
CHAPTER 8: The Map ADT
© Ake13bk/Shutterstock
In the early days of computing it became apparent that high-level languages such as Java were crucial for programmers to be productive. The compilers and interpreters that translated high-level languages into lower-level languages for machine execution were possibly the most complex programs that had ever been created at that time. To support these programs a data structure called a symbol table was devised. A symbol table did just as its name suggests—it provided a table that could hold symbols. The symbols we speak of actually were the identifiers used in the high-level programs being translated, and the tables held more than just the identifier names, of course; they also held important information related to the identifier such as its type, scope, and memory location:
| Symbol | Type | Scope | Location |
|---|---|---|---|
| value | integer | global | 47B43390 |
| cost | float | local | 537DA372 |
| i | integer | loop | 38DD2545 |
When the translation program first encountered an identifier it would add its information to the table. On subsequent encounters it would get the information related to the symbol from the table. Thus, a symbol table provided a mapping from symbols to the information related to the symbol:
cost → float, local, 537DA372
In the years since the creation of symbol tables, we have come to realize that such a data structure, one that provides a map from a given value to information related to that value, can be used for more than just symbol tables. That is why in this chapter we use the more generic term map to describe this structure. Nevertheless, our Map ADT is essentially a symbol table. It is similar to our Collection ADT and, like all of our collections, it supports the addition, removal, and discovery of information. The primary difference between our Collection ADT and our Map ADT is that our Map ADT explicitly separates the key information from the element—the key and the value mapped to, from the key, are separate entities.
Following our typical pattern, we first define an interface for our Map ADT, and then look at implementations and applications. One implementation approach in particular is very important. Hashing traces its origins back to those early symbol tables, where it was crucial to be able to quickly locate a symbol in the table. As you will see, with a well-designed hashing approach the cost to find a key can be O(1). Yes, O(1)—you cannot do better than that! Today, hashing is still used to implement compiler symbol tables, in addition to such important uses as memory management, database indexing, and Internet routing.
8.1 The Map Interface
Our maps will associate a key with a value. When a map structure is presented with a key—for example, through a get(key) operation—it returns the associated value, if there is one. A map acts much like a mathematical function. In fact, within the functional programming paradigm the term “map” means applying a function to all elements of a list, and returning the new list. Functions in mathematics relate each input value to exactly one output value. Present the function f(x) = x2 with the value 5, and it returns 52 or 25. The function f maps 5 onto 25, and nothing else. So it is with our maps. Another way of putting this is to say that a map structure does not permit duplicate keys (see Figure 8.1a which is not a map). The values on the other hand, may be duplicate—it is possible to have two distinct keys map onto the same value (see Figure 8.1(b) which is a map).
When we think of maps, keys, and associated values we typically think of using a key to retrieve the additional information associated with the key. For example, in Figure 8.2a the atomic number is used as a key to find the associated element name. However, it could be that the key itself is embedded in the information associated with it—much like the key fields of the elements in our collections. The key could be a string and the value associated with it could be a WordFreq object holding the same string plus the additional information of a count, as shown in Figure 8.2b. There can even be a situation where we want to use a map simply to hold keys, for example, to calculate the vocabulary density of a text we only need to store strings with no associated value. In such a case we can still use a map, by simply associating a key with itself as shown in Figure 8.2c.
We now define our MapInterface. Our maps will provide all of the basic operations associated with collections—the ability to add, remove, get, and determine membership of elements. However, given that maps separate keys from values, we cannot reuse the CollectionInterface abstract method definitions. With maps, all of these basic operations will refer separately to keys and values.

Figure 8.1 Rules for maps

Figure 8.2 Legal mapping variations
We have already stated that keys will be unique. Additionally, we disallow null keys. If a map operation is passed a null key as an argument, it will throw an IllegalArgument Exception. This unchecked exception is provided by the java.lang package.
Values, on the other hand, need not be unique (see Figure 8.1b) and can be null. Allowing null values permits us to store the fact that a key exists even though it is not yet associated with any value; for example, a new employee was hired but has not yet been assigned an office. Null values can also be used in the case where we are only interested in holding keys (see Figure 8.2d).
The Map interface takes two generic parameters, one indicating the key type and one indicating the value type. In addition to the basic collection-like operations mentioned above, it also requires our standard isEmpty, isFull, and size methods, plus an iterator. The code follows.
//--------------------------------------------------------------------------- // MapInterface.java by Dale/Joyce/Weems Chapter 8 // // A map provides (K = key, V = value) pairs, mapping the key onto the value. // Keys are unique. Keys cannot be null. // // Methods throw IllegalArgumentException if passed a null key argument. // // Values can be null, so a null value returned by put, get, or remove does // not necessarily mean that an entry did not exist. //--------------------------------------------------------------------------- package ch08.maps; import java.util.Iterator; public interface MapInterface<K, V> extends Iterable<MapEntry<K,V>> { V put(K k, V v); // If an entry in this map with key k already exists then the value // associated with that entry is replaced by value v and the original // value is returned; otherwise, adds the (k, v) pair to the map and // returns null. V get(K k); // If an entry in this map with a key k exists then the value associated // with that entry is returned; otherwise null is returned. V remove(K k); // If an entry in this map with key k exists then the entry is removed // from the map and the value associated with that entry is returned; // otherwise null is returned. // // Optional. Throws UnsupportedOperationException if not supported. boolean contains(K k); // Returns true if an entry in this map with key k exists; // Returns false otherwise. boolean isEmpty(); // Returns true if this map is empty; otherwise, returns false. boolean isFull(); // Returns true if this map is full; otherwise, returns false. int size(); // Returns the number of entries in this map. }
Depending on the circumstances, the put, get, and remove methods might return null to indicate that there was no value associated with the provided key argument. The client must be careful how it interprets a returned null value, since it is possible to have keys associated with null. If the distinction between a null indicating “no entry” and a null indicating an entry with a null value is important to a client, then it should use the contains method first to determine whether the entry exists.
Because a map holds pairs of objects it is possible to consider three iteration approaches—we could provide an iteration that returns the keys, or that returns the values, or that returns the key-value pairs. We have decided to require the last of these, an iteration that returns key-value pairs, as part of our map requirements. We create a new class MapEntry to represent the key-value pairs. This class requires the key and value to be passed as constructor arguments, and provides getter operations for both, plus a setter operation for the value, plus a toString. It is a relatively simple class and is also part of the ch08.maps package:
//--------------------------------------------------------------------------- // MapEntry.java by Dale/Joyce/Weems Chapter 8 // // Provides key, value pairs for use with a Map. // Keys are immutable. //--------------------------------------------------------------------------- package ch08.maps; public class MapEntry<K, V> { protected K key; protected V value; MapEntry(K k, V v) { key = k; value = v; } public K getKey() {return key;} public V getValue(){return value;} public void setValue(V v){value = v;} @Override public String toString() // Returns a string representing this MapEntry. { return "Key : " + key + " Value: " + value; } }
Looking back at MapInterface you will see that it extends Iterable<MapEntry <K,V>>. This means that any class that implements the MapInterface must provide an iterator method that returns an Iterator over MapEntry<K,V> objects.
Let us look at a short sample application, just to clarify the use of a map. This example uses the implementation developed in the next section. Each output statement includes a description of the predicted output. This makes it easier to check if our expectations are met. You should trace through the code to see if you agree with the predictions.
package ch08.apps;
import ch08.maps.*;
public class MapExample
{
public static void main(String[] args)
{
boolean result;
MapInterface<Character, String> example;
example = new ArrayListMap<Character, String>();
System.out.println("Expect 'true': " + example.isEmpty());
System.out.println("Expect '0': " + example.size());
System.out.println("Expect 'null': " + example.put('C', "cat"));
example.put('D', "dog"); example.put('P', "pig");
example.put('A', "ant"); example.put('F', "fox");
System.out.println("Expect 'false': " + example.isEmpty());
System.out.println("Expect '5: " + example.size());
System.out.println("Expect 'true': " + example.contains('D'));
System.out.println("Expect 'false': " + example.contains('E'));
System.out.println("Expect 'dog': " + example.get('D'));
System.out.println("Expect 'null': " + example.get('E'));
System.out.println("Expect 'cat': " + example.put('C', "cow"));
System.out.println("Expect 'cow': " + example.get('C'));
System.out.print("Expect 5 animals: ");
for (MapEntry<Character,String> m: example)
System.out.print(m.getValue() + " ");
System.out.println("
Expect 'pig': " + example.put('P', null));
System.out.println("Expect 'dog': " + example.remove('D'));
System.out.print("Expect 3 animals plus a 'null': ");
for (MapEntry<Character,String> m: example)
System.out.print(m.getValue() + " ");
}
}
The output from the sample program is below. Looks like all of the predictions were accurate!
Expect 'true': true Expect '0': 0 Expect 'null': null Expect 'false': false Expect '5: 5 Expect 'true': true Expect 'false': false Expect 'dog': dog Expect 'null': null Expect 'cat': cat Expect 'cow': cow Expect 5 animals: dog pig ant fox cow Expect 'pig': pig Expect 'dog': dog Expect 3 animals plus a 'null': ant fox cow null
8.2 Map Implementations
There are many ways to implement our Map ADT. Any of the internal representations we have used so far for collections can also form the basis for a map implementation. This is not surprising since a map can be viewed as a collection of MapEntry objects with the additional requirement that no two objects have the same key.
Let us briefly consider some possible approaches.
Unsorted Array
The array holds MapEntry objects. The put operation creates a new MapEntry object using the arguments provided by the client code. It then performs a brute force search of all the current keys in the array to prevent key duplication. If a duplicate key is found, then the associated MapEntry object is replaced by the new object and its value attribute is returned. For example,
map.put('C', "cow");
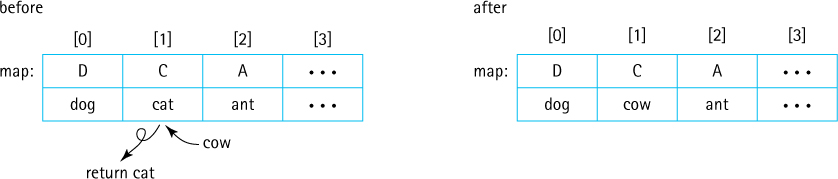
Otherwise, the new object is simply added at the “end” of the array, that is, in the first available array slot. For example:
map.put('B', "bat");

