
CHAPTER 11 Incident Handling
Introduction
In this chapter we will wrap up many of the concepts and ideas we reviewed in the past chapters into the narrative of an incident. Incident handling is an important facet of security, since it involves minimizing the adverse effects of the incident on the assets, implementing controls needed to decrease the exposure of the assets to the existing threats, and ultimately restoring IT services with as little impact to the organization as possible. By the end of the chapter you should be able to:
- Identify the major components of dealing with an incident
- Understand the incident handling lifecycle
- Prepare a basic policy outlining a methodology for the handling of an incident
- Use material seen so far to properly identify and classify an incident
- Judge when to start the process of containment and eradication of the incident
- Report on the incident to improve preparation for a similar incident in the future
- Know the elements of disaster recovery and business continuity planning
Incidents overview
According to NIST 800-61 rev2, a computer security incident is a violation or imminent threat of violation of computer security policies, acceptable use policies, or standard security practices. Examples of incidents include:
- An attacker commands a botnet to send high volumes of connection requests to your organization's web server, causing it to crash.
- Some users in your organization are tricked into opening a “quarterly report” sent via email that is actually malware; running the tool has infected their computers and established connections with an external host.
- An attacker obtains sensitive data and threatens your CEO that the details will be released publicly if the organization does not pay a designated sum of money.
- A user provides or exposes sensitive information to others through peer-to-peer file sharing services.
In earlier chapters, we have defined the components of information security concerns including threats, assets, and their characteristics as well as some common measures taken to minimize information security problems. Unfortunately, in spite of your best attempts, intruders are likely to find ways of creating problems for you. We call them incidents. To respond to incidents, it is useful to develop some standard procedures and refine these procedures based on your experience. We introduce the essential elements of incident handling procedures in this chapter.
Incident handling
How does one go about handling an incident? You have seen a preview of the issues encountered in responding to incidents when you faced the student email server issue in the design case in the early part of this book. Looking back, what steps should you have performed to respond to that incident? What about a virus infection, or a web page defacement? Are there any actions common to an appropriate response to all these incidents?
While some of the procedures dealing with each incident may vary, the overall process remains the same. These are described in NIST 800-61 rev.2, and involve 4 basic steps:
- Preparation
- Detection and analysis
- Containment, eradication, and recovery
- Postincident analysis

In the most effective organizations, these steps do not stand on their own. Instead, they are part of a cycle that repeats itself every time the organization faces an adverse event.
In the rest of this chapter, we will discuss the elements of handling a typical incident, following the NIST procedure.
Reference example – Incident handling gone bad
These days, with the high degree of professionalism in the IT world, it is difficult to find an example of really bad incident handling. Fortunately for us, on June 26, 2013, the Inspector General for the US Department of Commerce released an audit report of an exceptionally poorly handled incident at the Economic Development Administration (EDA), a relatively small unit in the US Department of Commerce, with an annual budget of about $460 million in 2012.
In summary, on December 6, 2011, the Department of Homeland Security alerted the EDA and the National Oceanic and Atmospheric Administration (NOAA) of potential malware in their IT systems. NOAA fixed its problems and brought back the affected systems into operation by January 12, 2012, i.e., about 35 days after the initial alert.
By contrast, the EDA, fearing widespread infection and potential state-actor involvement, insisted on an assurance of malware removal on all its systems. In this effort, it spent over $2.7 million in remediation expenses, including over $1.5 million in services from an IT contractor. This was more than half the EDA's total IT budget for the year. Even more interestingly, it paid $4,300 to the contractor to physically destroy $170,500 in IT equipment. IT equipment destroyed included printers, TVs, cameras, desktops, mice, and even keyboards.
The wanton destruction only stopped because by August 1, 2012, EDA had exhausted funds for its destructive efforts. The EDA therefore halted the destruction of its remaining IT components, valued at over $3 million. The EDA intended to resume its destructive activity once funds for such destruction became available.
All this, just to remove routine malware that affected two of its approximately 250 IT components (e.g., desktops, laptops, and servers).
This incident is a font of examples for what can go wrong at virtually every stage of the incident handling process. We will use the example throughout the chapter to illustrate what can go wrong. The incident would be funny, if it were not for our own taxes paying for this unhappy outcome.
Reference
- US Department of Commerce, OIG Final Report, “Economic Development Administration Malware Infections on EDA's Systems Were Overstated and the Disruption of IT Operations Was Unwarranted,” OIG-13-027-A, June 26, 2013, http://www.oig.doc.gov/OIGPublications/OIG-13-027-A.pdf (accessed 07/14/2013)
Preparation
Preparation is the first step in the creation of an incident response plan. Preparation involves more than just sitting around trying to think about all the possible threat scenarios that could affect the attributes of a specific asset, and the appropriate response to each of these scenarios. Instead of attempting to be fully prepared to handle all the different types of threat actions against all different assets, it is more productive to identify the basic steps that are common to all events, and plan the execution of each of these steps.
Creating a policy for incident response
Within incident preparation, the first step is to create a policy around incident response and obtain top management's agreement to the policy. An incident response policy describes the standard methods used by the organization for handling information security incidents. This may strike many as unnecessary paperwork but it is extremely important to execute in advance. This is because the policy will help you focus on the incident as a whole, from start to finish, without getting diverted by media and organizational pressures, including the possible consequences of any temporary controls you may have to put in place in order to contain or eradicate the threat. For example, if your university's web server is defaced, it is better to have a policy in place that allows IT to bring the website down for as long as necessary to deal with the issue, rather than having to obtain permissions in real time from stakeholders to do so. In fact, most stakeholders, including users of the website will find it more assuring to know that you are following standard procedures than to know that you are figuring out what to do in real time. The discussions involved in developing an incident response policy also provide management with an understanding of the issues they may have to deal with during an actual incident.
“Put it in writing!” This is an important concept in security and is something all managers understand. The difficulties in implementing this policy will vary greatly from organization to organization.
At the University of South Florida, official policies are first written, then vetted by internal IT units and steering committees, moved on to General Counsel for an 8-week vetting process with different entities on campus, from the faculty union group to Human Resources. The advantage of such a drawn out process is that it also helps to publicize the policy and increase security awareness. In other organizations, however, a simple email to an executive may suffice to implement the policy. One common point to both approaches, and a must for any policy, is the support of top management.
And this is why you need to have something in writing: if you have to pull the plug on a server because sensitive data may be leaking due to a hacker, you want to make absolutely sure someone has your back.
