
If you have read through the previous 15 chapters of this book, then by now you understand the major aspects involved in performance optimization and that it is a challenging and ongoing activity.
What I hope to do in this chapter is to provide a performance-monitoring checklist that can serve as a quick reference for database developers and DBAs when in the field. The idea is similar to the notion of tear-off cards of "best practices." This chapter does not cover everything, but it does summarize, in one place, some of the major tuning activities that can have quick and demonstrable impact on the performance of your SQL Server systems.
I have categorized these checklist items into the following sections:
Database design
Query design
Configuration settings
Database administration
Database backup
Each section contains a number of optimization recommendations and techniques and, where appropriate, cross-references to specific chapters in this book that provide full details.
Although database design is a broad topic and can't be given due justice in a small section in this query tuning book, I advise you to keep an eye on the following design aspects to ensure that you pay attention to database performance from an early stage:
Balancing under- and overnormalization
Benefiting from using entity-integrity constraints
Benefiting from using domain and referential integrity constraints
Adopting index-design best practices
Avoiding the use of the
sp_prefix for stored procedure namesMinimizing the use of triggers
While designing a database, you have the following two extreme options:
Reasonable normalization enhances database performance. The presence of wide tables with a large number of columns is usually a characteristic of an undernormalized database. Undernormalization causes excessive repetition of data, which can lead to improper results and often hurts query performance. For example, in an ordering system, you can keep a customer's profile and all the orders placed by the customer in a single table, as shown in Table 16-1.
Table 16.1. Original Customers Table
CustID | Name | Address | Phone | OrderDt | ShippingAddress |
|---|---|---|---|---|---|
100 | Liu Hong | Boise, ID, USA | 123-456-7890 | 08-Jul-04 | Boise, ID, USA |
100 | Liu Hong | Boise, ID, USA | 123-456-7890 | 10-Jul-04 | Austin, TX, USA |
Keeping the customer profile and the order information together in a single table will repeat the customer profile in every order placed by the customer, making the rows in the table very wide. Consequently, fewer customer profiles can be saved in one data page. For a query interested in a range of customer profiles (not their order information), more pages have to be read compared to that in the design in which customer profiles are kept in a separate table. To avoid the performance impact of undernormalization, you must normalize the two logical entities (customer profile and orders), which have a one-to-many type of relationship, into separate tables, as shown in Tables 16-2 and 16-3.
Table 16.3. Orders Table
CustID | OrderDt | ShippingAddress |
|---|---|---|
100 | 08-Jul-04 | Boise, ID, USA |
100 | 10-Jul-04 | Austin, TX, USA |
Similarly, overnormalization is also not good for query performance. Overnormalization causes excessive joins across too many narrow tables. Although a 20-table join can perform perfectly fine and a 2-table join can be a problem, a good rule of thumb is to more closely examine a query when it exceeds 6 to 8 tables in the join criteria. To fetch any useful content from the database, a database developer has to join a large number of tables in the SQL queries. For example, if you create separate tables for a customer name, address, and phone number, then to retrieve the customer information, you have to join three tables. If the data (for example, the customer name and address) has a one-to-one type of relationship and is usually accessed together by the queries, then normalizing the data into separate tables can hurt query performance.
Data integrity is essential to ensuring the quality of data in the database. An essential component of data integrity is entity integrity, which defines a row as a unique entity for a particular table. As per entity integrity, every row in a table must be uniquely identifiable. The column or columns serving as the unique row identifier for a table must be represented as the primary key of the table.
Sometimes, a table may contain an additional column, or columns, that also can be used to uniquely identify a row in the table. For example, an Employee table may have the columns EmployeeID and SocialSecurityNumber. The column EmployeeID, which serves as the unique row identifier, can be defined as the primary key, and the column SocialSecurityNumber can be defined as the alternate key. In SQL Server, alternate keys can be defined using unique constraints, which are essentially the younger siblings to primary keys. In fact, both the unique constraint and the primary key constraint use unique indexes behind the scenes.
It's worth noting that there is honest disagreement regarding the use of a natural key, such as the SocialSecurityNumber column in the previous example, and an artificial key, the EmployeeID. I've seen both designs succeed well, but they both have strengths and weaknesses. Rather than suggest one over the other, I'll provide you with a couple of reasons to use both and some of the costs associated with each. An identity column is usually an INT or a BIGINT, which makes it narrow and easy to index. Also, separating the value of the primary key from any business knowledge is considered good design in some circles. One of the drawbacks is that the numbers sometimes get business meaning, which should never happen. Also, you have to create a unique constraint for the alternate keys in order to prevent multiple rows where none should exist. Natural keys provide a clear, human-readable, primary key that has true business meaning. They tend to be wider fields, sometimes very wide, making them less efficient inside indexes. Also, sometimes the data may change, which has a profound trickle-down effect within your database and your enterprise.
