
Chapter 4
Getting Ready for Designing the Architecture
4.1 Introduction
The previous chapters focused on obtaining a good set of requirements that clearly establish the business need for the system under consideration and the qualities and functional capabilities this system must have to fulfill this need within the confines of a given a set of constraints. Of these requirements, the quality attribute scenarios developed from the business goals or mission objectives play the most significant role in the development of the architecture. However, operational scenarios for functional capabilities and the constraints may also have implied quality concerns that can have an impact on the architecture of a system and should be taken into account as well. We call all such requirements (quality attribute requirements and functional capabilities and constraints with implied quality concerns) that influence the architecture architecturally significant requirements (ASRs).
Although one may wish to take into consideration all ASRs when designing the architecture, these requirements typically conflict with each other and create complex trade-off situations that require an architect to look for a design that can try to achieve some balance among the opposing forces. For instance, when designing an architecture that makes the system modular for ease of making a change, one may introduce layers of indirection so that many modules may have to interact with each other to perform a given function. These interactions may therefore introduce latency that has an impact on how quickly the function can be performed. Thus, the two qualities (modifiability for ease of change and performance for quick response time) conflict with each other, and the balance may lie in finding the happy middle ground where the architect trades ease of making a change to achieve a faster response time.
Because of the conflicting nature of the ASRs leading to complex trade-off situations, it is preferred only to consider the most important of these requirements, which should be only a handful. The prioritized set of half a dozen or so ASRs is often referred to as the architecture drivers.
4.2 Architectural Drivers
From the product features (functional capabilities), quality attribute scenarios, and constraints detailed in the previous chapters, a list of significant architectural drivers for the building automation system is distilled. A prioritized list of such drivers for the building automation system is shown in Table 4.1. The priorities are shown as tuples, which are described further in the text.
Architectural Drivers for the Building Automation System Along with Their Sources and Their Priority
|
No. |
Architectural Driver |
Source |
Priority |
|
1 |
Support for adding new field device |
|
(H, H) |
|
2 |
International language support |
|
(M, M) |
|
3 |
Nonstandard unit support |
|
(H, M) |
|
4 |
Latency of alarm propagation |
|
(H, H) |
|
5 |
Load conditions |
|
(H, H) |
Note: H, high; L, low; M, medium.
Architectural drivers 1 through 5 relate to the quality attribute scenarios enumerated in Table 2.6 in Chapter 2. Architectural drivers 1 and 3 also correspond to the device management and dynamic reconfiguration, 2 to the internationalization and localization, and 4 to event management and alarm management product features shown in Figure 3.4 in Chapter 3. In addition, architectural drivers 1, 3, and 5 address the product variability constraint from Table 3.4 in Chapter 3.
You should note that although quality attribute scenarios are obviously significant architectural drivers, product features and constraints can also have implied quality concerns. It is therefore important to take these into account as well. That is precisely what we have done when coming up with the list of architectural drivers in Table 4.1.
Prioritizing of the architectural drivers is done by soliciting input from both the business and the technical stakeholders. The business stakeholders prioritize drivers based on their business value (H for high implies a system lacking that capability will not sell, M for medium implies a system lacking that capability will not be competitive, L for low implies something nice to have), whereas the technical stakeholders do so based on how difficult it would be to address a driver during the system design (H for high implies a driver that has a systemwide impact, M for medium implies a driver that has an impact on a significant part of the system, L for low implies a driver whose impact is fairly local and therefore not architecturally significant), resulting in nine different combinations in the following order of precedence: HH, HM, HL, MH, MM, ML, LH, LM, and LL.
Architectural drivers are a prioritized set of most significant architectural requirements derived predominantly from quality attribute scenarios as well as product features and constraints that have implied quality concerns.
4.3 Patterns
Once a prioritized set of architectural drivers is established, the architecture design can begin. But, how do we proceed? The building automation system, introduced in the previous lessons, has a modifiability quality attribute requirement—a need to integrate hardware devices from many different manufacturers. More concretely, the requirement cast as a quality attribute scenario states “a field engineer should be able to integrate a new hardware device into the system at runtime and the system should continue to operate with no downtime or side effects.” How do we achieve this requirement?
