, etc.)? That is the purpose of the “Emergency Scratch Codes” listed when you ran google-authenticator. The scratch codes are special authentication codes that can be used instead of the mobile app. If you ever find yourself without your mobile device, you can use a scratch code. The codes must be used in the order they are listed from top to bottom, and each code can only be used once (Figure 8.19). If you use all five codes, you'll need to run google-authenticator again to generate more.
Question
- Many websites and Internet services such as Google, Twitter, and Facebook have optional two-factor authentication systems. Do you use any services that provide this option? If so, do you use two-factor authentication with that account? Why or why not?

CRITICAL THINKING EXERCISE–FEUDALISM THE SECURITY SOLUTION FOR THE INTERNET?
Feudalism: The dominant social system in medieval Europe, in which the nobility held lands from the Crown in exchange for military service, and vassals were in turn tenants of the nobles, while the peasants (villeins or serfs) were obliged to live on their lord's land and give him homage, labor, and a share of the produce, notionally in exchange for military protection.27
The critical thinking exercise in Chapter 4 referred to the thinking among the designers of the Internet that security would be the responsibility of end users. How has that turned out? Well, it has been very difficult for end users to keep pace with security requirements.
During the heydays of the desktop, end users took responsibility for computer security. Some ISPs provided free antivirus subscriptions to their subscribers as part of their Internet packages, but the responsibility remained the end users’.
With the proliferation of smartphones and tablets, this model has changed considerably in a short time. End users have always expected security “out of the box.” As Bruce Schneier writes on his blog, two technology trends have largely made this a reality: cloud computing and vendor-controlled platforms. As cloud computing rises in popularity, more and more of our information resides on computers owned by companies including Google, Apple, Microsoft (Docs and email), and Facebook (pictures). Vendor-controlled platforms have transferred control over these devices and through them, our data, to the vendors of these platforms. The new smartphones and tablets are almost fully controlled by vendors.
In this world, we get very satisfactory levels of security, someone who knows more than we do takes care of security, but providing us with few, if any, details of such security. We cannot discuss the elements of our security with these vendors or bargain for security features. How is the email in users' Gmail account or photos in a Flickr used? Users generally have no idea. Users cannot view files or control cookies on their iPads. As Bruce writes, users “have so little visibility into the security of Facebook that [they] have no idea what operating system they're using.”
Users have shown that they like this trade-off – greater security and convenience in return for limited control over security, with the trust that the security will be done right. From the perspective of security alone, this is probably right. Providers do security far better than most end users can. Automatic backup, malware detection, and automatic updates are all core services provided at almost no cost. Yet, in spite of the huge benefits, users are inherently in a feudal relationship with these cloud providers and vendor-controlled platforms.
Whereas the currency in the medieval feudal era was labor, in the modern version, the currency is data. Users yield to the terms of the service provider with regard to their data and trust that the vendors will provide security. As the services become ever more sophisticated, providing context-aware benefits, there is greater temptation for users to share more of their data with the cloud providers. Not only email, but also calendars and address books. If all this data import and export takes time and we are happy with one provider and platform, we may even be willing to trust one provider entirely.
So, who are today's feudal lords? Google and Apple are canonical examples. Microsoft, Facebook, Amazon, Yahoo, and Verizon are contenders. What defense do users have against arbitrary changes in service terms by these vendors? We now know for example that almost all of these providers shared our data with the government without our consent or notice. Most users know that these providers sell the data for profit, though few if any, know how or to what purpose or what form.
In Medieval Europe, people pledged their allegiance to a feudal lord in exchange for that lord's protection. Today, we volunteer allegiance to a provider for that provider's protection. In Medieval Europe, peasants worked their lord's farms. Today, we toil on their sites, providing data, personal information (search queries, emails, posts, updates, and likes).
