
R E P R I N T 4
![]()
packetC Language and Parallel Processing of Masked Databases
by Ralph Duncan, Peder Jungck and Kenneth Ross
Network packet processing's increasing speeds and volume create an incentive to use parallel processing. Such processing often involves comparing selected packet data to the contents of large tables (e.g., for routing packets or controlling system access). Thus, commercial systems often use multiple network processors [1] to provide parallel processing in general and use associative memory chips to provide parallel table operations in particular. Parallel network programming is usually done in a C dialect with machine-specific extensions. The associative memory capabilities are often provided by ternary content addressable memory (TCAM) chips in order to supply the fast, mask-ing-based searches needed in this domain. TCAM use is normally controlled by vendor software, rather than by the application developer. Thus, an application is typically restricted to a small number of predefined templates and mediated by vendor system software. Thus, application developers cannot use high-level languages to express network table operations in an intuitive, portable way, nor exploit parallel devices like TCAMs in a flexible manner. This paper presents CloudShield's packetC® language [2], a C dialect that hides most host-machine specifics, supports coarse-grain parallelism and supplies high-level data type and operator extensions for packet processing. We describe packetC's database and record constructs that support network application table operations, including masked matching. We show how our implementation of packetC with network processors, FPGAs and TCAMs lets the user enjoy parallel performance benefits without the usual vendor constraints or reliance on hardware-specific programming.
Categories and Subject Descriptors D.3.3 [Programming Languages]: Language Constructs and Features – data types and structures
General Terms Languages.
Keywords high performance, network processing; programm ing languages; parallel processing, TCAMs
Systems for processing network packets are constantly pushed to provide faster performance. The amount of data to move is constantly increasing and the transmission mediums offer ever faster transmission speeds.
This need for faster packet processing is addressed by parallelism in both hardware and software. Network hardware parallelism typically uses network processing units (NPUs) with multithreaded architectures specialized for real-time packet processing [1]. This style of programming is often expressed at the level of assembly code or a C dialect, involving direct manipulation of machine-specific features, e.g., caches, register classes, queues.
Processing network packets often involves table-lookups, e.g., those involving routing tables or current flow data (Fig. 1 and Sect. 8.1). Ternary content addressable memory (T-CAM) is a popular means of exploiting parallelism in such look-ups [3]. However, high-level application developers have typically lacked a means to directly control CAM. Instead, such control has been reserved for network device vendors. A remark George Lawton made about network routers in the recent past is apt; “Typically, they have been commercial proprietary products over which users have had only limited control [4].” Even NPU C dialects that expose hardware specifics lack a general table data type or capabilities to control TCAM chips.
Our approach involves programming network applications in a high level language that hides hardware details, while using specialty chips like TCAMs for the hardware implementation. Thus, the packetC language has high-level database and record constructs to express table definition and operations but the packetC implementation is free to use any kind of CAM or no CAM at all (e.g., free to simply implement a table in memory). Our current implementation provides users with the parallel performance benefits of TCAM, as well as the benefit of programming masked table lookup operations in a flexible, portable way.
The paper is organized as follows. A short section reviews other network languages and summarizes commercial TCAM use. The next two sections present overviews of CloudShield's parallel programming model and the packetC language, respectively. We then present packetC databases, records and masking constructs in detail. Our experimental section presents two classic networking applications: flow tracking and access control. Because our emphasis is on giving users flexible, high-level language constructs for table-lookup, these experiments emphasize the characteristics of test source code as much as their mainstream parallel performance. A conclusion follows.
2. Related Work: Languages and TCAMs
A variety of high-level languages or C dialects exist for programming NPUs, including microengineC [5], NOVA [6] and Infineon® C (Infineon Technologies AG) [7]. These languages support classic network application domain needs in various ways, including support for finegrained tasking, for representing packet protocols in effective ways and for rapidly comparing bit fields and bit patterns. Such languages usually reflect machine particulars, like caches, register sets and memory banks. However, we do not know of any high-level language, other than packetC that provides a data type for packet processing tables and makes mask specification and masked table searches an integral part of the data type.
Whether programmable NPUs, field-programmable gate arrays (FPGAs) or application specific integrated circuits (ASICs) are used, commercial network applications require large tables for high-performance searches (unless advanced compression techniques are used). TCAM chips have been a popular means of providing fast searches of large tables through parallel hardware support.