One approach is to look for other systems that may address a similar problem. For instance, operating systems experience a high degree of variability in dealing with the underlying hardware devices on the machine that run them. How do you think this variability is handled?
Operating systems use a hierarchical layered structure in which each layer presents an abstract (virtual) machine to the layer above as shown in Figure 4.1. In this figure, a client of the operating system interacts with a layer at the highest level of abstraction, and the lower-level layers manage the variability in the underlying hardware. Higher-level layers are allowed to use the services of an adjacent lower-level layer but not the other way around.
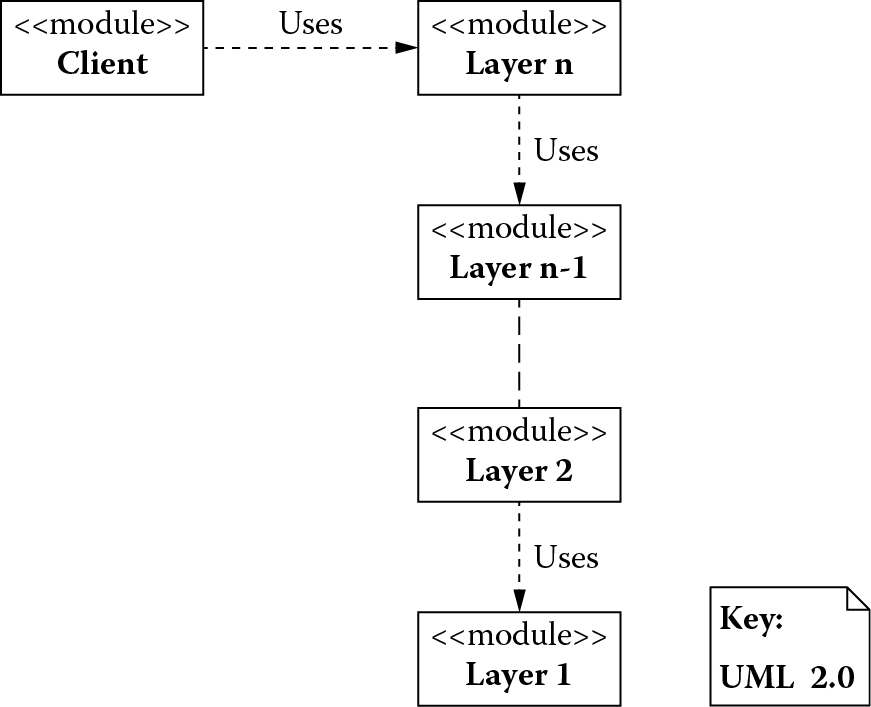
Figure 4.2 shows a typical scenario in which a client makes a request to view a file to the operating system, which in turn asks the file manager to read the file from the disk. The file manager uses the appropriate disk driver to read the disk.
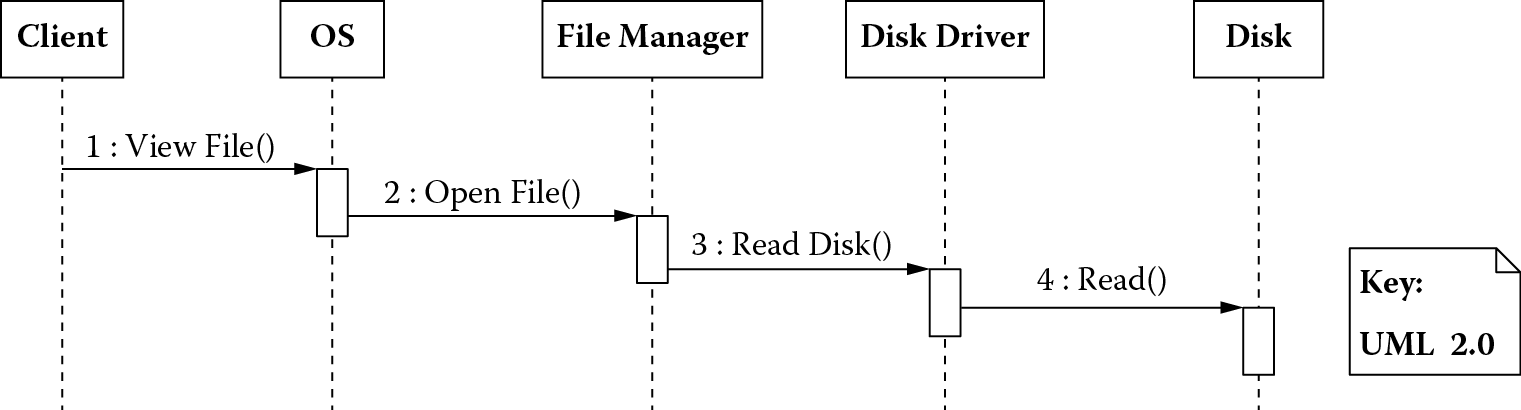
In this scenario, the disk driver directly interfaces with a physical disk, thereby abstracting away from the file manager the details of the protocol to follow when communicating with the physical disk. The file manager uses an appropriate disk driver to communicate with a physical disk, thereby abstracting away from the operating system the details of how requests are routed to and responses received from (possibly) a multitude of disk drives. Insofar as the operating system is concerned, there is a single (virtual) disk. The operating system abstracts away from the client how the underlying hardware disks are being managed.
