
In the first chapter, I stressed the importance of having a performance baseline that you can use to measure performance changes. In fact, this is one of the first things you should do when starting the performance-tuning process, since without a baseline you will not be able to quantify improvements. In this chapter, you will learn how to use the Performance Monitor tool to accomplish this and how to use the different performance counters that are required to create a baseline.
Specifically, I cover the following topics:
The basics of the Performance Monitor tool
How to analyze hardware resource bottlenecks using Performance Monitor
How to retrieve Performance Monitor data within SQL Server using dynamic management views
How to resolve hardware resource bottlenecks
How to analyze the overall performance of SQL Server
How to create a baseline for the system
Windows Server 2008 provides a tool called Performance Monitor, although all the documentation for it refers to System Monitor. This tool is part of a larger suite of data collection tools called the Reliability and Performance Monitor. Performance Monitor collects detailed information about the utilization of operating system resources. It allows you to track nearly every aspect of system performance, including memory, disk, processor, and the network. In addition, SQL Server 2008 provides extensions to the Performance Monitor tool to track a variety of functional areas within SQL Server.
Performance Monitor tracks resource behavior by capturing performance data generated by hardware and software components of the system such as a processor, a process, a thread, and so on. The performance data generated by a system component is represented by a performance object. A performance object provides counters that represent specific aspects of a component, such as % Processor Time for a Processor object.
There can be multiple instances of a system component. For instance, the Processor object in a computer with two processors will have two instances represented as instances 0 and 1. Performance objects with multiple instances may also have an instance called _Total to represent the total value for all the instances. For example, the processor usage of a computer with four processors can be determined using the following performance object, counter, and instance (as shown in Figure 2-1):
Performance object:
ProcessorCounter:
% Processor TimeInstance:
_Total
System behavior can be either tracked in real time in the form of graphs or captured as a log (called a counter log) for offline analysis.
To run the Performance Monitor tool, execute perfmon from a command prompt, which will open the Reliability and Performance Monitor suite. You can also right-click the Computer icon on the desktop or Start menu, expand Diagnostics, and then expand the Reliability and Performance Monitor. Both will allow you to open the Performance Monitor utility.
You will learn how to set up the individual counters in the "Creating a Baseline" section later in this chapter. First you will examine which counters you should choose in order to identify system bottlenecks and also how you can resolve some of these bottlenecks.
To get an immediate snapshot of a large amount of data that was formerly available only in Performance Monitor, SQL Server now offers the same data internally through a set of dynamic management views (DMVs) and dynamic management functions (DMFs). These are extremely useful mechanisms for capturing a snapshot of the current performance of your system. I'll introduce several of these throughout the book, but I'll focus on a few that are the most important for monitoring performance and for establishing a baseline.
The sys.dm_os_performance_counters view displays the SQL Server counters within a query, allowing you to apply the full strength of T-SQL to the data immediately. For example, this simple query will return the current value for Logins/sec:
SELECT cntr_value
FROM sys.dm_os_performance_counters
WHERE OBJECT_NAME = 'MSSQL$GF2008:General Statistics'
AND counter_name = 'Logins/sec'This returns the value of 15 for my server. For your server, you'll need to substitute the appropriate server name in the OBJECT_NAME comparison.
There are a large number of DMVs and DMFs that can be used to gather information about the server. Rather than cover them all, I'll introduce one more that you will find yourself accessing on a regular basis, sys.dm_os_wait_stats. This DMV shows an aggregated view of the threads within SQL Server that are waiting on various resources, collected since the last time SQL Server was started or the counters were reset. Identifying the types of waits that are occurring within your system is one of the easiest mechanisms to begin identifying the source of your bottlenecks. You can sort the data in various ways, but for the first example, I'll look at the waits that have the longest current count using this simple query:
SELECT TOP (10)
*
FROM sys.dm_os_wait_stats
ORDER BY wait_time_ms DESCFigure 2-2 displays the output.
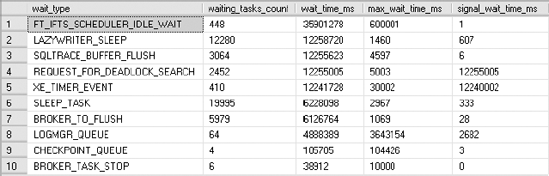
You can see not only the cumulative time that particular waits have occurred but also a count of how often they have occurred and the maximum time that something had to wait. From here, you can identify the wait type and begin troubleshooting. One of the most common types of waits is I/O. If you see ASYNCH_IO_COMPLETION, IO_COMPLETION, LOGMGR, WRITELOG, or PAGEIOLATCH in your top ten wait types, you may be experiencing I/O contention, and you now know where to start working. For a more detailed analysis of wait types and how to use them as a monitoring tool within SQL Server, read the Microsoft white paper "SQL Server 2005 Waits and Queues" (http://www.microsoft.com/technet/prodtechnol/sql/bestpractice/performance_tuning_waits_queues.mspx). Although it was written for SQL Server 2005, it is equally applicable to SQL Server 2008.
Typically, SQL Server database performance is affected by stress on the following hardware resources:
Memory
Disk I/O
Processor
Network
Stress beyond the capacity of a hardware resource forms a bottleneck. To address the overall performance of a system, you need to identify these bottlenecks, because they form the limit on overall system performance.
There is usually a relationship between resource bottlenecks. For example, a processor bottleneck may be a symptom of excessive paging (memory bottleneck) or a slow disk (disk bottleneck). If a system is low on memory, causing excessive paging, and has a slow disk, then one of the end results will be a processor with high utilization since the processor has to spend a significant number of CPU cycles to swap pages in and out of the memory and to manage the resultant high number of I/O requests. Replacing the processor with a faster one may help a little, but it would not be the best overall solution. In a case like this, increasing memory is a more appropriate solution, because it will decrease pressure on the disk and processor as well. Even upgrading the disk will probably be a better solution than upgrading the processor.
Note
The most common performance problem is usually I/O, either from memory or from the disk.
One of the best ways of locating a bottleneck is to identify resources that are waiting for some other resource to complete its operation. You can use Performance Monitor counters or DMVs such as sys.dm_os_wait_stats to gather that information. The response time of a request served by a resource includes the time the request had to wait in the resource queue, as well as the time taken to execute the request, so end user response time is directly proportional to the amount of queuing in a system.
For example, consider that the disk subsystem has a disk queue length of 10. Since the disk subsystem already has pending disk requests on it, a new disk request has to wait until the previous disk requests complete. If the time taken by an average disk transfer is one second, then the new disk request has to wait for about ten seconds before getting the attention of the disk subsystem. Therefore, the total response time of the disk request will be ten seconds wait time, plus one second disk transfer time.
Be aware that the absence of a queue does not mean that there is no bottleneck. When queue lengths start growing, however, it is a sure sign that the system is not able to keep up with the demand.
Not all resources have specific counters that show queuing levels, but most resources have some counters that represent an overcommittal of that resource. For example, memory has no such counter, but a large number of hard page faults represents the overcommittal of physical memory (hard page faults are explained later in the chapter in the section "Pages/sec and Page Faults/sec Counters"). Other resources, such as the processor and disk, have specific counters to indicate the level of queuing. For example, the counter Page Life Expectancy indicates how long a page will stay in the buffer pool without being referenced. This is an indicator of how well SQL Server is able to manage its memory, since a longer life means that a piece of data in the buffer will be there, available, waiting for the next reference. However, a shorter life means that SQL Server is moving pages in and out of the buffer quickly, possibly suggesting a memory bottleneck.
You will see which counters to use in analyzing each type of bottleneck shortly.
Once you have identified bottlenecks, you can resolve them in two ways:
You can increase resource throughput.
You can decrease the arrival rate of requests to the resource.
Increasing the throughput usually requires extra resources such as memory, disks, processors, or network adapters. You can decrease the arrival rate by being more selective about the requests to a resource. For example, when you have a disk subsystem bottleneck, you can either increase the throughput of the disk subsystem or decrease the amount of I/O requests.
Increasing the throughput means adding more disks or upgrading to faster disks. Decreasing the arrival rate means identifying the cause of high I/O requests to the disk subsystem and applying resolutions to decrease their number. You may be able to decrease the I/O requests, for example, by adding appropriate indexes on a table to limit the amount of data accessed or by partitioning a table between multiple disks.
Memory can be a problematic bottleneck because a bottleneck in memory will manifest on other resources, too. This is particularly true for a system running SQL Server. When SQL Server runs out of cache (or memory), a process within SQL Server (called lazy writer) has to work extensively to maintain enough free internal memory pages within SQL Server. This consumes extra CPU cycles and performs additional physical disk I/O to write memory pages back to disk.
SQL Server manages memory for databases, including memory requirements for data and query execution plans, in a large pool of memory called the memory pool. The memory pool consists of a collection of 8KB buffers to manage data pages and plan cache pages, free pages, and so forth. The memory pool is usually the largest portion of SQL Server memory. SQL Server manages memory by growing or shrinking its memory pool size dynamically.
You can configure SQL Server for dynamic memory management in SQL Server Management Studio (SSMS). Go to the Memory folder of the Server Properties dialog box, as shown in Figure 2-3.
