
![]()
Collections and Generics
There is scarcely even a code sample that doesn’t use a collection such as a List<T> or a Dictionary <K,V>. Large applications may have hundreds of thousands of collection instances in concurrent use. Selecting the right collection type for your needs — or trying to do better by writing your own — can provide significant performance benefits to many applications. Because as of .NET 2.0, collections are intimately linked with the CLR implementation of generic types, we begin our discussion with generics.
Often enough the need arises to create a class or method that can work equally well with any data type. Polymorphism and inheritance can help only to a certain extent; a method that requires complete genericity of its parameters is forced to work with System.Object, which leads to the two primary problems of generic programming in .NET prior to .NET 2.0:
- Type safety: how to verify operations on generic data types at compile-time and explicitly prohibit anything that may fail at runtime?
- No boxing: how to avoid boxing value types when the method’s parameters are System.Object references?
These are no small problems. To see why, consider the implementation of one of the simplest collections in .NET 1.1, the ArrayList. The following is a trivialized implementation that nonetheless exhibits the problems alluded above:
public class ArrayList : IEnumerable, ICollection, IList, ... {
private object[] items;
private int size;
public ArrayList(int initialCapacity) {
items = new object[initialCapacity];
}
public void Add(object item) {
if (size < items.Length – 1) {
items[size] = item;
++size;
} else {
//Allocate a larger array, copy the elements, then place ‘item’ in it
}
}
public object this[int index] {
get {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
return items[index];
}
set {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
items[index] = value;
}
}
//Many more methods omitted for brevity
}
We have highlighted throughout the code all the occurrences of System.Object, which is the “generic” type on which the collection is based. Although this may appear to be a perfectly valid solution, actual usage is not quite so flawless:
ArrayList employees = new ArrayList(7);
employees.Add(new Employee(“Kate”));
employees.Add(new Employee(“Mike”));
Employee first = (Employee)employees[0];
This ugly downcast to Employee is required because the ArrayList does not retain any information about the type of elements in it. Furthermore, it does not constrain objects inserted into it to have any common traits. Consider:
employees.Add(42); //Compiles and works at runtime!
Employee third = (Employee)employees[2]; //Compiles and throws an exception at runtime...
Indeed, the number 42 does not belong in a collection of employees, but nowhere did we specify that the ArrayList is restricted to instances of a particular type. Although it is possible to create an ArrayList implementation that restricts its items to a particular type, this would still be a costly runtime operation and a statement like employees.Add(42) would not fail to compile.
This is the problem of type safety; “generic” collections based on System.Object cannot guarantee compile-time type safety and defer all checks (if any) to runtime. However, this could be the least of our concerns from a performance viewpoint — but it turns out that there is a serious performance problem where value types are involved. Examine the following code, which uses the Point2D struct from Chapter 3 (a simple value type with X and Y integer coordinates):
ArrayList line = new ArrayList(1000000);
for (int i = 0; i < 1000000; ++i) {
line.Add(new Point2D(i, i));
}
Every instance of Point2D inserted to the ArrayList is boxed, because its Add method accepts a reference type parameter (System.Object). This incurs the cost of 1,000,000 heap allocations for boxed Point2D objects. As we have seen in Chapter 3, on a 32-bit heap 1,000,000 boxed Point2D objects would occupy 16,000,000 bytes of memory (compared to 8,000,000 bytes as plain value types). Additionally, the items reference array inside the ArrayList would have at least 1,000,000 references, which amounts to another 4,000,000 bytes — a total of 20,000,000 bytes (see Figure 5-1) where 8,000,000 would suffice. Indeed, this is the exact same problem which led us to abandon the idea of making Point2D a reference type; ArrayList forces upon us a collection that works well only with reference types!
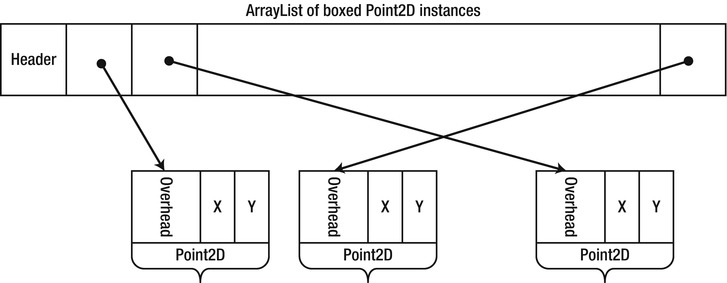
Figure 5-1 . An ArrayList that contains boxed Point2D objects stores references which occupy extra memory and forces the Point2D objects to be boxed on the heap, which adds overhead to them as well
Is there any room for improvement? Indeed, we could write a specialized collection for two-dimensional points, as follows (although we would also have to come up with specialized IEnumerable, ICollection, and IList interfaces for points...). It is exactly identical to the “generic” ArrayList, but has Point2D wherever we previously had object:
public class Point2DArrayList : IPoint2DEnumerable, IPoint2DCollection, IPoint2DList, ... {
private Point2D[] items;
private int size;
public ArrayList(int initialCapacity) {
items = new Point2D[initialCapacity];
}
public void Add(Point2D item) {
if (size < items.Length – 1) {
items[size] = item;
++size;
} else {
//Allocate a larger array, copy the elements, then place ‘item’ in it
}
}
public Point2D this[int index] {
get {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
return items[index];
}
set {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
items[index] = value;
}
}
//Many more methods omitted for brevity
}
A similar specialized collection for Employee objects would address the type safety problem we have considered earlier. Unfortunately, it is hardly practical to develop a specialized collection for every data type. This is precisely the role of the language compiler as of .NET 2.0 — to allow generic data types in classes and methods while achieving type safety and doing away with boxing.
.NET Generics
Generic classes and methods allow real generic code, which does not fall back to System.Object on the one hand and does not require specialization for each data type on the other hand. The following is a sketch of a generic type, List<T>, which replaces our previous ArrayList experiment and addresses both the type safety and boxing concerns:
public class List<T> : IEnumerable<T>, ICollection<T>, IList<T>, ... {
private T[] items;
private int size;
public List(int initialCapacity) {
items = new T[initialCapacity];
}
public void Add(T item) {
if (size < items.Length – 1) {
items[size] = item;
++size;
} else {
//Allocate a larger array, copy the elements, then place ‘item’ in it
}
}
public T this[int index] {
get {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
return items[index];
}
set {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
items[index] = value;
}
}
//Many more methods omitted for brevity
}
![]() Note If you are not familiar at all with the syntax of C# generics, Jon Skeet’s “C# in Depth” (Manning, 2010) is a good textbook. Through the rest of this chapter we assume you have written a generic class or at least consumed generic classes, such as the .NET Framework’s collections.
Note If you are not familiar at all with the syntax of C# generics, Jon Skeet’s “C# in Depth” (Manning, 2010) is a good textbook. Through the rest of this chapter we assume you have written a generic class or at least consumed generic classes, such as the .NET Framework’s collections.
If you have ever written a generic class or method, you know how easy it is to convert pseudo-generic code based on System.Object instances to truly generic code, with one or more generic type parameters. It is also exceptionally easy to use generic classes and methods by substituting generic type arguments where necessary:
List<Employee> employees = new List<Employee>(7);
employees.Add(new Employee(“Kate”));
Employee first = employees[0]; //No downcast required, completely type-safe
employees.Add(42); //Does not compile!
List<Point2D> line = new List<Point2D>(1000000);
for (int i = 0; i < 1000000; ++i) {
line.Add(new Point2D(i, i)); //No boxing, no references stored
}
Almost magically, the generic collection is type safe (in that it does not allow inappropriate elements to be stored in it) and requires no boxing for value types. Even the internal storage — the items array — adapts itself accordingly to the generic type argument: when T is Point2D, the items array is a Point2D[], which stores values and not references. We will unfold some of this magic later, but for now we have an effective language-level solution for the basic problems of generic programming.
