
3
Web 2.0 and the
Emergence
of Emergence
A History, Explanation, and Definition
of Enterprise 2.0
Before presenting the resolution of each of the cases discussed in chapter 2, we first need to understand a few recent technological developments. These occurred on the public Internet, where they gave rise to the phenomenon of Web 2.0. Web 2.0 is not mere “hype,” nor is it of interest only to e-tailers and other Internet companies. Rather, it is extremely relevant to all organizations that want to bring people together into communities that generate useful information and knowledge and solve problems effectively. In other words, the new tools of Web 2.0 are very much applicable to VistaPrint, Serena, the U.S. intelligence community, and Google—and to your organization as well.
This chapter explains what the new tools are and why they truly are something new under the sun. It also describes some of the powerful new resources and communities, like Wikipedia and Delicious, that have sprung up around them on the Internet. Finally, it defines what I have termed Enterprise 2.0, the phenomenon that occurs when organizations adopt the tools and approaches of Web 2.0. In chapter 4 we’ll return to the case studies to see four distinct examples of Enterprise 2.0 in action.
You don’t need to be a technology professional, or even a technophile or gadget lover, to understand this chapter, or to profit from Enterprise 2.0. You simply need to understand three trends and appreciate how they combine to yield a new and improved set of digital tools.
A New Version of the Web?
In September 2005 the technology writer and publisher Tim O’Reilly posted the following entry, titled “What Is Web 2.0?” on his company’s Web site: 1
The concept of “Web 2.0” began with a conference brainstorming session between O’Reilly and MediaLive International. Dale Dougherty, web pioneer and O’Reilly VP, noted that far from having “crashed,” the web was more important than ever, with exciting new applications and sites popping up with surprising regularity. What’s more, the companies that had survived the collapse seemed to have some things in common. Could it be that the dotcom collapse marked some kind of turning point for the web, such that a call to action such as “Web 2.0” might make sense? We agreed that it did …
O’Reilly and his colleagues examined companies, organizations, and sites that represented Web 2.0. These included the following:
• The collaboratively produced encyclopedia Wikipedia
• Social networking sites Facebook and MySpace
• Web-bookmarking resource Delicious 2
• Media-sharing sites YouTube (for videos) and Flickr (for photos)
• Blogging utilities such as Blogger and Typepad and the blog-tracking site Technorati
• Web search engine Google
• Location-based classified ad site craigslist
Most of these had appeared quite recently, a fact that lent support to the notion that there was in fact a new version of the Web. Further support for this idea came from the enormous popularity of many of these resources. According to the Alexa ranking service, by August 2008 six of the ten most popular sites in the world—Google, YouTube, Facebook, MySpace, Wikipedia, and Blogger—were part of the new Web described by O’Reilly. People were voting with their feet (or, to be more precise, their mouse clicks), and were migrating with startling speed away from Web 1.0 stalwarts to the Web 2.0 start-ups.
In a December 2006 post to his blog, O’Reilly offered a short definition: “Web 2.0 is the business revolution in the computer industry caused by the move to the Internet as platform, and an attempt to understand the rules for success on that new platform. Chief among those rules is this: Build applications that harness network effects to get better the more people use them.” 3 O’Reilly’s definition was very helpful. It articulated and crystallized important developments on the Internet and throughout the high-tech sector. But what about companies outside the computer industry? Did the new sites and communities, and the principles that underlie them, herald any important business changes for them? And what about executives, managers, and front-line employees who weren’t involved in building applications? What, if anything, did the new collaboration technologies and approaches mean for them? In other words, could VistaPrint, Serena, Google, and the U.S. intelligence community learn anything from Wikipedia, Blogger, and YouTube? What could “normal” organizations take away from the strange and wonderful new communities of Web 2.0?
To answer these questions, it’s necessary first to understand what changed—how the IT “toolkit” available for collaboration and interaction became significantly larger and better in the first few years of the millennium than it was during the era of groupware and knowledge management (KM) systems.
O’Reilly’s definition highlights network effects: the fact that some resources, like telephone networks and person-to-person auction Web sites, become more valuable to each member as they attract more and more members. Network effects are clearly fundamental, but nothing new; they were understood and deeply appreciated in many industries both before and after the arrival of the Internet. And network effects apply to many, if not most, communication and collaboration technologies, including e-mail, instant messaging (IM), groupware, and KM.
Three Trends Yield Better Tools
Network effects were a necessary but not sufficient condition in the transition from Web 1.0 to Web 2.0. To understand this transition more fully, and to appreciate what it means for all companies hoping to use technology in pursuit of business goals, we’ll need to become familiar with three recent trends. On the Internet the convergence of these three trends has led to Web 2.0. Enterprise 2.0 describes the same convergence on corporate intranets and extranets. I’ll give a tighter definition of Enterprise 2.0 after describing its underlying trends.
1. Free and Easy Platforms for Communication and Interaction
Some popular collaboration technologies—including e-mail, mobile phone texting, and some types of IM—are what I call channels. They essentially keep communications private. People beyond the sender and receiver(s) can’t view the contents of information sent over channels and usually don’t even know that communication has taken place. Information sent via channels isn’t widely visible, consultable, or searchable. Because no record exists of who sent what to whom, channels leave no trace of collaboration patterns.