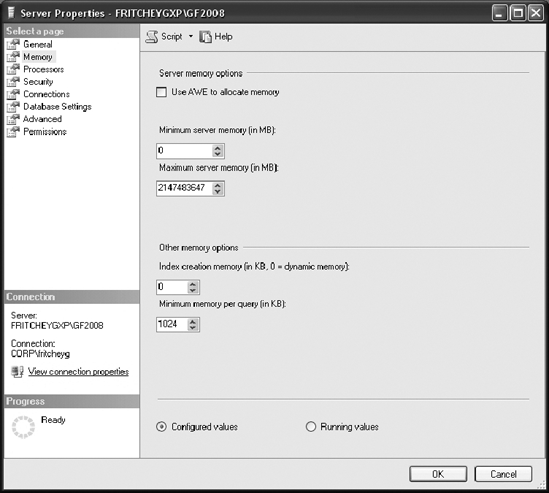
The dynamic memory range is controlled through two configuration properties: Minimum(MB) and Maximum(MB).
Minimum(MB), also known asmin server memory, works as a floor value for the memory pool. Once the memory pool reaches the same size as the floor value, SQL Server can continue committing pages in the memory pool, but it cannot be shrunk to less than the floor value. Note that SQL Server does not start with themin server memoryconfiguration value but commits memory dynamically, as needed.Maximum(MB), also known asmax server memory, serves as a ceiling value to limit the maximum growth of the memory pool. These configuration settings take effect immediately and do not require a restart.
Microsoft recommends that you use dynamic memory configuration for SQL Server, where min server memory will be 0 and max server memory will be the maximum physical memory of the system, assuming a single instance on the machine. You should not run other memory-intensive applications on the same server as SQL Server, but if you must, I recommend you first get estimates on how much memory is needed by other applications and then configure SQL Server with a max server memory value set to prevent the other applications from starving SQL Server of memory. On a system where SQL Server is running on its own, I prefer to set the minimum server memory equal to the max value and simply dispatch with dynamic management. On a server with multiple SQL Server instances, you'll need to adjust these memory settings to ensure each instance has an adequate value. Just make sure you've left enough memory for the operating system and external processes, as well as non-buffer-pool memory (which used to be called MemToLeave).
Memory within SQL Server can be roughly divided into buffer pool memory, which represents data pages and free pages, and nonbuffer memory, which consists of threads, DLLs, linked servers, and others. Most of the memory used by SQL Server goes into the buffer pool.
Note
SQL Server does consume more memory than simply that specified by the max_server_memory setting.
You can also manage the configuration values for min server memory and max server memory by using the sp_configure system stored procedure. To see the configuration values for these parameters, execute the sp_configure stored procedure as follows:
exec sp_configure 'min server memory (MB)' exec sp_configure 'max server memory (MB)'
Figure 2-4 shows the result of running these commands.

Note that the default value for the min server memory setting is 0MB, and for the max server memory setting it is 2147483647MB. Also, max server memory cannot be set to less than 4MB.
You can also modify these configuration values using the sp_configure stored procedure. For example, to set max server memory to 200MB and min server memory to 100MB, execute the following set of statements (set_memory.sql in the download):
USE master EXEC sp_configure 'show advanced option', '1' RECONFIGURE exec sp_configure 'min server memory (MB)', 100 exec sp_configure 'max server memory (MB)', 200 RECONFIGURE WITH OVERRIDE
The min server memory and max server memory configurations are classified as advanced options. By default, the sp_configure stored procedure does not affect/display the advanced options. Setting show advanced option to 1 as shown previously enables the sp_configure stored procedure to affect/display the advanced options.
The RECONFIGURE statement updates the memory configuration values set by sp_configure. Since ad hoc updates to the system catalog containing the memory configuration values are not recommended, the OVERRIDE flag is used with the RECONFIGURE statement to force the memory configuration. If you do the memory configuration through Management Studio, Management Studio automatically executes the RECONFIGURE WITH OVERRIDE statement after the configuration setting.
In some rare circumstances, you may need to allow for SQL Server sharing a system's memory. To elaborate, consider a computer with SQL Server and Exchange Server running on it. Both servers are heavy users of memory and thus keep pushing each other for memory. The dynamic-memory behavior of SQL Server allows it to release memory to Exchange Server at one instance and grab it back as Exchange Server releases it. You can avoid this dynamic-memory management overhead by configuring SQL Server for a fixed memory size. However, please keep in mind that since SQL Server is an extremely resource-intensive process, it is highly recommended that you have a dedicated SQL Server production machine.
Now that you understand SQL Server memory management, let's consider the performance counters you can use to analyze stress on memory, as shown in Table 2-1.
Table 2.1. Performance Monitor Counters to Analyze Memory Pressure
Object(Instance[,InstanceN]) | Counter | Description | Values |
|---|---|---|---|
|
| Free physical memory | System dependent |
| Rate of hard page faults | Average value < 50 | |
| Rate of total page faults | Compare with its baseline value for trend analysis | |
| Rate of input page faults | ||
| Rate of output page faults | ||
| Percentage of requests served out of buffer cache | Average value ≥ 90% | |
| Time page spends in buffer | Average value > 300 | |
| Pages written to disk by checkpoint | Average value < 30 | |
| Dirty aged pages flushed from buffer | Average value < 20 | |
|
| Number of processes waiting for memory grant | Average value = 0 |
| Maximum physical memory SQL Server can consume on the box | Close to size of physical memory | |
| Physical memory currently assigned to SQL Server | Close to | |
|
| Size, in bytes, of memory that this process has allocated that cannot be shared with other processes |
I'll now walk you through these counters to get a better idea of what you can use them for.
The Available Bytes counter represents free physical memory in the system. For good performance, this counter value should not be too low. If SQL Server is configured for dynamic memory usage, then this value will be controlled by calls to a Windows API that determines when and how much memory to release. Extended periods of time with this value very low and SQL Server memory not changing indicates that the server is under severe memory stress.
To understand the importance of the Pages/sec and Page Faults/sec counters, you first need to learn about page faults. A page fault occurs when a process requires code or data that is not in its working set (its space in physical memory). It may lead to a soft page fault or a hard page fault. If the faulted page is found elsewhere in physical memory, then it is called a soft page fault. A hard page fault occurs when a process requires code or data that is not in its working set or elsewhere in physical memory and must be retrieved from disk.
The speed of a disk access is in the order of milliseconds, whereas a memory access is in the order of nanoseconds. This huge difference in the speed between a disk access and a memory access makes the effect of hard page faults significant compared to that of soft page faults.
The Pages/sec counter represents the number of pages read from or written to disk per second to resolve hard page faults. The Page Faults/sec performance counter indicates the total page faults per second—soft page faults plus hard page faults—handled by the system.
Hard page faults, indicated by Pages/sec, should not be consistently high. If this counter is consistently very high, then SQL Server is probably starving other applications. There are no hard and fast numbers for what indicates a problem, because these numbers will vary widely between systems based on the amount and type of memory as well as the speed of disk access on the system.
If the Pages/sec counter is very high, then you can break it up into Pages Input/sec and Pages Output/sec:
Pages Input/sec: An application will wait only on an input page, not on an output page.Pages Output/sec: Page output will stress the system, but an application usually does not see this stress. Pages output are usually represented by the application's dirty pages that need to be backed out to the disk.Pages Output/secis an issue only when disk load become an issue.
Also, check Process:Page Faults/sec to find out which process is causing excessive paging in case of high Pages/sec. The Process object is the system component that provides performance data for the processes running on the system, which are individually represented by their corresponding instance name.
For example, the SQL Server process is represented by the sqlservr instance of the Process object. High numbers for this counter usually do not mean much unless Pages/sec is high. Page Faults/sec can range all over the spectrum with normal application behavior, with values from 0 to 1,000 per second being acceptable. This entire data set means a baseline is essential to determine the expected normal behavior.
The buffer cache is the pool of buffer pages into which data pages are read, and it is often the biggest part of the SQL Server memory pool. This counter value should be as high as possible, especially for OLTP systems that should have fairly regimented data access, unlike a warehouse or reporting system. It is extremely common to find this counter value as 99 percent or more for most production servers. A low Buffer cache hit ratio value indicates that few requests could be served out of the buffer cache, with the rest of the requests being served from disk.
When this happens, either SQL Server is still warming up or the memory requirement of the buffer cache is more than the maximum memory available for its growth. If this is consistently low, you should consider getting more memory for the system.
Page Life Expectancy indicates how long a page will stay in the buffer pool without being referenced. Generally, a low number for this counter means that pages are being removed from the buffer, lowering the efficiency of the cache and indicating the possibility of memory pressure. On reporting systems, as opposed to OLTP systems, this number may remain at a lower value since more data is accessed from reporting systems. A reasonable value to expect to see here is 300 seconds or more.
The Checkpoint Pages/sec counter represents the number of pages that are moved to disk by a checkpoint operation. These numbers should be relatively low, for example, less than 30 per second for most systems. A higher number means more pages are being marked as dirty in the cache. A dirty page is one that is modified while in the buffer. When it's modified, it's marked as dirty and will get written back to the disk during the next checkpoint. Higher values on this counter indicate a larger number of writes occurring within the system, possibly indicative of I/O problems.
The Lazy writes/sec counter records the number of buffers written each second by the buffer manager's lazy write process. This process is where the dirty, aged buffers are removed from the buffer by a system process that frees the memory up for other uses. A dirty, aged buffer is one that has changes and needs to be written to the disk. Higher values on this counter possibly indicate I/O issues or even memory problems. The Lazy writes/sec values should consistently be less than 20 for the average system.
The Memory Grants Pending counter represents the number of processes pending for a memory grant within SQL Server memory. If this counter value is high, then SQL Server is short of memory. Under normal conditions, this counter value should consistently be 0 for most production servers.
Another way to retrieve this value, on the fly, is to run queries against the DMV sys.dm_exec_query_memory_grants. A null value in the column grant_time indicates that the process is still waiting for a memory grant. This is one method you can use to troubleshoot query timeouts by identifying that a query (or queries) is waiting on memory in order to execute.