This solution alone appears to be insufficient when we require some additional capabilities from the generic parameters. Consider a method that performs a binary search in a sorted array. A completely generic version of it would not be capable of doing the search, because System.Object is not equipped with any comparison-related facilities:
public static int BinarySearch<T>(T[] array, T element) {
//At some point in the algorithm, we need to compare:
if (array[x] < array[y]) {
...
}
}
System.Object does not have a static operator < , which is why this method simply fails to compile! Indeed, we have to prove to the compiler that for every generic type argument we provide to the method, it will be able to resolve all method calls (including operators) on it. This is where generic constraints enter the picture.
Generic constraints indicate to the compiler that only some types are allowed as generic type arguments when using a generic type. There are five types of constraints:
//T must implement an interface:
public int Format(T instance) where T : IFormattable {
return instance.ToString(“N”, CultureInfo.CurrentUICulture);
//OK, T must have IFormattable.ToString(string, IFormatProvider)
}
//T must derive from a base class:
public void Display<T>(T widget) where T : Widget {
widget.Display(0, 0);
//OK, T derives from Widget which has the Display(int, int) method
}
//T must have a parameterless constructor:
public T Create<T>() where T : new() {
return new T();
//OK, T has a parameterless constructor
//The C# compiler compiles ’new T()’ to a call to Activator.CreateInstance<T>(),
//which is sub-optimal, but there is no IL equivalent for this constraint
}
//T must be a reference type:
public void ReferencesOnly<T>(T reference) where T : class
//T must be a value type:
public void ValuesOnly<T>(T value) where T : struct
If we revisit the binary search example, the interface constraint proves to be very useful (and indeed, it is the most often used kind of constraint). Specifically, we can require T to implement IComparable, and compare array elements using the IComparable.CompareTo method. However, IComparable is not a generic interface, and its CompareTo method accepts a System.Object parameter, incurring a boxing cost for value types. It stands to reason that there should be a generic version of IComparable, IComparable<T>, which serves here perfectly:
//From the .NET Framework:
public interface IComparable<T> {
int CompareTo(T other);
}
public static int BinarySearch<T>(T[] array, T element) where T : IComparable<T> {
//At some point in the algorithm, we need to compare:
if (array[x].CompareTo(array[y]) < 0) {
...
}
}
This binary search version does not incur boxing when comparing value type instances, works with any type that implements IComparable<T> (including all the built-in primitive types, strings, and many others), and is completely type safe in that it does not require runtime discovery of comparison capabilities.
INTERFACE CONSTRAINTS AND IEQUATABLE<T>
In Chapter 3 we have seen that a critical performance optimization for value types is to override the Equals method and implement the IEquatable<T> interface. Why is this interface so important? Consider the following code:
public static void CallEquals<T>(T instance) {
instance.Equals(instance);
}
The Equals call inside the method defers to a virtual call to Object.Equals, which accepts a System.Object parameter and causes boxing on value types. This is the only alternative that the C# compiler considers guaranteed to be present on every T we use. If we want to convince the compiler that T has an Equals method that accepts T, we need to use an explicit constraint:
//From the .NET Framework:
public interface IEquatable<T> {
bool Equals(T other);
}
public static void CallEquals<T>(T instance) where T : IEquatable<T> {
instance.Equals(instance);
}
Finally, you might want to allow callers to use any type as T, but defer to the IEquatable<T> implementation if T provides it, because it does not require boxing and is more efficient. What List<T> does in this regard is fairly interesting. If List<T> required an IEquatable<T> constraint on its generic type parameter, it wouldn’t be useful for types that don’t implement that interface. Therefore, List<T> does not have an IEquatable<T> constraint. To implement the Contains method (and other methods that require comparing objects for equality), List<T> relies on an equality comparer—a concrete implementation of the abstract EqualityComparer<T> class (which, incidentally, implements the IEqualityComparer<T> interface, used directly by some collections, including HashSet<T> and Dictionary<K,V>).
When List<T>.Contains needs to invoke Equals on two elements of the collection, it uses the EqualityComparer<T>.Default static property to retrieve an equality comparer implementation suitable for comparing instances of T, and calls its Equals(T, T) virtual method. It’s the EqualityComparer<T>.CreateComparer private static method that creates the appropriate equality comparer the first time it’s requested and subsequently caches it in a static field. When CreateComparer sees that T implements IEquatable<T>, it returns an instance of GenericEqualityComparer<T>, which has an IEquatable<T> constraint and invokes Equals through the interface. Otherwise, CreateComparer resorts to the ObjectEqualityComparer<T> class, which has no constraints on T and invokes the Equals virtual method provided by Object.
This trick employed by List<T> for equality checking can be useful for other purposes as well. When a constraint is available, your generic class or method can use a potentially more efficient implementation that does not resort to runtime type checking.
![]() Tip As you see, there are no generic constraints to express mathematical operators, such as addition or multiplication. This means that you can’t write a generic method that uses an expression such as a+b on generic parameters. The standard solution for writing generic numeric algorithms is to use a helper struct that implements an IMath<T> interface with the required arithmetic operations, and instantiate this struct in the generic method. For more details, see Rüdiger Klaehn’s CodeProject article, “Using generics for calculations,” available at http://www.codeproject.com/Articles/8531/Using-generics-for-calculations).
Tip As you see, there are no generic constraints to express mathematical operators, such as addition or multiplication. This means that you can’t write a generic method that uses an expression such as a+b on generic parameters. The standard solution for writing generic numeric algorithms is to use a helper struct that implements an IMath<T> interface with the required arithmetic operations, and instantiate this struct in the generic method. For more details, see Rüdiger Klaehn’s CodeProject article, “Using generics for calculations,” available at http://www.codeproject.com/Articles/8531/Using-generics-for-calculations).
Having examined most syntactic features of generics in C#, we turn to their runtime implementation. Before we can concern ourselves with this matter, it’s paramount to ask whether there is a runtime representation of generics — as we will see shortly, C++ templates, a similar mechanism, have no runtime representation to speak of. This question is easily answered if you look at the wonders Reflection can do with generic types at runtime:
Type openList = typeof(List<>);
Type listOfInt = openList.MakeGenericType(typeof(int));
IEnumerable<int> ints = (IEnumerable<int>)Activator.CreateInstance(listOfInt);
Dictionary<string, int> frequencies = new Dictionary<string, int>();
Type openDictionary = frequencies.GetType().GetGenericTypeDefinition();
Type dictStringToDouble = openDictionary.MakeGenericType(typeof(string), typeof(double));
As you see, we can dynamically create generic types from an existing generic type and parameterize an “open” generic type to create an instance of a “closed” generic type. This demonstrates that generics are first-class citizens and have a runtime representation, which we now survey.
Implementation of CLR Generics
The syntactic features of CLR generics are fairly similar to Java generics and even slightly resemble C++ templates. However, it turns out that their internal implementation and the limitations imposed upon programs using them are very different from Java and C++. To understand these differences we should briefly review Java generics and C++ templates.
A generic class in Java can have generic type parameters, and there is even a constraint mechanism quite similar to what .NET has to offer (bounded type parameters and wildcards). For example, here’s a first attempt to convert our List<T> to Java:
public class List<E> {
private E[] items;
private int size;
public List(int initialCapacity) {
items = new E[initialCapacity];
}
public void Add(E item) {
if (size < items.Length – 1) {
items[size] = item;
++size;
} else {
//Allocate a larger array, copy the elements, then place ‘item’ in it
}
}
public E getAt(int index) {
if (index < 0 || index >= size) throw IndexOutOfBoundsException(index);
return items[index];
}
//Many more methods omitted for brevity
}
Unfortunately, this code does not compile. Specifically, the expression new E[initialCapacity] is not legal in Java. The reason has to do with the way Java compiles generic code. The Java compiler removes any mentions of the generic type parameter and replaces them with java.lang.Object, a process called type erasure. As a result, there is only one type at runtime — List, the raw type — and any information about the generic type argument provided is lost. (To be fair, by using type erasure Java retains binary compatibility with libraries and applications that were created before generics — something that .NET 2.0 does not offer for .NET 1.1 code.)