Let me just reiterate that either approach can work well and that each provides plenty of opportunities for tuning. Either approach, properly applied and maintained, will protect the integrity of your data.
Besides maintaining data integrity, unique indexes—the primary vehicle for entity-integrity constraints—help the optimizer generate efficient execution plans. SQL Server can often search through a unique index faster than it can search through a nonunique index, because in a unique index each row is unique and, once a row is found, SQL Server does not have to look any further for other matching rows. If a column is used in sort (or GROUP BY or DISTINCT) operations, consider defining a unique constraint on the column (using a unique index), because columns with a unique constraint generally sort faster than ones with no unique constraint.
To understand the performance benefit of entity-integrity or unique constraints, consider this example. Modify the existing unique index on the Production.Product table:
CREATE NONCLUSTERED INDEX [AK_Product_Name] ON [Production].[Product] ([Name] ASC)
WITH (
DROP_EXISTING = ON)
ON [PRIMARY];
GOThe nonclustered index does not include the UNIQUE constraint. Therefore, although the [Name] column contains unique values, the absence of the UNIQUE constraint from the nonclustered index does not provide this information to the optimizer in advance. Now, let's consider the performance impact of the UNIQUE constraint (or a missing UNIQUE constraint) on the following SELECT statement:
SELECT DISTINCT
(p.[Name])
FROM Production.Product AS pFigure 16-1 shows the execution plan of this SELECT statement.
![Execution plan with no UNIQUE constraint on the [Name] column](http://imgdetail.ebookreading.net/data/55/9781430219026/9781430219026__sql-server-2008__9781430219026__figs__1601.png)
From the execution plan, you can see that the nonclustered index AK_Product_Name is used to retrieve the data, and then a Stream Aggregate operation is performed on the data to group the data on the [Name] column so that the duplicate [Name] values can be removed from the final result set. The Stream Aggregate operation would not have been required if the optimizer had been told in advance about the uniqueness of the [Name] column by defining the nonclustered index with a UNIQUE constraint, as follows:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_Name] ON [Production].[Product]
([Name] ASC)
WITH (
DROP_EXISTING = ON)
ON [PRIMARY];
GOFigure 16-2 shows the new execution plan of the SELECT statement.
![Execution plan with a UNIQUE constraint on the [Name] column](http://imgdetail.ebookreading.net/data/55/9781430219026/9781430219026__sql-server-2008__9781430219026__figs__1602.png)
In general, the entity-integrity constraints (that is, primary keys and unique constraints) provide useful information to the optimizer about the expected results, assisting the optimizer in generating efficient execution plans.
The other two important components of data integrity are domain integrity and referential integrity. Domain integrity for a column can be enforced by restricting the data type of the column, defining the format of the input data, and limiting the range of acceptable values for the column. SQL Server provides the following features to implement the domain integrity: data types, FOREIGN KEY constraints, CHECK constraints, DEFAULT definitions, and NOT NULL definitions. If an application requires that the values for a data column be restricted within a range of values, then this business rule can be implemented either in the application code or in the database schema. Implementing such a business rule in the database using domain constraints (such as the CHECK constraint) usually helps the optimizer generate efficient execution plans.
To understand the performance benefit of domain integrity, consider this example:
--Create two test tables
IF (SELECT OBJECT_ID('dbo.T1')
) IS NOT NULL
DROP TABLE dbo.T1 ;
GO
CREATE TABLE dbo.T1
(C1 INT
,C2 INT CHECK (C2 BETWEEN 10 AND 20)) ;
INSERT INTO dbo.T1
VALUES (11, 12) ;
GO
IF (SELECT OBJECT_ID('dbo.T2')
) IS NOT NULL
DROP TABLE dbo.T2 ;
GO
CREATE TABLE dbo.T2 (C1 INT, C2 INT) ;
INSERT INTO dbo.T2
VALUES (101, 102) ;Now, execute the following two SELECT statements:
SELECT T1.C1
,T1.C2
,T2.C2
FROM dbo.T1
JOIN dbo.T2
ON T1.C1 = T2.C2
AND T1.C2 = 20 ;GO
SELECT T1.C1
,T1.C2
,T2.C2
FROM dbo.T1
JOIN dbo.T2
ON T1.C1 = T2.C2
AND T1.C2 = 30 ;The two SELECT statements appear to be the same except for the predicate values (20 in the first statement and 30 in the second). Although the two SELECT statements have exactly the same form, the optimizer treats them differently because of the CHECK constraint on the T1.C2 column, as shown in the execution plan in Figure 16-3.
