
Chapter 3
Secure Software Design
3.1 Introduction
One of the most important phases in the software development life cycle (SDLC) is the design phase. During this phase, software specifications are translated into architectural blueprints that can be coded during the implementation (or coding) phase that follows. When this happens, it is necessary for the translation to be inclusive of secure design principles. It is also important to ensure that the requirements that assure software security are designed into the software in the design phase. Although writing secure code is important for software assurance, the majority of software security issues has been attributed to insecure or incomplete design. Entire classes of vulnerabilities that are not syntactic or code related such as semantic or business logic flaws are related to design issues. Attack surface evaluation using threat models and misuse case modeling (covered in Chapter 2), control identification, and prioritization based on risk to the business are all essential software assurance processes that need to be conducted during the design phase of software development. In this chapter, we will cover secure design principles and processes and learn about different architectures and technologies, which can be leveraged for increasing security in software. We will end this chapter by understanding the need for and the importance of conducting architectural reviews of the software design from a security perspective.
3.2 Objectives
As a CSSLP, you are expected to
- Understand the need for and importance of designing security into the software.
- Be familiar with secure design principles and how they can be incorporated into software design.
- Have a thorough understanding of how to threat model software.
- Be familiar with the different software architectures that exist and the security benefits and drawbacks of each.
- Understand the need to take into account data (type, format), database, interface, and interconnectivity security considerations when designing software.
- Know how the computing environment and chosen technologies can have an impact on design decisions regarding security.
- Know how to conduct design and architecture reviews with a security perspective.
This chapter will cover each of these objectives in detail. It is imperative that you fully understand the objectives and be familiar with how to apply them to the software that your organization builds or procures.
3.3 The Need for Secure Design
Software that is designed correctly improves software quality. In addition to quality aspects of software, there are other requirements that need to be factored into its design. Some are privacy requirements as well as globalization and localization requirements, including security requirements. We learned in earlier chapters that software can meet all quality requirements and still be insecure, warranting the need for explicitly designing the software with security in mind.
IBM Systems Sciences Institute, in its research work on implementing software inspections, determined that it was 100 times more expensive to fix software bugs after the software is in production than when it is being designed. The time that is necessary to fix identified issues is shorter when the software is still in the design phase. The cost savings are substantial because there is minimal to no disruption to business operations. Besides the aforementioned time and cost-saving benefits, there are several other benefits of designing security early in the SDLC. Some of these include the following:
- Resilient and recoverable software: Security designed into software decreases the likelihood of attack or errors, which assures resiliency and recoverability of the software.
- Quality, maintainable software that is less prone to errors: Secure design not only increases the resiliency and recoverability of software, but such software is also less prone to errors (accidental or intentional), and that is directly related to the reliability of the software. This makes the software easily maintainable while improving the quality of the software considerably.
- Minimal redesign and consistency: When software is designed with security in mind, there is a minimal need for redesign. Using standards for architectural design of software also makes the software consistent, regardless of who is developing it.
- Business logic flaws addressed: Business logic flaws are those which are characterized by the software’s functioning as designed, but the design itself makes circumventing the security policy possible. Business logic flaws have been commonly observed in the way password-recovery mechanisms are designed. In the early days, when people needed to recover their passwords, they were asked to answer a predefined set of questions for which they had earlier provided answers that were saved to their profiles on the system. These questions were either guessable or often had a finite set of answers. It is not difficult to guess the favorite color of a person or provide an answer from the finite set of primary colors that exists. The software responds to the user input as designed, and so there is really no issue of reliability. However, because careful thought was not given to the architecture by which password recovery was designed, there existed a possibility of an attacker’s brute-forcing or intelligently bypassing security mechanisms. By designing software with security in mind, business logic flaws and other architectural design issues can be uncovered, which is a main benefit of securely designing software.
Investing the time up front in the SDLC to design security into the software supports the “build-in” virtue of security, as opposed to trying to bolt it on at a later stage. The bolt-on method of implementing security can become very costly, time-consuming, and generate software of low quality characterized by being unreliable, inconsistent, and unmaintainable, as well as by being error prone and hacker prone.
3.4 Flaws versus Bugs
Although it may seem like many security errors are related to insecure programming, the majority of security errors are also architecture based. The line of demarcation between when a software security error is due to improper architecture and when it is due to insecure implementation is not always very distinct, as the error itself may be a result of both architecture and implementation failure. In the design stage, because no code is written, we are primarily concerned with design issues related to software assurance. For the rest of this chapter and book, we will refer to design and architectural defects that can result in errors as “flaws” and to coding/implementation constructs that can cause a breach in security as “bugs.”
It is not quite as important to know which security errors constitute a flaw and which ones a bug, but it is important to understand that both flaws and bugs need to be identified and addressed appropriately. Threat modeling and secure architecture design reviews, which will we cover later in this chapter, are useful in the detection of architecture (flaws) and implementation issues (bugs), although the latter are mostly determined by code reviews and penetration testing exercises after implementation. Business logic flaws that were mentioned earlier are primarily a design issue. They are not easily detectable when reviewing code. Scanners and intrusion detection systems (IDSs) cannot detect them, and application-layer firewalls are futile in their protection against them. The discovery of nonsyntactic design flaws in the logical operations of the software is made possible by security architecture and design reviews. Security architecture and design reviews using outputs from attack surface evaluation, threat modeling, and misuse cases modeling are very useful in ensuring that the software not only functions as it is expected to but that it does not violate any security policy while doing so. Logic flaws are also known as semantic issues. Flaws are broad classes of vulnerabilities that at times can also include syntactic coding bugs. Insufficient input validation and improper error and session management are predominantly architectural defects that manifest themselves as coding bugs.
3.5 Design Considerations
In addition to designing for functionality of software, design for security tenets and principles also must be conducted. In Chapter 2, we learned about various types of security requirements. In the design phase, we will consider how these requirements can be incorporated into the software architecture and makeup. In this section, we will cover how the identified security requirements can be designed and what design decisions are to be made based on the business need. We will start with how to design the software to address the core security elements of confidentiality, integrity, availability, authentication, authorization, and auditing, and then we will look at examples of how to architect the secure design principles covered Chapter 1.
3.5.1 Core Software Security Design Considerations
3.5.1.1 Confidentiality Design
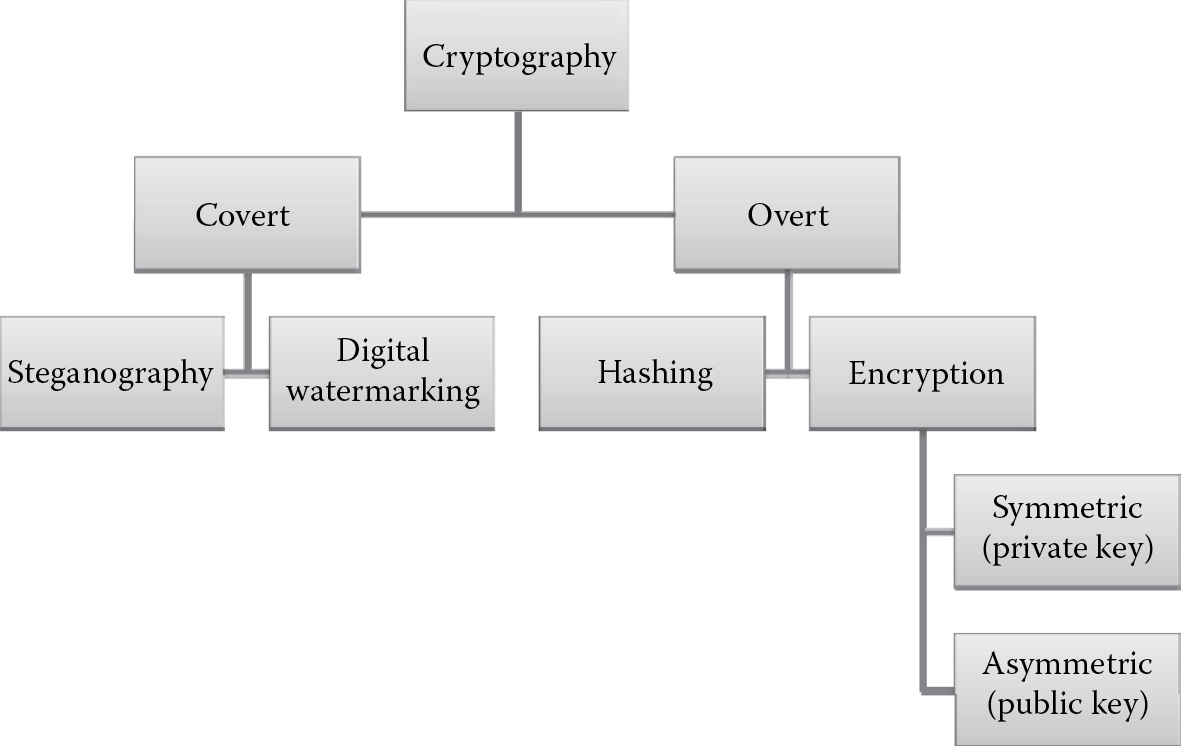
Disclosure protection can be achieved in several ways using cryptographic and masking techniques. Masking, covered in Chapter 2, is useful for disclosure protection when data are displayed on the screen or on printed forms; however, for assurance of confidentiality when the data are transmitted or stored in transactional data stores or offline archives, cryptographic techniques are primarily used. The most predominant cryptographic techniques include overt techniques such as hashing and encryption and covert techniques such as steganography and digital watermarking as depicted in Figure 3.1. These techniques were introduced in Chapter 2 and are covered here in a little more detail with a design perspective.
Cryptanalysis is the science of finding vulnerabilities in cryptographic protection mechanisms. When cryptographic protection techniques are implemented, the primary goal is to ensure that an attacker with resources must make such a large effort to subvert or evade the protection mechanisms that the required effort, itself, serves as a deterrent or makes the subversion or evasion impossible. This effort is referred to as work factor. It is critical to consider the work factor when choosing a technique while designing the software. The work factor against cryptographic protection is exponentially dependent on the key size. A key is a sequence of symbols that controls the encryption and decryption operations of a cryptographic algorithm, according to ISO/IEC 11016:2006. Practically, this is usually a string of bits that is supplied as a parameter into the algorithm for encrypting plaintext to cipher text or for decrypting cipher text to plaintext. It is vital that this key is kept a secret.
The key size, also known as key length, is the length of the key, measured usually in bits or bytes that are used in the algorithm. Given time and computational power, almost all cryptographic algorithms can be broken, except for the one-time pad, which is the only algorithm that is provably unbreakable by exhaustive brute-force attacks. This is, however, only true if the key used in the algorithm is truly random and discarded permanently after use. The key size in a one-time pad is equal to the size of the message itself, and each key bit is used only once and discarded.
In addition to protecting the secrecy of the key, key management is extremely critical. The key management life cycle includes the generation, exchange, storage, rotation, archiving, and destruction of the key as illustrated in Figure 3.2. From the time that the key is generated to the time that it is completely disposed of (or destroyed), it needs to be protected. The exchange mechanism itself needs to be secure so that the key is not disclosed when the key is shared. When the key is stored in configuration files or in a hardware security module (HSM) such as the Trusted Platform Modules (TPMs) chip for increased security, it needs to be protected using access control mechanisms, TPM security, encryption, and secure startup mechanisms, which we will cover in Chapter 7.
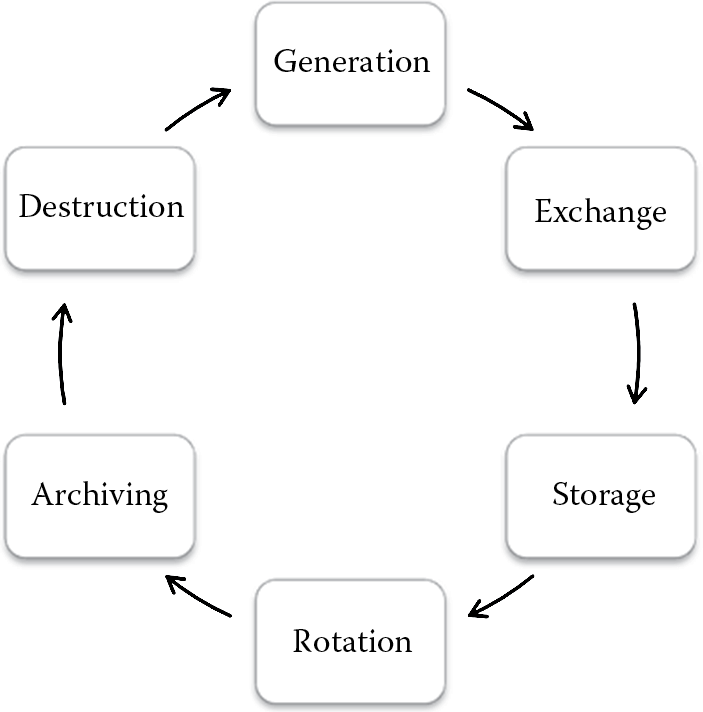
Rotation (swapping) of keys involves the expiration of the current key and the generation, exchange, and storage of a new key. Cryptographic keys need to be swapped periodically to thwart insider threats and immediately upon key disclosure. When the key is rotated as part of a routine security protocol, if the data that are backed up or archived are in an encrypted format, then the key that was used for encrypting the data must also be archived. If the key is destroyed without being archived, the corresponding key to decrypt the data will be unavailable, leading to a denial of service (DoS) should there be a need to retrieve the data for forensics or disaster recovery purposes.
Encryption algorithms are primarily of two types: symmetric and asymmetric.
3.5.1.1.1 Symmetric Algorithms
Symmetric algorithms are characterized by using a single key for encryption and decryption operations that is shared between the sender and the receiver. This is also referred to by other names: private key cryptography, shared key cryptography, or secret key algorithm. The sender and receiver need not be human all the time. In today’s computing business world, the senders and receivers can be applications or software within or external to the organization.
The major benefit of symmetric key cryptography is that it is very fast and efficient in encrypting large volumes of data in a short period. However, this advantage comes with significant challenges that have a direct impact on the design of the software. Some of the challenges with symmetric key cryptography include the following:
- Key exchange and management: Both the originator and the receiver must have a mechanism in place to share the key without compromising its secrecy. This often requires an out-of-band secure mechanism to exchange the key information, which requires more effort and time, besides potentially increasing the attack surface area. The delivery of the key and the data must be mutually exclusive as well.
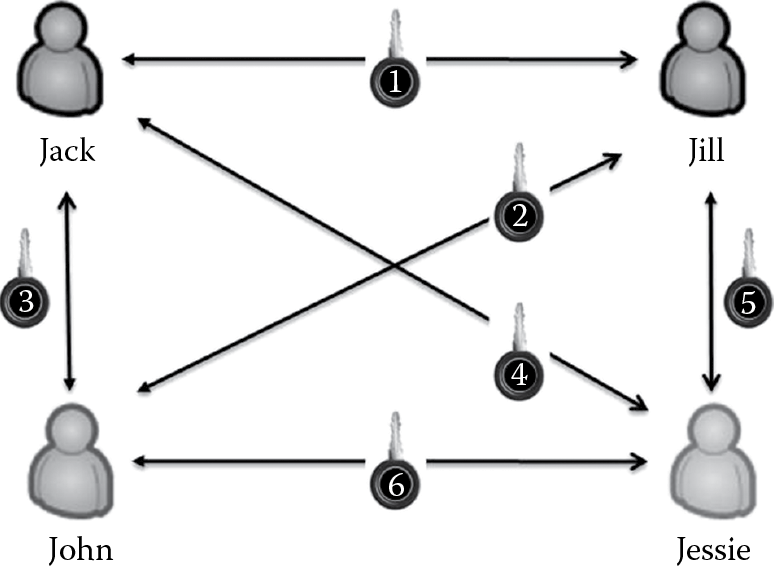
- Scalability: Because a unique key needs to be used between each sender and recipient, the number of keys required for symmetric key cryptographic operations is exponentially dependent on the number of users or parties involved in that secure transaction. For example, if Jack wants to send a message to Jill, then they both must share one key. If Jill wants to send a message to John, then there needs to be a different key that is used for Jill to communicate with John. Now, between Jack and John, there is a need for another key, if they need to communicate. If we add Jessie to the mix, then there is a need to have six keys, one for Jessie to communicate with Jack, one for Jessie to communicate with Jill, and one for Jessie to communicate with John, in addition to the three keys that are necessary as mentioned earlier and depicted in Figure 3.3. The computation of the number of keys can be mathematically represented as
So if there are 10 users/parties involved, then the number of keys required is 45 and if there are 100 users/parties involved, then we need to generate, distribute, and manage 4,950 keys, making symmetric key cryptography not very scalable.
- Nonrepudiation not addressed: Symmetric key simply provides confidentiality protection by encrypting and decrypting the data. It does not provide proof of origin or nonrepudiation.
Some examples of common symmetric key cryptography algorithms along with their strength and supported key size are tabulated in Table 3.1. RC2, RC4, and RC5 are other examples of symmetric algorithms that have varying degrees of strength based on the multiple key sizes they support. For example, the RC2-40 algorithm is considered to be a weak algorithm, whereas the RC2-128 is deemed to be a strong algorithm.
Symmetric Algorithms
|
Algorithm Name |
Strength |
Key Size |
|
DES |
Weak |
56 |
|
Skipjack |
Medium |
80 |
|
IDEA |
Strong |
128 |
|
Blowfish |
Strong |
128 |
|
3DES |
Strong |
168 |
|
Twofish |
Very strong |
256 |
|
RC6 |
Very strong |
256 |
|
AES / Rijndael |
Very strong |
256 |
3.5.1.1.2 Asymmetric Algorithms
In asymmetric key cryptography, instead of using a single key for encryption and decryption operations, two keys that are mathematically related to each other are used. One of the two keys is to be held secret and is referred to as the private key, whereas the other key is disclosed to anyone with whom secure communications and transactions need to occur. The key that is publicly displayed to everyone is known as the public key. It is also important that it should be computationally infeasible to derive the private key from the public key. Though there is a private key and a public key in asymmetric key cryptography, it is commonly known as public key cryptography.
Both the private and the public keys can be used for encryption and decryption. However, if a message is encrypted with a public key, it is only the corresponding private key that can decrypt that message. The same is true when a message is encrypted using a private key. That message can be decrypted only by the corresponding public key. This makes it possible for asymmetric key cryptographic to provide both confidentiality and nonrepudiation assurance.
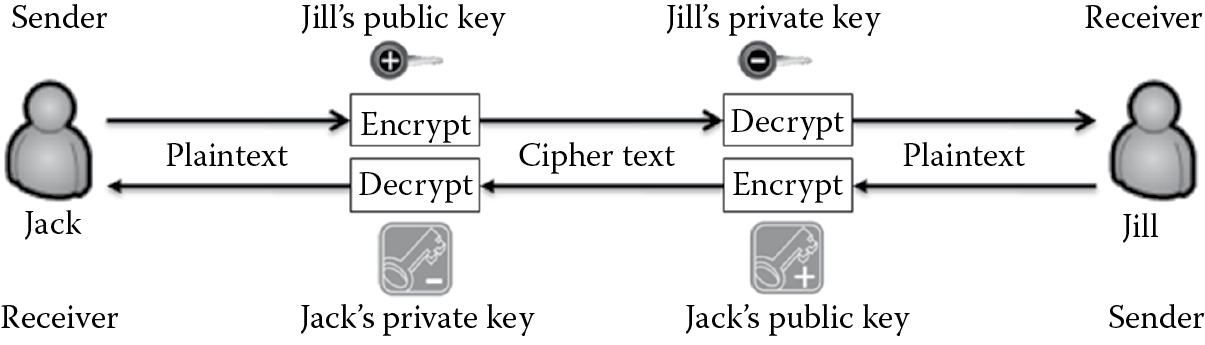
Confidentiality is provided when the sender uses the receiver’s public key to encrypt the message and the receiver uses the corresponding private key to decrypt the message, as illustrated in Figure 3.4. For example, if Jack wants to communicate with Jill, he can encrypt the plaintext message with her public key and send the resulting cipher text to her. Jill can user her private key that is paired with her public key and decrypt the message. Because Jill’s private key should not be known to anyone other than Jill, the message is protected from disclosure to anyone other than Jill, assuring confidentiality. Now, if Jill wants to respond to Jack, she can encrypt the plaintext message she plans to send him with his public key and send the resulting cipher text to him. The cipher text message can then be decrypted to plaintext by Jack using his private key, which again, only he should know.
In addition to confidentiality protection, asymmetric key cryptography also can provide nonrepudiation assurance. Nonrepudiation protection is known also as proof-of-origin assurance. When the sender’s private key is used to encrypt the message and the corresponding key is used by the receiver to decrypt it, as illustrated in Figure 3.5, proof-of-origin assurance is provided. Because the message can be decrypted only by the public key of the sender, the receiver is assured that the message originated from the sender and was encrypted by the corresponding private key of the sender. To demonstrate nonrepudiation or proof of origin, let us consider the following example. Jill has the public key of Jack and receives an encrypted message from Jack. She is able to decrypt that message using Jack’s public key. This assures her that the message was encrypted using the private key of Jack and provides her the confidence that Jack cannot deny sending her the message, because he is the only one who should have knowledge of his private key.
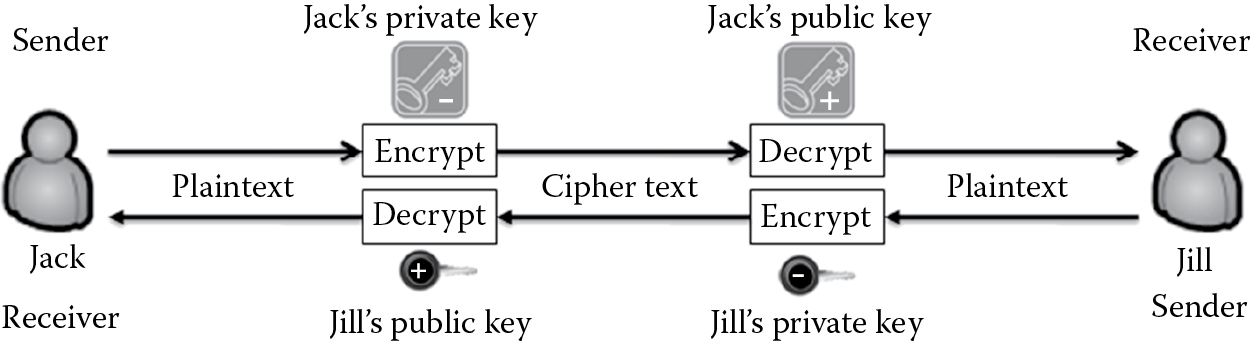
If Jill wants to send Jack a message and he needs to be assured that no one but Jill sent him the message, Jill can encrypt the message with her private key and Jack will use her corresponding public key to decrypt the message. A compromise in the private key of the parties involved can lead to confidentiality and nonrepudiation threats. It is thus critically important to protect the secrecy of the private key.
In addition to confidentiality and nonrepudiation assurance, asymmetric key cryptography also provides access control, authentication, and integrity assurance. Access control is provided because the private key is limited to one person. By virtue of nonrepudiation, the identity of the sender is validated, which supports authentication. Unless the private–public key pair is compromised, the data cannot be decrypted and modified, thereby providing data integrity assurance.
Asymmetric key cryptography has several advantages over symmetric key cryptography. These include the following:
- Key exchange and management: In asymmetric key cryptography, the overhead costs of having to securely exchange and store the key are alleviated. Cryptographic operations using asymmetric keys require a public key infrastructure (PKI) key identification, exchange, and management. PKI uses digital certificates to make key exchange and management automation possible. Digital certificates is covered in the next section.
- Scalability: Unlike symmetric key cryptography, where there is a need to generate and securely distribute one key between each party, in asymmetric key cryptography, there are only two keys needed per user: one that is private and held by the sender and the other that is public and distributed to anyone who wishes to engage in a transaction with the sender. One hundred users will require 200 keys, which is much easier to manage than the 4,950 keys needed for symmetric key cryptography.
- Addresses nonrepudiation: It also addresses nonrepudiation by providing the receiver assurance of proof of origin. The sender cannot deny sending the message when the message has been encrypted using the private key of the sender.
Although asymmetric key cryptography provides many benefits over symmetric key cryptography, there are certain challenges that are prevalent, as well. Public key cryptography is computationally intensive and much slower than symmetric encryption. This is, however, a preferable design choice for Internet environments.
Some common examples of asymmetric key algorithms include Rivest, Shamir, Adelman (RSA), El Gamal, Diffie–Hellman (used only for key exchange and not data encryption), and Elliptic Curve Cryptosystem (ECC), which is ideal for small, hardware devices such as smart cards and mobile devices.
3.5.1.1.3 Digital Certificates
Digital certificates carry in them the public keys, algorithm information, owner and subject data, the digital signature of the certification authority (CA) that issued and verified the subject data, and a validity period (date range) for that certificate. Because a digital certificate contains the digital signature of the CA, it can be used by anyone to verify the authenticity of the certificate itself.
The different types of digital certificates that are predominantly used in Internet settings include the following:
- Personal certificates are used to identify individuals and authenticate them with the server. Secure e-mail using S-Mime uses personal certificates.
- Server certificates are used to identify servers. These are primarily used for verifying server identity with the client and for secure communications and transport layer security (TLS). The Secure Sockets Layer (SSL) protocol uses server certificates for assuring confidentiality when data are transmitted. Figure 3.6 shows an example of a server certificate.
- Software publisher certificates are used to sign software that will be distributed on the Internet. It is important to note that these certificates do not necessarily assure that the signed code is safe for execution but are merely informative in role, informing the software user that the certificate is signed by a trusted, software publisher’s CA.
3.5.1.1.4 Digital Signatures
Certificates hold in them the digital signatures of the CAs that verified and issued the digital certificates. A digital signature is distinct from a digital certificate. It is similar to an individual’s signature in its function, which is to authenticate the identity of the message sender, but in its format it is electronic. Digital signatures not only provide identity verification but also ensure that the data or message have not been tampered with, because the digital signature that is used to sign the message cannot be easily imitated by someone unless it is compromised. It also provides nonrepudiation.
There are several design considerations that need to be taken into account when choosing cryptographic techniques. It is therefore imperative to first understand business requirements pertaining to the protection of sensitive or private information. When these requirements are understood, one can choose an appropriate design that will be used to securely implement the software. If there is a need for secure communications in which no one but the sender and receiver should know of a hidden message, steganography can be considered in the design. If there is a need for copyright and IP protection, then digital watermarking techniques are useful. If data confidentiality in processing, transit, storage, and archives need to be assured, hashing or encryption techniques can be used.
3.5.2 Integrity Design
Integrity in the design assures that there is no unauthorized modification of the software or data. Integrity of software and data can be accomplished by using any one of the following techniques or a combination of the techniques, such as hashing (or hash functions), referential integrity design, resource locking, and code signing. Digital signatures, covered earlier, also provide data or message alteration protection.
