
![]()
Concurrent Data Structures
In the previous chapter we introduced the need to consider thread safety when sharing state across multiple threads. The techniques demonstrated required the developer to understand the possible race conditions and select the cheapest synchronization technique to satisfy thread safety. These techniques, while essential, can often become tedious and make the simplest of algorithms seemingly overly complicated and hard to maintain. This chapter will explore the use of built-in concurrent data structures shipped with TPL that will simplify our multithreaded code while maximizing concurrency and efficiency.
Simplifying Thread Safety
Listing 5-1 defines a CsvRepository class that on construction loads all CSV files for a given directory into memory. When the client of the repository requires the contents of a given CSV file, a call is made to the generic Map method. The Map method is supplied a function that can turn a CSV row (string[]) into the supplied generic type argument. The Map method then returns an IEnumerable of the supplied generic type argument. Thus the repository returns each CSV row mapped to the more specific type.
Listing 5-1. Eager Loading CsvRepository
public class CsvRepository
{
private readonly string directory;
private Dictionary<string, List<string[]>> csvFiles;
public CsvRepository(string directory)
{
this.directory = directory;
csvFiles = new DirectoryInfo(directory)
.GetFiles("*.csv")
.ToDictionary(f => f.Name, f => LoadData(f.FullName).ToList());
}
public IEnumerable<string> Files { get { return csvFiles.Keys; }}
public IEnumerable<T> Map<T>(string dataFile,Func<string[],T> map )
{
return csvFiles[dataFile].Skip(1).Select(map);
}
private IEnumerable<string[]> LoadData(string filename)
{
using (var reader = new StreamReader(filename))
{
while (!reader.EndOfStream)
{ yield return reader.ReadLine().Split(','), }
}
}
}
While the code in Listing 5-1 works, it may be inefficient, as all the CSV files are loaded immediately. This could affect startup time, and even result in a greater memory footprint than is ultimately required. An alternative approach would be to load each CSV when the Map method is called for the first time for each CSV file; this is known as Lazy Loading. Listing 5-2 shows the refactored code to implement Lazy Loading.
Listing 5-2. Lazy Loading CsvRepository
public class CsvRepository
{
private readonly string directory;
private Dictionary<string, List<string[]>> csvFiles;
public CsvRepository(string directory)
{
this.directory = directory;
csvFiles = new DirectoryInfo(directory)
.GetFiles("*.csv")
.ToDictionary<FileInfo,string,
List<string[]>>(f => f.Name, f => null);
}
public IEnumerable<string> Files { get { return csvFiles.Keys; }}
public IEnumerable<T> Map<T>(string dataFile,Func<string[],T> map )
{
return LazyLoadData(dataFile).Skip(1).Select(map);
}
private IEnumerable<string[]> LoadData(string filename) { . . . }
private IEnumerable<string[]> LazyLoadData(string filename)
{
List<string[]> csvFile = null;
csvFile = csvFiles[filename];
if (csvFile == null)
{
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
csvFiles[filename] = csvFile;
}
return csvFile;
}
}
While Listing 5-2 achieves the goal of Lazy Loading, it does introduce a problem if this code is to be utilized in a multithreaded environment. When multiple threads access the repository at the same time, the following issues may arise.
- The same CSV could be loaded multiple times, as checking for null and loading the CSV file is not an atomic operation.
- The Dictionary class is not thread safe, and as such it may be possible that manipulating the Dictionary across multiple threads could put the Dictionary into an invalid state.
To resolve these issues, you could resort to a lock inside the LazyLoadData method to ensure that all access to the Dictionary is synchronized. Listing 5-3 shows the reworked LazyLoadData method. This new method fixes the preceding highlighted issues, but creates a new issue. The reason for the synchronization was to allow the repository to be shared by multiple threads; however, the locking strategy adopted potentially creates a bottleneck, if multiple threads require CSV access at the same time.
Listing 5-3. Thread-Safe Lazy Loading
private IEnumerable<string[]> LazyLoadData(string filename)
{
lock (csvFiles)
{
List<string[]> csvFile = null;
csvFile = csvFiles[filename];
if (csvFile == null)
{
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
csvFiles[filename] = csvFile;
}
return csvFile;
}
}
To reduce the number of possible bottlenecks, you could decide to synchronize only when you need to update the Dictionary. Listing 5-4 shows a refactored LazyLoadData method that now only acquires the lock on the Dictionary when accessing the Dictionary. This version will certainly have less contention, but there is now the possibility of two threads asking for the same unloaded CSV file and both threads loading it (although one of the two will ultimately become garbage).
Listing 5-4. Less Possibility for Contention
private IEnumerable<string[]> LazyLoadData(string filename)
{
List<string[]> csvFile = null;
lock (csvFiles)
{
csvFile = csvFiles[filename];
}
if (csvFile == null)
{
// Two threads could be loading the same csv
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
lock (csvFiles)
{
csvFiles[filename] = csvFile;
}
}
return csvFile;
}
To reduce contention and avoid loading the same CSV file repeatedly, you could introduce finer-grain locking. By having a lock for each CSV file you could allow multiple different CSV files to be accessed at the same time. When access is required to the same CSV file, the threads need to wait on the same lock. The aim of the lock is to protect the creation of the List<string> for a given CSV file, and as such you can’t use the List<string> itself. You therefore need a stand-in, something similar to a virtual proxy. This stand-in will be very quick and inexpensive to create. The stand-in will provide the fine-grained lock, and in addition will contain a field that points to the loaded CSV file. Listing 5-5 shows the refactored code.