The modifiability problem in the building automation system is similar to the scenario presented in the context of an operating system. Therefore, the provided solution can be adapted to resolving the modifiability problem as well. The example demonstrates that there can be a recurring problem that arises in a given context that can be resolved using a well-proven solution to the problem. That is, in the given example, the problem in the operating system domain also recurs in the building automation domain and is, therefore, resolved using a well-proven hierarchical layering structure or layers pattern.
A pattern therefore presents a well-proven solution to a recurring design problem that arises in specific design contexts. The structures designed by architects of software systems are often based on one or more patterns. Although there are numerous sources of architectural patterns (for software-intensive systems, see multivolume series on pattern-oriented software architecture: Buschmann et al., 1996, 2007a, 2007b; Schmidt et al., 2000; Kircher and Jain, 2004), the following sections show some classical architectural patterns used in software-intensive systems based on a classification suggested by Avgeriou and Zdun (2005). This classification is based on the predominant perspective or view an architect has of the system under design. A number of examples used for illustrating these patterns are taken from Duell et al. (1997).
A pattern is a proven solution to a recurring design problem that arises in specific design contexts.
4.3.1 Layered View
In a layered view, a system is seen as a complex heterogeneous entity that needs to be decomposed into its interacting parts. Patterns under this view deal with how these parts interact with each other while remaining as decoupled from each other as possible. Figure 4.3 shows patterns based on this perspective.
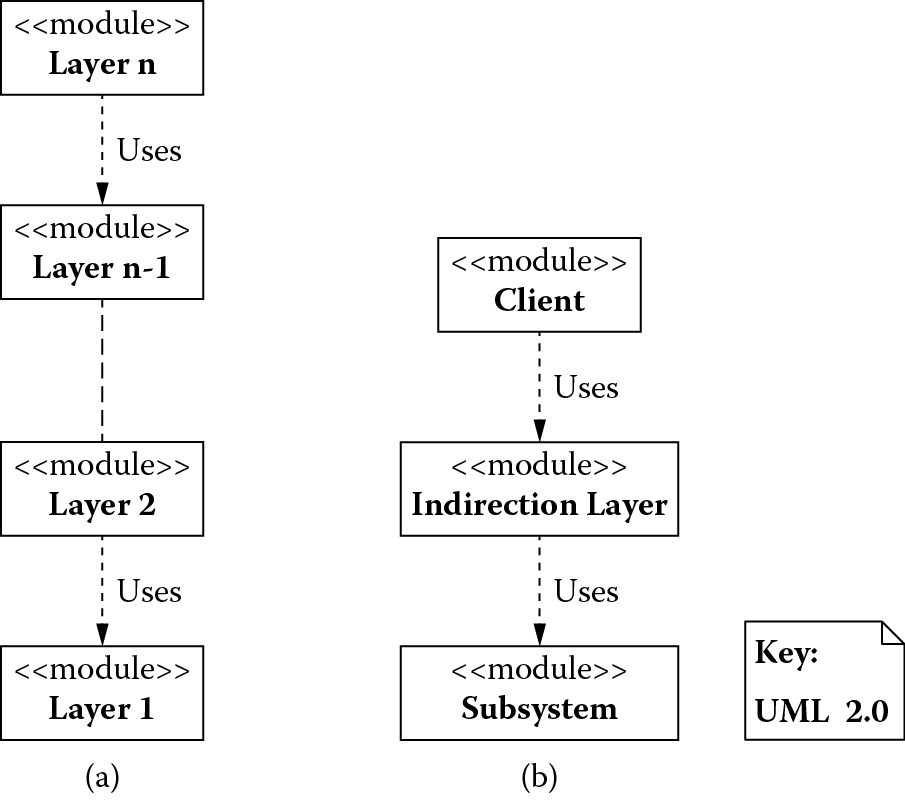
The layer pattern in Figure 4.3 decomposes a system into multiple layers of abstraction in which each layer provides a set of services to the layer above and uses the services of the layer below. A higher layer is only allowed to use an adjacent layer immediately below; bypassing a layer is not permitted. This pattern promotes modifiability, portability, and reusability in a system. Modifiability is improved because changes can be localized to a given layer, and the layer can further prevent these changes from propagating to other parts of a system by providing its services to higher layers via a standard stable interface. Portability is improved because, to deploy the system on multiple different platforms, only the platform-specific layers need to be modified. If layers represent different levels of abstraction, a subset of lower-level layers could serve as a foundational platform and be reused for developing a variable set of higher-level layers or vice versa.