At times, of course, this is exactly what people want. Communications that are meant to be private should indeed take place via channels. Many other communications and collaborations, however, do not need to be private and may in fact benefit from greater visibility. If a knowledge worker finds herself sending the same e-mail over and over again in response to questions from colleagues, for example, she may well want the ability to display the information somewhere public and point people to it (or, better yet, let them find it on their own). Team members may want to discuss the problems they’re working on publicly, so that others can help out if they have relevant knowledge. Channel technologies, unfortunately, aren’t much help in either of these scenarios.
The alternative to a channel is what I call a platform. Platforms are simply collections of digital content where contributions are globally visible (everyone with access to the platform can see them) and persistent (they stick around, and so can be consulted and searched for). Access to platforms can be restricted—for example, to only members of an R&D lab or a team working on a particular deal—so that sensitive content isn’t visible too widely, but the main goal of a platform technology is to make content widely and permanently available to its members.
Digital platforms are not rare; every Web site, whether on an intranet, extranet, or the Internet, is a platform. They’re not new, either; companies and people have been building Web sites since the mid-1990s. To see what kinds of platforms are new in the era of Web 2.0, recall the journalist A. J. Liebling’s mordant observation that “freedom of the press is limited to those who own one.” In the mid-1990s, the World Wide Web put a multimedia printing press and a global distribution network in the hands of everyone with a little bandwidth, a bit of money (for site-hosting fees), and moderate technical expertise (for coding HTML pages and uploading them to servers). Millions of people and companies took advantage of this opportunity. Hundreds of millions of people did not, however, even though they had Internet access.
Lots of these people, of course, had nothing to say or no desire to take advantage of the printing press offered by the Web. Many others, however, were daunted by the combination of time, expense, and technical skill required to set up and maintain their own Web site. I purchased the domain name mcafee.org many years ago, before the antivirus software company McAfee, Inc. (no relation, sadly) thought to pick it up, but I never did anything with it. My few attempts at coding HTML and maintaining a decent page, let alone a decent site, taught me that it was a lot of work, and I had plenty of other things to do.
Then blogs appeared, vastly reducing the amount of work required to publish on the Web. The term weblog, which was first used in 1997, came to refer to an individual’s frequently updated Web site. In 1999 the shortened form blog first appeared as a noun and a verb. By the start of the millennium, software tools were available that let people initiate and update blogs without having to transfer files to servers manually or learn HTML. With these tools, people simply used their Internet browser to enter text, links to other Web sites, and the other elements of a standard blog.
Blogs let people add online content with no hassle and no knowledge of low-level technical details. They’re an example of what I call free and easy platforms. In this description, free really does mean free of charge. Several advanced blogging platforms are available on the Web at no cost, so anyone with access to a connected computer can start contributing to the Internet’s global pool of information.
Free and easy platforms now exist on the Web for all types of media, including images, videos, sound, and text. And many of the currently popular Web 2.0 platforms like Facebook, MySpace, and Blogger allow their users to combine many types of media—all without having to pay anything or acquire skills beyond the ability to point, click, drag, drop, and type.
As I’m writing this, one of the most intriguing new free and easy platforms on the Web takes communications that have historically flowed through channels and migrates them to a platform. Twitter is a utility that lets people broadcast short messages—no more than 140 characters—to anyone and everyone who may be interested in reading them. These messages can be sent from a computer, mobile phone, PDA, and so on. Users tell Twitter which people they’re interested in “following,” and Twitter collects all messages from these people (and only these people) and presents them to the user in a chronological list. This list can be viewed on the same range of devices from which messages are sent. Users can reply to one another’s messages, but unless specifically requested otherwise, these replies are public; they become part of the Twitter platform rather than flowing through a private channel.
Twitter members use the utility to give updates on their location, plans, status, current work, thoughts and impressions, and many other aspects of their personal and professional lives. With Twitter they don’t have to guess in advance who might be interested in these updates, then use a channel technology to transmit them. Instead, they simply post their updates to a platform, letting others consume them at will. And if these updates spark a conversation or other type of follow-up, this too can take place on the public platform. It remains to be seen how successful or long-lived Twitter itself will be, but its current popularity indicates that there was pent-up demand for interaction and communication using platforms rather than channels.
Even though free and easy platforms are now widespread, many people still believe that it’s difficult to contribute online content. Those of us who started using computers before the birth of the Web, or even in the Web 1.0 era, often carry around the assumption that only technophiles (or, to use a less polite term, nerds) have the skills required to add material to an online platform.
It’s surprising how durable this assumption can be. In 2006 I was teaching an executive education program for senior executives, owners, and presidents of companies. I assigned a case I had written about the internal use of blogs at a bank and gave out one additional bit of homework: I pointed the participants to Blogger and told them to start their own blogs and report the blogs’ Internet addresses to me. What they reported instead was that they had no intention of completing the assignment. They told me how busy they were and said they had neither time nor inclination to mess around with blogs (whatever those were). Out of two classes with fifty to sixty participants each, I received fewer than fifteen blog addresses in all.
Trying to turn lemons into lemonade in class, I asked some of the people who had actually completed the task to describe the experience of starting a blog. They all shrugged and said it was no big deal, took about five minutes total, didn’t require any skills, and so on. I then asked all the participants why they thought I would give busy executives such an easy assignment. In both classes one smart student piped up, “To show us exactly how easy it was.” At that point, class discussion became interesting.