Listing 5-5. Finer-Grain Locking
public class CsvRepository
{
public class VirtualCsv
{
public List<string[]> Value;
}
private readonly string directory;
private Dictionary<string, VirtualCsv> csvFiles;
public CsvRepository(string directory)
{
this.directory = directory;
csvFiles = new DirectoryInfo(directory)
.GetFiles("*.csv")
.ToDictionary<FileInfo,string,VirtualCsv>(f => f.Name, f => new VirtualCsv());
}
public IEnumerable<string> Files { get { return csvFiles.Keys; }}
public IEnumerable<T> Map<T>(string dataFile,Func<string[],T> map )
{
return LazyLoadData(dataFile).Skip(1).Select(map);
}
private IEnumerable<string[]> LoadData(string filename){ . . . }
private IEnumerable<string[]> LazyLoadData(string filename)
{
lock (csvFiles[filename])
{
List<string[]> csvFile = csvFiles[filename].Value;
if (csvFile == null)
{
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
csvFiles[filename].Value = csvFile;
}
return csvFile;
}
}
}
With the modifications in Listing 5-5 you now have an implementation that guards access to each file separately, allowing multiple files to be accessed and loaded at the same time. This implementation ensures two things.
- Each CSV file is only loaded once.
- Multiple CSV files can be accessed concurrently, while preserving thread safety.
This latest version is therefore a vast improvement on previous versions in terms of thread safety and memory efficiency. If this was our homework assignment, the teacher might have written, “Good, but could do better.” When each thread requests a given CSV file, LazyLoadData will be called. LazyLoadData obtains the lock for the given CSV file, and then proceeds to return the previously loaded file or loads it. The step of obtaining the lock is required only if you do need to load the CSV file and update the dictionary. It is perfectly safe to execute List<string[]> csvFile = csvFiles[filename].Value without the need to obtain the lock, as the reading and writing of this value is atomic. By removing the lock around this piece of code you only pay the cost of synchronization when you need it: when initially loading the CSV file (see Listing 5-6).
Listing 5-6. Less Synchronization
private IEnumerable<string[]> LazyLoadData(string filename)
{
// Atomic operation, .NET 2.0+ Strong memory model means this is safe
List<string[]> csvFile = csvFiles[filename].Value;
if (csvFile == null)
{
lock (csvFiles[filename])
{
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
// Now the CSV file is fully loaded, use an atomic write to say it's available
csvFiles[filename].Value = csvFile;
}
}
return csvFile;
}
Listing 5-6 is more efficient in terms of synchronization, but it does create an opportunity for a race condition. If two threads attempt to access an unloaded CSV file, they will both end up loading the CSV file. Why?
Well, both threads will see that csvFile is null and proceed to the lock statement. The first one to arrive at the lock statement will enter the lock block and load the CSV file. The second thread will be waiting at the lock block, and once the first thread has completed it will then proceed to load the CSV file again. To resolve this problem, use a technique called double check locking. Listing 5-7 shows an implementation.
Listing 5-7. Double Check Locking
private IEnumerable<string[]> LazyLoadData(string filename)
{
List<string[]> csvFile = csvFiles[filename].Value;
if (csvFile == null)
{
lock (csvFiles[filename])
{
csvFile = csvFiles[filename].Value;
if (csvFile == null)
{
csvFile = LoadData(Path.Combine(directory, filename)).ToList();
csvFiles[filename].Value = csvFile;
}
}
}
return csvFile;
}
In the scenario where the CSV file has already been loaded, no synchronization is performed. If, however, the CSV file has not been loaded, then the lock is taken, which results in multiple threads requesting the same unloaded CSV file to be queued one behind another. As each thread gets the lock it checks again, since while waiting for the lock another thread may have loaded the CSV file. Therefore once the lock has been obtained, the null check is repeated and, if true, loads the CSV file. This technique means the creation path is a lot longer to execute; but accessing the resource, once created, is more efficient.
The code you have finally produced is now some way from its original state. The implementation of the CsvRepository is now organized along optimal concurrency principles, resulting in code that is harder to read and maintain. Further, the success of this code is reliant on the .NET 2.0 strong memory model; if that were to change, then the preceding code might become non-thread-safe. Alternatively you might think that having this level of complexity and coupling would be better encapsulated inside the platform, and to that end TPL exposes many concurrent data structures. This chapter will introduce these new types and demonstrate how greatly they simplify the implementation of thread-safe code, ensuring that you as a developer need to care a little less about the subtleties of the memory model.
The first of these data structures we will examine is Lazy<T>. The Lazy<T> type acts as a placeholder for an object that needs to be created not now, but sometime in the future. Why defer? The object could be expensive to create or use large amount of resources, so you don’t want to create it until you need it, and for now you just need a placeholder. This is the use case in Listing 5-5, where you created your own type, VirtualCSV. Listing 5-8 shows a simple use of Lazy<T>.
Listing 5-8. Simple Use of Lazy<T>
public class Person
{
public Person()
{
Thread.Sleep(2000);
Console.WriteLine("Created");
}
public string Name { get; set; }
public int Age { get; set; }
public override string ToString()
{
return string.Format("Name: {0}, Age: {1}", Name, Age);
}
}
class Program
{
static void Main(string[] args)
{
Lazy<Person> lazyPerson = new Lazy<Person>();
Console.WriteLine("Lazy object created");
Console.WriteLine("has person been created {0}", lazyPerson.IsValueCreated ? "Yes":"No");
Console.WriteLine("Setting Name");
lazyPerson.Value.Name = "Andy"; // Creates the person object on fetching Value
Console.WriteLine("Setting Age");
lazyPerson.Value.Age = 21; // Re-uses same object from first call to Value
Person andy = lazyPerson.Value;
Console.WriteLine(andy);
}
}
Running the program from Visual Studio with Ctrl+F5 produces the results shown in Figure 5-1.
