
It is very common to find database applications that use cursors to process one row at a time. Because data manipulation through a cursor in SQL Server incurs significant additional overhead, database applications should avoid using cursors. T-SQL and SQL Server are designed to work best with sets of data, not one row at a time. If a cursor must be used, then use a cursor with the least cost.
In this chapter, I cover the following topics:
The fundamentals of cursors
A cost analysis of different characteristics of cursors
The benefits and drawbacks of a default result set over cursors
Recommendations to minimize the cost overhead of cursors
When a query is executed by an application, SQL Server returns a set of data consisting of rows. Generally, applications can't process multiple rows together, so instead they process one row at a time by walking through the result set returned by SQL Server. This functionality is provided by a cursor, which is a mechanism to work with one row at a time out of a multirow result set.
Cursor processing usually involves the following steps:
Declare the cursor to associate it with a
SELECTstatement and define the characteristics of the cursor.Open the cursor to access the result set returned by the
SELECTstatement.Retrieve a row from the cursor. Optionally, modify the row through the cursor.
Once all the rows in the result set are processed, close the cursor, and release the resources assigned to the cursor.
You can create cursors using T-SQL statements or the data access layers (ADO, OLEDB, and ODBC) used to connect to SQL Server. Cursors created using data access layers are commonly referred to as client cursors. Cursors written in T-SQL are referred to as server cursors. You can write a T-SQL cursor processing for a table, t1, as follows (cursor.sql in the download):
--Associate a SELECT statement to a cursor and define the
--cursor's characteristics
DECLARE MyCursor CURSOR
/*<cursor characteristics>*/
FOR SELECT adt.AddressTypeId
,adt.NAME
,adt.ModifiedDate
FROM Person.AddressType adt
--Open the cursor to access the result set returned by the
--SELECT statement
OPEN MyCursor
--Retrieve one row at a time from the result set returned by
--the SELECT statement
DECLARE @AddressTypeId INT
,@Name VARCHAR(50)
,@ModifiedDate DATETIME
FETCH NEXT FROM MyCursor INTO @AddressTypeId, @Name, @ModifiedDate
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'NAME = ' + @Name
--Optionally, modify the row through the cursor
UPDATE Person.AddressType
SET Name = Name + 'z'
WHERE CURRENT OF MyCursor
FETCH NEXT FROM MyCursor INTO @AddressTypeId, @Name, @ModifiedDate
END
--Close the cursor and release all resources assigned to the
--cursor
CLOSE MyCursor
DEALLOCATE MyCursorThe overhead of the cursor depends on the cursor characteristics. The characteristics of the cursors provided by SQL Server and the data access layers can be broadly classified into three categories:
Cursor location: Defines the location of the cursor creation
Cursor concurrency: Defines the degree of isolation and synchronization of a cursor with the underlying content
Cursor type: Defines the specific characteristics of a cursor
Before looking at the costs of cursors, I'll take a few pages to introduce the various characteristics of cursors. You can undo the changes to the Person.AddressType table with this query:
UPDATE Person.AddressType SET [Name] = LEFT([Name],LEN([Name])-1);
Based on the location of a cursor creation, cursors can be classified into two categories:
Client-side cursors
Server-side cursors
The T-SQL cursors are always created on SQL Server. However, the database API cursors can be created on either the client side or the server side.
Client-Side Cursors
As its name signifies, a client-side cursor is created on the machine running the application, whether the app is a service, a data access layer, or the front end for the user. It has the following characteristics:
It is created on the client machine.
The cursor metadata is maintained on the client machine.
It is created using the data access layers.
It works against most of the data access layers (OLEDB providers and ODBC drivers).
It can be a forward-only or static cursor.
Note
Cursor types, including forward-only and static cursor types, are described later in the chapter in the "Cursor Types" section.
Server-Side Cursors
A server-side cursor is created on the SQL Server machine. It has the following characteristics:
It is created on the server machine.
The cursor metadata is maintained on the server machine.
It is created using either data access layers or T-SQL statements.
A server-side cursor created using T-SQL statements is tightly integrated with SQL Server.
It can be any type of cursor. (Cursor types are explained later in the chapter.)
Note
The cost comparison between client-side and server-side cursors is covered later in the chapter in the "Cost Comparison on Cursor Type" section.
Depending on the required degree of isolation and synchronization with the underlying content, cursors can be classified into the following concurrency models:
Read-Only
A read-only cursor is nonupdatable; no locks are held on the base table(s). While fetching a cursor row, whether an (S) lock will be acquired on the underlying row or not depends upon the isolation level of the connection and the locking hint used in the SELECT statement for the cursor. However, once the row is fetched, by default the locks are released.
The following T-SQL statement creates a read-only T-SQL cursor:
DECLARE MyCursor CURSOR READ_ONLY
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1The lack of locking makes the read-only type of cursor faster and safer. Just remember that you cannot manipulate data through the read-only cursor, which is the sacrifice you make for performance.
Optimistic
The optimistic with values concurrency model makes a cursor updatable. No locks are held on the underlying data. The factors governing whether an (S) lock will be acquired on the underlying row are the same as for a read-only cursor.