The scope is the part of the incident response policy that specifies the targets of the policy. It is recommended that the scope should be narrow and specified as closely as possible to what is achievable. The elements of the scope include (a) which assets are covered by the policy; (b) are there any exclusions to the policy; (c) are there departments within your organization with the autonomy to decline adherence to the policy; (d) can individual departments be more exclusive/stricter with their policy? Universities, for instance, are notoriously decentralized in terms of IT resources. In such organizations, it may even be necessary to try to find agreement on when a local security incident becomes an organization-wide concern.
Having a policy is not enough. Everyone involved must know what is in the policy. In the EDA case, as stated in the OIG report,
“DOC [staff] did not understand that there was a preexisting expectation of specific incident response services, as outlined in the service level agreement (SLA) between the [DOC] and EDA. This agreement clearly states [DOC's] obligated incident response services (e.g., investigation, forensics, and reverse engineering) and defines EDA's incident response responsibilities (e.g., reporting incidents and dealing with quarantined or deleted malware). Since [DOC] staff did not understand this agreement, they inaccurately assumed EDA was capable of performing its own incident analysis activities (e.g., determining the extent of the malware infection).”
Incident response team
Just as organizations have designated employees for specific functions, it is important to have staff designated to respond to incidents. These staff members are called the incident response team. Even though security incidents do not happen every day, the designated incident response staff develop experience into the expectations of the organization during incidents. The primary goal of the incident response team is to protect the overall computing infrastructure of the organization, and hence its members need to be aware of the overall IT architecture of the organization. The team is responsible for the overall incident handling cycle, including:
- quickly identifying threats to the campus data infrastructure,
- assessing the level of risk,
- immediately taking steps to mitigate the risks considered critical and harmful to the integrity of university information system resources,
- notifying management of the event and associated risk,
- notifying local personnel of any incident involving their resources,
- issuing a final report as needed, including lessons learned.
The incident response team (IRT) has multiple roles before, during, and after an incident. The roles of each member of the IRT must be part of the incident response policy. Often, membership to the IRT will cross departmental boundaries, and managers have to understand and agree that, when called upon, IRT members will be pulled from their current projects and allocated to the IRT, especially when it comes to the containment phase of the incident.
In a large organization, there may be a need to have multiple IRTs, one within each division of the organization. If such a framework is necessary, it is important that a central group be in charge of making security decisions when events start crossing the boundaries of the original affected division. For instance, a malware infection initially localized to computers in the College of Arts may threaten the integrity of the overall network if other campus areas are also infected. Containment of the infection at the college by interrupting the access of the college to the rest of the university network is something that falls under the jurisdiction of a central IRT group.
At the University of South Florida, individual units and departments are required by policy to alert the IRT as soon as any asset classified “restricted” is involved in an adverse event. Members of the incident response team should be brought together as soon as an incident is detected within the university. After normal operations are restored, a report must be presented to all members of the IRT and local system administrators, clearly outlining the extent of the breach, and the steps taken to avoid future incidents. These incidents will be reviewed by the head of the IT Security department as part of the continuous risk assessment program (risk assessment is discussed in Chapter 14).
The IRT will have one chair, usually a senior security analyst. This person will coordinate and help other IRT members to perform their functions when dealing with the incident, from communication with management, users, other IT personnel, vendors, ISP, etc. The chair of the IRT controls the situation as it evolves, especially from a technical perspective. As such, it is vital that this individual have high credibility within the organization for their competence, excellent communication skills, both oral and in writing, enough technical background to understand the situation, and to be able to make split-second, educated decisions based on the status updates given to him or her by the other members of the team.
Technical members of the IRT are selected depending on the threat action. For example, if an Oracle database was breached due to a compromised administrator account on the operating system, the IRT may include the following members:
- A person familiar with the OS to look at the OS system and logs, or at least extract them for analysis by someone familiar with data forensics.
- A database administrator to examine the Oracle database, contents, and logs to try to determine if anything was altered.
- A network engineer to review firewall and/or netflow logs to try to observe any traffic out of the ordinary.
- Desktop services personnel may be called if desktop machines provided the vector for the admin account to be compromised.
The IRT needs to be competent and the organization needs to invest as necessary to help the IRT maintain its competence. When the tide turns ugly, the IRT is the primary line of defense. In the EDA example, the OIG report has this to say about the Department of Commerce's (DOC) IRT:
“DOC CIRT's inexperienced staff and inadequate knowledge of EDA's incident response capabilities24 hindered its ability to provide adequate incident response services. DOC CIRT's incident handler managing EDA's initial incident response activities had minimal incident response experience, no incident response training, and did not have adequate skills to provide incident response services. The lack of experience, training, and skills led the incident handler to request the wrong network logging information (i.e., perform the wrong incident analysis), which led EDA to believe it had a widespread malware infection, and deviate from mandatory incident response procedures. The Department's Office of the Chief Information Officer should have ensured that all DOC CIRT staff met the Department's minimum incident response qualifications.”
Supporting team
During an incident, there is much more happening than technical sleuthing. Communication is an important aspect of the duties of the IRT. One of the special features of incidents relative to routine IT operations is the extreme interest among different constituencies for information. Often these information needs are inconsistent with each other. End users are greatly interested in knowing when their services will be restored. Compliance officers are interested in knowing whether any information has been compromised. If there is any possibility of wider public interest in the incident, the media is immediately interested in the comments of the senior-most executives of the organization before the next news show. When you receive these queries, often you will not have enough information to respond satisfactorily (Figure 11.1).

Managing information flow is important in these circumstances. It is especially important to resist the temptation of conveying speculation as informed “expert” opinion. While it is useful to acknowledge incidents, particularly those that affect end users, it is advisable to follow the concept of “need-to-know.” Need-to-know is an information management principle where a person is only provided the information that is necessary to perform their job.
Need-to-know does not imply that events are supposed to be kept secret. Instead, consistent adoption of need-to-know decreases unnecessary calls to IT personnel from managers seeking “privileged” information. Information seekers can be directed to websites or other channels specified in the incident response policy. Before updating such information, the IRT should consider the intervention of the legal department to decide on what will be disclosed, and how it will be disclosed. In terms of communication with the general public, three entities should be considered:
- Media Relations: if the organization has such a department, any and all information with the community outside the organization should be routed through this department. They have the know-how and experience on how to deal with an event.
- Legal Counsel: the legal department will verify if any federal or state disclosure laws apply to a particular event, especially when it involves problems with data confidentiality. Unintended disclosure may have severe financial and public relation consequences to the organization.