The indirection layer pattern shown in Figure 4.3 introduces a layer in a system to hide a component or subsystem providing access to its services indirectly to a client of that component or subsystem. This may be necessary when a client needs to communicate with a legacy subsystem (perhaps written in a different language and running on a different platform) without becoming coupled to its implementation details.
Layering is widely used in operating systems, communication systems, and information assurance. An interesting use of layering in operating systems is to separate the most essential functions from nonessential ones. The essential functions are implemented in a layer called the kernel, and the nonessential functions are implemented in higher-level layers that use the kernel. The advantage of this separation is that the kernel ends up being fairly small and can be designed to be highly reliable. The nonessential functions outside the kernel run with only user privileges, thus preventing undesirable effects when they fail. The system is also more secure because user privileges prevent nonessential functions from accessing more privileged operations/resources that could potentially compromise the system.
Communication systems use the Open System Interconnection (OSI) model (International Organization for Standardization/International Electrotechnical Commission [ISO/IEC] 7498-1), which is a seven-layer abstraction model that standardizes how systems communicate with each other. The lowest-level physical layer is concerned with the specification of the physical transmission medium (cable, hubs, repeaters, adapters, etc.). The data link layer uses the physical layer for transmitting data between two communicating points on a network. The network layer uses the data link, breaking the data into variable-length sequences called datagrams and using multiple routes to deliver them to their destination. The transport layer utilizes the network layer, chunking data into packets and ensuring reliable delivery of these packets to their destination. The session layer controls the connections between two communicating points on a network. Finally, the presentation layer handles any differences in the syntax and semantics of data that the network delivers and what an end-user application (the application layer) at the destination accepts.
Defense in depth, conceived by the National Security Agency (NSA), is an information assurance pattern that uses multiple layers of security in a system such that a breach of security in any one layer can be detected and prevented by subsequent layers from cascading to other (more critical) parts of the system.
4.3.2 Data Flow View
In a data flow view, a system is seen as one that transforms streams of data. Patterns under this view describe how streams of data can be successively processed or transformed by components that are independent of one another. Figure 4.4 shows patterns based on this perspective.