The optimistic concurrency model uses row versioning to determine whether a row has been modified since it was read into the cursor instead of locking the row while it is read into the cursor. Version-based optimistic concurrency requires a TIMESTAMP column in the underlying user table on which the cursor is created. The TIMESTAMP data type is a binary number that indicates the relative sequence of modifications on a row. Each time a row with a TIMESTAMP column is modified, SQL Server stores the current value of the global TIMESTAMP value, @@DBTS, in the TIMESTAMP column and then increments the @@DBTS value.
Before applying a modification through the optimistic cursor, SQL Server determines whether the current TIMESTAMP column value for the row matches the TIMESTAMP column value for the row when it was read into the cursor. The underlying row is modified only if the TIMESTAMP values match, indicating that the row hasn't been modified by another user in the meantime. Otherwise, an error is raised. In case of an error, first refresh the cursor with the updated data.
If the underlying table doesn't contain a TIMESTAMP column, then the cursor defaults to value-based optimistic concurrency, which requires matching the current value of the row with the value when the row was read into the cursor. The version-based concurrency control is more efficient than the value-based concurrency control since it requires less processing to determine the modification of the underlying row. Therefore, for the best performance of a cursor with the optimistic concurrency model, ensure that the underlying table has a TIMESTAMP column.
The following T-SQL statement creates an optimistic T-SQL cursor:
DECLARE MyCursor CURSOR OPTIMISTIC
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1Scroll Locks
A cursor with scroll locks concurrency holds a (U) lock on the underlying row until another cursor row is fetched or the cursor is closed. This prevents other users from modifying the underlying row when the cursor fetches it. The scroll locks concurrency model makes the cursor updatable.
The following T-SQL statement creates a T-SQL cursor with the scroll locks concurrency model:
DECLARE MyCursor CURSOR SCROLL_LOCKS
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1Since locks are held on the underlying rows (until another cursor row is fetched or the cursor is closed), it blocks all the other users trying to modify the row during that period. This hurts database concurrency.
Cursors can be classified into the following four types:
Forward-only cursors
Static cursors
Keyset-driven cursors
Dynamic cursors
Let's take a closer look at these four types in the sections that follow.
Forward-Only Cursors
These are the characteristics of forward-only cursors:
They operate directly on the base table(s).
Rows from the underlying table(s) are usually not retrieved until the cursor rows are fetched using the cursor
FETCHoperation. However, the database API forward-only cursor type, with the following additional characteristics, retrieves all the rows from the underlying table first:Client-side cursor location
Server-side cursor location and read-only cursor concurrency
They support forward scrolling only (
FETCH NEXT) through the cursor.They allow all changes (
INSERT, UPDATE, andDELETE) through the cursor. Also, these cursors reflect all changes made to the underlying table(s).
The forward-only characteristic is implemented differently by the database API cursors and the T-SQL cursor. The data access layers implement the forward-only cursor characteristic as one of the four previously listed cursor types. But the T-SQL cursor doesn't implement the forward-only cursor characteristic as a cursor type; rather, it implements it as a property that defines the scrollable behavior of the cursor. Thus, for a T-SQL cursor, the forward-only characteristic can be used to define the scrollable behavior of one of the remaining three cursor types.
A forward-only cursor with a read-only property can be created using a fast_forward statement. The T-SQL syntax provides a specific cursor type option, FAST_FORWARD, to create a fast-forward-only cursor. The nickname for the FAST_FORWARD cursor is the fire hose because it is the fastest way to move data through a cursor and because all the information flows one way. The following T-SQL statement creates a fast-forward-only T-SQL cursor:
DECLARE MyCursor CURSOR FAST_FORWARD
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1The FAST_FORWARD property specifies a forward-only, read-only cursor with performance optimizations enabled.
Static Cursors
These are the characteristics of static cursors:
They create a snapshot of cursor results in the
tempdbdatabase when the cursor is opened. Thereafter, static cursors operate on the snapshot in thetempdbdatabase.Data is retrieved from the underlying table(s) when the cursor is opened.
They support all scrolling options:
FETCH FIRST, FETCH NEXT, FETCH PRIOR, FETCH LAST, FETCH ABSOLUTE n, andFETCH RELATIVE n.Static cursors are always read-only; data modifications are not allowed through static cursors. Also, changes (
INSERT, UPDATE, andDELETE) made to the underlying table(s) are not reflected in the cursor.
The following T-SQL statement creates a static T-SQL cursor:
DECLARE MyCursor CURSOR STATIC
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1Some tests show that a static cursor can perform as well as, and sometimes faster than, a forward-only cursor. Be sure to test this behavior on your own system.
Keyset-Driven Cursors
These are the characteristics of keyset-driven cursors:
They are controlled by a set of unique identifiers (or keys) known as a keyset. The keyset is built from a set of columns that uniquely identify the rows in the result set.
They create the keyset of rows in the
tempdbdatabase when the cursor is opened.Membership of rows in the cursor is limited to the keyset of rows created in the
tempdbdatabase when the cursor is opened.On fetching a cursor row, it first looks at the keyset of rows in
tempdb, and then it navigates to the corresponding data row in the underlying table(s) to retrieve the remaining columns.They support all scrolling options.