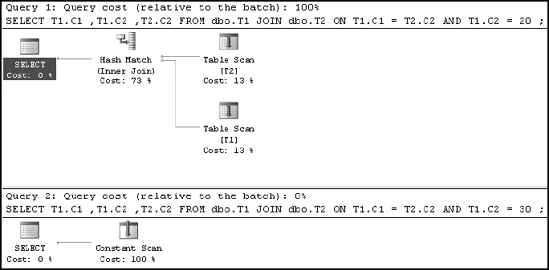
Figure 16.3. Execution plans with predicate values within and outside the CHECK constraint boundaries
From the execution plan, you can see that for the first query (with T1.C2 = 20) the optimizer accesses the data from both tables. For the second query (with T1.C2 = 30), since the optimizer understands from the corresponding CHECK constraint on the column T1.C2 that the column can't contain any value outside the range 10 to 20, the optimizer doesn't even access the data from the tables. Consequently, the relative cost of the second query is 0 percent.
I explained the performance advantage of referential integrity in detail in the section "Declarative Referential Integrity" of Chapter 11.
Therefore, use domain and referential constraints not only to implement data integrity but also to facilitate the optimizer in generating efficient query plans. To understand other performance benefits of domain and referential integrity, please refer to the section "Using Domain and Referential Integrity" of Chapter 11.
The most common optimization recommendation, and usually the biggest contributor to good performance, is to implement the correct indexes for the database workload. Unlike tables, which are used to store data and can be designed even without knowing the queries thoroughly (as long as the tables properly represent the business entities), indexes must be designed by reviewing the database queries thoroughly. Except in common and obvious cases, such as primary keys and unique indexes, please don't fall into the trap of designing indexes without knowing the queries. Even for primary keys and unique indexes, I advise you to validate the applicability of those indexes as you start designing the database queries. Considering the importance of indexes for database performance, you must be very careful while designing indexes.
Although the performance aspect of indexes is explained in detail in Chapters 4, 6, and 7, I'll reiterate a short list of recommendations for easy reference:
Choose narrow columns for indexes.
Ensure that the selectivity of the data in the candidate column is very high or that the column has a large number of unique values.
Prefer columns with the integer data type (or variants of the integer data type). Avoid indexes on columns with string data types such as
VARCHAR.For a multicolumn index, consider the column with higher selectivity toward the leading edge of the index.
Use the
INCLUDElist in an index as a way to make an index covering without changing the index key structure by adding columns to the key.While deciding the columns to be indexed, pay extra attention to the queries'
WHEREclauses and join criteria columns, which can serve as the entry points into the tables. Especially if aWHEREclause criterion on a column filters the data on a highly selective value or constant, the column can be a prime candidate for an index.While choosing the type of an index (clustered or nonclustered), keep in mind the advantages and disadvantages of clustered and nonclustered index types. For queries retrieving a range of rows, usually clustered indexes perform better. For point queries, nonclustered indexes are usually better.
Be extra careful while designing a clustered index, since every nonclustered index on the table depends on the clustered index. Therefore, follow these recommendations while designing and implementing clustered indexes:
Keep the clustered indexes as narrow as possible. You don't want to widen all your nonclustered indexes by having a wide clustered index.
Create the clustered index first, and then create the nonclustered indexes on the table.
If required, rebuild a clustered index in a single step using the
DROP_EXISTINGkeyword in theCREATE INDEXcommand. You don't want to rebuild all the nonclustered indexes on the table twice: once when the clustered index is dropped and again when the clustered index is re-created.Do not create a clustered index on a frequently updatable column. If you do so, the nonclustered indexes on the table will have difficulty remaining in sync with the clustered index key values.
To keep track of the indexes you've created and determine ones that you need to create, you should take advantage of the dynamic management views that SQL Server 2008 makes available to you. By checking the data in sys.dm_db_index_usage_stats on a regular basis, once a week or so, you can determine which of your indexes are actually being used and which ones are redundant. Indexes that are not contributing to your queries to help you improve performance are just a drain on the system, requiring more disk space and additional I/O to maintain the data inside the index as the data in the table changes. On the other hand, querying sys.dm_db_missing_indexes_details will show indexes deemed missing by the system and even suggest INCLUDE columns. You can access the DMV sys.dm_db_missing_indexes_groups_stats to see aggregate information about the number of times queries are called that could have benefited from a particular group of indexes. All this can be combined to give you an optimal method for maintaining the indexes in your system over the long term.
As a rule, don't use the sp_ prefix for user stored procedures, since SQL Server assumes that stored procedures with the sp_ prefix are system stored procedures, which are supposed to be in the master database. Using sp or usp as the prefix for user stored procedures is quite common. The performance hit of the sp_ prefix is explained in detail in the section "Be Careful Naming Stored Procedures" of Chapter 11.