2. A Lack of Imposed Structure
As the entrepreneurs and technologists of Web 2.0 were building the new free and easy platforms, they were also rethinking their own roles and making a fundamental shift. Instead of imposing their own ideas about how content and work on the platforms should be structured, they started working hard to avoid such imposed structure. In this context structure means a few specific things:
• Workflows: The steps that need to be taken to accomplish a piece of work. A workflow is the flowchart of a business process specifying tasks, sequences, decision points, possible branches, and so on.
• Decision rights: Who has the authority, permission, power, or ability to do various things. For example, the decision right over equipment purchases up to $1,000 may be given to an entry-level engineer in an R&D lab, while the decision right for more expensive purchases rests with the lab manager.
• Interdependencies: Who will work together and what their relationship will be. Interdependencies are closely tied to both workflows and decision rights. A workflow defines which parties will be interdependent within a business process, while the allocation of decision rights determines whether these parties will be “above” or “below” each other.
• Information: What data will be included, how it will be formatted and displayed, how data elements will relate to one another, what kinds of error checking will take place, what will constitute “good” or “complete” information, and so on.
Throughout the history of corporate computing, the norm has been to use technology to impose these work structures—to define workflows, interdependencies, decision rights allocations, and/or information needs—in advance and then use software to put them in place. ERP (enterprise resource planning), CRM (customer relationship management), SCM (supply chain management), procurement, and other types of “enterprise systems” enjoyed explosive growth starting in the mid-1990s. These applications differed in many respects, but they shared one fundamental similarity: they were used to define, then deploy, business processes that cut across several organizational groups, thus helping to ensure that the processes would be executed the same way every time in every location. The applications did so by imposing all the elements of work structure listed above.
The belief that technologies supporting collaborative work should impose work structures appears, in fact, to be an almost unquestioned assumption. Technology developers and corporate managers seem to have until quite recently shared the belief that good outcomes in group-level work come from tightly structured processes. This belief was reflected in the design of both groupware and KM systems. A review of groupware use by Paul Dourish of the University of California, Irvine, highlighted that fact that while the software was originally intended to facilitate “work as an improvised, moment-by-moment accomplishment,” it actually wound up being used to support workflows. According to Dourish, software containing “predefined formal descriptions of working processes” has constituted “perhaps the most successful form of groupware technology in current use.” 4 In other words, a genre of technology intended to support unstructured work has enjoyed its greatest success as a tool for imposing work structures. KM applications did not typically specify interdependencies between people or workflows, but they did tightly predefine the structure of the information to be included within the knowledge database, giving only certain people and groups the right to add to it.
It’s easy to understand where this faith in structure originates. It’s at least as old as the theories of the pioneering industrial engineer Frederick Winslow Taylor, who at the beginning of the twentieth century advocated studying work to determine the “one best way” of accomplishing it and then making sure that all workers followed the new standard. Later in the century, the quality revolution led by W. Edwards Deming, Joseph Juran, and others stressed that the best way to ensure consistently satisfactory outcomes was not to focus on the outcomes themselves, but rather to control the process used to create them. This could mean, for example, taking away a worker’s right to adjust his machine after it generated a single bad part and giving this right instead to an engineer who will use the techniques of statistical process control to determine if the machine had truly drifted out of specification. These techniques and the philosophy underlying them soon spread from the manufacturing sector to many other industries, to the point where standardized, tightly defined processes became an almost universal goal.
The work design philosophy of good outcomes via imposed structure and tight control is clearly appropriate in many circumstances, but is it always appropriate? Are there circumstances or contexts in which it’s better not to try to impose control? Can high-quality outcomes result from an undefined, nonstandardized, uncontrolled process?
The early history of Wikipedia provides a fascinating case study of these issues. Wikipedia is now famous as the online encyclopedia that anyone can edit. The Wikipedia community and the wiki technology that supports it, in other words, make virtually no attempt to impose any of the elements of work structure listed above: workflows and interdependencies are not specified in advance, nor is the information that must be contained in each article. Neither is there much in the way of explicit allocation of important decision rights. The Wikipedia community does have administrators, bureaucrats, and stewards who are appointed or elected to their positions, but these groups are not supposed to have any greater say in creating or modifying articles than would a newly arrived Wikipedian. As cofounder Jimmy Wales wrote in a 2003 e-mail, “I just wanted to say that becoming [an administrator] is *not a big deal*… I want to dispel the aura of “authority” around the position. It’s merely a technical matter that the powers given to [administrators] are not given out to everyone.” 5
Wikipedia’s egalitarianism and lack of imposed structure are so deeply entrenched and widely accepted now that it’s hard to believe that the community ever operated under a different set of ground rules. Yet it did. Founders Wales and Larry Sanger always had the goal of creating a high-quality encyclopedia that would be available free worldwide via the Internet. But they initially took the standard approach to ensuring high-quality results: they tightly structured the content-creation process. The first organization they created to build a Web-based encyclopedia was called Nupedia.
As its Wikipedia entry states, “… Nupedia was characterized by an extensive peer review process designed to make its articles of a quality comparable to that of professional encyclopedias.” Sanger, Wales, and an advisory board consisting of PhDs in a variety of fields set up the following seven-stage content-creation process for Nupedia:
1. Article assignment: Once an article topic had been proposed by a user, they identified the area editor (e.g., in philosophy, chemistry, sociology) and decided whether or not that user was qualified to write such an article. If the user was not qualified, the area editor attempted to find someone else with the right qualifications to write the article.
2. Lead reviewer selection: Following article assignment, the editor found a reviewer in the field, an expert in that domain, to read and anonymously critique the article.