3.5.2.1 Hashing (Hash Functions)
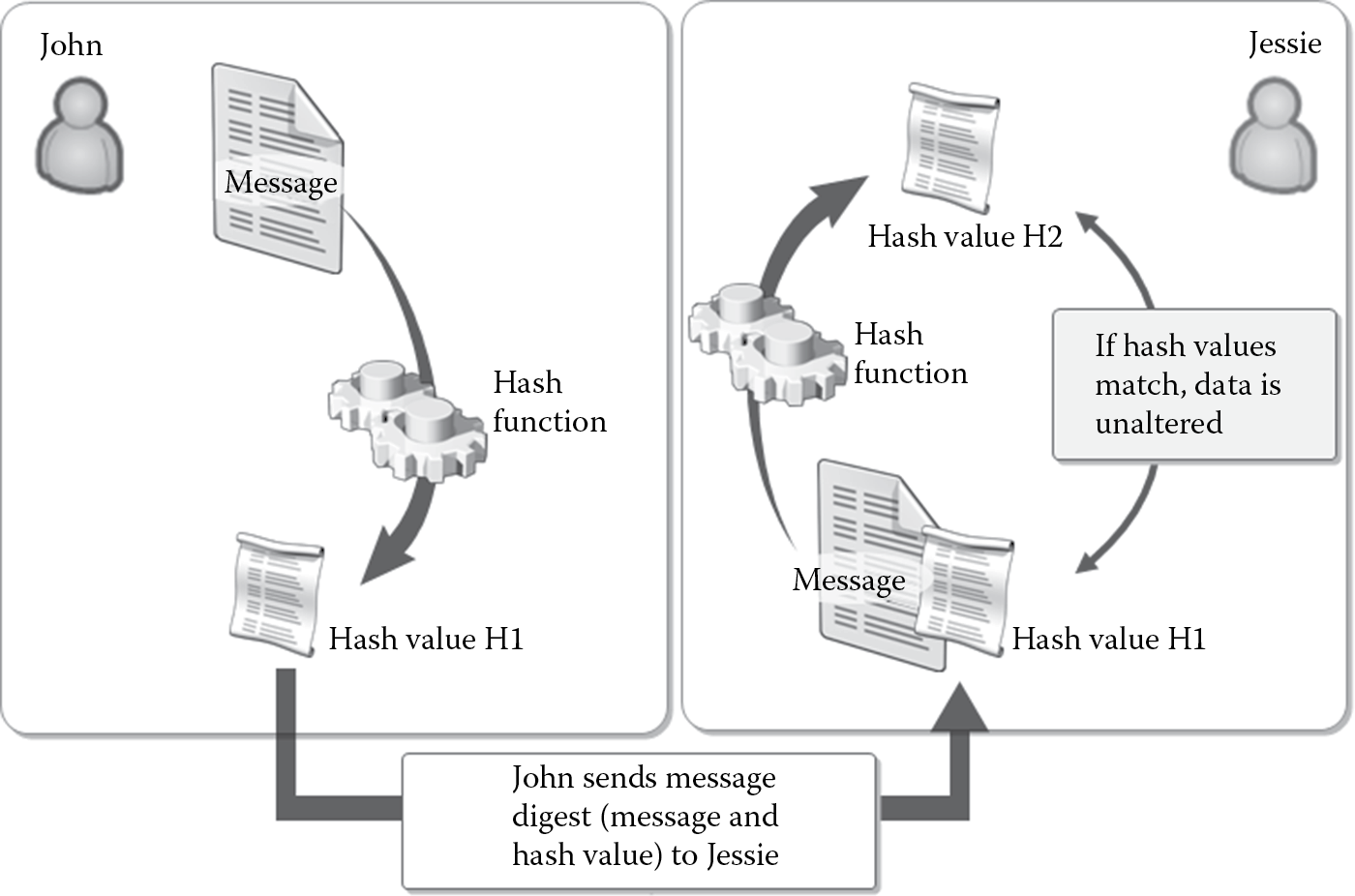
Here is a recap of what was introduced about hashing in Chapter 2: Hash functions are used to condense variable length inputs into an irreversible, fixed-sized output known as a message digest or hash value. When designing software, we must ensure that all integrity requirements that warrant irreversible protection, which is provided by hashing, are factored in. Figure 3.7 describes the steps taken in verifying integrity with hashing. John wants to send a private message to Jessie. He passes the message through a hash function, which generates a hash value, H1. He sends the message digest (original data plus hash value H1) to Jessie. When Jessie receives the message digest, she computes a hash value, H2, using the same hash function that John used to generate H1. At this point, the original hash value (H1) is compared with the new hash value (H2). If the hash values are equal, then the message has not been altered when it was transmitted.
In addition to assuring data integrity, it is also important to ensure that hashing design is collision free. “Collision free” implies that it is computationally infeasible to compute the same hash value on two different inputs. Birthday attacks are often used to find collisions in hash functions. A birthday attack is a type of brute-force attack that gets its name from the probability that two or more people randomly chosen can have the same birthday. Secure hash designs ensure that birthday attacks are not possible, which means that an attacker will not be able to input two messages and generate the same hash value. Salting the hash is a mechanism that assures collision-free hash values. Salting the hash also protects against dictionary attacks, which are another type of brute-force attack. A “dictionary attack” is an attempt to thwart security protection mechanisms by using an exhaustive list (like a list of words from a dictionary).
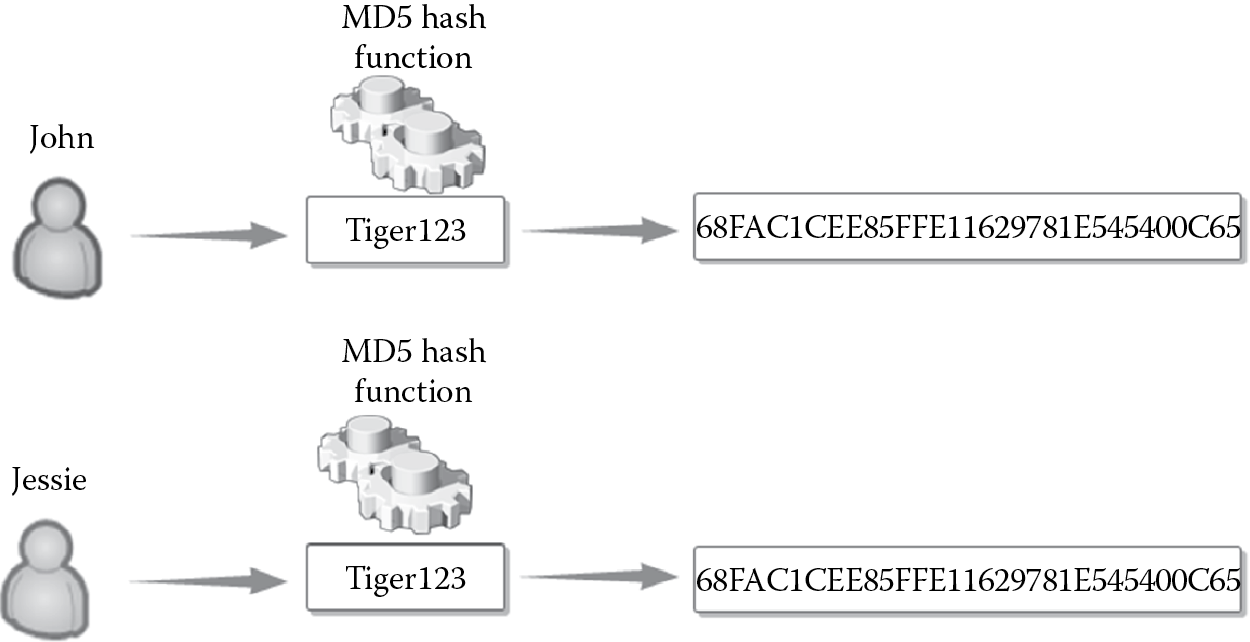
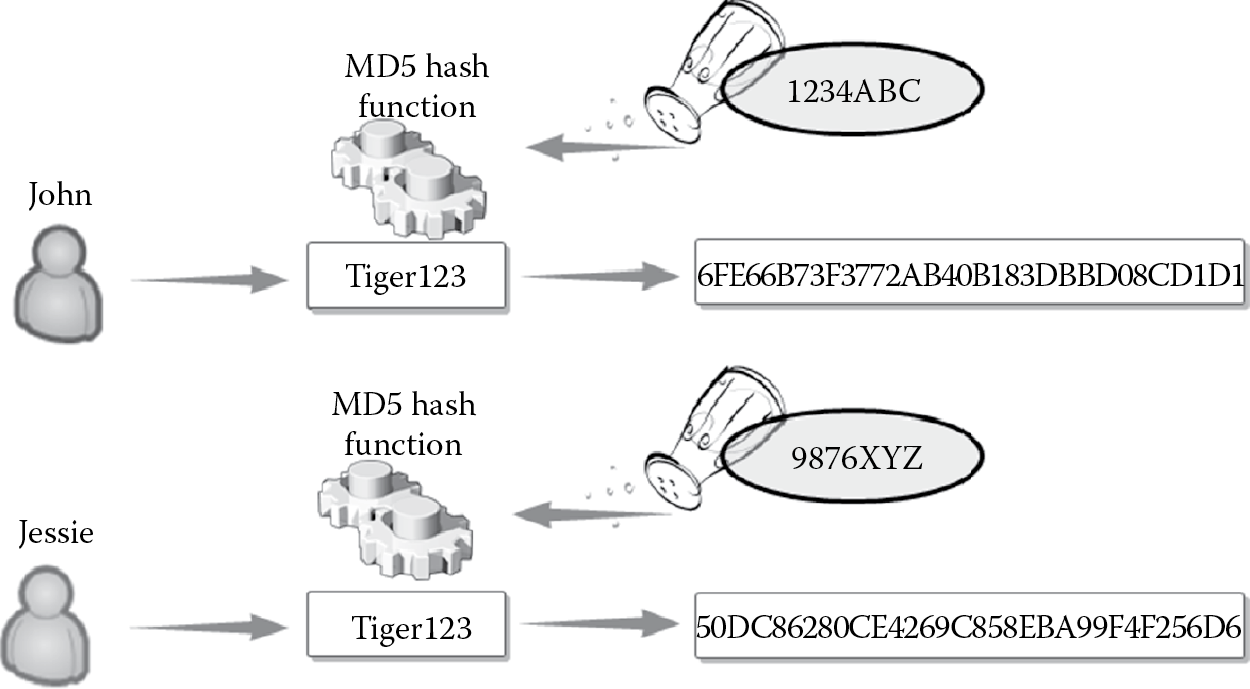
Salt values are random bytes that can be used with the hash function to prevent prebuilt dictionary attacks. Let us consider the following: There is a likelihood that two users within a large organization have the same password. Both John and Jessie have the same password, “tiger123” for logging into their bank account. When the password is hashed using the same hash function, it should produce the same hashed value as depicted in Figure 3.8. The password “tiger123” is hashed using the MD5 hash function to generate a fixed-sized hash value “9E107D9D372BB6826BD81D3542A419D6.”
Even though the user names are different, when the password is hashed, because it generates the same output, it can lead to impersonation attacks, where John can login as Jessie or vice versa. By adding random bytes (salt) to the original plaintext before passing it through the hash function, the output that is generated for the same input is made different. This mitigates the security issues discussed earlier. It is recommended to use a salt value that is unique and random for each user. When the salt value is “1234ABC” for John and is “9876XYZ” for Jessie, the same password, “tiger123” results in different hashed values as depicted in Figure 3.9.
Design considerations should take into account the security aspects related to the generation of the salt, which should be unique to each user and random.
Some of the most common hash functions are the MD2, MD4, and MD5, which were all designed by Ronald Rivest; the Secure Hash Algorithms family (SHA-0, SHA-1, SHA-, and SHA-2) designed by NSA and published by NIST to complement digital signatures and HAVAL. The Ronald Rivest MD series of algorithms generate a fixed, 128-bit size output and has been proven to be not completely collision free. The SHA-0 and SHA-1 family of hash functions generated a fixed, 160-bit sized output. The SHA-2 family of hash functions includes SHA-224 and SHA-256, which generate a 256-bit sized output and SHA-384 and SHA-512 which generate a 512-bit sized output. HAVAL is distinct in being a hash function that can produce hashes in variable lengths (128–256 bits). HAVAL is also flexible to let users indicate the number of rounds (3–5) to be used to generate the hash for increased security. As a general rule of thumb, the greater the bit length of the hash value that is supported, the greater the protection that is provided, making cryptanalysis work factor significantly greater. So when designing the software, it is important to consider the bit length of the hash value that is supported. Table 3.2 tabulates the different hash value lengths that are supported by some common hash functions.
Hash Functions and Supported Hash Value Lengths
|
Hash Function |
Hash Value Length (in bits) |
|
MD2, MD4, MD5 |
128 |
|
SHA |
160 |
|
HAVAL |
Variable lengths (128, 160, 192, 224, 256) |
Another important aspect when choosing the hash function for use within the software is to find out if the hash function has already been broken and deemed unsuitable for use. The MD5 hash function is one such example that the U.S. Computer Emergency Response Team (CERT) of the Department of Homeland Security (DHS) considers as cryptographically broken. DHS promotes moving to the SHA family of hash functions.
3.5.2.2 Referential Integrity
Integrity assurance of the data, especially in a relational database management system (RDBMS) is made possible by referential integrity, which ensures that data are not left in an orphaned state. Referential integrity protection uses primary keys and related foreign keys in the database to assure data integrity. Primary keys are those columns or combination of columns in a database table, which uniquely identify each row in a table. When the column or columns that are defined as the primary key of a table are linked (referenced) in another table, these column or columns are referred to as foreign keys in the second table. For example, as depicted in Figure 3.10, Customer_ID column in the CUSTOMER table is the primary key because it uniquely identifies a row in the table. Although there are two users with the same first name and last name, “John Smith,” the Customer_ID is unique and can identify the correct row in the database. Customers are also linked to their orders using their Customer_Id, which is the foreign key in the ORDER table. This way, all of the customer information need not be duplicated in the ORDER table. The removal of duplicates in the tables is done by a process called normalization, which is covered later in this chapter. When one needs to query the database to retrieve all orders for customer John Smith whose Customer_ID is 1, then two orders (Order_ID 101 and 103) are returned. In this case, the parent table is the CUSTOMER table and the child table is the ORDER table. The Order_ID is the primary key in the ORDER table, which, in turn, is established as the foreign key in the ORDER_DETAIL table. In order to find out the details of the order placed by customer Mary Johnson whose Customer_ID is 3, we can retrieve the three products that she ordered by referencing the primary key and foreign key relationships. In this case, in addition to the CUSTOMER table being the parent of the ORDER table, the ORDER table, itself, is parent to the ORDER_DETAIL child table.

Referential integrity ensures that data are not left in an orphaned state. This means that if the customer Mary Johnson is deleted from the CUSTOMER table in the database, all of her corresponding order and order details are deleted, as well, from the ORDER and ORDER_DETAIL tables, respectively. This is referred to as cascading deletes. Failure to do so will result in records being present in ORDER and ORDER_DETAILS tables as orphans with a reference to a customer who no longer exists in the parent CUSTOMER table. When referential integrity is designed, it can be set up to either delete all child records when the parent record is deleted or to disallow the delete operation of a customer (parent record) who has orders (child records), unless all of the child order records are deleted first. The same is true in the case of updates. If for some business need, Mary Johnson’s Customer_ID in the parent table (CUSTOMER) is changed, then all subsequent records in the child table (ORDER) should also be updated to reflect the change, as well. This is referred to as cascading updates.
Decisions to normalize data into atomic (nonduplicate) values and establish primary keys and foreign keys and their relationships, cascading updates and deletes, in order to assure referential integrity are important design considerations that ensure the integrity of data or information.
3.5.2.3 Resource Locking
In addition to hashing and referential integrity, resource locking can be used to assure data or information integrity. When two concurrent operations are not allowed on the same object (say a record in the database), because one of the operations locks that record from allowing any changes to it, until it completes its operation, it is referred to as resource locking. Although this provides integrity assurance, it is critical to understand that if resource locking protection is not properly designed, it can lead to potential deadlocks and subsequent DoS. Deadlock is a condition that exists when two operations are racing against each other to change the state of a shared object and each is waiting for the other to release the shared object that is locked.
When designing software, there is a need to consider the protection mechanisms that assure that data or information has not been altered in an unauthorized manner or by an unauthorized person or process, and the mechanisms need to be incorporated into the overall makeup of the software.
3.5.2.4 Code Signing
Code signing is the process of digitally signing the code (executables, scripts, etc.) with the digital signature of the code author. In most cases, code signing is implemented using private and public key systems and digital signatures. Each time code is built, it can be signed or code can be signed just before deployment. Developers can generate their own key or use a key that is issued by a trusted CA for signing their code. When developers do not have access to the key for signing their code, they can sign it at a later phase of the development life cycle, just before deployment, and this is referred to as delayed signing. Delayed signing allows development to continue. When code is signed using the code author’s digital signature, a cryptographic hash of that code is generated. This hash is published along with the software when it is distributed. Any alteration of the code will result in a hash value that will no longer match the hash value that was published. This is how code signing assures integrity and antitampering.
Code signing is particularly important when it comes to mobile code. Mobile code is code that is downloaded from a remote location. Examples of mobile code include Java applets, ActiveX components, browser scripts, Adobe Flash, and other Web controls. The source of the mobile code may not be obvious. In such situations, code signing can be used to assure the proof of origin or its authenticity. Signing mobile code also gives the runtime (not the code itself) permission to access system resources and ensures the safety of the code by sandboxing. Additionally, code signing can be used to ensure that there are no namespace conflicts and to provide versioning information when the software is deployed.
3.5.3 Availability Design
When software requirements mandate the need for continued business operations, the software should be carefully designed. The output from the business impact analysis can be used to determine how to design the software. Special considerations need to be given to software and data replication so that the MTD and the RTO are both within acceptable levels. Destruction and DoS protection can be achieved by proper coding/implementation of the software. Although no code is written in the design phase, in the software design, coding and configuration requirements such as connection pooling, memory management, database cursors, and loop constructions can be looked at. Connection pooling is a database access efficiency mechanism. A connection pool is the number of connections that are cached by the database for reuse. When your software needs to support a large number of users, the appropriate number of connection pools should be configured. If the number of connection pools is low in a highly transactional environment, then the database will be under heavy workload, experiencing performance issues that can possibly lead to DoS. Once a connection is opened, it can be placed in the pool so that other users can reuse that connection, instead of opening and closing a connection for each user. This will increase performance, but security considerations should be taken into account and this is why designing the software from a security (availability) perspective is necessary. Memory leaks can occur if the default query processing, thread limits are not optimized, or because of bad programming; so pertinent considerations of how memory will be managed need to be accounted for in design. Once the processes are terminated, allocated memory resources must be released. This is known as garbage collection and is another important design consideration. Coding constructs that use incorrect cursors and infinite loops can lead to deadlocks and DoS. When these constructs are properly designed, availability assurance is increased.
3.5.4 Authentication Design
When designing for authentication, it is important to consider multifactor authentication and single sign-on (SSO), in addition to determining the type of authentication required as specified in the requirements documentation. Multifactor or the use of more than one factor to authenticate a principal (user or resource) provides heightened security and is recommended. For example, validating and verifying one’s fingerprint (something you are) in conjunction with a token (something you have) and pin code (something you know) before granting access provides more defense in depth than merely using a username and password (something you know). Additionally, if there is a need to implement SSO, wherein the principal’s asserted identity is verified once and the verified credentials are passed on to other systems or applications, usually using tokens, then it is crucial to factor into the design of the software both the performance impact and its security. Although SSO simplifies credential management and improves user experience and performance because the principal’s credential is verified only once, improper design of SSO can result in security breaches that have colossal consequences. A breach at any point in the application flow can lead to total compromise, akin to losing the keys to the kingdom. SSO is covered in more detail in the technology section of this chapter.
3.5.5 Authorization Design
When designing for authorization, give special attention to the impact on performance and to the principles of separation of duties and least privilege. The type of authorization to be implemented as per the requirements must be determined as well. Are you going to use roles or will we need to use a resource-based authorization, such as a trusted subsystem with impersonation and delegation model, to manage the granting of access rights? Checking for access rights each and every time, as per the principle of complete mediation, can lead to performance degradation and decreased user experience. On the contrary, a design that calls for caching of verified credentials that are used for access decisions can become the Achilles’ heel from a security perspective. When dealing with performance versus security trade-off decisions, it is recommended to err on the side of caution, allowing for security over performance. However, this decision is one that needs to be discussed and approved by the business.
When roles are used for authorization, design should ensure that there are no conflicting roles that circumvent the separation of duties principle. For example, a user cannot be in a teller role and also in an auditor role for a financial transaction. Additionally, design decisions are to ensure that only the minimum set of rights is granted explicitly to the user or resource, thereby supporting least privilege. For example, users in the “Guest” or “Everyone” group account should be allowed only read rights and any other operation should be disallowed.
3.5.6 Auditing/Logging Design
Although it is often overlooked, design for auditing has been proven to be extremely important in the event of a breach, primarily for forensic purposes, and so it should be factored into the software design from the very beginning. Log data should include the who, what, where, and when aspects of software operations. As part of the “who,” it is important not to forget the nonhuman actors such as batch processes and services or daemons.
It is advisable to log by default and to leverage the existing logging functionality within the software, especially if it is commercial off-the-shelf (COTS) software. Because it is a best practice to append to logs and not overwrite them, capacity constraints and requirements are important design considerations. Design decisions to retain, archive, and dispose logs should not contradict external regulatory or internal retention requirements.
Sensitive data should never be logged in plaintext form. Say that the requirements call for logging failed authentication attempts. Then it is important to verify with the business if there is a need to log the password that is supplied when authentication fails. If requirements explicitly call for logging the password upon failed authentication, then it is important to design the software so that the password is not logged in plaintext. Users often mistype their passwords and logging this information can lead to potential confidentiality violation and account compromise. For example, if the software is designed to log the password in plaintext and user Scott whose password is “tiger” mistypes it as “tigwr,” someone who has access to the logs can easily guess the password of the user.
Design should also factor in protection mechanisms of the log itself; and maintaining the chain of custody of the logs will ensure that the logs are admissible in court. Validating the integrity of the logs can be accomplished by hashing the before and after images of the logs and checking their hash values. Auditing in conjunction with other security controls such as authentication can provide nonrepudiation. It is preferable to design the software to automatically log the authenticated principal and system timestamp and not let it be user-defined to avoid potential integrity issues. For example, using the Request.ServerVariables[LOGON_USER] in an IIS Web application or the T-SQL in-built getDate() system function in SQL Server is preferred over passing a user-defined principal name or timestamp.
We have learned about how to design software incorporating core security elements of confidentiality, integrity, availability, authentication, authorization, and auditing.
3.6 Information Technology Security Principles and Secure Design
Special Publication 800-27 of the NIST, which is entitled, “Engineering principles for information technology security (a baseline for achieving security),” provides various IT security principles as listed below. Some of these principles are people oriented, whereas others are tied to the process for designing security in IT systems.
- Establish a sound security policy as the “foundation” for design.
- Treat security as an integral part of the overall system design.
- Clearly delineate the physical and logical security boundaries governed by associated security policies.
- Reduce risk to an acceptable level.
- Assume that external systems are insecure.
- Identify potential trade-offs between reducing risk and increased costs and decreases in other aspects of operational effectiveness.
- Implement layered security. (Ensure no single point of vulnerability.)
- Implement tailored, system security measures to meet organizational security goals.
- Strive for simplicity.
- Design and operate an IT system to limit vulnerability and to be resilient in response.
- Minimize the system elements to be trusted.
- Implement security through a combination of measures distributed physically and logically.
- Provide assurance that the system is, and continues to be, resilient in the face of expected threats.
- Limit or contain vulnerabilities.
- Formulate security measures to address multiple, overlapping, information domains.
- Isolate public access systems from mission critical resources (e.g., data, processes, etc.).
- Use boundary mechanisms to separate computing systems and network infrastructures.
- Where possible, base security on open standards for portability and interoperability.
- Use common language in developing security requirements.
- Design and implement audit mechanisms to detect unauthorized use and to support incident investigations.
- Design security to allow for regular adoption of new technology, including a secure and logical technology upgrade process.
- Authenticate users and processes to ensure appropriate, access control decisions both within and across domains.
- Use unique identities to ensure accountability.
- Implement least privilege.
- Do not implement unnecessary security mechanisms.
- Protect information while it is processed, in transit, and in storage.
- Strive for operational ease of use.
- Develop and exercise contingency or disaster recovery procedures to ensure appropriate availability.
- Consider custom products to achieve adequate security.
- Ensure proper security in the shutdown or disposal of a system.
- Protect against all likely classes of attacks.
- Identify and prevent common errors and vulnerabilities.
- Ensure that developers are trained in how to develop secure software.
Some of the common, insecure design issues observed in software are the following:
- Not following coding standards
- Improper implementation of least privilege
- Software fails insecurely
- Authentication mechanisms easily bypassed
- Security through obscurity
- Improper error handling
- Weak input validation
3.7 Designing Secure Design Principles
In the following section we will look at some of the IT engineering security principles that are pertinent to software design. The following principles were introduced and defined in Chapter 1. It is revisited here as a refresher and discussed in more depth with examples.
3.7.1 Least Privilege
Although the principle of least privilege is more applicable to administering a system where the number of users with access to critical functionality and controls is restricted, least privilege can be implemented within software design. When software is said to be operating with least privilege, it means that only the necessary and minimum level of access rights (privileges) has been given explicitly to it for a minimum amount of time in order for it to complete its operation. The main objective of least privilege is containment of the damage that can result from a security breach that occurs accidentally or intentionally. Some of the examples of least privilege include the military security rule of “need-to-know” clearance level classification, modular programming, and nonadministrative accounts.
The military security rule of need-to-know limits the disclosure of sensitive information to only those who have been authorized to receive such information, thereby aiding in confidentiality assurance. Those who have been authorized can be determined from the clearance level classifications they hold, such as Top Secret, Secret, Sensitive but Unclassified, etc. Best practice also suggests that it is preferable to have many administrators with limited access to security resources instead of one user with “super user” rights.
Modular programming is a software design technique in which the entire program is broken down into smaller subunits or modules. Each module is discrete with unitary functionality and is said to be therefore cohesive, meaning each module is designed to perform one and only one logical operation. The degree of how cohesive a module is indicates the strength at which various responsibilities of a software module are related. The discreetness of the module increases its maintainability and the ease of determining and fixing software defects. Because each unit of code (class, method, etc.) has a single purpose and the operations that can be performed by the code is limited to only that which it is designed to do, modular programming is also referred to as the Single Responsibility Principle of software engineering. For example, the function CalcDiscount() should have the single responsibility to calculate the discount for a product, while the CalcSH() function should be exclusively used to calculate shipping and handling rates. When code is not designed modularly, not only does it increase the attack surface, but it also makes the code difficult to read and troubleshoot. If there is a requirement to restrict the calculation of discounts to a sales manager, not separating this functionality into its own function, such as CalcDiscount(), can lead potentially to a nonsales manager’s running code that is privileged to a sales manager. An aspect related to cohesion is coupling. Coupling is a reflection of the degree of dependencies between modules, i.e., how dependent one module is to another. The more dependent one module is to another, the higher its degree of coupling, and “loosely coupled modules” is the condition where the interconnections among modules are not rigid or hardcoded.
Good software engineering practices ensure that the software modules are highly cohesive and loosely coupled at the same time. This means that the dependencies between modules will be weak (loosely coupled) and each module will be responsible to perform a discrete function (highly cohesive).
Modular programming thereby helps to implement least privilege, in addition to making the code more readable, reusable, maintainable, and easy to troubleshoot.
The use of accounts with nonadministrative abilities also helps implement least privilege. Instead of using the “sa” or “sysadmin” account to access and execute database commands, using a “datareader” or “datawriter” account is an example of least privilege implementation.
3.7.2 Separation of Duties
When design compartmentalizes software functionality into two or more conditions, all of which need to be satisfied before an operation can be completed, it is referred to as separation of duties. The use of split keys for cryptographic functionality is an example of separation of duties in software. Keys are needed for encryption and decryption operations. Instead of storing a key in a single location, splitting a key and storing the parts in different locations, with one part in the system’s registry and the other in a configuration file, provides more security. Software design should factor in the locations to store keys, as well as the mechanisms to protect them.
Another example of separation of duties in software development is related to the roles that people play during its development and the environment in which the software is deployed. The programmer should not be allowed to review his own code nor should a programmer have access to deploy code to the production environment. We will cover in more detail the separation of duties based on the environment in the configuration section of Chapter 7.
When architected correctly, separation of duties reduces the extent of damage that can be caused by one person or resource. When implemented in conjunction with auditing, it can also discourage insider fraud, as it will require collusion between parties to conduct fraud.