- Law Enforcement: universities have a local University Police. No outside law enforcement agency is allowed to enter a campus, not even the CIA or FBI, without the knowledge of both the Universal Police and General Counsel.
These steps minimize the possibilities of rumor-mongering, ill-informed publicity, and general disorder during incident response.
Need-to-know is common in military and espionage settings as a way to keep personnel safe. If the enemy knows that a soldier or spy has no privileged information, the enemy is less likely to invest in the effort required to capture the soldier or spy.
Communication
Let's take a look at communication, since it is a key part of the response to an incident (Figure 11.2).
Reporting an incident for follow up Incidents may come to the IRT attention in a variety of ways.
On a Direct Report, the asset owner or custodian may report the incident himself. For instance, say you cultivate the healthy habit of looking up your Social Security Number on Google from time to time. One day, presto, you get a hit. It looks like the number was found on a word document from a class you took a long time ago at your previous university. As a knowledgeable user, you look up the IT person responsible for security immediately and report that your SSN is exposed.
Another possibility is an Anonymous Report. Organizations usually maintain processes by which someone can report an issue anonymously and not be afraid of reprisal. One such example could be allegations that a high-ranking university official is printing material of pornographic nature on university printers. This allegation would ring all sorts of bells at the university, from public relations risk to sexual harassment and inappropriate use of tax dollars. Understandably, assuming the allegation is true, an employee would not desire to see his or her name linked to such an allegation in fear of losing his or her job.

The Help Desk may be involved in the reporting as well. Maybe, during the process of resolving a problem, the help desk employee stumbled on to something. A misconfiguration of shared network drives, for instance, allowing too much access to users without need-to-know. Perhaps the Help Desk received a report from a user who found something. The reason we should consider the Help Desk as a separate reporting entity is because normally help desks have trouble tickets, which themselves may be visible to a large group of people. Consider how much detail would you like to see on a Help Desk ticket? It goes back to controlling the message and need-to-know.
Finally, Self-Audit methods such as periodical vulnerability assessment and log analysis may bring to surface breaches that must be handled. One common example is that of an administrator who discovers a breach because the computer CPU load was too high, causing availability issue. Once the administrator is called to analyze the problem it is quickly apparent that a runaway FTP process is the guilty party. This FTP site stores mp3 files for hackers to share with each other and it is heavily used, causing the high CPU load. Unfortunately, this is an all too common scenario.
Notifications More often than not, as soon as an incident becomes problematic, people in the organization will start asking questions. This is especially true for those folks affected by the event. If the event is affecting managers and other executive leaders, the pressure for quick communication and resolution will be even greater.
IT Personnel and the IT Help Desk should be maintained informed, especially when the event affects the availability of the asset. Users will quickly overwhelm the Help Desk with calls if the event involves an asset which criticality to the organization has been deemed “essential.” On a decentralized IT environment, like many large research universities across the United States, other IT organizations should also be informed to be in the lookout. For instance, if the event is a Denial of Service attack made possible thanks to an unpatched vulnerability, other units may wish to perform an emergency patching session before they also suffer the consequences of the DoS attack.
Management must be kept updated. It is a good idea to inform managers and other executives periodically, even if nothing has changed. This will keep phones from ringing, even those direct calls to engineers who are supposed to be dedicating 100% of their effort to the containment and eradication of the problem. Quick text messages and brief email messages with status updates are very useful in this situation.
End users and customers also get very edgy when they don't know what is going on. There are always two questions that are asked during an outage: when will the system be back, and what happened. At times they are both difficult to answer. In December 2013, Facebook suffered a massive outage throughout the Internet due to DNS problems. Even though the service itself was down for only 15–25 minutes, users around the globe were frustrated and confused, as one of the thousands of tweets sent out during the outage attest (Figure 11.3).

We can go back to our trusty EDA example to see what can go wrong with communication. In fact, the early part of the report lays the blame for the fiasco largely on poor communication between the Department of Commerce and its unit, the EDA. From the report:
DOC CIRT sent two incident notifications to the EDA. In the first incident notification on December 7, 2011, DOC CIRT's incident handler requested network logging information. However, instead of providing EDA a list of potentially infected components, the incident handler mistakenly provided EDA a list of 146 components within its network boundary. Receiving this notification, the subsidiary unit, the EDA believed it faced a substantial malware infection, affecting all the listed 146 components.
DOC CIRT's mistake resulted in a second incident notification. Early on December 8, 2011, an HCHB network staff member informed DOC CIRT that the incident handler's request for network logging information did not identify the infected components. Rather, the response merely identified EDA components residing on a portion of the HCHB network. The HCHB network staff member then performed the appropriate analysis identifying only two components exhibiting the malicious behavior in US-CERT's alert. With this new information, DOC CIRT sent EDA a second e-mail incident notification.
DOC CIRT's second incident notification was vague. DOC CIRT's second incident notification did not clearly explain that the first incident notification was inaccurate. As a result, EDA continued to believe a widespread malware infection was affecting its systems. Specifically, the second incident notification began by stating the information previously provided about the incident was correct.
EDA interpreted the statement as confirmation of the first incident notification, when DOC CIRT's incident handler simply meant to confirm EDA was the agency identified in US-CERT's alert. Nowhere in the notification or attachment does the DOC CIRT incident handler identify that there was a mistake or change to the previously provided information.
Although the incident notification's attachment correctly identified only 2 components exhibiting suspicious behavior – not the 146 components that DOC CIRT initially identified – the name of the second incident notification's attachment exactly matched the first incident notification's attachment, obscuring the clarification.
DOC CIRT and EDA's misunderstanding continued over the next 5 weeks, though additional communications occurred between DOC CIRT and EDA. Each organization continued to have a different understanding of the extent of the malware infection. DOC CIRT believed the incident affected only two components, whereas EDA believed the incident affected more than half of its components. Several factors contributed to these different interpretations:
- DOC CIRT assumed EDA understood that its second incident notification superseded the first incident notification and that there were only 2 potentially infected components – not 146. However, DOC CIRT did not follow up to establish whether EDA understood the new information.
- EDA responded to the second incident notification by providing a sample of two components (on the list identified in the first incident notification and that were exhibiting malicious behavior) for forensic analysis. DOC CIRT believed the sample to be the same two components identified in the second incident notification.
- When DOC CIRT confirmed that the sample of 2 components was infected with malware, EDA believed that DOC CIRT had confirmed the malware infection for all 146 components listed in the first incident notification.
