
CHAPTER 11
Advanced Topics
In this chapter, you will learn how to
• Determine strategies for data migration
• Select technologies and strategies to meet compliance requirements
• Store more data on the same hardware with deduplication and compression
This chapter introduces more advanced topics in storage management, including data migration, compliance, and deduplication and compression. Storage administrators often are tasked with improving the availability and speed of access to systems. Previous chapters explored making copies of data for business continuity (Chapter 7) and remote replication (Chapter 9), but this chapter looks at migrating data within a storage array to achieve high performance.
Another challenge for storage administrators is compliance with regulatory requirements and litigation holds. Some data, such as financial data, must be retained for a specified amount of time to adhere with regulatory requirements. Similarly, data related to ongoing litigation must be retained in case it is required for trial. Removing data for either of these reasons can result in fines, loss of customer reputation, or loss of a legal case. Therefore, it is important to be able to implement strategies to comply with these regulations and litigation holds on storage arrays and in other places where organizational data is stored.
Lastly, as data grows, storage administrators are looking for ways to store more data using the same hardware. Deduplication and compression technologies offer excellent options for conserving space without sacrificing availability.
Information Lifecycle Management
Data migration is a form of storage management where data of varying formats is transferred between hosts or storage systems. Data migration is a major driver for advanced storage system adoption. Not only is data often stored in heterogeneous technologies and applications, but it may take on a variety of forms and characteristics, all with differing implications for storage, access, availability, and recovery. Data migration can be array, host, or appliance based.
In array-based data migration, software on the storage array, built either into the array software or as an add-on feature, is used to manage migration, including setting up migration pairs, scheduling, and synchronization.
In host-based data migration, software residing on the device receiving the storage or managing the storage, known as a host, is used to manage the movement of data from one location to another.
In appliance-based data migration, stand-alone network appliances migrate files and volumes, interfacing with storage systems and providing a separate interface for managing the replication.
Data migration should be undertaken with a great deal of planning and care. Here are just a few considerations when migrating data:
• Duration of the migration task Depending on how much data must be migrated, data migration tasks can take a relatively short or long time. Longer migrations could impact the productivity of users of the system or, in worse cases, the availability of the system or systems that reside on the storage being migrated.
• Contingency plans should outages or other problems occur If data migrations cause a loss in availability, storage administrators should have a plan of action for restoring key systems quickly to meet recovery time objectives (RTOs).
• Compatibility issues Migrating data between heterogeneous systems may require devices in between to manage the replication. This is a common use for migration applications. Devices from different vendors may not support replication standards or may implement standards in such a way that makes replication, or the form of replication desired, difficult or impossible. Storage administrators must be aware of the requirements for replication in such systems and plan for how to handle compatibility issues.
• Data integrity The value of migrated information diminishes rapidly if the information migrated changes in the process. Sometimes metadata (data about data), such as creation date, author, and other information, is changed when information is moved. This can often be accepted as part of the migration process. However, information and the bits and bytes that make up files containing information should not be modified in transit. When information is consistent, its integrity is intact, but if changes occur, integrity is lost.

EXAM TIP File hashing uses a mathematical formula to generate a value that uniquely represents a file. Hashing is used to verify data integrity. The calculated hash value generated prior to a migration can be compared to the hash value generated using the same hashing algorithm on the data once it has been migrated. If the hash values match, the integrity of the data can be assumed to be intact. However, if the hash differs, the data should be retransmitted and compared again. Popular algorithms used for this purpose include Message Digest 5 (MD5) and Secure Hash Algorithm (SHA).
• Lost or missing data Similar to data integrity is data loss. Loss of data occurs when data on the source that is scheduled for migration is not present on the destination following a data migration. This can occur when a migration process skips files because of corruption, network contention, or other error conditions, and it is often logged in a migration log file that can be reviewed by administrators. Some storage administrators may find it helpful to set up alerts to notify them of files that are skipped in migration schedules.
Value of Data Based on Frequency of Access
Data that is accessed frequently is often viewed as more valuable than data that is accessed infrequently because the loss of availability to such data would have a greater impact on business productivity. Because of this, such data is often given more protection against loss or manipulation, and it is often placed on storage with higher availability, including additional redundancies and faster access speed.