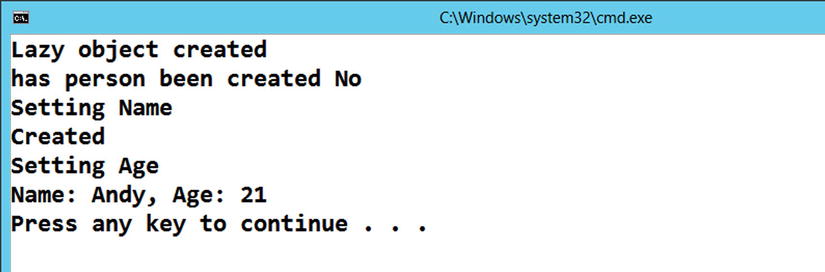
Figure 5-1. Output from Listing 5-8
Figure 5-1 clearly demonstrates that the person object doesn’t get created until the Value is requested, as shown by the “Created” message. The “Created” message only appears once, proving that subsequent calls made to lazyPerson.Value will result in the same object being returned. Lazy<T> is by default thread safe. If multiple threads share the same Lazy<T> object, the Lazy<T> object guarantees that only one object will ever be created. If, during the construction of the object, another thread requests the value, the second thread will block, waiting for the value to be fully constructed by the other thread. Once it has been constructed it is then shared with the second thread. If this level of thread safety is not required and you simply want lazy creation, an enumeration indicating thread safety is not required can be passed as a constructor parameter (see Listing 5-9).
Listing 5-9. Lazy<T>, No Thread Safety
static void Main(string[] args)
{
Lazy<Person> lazyPerson = new Lazy<Person>( LazyThreadSafetyMode.None);
Task<Person> p1 = Task.Run<Person>(() => lazyPerson.Value);
Task<Person> p2 = Task.Run<Person>(() => lazyPerson.Value);
Console.WriteLine(object.ReferenceEquals(p1.Result,p2.Result));
}
Since you have deliberately slowed down the construction of the Person object with a Thread.Sleep, running the code in Listing 5-9 will result in the constructor being called twice and both threads getting their own copies of Person. It turns out there is a halfway option that allows multiple objects to be created, but only the first one to be created will ever get exposed through the Value property. Listing 5-10 will cause two objects to be created, but the Person object returned from the Value property will be the same from both tasks. This technique can be useful if the creation logic is very cheap, and you only care about having one reference exposed. The thread safety logic for this approach is cheaper to implement inside the Lazy<T> object, as instead of using a full-blown lock an Interlocked.CompareExchange is used.
Listing 5-10. Possible Multiple Creation, but Only One Published
static void Main(string[] args)
{
Lazy<Person> lazyPerson = new Lazy<Person>( LazyThreadSafetyMode.PublicationOnly);
Task<Person> p1 = Task.Run<Person>(() => lazyPerson.Value);
Task<Person> p2 = Task.Run<Person>(() => lazyPerson.Value);
Console.WriteLine(object.ReferenceEquals(p1.Result,p2.Result));
}
![]() Note This behavior is only relevant when a race is in progress to create the object for the first time. Once creation has completed, no further creation will be initiated.
Note This behavior is only relevant when a race is in progress to create the object for the first time. Once creation has completed, no further creation will be initiated.
Running the code produces the output in Figure 5-2, clearly showing two objects get created, but both tasks are returning the same reference.
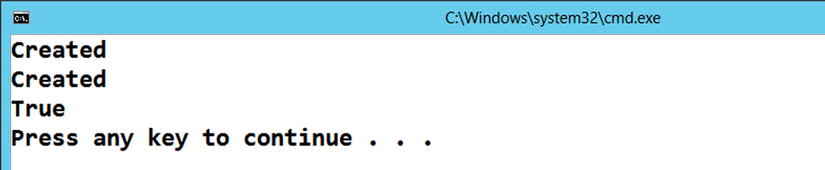
Figure 5-2. Non-thread-safe creation
Perhaps an obvious question is how does Lazy<T> create an instance of T? With the code you have developed so far it is relying on the fact that T has a public parameterless constructor. Lazy<T> is simply using reflection to create the instance. If you were to modify the Person class not to have one, then you would get not a compilation error but a runtime exception. To resolve this and thus support lazy construction scenarios where you need to supply construction parameters, Lazy<T> allows the supplying of a Func<T> that it will use to construct the object as opposed to using the constructor directly via reflection.
Listing 5-11 demonstrates a use of Lazy<T> that utilizes your supplied creation logic as opposed to a parameterless constructor. I find this the most common scenario for Lazy<T> as more often than not you need to supply constructor parameters; as an additional benefit it provides compile time checking for the creation logic.
Listing 5-11. Function to Create Object
public class Person
{
public Person(string name)
{
Name = name;
}
public string Name { get; private set; }
public int Age { get; set; }
public override string ToString()
{
return string.Format("Name: {0}, Age: {1}", Name, Age);
}
}
class Program
{
static void Main(string[] args)
{
// Would cause a runtime exception, since Person now does not have
// a parameterless constructor
// var lazyPerson = new Lazy<Person>()
var lazyPerson = new Lazy<Person>(() => new Person("Andy"));
}
}
Armed with this new type you can now refactor your CsvRepository to use Lazy<T> as opposed to your own homegrown locking strategy. Listing 5-12 shows the refactored code.
Listing 5-12. CsvRepository Using Lazy<T>
public class CsvRepository
{
private readonly string directory;
private Dictionary<string, Lazy<List<string[]>>> csvFiles;
public CsvRepository(string directory)
{
this.directory = directory;
csvFiles = new DirectoryInfo(directory)
.GetFiles("*.csv")
.ToDictionary(f => f.Name,
f => new Lazy<List<string[]>>(() => LoadData(f.Name).ToList()));
}
public IEnumerable<string> Files { get { return csvFiles.Keys; } }
public IEnumerable<T> Map<T>(string dataFile, Func<string[], T> map)
{
return csvFiles[dataFile].Value.Skip(1).Select(map);
}
private IEnumerable<string[]> LoadData(string filename)
{
using (var reader = new StreamReader(Path.Combine(directory, filename)))
{
while (!reader.EndOfStream)
{
yield return reader.ReadLine().Split(','),
}
}
}
}
Listing 5-12 has all the same behavior as our final double check locking version in Listing 5-7 , but is almost identical to our initial eager-loading version, Listing 5-1. The only change you have made is to wrap our List<string[]> with a Lazy<List<string[]>>. Creating items ahead of time often simplifies concurrency issues, and Lazy<T> allows for this without having to pay the ultimate price of creating the actual thing until it is required.