Not all is lost, though. By using an Object array instead, we can reconcile the compiler and still have a type-safe generic class that works well at compilation time:
public class List<E> {
private Object[] items;
private int size;
public void List(int initialCapacity) {
items = new Object[initialCapacity];
}
//The rest of the code is unmodified
}
List<Employee> employees = new List<Employee>(7);
employees.Add(new Employee(“Kate”));
employees.Add(42); //Does not compile!
However, adopting this approach in the CLR voices a concern: what is to become of value types? One of the two reasons for introducing generics was that we wanted to avoid boxing at any cost. Inserting a value type to an array of objects requires boxing and is not acceptable.
Compared to Java generics, C++ templates may appear enticing. (They are also extremely powerful: you may have heard that the template resolution mechanism in itself is Turing-complete.) The C++ compiler does not perform type erasure — quite the opposite — and there’s no need for constraints, because the compiler is happy to compile whatever you throw in its way. Let’s start with the list example, and then consider what happens with constraints:
template <typename T>
class list {
private:
T* items;
int size;
int capacity;
public:
list(int initialCapacity) : size(0), capacity(initialCapacity) {
items = new T[initialCapacity];
}
void add(const T& item) {
if (size < capacity) {
items[size] = item;
++size;
} else {
//Allocate a larger array, copy the elements, then place ‘item’ in it
}
}
const T& operator[](int index) const {
if (index < 0 || index >= size) throw exception(“Index out of bounds”);
return items[index];
}
//Many more methods omitted for brevity
};
The list template class is completely type-safe: every instantiation of the template creates a new class that uses the template definition as a... template. Although this happens under the hood, here is an example of what it could look like:
//Original C++ code:
list<int> listOfInts(14);
//Expanded by the compiler to:
class __list__int {
private:
int* items;
int size;
int capacity;
public:
__list__int(int initialCapacity) : size(0), capacity(initialCapacity) {
items = new int[initialCapacity];
}
};
__list__int listOfInts(14);
Note that the add and operator[] methods were not expanded — the calling code did not use them, and the compiler generates only the parts of the template definition that are used for the particular instantiation. Also note that the compiler does not generate anything from the template definition; it waits for a specific instantiation before it produces any code.
This is why there is no need for constraints in C++ templates. Returning to our binary search example, the following is a perfectly reasonable implementation:
template <typename T>
int BinarySearch(T* array, int size, const T& element) {
//At some point in the algorithm, we need to compare:
if (array[x] < array[y]) {
...
}
}
There’s no need to prove anything to the C++ compiler. After all, the template definition is meaningless; the compiler waits carefully for any instantiations:
int numbers[10];
BinarySearch(numbers, 10, 42); //Compiles, int has an operator <
class empty {};
empty empties[10];
BinarySearch(empties, 10, empty()); //Does not compile, empty does not have an operator <
Although this design is extremely tempting, C++ templates have unattractive costs and limitations, which are undesirable for CLR generics:
- Because the template expansion occurs at compile-time, there is no way to share template instantiations between different binaries. For example, two DLLs loaded into the same process may have separate compiled versions of list<int>. This consumes a large amount of memory and causes long compilation times, by which C++ is renowned.
- For the same reason, template instantiations in two different binaries are considered incompatible. There is no clean and supported mechanism for exporting template instantiations from DLLs (such as an exported function that returns list<int>).
- There is no way to produce a binary library that contains template definitions. Template definitions exist only in source form, as header files that can be #included into a C++ file.
After giving ample consideration to the design of Java generics C++ templates, we can understand better the implementation choice for CLR generics. CLR generics are implemented as follows. Generic types — even open ones, like List<> — are first-class runtime citizens. There is a method table and an EEClass (see Chapter 3) for each generic type and a System.Type instance can be produced as well. Generic types can be exported from assemblies and only a single definition of the generic type exists at compile-time. Generic types are not expanded at compile-time, but as we have seen the compiler makes sure that any operation attempted on generic type parameter instances is compatible with the specified generic constraints.
When the CLR needs to create an instance of a closed generic type, such as List<int>, it creates a method table and EEClass based on the open type. As always, the method table contains method pointers, which are compiled on the fly by the JIT compiler. However, there is a crucial optimization here: compiled method bodies on closed generic types that have reference type parameters can be shared. To digest this, let’s consider the List<T>.Add method and try to compile it to x86 instructions when T is a reference type:
//C# code:
public void Add(T item) {
if (size < items.Length – 1) {
items[size] = item;
++size;
} else {
AllocateAndAddSlow(item);
}
}
; x86 assembly when T is a reference type
; Assuming that ECX contains ‘this’ and EDX contains ‘item’, prologue and epilogue omitted
mov eax, dword ptr [ecx+4] ; items
mov eax, dword ptr [eax+4] ; items.Length
dec eax
cmp dword ptr [ecx+8], eax ; size < items.Length - 1
jge AllocateAndAddSlow
mov eax, dword ptr [ecx+4]
mov ebx, dword ptr [ecx+8]
mov dword ptr [eax+4*ebx+4], edx ; items[size] = item
inc dword ptr [eax+8] ; ++size
It’s clear that the method’s code does not depend on T in any way, and will work exactly as well for any reference type. This observation allows the JIT compiler to conserve resources (time and memory) and share the method table pointers for List<T>.Add in all method tables where T is a reference type.
![]() Note This idea requires some further refinement, which we will not carry out. For example, if the method’s body contained a new T[10] expression, it would require a separate code path for each T, or at least a way of obtaining T at runtime (e.g., through an additional hidden parameter passed to the method). Additionally, we haven’t considered how constraints affect the code generation — but you should be convinced by now that invoking interface methods or virtual methods through base classes requires the same code regardless of the type.
Note This idea requires some further refinement, which we will not carry out. For example, if the method’s body contained a new T[10] expression, it would require a separate code path for each T, or at least a way of obtaining T at runtime (e.g., through an additional hidden parameter passed to the method). Additionally, we haven’t considered how constraints affect the code generation — but you should be convinced by now that invoking interface methods or virtual methods through base classes requires the same code regardless of the type.
The same idea does not work for value types. For example, when T is long, the assignment statement items[size] = item requires a different instruction, because 8 bytes must be copied instead of 4. Even larger value types may even require more than one instruction; and so on.
To demonstrate Figure 5-2 in a simple setting, we can inspect using SOS the method tables of closed generic types that are all realizations of the same open generic type. For example, consider a BasicStack<T> class with only Push and Pop methods, as follows:
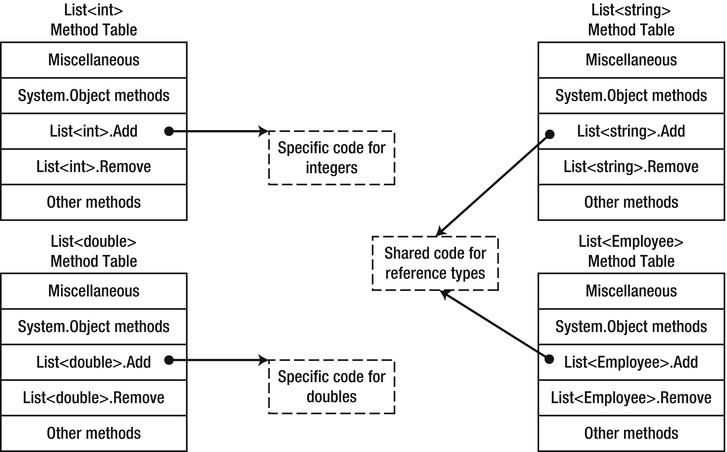
Figure 5-2 . The Add method table entries for reference type realizations of List<T> have shared pointers to a single method implementation, whereas the entries for value type realizations have separate versions of the code
class BasicStack<T> {
private T[] items;
private int topIndex;
public BasicStack(int capacity = 42) {
items = new T[capacity];
}
public void Push(T item) {
items[topIndex++] = item;
}
public T Pop() {
return items[--topIndex];
}
}
The method tables for BasicStack<string>, BasicStack<int[]>, BasicStack<int>, and BasicStack<double> are listed below. Note that the method table entries (i.e. code addresses) for the closed types with a reference type generic type argument are shared, and for the value types are not:
0:004> !dumpheap –stat
...