3.7.3 Defense in Depth
Layering security controls and risk mitigation safeguards into software design incorporates the principle of defense in depth. This is also referred to as layered defense. The reasons behind this principle are twofold, the first of which is that the breach of a single vulnerability in the software does not result in complete or total compromise. In other words, defense in depth is akin to not putting all the eggs in one basket. Second, incorporating the defense of depth in software can be used as a deterrent for the curious and nondetermined attackers when they are confronted with one defensive measure over another.
Some examples of defense in depth measures are
- Use of input validation along with prepared statements or stored procedures, disallowing dynamic query constructions using user input to defend against injection attacks
- Disallowing Cross-Site Scripting active scripting in conjunction with output encoding and input or request validation to defend against (XSS)
- The use of security zones, which separates the different levels of access according to the zone that the software or person is authorized to access
3.7.4 Fail Secure
Fail secure is the security principle that ensures that the software reliably functions when attacked and is rapidly recoverable into a normal business and secure state in the event of design or implementation failure. It aims at maintaining the resiliency (confidentiality, integrity, and availability) of software by defaulting to a secure state. Fail secure is primarily an availability design consideration, although it provides confidentiality and integrity protection as well. It supports the design and default aspects of the SD3 initiative, which implies that the software or system is secure by design, secure by default, and secure by deployment. In the context of software security, “fail secure” can be used interchangeably with “fail safe,” which is commonly observed in physical security.
Some examples of fail secure design in software include the following:
- The user is denied access by default and the account is locked out after the maximum number (clipping level) of access attempts is tried.
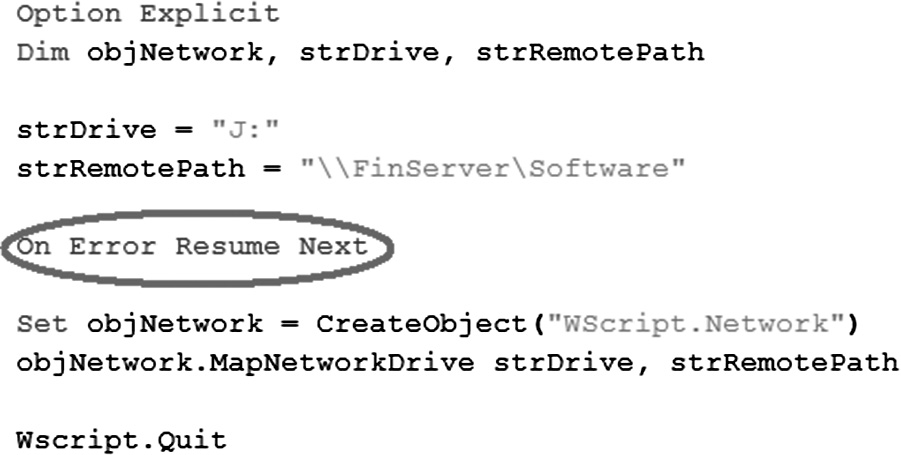
- Not designing the software to ignore the error and resume next operation. The On Error Resume Next functionality in scripting languages such as VBScript as depicted in Figure 3.11.
- Errors and exceptions are explicitly handled and the error messages are nonverbose in nature. This ensures that system exception information, along with the stack trace, is not bubbled up to the client in raw form, which an attacker can use to determine the internal makeup of the software and launch attacks accordingly to circumvent the security protection mechanisms or take advantage of vulnerabilities in the software. Secure software design will take into account the logging of the error content into a support database and the bubbling up of only a reference value (such as error ID) to the user with instructions to contact the support team for additional support.
3.7.5 Economy of Mechanisms
In Chapter 1, we noted that one of the challenges to the implementation of security is the trade-off that happens between the usability of the software and the security features that need to be designed and built in. With the noble intention of increasing the usability of software, developers often design and code in more functionality than is necessary. This additional functionality is commonly referred to as “bells-and-whistles.” A good indicator of which features in the software are unneeded bells-and-whistles is reviewing the requirements traceability matrix (RTM) that is generated during the requirements gathering phase of the software development project. Bells-and-whistles features will never be part of the RTM. While such added functionality may increase user experience and usability of the software, it increases the attack surface and is contrary to the economy of mechanisms, secure design principle, which states that the more complex the design of the software, the more likely there are vulnerabilities. Simpler design implies easy-to-understand programs, decreased attack surface, and fewer weak links. With a decreased attack surface, there is less opportunity for failure and when failures do occur, the time needed to understand and fix the issues is less, as well. Additional benefits of economy of mechanisms include ease of understanding program logic and data flows and fewer inconsistencies. Economy of mechanism in layman’s terms is also referred to as the KISS (Keep It Simple Stupid) principle and in some instances as the principle of unnecessary complexity. Modular programming not only supports the principle of least privilege but also supports the principle of economy of mechanisms.
Taken into account, the following considerations support the designing of software with the economies of mechanisms principle in mind:
- Unnecessary functionality or unneeded security mechanisms should be avoided. Because patching and configuration of newer software versions has been known to security features that were disabled in previous versions, it is advisable to not even design unnecessary features, instead of designing them and leaving the features in a disabled state.
- Strive for simplicity. Keeping the security mechanisms simple ensures that the implementation is not partial, which could result in compatibility issues. It is also important to model the data to be simple so that the data validation code and routines are not overly complex or incomplete. Supporting complex, regular expressions for data validation can result in algorithmic complexity weaknesses as stated in the Common Weakness Enumeration publication 407 (CWE-407).
- Strive for operational ease of use. SSO is a good example that illustrates the simplification of user authentication so that the software is operationally easy to use.
3.7.6 Complete Mediation
In the early days of Web application programming, it was observed that a change in the value of a QueryString parameter would display the result that was tied to the new value without any additional validation. For example, if Pamela is logged in, and the Uniform Resource Locator (URL) in the browser address bar shows the name value pair, user=pamela, changing the value “pamela” to “reuben” would display Reuben’s information without validating that the logged-on user is indeed Reuben. If Pamela changes the parameter value to user=reuben, she can view Reuben’s information, potentially leading to attacks on confidentiality, wherein Reuben’s sensitive and personal information is disclosed to Pamela.
While this is not as prevalent today as it used to be, similar design issues are still evident in software. Not checking access rights each time a subject requests access to objects violates the principle of complete mediation. Complete mediation is a security principle that states that access requests need to be mediated each time, every time, so that authority is not circumvented in subsequent requests. It enforces a system-wide view of access control. Remembering the results of the authority check, as is done when the authentication credentials are cached, can increase performance; however, the principle of complete mediation requires that results of an authority check be examined skeptically and systematically updated upon change. Caching can therefore lead to an increased security risk of authentication bypass, session hijacking and replay attacks, and man-in-the-middle (MITM) attacks. Therefore, designing the software to rely solely on client-side, cookie-based caching of authentication credentials for access should be avoided, if possible.
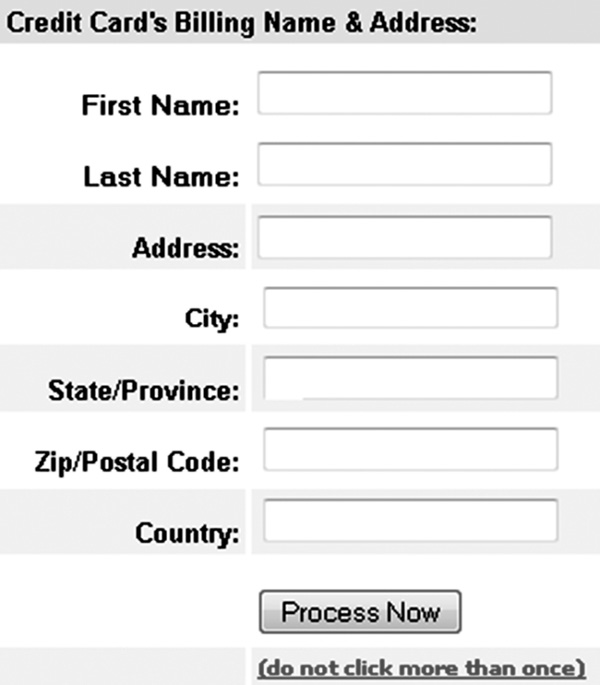
Complete mediation not only protects against authentication threats and confidentiality threats but is also useful in addressing the integrity aspects of software, as well. Not allowing browser postbacks without validation of access rights, or checking that a transaction is currently in a state of processing, can protect against the duplication of data, avoiding data integrity issues. Merely informing the user to not click more than once, as depicted in Figure 3.12, is not foolproof and so design should include the disabling of user controls once a transaction is initiated until the transaction is completed.
The complete mediation design principle also addresses the failure to protect alternate path vulnerability. To properly implement complete mediation in software, it is advisable during the design phase of the SDLC to identify all possible code paths that access privileged and sensitive resources. Once these privileged code paths are identified, then the design must force these code paths to use a single interface that performs access control checks before performing the requested operation. Centralizing input validation by using a single input validation layer with a single, input filtration checklist for all externally controlled inputs is an example of such design. Alternatively, using an external input validation framework that validates all inputs before they are processed by the code may be considered when designing the software.
Complete mediation also augments the protection against the weakest link. Software is only as strong as its weakest component (code, service, interface, or user). It is also important to recognize that any protection that technical safeguards provide can be rendered futile if people fall prey to social engineering attacks or are not aware of how to use the software. The catch 22 is that people who are the first line of defense in software security can also become the weakest link, if they are not made aware, trained, and educated in software security.
3.7.7 Open Design
Dr. Auguste Kerckhoff, who is attributed with giving us the cryptographic Kerckhoff ’s principle, states that all information about the crypto system is public knowledge except the key, and the security of the crypto system against cryptanalysis attacks is dependent on the secrecy of the key. An outcome of Kerckhoff’s principle is the open design principle, which states that the implementation of security safeguards should be independent of the design, itself, so that review of the design does not compromise the protection the safeguards offer. This is particularly applicable in cryptography where the protection mechanisms are decoupled from the keys that are used for cryptographic operations and algorithms used for encryption and decryption are open and available to anyone for review.
The inverse of the open design principle is security through obscurity, which means that the software employs protection mechanisms whose strength is dependent on the obscurity of the design, so much so that the understanding of the inner workings of the protection mechanisms is all that is necessary to defeat the protection mechanisms. A classic example of security through obscurity, which must be avoided if possible, is the hard coding and storing of sensitive information, such as cryptographic keys, or connection strings information with username and passwords inline code, or executables. Reverse engineering, binary analysis of executables, and runtime analysis of protocols can reveal these secrets. Review of the Diebold voting machines code revealed that passwords were embedded in the source code, cryptographic implementation was incorrect, the design allowed voters to vote an unlimited number of times without being detected, privileges could be escalated, and insiders could change a voter’s ballot choice, all of which could have been avoided if the design was open for review by others. Another example of security through obscurity is the use of hidden form fields in Web applications, which affords little, if any protection against disclosure, as they can be processed using a modified client.
Software design should therefore take into account the need to leave the design open but keep the implementation of the protection mechanisms independent of the design. Additionally, while security through obscurity may increase the work factor needed by an attacker and provide some degree of defense in-depth, it should not be the sole and primary security mechanism in the software. Leveraging publicly vetted, proven, tested industry standards, instead of custom developing one’s own protection mechanism, is recommended. For example, encryption algorithms, such as the Advanced Encryption Standard (AES) and Triple Data Encryption Standard (3DES), are publicly vetted and have undergone elaborate security analysis, testing, and review by the information security community. The inner workings of these algorithms are open to any reviewer, and public review can throw light on any potential weaknesses. The key that is used in the implementation of these proven algorithms is what should be kept secret.
Some of the fundamental aspects of the open design principle are as follows:
- The security of your software should not be dependent on the secrecy of the design.
- Security through obscurity should be avoided.
- The design of protection mechanisms should be open for scrutiny by members of the community, as it is better for an ally to find a security vulnerability or flaw than it is for an attacker.
3.7.8 Least Common Mechanisms
Least common mechanisms is the security principle by which mechanisms common to more than one user or process are designed not to be shared. Because shared mechanisms, especially those involving shared variables, represent a potential information path, mechanisms that are common to more than one user and depended on by all users are to be minimized. Design should compartmentalize or isolate the code (functions) by user roles, because this increases the security of the software by limiting the exposure. For example, instead of having one function or library that is shared between members with supervisor and nonsupervisor roles, it is recommended to have two distinct functions, each serving its respective role.
3.7.9 Psychological Acceptability
One of the primary challenges in getting users to adopt security is that they feel that security is usually very complex. With a rise in attacks on passwords, many organizations resolved to implement strong password rules, such as the need to have mixed-case, alphanumeric passwords that are to be of a particular length. Additionally, these complex passwords are often required to be periodically changed. While this reduced the likelihood of brute-forcing or guessing passwords, it was observed that the users had difficulty remembering complex passwords. Therefore they nullified the effect that the strong password rules brought by jotting down their passwords and sticking them under their desks and, in some cases, even on their computer screens. This is an example of security protection mechanisms that were not psychologically acceptable and hence not effective.
Psychological acceptability is the security principle that states that security mechanisms should be designed to maximize usage, adoption, and automatic application.
A fundamental aspect of designing software with the psychological acceptability principle is that the security protection mechanisms
- Are easy to use
- Do not affect accessibility
- Are transparent to the user
Users should not be additionally burdened as a result of security, and the protection mechanisms must not make the resource more difficult to access than if the security mechanisms were not present. Accessibility and usability should not be impeded by security mechanisms because users will elect to turn off or circumvent the mechanisms, thereby neutralizing or nullifying any protection that is designed.
Examples of incorporating the psychological acceptability principle in software include designing the software to notify the user through explicit error messages and callouts as depicted in Figure 3.13, message box displays and help dialogs, and intuitive user interfaces.
3.7.10 Leveraging Existing Components
Service-oriented architecture (SOA) is prevalent in today’s computing environment, and one of the primary aspects for its popularity is the ability it provides for communication between heterogeneous environments and platforms. Such communication is possible because the SOA protocols are understandable by disparate platforms, and business functionality is abstracted and exposed for consumption as contract-based, application programming interfaces (APIs). For example, instead of each financial institution writing its own currency conversion routine, it can invoke a common, currency conversion, service contract. This is the fundamental premise of the leveraging existing components design principle. Leveraging existing components is the security principle that promotes the reusability of existing components.
A common observance in security code reviews is that developers try to write their own cryptographic algorithms instead of using validated and proven cryptographic standards such as AES. These custom implementations of cryptographic functionality are also determined often to be the weakest link. Leveraging proven and validated cryptographic algorithms and functions is recommended.
Designing the software to scale using tier architecture is advisable from a security standpoint, because the software functionality can be broken down into presentation, business, and data access tiers. The use of a single data access layer (DAL) to mediate all access to the backend data stores not only supports the principle of leveraging existing components but also allows for scaling to support various clients or if the database technology changes. Enterprise application blocks are recommended over custom developing shared libraries and controls that attempt to provide the same functionality as the enterprise application blocks.
Reusing tested and proven, existing libraries and common components has the following security benefits. First, the attack surface is not increased, and second, no newer vulnerabilities are introduced. An ancillary benefit of leveraging existing components is increased productivity because leveraging existing components can significantly reduce development time.
3.8 Balancing Secure Design Principles
It is important to recognize that it may not be possible to design for each of these security principles in totality within your software, and trade-off decisions about the extent to which these principles can be designed may be necessary. For example, although SSO can heighten user experience and increase psychological acceptability, it contradicts the principle of complete mediation and so a business decision is necessary to determine the extent to which SSO is designed into the software or to determine that it is not even an option to consider. SSO design considerations should also take into account the need to ensure that there is no single point of failure and that appropriate, defense in-depth mitigation measures are undertaken. Additionally, implementing complete mediation by checking access rights and privileges, each and every time, can have a serious impact on the performance of the software. So this design aspect needs to be carefully considered and factored in, along with other defense in depth strategies, to mitigate vulnerability while not decreasing user experience or psychological acceptability. The principle of least common mechanism may seem contradictory to the principle of leveraging existing components and so careful design considerations need to be given to balance the two, based on the business needs and requirements, without reducing the security of the software. While psychological acceptability would require that the users be notified of user error, careful design considerations need to be given to ensure that the errors and exceptions are explicitly handled and nonverbose in nature so that internal, system configuration information is not revealed. The principle of least common mechanisms may seem to be diametrically opposed to the principle of leveraging existing components, and one may argue that centralizing functionality in business components that can be reused is analogous to putting all the eggs in one basket, which is true. However, proper defense in depth strategies should be factored into the design when choosing to leverage existing components.
3.9 Other Design Considerations
In addition to the core software security design considerations covered earlier, there are other design considerations that need to be taken into account when building software. These include the following:
- Programming language
- Data type, format, range, and length
- Database security
- Interface
- Interconnectivity
We will cover each of these considerations.
3.9.1 Programming Language
Before writing a single line of code, it is pivotal to determine the programming language that will be used to implement the design, because a programming language can bring with it inherent risks or security benefits. In organizations with an initial level of capability maturity, developers tend to choose the programming language that they are most familiar with or one that is popular and new. It is best advised to ensure that the programming language chosen is one that is part of the organization’s technology or coding standard, so that the software that is produced can be universally supported and maintained.
The two main types of programming languages in today’s world can be classified into unmanaged or managed code languages. Common examples of unmanaged code are C/C++ while Java and all .NET programming languages, which include C# and VB.Net, are examples of managed code programming languages.
Unmanaged code programming languages are those that have the following characteristics:
- The execution of the code is not managed by any runtime execution environment but is directly executed by the operating system. This makes execution relatively faster.
- Is compiled to native code that will execute only on the processor architecture (X86 or X64) against which it is compiled.
- Memory allocation is not managed and pointers in memory addresses can be directly controlled, which makes these programming languages more susceptible to buffer overflows and format string vulnerabilities that can lead to arbitrary code execution by overriding memory pointers.
- Requires developers to write routines to handle memory allocation, check array bounds, handle data type conversions explicitly, force garbage collection, etc., which makes it necessary for the developers to have more programming skills and technical capabilities.
Managed code programming languages, on the other hand, have the following characteristics:
- Execution of the code is not by the operating system directly, but instead, it is by a managed runtime environment. Because the execution is managed by the runtime environment, security and nonsecurity services such as memory management, exception handling, bounds checking, garbage collection, and type safety checking can be leveraged from the runtime environment and security checks can be asserted before the code executes. These additional services can cause the code to execute considerably slower than the same code written in an unmanaged code programming language. The managed runtime environment in the .NET Framework is the Common Language Runtime (CLR).
- Is not directly compiled into native code but is compiled into an Intermediate Language (IL) and an executable is created. When the executable is run, the Just-in-Time (JIT) compiler of the CLR compiles the IL into native code that the computer will understand. This allows for platform independence, as the JIT compiler handles the compilation of the IL into native code that is processor architecture specific. The Common Language Infrastructure (CLI) Standard provides encoding information and description on how the programming languages emit the appropriate encoding when compiled.
- Because memory allocation is managed by the runtime environment, buffer overflows and format string vulnerabilities are mitigated considerably.
- Time to develop software is relatively shorter because most memory management, exception handling, bounds checking, garbage collection, and type safety checking are automatically handled by the runtime environment. Type safety means that the code is not allowed to access memory locations outside its bounds if it is not authorized to do so. This also means that implicit casting of one data type to another, which can lead to errors and exceptions, is not allowed. Type safety plays a critical role in isolating assemblies and security enforcement. It is provided by default to managed code programming languages, making it an important consideration when choosing between an unmanaged or managed code programming language.
Choosing the appropriate programming language is an important design consideration. An unmanaged code programming language may be necessary when execution needs to be fast and memory allocation needs to be explicitly controlled. However, it is important to recognize that such degrees of total control can also lead to total compromise when a security breach occurs, and so careful attention should be paid when choosing an unmanaged code programming language over a managed code one. One strategy to get the benefits of both unmanaged and managed code programming languages is to code the software in a managed code language and call unmanaged code using wrappers only when needed, with defense in-depth protection mechanisms implemented alongside. It also must be understood that while managed code programming languages are less prone to errors caused by the ignorance of developers and or to security issues, it is no panacea to security threats and vulnerabilities. Regardless of whether one chooses an unmanaged or managed code programming language, security protection mechanisms must be carefully and explicitly designed.
3.9.2 Data Type, Format, Range, and Length
While protection mechanisms such as encryption, hashing, and masking help with confidentiality assurance, data type, format, range, and length are important design considerations, the lack of which can potentially lead to integrity violations.
Programming languages have what is known as built-in or primitive data types. Some common examples of primitive data types are Character (character, char), Integer (integer, int, short, long, byte), Floating-point numbers (double, float, real), and Boolean (true or false). Some programming languages also allow programmers to define their own data types; this is not recommended from a security standpoint because it potentially increases the attack surface. Conversely, strongly typed programming languages do not allow the programmer to define their own data types to model real objects, and this is preferred from a security standpoint as it does not allow the programmer to increase the attack surface.
The set of values and the permissible operations on that value set are defined by the data type. For example, a variable that is defined as an integer data type can be assigned a whole number but never a fraction. Integers may be signed or unsigned. Unsigned integers are those that allow only positive values, while signed integers allow both positive and negative values. Table 3.3 depicts the size and ranges of values dependent on the integer data type.
Integer Data Type Size and Ranges
|
Name |
Size (in bits) |
Range |
|
|
Unsigned |
Signed |
||
|
Byte |
8 |
0 to 255 |
−128 to +127 |
|
int, short, Int16, Word |
16 |
0 to 65,535 |
−32,768 to +32,767 |
|
long int, Int32, Double Word |
32 |
0 to 4,294,967,295 |
−2,147,483,648 to +2,147,483,647 |
|
long long |
64 |
0 to 18,446,744,073,709,551,615 |
−9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 |
The reason why the data type is an important design consideration is because it is not only important to understand the limits that can be stored in memory for a variable defined as a particular data type, but it is also vital to know of the permissible operations on a data type. Failing to understand data type permissible operations can lead to conversion mismatches and casting or conversion errors that could prove detrimental to the secure state of the software.
When a numeric data type is converted from one data type to another, it can either be a widening conversion (also known as expansion) or a narrowing conversion (also known as truncation). Widening conversions are those where the data type is converted from a type that is of a smaller size and range to one that is of a larger size and range. An example of a widening conversion would be converting an “int” to a “long.” Table 3.4 illustrates widening conversions without the loss the data.
Conversions of Data Types without Loss of Data
|
Type |
Can be Converted without Loss of Data to |
|
Byte |
UInt16, Int16, UInt32, Int32, UInt64, Int64, Single, Double, Decimal |
|
SByte |
Int16, Int32, Int64, Single, Double, Decimal |
|
Int16 |
Int32, Int64, Single, Double, Decimal |
|
UInt16 |
UInt32, Int32, UInt64, Int64, Single, Double, Decimal |
|
Char |
UInt16, UInt32, Int32, UInt64, Int64, Single, Double, Decimal |
|
Int32 and UInt32 |
Int64, Double, Decimal |
|
Int64 and UInt64 |
Decimal |
|
Single |
Double |
Not all widening conversions happen without the potential loss of data. In some cases, not only is data loss evident, but there is a loss of precision, as well. For example, converting from an Int64 or a single data type to a double data type can lead to loss of precision.
A narrowing conversion, on the other hand, can lead to loss of information. An example of a narrowing conversion is converting a Decimal data type to an Integer data type. This can potentially cause data loss truncation if the value being stored in the Integer data type is greater than its allowed range. For example, changing the data type of the variable “UnitPrice” that holds the value $19.99 from a Decimal data type to an Integer data type will result in storing $19 alone, ignoring the values after the decimal and causing data integrity issues. Improper casting or conversion can result in overflow exceptions or data loss. Input length and range validation using regular expression (RegEx) and maximum length (maxlength) restrictions, in conjunction with exception management protection controls, need to be designed to alleviate these issues.
3.9.3 Database Security
Just as important as data design is for security is the design of the database for the reliability, resiliency, and recoverability of software that depends on the data stored in the database. Not only is protection essential when data are in transit, but also when data are at rest, in storage, and in archives. Using a biological analogy, one can call the database that is connected to the network the heart of the organization, and a breach at this layer could prove disastrous to the life and continuity of the business. Regulations such as HIPAA and GLBA impose requirements to protect personally identifiable information (PII) when it is stored, and willful neglect can lead to fines being levied, incarceration of officers of the corporation, and regulatory oversight. The application layer is seen to be the conduit of attacks against the data stored in databases or data stores, as is evident with many injection attacks, such as SQL injection and Lightweight Directory Access Protocol (LDAP) injection attacks. Using such attacks, an attacker can steal, manipulate, or destroy data.
Database security design considerations are critically important because they have an impact on the confidentiality, integrity, and availability of data. One kind of attack against the confidentiality of data is the inference attack. An inference attack is one that is characterized by an attacker gleaning sensitive information about the database from presumably hidden and trivial pieces of information using data mining techniques without directly accessing the database. It is difficult to protect against an inference attack because the trivial piece of information may be legitimately obtained by the attacker. Inference attacks often go hand in hand with aggregation attacks. An aggregation attack is one where information at different, security classification levels, which are primarily nonsensitive in isolation, end up becoming sensitive information when pieced together as a whole. A well-known example of aggregation is the combining of longitudinal and latitudinal coordinates along with supply and delivery information to piece together and glean possible army locations. Individually, the longitudinal and latitudinal coordinates are generally not sensitive. Neither is the supply and delivery information. But when these two pieces of information are aggregated, the aggregation can reveal sensitive information through inference. Therefore, database queries that request trivial and nonsensitive information from various tables within the database must be carefully designed to be scrutinized, monitored, and audited.
Polyinstantiation, database encryption, normalization, and triggers and views are important protection design considerations concerning the organization’s database assets.
3.9.3.1 Polyinstantiation
A well-known, database security approach to deal with the problems of inference and aggregation is polyinstantiation. Polyinstantiation means that there exist several instances (or versions) of the database information, so that what is viewed by a user is dependent on the security clearance or classification level attributes of the requesting user. For example, many instances of the president’s phone number are maintained at different classification levels and only users with top secret clearance will be allowed to see the phone number of the president of the country, while those with no clearance are given a generic phone number to view. Polyinstantiation addresses inference attacks by allowing a means to hide information by using classification labels. It addresses aggregation by allowing the means to label different aggregations of data separately.
3.9.3.2 Database Encryption
Perimeter defenses such as firewalls offer little to no protection to stored, sensitive data from internal threat agents who have the means and opportunity to access and exploit data stored in databases. The threat to databases comes not only from external hackers but also from insiders who wish to compromise the data, i.e., data that are essentially the crown jewels of an organization. In fact, while external attacks may be seen on the news, many internal attacks often go unpublicized, even though they are equally, if not more, devastating to an organization. Insider threats to databases warrant close attention, especially those from disgruntled employees in a layoff economy. Without proper, database security controls, we leave an organization unguarded and solely reliant on the motive of an insider, who already has the means and the opportunity.
Data-at-rest encryption is a preventive, control mechanism that can provide strong protection against disclosure and alteration of data, but it is important to ensure that along with database encryption, proper authentication and access control protection mechanisms exist to secure the key that is used for the encryption. Having one without the other is equivalent to locking the door and leaving the key under the doormat, and this really provides little protection. Therefore, a proper database encryption strategy is necessary to implement database security adequately. This strategy should include encryption, access control, auditing for security and logging of privilege database operations and events, and capacity planning.
Encryption not only has an impact on performance but also on data size. If fields in the database that are indexed are encrypted, then lookup queries and searches will take significantly longer, therefore degrading performance. Additionally, most encryption algorithms output fixed, block sizes and pad the input data to match the output size. This means that smaller-sized input data will be padded and stored with an increased size and the database design must take this into account to avoid padding and truncation issues. To transform binary cipher text to character-type data where encoding is used with encryption, the data size is increased by approximately one-third its original size, and this should be factored into design, as well.