They allow all changes through the cursor. An
INSERTperformed outside the cursor is not reflected in the cursor, since the membership of rows in the cursor is limited to the keyset of rows created in thetempdbdatabase on opening the cursor. AnINSERTthrough the cursor appears at the end of the cursor. ADELETEperformed on the underlying table(s) raises an error when the cursor navigation reaches the deleted row. AnUPDATEon the nonkeyset columns of the underlying table(s) is reflected in the cursor. AnUPDATEon the keyset column(s) is treated like aDELETEof an old key value and theINSERTof a new key value. If a change disqualifies a row for membership or affects the order of a row, the row does not disappear or move unless the cursor is closed and reopened.
The following T-SQL statement creates a keyset-driven T-SQL cursor:
DECLARE MyCursor CURSOR KEYSET
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1Dynamic Cursors
These are the characteristics of dynamic cursors:
They operate directly on the base table(s).
The membership of rows in the cursor is not fixed, since they operate directly on the base table(s).
Like forward-only cursors, rows from the underlying table(s) are not retrieved until the cursor rows are fetched using a cursor
FETCHoperation.They support all scrolling options except
FETCH ABSOLUTE n, since the membership of rows in the cursor is not fixed.They allow all changes through the cursor. Also, all changes made to the underlying table(s) are reflected in the cursor.
They don't support all properties and methods implemented by the database API cursors. Properties such as
AbsolutePosition, Bookmark, andRecordCount, as well as methods such ascloneandResync, are not supported by dynamic cursors but are supported by keyset-driven cursors.
The following T-SQL statement creates a dynamic T-SQL cursor:
DECLARE MyCursor CURSOR DYNAMIC
FOR SELECT adt.Name
FROM Person.AddressType AS adt
WHERE adt.AddressTypeID = 1The dynamic cursor is absolutely the slowest possible cursor to use in all situations. Take this into account when designing your system.
Now that you've seen the different cursor flavors, let's look at their costs. If you must use a cursor, you should always use the lightest-weight cursor that meets the requirements of your application. The cost comparisons among the different characteristics of the cursors are detailed next.
The client-side and server-side cursors have their own cost benefits and overhead, as explained in the sections that follow.
Client-Side Cursors
Client-side cursors have the following cost benefits compared to server-side cursors:
Higher scalability: Since the cursor metadata is maintained on the individual client machines connected to the server, the overhead of maintaining the cursor metadata is taken up by the client machines. Consequently, the ability to serve a larger number of users is not limited by the server resources.
Fewer network round-trips: Since the result set returned by the
SELECTstatement is passed to the client where the cursor is maintained, extra network round-trips to the server are not required while retrieving rows from the cursor.Faster scrolling: Since the cursor is maintained locally on the client machine, it's faster to walk through the rows of the cursor.
Highly portable: Since the cursor is implemented using data access layers, it works across a large range of databases: SQL Server, Oracle, Sybase, and so forth.
Client-side cursors have the following cost overhead or drawbacks:
Higher pressure on client resources: Since the cursor is managed at the client side, it increases pressure on the client resources. But it may not be all that bad, considering that most of the time the client applications are web applications and scaling out web applications (or web servers) is quite easy using standard load-balancing solutions. On the other hand, scaling out a transactional SQL Server database is still an art!
Support for limited cursor types: Dynamic and keyset-driven cursors are not supported.
Only one active cursor-based statement on one connection: As many rows of the result set as the client network can buffer are arranged in the form of network packets and sent to the client application. Therefore, until all the cursor's rows are fetched by the application, the database connection remains busy, pushing the rows to the client. During this period, other cursor-based statements cannot use the connection.
Server-Side Cursors
Server-side cursors have the following cost benefits:
Multiple active cursor-based statements on one connection: While using server-side cursors, no results are left outstanding on the connection between the cursor operations. This frees the connection, allowing the use of multiple cursor-based statements on one connection at the same time. In the case of client-side cursors, as explained previously, the connection remains busy until all the cursor rows are fetched by the application and therefore cannot be used simultaneously by multiple cursor-based statements.
Row processing near the data: If the row processing involves joining with other tables and a considerable amount of set operations, then it is advantageous to perform the row processing near the data using a server-side cursor.
Less pressure on client resources: It reduces pressure on the client resources. But this may not be that desirable, because if the server resources are maxed out (instead of the client resources), then it will require scaling out the database, which is a difficult proposition.
Support for all cursor types: Client-side cursors have limitations on which types of cursors can be supported. There are no limits on the server-side cursors.
Server-side cursors have the following cost overhead or disadvantages:
Lower scalability: They make the server less scalable since server resources are consumed to manage the cursor.
More network round-trips: They increase network round-trips, if the cursor row processing is done in the client application. The number of network round-trips can be optimized by processing the cursor rows in the stored procedure or by using the cache size feature of the data access layer.