3. Lead review: The lead review process was blind and confidential. The author, reviewer, and editor corresponded on a private Web site to determine whether or not the article met Nupedia’s standards for inclusion.
4. Open review: Once an article passed lead review, it was then “opened” up to the general public for review. An article had to be approved by the section editor, lead reviewer, and at least one category peer reviewer before it was deemed suitable for publication.
5. Lead copyediting: Once an article had passed open review, an e-mail was sent to Nupedia’s list of copyeditors asking participants to sign up to copyedit the article. The author selected two volunteer editors and worked with them to get the article ready for the next stage.
6. Open copyediting: After lead copyrighting was finished, an open copyediting period, lasting at least a week, was set aside so that members of the general public could make changes. Final edits were approved by the two lead copyeditors.
7. Final approval and markup: After the category editor and two lead copyeditors had given their final approval, the article was posted on Nupedia. At the end of this process the article’s original author was eligible for a free Nupedia T-shirt or coffee cup. 6
Not everyone could participate in Nupedia; a policy document stated, “We wish editors to be true experts in their fields and (with few exceptions) possess PhDs.” 7
After eighteen months of operation and $250,000 in expenditures, the Nupedia site contained only twelve articles. 8
In the fall of 2000, concerned by the lack of positive momentum in Nupedia, Wales and Sanger started to investigate alternative models for content production. On January 2, 2001, Ben Kovitz had lunch with his friend Sanger and told him about wikis, Ward Cunningham’s technology to enhance collaboration among software developers.
Cunningham had found it difficult to share his innovations and knowledge concerning software development techniques with his colleagues. In 1995 he addressed this problem by creating Web pages that could be not only read but also edited by any reader. He called his creation WikiWikiWeb, which was later shortened to wiki.
Users can add, delete, or edit any part of a wiki. A wiki is typically supported by a database that keeps track of all changes, allowing users to compare changes and also revert to any previous version. With a wiki, all contributions are stored permanently and all actions are visible and reversible.
Sanger thought that a wiki might help solve the problems facing Nupedia. On the evening following his lunch with Kovitz he let Wales know about his new discovery and recommended that they experiment with a “wikified” Nupedia. Most of the members of the advisory board were not interested in a free-forall encyclopedia construction project, but Wales and Sanger decided to proceed with the experiment.
On January 15, 2001, Wales and Sanger set up a separate Web site—www.wikipedia.com—supported by wiki technology. Sanger sent a note to the Nupedia volunteers list encouraging its members to check out this new attempt: “Humor me. Go there and add a little article. It will take all of five or ten minutes.” 9
At the end of January there were 617 articles on Wikipedia. March saw 2,221 articles on the new platform, July 7,243, and December approximately 19,000. On September 26, 2003, Nupedia was formally shut down. It had 24 completed articles.
As of June 2008, Wikipedia was by far the largest reference work in the world, with more than 2.4 million articles in English, more than 500,000 each in German, Polish, and French, and more than 250,000 in each of six other languages. Clearly, the founders’ shift in philosophy away from imposed work structures and toward the use of wiki technology supporting the new approach of freeform, egalitarian collaboration unleashed a huge amount of energy and enthusiasm. But did it lead to the creation of high-quality encyclopedia entries, or to the proliferation of junk? We’ll take up that question shortly.
Yahoo!’s purchase in late 2005 of the Web-based bookmarking site Delicious provides another example of the same broad shift in philosophy away from imposed structure, in this case the structure of the millions of pages that make up the Web. Early in its history Yahoo!’s founders said that it stood for “Yet Another Hierarchical Officious Oracle,” poking fun at themselves but also revealing their vision for the company. Yahoo! attempted to organize the Web’s content into a hierarchical structure, placing individual sites into predefined categories like Health, Arts, and Computers and then creating subcategories within them. Below are a couple of pictures of Yahoo!’s home page showing how this categorization evolved over time (see figure 3-1).
The company employed taxonomists to create and update this structure. Taxonomy is the science of classifying things, usually hierarchically. Carl Linnaeus’s classification of living things—by kingdom, phylum, class, order, family, genus, and species—is perhaps the best-known example. Taxonomies are developed by experts and then rolled out to users to help them make sense of the world and relate things to one another.
I used to use Yahoo!’s taxonomy of the Web a lot. I stopped when I sensed that the Web was becoming too big and growing too fast; the professional taxonomists couldn’t keep up. As figures 3-2 and 3-3 show, Yahoo!’s taxonomy also became less important to the company itself over time. It occupied successively less and less of the home page, the company’s prime Web real estate, and disappeared from it altogether in August 2006.
FIGURE 3-1
December 1998 Yahoo! homepage showing its web categorization

Source: http://web.archive.Org/web/*/http://yahoo.com.
I didn’t pay much more attention to Web categorization schemes until I started hearing about Delicious. Delicious is a Web site that lets members store all their bookmarks on the Web itself so that they’re accessible from anywhere. More importantly, it allows members to add tags to those sites—simple, one-word descriptions that serve as reminders of what the page is about and also enable users to group sites together.
FIGURE 3-2
December 2004 Yahoo! homepage showing its Web categorization near the bottom of the page
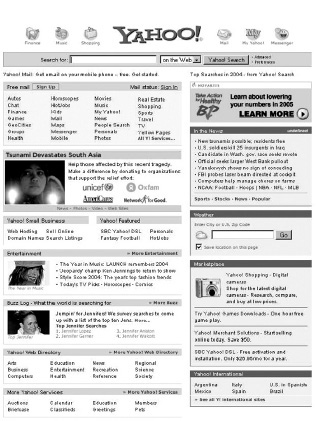
Source: http://web.archive.org/web/*/http://yahoo.com.