Triggers provide a very attractive method for automating behavior within the database. Since they fire as data is manipulated by other processes, regardless of the process, they can be used to ensure certain functions are run as the data changes. That same functionality makes them dangerous since they are not immediately visible to the developer or DBA working on a system. They must be taken into account when designing queries and when troubleshooting performance problems. Because they are a somewhat hidden cost, their use should be considered very carefully. Be sure that the only way to solve the problem presented is with a trigger. If you do use a trigger, document that fact in as many places as you can to ensure that the existence of the trigger is taken into account by other developers and DBAs.
Here's a list of the performance-related best practices you should follow when designing the database queries:
Use the command
SET NOCOUNT ON.Explicitly define the owner of an object.
Avoid nonsarable search conditions.
Avoid arithmetic operators and functions on
WHEREclause columns.Avoid optimizer hints.
Stay away from nesting views.
Ensure no implicit data type conversions.
Minimize logging overhead.
Adopt best practices for reusing execution plans.
Adopt best practices for database transactions.
Eliminate or reduce the overhead of database cursors.
I further detail each best practice in the following sections.
As a rule, always use the command SET NOCOUNT ON as the first statement in stored procedures, triggers, and other batch queries to avoid the network overhead associated with the return of the number of rows affected, after every execution of a SQL statement. The command SET NOCOUNT is explained in detail in the section "Use SET NOCOUNT" of Chapter 11.
As a performance best practice, always qualify a database object with its owner to avoid the runtime cost required to verify the owner of the object. The performance benefit of explicitly qualifying the owner of a database object is explained in detail in the section "Do Not Allow Implicit Resolution of Objects in Queries" of Chapter 9.
Be vigilant when defining the search conditions in your query. If the search condition on a column used in the WHERE clause prevents the optimizer from effectively using the index on that column, then the execution cost for the query will be high in spite of the presence of the correct index. The performance impact of nonsargable search conditions is explained in detail in the corresponding section of Chapter 11.
Additionally, please be careful while defining your application features. If you define an application feature such as "retrieve all products with product name ending in caps," then you will have queries scanning the complete table (or the clustered index). As you know, scanning a multimillion-row table will hurt your database performance. Unless you use an index hint, you won't be able to benefit from the index on that column. However, since the use of an index hint overrides the decisions of the query optimizer, it's generally not recommended that you use index hints either, as explained in Chapter 11. To understand the performance impact of such a business rule, consider the following SELECT statement:
SELECT p.* FROM Production.Product AS p WHERE p.[Name] LIKE '%Caps'
In Figure 16-4, you can see that the execution plan used the index on the [Name] column but had to perform a scan instead of a seek. Since an index on a column with character data types (such as CHAR and VARCHAR) sorts the data values for the column on the leading-end characters, the use of a leading % in the LIKE condition didn't allow a seek operation into the index. The matching rows may be distributed throughout the index rows, making the index noneffective for the search condition and thereby hurting the performance of the query.
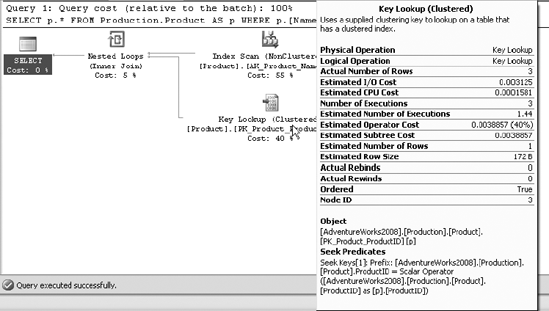
Always try not to use arithmetic operators and functions on columns in the WHERE and JOIN clauses. Using operators and functions on them prevents the use of indexes on those columns. The performance impact of using arithmetic operators on WHERE clause columns is explained in detail in the section "Avoid Arithmetic Operators on the WHERE Clause Column" of Chapter 11, and the impact of using functions is explained in detail in the section "Avoid Functions on the WHERE Clause Column" of the same chapter.
To see this in action, consider the following queries (badfunction.sql in the download):
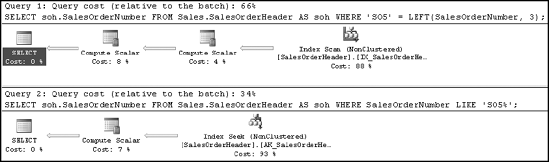
SELECT soh.SalesOrderNumber FROM Sales.SalesOrderHeader AS soh WHERE 'SO5' = LEFT(SalesOrderNumber, 3); SELECT soh.SalesOrderNumber FROM Sales.SalesOrderHeader AS soh WHERE SalesOrderNumber LIKE 'SO5%';
These are basically the same logic: checking SalesOrderNumber to see whether it is equal to S05. However, the first performs a function on the SalesOrderNumber column, while the second uses a LIKE clause to check for the same data. Figure 16-5 shows the resulting execution plans.
As you can see in Figure 16-5, the first query forces an Index Scan operation, while the second is able to perform a nice clean Index Seek. This demonstrates clearly why you should avoid functions and operators.