HSM
Hierarchical storage management (HSM) presents files and directories as a composite object with a single integrated file interface. HSM provides a mechanism for the automated movement of files or records from primary storage to more cost-effective, slower, secondary storage without changing the way they are represented to end users of the storage system. The term gets its name from the use of different storage tiers or levels that reside in a hierarchy organized by storage speed. The data is organized by moving it from one storage tier to another. This process of moving files one medium to another storage medium is called migration.
Real-time monitoring and network policies are used to determine how data and storage are migrated in HSM. Based on the criteria established in the file system policies, HSM determines where in the tier the hierarchy files should be located. HSM aims at archiving files in a more effective way so that the user is not required to decide when files need to be archived. Users can store all files in the same place, but the HSM determines which files should be placed on fast storage and which should be placed on slower storage or archived to offline or nearline storage.
The most common use of HSM is in distributed systems and not in stand-alone systems. Types of storage devices used in HSM include RAID arrays, storage arrays, disks, flash media, optical drives, and tapes.
The only task that managers need to do is configure the system with thresholds for each tier so that the system can measure file access and make choices as to where each file should be stored. These rules automatically back up files if the defined thresholds are met. And once this configuration is done, all system backup/archiving is done without user interruption.
EXAM TIP It is best to take a baseline of the system first to understand what normal activity looks like before configuring HSM rules.
One real-time example of a hierarchical storage management system is streaming video sites. Short video previews, along with the most often accessed videos, may be loaded to high-speed disks. When a user selects a video that is present on a slower disk, the preview is loaded from high-speed disks, while the remainder of the video is loaded from a slower disk at short delay. This improves the performance of the system and reduces the cost of storage because archived data is stored on cheaper disks and high speed is provided with only a few high-speed disks.
Storage Tiers
As discussed previously, HSM is storing information in various hierarchies of devices to reduce the cost of storage. This is achieved by using tiered storage. Different types of data are stored in different storage devices, and storage managers who know the importance of the data and the credibility of the devices decide on this differentiation. Storage tiers are typically found in larger organizations, but as the costs of storage tiers go down, more smaller organizations are taking advantage of storage tiers in managing data.
Various tiers of storage are managed by every organization, and the degree of tiering depends on various factors. In the earlier days, only two-tiered storage was in practice because of a lack of automated tools to manage data. With the advent of technology, multitiered storage is now available for storage managers.
Tier 0 and tier 1 usually hold sensitive information that needs to be retrieved in a short amount of time. All important business files that users will access now and then are stored in tier 0 and tier 1. Other files that are not often needed but would be used anytime are stored in tiers 2 and 3, while old information used only for analysis or not important reasons is stored in tier 4, as shown in Figure 11-1.
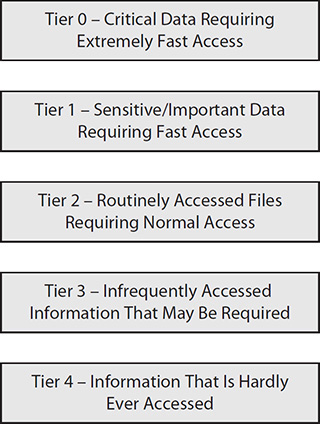
Figure 11-1 Tiers
EXAM TIP The tiers are organized with tier 0 at the top containing the data that has the highest availability need.
Manual Storage Tiering
Manual storage tiering, or passive storage tiering, refers to the process of collecting performance information on a set of drives and then manually placing the data on different drives based on the performance requirement for the data. The process is labor intensive and does not dynamically adjust as the load on the application increases or decreases over time. Manual storage tiering is passive, where data is placed on one tier based on its importance and the data remains in the same tier all through its lifecycle until being deleted.
EXAM TIP Storage administrators can choose what file types should be migrated. For example, a storage administrator may decide that executable files need not be migrated along with many other file types because business rules define a minimum load time for applications.
