
Chapter 6
Domain 4: Incident Response and Recovery
As a Systems Security Certified Practitioner (SSCP) you may be called upon to be a member of an incident response team and take an active part in security investigations. As an integral member of the security team you will be required to determine the difference between an event and an incident using many tools, logs, and monitoring techniques. Once an incident is identified, you may be required to take specific corrective or recovery actions, follow procedures, and record events according to incident response plans. You will need an understanding of how to handle incidents using proven methods that result in the preservation of a scene as well as careful acquisition, recording, and tracking of evidence. You will be expected to use plans and procedures that produce consistent results during an incident investigation.
As an IT team member, you may be required to perform duties in support of business continuity. A thorough understanding of the business continuity plan will enable you to take the required actions assigned to you during an incident or crisis that may cause potential harm to a portion or all of the business. It will be important for you to understand the terminology and techniques that may be applied during such an event.
In the event that parts of the enterprise are physically damaged, you may be involved in recovery operations. The disaster recovery plan will illustrate concepts and how they can be used in order to mitigate damages and recover business operations during an emergency event. You'll also be required to understand the recovery process so the business operations can be restored as quickly as possible.
Event and Incident Handling Policy
The incident response policy is part of the overall IT security policy for the organization. It is a high-level document that generally includes all aspects of the organization and all geographic locations. With very large organizations that span globally diverse countries or that include independent operating units or divisions, a number of incident response policies might be written to address individual locations or corporate requirements. The incident response policy establishes the foundation, authorities, and concepts upon which all incident response plans can be built.
The incident response policy includes the following components:
- Policy Charter A brief statement from the chief executive officer or highest executive sponsoring the policy on behalf of the organization.
- Objectives of the Policy A brief statement stating the desires of management to formulate plans, establish procedures, identify responsibilities, and take the required actions to discover and respond to incidents in a timely manner according to plan in an effort to mitigate damage to organizational assets.
- Standards A statement that the policy must adhere to laws, regulations, or standards to which the organization is subject.
- Scope and Limitations A statement concerning the breadth and depth of the policy. This may refer to the limitations of this response policy if there are separate policies for international divisions and other business units such as acquired or merged corporations, which may have their own policies.
- Roles and Responsibilities A statement defining the high-level responsibilities of executives and managers to formulate incident response plans, ensure the provisioning and assignment of individuals, and ensure that when activated the plan will be effective.
- Terms and Definitions A list of terms and definitions that enable all individuals to communicate effectively and consistently.
- Adherence A statement that details mandatory adherence to all plans, processes, and procedures created under the policy.
- Penalties A statement detailing a range of penalties that may be applied when lack of adherence to the policy occurs.
Standards
Standards are the criteria that the organization must meet or be in compliance with in order to avoid fines or other actions levied against the organization. Standards may be required to meet a contractual agreement between partner organizations. In some industries, industry standards such as the Payment Card Industry Data Security Standard (PCI DSS) are enforced to set various performance criteria and reporting standards. Federal regulatory bodies may also apply standards that must be adhered to during normal business and during times of crisis.
Standards imposed by industry organizations and regulatory agencies should be applied to an incident response policy. That may include requirements with respect to reporting the occurrence of an incident, recording aspects of handling the incident, and reporting the final outcome and incident closure.
Procedures
Procedures are lists the steps or activities that response teams should follow to perform all required duties as listed in an incident response plan. An organization may have several different incident response plans, depending on the nature of the incident.
Guidelines
Guidelines are informal lists of best practices or good practices either internal to the organization or as listed in various best practice frameworks such as an Information Technology Infrastructure Library (ITIL). A guideline may be a recommended course of action that is not included as an established procedure.
Creating and Maintaining an Incident Response Plan
When creating an incident response plan, individuals responsible should take into consideration various terms and definitions to be used throughout the organization. These terms and definitions should be integrated into the plan so that all of those involved may refer to the same terminology. Here is a list of some of these terms:
- Event An event is any occurrence of state change on a network, a system, a device, or software. The state change refers to an on/off condition, just as with a light switch. An event could be as simple as a user logging on, an application opening a specific port, the detection of certain type of packet on the network, or CPU usage reaching a set marked level. In other words, anything that happens could be listed as an event. All events as well as all activity might be logged. In some instances, events might be logged only after they reach a certain threshold.
On any network, there could be a great number of events happening all the time. Only a small fraction of these events might be classified as incidents.
- Incident An incident is an event that could cause harm to the organization. All incidents are events. In most organizations, an incident is defined as an activity that is a serious threat to or violation of the security policies, security practices, or acceptable use policies of the organization.
- Clipping Level A clipping level is a threshold of activity that, after crossed, sets off an operator alarm or alert. For instance, an intrusion detection system (IDS) may be set for a specific level of monitoring. In a denial-of-service flood, a large number of a certain type of packet will flood the network. Normally, intrusion detection system may be set to ignore this type of packet, but once the flood of these packets eclipses the threshold of the clipping level, the operator is alerted or other action is taken.
- Alert, Warning, Alarm An alert, warning, or alarm is a method of gaining the operator's attention. In many contexts, an alert is an email message to the operator stating that some noticeable activity has occurred. Warnings and alarms may appear on the operator's console in the form of banners, sounds, or other techniques to gain the operator's immediate attention.
- Baseline A baseline is an established criteria for measuring normal events as well as normal activity and traffic on the network. Baselines may be established for various network locations, network devices, as well as server performance on the network. They can be utilized for detecting events that are outside normally, established criteria.
- Tuning Tuning is the act of adjusting a device such as an intrusion detection system or intrusion prevention system to detect events, intrusions, and other anomalies that have exceeded the clipping level set for the device.
The incident response plan will detail the activities that should take place once an incident is detected. Some organizations may refer to the activities as an incident response cycle. The following phases are involved in a normal incident response plan:
- Prevent and Protect Of course, all organizations, as good practice, should perform risk assessments and, based upon the identified threats and vulnerabilities, take the necessary steps to mitigate any threats to the network. As a matter of ongoing operations, the network should be regularly monitored and all events should be logged appropriately. The prevent and protect cycle should be ongoing for all networks.
- Detect When prevention and protection efforts are unsuccessful, an operator should be alerted to take immediate action and implement an incident response plan. This plan should include the ability to identify and contain malicious and unauthorized activity on critical networks. The detection could be automated through the use of a monitoring device, software, or hardware appliance. This automatically creates an operator alert when a set threshold has been reached or exceeded.
Detection can also be manual, such as through log analysis, operator investigation, or observation. Operators using investigation or intuitive processes determine that there is a problem on the network.
- Analyze Analysis of a suspicious event is conducted to discover whether the event is in fact an incident and whether it is malicious or unintentional and to assess its impact, scope, and severity. Events must be classified as to their cause and impact because of the vast number the events that occur on a daily basis.
A great many sources can be used when analyzing data and information. In some cases, analysis involves tracking the event through various devices on the network. Triage is a medical term used in the analysis of events or situations and setting priorities. By setting priorities, incident response team can address various events and incidents in an orderly fashion.
