
Stored procedures improve the reusability of an execution plan by explicitly converting the variable parts of the queries into parameters. This allows execution plans to be reused when the queries are resubmitted with the same or different values for the variable parts. Since stored procedures are mostly used to implement complex business rules, a typical stored procedure contains a complex set of SQL statements, making the price of generating the execution plan of a stored procedure a bit costly. Therefore, it is usually beneficial to reuse the existing execution plan of a stored procedure instead of generating a new plan. However, sometimes the existing plan may not be applicable, or it may not provide the best processing strategy during reuse. SQL Server resolves this condition by recompiling statements within stored procedures to generate a new execution plan.
In this chapter, I cover the following topics:
The recompilation of stored procedures can be both beneficial and harmful. Sometimes, it may be beneficial to consider a new processing strategy for a query instead of reusing the existing plan, especially if the data distribution in the table (or the corresponding statistics) has changed or new indexes are added to the table. Recompiles in SQL Server 2008 are at the statement level. This increases the overall number of recompiles that can occur within a procedure, but it reduces the effects and overhead of recompiles in general. Statement-level recompiles reduce overhead because they recompile an individual statement only rather than all the statements within a procedure, whereas the older method of recompiles caused a procedure, in its entirety, to be recompiled over and over. Despite this smaller footprint for recompiles, it's something to be reduced and controlled as much as possible.
To understand how the recompilation of an existing plan can sometimes be beneficial, assume you need to retrieve some information from the Production.WorkOrder table. The stored procedure may look like this (spWorkOrder.sql in the download):
IF (SELECT OBJECT_ID('dbo.spWorkOrder')
) IS NOT NULL
DROP PROCEDURE dbo.spWorkOrder;
GO
CREATE PROCEDURE dbo.spWorkOrder
AS
SELECT wo.WorkOrderID
,wo.ProductID
,wo.StockedQty
FROM Production.WorkOrder AS wo
WHERE wo.StockedQty BETWEEN 500 AND 700 ;With the current indexes, the execution plan for the SELECT statement, which is part of the stored procedure plan, scans the index PK_WorkOrder_ID, as shown in Figure 10-1.

This plan is saved in the procedure cache so that it can be reused when the stored procedure is reexecuted. But if a new index is added on the table as follows, then the existing plan won't be the most efficient processing strategy to execute the query:
CREATE INDEX IX_Test ON Production.WorkOrder(StockedQty,ProductID)
Since index IX_Test can serve as a covering index for the SELECT statement, the cost of a bookmark lookup can be avoided by using index IX_Test instead of scanning PK_WorkOrder_WorkOrderID. SQL Server automatically detects this change and thereby recompiles the existing plan to consider the benefit of using the new index. This results in a new execution plan for the stored procedure (when executed), as shown in Figure 10-2.

In this case, it is beneficial to spend extra CPU cycles to recompile the stored procedure so that you generate a better execution plan.
SQL Server automatically detects the conditions that require a recompilation of the existing plan. SQL Server follows certain rules in determining when the existing plan needs to be recompiled. If a specific implementation of a stored procedure falls within the rules of recompilation (execution plan aged out, SET options changed, and so on), then the stored procedure will be recompiled every time it meets the requirements for a recompile, and SQL Server may not generate a better execution plan. To see this in action, you'll need a different stored procedure. The following procedure returns all the rows from the WorkOrder table (spWorkOrderAll.sql in the download):
IF (SELECT OBJECT_ID('dbo.spWorkOrderAll')
) IS NOT NULL
DROP PROCEDURE dbo.spWorkOrderAll;
GO
CREATE PROCEDURE dbo.spWorkOrderALL
AS
SELECT *
FROM Production.WorkOrder AS woBefore executing this procedure, drop the index IX_Test:
DROP INDEX Production.WorkOrder.IX_Test
When you execute this procedure, the SELECT statement returns the complete data set (all rows and columns) from the table and is therefore best served through a table scan on the table WorkOrder. As explained in Chapter 4, the processing of the SELECT statement won't benefit from a nonclustered index on any of the columns. Therefore, ideally, creating the nonclustered index, as follows, before the execution of the stored procedure shouldn't matter:
EXEC dbo.spWorkOrderAll GO CREATE INDEX IX_Test ON Production.WorkOrder(StockedQty,ProductID) GO EXEC dbo.spWorkOrderAll --After creation of index IX_Test
But the stored procedure execution after the index creation faces recompilation, as shown in the corresponding Profiler trace output in Figure 10-3.

The SP:Recompile event was used to trace the statement recompiles. You can also use the SQL:StmtRecompile event, even with stored procedures. In this case, the recompilation is of no real benefit to the stored procedure. But unfortunately, it falls within the conditions that cause SQL Server to recompile the stored procedure on every execution. This makes plan caching for the stored procedure ineffective and wastes CPU cycles in regenerating the same plan on this execution. Therefore, it is important to be aware of the conditions that cause the recompilation of stored procedures and to make every effort to avoid those conditions when implementing stored procedures. I will discuss these conditions next, after identifying which statements cause SQL Server to recompile the stored procedure in the respective case.
SQL Server can recompile individual statements within a procedure or the entire procedure. Thus, to find the cause of recompilation, it's important to identify the SQL statement that can't reuse the existing plan.
You can use the Profiler tool to track stored procedure recompilation. You can also use Profiler to identify the stored procedure statement that caused the recompilation. Table 10-1 shows the relevant events and data columns you can use (sprocTrace.tdf in the download).