As an alternative, various packet classification algorithms have been proposed for reducing memory storage and access requirements, thus precluding the need for specialized hardware. Major algorithms types include grid-of-tries, bit vector linear search, cross-producting and recursive flow classification, and decision tree approaches [8, 9]. These algorithms have made memory-based packet classification more attractive, but using TCAMs for tables s pervasive enough to be characterized as current commercial practice and addressed here as commonplace.
Content addressable memories take a bit pattern and return one or more addresses with memory contents that match the pattern. A TCAM effectively associates a mask bit with each data bit to indicate whether the data bit should be considered when evaluating a match. TCAM is well-suited to network applications, for example to compare in parallel the network portion of all the addresses in a routing table against a destination address.
Typically, when TCAMs are deployed in commercial systems they are not directly controlled by customer programs that are written in a high-level language and execute on the data-plane where packets are examined. Using TCAMs from a customer perspective, therefore, is not usually a matter of manipulating a high-level data type. For example, the TCAMs in Cisco Technology Inc.'s Catalyst® Switch families are partitioned among multiple tables by the user specifying one of several vendor-supplied templates [10]. Particular TCAM values (i.e., masks, access control entry values) are not directly programmable by users but are created by user interaction with vendor-supplied system software (e.g., with Cisco Technology Inc.'s ACL feature manager) [11].
Apparently, the QuantumFlow Processor™ (Cisco Technology, Inc.) offers 40 packet processor cores or packet processor engines (PPEs) on a chip. Commercial materials state that the architecture offers high-speed interfaces to TCAM and “reduced latency memory,” as well as “large per service databases available to each PPE.“[12]. The QuantumFlow PPEs seem to be programmable via an “ANSI C application programming interface” but this appears to be a development vehicle for the vendor, not a language available to customers for high-level programming [13].
In contrast, packetC is meant to provide both network hardware vendors and customers with high-level language constructs for packet processing in general and masked tables in particular. The next sections review the Cloud-Shield parallel processing model and packetC language, respectively.
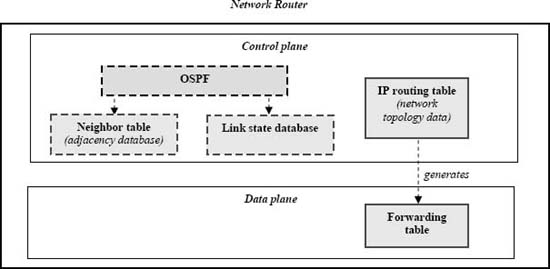
Figure 1. Simplified view of typical network routing tables. Copyright CloudShield Technologies, 2010.
3. A Parallel Packet Processing Model
Distinctive, high-level aspects of the model (Fig. 2) include
- Coarse-grained parallelism,
- Machine characteristic hiding,
- Host system executive responsibilities and
- Shared and private memory division.
Our model provides a developer with an intuitive view of parallel packet processing at a coarse-grained level. Parallel tasks are expressed as copies of a small program that processes one packet at a time in end-to-end fashion (i.e., we use single program multiple data (SPMD) parallelism. This frees the developer from task management mechanics, like synchronizing tasks.
As many machine characteristics as possible are hidden, not only so that customers can port their code but so that we can replace our product's subsystems with significantly different chips or replace hardware with software implementations without rendering existing programs obsolete. Hence, the language does not reflect register classes, caches, memory banks, etc.
The model requires the host system to play a very active role: managing the execution of program copies, handling packet ingress and egress, and pre-calculating layer offsets (protocol header locations) that are present in the packet.
The model requires that the host system prepare two things for a packet program copy each time before it is executed:
![]() A copy of the packet as an array of unsigned bytes (in big endian order).
A copy of the packet as an array of unsigned bytes (in big endian order).
![]() A collection of flags and integers (termed the Packet Information Block) that indicate whether protocol headers for certain network layers are present in the packet and, if they are, the offset from the packet ar ray's start where that header resides.
A collection of flags and integers (termed the Packet Information Block) that indicate whether protocol headers for certain network layers are present in the packet and, if they are, the offset from the packet ar ray's start where that header resides.