Some of the important factors that must be taken into account when determining the database encryption strategy are listed below. These include, but are not limited to, the following:
- Where the data should be encrypted: at its point of origin in the application or in the database where they reside?
- What should be the minimum level of data classification before it warrants protection by encryption?
- Is the database designed to handle data sizes upon encryption?
- Is the business aware of the performance impact of implementing encryption and is the trade-off between performance and security within acceptable thresholds for the business?
- Where will the keys used for cryptography operations be stored?
- What authentication and access control measures will be implemented to protect the key that will be used for encryption and decryption?
- Are the individuals who have access to the database controlled and monitored?
- Are there security policies in effect to implement security auditing and event logging at the database layer in order to detect insider threats and fraudulent activities?
- Should there be a breach of the database, is there an incident management plan to contain the damage and respond to the incident?
Database encryption can be accomplished in one of two ways:
- Using native Database Management System (DBMS) encryption
- Leveraging cryptographic resources external to the database
In native DBMS encryption, the cryptographic operations including key storage and management are handled within the database itself. Cryptographic operations are transparent to the application layer, and this type of encryption is commonly referred to as Transparent Database Encryption (TDE). The primary benefit of this approach is that the impact on the application is minimal, but there can be a substantial performance impact. When native DBMS encryption capabilities are used, the performance and strength of the algorithm along with the flexibility to choose what data can be encrypted must be taken into account. From a security standpoint, the primary drawback to using native DBMS encryption is the inherent weakness that exists in the storage of the encryption key within the DBMS itself. The protection of this key will be primarily dependent on the strength of the DBMS access control protection mechanisms, but users who have access to the encrypted data will probably have access rights to the encryption key storage as well. When cryptographic resources external to the database are leveraged, cryptographic operations and key storage and management are off-loaded to external cryptographic infrastructure and servers. From a security standpoint, database architectures that separate encryption processing and key management are recommended and preferred as such architecture increases the work factor necessary for the attacker. The separation of the encrypted data from the encryption keys brings a significant security benefit. When these keys are stored in HSMs, they increase the security protection substantially and make it necessary for the attacker to have physical access in order to compromise the keys. Additionally, leveraging external infrastructure and servers for cryptographic operations moves the computational overhead away from the DBMS, significantly increasing performance. The primary drawbacks of this approach are the need to modify or change applications, monitor and administer other servers, and communications overhead.
Each approach has its own advantages and disadvantages and when choosing the database encryption approach, it is important to do so only after fully understanding the pros and cons of each approach, the business need, regulatory requirements, and database security strategy.
3.9.3.3 Normalization
The maintainability and security of a database are directly proportional to its organization of data. Redundant data in databases not only waste storage but also imply the need for redundant maintenance as well as the potential for inconsistencies in database records. For example, if data are held in multiple locations (tables) in the database, then changes to data must be performed in all locations holding the same data. The change in the price of a product is much easier to implement if the product price is maintained only within the product table. Maintaining product information in more than one table in the database will require implementing changes to product-related information in each table. This cannot only be a maintenance issue, but also, if the updates are not uniformly applied across all tables that hold product information, inconsistencies can occur leading to loss of data integrity.
Normalization is a formal technique that can be used to organize data so that redundancy and inconsistency are eliminated. The organization of data is based on certain rules, and each rule is referred to as a “normal form.” There are primarily three data organization or normalization rules. The database design is said to be in the normal form that corresponds to the number of rules the design complies with. A database design that complies with one rule is known to be in first normal form, notated as 1NF. A design with two rules is known to be in second normal form, notated as 2NF, and one with compliance to all three rules is known to be in third normal form, notated as 3NF. Fourth (4NF) and Fifth (5NF) Normal Form of database design exist, as well, but they are seldom implemented practically. Table 3.5 is an example of a table that is in unnormalized form.
Unnormalized Form
|
Customer_ID |
First_Name |
Last_Name |
Sales_Rep_ID |
Product_1 |
Product_2 |
|
1 |
Paul |
Schmidt |
S101 |
CSSLPEX1 |
CSSLPEX2 |
|
2 |
David |
Thompson |
S201 |
SSCPEX1 |
SSCPEX2 |
First Normal Form (1NF) mandates that there are no repeating fields or groups of fields within a table. This means that related data are stored separately. This is also informally referred to as the “No Repeating Groups” rule. When product information is maintained for each customer record separately instead of being repeated within one table, it is said to be compliant with 1NF. Table 3.6 is an example of a table that in is 1NF.
First Normal Form (1NF)
|
Customer_ID |
First_Name |
Last_Name |
Sales_Rep_ID |
Product_Code |
|
1 |
Paul |
Schmidt |
S101 |
CSSLPEX1 |
|
1 |
Paul |
Schmidt |
S101 |
CSSLPEX2 |
|
2 |
David |
Thompson |
S201 |
SSCPEX1 |
|
2 |
David |
Thompson |
S201 |
SSCPEX2 |
Second Normal Form (2NF) mandates that duplicate data are removed. A table in 2NF must first be in 1NF. This is also informally referred to as the “Eliminate Redundant Data” rule. The elimination of duplicate records in each table addresses data inconsistency and, subsequently, data integrity issues. 2NF means that sets of values that apply to multiple records are stored in separate tables and related using a primary key (PK) and foreign key (FK) relationship. In the previous table, Product_Code is not dependent on the Customer_ID PK, and so, in order to comply with 2NF, they must be stored separately and associated using a table. Table 3.7 and Table 3.8 are examples of tables that are in 2NF. Third Normal Form (3NF) is a logical extension of the 2NF, and for a table to be in 3NF, it must first be in 2NF. 3NF mandates that data that are not dependent on the uniquely identifying PK of that table are eliminated and maintained in tables of their own. This is also referred to informally as the “Eliminate Non-Key-Dependent Duplicate Data” rule. Because the Sales_Rep_ID is not dependent on the Customer_ID in the CUSTOMER table, for the table to be in 3NF, data about the sales representatives must be maintained in their own table. Table 3.9 and Table 3.10 are examples of tables that are in 3NF.
Customer Table in Second Normal Form (2NF)
|
Customer_ID |
First_Name |
Last_Name |
Sales_Rep_ID |
|
1 |
Paul |
Schmidt |
S101 |
|
2 |
David |
Thompson |
S201 |
Customer Order Table in Second Normal Form (2NF)
|
Customer_ID |
Product_Code |
|
1 |
CSSLPEX1 |
|
1 |
CSSLPEX2 |
|
2 |
SSCPEX1 |
|
2 |
SSCPEX2 |
Customer Table in Third Normal Form (3NF)
|
Customer_ID |
First_Name |
Last_Name |
|
1 |
Paul |
Schmidt |
|
2 |
David |
Thompson |
Sales Representative Table in Third Normal Form (3NF)
|
Sales_Rep_ID |
Sales_Rep_Name |
Sales_Rep_Phone |
|
S101 |
Marc Thompson |
(202) 529-8901 |
|
S201 |
Sally Smith |
(417) 972-1019 |
Benefits of normalization include elimination of redundancy and reduction of inconsistency issues. Normalization yields security benefits as well. Data integrity, which assures that the data are not only consistent but also accurate, can be achieved through normalization. Additionally, permissions for database operations can be granted at a more granular level per table and limited to users, when the data are organized using normal form. Data integrity in the context of normalization is the assurance of consistent and accurate data within a database.
It must also be recognized that although the security and database maintainability benefits of normalization are noteworthy, there is one primary drawback to normalization, which is degraded performance. When data that are not organized in a normalized form are requested, the performance impact is mainly dependent on the time it takes to read the data from a single table, but when the database records are normalized, there is a need to join multiple tables in order to serve the requested data. In order to increase the performance, a conscious decision may be required to denormalize a normalized database. Denormalization is the process of decreasing the normal form of a database table by modifying its structure to allow redundant data in a controlled manner. A denormalized database is not the same as a database that has never been normalized. However, when data are denormalized, it is critically important to have extraneous control and protection mechanisms that will assure data consistency, accuracy, and integrity. A preferred alternate to denormalizing data at rest is to implement database views.
3.9.3.4 Triggers and Views
A database trigger is a special type of procedure that is automatically executed upon the occurrence of certain conditions within the database. It differs from a regular procedure in its manner of invocation. Regular, stored procedures and prepared statements are explicitly fired to run by either a user, an application, or, in some cases, even a trigger itself. A trigger, on the other hand, is fired to run implicitly by the database when the triggering event occurs. Events that fire triggers may be one or more of the following types:
- Data Manipulation Language (DML) statements that modify data, such as INSERT, UPDATE, and DELETE.
- Data Definition Language (DDL) statements that can be used for performing administrative tasks in the database, such as auditing and regulating database operations.
- Error events (OnError).
- System events, such as Start, Shutdown, and Restart.
- User events, such as Logon and Logoff.
Triggers are useful not only for supplementing existing database capabilities, but they can also be very useful for automating and improving security protection mechanisms. Triggers can be used to
- Enforce complex business rules such as restricting alterations to the database during nonbusiness hours or automatically computing the international shipping rates when the currency conversion rate changes.
- Prevent invalid transactions.
- Ensure referential integrity operations.
- Provide automated, transparent auditing and event-logging capabilities. If a critical business transaction that requires auditing is performed, one can use DML triggers to log the transaction along with pertinent audit fields in the database.
- Enforce complex security privileges and rights.
- Synchronize data across replicated tables and databases, ensuring the accuracy and integrity of the data.
Although the functional and security benefits of using triggers are many, triggers must be designed with caution. Excessive implementation of triggers can cause overly complex application logic, which makes the software difficult to maintain besides increasing the potential attack surface. Also, because triggers are responsive to triggering events, they cannot perform commit or rollback operations, and poorly constructed triggers can cause table and data mutations, impacting accuracy and integrity. Furthermore, when cascading triggers, which are characterized when triggers invoke other triggers, are used, interdependencies are increased, making troubleshooting and maintenance difficult.
A database view is a customized presentation of data that may be held in one or more physical tables (base tables) or another view itself. A view is the output of a query and is akin to a virtual table or stored query. A view is said to be virtual because unlike the base tables that supply the view with data, the view itself is not allocated any storage space in the physical database. The only space that is allocated is the space necessary to hold the stored query. Because the data in a view are not physically stored, a view is dynamically constructed when the query to generate the view is executed. Just like on a base table, DML CRUD (create, read, update, and delete) operations to insert, view, modify, or remove data, with some restrictions, can be performed on views. However, it must be understood that operations performed on the view affect the base tables serving the data, and so the same data integrity constraints should be taken into account when dealing with views.
Because views are dynamically constructed, data that are presented can be custom-made for users based on their rights and privileges. This makes it possible for protection against disclosure so that only those who have the authorization to view certain types of data are allowed to see those types of data and that they are not allowed to see any other data. Not only do views provide confidentiality assurance, they also support the principle of “need to know.” Restricting access to predetermined sets of rows or columns of a table increases the level of database security. Figure 3.14 is an example of a view that results by joining the CATEGORY, PRODUCT, and ORDER tables.
Views can also be used to abstract internal database structure, hiding the source of data and the complexity of joins. A join view is defined as one that synthesizes the presentation of data by joining several base tables or views. The internal table structures, relationships, and constraints are protected and hidden from the end user. Even an end user who has no knowledge of how to perform joins can use a view to select information from various database objects. Additionally, the resulting columns of a view can be renamed to hide the actual database naming convention that an attacker can use to his or her advantage when performing reconnaissance. Views can also be used to save complicated queries. Queries that perform extensive computations are good candidates to be saved as views so that they can be repeatedly performed without having to reconstruct the query each and every time.
3.9.4 Interface
3.9.4.1 User Interface
The Clark and Wilson security model, more commonly referred to as the access triple security model, states that a subject’s access to an object should always be mediated via a program and no direct subject–object access should be allowed. A user interface (UI) between a user and a resource can act as the mediating program to support this security model. User interfaces design should assure disclosure protection. Masking of sensitive information, such as a password or credit card number by displaying asterisks on the screen, is an example of a secure user interface that assures confidentiality. A database view can also be said as an example of a restricted user interface. Without giving an internal user direct access to the data objects, be they on the file system or the database, and requiring the user to access the resources using a UI protects against inference attacks and direct database attacks. Abstractions using user interfaces are also a good defense against insider threats. The UI provides a layer where auditing of business-critical and privileged actions can be performed, thereby increasing the possibility of uncovering insider threats and fraudulent activities that could compromise the security of the software.
3.9.4.2 Security Management Interfaces (SMI)
SMIs are interfaces used to configure and manage the security of the software itself. These are administrative interfaces with high levels of privilege. A SMI can be used for user-provisioning tasks such as adding users, deleting users, enabling or disabling user accounts, as well as granting rights and privileges to roles, changing security settings, configuring audit log settings and trails, exception logging, etc. An example of an SMI is the setup screens that are used to manage the security settings of a home router. Figure 3.15 depicts the SMI for a D-Link home router.
From a security standpoint, it is critical that these SMIs are threat modeled, as well, and appropriate protection designed, because these interfaces are usually not captured in the requirements explicitly. They are often observed to be the weakest link, as they are overlooked when threats to the software are modeled. The consequences of breaching an administrative interface are usually severe because the attacker ends up running with elevated privileges. A compromise of an SMI can lead to total compromise, disclosure, and alteration and destruction threats, besides allowing attackers to use these as backdoors for installing malware (Trojans, rootkits, spyware, adware, etc.). Not only should strong protection controls be implemented to protect SMIs, but these must be explicitly captured in the requirements, be part of the threat modeling exercise, and designed precisely and securely. Some of the recommended protection controls for these highly privileged and sensitive interfaces are as follows:
Avoid remote connectivity and administration, requiring administrators to log on locally
Employ data protection in transit, using channel security protection measures at the transport (e.g., SSL) or network (e.g., IPSec) layer.
Use least privilege accounts and RBAC to control access to and functionality of the interfaces
3.9.5 Interconnectivity
In the world we live in today, rarely is software deployed in a silo. Most business applications and software are highly interconnected, creating potential backdoors for attackers if they are designed without security in mind. Software design should factor in design consideration to ensure that the software is reliable, resilient, and recoverable. Upstream and downstream compatibility of software should be explicitly designed. This is particularly important when it comes to delegation of trust, SSO, token-based authentication, and cryptographic key sharing between applications. If an upstream application has encrypted data using a particular key, there must be a secure means to transfer the key to the downstream applications that will need to decrypt the data. When data or information are aggregated from various sources, as is the case with mashups, software design should take into account the trust that exists or that needs to be established between the interconnected entities. Modular programming with the characteristics of high cohesion and loose coupling help with interconnectivity design as it reduces complex dependencies between the connected components, keeping each entity as discreet and unitary as possible.
3.10 Design Processes
When you are designing software with security in mind, certain security processes need to be established and completed. These processes are to be conducted during the initial stages of the software development project. These include attack surface evaluation, threat modeling, control identification and prioritization, and documentation. In this section, we shall look at each of these processes and learn how they can be used to develop reliable, recoverable, and hack-resilient, secure software.
3.10.1 Attack Surface Evaluation
A software or application’s attack surface is the measure of its exposure of being exploited by a threat agent, i.e., weaknesses in its entry and exit points that a malicious attacker can exploit to his or her advantage. Because each accessible feature of the software is a potential attack vector that an intruder can leverage, attack surface evaluation aims at determining the entry and exit points in the software that can lead to the exploitation of weaknesses and manifestation of threats. Often, attack surface evaluation is done as part of the threat modeling exercise during the design phase of the SDLC. We will cover threat modeling in a subsequent section. The determination of the software’s “attackability” or the exposure to attack can commence in the requirements phase of the SDLC, when security requirements are determined by generating misuse cases and subject–object matrices. During the design phase, each misuse case or subject–object matrix can be used as an input to determine the entry and exit points of the software that can be attacked.
The attack surface evaluation attempts to enumerate the list of features that an attacker will try to exploit. These potential attack points are then assigned a weight or bias based on their assumed severity so that controls may be identified and prioritized. In the Windows operating system, open ports, open Remote Procedural Call (RPC) end points and sockets, open named pipes, Windows default and SYSTEM services, active Web handler files (active server pages, Hierarchical Translation Rotation (HTR) files, etc.), Internet Server Application Programming Interface (ISAPI) filters, dynamic Web pages, weak access control lists (ACLs) for files and shares, etc., are attackable entry and exit points. In the Linux and *nix operating systems, setuid root applications and symbolic links are examples of features that can be attacked.
3.10.1.1 Relative Attack Surface Quotient
The term relative attack surface quotient (RASQ) was introduced by renowned author and Microsoft security program manager Michael Howard to describe the relative attackability or likely opportunities for attack against software in comparison to a baseline. The baseline is a fixed set of dimensions. The notion of the RASQ metric is that, instead of focusing on the number of code level bugs or system level vulnerabilities, we are to focus on the likely opportunities for attack against the software and aim at decreasing the attack surface by improving the security of software products. This is particularly important to compute for shrink-wrap products, such as Windows OS, to show security improvements in newer versions, but the same can be determined for version releases of business applications as well. With each attack point assigned a value, referred to as the attack bias, based on its severity, the RASQ of a product can be computed by adding together the effective attack surface for all root vectors. A root vector is a particular feature of the OS or software that can positively or negatively affect the security of the product. The effective attack surface value is defined as the product of the number of attack surfaces within a root attack vector and the attack bias. For example, a service that runs by default under the SYSTEM account and opens a socket to the world is a prime attack candidate, even if the software is implemented using secure code, when compared to a scenario wherein the ACLS to the registry are weak. Each is assigned a bias, such as 0.1 for a low threat and 1.0 for a severe threat.
Researchers Howard, Pincus, and Wing, in their paper entitled “Measuring relative attack surfaces,” break down the attack surface into three formal dimensions: targets and enablers, channels and protocols, and access rights. A brief introduction of these dimensions is given here.
- Targets and enablers are resources that an attacker can leverage to construct an attack against the software. An attacker first determines if a resource is a target or an enabler, and, in some cases, a target in a particular attack may be an enabler to another kind of attack and vice versa. The two kinds of targets and enablers are processes and data. Browsers, mailers, and servers are examples of process targets and enablers, while files, directories, and registries are examples of data targets and enablers. One aspect of determining the attack surface is determining the number of potential process and data targets and enablers and the likely opportunities to attack each of these.
- Channels and protocols are mechanisms that allow for communication between two parties. The means by which a sender (or an attacker) can communicate with a receiver (a target) is referred to as a channel and the rule by which information is exchanged is referred to as a protocol. The endpoints of the channel are processes. There are two kinds of channels: message-passing channels and shared-memory channels. Examples of message-passing channels include sockets, RPC connections, and named pipes that use protocols such as ftp, http, RPC, and streaming to exchange information. Examples of shared-memory channels include files, directories, and registries that use open-before-read file protocols, concurrency access control checks for shared objects, and resource locking integrity rules. In addition to determining the number and “attackability” of targets and enablers, determining the attack surface includes the determination of channel types, instances of each channel type and related protocols, processes, and access rights.
- Access rights are the privileges associated with each resource, regardless of whether it is a target or enabler. These include read, write, and execute rights that can be assigned not only to data and process targets such as files, directories, and servers but also to channels (which are essentially data resources) and endpoints (process resources). Table 3.11 is a tabulation of various root attack vectors to formal dimensions.
A complete explanation of computing RASQ is beyond the scope of this book, but a CSSLP must be aware of this concept and its benefits. Although the RASQ score may not be truly indicative of a software product’s true exposure to attack or its security health, it can be used as a measurement to determine the improvement of code quality and security between versions of software. The main idea is to improve the security of the software by reducing the RASQ score in subsequent versions. This can also be extended within the SDLC, itself, wherein the RASQ score can be computed before and after software testing and/or before and after software deployment to reflect improvement in code quality and, subsequently, security. The paper by researchers Howard, Pincus, and Wing is recommended reading for additional information on RASQ.
Mapping RASQ Attack Vectors into Dimensions
|
Dimensions |
Attack Vector |
|
Targets (process) |
Services Active Web handlers Active ISAPI filters Dynamic Web pages |
|
Targets (process), constrained by access rights |
Services running by default Services running as SYSTEM |
|
Targets (data) |
Executable virtual directories Enabled accounts |
|
Targets (data), constrained by access rights |
Enabled accounts in admin group Enabled guest account Weak ACLS in file system Weak ACLs in registry Weak ACLs on shares |
|
Enablers (process) |
VBScript enabled JScript enabled ActiveX enabled |
|
Channels |
Null sessions to pipes and shares |
3.10.2 Threat Modeling
Threats to software are manifold. They range from disclosure threats against confidentiality to alteration threats against integrity to destruction threats against availability, authentication bypass, privilege escalation, impersonation, deletion of log files, MITM attacks, session hijacking and replaying, injection, scripting, overflow, and cryptographic attacks. We will cover the prevalent attack types in more detail in Chapter 4.
3.10.2.1 Threat Sources/Agents
Like the various threats to software, several threat sources/agents also exist. These may be human or nonhuman. Nonhuman threat agents include malicious software (malware) such as viruses and worms, which are proliferative, and spyware, adware, Trojans, and rootkits that are primarily stealthy as depicted in Figure 3.16.
Human threat agents range from the ignorant user who causes plain, user error to the organized cybercriminals who can orchestrate infamous and disastrous threats to national and corporate security. Table 3.12 tabulates the various human threat agents to software based on their increasing degree of knowledge and the extent of damage they can cause.
3.10.2.2 What Is Threat Modeling?
Threat modeling is a systematic, iterative, and structured security technique that should not be overlooked during the design phase of a software development project. Threat modeling is extremely crucial for developing hack-resilient software. It should be performed to identify security objectives and threats to and vulnerabilities in the software being developed. It provides the software development team an attacker’s or hostile user’s viewpoint, as the threat modeling exercise aims at identifying entry and exit points that an attacker can exploit. It also helps the team to make design and engineering trade-off decisions by providing insight into the areas where attention is to be prioritized and focused, from a security viewpoint. The rationale behind threat modeling is the premise that unless one is aware of the means by which software assets can be attacked and compromised, the appropriate levels of protection cannot be accurately determined and applied. Software assets include the software processes themselves and the data they marshal and process. With today’s prevalence of attacks against software or at the application layer, no software should be considered ready for implementation or coding until after its relevant threat model is completed and the threats identified.
3.10.2.3 Benefits
The primary benefit of threat modeling during the design phase of the project is that design flaws can be addressed before a single line of code is written, thereby reducing the need to redesign and fix security issues in code at a later time. Once a threat model is generated, it should be iteratively visited and updated as the software development project progresses. In the design phase, threat models development commences as the software architecture teams identify threats to the software. The development team can use the threat model to implement controls and write secure code. Testers can use the threat models to not only generate security test cases but also to validate the controls that need to be present to mitigate the threats identified in the threat models. Finally, operations personnel can use threat models to configure the software securely so that all entry and exit points have the necessary protection controls in place. In fact, a holistic threat model is one that has taken inputs from representatives of the design, development, testing, and deployment and operations teams.
3.10.2.4 Challenges
Although the benefits of threat modeling are extensive, threat modeling does come with some challenges, the most common of which are given here. Threat modeling
- Can be a time-consuming process when done correctly.
- Requires a fairly mature SDLC.
- Requires the training of employees to correctly model threats and address vulnerabilities.
- Is not the most exciting exercise to be conducted. Developers prefer coding, and quality assurance personnel prefer testing over threat modeling.
- Is often not directly related to organizational business operations, and it is difficult to show demonstrable return on investment for threat models.
3.10.2.5 Prerequisites
Before we delve into the threat modeling process, let us first answer the question about what some of the prerequisites for threat modeling are. For threat models to be effective within an organization, it is essential to meet the following conditions:
- The organization must have clearly defined information security policies and standards. Without these instruments of governance, the adoption of threat modeling as an integral part of the SDLC within the organization will be a challenge. This is because, when the business and development teams push back and choose not to generate threat models because of the challenges imposed by the iron triangle, the information security organization will have no basis on which to enforce the need for threat modeling.
- The organization must be aware of compliance and regulatory requirements. Just as organizational policies and standards function as internal governance instruments, arming the information security organization to enforce threat modeling as part of the SDLC, compliance and regulatory requirements function as external governance mandates that need to be factored into the software design addressing security.
- The organization must have a clearly defined and mature SDLC process. Because the threat modeling activity is initiated during the design phase of a software development project, it is important that the organization employ a structured approach to software development. Ad hoc development will yield ad hoc, incomplete, and inconsistent threat models. Additionally, because threat modeling is an iterative process and the threat model needs to be revisited during the development and testing phase of the project, those phases need to be part of the SDLC.
- The organization has a plan to act on the threat model. The underlying vulnerabilities that could make the threats (identified through the threat modeling exercise) materialize must also be identified and appropriately addressed. Merely completing a threat modeling exercise does no good in securing the software being designed. To generate a threat model and not act on it is akin to buying an exercise machine and not using it but expecting to get fit and in shape. The threat model needs to be acted upon. In this regard, it is imperative that the organization trains its employees to appropriately address the identified threats and vulnerabilities. Awareness, training, and education programs to teach employees how to threat model software and how to mitigate identified threats are necessary and critical for the effectiveness of the threat modeling exercise
3.10.2.6 What Can We Threat Model?
Because threat models require allocation of time and resources and have an impact on the project life cycle, threat modeling is to be performed selectively, based on the value of the software as an asset to the organization and on organizational needs.
We can threat model existing, upcoming versions, new, and legacy software. It is particularly important to threat model legacy software because the likelihood that software was originally developed with threat models and security in mind, and with consideration of present-day threats, is slim. When there is an organizational need to threat model legacy software, it is recommended to do so when the next version of the legacy software is being designed. We can also threat model interfaces (APIs, Web services, etc.) and third-party components. When third-party components are threat modeled, it is important to notify the software owner/publisher of the activity and gain their approval to avoid any intellectual property (IP) legal issues or violations of end user licensing agreements (EULAs). Threat modeling third-party software is often a behavioral or black box kind of testing, because performing structural analysis and inspections by reverse engineering COTS components, without proper authorization from the software publisher, can have serious IP violation repercussions.
3.10.2.7 Process
As a CSSLP, it is imperative for one to not only understand the benefits, key players, challenges, and prerequisites in developing a threat model, but one must also be familiar with the steps involved in threat modeling. The threat modeling process can be broken down into three, high-level phases, namely, define, model, and measure as depicted in Figure 3.17. Each phase is further broken into more specific activities, and through each activity, the threat modeling exercise takes inputs and generates outputs that are to be acted upon.

In the definition phase of the threat model, the following activities are conducted.
- Identify security objectives and assets: Security objectives are those high-level objectives of the application that have an impact on the security tenets of the software. These include the requirements that have an impact on confidentiality, integrity, availability, authentication, authorization, auditing, session management, error and exception management, and configuration management. Some examples of security objectives include
- Prevention of data theft
- Protection of IP
- Provide high availability
Inputs that can be used to identify security objectives are
- Internal organizational policies and standards
- Regulations, compliance, and privacy requirements
- Business and functional requirements
Assets are those items that are of value to the business. Primarily assets need to be protected because their loss can cause a disruption to the business. Some of the other reasons that enforce the need to protect assets today are regulations, compliance, privacy, or the need to have a competitive advantage. Assets may be tangible, such as credit card data, PII, and the HR software, or intangible, such as customer loyalty or corporate brand and reputation.
- Profile the application: The process of profiling the application includes creating an overview of the application by identifying the attributes of the application. This activity includes the following steps:
- Identify the physical topology: The physical topology of the application gives insight into where and how the applications will be deployed. Will it be an internal-only application or will it be deployed in the demilitarized zone or will it be hosted in the cloud?
- Identify the logical topology: This includes determining the logical tiers (presentation, business, service, and data) of the application.
- Determine components, services, protocols, and ports that need to be defined, developed, and configured for the application.