Table 10.1. Events and Data Columns to Analyze Stored Procedure Recompilation for Stored Procedures Event Class
Event | Data Column |
|---|---|
|
|
|
|
|
|
|
|
|
|
Consider the following simple stored procedure (create_p1.sql in the download):
IF(SELECT OBJECT_ID('dbo.p1')) IS NOT NULL
DROP PROC dbo.p1;
GO
CREATE PROC dbo.p1
AS
CREATE TABLE #t1(c1 INT);
INSERT INTO #t1 (
c1
) VALUES ( 42 ) ; -- data change causes recompile
GOOn executing this stored procedure the first time, you get the Profiler trace output shown in Figure 10-4.
EXEC dbo.p1;

In Figure 10-4, you can see that you have a recompilation event (SP:Recompile), indicating that the stored procedure went through recompilation. When a stored procedure is executed for the first time, SQL Server compiles the stored procedure and generates an execution plan, as explained in the previous chapter.
Since execution plans are maintained in volatile memory only, they get dropped when SQL Server is restarted. On the next execution of the stored procedure, after the server restart, SQL Server once again compiles the stored procedure and generates the execution plan. These compilations aren't treated as a stored procedure recompilation, since a plan didn't exist in the cache for reuse. An SP:Recompile event indicates that a plan was already there but couldn't be reused.
Note
I discuss the significance of the EventSubClass data column later in the "Analyzing Causes of Recompilation" section.
To see which statement caused the recompile, look at the TextData column within the SP:Recompile event. It shows specifically the statement being recompiled. You can also identify the stored procedure statement causing the recompilation by using the SP:StmtStarting event in combination with a recompile event. The SP:StmtStarting event immediately before the SP:Recompile event indicates the stored procedure statement that caused the recompilation, as shown in Figure 10-5. It's generally easier to use the TextData column, but in very complicated procedures it might make sense to use the SP:StmtStarting event.
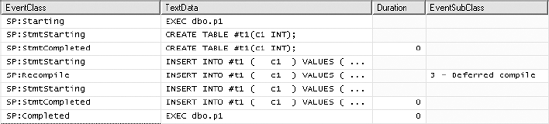
Note that after the stored procedure recompilation, the stored procedure statement that caused the recompilation is started again to execute with the new plan. You may use either the SP:StmtStarting event or the SP:StmtCompleted event to identify the stored procedure statement causing the recompilation; using both the events will duplicate the information, and the SP:Recompile event will further duplicate the information.
To improve performance, it is important that you analyze the causes of recompilation. Often, recompilation may not be necessary, and you can avoid it to improve performance. Knowing the different conditions that result in recompilation helps you evaluate the cause of a recompilation and determine how to avoid recompiling when it isn't necessary. Stored procedure recompilation occurs for the following reasons:
The schema of regular tables, temporary tables, or views referred to in the stored procedure statement have changed. Schema changes include changes to the metadata of the table or the indexes on the table.
Bindings (such as defaults/rules) to the columns of regular or temporary tables have changed.
Statistics on the table indexes or columns have changed past a certain threshold.
An object did not exist when the stored procedure was compiled, but it was created during execution. This is called deferred object resolution, which is the cause of the preceding recompilation.
SEToptions have changed.The execution plan was aged and deallocated.
An explicit call was made to the
sp_recompilesystem stored procedure.There was an explicit use of the
RECOMPILEclause.
You can see these changes in Profiler. The cause is indicated by the EventSubClass data column value for the SP:Recompile event, as shown in Table 10-2.
Table 10.2. EventSubClass Data Column Reflecting Causes of Recompilation
| Description |
|---|---|
1 | Schema or bindings to regular table or view changed |
2 | Statistics changed |
3 | Object did not exist in the stored procedure plan but was created during execution |
4 |
|
5 | Schema or bindings to temporary table changed |
6 | Schema or bindings of remote rowset changed |
7 |
|
8 | Query notification environment changed |
9 | MPI view changed |
10 | Cursor options changed |
11 |
|
Let's look at some of the reasons listed in Table 10-2 for recompilation in more detail and discuss what you can do to avoid them.
When the schema or bindings to a view, regular table, or temporary table change, the existing stored procedure execution plan becomes invalid. The stored procedure must be recompiled before executing any statement that refers to such an object. SQL Server automatically detects this situation and recompiles the stored procedure.
Note
I talk about recompilation due to schema changes in more detail in the "Benefits and Drawbacks of Recompilation" section.
SQL Server keeps track of the number of changes to the table. If the number of changes exceeds the recompilation threshold (RT) value, then SQL Server automatically updates the statistics when the table is referred to in the stored procedure, as you saw in Chapter 7. When the condition for the automatic update of statistics is detected, SQL Server automatically recompiles the stored procedure, along with the statistics update.
The RT is determined by a set of formula that depend on the table being a permanent table or a temporary table (not a table variable) and how many rows are in the table. Table 10-3 shows the basic formula so that you can determine when you can expect to see a statement recompile because of data changes.
Table 10.3. Formula for Determining Data Changes
Type of Table | Formula |
|---|---|
Permanent table | If number of rows (n) <= 500, RT = 500 IF n > 500, RT = 500 + .2 * n |
Temporary table | If n < 6, RT = 6 If 6 <= n <= 500, RT = 500 IF n > 500, RT = 500 + .2 * n |
To understand how statistics changes can cause recompilation, consider the following example (stats_changes.sql in the download). The stored procedure is executed the first time with only one row in the table. Before the second execution of the stored procedure, a large number of rows are added to the table.
Note
Please ensure that the AUTO_UPDATE_STATISTICS setting for the database is ON. You can determine the AUTO UPDATE STATISTICS setting by executing the following query: SELECT DATABASEPROPERTYEX('AdventureWorks2008', 'IsAutoUpdateStatistics').