System calculation of protocol offsets before a program copy is triggered is significant because detecting the presence of various standard network protocols involves non-trivial processing. Thus, the model frees application developers to concentrate on what is distinctive in their application, rather than what is common to virtually all of them. We describe processing and accessing this layer information in another paper [2].
The model partitions shared and private memory in a straightforward way:
- A global memory holds scalars and aggregates shared by all packet programs.
- Each program copy has a private memory that contains variables and aggregates that are not visible to other program copies.
Global memory contains three categories of data:
- Ordinary C-style scalar variables and aggregates that are shared among the program copies (e.g., counters).
- search terms – strings or regular expressions for driving searches of packet's payloads (contents).
- tables – varied data in aggregate form – typically, tuple data that combines multiple fields from one or more protocol headers present in the packets.
The model, itself, does not presume particular mechanisms for synchronizing access to global data.
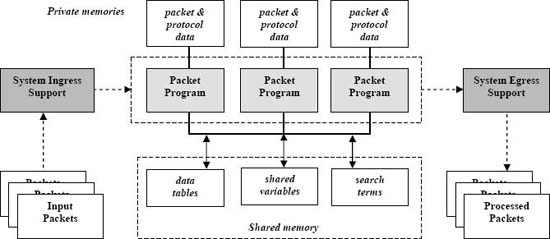
Figure 2. Parallel packet processing model. Copyright CloudShield Technologies, 2010.
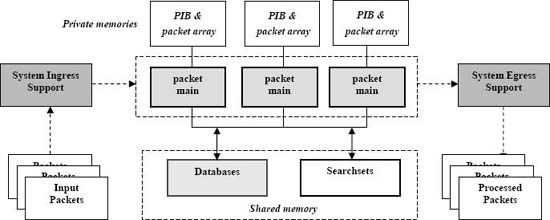
Figure 3. Mapping the packet processing model to packetC language constructs. Copyright CloudShield Technologies, 2010.
A high-level programming language based on this model must provide packet-level parallelism, distinguish global and shared memory contents and offer extended data types to manage search term and table data. The next section describes the packetC language we developed to address these goals.
packetC was developed from the model and these goals:
- Use C99 variant of C for operators (arithmetic, logical and bitwise), conditional statements and overall syntax.
- Reduce runtime exceptions and performance uncertainties by removing pointers, address operators and dynamic memory allocation (and by using unsigned integer arithmetic that wraps, rather than overflows or underflows).
- Increase reliability by stronger typing rules and by disallowing implicit type conversions or promotions, requiring explicit, readily traced conversions.
- Support the model's SPMD parallelism and shared memory aggregates for table and search data.
Since another paper [2] provides an overview of the packetC language, this discussion sketches selected features that are most involved with parallelism. Language constructs central to the paper's concern, databases and records, are discussed in detail by the subsequent section.
- Packet program copies are expressed with a packet main program – the unit of parallel execution.
- Variables declared outside of either main or a function are deemed to be in the global (shared) memory; copies of all others are assigned to private memories.
Fig. 3 above shows how the high-level model aspects have been mapped to packetC language constructs.
The basic unit of packetC parallelism, a packet module or packet main, looks much like a C main function with accompanying type, variable and function declarations. The example code below shows its structure.
packet module malwareDetector;
// GLOBAL SECTION
// type, database & searchset decls
// function declarations
int trojansFound = 0; //sharedCounter
void someUtilityFn(int i) {…}
void main {
// C-style blocks of decls & stmts
short myShortVar;
…
// body of program to be replicated
trojansFound++;
…
}
Global declarations are visible from the point of their appearance to the bottom of the module text. The extended aggregate types, databases and searchsets, are always declared here and shared by all program copies.
Distinctive packetC data structures and types include:
- The pre-calculated protocol information is available to each packet main in a system-provided structure, the packet information block (PIB) [16].
- Shared session and protocol data for classic network application tables are kept in database aggregates and in individual records.
- Shared search items in string and regular expression form are represented by the searchset aggregate type.
Now that we have sketched packetC parallelism, shared memory and protocol header representation, we turn to how packetC represents table information in a portable way and how it provides masked searching of table data.