00173b40 1 16 BasicStack`1[[System.Double, mscorlib]]
00173a98 1 16 BasicStack`1[[System.Int32, mscorlib]]
00173a04 1 16 BasicStack`1[[System.Int32[], mscorlib]]
001739b0 1 16 BasicStack`1[[System.String, mscorlib]]
...
0:004> !dumpmt -md 001739b0
EEClass: 001714e0
Module: 00172e7c
Name: BasicStack`1[[System.String, mscorlib]]
...
MethodDesc Table
Entry MethodDe JIT Name
...
00260360 00173924 JIT BasicStack`1[[System.__Canon, mscorlib]].Push(System.__Canon)
00260390 0017392c JIT BasicStack`1[[System.__Canon, mscorlib]].Pop()
0:004> !dumpmt -md 00173a04
EEClass: 001714e0
Module: 00172e7c
Name: BasicStack`1[[System.Int32[], mscorlib]]
...
MethodDesc Table
Entry MethodDe JIT Name
...
00260360 00173924 JIT BasicStack`1[[System.__Canon, mscorlib]].Push(System.__Canon)
00260390 0017392c JIT BasicStack`1[[System.__Canon, mscorlib]].Pop()
0:004> !dumpmt -md 00173a98
EEClass: 0017158c
Module: 00172e7c
Name: BasicStack`1[[System.Int32, mscorlib]]
...
MethodDesc Table
Entry MethodDe JIT Name
...
002603c0 00173a7c JIT BasicStack`1[[System.Int32, mscorlib]].Push(Int32)
002603f0 00173a84 JIT BasicStack`1[[System.Int32, mscorlib]].Pop()
0:004> !dumpmt -md 00173b40
EEClass: 001715ec
Module: 00172e7c
Name: BasicStack`1[[System.Double, mscorlib]]
...
MethodDesc Table
Entry MethodDe JIT Name
...
00260420 00173b24 JIT BasicStack`1[[System.Double, mscorlib]].Push(Double)
00260458 00173b2c JIT BasicStack`1[[System.Double, mscorlib]].Pop()
Finally, if we inspect the actual method bodies, it becomes evident that the reference type versions do not depend at all on the actual type (all they do is move references around), and the value type versions do depend on the type. Copying an integer, after all, is different from copying a double floating-point number. Below are the disassembled versions of the Push method, with the line that actually moves the data around highlighted:
0:004> !u 00260360
Normal JIT generated code
BasicStack`1[[System.__Canon, mscorlib]].Push(System.__Canon)
00260360 57 push edi
00260361 56 push push esi
00260362 8b7104 push mov esi,dword ptr [ecx+4]
00260365 8b7908 push mov edi,dword ptr [ecx+8]
00260368 8d4701 push lea eax,[edi+1]
0026036b 894108 push mov dword ptr [ecx+8],eax
0026036e 52 push edx
0026036f 8bce push mov ecx,esi
00260371 8bd7 push mov edx,edi
00260373 e8f4cb3870 push call clr!JIT_Stelem_Ref (705ecf6c)
00260378 5e push pop esi
00260379 5f push pop edi
0026037a c3 push ret
0:004> !u 002603c0
Normal JIT generated code
BasicStack`1[[System.Int32, mscorlib]].Push(Int32)
002603c0 57 push edi
002603c1 56 push esi
002603c2 8b7104 mov esi,dword ptr [ecx+4]
002603c5 8b7908 mov edi,dword ptr [ecx+8]
002603c8 8d4701 lea eax,[edi+1]
002603cb 894108 mov dword ptr [ecx+8],eax
002603ce 3b7e04 cmp edi,dword ptr [esi+4]
002603d1 7307 jae 002603da
002603d3 8954be08 mov dword ptr [esi+edi*4+8],edx
002603d7 5e pop esi
002603d8 5f pop edi
002603d9 c3 ret
002603da e877446170 call clr!JIT_RngChkFail (70874856)
002603df cc int 3
0:004> !u 00260420
Normal JIT generated code
BasicStack`1[[System.Double, mscorlib]].Push(Double)
00260420 56 push esi
00260421 8b5104 mov edx,dword ptr [ecx+4]
00260424 8b7108 mov esi,dword ptr [ecx+8]
00260427 8d4601 lea eax,[esi+1]
0026042a 894108 mov dword ptr [ecx+8],eax
0026042d 3b7204 cmpyg esi,dword ptr [edx+4]
00260430 730c jae 0026043e
00260432 dd442408 fld qword ptr [esp+8]
00260436 dd5cf208 fstp qword ptr [edx+esi*8+8]
0026043a 5e pop esi
0026043b c20800 ret 8
0026043e e813446170 call clr!JIT_RngChkFail (70874856)
00260443 cc int 3
We have already seen that the .NET generics implementation is fully type-safe at compile-time. It only remains to ascertain that there is no boxing cost incurred when using value types with generic collections. Indeed, because the JIT compiler compiles a separate method body for each closed generic type where the generic type arguments are value types, there is no need for boxing.
To summarize, .NET generics offer significant advantages when contrasted with Java generics or C++ templates. The generic constraints mechanism is somewhat limited compared to the Wild West that C++ affords, but the flexibility gains from sharing generic types across assemblies and the performance benefits from generating code on demand (and sharing it) are overwhelming.
The .NET Framework ships with a large number of collections, and it is not the purpose of this chapter to review every one of them — this is a task best left to the MSDN documentation. However, there are some non-trivial considerations that need to be taken into account when choosing a collection, especially for performance-sensitive code. It is these considerations that we will explore throughout this section.
![]() Note Some developers are wary of using any collection classes but built-in arrays. Arrays are highly inflexible, non-resizable, and make it difficult to implement some operations efficiently, but they are known for having the most minimal overhead of any other collection implementation. You should not be afraid of using built-in collections as long as you are equipped with good measurement tools, such as those we considered in Chapter 2. The internal implementation details of the .NET collections, discussed in this section, will also facilitate good decisions. One example of trivia: iterating a List<T> in a foreach loop takes slightly longer than in a for loop, because foreach- enumeration must verify that the underlying collection hasn’t been changed throughout the loop.
Note Some developers are wary of using any collection classes but built-in arrays. Arrays are highly inflexible, non-resizable, and make it difficult to implement some operations efficiently, but they are known for having the most minimal overhead of any other collection implementation. You should not be afraid of using built-in collections as long as you are equipped with good measurement tools, such as those we considered in Chapter 2. The internal implementation details of the .NET collections, discussed in this section, will also facilitate good decisions. One example of trivia: iterating a List<T> in a foreach loop takes slightly longer than in a for loop, because foreach- enumeration must verify that the underlying collection hasn’t been changed throughout the loop.