- DOC CIRT did not retain the first incident notification showing 146 components or document initial incident response activities. Therefore, when DOC CIRT management became involved in the incident response activities, they could not see that a misunderstanding had occurred.
Compliance
Compliance is the act of following applicable laws, regulations, rules, industry codes, and contractual obligations. Ideally, compliance requirements are best-practices developed to avoid well-known past mistakes. In practice though, compliance is often important because non-compliance leads to avoidable penalties. In any case, you need to be aware of any compliance requirements associated with incident response that are applicable to your context and act accordingly.
As an example of compliance requirements in incident response, the Federal Information Security Management Act1 (FISMA) requires Federal agencies to establish incident response capabilities. Each Federal civilian agency is required to designate a primary and secondary point of contact (POC) with US-CERT, the United States Computer Emergency Readiness Team,2 and report all incidents consistent with the agency's incident response policy.
As an example of FISMA compliance, when a known or suspected loss, theft, or compromise of PII (personally identifiable information) involving US Navy systems occurs, the Department of the Navy is required to:
- use OPNAV Form 5211/13 to make initial and follow up reports,
- send form US-CERT within 1 hour of discovering a breach has occurred,
- report to the DON CIO Privacy Office within 1 hour,
- report to the Defense Privacy Office,
- report to Navy, USMC, BUMED chain of command, as applicable.
Hardware and software
To be effective, the IRT needs the appropriate tools. A sampling of the hardware and software recommended by NIST 800-61 rev.2 for incident response includes:
- backup devices to create disk images or other incident data,
- laptops for gathering, analyzing data, and writing reports,
- spare computer hardware for “crash and burn” purposes, such as trying out malware and other payload found and considered “unknown,”
- packet analyzers to capture and analyze network traffic,
- digital forensics software to recover erased data, analyze modified, access, and creation (MAC) timelines, log analysis, etc.
- evidence gathering accessories such as digital cameras, audio recorders, chain of custody forms, etc.
One of your best friends during this part of the process is a search engine. A web search on a log snippet, an FTP banner, for instance, may reveal valuable information such as location of log files, configuration files, and other important clues to help the security team to build a more complete timeline for the event.
Out of the 855 incidents analyzed in the Verizon Data Breach Report of 2013, 81% leveraged hacking, 69% included malware, and 61% featured a combination of both. Therefore, it is only natural to assume that most of the time the members of IRT will be involved in the investigation and analysis of a hacking or malware infection and use specialized tools extensively. We have therefore devoted an entire chapter to such analysis.
Training
IT is an ever-changing world. New technologies, new acronyms bring along new assets and new threats. It is the job of the security analyst such as you to maintain awareness of those new assets and threats, especially those that may introduce risks to the organization. Some of you may have the luxury of specializing in an area of security, such as encryption or forensics. The core members of the IRT, however, must be generalists. They must be able to step back from their day-to-day functions and have a 30,000 feet view of the enterprise, assets, controls, threat actions, and consequences.
A security certification is a good start, not necessarily because you will retain all the hundreds of pages of information that will be thrown at you, like being asked to drink from a fire hose, but because it offers a baseline set of information on all aspects of security, especially things you may not have thought of quite yet. Good certifications will build on the introductory information provided in this book.
One such certification, offered by the ISC2 organization, is the Certified Information System Security Professional certification, or CISSP. The CISSP is based on what is known as the Common Body of Knowledge, information deemed important to security professionals around the world, including:
Access Control
Telecommunications and Network Security
Information Security Governance and Risk Management
Software Development Cryptography
Security Architecture and Design
Security Operations
Business Continuity and Disaster Recovery Planning
Legal, Regulations, Investigations, and Compliance
Physical (Environmental) Security
Other facets of training also merit consideration. Media Relations personnel, for instance, should be instructed on how to interact with the media, including the control of the message, the importance of not revealing sensitive information. Revealing technical details on how a malware infection was detected and controlled, for instance, could alert hackers and malware developers on how to sidestep the same controls in future releases of the malware. In certain situations, this control of the message goes directly against the principle that the public should always be communicated fully and effectively. Media Relations is a balancing act when it comes to incident response, much like implementing security controls: revealing too much may be a problem, revealing too little may also make matters worse.
Detection and analysis
The steps in the previous section ensure that the organization is prepared to an incident should it occur. In this section, we will look at the general incident detection and analysis process. Later in the book, we will take a more detailed look at some specific incident analysis techniques.
Initial documentation
According to NIST 800-61rev2, IRT members should ensure that the incident is properly documented, starting as soon as the event is detected. While this documentation will evolve as detection and analysis run their course, at the very least, information about the following items must be present in the documentation of an incident:
- The current status of the incident (new, in progress, forwarded for investigation, resolved, etc.)
- A summary of the incident
- Indicators related to the incident
- Other incidents related to this incident
- Actions taken by all incident handlers on this incident
- Chain of custody, if applicable
- Impact assessments related to the incident
- Contact information for other involved parties (e.g., system owners, system administrators)
- A list of evidence gathered during the incident investigation
- Comments from incident handlers
- Next steps to be taken (e.g., rebuild the host, upgrade an application).
Detecting an incident
Your organization has gone through the process of preparing for a security incident. You planned, trained, made a few purchases. Your analysis hardware is ready to go. Media Relations is prepped. Unfortunately, chances are your IRT will not have to wait for long to be put to the test. But how will the organization come to the realization that something is amiss? How will the incident be detected?
Visible changes to services One of the most common ways in which an organization discovers something is wrong with a system or data is through a visible change on the same data or system. Web defacement, for instance, is an example. Users of a website will quickly notice something is amiss when they visit the site and are greeted with the page shown in Figure 11.4.
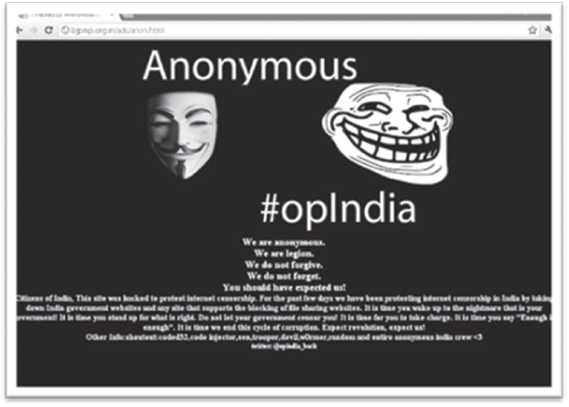
According to the VERIS Data Breach Report of 2012, an astonishing 92% of the breaches are reported by a third party. Let's put this into perspective, because it is pretty important. No matter what “silver bullet” a security vendor tries to sell you to protect your assets, to monitor the health of your security, chances are that when you have a breach, it will be reported to you by a third party.