Target Server Memory (KB) indicates the total amount of dynamic memory SQL Server is willing to consume. Total Server Memory (KB) indicates the amount of memory currently assigned to SQL Server. The Total Server Memory (KB) counter value can be very high if the system is dedicated to SQL Server. If Total Server Memory (KB) is much less than Target Server Memory (KB), then either the SQL Server memory requirement is low, the max server memory configuration parameter of SQL Server is set at too low a value, or the system is in warm-up phase. The warm-up phase is the period after SQL Server is started when the database server is in the process of expanding its memory allocation dynamically as more data sets are accessed, bringing more data pages into memory.
You can confirm a low memory requirement from SQL Server by the presence of a large number of free pages, usually 5,000 or more.
When there is high stress on memory, indicated by a large number of hard page faults, you can resolve memory bottleneck using the flowchart shown in Figure 2-5.
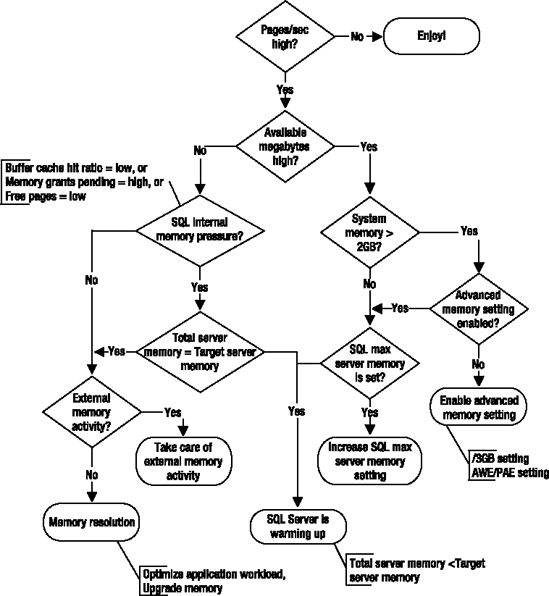
A few of the common resolutions for memory bottlenecks are as follows:
Optimizing application workload
Allocating more memory to SQL Server
Increasing system memory
Changing from a 32-bit to a 64-bit processor
Enabling 3GB of process space
Using memory beyond 4GB within 32-bit SQL Server
Let's take a look at each of these in turn.
Optimizing application workload is the most effective resolution most of the time, but because of the complexity and challenges involved in this process, it is usually considered last. To identify the memory-intensive queries, capture all the SQL queries using SQL Profiler (which you will learn how to use in Chapter 3), and then group the trace output on the Reads column. The queries with the highest number of logical reads contribute to most of the memory stress. You will see how to optimize those queries in more detail throughout this book.
As you learned in the "SQL Server Memory Management" section, the max server memory configuration can limit the maximum size of the SQL Server memory pool. If the memory requirement of SQL Server is more than the max server memory value, which you can tell through the number of hard page faults, then increasing the value will allow the memory pool to grow. To benefit from increasing the max server memory value, ensure that enough physical memory is available in the system.
The memory requirement of SQL Server depends on the total amount of data processed by SQL activities. It is not directly correlated to the size of the database or the number of incoming SQL queries. For example, if a memory-intensive query performs a cross join between two small tables without any filter criteria to narrow down the result set, it can cause high stress on the system memory.
One of the easiest and cheapest resolutions is to simply increase system memory. However, it is still important to find out what is consuming the physical memory, because if the application workload is extremely memory intensive, you will soon be limited by the maximum amount of memory a system can access. To identify which queries are using more memory, you can query the sys.dm_exec_query_memory_grants DMV. Just be careful when running queries against this DMV using a JOIN or an ORDER BY statement because, if your system is already under memory stress, these actions can lead to your query needing its own memory grant.
Something to keep in mind is the memory needed by SQL Server outside the buffer pool. This is referred to as nonbuffer memory and used to be called MemToLeave. One of the worst memory problems for queries occurs when the size of the query itself, not the data returned but the T-SQL code, exceeds 8KB in size. This memory is allocated at startup using the –g switch. If your queries are large (again, greater than 8KB in size), they will need to take advantage of this memory allocation. You will need to make sure you have enough memory available on your server for this. Using extended stored procedures, distributed queries, and automation objects also places a strain on this memory space.
Switching the physical server from a 32-bit processor to a 64-bit processor (and the attendant Windows Server software upgrade) radically changes the memory management capabilities of SQL Server. The limitations on SQL Server for memory go from 3GB (not counting up to 64GB of additional data cache available through Address Windowing Extensions [AWE]) to a limit of up to 8TB depending on the version of the operating system and the specific processor type. Limitations experienced with the AWE are removed since the memory used in 64-bit systems can be used for both data and the procedure cache, unlike AWE memory. No other switches or extra mechanisms are needed for SQL Server to take advantage of this memory space.
Standard 32-bit addresses can map a maximum of 4GB of memory. The standard address spaces of 32-bit Windows operating systems processes are therefore limited to 4GB. Out of this 4GB process space, by default the upper 2GB is reserved for the operating system, and the lower 2GB is made available to the application. If you specify a /3GB switch in the boot.ini file of the 32-bit OS, the operating system reserves only 1GB of the address space, and the application can access up to 3GB. This is also called 4-gig tuning (4GT). No new APIs are required for this purpose.
Therefore, on a machine with 4GB of physical memory and the default Windows configuration, you will find available memory of about 2GB or more. To let SQL Server use up to 3GB of the available memory, you can add the /3GB switch in the boot.ini file as follows:
[boot loader] timeout=30 default=multi(0)disk(0)rdisk(0)partition(1)WINNT [operating systems] multi(0)disk(0)rdisk(0)partition(1)WINNT= "Microsoft Windows Server 2008 Advanced Server" /fastdetect /3GB
The /3GB switch should not be used for systems with more than 16GB of physical memory, as explained in the following section, or for systems that require a higher amount of kernel memory.
SQL Server 2008 on 64-bit systems can support up to 8TB on an x64 platform and up to 7TB on the IA64. There is a further limit on Windows 2003 of 1TB. As more memory is available from the OS, the limits imposed by SQL Server are reached. This is without having to use any other switches or extended memory schemes.
All processors based on the IA-32 architecture, beginning with the Intel Pentium Pro, support a new 36-bit physical addressing mode called Physical Address Extension (PAE). PAE allows up to 64GB of physical memory, depending upon the operating system. The PAE mode kernel requires an Intel Architecture processor (Pentium Pro or newer) and more than 4GB of RAM.
Windows Server operating systems that are 32-bit implement Address Windowing Extensions to access up to 64GB of physical memory with the PAE addressing mode. This memory is available for the buffer cache, for data storage only, but cannot be used by operations and tasks to increase the number of, for example, databases available on the system.
Accessing memory beyond 4GB in a 32-bit Windows Server OS requires configuration at two levels: the operating system level and the application level. To enable the operating system to access more than 4GB of physical memory, add a /PAE switch in the boot.ini file as follows:
[boot loader] timeout=30 default=multi(0)disk(0)rdisk(0)partition(1)WINNT [operating systems] multi(0)disk(0)rdisk(0)partition(1)WINNT= "Microsoft Windows Server 2008 Advanced Server" /fastdetect /PAE
Once you have modified boot.ini, you can use sp_configure to enable SQL Server 2008 to access more than 4GB of physical memory. The following example (set_5GigMemory.sql in the download) shows how to enable 5GB:
sp_configure 'show advanced options', 1 RECONFIGURE GO sp_configure 'awe enabled', 1 RECONFIGURE GO sp_configure 'max server memory', 5120 RECONFIGURE GO
The operating system must be restarted for the /PAE switch to take effect. The associated restart of SQL Server puts the AWE configuration into effect.
Instances of SQL Server 2008 do not dynamically manage the size of the address space when AWE memory is enabled; therefore, setting the max server memory configuration parameter of SQL Server is mandatory while using AWE memory. On a dedicated SQL Server machine, max server memory may be set to (total physical memory – 200MB) so that enough physical memory is kept aside for the operating system and other essential tools/applications.
While running multiple instances of SQL Server 2008 on the same computer, you must ensure the following with each instance using AWE memory:
Each instance has a
max server memorysetting.When setting
max server memory, you need to take into account the amount of nonbuffer pool memory (formerly calledMemToLeave) that you may need for SQL Server to operate.The sum of the
max server memoryvalues for all the instances should be less than the amount of physical memory in the computer.
Considering the preceding factors, in a SQL Server 2008 cluster environment with two nodes and AWE/PAE enabled, the max server memory value on each node should be less than half the system physical memory.
Note
If you use the /3GB feature along with AWE/PAE, then an instance of SQL Server will be limited to a maximum of 16GB of extended memory.
This limitation is because of the internal design of the Windows Server operating system. Limiting the system space within the process space to 1GB using the /3GB switch allows the Windows Server operating system to manage physical memory up to 16GB. Therefore, to access memory beyond 16GB, you should not use the /3GB switch.
SQL Server is a heavy user of the hard disk, and since disk speeds are comparatively much slower than memory and processor speeds, a contention in disk resources can significantly degrade SQL Server performance. Analysis and resolution of any disk resource bottleneck can improve SQL Server performance significantly.
To analyze disk performance, you can use the counters shown in Table 2-2.