First, recall the collection classes shipped with .NET 4.5 — excluding the concurrent collections, which we discuss separately — and their runtime performance characteristics. Comparing the insertion, deletion, and lookup performance of collections is a reasonable way to arrive at the best candidate for your needs. The following table lists only the generic collections (the non-generic counterparts were retired in .NET 2.0):
There are several lessons to be learned from collection design, the choice of collections that made the cut to be included in the .NET Framework, and the implementation details of some collections:
- The storage requirements of different collections vary significantly. Later in this chapter we will see how internal collection layout affects cache performance with List<T> and LinkedList<T>. Another example is the SortedSet<T> and List<T> classes; the former is implemented in terms of a binary search tree with n nodes for n elements, and the latter in terms of a contiguous array of n elements. On a 32-bit system, storing n value types of size s in a sorted set requires (20 + s)n bytes of storage, whereas the list requires only sn bytes.
- Some collections have additional requirements of their elements to achieve satisfactory performance. For example, as we have seen in Chapter 3, any implementation of a hash table requires access to a good hash code for the hash table’s elements.
- Amortized O(1) cost collections, when executed well, are hardly distinguishable from true O(1) cost collections. After all, few programmers (and programs!) are wary of the fact that List<T>.Add may sometimes incur a significant memory allocation cost and run for a duration of time that is linear in the number of list elements. Amortized time analysis is a useful tool; it has been used to prove optimality bounds on numerous algorithms and collections.
- The ubiquitous space-time tradeoff is present in collection design and even the choice of which collections to include in the .NET Framework. SortedList<K,V> offers very compact and sequential storage of elements at the expense of linear time insertion and deletion, whereas SortedDictionary<K,V> occupies more space and is non-sequential, but offers logarithmic bounds on all operations.
![]() Note There’s no better opportunity to mention strings, which are also a simple collection type — a collection of characters. Internally, the System.String class is implemented as an immutable, non-resizable array of characters. All operations on strings result in the creation of a new object. This is why creating long strings by concatenating thousands of smaller strings together is extremely inefficient. The System.Text.StringBuilder class addresses these problems as its implementation is similar to List<T>, and doubles its internal storage when it’s mutated. Whenever you need to construct a string from a large (or unknown) number of smaller strings, use a StringBuilder for the intermediate operations.
Note There’s no better opportunity to mention strings, which are also a simple collection type — a collection of characters. Internally, the System.String class is implemented as an immutable, non-resizable array of characters. All operations on strings result in the creation of a new object. This is why creating long strings by concatenating thousands of smaller strings together is extremely inefficient. The System.Text.StringBuilder class addresses these problems as its implementation is similar to List<T>, and doubles its internal storage when it’s mutated. Whenever you need to construct a string from a large (or unknown) number of smaller strings, use a StringBuilder for the intermediate operations.
This richness of collection classes may seem overwhelming, but there are cases when none of the built-in collections is a good fit. We will consider a few examples later. Until .NET 4.0, a common cause of complaint with respect to the built-in collections was the lack of thread safety: none of the collections in Table 5-1 is safe for concurrent access from multiple threads. In .NET 4.0 the System.Collections.Concurrent namespace introduces several new collections designed from the ground up for concurrent programming environments.
Table 5-1. Collections in the .NET Framework
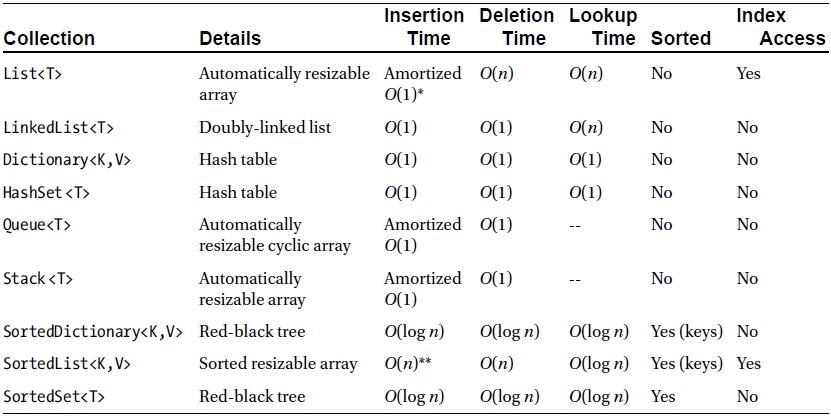
* By “amortized” in this case we mean that there are operations that may take O(n) time, but most operations will take O(1) time, such that the average time across n operations is O(1).
** Unless the data are inserted in sort order, in which case O(1).
With the advent of the Task Parallel Library in .NET 4.0, the need for thread-safe collections became more acute. In Chapter 6 we will see several motivating examples for accessing a data source or an output buffer concurrently from multiple threads. For now, we focus on the available concurrent collections and their performance characteristics in the same spirit of the standard (non-thread-safe) collections we examined earlier.
Table 5-2.Concurrent Collections in the .NET Framework
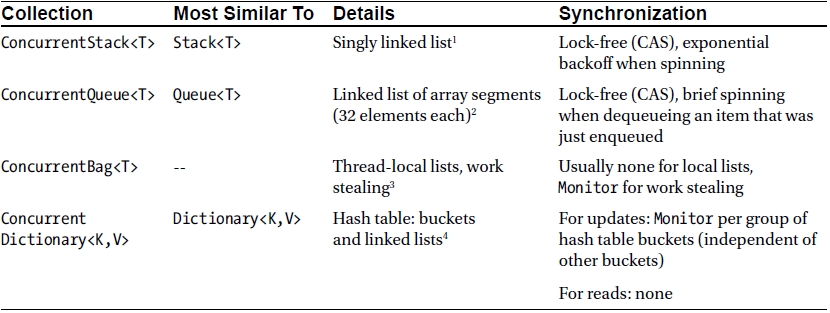
Notes on the “Details” column:
1. In Chapter 6 we will see a sketch implementation of a lock-free stack using CAS, and discuss the CAS atomic primitive on its own merit.
2. The ConcurrentQueue<T> class manages a linked list of array segments, which allows it to emulate an unbounded queue with a bounded amount of memory. Enqueuing or dequeuing items involves only incrementing pointers into array segments. Synchronization is required in several locations, e.g., to ensure that items are not dequeued before the enqueuing thread has completed the enqueue operation. However, all synchronization is CAS-based.
3. The ConcurrentBag<T> class manages a list of items in no specific order. Items are stored in thread-local lists; adding or removing items to a thread-local list is done at the head of the list and usually requires no synchronization. When threads have to steal items from other threads’ lists, they steal from the tail of the list, which causes contention only when there are fewer than three items in the list.
4. ConcurrentDictionary<K,V> uses a classic hash table implementation with chaining (linked lists hanging off each bucket; for a general description of a hash table’s structure, see also Chapter 3). Locking is managed at the bucket level—all operations on a certain bucket require a lock, of which there is a limited amount determined by the constructor’s concurrencyLevel parameter. Operations on buckets that are associated with different locks can proceed concurrently with no contention. Finally, all read operations do not require any locks, because all mutating operations are atomic (e.g., inserting a new item into the list hanging off its bucket).
Although most concurrent collections are quite similar to their non-thread-safe counterparts, they have slightly different APIs that are affected by their concurrent nature. For example, the ConcurrentDictionary<K,V> class has helper methods that can greatly minimize the amount of locks required and address subtle race conditions that can arise when carelessly accessing the dictionary:
//This code is prone to a race condition between the ContainsKey and Add method calls:
Dictionary<string, int> expenses = ...;
if (!expenses.ContainsKey(“ParisExpenses”)) {
expenses.Add(“ParisExpenses”, currentAmount);
} else {
//This code is prone to a race condition if multiple threads execute it:
expenses[“ParisExpenses”] += currentAmount;
}
//The following code uses the AddOrUpdate method to ensure proper synchronization when
//adding an item or updating an existing item:
ConcurrentDictionary<string, int> expenses = ...;
expenses.AddOrUpdate(“ParisExpenses”, currentAmount, (key, amount) => amount + currentAmount);
The AddOrUpdate method guarantees the necessary synchronization around the composite “add or update” operation; there is a similar GetOrAdd helper method that can either retrieve an existing value or add it to the dictionary if it doesn’t exist and then return it.