August 2006 Yahoo! homepage*
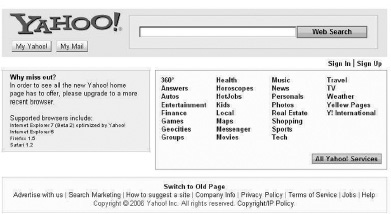
Source: http://web.archive.org/web/*/http://yahoo.com.
* The company’s taxonomy of the Web no longer appears.
My Delicious tags include “blogs,” “web2.0,” and “business.” I generated these tags on my own, instead of selecting them from any predefined list. When choosing a tag, I was able to enter any string of letters, numbers, and symbols that made sense to me. I couldn’t do anything remotely like this with Yahoo!, where I could only passively accept the company’s taxonomy but had no real ability to extend or modify it. Delicious does no error checking or second-guessing; it “allowed” both “enterprise2.0” and “enterprise2.0,”. In sharp contrast to the original Yahoo! taxonomy, Delicious imposes no structure on the Web’s content. Instead, it lets me and all other users create whatever categorizations are useful for ourselves.
A broad concern about this approach, though, is that it leads to messiness. If no one is telling me and all the other Delicious users what tags are acceptable—if we’re all able to enter as many different strings of letters and numbers as we like—won’t it be impossible for Delicious itself ever to add up to anything? Won’t it become just a huge sprawling collection of individuals’ idiosyncratic bookmarks and tags, with little commonality or overlap? In short, if some entity (like Yahoo!) doesn’t predefine a structure (like its Web categorization) and then take responsibility for placing things within that structure, isn’t chaos the inevitable result? To see why this is not always the case, and to understand the third trend underlying Web 2.0 and Enterprise 2.0, it will be helpful to review a bit of history.
Figure 3-4 shows my Delicious tags at one point in time. The number shows how many times I’ve used that tag. 10
FIGURE 3-4
Delicious tags at one point in time

3. Mechanisms to Let Structure Emerge
Several years ago the mathematician and writer John Allen Paulos gave voice to a widespread concern about the Web’s growth with the observation, “The Internet is the world’s largest library. It’s just that all the books are on the floor.” He meant that there was no equivalent of a card catalog for the Web’s content. People who put up Web sites were under no obligation to categorize their contents accurately, and there was nothing like the Dewey Decimal or Library of Congress system to classify what a site was about. Yahoo! tried to do this on its own by employing many people to look at Web sites and place them within the company’s hierarchy of online content. This approach worked for a time, but eventually the Web grew too fast for Yahoo! to keep up.
Web 1.0 search engines developed by Lycos, Alta Vista, Infoseek, Excite, HotBot, and others provided an alternative to Yahoo!’s hierarchy. They worked by automatically visiting as many sites as possible, a process known as “Web crawling,” and analyzing their content, primarily their text, to determine what they were about. Lycos, Alta Vista, and their early competitors looked at each page in isolation, relying either on its key words and how often they appeared, on the page’s description of it-self—typically contained in its “metadata,” a special section of the page’s HTML code invisible to human viewers—or on some combination of these and other factors.
There were two serious problems with this approach to searches. First, if several Web sites existed on the same topic, it was difficult to determine which was the best. If, for example, five pages were devoted to the Boston Red Sox, which should the search engine rank highest—the one that used the team’s name most often? Second, it relied on the accuracy of the Web sites’ and pages’ own descriptions. And since search results drive Web traffic and Web traffic generates advertising revenue and e-commerce sales, Web site owners had strong incentives to misrepresent what their sites and pages were about. They could do this either by lying in their pages’ metadata or by adding key terms like Boston Red Sox thousands of times in the Web’s equivalent of invisible ink. These two factors combined to make Web searching an intensely frustrating experience for many people, a feeling captured in Paulos’s quote. In December 1998 the online magazine Salon.com chronicled the results of a search for “President Clinton”: “Infoseek does a decent job returning the Oval Office site at the top of the list, but Excite sends you to an impeachment poll on Tripod and the Paula Jones Legal Defense Fund—the president’s page doesn’t even make it into the first 10 results. Hotbot’s top result is a site called Tempting Teens—“ ‘All the Kinky Things that make our Government what it is.’” 11
The Salon.com article, written by Scott Rosenberg, identified a newly available engine that did a better job of returning relevant results. It was called Google, and it took a very different approach to search. Google relied on other sites to determine how good a given site was, and therefore how prominently it should be featured in search results. Google’s founders, Larry Page and Sergey Brin, were PhD students at Stanford and were inspired in part by the standard method for judging academic papers: a good academic paper is one that’s referenced or cited by many other papers, and “citation indexes” have long been used by scholars.
Page and Brin realized that the authors of Web pages cite one another just the way the authors of scholarly papers do. But on the Web, citations take the form of links from one page to another. The two students developed an algorithm that ranked pages based on how many other pages linked to them, giving more weight to pages that were themselves heavily linked to. It is this algorithm, which came to be known as PageRank, that lies at the heart of the Google search engine.