- Identify the identities that will be used in the application: Identify human and nonhuman actors of the system. Examples include customers, sales agents, system administrators, and database administrators.
- Identify data elements: Examples include product information and customer information.
- Generate a data access control matrix: This includes the determination of the rights and privileges that the actors will have on the identified data elements. Rights usually include CRUD privileges. For each actor the data access control matrix as depicted in Figure 3.18 must be generated.
- Identify the technologies that will be used in building the application.
- Identify external dependencies: The output of this activity is an architectural makeup of the application.
In the modeling phase of the threat modeling exercise, the following activities are conducted:
- Decompose the application: With an understanding of the application makeup, it is important to break down (decompose) the application into finer components. A thorough understanding of how the application will work, also referred to as the “mechanics” of the application, will help uncover pertinent threats and vulnerabilities. The decomposition activity is made up of the following steps:
- Identify trust boundaries: Boundaries help identify actions or behavior of the software that is allowed or not allowed. A trust boundary is the point at which the trust level or privilege changes. Identification of trust boundaries is critical to ensure that the adequate levels of protection are designed within each boundary.
- Identify entry points: Entry points are those items that take in user input. Each entry point can be a potential threat source, and so all entry points must be explicitly identified and safeguarded. Entry points in a Web application could include any page that takes in user input. Some examples include the search page, logon page, registration page, checkout page, and account maintenance page.
- Identify exit points: It is just as important to identify exit points of the application as it is to identify entry points. Exit points are those items that display information from within the system. Exit points also include processes that take data out of the system. Exit points can be the source of information leakage and need to be equally protected. Exit points in a Web application include any page that displays data on the browser client. Some examples are the search results page, product page, and view cart page.
- Identify data flows: Data flow diagrams (DFDs) and sequence diagrams assist in the understanding of how the application will accept, process, and handle data as they are marshaled across different trust boundaries. It is important to recognize that a DFD is not a flow chart but a graphical representation of the flow of data, the backend data storage elements, and relationships between the data sources and destinations. Data flow diagramming uses a standard set of symbols.
- Identify privileged code: Code that attempts to perform privileged operations on resources that are deemed privileged is known as privileged code. Some of these privileged resources include environment variables, event logs, file systems, queuing infrastructures, registry, domain controllers, Domain Name Servers (DNS), sockets, and Web services. Examples of privileged operations include serialization, code access security (CAS) permissions, reflection, and invocation of unmanaged code calls. It is extremely important to ensure that the operations and resources used by privileged code are protected from malicious mis-actors and so they need to be identified and captured as part of the threat model.
- Document the security profile: This involves the identification of the design and implementation mechanisms that impact the security tenets of the application.
- Identify threats and vulnerabilities: During this activity, the intent is to identify relevant threats that can compromise the assets. It is important that members of architecture, development, test, and operations teams are part of this activity, in conjunction with security team members. The two primary ways in which threats and vulnerabilities can be identified are: (1) think like an attacker (brainstorming and using attack trees) and (2) use a categorized threat list.
- Think like an attacker (brainstorming and using attack trees)
To think like an attacker is to subject the application to a hostile user’s perspective. One can start by brainstorming possible attack vectors and threat scenarios using a whiteboard. Although brainstorming is a quick and simple methodology, it is not very scientific and has the potential of identifying nonrelevant threats and not identifying pertinent threats. So another approach is to use an attack tree.
An attack tree is a hierarchical treelike structure, which has either an attacker’s objective (e.g., gain administrative level privilege, determine application makeup and configuration, and bypass authentication mechanisms) or a type of attack (e.g., buffer overflow and cross-site scripting) at its root node. Figure 3.19 is an illustration of an attack tree with the attacker’s objective at its root node. Figure 3.20 depicts an attack tree with an attack vector at its root node. When the root node is an attack vector, the child node from the root nodes is the unmitigated or vulnerability condition. The next level node (child node of an unmitigated condition) is usually the mitigated condition or a safeguard control to be implemented. One can also use the OWASP Top 10 or the CWE/SANS Top 25 most dangerous programming errors as a starting point to identify root vectors pertinent to their application. It is a method of collecting and identifying potential attacks in a structured and hierarchical manner. It is a method used by security professionals because it allows the threat modeling team to analyze threats in finer detail and greater depth. The treelike structure provides a descriptive breakdown of various attacks that the attacker could use to compromise the asset. The creation of attack trees for your organization has the added benefit of creating a reusable representation of security issues that can be used across multiple projects to focus mitigation efforts. Developers are given insight into the types of attacks that can be used against their software and then implement appropriate safeguard controls, while test teams can use the attack trees to write test plans. The tests ensure that the controls are in place and effective.
- Use categorized threat lists
In addition to thinking like an attacker, another methodology to identify threats is using a categorized list of threats. Some methodologies, such as the NSA IAM methodology, OCTAVE risk modeling, and Microsoft STRIDE, have as part of their methodology a list of threat types or categories that can be used to identify threats. STRIDE is an acronym for a category of threats. Using the STRIDE category threat list is a goal-based approach to threat modeling because the goals of the attacker are taken into consideration. Table 3.13 depicts the Microsoft STRIDE category of threats.
STRIDE Category of Threats
Goal
Description
Spoofing
Can an attacker impersonate another user or identity?
Tampering
Can the data be tampered with while it is in transit or in storage or archives?
Repudiation
Can the attacker (user or process) deny the attack?
Information Disclosure
Can information be disclosed to unauthorized users?
Denial of service
Is denial of service a possibility?
Elevation of privilege
Can the attacker bypass least privilege implementation and execute the software at elevated or administrative privileges?
When a category of threats is used, there is a high degree of likelihood that a particular threat may have cross-correlation with other threats. For example, the elevation of privilege may be as a result of spoofing due to information disclosure or simply the result of the lack of repudiation controls. In such cases, it is recommended to use your best judgment when categorizing threats. One can select the most relevant category or document all of the applicable threat categories and rank them according to the likelihood of the threat being materialized.
In the measurement phase of the threat modeling exercise, the following activities are conducted:
- Document the threats: The importance of documenting the threat model cannot be underestimated because threat modeling is iterative, and, through the life cycle of the project, the protection controls to address the identified threats in the threat model need to be appropriately implemented, validated, and the threat model itself updated. Threats can be documented diagrammatically or in textual format. Diagrammatic documentation provides a context for the threats. Textual documentation allows for more detail of each threat. It is best advised to do both. Document each threat diagrammatically and expand on the details of the threat using textual description.
When documenting the threats, it is recommended to use a template to maintain consistency of documenting and communicating the threats. Some of a threat’s attributes that need to be documented include the type of threat with a unique identifier, the description, the threat target, attack techniques, security impact, the likelihood or risk of the threat’s materializing, and, if available, the possible controls to implement. Figure 3.21 depicts the textual documentation of an injection attack.
- Prioritize the threats: It was mentioned earlier that the threat modeling exercise is a systematic and structured methodology that is performed to assist teams in making security versus engineering design or business trade-off decisions. Merely cataloging a list of threats provides little assistance to a design team that needs to decide how to address the threat. Providing the design team with a ranking or rating of the identified and documented threats proves invaluable in prioritizing decisions that impact the allocation of resources to address the threats.
There are several ways to quantitatively or qualitatively determine the risk ranking for a threat. These range from the simple, nonscientific, Delphi heuristic methodology to more statistically sound risk ranking using the probability of impact and the business impact. The three common ways to rank threats are:
- Document the threats: The importance of documenting the threat model cannot be underestimated because threat modeling is iterative, and, through the life cycle of the project, the protection controls to address the identified threats in the threat model need to be appropriately implemented, validated, and the threat model itself updated. Threats can be documented diagrammatically or in textual format. Diagrammatic documentation provides a context for the threats. Textual documentation allows for more detail of each threat. It is best advised to do both. Document each threat diagrammatically and expand on the details of the threat using textual description.
- Delphi ranking
- Average ranking
- Probability × Impact (P × I) ranking
- Think like an attacker (brainstorming and using attack trees)
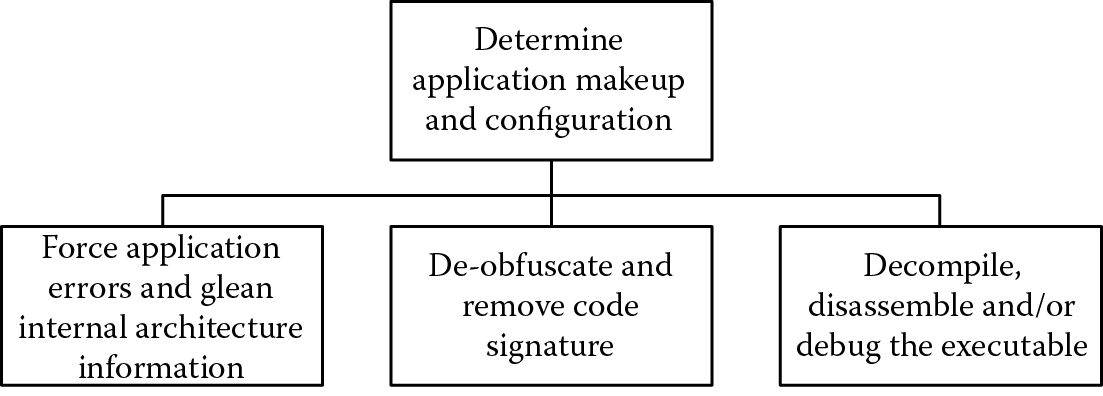

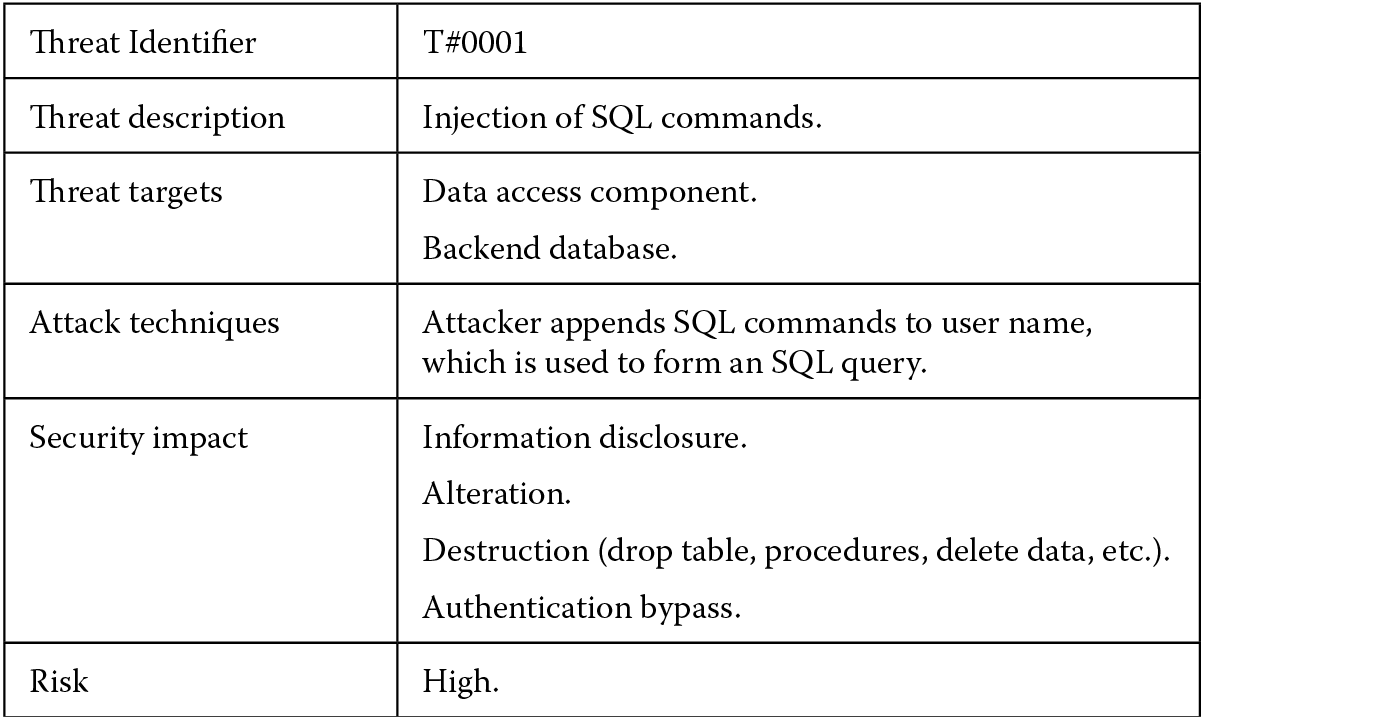
- Delphi Ranking — The Delphi technique of risk ranking is one in which each member of the threat modeling team makes his or her best guesstimate on the level of risk for a particular threat. During a Delphi risk ranking exercise, individual opinions on the level of risk for a particular threat are stated and the stated opinions are not questioned but accepted as stated. The individuals who are identified for this exercise include both members with skills at an expert level and those who are not skilled, but the participating members only communicate their opinions to a facilitator. This is to avoid dominance by strong personalities who can potentially influence the risk rank of the threat. The facilitator must provide, in advance, predefined ranking criteria (1, Critical; 2, Severe; 3, Minimal) along with the list of identified threats, to ensure that the same ranking criteria are used by all members. The criteria are often based merely on the potential impact of the threat materializing, and the ranking process is performed until there is consensus or confidence in the way the threats are ranked. While this may be a quick method to determine the consensus of the risk potential of a threat, it may not provide a complete picture of the risk and should be used sparingly and only in conjunction with other risk ranking methodologies. Furthermore, ambiguous or undefined risk ranking criteria and differing viewpoints and backgrounds of the participants can lead to the results’ being diverse and the process itself, inefficient.
- Average Ranking — Another methodology to rank the risk of the threat is to calculate the average of numeric values assigned to risk ranking categories. One such risk ranking categorization framework is DREAD, which is an acronym for damage potential, reproducibility, exploitability, affected users, and discoverability. Each category is assigned a numerical range, and it is preferred to use a smaller range (such as 1 to 3 instead of 1 to 10) to make the ranking more defined, the vulnerabilities less ambiguous, and the categories more meaningful.
- Damage potential ranks the damage that will be caused when a threat is materialized or vulnerability exploited.
- 1 = Nothing
- 2 = Individual user data are compromised or affected
- 3 = Complete system or data destruction
- Reproducibility ranks the ease of being able to re-create the threat and the frequency of the threat exploiting the underlying vulnerability successfully.
- 1 = Very hard or impossible, even for administrators of the application
- 2 = One or two steps required; may need to be an authorized user
- 3 = Just the address bar in a Web browser is sufficient, without authentication
- Exploitability ranks the effort that is necessary for the threat to be manifested and the preconditions, if any, that are needed to materialize the threat.
- 1 = Advanced programming and networking knowledge, with custom or advanced attack tools
- 2 = Malware exists on the Internet, or an exploit is easily performed using available attack tools
- 3 = Just a Web browser
- Affected users ranks the number of users or installed instances of the software that will be impacted if the threat materializes.
- 1 = None
- 2 = Some users or systems, but not all
- 3 = All users
- Discoverability ranks how easy it is for external researchers and attackers to discover the threat, if left unaddressed.
- 1 = Very hard to impossible; requires source code or administrative access
- 2 = Can figure it out by guessing or by monitoring network traces
- 3 = Information is visible in the Web browser address bar or in a form
Once values have been assigned to each category, then the average of those values is computed to give a risk ranking number. Mathematically, this can be expressed as
- Damage potential ranks the damage that will be caused when a threat is materialized or vulnerability exploited.
(Dvalue + Rvalue + Evalue + Avalue + DIvalue)/5
Figure 3.22 is an example illustrating the use of an average ranking to rank various Web application threats.
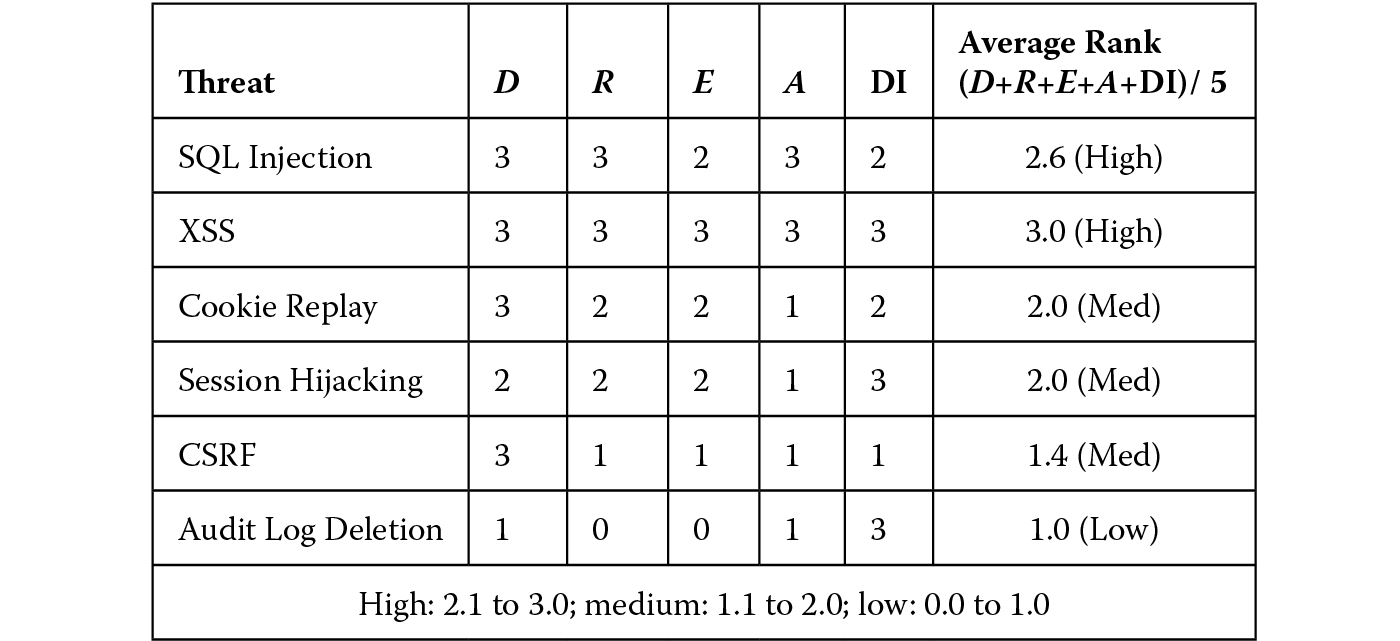
The average rank and categorization into buckets such as high, medium, or low can then be used to prioritize mitigation efforts.
- Probability × Impact (P × I) Ranking — Conventional risk management calculation of the risk to a threat materializing or to exploiting a vulnerability is performed by using the product of the probability (likelihood) of occurrence and the impact the threat will have on business operations, if it materializes. Organizations that use risk management principles for their governance use the formula shown below to assign a risk ranking to the threats and vulnerabilities.
Risk = Probability of Occurrence × Business Impact
This methodology is relatively more scientific than the Delphi or the average ranking methodology. For the Probability × Impact (P × I) ranking methodology, we will once again take into account the DREAD framework. The risk rank will be computed using the following formula:
Risk = Probability of Occurrence × Business Impact
Risk = (Rvalue + Evalue + DIvalue) × (Dvalue + Avalue)
Figure 3.23 is an example illustrating the use of the P × I ranking methodology to rank various Web application threats.
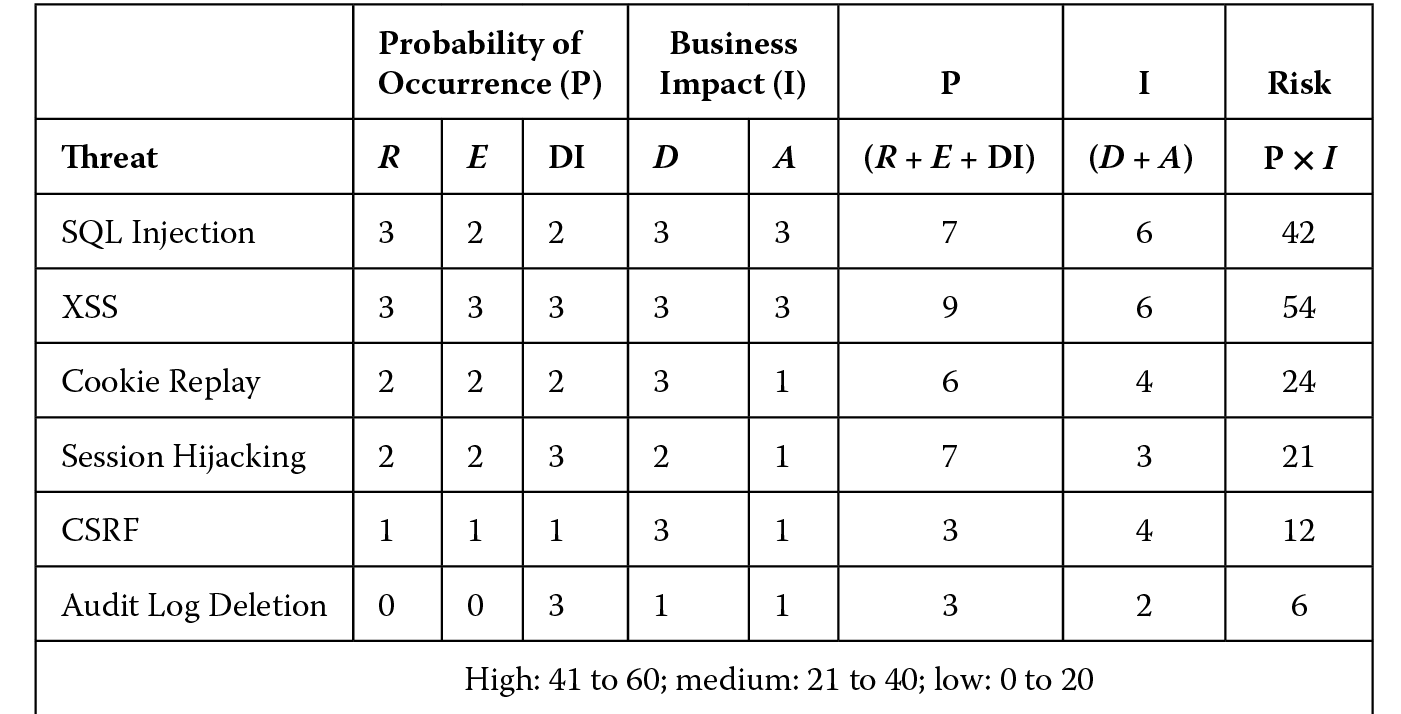
From this example, we can see that the cross-site scripting (XSS) threat and SQL injection threats are high risks, which need to be mitigated immediately, while the cookie replay and session hijacking threats are of medium risk. There should be a plan in place to mitigate those as soon as possible. CSRF and audit log deletion threats have a low risk rank and may be acceptable. To prioritize the efforts of these two, high risk items (SQL injection and XSS), we can use the computed risk rank (P × I) or we can use either the probability of occurrence (P) or business impact (I) value. Because both SQL injection and XSS have the same business impact value of 6, we can use the probability of occurrence value to prioritize mitigation efforts, choosing to mitigate XSS first and then SQL injection, because the probability of occurrence value for XSS is 9, while the probability of occurrence value for SQL injection is 7.
3.10.2.8 Comparison of Risk Ranking Methodologies
While the Delphi methodology usually focuses on risk from a business impact vantage point, the average ranking methodology, when using the DREAD framework, takes into account both business impact (damage potential and affected users) and the probability of occurrence (reproducibility, exploitability, and discoverability); however, because of averaging the business impact and probability of occurrence values uniformly, the derived risk rank value does not give insight into the deviation (lower and upper limits) from the average. This can lead to uniform application of mitigation efforts to all threats, thereby potentially applying too much mitigation control effort on threats that are not really certain or too little mitigation control effort on threats that are serious. The P × I ranking methodology gives insight into risk as a measure of both probability of occurrence and the business impact independently, as well as when considered together. This allows the design team the flexibility to reduce the probability of occurrence or alleviate the business impact independently or together, once it has used the P × I risk rank to prioritize where to focus its mitigation efforts. Additionally, the P × I methodology gives a more accurate picture of the risk. Notice that in the average ranking methodology, both cookie replay and session hijacking threats had been assigned a medium risk of 2.0. This poses a challenge to the design team: which threat must one consider mitigating first? However, in the P × I ranking of the same threats, you notice that the cookie replay threat has a risk score of 24, whereas the session hijacking threat has a risk score of 21, based on probability of occurrence and business impact. This facilitates the design team’s consideration of mitigating the cookie replay threat before addressing the session hijacking threat.
3.10.2.9 Control Identification and Prioritization
Threats to software are inevitable, and the threat modeling exercise helps us identify entry and exit points that can render the software vulnerable to attack. Knowledge of vulnerabilities is worthless unless appropriate controls are identified to mitigate the threats that can exploit the vulnerabilities. The identification of controls needs to be specific to each threat. A threat may be completely mitigated by a single control or a combination of controls may be necessary. In instances where more than one control is needed to mitigate a threat, the defense in depth measures should ensure that the controls complement rather than contradict one another. It is also important to recognize that the controls (safeguards and countermeasures) do not eliminate the threat but only reduce the overall risk that is associated with the threat. Figure 3.24 is an illustration of documenting identifying controls to address a threat.

Because addressing all the identified threats is unlikely to be economically feasible, it is important to address the threats that pose the greatest risk before addressing those that have minimal impact to business operations. The risk ranks derived from the security risk assessment activity (SRA) of the threat modeling exercise are used to prioritize the controls that need to be implemented. Quantitative risk ranks are usually classified into qualitative bands such as high, medium, or low or, based on the severity of the threat, into severity 1, severity 2, and severity 3. These bands are also known as bug bars or bug bands, and they are not just limited to security issues. There are bug bars for privacy as well. Bug bars help with prioritizing the controls to be implemented post design.
3.11 Architectures
Because business objectives and technology change over time, it is important for software architectures to be strategic, holistic, and secure. Architecture must be strategic, meaning that the software design factors in a long-term perspective and addresses more than just the short-term, tactical goals. This reduces the need for redesigning the software when there are changes in business goals or technology. By devising the architecture of software to be highly cohesive and loosely coupled, software can be scaled with minimal redesign when changes are required. Architecture must also be holistic. This means that software design is not just IT-centric in nature but is also inclusive of the perspectives of the business and other stakeholders. In a global economy, locale considerations are an important, architectural consideration as well. Holistic software architecture also means that it factors not only the people, process, and technology aspects of design but also the network, host, and application aspects of software design. Implementation security across the different layers of the Open Systems Interconnect (OSI) reference model of ISO/IEC 7498-1:1994 is important so that there is no weak link from the physical layer to the application layer. Table 3.14 illustrates the different layers of the OSI reference model, the potential threats at each layer, and what protection control or technology can be leveraged at each layer. Using IPSec at the network layer (layer 3), SSL at the transport layer (layer 4), and Digital Rights Management (DRM) at the presentation layer (layer 6) augments the protection controls that are designed at the application layer (layer 7), and this demonstrates two, secure design principles: defense in depth and leveraging existing components.
Finally, software architecture must be not only strategic and holistic but also secure. The benefits of enterprise security architecture are many. Some of these are listed here. Enterprise security architecture
- Provides protection against security-related issues that may be related to the architecture (flaws) or implementation (bugs) or both.
- Makes it possible to implement common security solutions across the enterprise.
- Promotes interoperability and makes it easy for integrating systems while effectively managing risk.
- Allows for leveraging industry-leading best practices. The OWASP Enterprise Security Application Programming Interface (ESAPI) is an example of a toolkit that can be leveraged to uniformly manage risks by allowing software development team members to guard against flaws and bugs.
- Facilitates decision makers to make better and quicker security-related decisions across the enterprise.