Automated Storage Tiering
Automated storage tiering (AST) refers to the storage software management feature that dynamically moves information between different disk types, such as Serial Attached SCSI (SAS) to Serial Advanced Technology Attachment (SATA), and between Redundant Array of Independent Disks (RAID) levels, such as RAID 10 consisting of striped mirror sets or RAID 5 consisting of striping with parity. The storage types are organized based on their speed and given a tier number. Active storage automatically moves data to less expensive tiers, thereby freeing higher tiers for relevant data. This is done so that space, performance, and cost requirements are met.
AST makes use of policies that are set up by storage administrators. For example, a data storage manager can assign data that is not used frequently to slower, less expensive universal serial bus (USB) SATA storage, as well as allow it to be automatically moved to higher-performing locally attached Small Computer System Interface (SCSI) or solid-state drives (SSDs) when it becomes more active. The converse of this situation also holds true.
Compliance
Regulations specify how certain data such as personally identifiable information (PII), electronic personal health information (ePHI), and financial records must be stored and protected. Once an organization determines which regulations it must comply with, storage and other technology must be implemented to satisfy the requirements of these regulations. Compliance requirements usually contain security and retention specifications. Security was discussed in Chapter 8, but retention is discussed here.
Retention Policy
An organization’s retention policy is an important part of storage management because it defines how long information should be stored and maintained in the system until it is ultimately deleted or destroyed. Despite the desire of most organizations to save data, data should have an expected life span that ends with deletion or destruction. With the continual increase of digital information, it is essential for organizations to have a proper retention policy to properly store, organize, and manage organizational data. Otherwise, the organization will be overwhelmed with data, making it harder to search for the data that is needed and more costly to store and manage the data. It can also create additional risks for data breaches or e-discovery because there is more potential data to be lost or collected in a legal case.
The most common retention policy in use now is deleting documents and files after disuse, which means deleting files that are a certain year old and that are not used for certain period of time. This would ensure that frequently used files are not deleted even though they are old and ensure that never used files are deleted even though they are not old.
In planning a retention policy, organizations must consider the value of data over time and the type of data they are storing. Some data may need to be retained for a specified interval in regulations. Such legal requirements define proper retention policies for certain data types such as financial documents, personal information, hazardous chemical, or safety information.
The major benefits of retention policies include reduced costs of managing data, better organization, faster retrieval of important information, and lower cost and burden to produce data relevant to litigation holds.
Retention policies reduce the costs of managing data. Without regular removal, organizational data will grow exponentially and make it costly and difficult to store and maintain, resulting in additional hardware, maintenance, backup, and security for data that may no longer be providing value for the organization.
Retention policies result in better organization and faster retrieval of important information. When unnecessary information is pruned from storage systems, relevant data can more easily be found and retrieved. This is especially true when HSM or other tiering technologies are used because it allows for a greater likelihood that relevant data will reside on faster tiers since unnecessary data that could potentially consume faster tier storage has been removed from the system entirely.
Retention policies result in a lower cost and burden to produce data relevant to litigation holds. Litigation holds operate on data that has not been removed already. When lawsuits require any evidence in the form of electronic information, this should be easily fetched and displayed to the concerned authorities. Having large chunks of data would increase of time and efforts in fetching data from the system. Also, in some cases, the most important files may be deleted, and no further legal action can be carried forward without the availability of data. In such cases, retention policies would serve the organization by defining what documents may be deleted and when they should be deleted. Also, deleting information from the system would sometimes help during legal cases. Some information present in the system may serve as evidence during the trial, which may turn the case against the organization itself. Therefore, retention policies would ensure that unwanted data is not stored in the system anymore and ensure that information that is to be used in a legal case is not deleted.
It is important for system administrators and storage managers to classify data based on the information it contains. For example, a document might be classified as a contract, HR file, or tax document, to name a few. The organization may have policies for each of these data types that would define how long the document should persist in storage and whether the document should be archived at a point in time to secondary storage.
Archiving and Purging
The data present in the organizations is increasing every day, which increases the cost to manage data. Additional storage can be implemented, or data can be archived or purged. Purging is the concept of deleting obsolete data from the database if that the data is not important to the organization. Data is deleted based on age, type, and importance.