Table 2.2. Performance Monitor Counters to Analyze I/O Pressure
Object(Instance[,InstanceN]) | Counter | Description | Values |
|---|---|---|---|
|
| Percentage of time disk was busy | Average value < 85% |
| Number of outstanding disk requests at the time performance data is collected | Average value < 2 per disk | |
| Average number of queued disk requests during the sample interval | Average value < 2 per disk | |
| Rate of read/write operations on disk | Maximum value < 100 per disk | |
| Amount of data transfer to/from per disk per second | Maximum value < 10MB per second | |
| Average time in ms to read from disk | Average value < 10 ms | |
| Average time in ms to write to disk | Average value < 10 ms |
The PhysicalDisk counters represent the activities on a physical disk. LogicalDisk counters represent logical subunits (or partitions) created on a physical disk. If you create two partitions, say C: and D: on a physical disk, then you can monitor the disk activities of the individual logical disks using logical disk counters. However, because a disk bottleneck ultimately occurs on the physical disk, not on the logical disk, it is usually preferable to use the PhysicalDisk counters.
Note that for a hardware redundant array of independent disks (RAID) subsystem (see the "Using a RAID Array" section for more on RAID), the counters treat the array as a single physical disk. For example, even if you have ten disks in a RAID configuration, they will all be represented as one physical disk to the operating system, and subsequently you will have only one set of PhysicalDisk counters for that RAID subsystem. The same point applies to storage area network (SAN) disks (see the "Using a SAN System" section for specifics).
The % Disk Time counter monitors the percentage of time the disk is busy with read/write activities. It should not be continuously high. If this counter value is consistently more than 85 percent, then you must take steps to bring it down. You could upgrade the disk subsystem, but a more effective solution is to avoid going to the data disk as much as possible. Even a consistent disk usage of 5 percent may adversely affect performance.
For performance, it is always beneficial to cache the disk contents in memory since disk access is in the order of milliseconds, whereas memory access is in the order of nanoseconds. SQL Server adopts this strategy by caching the data pages in its buffer cache. But if SQL Server has to go to disk often, as indicated by a high % Disk Time value, then the slow access time of the disk compared to that of the memory will hurt the performance of the database.
Current Disk Queue Length is the number of requests outstanding on the disk subsystem at the time the performance data is collected. It includes requests in service at the time of the snapshot. A disk subsystem will have only one disk queue. You should use this counter value to support the conclusion made from the % Disk Time counter. A consistent disk queue length of two per disk indicates the possibility of a bottleneck on the disk.
For example, in a RAID configuration with 10 disks, a consistent disk queue length of 2 per disk, or 20 (= 10 disks × 2 per disks), for the complete disk subsystem indicates a disk bottleneck. RAID controllers usually distribute disk I/Os uniformly across all disks in the disk subsystem, but because of the obvious chances of nonuniform disk I/O, consider the following range of values for the Current Disk Queue Length counter:
Less than (2 + # of spindles) is an excellent value to see. In the worst case, the two requests in the queue may be pending on the same disk.
Less than (2 × # of spindles) is a fair value to see. In the best case, the queued requests may be uniformly distributed across all the disks in the disk subsystem with two requests pending per disk.
If you do not suspect dynamic variation in disk loads, then you may use the Avg. Disk Queue Length counter since this counter represents the average of the instantaneous values provided by the Current Disk Queue Length counter. If you think you may have a disk issue based on the queue length, you should also check the Average Disk Seconds Per Transfer value for the same disk. Finally, check the wait states of your processes to see whether you are experiencing I/O waits.
Disk Transfers/sec monitors the rate of read and write operations on the disk. A typical disk today can do about 180 disk transfers per second for sequential I/O and 100 disk transfers per second for random I/O. In the case of random I/O, Disk Transfers/sec is lower because more disk arm and head movements are involved. OLTP workloads, which are workloads for doing mainly singleton operations, small operations, and random access, are typically constrained by disk transfers per second. So, in the case of an OLTP workload, you are more constrained by the fact that a disk can do only 100 disk transfers per second than by its throughput specification of 10MB per second.
Because of the inherent slowness of a disk, it is recommended that you keep disk transfers per second as low as possible. You will see how to do this next.
The Disk Bytes/sec counter monitors the rate at which bytes are transferred to or from the disk during read or write operations. A typical disk can transfer about 10MB per second. Generally, OLTP applications are not constrained by the disk transfer capacity of the disk subsystem since the OLTP applications access small amounts of data in individual database requests. If the amount of data transfer exceeds the capacity of the disk subsystem, then a backlog starts developing on the disk subsystem, as reflected by the Disk Queue Length counters.
Avg. Disk Sec/Read and Avg. Disk Sec/Write track the average amount of time it takes in milliseconds to read from or write to a disk. Having an understanding of just how well the disks are handling the writes and reads that they receive can be a very strong indicator of where problems lie. If it's taking more than about 10 ms to move the data from or to your disk, you may need to take a look at the hardware and configuration to be sure everything is working correctly. You'll need to get even better response times for the transaction log to perform well.
A few of the common disk bottleneck resolutions are as follows:
Optimizing application workload
Using a faster disk drive
Using a SAN system
Aligning disks properly
Using a battery-backed controller cache
Adding system memory
Creating multiple files and filegroups
Placing the table and the index for that table on different disks
Saving the log file to a separate physical drive
Using partitioned tables
I'll now walk you through each of these resolutions in turn.
I cannot stress enough how important it is to optimize an application's workload in resolving a performance issue. The queries with the highest number of reads will be the ones that cause a great deal of disk I/O. I'll cover the strategies for optimizing those queries in more detail throughout the rest of this book.
One of the easiest resolutions, and one that you will adopt most of the time, is to use disk drives with faster disk transfers per second. However, you should not just upgrade disk drives without further investigation; you need to find out what is causing the stress on the disk.
One way of obtaining disk I/O parallelism is to create a single pool of drives to serve all SQL Server database files, excluding transaction log files. The pool can be a single RAID array, which is represented in Windows Server 2008 as a single physical disk drive. The effectiveness of a drive pool depends on the configuration of the RAID disks.
Out of all available RAID configurations, the most commonly used RAID configurations are the following (see Figure 2-6):
RAID 0: Striping with no fault tolerance
RAID 1: Mirroring
RAID 5: Striping with parity
RAID 1+0: Striping with mirroring
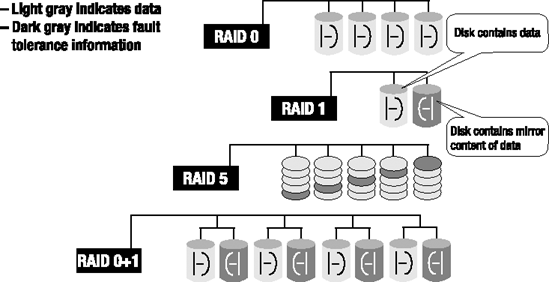
RAID 0
Since this RAID configuration has no fault tolerance, you can use it only in situations where the reliability of data is not a concern. The failure of any disk in the array will cause complete data loss in the disk subsystem. Therefore, you cannot use it for any data file or transaction log file that constitutes a database, except for the system temporary database called tempdb.
The number of I/Os per disk in RAID 0 is represented by the following equation:
In this equation, Reads is the number of read requests to the disk subsystem, and Writes is the number of write requests to the disk subsystem.
RAID 1
RAID 1 provides high fault tolerance for critical data by mirroring the data disk onto a separate disk. It can be used where the complete data can be accommodated in one disk only. Database transaction log files for user databases, operating system files, and SQL Server system databases (master and msdb) are usually small enough to use RAID 1.
The number of I/Os per disk in RAID 1 is represented by the following equation:
RAID 5
This configuration is a good option in many cases. It provides reasonable fault tolerance by effectively using only one extra disk to save the computed parity of the data in other disks, as shown in Figure 2-6. When there is a disk failure in RAID 5 configuration, I/O performance becomes terrible, although the system does remain usable while operating with the failed drive.
Any data where writes make up more than 10 percent of the total disk requests is not a good candidate for RAID 5. Thus, use RAID 5 on read-only volumes or volumes with a low percentage of disk writes.
The number of I/Os per disk in RAID 5 is represented by the following equation:
As shown in the preceding equation, the write operations on the RAID 5 disk subsystem are magnified four times. For each incoming write request, the following are the four corresponding I/O requests on the disk subsystem:
One read I/O to read existing data from the data disk whose content is to be modified
One read I/O to read existing parity information from the corresponding parity disk
One write I/O to write the new data to the data disk whose content is to be modified
One write I/O to write the new parity information to the corresponding parity disk
Therefore, the four I/Os for each write request consist of two read I/Os and two write I/Os.
In an OLTP database, all the data modifications are immediately written to the transaction log file as part of the database transaction, but the data in the data file itself is synchronized with the transaction log file content asynchronously in batch operations. This operation is managed by the internal process of SQL Server called the checkpoint process. The frequency of this operation can be controlled by using the recovery interval (min) configuration parameter of SQL Server.
Because of the continuous write operation in the transaction log file for a highly transactional OLTP database, placing transaction log files on a RAID 5 array will significantly degrade the array's performance. Although you should not place the transactional log files on a RAID 5 array, the data files may be placed on RAID 5, since the write operations to the data files are intermittent and batched together to improve the efficiency of the write operation.
RAID 1+0 (RAID 10)
RAID 1+0 (also referred to as 0+1 and 10) configuration offers a high degree of fault tolerance by mirroring every data disk in the array. It is a much more expensive solution than RAID 5, since double the number of data disks are required to provide fault tolerance. This RAID configuration should be used where a large volume is required to save data and more than 10 percent of disk requests are writes. Since RAID 1+0 supports split seeks (the ability to distribute the read operations onto the data disk and the mirror disk and then converge the two data streams), read performance is also very good. Thus, use RAID 1+0 wherever performance is critical.