Choosing the right collection is not only about its performance considerations. The way data are laid out in memory is often more critical to CPU-bound applications than any other criterion, and collections affect this layout greatly. The main factor behind carefully examining data layout in memory is the CPU cache.
Modern systems ship with large main memories. Eight GB of memory is fairly standard on a mid-range workstation or a gaming laptop. Fast DDR3 SDRAM memory units are capable of ∼ 15 ns memory access latencies, and theoretical transfer rates of ∼ 15 GB/s. Fast processors, on the other hand, can issue billions of instructions per second; theoretically speaking, stalling for 15 ns while waiting for memory access can prevent the execution of dozens (and sometimes hundreds) of CPU instructions. Stalling for memory access is the phenomenon known as hitting the memory wall.
To distance applications from this wall, modern processors are equipped with several levels of cache memory, which has different internal characteristics than main memory and tends to be very expensive and relatively small. For example, one of the author’s Intel i7-860 processor ships with three cache levels (see Figure 5-3):
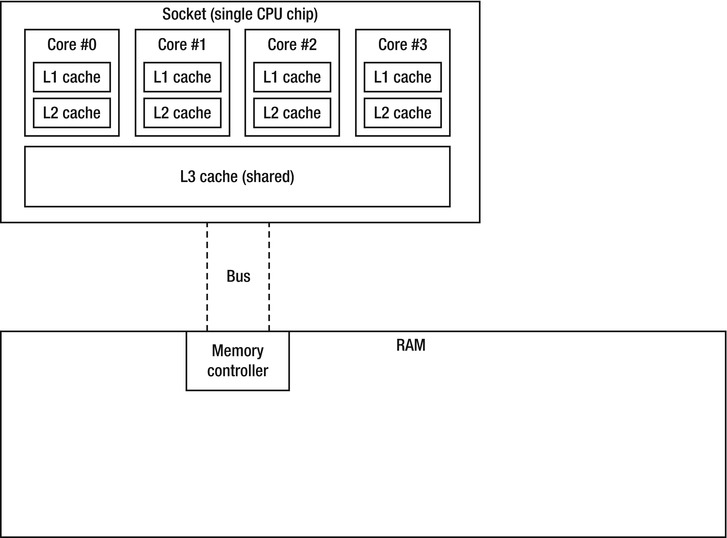
Figure 5-3 . Intel i7-860 schematic of cache, core, and memory relationships
- Level 1 cache for program instructions, 32 KB, one for each core (total of 4 caches).
- Level 1 cache for data, 32 KB, one for each core (total of 4 caches).
- Level 2 cache for data, 256 KB, one for each core (total of 4 caches).
- Level 3 cache for data, 8 MB, shared (total of 1 cache).
When the processor attempts to access a memory address, it begins by checking whether the data is already in its L1 cache. If it is, the memory access is satisfied from the cache, which takes ∼ 5 CPU cycles (this is called a cache hit). If it isn’t, the L2 cache is checked; satisfying the access from the L2 cache takes ∼ 10 cycles. Similarly, satisfying the access from L3 cache takes ∼ 40 cycles. Finally, if the data isn’t in any of the cache levels, the processor will stall for the system’s main memory (this is called a cache miss). When the processor accesses main memory, it reads from it not a single byte or word, but a cache line, which on modern systems consists of 32 or 64 bytes. Accessing any word on the same cache line will not involve another cache miss until the line is evicted from the cache.
Although this description does not do justice to the true hardware complexities of how SRAM caches and DRAM memories operate, it provides enough food for thought and discussion of how our high-level software algorithms can be affected by data layout in memory. We now consider a simple example that involves a single core’s cache; in Chapter 6 we will see that multiprocessor programs can afflict additional performance loss by improperly utilizing the caches of multiple cores.
Suppose the task at hand is traversing a large collection of integers and performing some aggregation on them, such as finding their sum or average. Below are two alternatives; one accesses the data from a LinkedList< int > and the other from an array of integers (int[]), two of the built-in .NET collections.
LinkedList<int> numbers = new LinkedList<int>(Enumerable.Range(0, 20000000));
int sum = 0;
for (LinkedListNode<int> curr = numbers.First; curr != null; curr = curr.Next) {
sum += curr.Value;
}
int[] numbers = Enumerable.Range(0, 20000000).ToArray();
int sum = 0;
for (int curr = 0; curr < numbers.Length; ++curr) {
sum += numbers[curr];
}
The second version of the code runs 2× faster than the first on the system mentioned above. This is a non-negligible difference, and if you only consider the number of CPU instructions issued, you might not be convinced that there should be a difference at all. After all, traversing a linked list involves moving from one node to the next, and traversing an array involves incrementing an index into the array. (In fact, without JIT optimizations, accessing an array element would require also a range check to make sure that the index is within the array’s bounds.)
; x86 assembly for the first loop, assume ‘sum’ is in EAX and ‘numbers’ is in ECX
xor eax, eax
mov ecx, dword ptr [ecx+4] ; curr = numbers.First
test ecx, ecx
jz LOOP_END
LOOP_BEGIN:
add eax, dword ptr [ecx+10] ; sum += curr.Value
mov ecx, dword ptr [ecx+8] ; curr = curr.Next
test ecx, ecx
jnz LOOP_BEGIN ; total of 4 instructions per iteration
LOOP_END:
...
; x86 assembly for the second loop, assume ‘sum’ is in EAX and ‘numbers’ is in ECX
mov edi, dword ptr [ecx+4] ; numbers.Length
test edi, edi
jz LOOP_END
xor edx, edx ; loop index
LOOP_BEGIN:
add eax, dword ptr [ecx+edx*4+8] ; sum += numbers[i], no bounds check
inc edx
cmp esi, edx
jg LOOP_BEGIN ; total of 4 instructions per iteration
LOOP_END:
...
Given this code generation for both loops (and barring optimizations such as using SIMD instructions to traverse the array, which is contiguous in memory), it is hard to explain the significant performance difference by inspecting only the instructions executed. Indeed, we must analyze the memory access patterns of this code to reach any acceptable conclusions.
In both loops, each integer is accessed only once, and it would seem that cache considerations are not as critical because there is no reusable data to benefit from cache hits. Still, the way the data is laid out in memory affects greatly the performance of this program — not because the data is reused, but because of the way it is brought into memory. When accessing the array elements, a cache miss at the beginning of a cache line brings into the cache 16 consecutive integers (cache line = 64 bytes = 16 integers). Because array access is sequential, the next 15 integers are now in the cache and can be accessed without a cache miss. This is an almost-ideal scenario, with a 1:16 cache miss ratio. On the other hand, when accessing linked list elements, a cache miss at the beginning of a cache line can bring into cache at most 3 consecutive linked list nodes, a 1:4 cache miss ratio! (A node consists of a back pointer, forward pointer, and integer datum, which occupy 12 bytes on a 32-bit system; the reference type header brings the tally to 20 bytes per node.)
The much higher cache miss ratio is the reason for most of the performance difference between the two pieces of code we tested above. Furthermore, we are assuming the ideal scenario in which all linked list nodes are positioned sequentially in memory, which would be the case only if they were allocated simultaneously with no other allocations taking place, and is fairly unlikely. Had the linked list nodes been distributed less ideally in memory, the cache miss ratio would have been even higher, and the performance even poorer.