Changes in the hardware computing power have led to shifts in software architectures from the centralized mainframe architecture to the highly distributed computing architecture. Today, many distributed architectures, such as the client/server model, P2P networking, SOA, rich Internet applications (RIA), pervasive computing, Software as a Service (SaaS), cloud computing, and Virtualization, exist and are on the rise. In the following section, we will look into the different types of architectures that are prevalent today and how to design software to be secure when using these architectures.
3.11.1 Mainframe Architecture
Colloquially referred to as the Big Iron, mainframes are computers that are capable of bulk data processing with great computation speed and efficiency. The speed is usually measured in millions of instructions per second (MIPS). In the early days of mainframe, computing involved tightly coupled mainframe servers and dumb terminals that were merely interfaces to the functionality that existed on the high processing, backend servers. All processing, security, and data protection was the responsibility of the mainframe server, which usually operated in a closed network with a restricted number of users.
In addition to the increased computational speed, redundancy engineering for high availability, and connectivity over IP networks, today’s mainframe computing brings remote connectivity, allowing scores of users access to mainframe data and functionality. This is possible because of the access interfaces, including Web interfaces that have been made available in mainframes. The mainframe provides one of the highest degrees of security inherently with an Evaluation Assurance Level of 5. It has its own networking infrastructure, which augments its inherent, core, security abilities.
However, with the increase in connectivity, the potential for attack increases and the security provided by the closed network and restricted access control mechanisms wanes. Furthermore, one of the challenges surfacing is that the number of people skilled in the operational procedures and security of mainframes is dwindling, with people’s retiring or moving toward newer platforms. This is an important issue from a security standpoint because those who are leaving are the ones who have likely designed the security of these mainframes and this brain drain can leave the mainframe systems in an operationally insecure state.
To address security challenges in the evolving mainframe computing architecture, data encryption and end-to-end transit protection are important risk mitigation controls to implement. Additionally, it is important to design in the principle of psychological acceptability by making security transparent. This means that solutions that require rewriting applications, mainframe Job Control Language (JCL), and network infrastructure scripts, must be avoided. The skills shortage problem must be dealt with by employing user education and initiatives that make a future in mainframe lucrative, especially in relation to its crossover with new applications and newer, open platforms such as Linux.
3.11.2 Distributed Computing
Business trends have moved from the centralized world of the mainframe to the need for more remote access; so, a need for distributed computing arose. Distributed computing is primarily of the following types: client/server model and peer-to-peer (P2P).
- Client/Server model: Unlike the case of a traditional monolithic mainframe architecture where the server does the heavy lifting and the clients were primarily dumb terminals, in client/server computing, the client is also capable of processing and is essentially a program that requests service from a server program which may in turn be a client requesting service from other backend server programs. This distinction is, however, thinning with the mainframe computing model becoming more interconnected. Within the context of software development, clients that perform minimal processing are referred to commonly as thin clients, while those which perform extensive processing are known as fat clients. With the rise in SaaS, the number of thin-client deployments is expected to increase. The client/server model is the main architecture in today’s network computing. This model makes it possible to interconnect several programs that are distributed across various locations. The Internet is a primary example of client/server computing.
When designing applications for operating in a client/server architecture, it is important to design the software to be scalable, highly available, easily maintainable, and secure. Logically breaking down the software’s functionality into chunks or tiers has an impact on the software’s ease of adapting to changes. This type of client/server architecture is known as N-Tier architecture, where N stands for the number of tiers the software is logically broken into. 1-Tier means there is only one tier. All the necessary components of the software, which include the presentation (user interface), the business logic, and the data layer, are contained within the same tier, and, in most cases, within the same machine. When software architecture is 1-Tier, the implementation of the software is usually done by intermixing client and server code, with no distinct tiering. This type of programming is known as spaghetti code programming. Spaghetti code is complex, with unstructured go-to statements and arbitrary flow. 1-Tier architecture spaghetti code is highly coupled. This makes it very difficult to maintain the software. While 1-Tier architecture may be the simplest and easiest to design, it is not at all scalable, difficult to maintain, and must be avoided, unless the business has a valid reason for such a design. In a 2-Tier architecture, the software is functionally broken into a client program and a server program. The client usually has the presentation and business logic layer while the server is the backend data or resource store. A Web browser (client) requesting the Web server (server) to serve it Web pages is an example of 2-Tier architecture. While this provides a little more scalability than 1-Tier architecture, it still requires updating the entire software, so changes are all-or-nothing, making it difficult to maintain and scale. The most common N-Tier architecture is the 3-Tier architecture, which breaks the software functionality distinctly into three tiers; the presentation tier, the business logic tier, and the data tier. The benefits of the 3-Tier architecture are as follows:
- Changes in a tier are independent of the other tiers. So if you choose to change the database technology, the presentation and business logic tiers are not necessarily affected.
- It encapsulates the internal makeup of the software by abstracting the functionality into contract-based interfaces between the tiers.
However, this can also make the design complex and if error-reporting mechanisms are not designed properly, it can make troubleshooting very difficult. Further, it introduces multiple points of failure, which can be viewed as a detriment; however, this can be also viewed as a security benefit because it eliminates a single point of failure.
- Peer-to-Peer: When one program controls other programs, as is usually the case with client/server architecture, it is said to have a master and slave configuration. However, in some distributed computing architecture, the client and the server programs each have the ability to initiate a transaction and act as peers. Such a configuration is known as a P2P architecture. Management of these resources in a P2P network is not centralized but spread among the resources on the P2P network uniformly, and each resource can function as a client or a server. File-sharing programs and instant messaging are well-known examples of this type of architecture. P2P file-sharing networks are a common ground for hackers to implant malware, so when P2P networks are designed, it is imperative to include strong access control protection to prevent the upload of malicious files from sources that are not trusted.
When you are designing software to operate in a distributed computing environment, security becomes even more important because the attack surface includes the client, the server, and the networking infrastructure. The following security design considerations are imperative to consider in distributed computing:
- Channel security: As data are passed from the client to the server and back or from one tier to another, it is necessary to protect the channel on which the data are transmitted. Transport level protocols such as SSL or network level protection using IPSec are means of implementing channel security.
- Data confidentiality and integrity: Protecting the data using cryptographic means such as encryption or hashing is important to protect against disclosure and alteration threats.
- Security in the call stack/flow: Distributed systems often rely on security protection mechanisms such as validation and authorization checks at various points of the call stack/flow. Design should factor in the entire call stack of software functionality so that security is not circumvented at any point of the call stack.
- Security zoning: Zoning using trust boundaries is an important security protection mechanism. There exists a security boundary between the client and the server in a client/server distributed computing architecture, and these trust levels should be determined and appropriately addressed. For example, performing client-side input validation may be useful for heightening user experience and performing, but trusting the client for input validation is a weak security protection mechanism, as it can be easily bypassed.
3.11.3 Service Oriented Architecture
SOA is a distributed computing architecture that has the following characteristics:
- Abstracted business functionality: The actual program, business logic, processes, and the database are abstracted into logical views, defined in terms of the business operations and exposed as services. The internal implementation language, inner working of the business operation, or even the data structure is abstracted in the SOA.
- Contract-based interfaces: Communication (messages) between the service providing unit (provider agent) and the consuming unit (requestor agent) is done using messages that are of a standardized format delivered through an interface. Developers do not need to understand the internal implementation of the service, as long as they know how to invoke the service using the interface contract.
- Platform neutrality: Messages in SOA are not only standardized, but they are also sent in a platform-neutral format. This maximizes cross-platform operability and makes it possible to operate with legacy systems. Most SOA implementations use the Extensible Markup Language (XML) as their choice of messaging because it is platform neutral.
- Modularity and reusability: Services are defined as discreet, functional units (modular) that can be reused. Unlike applications that are tightly coupled in a traditional computing environment, SOA is implemented as loosely coupled network services that work together to form the application. The centralization of services that allows for reusability can be viewed on one hand as minimizing the attack surface but, on the other, as the single point of failure. Therefore, careful design of defense in depth protection is necessary in SOA implementations.
- Discoverability: In order for the service to be available for use, it must be discoverable. The service’s discoverability and interface information are published so that requestor agents are made aware of what the service contract is and how to invoke it. When SOA is implemented using Web services technology, this discoverable information is published using Universal Description, Discovery and Interface (UDDI). UDDI is a standard published by the Organization for the Advancement of Structured Information Standards (OASIS). It defines a universal method for enterprises to dynamically discover and invoke Web services. It is a registry of services and could be called the yellow pages of the interface definition of services that are available for consumption.
- Interoperability: Because knowledge of the internal structure of the services is not necessary and the messaging between the provider and requestor agents is standardized and platform neutral, heterogeneous systems can interoperate, even in disparate processing environments, as long as the formal service definition is adhered to. This is one of the primary benefits of SOA.
Although SOA is often mistakenly used synonymously with Web services technologies, SOA can be implemented using several technologies. The most common technologies used to architect SOA solutions are Component Object Model (COM), Common Object Request Broker Architecture (CORBA), and Web services (WS). Web services provide platform and vendor neutrality, but it must be recognized that performance and implementation immaturity issues can be introduced. If platform and vendor neutrality are not business requirements, then using COM or CORBA implementations along with XML-based protocols for exchanging information such as Simple Object Access Protocol (SOAP) may be a better choice for performance. However, SOAP was not designed with security in mind and so can be intercepted and modified while in transit. Web services are appropriate for software in environments
- Where reliability and speed are not assured (e.g., the Internet)
- Where managing the requestor and provider agents need to be upgraded at once, when deployment cannot be managed centrally
- Where the distributed computing components run on different platforms
- When products from different vendors need to interoperate
- When an existing software functionality or the entire application can be wrapped using a contract-based interface and needs to be exposed for consumption over a World Wide Web (WWW)
Although SOA brings with it many benefits, such as interoperability and platform/vendor neutrality, it also brings challenges when it comes to performance and security. SOA implementation design needs to factor in various considerations. These include the following:
- Secure messaging: Because SOA messages traverse on networks that are not necessarily within the same domain or processing environment, such as the Internet, they can be intercepted and modified by an attacker. This mandates the need for confidentiality, integrity, and transport level protection. Any one or a combination of the following methods can be used to provide secure messaging:
- XML encryption and XML signature: When an XML protocol for exchanging information is used, an entire message or portions of a message can be encrypted and signed using XML security standards. WS-Security is the Web services security standard that can be used for securing SOAP messages by providing SOAP extensions that define mechanisms using XML encryption and XML signature. This assures confidentiality and integrity protection.
- Implement TLS: Use SSL/TLS to secure messages in transit. Hypertext Transport Protocol (HTTP) over SSL/TLS (HTTPS) can be used to secure SOAP messages that are transmitted over HTTP.
- Resource protection: When business functionality is abstracted as services using interfaces that are discoverable and publicly accessible, it is mandatory to ensure that these service resources are protected appropriately. Identification, authentication, and access control protection are critical to assure that only those who are authorized to invoke these services are allowed to do so. Services need to be identity aware, meaning that the services need to identify and authenticate one another. Identification and authentication can be achieved using token-based authentication, the SOAP authentication header, or transport layer authentication.
- Contract negotiation: The Web Service Description Language (WSDL) is an XML format used to describe service contracts and allowed operations. This also includes the network service endpoints and their messages. Newer functionalities in a service can be used immediately upon electronic negotiation of the contract and invocation, but this can pose a legal liability challenge. It is therefore recommended that the contract-based interfaces of the services be predefined and agreed upon between organizations that plan to use the services in an SOA solution. However, in an Internet environment, establishing trust and service definitions between provider agents (service publisher) and requestor agents (service consumer) are not always just time-consuming processes, but in some cases are impossible. This is the reason why most SOA implementations depend on the WSDL interface, which provides the service contract information implicitly. This mandates the need to protect the WSDL interface against scanning and enumeration attacks.
- Trust relationships: Establishing the trust between the provider and the consumer in an SOA solution is not a trivial undertaking, and it must be carefully considered when designing the SOA. Although identification and authentication are necessary, mere identity verification of a service or the service provider does not necessarily mean that the service, itself, can be trusted. The primary SOA trust models that can be used to assure the trustworthiness of a service are described here.
- Pairwise trust model: In this model, during the time of service configuration, each service is provided with all of the other services that it can interact (paired) with. Although this is the simplest of trust models, it cannot scale very well, because the adding of each new service will require associating or pairing a trust relationship with every other service, which can be resource intensive and time-consuming.
- Brokered trust model: In this model, an independent third party acts as a middleman (broker) to provide the identity information of the services that can interact with one another. This facilitates the distribution of identity information because services need not be aware of the identity of other services they must interact with but simply need to verify the identity of the service broker.
- Federated trust model: In this model, the trust relationship is established (federated) between two separate organizations. Either a pairwise or brokered trust relationship can be used within this model, but a predefinition of allowed service contracts and invocation protocols and interfaces is necessary. The location where the federated trust relationship mapping is maintained must be protected as well.
- Proxy trust model: In this model, perimeter defense devices are placed between the providers and requestor. These devices act as a proxy for allowing access to and performing security assertions for the services. An XML gateway is an example of a proxy trust device. However, the proxy device can become the single point of failure if layered defensive protection and least privilege controls are not in place. An attacker who bypasses the proxy protection can potentially have access to all internal services, if they are not designed, developed, and deployed with security in mind.
3.11.4 Rich Internet Applications
With the ubiquitous nature of the Web and the hype in social networking, it is highly unlikely that one has not already come across RIAs. Some examples of RIAs in use today are Facebook and Twitter. RIAs bring the richness of the desktop environment and software onto the Web. A live connection (Internet Protocol) to the network and a client (browser, browser plug-in, or virtual machine) are often all that is necessary to run these applications. Some of the frameworks that are commonly used in RIA are AJAX, Abode Flash/Flex/AIR, Microsoft Silverlight, and JavaFX. With increased client (browser) side processing capabilities, the workload on the server side is reduced, which is a primary benefit of RIA. Increased user experience and user control are also benefits that are evident.
RIA has some inherent, security control mechanisms as well. These include Same Origin Policy (SOP) and sandboxing. The origin of a Web application can be determined using the protocol (http/https), host name, and port (80/443) information. If two Web sites have the same protocol, host name, and port information or if the document.domain properties of two Web resources are the same, it can be said that both have the same source or origin. The goal of SOP is to prevent a resource (document, script, applets, etc.) from one source from interacting and manipulating documents in another. Most modern-day browsers have SOP security built into them and RIA with browser clients intrinsically inherit this protection. RIAs also run within the security sandbox of the browser and are restricted from accessing system resources unless access is explicitly granted. However, Web application threats, such as injection attacks, scripting attacks, and malware, are all applicable to RIA. With RIA, the attack surface is increased, which includes the client that may be susceptible to security threats. If sandboxing protection is circumvented, host machines that are not patched properly can become victims of security threats. This necessitates the need to explicitly design Web security protection mechanisms for RIA. Ensure that authentication and access control decisions are not dependent on client-side verification checks. Data encryption and encoding are important protection mechanisms. To assure SOP protection, software design should factor in determining the actual (or true) origin of data and services and not just validate the last referrer as the point of origin.
3.11.5 Pervasive Computing
The dictionary definition of the word, “pervade” is “to go through” or “to become diffused throughout every part of” and, as the name indicates, pervasive computing is characterized by computing being diffused through every part of day-to-day living. It is a trend of everyday distributed computing that is brought about by converging technologies, primarily the wireless technologies, the Internet, and the increase in use of mobile devices such as smart phones, personal digital assistants (PDAs), laptops, etc. It is based on the premise that any device can connect to a network of other devices.
There are two elements of pervasive computing and these include pervasive computation and pervasive communication. Pervasive computation implies that any device, appliance, or equipment that can be embedded with a computer chip or sensor can be connected as part of a network and access services from and through that network, be it a home network, work network, or a network in a public place like an airport, a train station, etc. Pervasive communication implies that the devices on a pervasive network can communicate with each other over wired and wireless protocols, which can be found pretty much everywhere in this digital age.
One of the main objectives of pervasive computing is to create an environment where connectivity of devices is unobtrusive to everyday living, intuitive, seamlessly portable, and available anytime and anyplace. This is the reason why pervasive computing is also known as ubiquitous computing and in laymen terms, everyday–everywhere computing. Wireless protocols remove the limitations imposed by physically wired computing and make it possible for such an “everywhere” computing paradigm. Bluetooth and ZigBee are examples of two, common, wireless protocols in a pervasive computing environment. Smart phones, PDAs, smart cars, smart homes, and smart buildings are some examples of prevalent pervasive computing.
In pervasive computing, devices are capable of hopping on and hopping off a network anytime, anywhere, making this type of computing an ad hoc, plug-and-play kind of distributed computing. The network is highly heterogeneous in nature and can vary in the number of connected devices at any given time. For example, when you are at an airport, your laptop or smart phone can connect to the wireless network at the airport, becoming a node in that network, or your smart phone can connect via Bluetooth to your car, allowing access to your calendar, contacts, and music files on your smart phone via the car’s network.
While the benefits of pervasive computing include the ability to be connected always from any place, from a security standpoint, it brings with it some challenges that require attention. The devices that are connected as part of a pervasive network are not only susceptible to attack themselves, but they can also be used to orchestrate attacks against the network where they are connected. This is why complete mediation, implemented using node-to-node authentication, must be part of the authentication design. Applications on the device must not be allowed to directly connect to the backend network but instead should authenticate to the device, and the device in turn should authenticate to the internal applications on the network. Using the TPM chip on the device is recommended over using the easily spoofable media access control (MAC) address for device identification and authentication. Designers of pervasive computing applications need to be familiar with lower level mobile device protection mechanisms and protocol.
System designers are now required to design protection mechanisms against physical security threats as well. Owing to the small size of most mobile computing devices, they are likely to be stolen or lost. This means that the data stored on the device itself is protected against disclosure threats using encryption or other cryptographic means. Because a device can be lost or stolen, applications on the device should be designed to have an “auto-erase” capability that can be triggered either on the device itself or remotely. This means that data on the device are completely erased when the device is stolen or a condition for erasing data (e.g., tampering and failed authentication) is met. The most common triggering activity is the incorrect entry of the personal identification number (PIN) more times than the configured number of allowed authentication attempts. Encryption and authentication are of paramount importance for protection of data in pervasive computing devices. Biometric authentication is recommended over PIN-based authentication, as this will require an attacker to spoof physical characteristics of the owner, significantly increasing his or her work factor.
Wireless networks configuration and protocols on which a significant portion of pervasive computing is dependent are susceptible to attack as well. Most wireless access points are turned on with default manufacturer settings, which can be easily guessed if not broadcast as the service set identifier (SSID). The SSID lets other 802.11× devices join the network. Although SSID cloaking, which means that the SSID is not broadcast, is not foolproof, it increases protection against unapproved rogue and not previously configured devices’ discovering the wireless network automatically. For a device to connect to the network, it must know the shared secret, and in this shared secret, authentication mechanism affords significantly more protection than open network authentication.
Not only is the wireless network configuration an area of threat, but the protocols themselves can be susceptible to breaches in security. The Wired Equivalent Privacy (WEP) uses a 40-bit RC4 stream cipher for providing cryptographic protection. This has been proven to be weak and has been easily broken. Using Wi-Fi protected access (WPA and WPA2) is recommended over WEP in today’s pervasive computing environments. Attacks against the Bluetooth protocol are also evident, which include Bluesnarfing, Bluejacking, and Bluebugging.
A layered approach to pervasive computing security is necessary. The following are some proven best practices that are recommended as protection measures in a pervasive computing environment:
- Ensure that physical security protections (locked doors, badged access, etc.) are in place, if applicable.
- Change wireless access point devices’ default configurations and do not broadcast SSID information.
- Encrypt the data while in transit using SSL/TLS and on the device.
- Use a shared-secret authentication mechanism to keep rogue devices from hopping onto your network.
- Use device-based authentication for internal application on the network.
- Use biometric authentication for user access to the device, if feasible.
- Disable or remove primitive services such as Telnet and FTP.
- Have an auto-erase capability to prevent data disclosure should the device be stolen or lost.
- Regularly audit and monitor access logs to determine anomalies.
3.11.6 Software as a Service (SaaS)
Traditionally, software was designed and developed to be deployed on the client systems using packagers and installers. Upon installation, the software files would be hosted on the client system. Patches and updates would then have to be pushed to each individual client system on which the software was installed. There is also a time delay between the time that newer features of the software are developed and the time it is made available to all the users of the software. Not only is this model of software development time intensive, but it is also resource and cost intensive.
To address the challenges imposed by traditional software development and deployment, software is designed today to be available as a service to the end users or clients. In this model, the end users are not the owners of the software, but they pay a royalty or subscription for using the business functionality of software, in its entirety or in parts. SaaS is usually implemented using Web technologies and the software functionality is delivered over the Internet. This is why the SaaS model is also referred to as a Web-based software model, an On-demand model, or a hosted software model.
It can be likened to the client/server model wherein the processing is done on the server side with some distinctions. One distinction is that the software is owned and maintained by the software publisher and the software is hosted on the provider’s infrastructure. End user or client data are also stored in the software publisher’s hosting environment. Furthermore, more than one client (also referred to as a tenant) can take advantage of the software functionality and a single instance of software can serve multiple clients at the same time. This is referred to as the multitenancy of SaaS. This one-code-base-serving-all feature requires administration to be centralized for all clients, and it is the responsibility of the software publisher to ensure that its software is reliable, resilient, and recoverable. Some of the well-known examples of SaaS implementations are the customer relationship management Salesforce.com, Google Docs, and Microsoft’s Hosted Exchange services.
The SaaS model is garnering a lot of acceptance today primarily for the benefits it provides. These include the following:
- Reduced cost: Instead of paying huge costs for licensing software, clients can now use the business applications on-demand and pay only for the services they use. There is no requirement for supporting infrastructure.
- Time saving and speed of delivery: With the software already available for use as a service, time and resource (personnel) investment to develop the same functionality in house is reduced. This—along with lower training requirements, no need to test the application, and no ongoing changes to the business processes—makes it possible for organizations to quickly market their existing products and services.
- Integrity of versions: With the software being centrally administered and managed by the software publisher, the client is not responsible for patching and version updates, thereby ensuring versions are not outdated.
As with any other architecture, along with the benefits come some challenges, and SaaS is no exception. We will focus primarily on the security concerns that come with choosing SaaS as the architecture. The primary security considerations concern data privacy and security, data separation, access control, and availability.
- Data privacy and security: Because the data will be stored in a shared hosting environment with the possibility of multiple tenants, it is imperative to ensure that data stored on the software publisher’s environment is not susceptible to disclosure. This makes it necessary for the software designers to ensure that the sensitive, personal, and private data are protected before being stored in an environment that they have little to no control over. Encryption of data at rest is an important design consideration.
- Data separation: It is also important to ensure that the data of one client is stored separately from that of another client in the software publisher’s data stores.
- Access control: Because the services and data are shared across multiple tenants, it is imperative to ensure that the SaaS provider follows and implements strong access control protections. With multiple tenants possibly authenticated and connected to the shared hosting infrastructure, authorization decisions must be user based, i.e., dependent on the user that is requesting service and data. The Brewer and Nash Chinese Wall security model must be implemented to avoid any conflicts of interest in an SaaS environment.
- Availability: In a shared hosting environment, the disruption of the business operations of a tenant, either deliberately or accidently, can potentially cause disruption to all tenants on that same host. “Will the data be readily available whenever necessary?” is a primary question to answer when considering the implementation of an SaaS solution. Redundancy and high availability designs are imperative. The disaster recovery strategy must be multilevel in nature, meaning that the data are backed up from disk to disk and then to tape, and the tape backups function only as secondary data sources upon disaster.
With the gain in SaaS computing and the prevalence of security threats, SaaS providers are starting to make security integral to their service offerings. Software as a Secure Service (SaSS) is the new acronym that is starting to gain ground as the differentiator between providers who assure protection mechanisms and those who do not.
3.11.7 Integration with Existing Architectures
We have discussed different kinds of software architectures and the pros and cons of each. Unless we are developing new software, we do not start designing the entire solution anew. We integrate with existing architecture when previous versions of software exist. This reduces rework significantly and supports the principle of leveraging existing components. Integration with legacy components may also be the only option available as a time-saving measure or when pertinent specifications, source code, and documentation about the existing system are not available. It is not unusual to wrap existing components with newer generation wrappers. Façade programming makes it possible for such integration. When newer architectures are integrated with existing ones, it is important to determine that backward compatibility and security are maintained. Components written to operate securely in an architecture may wane in its protection when integrated with another. For example, when the business logic tier that performs access control decisions in a 3-tier architecture is abstracted using services interfaces as part of an SOA implementation, authorization decisions that were restricted to the business logic tier can now be discovered and invoked. It is therefore critical to make sure that integration of existing and new architectures does not circumvent or reduce security protection controls or mechanisms and maintains backward compatibility, while reducing rework.
3.12 Technologies
Holistic security, as was aforementioned, includes a technology component, in addition to the people and process components. The secure design principle of leveraging existing components does not apply to software components alone but to technologies as well. If there is an existing technology that can be used to provide business functionality, it is recommended to use it. This not only reduces rework but has security benefits, too. Proven technologies have the benefit of greater scrutiny of security features than do custom implementations. Additionally, custom implementations potentially can increase the attack surface. In the following section, we will cover several technologies that can be leveraged, their security benefits, and issues to consider when designing software to be secure.
3.12.1 Authentication
The process of verifying the genuineness of an object or a user’s identity is authentication. This can be done using authentication technologies. In Chapter 1, we covered the various techniques by which authentication can be achieved. These ranged from proving one’s identity using something one knows (knowledge based), such as username and password/pass-phrase, to using something one has (ownership based), such as tokens, public key certificates, and smart cards, to using something one is (characteristic based), such as biometric fingerprints, retinal blood patterns, and iris contours. Needing more than one factor (knowledge, ownership, or characteristic) for identity verification increases work factor for an attacker significantly and technologies that can support multifactor authentication seamlessly must be considered in design.
The Security Support Provider Interface (SSPI) is an implementation of the IETF RFCs 2743 and 2744, commonly known as Generic Security Service API (GSSAPI). SSPI abstracts calls to authenticate and developers can leverage this, without needing to understand the complexities of this authentication protocol or, even worse, trying to write their own. Custom authentication implementation on an application-to-application basis is proven not only to be inefficient, but it can also introduce security flaws and must be avoided. SSPI supports interoperability with other authentication technologies by providing a pluggable interface, but it also includes by default the protocols to negotiate the best security protocol (SPNEGO), delegate (Kerberos), securely transmit (SChannel), and protect credentials using hashes (Digest).
Before developers start to write code, it is important that the software designers take into account the different authentication types and the protocols and interfaces used in each type.
3.12.2 Identity Management
Authentication and identification go hand in hand. Without identification, not only is authentication not possible, but accountability is nearly impossible to implement. Identity management (IDM) is the combination of policies, processes, and technologies for managing information about digital identities. These digital identities may be those of a human (users) or a nonhuman (network, host, application, and services). User identities are primarily of two types: insiders (e.g., employees and contractors) and outsiders (e.g., partners, customers, and vendors). IDM answers the questions, “Who or what is requesting access?” “How are they or it authenticated?”, and “What level of access can be granted based on the security policy?”
IDM life cycle is about the provisioning, management, and deprovisioning of identities as illustrated in Figure 3.25.