As a rule, avoid the use of optimizer hints, such as index hints and join hints, because they overrule the decision-making process of the optimizer. In general, the optimizer is smart enough to generate efficient execution plans and works the best without any optimizer hint imposed on it. The same applies to plan guides. Although forcing a plan in rare circumstances will help, for the most part rely on the optimizer to make good choices. For a detailed understanding of the performance impact of optimizer hints, please refer to the corresponding section "Avoiding Optimizer Hints" of Chapter 11.
A nested view is when one view calls another view, which calls more views, and so on. This can lead to very confusing code since the views are masking the operations being performed and because although the query may be very simple, the execution plan and subsequent operations by the SQL engine can be very complex and expensive. The same rule applies to nesting user-defined functions.
When you create variables in a query, be sure those variables are of the same data type as the columns that they will be used to compare against. Even though SQL Server can and will convert, for example, a VARCHAR to a DATE, that implicit conversion will prevent indexes from being used. You have to be just as careful in situations like table joins so that the primary key data type of one table matches the foreign key of the table being joined.
SQL Server maintains the old and new states of every atomic action (or transaction) in the transaction log to ensure database consistency and durability, creating the potential for a huge pressure on the log disk and often making the log disk a point of contention. Therefore, to improve database performance, you must try to optimize the transaction log overhead. Besides the hardware solutions discussed later in the chapter, you should adopt the following query-design best practices:
Prefer table variables over temporary tables for small result sets. The performance benefit of table variables is explained in detail in the section "Using Table Variables" of Chapter 10.
Batch a number of action queries in a single transaction. You must be careful when using this option, because if too many rows are affected within a single transaction, the corresponding database objects will be locked for a long time, blocking all other users trying to access the objects.
Reduce the amount of logging of certain operations by using the Bulk Logged recovery model. Primarily this is for use when dealing with large-scale data manipulation. You also will use minimal logging when Bulk Logged is enabled and you use the
WRITEclause of theUPDATEstatement or drop or create indexes.
The best practices for optimizing the cost of plan generation can be broadly classified into two categories:
Caching execution plans effectively
Minimizing recompilation of execution plans
Caching Execution Plans Effectively
You must ensure that the execution plans for your queries are not only cached but also reused often by adopting the following best practices:
Avoid executing queries as nonparameterized, ad hoc queries. Instead, parameterize the variable parts of a query and submit the parameterized query using a stored procedure or the
sp_executesqlsystem stored procedure.Use the same environment settings (such as
ANSI_NULLS) in every connection that executes the same parameterized queries, because the execution plan for a query is dependent on the environment settings of the connection.As explained earlier in the section "Explicitly Define the Owner of an Object," explicitly qualify the owner of the objects while accessing them in your queries.
The preceding aspects of plan caching are explained in detail in Chapter 9.
Minimizing Recompilation of Execution Plans
To minimize the cost of generating execution plans for stored procedures, you must ensure that the plans in the cache are not invalidated or recompiled for reasons that are under your control. The following recommended best practices minimize the recompilation of stored procedure plans:
Do not interleave DDL and DML statements in your stored procedures. You must put all the DDL statements at the top of the stored procedures.
In a stored procedure, avoid using temporary tables that are created outside the stored procedure.
Avoid recompilation caused by statistics changes on temporary tables by using the
KEEPFIXED PLANoption.Prefer table variables over temporary tables for very small data sets.
Do not change the
ANSI SEToptions within a stored procedure.If you really can't avoid a recompilation, then identify the stored procedure statement that is causing the recompilation, and execute it through the
sp_executesqlsystem stored procedure.
The causes of stored procedure recompilation and the recommended solutions are explained in detail in Chapter 10.
The more effectively you design your queries for concurrency, the faster the queries will be able to complete without blocking one another. Consider the following recommendations while designing the transactions in your queries:
Keep the scope of the transactions as short as possible. In a transaction, include only the statements that must be committed together for data consistency.
Prevent the possibility of transactions being left open because of poor error-handling routines or application logic by using the following techniques:
Use
SET XACT_ABORT ONto ensure that a transaction is aborted or rolled back on an error condition within the transaction.After executing a stored procedure or a batch of queries containing a transaction from a client code, always check for an open transaction, and roll back any open transactions using the following SQL statement:
IF @@TRANCOUNT > 0 ROLLBACK
Use the lowest level of transaction isolation required to maintain data consistency. The amount of isolation provided by the Read Committed isolation level, the default isolation level, is sufficient most of the time. If an application feature (such as reporting) can tolerate dirty data, consider using the Read Uncommitted isolation level or the
NOLOCKhint.
The impact of transactions on database performance is explained in detail in Chapter 12.