Less portable: Server-side cursors implemented using T-SQL cursors are not readily portable to other databases because the syntax of the database code managing the cursor is different across databases.
As expected, cursors with a higher concurrency model create the least amount of blocking in the database and support higher scalability, as explained in the following sections.
Read-Only
The read-only concurrency model provides the following cost benefits:
Lowest locking overhead: The read-only concurrency model introduces the least locking and synchronization overhead on the database. Since (
S) locks are not held on the underlying row after a cursor row is fetched, other users are not blocked from accessing the row. Furthermore, the (S) lock acquired on the underlying row while fetching the cursor row can be avoided by using theNOLOCKlocking hint in theSELECTstatement of the cursor.Highest concurrency: Since locks are not held on the underlying rows, the read-only cursor doesn't block other users from accessing the underlying table(s).
The main drawback of the read-only cursor is as follows:
Nonupdatable: The content of underlying table(s) cannot be modified through the cursor.
Optimistic
The optimistic concurrency model provides the following benefits:
Low locking overhead: Similar to the read-only model, the optimistic concurrency model doesn't hold an (
S) lock on the cursor row after the row is fetched. To further improve concurrency, theNOLOCKlocking hint can also be used, as in the case of the read-only concurrency model. Modification through the cursor to an underlying row requires exclusive rights on the row as required by an action query.High concurrency: Since locks aren't held on the underlying rows, the cursor doesn't block other users from accessing the underlying table(s). But the modification through the cursor to an underlying row will block other users from accessing the row during the modification.
The following are the cost overhead of the optimistic concurrency model:
Row versioning: Since the optimistic concurrency model allows the cursor to be updatable, an additional cost is incurred to ensure that the current underlying row is first compared (using either version-based or value-based concurrency control) with the original cursor row fetched, before applying a modification through the cursor. This prevents the modification through the cursor from accidentally overwriting the modification made by another user after the cursor row is fetched.
Concurrency control without a
TIMESTAMPcolumn: As explained previously, aTIMESTAMPcolumn in the underlying table allows the cursor to perform an efficient version-based concurrency control. In case the underlying table doesn't contain aTIMESTAMPcolumn, the cursor resorts to value-based concurrency control, which requires matching the current value of the row to the value when the row was read into the cursor. This increases the cost of the concurrency control.
Scroll Locks
The major benefit of the scroll locks concurrency model is as follows:
Simple concurrency control: By locking the underlying row corresponding to the last fetched row from the cursor, the cursor assures that the underlying row can't be modified by another user. It eliminates the versioning overhead of optimistic locking. Also, since the row cannot be modified by another user, the application is relieved from checking for a row-mismatch error.
The scroll locks concurrency model incurs the following cost overhead:
Highest locking overhead: The scroll locks concurrency model introduces a pessimistic locking characteristic. A (
U) lock is held on the last cursor row fetched, until another cursor row is fetched or the cursor is closed.Lowest concurrency: Since a (
U) lock is held on the underlying row, all other users requesting a (U) or an (X) lock on the underlying row will be blocked. This can significantly hurt concurrency. Therefore, please avoid using this cursor concurrency model unless absolutely necessary.
Each of the basic four cursor types mentioned in the "Cursor Fundamentals" section earlier in the chapter incurs a different cost overhead on the server. Choosing an incorrect cursor type can hurt database performance. Besides the four basic cursor types, a fast-forward-only cursor, a variation of the forward-only cursor, is provided to enhance performance. The cost overhead of these cursor types is explained in the sections that follow.
Forward-Only Cursors
These are the cost benefits of forward-only cursors:
Lower cursor open cost than static and keyset-driven cursors: Since the cursor rows are not retrieved from the underlying table(s) and are not copied into the
tempdbdatabase during cursor open, the forward-only T-SQL cursor opens very quickly. Similarly, the forward-only, server-side API cursors with optimistic/scroll locks concurrency also open quickly since they do not retrieve the rows during cursor open.Lower scroll overhead: Since only
FETCH NEXTcan be performed on this cursor type, it requires a lower overhead to support different scroll operations.Lower impact on the
tempdbdatabase than static and keyset-driven cursors: Since the forward-only T-SQL cursor doesn't copy the rows from the underlying table(s) into thetempdbdatabase, no additional pressure is created on the database.
The forward-only cursor type has the following drawbacks:
Lower concurrency: Every time a cursor row is fetched, the corresponding underlying row is accessed with a lock request depending on the cursor concurrency model (as noted earlier when talking about concurrency). It can block other users from accessing the resource.
No backward scrolling: Applications requiring two-way scrolling can't use this cursor type. But if the applications are designed properly, then it isn't difficult to live without backward scrolling.
Fast-Forward-Only Cursor
The fast-forward-only cursor is the fastest and least expensive cursor type. This forward-only and read-only cursor is specially optimized for performance. Because of this, you should always prefer it to the other SQL Server cursor types.
Furthermore, the data access layer provides a fast-forward-only cursor on the client side, making the cursor overhead almost disappear by using a default result set.
Note
The default result set is explained later in the chapter in the section "Default Result Set."