The number of I/Os per disk in RAID 1+0 is represented by the following equation:
Storage area networks (SANs) remain largely the domain of large-scale enterprise systems, although the cost is coming down. A SAN can be used to increase performance of a storage subsystem by simply providing more spindles and disk drives to read from and write to. A "drive" as seen by the operating system is striped across multiple redundant drives in a SAN in a manner similar to that of RAID 5 but without the overhead of RAID 5 or the performance loss caused by disk failures. Because of their size, complexity, and cost, SANs are not necessarily a good solution in all cases. Also, depending on the amount of data, direct attached storage (DAS) can be configured to run faster. The principal strength of SAN systems is not reflected in performance but rather in the areas of scalability, availability, and maintenance.
Aligning a disk drive is not a well-known issue, but more and more DBAs are becoming aware of it. The way data is stored on a disk is in a series of sectors (also referred to as blocks) that are stored on tracks. A disk is out of alignment when the size of the track, determined by the vendor, consists of a number of sectors different from the default size that you're writing to. This will mean that one sector will be written correctly, but the next one will have to cross two tracks. This can more than double the amount of I/O required to write or read from the disk. The key is to align the partition so that you're storing the correct number of sectors for the track.
For best performance, use a caching RAID controller for SQL Server files, because the controller guarantees that data entrusted to it is written to disk eventually, no matter how large the queue is or even if power fails. When using a controller cache, the write requests to the RAID controller are written to the controller cache, and the subsequent disk operations are scheduled asynchronously. This asynchronous technique of doing I/Os for the write requests improves the performance of database queries significantly. The amount of performance improvement depends on the size of the controller cache and number of write requests.
When there is an unreliable battery backup, power disruptions will cause a loss of new/modified data (that is, dirty data) in the controller cache that was not flushed to the disk. If this dirty data belonged to a committed transaction, then the consistency of the data will be compromised.
For example, if a user commits a database transaction, the dirty data for the transaction will be written to the controller cache, and the user will be informed about a successful completion of the transaction. But should the power go down before this committed data is written to the disk, then all the data in the cache will be lost unless the controller has a reliable battery backup.
To avoid data inconsistency, ensure from your disk vendor that the controller cache has a reliable battery backup.
When physical memory is scarce, the system starts writing the contents of memory back to disk and reading smaller blocks of data more frequently, causing a lot of paging. The less memory the system has, the more the disk subsystem is used. This can be resolved using the memory bottleneck resolutions enumerated in the previous section.
In SQL Server, each user database consists of one or more data files and one or more transaction log files. The data files belonging to a database can be grouped together in one or more filegroups for administrative and data allocation/placement purposes. For example, if a data file is placed in a separate filegroup, then write access to all the tables in the filegroup can be controlled collectively by making the filegroup read-only (transaction log files do not belong to any filegroup).
You can create a filegroup for a database from SQL Server Management Studio, as shown in Figure 2-7. The filegroups of a database are presented in the Filegroups pane of the Database Properties dialog box.
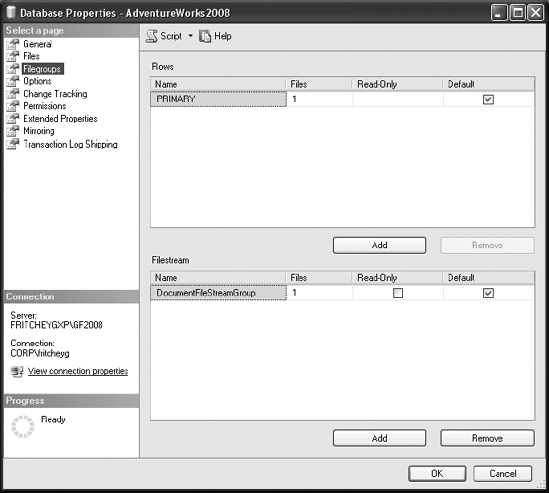
In Figure 2-7, you can see that there is only a single filegroup created by default with AdventureWorks2008. You can add multiple files to multiple filegroups distributed across drives so that work can be done in parallel across the groups and files.
You can add a data file to a filegroup in the Database Properties dialog box in the Files window by selecting from the drop-down list, as shown in Figure 2-8.
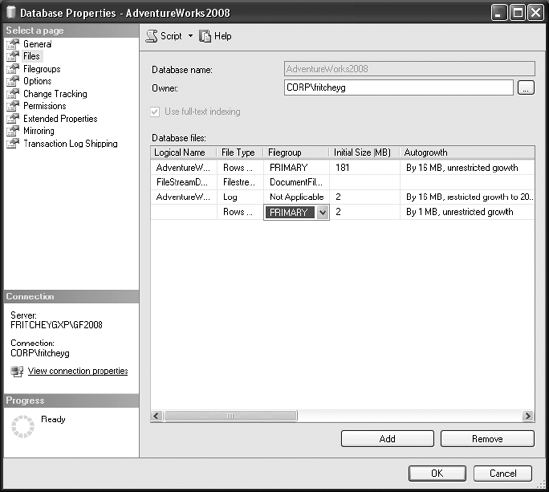
You can also do this programmatically, as follows (filegroup.sql in the download):
ALTER DATABASE AdventureWorks2008 ADD FILEGROUP INDEXES ; ALTER DATABASE AdventureWorks2008 ADD FILE (NAME = AdventureWorks2008_Data2, FILENAME = 'C:Program FilesMicrosoft SQLServerMSSQL10.GF2008MSSQLDATAAdventureWorks2008_2.ndf', SIZE = 1MB, FILEGROWTH = 10%) TO FILEGROUP Indexes;
In a system with multiple processors, SQL Server can take advantage of multiple files and filegroups by performing multiple parallel scans on the data files. As tables in a file are accessed sequentially, a thread is created to read the associated data file. If a filegroup consists of four data files, then four threads will be created to read data in parallel. If the data files are placed on four different physical disks, then all the disk spindles can work simultaneously. Therefore, in a multidisk subsystem, it is usually advantageous to have multiple files in the filegroup.
Using multiple files and filegroups also enables you to improve the performance of join operations. By separating tables that are frequently joined into separate filegroups and then putting files within the filegroups on separate disks or LUNS, the separated I/O paths can result in improved performance. For example, consider the following query:
SELECT *
FROM t1
INNER JOIN t2
ON t1.c1 = t2.c2If the tables t1 and t2 are placed in separate filegroups containing one file each, then on a multiple-processor system a separate thread will be created for each table. With the files of the two filegroups on different physical disks, data from both the tables can be retrieved simultaneously.
It is recommended for performance and recovery purposes that, if multiple filegroups are to be used, the primary filegroup should be used only for system objects and secondary filegroups should be used only for user objects. This approach improves disk I/O and the ability to recover from corruption. The recoverability of a database is higher if the primary data file and the log files are intact. Use the primary filegroup for system objects only, and store all user-related objects on a secondary filegroup.
Spreading a database into multiple files, even onto the same drive, makes it easy to move the database files onto separate drives, making future disk upgrades easier. For example, to move a user database file (AdventureWorks2008_2.ndf) to a new disk subsystem (F:), you can follow these steps:
Detach the user database as follows (
file_move.sqlin the code download):USE master; GO sp_detach_db 'AdventureWorks2008'; GO
Copy the data file
AdventureWorks2008_2.ndfto a folderF:Dataon the new disk subsystem.Reattach the user database by referring files at appropriate locations, as shown here:
USE master; GO sp_attach_db 'AdventureWorks2008' , 'C:Program FilesMicrosoft SQL ServerMSSQL10.GF2008MSSQLDATAAdventureWorks2008.mdf' , 'F:DATAAdventureWorks2008_2.ndf ' , 'C:Program FilesMicrosoft SQL ServerMSSQL10.GF2008MSSQLDATAAdventureWorks2008.ldf '; GO
To verify the files belonging to a database, execute the following commands:
USE Adventureworks2008 GO SELECT * FROM sys.database_files GO
You may have noticed in Figure 2-8 that one of the files in the AdventureWorks2008 database is of type FileStream. The FileStream data storage was introduced with SQL Server 2008. Its purpose is to separate the work of maintaining unstructured data, large binary files, XML, and so on, from the database, moving that work to the Windows Server file system. So, although the data in a FileStream column can be treated as a column in a table, the processing of the data is not handled by the database engine, thereby decreasing the workload of the SQL Server.
You can insert, update, and delete filestream data through T-SQL commands or by calling directly to streaming interfaces using OpenFile() and WriteFile() from .NET programming languages. For larger sets of unstructured data, when the data stored in the large object column is larger than 1MB, using FileStream provides a serious increase in performance. Smaller data sets are better off being stored within the database using more traditional types such as VARCHAR(MAX) or VARBINARY(MAX).
If a system has multiple processors, SQL Server can take advantage of multiple filegroups by accessing tables and corresponding nonclustered indexes using separate I/O paths. A nonclustered index can be created on a specific filegroup as follows:
CREATE INDEX i1 ON t1 (c1) ON Indexes
Tip
The nonclustered index and other types of indexes are explained in Chapter 4.
SQL Server log files should always, where possible, be located on a separate hard disk drive from all other SQL Server database files. Transaction log activity primarily consists of sequential write I/O, unlike the nonsequential (or random) I/O required for the data files. Separating transaction log activity from other nonsequential disk I/O activity can result in I/O performance improvements, because it allows the hard disk drives containing log files to concentrate on sequential I/O.