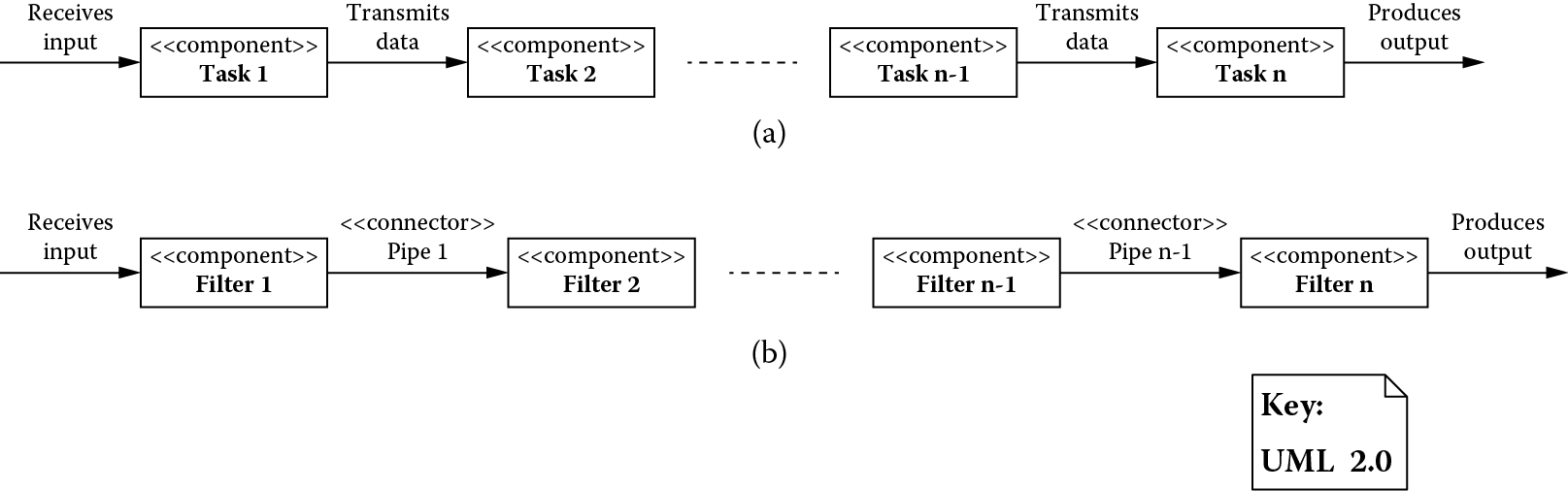
Architectural patterns based on a data flow view: (a) batch sequential and (b) pipes and filters.
Figure 4.4 shows the batch sequential pattern by which a system performs a task using a series of components with each component representing some step in the sequence of the whole task. During each step in the sequence, a batch of data input for the task is processed and sent as a whole to the next step. Figure 4.4 shows the pipes-and-filters pattern, which is similar to batch sequential except a processing component is called a filter and adjacent filters communicate with each other via connectors called pipes. Filters and pipes can be flexibly composed as adjacent filters do not have to know about each other. Filters process data incrementally, and pipes act as data buffers, creating a potential for filters to work in parallel; a filter can start placing its output incrementally on a pipe, and a filter waiting for this data can start processing as soon as the first increment arrives.
Financial applications use a wide variety of data formats, including Interactive Financial Exchange (IFX), Open Financial Exchange (PFX), and Electronic Data Interchange (EDI). When integrating these applications, the data in one format may need to be transformed into another format. Filters can be designed to take one of the data formats as inputs and transform it into the desired format. These filters can then be flexibly combined to achieve the desired data flow.
Water treatment plants illustrate the use of pipes and filters; water pipes play a role similar to data pipes, and various stages of treating water (removing sediment, adding chlorine, adding fluoride, etc.) correspond to filters. These filters can be changed or combined in any order, and new filters can be added. For instance, a homeowner may feed the water to a refrigerator, which may filter chemicals and cool the water for drinking.
4.3.3 Data-Centered View
In a data-centered view, a system is seen as a persistent shared data store accessed and modified by a number of components. Patterns under this view describe how a data store is accessed by multiple components. Figure 4.5 shows patterns based on this perspective.