When the data is archived, it is moved from primary storage to a secondary storage device such as a tape or an offline disk. The data is stored in backup tables so that the metadata and structure of the original data is still preserved so that it can be reintegrated into the data set if necessary at a later time.
Preservation and Litigation Holds
Litigation holds, sometimes known as legal holds, are exceptions to an organization’s normal data purging activities. Litigation holds specify that data potentially relevant to ongoing or expected litigation be preserved. The reason for this exception is to prevent organizations from deleting incriminating or damaging files from their storage that could be used against them in court, and organizations and employees who do not comply with litigation holds could face spoliation of evidence charges that can result in fines or jail time. Spoliation is intentionally deleting evidence related to litigation.
EXAM TIP An organization’s legal counsel (your attorney) will send a notification to hold data related to certain key terms. Storage administrators must then set aside media that would normally be recycled, overwritten, or destroyed such as backup tapes, e-mail archives, and changes or deletions to files on network shares.
Through a process known as culling, files related to the litigation can be copied to a litigation repository so that they are preserved for discovery in the litigation. Discovery is the process in a legal case where each party obtains evidence from the opposing party. An organization may have many different litigation holds and could manage multiple repositories to hold such information. There are automated tools that can actively scan data, such as e-mail, instant messages, and data repositories, to copy out data when changes are made or new data is added. For example, the popular e-mail program Microsoft Exchange has litigation hold features built in to track changes made to mailboxes, allow for the export of the mailboxes, and prevent deletion of messages from a mailbox.
The most important consideration for an organization in deleting data is to make sure that no important legal document is deleted from the system. Also, there are legal requirements on how long data should be stored in the system. The documents such as agreements with customers, management policies, structural documents, and so on should be stored somewhere in the system and should be restored as and when needed. Hence, organizations should ensure that such data is stored in the primary database or increase the speed of retrieving such data from archival storage. Litigation hold or preservation order is nothing but the instruction issued to the members of the organization to preserve all records and documents that are of importance to an anticipated lawsuit from being destroyed or modified. The data should be easily accessible even though it is stored in archival storage. To hold data properly for litigation, it is essential to have a sound retention policy in the organization. It is the responsibility of storage managers or system administrators to ensure that such data is properly preserved when a litigation hold is issued.
Advanced Storage Methods
In addition to the storage methods discussed so far, including file and block storage, organizations can use content-addressable storage (CAS) or object-oriented storage (OOS) for specific data needs.
Content-Addressable Storage
Content-addressable storage is a mechanism through which information that does not change often is provided a name that indicates its storage location. Files in CAS are given a retention period that defines how long the files will exist in storage. Once the file is created, it cannot be deleted or changed until its retention period expires. CAS allows for fast access to data because storage systems do not need to query a file table to identify the place on disk where the blocks making up the file exist.
Object-Oriented Storage
Object-oriented storage stores data in the form of objects rather than files or blocks. Every object includes the original data, some amount of metadata, and a unique identifier. This type of storage can be implemented at multiple levels such as device, system, and interface levels.
The retrieval of data in OOS is simple. The operating system reads the unique identifier and the metadata that is stored along with the data and fetches the same from the storage. OOS is not well suited to data that is dynamic, but OOS is highly advantageous when it comes to distributed data such as cloud operations.
Deduplication and Compression
Deduplication and compression are the techniques that can be used to store more data on the same hardware by storing only one copy of a file or portion of a file and replacing all duplicates with pointers. However, this comes with the cost of high complexity in implementing the techniques such that the performance of the system does not drop but storage space is enhanced.
Deduplication is the technique by which storage space can be reduced by eliminating redundant data that is present in the system. The redundant data is replaced with references to original data, which are called pointers. For example, on a mail server, deduplication would hold a single copy of messages or attachments in the database. The recipients’ mailbox would have a reference pointer to the database copy. When the same message or the same attachment is sent to multiple users, only one copy is stored in the database, and mailboxes all point back to the same file.