- Respond Each organization has its own response and containment procedures based upon its distinct mission and different authorities. Response should be immediate in an effort to mitigate damage and contain the intrusion. Various actions undertaken by the team should be recorded for future reference. Response to intrusion should never be delayed in an attempt to find out where the attack originates. Immediate protection of the local enterprise environment must be the primary consideration.
Activities during the response include activating response teams, notifying management and executive members, and initiating contact with law enforcement agencies. Response activities should also minimize the knowledge that an attack has happened and contain the information on a need-to-know basis. Incident response plans must have a complete media communication section identifying spokespersons and the information that may be disseminated.
- Resolve The resolution of any cyber incident involves mitigating immediate damages and taking the actions required to prohibit additional attacks from the same vector. The resolution may include determining a source of attack, if possible, and taking actions such as adding firewall rules to guard against future activities. Resolution may also involve an after action report outlining a definition of the incident, actions taken, and future mitigation techniques.
An incident response plan should be created to address various levels of escalation of an incident. Not all incidents are created equal. Therefore, various response strategies may be implemented, depending on the triage or estimated severity of damage an incident may create. A typical table of alert levels is illustrated in Table 6.1.
Table 6.1 Alert levels
| Level | Label | Description of Risk |
| 4 | Severe | Highly disruptive levels of consequences are occurring or imminent. |
| 3 | Substantial | Observed or eminent degradation of critical functions with a significant level of risk. |
| 2 | Elevated | Early indications of the potential of risk. |
| 1 | Guarded | Baseline of risk acceptance. |
| 0 | Normal | Normal operations. |
Utilizing various levels or stages to describe an event is beneficial. For instance, different cyber incident stages may involve different personnel on a response team. Also, reporting responsibilities may depend on the stage.
Law Enforcement and Media Communication
A communication plan is a vital part of an incident response plan. During an incident or disaster event, the news media, business partners, and government agencies may require incident reports, event information, and news release or press statements concerning the event. It is very important to clearly describe in an incident response plan who within the organization is responsible to handle a press or law enforcement contact and what the correct message should be. On the other hand, through training, orientation, and policy, all personnel should be aware of how to handle any media inquiries and to whom to forward media inquiries. It is also important to include incident nondisclosure statements and all third-party vendor and contractor contracts.
Consideration should be given to the communications released to both law enforcement and the news media.
- Law Enforcement Communication An incident response plan must include the notification criteria of law enforcement agencies such as local police, FBI, and Secret Service. Depending upon law enforcement jurisdictions and international laws or regulations notification requirements will differ. For example, those organizations covered by the Health Information Portability and Accountability Act (HIPAA) and regulatory bodies such as the Department of Health and Human Services must report certain information breaches that affect individuals, to the media and certain other government agencies. On the international stage, many countries have adopted information reporting requirements based on the breach of privacy through the release of personally identifiable information (PII).
A major consideration when law enforcement is involved is determining the amount or type of evidence that can be collected. In some instances, private information, personal identification information, HIPAA-restricted information, and corporate confidential information may be part of the evidence of an incident. Evidence that is collected may become public through various court procedures.
An incident response plan should clearly specify the person or persons from the organization who are authorized to contact law enforcement and under what circumstances triggers the contact. It should also state what information they can provide and what services they can request. The response plan should include all of the law enforcement agency communication contacts, including with the name of the individual and their working hours and after-hours contact information. Meetings should be held with all law enforcement contact personnel prior to any incident to gain a full understanding of the responsibilities of all parties.
- Media Communication News media organizations in the world of 24/7 news coverage can be quite competitive in obtaining information that has the potential of being sensationalized through media outlets. Depending on how high the profile of the organization is or the type of information breach, media outlets may swarm the organization for information. Incident response teams should be trained and tested on how to redirect media questions and inquiries. It is important that all individuals within an organization understand the importance of information dissemination. Clear restrictions should be placed on the release of incident or information breach information through unauthorized channels such as Twitter, Facebook, or other social media sites.
The incident response plan should also include the departments responsible for handling dissemination of specialized information such as the legal department, public-relations department, investor relations department, and marketing department. Each of these departments should be involved in an incident response plan and determine how they will handle distribution of different types of authorized information that should be released to the media, shareholders, customers, and affected individuals.
Building in Incident Response Team
An incident response team is the core of the incident response plan. The members involved in an incident response team may vary depending upon the structure of the organization or the nature of the incidents encountered The proper structure of an incident response team includes representatives of the IT department, the human resources department, legal services, public relations, executive management, accounting/auditing, and the physical security department. A good incident response team consists of named individuals, and their alternates, who participate in training and exercises to adequately perform their duties during an incident. Ad hoc or “only person available” team membership should be avoided, but if that's the normal response action for a department, each person that might respond should receive incident response training. Secondary or supporting team members should also be identified, such as network administrators, database administrators, and technical experts.
An incident response plan should also identify third-party forensic companies that may be engaged depending upon the severity level of the incident.
Incident response teams may be constructed both on needs and geographic requirements. Here are some of the different types of teams:
- Full-Time Response Team This type of incident response team features full-time members who respond to incidents on a daily basis. Very large corporations, financial institutions, banks, and other organizations require full-time response teams based on the frequency of incidents.
- Functional Response Team Functional response team members report to other managers and departments throughout the organization and become members of incident response teams when they are required. A typical structure for an incident response team involved members from the HR department, legal, information security, IT, and other departments make up an incident response team.
- Outsourced Response Team Many organizations contract out network and system monitoring as well as the response to intrusions. Managed service contracts that involve handling incidents and providing incident response or offered by large organizations such as Hewlett-Packard, Dell and IBM. In many cases, the contract will also involve some local individuals within the company to assist the third-party response team. A hybrid incident response team is the combination of an external team and an internal team.
Incident Response Records
Incident response plans should be the requirement that the incident response team should be required to make incident response plans and keep activity records starting at the beginning of the incident and continuing through resolution. Team responders should record all actions and activities, either during the process or immediately thereafter, to completely document all actions taken during the event. The collection and documentation of all evidence, description of the scene, statements from individuals, and evidence processing notes must be filed and maintained in the event of a formal forensics examination or eventual legal action. Team responders should record all actions and activities, either during the process or immediately thereafter, to adequately document all actions taken. In the event of a forensic examination or eventual legal action, the collection and documentation of all evidence, description of the scene, statements from individuals, and evidence processing notes must be filed and maintained.
Many incident response teams regularly review after-action reports to identify areas of improvement.
A wide range of incident report templates are available on the Internet. At a minimum, the following incident response information should be recorded:
- Date and time of incident
- Type of incident or incident level
- Incident summary
- Incident discovery information
- Actions taken by individuals
- Contact information for individuals involved
- After-action report
Security Event Information
All digital records associated with an event that leads to an incident response must be retained. Event discovery or alerts may be triggered automatically through the use of intrusion prevention systems (IPSs) or intrusion detection systems (IDSs) or a number of other software solutions or hardware appliances. Events may also be discovered through manual review of system logs or other blog information.
Security Information and Event Management (SIEM) systems are used to provide a common platform to collect historical log information as well as real-time information from monitored devices. (Note that other texts may refer to this subject as Security Event and Information Management, or SEIM.) Applications are available that provide easy searching through multiple logs for correlating event information. The output logs of both real-time and historical investigations should be stored for an appropriate retention period. Corporate policy may require that event logs be kept for an indefinite period of time. The default on some log acquisition systems is 30 to 60 days.