Google was the first search engine to view the Web as a community rather than a collection of individual sites, to realize that members of this community referenced one another heavily via hyperlinks ( just as members of a scientific community do via citations), and to use these links to determine ranking within the community. Search engines stand or fall based on how good their rankings are, and from its inception Google’s appeared to be very good indeed. In his Salon.com article, Rosenberg wrote, “Since discovering Google a few weeks ago, I’ve been so impressed with its usefulness and accuracy that I’ve made it my first search stop.”
Since December 1998 many, many people have joined him. In June 2006 the Oxford English Dictionary included the verb “to Google,” meaning, “To use the Google search engine to find information on the Internet … To search for information about (a person or thing) using the Google search engine.” 12
Page and Brin realized that Paulos’s image of the Web as a mountain of valuable but unstructured content was vivid but wrong. Web content is not unstructured; it is in fact highly structured as a result of all the links from one page to another. This structure can be exploited not just for navigation ( hopping from page to page via links) but also for searching. Links provide so much structure, in fact, that the Web appears to us to be a very orderly place; thanks to Google, we can find what we want on it.
Ant colonies are similar to the Web in that they appear highly structured even though no central authority is in charge. Colonies have complex social structures and use sophisticated strategies to forage, defend themselves, and make war. This happens not because the queen ant sends out orders, but because each ant is programmed by its DNA to do certain things (carry an egg, fight an intruder, go to where food is) in response to local signals (usually chemical scents from other ants, eggs, intruders, food, and so on). As ants interact with one another and their environment, they send and receive signals, and these low-level activities yield high-level structure.
Complexity science uses the term emergent to describe systems such as ant colonies and the Web. Emergence is the appearance of global structure as the result of local interactions. It doesn’t happen in most systems; what’s necessary is a set of mechanisms to do critical things such as connecting the system’s elements and providing feedback among them.
The Web’s emergent nature doesn’t stem from the fact that it’s a huge collection of digital documents; if the contents of the Library of Congress were digitized tomorrow and put online, they would not constitute an emergent system. The Web is emergent because it’s the dynamic creation of countless people around the world interacting with one another via links as they create new content.
This is a key difference between the public Internet and most corporate intranets today. Whereas public Web sites are built by millions of people, most intranets are built and maintained by a small group. Emergence requires large numbers of actors and interactions, but intranets are produced by only a few people (even though they are passively consumed by many). In addition, most intranet pages aren’t as heavily interlinked as pages on the Internet.
Tagging, as implemented on Delicious and many other sites, is another way to let structure emerge over time. As discussed above, I and all the other Delicious users have complete freedom to define our own tags. It turns out, though, that we tend to use the same relatively small group of words as tags to describe Web pages that we’ve bookmarked. Delicious takes advantage of this fact in several ways. For example, the site includes “tag clouds,” which are views of the most popular tags. Figure 3-5 shows a tag cloud for all Delicious users at one point in time; it’s arranged alphabetically, with the size of the word indicating its relative popularity. Shaded tags are ones that I’ve used; this feature helps me understand where I fit into the universe of Delicious users. Clicking on any word brings up a list of the Web pages that have been tagged with that word, so that users can also see what other tags have been applied to that page, how many Delicious users have tagged the page, and the collection of pages and tags associated with each user (if they give permission for this data to be made public).
FIGURE 3-5
The Delicious tag cloud at one point in time

Source: Delicious.
The information architect Thomas Vander Wal describes a tag cloud as a folksonomy, a categorization system developed over time by folks. A folksonomy is an alternative to a taxonomy, which is a categorization system developed at a single point in time by an authority. Taxonomies are not always inferior, and they haven’t become irrelevant in the Internet era; the classification of living things into kingdoms, phyla, classes, orders, families, genuses, and species is a long-standing and very useful taxonomy. But the success of Delicious indicates that folksonomies offer advantages for categorizing multidimensional and fast-changing content.
Tagging, like linking, fulfills the standard criteria for emergence:
• It’s conducted by many agents spread all over a digital platform like the Internet.
• These agents are acting independently and with great autonomy. I don’t pick my tags from any predefined list; I make up whatever ones are useful to me.
• Agents are also acting in their own self-interest. My Delicious tags help me navigate my own bookmarks. The fact that they help reveal the Web’s structure to everyone else is peripheral to me, but central to the value of Delicious for everyone else.
The high-level structure of the Delicious folksonomy, which changes over time and is visible in its cloud views, can’t be predicted by observing low-level activities. My tags, in other words, won’t tell you anything about what’s going on across Delicious as a whole, just as watching a single ant won’t tell you what the entire colony is up to. Complexity science uses the term irreducible to describe this sharp disconnect between low-level behaviors and high-level structure.
Like the PageRank algorithm, tags, folksonomies, and tag clouds of online content are relatively recent innovations. Delicious first appeared in 2003; the photo-sharing Web site Flickr, sometimes credited with showing the Web’s first tag clouds, was launched in 2004. Tagging has since spread to other popular Web 2.0 sites like YouTube and Facebook.
All of these sites are examples of what I call emergent social software platforms (ESSPs). Let’s break this definition down a bit. Social software enables people to rendezvous, connect, or collaborate through computer-mediated communication and to form online communities. 13 Platforms, as discussed above, are digital environments in which contributions and interactions are globally visible and persistent over time. Emergent means that the software is freeform and contains mechanisms like links and tags to let the patterns and structure inherent in people’s interactions become visible over time. Freeform means that the software is most or all of the following:
• Optional
• Free of imposed structure such as workflow, interdependencies, and decision right allocations
• Egalitarian, or indifferent to credentials, titles, and other forms of “rank”
• Accepting of many types of data
ESSPs share a few technical features, which I summarize with the acronym SLATES (search, links, authoring, tagging, extensions, signals).