A concluding example that shows another aspect of cache-related effects is the known algorithm for matrix multiplication by blocking. Matrix multiplication (which we revisit again in Chapter 6 when discussing C++ AMP) is a fairly simple algorithm that can benefit greatly from CPU caches because elements are reused several times. Below is the naïve algorithm implementation:
public static int[,] MultiplyNaive(int[,] A, int[,] B) {
int[,] C = new int[N, N];
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
for (int k = 0; k < N; ++k)
C[i, j] += A[i, k] * B[k, j];
return C;
}
In the heart of the inner loop there is a scalar product of the i-th row in the first matrix with the j-th column of the second matrix; the entire i-th row and j-th column are traversed. The potential for reuse by caching stems from the fact that the entire i-th row in the output matrix is calculated by repeatedly traversing the i-th row of the first matrix. The same elements are reused many times. The first matrix is traversed in a very cache-friendly fashion: its first row is iterated completely N times, then its second row is iterated completely N times, and so on. This does not help, though, because after the outer loop is done with iteration i, the method it does not the i-th row again. Unfortunately, the second matrix is iterated in a very cache-unfriendly fashion: its first column is iterated completely N times, then its second column, and so on. (The reason this is cache-unfriendly is that the matrix, an int[,], is stored in memory in row-major order, as Figure 5-4 illustrates.)

Figure 5-4 . The memory layout of a two dimensional array (int[,]). Rows are consecutive in memory, columns are not
If the cache was big enough to fit the entire second matrix, then after a single iteration of the outer loop the entire second matrix would be in the cache, and subsequent accesses to it in column-major order would still be satisfied from cache. However, if the second matrix does not fit in the cache, cache misses will occur very frequently: a cache miss for the element (i,j) would produce a cache line that contains elements from row i but no additional elements from column j, which means a cache miss for every access!
Matrix multiplication by blocking introduces the following idea. Multiplying two matrices can be performed by the naïve algorithm above, or by splitting them into smaller matrices (blocks), multiplying the blocks together, and then performing some additional arithmetic on the results.
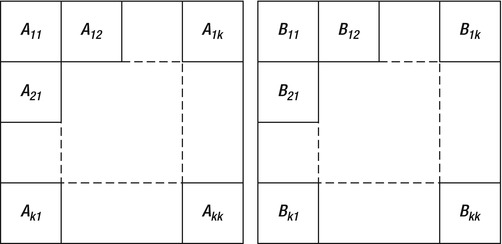
Figure 5-5 . Matrices A and B given in block form, k × k blocks each
Specifically, if the matrices A and B are given in block form, as in Figure 5-5, then the matrix C = AB can be calculated in blocks, such that C ij = Ai1B1j + Ai2B2j + ... + AikBkj. In practice, this leads to the following code:
public static int[,] MultiplyBlocked(int[,] A, int[,] B, int bs) {
int[,] C = new int[N, N];
for (int ii = 0; ii < N; ii += bs)
for (int jj = 0; jj < N; jj += bs)
for (int kk = 0; kk < N; kk += bs)
for (int i = ii; i < ii + bs; ++i)
for (int j = jj; j < jj + bs; ++j)
for (int k = kk; k < kk + bs; ++k)
C[i, j] += A[i, k] * B[k, j];
return C;
}
The apparently complex six nested loops are quite simple—the three innermost loops perform naïve matrix multiplication of two blocks, the three outermost loops iterate over the blocks. To test the blocking multiplication algorithm, we used the same machine from the previous examples (which has an 8 MB L3 cache) and multiplied 2048 × 2048 matrices of integers. The total size of both matrices is 2048 × 2048 × 4 × 2 = 32 MB, which does not fit in the cache. The results for different block sizes are shown in Table 5-3. In Table 5-3 you can see that blocking helps considerably, and that finding the best block size can have a significant secondary effect on performance:
Table 5-3. Timing results of blocking multiplication for varying block sizes

There are many additional examples where cache considerations are paramount, even outside the arena of algorithm design and collection optimization. There are also some even more refined aspects of cache and memory-related considerations: the relationships between caches at different levels, effects of cache associativity, memory access dependencies and ordering, and many others. For more examples, consider reading the concise article by Igor Ostrovsky, “Gallery of Processor Cache Effects” (http://igoro.com/archive/gallery-of-processor-cache-effects/ , 2010).
There are a great many collections well known in the computer science literature, which haven’t made the cut for being included in the .NET Framework. Some of them are fairly common and your applications may benefit from using them instead of the built-in ones. Furthermore, most of them offer sufficiently simple algorithms that can be implemented in a reasonable time. Although it is not our intent to explore the large variety of collections, below are two examples that differ greatly from the existing .NET collections and offer insight into situations where custom collections may be useful.
The disjoint-set data structure (often called union-find) is a collection in which partitions of elements into disjoint subsets are stored. It differs from all .NET collections because you do not store elements in it. Instead, there is a domain of elements in which each element forms a single set, and consecutive operations on the data structure join sets together to form larger sets. The data structure is designed to perform two operations efficiently:
- Union: Join two subsets together to form a single subset.
- Find: Determine to which subset a particular element belongs. (Most commonly used to determine whether two elements belong to the same subset.)
Typically, sets are manipulated as representative elements, with a single representative for each set. The union and find operations, then, receive and return representatives instead of entire sets.
A naïve implementation of union-find involves using a collection to represent each set, and merging the collections together when necessary. For example, when using a linked list to store each set, the merge takes linear time and the find operation may be implemented in constant time if each element has a pointer to the set representative.
The Galler-Fischer implementation has much better runtime complexity. The sets are stored in a forest (set of trees); in each tree, every node contains a pointer to its parent node, and the root of the tree is the set representative. To make sure that the resulting trees are balanced, when trees are merged, the smaller tree is always attached to the root of the larger tree (this requires tracking the tree’s depth). Additionally, when the find operation executes, it compresses the path from the desired element to its representative. Below is a sketch implementation:
public class Set<T> {
public Set Parent;
public int Rank;
public T Data;
public Set(T data) {
Parent = this;
Data = data;
}
public static Set Find(Set x) {
if (x.Parent != x) {
x.Parent = Find(x.Parent);
}
return x.Parent;
}
public static void Union(Set x, Set y) {
Set xRep = Find(x);
Set yRep = Find(y);
if (xRep == yRep) return; //It’s the same set
if (xRep.Rank < yRep.Rank) xRep.Parent = yRep;
else if (xRep.Rank > yRep.Rank) yRep.Parent = xRep;
else {
yRep.Parent = xRep;
++xRep.Rank; //Merged two trees of equal rank, so rank increases
}
}
}
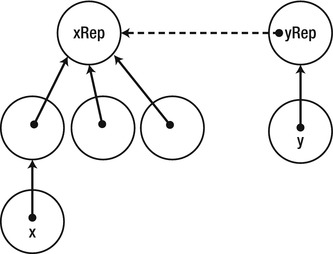
Figure 5-6 . Merge of two sets x and y where y’s set is smaller. The dashed arrow is the result of the merge
Accurate runtime analysis of this data structure is quite complex; a simple upper bound is that the amortized time per operation in a forest with n elements is O(log* n), where log*n (the iterated logarithm of n) is the number of times the logarithm function must be applied to get a result that is smaller than 1, i.e. the minimal number of times “log” must appear in the inequality log log log ... log n ≤ 1. For practical values of n, e.g., n ≤ 1050, this is no more than 5, which is “effectively constant.”
A skip list is a data structure that stores a sorted linked list of elements and allows lookup in O(logn) time, comparable to a binary search in an array or lookup in a balanced binary tree. Clearly, the major problem with performing a binary search in a linked list is that linked lists do not allow random access by index. Skip lists address this limitation by using a hierarchy of increasingly sparse linked lists: the first linked list links together all the nodes; the second linked list links together nodes 0, 2, 4, ...; the third linked list links together nodes 0, 4, 8, ...; the fourth linked list links together nodes 0, 8, 16, ...; and so forth.