Incident Response Containment and Restoration
The incident response plan should provide the details of all actions to be taken during a specific incident. Actions might include isolating the device from the network by, for example, disconnecting the Ethernet plug or pulling the power plug from the wall to shut down the affected network equipment. Plans may differ depending upon forensic investigation requirements. For instance, a forensic investigation might include disconnecting the device from the network but keeping the unit powered up so that volatile RAM memory can be recorded or examined. A Faraday bag may be utilized to shield a device that is connected to a wireless access point. A Faraday bag is designed as a shield to prohibit a device from transmitting or receiving radio signals.
It is never advisable to not take action and “monitor” an attack while it is in progress. In some cases, an IT individual may attempt to trace an attack back to its origin rather than terminating the attack. Such a trace is usually fruitless as attackers have many ways of disguising their actual location. Devices such as log files, monitoring appliances, honeypots, bastion hosts, and other devices may record the IP address or vectors of an attack. If an attack is discovered and not stopped, the organization may face various legal liabilities.
Many corporate incident response policies require that a post-incident restoration action be invoked after an attack. These usually require that the attack unit be reimaged or restored from known good backups. Rarely are devices placed back into service after only one anti-malware or antivirus scan.
Implementation of Countermeasures
Countermeasures are usually put in place as a response to a risk analysis. In many cases they are intended to mitigate specific threats or vulnerabilities. Controls involve a much broader category of risk mitigation tools and may be put in place in response to best practices or due care. In many situations, the terms countermeasure and control are used interchangeably.
As an SSCP, you may be involved in implementing countermeasures throughout the organization. These countermeasures may include hardware devices such as IPSs/IDSs, antivirus software, anti-malware software, and network-based hardware appliances. Countermeasures, such as intrusion detection and prevention devices, must be adjusted or tuned correctly to be effective on a network. A false sense of security may be prompted by an ineffectively adjusted protection device. Every network protection device should have an established baseline and the performance of the device should be measured regularly against the baseline.
The application of countermeasures in a network or on a device such as a host computer does not relieve the operators or administrators from responsibility. User training is important so that controls and countermeasures are installed and operated correctly.
Understanding and Supporting Forensic Investigations
Thanks to many crime shows, many are familiar with the science of forensics and a forensics investigation. We all know it involves the identification and analysis of materials usually found at an incident scene. Usually at the point of acquisition, the decision as to whether it constitutes evidence has not yet been determined. The goal of forensics and the forensics examiner is to analyze material using professional assessment techniques to answer various questions for investigators.
Digital forensics involves the investigation of computer related incidents and the gathering of computer related information that may have originated during an incident or an attack. All materials collected during a digital forensic investigation are subject to the same procedural guidelines and practices so that the evidence may be presented in a legal court trial.
A number of organizations establish guidelines for use during computer forensic investigations:
- Identifying Evidence Responding individuals must begin documenting everything that they find at an incident scene. They must record the facts as they present themselves, such as the location of devices, witness statements, obvious evidence, and suspected evidence owners as well as the nature of the incident. It also involves identifying the potential harm to the organization.
- Collecting or Acquiring Evidence Adhering to proper evidence collection and documentation techniques while minimizing incident scene contamination is vitally important. A chain of custody must be provided whereby every transition of possession is completely documented. It is important to preserve the accuracy and integrity of evidence through proper collection techniques at an incident scene. The chain of custody must be preserved from the moment the material is collected.
- Examining or Analyzing the Evidence The evidence is investigated and analyzed using sound scientific tests and methods which are acceptable both in the forensic community as well as in the court of law. The use of proven investigation tools to determine character and ownership of the evidence is required and may be required to be replicated by other forensics examiners.
- Presentation of Evidence and Findings Forensics examiners must present their evidence, findings, and professional opinions in documentation such as court presentations and legal briefs. Quite often, forensics examiners are required to testify as expert witnesses.
Incident Scene
In general practice, it's advisable to refer to the physical location of an incident as an incident scene rather than a crime scene. This avoids a rush to judgment as well as possibly unfounded or inaccurate accusations of individuals at the location.
In the case of the cyber incident, the incident scene is located in two environments:
- Physical Environment The physical environment is of course the actual location of the hardware involved. This may include simply the user workstation, a server in a rack, or even an entire network domain. In some cases the physical environment may be quite small, such as a cell phone, pad, or individual laptop.
- Digital Environment The incident scene in a digital environment may be much more complex and require greater expertise to acquire materials and evidence. Some evidence may be retained in volatile RAM or on an attached hard disk drive, other evidence concerning the same incident may be stored on servers, network-attached storage, storage area networks, and even cloud-based storage. With each of these remote locations, increasingly sophisticated techniques may be required to acquire the evidence.
First responders to digital incident must be trained on how to preserve a digital incident scene. If evidence is contaminated, changed, or altered it is no longer any use during the investigation. During an attack or other incident, users should be educated to step away from their host machines workstations or other digital equipment to allow the incident response team and forensics examiners to gather material and data.
It is a well-known fact in forensic science that just observing evidence changes it. For instance, let's say that you want to check a file to see when it was last accessed. By doing this, you put the current date on that file.
Volatility of Evidence
The volatility of evidence determines the priority that evidence must be collected. The volatility is determined by the life expectancy of evidence once power is withdrawn. As might be expected, evidence resident in RAM will be deleted or eliminated once power is withdrawn.
The following list includes evidence from the most volatile to the least volatile:
- CPU, cache, and register contents
- Routing tables, ARP cache, process tables, kernel statistics
- Random access memory (RAM)
- Temporary file system/swap space/page files
- Data on hard disk
- Network archive data/storage area networks/network attached storage
- Remote-based cloud storage
- Data contained on archival media, disk-based backup, tape-based backup, USB drives
Forensic investigators usually acquire and process data in the order of volatility. Some incident response plans call for immediate disconnection and shut down of the target host or server. This eliminates the accessibility to any volatile memory that might be stored in RAM or register type devices.
Forensic Principles
Dr. Edmund Locard was a pioneer in forensic science and formulated Locard's exchange principle, which states that the perpetrator of a crime will bring something to a crime scene and leave with something from it. This is the foundation of trace evidence, that the perpetrator may leave dirt, hair, fingerprints, smudges, oils, or other residue at a crime scene. It also holds that the trace evidence from a crime scene will leave with the perpetrator, such as carpet fibers and other minute pieces of evidence that may link the perpetrator to the location.
In digital forensics, Locard's exchange principle holds that any perpetrator of an intrusion leaves behind trace evidence within the system. This trace evidence may be used to identify the attacker.
Chain of Custody
Chain of custody refers to a forensic principle whereby each movement or transfer of data must be recorded and logged appropriately. If the chain of custody is disrupted by any means, evidence may not be presented in court. Evidence should be appropriately identified, including the circumstances under which it was collected it, including a detailed description of the material when it was collected, as well as other important information. In most cases, evidence is packed in poly bags for transport to a forensic laboratory or storage location.