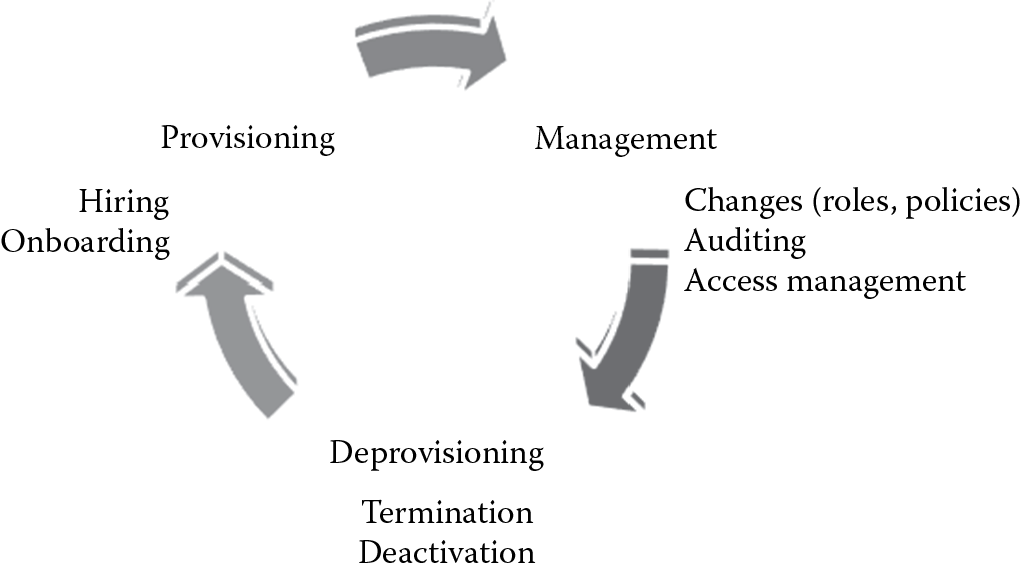
Provisioning of identities includes the creation of digital identities. In an enterprise that has multiple systems, provisioning of an identity in each system can be a laborious, time-consuming, and inefficient process, if it is not automated. Automation of provisioning identities can be achieved by coding business processes, such as hiring and on-boarding, and this requires careful design. Roles in a user provisioning system are entitlement sets that span multiple systems and applications. Privileges that have some meaning in an application are known as entitlements. User provisioning extends role-based access control (RBAC) beyond single applications by consolidating individual system or application entitlements into fewer business roles, making it easier for a business to manage its users and their access rights.
The management of identities includes the renaming of identities, addition or removal of roles, the rights and privileges that are associated with those roles, the changes in regulatory requirements and policies, auditing of successful and unsuccessful access requests, and synchronization of multiple identities for access to multiple systems. When identities are renamed, it is imperative to document and record these changes. It is also important to maintain the histories of activity of the identities before they were renamed and map those histories to the new identity names to assure nonrepudiation capabilities.
Deprovisioning of identities includes termination access control (TAC) processes that are made up of the notification of termination and the deactivation or complete removal of identities. Organizations today are required to provide auditable evidence that access controls are in place and effective. The Sarbanes–Oxley (SOX) 404 section mandates that an annual review of the effectiveness of controls must be conducted and this applies to identity and access management (IAM) controls as well. Users are given rights and privileges (entitlements) over time but are rarely revoked of these entitlements when they are no longer needed. A business needs to be engaged in reviewing and approving access entitlements of identities, and the process is referred to as access certification. For legal and compliance reasons, it may be required to maintain a digital identity even after the identity is no longer active, and so deactivation may be the only viable option. If this is the case, software that handles termination access must be designed to allow “deactivate” only and not allow true “deletes” or “complete removal.” Deactivation also makes it possible for the identity to remain as a backup just in case there is a need: however, this can pose a security threat as an attacker could reactivate a deactivated identity and gain access. The deactivated identities are best maintained in a backup or archived system that is offline with restricted and audited access.
Some of the common technologies that are used for IDM are as follows:
- Directories
A directory is the repository of identities. Its functionality is similar to that of yellow pages. A directory is used to find information about users and other identities within a computing ecosystem. Identity information can be stored and maintained in network directories or backend application databases and data stores. When software is designed to use integrated authentication, it leverages network directories that are accessed using the Lightweight Directory Access Protocol (LDAP). LDAP replaced the more complex and outdated X.500 protocol.
Directories are a fundamental requirement for IDM and can be leveraged to eliminate silos of identity information maintained within each application. Some of the popular directory products are IBM (Tivoli) directory, Sun ONE directory, Oracle Internet Directory (OID), Microsoft Active Directory, Novell eDirectory, OpenLDAP, and Red Hat Directory Server.
- Metadirectories and virtual directories
User roles and entitlements change with business changes and when the identity information and privileges tied to that identity change, those changes need to be propagated to systems that use that identity. Propagation and synchronization of identity changes from the system of record to managed systems are made possible by engines known as metadirectories. Human resources (HR), customer records management (CRM) systems, and corporate directory are examples of system of record. Metadirectories simplify identity administration. They reduce challenges imposed by manual updates and can be leveraged within software to automate change propagation and save time. Software design should include evaluating the security of the connectors and dependencies between identity source systems and downstream systems that use the identity. Microsoft Identity Lifecycle Management is an example of a metadirectory.
Metadirectories are like internal plumbing necessary for centralizing identity change and synchronization, but they usually do not have an interface that can be invoked. This shortfall gave rise to virtual directories. Within the context of an identity services-based architecture, virtual directories provide a service interface that can be invoked by an application to pull identity data and change it into claims that the application can understand. Virtual directories provide more assurance than metadirectories because they also function as gatekeepers and ensure that the data used are authorized and compliant to the security policy.
Designing to leverage IDM processes and technologies is important because it reduces risk by the following:
- Consistently automating, applying, and enforcing identification, authentication, and authorization security policies.
- Deprovisioning identities to avoid lingering identities past their allowed time. This protects against an attacker who can use an ex-employee’s identity to gain access.
- Mitigating the possibility of a user or application gaining unauthorized access to privileged resources.
- Supporting regulatory compliance requirements by providing auditing and reporting capabilities.
- Leveraging common security architecture across all applications.
3.12.3 Credential Management
Chapter 1 covered different types of authentication, each requiring specific forms of credentials to verify and assure that entities that requested access to objects were truly whom they/it claimed to be. The identifying information that is provided by a user or system for validation and verification is known as credentials or claims. Although usernames and passwords are among the most common means of providing identifying information, authentication can be achieved by using other forms of credentials. Tokens, certificates, fingerprints, and retinal patterns are examples of other types of credentials.
Credentials need to be managed and credential management API can be used to obtain and manage credential information, such as user names and passwords. Managing credentials encompasses their generation, storage, synchronization, reset, and revocation. In this section, we will cover managing passwords, certificates, and SSO technology.
3.12.4 Password Management
When you use passwords for authentication, it is important to ensure that the passwords that are automatically generated, by the system, are random and not sequential or easily guessable. First and foremost, blank passwords should not be allowed. When users are allowed to create passwords, dictionary words should not be allowed as passwords because they can be discovered easily by using brute-force techniques and password-cracking tools. Requiring alphanumeric passwords with mixed cases and special characters increases the strength of the passwords.
Passwords must never be hardcoded in clear text and stored in-line with code or scripts. When they are stored in a database table or a configuration file, hashing them provides more protection than encryption because the original passwords cannot be determined. Although providing a means to remember passwords is good for user experience, from a security standpoint, it is not recommended.
Requiring the user to supply the old password before a password is changed, mitigates automated password changes and brute-force attacks. When passwords are changed, it is necessary to ensure that the change is replicated and synchronized within other applications that use the same password. Password synchronization fosters SSO authentication and addresses password management problems within an enterprise network.
When passwords need to be recovered or reset, special attention must be given to assure that the password recovery request is, first and foremost, a valid request, This assurance can be obtained by using some form of identification mechanism that cannot be easily circumvented. Most nonpassword-based authentication applications have a question and answer mechanism to identify a user when passwords need to be recovered. It is imperative for these questions and answers to be customizable by the user. Questions such as “What is your favorite color?” or “What is your mother’s maiden name” do not provide as heightened a protection as do questions that can be defined and customized by the user.
Passwords must have expiration dates. Allowing the same password to be used once it has expired should be disallowed. One-time passwords (OTPs) provide maximum protection because the same password cannot be reused.
LDAP technology using directory servers can be used to implement and enforce password policies for managing passwords. One password policy for all users or a different policy for each user can be established. Directory servers can be used to notify users of upcoming password expirations, and they can also be used to manage expired passwords and account lockouts.
3.12.5 Certificate Management
Authentication can also be accomplished by using digital certificates. Today, asymmetric cryptography and authentication using digital certificates is made possible by using a PKI, as depicted in Figure 3.26.
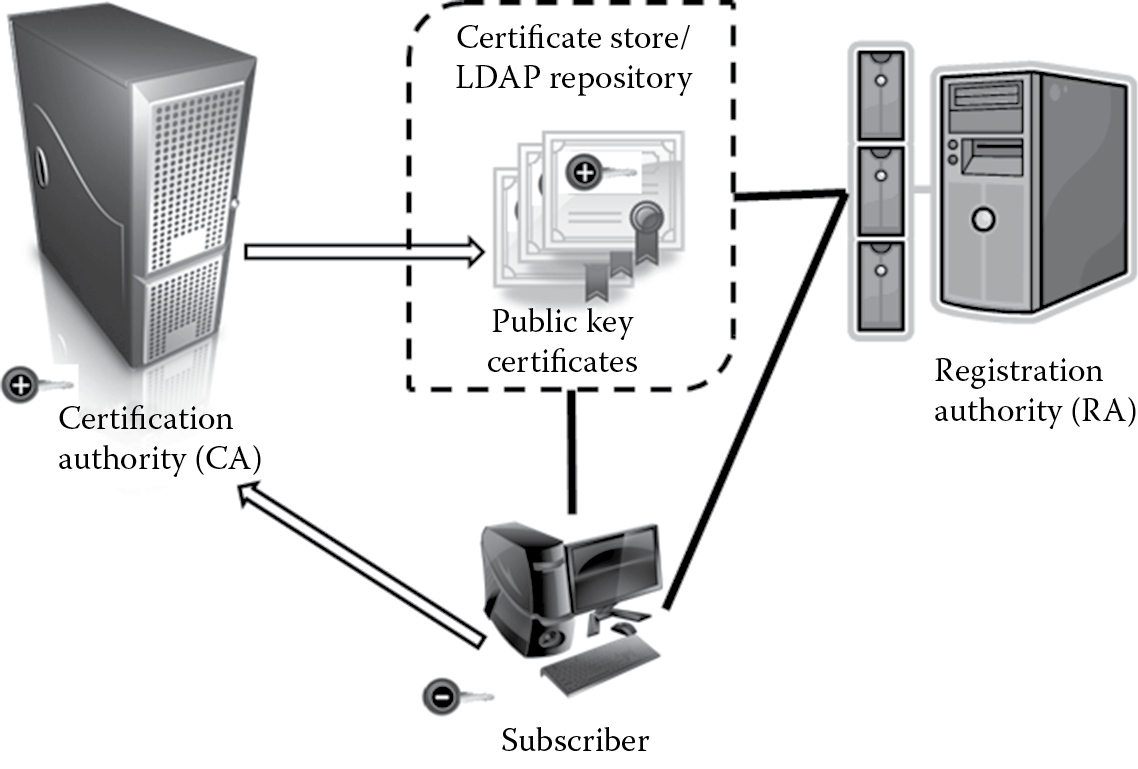
PKI makes secure communications, authentication, and cryptographic operations such as encryption and decryption possible. It is the security infrastructure that uses public key concepts and techniques to provide services for secure e-commerce transactions and communications. PKI manages the generation and distribution of public/private key pairs and publishes the public keys as certificates.
PKI consists of the following components:
- A certificate authority (CA), which is the trusted entity that issues the digital certificate that holds the public key and related information of the subject.
- A registration authority (RA), which functions as a verifier for the CA before a digital certificate is issued by the CA to the requestor.
- A certificate management system with directories in which the certificates can be held and with revocation abilities to revoke any certificates whose private keys have been compromised (disclosed). The CA publishes the certificate revocation lists (CRLs), which contain all certificates revoked by the CA. CRLs make it possible to withdraw a certificate whose private key has been disclosed. In order to verify the validity of a certificate, the public key of the CA is required and a check against the CA’s CRL is made. The certification authority itself needs to have its own certificates. These are self-signed, which means that the subject data in the certificates are the same as the name of the authority who signs and issues the certificates.
PKI management includes the creation of public/private key pairs, public key certificate creation, private key revocation and listing in CRL when the private key is compromised, storage and archival of keys and certificates, and the destruction of these certificates at end of life. PKI is a means to achieve interorganizational trust and enforcement of restrictions on the usage of the issued certificates.
The current, internationally recognized, digital certificate standard is ITU X.509 version 3 (X.509 v3), which specifies formats for the public key, the serial number, the name of the pair owner, from when and for how long the certificate will be valid, the identifier of the asymmetric algorithm to be used, the name of the CA attesting ownership, the certification version numbers that the certificate conforms to, and an optional set of extensions, as depicted in Figure 3.27.
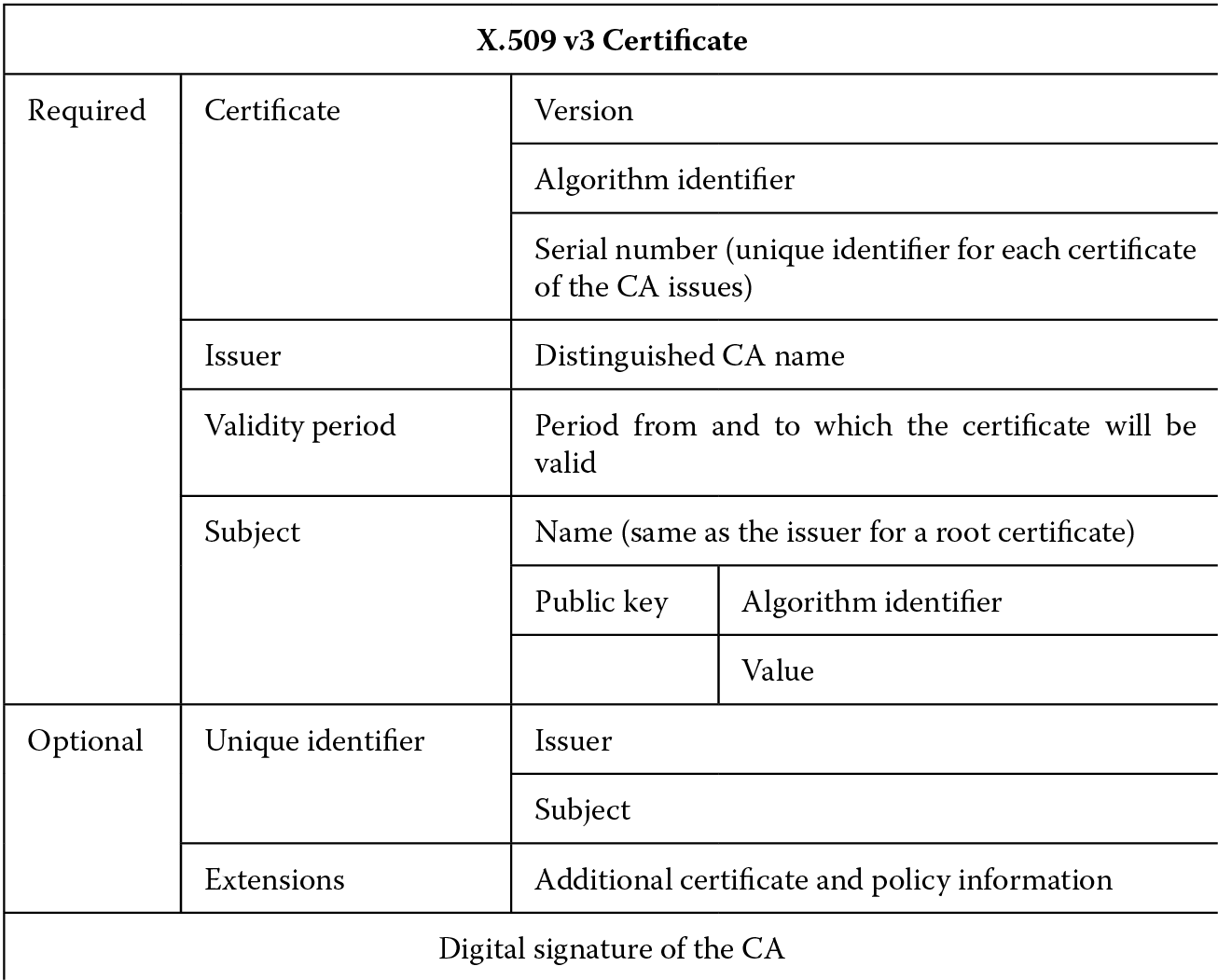
In addition to using PKI for authentication, X.509 certificates make possible strong authorization capabilities by providing Privilege Management Infrastructure (PMI) using X.509 attribute certificates, attribute authorities, target gateways, and authorization policies as depicted in Figure 3.28.
PMI makes it possible to define user access privileges in an environment that has to support multiple applications and vendors.
With the prevalence in online computing, the need for increased online identity assurance and browser representation of online identities gave rise to a special type of X.509 certificate. These are known as extended validation (EV) certificates. Unlike traditional certificates, which protected information only between a sender and a receiver, EV certificates also provide assurance that the sites or remote servers that users are connecting to are legitimate. EV certificates undergo more extensive validation of owner identity before they are issued, and they identify the owners of the sites that users connect to and thereby address MITM attacks. The main objectives of EV certificates are to improve user confidence and reduce Phishing attack threats.
3.12.6 Single Sign-On (SSO)
SSO makes it possible for users to log into one system and after being authenticated, launch other applications without having to provide their identifying information again. It is possible to store user credentials outside of an application and automatically reuse validated credentials in systems that prompt for them. However, SSO is usually implemented in conjunction with other technologies. The two common technologies that make sharing of authentication information possible are Kerberos and Secure Assertion Markup Language (SAML).
Credentials in a Kerberos authentication system are referred to as tickets. When you first log in to a system implemented with Kerberos and your password is verified, you are granted a master ticket, also known as a Ticket Granting Ticket (TGT), by the Ticket Granting Server (TGS). The TGT will act as proxy for your credentials. When you need to access another system, you present your master TGT to the Kerberos server and get a ticket that is specific to that other system. The second ticket is then presented to the system you are requesting access as a proof of who you are. When your identity is verified, access is granted to the system accordingly. All tickets are stored in what is called a ticket cache in the local system. Kerberos-based SSO can be used within the same domain in which the TGS functions and the TGT is issued. So Kerberos is primarily used in an intranet setting. Kerberos-based SSO is easier to implement in an intranet setting than SSO in an Internet environment.
To implement SSO in an Internet environment with multiple domains, SAML can be used. SAML allows users to authenticate themselves in a domain and use resources in a different domain without having to reauthenticate them. It is predominantly used in a Web-based environment for SSO purposes. The WS-Security specification recommends using SAML tokens for token-based authentication. SAML tokens can be used to exchange not just authentication information but also authorization data, user profiles, and preferences and so is a preferred choice. Although SAML tokens are a de facto standard for making authentication decisions in SOA implementations, authorization is often implemented as a custom solution. The OASIS eXtensible Access Control Markup Language (XACML) standard can be used for making authorization decisions and is recommended.
A concept related to SSO is federation. Federation extends SSO across enterprises. In a federated system, an individual can log into one site and access services at another, affiliated site without having to log in each time or reestablish an identity. For example, if you use an online travel site to book your flights, your same identity can be used in an affiliated, vacations and tours site to book your vacation package without having to create an account in the vacations site or login into it. Federation mainly fulfills a user need for convenience and when it is implemented, implementation must be done with legal protection agreements that can be enforced between the two affiliated companies. Until the SAML 2.0 standard specification was developed, organizations that engaged in federation had to work with three primary protocols, namely, OASIS SAML 1.0, Liberty Alliance ID-FF 1.1 and 1.2, and Shibboleth. OASIS SAML primarily dealt with business-to-business (B2B) federation, whereas Liberty focused on the B2B federation, and Shibboleth focused on educational institutions that required anonymity when engaging in federation. SAML 2.0 alleviates the challenges of multiprotocol complexity, making it possible to implement federation more easily. SAML 2.0 makes federation and interoperability possible with relative ease because the need to negotiate, map, and translate protocols are no longer necessary. It is also an open standard for Web-based, SSO service.
Although SSO is difficult to implement because trust needs to be established between the application that performs the authentication and the supported systems that will accept the authenticated credentials, it is preferred because it reduces the likelihood of human error. However, the benefits of simplified user authentication that SSO brings with it must be balanced with the following concerns about the SSO infrastructure:
- The ability to establish trust between entities participating in the SSO architecture.
- SSO implementation can be a single point of failure. If the SSO credentials are exposed, all systems in the SSO implementation are susceptible to breach. In layman’s terms, the loss of SSO credentials is akin to losing the key to the entire kingdom.
- SSO implementation can be a source for DoS. If the SSO system fails, all users who depend on the SSO implementation will be unable to log into their systems, causing a DoS.
- SSO deployment and integration cost can be excessive.
3.12.7 Flow Control
In distributed computing, controlling the flow of information between processes on two systems that may or may not be trusted poses security challenges. Several security issues are related to information flow. Sensitive information (bank account information, health information, social security numbers, credit card statements, etc.) stored in a particular Web application should not be displayed on a client browser to those who are not authorized to view that information. Protection against malware such as spyware and Trojans means that network traffic that carries malicious payload is not allowed to enter the network. By controlling the flow of information or data, several threats to software can be mitigated and delivery of valid messages guaranteed. Enforcing security policies concerning how information can flow to and from an application, independent of code level security protection mechanisms, can be useful in implementing security protection when the code itself cannot be trusted. Firewalls, proxies, and middleware components such as queuing infrastructure and technologies can be used to control the rate of data transmission and allow or disallow the flow of information across trust boundaries.
3.12.7.1 Firewalls and Proxies
Firewalls, more specifically network layer firewalls, separate the internal network of an organization from that of the outside. They also are used to separate internal subnetworks from one another. The firewall is an enforcer of security policy at the perimeter and all traffic that flows through it is inspected. Whether network traffic is restricted or not is dependent on the predefined rules or security policy that is configured into the firewall.
The different types of firewalls that exist are packet filtering, proxy, stateful, and application layer firewall. Each type is covered in more detail in this section.
- Packet filtering: This type of firewall filters network traffic based on information that is contained in the packet header, such as source address, destination address, network ports, and protocol and state flags. Packet filtering firewalls are stateless, meaning they do not keep track of state information. These are commonly implemented using ACLs, which are primarily text-based lines of rules that define which packets are allowed to pass through the firewall and which ones should be restricted. They are also known as first generation firewalls. These are application independent, scalable, and faster in performance but provide little security because they look only at the header information of the packets. Because they do not inspect the contents (payload) of the packets, packet filtering firewalls are defenseless against malware threats. Packet filtering firewalls are also known as first-generation firewalls.
- Proxy: Proxy firewalls act as a middleman between internal trusted networks and the outside untrusted ones. When a packet arrives at a proxy firewall, the firewall terminates the connection from the source and acts as a proxy for the destination, inspects the packet to ascertain that it is safe before forwarding the packet to the destination. When the destination system responds, the packet is sent to the proxy firewall, which will repackage the packet with its own source address and abstract the address of the internal destination host system. Proxy firewalls also make decisions, as do packet filtering firewalls. However, proxy firewalls, by breaking the connection, do not allow direct connection between untrusted and trusted systems. Proxy firewalls are also known as second-generation firewalls.
- Stateful: Stateful firewalls or third-generation firewalls have the capability to track dialog by maintaining a state and data context in the packets within a state table. Unlike proxy firewalls, they are not as resource intensive and are usually transparent to the user.
- Application layer: Because stateless and stateful firewalls look only at a packet’s header and not at the data content (payload) contained within a packet, application specific attacks will go undetected and pass through stateless and stateful firewalls. This is where application layer firewalls or layer 7 firewalls come in handy. Application layer firewalls provide flow control by intercepting data that originate from the client. The intercepted traffic is examined for potentially dangerous threats that can be executed as commands. When a threat is suspected, the application layer firewall can take appropriate action to contain and terminate the attack or redirect it to a honeypot for additional data gathering.
One of the two options in Requirement 6.6 of the PCI Data Security Standard is to have a (Web) application firewall positioned between the Web application and the client end point. The other option is to perform application code reviews. Application firewalls are starting to gain importance, and this trend is expected to continue because hackers are targeting the application layer.
3.12.7.2 Queuing Infrastructure and Technology
Queuing infrastructure and technology are useful to prevent network congestion when a sender sends data faster than a receiver can process it. Legacy applications are usually designed to be single threaded in their operations. With the increase in rich client functionality and without proper flow control, messages can be lost. Queuing infrastructure and technology can be used to backlog these messages in the right order for processing and guarantee delivery to the intended recipients. Some of the well-known queuing technologies include the Microsoft Message Queuing (MSMQ), Oracle Advance Queuing (AQ), and the IBM MQ Series.
3.12.8 Auditing/Logging
One of the most important design considerations is to design the software so it can provide historical evidence of user and system actions. Auditing or logging of user and system interactions within an application can be used as a detective means to find out who did what, where, when, and sometimes how. Regulation such as SOX, HIPAA, and Payment Card Industry Data Security Standard (PCI DSS) require companies to collect and analyze logs from various sources as means to demonstrate due diligence and comprehensive security. Information that is logged needs to be processed to deduce patterns and discover threats. However, before any processing takes place, it is best practice to consolidate the logs, after synchronizing the time clocks of the logs. Time clock synchronization makes it possible to correlate events recorded in the application log data to real-world events, such as badge readers, security cameras, and closed circuit television (CCTV) recordings. Log information needs to be protected when stored and in transit. System administrators and users of monitored applications should not have access to logs. This is to prevent anyone from being able to remove evidence from logs in the event of fraud or theft. The use of a log management service (LMS) can alleviate some of this concern. Also, IDSs and intrusion protection systems (IPSs) can be leveraged to record and retrieve activity. In this section, we will cover auditing technologies, specifically Syslog, IDS, and IPS.
3.12.8.1 Syslog
When logs need to be transferred over an IP network, syslog can be used. Syslog is used to describe the protocol, the application that receives and sends, as well as the logs. The protocol is a client/server protocol in which the client application transmits the logs to the syslog receiver server (commonly called a syslog daemon, denoted as syslogd). Although syslog uses the connectionless User Datagram Protocol (UDP) with no delivery confirmation as its underlying transport mechanism, syslog can use the connection-oriented Transmission Control Protocol (TCP) to assure or guarantee delivery. Reliable log delivery assures that not only are the logs received successfully by the receiver but that they are received in the correct order. It is a necessary part of a complete security solution and can be implemented using TCP. It can be augmented by using cache servers, but when this is done, the attack surface will include the cache servers and appropriate technical, administrative, and physical controls need to be in place to protect the cache servers.
Syslog can be used in multiple platforms and is supported by many devices, making it the de facto standard for logging and transmitting logs from several devices to a central repository where the logs can be consolidated, integrated, and normalized to deduce patterns. Syslog is quickly gaining importance in the Microsoft platforms and is the standard logging solution for Unix and Linux platforms. NIST Special Publication 800-92 provides resourceful guidance on Computer Security Log Management and highlights how Syslog can be used for security auditing as well. However, Syslog has an inherent security weakness to which attention must be paid. Data that are transmitted using Syslog is in clear text, making it susceptible to disclosure attacks. Therefore, TLS measures using wrappers such as SSL wrappers or Secure Shell (SSH) tunnels must be used to provide encryption for confidentiality assurance. Additionally, integrity protection using SHA or MD5 hash functions is necessary to ensure that the logs are not tampered or tainted while they are in transit or stored.
3.12.8.2 Intrusion Detection System (IDS)
IDSs can be used to detect potential threats and suspicious activities. IDSs can be monitoring devices or applications at the network layer (NIDS) or host (HIDS) layer. They filter both inbound and outbound traffic and have alerting capabilities, which notify administrators of imminent threats. One of the significant challenges with NIDS is that malicious payload data that are encrypted, as is the case with encrypted viruses, cannot be inspected for threats and can bypass filtration or detection.