To perform a lookup for an element in the skip list, the procedure iterates the sparsest list first. When an element is encountered that is greater than or equal to the desired element, the procedure returns to the previous element and drops to the next list in the hierarchy. This repeats until the element is found. By using O(logn) lists in the hierarchy, O(logn) lookup time can be guaranteed.
Unfortunately, maintaining the skip list elements is not at all trivial. If the entire linked list hierarchy must be reallocated when elements are added or removed, it would offer no advantages over a trivial data structure such as SortedList<T>, which simply maintains a sorted array. A common approach is to randomize the hierarchy of lists (see Figure 5-7), which results in expected logarithmic time for insertion, deletion, and lookup of elements. The precise details of how to maintain a skip list can be found in William Pugh’s paper, “Skip lists: a probabilistic alternative to balanced trees” (ACM, 1990).
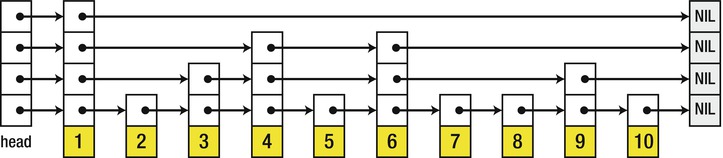
Figure 5-7 . Skip list structure with four randomized lists in the hierarchy (Image from Wikipedia: http://upload.wikimedia.org/wikipedia/commons/8/86/Skip_list.svg, released into the public domain.)
{kind=link}
It may also be the case that you have a unique situation which warrants the use of a completely custom collection. We call these one-shot collections, because they might be an undeniably new invention tailored to your specific domain. As time goes by you may find that some of the one-shot collections you implemented are in fact quite reusable; in this subsection we will take a look at one example.
Consider the following application. You are running a candy exchange system, which keeps candy traders up to date with prices for various candy types. Your main data table is stored in memory and contains a row for each type of candy, listing its current price. Table 5-4 is an example of the data at a certain instant in time:
Table 5-4. Example of data table for the candy exchange system
| Type of Candy | Price ($) |
|---|---|
| Twix | 0.93 |
| Mars | 0.88 |
| Snickers | 1.02 |
| Kisses | 0.66 |
There are two types of clients in your system:
- Candy traders are connected to your system through a TCP socket and periodically ask you for up-to-date information on a certain type of candy. A typical request from a trader is “What’s the price of Twix?” and your response is “$0.93”. There are tens of thousands of these requests per second.
- Candy suppliers are connected to your system through a UDP socket and periodically send you candy price updates. There are two subtypes of requests:
- “Update the price of Mars to $0.91”. No response is necessary. There are thousands of these requests per second.
- “Add a new candy, Snowflakes, with a starting price of $0.49”. No response is necessary. There are no more than a few dozens of these requests per day.
It is also known that 99.9 % of operations read or update the price of candy types that existed at the beginning of the trade; only 0.1 % of operations access candy types that were added by the add operation.
Armed with this information, you set out to design a data structure — a collection — to store the data table in memory. This data structure must be thread-safe, because hundreds of threads may be competing for access to it at a given time. You need not concern yourself with copying the data to persistent storage; we are inspecting only its in-memory performance characteristics.
The shape of the data and the types of requests our system serves suggest strongly that we should use a hash table to store the candy prices. Synchronizing access to a hash table is a task best left to ConcurrentDictionary <K,V>. Reads from a concurrent dictionary can be satisfied without any synchronization, whereas update and add operations require synchronization at a fairly fine-grained level. Although this may be an adequate solution, we set ourselves a higher bar: we would like reads and updates to proceed without any synchronization in the 99.9 % of operations on pre-existing candy types.
A possible solution to this problem is a safe-unsafe cache. This collection is a set of two hash tables, the safe table and the unsafe table. The safe table is prepopulated with the candy types available at the beginning of the trade; the unsafe table starts out empty. Operations on the safe table are satisfied without any locks because it is not mutated; new candy types are added to the unsafe table. Below is a possible implementation using Dictionary <K,V> and ConcurrentDictionary <K,V>:
//Assumes that writes of TValue can be satisfied atomically, i.e. it must be a reference
//type or a sufficiently small value type (4 bytes on 32-bit systems).
public class SafeUnsafeCache<TKey, TValue> {
private Dictionary<TKey, TValue> safeTable;
private ConcurrentDictionary<TKey, TValue> unsafeTable;
public SafeUnsafeCache(IDictionary<TKey, TValue> initialData) {
safeTable = new Dictionary<TKey, TValue>(initialData);
unsafeTable = new ConcurrentDictionary<TKey, TValue>();
}
public bool Get(TKey key, out TValue value) {
return safeTable.TryGetValue(key, out value) || unsafeTable.TryGetValue(key, out value);
}
public void AddOrUpdate(TKey key, TValue value) {
if (safeTable.ContainsKey(key)) {
safeTable[key] = value;
} else {
unsafeTable.AddOrUpdate(key, value, (k, v) => value);
}
}
}
A further refinement would be to periodically stop all trade operations and merge the unsafe table into the safe table. This would further improve the expected synchronization required for operations on the candy data.
IMPLEMENTING IENUMERABLE <T>AND OTHER INTERFACES
Almost any collection will eventually implement IEnumerable <T> and possibly other collection-related interfaces. The advantages of complying with these interfaces are numerous, and as of .NET 3.5 have to do with LINQ as much as anything. After all, any class that implements IEnumerable <T> is automatically furnished with the variety of extension methods offered by System.Linq and can participate in C# 3.0 LINQ expressions on equal terms with the built-in collections.
Unfortunately, naïvely implementing IEnumerable<T> on your collection sentences your callers to pay the price of interface method invocation when they enumerate it. Consider the following code snippet, which enumerates a List<int>:
List<int> list = ...;
IEnumerator<int> enumerator = list.GetEnumerator();
long product = 1;
while (enumerator.MoveNext()) {
product *= enumerator.Current;
}
There are two interface method invocations per iteration here, which is an unreasonable overhead for traversing a list and finding the product of its elements. As you may recall from Chapter 3, inlining interface method invocations is not trivial, and if the JIT fails to inline them successfully, the price is steep.
There are several approaches that can help avoid the cost of interface method invocation. Interface methods, when invoked directly on a value type variable, can be dispatched directly. Therefore, if the enumerator variable in the above example had been a value type (and not IEnumerator<T>), the interface dispatch cost would have been prevented. This can only work if the collection implementation could return a value type directly from its GetEnumerator method, and the caller would use that value type instead of the interface.
To achieve this, List<T> has an explicit interface implementation of IEnumerable<T>.GetEnumerator, which returns IEnumerator<T>, and another public method called GetEnumerator, which returns List<T>.Enumerator— an inner value type:
public class List<T> : IEnumerable<T>, ... {
public Enumerator GetEnumerator() {
return new Enumerator(this);
}
IEnumerator<T> IEnumerable<T>.GetEnumerator() {
return new Enumerator(this);
}
...
public struct Enumerator { ... }
}
This enables the following calling code, which gets rid of the interface method invocations entirely:
List<int> list = ...;
List.Enumerator<int> enumerator = list.GetEnumerator();
long product = 1;
while (enumerator.MoveNext()) {
product *= enumerator.Current;
}
An alternative would be to make the enumerator a reference type, but repeat the same explicit interface implementation trick on its MoveNext method and Current property. This would also allow callers using the class directly to avoid interface invocation costs.
Summary
Throughout this chapter we have seen more than a dozen collection implementations and compared them from the memory density, runtime complexity, space requirements, and thread-safety perspectives. You should now have a better intuition for choosing collections and proving the optimality of your choices, and shouldn’t fear to steer away from what the .NET Framework has to offer and implement a one-shot collection or use an idea from the computer science literature.