The evidence documentation must include, at a minimum, the following information:
- Date and time of collection
- Description of the evidence
- Who collected the evidence
- Incident identification or summary
- Evidence discovery information
- Actions taken by individuals
- Contact information for individuals involved
- Chain of custody
- Other collection or handling information
Proper Investigation and Analysis of Evidence
Proper steps must be taken to ensure that data could not be altered. While working with a live hard disk, the forensic investigator will use a specialized write-block hard disk controller that will prevent the writing of any information on the hard drive during an investigation. Figure 6.1 illustrates an industry-standard write blocker attached to a hard drive under investigation.

Figure 6.1 A hard drive attached to a Tableau portable forensic write blocker
All data on a hard drive under investigation should immediately be copied using industry-standard bit copy software. Products such as EnCase, developed by Guidance Software, and Forensics Toolkit from Access Data offer a suite of tools used by digital forensic examiners to not only create a bit-for-bit copy of hard drive data but also hash the contents to ensure data integrity between the original hard drive source and the copy. The hash value will ensure that no changes have been made to the original disk image. The hash value for an image can be calculated and compared with the original hash value of the data. A data copy should always be used during an examination, while the original is stored as primary evidence.
Interpretation and Reporting Assessment Results
While the forensic examiner is performing the examination of the evidence, they will allow the character of the evidence to lead to various suppositions and potential conclusion possibilities. This is the interpretation process that the forensic expert will use to determine the importance or significance of various pieces of the evidence information. Through experience, training, and proven forensic examination techniques, the forensic examiner will interpret the data and formulate a conclusion. On occasion, the data will be insufficient to draw any conclusions.
Once the forensic examiner has examined the evidence, they will prepare a report. The examiner's report is very important as it provides information concerning the evidence, the analysis techniques, and the resulting findings to the incident investigator, the prosecutor, other attorneys and possibly the court by way of testimony. Forensic examiner reports differ in content but generally contain the following sections:
- Summary of findings
- Identity of the reporting agency
- Incident or case identifier or submission number
- Incident or case investigator
- Identity of the forensic examiner
- Identity of the submitter (if different)
- Date of receipt of evidence
- Date of report
- Descriptive list of items submitted for examination, including serial number, manufacturers, make, and model
- Identity and signature of the examiner
- Brief description of steps taken during examination, such as string searches, graphics, image searches, and recovering erased files
- Detail of findings
- Results/conclusions
It is quite common for either legal side of the court case to request to see the “examiner's notes.” The forensic investigator must keep a log of every action taken and test applied during the evidence examination process.
Understanding and Supporting the Business Continuity Plan and the Disaster Recovery Plan
As a security practitioner, it is essential to understand both business continuity and disaster recovery programs for the organization. It is almost certain that you will be involved in either or both programs, either during the planning and creation phase or in the event that one or either plan must be put into action.
These plans are created with the assistance of key personnel such as department heads, executives, and subject matter experts throughout the organization. Each plan is the result of an executive-sponsored policy that directs the creation and implementation of such a plan.
The very survival of the business or enterprise rests upon the accuracy of the procedures directed in each plan. A great many businesses neglect to either formulate a plan or maintain the plan over time.
Emergency Response Plans and Procedures
Emergency response plans differ from incident response plans in that an incident response plan usually refers to a network intrusion. Emergency response is generally much broader in nature. For instance, an incident may be a network intrusion that plants malware on several host machines. An emergency is the network being down for an appreciable amount of time, affecting ongoing business operations.
There are two types of emergency response plans:
- Disaster Recovery Plan A disaster recovery plan (DRP) is a documented set of procedures used to recover and restore IT infrastructure, data, applications, and business communications after a disaster event. A disaster may be natural, in the form of a flood, tornado, or wildfire, or it may be man-made, in the form of a terrorist attack or willful destruction of property. Man-made disasters can be intentional or unintentional.
- Business Continuity Plan The business continuity plan (BCP) is a documented set of procedures used to continue business operations in some form to enable the organization to maintain its business capacity during some event. This plan may entail substituting equipment or workspaces, temporarily relocating equipment and individuals, and reducing or eliminating noncritical services for a period of time. An event for which a business continuity plan can be used might be a localized fire, power outage, weather-related event, or man-made disaster.
Business Continuity Planning
Business continuity planning is a set of procedures and prearrangements that can be put into action in the event of a disaster. The effort of the continuity plan is to maintain, as best as possible, business as usual in the face of a crisis. The business continuity plan is the result of a business continuity policy approved at the executive level. A substantial commitment of personnel and funds is required to achieve an actionable plan. Without significant corporate executive support, a business continuity plan stands little chance of success.
A number of terms are used when creating a business continuity plan. These terms are described in the following sections.
Business Impact Analysis
A business impact analysis is performed to determine the resulting impact to the business of the full or partial loss of an operational functional unit of the business. For instance, a manufacturing unit was shut down because of a hurricane flooding the facility. What effect would it have on the overall performance of the business? In some cases, manufacturing may be shifted to another location. If manufacturing cannot be shifted to another location, the issue becomes how long the business can survive and be a viable entity without the manufacturing unit.
The business impact analysis determines the functions of the business that are critical and functions of the business that are noncritical. Every business is unique and, depending upon the types of goods and services provided, has both essential and nonessential business functions within it. In order for a business impact analysis to be successful, all functions of a business, essential or not, must be identified. Once identified, they are categorized as to essential or nonessential activities. This categorization may be simply ranking the activities on a 1-to-5 scale with, for example, 5 being the most essential.
Maximum Tolerable Downtime
Maximum tolerable downtime (MTD) is the total amount of time the organization can be without the department or business function before irreparable harm is done to the organization. In other words, the maximum tolerable downtime is the point after which the survivability of the business is in question. In some circles, maximum tolerable downtime may also be referred to as maximum tolerable period of disruption (MTPoD).
Recovery Time Objective
Recovery time objective (RTO) is a point in time when a lost or “down” business functionality has been totally restored. Each operational business function may support a different recovery time objective depending upon the function or service. Recovery time objective can be categorized in minutes, hours, days, weeks, or even months. Of course, recovery time is based on a great many factors, including labor, repair parts, new equipment delivery, and event facility repair and build-out. Naturally, the recovery time objective cannot be longer than the maximum tolerable downtime.
Recovery Point Objective
Recovery point objective (RPO) specifies a point in time to which data can be restored. The recovery point could be the last full backup plus any completed incremental or differential backups that might've taken place after the full backup. The more frequent the backup, the less data will be lost during a business disruption event. For instance, if the organization uses a dual-write technique such as a RAID-1 mirror backup where the second drive is a cloud drive or off-premises drive, the recovery point objective could be at the point of the business disruption event.
Figure 6.2 illustrates a timeline with the business disruption event in the center (the crash event). The maximum tolerable downtime (MTD) indicates the maximum time the organization can be without the business operational unit. The recovery time objective (RTO) is the point at which full operation will be restored, and the recovery point objective (RPO) indicates the point in time at which reliable data for backup purposes is available. Notice that the vertical line represents cost. The bell-shaped graph represents a cost versus timeline. For example, the closer you move the recovery time objective to the business disruption event, the more it will cost the organization. The closer you move the recovery point objective to the business disruption event, meaning that backups are made more frequently (up to complete data mirroring), the more costly it is for the firm to create the backups.