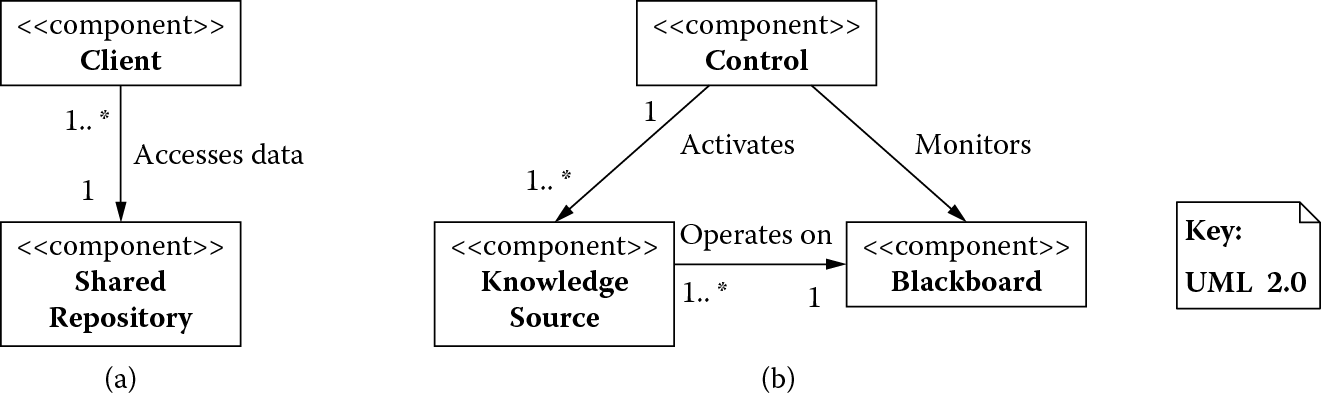
Architectural patterns based on a data-centered view: (a) shared repository and (b) blackboard.
Figure 4.5 shows the shared repository pattern in which one component of the system acts as a central shared data repository accessed by other independent components. A shared repository must handle issues associated with resource contention. A shared repository may be a passive data store or it may be active, maintaining a registry of clients and notifying them of specific events (such as data created, updated, or deleted) in the repository when they happen.
Figure 4.5 shows a blackboard, which breaks a complex problem for which no deterministic solution exists into smaller subproblems that can be deterministically solved by expert knowledge sources. The results of these knowledge sources are used in a heuristic computation to incrementally arrive at a solution for the complex problem. A blackboard serves as a shared repository for these knowledge sources, which use it to post results of their computation and also periodically access it to see if new inputs are presented for further processing. A control component monitors and coordinates access to the blackboard by these knowledge sources.
The blackboard pattern has been used in diverse domains, such as image and speech recognition, cryptanalysis and surveillance. For a speech recognition system, the input is speech recorded in waveform, and the output is English (or any other language) sentences. This transformation involves linguistic, acoustic, phonetic, and statistical expertise that can successfully convert acoustic waveforms into phonemes, syllables, words, phrases, and finally sentences.
Cryptanalysis leverages multiple sources, such as codebooks, translators, and traffic analysis for decrypting a coded message. The input comes in as encrypted message that is incrementally transformed by these sources into a decrypted message in English or any other desired language.
The military uses input from multiple sources, such as radar, infrared detectors, global positioning systems, communication, and electronic intelligence, for their surveillance systems. A surveillance system collects data from these diverse sources, fusing together and analyzing it for assessing a given situation.
Criminal investigations also involve a kind of blackboard pattern in which the lead detectives may use a blackboard (literally) to post forensic evidence, ballistic reports, crime scene data, and so on. They use different experts (forensic, ballistic, etc.) to piece together these data to solve the crime.
4.3.4 Adaptation View
In an adaptation view, a system is seen as a core part that is stable and an adaptable part that changes over time or in different versions of the system. Patterns under this view deal with how the system adapts itself during its evolution. Figure 4.6 shows patterns based on this perspective.