Static Cursors
These are the cost benefits of static cursors:
Lower fetch cost than other cursor types: Since a snapshot is created in the
tempdbdatabase from the underlying rows on opening the cursor, the cursor row fetch is targeted to the snapshot instead of the underlying rows. This avoids the lock overhead that would otherwise be required to fetch the cursor rows.No blocking on underlying rows: Since the snapshot is created in the
tempdbdatabase, other users trying to access the underlying rows are not blocked.
On the downside, the static cursor has the following cost overhead:
Higher open cost than other cursor types: The cursor open operation of the static cursor is slower than that of other cursor types, since all the rows of the result set have to be retrieved from the underlying table(s) and the snapshot has to be created in the
tempdbdatabase during the cursor open.Higher impact on
tempdbthan other cursor types: There can be significant impact on server resources for creating, populating, and cleaning up the snapshot in thetempdbdatabase.
Keyset-Driven Cursors
These are the cost benefits of keyset-driven cursors:
Lower open cost than the static cursor: Since only the keyset, not the complete snapshot, is created in the
tempdbdatabase, the keyset-driven cursor opens faster than the static cursor. SQL Server populates the keyset of a large keyset-driven cursor asynchronously, which shortens the time between when the cursor is opened and when the first cursor row is fetched.Lower impact on
tempdbthan that with the static cursor: Because the keyset-driven cursor is smaller, it uses less space intempdb.
The cost overhead of keyset-driven cursors is as follows:
Higher open cost than forward-only and dynamic cursors: Populating the keyset in the
tempdbdatabase makes the cursor open operation of the keyset-driven cursor costlier than that of forward-only (with the exceptions mentioned earlier) and dynamic cursors.Higher fetch cost than other cursor types: For every cursor row fetch, the key in the keyset has to be accessed first, and then the corresponding underlying row in the user database can be accessed. Accessing both the
tempdband the user database for every cursor row fetch makes the fetch operation costlier than that of other cursor types.Higher impact on
tempdbthan forward-only and dynamic cursors: Creating, populating, and cleaning up the keyset intempdbimpacts server resources.Higher lock overhead and blocking than the static cursor: Since row fetch from the cursor retrieves rows from the underlying table, it acquires an (
S) lock on the underlying row (unless theNOLOCKlocking hint is used) during the row fetch operation.
Dynamic Cursor
The dynamic cursor has the following cost benefits:
Lower open cost than static and keyset-driven cursors: Since the cursor is opened directly on the underlying rows without copying anything to the
tempdbdatabase, the dynamic cursor opens faster than the static and keyset-driven cursors.Lower impact on
tempdbthan static and keyset-driven cursors. Since nothing is copied intotempdb, the dynamic cursor places far less strain ontempdbthan the other cursor types.
The dynamic cursor has the following cost overhead:
Higher lock overhead and blocking than the static cursor: Every cursor row fetch in a dynamic cursor requeries the underlying table(s) involved in the
SELECTstatement of the cursor. The dynamic fetches are generally expensive, since the original select condition might have to be reexecuted.
The default cursor type for the data access layers (ADO, OLEDB, and ODBC) is forward-only and read-only. The default cursor type created by the data access layers isn't a true cursor but a stream of data from the server to the client, generally referred to as the default result set or fast-forward-only cursor (created by the data access layer). In ADO.NET, the DataReader control has the forward-only and read-only properties and can be considered as the default result set in the ADO.NET environment. SQL Server uses this type of result set processing under the following conditions:
The application, using the data access layers (ADO, OLEDB, ODBC), leaves all the cursor characteristics at the default settings, which requests a forward-only and read-only cursor.
The application executes a
SELECTstatement instead of executing aDECLARE CURSORstatement.
Note
Because SQL Server is designed to work with sets of data, not to walk through records one by one, the default result set is always faster than any other type of cursor.
The only request sent from the client to SQL Server is the SQL statement associated with the default cursor. SQL Server executes the query, organizes the rows of the result set in network packets (filling the packets as best as possible), and then sends the packets to the client. These network packets are cached in the network buffers of the client. SQL Server sends as many rows of the result set to the client as the client-network buffers can cache. As the client application requests one row at a time, the data access layer on the client machine pulls the row from the client-network buffers and transfers it to the client application.
The following sections outline the benefits and drawbacks of the default result set.
The default result set is generally the best and most efficient way of returning rows from SQL Server for the following reasons:
Minimum network round-trips between the client and SQL Server: Since the result set returned by SQL Server is cached in the client-network buffers, the client doesn't have to make a request across the network to get the individual rows. SQL Server puts most of the rows that it can in the network buffer and sends to the client as much as the client-network buffer can cache.
Minimum server overhead: Since SQL Server doesn't have to store data on the server, this reduces server resource utilization.
Multiple Active Result Sets
SQL Server 2005 introduced the concept of multiple active result sets (MARS) wherein a single connection can have more than one batch running at any given moment. In prior versions, a single result set had to be processed or closed out prior to submitting the next request. MARS allows multiple requests to be submitted at the same time through the same connection. MARS is enabled on SQL Server all the time. It is not enabled by a connection unless that connection explicitly calls for it. Transactions must be handled at the client level and have to be explicitly declared and committed or rolled back. With MARS in action, if a transaction is not committed on a given statement and the connection is closed, all other transactions that were part of that single connection will be rolled back.