Like put, the get, remove, and contains operations would all require brute force searches of the current array contents, so they are all O(N).
Sorted Array
A sorted array is the same as an unsorted array except the entries are maintained in sorted order by key. Depending on the implementation details, clients may be required to use Comparable keys or provide a Comparator object. With this approach the binary search algorithm can be used, greatly improving the efficiency of the important get and contains operations. Although it is not a requirement, in general it is expected that a map will provide fast implementation of these two operations.
Unsorted Linked List
As with the unsorted array, a brute force search of the linked list is required for most operations. Therefore, there is no time efficiency advantage to using an unsorted linked list as compared to an unsorted array. The put operation, for example, looks much the same as the put operation for the unsorted array. The following figure depicts what happens when a key is reused to put a second value into the map.

When a new key is put into a map, the map still must be searched to make sure there are no duplicates. Then, the new entry is placed in an “easy” location, probably either the front or the rear of the linked list. There is conceivably some benefit to using the front of the array for insertion of a new key/value pair, as for many applications, an entry recently inserted into a map is highly likely to be searched for soon afterward.
In terms of space, a linked list grows and shrinks as needed so it is possible that some advantage can be found in terms of memory management, as compared to an array. Do not forget, however, that a linked list uses an extra memory reference, to hold the link, for each element.
Sorted Linked List
Even though a linked list is kept sorted, it does not permit use of the binary search algorithm as there is no efficient way to inspect the “middle” element. So there is not much advantage to using a sorted linked list to implement a map, as compared to an unsorted linked list. It is possible to make use of the sorted nature of the list to discontinue a search for a given key once a key with a higher value has been encountered. Although helpful, this approach does not provide a faster order of growth efficiency.
Binary Search Tree
If a map can be implemented as a balanced binary search tree, then all of the primary operations (put, get, remove, and contains) can exhibit efficiency O(log2N). The tree may use the key of each entry for comparison purposes and so, as with the sorted array approach, clients would be required to use Comparable keys or provide a Comparator object. The time efficiency benefits depend on the tree remaining balanced:

An ArrayList-Based Implementation
We provide an implementation of a map using an ArrayList of MapEntry objects as the internal representation. The ArrayList is unsorted so the analysis above in the subsection “Unsorted Array” applies. This implementation, although not a good example of an efficient approach, does clearly show the relationships among the various operations and the use of the helper class MapEntry.
//--------------------------------------------------------------------------- // ArrayListMap.java by Dale/Joyce/Weems Chapter 8 // // Implements a map using an ArrayList. // // A map provides (K = key, V = value) pairs, mapping the key onto the value. // Keys are unique. Keys cannot be null. // // Methods throw IllegalArgumentException if passed a null key argument. // // Values can be null, so a null value returned by put, get, or remove does // not necessarily mean that an entry did not exist. //--------------------------------------------------------------------------- package ch08.maps; import java.util.*; // Iterator, ArrayList public class ArrayListMap<K, V> implements MapInterface<K,V> { protected ArrayList<MapEntry<K, V>> map; public ArrayListMap() { map = new ArrayList<MapEntry<K, V>>(); } public ArrayListMap(int initCapacity) { map = new ArrayList<MapEntry<K, V>>(initCapacity); } public V put(K k, V v) // If an entry in this map with key k already exists then the value // associated with that entry is replaced by value v and the original // value is returned; otherwise, adds the (k, v) pair to the map and // returns null. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); MapEntry<K, V> entry = new MapEntry<K, V>(k, v); MapEntry<K,V> temp; Iterator<MapEntry<K,V>> search = map.iterator(); // Arraylist iterator while (search.hasNext()) { temp = search.next(); if (temp.getKey().equals(k)) { search.remove(); map.add(entry); return temp.getValue(); // k found, exits method } } // No entry is associated with k. map.add(entry); return null; } public V get(K k) // If an entry in this map with a key k exists then the value associated // with that entry is returned; otherwise null is returned. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); for (MapEntry<K,V> temp: map) // uses ArrayList iterator if (temp.getKey().equals(k)) return temp.getValue(); // k found, exits method // No entry is associated with k. return null; } public V remove(K k) // If an entry in this map with key k exists then the entry is removed // from the map and the value associated with that entry is returned; // otherwise null is returned. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); MapEntry<K,V> temp; Iterator<MapEntry<K,V>> search = map.iterator(); // Arraylist iterator while (search.hasNext()) { temp = search.next(); if (temp.getKey().equals(k)) { search.remove(); return temp.getValue(); // k found, exits method } } // No entry is associated with k. return null; } public boolean contains(K k) // Returns true if an entry in this map with key k exists; // Returns false otherwise. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); for (MapEntry<K,V> temp: map) if (temp.getKey().equals(k)) return true; // k found, exits method // No entry is associated with k. return false; } public boolean isEmpty() // Returns true if this map is empty; otherwise, returns false. { return (map.size() == 0); // uses ArrayList size } public boolean isFull() // Returns true if this map is full; otherwise, returns false. { return false; // An ArrayListMap is never full } public int size() // Returns the number of entries in this map. { return map.size(); // uses ArrayList size } public Iterator<MapEntry<K,V>> iterator() // Returns the Iterator provided by ArrayList. { return map.iterator(); // returns ArrayList iterator } }
A few notes about the implementation:
Two constructors are provided, one for which the client indicates the original capacity and one that uses the default capacity of an
ArrayList, 10, for the original capacity.Since an
ArrayListis unbounded, ourArrayListMapis unbounded and theisFullmethod simply returnsfalse.Within the code, in order to determine if an entry with a particular key exists, we create an iterator on the
ArrayListand walk through it, checking the keys of the map entries. Alternately, if anequalsmethod is defined for ourMapEntryclass which returnstrueif twoMapEntryobjects have the samekeyattribute, then it is possible to use thecontainsmethod of theArrayListclass (which in turn would use theMapEntry equalsmethod). Although this would make the code for ourArrayListMapclass simpler, it does not improve efficiency since in either case theArrayListentries must be traversed.For the
iteratormethod we simply return theIteratorprovided by theArrayListclass. This same approach could be used by any other implementation approach that uses a wrappedIterableobject as its internal representation of the map.Because we also make use of the built-in
ArrayList iteratormethod within ourputmethod implementation,putdoes not act exactly like the aforementioned put operation for an unsorted array approach. Can you see the difference? If we attempt to put an entry that duplicates a previously entered key, rather than replacing its associated value, we remove the entry altogether (which causes the remaining entries to be shifted) and insert a new entry at the end of the list.
8.3 Application: String-to-String Map
Here we develop a short yet versatile application that demonstrates the use of our Map ADT. Suppose there is a text file containing pairs of related strings, one pair per line. Assume that none of the strings contain the character #—we can use # as a delimiter to separate the strings. Assume that there are no empty strings included and that the first string of each pair is unique—the first string will act as a key.
Our application reads the text file line by line, putting the information into a map object, using the first string on a line as the key and the second string as the associated value. The application then prompts the user to enter a string and if the user replies with one of the previously read keys, the application displays the associated value. In order to allow the application to provide appropriate prompts, the first line of the text file contains a pair of strings indicating the meanings of the keys and the values. As an example, suppose the file numbers.txt contains
Number between 0 and 100#The Number is: 0#Zero 1#One 2#Two . . . 99#Ninety-Nine 100#One Hundred
A run of the application using numbers.txt as input reads the text file, builds the maps, and then interacts with the user:
Enter Number between 0 and 100 (XX to exit): 12 The Number is: Twelve Enter Number between 0 and 100 (XX to exit): 134 No information available. Enter Number between 0 and 100 (XX to exit): 56 The Number is: Fifty-Six Enter Number between 0 and 100 (XX to exit): XX
Assuming one understands the Map ADT and its interface the application is straightforward and easy to create. A command line argument indicates the location and name of the input file, and a Scanner object, set up with appropriate delimiters, is used to scan the file. The application first scans and saves the information from the first line to use when interacting with the user. Next it scans the key/value string pairs until it reaches the end of the file, saving the information in the pairs map. Finally, it repeatedly prompts the user for a string and if a matching key exists in the pairs map, it displays the corresponding value. Otherwise it reports, “No information available.” Here is the code with the map-related commands emphasized.
//--------------------------------------------------------------------------- // StringPairApp.java by Dale/Joyce/Weems Chapter 8 // // Reads # separated pairs of strings from specified input file. // First pair of strings provides descriptive info. // Remaining pairs of strings stored in a map as key - value pairs. // Prompts user for a key and if it exists, displays the associated value. //--------------------------------------------------------------------------- package ch08.apps; import java.io.*; import java.util.*; import ch08.maps.*; public class StringPairApp { public static void main(String[] args) throws IOException { // Create map MapInterface<String, String> pairs = new ArrayListMap<String, String>(); // Set up file reading String fname = args[0]; // input file of text FileReader fin = new FileReader(fname); Scanner info = new Scanner(fin); info.useDelimiter("[#\n\r]"); // delimiters are # signs, line feeds, // carriage returns // get information about the key and value String keyInfo = info.next(); String valueInfo = info.next(); info.nextLine(); // Reads the key/value pairs from the file and puts them into the map String key, value; while (info.hasNext()) { key = info.next(); value = info.next(); info.nextLine(); pairs.put(key, value); } // Interact with user, getting keys and displaying value Scanner scan = new Scanner(System.in); final String STOP = "XX"; key = null; while (!STOP.equals(key)) { System.out.println(" Enter " + keyInfo + " (" + STOP + " to exit):"); key = scan.next(); if (!STOP.equals(key)) if (pairs.contains(key)) System.out.println(valueInfo + " " + pairs.get(key)); else System.out.println(" No information available."); } } }
Now we look at a few more examples of how one might use this application. The file glossary.txt, found in the input folder, contains this text’s definitions as key/value pairs. Using it as input to the StringPairApp application we get a means to look up definitions:
Enter Data Structure's Term (XX to exit): Leaf Definition A tree node that has no children Enter Data Structure's Term (XX to exit): Ancestor Definition A parent of a node, or a parent of an ancestor Enter Data Structure's Term (XX to exit): Garbage Definition The set of currently unreachable objects Enter Data Structure's Term (XX to exit): XX
Nice! OK, one more example. The file periodic.txt contains a list of atomic element numbers and names:
Atomic Number#Element Name 1# Hydrogen 2# Helium 3# Lithium . . . 118# Ununoctium
Our application lets us look up element names based on number:
Enter Atomic Number (XX to exit): 6 Element Name Carbon Enter Atomic Number (XX to exit): 36 Element Name Krypton Enter Atomic Number (XX to exit): 200 No information available. Enter Atomic Number (XX to exit): 118 Element Name Ununoctium Enter Atomic Number (XX to exit): XX
8.4 Hashing
As the name implies, the purpose of a Map ADT is to map keys onto their corresponding values. Although an efficient mapping is not required as part of the specification of the ADT, it is implied and expected. In particular, when using an implementation of a Map ADT, a programmer expects efficient implementations of the observer methods get and contains. If we consider the approaches discussed in Section 8.2, “Map Implementations,” we see that the unsorted array (including the ArrayList-based implementation we presented later in the section), unsorted linked list, and sorted linked list all support O(N) implementations of the observer methods—this is not efficient. Both the sorted array and balanced binary search tree approaches do better, allowing get and contains implementations that are O(log2N). That is good.
Let us do better!
Consider the first example of Section 8.3, “Application: String-to-String Map” where, based on the contents of the numbers.txt file, the integers between 0 and 100 were mapped onto their description as words. By the time all of the data is loaded into the underlying array it looks something like this:

Consider, for example, a call to map.contains("91"). Our ArrayList-based application searches the first 92 slots of the array before finding a match and returning true. The contains method is O(N). Even if we chose a sorted array-based implementation for our map that can use binary search, the search would require seven comparisons (O(log2N)) before locating the target key. However, in this case, we can see that it would be possible to simply read the user’s input as an integer and use that integer as the index into the underlying array (the value associated with 91 is in array location 91). That is O(1)—a constant time search for the entry.
This is promising. Let us further explore this idea of using the key as an index into an array of entries. Can we somehow get this approach to work in the general case? In theory, that is not an impossible dream. The approach presented next is called hashing (you will learn why in the next section) and the underlying data structure—the array that holds the entries—is called a hash table.
Hashing involves determining array indices directly from the key of the entry being stored/accessed. Hashing is an important approach involving many inter-related considerations. Here we present the related ideas one at a time, so although you may have concerns about holes in the approach as we first start to describe it, we hope that by the time you reach the end of the discussion you will agree that this is a clever and interesting solution to efficient storage/retrieval.
Let us continue by looking at a more pragmatic example, a list of employees of a fairly small company. First we will consider a company with 100 employees, each of whom has an ID number in the range 0 to 99. We want to access the employee information by the key idNum. If we store the entries in a hash table that is indexed from 0 to 99, we can directly access any employee’s information through the array index, just as discussed for the numbers example above. A one-to-one correspondence exists between the entry keys and the array indices; in effect, the array index functions as the key of each entry.
In practice, this perfect relationship between the key value and the location of an entry is not so easy to establish or maintain. Consider a similar small company with 100 employees, but this company uses five-digit ID numbers to identify employees. If we use the five-digit ID number as our key, then the range of key values is from 00000 to 99999. It seems wasteful to set up a hash table of 100,000 locations, of which only 100 are needed, just to make sure that each employee’s entry is in a perfectly unique and predictable location.
What if we limit the hash table size to the size that we actually need (an array of 100 entries) and use just the last two digits of the key to identify each employee? For instance, the entry for employee 53374 is stored in employeeList[74], and the entry for employee 81235 is in employeeList[35]. The entries are located in the hash table based on a function of the key value:
location = (idNum % 100);
The key idNum is divided by 100, and the remainder is used as an index into the hash table of employee entries, as illustrated in Figure 8.3. This function assumes that the hash table is indexed from 0 to 99 (MAX_ENTRIES = 100). In the general case, given an integral key, for example idNum, and the size of the storage array, such as MAX_ENTRIES, we can associate a hash table location with the key using the statement:
location = (idNum % MAX_ENTRIES);
The function f(idNum) = idNum % MAX_ENTRIES used here is called a compression function because it “compresses” the wider domain of numbers (0 to idNum), representing the keys, into the smaller range of numbers (0 to MAX_ENTRIES - 1), representing the indices of the hash table. Of course, keys will not always be integral—for now we assume they are and we will address the important issue of nonintegral keys in Section 8.5, “Hash Functions.”
The compression function has two uses. First it is used to determine where in the hash table to store an entry. Figure 8.4 shows a hash table whose entries—information for the employees with the key values (unique ID numbers) 12704, 31300, 49001, 52202, and 65606—were added using the compression function (idNum % 100) to determine the storage index. To simplify our figures in the remainder of this section, we use the key value, in this case the idNum, to represent the entire entry stored along with the key. Note that with this approach the entries are not stored contiguously as has been done with all previous array-based approaches in the text. For example, because no entries whose keys produce the hash values 3 or 5 have been added yet in Figure 8.4, the hash table slots [03] and [05] are logically “empty.”

Figure 8.3 Using a compression function to determine the location of the entry in a hash table

Figure 8.4 Result of adding entries based on a compression function
The second use of the compression function is to determine where to look for an entry. If the information corresponding to idNum 65606 is requested, the retrieval method uses 65606 % 100 = 06 as the index into the hash table to retrieve the information.
It is not quite that simple, which is OK. We cannot expect to obtain constant time storage and retrieval without some complexity, correct?
Collisions
By now you are probably objecting to this scheme on the grounds that it does not guarantee unique array locations for each key. For example, unique ID numbers 01234 and 91234 both “compress” to the same location: 34. This is called a collision. The problem of minimizing such collisions is the biggest challenge in designing a good hashing system and we discuss it in Section 8.5, “Hash Functions.”
Assuming that some collisions occur, where should the entries be stored that cause them? We briefly describe several popular collision-handling algorithms next. Whatever scheme is used to find the place to store an entry will also need to be used when trying to find the entry. The choice of collision-handling algorithm also impacts entry removal options.
In our discussion of collision resolution policies, we will assume use of an array info to hold the information, and the int variable location to indicate an array/hash-table slot.
Linear Probing
A simple scheme for resolving collisions is to store the colliding entry into the next available space. This technique is known as linear probing. In the situation depicted in Figure 8.5, we want to add the employee entry with the key ID number 77003. The compression function returns 03. But there already is an entry stored in this hash table slot, the record for employee 50003. The location is incremented to 04, and the next hash table slot is examined. Because info[04] is also in use, location is incremented again. This time a slot that is empty is found, so the new entry is stored into info[05].
What happens if the last index in the hash table is reached and that space is in use? The hash table can be considered to be a circular structure so searching for an empty slot can continue at the beginning of the table. This approach is similar to our circular array-based queue presented in Chapter 4.
How do we know whether a hash table slot is “empty”? Assuming we have an array of objects, this is easy—just check whether the value of the array slot is null.
To search for an entry in support of the get and contains operations using this collision-handling technique, the compression function is evaluated on the target key, and the result is used to obtain an entry from the table. The target key is compared to the key of the entry from the table. If the keys do not match, linear probing is used, beginning at the next slot in the hash table. Searching continues until either a matching entry is found (a successful search) or a null entry is found (an unsuccessful search).