Given the packetC goals of portability and reliability, the language handles table data via a database construct that:
- Is rooted in C-style structure base types to provide a basis for strong typing,
- Disguises the underlying hardware implementation (i.e., whether it is done via TCAM/CAM chips or not), so that packetC programs can be portable.
packetC syntax presents databases as if they were one-dimensional arrays of structures, as shown below.
struct stype { short dest; short src;};
database stype myDB[50];
Since neither packetC syntax nor semantics exposes the underlying hardware organization, systems can implement databases by using TCAMs, ordinary memory, specialized chips, etc. (In practice, commercial TCAMs usually have 128 or 512-bit elements, so packetC implementations may need to impose database size limits and need to pad user base types to match hardware specifics).
5.1 Database Types: Masks and Automatic Mirroring
Network applications often match data in the current packet against a subset of each database record, e.g., find a database record which matches an Internet Protocol (IP) source address. Mask bits associated with each database element indicate whether the corresponding bits of the data portion are to be used in matching (see Fig. 4).
Because masked matching is an essential part of network table searching, packetC databases are automatically masked by the packetC compiler, which implicitly constructs each database to consist of a data field and a mask field, with each of them having the base type specified by the user's database declaration. (In the example below, packetC structure tags always define a named type, so a C-style typedef is not needed to establish the type name).
struct stype { short dest; short src;};
database stype myDB[50];
// each element of myDB has the structure:
{ stype data; stype mask;};
Individual database elements are accessed by using array indexing syntax. An element's data and mask fields may be accessed explicitly, as shown by the example below, which continues the sample code begun just above.
myDB[newRow].data = { destValue, srcValue };
myDB[5].mask.dest = ~0;
srcVar = myDB[matchedRow].src; // defaults to ‘data’ half
5.2 Declarations and Default Mask Values
Defining masks in terms of structure fields is more intuitive and reliable than defining them in terms of long hexadecimal literals; this is especially true when database elements can reach 128 to 512 bits in length. packetC users can explicitly define mask values in declarations or can omit the mask part and allow the packetC compiler to supply default values.
// init 1st DB element w/ explicit mask value
database stype db[10] = { {{255,16},{~0,0}} };
// init 1st DB element, implicit mask value
database stype db2[5] = { {{255,16}} };
In the second declaration above, an initial mask value has been omitted but the element's data value, {255,16} is still surrounded by a set of curly braces for the element as a whole – {{255,16}}. Default mask values are set equal to 1 for every bit (i.e., allowing the corresponding data half's contents to be used during matching). Thus, the default mask for the 2-field mask of stype is {~0, ~0}. The sole exception is pad fields of a packetC bit-field container. As intuition suggests, default mask bits for a pad field are set to zero.
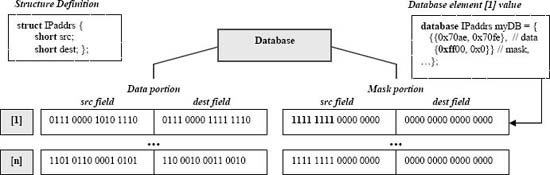
Figure 4. Setting mask bits to use only the IP address src field when matching element [1]. Copyright CloudShield Technologies, 2010.
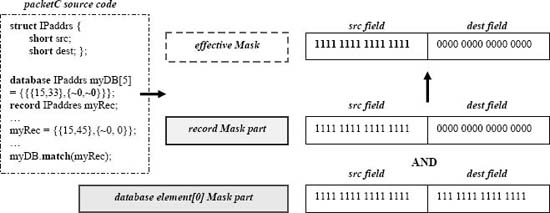
Figure 5. Match forming an effective mask from a database element mask and record mask. Copyright CloudShield Technologies, 2010.
5.3 Records and Database Operators
The packetC record construct is analogous to a single element of a database and shares the database characteristics of automatic mirroring into data and mask halves. Thus records offer a means of inserting and extracting individual elements from databases. A record declaration involves specifying a base type and, optionally, specifying data and mask initial values:
record baseType aRec = {{0,16},{0,~0}};
Both record and structure base type arguments play a role in database operations. packetC's designers felt that using C-style symbols for database operations would be hopelessly opaque and using library function calls for them would fail to fully integrate databases into the language. Thus, we use C++-style method syntax for database operations and use the form:
<dbID>‘.’<operation>’(’ optionalArgs ‘)’
Depending on the operator, various types of arguments are allowed as exemplified below.
row = myDB.insert( aRecord );
myDB[3].delete();
myDB[4].data = myStruct; // subscripting
For this discussion match is the most important database operation, since it is the basic table search operation and the one that most reveals whether parallelism is being effectively harnessed. When match's first argument is a structure, each individual database element's mask is the only one applied. If the first argument is a record, then each comparison effectively uses a logical AND of the record's mask portion and the particular database element's mask portion (Fig. 5). If an optional second argument is present (a structure) the matching element's data contents are written to it. In any case, a successful match returns the matching element's index, while a failure to match any element must be handled by packetC's C++-style system of try and catch constructs. Some match examples follow.
rownum = myDB.match( myStruct );
rownum = myDB.match( myRecord );
The next section describes how matching constructs are currently implemented in fielded systems.