Figure 6.2 A cost/timeline graph Illustrating the relationship between MTD, RTO, and RPO
Since business units require IT processing to perform their duties, IT systems and business network capabilities must be fully operational prior to the maximum tolerable downtime (MTD) of the departments served.
Disaster Recovery Planning
After a disaster event, it is extremely important to restore IT services and functions. The restoration process may be detailed for a disaster recovery plan. The high-level disaster recovery policy is an executive-supported policy that sets forth the creation of the disaster recovery plan (DRP).
In the event of a disaster affecting IT operations, all IT personnel, including you as an SSCP, will participate in recovery efforts to restore IT services as soon as possible. As you have seen, in business continuity planning, the majority of business operations are contingent upon active and reliable IT services and functions.
The difference between a disaster recovery plan and an incident response plan is that an incident response plan details the methods and procedures used to detect and stop an imminent threat to the organization's IT assets while the disaster recovery plan is designed to rebuild, recover, and restore damaged assets to full operational capacity. Restoration operations may take a period of time and significant coordination and effort to rebuild or refurbish facilities, restore order, restore and provision hardware products, and restore data and applications from backup sources.
There are some things to consider during the creation of the disaster recovery plan. Some of these considerations are detailed in the following sections.
Identification and Ranking of Disaster Types
As with incident response planning, a disaster recovery plan begins with identifying various disaster types. Disasters may be the result of either natural causes or man-made causes. Natural disasters include hurricanes, tornadoes, mudslides, forest fires, floods, and other disasters caused by weather-related events, and man-made disasters, either intentional or unintentional, may be caused by fires, bombs, terrorist activities, civil unrest, and acts of war, just to name a few.
It is very difficult to have a large number of disaster plans with a response to each particular type of disaster. Imagine communicating to a senior executive on the phone that IT operations has experienced a disaster due to fire. The very next question might be, How big was the fire? Was it localized? Did it take down the entire IT installation and facility? And how serious was it? So as you can see, the overall effects of disasters might differ.
Many organizations find it convenient to establish a disaster classification system to describe to all individuals the severity of the disaster and the type of restoration response to expect. Figure 6.3 illustrates a typical disaster classification chart. In this example, there are only three grades of disasters—one, three, and five—which allows for other numbers or levels of classification to be substituted if required. Other columns may be added to indicate programs of plans to invoke, persons to notify, and other disaster information.

Figure 6.3 A typical disaster classification system
Disaster Preparation
On occasion, certain disasters come with a warning. For instance, depending upon the geographic location of the organization, an IT operation such as a data center may have knowledge of an impending hurricane, forest fire, or potential flood hours if not days ahead of time. In this instance, a disaster preparation plan may be invoked, where critical data is backed up to an offsite location or to a cloud service provider, which should be of significant geographic distance from the primary IT location so as not to be involved in the same disaster.
Provisions may be made to protect facilities from wind, flood, or fire, and protection must be afforded to all staff members in expectation of a disaster event. Remember, the primary concern in any disaster is the safety and preservation of human life.
Identification of Physical and Virtual Assets
The IT organization should have a complete inventory of all hardware assets and virtual assets at the physical site. This would include all network hardware, network telecommunications equipment, telephone communications equipment, user workstations, wiring diagrams, and a complete description of all configurations of network equipment such as routers, switches, firewalls, and servers. Virtual assets such as applications and data should be inventoried, and the inventory should be recorded. Naturally, in the case of disaster preparedness, all of this information should be stored and backed up to a geographically remote location.
Availability of Restoration Products, Building Components, and Labor
Various considerations must be made during the creation of a disaster recovery plan. Consideration must be given to the sources and availability of products used to restore the physical facility as well as networking electronic components required to rebuild the data center. Along with the inventory of hardware assets, a list should be created of potential sources of replacement products. The disaster recovery plan should include the methods of purchasing and paying for replacement products in the event that the accounting department and purchasing department have been displaced by the same disaster.
During significant natural disasters such as Hurricane Katrina and Hurricane Sandy, the availability of goods, supplies, building materials, and labor were at a premium. As part of their disaster planning, some large corporations keep small denomination currency and gold to use as larger to pay for goods and services during a severe emergency. In the event of a severe natural disaster, credit cards will be of little use due to a power outage or an Internet outage.
Labor and personnel must be considered in the creation of a disaster recovery plan. During a severe natural disaster, third-party labor such as contractors and a skilled labor force may either not be available or be available to the highest bidder. On the other hand, it might be anticipated that the organization's personnel may not be available either, through lack of transportation, personal disaster, and through lack of basic services.
Interim or Alternate Processing Strategies
During a disaster event and recovery operation, the primary IT facility may not physically be available to carry out IT operations. In some disaster scenarios, it may be temporarily disabled, while in other, more severe scenarios, it may be totally destroyed and need to be totally rebuilt.
The disaster recovery plan must include the possibility of relocating IT operations. The different relocation options will respond directly to the recovery time objective. For instance, services may be made available for almost instant switchover, while other services may require the transportation and configuration of hardware in a remote location. Each strategy affects the variables of time to restore services and cost to restore services.
- Hot Site A hot site is an alternate IT processing facility that can be brought online within a very short period of time. The hot site will maintain duplicate equipment but no applications or data. The hot site will maintain duplicate equipment and duplicate sets of data. To be effective, the hot site should be significantly geographically separate from the primary site so it's not involved in the same disaster. If the hot site is not an integral function of the organization and is a third-party contractor location, in many cases it is utilized for a short period of time, measured in either hours or days, while a less costly alternate site is made ready.
- Warm Site A warm site is an alternate IT processing facility that has equipment installed and usually configured. The warm site does not have duplicate data installed and must be provisioned from backups. It is less costly than the hot site and still requires hours and sometimes days to bring online.
- Cold Site A cold site is a location that is provisioned with HVAC, power, and communications lines and can be used for complete IT restoration. A cold site does not have network hardware or communications equipment. Equipment would have to be ordered, shipped in, and installed. After installation, all data would have to be restored from backups. With testing and configuration, a cold site offers the longest recovery time, requiring in many cases weeks of preparation. But on the other hand, it is the least costly.
- Contracted or Mutual Sites A contracted or mutual site is made available through an arrangement with the IT department of another organization, where the other organization offers equipment and processing time under a contract or by mutual agreement. This type of an arrangement may also be between different IT departments or divisions within the same organization. In some instances, a mutual site is referred to as a multiprocessing site—one site cannot support the entire IT department, so multiple sites are used as a type of cluster. Normally this scenario is similar to a warm site, where the contracting organization offers access to IT processing capacity and data must be restored from backups to begin operation.
- Cloud Sites Cloud providers now offer a service that consists of the use of either a hot site or a warm site, depending on costs and requirements. Using the Infrastructure as a Service (IaaS) model, the cloud service provider can rapidly duplicate the client's IT service configuration and provision data from backup locations. Some organizations are making use of cloud sites for immediate switchover, while other organizations make use of a less costly service that will require a little more time to bring online.