When connecting through ODBC, to enable MARS, include SQL_COPT_SS_MARS_ENABLED = SQL_MARS_ENABLED_YES as part of the connection properties. When using an OLEDB connection, you have to set the following property and value: SSPROP_INIT_MARSCONNECTION =VARIANT_TRUE.
While there are advantages to the default result set, there are drawbacks as well. Using the default result set requires some special conditions for maximum performance:
Doesn't support all properties and methods: Properties such as
AbsolutePosition,Bookmark, andRecordCount, as well as methods such asClone, MoveLast, MovePrevious, andResync, are not supported.Locks may be held on the underlying resource: SQL Server sends as many rows of the result set to the client as the client-network buffers can cache. If the size of the result set is large, then the client-network buffers may not be able to receive all the rows. SQL Server then holds a lock on the next page of the underlying table(s), which has not been sent to the client.
To demonstrate these concepts, consider the following test table (create_t1.sql in the download):
USE AdventureWorks2008 ;
GO
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1;
GO
CREATE TABLE dbo.t1 (c1 INT, c2 CHAR(996));
CREATE CLUSTERED INDEX i1 ON dbo.t1 (c1);
INSERT INTO dbo.t1
VALUES (1, '1'),
INSERT INTO dbo.t1
VALUES (2, '2'),
GOConsider a web page accessing the rows of the test table using ADO with OLEDB, with the default cursor type for the database API cursor (ADODB.Recordset object) as follows (default_cursor.asp in the download):
<%
Dim strConn, Conn, Rs
Conn = CreateObject("ADODB.Connection")
strConn = "Provider=SQLOLEDB;" _
& "Data Source=FRITCHEYGXPGF2008;" _
& "Initial Catalog=AdventureWorks2008;" _
& "Integrated Security=SSPI; Persist Security Info=False;"
Conn.Open(strConn)
Rs = CreateObject("ADODB.Recordset")
'Declare & open a database API cursor with default settings
' (forward-only, read-only are the default settings)
Rs.Open("SELECT * FROM t1", Conn)
'Consume the rows in the cursor one row at a time
While Not Rs.EOF
'Fetch a row from the cursor
Response.Write("c1 = " & Rs.Fields("c1").Value & "<BR>")
Rs.MoveNext
End While
'Close the cursor and release all resources assigned to the
'cursor
Rs.Close
Rs = Nothing
Conn.Close
Conn = Nothing
%>Note that the table has two rows with the size of each row equal to 1,000 bytes (= 4 bytes for INT + 996 bytes for CHAR(996)) without considering the internal overhead. Therefore, the size of the complete result set returned by the SELECT statement is approximately 2,000 bytes (= 2 × 1,000 bytes).
You can execute the code of the preceding web page step-by-step using Microsoft Visual Studio .NET. On execution of the cursor open statement (Rs.Open), a default result set is created on the client machine running the code. The default result set holds as many rows as the client-network buffer can cache.
Since the size of the result set is small enough to be cached by the client-network buffer, all the cursor rows are cached on the client machine during the cursor open statement itself, without retaining any lock on table t1. You can verify the lock status for the connection using the sys.dm_tran_locks dynamic management view. During the complete cursor operation, the only request from the client to SQL Server is the SELECT statement associated to the cursor, as shown in the Profiler output in Figure 14-1.
To find out the effect of a large result set on the default result set processing, let's add some more rows to the test table (addrows.sql in the download):
--Add 100000 rows to the test table
SELECT TOP 100000
IDENTITY( INT,1,1 ) AS n
INTO #Tally
FROM Master.dbo.SysColumns sc1
,Master.dbo.SysColumns sc2 ;
INSERT INTO t1
SELECT n
,n
FROM #Tally AS t ;
GOThis increases the size of the result considerably. Depending on the size of the client-network buffer, only part of the result set can be cached. On execution of the Rs.Open statement, the default result set on the client machine will get part of the result set, with SQL Server waiting on the other end of the network to send the remaining rows.
On my machine, during this period, the locks shown in Figure 14-2 are held on the underlying table t1 as obtained from the output of sys.dm_tran_locks.
Figure 14.2. sys.dm_tran_locks output showing the locks held by the default result set while processing the large result set
The (IS) lock on the table will block other users trying to acquire an (X) lock. To minimize the blocking issue, follow these recommendations:
Process all rows of the default result set immediately.
Keep the result set small. As demonstrated in the example, if the size of the result set is small, then the default result set will be able to read all the rows during the cursor open operation itself.
While implementing a cursor-centric functionality in an application, you have two choices. You can use either a T-SQL cursor or a database API cursor. Because of the differences between the internal implementation of a T-SQL cursor and a database API cursor, the load created by these cursors on SQL Server is different. The impact of these cursors on the database also depends on the different characteristics of the cursors, such as location, concurrency, and type. You can use the SQL Profiler tool to analyze the load generated by the T-SQL and database API cursors using the events and data columns listed in Table 14-1.