6. Current Hardware Implementation
packetC does not dictate that databases must be implemented via TCAMs; we could implement a database as an array of structures (with data and mask portions). However, our current implementation does use TCAM chips, although we have changed chips at times and other vendors' chips or alternatives could be substituted.
CloudShield Technologies' products [15] use multi-core NPUs much as our rivals do. However, our approach uses micro-coded interpreters running on NPUs to interpret user programs and, when appropriate, to push data to specialized processors.
- Microcode running on a dedicated subset of NPU cores works with FPGAs to control the packet pipeline, analyze packets and pre-locate headers.
- An ensemble of NPUs, each running multiple contexts, executes SPMD copies of packetC programs.
- A custom FPGA manages shared memory for scalars and arrays, and manages access to the T-CAM.
- TCAM chips and regular expression processors implement operations on packetC's database and sear-chset types, respectively [1].
Data flow from an interpreter through the FPGA to the TCAM chips is shown in figure 6 below.
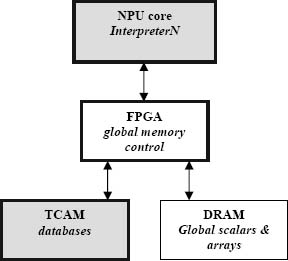
Figure 6. NPU-based interpreter accesses TCAM through FPGA, which serves as a controller for global memory elements.
Our packetC compiler and assembler generate a proprietary bytecode that combines RISC-style arithmetic with high-level instructions for database and string search operations. Thus, the tools emit a single, high-level instruction for a database match operation as shown below.
rownum = myDB.match( myRecord );
// maps to 1 bytecode insn;
// idealized bytecode example below
Database_match(maskKind, myRecord.data,
myRecord.mask, returnInfoDirective)
When the interpreter encounters a match bytecode, it sends the FPGA a match command, data to be matched and (optionally) the secondary mask (Fig. 5 and 7).
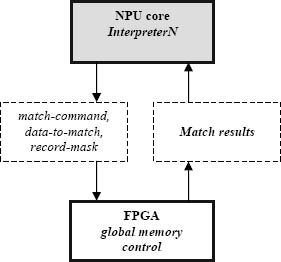
Figure 7. Communications for database match between an interpreter and the FPGA managing global memory.
Neither the compiler nor the interpreter is TCAM-specific. Only the global memory subsystem and its FPGA have TCAM dependencies. Although other implementations, such as software based matching, can be used, a TCAM implementation has the benefit that every TCAM element is evaluated for a match during the same cycle. Thus, as the following experiments show, it takes the same amount of machine time to compare data against a TCAM with one database element in it as it does to compare it to a database with 100,000 elements.
8. Performance: Parallel Database Access
This section presents two experiments that demonstrate parallel performance benefits when using packetC high-level database constructs. Both experiments used a CloudShield CS-2000 chassis [15] with a DPPM-800 10 Gigabit Ethernet blade hosting the packetC application. The DPPM-800 contains an Intel Corporation® IXP 2800 NPU, custom Xilinx, Inc.® Virtex® 5 FPGAs and Netlog-ic, Inc.® NSE 5512 TCAM chips to implement the databases. We used an IXIA® X16 traffic generator to generate network traffic at 10 gigabits per second (Gbps) and roughly 14 million packets per second.
8.1 Experiment 1: Dynamic Table of Traffic Flows
Traffic flows or packet flows are a related sequence of packets that form a coherent communication from a source to a destination across a network. The first experimental application builds a large database dynamically, populated with 5-tuple records that each characterize a traffic flow that has been encountered. (A network tuple for tracking flows is typically constructed from several fields of standard protocol headers).