- Mobile Sites A mobile site is a site usually based in 18-wheeler trailers. Under contract, this type of site may be transported to the required location. Mobile sites can be expanded by connecting trailers of equipment together. Mobile sites are usually self-contained and feature a portable generator system to power the equipment. Depending upon the contract, 18-wheeler trailers may be dedicated and outfitted with the exact equipment required to duplicate the IT operation. Transportation, availability, and available communications infrastructure should be prime considerations in using a mobile site and a disaster recovery plan.
When employing any of the types of recovery site options, the planners must consider several important factors:
- Transportation of essential personnel to the backup location
- Room and board for essential personnel at the backup location
- Commitment of essential personnel, which may be hindered by the possibility of the destruction of homes, local infrastructure, and dislocation of immediate family
- Salaries, payment for personnel living expenses, and transportation
It is important to consider cross training of personnel or duplicate personnel with alternate skill sets and the availability of contractors in the remote recovery site location.
Restoration Planning
Disaster preparedness and restoration planning is the formulation of plans that reduce the vulnerability to threats and provide a set of procedures for restoration after a disaster event. In addition to the safety and protection of human life, many other items must be taken in consideration during the creation of a disaster recovery plan:
- Power and essential communications
- Personnel in the labor force
- Essential supplies such as shelter, food, and water
- Transportation
- Building materials and construction components
- Data processing hardware and infrastructure components
- Data communications
- Backup data
Disaster preparedness planners, when creating a disaster recovery plan, should consider alternate sources for any of these requirements.
Backup and Redundancy Implementation
It is important that as a security practitioner you are familiar with all of the different types of backup and data restoration solutions. Data backup and restoration solutions are driven by two primary considerations: time and cost. As you saw with recovery time objectives (RTOs) and recovery point objectives (RPOs), fast recovery times and minimal data loss come with a price. By varying the time frame, not only is the cost affected, but the type of technology used for data backup storage may change.
Not all data needs to be backed up equally. When creating a backup program for the organization, data may be prioritized by importance or frequency of use. For instance, data required for immediate use, such as customer information or accounting data, may be considered vitally important to corporate operations. The decision might be made to prioritize this data and back it up in such a manner as to provide a very fast restoration process. Other data, such as sales transactions, database archives, or archived communications such as emails, may be backed up using a method that is far less expensive and may require a much longer time to restore.
In years past, data was backed up sequentially on magnetic tape. Many may remember the reel-to-reel tapes featured in science-fiction movies. While some of these devices still exist in mainframe computer centers, most tape backup today is performed on tape cartridges and specialized machines. It is not unusual to back up data on DVDs and hard disk arrays and to the cloud.
When removable media is involved, various backup scenarios may be used. The selection of the backup scenario is based upon several factors:
- Required time to back up all of the data
- Required time to restore all of the data
- Cost of labor in time and effort
- Cost of backup media (life of backup media)
When considering these criteria, several backup scenarios can be employed. Of course, at some point in time all of the data must be backed up, which is usually referred to as a full backup. The selection of backup techniques between full backups depend upon the criteria. Various backup techniques are described in the following sections.
Mirrored Backup
A mirrored backup features the immediate writing of data to two different locations. “Online data” refers to data that is backed up in the local IT facility. The second copy of the data is transmitted to a separate storage device located in a distant location so as to be separate from any natural disaster. A mirrored backup may also be cloud based.
A mirrored backup requires the use of two identical storage devices. These identical storage devices may be in physically separate locations. A mirrored backup is the most expensive type of backup/restoration system and is usually used for vital data that must be immediately available at all times. Mirrored backups are not used for archive data, applications, operating systems, or other types of data that might be backed up to magnetic or optical media.
Full Backup
A full backup is the contiguous copy of the entire system and data. A full backup may include the entire operating system, applications, and data associated with the system. It may also refer to a subset of data. For instance, a full backup may be created of the customer transactions database. This database may have been prioritized as being vitally important to the organization and therefore has its own backup schedule. Normally, full backups to tape or offline storage are made at least weekly.
Differential Backup
A full backup may be created once a week, then daily backups must be made of the transactions for each day. The differential backup records all of the transactions since the full backup. For instance, the transactions occurring on Monday will be recorded. On Tuesday, all of the transactions occurring on Tuesday will be added to the backup of all of the transactions occurring on Monday. On Wednesday, all of the Wednesday transactions will be added to the backup of all of the Monday and Tuesday transactions. So on each day, the transactions are just appended to the previous day's backup file.
The advantage is in the event of a restoration, only one file must be added to the full backup file to create a record of all transactions that have occurred. The disadvantage may be in media cost; the backup for each day requires more media because of the amount of data stored each day. Figure 6.4 illustrates the concepts of a differential backup.

Figure 6.4 An illustration of a differential backup
Incremental Backup
Again, assuming a full backup was created once a week, daily backups must be created for the transactions of each day. In the case of incremental backup, the transactions occurring on Monday are backed up into a file. Tuesday's transactions are backed up into a second file. Wednesday's transactions are backed up into a third file. Thursday and Friday transactions are similarly backed up into separate files. In the event of a restoration, each of the files must be added to the others and finally to the full backup to form a contiguous data file containing not only all of the existing information from Sunday but also the information from the rest of the week.
The advantage to this program is that each day's backup may be created much faster. Each day's data is in one file. The cost of media for each day is reduced because it is only storing one day's worth of information. The obvious disadvantage is that if a full restoration is required, it takes much longer to combine all of the different daily files together with the full backup prior to being able to restore all the data to the affected device. Figure 6.5 illustrates incremental backup.
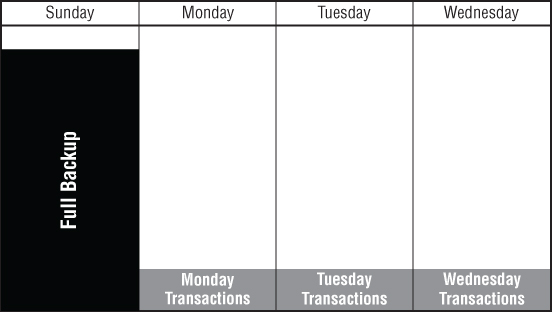
Figure 6.5 An illustration of an incremental backup
Backup Storage Considerations
Data that is stored as backup is extremely important to the organization. When formulating a backup program, various aspects should be given consideration:
- Data Encryption Data stored in offsite locations should be encrypted for protection.
- Reliable Transmission Methods Data transmitted to offsite locations should be both encrypted and hashed to provide confidentiality and integrity of the data.
- Bonded Courier Service If tapes are created onsite and physically stored in a separate location, the transportation service should be bonded and reliable.
- Restricted Off-Site Access Backup data stored offsite must not be able to be accessed except by authorized personnel performing a restoration.
- Proper Identification of All Physical Media Tapes should be labeled and bar-coded, and the tape label should be encoded on the tape itself for identification purposes. All labeled materials stored offsite should be recorded and the records should be maintained in an inventory.
Electronic Vaulting, Remote Journaling, and Clustering
Electronic vaulting is another name for transmitting data offsite to either a physical storage location or a cloud storage location. At the physical storage location, the transmitted data is recorded onto tape or media, while on the cloud storage location, virtual storage techniques may be employed. With electronic vaulting, data transmission should be encrypted and validated for integrity, such as employing IPsec as a transmission encryption and integrity coding system.