IF EXISTS ( SELECT *
FROM sys.objects
WHERE OBJECT_ID = OBJECT_ID(N'[dbo].[NewOrders]')
AND TYPE IN (N'U') )
DROP TABLE [dbo].[NewOrders] ;
GO
SELECT *
INTO dbo.NewOrders
FROM sales.SalesOrderDetail ;
GO
CREATE INDEX IX_NewOrders_ProductID ON dbo.NewOrders (ProductID) ;
GO
IF EXISTS ( SELECT *
FROM sys.objects
WHERE object_id = OBJECT_ID(N'[dbo].[spNewOrders]')
AND type IN (N'P', N'PC') )
DROP PROCEDURE [dbo].[spNewOrders] ;
GO
CREATE PROCEDURE dbo.spNewOrders
AS
SELECT nwo.OrderQty
,nwo.CarrierTrackingNumber
FROM dbo.NewOrders nwo
WHERE ProductID = 897 ;
GO
SET STATISTICS XML ON ;
EXEC dbo.spNewOrders ;
SET STATISTICS XML OFF ;
GONext, still in stats_changes.sql, you modify a number of rows before reexecuting the stored procedure:
UPDATE dbo.NewOrders SET ProductID = 897 WHERE ProductID BETWEEN 800 AND 900 ; GO SET STATISTICS XML ON ; EXEC dbo.spNewOrders ; SET STATISTICS XML OFF ; GO
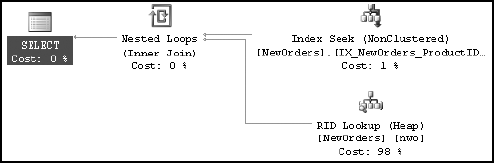
The first time, SQL Server executes the SELECT statement of the stored procedure using an Index Seek operation, as shown in Figure 10-6.
Note
Please ensure that the setting for the graphical execution plan is OFF; otherwise, the output of STATISTICS XML won't display.
While reexecuting the stored procedure, SQL Server automatically detects that the statistics on the index have changed. This causes a recompilation of the SELECT statement within the procedure, with the optimizer determining a better processing strategy, before executing the SELECT statement within the stored procedure, as you can see in Figure 10-7.
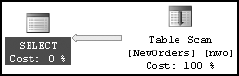
Figure 10-8 shows the corresponding Profiler trace output (with the Auto Stats event added).

In Figure 10-7, you can see that to execute the SELECT statement during the second execution of the stored procedure, a recompilation was required. From the value of EventSubClass (2 – Statistics Changed), you can understand that the recompilation was due to the statistics change. As part of creating the new plan, the statistics are automatically updated, as indicated by the Auto Stats event. You can also verify the automatic update of the statistics using the DBCC SHOW_STATISTICS statement, as explained in Chapter 7.
Stored procedures often dynamically create and subsequently access database objects. When such a stored procedure is executed for the first time, the first execution plan won't contain the information about the objects to be created during runtime. Thus, in the first execution plan, the processing strategy for those objects is deferred until the runtime of the stored procedure. When a DML statement (within the stored procedure) referring to one of those objects is executed, the stored procedure is recompiled to generate a new plan containing the processing strategy for the object.
Both a regular table and a local temporary table can be created within a stored procedure to hold intermediate result sets. The recompilation of the stored procedure due to deferred object resolution behaves differently for a regular table when compared to a local temporary table, as explained in the following section.
Recompilation Due to a Regular Table
To understand the stored procedure recompilation issue by creating a regular table within the stored procedure, consider the following example (regular.sql in the download):
IF(SELECT OBJECT_ID('dbo.p1')) IS NOT NULL
DROP PROC dbo.p1;
GO
CREATE PROC dbo.p1
AS
CREATE TABLE dbo.p1_t1(c1 INT); --Ensure table doesn't exist
SELECT * FROM dbo.p1_t1; --Causes recompilation
DROP TABLE dbo.p1_t1;
GO
EXEC dbo.p1; --First execution
EXEC dbo.p1; --Second executionWhen the stored procedure is executed for the first time, an execution plan is generated before the actual execution of the stored procedure. If the table created within the stored procedure doesn't exist (as expected in the preceding code) before the stored procedure is created, then the plan won't contain the processing strategy for the SELECT statement referring to the table. Thus, to execute the SELECT statement, the stored procedure needs to be recompiled, as shown in Figure 10-9.

Figure 10.9. Profiler trace output showing a stored procedure recompilation because of a regular table
You can see that the SELECT statement is recompiled when it's executed the second time. Dropping the table within the stored procedure during the first execution doesn't drop the stored procedure plan saved in the procedure cache. During the subsequent execution of the stored procedure, the existing plan includes the processing strategy for the table. However, because of the re-creation of the table within the stored procedure, SQL Server considers it a change to the table schema. Therefore, SQL Server recompiles the stored procedure before executing the SELECT statement during the subsequent execution of the stored procedure. The value of the EventSubClass for the corresponding SP:Recompile event reflects the cause of the recompilation.
Recompilation Due to a Local Temporary Table
Most of the time in the stored procedure you create local temporary tables instead of regular tables. To understand how differently the local temporary tables affect stored procedure recompilation, modify the preceding example by just replacing the regular table with a local temporary table:
IF(SELECT OBJECT_ID('dbo.p1')) IS NOT NULL
DROP PROC dbo.p1;
GO
CREATE PROC dbo.p1
AS
CREATE TABLE #p1_t1(c1 INT); -- # designates local temp table
SELECT * FROM #p1_t1; --Causes recompilation on 1st execution
DROP TABLE #p1_t1; --Optional
GO
EXEC dbo.p1; --First execution
EXEC dbo.p1; --Second executionSince a local temporary table is automatically dropped when the execution of a stored procedure finishes, it's not necessary to drop the temporary table explicitly. But, following good programming practice, you can drop the local temporary table as soon as its work is done.