Deduplication Levels
Deduplication can be performed by checking for duplicate files, called file-level deduplication, or by looking for duplicate blocks that make up files, called block-level deduplication.
File-Level Deduplication
File-level deduplication is used with backup and archiving solutions to store only one copy of a file. Duplicate files are identified by creating and comparing a hash of files on the system with new files that are added. If a file with a duplicate hash value is added, a pointer or stub is created that points back to the file already on the disk, and the new file is not copied over. File-level deduplication is also called single-instance storage (SIS).
EXAM TIP When used in backup solutions, once a file has been backed up, it will not be copied again unless it is changed. This dramatically reduces the amount of storage necessary for ongoing backups.
Block-Level Deduplication
Block-level deduplication compares the blocks that make up a file to blocks that already exist on the storage system. Two files may be different, but they may have portions of data that are the same. If identical data is comprised within a block, the system will identify the identical blocks and store only one of them. Block-level deduplication, sometimes called subfile deduplication, since it operates at a level beneath the file, can result in greater disk savings than file-level deduplication.
To speed up the process of hashing all the blocks, block-level deduplication stores the unique hash of each block in a database. When new files are created or copied to the storage, the system creates hashes of the blocks making up those files and queries the database to see whether they already exist. Blocks are stored on the system if they are not already in the database, and their hash values are added to the database. If a duplicate is found, a pointer to the original file is created instead.
Inline and Postprocess Deduplication
There are two variations in performing deduplication, and they are inline and postprocess deduplication. Inline deduplication is the process by which duplication of data is prevented immediately as the data enters the storage system. When data enters the storage device, the hash calculations analyze for any duplicate data. If duplicates are found, inline deduplication does not store the data, but instead adds a reference to the original data. The advantage of inline deduplication is the prevention of data duplication at the creation of data itself, which eliminates the need for more storage space. However, inline deduplication comes at a cost of lower performance of systems in storing data because of hash calculations and redundancy analysis.
Postprocess deduplication performs a redundancy analysis once the data is stored in the system. Since the system waits for new data to be stored before calculating hash functions and analyzing for redundancy, there is little drop in performance of the system with the use of postprocess deduplication. However, the disadvantage of postprocess deduplication is the need for more storage space in order to store duplicate data until it is analyzed for duplicates.
Source and Target Deduplication
Data deduplication can also be classified based on where the process occurs, either at the place where data is created or at the place where it is stored. Depending on the location of the process, the deduplication process is classified as either source deduplication or target deduplication.
Source deduplication is performed at the source of the data (that is, where the data is originally created), and target deduplication is performed at the place where the data is stored. Most often, source deduplication is performed as the system periodically checks the file systems for duplicate hashes when new data is created. When the hashes of new data created match with the existing hashes, the new data is removed and replaced with the pointer to the original data.
Deduplication Software and Appliances
Many leading storage device manufacturers have come out with strategies and software for performing deduplication. When looking for a deduplication system, consider these requirements. The software and appliances should provide required deduplication functionality without affecting the performance of the system. The software should increase the speed of backups and reduce the amount of bandwidth needed. Also, the software should save both time and money in implementing the features. An organization’s requirements will determine which software would be suitable for its business needs.
Performance and Capacity Implications
The deduplication process increases the performance of system reads by a greater percentage than if deduplication is not in use. It also increases the storage capacity of the systems. The files can now be stored in a reduced storage space. Also, the deduplication technique helps in reducing the number of bytes transferred between the source and the destination. This significantly reduces the bandwidth that is required. However, the deduplication process does come with a performance impact to analyze files, so this must also be considered when deploying a solution.
Reduction Ratios for Data Types
Any new technology is considered effective only when the numbers show the benefits. The effectiveness of the deduplication technique discussed previously can be expressed in the form of a reduction ratio that is the ratio of protected data that can be stored to the actual capacity of the system. For example, a 20:1 reduction ratio means that 20 times the amount of data can be stored and protected than the actual data storage capacity of the system. In real time, this means that when there is a 1TB system, deduplication makes it possible to protect up to 20TB data. To calculate the reduction ratio, create a fraction with the total amount of data stored on top and the amount of deduplicated data on the bottom and then reduce the fraction. For example, if 500GB of data is deduped to 125GB, you would create a fraction that looks like this:
500/125
This fraction turns into 4/1 when reduced. You would represent this as 4:1.