First, we define a structure type with the desired tuple information, in this case drawn from the packets' IPv4 and Transmission Control Protocol (TCP) header fields.
struct ipv4Tuple {
int scrAddr;
int destAddr;
short srcPort;
short destPort;
byte protocol;
};
We then define a database of such structures and a record with this e base type to facilitate entering new elements into the database. We tested databases initialized to have 10, 100, 1,000, 10,000 and 100,000 elements.
database ipv4Tuple flowTable[100000];
recordipv4Tuple flow;
As a packet arrives, the program copy searches the database to determine whether the flow to which the packet belongs has already been entered into the database. If not, a database record to represent this new flow is created and added. Since constructs are as important as performance to our discussion, the entire application, sans code already presented, follows.
packet module flowtrack;
#include "cloudshield.ph"
#include "protocols.ph" // define headers
// structure, database and record decls
// … <snip>
// Application watch variables:
int packetCount, rowNum, recordMatch;
int noMatch, numRows, tableFull;
void main($PACKET pkt, $PIB pib, $SYS sys)
{
packetCount++;
// Build record, using predefined ‘ipv4’
// & ‘tcp’ descriptors from “protocols.h”
flow.data.scrAddr = ipv4.sourceAddress;
flow.data.destAddr =
ipv4.destinationAddress;
flow.data.srcPort = tcp.sourcePort;
flow.data.destPort = tcp.destinationPort;
flow.data.protocol = ipv4.protocol;
// search for flow in table
try {
ipv4Tuple fl;
fl = flow.data;
rowNum = flowTable.match( fl );
recordMatch++;
}
catch ( ERR_DB_NOMATCH ) {
noMatch++;
// insert flow into flow table
try {
flowTable.insert( flow );
numRows++;
}
catch ( ERR_DB_FULL ) {
tableFull++;
// call CAM clean (hypothetical)
}
}
pib.action = FORWARD_PACKET;
}
The experiment applied traffic containing multiple flows to the application at the maximum rate possible for a 10 gigabit Ethernet interface. We used tables of differentsizes and traffic containing differing numbers of flows, including test runs that used a table size of 100,000 elements and automatically-generated network traffic containing more than 100,000 flows.
Under these conditions, the database eventually becomes full at 100,000 flow records. Encountering additional flows then results in incrementing the tableFull count, while the matching and missing counters continue to increment as appropriate. A more realistic application might include a CAM clean function to manage table overflow by deleting elements on the basis of age.
Fig. 8 depicts some aspects of the experiment's performance that illustrate truisms about applying TCAM parallelism to this kind of network application. Since the TCAM searches all its elements in parallel, it takes the same amount of time to search a database with 100,000 entries as it does to search one with 10. (Note that TCAMs may have 256K to 512K elements).
Fig 8(b) shows that this system's increases in output match increases in input speed until around 3.9 Mpps (million packets per second), when its capacity is reached. After it is saturated, the system's output remains constant, i.e., this particular system configuration (including the application and system software tuning) cannot exceed 3.9 Mpps for this kind of network traffic.
The practical performance result is that a high-level language flow-tracking application can track 100,000 flows with no packet loss up to 2.26 Gbps (assuming 72-byte packets) and over 3,900,000 packets per second processed on this particular system. This behavior is independent of whether input packets match existing TCAM hit contents or not and independent of table overflow conditions.
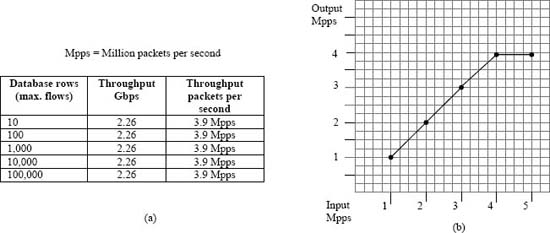
Figure 8. Flow matching performance statistics showing truisms: (a) Throughput is independent of the percentage of TCAM contents used. (b) Once the network device's capacity is reached, output is constant. Copyright CloudShield Technologies, 2010.
8.2 Experiment 2: Access Control and Subnets
This experiment's packetC application uses a small, statically-defined database to enforce network usage policies. Specifically, three subnets are defined as follows:
- 192.168.100.x - legally sanctioned intranet; traffic is allowed to flow between hosts on this subnet.