Figure 10-10 shows the Profiler trace output for the preceding example.

Figure 10.10. Profiler trace output showing a stored procedure recompilation because of a local temporary table
You can see that the stored procedure is recompiled when executed for the first time. The cause of the recompilation, as indicated by the corresponding EventSubClass value, is the same as the cause of the recompilation on a regular table. However, note that when the stored procedure is reexecuted, it isn't recompiled, unlike the case with a regular table.
The schema of a local temporary table during subsequent execution of the stored procedure remains exactly the same as during the previous execution. A local temporary table isn't available outside the scope of the stored procedure, so its schema can't be altered in any way between multiple executions. Thus, SQL Server safely reuses the existing plan (based on the previous instance of the local temporary table) during the subsequent execution of the stored procedure and thereby avoids the recompilation.
Note
To avoid recompilation, it makes sense to hold the intermediate result sets in the stored procedure using local temporary tables, instead of using temporarily created regular tables as an alternative.
The execution plan of a stored procedure is dependent on the environment settings. If the environment settings are changed within a stored procedure, then SQL Server recompiles the stored procedure on every execution. For example, consider the following code (set.sql in the download):
IF(SELECT OBJECT_ID(' dbo.p1')) IS NOT NULL
DROP PROC dbo.p1;
GO
CREATE PROC dbo.p1
AS
SELECT 'a' + null + 'b'; --1st
SET CONCAT_NULL_YIELDS_NULL OFF;
SELECT 'a' + null + 'b'; --2nd
SET ANSI_NULLS OFF;
SELECT 'a' + null + 'b'; --3rd
GO
EXEC dbo.p1; --First execution
EXEC dbo.p1; --Second executionChanging the SET options in the stored procedure causes SQL Server to recompile the stored procedure before executing the statement after the SET statement. Thus, this stored procedure is recompiled twice: once before executing the second SELECT statement and once before executing the third SELECT statement. The Profiler trace output in Figure 10-11 shows this.

Figure 10.11. Profiler trace output showing a stored procedure recompilation because of a SET option change
If the procedure were reexecuted, you wouldn't see a recompile since those are now part of the execution plan.
Since SET NOCOUNT does not change the environment settings, unlike the SET statements used to change the ANSI settings as shown previously, SET NOCOUNT does not cause stored procedure recompilation. I explain how to use SET NOCOUNT in detail in Chapter 11.
SQL Server manages the size of the procedure cache by maintaining the age of the execution plans in the cache, as you saw in Chapter 9. If a stored procedure is not reexecuted for a long time, then the age field of the execution plan can come down to 0, and the plan can be removed from the cache because of memory shortage. When this happens and the stored procedure is reexecuted, a new plan will be generated and cached in the procedure cache. However, if there is enough memory in the system, unused plans are not removed from the cache until memory pressure increases.
SQL Server automatically recompiles stored procedures when the schema changes or statistics are altered enough. It also provides the sp_recompile system stored procedure to manually mark stored procedures for recompilation. This stored procedure can be called on a table, view, stored procedure, or trigger. If it is called on a stored procedure or a trigger, then the stored procedure or trigger is recompiled the next time it is executed. Calling sp_recompile on a table or a view marks all the stored procedures and triggers that refer to the table/view for recompilation the next time they are executed.
For example, if sp_recompile is called on table t1, all the stored procedures and triggers that refer to table t1 are marked for recompilation and are recompiled the next time they are executed:
sp_recompile 't1'
You can use sp_recompile to cancel the reuse of an existing plan when executing dynamic queries with sp_executesql. As demonstrated in the previous chapter, you should not parameterize the variable parts of a query whose range of values may require different processing strategies for the query. For instance, reconsidering the corresponding example, you know that the second execution of the query reuses the plan generated for the first execution. The example is repeated here for easy reference:
DBCC FREEPROCCACHE; --Clear the procedure cache
GO
DECLARE @query NVARCHAR(MAX);
DECLARE @param NVARCHAR(MAX);
SET @query = N'SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= @CustomerId;'
SET @param = N'@CustomerId INT';
EXEC sp_executesql @query, @param, @CustomerId = 1
EXEC sp_executesql @query, @param, @CustomerId = 30118The second execution of the query performs an Index Scan operation on the SalesOrderHeader table to retrieve the data from the table. As explained in Chapter 4, an Index Seek operation may have been preferred on the SalesOrderHeader table for the second execution. You can achieve this by executing the sp_recompile system stored procedure on the SalesOrderHeader table as follows:
EXEC sp_recompile 'Sales.SalesOrderHeader'
Now, if the query with the second parameter value is reexecuted, the plan for the query will be recompiled as marked by the preceding sp_recompile statement. This allows SQL Server to generate an optimal plan for the second execution.
Well, there is a slight problem here: you will likely want to reexecute the first statement again. With the plan existing in the cache, SQL Server will reuse the plan (the Index Scan operation on the SalesOrderHeader table) for the first statement even though an Index Seek operation (using the index on the filter criterion column soh.CustomerID) would have been optimal. One way of avoiding this problem can be to create a stored procedure for the query and use a WITH RECOMPILE clause, as explained next.
SQL Server allows a stored procedure to be explicitly recompiled using the RECOMPILE clause with the CREATE PROCEDURE or EXECUTE statement. These methods decrease the effectiveness of plan reusability, so you should consider them only under the specific circumstances explained in the following sections.