Figure 8.5 Handling collisions with linear probing
There is a boundary-case issue or bug with our search approach. If searching for an entry that is not contained in the hash table and the hash table is full, the code will continuously wrap around, fruitlessly searching forever. We can solve this issue by storing the original location returned by the compression function and then discontinuing the search if it returns to that location. In practice this is not an issue—as we will discuss later, most hashing schemes increase the size of the underlying array if their load factor (the percentage of array slots being used) rises above a preset threshold. In that case, the array will never be full and we need not worry about the infinite loop.
Entry Removal
Although we have discussed the insertion and retrieval of entries in the hash table, we have not yet mentioned how to remove an entry. Look at an example. Consider Figure 8.6. Suppose we remove the entry with the key 77003 by setting info[05] to null. A subsequent search for the entry with the key 42504 would begin at info[04]. The entry in this slot is not the one being searched for, so the code next tests info[05]. This slot, which formerly was occupied by the entry that was removed, is now empty (contains null), but the search cannot be terminated—the record being searched for is in the next slot.
Not being able to assume that an empty array slot indicates the end of a linear probe severely undermines the efficiency of this approach. Even when the hash table is sparsely populated, every location must be examined before determining that an entry is not present. Because the primary goal of a hashing approach is to provide fast search, this is not a tenable solution. What else can we do?
One approach is to indicate, with a special reserved value stored in a hash table slot, that the slot once held an entry, but that the entry has been deleted. For example, if we use the value 00000 as the special value, then the hash table in Figure 8.7 shows what the hash table from Figure 8.6 contains after removal of the entry with key 77003.

Figure 8.6 Linear probing

Figure 8.7 Using 00000 to indicate removal
With this approach, when searching the hash table to support get, contains, or remove, any hash table slot containing the special value is skipped over. The add operation, on the other hand, upon seeing the special value, acts as if it has seen a null and uses the slot for the new entry. After all, the location is available and can be used to hold real information. Note that with this approach, when searching for a key, the code can terminate the search (unsuccessfully) when a null value is encountered. For example, if checking to see if the hash table pictured in Figure 8.7 contains the key 17203, the code would inspect hash table slots 03 (not a match), 04 (not a match), 05 (special value), 06 (not a match), and 07 (null).
For the special value approach to work we must assume that no entry actually uses the value as its key. A similar approach does not suffer from this restriction. If an additional value, for example, a boolean value, is associated with each hash table slot, it can be used to indicate whether or not the slot previously held a value (see Figure 8.8). This is essentially the same as the special value approach except the code checks the boolean value instead of looking for the special value.
Another approach to this issue is to disallow removal of entries. Make remove an illegal operation. Although this may seem like a drastic approach there are many situations where it is not an issue. Collections are often used to store static information for fast retrieval, in which case, the remove operation is not needed.
Quadratic Probing
One problem with linear probing is that it results in a situation called clustering. Suppose keys end up being distributed randomly, resulting in a uniform distribution of used indices throughout the hash table’s index range. Initially, entries are added throughout the hash table, with each slot being equally likely to be filled. Over time, after a number of collisions have been resolved, the distribution of entries in the hash table becomes less and less uniform. The entries tend to cluster together, as multiple keys begin to compete for a single location. This phenomena happens even with a good random distribution of keys. Why?

Figure 8.8 Using a boolean to indicate removal
Consider the hash table in Figure 8.6. Only an entry whose key produces the compression value 08 would be inserted into hash table slot [08]. However, any entries with keys that produce a compression value of 03, 04, 05, 06, or 07 would be inserted into hash table slot [07]. That is, hash table slot [07] is five times more likely than hash table slot [08] to be filled. As soon as there is a collision or two entries otherwise end up beside each other in the hash table, the probability that the two of them viewed as a unit are “hit” is twice as high as any other slot in the hash table. And this probability-driven effect escalates as more entries are added, resulting in clusters of used locations throughout the hash table. Clustering results in inconsistent efficiency of collection operations and makes the use of a load threshold for the underlying array even more important when linear probing is used.
Clustering is a side effect of linear probing. Another collision resolution approach, called quadratic probing, reduces the cluster effect. In linear probing, the code adds the constant value 1 to the location until it finds an open hash table slot. With quadratic probing the value added at each step is dependent on how many locations have already been inspected. The first time it looks for a new location it adds 1 to the original location, the second time it adds 4 to the original location, the third time it adds 9 to the original location, and so on—the ith time it adds i2.
Because we jump ahead more and more spaces, each time a “probe” fails to find an available slot, the clustering effect is reduced. The example shown in Figure 8.9 makes the difference clear to see. We must take care with this approach, however, because we could find ourselves in an infinite loop of probes even though there are empty slots in the hash table. We can solve this issue by keeping track of how many probes have been attempted and if the count reaches the size of the hash table, discontinuing our search. Even better we can maintain a load threshold below 50% and use a hash table size that is a prime number. Theorists have proven that the degenerate, infinite loop situation will not occur as long as we meet those conditions.

Figure 8.9 Linear versus quadratic probing

Figure 8.10 Handling collisions with buckets
Buckets and Chaining
Another, perhaps better, alternative for handling collisions is to allow entries to share the same location. One approach lets each computed location contain slots for multiple entries, rather than just a single entry. Each of these multientry locations is called a bucket. Figure 8.10 shows an example with buckets that can contain three entries each. Using this approach, we can allow collisions to produce duplicate entries at the same location, up to a point. When the bucket becomes full, we must again deal with the problem of determining a new location.

Figure 8.11 Handling collisions with chaining
Another solution, which avoids this problem, is to store a linked list of entries at each location. Each hash table slot accesses a chain of entries. Figure 8.11 illustrates this approach. The entry in the hash table at each location contains a reference to a linked list of entries.
To search for a given entry, we first apply the compression function to the key and then search the indicated chain for the entry. Searching is not eliminated, but it is limited to entries that actually share a compression value. By contrast, with linear probing we may have to search through many additional entries if the slots following the location are filled with entries from collisions on other locations.
8.5 Hash Functions
To get the most benefit from the hashing system described in the previous section we need for the eventual locations used in the underlying array to be as spread out as possible. Two factors affect this spread—the size of the underlying array and the set of integral values presented to the compression function. First we will discuss the size factor and then turn our attention to the primary topic of this section—generating a good set of integral values.
Array Size
One way to minimize collisions with a hash system is to use an array that has significantly more space than is actually needed for the number of entries, thereby increasing the range of the compression function. This extra space reduces the negative impact of collisions by providing a wide range of target values.
Selecting the array size involves a space versus time trade-off. The larger the range of array indices, the less likely it is that two keys will end up at the same location. However, allocating an array that contains too large a number of empty slots wastes space. In most cases though, we prefer to err on the side of using too much space, because in most cases, space is not an issue.
Hash systems will often monitor their own load—the percentage of array indices being used. Once the load reaches a certain level, for example 75%, the system is rebuilt using a larger array. This approach is similar to the one we used to create unbounded array-based ADTs in previous chapters, although in those cases we only executed the private enlarge method when the underlying structure was full, and in this case we enlarge it preemptively, when it is 75% full, to help ensure efficient operation. This approach is used within the Java Library hash-based classes and is also the approach we use for the map implementation we present in the next section. This approach is often called rehashing because after the array is enlarged all of the previous entries have to be “rehashed”, that is they have to be reinserted into the new array—they cannot just remain in their previous locations.
The Hash Function
In the discussion of hashing systems so far we have been assuming that our keys are integral and that when these keys are fed to the compression function the result will be a nice spread of target hash table locations. These assumptions allowed us to concentrate on the processes of a hash system, but it is not difficult to see that neither assumption is well founded:
Key information might not be integral. For example, it is not unusual for a string to be used as a key—perhaps a person’s full name, the name of a country, a word in a glossary, an identifier in a computer program, a Web URL, and so on.
Even if the key information within a certain domain is integral, it might not be well suited for use as input to the compression function. Imagine, for example, an encoding system for cities that assigns a nine-digit code to each city in the world, with the first four digits representing a city’s name, the next two digits representing a city’s region, and the last three digits representing the city’s country:

Such a system is capable of assigning unique nine-digit keys to up to 10,000 cities in each of up to 100 regions, in each of up to 1,000 countries. But if you used this key to store information about the cities, in a hash system with an underlying array of size 1,000 that used buckets of linked lists to resolve collisions, you will likely end up with an inefficient system. For example, if your data set consists of 5,000 cities from China your array will consist of 999 empty slots and one slot, slot [038], that holds a 5,000-entry linked list. This is not what we hope for when we decide to use hash-based storage.
The solution to these issues is to add another level of transformation that takes us from key value to the hash table location. This new transformation is provided by a function called the hash function and occurs before applying the compression function. The hash function accepts a key as input and produces an integer as output (in our case, using Java, it produces an int). It does this whether or not the key is integral. The int produced by the hash function is called the hash code for the key, and is passed to the compression function so that the final result represents an index in the target hash table as shown below. Synonyms for “hash code” include “hash value,” and sometimes we just use the word “hash.”