REFERENCES
Schneier, B. “Feudal security,” http://www.schneier.com/blog/archives/2012/12/feudal_sec.html (accessed 07/14/2013)
Schneier, B. “More on feudal security,” http://www.schneier.com/blog/archives/2013/06/more_on_feudal.html (accessed 07/14/2013)
CRITICAL THINKING EXERCISE QUESTIONS
- Do you agree with the parallels drawn by Bruce Schneier between feudalism in medieval times and the relationship of modern technology users to large providers such as Google and Apple?
- Bruce Schneier thinks that government intervention is “the only way” to fix the asymmetric power relationship between the large providers and end users in today's technology world. In light of the revelations of the US government's own controversial data monitoring of US citizens, do you agree with this assessment?
- Do you think the free market can alleviate some of Bruce Schneier's concerns?
DESIGN CASE
At Sunshine University, students have the ability to use their Sunshine login and password to manage their classwork enrollment every semester. Right after the beginning of the Fall semester, after the drop-add period is over, you are called to the Registrar's Office to investigate a case. A student is complaining that all of her classes were dropped from the system, but she claims she did not do it.
- Research and describe the concept of non-repudiation.
- How does it apply to electronic authentication, particularly to this situation?
Upon further investigation, you find out that the student's former boyfriend, upset after the break up, used the student's Sunshine credentials to login to the system and drop all of her classes.
- How do you think the boyfriend obtained the credentials to the other student's account?
- How could the system be modified to use biometrics to ensure non-repudiation?
- Besides biometrics, what other suggestions for authentication methodologies, technical or non-technical, would you offer to help ensure non-repudiation?
- As universities move more and more towards online courses, what other situations could arise in which a simple login and password would not be enough to ascertain the student's identity and prevent fraud?
- How could the student have prevented this incident?
1http://www.justice.gov/opcl/privstat.htm
2https://www.oasis-open.org/committees/tc_home.php?wg_abbrev = provision
4For a readable account of the state of the market, http://www.dailymail.co.uk/sciencetech/article-2331984/Think-strong-password-Hackers-crack-16-character-passwords-hour.html#ixzz2UcKeZwyW (accessed 04/4/2013)
5http://csrc.nist.gov/publications/nistpubs/800-63/SP800-63V1_0_2.pdf
6A measure of the disorder or randomness in a closed system: Houghton Mufflin Harcourt eReference
7An essay on the topic by Bruce Schneier, “Passwords are not broken, but how we choose them sure is,” http://www.schneier.com/essay-246.html (accessed 07/18/2013)
8http://googleonlinesecurity.blogspot.com/2012/03/improved-google-authenticator-app-to.html
9Jain, A.K., Bolle, R., Pankanti, S., eds. Biometrics: Personal Identification in Networked Society. Kluwer Academic Publications, 1999
10Biometrics was in the news in June 2013 when the US Supreme Court ruled lawful the collection of biometric identification of an arrestee and the use of such biometric identification in the detection of other unrelated crimes. Maryland vs. King, http://www.scotusblog.com/case-files/cases/maryland-v-king/ (Accessed 10/11/13)
11Matsumoto, T. et al. Impact of Artificial “Gummy” Fingers on Fingerprint Systems. International Society of Optics, 2002
12Daugman, J. Encyclopedia of Biometrics. Springer, 2010
13“Equinox Fitness Clubs Case Study.” IRIS In Action. IRISID. Web. 15 May 2013
14Bruce Schneier, Crypto-gram, January 15, 2009
15http://www.kerberos.org/about/FAQ.html
16https://wiki.jasig.org/display/CASC/Client + Feature+Matrix
17https://www.oasis-open.org/committees/security/
18http://www.merriam-webster.com/dictionary/shibboleth
19http://www.switch.ch/aai/about/federation
20http://www.incommonfederation.org/participants
21http://www.ukfederation.org.uk
22http://openid.net/specs/openid-authentication-2_0.html
23http://openid.net/specs/openid-attribute-exchange-1_0.html
24http://janrain.com/resources/industry-research/consumer-perceptions-of-online-registration-and-social-login