RECOMPILE Clause with the CREATE PROCEDURE Statement
Sometimes the plan requirements of a stored procedure may vary as the parameter values to the stored procedure change. In such a case, reusing the plan with different parameter values may degrade the performance of the stored procedure. You can avoid this by using the RECOMPILE clause with the CREATE PROCEDURE statement. For example, for the query in the preceding section, you can create a stored procedure with the RECOMPILE clause:
IF(SELECT OBJECT_ID('dbo.spCustomerList')) IS NOT NULL
DROP PROC dbo.spCustomerList
GO
CREATE PROCEDURE dbo.spCustomerList
@CustomerId INT
WITH RECOMPILE
AS
SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= @CustomerId;
GOThe RECOMPILE clause prevents the caching of the stored procedure plan. Every time the stored procedure is executed, a new plan will be generated. Therefore, if the stored procedure is executed with the soh.CustomerID value as 30118 or 1, like so:
EXEC spCustomerList @CustomerId = 1 EXEC spCustomerList @CustomerId = 30118
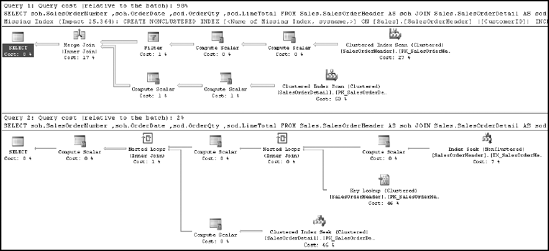
a new plan will be generated during the individual execution, as shown in Figure 10-12.
RECOMPILE Clause with the EXECUTE Statement
As shown previously, specific parameter values in a stored procedure may require a different plan, depending upon the nature of the values. You can take the RECOMPILE clause out of the stored procedure and use it on a case-by-case basis when you execute the stored procedure, as follows:
EXEC dbo.spCustomerList @CustomerId = 1 WITH RECOMPILE
When the stored procedure is executed with the RECOMPILE clause, a new plan is generated temporarily. The new plan isn't cached, and it doesn't affect the existing plan. When the stored procedure is executed without the RECOMPILE clause, the plan is cached as usual. This provides some control over reusability of the existing plan cache rather than using the RECOMPILE clause with the CREATE PROCEDURE statement.
Since the plan for the stored procedure when executed with the RECOMPILE clause is not cached, the plan is regenerated every time the stored procedure is executed with the RECOMPILE clause. However, for better performance, instead of using RECOMPILE, you should consider creating separate stored procedures, one for each set of parameter values that requires a different plan.
Sometimes recompilation is beneficial, but at other times it is worth avoiding. If a new index is created on a column referred to in the WHERE or JOIN clause of a query, it makes sense to regenerate the execution plans of stored procedures referring to the table so they can benefit from using the index. However, if recompilation is deemed detrimental to performance, you can avoid it by following these implementation practices:
Do not interleave DDL and DML statements.
Avoid recompilation caused by statistics changes:
Use the
KEEPFIXED PLANoption.Disable the auto update statistics feature on the table.
Use table variables.
Avoid changing
SEToptions within the stored procedure.Use the
OPTIMIZE FORquery hint.Use plan guides.
In stored procedures, DDL statements are often used to create local temporary tables and to change their schema (including adding indexes). Doing so can affect the validity of the existing plan and can cause recompilation when the stored procedure statements referring to the tables are executed. To understand how the use of DDL statements for local temporary tables can cause repetitive recompilation of the stored procedure, consider the following example (ddl.sql in the download):
IF (SELECT OBJECT_ID('dbo.spTempTable')
) IS NOT NULL
DROP PROC dbo.spTempTable
GO
CREATE PROC dbo.spTempTable
AS
CREATE TABLE #MyTempTable (ID INT, Dsc NVARCHAR(50))
INSERT INTO #MyTempTable (
ID,
Dsc
) SELECT ProductModelId, [Name]
FROM Production.ProductModel AS pm; --Needs 1st recompilation
SELECT * FROM #MyTempTable AS mtt;
CREATE CLUSTERED INDEX iTest ON #MyTempTable (ID);
SELECT *
FROM #MyTempTable AS mtt; --Needs 2nd recompilation
CREATE TABLE #t2 (c1 INT);
SELECT *
FROM #t2;
--Needs 3rd recompilation
GO
EXEC spTempTable --First executionThe stored procedure has interleaved DDL and DML statements. Figure 10-13 shows the Profiler trace output of the preceding code.

You can see that the stored procedure is recompiled four times:
The execution plan generated for a stored procedure when it is first executed doesn't contain any information about local temporary tables. Therefore, the first generated plan can never be used to access the temporary table using a DML statement.
The second recompilation comes from the changes encountered in the data contained within the table as it gets loaded.
The third recompilation is due to a schema change in the first temporary table (
#MyTempTable). The creation of the index on#MyTempTableinvalidates the existing plan, causing a recompilation when the table is accessed again. If this index had been created before the first recompilation, then the existing plan would have remained valid for the secondSELECTstatement too. Therefore, you can avoid this recompilation by putting theCREATE INDEXDDL statement above all DML statements referring to the table.The fourth recompilation of the stored procedure generates a plan to include the processing strategy for
#t2. The existing plan has no information about#t2and therefore cannot be used to access#t2using the thirdSELECTstatement. If theCREATE TABLEDDL statement for#t2had been placed before all the DML statements that could cause a recompilation, then the first recompilation itself would have included the information on#t2, avoiding the third recompilation.
In the "Analyzing Causes of Recompilation" section, you saw that a change in statistics is one of the causes of recompilation. On a simple table with uniform data distribution, recompilation due to a change of statistics may generate a plan identical to the previous plan. In such situations, recompilation can be unnecessary and should be avoided if it is too costly.
You have two techniques to avoid recompilations caused by statistics change:
Use the
KEEPFIXED PLANoption.Disable the auto update statistics feature on the table.