A good hash function minimizes collisions by generating hash codes, which ultimately lead to a uniform spread of entries throughout the hash table. We say “minimizes collisions” because it is extremely difficult to avoid them completely.
So, how do we create a hash function and more importantly, how do we create a good hash function?
Selecting, Digitizing, and Combining
Anything stored on a computer is composed of a sequence of bits, 1s and 0s. Movies, sounds, images, strings, books, songs, student records—everything. Since a sequence of bits can be interpreted as a binary number people sometimes say that “computers only operate on binary numbers.” While that is a simplification of computing it is technically true, and it tells us that no matter what form a key takes it is possible to transform it into a binary number. Given a binary number it is possible to generate a related int—for example, simply use the most significant (or least significant) 32 bits of the binary number.
We typically do not want to follow this exact procedure in practice, but it does demonstrate, in theory, it is possible to create a hash function that transforms keys of any data type/class into hash codes of type int.
Let us consider how we might create a hash function for use with our nine-digit city code example. As we have seen, we do not want to simply use the nine-digit code directly because it will most likely not provide a good spread of hash codes. So what do we do? A common approach is to split the hash function activity into three steps:
Selecting. Identify selected parts of the key to be used in the next step. In our city code example, we make the obvious choice and identify part A = first four digits (the city code), part B = next two digits (the region code), and part C = last three digits (the country code). Although in this case we use the entire key, this is not required. For example, if the key is a string we could use every other character as a “part,” or if the key is an image we could use the values of a subset of pixels.
Digitizing. The selected parts are all transformed to integers. For the city codes just use the code as a number, for a string character use its underlying character code, and for a pixel use its gray scale level or some arithmetic combination of its color codes.
Combining. Combine the digitized parts using some arithmetic function. In our city code example, we might try
[(A × C) + B]or[A2+ (B × C)],for example. The result is our hash code. In other situations we might concatenate or exclusive-OR some parts together. We hope to find a function that minimizes collisions yet at the same time is not too expensive to calculate.
In practice it might be possible to combine or skip steps, depending on the data being hashed.
Once the hash code is computed, it is passed to the compression function (if necessary) and the result is used as an index into the hash table. If a collision occurs, then more processing, some sort of probing, is needed to find the final target location. We sometimes shorten the description of application of a hash function to just the word “hashes,” as in “‘Yiyang, Hunan, China’ hashes to 122,278”.
Many different schemes are used for computing hash functions, with variations for all three steps possible. Schemes have impressive-sounding names such as polynomial, midsquare, cyclic-shift, boundary, and/or shift folding, and so forth. No matter how fancy the names, all the methods consist of one or more of the aforementioned steps.
Other Considerations
There are many things to consider when defining and using a hash function:
A hash code is not unique. The input to a hash function is typically a key of some sort, but do not forget that two separate keys might generate the same hash code. For example, if a hash function for a string consists of adding together the ASCII code values of its first six characters, then the following two strings hash to the same value: “listen” and “silent.” Do not use a hash code as a key.
If two entries are considered to be equal, then they should hash to the same value. For example, suppose we have
Gemobjects with attributesweight,color, andquality, and within our domain two gems are considered equal if they have the sameweightandquality. In that case the hash function should not use thecolorattribute when computing the hash code. Although a red gem of weight 16.4 and quality level 2.3 might appear different to us than a green gem of the same weight and quality, since within the domain they are considered equal then their hash values must be equal. Otherwise we cannot use a hashing system for storage and retrieval—storage and retrieval is based on the concept of equality.Be aware of the range of the compression function. For example, in Java the % operator can return a negative value: –23 % 5 is –3. If % is used for the compression function in a Java implementation, you must ensure that the output from the hash function is nonnegative. Otherwise, a negative hash table location might be generated by the compression function which would lead to an
ArrayIndexOut OfBoundsExceptionbeing thrown. It is easy to prevent this problem by using an if-else guard statement or theMathclass’sabs(absolute value) method. Alternatively you can just ensure it is not possible to generate a negative number by carefully choosing your hash function. If using this latter approach, be aware that arithmetic overflow may occur during the execution of your hash function, in which case although it appears negative numbers cannot be generated, they might appear as a result of the overflow.When defining a hash function, we should consider the work required to calculate the function. Even if a hash function always produces unique values, it is not a good choice if it takes too long to compute. In some cases clever algorithms can be used to reduce computation time. For example, if you have parts A, B, and C selected and wish to apply the mathematical function 5A3 + BA2 + CA you could implement it as follows:
hashcode = (5 * A * A * A) + (B * A * A) + (C * A);
A more clever approach, known as Horner’s method, gives the following equivalent implementation:
hashcode = ((((5 * A) + B) * A) + C) * A;
and reduces the number of costly multiplications from 6 to 3. Similarly, a knowledge of bit-level representations and the effects of left and right shifts can be used to decrease computation time in some cases.
Do not overcompensate in terms of calculation efficiency. The previous example (see the first bulleted item) of a hash function for strings that consisted of adding together the ASCII code values of the string’s first eight characters is efficient (additions are “cheap”) but not a good choice if you have a large hash table. Suppose your hash table size is 100,000. Inasmuch as ASCII character codes are at most 127 then the maximum hash code you can generate with your mathematical function is 8 × 127 = 1,016. The range of potentially generated values uses only about 1% of the table! An alternate hash function, perhaps one that combines multiplication and addition of ASCII code values that results in a larger range of potential hash codes, will likely mean less collisions and a more efficient hashing system.
It is possible to use knowledge of the domain of a required hash function to help you devise a good function, or conversely, to avoid creating a poor function. In our city code example used previously, we showed how knowledge of the nine-digit code cautions us against using only the last three digits (the country code) as the hash code. We can imagine many other similar situations. Suppose, for example, we devise a hash function aimed at transforming strings into hash codes that uses a well-conceived mathematical combination of the first and last four characters of the string. Such a scheme might work well in many situations. But what happens if we try to use it to store information about Web addresses:
See the problem? Many, and we do mean many, Web addresses begin and end with the same characters and in the scheme described here they would all hash to the same location. Knowing that your hash function is to be used to hash Web locations should inform you not to use this approach.
Java’s Support for Hashing
Java provides good support for hashing. The Java library includes two important hash-based collection classes—the HashMap, which we discuss in Section 8.7, “Map Variations,” and the HashSet which uses a hash table approach to implementing a set (see Section 5.7, “Collection Variations,” for a definition of the Set ADT). More importantly for the current discussion, the Java Object class exports a hashCode method that returns an int hash code. Because all Java objects ultimately inherit from Object, all Java objects have an associated hash code. Therefore, just as we can assume that all objects in Java support the toString and equals methods, we can assume that all objects support the hashCode method.
Similar to the way the Object class treats equals and toString, the standard Java hashCode for an object is a function of the object’s memory location. As a consequence, it cannot be used to relate separate objects with identical contents. For example, even if circleA and circleB have identical attribute values, it is very unlikely that they have the same hash code. Of course, if circleA and circleB are aliases, if they both reference the same object, then their Object-based hash codes are identical because they hold the same memory reference.
For most applications, hash codes based on memory locations are not useful. Therefore, many of the Java classes that define commonly used objects (such as String and Integer) override the Object class’s hashCode method with one that is based on the contents of the object. Just as we override the Object class’s toString and equals methods when defining a class whose objects may need to support those methods, we should override the hashCode method as necessary. In fact, it is good programming practice to always override the equals and hashCode methods together, if you intend to override either one. It is important that these two methods are consistent with one another.
In Chapter 5 we defined a FamousPerson class. An object of this class has String attributes firstName, lastName, and fact, and an int attribute yearOfBirth. The equals method for this class is based on names only, that is two FamousPerson objects are considered equal if and only if both their first and last names are equal. Any definition of the hashCode method for this class should therefore be based strictly on the first and last name attributes. Here is an example:
@Override
public int hashCode()
// Returns a hash code value for this FamousPerson object.
{
return Math.abs((lastName.hashCode() * 3) + firstName.hashCode());
}
As you can see, the above method makes use of the predefined hashCode method of the String class. The call to the absolute value method of the Math class ensures that it will return a positive result. Here is an example of what this method returns for a sample of famous people:
Edsger Dijkstra: 1960658654 Grace Hopper: 2019100524 Alan Turing: 1038687573
Complexity
We began our discussion of hashing by trying to find a collection implementation where the addition, removal, and most importantly, the discovery of entries had a complexity of O(1). If our hash function is efficient and never produces duplicates, and the hash table size is large compared to the expected number of entries in the collection, then we have reached our goal. In general, this is not the case.
Clearly, as the number of entries approaches the array size, the efficiency of the algorithms deteriorates. This is why the load of the hash table is monitored. If the table needs to be resized and the entries all need to be rehashed, a one-time heavy cost is incurred.
A precise analysis of the complexity of hashing depends on the domain and distribution of keys, the hash function, the size of the table, and the collision resolution policy. In practice it is usually not difficult to achieve close to O(1) efficiency using hashing. For any given application area, it is possible to test variations of hashing schemes to see which works best.
8.6 A Hash-Based Map
In Section 8.1, “The Map Interface,” we introduced the Map, an ADT that maps keys to values with a goal of supporting fast retrieval. In Sections 8.4, “Hashing,” and 8.5, “Hash Functions,” we learned about hashing, a system for fast storage and retrieval of information. It is time to put the two together. Here we present an implementation of our Map ADT called the HMap with the following characteristics:
HMapis implemented with an internal hash table that uses thehashCodemethod of the key class (the argument passed through the generic parameterK) and linear probing to determine storage locations. To guard against a key class that might return negative hash code values, we apply the absolute value operation from theMathclass to all returned hash codes.An
HMapis unbounded. A privateenlargemethod increases the size of the internal hash table (i.e., the internal array) by an amount equal to the original capacity on an as-needed basis. TheisFullmethod always returnsfalse.The internal hash table has a default capacity of 1,000 and a default load factor of 75%. Thus, if an
HMapobject is instantiated using the default constructor (the constructor with no parameters) and the number ofMapEntryobjects held by the table reaches 751, the size of the hash table is increased to 2,000. The next increase, if necessary, is to 3,000, and so on.Two constructors are provided, the default constructor described in the previous bullet item and a constructor which allows the client to indicate the original capacity and load factor.
Recall that in the Map interface,
removeis listed as an optional operation. OurHMapdoes not support theremoveoperation. Invokingremovewill result in the uncheckedUnsupported-OperationExceptionbeing thrown. Theremoveoperation is similarly prohibited by any returnedIterator. A client usingHMapcanaddandputkey/value pairs but cannotremovethem. Although this approach does somewhat limit how anHMapcan be used, there are still many clients that can productively use the class, and it permits us to disregard the complexities normally associated with hash table entry removal.
The Implementation
Here is the HMap code listing. The listing is followed by some discussion and examples of how to use the HMap.
//--------------------------------------------------------------------------- // HMap.java by Dale/Joyce/Weems Chapter 8 // // Implements a map using an array-based hash table, linear probing collision // resolution. // // The remove operation is not supported. Invoking it will result in the // unchecked UnsupportedOperationException being thrown. // // A map provides (K = key, V = value) pairs, mapping the key onto the value. // Keys are unique. Keys cannot be null. // // Methods throw IllegalArgumentException if passed a null key argument. // // Values can be null, so a null value returned by put or get does // not necessarily mean that an entry did not exist. //--------------------------------------------------------------------------- package ch08.maps; import java.util.Iterator; public class HMap<K, V> implements MapInterface<K,V> { protected MapEntry[] map; protected final int DEFCAP = 1000; // default capacity protected final double DEFLOAD = 0.75; // default load protected int origCap; // original capacity protected int currCap; // current capacity protected double load; protected int numPairs = 0; // number of pairs in this map public HMap() { map = new MapEntry[DEFCAP]; origCap = DEFCAP; currCap = DEFCAP; load = DEFLOAD; } public HMap(int initCap, double initLoad) { map = new MapEntry[initCap]; origCap = initCap; currCap = initCap; load = initLoad; } private void enlarge() // Increments the capacity of the map by an amount // equal to the original capacity. { // create a snapshot iterator of the map and save current size Iterator<MapEntry<K,V>> i = iterator(); int count = numPairs; // create the larger array and reset variables map = new MapEntry[currCap + origCap]; currCap = currCap + origCap; numPairs = 0; // put the contents of the current map into the larger array MapEntry entry; for (int n = 1; n <= count; n++) { entry = i.next(); this.put((K)entry.getKey(), (V)entry.getValue()); } } public V put(K k, V v) // If an entry in this map with key k already exists then the value // associated with that entry is replaced by value v and the original // value is returned; otherwise, adds the (k, v) pair to the map and // returns null. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); MapEntry<K, V> entry = new MapEntry<K, V>(k, v); int location = Math.abs(k.hashCode()) % currCap; while ((map[location] != null) && !(map[location].getKey().equals(k))) location = (location + 1) % currCap; if (map[location] == null) // k was not in map { map[location] = entry; numPairs++; if ((float)numPairs/currCap > load) enlarge(); return null; } else // k already in map { V temp = (V)map[location].getValue(); map[location] = entry; return temp; } } public V get(K k) // If an entry in this map with a key k exists then the value associated // with that entry is returned; otherwise null is returned. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); int location = Math.abs(k.hashCode()) % currCap; while ((map[location] != null) && !(map[location].getKey().equals(k))) location = (location + 1) % currCap; if (map[location] == null) // k was not in map return null; else // k in map return (V)map[location].getValue(); } public V remove(K k) // Throws UnsupportedOperationException. { throw new UnsupportedOperationException("HMap does not allow remove."); } public boolean contains(K k) // Returns true if an entry in this map with key k exists; // Returns false otherwise. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); int location = Math.abs(k.hashCode()) % currCap; while (map[location] != null) if (map[location].getKey().equals(k)) return true; else location = (location + 1) % currCap; // if get this far then no current entry is associated with k return false; } public boolean isEmpty() // Returns true if this map is empty; otherwise, returns false. { return (numPairs == 0); } public boolean isFull() // Returns true if this map is full; otherwise, returns false. { return false; // An HMap is never full } public int size() // Returns the number of entries in this map. { return numPairs; } private class MapIterator implements Iterator<MapEntry<K,V>> // Provides a snapshot Iterator over this map. // Remove is not supported and throws UnsupportedOperationException. { int listSize = size(); private MapEntry[] list = new MapEntry[listSize]; private int previousPos = -1; // previous position returned from list public MapIterator() { int next = -1; for (int i = 0; i < listSize; i++) { next++; while (map[next] == null) next++; list[i] = map[next]; } } public boolean hasNext() // Returns true if iteration has more entries; otherwise returns false. { return (previousPos < (listSize - 1)); } public MapEntry<K,V> next() // Returns the next entry in the iteration. // Throws NoSuchElementException - if the iteration has no more entries { if (!hasNext()) throw new IndexOutOfBoundsException("illegal invocation of next " + " in HMap iterator. "); previousPos++; return list[previousPos]; } public void remove() // Throws UnsupportedOperationException. // Not supported. Removal from snapshot iteration is meaningless. { throw new UnsupportedOperationException("Unsupported remove attempted " + "on HMap iterator. "); } } public Iterator<MapEntry<K,V>> iterator() // Returns a snapshot Iterator over this map. // Remove is not supported and throws UnsupportedOperationException. { return new MapIterator(); } }
The three operations (put, get, and contains) that must determine if the map holds a given key k, all follow the same general pattern exemplified by the following code:
int location = Math.abs(k.hashCode()) % currCap; while ((map[location] != null) && !(map[location].getKey().equals(k))) location = (location + 1) % currCap;
First, location is set using the hashCode method of the key class. Then linear probing is used until either an empty array slot is found (one where map[location] == null) or a MapEntry object with key k is found (note that we make use of the short-circuit property of the Java && operation to protect ourselves from using a null reference). If the object with key k is found then the appropriate action takes place— replacement for the put operation, return for the get operation, and return true for the contains operation. Otherwise, in the case of a location containing null being found, again the appropriate action takes place—insertion for the put operation, return null for the get operation, and return false for the contains operation.
The private enlarge method deserves some discussion. Because put is the only way to add information to the map it is the only place where enlarge is invoked:
if (map[location] == null) // k was not in map
{
map[location] = entry;
numPairs++;
if ((float)numPairs/currCap > load)
enlarge();
return null;
}
The enlarge method first stores all of the current entries of the map by creating an Iterator. It then instantiates a new array of MapEntry objects of the appropriate size. Finally, it “walks through” the saved Iterator, adding each of the MapEntry objects into the new array using the put operation. The put operation spreads the entries across the newly enlarged array.
Overall, enlarge is a costly operation, especially if an expensive hash function is in use. Although enlarge only executes on a rare basis and we can amortize its cost across the large number of put operations that must precede its invocation, the actual cost does all occur at once. If you are designing a system where consistent rapid response is a requirement you need to be aware of this and consider how you can originally allocate enough space to your hash table to avoid the use of enlarge.
Finally, we should note why we did not use an anonymous inner class to provide the required Iterator object that is returned by the iterator method, as we have done for previous ADT implementations. For the hash table–based map, our approach to iteration is to search through the entire underlying map array, creating a new array, list, that holds references to only the non-null entries. In other words, the list array will hold a “snapshot” of the MapEntry entries that have been stored so far, without all of the intervening null entries.