Since SQL Server is designed to work with sets of data, processing multiple rows using DML statements is generally much faster than processing the rows one by one using database cursors. If you find yourself using lots of cursors, reexamine the logic to see whether there are ways you can eliminate the cursors. If you must use a database cursor, then use the database cursor with the least overhead, which is the FAST_FORWARD cursor type (generally referred to as the fast-forward-only cursor), or use the equivalent DataReader object in ADO.NET.
The performance overhead of database cursors is explained in detail in Chapter 14.
Here's a checklist of the server and database configurations settings that have a big impact on database performance:
Affinity mask
Memory configuration options
Cost threshold for parallelism
Max degree of parallelism
Optimize for ad hoc workloads
Query governor cost limit
Fill factor (%)
Blocked process threshold
Database file layout
Database compression
I cover these settings in more detail in the sections that follow.
As explained in the section "Parallel Plan Optimization" of Chapter 9, this setting is a special configuration setting at the server level that you can use to restrict the specific CPUs available to SQL Server. It is recommended that you keep this setting at its default value of 0, which allows SQL Server to use all the CPUs of the machine.
As explained in the section "SQL Server Memory Management" of Chapter 2, it is strongly recommended that you keep the memory configuration of SQL Server at the default dynamic setting. For a dedicated SQL Server box, the max server memory setting may be configured to a nondefault value, determined by the system configuration, under the following two situations:
SQL Server cluster with active/active configuration: In active/active configuration, both SQL Server nodes accept incoming traffic and remain available to run a second instance of SQL Server if the other node fails, accepting the incoming traffic for the other SQL Server. Since both nodes must be capable of running two instances of SQL Server, the
max server memorysetting for each SQL Server instance must be set to less than half of the physical memory so that both SQL Server instances can run simultaneously on a single node, when needed. Because of this and other resource shortcomings, active/active configurations are not encouraged (the nickname for active/active is fail/fail).More than 4GB of physical memory: If a SQL Server machine has more than 4GB of physical memory and the
PAEswitch (inboot.ini) is set, then set theawe enabledparameter of SQL Server to allow SQL Server to access the memory beyond 4GB, and set themax server memorysetting to a value approximately 200MB less than the physical memory. ThePAEandAWEsettings are explained in detail in the section "Using Memory Beyond 4GB Within SQL Server" of Chapter 2. A 64-bit machine won't have to deal with these same issues because the configuration requirements are not the same to access beyond 4GB of memory.
Another memory configuration to consider for a SQL Server machine is the /3GB setting at the operating system level. If the machine has 4GB of physical memory, then you can add this setting to the boot.ini file, allowing SQL Server to use the physical memory up to 3GB. Again, this assumes that more memory is not needed for the operating system or other services running on the machine. These memory configurations of SQL Server are explained in detail in the sections "Memory Bottleneck Analysis" and "Memory Bottleneck Resolutions" of Chapter 2.
On systems with multiple processors, the parallel execution of queries is possible. The default value for parallelism is 5. This represents a cost estimate by the optimizer of a five-second execution on the query. In most circumstances, I've found this value to be too low, meaning a higher threshold for parallelism results in better performance. Testing on your system will help determine the appropriate value.
When a system has multiple processors available, by default SQL Server will use all of them during parallel executions. To better control the load on the machine, you may find it useful to limit the number of processors used by parallel executions. Further, you may need to set the affinity so that certain processors are reserved for the operating system and other services running alongside SQL Server. OLTP systems frequently receive a benefit from disabling parallelism entirely.
If the primary calls being made to your system come in as ad hoc or dynamic SQL instead of through well-defined stored procedures or parameterized queries, such as you might find in some of the implementation of object relational mapping (ORM) software, turning optimize for ad hoc workloads on will reduce the consumption of procedure cache as plan stubs are created for initial query calls instead of full execution plans. This is covered in detail in Chapter 10.
To reduce contention and prevent a few processes from taking over the machine, you can set query governor cost limit so that any given query execution has an upper time limit in seconds. This value is based on the estimated cost as determined by the optimizer, so it prevents queries from running if they exceed the cost limit set here. Setting the query governor is another reason to maintain the index statistics in order to get good execution plan estimates.
When creating a new index or rebuilding an existing one, a default fill factor (the amount of free space to be left on a page) is determined with this setting. Choosing an appropriate value for your system requires testing and knowledge of the use of the system. Fill factor was discussed in detail in Chapter 4.
The blocked process threshold setting defines in seconds when a blocked process report is fired. When a query runs and exceeds the threshold, the report is fired, and an alert, which can be used to send an email or a text message, is fired. Testing an individual system determines what value to set this to. You can monitor for this using events within traces defined by SQL Profiler.
For easy reference, I'll list the best practices you should consider when laying out database files:
Place the data and transaction log files of a user database on different disks, allowing the transaction log disk head to progress sequentially without being moved randomly by the nonsequential I/Os commonly used for the data files.