Using the KEEPFIXED PLAN Option
SQL Server provides a KEEPFIXED PLAN option to avoid recompilations due to a statistics change. To understand how you can use KEEPFIXED PLAN, consider stats_changes.sql with an appropriate modification to use the KEEPFIXED PLAN option:
--Create a small table with one row and an index
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1 ;
GO
CREATE TABLE dbo.t1 (c1 INT, c2 CHAR(50)) ;
INSERT INTO dbo.t1
VALUES (1, '2') ;
CREATE NONCLUSTERED INDEX i1 ON t1 (c1) ;
--Create a stored procedure referencing the previous table
IF (SELECT OBJECT_ID('dbo.p1')
) IS NOT NULL
DROP PROC dbo.p1 ;
GO
CREATE PROC dbo.p1AS
SELECT *
FROM t1
WHERE c1 = 1
OPTION (KEEPFIXED PLAN) ;
GO
--First execution of stored procedure with 1 row in the table
EXEC dbo.p1 ;
--First execution
--Add many rows to the table to cause statistics change
WITH Nums
AS (SELECT 1 AS n
UNION ALL
SELECT n + 1
FROM Nums
WHERE n < 1000
)
INSERT INTO t1
SELECT 1
,N
FROM Nums
OPTION (MAXRECURSION 1000) ;
GO
--Reexecute the stored procedure with a change in statistics
EXEC dbo.p1 --With change in data distributionFigure 10-14 shows the Profiler trace output.

Figure 10.14. Profiler trace output showing the role of the KEEPFIXED PLAN option in reducing recompilation
You can see that, unlike in the earlier example with changes in data, there's no Auto Stats event (see Figure 10-8). Consequently, there's no recompilation. Therefore, by using the KEEPFIXED PLAN option, you can avoid recompilation due to a statistics change.
Note
Before you consider using this option, ensure that any new plans that would have been generated are not superior to the existing plan.
Disable Auto Update Statistics on the Table
You can also avoid recompilation due to a statistics update by disabling the automatic statistics update on the relevant table. For example, you can disable the auto update statistics feature on table t1 as follows:
EXEC sp_autostats 't1', 'OFF'
If you disable this feature on the table before inserting the large number of rows that causes statistics change, then you can avoid the recompilation due to a statistics change.
However, be very cautious with this technique, since outdated statistics can adversely affect the effectiveness of the cost-based optimizer, as discussed in Chapter 7. Also, as explained in Chapter 7, if you disable the automatic update of statistics, you should have a SQL job to update the statistics regularly.
One of the variable types supported by SQL Server 2008 is the table variable. You can create the table variable data type like other data types, using the DECLARE statement. It behaves like a local variable, and you can use it inside a stored procedure to hold intermediate result sets, as you do using a temporary table.
You can avoid the recompilations caused by a temporary table if you use a table variable. Since statistics are not created for table variables, the different recompilation issues associated with temporary tables are not applicable to it. For instance, consider create_p1.sql used in the section "Identifying the Statement Causing Recompilation." It is repeated here for your reference:
IF(SELECT OBJECT_ID('dbo.p1')) IS NOT NULL
DROP PROC dbo.p1;
GO
CREATE PROC dbo.p1
AS
CREATE TABLE #t1(c1 INT);
INSERT INTO #t1 (
c1
) VALUES ( 42 ) ; -- data change causes recompile
GO
EXEC dbo.p1; --First executionBecause of deferred object resolution, the stored procedure is recompiled during the first execution. You can avoid this recompilation caused by the temporary table by using the table variable as follows:
IF(SELECT OBJECT_ID('dbo.p1')) IS NOT NULL
DROP PROC dbo.p1
GO
CREATE PROC dbo.p1
AS
DECLARE @t1 TABLE(c1 INT)
INSERT INTO @t1 (
C1
) VALUES (42); --Recompilation not needed
GO
EXEC dbo.p1; --First executionFigure 10-15 shows the Profiler trace output for the first execution of the stored procedure. The recompilation caused by the temporary table has been avoided by using the table variable.
Additional benefits of using the table variables are as follows:
No transaction log overhead: No transaction log activities are performed for table variables, whereas they are for both regular and temporary tables.
No lock overhead: Since table variables are treated like local variables (not database objects), the locking overhead associated with regular tables and temporary tables does not exist.
No rollback overhead: Since no transaction log activities are performed for table variables, no rollback overhead is applicable for table variables. For example, consider the following code (
rollback.sqlin the download):DECLARE @t1 TABLE(c1 INT) INSERT INTO @t1 VALUES(1) BEGIN TRAN INSERT INTO @t1 VALUES(2) ROLLBACK SELECT * FROM @t1 --Returns 2 rows
The
ROLLBACKstatement won't roll back the second row insertion into the table variable.
However, table variables have their limitations. The main ones are as follows:
No DDL statement can be executed on the table variable once it is created, which means no indexes or constraints can be added to the table variable later. Constraints can be specified only as part of the table variable's
DECLAREstatement. Therefore, only one index can be created on a table variable, using thePRIMARY KEYorUNIQUEconstraint.No statistics are created for table variables, which means they resolve as single-row tables in execution plans. This is not an issue when the table actually contains only a small quantity of data, approximately less than 100 rows. It becomes a major performance problem when the table variable contains more data since appropriate decisions regarding the right sorts of operations within an execution plan are completely dependent on statistics.
The following statements are not supported on the table variables:
INSERT INTO TableVariable EXEC StoredProcedureSELECT SelectList INTO TableVariable FROM TableSET TableVariable = Value
It is generally recommended that you not change the environment settings within a stored procedure and thus avoid recompilation because the SET options changed. For ANSI compatibility, it is recommended that you keep the following SET options ON:
ARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIERANSI_NULLSANSI_PADDINGANSI_WARNINGS
NUMERIC_ROUNDABORT should be OFF.