Performance monitoring Another typical scenario is the breach causing performance issue. At times, either as a direct or indirect result of malware installed by a hacker, a computer system may become sluggish to such an extent that it becomes noticeable either to users or to administrators.
One of the popular uses for hacked computers is the use of the machine's storage as a repository of data, either for illegally sharing music, movies, or pornographic material. The latter seems to gain lots of attention from other hackers and lurkers (folks who frequent hacking circles but do not share any data). Once a computer is exposed to a malware and pornographic material shared from it, a user on the computer will quickly notice a decrease in performance because most of the computer's CPU and network bandwidth will likely be used for downloading of that material. This generally results in a call to the help desk.
Understanding normal behavior
In order to detect anything that is “abnormal,” administrators must first determine the baseline or normal behavior of the system. Some desktop computers in the university, for instance, are only used from 8 am to 5 pm, Monday through Friday. Therefore, the detection of a login attempt to these computers at 2 a.m. on Saturday should raise all sorts of warning flags.
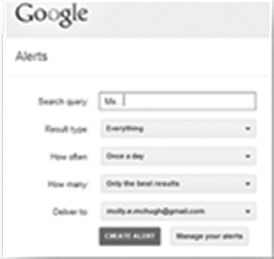
PII monitoring As a direct result of all the big breaches on large corporations and the resulting onslaught of coverage in the news, individuals have begun to be more careful with their personal information. As part of this process, users may head over to Google or other search engines and search for their own personal information, such as their Social Security Number (Figure 11.5).
Ten years ago it was common for professors to post students’ grades in front of their office door. Instead of using names, in order to protect the students’ identities, professors used Social Security Numbers (oh, the irony).
Now, ten years later, many professors still have the Word documents they used to post on their doors, with SSNs and grades. At times, these forgotten files end up in places where search engine crawlers pick them up and expose them to the world.
Google Alerts
Google Alerts is a tool offered by Google to help users keep track of topics of interest. A good use of the tool is to set it up to provide you with an alert every time your name is indexed by the Google crawler. You can enter the search query “John Doe” and instruct Google Alerts to send you an email as soon as it finds a new web page with the name John Doe in it.3
File integrity monitoring File integrity tools are software applications that monitor the integrity of files in a computer system. If a monitored file on a computer is modified, the administrator of the system will be immediately notified. These tools are often part of larger suites called Host-based Intrusion Detection Systems (HIDS). They are host-based because they are applications that run on a computer host, versus Network-based Intrusion Detection Systems, normally referred to simply as IDS.
Take the web defacement situation, for instance. Had the index.html (or equivalent primary file) been monitored by a file integrity tool, as soon as the page's integrity was affected (by the change in content), the web administrator would have been notified. Many tools also have options to automatically restore a file when it detects a change. Popular examples of tools containing file integrity monitoring applications are OSSEC (Figure 11.6), Samhain, and Tripwire.
File integrity monitoring tools quickly bring to light the concept of an FP or False Positive. A false positive is a find that appears to be a problem (a positive) but upon further investigation turns out not to be a problem (therefore, false). You also learned about this concept in statistics as a type-2 error. This concept is found in many “security detection” tools, from firewalls to vulnerability scanners.
Let's examine the specific issue of false positives in a file integrity tool. During installation of the tool, the administrator will be asked to specify what needs to be monitored. This is a decision that must be made carefully. What would happen, for instance, if you decide to monitor the integrity of the web server access log file? The access log file for a web server changes every time someone accesses your website. Therefore, warning bells would go off every time you had a visitor – a false positive.
While this may be “neat” for a slow website, on a busier site it would quickly cause you to neglect the warning. So, it is worth monitoring at all? In the case of a log file, the answer is no. But how about monitoring a configuration file? Or the index.html file on a website. Those may be worth monitoring.
Anonymous report At times individuals may be hesitant to report adverse events in fear of reprisal. Most institutions have means for employers and other parties to report perceived or possible events anonymously. These events could be, for instance, potential fraud incidents, inappropriate use of the organization's computing infrastructure by managers or other administrative employees, allegations of sexual harassment over emails, etc.
In many cases, internal institutional policies require that any and all allegation received by these anonymous reporting mechanisms be investigated. While in a perfect world this may be a good policy to follow, institutions have to be aware of the fact that individuals in position of power within organizations are at times not liked. Blindly following allegations, repeatedly, without proper verifications, could itself be a threat action against a personnel asset (a manager, for instance) putting the institution at risk.
Log analysis Logs are records of the performance of a machine. Logs are a security analyst's best friend. In terms of incident detection, logs are used by security administrators to determine the exact times when the system was under attack and what threat actions were used by a hacker (Figure 11.7).

In a Linux system, most logs are located under the /var/log directory. The majority of the operating system logs are controlled by the syslog daemon. The /var/log/messages file will usually be the first one a security analyst will examine, looking for irregularities such as strange error messages, irregular reboots, etc. Log analysis is covered in more detail in a later chapter (Figure 11.8).
In terms of detection, your organization may have a Log Consolidation solution, or a full-blown Security Incident Event Manager (SIEM). In a Log Consolidation solution, logs from multiple systems and applications are consolidated into a separate server for monitoring, forensics, and performance analysis. SIEM systems integrate consolidation with analysis. These systems look for patterns of irregularities across multiple systems to determine the possibility of any threats or breaches.
For log analysis to be effective, it is key that the clocks between all the servers feeding their logs in to the log consolidation server be synchronized. This synchronization is important to ensure that timelines are interpreted correctly when hackers probe, attack, and breach multiple systems.

Log consolidation has another advantage. Besides being able to look at log events in one place, making it easier to slice and dice the data to look for specific events, it also copies the log data on to another server, maintaining the integrity of the log. This is particularly useful when examining data looking for evidence of fraud perpetuated by individuals with administrative privileges. A Database Administrator is generally able to cover his or her tracks on the database system server itself but a DBA should not have more than read-only permission on a log consolidation or SIEM server.
End point protection management consoles End point protection or EPP is the evolution of our old friend the antivirus application. An EPP implies more than simply monitoring and protecting a computer system against a virus infection. EPP solutions usually include:
- Antivirus protection against malware “trying to install itself” on a computer, usually known as “On Access” protection or “Realtime” protection.
- AV protection with removal and/or quarantine of files that are found on your computer, already downloaded, either installed or not, through “On Demand” or “scheduled” scans.