Concurrent Collections
The standard .NET collection types Dictionary<K,V>, Queue<T>, Stack<T>, and the like form the bedrock of many applications. Unfortunately these collections are not thread safe, so having versions of them that work in a multithreaded environment would be a great asset. The remainder of this chapter will be spent examining a set of types that at first glance provide thread-safe versions of these standard collection types. It is important to understand that while these types have been implemented as a replacement for the non-thread-safe ones, they have at times a very different API.
The API has been designed with concurrency in mind; this is possibly best explained via the use of an example. Listing 5-13 shows the safe way of ensuring that a queue has at least one item before attempting to dequeue. If a check was not made and an attempt to dequeue was made against an empty queue, an exception would be thrown. Since you don’t want to use exceptions for flow control, check if the operation is allowed before making the call. Now imagine you wanted to use a shared instance of the Queue<T> class with multiple threads. Unfortunately the Queue<T> type is not thread safe and so it would not be recommended to share this Queue<T> object between multiple threads. However, even if work was undertaken by Microsoft to ensure that the internal mechanics of the Queue<T> class were thread safe, this code would still not be fit for this purpose! Why?
Listing 5-13. Safe Use of Queue<T>
Queue<int> queue = new Queue<int>();
. . .
if (queue.Count > 0)
{
int val = queue.Dequeue();
}
The internal thread safety of the object is just one issue. Assume for now that the Queue<T> class is thread safe. Assume also that the code in Listing 5-13 is being executed by multiple threads. As long as there are more items in the queue than threads attempting to dequeue, life is good. If there are two consumers and only one item in the queue, then you have a race condition. Both threads examine the Count; both move forward to dequeue; one dequeues successfully; and the second one throws an exception. While both the Count and Dequeue operations are thread safe, what you actually require is a method on the Queue<T> type that performs both these operations inside the Queue<T> type itself—in other words, make the check and dequeue operation a single atomic operation against the queue. It therefore does not make sense to have a simple dequeue operation on a concurrent queue working in the same way as the regular Queue<T> type, and so you will not find one. What you will find is a TryDequeue operation as shown in Listing 5-14. As its name suggests, TryDequeue attempts to dequeue, but if it fails due to no items it will return false, as opposed to throwing an exception.
Listing 5-14. ConcurrentQueue-Appropriate API
ConcurrentQueue<int> queue = new ConcurrentQueue<int>();
int val;
if (queue.TryDequeue(out val))
{
Console.WriteLine(val);
}
There are many other examples where finer-grained operations on the original collection types have been replaced or augmented with larger atomic operations. The remainder of this chapter will explore how you can use these new types to simplify the process of writing thread-safe algorithms.
As stated earlier, the base class library type Dictionary<K,V> is not thread safe. Attempting to share such an object across multiple threads could result in unexpected behavior. Listing 5-1’s implementation of the CsvRepository used Dictionary<string,List<string[]>>; the Map method could be safely used across multiple threads since the dictionary was completely built as part of the CsvRepository constructor and all further uses were read based. What if you changed CsvRepository to provide access not just to CSV files that were present at construction time, but also to whatever files are currently in the directory when the Map method is called? This would prevent you from prebuilding the dictionary in the constructor. Listing 5-15 shows a non-thread-safe version. Calling the Map method from multiple threads may very well work, but it may also fail.
Listing 5-15. Non-Thread-Safe Dynamic CsvRepository
public class DynamicLazyCsvRepository
{
private readonly string directory;
private Dictionary<string, List<string[]>> csvFiles;
public DynamicLazyCsvRepository(string directory)
{
this.directory = directory;
csvFiles = new Dictionary<string, List<string[]>>();
}
public IEnumerable<string> Files {
get { return new DirectoryInfo(directory).GetFiles().Select(fi => fi.FullName);}
}
public IEnumerable<T> Map<T>(string dataFile, Func<string[], T> map)
{
List<string[]> csvFile;
if (!csvFiles.TryGetValue(dataFile, out csvFile))
{
csvFile = LoadData(dataFile).ToList();
csvFiles.Add(dataFile,csvFile);
}
return csvFile.Skip(1).Select(map);
}
private IEnumerable<string[]> LoadData(string filename)
{
using (var reader = new StreamReader(Path.Combine(directory, filename)))
{
while (!reader.EndOfStream)
{
yield return reader.ReadLine().Split(','),
}
}
}
Failure may occur when two threads ask for the same unloaded CSV file, as both threads may well attempt to load it. Once each thread has loaded the CSV file, they then attempt to add it to the dictionary; the first will succeed but the second will receive an exception stating the item already exists (Figure 5-3). This would never have been a problem when running in a single-threaded environment.