The major portion of time required to access data from a hard disk is spent on the physical movement of the disk spindle head to locate the data. Once the data is located, the data is read electronically, which is much faster than the physical movement of the head. With only sequential I/O operations on the log disk, the spindle head of the log disk can write to the log disk with a minimum of physical movement. If the same disk is used for data files, however, the spindle head has to move to the correct location before writing to the log file. This increases the time required to write to the log file and thereby hurts performance.
Furthermore, for SQL Server with multiple OLTP databases, the transaction log files should be physically separated from each other on different physical drives to improve performance. An exception to this requirement is a read-only database or a database with very few database changes. Since no online changes are made to the read-only database, no write operations are performed on the log file. Therefore, having the log file on a separate disk is not required for the read-only databases.
In addition to simply adding files to filegroups and letting SQL Server distribute the data between them, it's possible to define a horizontal segmentation of data called a partition so that data is divided up between multiple files by the partition. A filtered set of data is a segment; for example, if the partition is by month, the segment of data is any given month. Creating a partition moves the segment of data to a particular file and only that file. This provides a massive increase in speed because, when querying against well-defined partitions, only the files with the partitions of data you're interested in will be accessed during a given query. If you assume for a moment that data is partitioned by month, then each month's data file can be set to read-only as each month ends. That read-only status means that no locking will occur on a file as read queries are run against it, further increasing the performance of your queries. Partitions can actually be mapped to the same files within a filegroup, which won't offer any performance improvements but can be used for easier maintenance of the data.
SQL Server 2008 makes heavy use of any processor resource available. You can use the Performance Monitor counters in Table 2-3 to analyze pressure on the processor resource.
Table 2.3. Performance Monitor Counters to Analyze CPU Pressure
Object(Instance[,InstanceN]) | Counter | Description | Values |
|---|---|---|---|
|
| Percentage of time processor was busy | Average value < 80% |
| Percentage of processor time spent in privileged mode | Average value < 10% | |
|
| Number of requests outstanding on the processor | Average value < 2 |
| Rate at which processor is switched per processor from one thread to another | Average value < 1,000 | |
|
| SQL command batches received per second | Based on your standard workload |
| Number of times SQL is compiled | Average value > 100 | |
| Number of recompiles |
I'll now walk you through these counters in more detail.
% Processor Time should not be consistently high (greater than 75 percent). The effect of any sustained processor time greater than 90 percent is the same as that with 100 percent. If % Processor Time is consistently high and disk and network counter values are low, your first priority must be to reduce the stress on the processor.
For example, if % Processor Time is 85 percent and % Disk Time is 50 percent, then it is quite likely that a major part of the processor time is spent on managing the disk activities. This will be reflected in the % Privileged Time counter of the processor, as explained in the next section. In that case, it will be advantageous to optimize the disk bottleneck first. Further, remember that the disk bottleneck in turn can be because of a memory bottleneck, as explained earlier in the chapter.
You can track processor time as an aggregate of all the processors on the machine, or you can track the percentage utilization individually to particular processors. This allows you to segregate the data collection in the event that SQL Server runs on three processors of a four-processor machine.
Processing on a Windows server is done in two modes: user mode and privileged (or kernel) mode. All system-level activities, including disk access, are done in privileged mode. If you find that % Privileged Time on a dedicated SQL Server system is 20 to 25 percent or more, then the system is probably doing a lot of I/O—likely more than you need. The % Privileged Time counter on a dedicated SQL Server system should be at most 5 to 10 percent.
Processor Queue Length is the number of threads in the processor queue. (There is a single processor queue, even on computers with multiple processors.) Unlike the disk counters, the Processor Queue Length counter does not read threads that are already running. On systems with lower CPU utilization, the Processor Queue Length counter is typically 0 or 1.
A sustained Processor Queue Length counter of greater than 2 generally indicates processor congestion. Because of multiple processors, you may need to take into account the number of schedulers dealing with the processor queue length. A processor queue length more than two times the number of schedulers (usually 1:1 with processors) can also indicate a processor bottleneck. Although a high % Processor Time counter indicates a busy processor, a sustained high Processor Queue Length counter is a more certain indicator. If the recommended value is exceeded, this generally indicates that there are more threads ready to run than the current number of processors can service in an optimal way.
The Context Switches/sec counter monitors the combined rate at which all processors on the computer are switched from one thread to another. A context switch occurs when a running thread voluntarily relinquishes the processor, is preempted by a higher-priority ready thread, or switches between user mode and privileged mode to use an executive or a subsystem service. It is the sum of Thread:Context Switches/sec for all threads running on all processors in the computer, and it is measured in numbers of switches.
A figure of 300 to 1,000 Context Switches/sec per processor is excellent to fair. Abnormally high rates, greater than 20,000 per second, can be caused by page faults due to memory starvation.
Batch Requests/sec gives you a good indicator of just how much load is being placed on the system, which has a direct correlation to how much load is being placed on the processor. Since you could see a lot of low-cost queries on your system or a few high-cost queries, you can't look at this number by itself but must reference the other counters defined in this section; 1,000 requests in a second would be considered a busy system. Greater values may be cause for concern. The best way to know which value has meaning within your own systems is to establish a baseline and then monitor from there.
The SQL Compilations/sec counter shows both batch compiles and statement recompiles as part of its aggregation. This number can be extremely high when a server is first turned on (or after a failover or any other startup type event), but it will stabilize over time. Once stable, 100 or more compilations in one second will certainly manifest as problems in the processor. Chapter 9 covers SQL compilation in detail.
SQL Recompilations/sec is a measure of the recompiles of both batches and statements. A high number of recompiles will lead to processor stress. Because statement recompiles are part of this count, it can be much higher than in versions of SQL Server prior to 2005. Chapter 10 covers query recompilation in detail.
A few of the common processor bottleneck resolutions are as follows:
Optimizing application workload
Eliminating or reducing excessive compiles/recompiles
Using more or faster processors
Using a large L2/L3 cache
Running with more efficient controllers/drivers
Not running unnecessary software
Let's consider each of these resolutions in turn.
To identify the processor-intensive queries, capture all the SQL queries using SQL Profiler (which I will discuss in the next chapter), and then group the Profiler trace output on the CPU column. The queries with the highest amount of CPU time contribute the most to the CPU stress. You should then analyze and optimize those queries to reduce stress on the CPU. You can also query directly against the sys.dm_exec_query_stats view to see immediate issues in real time. Finally, using both a query hash and a query plan hash, you can identify and tune common queries or common execution plans (this is discussed in detail in Chapter 9). Most of the rest of the chapters in this book are concerned with optimizing application workload.
A certain number of query compiles and recompiles is simply to be expected. It's when there is a large number of these over sustained periods that a problem exists. It's also worth noting the ratio between them. A high number of compiles and a very low number of recompiles means that few queries are being reused within the system (query reuse is covered in detail in Chapter 9). A high number of recompiles will cause high processor use. Methods for addressing recompiles are covered in Chapter 10.
One of the easiest resolutions, and one that you will adopt most of the time, is to increase system processing power. However, because of the high cost involved in a processor upgrade, you should first optimize CPU-intensive operations as much as possible.
The system's processing power can be increased by increasing the power of individual processors or by adding more processors. When you have a high % Processor Time counter and a low Processor Queue Length counter, it makes sense to increase the power of individual processors. In the case of both a high % Processor Time counter and a high Processor Queue Length counter, you should consider adding more processors. Increasing the number of processors allows the system to execute more requests simultaneously.
Modern processors have become so much faster than memory that they need at least two levels of memory cache to reduce latency. On Pentium-class machines, the fast L1 cache holds 8KB of data and 8KB of instructions, while the slower L2 cache holds up to 6MB of mixed code and data. New processors are shipping with an L3 cache on top of the others varying in size from 6MiB to 256MiB and 2MB (MiB refers to mebibyte, a binary representation, 220, that is very similar in size to but not exactly the same as a megabyte, which is 106). References to content found in the L1 cache cost one cycle, references to the L2/L3 cache cost four to seven cycles, and references to the main memory cost dozens of processor cycles. With the increase in processing power, the latter figure will soon exceed 100 cycles. In many ways, the cache is like small, fast, virtual memory inside the processor.
Database engines like L2/L3 caches because they keep processing off the system bus. The processor does not have to go through the system bus to access memory; it can work out of the L2/L3 cache. Not having enough L2/L3 cache can cause the processor to wait a longer period of time for the data/code to move from the main memory to the L2/L3 cache. A processor with a high clock speed but a low L2/L3 cache may waste a large number of CPU cycles waiting on the small L2/L3 cache. A large L2/L3 cache helps maximize the use of CPU cycles for actual processing instead of waiting on the L2/L3 cache.
Today, it is very common to have megabyte caches on four-way systems. With new four- and eight-way systems, you will often get up to a 6MB L2 cache and, as mentioned earlier, 256MiB on L3. For example, sometimes you may get a performance improvement of 20 percent or more simply by using a 512KB L2 cache instead of a 256KB L2 cache.
There is a big difference in % Privileged Time consumption between different controllers and controller drivers on the market today. The techniques used by controller drivers to do I/O are quite different and consume different amounts of CPU time. If you can change to a controller that frees up 4 to 5 percent of % Privileged Time, you can improve performance.
If you have screen savers running on your system, they may use a large amount of processor time. This is particularly true of screen savers that use OpenGL (a software interface that supports the production of high-quality, three-dimensional color imaging), because they can easily take away 15 percent of processor time on a server that lacks an OpenGL graphics card. Because you can run your servers with the monitor switched off for the majority of the time, simply disable any screen savers on your server or, as a preventive measure, use the blank screen saver. Please do remember to lock your server for security.