- Firewall protection.
- HIDS, Host-based Intrusion Detection (optional).
- File Integrity (optional).
- Identity Theft (option).
- Children Access Monitoring (optional).
As you can see, EPP suites are quite a change from “just” a malware protection suite. Often times they also include “hooks” for management of other server applications, such as email, web servers, etc., getting closer and closer to a SIEM solution. While the cost or effort to install and configure a full-blown SIEM or log consolidation solution may be cost-prohibitive for an organization, EPP management consoles are often included with the price of the license for EPPs. Since even the smallest organizations invest in end point protection, they have the option of using EPP management suites to perform some log analysis functions (Figure 11.9).
Internal investigations Finally, it is worth mentioning those events found by internal investigations. Notably, we are talking about investigations originated by Internal Audit, State Auditors (if you work at a State entity), Human Resources, University Police, or General Counsel. At times, these investigations may start with something totally out of the technical area but need IT help for further evidence. For instance, if an employee is fired and ends up suing your workplace for unlawful termination, you may be asked by General Counsel to produce all emails between the executives of your workplace discussing the subject.

Another possible scenario would be internal auditors investigating a department's operations and find PII stored without approval from the security office and against policy. In this case, it is important to locate all irregularly stored information, classify it, and apply the appropriate controls before other audits (such as a credit card PCI audit, for instance) and other more severe problems threaten the data.
Analyzing the incident
Once there is an agreement that “yeah, there is an incident,” the IRT will start the process of analyzing the incident. The goal of the analysis is to discover all adverse events that compose the incident in order to properly and effectively manage the next phase of the cycle – containment and eradication. If the incident is not analyzed thoroughly, your organization will get stuck in a loop of detection and containment, with each iteration bringing more and more potential damage to the confidentiality, integrity, or availability of the asset involved.
Analysis will obviously change depending on the situation. In practice, you always should try to gauge the return you could possibly get from the analysis. For instance, let's suppose there was a malware outbreak in the Chemistry Department. Ten computers in the open use lab were infected with apparently the same malware strain. All of them presented the same backdoor, the same botnet, and using the same port number. If you have the time and resources available it would be ok to take a close look at all the machines, look for log files for the backdoors, check to see if any traces of actual human connections were noted using the system. On the other hand, since these are all open use lab machines with no personal data stored in them, it may be easier to only examine a sample of the machines.
Internet Search Engines are an incredible source of knowledge that can be easily tapped to gain information during analysis. Everything from FTP banners to port numbers on botnets can be searched to gain more insight on a particular malware installation.
Finally, as part of the analysis, you should be able to determine the stakeholders and any possible restricted or essential asset that may be affected by the incident. These assets will be your primary targets for protection and eradication going into the next phase of the incident management.
Containment, eradication, and recovery
Containment is the act of preventing the expansion of harm. Typically, this involves disconnecting affected computers from the network. For many incidents, there comes a point during the analysis when an event merits containment even before the analysis of the whole incident has been completed. This happens when the analyst is confident that the ongoing events merit action, and/or determines that the risk to the asset is too high for events to continue as is. Since containment may involve temporary shutdown of services, this decision needs careful thought in balancing the expected losses from disrupted services with the expected losses from spreading harm to other machines. The same consideration has to be made when we consider eradication, the removal of the causes of the adverse event (Figure 11.10).
There is no secret recipe for finding this branching point. It is largely determined by the experience of those individuals who are part of the IRT, along with input from management if possible.
Going back to our open use lab example, once the first computer is thoroughly analyzed, the software on the machine can be wiped and reinstalled. This is the recovery point, when the computer is turned back to the owner for normal operations. If this situation included a professor's computer that should be investigated, the IRT group may consider obtaining a copy of the hard drive and then releasing the machine to be wiped, data backed up, and OS reinstalled. By obtaining a copy or disk image we can quickly release the machine to be recovered without impairing the end user's duties while the analysis period continues.
Considering a more urgent example, if during analysis the IRT members find out that a backdoor is being used to actively transfer PII from a hacked server to other off-campus hosts, the connection should be broken as soon as possible. Thereafter, the backdoor can be handled, either through network access control lists, firewalls, or actual removal of the backdoor from the server prior to analysis. In all situations, the confidentiality, integrity, and availability of the asset must come before the needs of the analyst.
IRT should be aware of the impact of acting upon an asset involved in an adverse event, both at the micro and macro levels. Here's a situation when decisions may change drastically as data is available for analysis.
1:00 pm: A machine in the College of Medicine is found to have a backdoor.
During analysis, a few things should come to mind right away. “College of Medicine” is one of those Colleges that “may” have HIPAA compliance requirements associated with the data. Find out immediately if the machine contains HIPAA data. If the machine contains HIPAA data it must be handled immediately.
1:10 pm: Computer does not contain HIPAA data. It belongs to a faculty in Radiology, outside the HIPAA zone.
After a quick phone call to the local administrator we find that the computer in question does NOT contain HIPAA data. IRT “could” move to act if needed. What is the threat action posed by the box?
1:30 pm: Computer determined to be part of a grant bringing 100 million dollars to the University.
There better be serious backing up from the College Dean and possibly from the Provost before anything is done to this machine that could even remotely jeopardize anything running on this box.
Certain actions performed by the IRT during containment may prove difficult to recover from. Actions performed to contain a specific situation may put the organization at risk in other areas. Restarting HR systems to finish removing malware may interrupt payroll processing if performed at the wrong time. For these reasons, to the extent possible, it is important to notify all stakeholders before changes are performed on assets for containment. Please note that IRT members must continue to observe need-to-know during these notifications. A payroll manager may have to be filled in as to why a server is being restarted, but not necessarily everyone in the payroll department.
Another decision that needs to be made during containment is whether to sit back and observe hacker behavior or immediately contain the problem. It all boils down to the potential amount of damage to assets. While the initial jerk reaction of system administrators is to immediately squash the bugs and remove all tracks, observation may be beneficial to the organization. It may reveal other attack vectors used by the hacker, other assets already under hacker control, and many other useful pieces of information.
IRT members and administrators have to be careful when pulling the plug on hackers. Efforts to do so should be orchestrated and coordinated as much as possible. Hackers have been known to turn destructive when found out, in an effort to further cover their tracks and remove all local logging information that may lead to their capture. Database administrators involved in fraudulent situations may set up traps that, when invoked, totally destroy the database and all data contained in it.