The list array is then used to provide the hasNext and next operations. The remove operation is not supported. In any case, in order to set up the list array we need to perform some initial processing, when the Iterator object is created. This processing must take place in a constructor. But constructors are not supported by anonymous classes— after all, an anonymous class does not have a name, so there is no way to “name” the constructor. Thus, we use a “regular” inner class in this case to support iteration.
Using the HMap class
We can use the HMap class in the same way we used our ArrayListMap class. For example, to use the HMap class to support the StringPairApp application presented in Section 8.3, “Application: String-to-String Map,” all we need to do is change the line
MapInterface<String, String> pairs = new ArrayListMap<String, String>();
to
MapInterface<String, String> pairs = new HMap<String, String>();
It might be interesting to see how HMap performs on the Text Analysis experiment we used in both Chapter 5, “The Collection ADT,” and Chapter 7, “The Binary Search Tree ADT.” You may recall that our application, VocabularyDensity, reads a given text file and computes the ratio of its number of unique words to total number of words. We used the application to analyze a collection of texts including, among others, the Complete Works of Shakespeare and an edition of the Encyclopaeda Brittanica. Perhaps the most interesting text file analyzed was one we called “Mashup,” which consisted of a concatenation of 121 files from the Gutenberg site including novels, “complete works,” dictionaries, and technical manuals, plus Spanish, French, and German language texts in addition to the English. What happens if we “hash the mash”?
The VocDensMeasureHMap application can be found in package ch08.apps. As before, the application reads through the words from the input text, checking each word to see whether or not it already exists in the map. If not, the word is added, and if so, the word is skipped. In either case we increment the number of total words. When finished we simply divide the number of words in the map by the total number of words. Because we are only interested in the words themselves, which are used as the keys, we use null values when putting information into the map. We set the initial capacity to 2,404,198, which is exactly twice the number of unique words in the mashup.txt file. How do the results compare to previous attempts, in terms of execution time? (Times are approximate):
Unsorted Array: 10 hours
Sorted Array (uses binary search): 7 minutes, 10 seconds
Binary Search Tree: 100 seconds
Hash Map: 66 seconds
Well, that is a little disappointing although requiring 66% of the time needed by the binary search tree is some improvement. But wait—there is quite a bit of overhead associated with just reading the input file word by word. Experimentation shows that the cost of this activity, which is unavoidable for our application yet is not directly related to the storage/retrieval mechanism, is approximately 51 seconds. We can relist our last two results, subtracting out this overhead cost, and get (approximately):
Binary Search Tree: 50 seconds
Hash Map: 15 seconds
Now we can state that the hash map approach only takes about 30% of the time of the binary search tree result, a more satisfying result.
8.7 Map Variations
The Map ADT is important, versatile, and widely used. Some programming languages, (e.g., Awk, Haskell, JavaScript, Lisp, MUMPS, Perl, PHP, Python, and Ruby), directly support it as part of the base language, although in some cases there are limitations on what can be used as a key and/or value. Many other languages, including Java, C++, Objective-C, and Smalltalk provide map functionality through their standard code libraries.
Maps are known by many names:
Symbol table. As discussed in the chapter introduction, symbol tables were one of the first carefully studied and designed data structures, and were related to compiler design. Classically they associate a program symbol with its attributes—so they are indeed maps.
Dictionary. The idea of looking up a word (the key) in a dictionary to find its definition (the value) makes the concept of a dictionary a good fit for maps. So in some textbooks and some programming libraries you will find maps are called dictionaries.
Hashes. Because a hash system is a very efficient and common way to implement a map, you will sometimes see the two terms used interchangeably. For example, when using the Perl language one might say “hashes are a powerful structure” or “insert the element into a hash.”
Associative Arrays. You can view a standard array as a map—it maps indices onto values. With a little bit more imagination you can view a map as an array—one that associates keys with values rather than indices with values. Therefore, the term “associative array” is becoming the commonly used term that represents symbol tables, dictionaries, hashes, and maps.
A Hybrid Structure
We have seen how a hash table, under the right conditions, supports fast storage and retrieval of information. Suppose we have a situation where we need fast storage and retrieval, but we also need to be able to iterate through the stored entries in the order in which they were placed into the collection. The only structures that we have studied so far that support such an iteration are the unsorted array (assuming the remove operation is implemented carefully) and the unsorted linked list (assuming we insert entries at the end of the list)—but neither of these provide efficient storage and retrieval. They are both O(N) for these operations.
Is there some way we could use a hash table to solve our problem?
The problem is that a hash table spreads things all across the underlying array in no particular order. Suppose we create a map with the following declaration:
HMap<Character, String> animals = new HMap<Character, String>;
and then execute:
animals.put('A', "ant"); animals.put('B', "bat"); animals.put('C', "cat");
The result might look something like this:

As you can see, the entries are spread around and there is no way to recapture the original order of insertion. If we expand the contents of the internal data to hold a count of how many entries have been entered so far, and associate the value of that count with each entry as it is stored in the array, then at least we have saved the order of insertion for later use. The result might look like this:

Now at least we have captured the entry order information and can, with a bit of work, create the desired iteration. To do this we need to look through the entire internal array, find the entries, and then sort them in increasing order of entry. Seems like a lot of work to reclaim information that was already available to us. Is there a better way?
What if we maintain a second internal array named list, with references into the map array, kept in the desired order:

Now we are getting somewhere. The hashing scheme works as before so this approach supports fast storage and retrieval, and when we need to iterate on insertion order we can just use values from the list array to access the entries in the map array in the desired sequence.
But what happens when an entry is removed? Maintaining the information correctly after a remove operation is going to be difficult and costly. When the remove operation is invoked it is not difficult to find the entry in the map array—we just use the hash function and collision resolution approach. Once the entry is found the contents of the map array at that index can be set to null. But the list array also needs to be updated. Because there is no link back to the list array from map, we need to search the list array to find the correct location to update—and once found in order to remove the information at that location we need to shift all remaining entries to the “left” one slot. So, if we use this approach we have transformed remove from an expected efficiency of O(1) to a best case efficiency of O(N). For some systems this might be too high a cost.
Let us try one more time. We need a support structure that supports fast addition. We need to be able to iterate through the entries in the order in which they are inserted into the map. And we need a reasonably quick remove operation. A doubly linked list (see Section 4.7, “Queue Variations”) supports fast removal. If we embed the list within the map entries themselves then we have the desired relationship between the map entries and the list elements.
The result might look something like this:

Although the figure looks complex, this approach meets our requirements. It is a hash table–based map with an embedded doubly linked list. This is very similar by the way, to a Java Library class—the LinkedHashMap.
Java Support for Maps
The Java Library includes a Map interface. Like our maps, the maps in the library use two generic parameters—K for the types of keys and V for the types of values. A nested class, Entry, fulfills the role of our MapEntry class. The interface, being a part of a professional API, is more complex than our MapInterface. It defines 25 abstract methods, has eight subinterfaces, and is implemented by 19 classes within the library. Nevertheless, in terms of its core functionality, it is equivalent to our map interface.
Of the 19 implementing classes, of special note to us is the HashMap class. The HashMap class permits null keys. Other than that it is very similar to our HMap class (or perhaps we should state that the other way around—our HMap class is similar to the library class!). HashMap provides both a default capacity and load factor, and allows the client to set these through a constructor if they wish, just like our HMap. And like our HMap, assuming a reasonably well-behaved hash function and distribution of keys, HashMap provides constant time storage, removal, and retrieval. The library’s hash map provides more operations than our version does; in fact it implements 24 operations in addition to the 12 it inherits from its ancestors. Professional Java programmers typically make heavy use of the HashMap class to support their work.
Summary
Maps associate unique keys with values. The Map is our only data structure that requires two generic parameters, one to indicate the key class and the other to indicate the value class. Following our typical pattern we first defined an interface for our Map ADT using Java’s interface construct. We then discussed many implementation approaches and provided an ArrayList-based implementation. The StringPairApp exemplified a simple yet powerful program using a map, in this case our ArrayListMap.
One map implementation approach in particular is very important. The goal of hashing is to produce a search that approaches O(1) efficiency. Because of collisions of hash locations, searching or rehashing is sometimes necessary. A good hash function minimizes collisions and distributes the entries randomly across the hash table. Our hash table–based implementation of the map, the HMap, produced the fastest processing yet (and we will not do better) for the vocabulary density problem.
In the Variations section we surveyed how maps are provided and named in several programming languages. Finally, we discussed a hybrid structure consisting of a hash table with a linked list threaded through the entries, a structure providing the benefits of hashing while still allowing easy insertion order-based iteration.
Exercises
8.1 The Map Interface
-
Give an example of a mathematical function such that
it maps some of its input values to identical output values (a → x, b → x).
none of its input values map to the same output value (this is called a one-to-one mapping).
it has an inverse function.
-
Describe an information processing situation where you might use a mapping that
is one to one (see previous question).
is not one to one.
-
The first paragraph of Section 8.1 states that a rule limiting a mapping so that each key maps to exactly one value is equivalent to a rule requiring a mapping to have unique keys. Explain.
-
Show how you would declare a map of type
ArrayListMaprepresenting student (unique) names mapped onto their birthdays.
representing countries mapped onto their populations.
representing the number of sides of a polygon, mapped to the name of the polygon.
-
Critique the following code which is intended to print out whether or not a key value
k1is used in a map namedrelationships:if (relationships.get(k1) != null) System.out.println("yes it does"); else System.out.println("no it does not");Now rewrite the code so that it works correctly.
-
What is the output of the following code—
ArrayListMapis an implementation of theMapInterfaceand is presented in Section 8.2:
MapInterface<Character, String> question;
question = new ArrayListMap<Character, String>();
System.out.println(question.isEmpty());
System.out.println(question.size());
System.out.println(question.put('M', "map"));
question.put('D', "dog"); question.put('T', "Top");
question.put('A', "ant"); question.put('t', "Top");
System.out.println(question.isEmpty());
System.out.println(question.size());
System.out.println(question.contains('D'));
System.out.println(question.contains('E'));
System.out.println(question.get('D'));
System.out.println(question.get('E'));
System.out.println(question.put('D', "dig"));
System.out.println(question.get('D'));
for (MapEntry<Character,String> m: question)
System.out.print(m.getValue() + " ");
System.out.println(question.remove('D'));
System.out.println(question.remove('D'));
for (MapEntry<Character,String> m: question)
System.out.print(m.getValue() + " ");
8.2 Map Implementations
-
In this section we discussed several approaches to implementing a map using previously studied data structures, and in some cases we discussed the implementation of the
putoperation. For each approach (Unsorted Array, Sorted Array, Unsorted Linked List, Sorted Linked List, and Binary Search Tree), describe how you would implement the following operations.isEmpty()contains(K k)remove(K k)iterator()
-
Bob studies the code for
ArrayListMapand announces that he has discovered an “easier approach to thecontainsmethod” as shown below. What do you tell Bob?public boolean contains(K k) // Returns true if an entry in this map with key k exists; // Returns false otherwise. { return map.contains(k); }
-
Describe the ramifications of each of the following changes to
ArrayListMap:In the single statement of the second constructor
initCapacityis changed to10.The if statement is removed from the beginning of the
putmethod.Within the
putmethod the boolean expression(temp.getKey(). equals(k))is changed to(k.equals(temp.getKey()).The
getmethod is rewritten as follows:public V get(K k) // If an entry in this map with a key k exists then the value // associated with that entry is returned; otherwise null is returned. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); V result = null; for (MapEntry<K,V> temp: map) if (temp.getKey().equals(k)) result = temp.getValue(); return result; }
the
containsmethod is rewritten as follows:public boolean contains(K k) // Returns true if an entry in this map with key k exists; // Returns false otherwise. { if (k == null) throw new IllegalArgumentException("Maps do not allow null keys."); boolean result = false; for (MapEntry<K,V> temp: map) if (temp.getKey().equals(k)) result = true return result; }
-
 Implement the Map ADT using
Implement the Map ADT usingan Unsorted Array.
a Sorted Array.
an Unsorted Linked List.
a Binary Search Tree.
8.3 Application: String-to-String Map
-
Create a text file similar to
numbers.txtandperiodic.txtof your own devising that captures an interesting “string-to-string map.” Use it as input to theStringPairAppapplication. -
 Create an application, similar to
Create an application, similar to StringPairApp, which acts as a chemistry quiz. It randomly generates a periodic number between 1 and 118 and asks the user for the corresponding element. It then checks their answer against the correct answer (using a map based on theperiodic.txtfile) and reports the result, displaying the correct answer if they get it wrong. It repeats this for 10 questions and then reports the percentage of correct answers. How can your application be made more generally usable? -
Java reserved words can be categorized into subsets such as “primitive types,” “control,” “access control,” etc. Research the reserved words and create your own categorization scheme. Then
Create an application called
Categoriesthat first creates a map based on your categorization of reserved words (e.g.,int→ “primitive type”) and then reads a.javafile and displays the keyword types found in the file. For example, ifMapEntry.javais the input file then the output, depending on your categorization, might look like this:control, organization, access control, definition, control . . .because of the sequence of reserved wordsfor(see opening comment),package, public, class, protected, . . .Improve your application so that it ignores the contents of literal strings.
Improve your application so that it ignores the contents of comments.
8.4 Hashing
-
For each of the following array sizes indicate whether or not the following sequence of key insertions 21, 75, 240, 413, 1368, 9021, 9513 using a hashing system causes a collision when the appropriate compression function is used:
10
15
17
21
50
100
1,000
10,000
-
Show the array that results from the following sequence of key insertions using a hashing system under the given conditions: 5, 205, 406, 5205, 8205, 307 (you can simply list the non-null array slots and their contents)
array size is 100, linear probing used.
array size is 100, quadratic probing used.
array size is 101, linear probing used.
array size is 1,000, linear probing used.
array size is 100, with buckets consisting of linked lists.
-
For each of the situations described in Exercise 15, indicate how many comparisons are required to search for the key 307, after all insertions were made. The key 406? The key 506?
-
Show the array that results from the following sequence of operations using a hashing system under the given conditions: insert 5, insert 205, insert 406, remove 205, insert 407, insert 806, insert 305 (you can simply list the non-null array slots and their contents)
array size is 100, linear probing used, the value –1 indicates a removed entry.
array size is 10, linear probing used, the value –1 indicates a removed entry.
array size is 10, linear probing used, an additional value of type
booleanis used, withtrueindicating a slot has been used.array size is 10, with buckets consisting of linked lists.
8.5 Hash Functions
-
Describe three domains/application areas where you might expect to be able to define a perfect hash function (no collisions).
-
Discuss rehashing (enlarging a hash table dynamically). Why? When? How?
-
In the nine-digit city code example suppose the hash function used is [(A × C) + B]. What is the hash code for each of the following cities?
Hangzhou, Zhejiang, China: 001112038
Lancaster, Pennsylvania, USA: 012113103
Yiyang, Hunan, China: 321732038
Beaver Falls, Pennsylvania, USA: 54213103
Seoul, Seoul, South Korea: 010313121
-
Critique the following hash functions for a domain consisting of people with attributes
firstName,lastName,number(used to resolve identical first and last names, e.g., “John Smith 0,” “John Smith 1,” etc.), andage. The names are of classStringand the other two attributes are of typeint.hash function returns (
age)2hash function returns (
age)2 +lastName.hashCode()hash function returns
lastName.hashCode() + firstName.hashCode()hash function returns
lastName.hashCode() + firstName.hashCode() + number
-
Define a viable hash function for the following domains with a targeted hash code size of five digits:
randomized citizen identification numbers of length 10 digits.
randomized citizen identification numbers of length 10 where the last three digits indicate occupation.
Web URLs.
file names.
country names.
telephone numbers consisting of two-digit country code, three-digit area code, three-digit exchange code, and four-digit number.
-
Add
equalsandhashCodemethods (unless they are already defined) to the following classes. Create a test driver to show that your code works properly.The
FamousPersonclass defined in Chapter 5 and found in thesupportpackage.The
Dateclass defined in Chapter 1 and found in thech01.datespackage.The
WordFreqclass defined in Chapter 7 and found in thesupportpackage.The
Cardclass defined in Chapter 6 and found in thesupport.cardspackage.The
CardDeckclass defined in Chapter 6 and found in thesupport.cardspackage.
-
Add the
hashCodemethod defined in Section 8.5 on page 530 to theFamousPersonclass. Write an application that reads theinput/FamousCS.txtfile, creates aFamousPersonobject for each line of the file, and generates and saves its associatedhashCode()value in an array.Output the values from the array in sorted order.
Replace each array value A with the value A % 1,000, and again output the values in the array in sorted order.
Replace each array value A with the value A % 100, and again output the values in the array in sorted order.
Replace each array value A with the value A % 10, and again output the values in the array in sorted order.
Write a report about your observations on the output.
Repeat this entire exercise, but use a hash function of your own devising.
8.6 A Hash-Based Map
-
If our
HMapimplementation is used (load factor of 75% and an initial capacity of 1,000), how many times is theenlargemethod called if the number of unique entries put into the map is100
750
2,000
10,000
100,000
-
Your friend Diane says “my hash map implementation uses buckets of linked lists, so I don’t need to worry about load factors.” What do you tell her?
-
Describe the ramifications of each of the following changes to
HMap:The signature of the second constructor is changed from
public HMap(int initCap, double initLoad) to public HMap(double initLoad, int initCap)
The call to the
Math.absmethod withinput is dropped.The statement
currCap = currCap + origCap;is dropped from theenlarge method.The opening if statement is removed from the
putmethod.The opening if statement is removed from the
getmethod.The code for the
removemethod is changed to:if (k == null) throw new IllegalArgumentException("null keys not allowed"); int location = Math.abs(k.hashCode()) % currCap; while ((map[location] != null) && !(map[location].getKey().equals(k))) location = (location + 1) % currCap; if (map[location] == null) // k was not in map return null; else // k in map { V hold = (V)map[location].getValue(); map[location] = null; return V; }Within the for loop of the
MapIteratorconstructor the firstnext++is dropped.
-
Change the
HMapclass (and create a test driver to show that your changes work correctly) so that:It includes a
toStringmethod that prints out the entire contents of the internal array, showing the array index along with its contents. This is helpful for testing the rest of this exercise and some of the following exercises also.It uses quadratic probing.
It provides a working
removemethod, using an additionalbooleanvalue associated with each hash table slot to track removal.Instead of probing it uses buckets of linked lists of
MapEntryobjects.
-
Create an application that uses
HMapand reads a list of words from a provided file and outputs whether or not any word repeats. As soon as the application determines there is at least one repeated word it can display “<such and such word> repeats” and terminate. If no words repeat it displays “No words repeat” and terminates. -
Add a
toStringmethod to theHMapclass (see Exercise 28a). ModifyString-PairMap2, found in thech08.appspackage so that instead of interacting with the user it simply reads the information from the file, stores the information in theHMap, and then “prints” theHMap. Run the application on each of the following files, using a reasonable starting capacity (150% the number of pairs) and a load threshold of 80%, and discuss what you see.input/numbers.txtinput/periodic.txtinput/glossary.txt
8.7 Map Variations
-
Research: Write a short report about the support for maps in two different languages—one language for which the support is part of the language itself and another for which the support is provided through a standard library.
-
Our final solution to the problem of creating an efficient storage/retrieval structure that supports iterating through the entries in insertion order was a hash map with an embedded doubly linked list. Create a drawing similar to the one shown at the end of the section for the internal view of this structure under each of the following situations:
The structure has just been instantiated. Nothing has been added yet.
Continuing from part (a) you put(“b,” “bat”) which hashes to location 2, put(“p,” “pig”) which hashes to location 4, and put(“g,” “goat”) which hashes to location 6.
Continuing from part (b), you put(“a,” “ant”) which hashes to location 0, and then remove(“p”).
Continuing from part (c) you put(“b,” “bear”).
-
Implement the hash map with an embedded doubly linked list described in the “A Hybrid Structure” subsection. Include a test driver to show that your implementation works properly.
-
Create a new version of the
StringPairApp, found in thech08.appspackage, that uses the Java LibraryHashMapclass in place of this text’sArrayListMapclass.