When possible, no unnecessary software should be running on the same server as SQL Server. Exterior applications that have nothing to do with maintaining the Windows Server or SQL Server are best placed on a different machine.
In SQL Server OLTP production environments, you find few performance issues that are because of problems with the network. Most of the network issues you face in the OLTP environment are in fact hardware or driver limitations or issues with switches or routers. Most of these issues can be best diagnosed with the Network Monitor tool. However, Performance Monitor also provides objects that collect data on network activity, as shown in Table 2-4.
Table 2.4. Performance Monitor Counters to Analyze Network Pressure
Object(Instance[,InstanceN]) | Counter | Description | Values |
|---|---|---|---|
|
| Rate at which bytes are transferred on the NIC | Average value < 50% of NIC capacity |
|
| Percentage of network bandwidth in use on a network segment | Average value < 80% of network bandwidth |
You can use the Bytes Total/sec counter to determine how the network interface card (NIC) or network adapter is performing. The Bytes Total/sec counter should report high values to indicate a large number of successful transmissions. Compare this value with that reported by the Network InterfaceCurrent Bandwidth performance counter, which reflects each adapter's bandwidth.
To allow headroom for spikes in traffic, you should usually average no more than 50 percent of capacity. If this number is close to the capacity of the connection and if processor and memory use are moderate, then the connection may well be a problem.
The % Net Utilization counter represents the percentage of network bandwidth in use on a network segment. The threshold for this counter depends on the type of network. For Ethernet networks, for example, 30 percent is the recommended threshold when SQL Server is on a shared network hub. For SQL Server on a dedicated full-duplex network, even though near 100 percent usage of the network is acceptable, it is advantageous to keep the network utilization below an acceptable threshold to keep room for the spikes in the load.
Note
You must install the Network Monitor Driver to collect performance data using the Network Segment object counters.
In Windows Server 2008, you can install the Network Monitor Driver from the local area connection properties for the network adapter. The Network Monitor Driver is available in the network protocol list of network components for the network adapter.
A few of the common network bottleneck resolutions are as follows:
Optimizing application workload
Adding network adapters
Moderating and avoiding interruptions
Let's consider these resolutions in more detail.
To optimize network traffic between a database application and a database server, make the following design changes in the application:
Instead of sending a long SQL string, create a stored procedure for the SQL query. Then, you just need to send over the network the name of the stored procedure and its parameters.
Group multiple database requests into one stored procedure. Then, only one database request will be required across the network for the set of SQL queries implemented in the stored procedure.
Request a small data set. Do not request table columns that are not used in the application logic.
Move data-intensive business logic into the database as stored procedures or database triggers to reduce network round-trips.
You can add network adapters so that you have one network adapter per processor. Generally, you should add a network adapter only if you need the increased bandwidth, because each additional network adapter has some intrinsic overhead. However, if one of the processors is nearly always active (that is, Processor\% Processor Time consistently equals 100 percent) and more than half of its time is spent servicing deferred procedure calls (that is, Processor\% DPC Time exceeds 50 percent), then adding a network card is likely to improve system performance.
If a network adapter does not use Network Driver Interface Specification (NDIS) miniport drivers, you cannot modify the distribution of deferred procedure calls (DPCs) for better performance. An NDIS miniport driver (also called a miniport driver) manages a NIC and interfaces with higher-level drivers. It communicates with its NIC and higher-level drivers through the NDIS library.
To be able to modify the distribution of DPCs and because other NDIS optimizations might be unavailable, you may consider upgrading an individual network adapter instead of adding a new adapter.
When adding or upgrading network adapters, choose adapters with drivers that support interrupt moderation and/or interrupt avoidance. Interrupt moderation allows a processor to process interrupts more efficiently by grouping several interrupts into a single hardware interrupt. Interrupt avoidance allows a processor to continue processing interrupts without new interrupts queued until all pending interrupts are completed.
To analyze the overall performance of a SQL Server, besides examining hardware resource utilization, you should also examine some general aspects of SQL Server itself. You can use the performance counters presented in Table 2-5.
Table 2.5. Performance Monitor Counters to Analyze Generic SQL Pressure
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
|
|
|
|
|
|
|
|
Let's take a look at each of these counters in context.
To analyze the possibility of missing indexes causing table scans or large data set retrievals, you can use the counters in Table 2-6.
Table 2.6. Performance Monitor Counter to Analyze Excessive Data Scans
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
FreeSpace Scans/sec
This counter represents inserts into a table with no physical ordering of its rows—such a table is also called a heap table. Extra processing is required to define and store a heap table since SQL Server normally uses the clustered index as a storage mechanism for the table data. A heap table requires an additional, internal column called a uniquifier to be generated for each row inserted. Therefore, it is usually recommended that you physically order the table rows by using a clustered index on the table. You will learn about heap tables and clustered indexes in Chapter 5.
Full Scans/sec
This counter monitors the number of unrestricted full scans on base tables or indexes. A few of the main causes of high Full Scans/sec are as follows:
Missing indexes
Too many rows requested
To further investigate queries producing the preceding problems, use SQL Profiler to identify the queries (I will cover this tool in the next chapter). Queries with missing indexes or too many rows requested will have a large number of logical reads and an increased CPU time.
Be aware of the fact that full scans may be performed for the temporary tables used in a stored procedure, because most of the time you will not have indexes (or you will not need indexes) on temporary tables. Still, adding this counter to the baseline helps identify the possible increase in the use of temporary tables, which are usually not good for performance.
Dynamic Management Views
Another way to check for missing indexes is to the query the dynamic management view sys.dm_db_missing_index_details. This management view returns information that can suggest candidates for indexes based on the execution plans of the queries being run against the database. The view sys.dm_db_missing_index_details is part of a series of DMVs collectively referred to as the missing indexes feature. These DMVs are based on data generated from execution plans stored in the cache. You can query directly against this view to gather data to decide whether you want to build indexes based on the information available from within the view. Missing indexes will also be shown within the XML execution plan for a given query, but I'll cover that more in the next chapter.
The opposite problem to a missing index is one that is never used. The DMV sys.dm_db_index_usage_stats shows which indexes have been used, at least since the last reboot of the system. You can also view the indexes in use with a lower-level DMV, sys.dm_db_index_operational_stats. It will help to show where indexes are slowing down because of contention or I/O. I'll cover these both in more detail in Chapter 10.
To analyze the impact of database blocking on the performance of SQL Server, you can use the counters shown in Table 2-7.
Table 2.7. Performance Monitor Counters to Analyze SQL Server Locking
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
|
|
Total Latch Wait Time (ms)
Latches are used internally by SQL Server to protect the integrity of internal structures, such as a table row, and are not directly controlled by users. This counter monitors total latch wait time (in milliseconds) for latch requests that had to wait in the last second. A high value for this counter indicates that SQL Server is spending too much time waiting on its internal synchronization mechanism.
Lock Timeouts/sec and Lock Wait Time (ms)
You should expect Lock Timeouts/sec to be 0 and Lock Wait Time (ms) to be very low. A nonzero value for Lock Timeouts/sec and a high value for Lock Wait Time (ms) indicate that excessive blocking is occurring in the database.
Two approaches can be adopted in this case:
You can identify the costly queries using data from SQL Profiler or by querying
sys.dm_exec_query_statsand then optimize the queries appropriately.You can use blocking analysis to diagnose the cause of excessive blocking. It is usually advantageous to concentrate on optimizing the costly queries first, because this, in turn, reduces blocking for others. In Chapter 12, you will learn how to analyze and resolve blocking.
Number of Deadlocks/sec
You should expect to see a 0 value for this counter. If you find a nonzero value, then you should identify the victimized request and either resubmit the database request automatically or suggest that the user do so. More important, an attempt should be made to troubleshoot and resolve the deadlock. Again, Chapter 12 shows how to do this.
Since generating an execution plan for a stored procedure query requires CPU cycles, you can reduce the stress on the CPU by reusing the execution plan. To analyze the number of stored procedures that are recompiling, you can look at the counter in Table 2-8.
Table 2.8. Performance Monitor Counter to Analyze Execution Plan Reusability
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
Recompilations of stored procedures add overhead on the processor. You should see a value close to zero for the SQL Re-Compilations/sec counter. If you consistently see nonzero values, then you should use SQL Profiler to further investigate the stored procedures undergoing recompilations. Once you identify the relevant stored procedures, you should attempt to analyze and resolve the cause of recompilations. In Chapter 10, you will learn how to analyze and resolve various causes of recompilation.
SQL Server provides additional performance counters to track some general aspects of a SQL Server system. Table 2-9 lists a few of the most commonly used counters.
Table 2.9. Performance Monitor Counters to Analyze Volume of Incoming Requests
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
|
|
User Connections
Multiple read-only SQL Servers can work together in a load-balancing environment (where SQL Server is spread over several machines) to support a large number of database requests. In such cases, it is better to monitor the User Connections counter to evaluate the distribution of user connections across multiple SQL Server instances. User Connections can range all over the spectrum with normal application behavior. This is where a normal baseline is essential to determine the expected behavior. You will see how you can establish this baseline shortly.
Batch Requests/sec
This counter is a good indicator of the load on SQL Server. Based on the level of system resource utilization and Batch Requests/sec, you can estimate the number of users SQL Server may be able to take without developing resource bottlenecks. This counter value, at different load cycles, also helps you understand its relationship with the number of database connections. This also helps you understand SQL Server's relationship with Web Request/sec, that is, Active Server Pages.Requests/sec for web applications using Microsoft Internet Information Services (IIS) and Active Server Pages (ASP). All this analysis helps you better understand and predict system behavior as the user load changes.