It is for this reason that FBI agents involved in sting operations against hackers forcibly and speedily remove individuals from keyboards and other input devices as soon as possible when they are caught. This minimizes the possibility that the hackers might initiate scripts to destroy assets and evidence.
Lessons learned
The final stage of the incident handling procedure is also what allows us to prepare for the next incident. In this final part, IRT members gather their notes and finalize their documentation. The documentation should contain all individual adverse events involved in this incident, together with time stamps and assets involved, as well as:
- Indicate which areas of the organization were involved in the accident and what was the resulting breach;
- How the threats were handled individually by each department and together under the coordination of the IRT;
- Extent to which existing procedures were appropriate to handle the issues and opportunities for improvement;
- The extent to which the assets were appropriately identified and classified, so that the IRT could make quick judgment calls as the situation evolved;
- Extent to which information sharing with stakeholders was done satisfactorily;
- Opportunities for preemptive detection to avoid similar issues from happening;
- Technical measures necessary to be taken to avoid similar issues in the future.
So, how was the EDA incident finally resolved?
In February 2013, over a year after the initial alert, the Office of the Inspector General at the Department of Commerce (DOC) assured the EDA and the DOC that the damage was limited to two systems. Assured that there was no significant incident, the DOC started recovery efforts in February 2013, and needed only a little longer than 5 weeks to restore EDA's former operational capabilities. By comparison, EDA's incomplete efforts spanned almost a year.
Specifically, the [DOC] provided EDA with enterprise e-mail, account management services, help desk support services, and a securely configured and uniform image for its laptops. Additionally, the Department restored EDA users’ access to critical business applications.
The disaster
In the world of incidents there is that monster that has huge repercussion throughout the whole organization and can quickly bring a prosperous company down to its knees: the disaster. A disaster is a calamitous event that causes great destruction. A disaster may be considered a huge incident, or an incident so large that it involves multiple sub-incidents, or an incident that affects the entire organization. Whichever way you look at it, a disaster is an incident with major implications on multiple stakeholders.
Let's start with a few definitions. Disaster Recovery (DR) is the process adopted by the IT organization in order to bring systems back up and running. DR may involve moving operations to a redundant site, recovering services and data.
In 2002, a hardware failure in the student email servers caused all 30,000 student email accounts to be lost at the University of South Florida, including the data they contained. Immediately the DR plan kicked in gear, calling for the re-creation of all student email accounts. These accounts were to be initially empty but would allow students to start sending and receiving emails. Once that was done, all data mailboxes were extracted from tape and restored to the users’ mailboxes. The entire DR process in this case took about 3 weeks.
DR is an extremely complex process and is something usually tackled by individuals with years of experience in the organization. In large organizations, there are often individuals solely dedicated to the subject. In all likelihood, you are not likely to be given DR responsibilities in the early part of your career, so the subject is not covered in detail in this book. The topic is introduced here to familiarize you with some basic concepts and to enable you to contribute to the process.
DR is a piece of the bigger picture, Business Continuity Planning or BCP. Business continuity planning is the process for maintaining operation under adverse conditions. During BCP, planners contemplate what would happen in case of a disaster, and what would be minimally necessary to help the organization continue to operate. In the case of the USF email system, questions included how students would turn in their assignments, which funds would be used to purchase new hardware, how to make any insurance claims, and what other effects did the outage have on the organization?
By its nature, BCP and DR involve and are often led by entities other than IT. For instance, it makes no sense for organizations to work isolated from each other when preparing for a hurricane or a tornado. Such events will affect the entire organization. HR may require that all individuals stay at home if there is a possibility of a hurricane level 4 or higher. Meanwhile, IT may need employees to physically be present to shut down servers and desktops. Co-ordination between these groups will ensure that appropriate actions are performed.
An important part of BCP is the Business Impact Analysis or BIA. Business Impact Analysis is the identification of services and products that are critical to the organization. This is when the classification of assets we've seen in previous chapters comes in play. Essential assets must be those that directly support the services and products that result from the BIA. The BIA then dictates the prioritization of the DR procedure.
The primary objective of any BCP/DR plan is to keep employees and their families safe. Nothing should be done that puts an employee in jeopardy, and preparations should be made to allow for methods of implementing recovery of assets that do not include hazardous situations. Here are some other things to consider:
- A call list, maybe something as simple as a card-sized list of phone numbers, is an incredibly useful tool for employees to have in case of a disaster.
- How you will inform fellow employees if local phone systems are down?
- If you back up your data to tape, locally, by a device attached to your server, how will you recover the data at a redundant site? Which data should be restored first?
- Does anyone besides you know how to restore the data? Are there instructions published somewhere? If the expectation is that someone will read a 100-page manual before initiating the restore, the procedure must be simplified.
- Are test restores done regularly? Tapes and other media go bad, get scratched, and become unreadable.
- Are there means to acquire new hardware to quickly replace the hardware damaged by the disaster? If cyber insurance is involved, does someone know the details on how to activate it?
Example case–on-campus piracy
These are the personal notes of a System Administrator on a case at the University of South Florida. This case happened prior to 2005 and all personal names and host names were changed to protect the individuals involved. Such detailed incident reports are difficult to find in the public domain because they are usually need-to-know and never published.
We will call the students Greg Apple and John Orange. Both students were undeclared majors. The SA's notes on the timeline of the incident are as follows.
Monday, Oct 17:
I received reports that the root partition on SERVER-A was full. It turns out two students (login names jorange and gapple) had been using /tmp to store about 10GB worth of zipped files. I removed most of the files.
In the evening, our Network Administrator sent me this mail:
“I wacked an account by the name of gapple on SERVER-A tonight … He had 2 logins from different sides of the country at the same time … On top of this he seems to have picked up a password file, which is in his account, from somewhere off the net … Also, do a last on this guy, it doesn't appear as if he ever sleeps … I'll talk to you in the morning….”
The password file seemed to have originated from somedomain.com.
Together with the password file on gapple's account there was a file containing a long directory listing from a user “mikel”. I did a finger on [email protected] and ‘bingo’, there he was. I sent mail to [email protected] but I did not get any reply.
Tuesday, Oct 18:
I noticed in the morning when I logged in to SERVER-A that jorange had a telnet session to somedomain.com. I decided to check his home directory and its layout looked very similar to gapple. I ftp'd some of the files he had stored on /tmp over to my PC and unzipped. They turned out to be pirated games. I started monitoring jorange's actions very closely.