Many files that share similar portions of data, such as groups of files based on the same template, multiple versions of files, or backups of the same data, can see the highest reduction ratios, while disparate data sets will see less of a reduction.
Chapter Summary
This chapter provided an overview of more advanced topics in storage management, including data migration, compliance, deduplication, and compression.
Data Migration
• Data migration is the transfer of data consisting of files or even file systems from one system to another. Data migration is implemented in three different locations:
• Array-based data migration uses software on the storage device to manage the migration.
• Host-based data migration uses software on the device receiving the storage to manage the data migration.
• Appliance-based data migration uses a device that is neither the storage device nor the host that is accessing the storage. The appliance is outside the transfer between devices, but it manages the data migration.
• Companies generally assign a higher value to data that is accessed more frequently because the loss of availability to this data would result in greater cost to the organization. This business logic is used to make decisions on how to best store data, such as with hierarchical storage management. HSM can move files to faster or slower media based on the frequency of access. This helps reduce the costs of storing data and results in higher performance of the data used most often.
• Media is categorized by its speed in tiers. Tier 0 is the fastest media, and lower tiers are progressively slower. Tier 0 might be data that is stored in SSD or cache, while tier 4 may be data archived to tape. The process can be manual or automatic.
Compliance
• Storage administrations must adhere to regulations that specify how certain types of data, such as personal identifiable information, financial information, or health information, must be handled.
• A retention policy defines how long information should be stored and maintained in the system until it is ultimately deleted or destroyed.
• The classification of data helps storage administrators apply the correct business logic and compliance requirements to the data.
• Archiving and purging can reduce the amount of data that is maintained in active storage.
• Litigation may require some data to be preserved past its normal archival or purging period because it may be relevant in an expected or ongoing legal case. This data must be protected against deletion.
Advanced Storage Methods
• Content-addressable storage (CAS) is a mechanism through which information that does not change often is provided a name that indicates its storage location.
• Object-oriented storage (OOS) stores data in the form of objects rather than files or blocks. Every object includes the original data, some amount of metadata, and a unique identifier. This type of storage can be implemented at multiple levels such as the device, system, and interface levels.
Deduplication and Compression
• Deduplication removes identical data from a storage system. Only one copy of duplicate data is stored on the system, and additional copies are only pointers back to the first copy.
• File-level deduplication looks for identical files, while block-level deduplication looks for identical blocks within files.
• Inline deduplication performs the deduplication when it is received by the storage system and before data is written to disk. This option requires the least amount of storage space but can impact performance.
• Postprocess deduplication writes data to disk and then deduplicates it later when resources are available. This process requires additional storage for the data that has not been deduplicated, but it has a lower impact on performance.
• Deduplication can be performed on the storage array, managed by the host, or managed by a separate appliance.
Chapter Review Questions
1. In host-based data migration, what is the host?
A. The physical device receiving the storage
B. The software on the device sending information to be stored
C. The device managing the storage
D. A network software used to transfer data between devices
2. Longer migrations could cause which of the following? (Choose the best answer.)
A. A decrease in the productivity of users and a decrease in the availability of the systems that reside on the storage being migrated
B. An increase in available space on the receiving device
C. A more effective storage of data and a more thorough analysis of the data being migrated
D. A decrease in the availability of the systems that reside on the storage that is not being migrated
3. Appliance-based data migration specifically refers to which of the following?
A. A data migration in which software on the array is used to manage migration, including setting up migration pairs, scheduling, and synchronization
B. A data migration in which stand-alone network appliances migrate files and volumes, interfacing with storage systems and providing a separate interface for managing the replication
C. A data migration in which a host is used to manage the movement of data from one location to another
D. A data migration in which data of varying formats is transferred between hosts or storage systems
4. Tom is organizing a data system and realizes that certain pieces of data are not accessed as regularly. What should Tom use in order to save money and increase productivity?