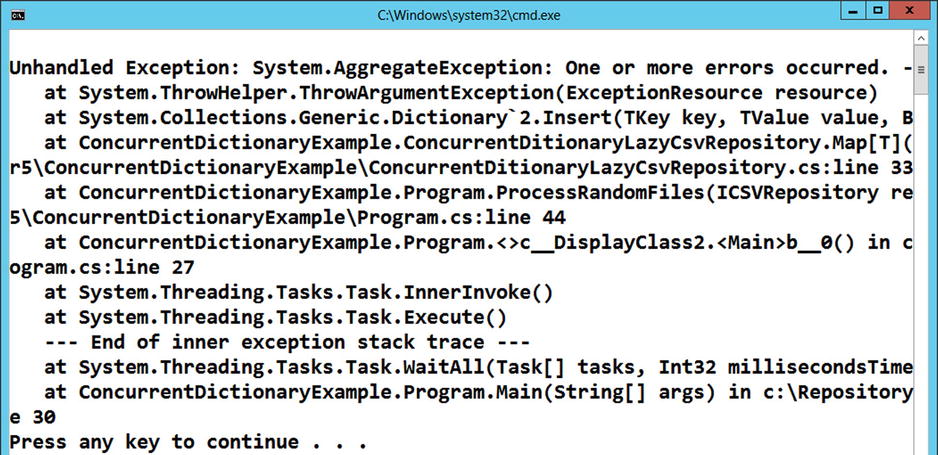
Figure 5-3. Attempting to add same value to dictionary
The more fundamental issue with this code is that the Dictionary<K,V> type is not thread safe, so even if you never get an exception, you may still have harmed the internal state of the dictionary. The ConcurrentDictionary<K,V> on the other hand is thread safe, so using it avoids the risk of internal corruption. As we said earlier, just because this type is a thread-safe version of a dictionary, it does not therefore follow that the API will be identical. Also as discussed earlier, the Add method on the Dictionary<K,V> type throws an exception when an attempt is made to add a value with the same key. In a non-multithreaded environment this can be prevented by checking if the key exists before adding. In a multithreaded environment, however, you can’t do that, since each call to the dictionary could be interlaced with another thread making similar calls. For that reason there is no Add method on the ConcurrentDictionary<K,V> only a TryAdd method, which will return false if the add fails due to the key already being present. Listing 5-16 shows an initial refactoring to ConcurrentDictionary<K,V>.
Listing 5-16. Initial Refactor to ConcurrentDictionary
public class ConcurrentDictionaryLazyCsvRepository
{
private readonly string directory;
private ConcurrentDictionary<string, List<string[]>> csvFiles;
public ConcurrentDictionaryLazyCsvRepository(string directory)
{
this.directory = directory;
csvFiles = new ConcurrentDictionary<string, List<string[]>>();
}
public IEnumerable<string> Files {
get { return new DirectoryInfo(directory).GetFiles().Select(fi => fi.FullName); }
}
public IEnumerable<T> Map<T>(string dataFile, Func<string[], T> map)
{
List<string[]> csvFile;
if (!csvFiles.TryGetValue(dataFile, out csvFile))
{
csvFile = LoadData(dataFile).ToList();
csvFiles.TryAdd(dataFile, csvFile);
}
return csvFile.Skip(1).Select(map);
}
. . .
}
This initial refactoring satisfies the issue of thread safety, but masks a bigger issue. While you are only ever adding one dictionary entry per file, there is still the possibility of loading the CSV file many times. If two threads were to request the same unloaded CSV file, both would still load the file, which is clearly not what you want. What you want is for the CSV file to be loaded once only. The problem is that the process of checking if the item is in the dictionary, creating it, and adding it to the dictionary is not atomic. To resolve this you could perhaps use the AddOrGet method on the ConcurrentDictionary. This method takes the key and can either take the object to associate with the supplied key or a function that will create the object. The method returns the value associated with the supplied dictionary key. If a value is already associated with the key, the supplied value is ignored, and the associated value is returned. If the key is not present in the dictionary, the supplied value is inserted into the dictionary, and returned. Listing 5-17 shows a possible refactoring of the Map method. However this is not really much of an improvement, apart from being simpler code. The AddOrGet method on the ConcurrentDictionary will not prevent LoadData being called multiple times for the same key. It just removes the need to make two method calls for TryGetValue and then TryAdd. If only the object you wanted to place into the Dictionary were cheap to create this would not be an issue, as creating it many times would not matter as long as ultimately there is only one copy in the dictionary.
Listing 5-17. GetOrAdd
public IEnumerable<T> Map<T>(string dataFile, Func<string[], T> map)
{
var csvFile = csvFiles.GetOrAdd(dataFile, df => LoadData(df).ToList());
return csvFile.Skip(1).Select(map);
}
So while GetOrAdd doesn’t solve our problem entirely, it does get you very close. To make it work you need to guarantee that the CSV data is loaded once only. You have already seen how to achieve this in a thread-safe way, Lazy<T>. By creating a Lazy<T> object that will ultimately load the data, you can safely create multiple lazy objects very cheaply, and rely on the fact that only one of them will ever reside in the dictionary. As long as you only ask for the value of the lazy object from a dictionary lookup, you can rely on the behavior of Lazy<T> to ensure you only get one copy of the CSV file loaded. Listing 5-18 shows an implementation utilizing ConcurrentDictionary with Lazy<T>
Listing 5-18. GetOrAdd with Lazy<T>
public class ConcurrentDictionaryLazyCsvRepository
{
private readonly string directory;
private ConcurrentDictionary<string, Lazy<List<string[]>>> csvFiles;
public ConcurrentDictionaryLazyCsvRepository(string directory)
{
this.directory = directory;
csvFiles = new ConcurrentDictionary<string, Lazy<List<string[]>>>();
}
public IEnumerable<string> Files {
get { return new DirectoryInfo(directory).GetFiles().Select(fi => fi.FullName); }
}
public IEnumerable<T> Map<T>(string dataFile, Func<string[], T> map)
{
var csvFile = new Lazy<List<string[]>>(() => LoadData(dataFile).ToList());
csvFile = csvFiles.GetOrAdd(dataFile, csvFile);
return csvFile.Value.Skip(1).Select(map);
}
I personally find the combination of ConcurrentDictionary<K,V> and Lazy<T> very useful. Other atomic operations on the ConcurrentDictionary<K,V> include AddOrUpdate and TryUpdate. AddOrUpdate method allows you to supply different values to use in the case that the Dictionary performs an Add or an Update. TryUpdate allows you to supply a comparison value, and if the value in the Dictionary is not the same as the comparison value, the value is not replaced.