IDSs are not firewalls but can be used with one. Firewalls are your first line of network or perimeter defense, but they may be required to allow traffic to enter through certain ports such as port 80 (http), 443 (https), or 21 (ftp). This is where IDSs can come in handy, as they will provide protection against malicious traffic and threats that pass through firewalls. Additionally, IDSs are more useful than firewalls for detecting insider threats and fraudulent activities that originate from within the firewalls.
IDSs are implemented in one of the following ways:
- Signature based: Similar to how antivirus detects malware threats, signature-based IDSs detect threats by looking for specific signatures or patterns that match those of known threats. The weakness of this type of IDS is that new and unknown threats, whose signatures are not known yet, or polymorphic threats with changing signatures will not be detected and can evade intrusion detection. Snort is a very popular and widely used, freely available, open-source, signature-based IDS for both Linux and Window OSs.
- Anomaly based: An anomaly-based IDS operates by monitoring and comparing network traffic against an established baseline of what is deemed “normal” behavior. Any deviation from the normal behavioral pattern causes an alert as a potential threat. The advantage of this type of IDS is that it can be used to detect and discover newer threats. Anomaly-based IDSs are commonly known also as behavioral IDSs.
- Rule based: A rule-based IDS operates by detecting attacks based on programmed rules. These rules are often implemented as IF-THEN-ELSE statements.
When implemented with logging, an IDS can be used to provide auditing capabilities.
3.12.8.3 Intrusion Prevention Systems (IPS)
Most intrusion prevention systems (IDSs) are passive and simply monitor for and alert on imminent threats. Some current IDSs are reactive in operation as well and are capable of performing an action or actions in response to a detected threat. When these actions are preventive in nature, containing the threat first and preventing it from being manifested, these IDSs are referred to as intrusion prevention systems (IPSs). An IPS provides proactive protection and is essentially a firewall that combines network level and application level filtering. Some examples of proactive IPS actions include blocking further traffic from the source IP address and locking out the account when brute-force threats are detected.
When implemented with logging, an IPS can be used to provide auditing capabilities.
3.12.9 Data Loss Prevention
The most important asset of an organization, second only to its people assets, is data, and data protection is important to assure its confidentiality, integrity, and availability.
The chronology of data breaches, news reports, and regulatory requirements to protect data reflect the prevalence and continued growth of data theft that costs companies colossal remediation sums and loss of brand. Data encryption mitigates data disclosure in events of physical theft and perimeter devices such as firewalls can provide some degree of protection by filtering out threats that are aimed at stealing data and information from within the network. While this type of ingress filtration can be useful to protect data within the network, it does little to protect data that leaves the organizational network. This is where data loss prevention (DLP) comes in handy. DLP is the technology that provides egress filtration, meaning it prevents data from leaving the network. E-mails with attachments containing sensitive information are among the primary sources of data loss when data are in motion. By mistyping the recipient’s e-mail address when sharing information with a client, vendor, or partner, one can unintentionally disclose information. A disgruntled employee can copy sensitive data onto an end-point device (such as portable hard drive or USB) and take it out of the network.
DLP prevents the loss of data by not allowing information that is classified and tagged as sensitive to be attached or copied. Tagging is the process of labeling information that is classified with its appropriate classification level. This can be an overwhelming endeavor to organizations that have a large amount of information that needs to be tagged, so tagging requires planning and strategy, along with management and business support. The business owner of the data is ultimately responsible and must be actively engaged either directly or by delegating a data custodian to work with the IT team, so that data are not only appropriately classified but also appropriately tagged. DLP brings both mandatory (labeling) and discretionary (based on discretion of the owner) security into effect.
Successful implementations of DLP bring not only technological protection but also the assurance that required human resource and process elements are in place. DLP technology works by monitoring the tagged data elements, detecting and preventing loss, and remediating should the data leave the network. Additionally, DLP technology protection includes protecting the gateway as well as the channel. DLP control is usually applied at the gateway, the point at which data can leave the network (escape point), at the next logical level from where data are stored. DLP also includes the protection of data when they are in transit and work in conjunction with TLS mechanisms by protecting the channel. It must be recognized that protecting against data loss by applying DLP technology can be thwarted if the users (people) are not aware of and educated about the mechanisms and the impact of sensitive data walking out of the door. DLP can also be implemented through a corporate security policy that mandates the shredding of sensitive documents, disallowing the printing of and storing of sensitive information in storage devices that can be taken out of the organization.
We have covered the ways by which DLP can protect the data that is on the inside from leaving the network, but in today’s world, there is a push toward the SaaS model of computing. In such situations, organizational data are stored on the outside in the service provider’s shared-hosted network. When this is the case, data protection includes preventing data leakage when data are at rest or stored, as well as when it is being marshaled to and from the SaaS provider. Cryptographic protection and access control protection mechanisms can be used to prevent data leakage in SaaS implementations. SaaS is a maturing trend, and it is recommended that when data are stored on the outside, proper Chinese Wall access control protection exist, based on the requestor’s authorized privileges, to avoid any conflict of interest. TLS protection alleviates data loss while the data are in motion between the organization and the SaaS provider.
3.12.10 Virtualization
Virtualization is a software technology that divides a physical resource (such as a server) into multiple virtual resources called virtual machine (VM). It abstracts computer resources and reproduces the physical characteristics and behavior of the resources. Virtualization facilitates the consolidation of physical resources while simplifying deployment and administration. Not only can physical resources (servers) be virtualized, but data storage, networks, and applications can be virtualized as well. When virtualization technology leverages a single physical server to run multiple operating systems, or multiple sessions of a single OS, it is commonly referred to as platform virtualization. Storage area networks (SANs) are an example of data storage virtualization.
Virtualization is gaining a lot of ground today and its adoption is expected to continue to rise in the coming years. Some of the popular and prevalent virtualization products are VMware, Microsoft Hyper-V, and Xen.
Benefits of virtualization include the following:
- Consolidation of physical (server) resources and thereby reduced cost
- Green computing; reduced power and cooling
- Deployment and administration ease
- Isolation of application, data, and platforms
- Increased agility to scale IT environment and services to the business
Though virtualization aims at reducing cost and improving agility, without proper consideration of security, these goals may not be realized, and the security of the overall computing ecosystem can be weakened. It is therefore imperative to determine the security and securability of virtualization before selecting virtualization products. On one hand, it can be argued that virtualization increases security because virtual machines are isolated from one another and dependent on a single host server, making it possible to address physical security breaches relatively simply when compared to having to manage multiple stand-alone servers. On the other hand, virtualization can be said to increase the attack surface because virtualization software known as the hypervisor as depicted in Figure 3.29, which controls and manages virtual machines and their access to host resources, is a software that could potentially have coding bugs and it runs with privileged access rights, making it susceptible to attack.
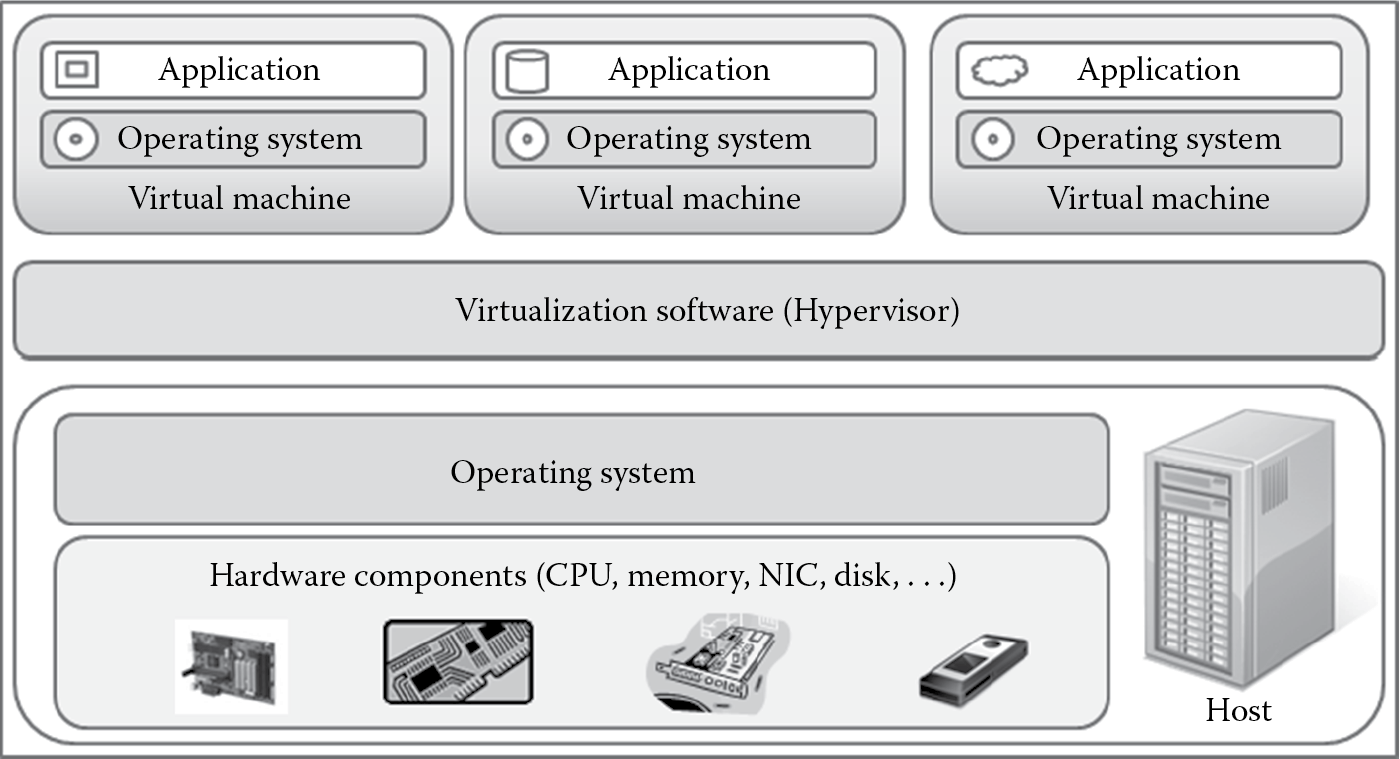
Other security concerns of virtualization that require attention include the need to
- Implement all of the security controls such as antivirus, system scans, and firewalls as one would in a physical environment.
- Protect not only the VM but also the VM images from being altered.
- Patch and manage all of the VM appliances.
- Ensure protection against jail-breaking out of a VM. It is speculated that it is possible to attack the hypervisor that controls the VMs and circumvent the isolation protection that virtualization brings. Once the hypervisor is compromised, one can jump from (jail-break out of) one VM to another.
- Inspect inter-VM traffic by IDS and IPS, which themselves can be VM instances.
- Implement defense-in-depth safeguard controls.
- Control VM sprawl. VM sprawl is the uncontrolled proliferation of multiple VM instances. It wastes resources and creates unmonitored servers that could contain sensitive data and makes troubleshooting and cleanup of unneeded servers extremely difficult.
Additionally, it is important to understand that technologies to manage VM security are still immature and currently in development. One such development is VM security API that makes it possible to help software development teams leverage security functionality and introspection ability within the virtualization products. However, performance considerations when using VM API need to be factored in.
3.12.11 Digital Rights Management
Have you ever experienced the situation when you chose to skip over the “FBI Anti-piracy Warning” screen that appears when you load a Region 1 DVD movie and found out that you were not allowed to do so, as illustrated in Figure 3.30? This is referred to as forward locking and is a liability protection measure against violators who cannot claim ignorance of the consequences of their violating act. In this case, it is about copyright infringement and antipiracy protection. Forward locking is one example of a protection mechanism’s using technology that is collectively known as DRM.

DRM refers to a broad range of technologies and standards that are aimed at protecting IP and content usage of digital works using technological controls. Copyright law (covered in detail in Chapter 6) is a deterrent control only against someone who wishes to make a copy of a protected file or resource (documents, music files, movies, etc.). It cannot prevent someone from making an illegal copy. This is why technology-based protection is necessary, and DRM helps in this endeavor. DRM is about protecting digital works, and it differs in its function from copyright law. Copyright law functions by permitting all that which is not forbidden. DRM conversely operates by forbidding all that which is not permitted.
DRM not only provides copy protection but can be configured granularly to provide usage rights and assure authenticity and integrity as well. This is particularly important when you have the need to share files with an external party over whom you have no control, such as a business partner or customer, but you still want to control the use of the files. DRM provides presentation layer (OSI layer 6) security not by preventing an unauthorized user from viewing the file but by preventing the receiving party from copying, printing, or sharing the file even though he may be allowed to open and view it. One of the most common ways in which file sharing is restricted is by tying the file to a unique hardware identifier or some hardware property that is not duplicated in other systems. This means that even though the file may be copied, it is still unusable in an unauthorized system or by a user who is not authorized. This type of protection mechanism is evident in music purchased from the iTunes store. Music purchased from the iTunes store is authorized to be used on one computer, and when it is copied over to another, it does not work unless proper authorization of the new computer is granted. DRM also assures content authenticity and integrity of a file, because it provides the ability to granularly control the use of a file.
The three core entities of a DRM architecture includes users, content, and rights. DRM implementation is made possible through the relationships that exist among these three core entities. Users can create and/or use content and are granted rights over the content. The user entity can be anyone: privileged or nonprivileged, employee or nonemployee, business partner, vendor, customer, etc. It need not be human, as a system can participate in a DRM implementation. The content entity refers to the protected resource, such as a music file, a document, or a movie. The rights entity expresses permissions, constraints, and obligations that the user entity has over the content entity. The expression of rights is made possible by formal language, known as Rights Expression Language (REL). Some examples of REL include the following:
- Open Digital Rights Language (ODRL): A generalized, open standard under development that expresses rights using XML.
- eXtensible rights Markup Language (XrML): Another generalized REL that is more abstract than ODRL. XrML is more of a metalanguage that can be used for developing other RELs.
- Publishing Requirements for Industry Standard Metadata (PRISM): Unlike ODRL and XrML, PRISM can be used to express rights specific to a task and is used for syndication of print media content such as newspapers and magazines. This is used primarily in a B2B setting where the business entities have a contractual relationship and the REL portion of PRISM is used to enforce copyright protection.
It must be recognized that an REL expresses rights, but it has no ability to enforce the rights. It is therefore critical for a software architect to design a protection mechanism, be it user-supplied data or hardware property, to restrict or grant usage rights. The entire DRM solution must be viewed from a security standpoint to ensure that there is no weak link that will circumvent the protection DRM provides.
Although DRM provides many benefits pertinent to IP protection, it does come with some challenges as well. Some of the common challenges are
- Using a hardware property as part of the expression of rights generally provides more security and is recommended. However, as the average life of hardware is not more than a couple of years, tying protection mechanisms to a hardware property can result in DoS when the hardware is replaced. Tying usage rights over content to a person alleviates this concern, but it is important to ensure that the individual’s identity cannot be spoofed.
- Using personal data to uniquely identify an individual as part of the DRM solution could lead to some privacy concerns. The Sony rootkit music CD is an example of improper design that caused the company to lose customer trust, suffer several class action lawsuits, and recall its products.
- DRM not only forbids illegal copying, but it restricts and forbids legal copying (legitimate backups) as well, thereby affecting fair use.
When you design DRM solutions, you need to take into consideration both its benefits and challenges and security considerations should be in the forefront.
3.13 Secure Design and Architecture Review
Once software design is complete, before you exit the design phase and enter the development phase, it is important to conduct a review of the software’s design and architecture. This is to ensure that the design meets the requirements. Not only should the application be reviewed for its functionality, but it should be reviewed for its security as well. This makes it possible to validate security design before code is written, thereby affording an opportunity to identify and fix any security vulnerabilities upfront, minimizing the need for reengineering at a later phase. The review should take into account the security policies and the target environment where the software will be deployed. Also, the review should be holistic in coverage, factoring in the network and host level protections that are to be in place so that safeguards do not contradict each other and minimize the protection they provide. Special attention should be given to the security design principles and security profile of the application to assure confidentiality, integrity, and availability of the data and of the software itself. Additionally, layer-by-layer analysis of the architecture should be performed so that defense in depth controls are in place.
3.14 Summary
The benefits of designing security into the software early are substantial and many. When you design software, security should be in forefront, and you should take into consideration secure design principles to assure confidentiality, integrity, and availability. Threat modeling is to be initiated and conducted during the design phase of the SDLC to determine entry and exit points that an attacker could use to compromise the software asset or the data it processes. Threat models are useful to identify and prioritize controls (safeguards) that can be designed, implemented (during the development phase), and deployed. Software architectures and technologies can be leveraged to augment security in software. Design reviews from a security perspective provide an opportunity to address security issues without its being too expensive. No software should enter the development phase of the SDLC until security aspects have been designed into it.
3.15 Review Questions
- During which phase of the software development lifecycle (SDLC) is threat modeling initiated?
A. Requirements analysis
B. Design
C. Implementation
D. Deployment
- Certificate authority, registration authority, and certificate revocation lists are all part of which of the following?
A. Advanced Encryption Standard (AES)
B. Steganography
C. Public Key Infrastructure (PKI)
D. Lightweight Directory Access Protocol (LDAP)
- The use of digital signatures has the benefit of providing which of the following that is not provided by symmetric key cryptographic design?
A. Speed of cryptographic operations
B. Confidentiality assurance
C. Key exchange
D. Nonrepudiation
- When passwords are stored in the database, the best defense against disclosure attacks can be accomplished using
A. Encryption
B. Masking
C. Hashing
D. Obfuscation
- Nicole is part of the “author” role as well as she is included in the “approver” role, allowing her to approve her own articles before it is posted on the company blog site. This violates the principle of
A. Least privilege
B. Least common mechanisms
C. Economy of mechanisms
D. Separation of duties
- The primary reason for designing single sign-on (SSO) capabilities is to
A. Increase the security of authentication mechanisms
B. Simplify user authentication
C. Have the ability to check each access request
D. Allow for interoperability between wireless and wired networks
- Database triggers are primarily useful for providing which of the following detective software assurance capability?
A. Availability
B. Authorization
C. Auditing
D. Archiving
- During a threat modeling exercise, the software architecture is reviewed to identify
A. Attackers
B. Business impact
C. Critical assets
D. Entry points
- A man-in-the-middle (MITM) attack is primarily an expression of which type of the following threats?
A. Spoofing
B. Tampering
C. Repudiation
D. Information disclosure
- IPSec technology, which helps in the secure transmission of information, operates in which layer of the Open Systems Interconnect (OSI) model?
A. Transport
B. Network
C. Session
D. Application
- When internal business functionality is abstracted into service-oriented contract based interfaces, it is primarily used to provide for
A. Interoperability
B. Authentication
C. Authorization
D. Installation ease
- At which layer of the OSI model must security controls be designed to effectively mitigate side channel attacks?
A. Transport
B. Network
C. Data link
D. Physical
- Which of the following software architectures is effective in distributing the load between the client and the server but because it includes the client to be part of the threat vectors it increases the attack surface?
A. Software as a Service (SaaS)
B. Service-oriented architecture (SOA)
C. Rich Internet application (RIA)
D. Distributed network architecture (DNA)
- When designing software to work in a mobile computing environment, the Trusted Platform Module (TPM) chip can be used to provide which of the following types of information?
A. Authorization
B. Identification
C. Archiving
D. Auditing
- When two or more trivial pieces of information are brought together with the aim of gleaning sensitive information, it is referred to as what type of attack?
A. Injection
B. Inference
C. Phishing
D. Polyinstantiation
- The inner workings and internal structure of backend databases can be protected from disclosure using
A. Triggers
B. Normalization
C. Views
D. Encryption
- Choose the best answer. Configurable settings for logging exceptions, auditing and credential management must be part of
A. Database views
B. Security management interfaces
C. Global files
D. Exception handling
- The token that is primarily used for authentication purposes in an SSO implementation between two different organizations is
A. Kerberos
B. Security Assert Markup Language (SAML)
C. Liberty alliance ID-FF
D. One time password (OTP)
- Syslog implementations require which additional security protection mechanisms to mitigate disclosure attacks?
A. Unique session identifier generation and exchange
B. Transport layer security
C. Digital Rights Management (DRM)
D. Data loss prevention (DLP)
- Rights and privileges for a file can be granularly granted to each client using which of the following technologies?
A. Data loss prevention (DLP)
B. Software as a Service
C. Flow control
D. Digital Rights Management
References
Adams, G. 2008. 21st Century mainframe data security: An exercise in balancing business priorities. http://www.mainframezone.com/mainframe-executive/september-october-2008 (accessed Sept. 30, 2010).
Booth, D., H. Haas, F. McCabe, E. Newcomer, M. Champion, C. Ferris, and D. Orchard. 2004. Service oriented architecture. http://www.w3.org/TR/ws-arch/#service_oriented_architecture (accessed Sept. 30, 2010).
Cochran, M. 2008. Writing better code—Keepin’ it cohesive. http://www.c-sharpcorner.com/uploadfile/rmcochran/csharpcohesion02142008092055am/csharpcohesion.aspx (accessed Sept. 30, 2010).
Coyle, K. 2003. The technology of rights: Digital rights management. http://www.kcoyle.net/drm_basics.pdf (accessed Sept. 30, 2010).
Exforsys, Inc. 2007. NET type safety. http://www.exforsys.com/tutorials/csharp/.-net-type-safety.html (accessed Sept. 30, 2010).
Fei, F. 2007. Managed code vs. unmanaged code? http://social.msdn.microsoft.com/Forums/en-US/csharpgeneral/thread/a3e28547-4791-4394-b450-29c82cd70f70/ (accessed Sept. 30, 2010).
Fogarty Wed, K. 2009. Server virtualization: Top five security concerns. http://www.cio.com/article/492605/Server_Virtualization_Top_Five_Security_Concerns (accessed Sept. 30, 2010).
Grossman, J. 2007. Seven business logic flaws that put your Website at risk. Whitepaper. http://www.whitehatsec.com/home/resource/whitepapers/business_logic_flaws.html (accessed Sept. 30, 2010).
Hitachi ID Systems, Inc. Defining identity management. Whitepaper. http://identity-manager.hitachi-id.com/docs/identity-management-defined.html (accessed Sept. 30, 2010).
Housley, R., W. Polk, W. Ford, and D. Solo. 2002. Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. Report IETF RFC 3280. http://www.ietf.org/rfc/rfc3280.txt (accessed Sept. 30, 2010).
International Telecommunication Union. 2006. Security in telecommunications and information technology. http://www.itu.int/publ/T-HDB-SEC.03-2006/en (accessed Sept. 30, 2010).
Kaushik, N. 2008. Virtual directories + provisioning = No more metadirectory. http://blog.talkingidentity.com/2008/03/virtual_directories_provisioni.html (accessed Sept. 30, 2010).
Kent, K., and M. Souppaya. 2006. Guide to computer security log management. Special Publication 800-92 (SP 800-92), National Institute of Standards and Technology (NIST). http://csrc.nist.gov/publications/nistpubs/800-92/SP800-92.pdf (accessed Sept. 30, 2010).
Kohno, T., A. Stubblefield, A. D. Rubin, and D. S. Wallach. 2004. Analysis of an electronic voting system. IEEE Symposium on Security and Privacy 2004: 27–40.
LaPorte, P. 2009. Emerging market: Data loss prevention gets SaaS-y. ECommerce Times. http://www.ecommercetimes.com/rsstory/66562.html (accessed Sept. 30, 2010).
Microsoft, Inc. n.d. Extended validation certificates—FAQ. http://www.microsoft.com/windows/products/winfamily/ie/ev/faq.mspx (accessed Sept. 30, 2010).
Microsoft, Inc. 2003. Logon and authentication technologies. http://technet.microsoft.com/en-us/library/cc780455(WS.10).aspx (accessed Sept. 30, 2010).
Microsoft, Inc. 2007. Description of the database normalization basics. http://support.microsoft.com/kb/283878 (accessed Sept. 30, 2010).
Microsoft, Inc. 2009. A safer online experience. Whitepaper. http://download.microsoft.com/download/D/5/6/D562FBD1-B072-47F9-8522-AF2B8F786015/A%20Safer%20Online%20Experience%20FINAL.pdf (accessed Sept. 30, 2010).
Microsoft Solutions Developer Network (MSDN). n.d. Managing trigger security. http://msdn.microsoft.com/en-us/library/ms191134.aspx (accessed Sept. 30, 2010).
Messmer, E. 2009. Virtualization security remains a work in progress. http://www.networkworld.com/news/2009/122209-outlook-virtualization-security.html (accessed Sept. 30, 2010).
National Institute of Standards and Technology (NIST). n.d. Pervasive computing. http://www.itl.nist.gov/pervasivecomputing.html (accessed Sept. 30, 2010).
Newman, R C. 2010. Computer Security: Protecting Digital Resources. Sudbury, MA: Jones and Bartlett Learning.
O’Neill, D. 1980. The management of software engineering. Parts I–V. IBM Systems Journal 19(4): 414–77.
Oracle, Inc. n.d., a. Triggers. 11g Release 1 (11.1). http://download.oracle.com/docs/cd/B28359_01/server.111/b28318/triggers.htm#CNCPT118 (accessed Sept. 30, 2010).
Oracle, Inc. n.d., b. Views. 11g Release 1 (11.1). Schema Objects. http://download.oracle.com/docs/cd/B28359_01/server.111/b28318/schema.htm#CNCPT311>. (accessed Sept. 30, 2010).
Pettey, C. 2007. Organizations that rush to adopt virtualization can weaken security. http://www.gartner.com/it/page.jsp?id=503192 (accessed Sept. 30, 2010).
Phelps, J. R., and M. Chuba. 2005. IBM targets security issues with its new mainframe. Gartner 2005: 1–3.
Reed, D. 2003. Applying the OSI seven layer network model to information security. Whitepaper. SANS Institute InfoSec Reading Room 1–31. http://www.sans.org/reading_room/whitepapers/protocols/applying-osi-layer-network-model-information-security_1309 (accessed Nov. 29, 2010).
RSA Security, Inc. 2002. Securing data at rest: Developing a database encryption strategy. http://www.rsa.com/products/bsafe/whitepapers/DDES_WP_0702.pdf (accessed Sept. 30, 2010).
Singhal, A., T. Winograd, and K. Scarfone. 2007. Guide to secure Web services. National Institute of Standards and Technology Special Publication SP-800-95.
Stanford, V. 2002. Pervasive health care applications face tough security challenges. IEEE Pervasive Computing 1(2): 8–12.
Stephens, R. K., R. R. Plew, and A. Jones. 2008. The normalization process. In Sams Teach Yourself SQL in 24 Hours, 4th ed., 61–71. Indianapolis, IN: Sams.
Stoneburner, G., C. Hayden, and A. Feringa. 2004. Engineering principles for information technology security (A baseline for achieving security). National Institute of Standards and Technology Special Publication SP-800-27: sect. 3.3 (accessed September 30, 2010).
Sun Microsystems, Inc. 2004. Identity management: Technology cornerstone of the virtual enterprise. White Paper. http://www.sun.com/software/products/identity/wp_virtual_enterprise.pdf (accessed Sept. 30, 2010).
Sun Microsystems, Inc. 2007. Federation, SAML, and Web Services. Sun Java System Access Manager 7.1 Technical Overview, chap. 5. http://docs.sun.com/app/docs/doc/819-4669/ (accessed Sept. 30, 2010).
Syslog.org. n.d. Syslog. http://www.syslog.org/ (accessed Sept. 30, 2010).
Tomhave, B. 2008. Key management: The key to encryption. EDPACS: The EDP Audit, Control, and Security Newsletter 38(4): 12–19.
Williams, J. 2008. The trinity of RIA security explained of servers, data and policies. http://www.theregister.co.uk/2008/04/08/ria_security/ (accessed Sept. 30, 2010).
Zeldovich, N. 2007. Securing untrustworthy software using information flow control. Doctoral thesis. Stanford University, Stanford, CA. http://www.scs.stanford.edu/~nickolai/papers/zeldovich-thesis-phd.pdf (accessed Sept. 30, 2010).