A. Remove the infrequently accessed files from the system and transfer all the remaining data to a larger hard drive.
B. Use personally identifiable information to redistribute itself into a more easily accessible data structure.
C. Upgrade the entire system to a solid-state drive to speed up access for all data on the system.
D. Use hierarchical storage management to automatically move files from primary storage to more cost-effective, slower, secondary storage without changing the way they are represented to end users.
5. What is the most common retention policy in use now?
A. Deleting files that are of a certain age that have not been used recently
B. Maintaining all files ever used but transferring older files to a secure secondary file system
C. Deleting files that are of a certain age, regardless of the frequency of their use
D. Maintaining all files ever used but transferring files that have remained unused for a certain length of time to a secure secondary file system
6. Inline deduplication refers to:
A. A redundancy analysis performed once the data is stored in the system
B. The removal of duplicates within a data set before it is entered into the data system
C. The process by which the duplication of data is prevented immediately as the data enters the storage system
D. The process that cannot impact performance that prevents identical data from entering a storage system
7. In addition to increasing the performance of the system and increasing the storage capacity of the systems, deduplication:
A. Creates a hierarchical storage management system
B. Helps reduce the number of bytes transferred between the source and destination
C. Removes data with similar, but not identical, information from a system
D. Ensures that at least two versions of a file are always present on a system
Chapter Review Answers
1. A is the correct answer. The device receiving the storage is known as a host. B, C, and D are incorrect. B is incorrect because the software sending the information is an application. C is incorrect because the device managing the storage could be external to the one providing or receiving the storage. D is incorrect because a host is a machine, not software.
2. A is the correct answer. Longer migrations could impact the productivity of users of the system or, in worse cases, the availability of the system or systems that reside on the storage being migrated.
B, C, and D are incorrect. B is incorrect because migrations, long or short, would have the same impact on available disk space. C is incorrect because longer migrations are no more effective than shorter ones. D is incorrect because the availability of systems being migrated would be impacted first. Other systems may be impacted, but not as greatly as the ones being migrated.
3. B is the correct answer. In appliance-based data migration, stand-alone network appliances migrate files and volumes, interfacing with storage systems and providing a separate interface for managing the replication.
A, C, and D are incorrect. A is incorrect because software on the array that manages the migration is array-based migration. C is incorrect because this depicts host-based migration. D is incorrect because the answer simply describes migration in general.
4. D is the correct answer. Having a cheaper, slower secondary storage for less commonly used items allows the size of the primary storage volume to be smaller, thereby allowing for a decrease in costs for the primary storage. Also, keeping fewer items in the primary storage volume increases the overall speed at which items can be accessed and subsequently increases the end user’s ability to be productive.
A, B, and C are incorrect. A is incorrect because removing the infrequently accessed files would make them unavailable. B is incorrect because PII is information that cannot be used to redistribute itself. C is incorrect because upgrading the entire system to solid state would be overly expensive.
5. A is the correct answer. The most common retention policy in use now is deleting documents and files after disuse, which means deleting files that are a certain age and that are not used for a certain period of time.
B, C, and D are incorrect. B and D are incorrect because maintaining all files ever used results in management costs and risks for data that are unnecessary for the business. C is incorrect because frequency of use should be a determination of the data value.
6. C is the correct answer. Inline deduplication is the process by which duplication of data is prevented immediately as the data enters the storage system. A, B, and D are incorrect. A is incorrect because inline deduplication performs the analysis while the data is stored. B is incorrect because inline deduplication does not perform the operation before the data is transferred. Instead, it is performed while it is transferred. D is incorrect because performance can be impacted.
7. B is the correct answer. The deduplication process increases the performance of the system by a greater percentage and increases the storage capacity of the systems. The deduplication technique also helps reduce the number of bytes transferred between the source and destination.
A, C, and D are incorrect. A is incorrect because deduplication does not create a hierarchy of any sort. C is incorrect because deduplication operates on identical pieces of data, not just similarities. If it operated on similarities, some data would be lost. D is incorrect because deduplication stores only one version of a file.