Last, it is worth mentioning that the implementation tries to keep contention low when accessing the dictionary. Figure 5-4 shows how ConcurrentDictionary<K,V> holds the key value pairs. It implements a chained hash table, in which each slot represents a set of possible values for a given hash value modulo the number of slots.
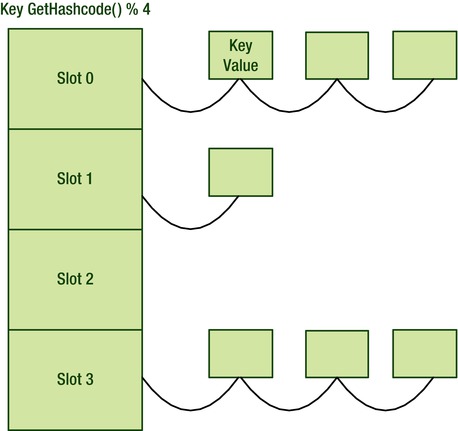
Figure 5-4. Concurrent dictionary data structure
Manipulating such a data structure by multiple threads will require synchronization. To do this it does not have a single lock to guard all access to the internals; rather it has a lock per slot. You can therefore add two values to the dictionary as long as their hashes don’t end up in the same slot. If too many items end up inside one slot, the hash table is rebuilt with more slots to maintain access speed. Growing the dictionary will require all locks to be obtained by one thread; to limit this effect an initial size can be supplied as part of construction.
ConcurrentQueue<T> and ConcurrentStack<T>
ConcurrentQueue<T> and ConcurrentStack<T> provide thread-safe implementations of FIFO and LIFO, respectively. Having multiple threads consume items from one of these data structures lends itself to load-balancing the processing across a fixed number of threads. For example, suppose you have 20 files to process and four cores at your disposal. Giving each thread five files may seem logical, and would work assuming each file requires exactly the same amount of processing. Placing all work items into a queue and then letting each thread consume the next work item as it becomes free will result in fair distribution of the work when the work items could require differing amounts of processing. Listing 5-19 shows an example of a simple producer consumer implementation.
Listing 5-19. Simple Producer and Consumers
public class Program
{
static void Main(string[] args)
{
var queue = new ConcurrentQueue<string>();
foreach (FileInfo file in new DirectoryInfo(@"C:Data")
.GetFiles("*.csv",SearchOption.AllDirectories))
{
queue.Enqueue(file.FullName);
}
var consumers = new Task[4];
for (int i = 0; i < consumers.Length; i++)
{
consumers[i] = Task.Run(() => Consumer(queue));
}
Task.WaitAll(consumers);
}
public static void Consumer(ConcurrentQueue<string> queue)
{
string file;
while (queue.TryDequeue(out file))
{
Console.WriteLine("{0}:Processing {1}",Task.CurrentId,file);
}
}
}
Listing 5-19 shows a simple example of a queue in which all the files to be processed are enqueued. The queue is then shared with four tasks, each of which will attempt to dequeue a filename and then process it. Notice that you are not calling a Dequeue method but TryDequeue. As mentioned earlier there is no Dequeue method as there is no thread-safe way to guarantee that there is an item to dequeue. You therefore have to use TryDequeue, which will return true if there is an item, the out parameter containing the dequeued item. If there are no items in the queue it will return false. There is, on the other hand, an Enqueue method, since this should only fail in exceptional circumstances, and therefore no need for a TryEnqueue method. Each of the consumer tasks will keep taking items from the queue until there are no more items to consume.
The consumers process the items in the order they were enqueued. Obviously if you used a ConcurrentStack<T> you would replace the Enqueue with a Push call and a TryDequeue with a TryPop. The items would then be processed in reverse order (LIFO).
You will often need to store a variable number of items for later consumption. A list is a standard data structure that achieves that goal and in addition preserves the order of insertion. So a list has items and order. A bag is another standard computer science data structure, which differs from a list in that a bag maintains all the items you add to it but doesn’t guarantee the order. The base class library in .NET 4.0 provides a List<T> to implement a list, but this implementation is non-thread-safe. TPL does not provide a concurrent list but does offer a concurrent bag that you can use safely across threads without any application synchronization.
It is probably best to first describe what this type is not for. At first glance, you may be thinking, if I have multiple threads that wish to add and remove or fetch items from a shared bag, then this is the type for me. Unfortunately you would be wrong! A regular List<T> and a lock is more efficient. So what is it for? The ConcurrentBag<T> is useful for implementing a very specific form of the producer/consumer pattern. To implement the producer/consumer pattern the ConcurrentBag<T> has two key methods:
- void Add(T item)
- bool TryTake(T out item)
The ConcurrentBag<T> works best when the producer and consumer are running on the same thread. The reason for this is that each thread that adds items to the bag will have its own local linked list of items. A thread favors consuming items from its own local list before trying to steal items from another thread’s list.
Algorithms that benefit from this take the following form: each thread takes items from the bag and decomposes them for further processing, ideally on the same thread. With multiple threads producing and consuming items from a shared bag, when a thread has no more items to process it will steal work from another thread. This provides a form of load balancing across the running threads. Listing 5-20 demonstrates this technique by walking the file system looking for files that match a given pattern. A task is created for each immediate directory under the initial directory, and supplied with the subdirectory it needs to explore, along with the file pattern match and a shared ConcurrentBag<DirectoryInfo>. Each task then walks its part of the directory structure by adding subdirectories to the bag and files that match to its own private result set. The task keeps looping, executing TryTake to obtain further subdirectories to explore. Once it has exhausted its part of the tree the TryTake will yield results from other tasks that have not completed their parts of the tree. Thus the tasks will run against their own highly concurrent internal list until they run out of work, then they will steal work from other threads’ lists. When there are no more items in the bag all the tasks will have completed.