• Search: For any information platform to be valuable, its users must be able to find what they are looking for. Web page layouts and navigation aids can help with this, but users are increasingly bypassing these in favor of keyword searches. It might seem that orderly intranets maintained by a professional staff would be easier to search than the huge, dynamic, uncoordinated Internet, but a simple survey shows that this is evidently not the case.
I start many of my speeches and presentations by asking people to raise their hands if it’s easier for them to find what they want on their company’s intranet than it is on the public Internet. Very few people have ever raised their hands.
• Links: As discussed above, links are the main reason that searching on the Internet (thanks to Google and similar search engines) is so much more satisfying than doing so on most intranets. Search technology like Google’s works best when there’s a dense link structure that changes over time and reflects the opinions of many people. This is the case on the Internet, but not on most of today’s intranets, where links are made only by the relatively small internal Web development group. In order for this to change within companies, many people have to be given the ability to make links. The most straightforward way to accomplish this end is to let the intranet be authored by a large group rather than a small one.
• Authoring: Blogs and Wikipedia have shown that many people have a desire to author, that is, write for a broad audience. As wiki inventor Ward Cunningham said, “I wanted to stroke that story-telling nature in all of us … I wanted people who wouldn’t normally author to find it comfortable authoring, so that there stood a chance of us discovering the structure of what they had to say.” 14 Cunningham’s point is not that there are a lot of undiscovered Shakespeares out there, but rather that most people have something to contribute, whether it’s knowledge, insight, experience, a fact, an edit, a link, and so on; authorship is a way to elicit these contributions. When authoring tools are used within a company, the intranet platform shifts from being the creation of a few to becoming the constantly updated, interlinked work of many.
• Tags: A survey from Forrester Research revealed that what experienced users wanted most from their companies’ intranets, after better searching mechanisms, was better categorization of content. 15 Sites like Delicious and Flickr aggregate large amounts of content and then essentially outsource the work of categorization to their users by letting them attach tags. These sites don’t try to impose an up-front categorization scheme; instead they let one emerge over time as a result of users’ actions, which collectively create a folksonomy. In addition to building folksonomies, tags provide a way to keep track of the platforms knowledge workers visit, making patterns and processes in knowledge work more visible as a result.
• Extensions: Moderately “smart” computers take tagging one step further by automating some of the work of categorization and pattern matching. They use algorithms to say to users, “If you liked that, then by extension you’ll like this.” Amazon’s system of recommendations was one early example of the use of extensions on the Web. The browser toolbar from stumbleupon.com is another. With it, users simply select a topic they’re interested in and hit the “stumble” button. They’re then taken to a Web site on that topic. If they like it, they click a “thumbs up” button on the toolbar; if not, they click a “thumbs down” button. They next stumble onto another site. Over time, StumbleUpon matches preferences to send users only to sites they’ll like. It’s surprising how quickly, and how well, this simple system works. It reasons by extension, homing in on user tastes with great speed.
• Signals: Even with powerful tools to search and categorize platform content, a user can still feel overwhelmed. New content is added so often that it can become a full-time job just to check for updates on all sites of interest. The final element of the SLATES infrastructure is technology to signal users when new content of interest appears. Signals can come as e-mail alerts, but these contribute to overloaded in-boxes and may be treated as spam. A relatively novel technology called RSS (which usually refers to “really simple syndication”) provides another solution. Authors such as bloggers use RSS to generate a short notice each time they add new content. The notice usually consists of a headline that is also a link back to the full content. Software for users called “aggregators” or “readers” periodically queries sites of interest for new notices, downloads them, puts them in order, and displays their headlines. With RSS, users no longer have to surf constantly to check for changes; instead, they simply consult their aggregators, click on headlines of interest, and are taken to the new content.
With this background, it’s now possible to give a more precise definition of Enterprise 2.0:
Enterprise 2.0 is the use of emergent social software platforms by organizations in pursuit of their goals.
This definition does not apply just to the computer industry—it’s applicable to any setting in which ESSPs are deployed. And it focuses not on the Internet and social trends, but rather on organizations such as companies and public-sector agencies. Enterprise 2.0, then, is about how organizations use the newly available ESSPs to do their work better. These ESSPs can include all appropriate participants—employees, suppliers, customers, prospective customers, and so on. In other words, Enterprise 2.0 is not just about intranets and does not take place solely behind the firewall; it encompasses extranets and public Web sites as well.
I want to make for the first time a point that will be repeated throughout this book: Enterprise 2.0 is not primarily a technological phenomenon. The preceding discussion stressed tools—ESSPs and their building blocks. The appearance of these novel tools is a necessary but not sufficient condition for allowing new modes of interaction, collaboration, and innovation, and for delivering the benefits that will be discussed later in this book. To make full use of these tools, however, organizations will have to do much more than simply deploy ESSPs; they’ll also have to put in place environments that encourage and allow people to use ESSPs widely, deeply, and productively. On the Web, Wikipedia provides one example of such an environment, showing how it came about and how effective it can be.
The example of Wikipedia illustrates that some of the mechanisms of emergence are organizational and managerial, rather than purely technical. In other words, leaders can’t simply assume that healthy communities will self-organize and act in a coherent and productive manner after Web 2.0 tools are deployed. Organizations are not ant colonies, and an examination of Wikipedia’s history reveals that much effort has gone into defining the social ground rules of the community so that its members interact with one another in largely positive ways. These ground rules fall into two groups: informal norms, and formal policies and guidelines.