- 192.168.200.x - is a known rogue network. Traffic detected on this subnet is redirected to a special "capture port".
- All other traffic - is not allowed by policy and is dropped
Since packetC's high-level attributes are a key interest, the source code is shown below (although port-steering logic based on network topology is omitted for clarity).
packet module accessControl;
#include "cloudshield.ph"
#include "protocols.ph"
struct ipv4Tuple {
int scrAddr;
int destAddr;
};
database ipv4Tuple flowTable[2] =
{{{192.168.100.0,192.168.100.0},
{255.255.255.0, 255.255.255.0}},
{{192.168.200.0, 192.168.200.0},
{255.255.255.0, 255.255.255.0}}};
record ipv4Tuple flow;
int disallowedPackets;
int roguePackets;
int totalPackets;
int rowNum;
const int capturePort = 4;
void main($PACKET pkt, $PIB pib, $SYS sys)
{
totalPackets++;
// build record
flow.data.scrAddr =
ipv4.sourceAddress;
flow.data.destAddr =
ipv4.destinationAddress;
// search for flow in table
try {
ipv4Tuple fl;
fl = flow.data;
rowNum = flowTable.match( fl );
// Action table
switch (rowNum) {
case 0:
allowedPackets++;
pib.action = FORWARD_PACKET;
break;
case 1:
roguePackets++;
sys.outPort = capturePort;
pib.action = FORWARD_PACKET;
break;
default:
disallowedPackets++;
pib.action = DROP_PACKET;
break;
}
}
catch ( ERR_DB_NOMATCH ) {
disallowedPackets++;
pib.action = DROP_PACKET;
}
}
We made test runs at 1, 2, 3, 4, 5, 6 and 7 Mpps, using tens of millions of packets per test (Fig 9.a). As Fig. 9.b shows, system output speed kept pace with system input until a 5 Mpps speed was reached with 72-byte packets.
The application was able to track flows, make access policy decisions and take associated actions with no packet loss until capacity is reached at 5 Mpps.
Both tests are unusually brief for network applications, although we are not showing a large include file with enumeration and structure declarations for standard network protocols (e.g., IPv4, IPv6, TCP, etc.). Still, the unique portions written for the applications are concise. The performance exhibited is reasonably typical for the current state of the art. Important ways in which the applications and their performance compare with the norm are discussed in the next section.
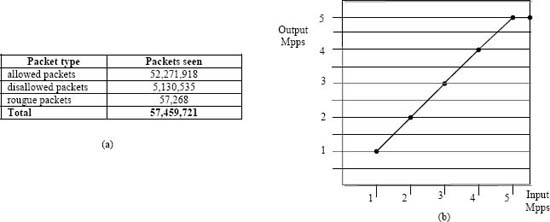
Figure 9. Access Control experiment: (a) Test run with tens of millions of packets, (b) The system becomes oversubscribed at 5 Mpps.
We believe the value of packetC and our implementation of its table-lookup operations consists of
- High-level language constructs to express table structure and masked table look-up in a natural way.
- Portable table constructs that can be mapped to a variety of chips or to algorithmic implementations.
- An effective TCAM implementation that does not constrai developers to use predefined vendor templates for a few flow representations.
The source code shown for the two experiments is understandable to readers who are largely unfamiliar with network applications. The indexing syntax used with databases is intuitive. Automatic mirroring of databases and records into “data” and “mask” portions provides valuable flexibility in matching (e.g., in wildcarding flow data).
We report performance in the 2-10Gbps range, state-of-the-practice commercial performance, achieved with high-level programming. To our best knowledge, there are no comparable C-dialect extensions. As a commercial product; packetC's natural rivals are our Silicon Valley peers' predefined TCAM templates or vendor-specific application programming interfaces (APIs) that are often veiled by non-disclosure agreements.
We are not arguing whether TCAM is the most effective form of packet processing parallelism [17]. Our intent is to show that intuitive type and operator extensions to a high-level, non-proprietary language can deliver state-of-the-practice parallel performance. The results show that our implementation, which executes micro-coded interpreters on NPUs, harnesses parallelism, promotes portability and facilitates transparently swapping out specialized chips in a heterogeneous processing environment.