Listing 5-20. Directory Walker
public class ParallelFileFinderWithBag
{
public static List<FileInfo> FindAllFiles(string path, string match)
{
var fileTasks = new List<Task<List<FileInfo>>>();
var directories = new ConcurrentBag<DirectoryInfo>();
foreach (DirectoryInfo dir in new DirectoryInfo(path).GetDirectories())
{
fileTasks.Add(Task.Run<List<FileInfo>>(() => Find(dir, directories, match)));
}
return (from fileTask in fileTasks
from file in fileTask.Result
select file).ToList();
}
private static List<FileInfo> Find(DirectoryInfo dir,
ConcurrentBag<DirectoryInfo> directories, string match)
{
var files = new List<FileInfo>();
directories.Add(dir);
DirectoryInfo dirToExamine;
while (directories.TryTake(out dirToExamine))
{
foreach (DirectoryInfo subDir in dirToExamine.GetDirectories())
{
directories.Add(subDir);
}
files.AddRange(dirToExamine.GetFiles(match));
}
return files;
}
}
In summary, ConcurrentBag<T> is not a general purpose thread-safe bag implementation. ConcurrentBag<T> is ideal when tasks need to further decompose work for future processing. Ideally the processing of decomposed work will be processed by the same thread that inserted the item into the bag; when a thread runs out of its own local items it is kept busy by stealing items from another thread for processing, which could result in the addition of more local work. Unlike a ConcurrentQueue<T> or ConcurrentStack<T>, the order the items to be processed is undefined.
Consider the producer/consumer implementation in Listing 5-21. The program creates a simple web server that delivers the current time when the following request is made from a browser: http://localhost:9000/Time. A single producer task is created, which has the role of listening for inbound HTTP requests, and then placing them on a concurrent queue. There are four consumer tasks, each of which is trying to obtain work from the concurrent queue.
Listing 5-21. Busy Producer Consumer
class Program
{
static void Main(string[] args)
{
HttpListener listener = new HttpListener();
listener.Prefixes.Add("http://+:9000/Time/");
listener.Start();
var requestQueue = new ConcurrentQueue<HttpListenerContext>();
var producer = Task.Run(() => Producer(requestQueue, listener));
Task[] consumers = new Task[4];
for (int nConsumer = 0; nConsumer < consumers.Length; nConsumer++)
{
consumers[nConsumer] = Task.Run(() => Consumer(requestQueue));
}
Console.WriteLine("Listening...");
Console.ReadLine();
}
public static void Producer(ConcurrentQueue<HttpListenerContext> queue, HttpListener listener)
{
while (true)
{
queue.Enqueue(listener.GetContext());
}
}
public static void Consumer(ConcurrentQueue<HttpListenerContext> queue)
{
while (true)
{
HttpListenerContext ctx;
if (queue.TryDequeue(out ctx))
{
Console.WriteLine(ctx.Request.Url);
Thread.Sleep(5000); // Simulate work
using (StreamWriter writer = new StreamWriter(ctx.Response.OutputStream))
{
writer.WriteLine(DateTime.Now);
}
}
}
}
}
While the application works, there is one major drawback in that when a consumer has no work to process, it executes a busy wait. The TryDequeue method returns immediately either with a value of true and an item to process, or most probably a return value of false, indicating nothing to process. In the case of no item, the code then simply tries again, hence the busy wait. In this situation it would be preferable if the thread simply went to sleep until an item of work becomes available, as in the producer/consumer pattern implemented in Chapter 4 with Pulse and Wait.
The Concurrent data structures are all about nonblocking, but as you can see there are times when you may desire blocking behavior. To that end TPL also includes a BlockingCollection<T>. BlockingCollection<T> adds blocking semantics to ConcurrentBag<T>,ConcurrentQueue<T>, and ConcurrentStack<T>. When creating the blocking collection you simply supply as a parameter an instance of the underlying collection type you wish to use; if you don’t supply one it will use a ConcurrentQueue<T>. Since BlockingCollection<T> can wrap any of the collection types, it provides Add methods for adding and Take methods for removing. If the underlying collection is a ConcurrentQueue<T> the Add/Take will exhibit FIFO behavior; if it’s a ConcurrentStack<T> they will exhibit LIFO behavior. The Take method is a blocking call so if no items are available from the underlying collection, the thread will be suspended until an item becomes available. The producer/consumer pattern has now been rewritten in Listing 5-22 to take advantage of BlockingCollection<T>. The consumer threads now peacefully sleep while waiting for items to process.
Listing 5-22. Blocking Producer/Consumer
public class Program
{
static void Main(string[] args)
{
HttpListener listener = new HttpListener();
listener.Prefixes.Add("http://+:9000/Time/");
listener.Start();
var requestQueue = new BlockingCollection<HttpListenerContext>(
new ConcurrentQueue<HttpListenerContext>());
var producer = Task.Run(() => Producer(requestQueue, listener));
Task[] consumers = new Task[4];
for (int nConsumer = 0; nConsumer < consumers.Length; nConsumer++)
{
consumers[nConsumer] = Task.Run(() => Consumer(requestQueue));
}
Console.WriteLine("Listening..");
Console.ReadLine();
listener.Stop();
}
public static void Producer(BlockingCollection<HttpListenerContext> queue,
HttpListener listener)
{
while (true)
{
queue.Add(listener.GetContext());
}
}
public static void Consumer(BlockingCollection<HttpListenerContext> queue)
{
while (true)
{
HttpListenerContext ctx = queue.Take();
Thread.Sleep(5000); // Simulate work
Console.WriteLine(ctx.Request.Url);
using (var writer = new StreamWriter(ctx.Response.OutputStream))
{
writer.WriteLine(DateTime.Now);
}
}
}
}
Listing 5-22 provides blocking behavior for the consumers. The Add operations, however, will not block, so currently all HTTP requests get enqueued. You may want to limit the size of the queue, and either timeout the client or return an appropriate response code. To enable this behavior, create the BlockingCollection<T> with a given capacity; once the collection reaches this level, Add operations will block. Alternatively you can call TryAdd, which will not block but instead return false if the addition fails, allowing you to inform the client that you are too busy (see Listing 5-23).