Journaling is a database term that refers to recording transactions and creating a transaction log. A transaction log may be used in conjunction with the last known good database copy to create an up-to-date database. If an IT transaction is interrupted, a journal can be used along with the original database copy to restore information as of the last transaction.
Clustering refers to using a combination of servers or systems to reduce the risk associated with a single point of failure. A cluster of anything provides a configuration that reduces risk and provides high availability. A term used in clustering is automatic failover, which provides system redundancy. In the event of a failover, the secondary system takes over all server operations, and the failover is transparent to the user. This is primarily used in environments that require high availability and continuous use.
Load-balancing clustering is a technique of utilizing various servers and systems in an array to spread the workload. In this technique, various algorithms are used to send work to each one of the cluster servers so that one server does not receive all of the workload. Load-balancing clustering differs from server clustering in that server clustering provides redundancy of servers while load balancing provides availability of servers.
Redundant Array of Independent Disks
Redundant Array of Independent Disks (RAID) is a method of storing data across several different hard disks. Using this system, data is written to a series of hard disks in such a manner as to provide either speed or data redundancy. A RAID array can be viewed as a stack of two or more hard disks that are written to using either software or hardware implementations.
RAID is based on several data recording concepts that may be combined in a number of ways to reach the desired results. These recording concepts include parity, mirroring, and striping.
- Parity Parity is performed by adding a separate bit to the data to provide data integrity. Parity is an old data integrity method that provides the reliability of being able to determine if a bit has been dropped during the transmission process.
- Mirroring Using this technique, the system writes data to separate hard disk drives. Mirroring is accomplished using either hardware or software; it requires writing data to two disks at the same time. The advantage to data mirroring is data redundancy. The disadvantage is that both drives must write at the same time, thus reducing the writing speed.
- Striping Striping is a method of writing information to all disks at the same time. Data is broken down into either bytes or blocks. The advantage of striping is speed because a part of the information is written to each disk at the same time.
Different RAID levels are specified by a number that indicates a particular type of configuration. It is important to know that some RAID levels offer redundancy while other RAID levels offer speed.
- RAID-0 This configuration stripes data across multiple hard drives. The benefit is speed and access. There is no data redundancy.
- RAID-1 This configuration features writing identical data to two different storage locations such as cloud storage or local hard drives. It offers a simple data redundancy configuration by having identical information written to two different locations.
- RAID-2 This configuration stripes data across multiple disk drives at the bit level. It is difficult to implement and generally not used.
- RAID-3 This configuration stripes data across multiple drives at the bit level and uses a separate disk drive for the parity bit. This RAID level is rarely used.
- RAID-4 This configuration is similar to RAID-3, but it stripes data across multiple drives at the block level. It also uses a separate disk for the parity bit. The RAID-4 level is very rarely used in a production environment.
- RAID-5 This configuration is one of the most popular RAID configurations. RAID-5 uses a technique of striping data across multiple drives and incorporating the parity bit on each of the drives. If a drive fails, the data may be reconstructed using the data and parity bit contained on the other drives. A minimum of three drives must be used in a RAID-5 implementation.
Various other types of RAID configurations exist that are based on combinations of the preceding RAID techniques.
Business Continuity Plan and Disaster Recovery Plan Testing and Drills
The business continuity plan (BCP) and disaster recovery plan (DRP) should be verified at least once every year. This procedure is accomplished through the use of a variety of tests and drills with the personnel involved. The various types of tests are based on time, cost, complexity, and risk to the organization. For example, taking the IT department offline to test the capability of a failover to a remote site might pose a substantial risk to the organization. However, many government and military organizations perform this type of test to test readiness in the event of an emergency.
There are various types of tests used to validate either the business continuity plan or the disaster recovery plan:
- Checklist Test The checklist or desk check test is performed by the personnel involved in the plan. Primarily, it involves mentally understanding their responsibilities, reviewing procedures, and updating contact and other required information. Individuals are asked to document any changes or updates made to their areas of responsibility since the last checklist test.
- Structured Walk-Through Test In a structured walk-through test, individuals with responsibility of performing some action or activity in the plan, as well as individuals from key departments involved in the plan, attend a structured walk-through meeting. During the meeting, those involved validate that the plan is correct and that they understand their responsibilities. The structured walk-through test is the most common of the plan tests and may be performed frequently across different business units.
- Simulation Test The simulation test features actual steps that would be taken during an actual emergency or disaster. For instance, files may be restored from backup, generators may be started and switched over, and other physical items may be tested. This is a simulation, and all individuals involved are aware of that. The normal business of the organization is not affected by a simulation test. The output of a simulation test is to specifically test the validity of the plan and the activities, techniques, and responsibilities as specified in the plan.
- Parallel Test A parallel test involves performing IT processing using alternate techniques such as a hot site or warm site. Throughout this test, organizational activities are not interrupted. This type of test must be planned for and budgeted because it incurs substantial cost to the organization. Individuals must be transported to an alternate site, data must be restored from remote backups, and processing must occur as if it were a production site. On many occasions, auditors or observers record the activities.
- Full Interrupt Test In full interrupt testing, business operations are interrupted and the alternate site is brought online into full operation. Processing is performed using the alternate site data and equipment. As can be imagined, this type of test is very intrusive and disruptive to ongoing operations. The organization faces great risk when performing full interrupt testing. A number of things can go wrong, including not being able to bring the original site back to full production mode in a timely manner.
As an SSCP, you will be expected to perform many roles as assigned during both continuity and disaster preparedness testing. You must understand the reasons for the testing and the importance of your role to its success.
Summary
As a security practitioner, you will be closely involved with various aspects of planning, testing and possibly executing incident plans, business continuity, and business recovery plans. As such, it is important to understand the basic concepts of each practice.
In this chapter, you gained an understanding of how to handle incidents using consistent and applied techniques. You learned what the elements of an incident response policy are and that, as in all policies, it must have executive-level support. The incident response plan is the result of a policy directive and requires the interaction and input of many corporate individuals, including heads of departments and subject matter experts. The incident response plan requires a commitment in both time and funding. It also requires training individuals so they understand their responsibilities as possible members of the incident response team. You saw how incident analysis, sometimes referred to as triage during multiple incidents or attacks, is used to prioritize the efforts of the incident response team to mitigate harm to the organization.
During forensic investigations, you may play a role as part of an incident response team while gathering information as well as evidence from the incident scene. In this chapter you learned how to recover and record evidence and provide a continuous tracking method, referred to as chain of custody. We also discussed Locard's exchange principle, which states that a perpetrator will always leave something at the crime scene and will also take something from the crime scene.
You learned the importance of a business continuity plan. The business continuity plan provides the responsibilities, criteria, and procedures to maintain business operations as close to normal as possible during an incident or a disaster. This involves prioritizing business activities that must be maintained before business activities that are support operations. The disaster recovery plan is put into action after a disaster occurs. It provides the responsibilities, criteria, and procedures necessary to restore and recover back to normal operations after a disaster.
We discussed the various techniques of backing up data and providing redundancy for data storage as well as network operations. We also discussed the importance of testing so that every individual is aware of their responsibilities and plans are carried out as intended.
Exam Essentials
- Events Understand that an event is any observable occurrence in a system or network. An event may be as simple as a user logging on, an application opening a port, or data transferring between systems.