Placing the transaction log on a dedicated disk also enhances data protection. If a database disk fails, you will be able to save the completed transactions until the point of failure by performing a backup of the transaction log. By using this last transaction log backup during the recovery process, you will be able to recover the database up to the point of failure, also known as point-in-time recovery.
Avoid RAID 5 for transaction logs because, for every write request, RAID 5 disk arrays incur twice the number of disk I/Os compared to RAID 1 or 10.
You may choose RAID 5 for data files, since even in a heavy OLTP system the number of read requests is usually seven to eight times that of writes, and for read requests the performance of RAID 5 is similar to that of RAID 1 and RAID 10 with an equal number of total disks.
If the system has multiple CPUs and multiple disks, spread the data across multiple data files distributed across the disks.
For a detailed understanding of database file layout and RAID subsystems, please refer to the section "Disk Bottleneck Resolutions" of Chapter 2.
SQL Server 2008 supplies data compression with the Enterprise and Developer Editions of the product. This can provide a great benefit in space used and sometimes in performance as more data gets stored on an index page. These benefits come at added overhead in the CPU and memory of the system. Take this into account as you implement compression.
For your reference, here is a short list of the performance-related database administrative activities that you should perform while managing your database server on a regular basis:
Keep the statistics up-to-date.
Maintain a minimum amount of index defragmentation.
Cycle the SQL error log file.
Avoid automatic database functions such as
AUTO_CLOSEorAUTO_SHRINK.Minimize the overhead of SQL tracing.
In the following sections, I detail these activities.
Note
For a detailed explanation of SQL Server 2008 administration needs and methods, please refer to the Microsoft SQL Server Books Online article "Administration: How To Topics" (http://msdn.microsoft.com/en-us/library/bb522544.aspx).
Although the performance impact of database statistics is explained in detail in Chapter 7, here's a short list for easy reference:
Allow SQL Server to automatically maintain the statistics of the data distribution in the tables by using the default settings for the configuration parameters
AUTO_CREATE_STATISTICSandAUTO_UPDATE_STATISTICS.As a proactive measure, in addition to the continual update of the statistics by SQL Server, you can programmatically update the statistics of every database object on a regular basis as you determine it is needed and supported within your system. This practice partly protects your database from having outdated statistics in case the auto update statistics feature fails to provide a satisfactory result. In Chapter 7, I illustrate how to set up a SQL Server job to programmatically update the statistics on a regular basis.
Note
Please ensure that the statistics update job is scheduled after the completion of the index defragmentation job, as explained later in the chapter.
The following best practices will help you maintain a minimum amount of index defragmentation:
Defragment a database on a regular basis during nonpeak hours.
On a regular basis, determine the level of fragmentation on your indexes and then, based on that fragmentation, either rebuild the index or defrag the index by executing the defragmentation queries outlined in Chapter 4.
By default, the SQL Server error log file keeps growing until SQL Server is restarted. Every time SQL Server is restarted, the current error log file is closed and renamed errorlog.1, then errorlog.1 is renamed errorlog.2, and so on. Subsequently, a new error log file is created. Therefore, if SQL Server is not restarted for a long time, as expected for a production server, the error log file may grow to a very large size, making it not only difficult to view the file in an editor but also very memory unfriendly when the file is opened.
SQL Server provides a system stored procedure, sp_cycle_errorlog, that you can use to cycle the error log file without restarting SQL Server. To keep control over the size of the error log file, you must cycle the error log file periodically by executing sp_cycle_errorlog as follows:
EXEC master.dbo.sp_cycle_errorlog
Use a SQL Server job to cycle the SQL Server log on a regular basis.
AUTO_CLOSE cleanly shuts down a database and frees all its resources when the last user connection is closed. This means all data and queries in the cache are automatically flushed. When the next connection comes in, not only does the database have to restart, but all the data has to be reloaded into the cache and stored procedures, and the other queries have to be recompiled. That's an extremely expensive operation for most database systems. Leave AUTO_CLOSE set to the default of OFF.
AUTO_SHRINK periodically shrinks the size of the database. It can shrink the data files and, when in Simple Recovery mode, the log files. While doing this, it can block other processes, seriously slowing down your system. Since, more often than not, file growth is also set to occur automatically on systems with AUTO_SHRINK enabled, your system will be slowed down yet again when the data or log files have to grow. Set your database sizes to an appropriate size, and monitor them for growth needs. If you must grow them automatically, do so by physical increments, not by percentages.
One of the most common ways of analyzing the behavior of SQL Server is to trace the SQL queries executed on SQL Server. For easy reference, here's a list of the performance-related best practices for SQL tracing:
Capture trace output using a server-side trace (not Profiler).
Limit the number of events and data columns to be traced.
Discard starting events while analyzing costly and slow queries.
Limit trace output size.