Table 14.1. Events and Data Columns to Analyze SQL Server Overhead with Cursors
Events | Data Column | |
|---|---|---|
Event Class | Event | |
| All events |
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
| ||
|
Even the optimization options for these cursors are different. Let's analyze the overhead of these cursors one by one.
The T-SQL cursors implemented using T-SQL statements are always executed on SQL Server, since they need the SQL Server engine to process their T-SQL statements. You can use a combination of the cursor characteristics explained previously to reduce the overhead of these cursors. As mentioned earlier, the most lightweight T-SQL cursor is the one created not with the default settings but by manipulating the settings to arrive at the forward-only read-only cursor. That still leaves the T-SQL statements used to implement the cursor operations to be processed by SQL Server. The complete load of the cursor is supported by SQL Server without any help from the client machine. To analyze the overhead of T-SQL cursors on SQL Server, suppose an application requirement consists of the following functionalities:
Identify all products (from the
Production.WorkOrdertable) that have been scrapped.For each scrapped product, determine the money lost, where
Money lost per product = Units in stock × Unit price of the product
Calculate the total loss.
Based on the total loss, determine the business status.
The "For each" phrase in the second point suggests that these application requirements could be served by a cursor. You can implement this application requirement using a T-SQL cursor as follows (app_requirements.sql in the download):
IF (SELECT OBJECT_ID('dbo.spTotalLoss_CursorBased')
) IS NOT NULL
DROP PROC dbo.spTotalLoss_CursorBased ;
GO
CREATE PROC dbo.spTotalLoss_CursorBased
AS --Declare a T-SQL cursor with default settings, i.e., fast
--forward-only to retrieve products that have been discarded
DECLARE ScrappedProducts CURSOR
FOR SELECT p.ProductID
,wo.ScrappedQty
,p.ListPrice
FROM Production.WorkOrder AS wo
JOIN Production.ScrapReason AS sr
ON wo.ScrapReasonID = sr.ScrapReasonID
JOIN Production.Product AS p
ON wo.ProductID = p.ProductID ;
--Open the cursor to process one product at a time
OPEN ScrappedProducts ;
DECLARE @MoneyLostPerProduct MONEY = 0
,@TotalLoss MONEY = 0 ;
--Calculate money lost per product by processing one product
--at a time
DECLARE @ProductId INT
,@UnitsScrapped SMALLINT
,@ListPrice MONEY ;
FETCH NEXT FROM ScrappedProducts INTO @ProductId, @UnitsScrapped,
@ListPrice ;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @MoneyLostPerProduct = @UnitsScrapped * @ListPrice ;
--Calculate total loss
SET @TotalLoss = @TotalLoss + @MoneyLostPerProduct ;
FETCH NEXT FROM ScrappedProducts INTO @ProductId, @UnitsScrapped,
@ListPrice ;
END--Determine status
IF (@TotalLoss > 5000)
SELECT 'We are bankrupt!' AS Status ;
ELSE
SELECT 'We are safe!' AS Status ;
--Close the cursor and release all resources assigned to the cursor
CLOSE ScrappedProducts ;
DEALLOCATE ScrappedProducts ;
GOThe stored procedure can be executed as follows, but execute it twice to take advantage of plan caching:
EXEC dbo.spTotalLoss_CursorBased
Figure 14-3 shows the Profiler trace output for this stored procedure.
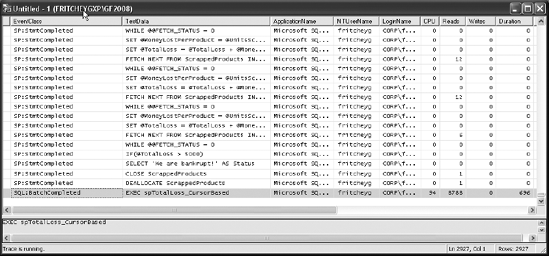
Figure 14.3. Profiler trace output showing the total cost of the data processing using a T-SQL–based cursor
As you can see in Figure 14-3, lots of statements are executed on SQL Server. Essentially, all the SQL statements within the stored procedure are executed on SQL Server, with the statements within the WHILE loop executed several times (one for each row returned by the cursor's SELECT statement).
The total number of logical reads performed by the stored procedure is 8,788 (indicated by the last SQL:BatchCompleted event). Well, is it high or low? Considering the fact that the Production.Products table has only 13 pages and the Production.WorkOrder table has only 524, it's surely not low. You can determine the number of pages allocated to these tables by querying the dynamic management view sys.dm_db_index_physical_stats:
SELECT SUM(page_count)
FROM sys.dm_db_index_physical_stats(DB_ID('AdventureWorks2008'),
OBJECT_ID('Production.WorkOrder'),
DEFAULT, DEFAULT, DEFAULT)Note
The sys.dm_db_index_physical_stats DMV is explained in detail in Chapter 8.