Although the following approach is not recommended, you can avoid the recompilation caused by some of these SET options changes by resetting the options for the connection as shown in the following modifications to set.sql:
IF(SELECT OBJECT_ID('p1')) IS NOT NULL
DROP PROC p1
GO
CREATE PROC p1
AS
SELECT 'a' + null + 'b' --1st
SET CONCAT_NULL_YIELDS_NULL OFFSELECT 'a' + null + 'b' --2nd SET ANSI_NULLS OFF SELECT 'a' + null + 'b' --3rd GOSET CONCAT_NULL_YIELDS_NULL OFFSET ANSI_NULLS OFFEXEC p1SET CONCAT_NULL_YIELDS_NULL ON --Reset to defaultSET ANSI_NULLS ON --Reset to default
Figure 10-16 shows the Profiler trace output.
Figure 10.16. Profiler trace output showing effect of the ANSI SET options on stored procedure recompilation
You can see that there were fewer recompilations when compared to the original set.sql code (Figure 10-11). Out of the SET options listed previously, the ANSI_NULLS and QUOTED_ IDENTIFIER options are saved as part of the stored procedure when it is created. Therefore, setting these options in the connection outside the stored procedure won't affect any recompilation issues; only re-creating the stored procedure can change these settings.
Although you may not always be able to reduce or eliminate recompiles, using the OPTIMIZE FOR query hint will help ensure you get the plan you want when the recompile does occur. The OPTIMIZE FOR query hint uses parameter values supplied by you to compile the plan, regardless of the values of the parameter passed in by the calling application.
For an example, examine spCustomerList from earlier in the chapter. You know that if this procedure receives certain values, it will need to create a new plan. Knowing your data, you also know two more important facts: the frequency that this query will return small data sets is exceedingly small, and when this query uses the wrong plan, performance suffers. Rather than recompiling it over and over again, modify it so that it creates the plan that works best most of the time:
IF(SELECT OBJECT_ID('dbo.spCustomerList')) IS NOT NULL
DROP PROC dbo.spCustomerList
GO
CREATE PROCEDURE dbo.spCustomerList
@CustomerId INT
AS
SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotalFROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= @CustomerId
OPTION (OPTIMIZE FOR (@CustomerID = 1));
GOWhen this query is executed the first time or it's recompiled for any reason, it always gets the same execution plan. To test this, execute the procedure this way:
EXEC dbo.spCustomerList @CustomerId = 7920 WITH RECOMPILE; EXEC dbo.spCustomerList @CustomerId = 30118 WITH RECOMPILE;
Just as earlier in the chapter, this will force the procedure to be recompiled each time it is executed. Figure 10-17 shows the resulting execution plans.
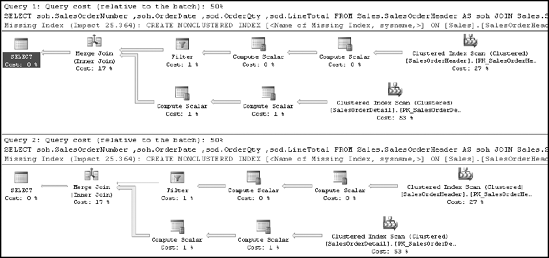
Unlike earlier in the chapter, recompiling the procedure now does not result in a new execution plan. Instead, the same plan is generated, regardless of input, because the query optimizer has received instructions to use the value supplied, @CustomerId = 1, when optimizing the query.
This can reduce the number of recompiles, and it does help you control the execution plan generated. It requires that you know your data very well. If your data changes over time, you may need to reexamine areas where the OPTIMIZE FOR query hint was used.
SQL Server 2008 introduces one more wrinkle on the OPTIMIZE FOR query hint. You can specify that the query be optimized using OPTIMIZE FOR UNKOWN. This is almost the opposite of the OPTIMIZE FOR hint. What you are directing the processor to do is perform the optimization based on statistics, always, and to ignore the actual values passed when the query is optimized. You can use it in combination with OPTIMIZE FOR <value>. It will optimize for the value supplied on that parameter but will use statistics on all other parameters.
A plan guide allows you to use query hint or other optimization techniques without having to modify the query or procedure text. This is especially useful when you have a third-party product with poorly performing procedures you need to tune but can't modify. As part of the optimization process, if a plan guide exists when a procedure is compiled or recompiled, it will use that guide to create the execution plan.
In the previous section, I showed you how using OPTIMIZE FOR would affect the execution plan created on a procedure. The following is the query from the original procedure, with no hints (plan_guide.sql in the download):
IF(SELECT OBJECT_ID('dbo.spCustomerList')) IS NOT NULL
DROP PROC dbo.spCustomerList
GO
IF(SELECT OBJECT_ID('dbo.spCustomerList')) IS NOT NULL
DROP PROC dbo.spCustomerList
GO
CREATE PROCEDURE dbo.spCustomerList
@CustomerId INT
AS
SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= @CustomerId
GONow assume for a moment that this query is part of a third-party application and you are not able to modify it to include OPTION (OPTIMIZE FOR). To provide it with the query hint, OPTIMIZE FOR, create a plan guide as follows:
sp_create_plan_guide
@name = N'MyGuide',
@stmt = N'SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= @CustomerId',
@type = N'OBJECT',
@module_or_batch = N'dbo.spCustomerList',
@params = NULL,
@hints = N'OPTION (OPTIMIZE FOR (@CustomerId = 1))'Now, when the procedure is executed with each of the different parameters, even with the RECOMPILE being forced, Figure 10-18 shows the results:
EXEC dbo.spCustomerList @CustomerId = 7920 WITH RECOMPILE; EXEC dbo.spCustomerList @CustomerId = 30118 WITH RECOMPILE;
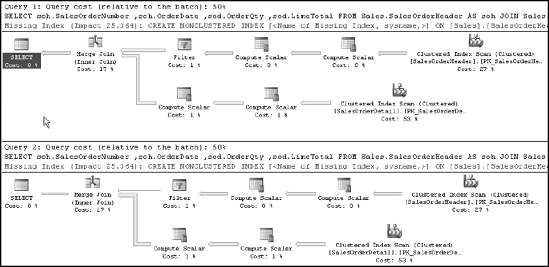
The results are the same as when the procedure was modified, but in this case, no modification was necessary.