Listing 5-23. Bounded Collection
var requestQueue = new BlockingCollection<HttpListenerContext>(
new ConcurrentQueue<HttpListenerContext>() ,2);
. . .
public static void Producer(BlockingCollection<HttpListenerContext> queue,
HttpListener listener)
{
while (true)
{
HttpListenerContext ctx = listener.GetContext();
if (!queue.TryAdd(ctx))
{
ctx.Response.StatusCode =(int) HttpStatusCode.ServiceUnavailable;
ctx.Response.Close();
}
}
}
Listing 5-23 creates a blocking queue that has a capacity of two. Any attempt to grow the queue past a length of two will result in the TryAdd operation returning false, and the client being sent the busy status.
The web server is currently terminated by just ending the process, which is not exactly graceful. You can refactor the code to signal to the producer task that you wish to shut down by sending a URL in the form of http://localhost:9000/Time?stop=true. On the main thread, replace the Console.ReadLine() with a wait on the producer task. While this will result in graceful shutdown of the producer task, what about the consumers? You could use a cancellation token, which would be useful if you don’t care about completing all the queued-up work. Alternatively you could make use of the CompleteAdding method on the blocking collection to signal that no more items will be enqueued, and any thread blocking on a call to Take will be awakened with an InvalidOperationException. If there are more work items, calls to Take will continue to return the next item until there are no more, and then the exception will be thrown. CompleteAdding therefore allows you to wake up threads waiting for items, but still allow all items inside the blocking collection to be processed. Listing 5-24 shows an example of graceful shutdown.
Listing 5-24. Graceful Shutdown
public class Program
{
static void Main(string[] args)
{
HttpListener listener = new HttpListener();
listener.Prefixes.Add("http://+:9000/Time/");
listener.Start();
var requestQueue = new BlockingCollection<HttpListenerContext>(
new ConcurrentQueue<HttpListenerContext>());
var producer = Task.Run(() => Producer(requestQueue, listener));
Task[] consumers = new Task[4];
for (int nConsumer = 0; nConsumer < consumers.Length; nConsumer++)
{
consumers[nConsumer] = Task.Run(() => Consumer(requestQueue));
}
Console.WriteLine("Listening..");
producer.Wait();
Task.WaitAll(consumers);
}
public static void Producer(BlockingCollection<HttpListenerContext> queue,
HttpListener listener)
{
while (true)
{
HttpListenerContext ctx = listener.GetContext();
if (ctx.Request.QueryString.AllKeys.Contains("stop")) break;
if (!queue.TryAdd(ctx))
{
ctx.Response.StatusCode = (int) HttpStatusCode.ServiceUnavailable;
ctx.Response.Close();
}
}
queue.CompleteAdding();
Console.WriteLine("Producer stopped");
}
public static void Consumer(BlockingCollection<HttpListenerContext> queue)
{
try
{
while (true)
{
HttpListenerContext ctx = queue.Take();
Console.WriteLine(ctx.Request.Url);
Thread.Sleep(5000);
using (var writer = new StreamWriter(ctx.Response.OutputStream))
{
writer.WriteLine(DateTime.Now);
}
}
}
catch (InvalidOperationException error) {}
Console.WriteLine("{0}:Stopped",Task.CurrentId);
}
}
![]() Note Once CompleteAdding has been called, any attempt to add to the collection will cause an exception to be thrown.
Note Once CompleteAdding has been called, any attempt to add to the collection will cause an exception to be thrown.
It turns out Take is just one of the ways to consume items from a BlockingCollection<T>. An alternative and often far more convenient way is via foreach. One important thing to note is that while BlockingCollection<T> implements IEnumerable<T>, this is not the target for the consuming enumeration, since it will just deliver all items in the collection without consuming them. To consume the items as you enumerate them you need to use a consuming enumerable. To obtain this you call GetConsumingEnumerable against the BlockingCollection<T>; this will return an IEnumerable<T> but as you iterate through you remove the item from the collection, in the same way as you would with Take. When there are no more items to consume, the foreach is blocked, until either an item becomes available or CompleteAdding is called. Listing 5-25 shows an example of consuming the queue using a foreach.
Listing 5-25. Consuming Enumerable Consumer
public static void Consumer(BlockingCollection<HttpListenerContext> queue)
{
foreach (HttpListenerContext ctx in queue.GetConsumingEnumerable())
{
Console.WriteLine(ctx.Request.Url);
using (var writer = new StreamWriter(ctx.Response.OutputStream))
{
writer.WriteLine(DateTime.Now);
}
}
Console.WriteLine("{0}:Stopped", Task.CurrentId);
}
Earlier we spoke about BlockingCollection<T> simply wrapping one of the underlying concurrent collections. It turns out that it is not bound to specific collection types, but rather to any type that implements IProducerConsumerCollection<T>. This interface provides all the necessary features that the BlockingCollection<T> needs to provide blocking behavior to a nonblocking collection. Essentially there are nonblocking TryAdd and TryTake methods. As long as all access to the underlying collection goes via the BlockingCollection<T>, it can determine if there are items in the collection and therefore build the blocking behavior.
Summary
In this chapter, we have shown that highly concurrent code doesn’t need to be overly complex. The Concurrent Collections and Lazy<T> provided by TPL make the expression of the code clear and simple while delivering highly concurrent solutions. Writing multithreaded code utilizing concurrent data structures is often the key to making solutions scale.