Peder Jungck, Dwight Mulcahy and Ralph Duncan are the co-authors of the packetC language. Gary Oblock and Matt White contributed to language and compiler development. Andy Norton, Greg Triplett, Kai Chang, Mary Pham, Alfredo Chorro-Rivas and Minh Nguyen provided valuable help.
[1] “Network Processor Design, Vol. 3: Issues and Practices,” M. Franklin, P. Crowley, H. Hadimioglu, P. Onufryk, eds., Morgan Kaufmann Publishers, San Francisco, California, 2005.
[2] R. Duncan and P. Jungck. packetC language for high performance packet processing. In Proceedings of the 11th IEEE Intl. Conf. High Performance Computing and Communications, (Seoul, South Korea), pp. 450-457, June 25-27, 2009.
[3] W. Wu, “Packet Forwarding Technologies,” Auerbach Publications, New York, 2008, Chapter 9.
[4] G. Lawton, Routing faces dramatic changes. Computer, 42(9), 15-17, 2009.
[5] Intel Microengine C Compiler Language Support: Reference Manual. Intel Corporation, order number 278426-004, August 10, 2001.
[6] L. George and M. Blume. Taming the IXP network processor. In Proceedings of the ACM SIGPLAN '03 Conference on Programming Language Design and Implementation, San Diego, California, USA, ACM, pp. 26-37, June 2003.
[7] J. Wagner and R. Leupers: C compiler design for a network processor. IEEE Trans. on CAD, 20(11): 1-7, 2001.
[8] F. Baboescu, S. Singh and M. Varghese. Packet Classification for Core Routers: Is there an alternative to CAMs?. In Proceedings of the 22nd Annual Joint Conference of .the IEEE Computer and Communications. IEEE Societies., Vol 1, pp. 53-63., March 30-April 3, 2003.
[9] D. Liu, Z. Chen, B. Hua, N. Yu, and X. Tang: High-performance packet classification algorithm for multithreaded IXP network processor. ACM Trans. on Embedded Computing Systems, 7(2), article 16, February, 2008.
[10] Cisco Systems, Inc., “Configuring SDM Templates,” in Catalyst 3750 Switch Software Configuration Guide, Rel. 12.1(19) EA1, available at http://www.cisco.com/en/US/docs/switches/lan/catalyst-3750/software/release/12.1_19_ea1/configuration/guide/swsdm.-html, retrieved January 25, 2010.
[11] Cisco Systems, Inc. “Understanding ACL on Catalyst 6500 Series Switches,” available at http://www.cisco.com/en/US/products/hw-/switches/ps708/products_white_paper09186a00800c9470.shtml, retrieved on January 25, 2010.
[12] Cisco Systems, Inc. “The Cisco QuantumFlow Processor: Cisco's Next Generation Network Processor,” commercial datasheet, esp. pp. 4-7, available at http://www.cisco.com/en/US/prod-/collateral-/routers/ps9343/solution_overview_c22-448936.html, 2008., retrieved January 25, 2010.
[13] Cisco Systems, Inc. “Cisco ASR 1000 Series Aggregation Service Routers: A New Paradigm for the Enterprise WAN,” product brochure, esp. page. 4, available at http://www.cisco.com/en/US/prod-/collateral/routers/ps9343/brochure_c02-450721_ps9343_-Products_Brochure.html, 2008-2009, retrieved January 25, 2010.
[14] International Organization for Standardization (ISO) 7498. Open Systems Interconnections (OSI) reference model, 1983.
[15] CloudShield Technologies. CS-2000 Technical Specifications. Product datasheet available from CloudShield Technologies, 212 Gibraltar Dr., Sunnyvale, CA, USA 94089, 2006.
[16] R. Duncan, P. Jungck and K. Ross. A paradigm for processing network protocols in parallel. Proceedings of the 10th Intl. Conf. on Algorithms and Architectures for Parallel Processing, (Busan, South Korea), pp. 52-67, May 21-23, 2010.
[17] F. Baboescu, S. Singh, G. Varghese. Packet classification for core routers: is there an alternative to CAMs? Proceedings of the IEEE Infocom Conference, (San Francisco, California), April 2003.
R. Duncan, P. Jungck, and K. Ross. “packetC language and parallel processing of masked databases.” Proceedings of the 39th Intl. Conf. on Parallel Processing (San Diego, CA), September 13–16, 2010, pp. 472–481. Reprinted with permission from the IEEE.