Various types of plan guides exist. The previous example is an object plan guide, which is a guide matched to a particular object in the database, in this case spCustomerList. You can also create plan guides for ad hoc queries that come into your system repeatedly by creating a SQL plan guide that looks for particular SQL statements. Instead of a procedure, the following query gets passed to your system and needs an OPTIMIZE FOR query hint:
SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID >= 1Running this query results in the execution plan you see in Figure 10-19.

To get a query plan guide, you first need to know the precise format used by the query in case parameterization, forced or simple, changes the text of the query. The text has to be precise. If your first attempt at a query plan guide looked like this (bad_guide.sql in the download):
EXECUTE sp_create_plan_guide @name = N'MyBadSQLGuide', @stmt = N'SELECT soh.SalesOrderNumber ,soh.OrderDate ,sod.OrderQty ,sod.LineTotal from Sales.SalesOrderHeader AS soh join Sales.SalesOrderDetail AS sod on soh.SalesOrderID = sod.SalesOrderID where soh.CustomerID >= @CustomerId', @type = N'SQL', @module_or_batch = NULL, @params = N'@CustomerId int', @hints = N'OPTION (TABLE HINT(soh, FORCESEEK))';
then you'll still get the same execution plan when running the select query. This is because the query doesn't look like what was typed in for the bad_guide.sql plan guide. Several things are different such as the spacing and the case on the JOIN statement. You can drop this bad plan guide using the T-SQL statement:
EXECUTE sp_control_plan_guide @Operation = 'Drop', @name = N'MyBadSQLGuide'
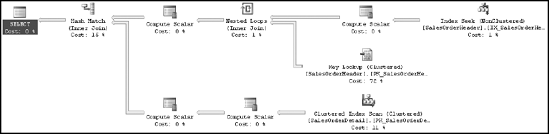
Inputting the correct syntax will create a new plan:
EXECUTE sp_create_plan_guide
@name = N'MyGoodSQLGuide',
@stmt = N'SELECT soh.SalesOrderNumber
,soh.OrderDate
,sod.OrderQty
,sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderIDWHERE soh.CustomerID >= 1', @type = N'SQL', @module_or_batch = NULL, @params = NULL, @hints = N'OPTION (TABLE HINT(soh, FORCESEEK))';
Now when the query is run, a completely different plan is created, as shown in Figure 10-20.
One other option exists when you have a plan in the cache that you think performs the way you want. You can capture that plan into a plan guide to ensure that the next time the query is run, the same plan is executed. You accomplish this by running sp_create_plan_guide_from_handle.
To test it, first clear out the procedure cache so you can control exactly which query plan is used:
DBCC FREEPROCCACHE
With the procedure cache clear and the existing plan guide, MyGoodSQLGuide, in place, rerun the query. It will use the plan guide to arrive at the execution plan displayed in Figure 10-20. To see whether this plan can be kept, first drop the plan guide that is forcing the Index Seek operation:
EXECUTE sp_control_plan_guide @Operation = 'Drop', @name = N'MyGoodSQLGuide';
If you were to rerun the query now, it would revert to its original plan. However, right now in the plan cache, you have the plan displayed in Figure 10-20. To keep it, run the following script:
DECLARE @plan_handle VARBINARY(64)
,@start_offset INT
SELECT @plan_handle = qs.plan_handle
,@start_offset = qs.statement_start_offset
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,
qs.statement_start_offset,
qs.statement_end_offset) AS qp
WHERE text LIKE N'SELECT soh.SalesOrderNumber%'EXECUTE sp_create_plan_guide_from_handle @name = N'ForcedPlanGuide',
@plan_handle = @plan_handle, @statement_start_offset = @start_offset ;
GOThis creates a plan guide based on the execution plan as it currently exists in the cache. To be sure this works, clear the cache again. That way, the query has to generate a new plan. Rerun the query, and observe the execution plan. It will be the same as that displayed in Figure 10-20 because of the plan guide created using sp_create_plan_guide_from_handle.
Plan guides are useful mechanisms for controlling the behavior of SQL queries and stored procedures, but you should use them only when you have a thorough understanding of the execution plan, the data, and the structure of your system.
As you learned in this chapter, stored procedure recompilation can both benefit and hurt performance. Recompilations that generate better plans improve the performance of the stored procedure. However, recompilations that regenerate the same plan consume extra CPU cycles without any improvement in processing strategy. Therefore, you should look closely at recompilations to determine their usefulness. You can use Profiler to identify which stored procedure statement caused the recompilation, and you can determine the cause from the EventSubClass data column value in Profiler and trace output. Once you determine the cause of the recompilation, you can apply different techniques to avoid the unnecessary recompilations.
Up until now, you have seen how to benefit from proper indexing and plan caching. However, the performance benefit of these techniques depends on the way the queries are designed. The cost-based optimizer of SQL Server takes care of many of the query design issues. However, you should adopt a number of best practices while designing queries. In the next chapter, I will cover some of the common query design issues that affect performance.