Norms
Founder Jimmy Wales summarized Wikipedia’s norms this way: “Our community has an atmosphere of love and respect for each other, a real passion for the work, a real interest in getting it right. We make it fun and easy for good people to get involved.” 16
Early Wikipedians worked to create a cooperative and helpful culture. Most decisions are made by consensus among senior members of the community. Votes are often taken, but their results are not binding; they’re intended to provide information on a matter, not settle it. Overly harsh or argumentative contributors are corrected by their peers and barred if they are found repeatedly ignoring counsel and violating norms.
The wiki technology itself helps reinforce this culture because any participant has the ability to edit or remove anyone else’s contribution. As a result, the incentive to create graffiti and deface entries essentially vanishes, since negative contributions can be erased with just a few clicks. As Wales has put it, “The wiki model is different because it gives you an incentive when you’re writing. If you write something that annoys other people, it’s just going to be deleted. So if you want your writing to survive, you really have to strive to be cooperative and helpful.” 17
Policies and Guidelines
To complement and reinforce these norms, the Wikipedia community formulated a set of policies and guidelines for editing. These have been summarized as the “five pillars of Wikipedia”:
Wikipedia is an encyclopedia incorporating elements of general encyclopedias, specialized encyclopedias, and almanacs. All articles must follow our no original research policy and strive for accuracy; Wikipedia is not the place to insert personal opinions, experiences, or arguments. Furthermore, Wikipedia is not an indiscriminate collection of information. Wikipedia is not a trivia collection, a soapbox, a vanity publisher, an experiment in anarchy or democracy, or a web directory. Nor is Wikipedia a dictionary, a newspaper, or a collection of source documents.
Wikipedia has a neutral point of view, which means we strive for articles that advocate no single point of view. Sometimes this requires representing multiple points of view; presenting each point of view accurately; providing context for any given point of view, so that readers understand whose view the point represents; and presenting no one point of view as “the truth” or “the best view.” It means citing verifiable, authoritative sources whenever possible, especially on controversial topics. When a conflict arises as to which version is the most neutral, declare a cool-down period and tag the article as disputed; hammer out details on the talk page and follow dispute resolution.
Wikipedia is free content that anyone may edit. All text is available under the GNU Free Documentation License (GFDL) and may be distributed or linked accordingly. Recognize that articles can be changed by anyone and no individual controls any specific article; therefore, any writing you contribute can be mercilessly edited and redistributed at will by the community. Do not submit copyright infringements or works licensed in a way incompatible with the GFDL.
Wikipedia has a code of conduct: Respect your fellow Wikipedians even when you may not agree with them. Be civil. Avoid making personal attacks or sweeping generalizations. Stay cool when the editing gets hot; avoid edit wars by following the three-revert rule; remember that there are 1,495,425 articles on the English Wikipedia to work on and discuss. Act in good faith, never disrupt Wikipedia to illustrate a point, and assume good faith on the part of others. Be open and welcoming.
Wikipedia does not have firm rules besides the five general principles elucidated here. Be bold in editing, moving, and modifying articles, because the joy of editing is that although it should be aimed for, perfection isn’t required. And don’t worry about messing up. All prior versions of articles are kept, so there is no way that you can accidentally damage Wikipedia or irretrievably destroy content. But remember—whatever you write here will be preserved for posterity. 18
None of these policies and guidelines was in place when Larry Sanger sent out his e-mail to the Nupedia community in January 2001 asking them to experiment with the new wiki technology. Instead, they emerged over time as it became clear that more structure was needed. And as the final pillar of Wikipedia indicates, members of the community are aware that its structure continues to be emergent and will never be written in stone. As I write this section in mid-2008, for example, an active debate continues about whether Wikipedia should have stricter or looser criteria for including new articles and keeping versus deleting existing ones. “Deletionists” and “inclusionists” disagree on this topic and continue to argue their positions within the community.
How well do these norms and policies work? In late 2005 the scientific journal Nature conducted a study comparing the accuracy of science entries in Wikipedia with that of the online version of Encyclopedia Britannica. Experts examined the same set of 42 science articles from each reference work and noted both major and minor errors. The study found that Encyclopedia Britannica had 123 errors, whereas Wikipedia had 162, for averages of 2.9 and 3.9 errors per article respectively. Each encyclopedia had four major errors.
Timo Hannay, publishing director of nature.com and a blogger on Nature’s Web site, noted:
Going through the subject-by-subject results, I make the final score 22-10 in favour of Britannica, with 10 draws … If you believe that an encyclopedia should be judged by its weakest entries (in general I don’t), or if you’re the subject of an error or slur (thankfully I’m nowhere near famous enough), then the anecdotal outliers might be more important to you than averaged results. But most readers simply want to know whether a source can generally be relied upon. What these results say to me is that Wikipedia isn’t bad in this regard—and that if it’s really important to get your facts right then even Britannica isn’t completely dependable … A key outstanding question is whether or not Wikipedia can ever surpass Britannica in quality. Since it evidently already does in some subjects, I think the answer is yes, but we will have to wait and see. Frankly, I still can’t get over the fact that it works at all. 19
The study’s list of errors on Wikipedia was made widely available on December 22, 2005. By January 25, 2006, all of them had reportedly been corrected. 20 Something about this new way of organizing and collaborating was clearly working.