The value of this counter can range over a wide spectrum with normal application behavior. A normal baseline is essential to determine the expected behavior. Let's move on to look at creating one now.
Now that you have looked at a few of the main performance counters, let's see how to bring these counters together to create a system baseline. These are the steps you need to follow:
Create a reusable list of performance counters.
Create a counter log using your list of performance counters.
Minimize Performance Monitor overhead.
Run the Performance Monitor tool on a Windows Server 2008 machine connected to the same network as that of the SQL Server system. Add performance counters to the View Chart display of the Performance Monitor through the Properties
For example, to add the performance counter Processor(_Total)\% Processor Time, follow these steps:
Select the option Select Counters from Computer, and specify the computer name running SQL Server in the corresponding entry field.
Click the box next to the performance object
Processor.Choose the
% Processor Timecounter from the list of performance counters.Choose
instance _Totalfrom the instances in the Instances of Selected Object list.Click the Add button to add this performance counter to the list of counters to be added.
Continue as needed with other counters. When finished, click the OK button.
When creating a reusable list for your baseline, you can repeat the preceding steps to add all the performance counters listed in Table 2-10.
Table 2.10. Performance Monitor Counters to Analyze SQL Server Performance
Object(Instance[,InstanceN]) | Counter |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Once you have added all the performance counters, close the Add Counters dialog box. To save the list of counters as an .htm file, right-click anywhere in the right frame of Performance Monitor, and select the Save As menu item.
The .htm file lists all the performance counters that can be used as a base set of counters to create a counter log, or to view Performance Monitor graphs interactively, for the same SQL Server machine. To also use this list of counters for other SQL Server machines, open the .htm file in an editor such as Notepad, and replace all instances of \SQLServerMachineName with '' (a blank string), without the quotes.
You can also use this counter list file to view Performance Monitor graphs interactively in an Internet browser, as shown in Figure 2-10.
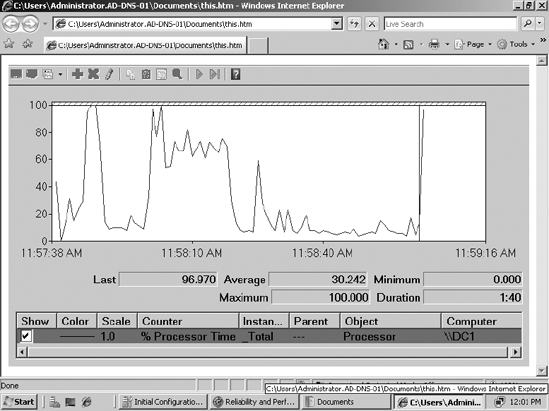
Performance Monitor provides a counter log facility to save the performance data of multiple counters over a period of time. You can view the saved counter log using Performance Monitor to analyze the performance data. It is usually convenient to create a counter log from a defined list of performance counters. Simply collecting the data rather than viewing it through the GUI is the preferred method of automation to prepare for troubleshooting your server's performance or establishing a baseline.
Expand Data Collector Sets
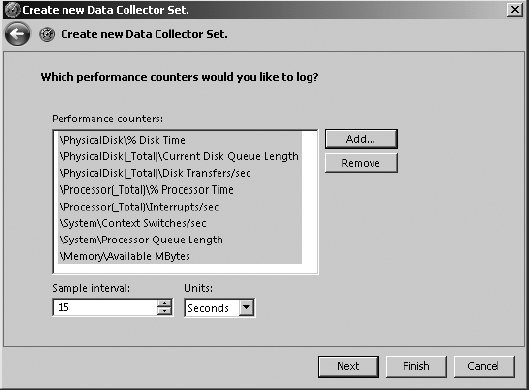
Tip
I'll offer additional suggestions for these settings in the section that follows.
For additional information on how to create counter logs using Performance Monitor, please refer to the Microsoft Knowledge Base article "Performance Tuning Guidelines for Windows Server 2008" at http://download.microsoft.com/download/9/c/5/9c5b2167-8017-4bae-9fde-d599bac8184a/Perf-tun-srv.docx.
The Performance Monitor tool is designed to add as little overhead as possible, if used correctly. To minimize the impact of using this tool on a system, consider the following suggestions:
Limit the number of counters, specifically performance objects.
Use counter logs instead of viewing Performance Monitor graphs interactively.
Run Performance Monitor remotely while viewing graphs interactively.
Save the counter log file to a different local disk.
Increase the sampling interval.
Let's consider each of these points in more detail.
Limit the Number of Counters
Monitoring large numbers of performance counters with small sampling intervals could incur some amount of overhead on the system. The bulk of this overhead comes from the number of performance objects you are monitoring, so selecting them wisely is important. The number of counters for the selected performance objects does not add much overhead, because it gives only an attribute of the object itself. Therefore, it is important to know what objects you want to monitor and why.
Prefer Counter Logs
Use counter logs instead of viewing a Performance Monitor graph interactively, because Performance Monitor graphing is more costly in terms of overhead. Monitoring current activities should be limited to short-term viewing of data, troubleshooting, and diagnosis. Performance data reported via a counter log is sampled, meaning that data is collected periodically rather than traced, whereas the Performance Monitor graph is updated in real time as events occur. Using counter logs will reduce that overhead.
View Performance Monitor Graphs Remotely
Since viewing the live performance data using Performance Monitor graphs creates a fair amount of overhead on the system, run the tool remotely on a different machine, and connect to the SQL Server system through the tool. To remotely connect to the SQL Server machine, run the Performance Monitor tool on a machine connected to the network to which the SQL Server machine is connected.
As shown in Figure 2-9, type the computer name (or IP address) of the SQL Server machine in the Select Counters from Computer box. Be aware that if you connect to the production server through a Windows Server 2008 terminal service session, the major part of the tool will still run on the server.
Save Counter Log Locally
Collecting the performance data for the counter log does not incur the overhead of displaying any graph. So, while using counter log mode, it is more efficient to log counter values locally on the SQL Server system instead of transferring the performance data across the network. Put the counter log file on a local disk other than the ones that are monitored.
Increase the Sampling Interval
Because you are mainly interested in the resource utilization pattern during baseline monitoring, you can easily increase the performance data sampling interval to 60 seconds or more to decrease the log file size and reduce demand on disk I/Os. You can use a short sampling interval to detect and diagnose timing issues. Even while viewing Performance Monitor graphs interactively, increase the sampling interval from the default value of one second per sample. Just remember, changing the sampling size, up or down, can affect the granularity of the data as well as the quantity. You have to weigh these choices carefully.
The default behavior of a database application changes over time because of various factors such as the following:
Change of data
Change of user group
Change in usage pattern of the application
Addition to or change in application functionalities
Change in software environment because of the installation of new service packs or software upgrades
Change in hardware environment
Because of the preceding changes, the baseline created for the database server slowly loses its significance. It may not always be accurate to compare the current behavior of the system with an old baseline. Therefore, it is important to keep the baseline up-to-date by creating a new baseline at regular time intervals. It is also beneficial to archive the previous baseline logs so that they can be referred to later, if required.
The counter log for the baseline or the current behavior of the system can be analyzed using the Performance Monitor tool by following these steps:
Open the counter log. Use Performance Monitor's toolbar item View Log File Data, and select the log file name.
Add all the performance counters to analyze the performance data. Note that only the performance objects, counters, and instances selected during the counter log creation are shown in the selection lists.
Analyze the system behavior at different parts of the day by adjusting the time range accordingly, as shown in Figure 2-12.
During a performance review, you can analyze the system-level behavior of the database by comparing the current value of performance counters with the latest baseline. Take the following considerations into account while comparing the performance data:
Use the same set of performance counters in both cases.
Compare the minimum, maximum, or average value of the counters as applicable for the individual counters. I explained the specific values for the counters earlier.
Some counters have an absolute good/bad value as mentioned previously. The current value of these counters need not be compared with the baseline values. For example, if the current average value of the
Pages/seccounter is 100, then it indicates that the system has developed a memory bottleneck. Even though it does not require a comparison with the baseline, it is still advantageous to review the corresponding baseline value, because the memory bottleneck might have existed for a long time. Having the archived baseline logs helps detect the first occurrence of the memory bottleneck.Some counters do not have a definitive good/bad value. Because their value depends on the application, a relative comparison with the corresponding baseline counters is a must. For example, the current value of the
User Connectionscounter for SQL Server does not signify anything good or bad with the application. But comparing it with the corresponding baseline value may reveal a big increase in the number of user connections, indicating an increase in the workload.Compare a range of value for the counters from the current and the baseline counter logs. The fluctuation in the individual values of the counters will be normalized by the range of values.
Compare logs from the same part of the day. For most applications, the usage pattern varies during different parts of the day. To obtain the minimum, maximum, and average value of the counters for a specific time, adjust the time range of the counter logs as shown previously.
Once the system-level bottleneck is identified, the internal behavior of the application should be analyzed to determine the cause of the bottleneck. Identifying and optimizing the source of the bottleneck will help use the system resources efficiently.
In this chapter, you learned that you can use the Performance Monitor tool to analyze the effect on system resources of a slow-performing database application, as well as the overall behavior of SQL Server. For every resultant system bottleneck, there are two types of resolutions: hardware resolutions and application optimization. Of course, it is always beneficial to optimize the database application before considering a hardware upgrade.
In the next chapter, you will learn how to analyze the workload of a database application for performance tuning.