If you decide to run Profiler for very short tracing, run the tool remotely.
Avoid online data column sorting while using Profiler.
These best practices are explained in detail in the section "SQL Profiler Recommendations" of Chapter 3.
Although database backup is a broad topic and can't be given due justice in this query optimization book, I suggest that for database performance you be attentive to the following aspects of your database backup process:
The next sections go into more detail on these suggestions.
For an OLTP database, it is mandatory that the database be backed up regularly so that, in case of a failure, the database can be restored on a different server. For large databases, the full database backup usually takes a very long time, so full backups cannot be performed often. Consequently, full backups are performed at widespread time intervals, with incremental backups and transaction log backups scheduled more frequently between two consecutive full backups. With the frequent incremental and transaction log backups set in place, if a database fails completely, the database can be restored up to a point in time.
Incremental backups can be used to reduce the overhead of a full backup by backing up only the data changed since the last full backup. Because this is much faster, it will cause less of a slowdown on the production system. Each situation is unique, so you need to find the method that works best for you. As a general rule, I recommend taking a weekly full backup and then daily incremental backups. From there you can determine the needs of your transaction log backups.
The frequent backup of the transaction log adds overhead to the server, even during peak hours. To minimize the performance impact of transaction log backup on incoming traffic, consider the following three aspects of transaction log backups:
Performance: You can back up the transaction log only if the size of the log file is greater than 20 percent of the total size of all the data files. This option is best for the database performance, since the transaction log is backed up only when it is significantly full. However, this option is not good for minimizing data loss, and the amount of data loss (in terms of time) cannot be quantified, because if the log disk fails and the database needs to be recovered from backup, then the last log backup up to which the database can be recovered may be far in the past. Additionally, the delayed backup of the transaction log causes the log file to grow up to 20 percent of the total size of the data files, requiring a large log-disk subsystem.
Disk space: You can back up the transaction log whenever the size of the log file becomes greater than 500MB. This option is good for disk space and may be partly good for performance, too, if the 500MB log space doesn't fill up quickly. However, as with the previous option, the amount of data loss (in terms of time) cannot be quantified, because it may take a random amount of time to fill the 500MB log. If the log disk fails, then the database can be recovered up to the last log backup, which may be far in the past.
Data loss: To minimize and quantify the maximum amount of data loss in terms of time, back up the log frequently. If a business can withstand the maximum data loss of 60 minutes, then the interval of the transaction log backup schedule must be set to less than 60 minutes.
Because, for most businesses, the acceptable amount of data loss (in terms of time) usually takes precedence over conserving the log-disk space or providing an ideal database performance, you must take into account the acceptable amount of data loss while scheduling the transaction log backup instead of randomly setting the schedule to a low time interval.
When multiple databases need to be backed up, you must ensure that all full backups are not scheduled at the same time so that the hardware resources are not pressurized at the same time. If the backup process involves backing up the databases to a central SAN disk array, then the full backups from all the database servers must be distributed across the backup time window so that the central backup infrastructure doesn't get slammed by too many backup requests at the same time. Flooding the central infrastructure with a great deal of backup requests at the same time forces the components of the infrastructure to spend a significant part of their resources just managing the excessive number of requests. This mismanaged use of the resources increases the backup durations significantly, causing the full backups to continue during peak hours and thus affecting the performance of the user requests.
To minimize the impact of the full backup process on database performance, you must first determine the nonpeak hours when full backups can be scheduled, and then you distri-bute the full backups across the nonpeak time window as follows:
Identify the number of databases that must be backed up.
Prioritize the databases in order of their importance to the business.
Determine the nonpeak hours when the full database backups can be scheduled.
Calculate the time interval between two consecutive full backups as follows:
Time interval = (Total backup time window) / (Number of full backups) Schedule the full backups in order of the database priorities, with the first backup starting at the start time of the backup window and the subsequent backups spread uniformly at time intervals as calculated in the preceding equation.
This uniform distribution of the full backups will ensure that the backup infrastructure is not flooded with too many backup requests at the same time and will thus reduce the impact of the full backups on the database performance.
For relatively large databases, the backup durations and backup file sizes usually become an issue. Long backup durations make it difficult to complete the backups within the administrative time windows and thus start affecting the end user's experience. The large size of the backup files makes space management for the backup files quite challenging, and it increases the pressure on the network when the backups are performed across the network to a central backup infrastructure.
The recommended way to optimize the backup duration, the backup file size, and the resultant network pressure is to use backup compression. SQL Server 2008 introduces the concept of backup compression for the Enterprise Edition of the product. Many third-party backup tools are available that support backup compression.
Performance optimization is an ongoing process. It requires continual attention to database and query characteristics that affect performance. The goal of this chapter was to provide you with a checklist of these characteristics to serve as a quick and easy reference during the development and maintenance phase of your database applications.