Will (the network administrator) informed me that thepoint.com is a freenet site, with full fledged internet connections and shell access. He also told me he has an account there. Since I had not received anything from root@thepoint, I told Will to log in and see if he could snoop around “mikel's” directory, since it was 755. Will found 3 password files and more games.
***********************************************
From the log files, I have found connections from the following hosts to either gapple's or jorange's accounts:
- [email protected] – Jack Laughlin's account
- hopi.anotherdomain.net
- [email protected] – Mike Lee's account
- server0.thriddomain.net – Randy Sharr's account
There might be more accounts compromised on these sites.
************************************************
Evidence on gapple:
- Password file from somedomain.com.
- File containing listing of the directory thepoint.com:/˜mikel
- Log files indicating logins from gapple@servera to jorange@servera.
Evidence on jorange:
- Pirated software on /tmp. We have copies of the stuff locally on to another server but the actual files were removed last night before the account was closed.
- Mail received by jorange from anonymous users, giving the location of a new site for pirated software. The existence of this new site was confirmed.
- Log files of ftp transfers from somedomain.com, using a fake account mikel. The existence of the [email protected] account and its contents – pirated software – were confirmed by [email protected].
As a result of these findings, both students were suspended from the University for breach of the Code of Ethics.
SUMMARY
In this chapter, we looked at the incident handling process. We saw that effective organizations do not wait for incidents to happen before figuring out how to deal with them. Rather, they proactively prepare to deal with information security incidents. Such preparation involved developing a policy to guide incident response, agreements on communication plans, procedures for establishing incident response teams, and acquiring appropriate tools to respond to incidents. Incidents are detected by noticing abnormal behavior. We saw that while responding to incidents, it may become necessary to disable services to contain the damage. Finally, we introduced concepts related to disasters or large-scale incidents.
CHAPTER REVIEW QUESTIONS
- What is an information security incident?
- Provide some examples of incidents, preferably some that you have experienced yourself.
- What are the basic steps involved in handling an incident?
- Which of the above in your opinion is the most important? Why?
- What are the important activities involved in preparing for an incident?
- What is an incident response policy? Why is it useful?
- View the incident response policy for an organization (these are easily available online). What are the elements of the policy? What did you find most interesting about the policy?
- What is the scope of an information security policy? Why is it useful to define the scope of a policy?
- What is the incident response team? How is it constituted?
- What are some common issues involved in communicating about incidents?
- What is the need-to-know principle? Why can it be useful in incident handling?
- What is compliance? What is its relevance for incident handling?
- How can training help incident handling?
- Pick an information security certification of your choice and read its curriculum? In about one sentence each, describe how three modules of the curriculum might improve your ability to handle incidents?
- What are the common ways by which incidents are detected?
- What is log analysis? What can it be used for?
- If you used a file integrity tool such as OSSEC on your home computer, what folders would be most appropriate to monitor using the tool? Why? (you may want to try an open source tool such as OSSEC)
- What are the goals of incident analysis?
- What is containment? Why is it important? What are some measures you can take to contain the damage from a virus attack?
- What is eradication? What are some measures you can take to eradicate a virus attack?
- How can incident handling improve an organization's information security in the future?
- Treat the last semester as an incident. Write a simple “lessons learned” paragraph following a template analogous to the template used for information security incidents. Appropriately anonymize/generalize the lessons learned to maintain your privacy.
- What is a disaster? What is disaster recovery?
- What is business continuity planning? What are some things you can do as part of a business continuity planning exercise for your personal data?
- What is business impact analysis? How is it useful?
EXAMPLE CASE QUESTIONS
- Which of the incident detection mechanisms described in the chapter led to the detection of the incident?
- Who would be the appropriate people at the university campus to be notified of the incident once it was detected?
- What lessons did you learn from reading about the incident?
HANDS-ON ACTIVITY–INCIDENT TIMELINE USING OSSEC
In this exercise, you will use the copy of OSSEC that was installed during the hands-on exercise in Chapter 9 to monitor a simulated incident and construct an incident timeline.
To begin the incident simulation, switch to the super user account and execute the simulator script:
[alice@sunshine ~]$ su - Password: thisisasecret [root@sunshine ˜]# /opt/book/ incident-handling/scripts/begin_incident ######################################## ########################## Simulated Incident has begun! This script will run for 10-20 minutes. ######################################## ##########################
Once the script completes, start the OSSEC-WebUI interface by opening a web browser and visiting http://sunshine.edu/ossec
QUESTIONS
- How did the attacker attempt to access the system? What account was his/her target?
- Once the account was compromised, were any other accounts compromised?
- Was any new software installed?
- Were any new network ports opened or closed?
- Were any accounts added to the system?
- Generate a timeline of the major events that occurred in the incident. A Microsoft Word template for the timeline can be downloaded from http://office.microsoft.com/en-us/templates/timeline-TC001016265.aspx
CRITICAL THINKING EXERCISE–DESTRUCTION AT THE EDA
The EDA report is very useful reading for anyone interested in information security incident handling. For further thinking, here is another excerpt from the report:
Despite recovery recommendations from DHS and NSA advising EDA to focus on quickly and fully recovering its IT systems, EDA focused instead on building a new, improved IT infrastructure and redesigning its business applications. In September 2012 (8 months after isolation), EDA leadership presented to the Commerce IT Review Board (CITRB) a request to reprogram funds to carry out its recovery efforts; the CITRB did not approve EDA's request. EDA estimated it would need over $26 million disbursed in the next 3 years (an increase from $3.6 million to approximately $8.83 million, or about 2.5 times more, to the bureau's average annual IT budget) to fund its recovery efforts.
- Those suspicious of large government would use this information in the OIG report to suggest that the EDA merely used the incident as an excuse to destroy its existing IT infrastructure so it could secure funding for brand new IT equipment, an instance of gold-plating its infrastructure. How would you support or reject this suggestion based on the information in the report?
DESIGN CASE
You are asked by the Provost to prepare a one-page document describing what steps you would take in order to create an incident response team and prepare for hacking attacks. Prompted by a vendor of cyber insurance who convincingly presented a doom and gloom scenario, the Provost and President are concerned that Sunshine University would not be able to act quickly and decisively to resolve any issues that may occur and this will affect the image of the university. In your report, consider the following:
- What points should be addressed in an incident response policy?
- Which units should have representation on the IRT and why?
- Argue for centralization of resources in terms of campus security.
- Research the reporting requirements in your State in case of a breach.
- Research the protection offered by cyber security insurance.
1http://csrc.nist.gov/groups/SMA/fisma/index.html
3You can setup Google Alerts here: http://www.google.com/alerts?hl=en