- Incidents Know that an incident is an event with the potential to cause harm to the organization. An incident is usually considered an intrusion by an outside force, but it may also be caused by an internal user. An incident may also be intentional or unintentional.
- Incident Response Plan Understand that an incident response plan is a set of established responsibilities, criteria, and procedures to be initiated upon the discovery of an incident.
- Nature of an Incident Response Team Understand that the incident response team is an assortment of multidisciplined individuals from across the organization who aid in the mitigation of harm and the containment of an incident.
- User Workstation or Server and Restoration Techniques after an Attack Know that it is easier to rebuild a workstation or server from an image file or a backup than it is to try to eradicate a virus or root kit from the system.
- Chain of Custody for Forensics Evidence Understand the specific steps and criteria required for the acquisition, handling, recording, and processing of evidence so that it's valid and admissible in a court of law.
- Gathering Evidence Based on Volatility Live evidence, or evidence still in memory, may be collected by the forensic team while the target machine still has power. Know that the evidence is always gathered from the most volatile memory such as CPU cache and primary memory such as RAM, and then the secondary memory locations such as hard disks, USB drives, or even cloud storage.
- Hard Disk Forensic Examination Techniques Understand that data is retrieved from a hard disk using a bit copy software technique to ensure that every bit is recorded correctly. A write blocker prohibits any information from being written onto the drive. Any examination of the data is performed on a hashed copy while the original is maintained in a safe storage.
- Business Continuity Planning Understand that business continuity planning results in the development of a business continuity plan, which is a set of responsibilities, criteria, and procedures to be followed when an incident or disaster event occurs. The purpose of a business continuity plan is to maintain business operations as normally as possible after the occurrence of an incident or disaster event.
- The Concepts MTD, RTO, and RPO Know that the concepts involved in business continuity planning involve maximum tolerable downtime, recovery time objective, and recovery point objective.
- Alternate Site Processing Strategies Understand that, during a disaster, the business continuity plan may call for the use of a cold site, warm site, or hot site or possibly a multiple-processing site or mobile site as an alternate location for the organization's data center.
Written Lab
You can find the answers in Appendix A.
- Write a paragraph explaining the difference between business continuity planning and disaster recovery planning.
- Describe what is performed during triage.
- Briefly explain MTD, RTO, and RPO
- Describe the activities of an incident response team.
Review Questions
You can find the answers in Appendix B.
- Which is the most volatile memory?
A. Hard disk
B. CPU cache
C. RAM
D. USB drive
- Which option provides the best description of the first action to take during incident response?
A. Determine the source and vector of the threat.
B. Follow the procedures in the incident response plan.
C. Disconnect the affected computers.
D. Alert the third-party incident response team.
- Which option most accurately describes continuity of operations after a disaster event?
A. Controlling risk to the organization
B. Planned procedures that are performed when a security-related incident occurs
C. Planned activities that enable the organizations critical business functions to return to operations
D. Transferring risk to a third-party insurance carrier
- When considering a disaster which of the following is not a commonly accepted definition?
Which choice
A. An occurrence that is outside the normal functional baselines
B. An occurrence or imminent threat to the enterprise of widespread or severe damage, injury, loss of life, or loss of property
C. An emergency that is beyond the normal response resources of the enterprise
D. A suddenly occurring event that has a long-term negative impact on major IT infrastructure
- Which of the following is not an accurate statement about an organizations incident response policy?
A. It should require the ability to respond quickly and effectively to an incident.
B. It should require the prevention of future damage from an incident.
C. It should require the retaliation against repeat attackers.
D. It can require the repair of damage done from an incident.
- Which option is not a responsibility of the person designated to manage the continuity planning process?
A. Providing information and direction to senior management staff
B. Providing stress mitigation programs to employees after an asset loss event
C. Analyzing and identifying all critical business functions
D. Coordinating and planning integration among business units
- Which disaster recovery/emergency management plan testing type is considered the most cost-effective and efficient way to identify areas of overlap in the plan before conducting a more demanding training exercise?
A. Full failover test
B. Structured walk-through test
C. Tabletop exercise
D. Bullet point test
- Which of the following options best describes a cold site?
A. An alternate processing facility with established electrical wiring and HVAC but no data processing hardware
B. An alternate processing facility with most data processing hardware and software installed, which can be operational within a matter of hours to a few days
C. An alternate processing facility that has all hardware and software installed and is mirrored with the original site and can be operational within a very short period of him him him him time
D. A mobile trailer with portable generators and air-conditioning
- Which of the following statements is an incorrect description of a control?
A. Detective controls monitor for attacks and instigate preventative or corrective controls.
B. Controls reduce the possibility that vulnerabilities will be attacked.
C. The effect of an attack is reduced through the use of controls
D. Restorative controls reduce the likelihood of a deliberate attack.
- Which of the five disaster recovery testing types creates the most risk for the enterprise?
A. Simulation
B. Parallel
C. Structured walk-through
D. Full interruption
- Which of the following options would require the longest setup time?
A. Mobile or portable alternate IT computing service
B. Hot site
C. Cold site
D. Warm site
- A backup site is best described by which of the following options?
A. A computer facility with electrical power and HVAC but with no applications or installed data on the workstations or servers prior to the event
B. A computer facility with available electrical power and HVAC and some print/file servers. No equipment has been installed at the site.
C. An alternate computing location with little power and air-conditioning is but no telecommunications capability
D. A computer facility with power and HVAC and all servers and communications. All applications are ready to be installed and configured, and recent data is available to be restored to the site.
- What is the prime objective of the continuity plan?
A. To make sure everyone understands their responsibility and the procedures they must follow
B. To inform everyone that a disaster or incident event has occurred
C. To maintain business operations, as best as possible, until all operations can be restored
D. To rebuild the facility after disaster occurrence
- Which option best describes an incremental backup?
A. Daily backups are appended to previous backups.
B. Daily backups are maintained in separate files.
C. Daily backups are appended to the full backup.
D. Daily backups are mirrored to the cloud.
- Which option is most accurate regarding a recovery point objective?
A. The time after which the viability of the enterprise is in question
B. The point at which the most accurate data is available for restoration
C. The point at which the least accurate data is available for restoration
D. The target time full operations should be restored after disaster
- Which team is made up of members from across the enterprise?
A. Dedicated full-time incident response team
B. Functional incident response team
C. Third-party incident response team
D. Expert incident response team
- Evidence should be tracked utilizing which of the following methods?
A. Record of evidence
B. Chain of custody
C. Evidence recovery tag
D. Investigators evidence notebook
- Prior to analysis, data should be copied from a hard disk utilizing which of the following?
A. Write protect tool
B. Block data copy software
C. Bit data copy software
D. Memory dump tool
- Upon arriving at an incident scene, the incident response team should do which of the following?
A. Turn off the affected machine to stop the attack.
B. Follow the procedures specified in the incident response plan.
C. Quickly unplug the Ethernet plug.
D. Take photographs of the crime scene before it can be disturbed.
- A clipping level does which of the following?
A. Reduces noise signals on the IT infrastructure
B. Removes unwanted packets
C. Defines a threshold of activity that, after crossed, sets off an operator alarm or alert
D. Provides real-time monitoring