In most cases, you can avoid cursor operations by rewriting the functionality using SQL queries, concentrating on set-based methods of accessing the data. For example, you can rewrite the preceding stored procedure using SQL queries (instead of the cursor operations) as follows (no_cursor.sql in the download):
IF (SELECT OBJECT_ID('dbo.spTotalLoss')
) IS NOT NULL
DROP PROC dbo.spTotalLoss;
GO
CREATE PROC dbo.spTotalLoss
AS
SELECT CASE --Determine status based on following computation
WHEN SUM(MoneyLostPerProduct) > 5000 THEN 'We are bankrupt!'
ELSE 'We are safe!'
END AS Status
FROM (--Calculate total money lost for all discarded products
SELECT SUM(wo.ScrappedQty * p.ListPrice) AS MoneyLostPerProduct
FROM Production.WorkOrder AS wo
JOIN Production.ScrapReason AS sr
ON wo.ScrapReasonID = sr.ScrapReasonID
JOIN Production.Product AS p
ON wo.ProductID = p.ProductID
GROUP BY p.ProductID
) DiscardedProducts;
GOIn this stored procedure, the aggregation functions of SQL Server are used to compute the money lost per product and the total loss. The CASE statement is used to determine the business status based on the total loss incurred. The stored procedure can be executed as follows, but again, do it twice so that you can see the results of plan caching:
EXEC dbo.spTotalLoss
Figure 14-4 shows the corresponding Profiler trace output.

Figure 14.4. Profiler trace output showing the total cost of the data processing using an equivalent SELECT statement
From Figure 14-4, you can see that the second execution of the stored procedure, which reuses the existing plan, uses a total of 543 logical reads; however, even more importantly than the reads, the CPU drops from 94 in Figure 14-3 to 16 in Figure 14-4 and the duration goes from 696 ms to 20 ms. Using SQL queries instead of the cursor operations made the duration 34.8 times faster.
Therefore, for better performance, it is almost always recommended that you use set-based operations in SQL queries instead of T-SQL cursors.
An ineffective use of cursors can degrade the application performance by introducing extra network round-trips and load on server resources. To keep the cursor cost low, try to follow these recommendations:
Use set-based SQL statements over T-SQL cursors, since SQL Server is designed to work with sets of data.
Use the least expensive cursor:
While using SQL Server cursors, use the
FAST_FORWARDcursor type, which is generally referred to as the fast-forward-only cursor.While using the API cursors implemented by ADO, OLEDB, or ODBC, use the default cursor type, which is generally referred to as the default result set.
While using
ADO.NET, use theDataReaderobject.
Minimize impact on server resources:
Use a client-side cursor for API cursors.
Do not perform actions on the underlying table(s) through the cursor.
Always deallocate the cursor as soon as possible.
Redesign the cursor's
SELECTstatement (or the application) to return the minimum set of rows and columns.Avoid T-SQL cursors entirely by rewriting the logic of the cursor as set-based statements, which are generally more efficient than cursors.
Use a
TIMESTAMPcolumn for dynamic cursors to benefit from the efficient version-based concurrency control compared to the value-based technique.
Minimize impact on
tempdb:Minimize resource contention in
tempdbby avoiding the static and keyset-driven cursor types.Minimize latch contention in
tempdb. When a static or keyset-driven cursor is opened in SQL Server, thetempdbdatabase is used to hold either the keyset or the snapshot for the cursor management. It creates "worktables" in thetempdbdatabase.Creating a lot of worktables can cause latch contention in the
tempdbdatabase on the Page Free Space (PFS) or Shared Global Allocation Map (SGAM) page. In that case, the output of thesys.dm_exec_requestsDMV will show alast_wait_typeofPAGELATCH_EXorLATCH_EX, and thewait_resourcewill show2:1:1(for PFS) or2:1:2(for SGAM). Spreading thetempdbdatabase among multiple files generally minimizes the contention on these pages. Just make sure each of thetempdbfiles is the same size.Reduce or eliminate the
autogrowoverhead. Set the size of thetempdbdatabase to the maximum size to which it can grow. Generally, I recommend that system databases such astempdbnot be allowed to autogrow, but if they must, then be sure to use set growth numbers, not allowing the file to grow by percentages. That can, in some circumstances, cause excessive blocking while processes are forced to wait for new space to be allocated. You should also be sure to keep the file size the same when using multiple files withtempdb.
Minimize blocking:
Use the default result set, fast-forward-only cursor, or static cursor.
Process all cursor rows as quickly as possible.
Avoid scroll locks or pessimistic locking.
Minimize network round-trips while using API cursors:
Use the
CacheSizeproperty of ADO to fetch multiple rows in one round-trip.Use client-side cursors.
Use disconnected record sets.
As you learned in this chapter, a cursor is the natural extension to the result set returned by SQL Server, enabling the calling application to process one row of data at a time. Cursors add a cost overhead to application performance and impact the server resources.
You should always be looking for ways to avoid cursors. Set-based solutions work better in almost all cases. However, if the cursor operation is mandated, then choose the best combination of cursor location, concurrency, type, and cache size characteristics to minimize the cost overhead of the cursor.
In the next chapter, I show how to put everything together to analyze the workload of a database in action.