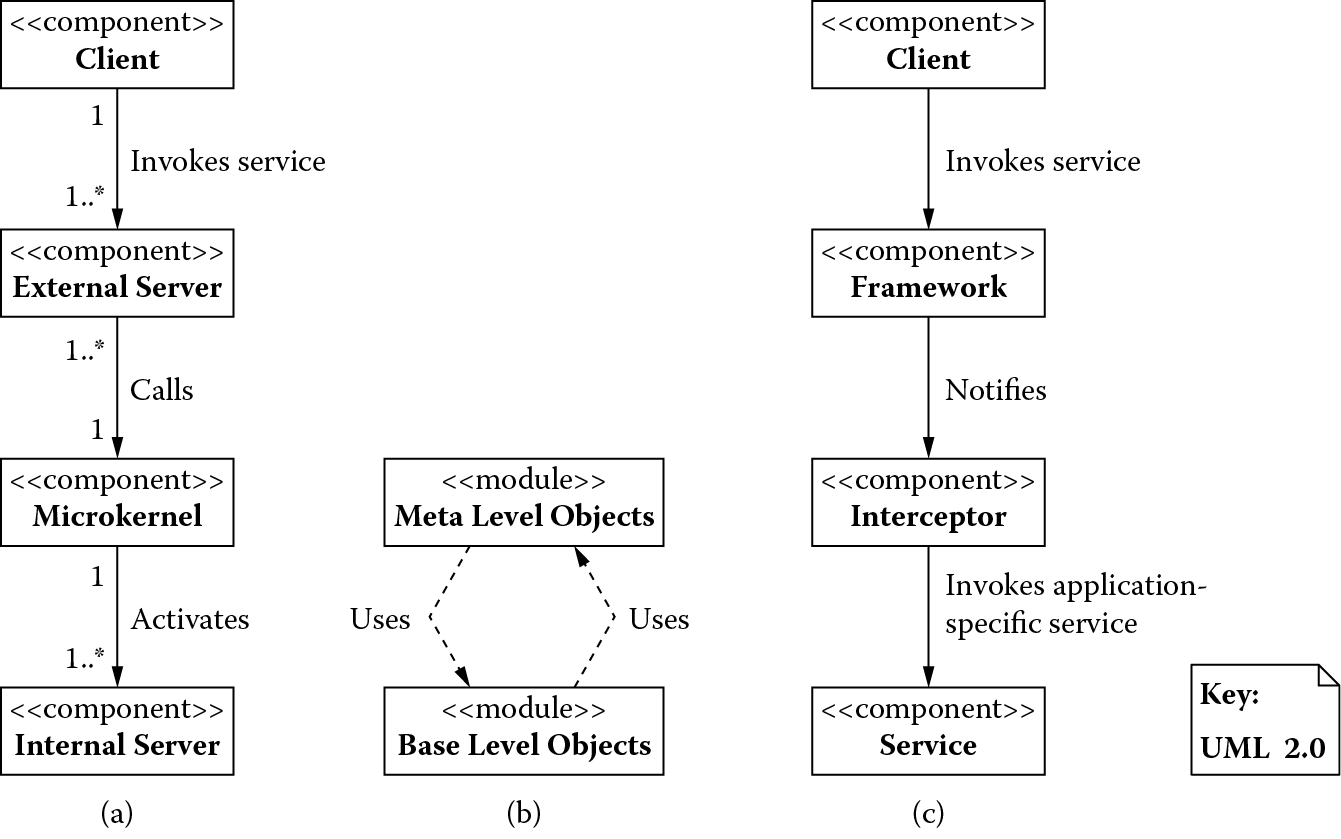
Architectural patterns based on an adaptation view: (a) microkernel, (b) reflection, and (c) interceptor.
Figure 4.6 shows the microkernel pattern in which the system is structured as internal servers and external servers. Clients access the microkernel only through external servers. The internal servers are hidden from the clients and can be adapted to realize parts that need adaptation. In a gaming system, the gaming console serves as a microkernel, and the game cartridges or cards are the internal servers. The input devices of the gaming console, such as buttons, joystick, and the like, serve as external servers through which the player (client) interacts.
Figure 4.6 shows the reflection pattern in which aspects of the system (structural or behavioral) that can change at any point in time are stored in meta-level objects. The base-level objects can query the meta-level objects to obtain this structural or behavioral information to execute the functionality they need. When viewing the legislative branch of the US government, the Constitution serves as a meta-level object, and the Congress is the base-level object. The Congress conducts itself according to the information contained in the Constitution, and the Constitution provides the mechanism for changing the (structure and behavior of) the Congress. Meta-level objects may also query the base-level objects and execute functionality based on their state. For instance, which rule of the Constitution applies depends on what state the Congress is in. In the event of a deadlock in the Senate, the vice president casts a vote to break the deadlock.
Figure 4.6 shows the interceptor pattern; a system is structured as a framework and a client that can extend this framework. The framework provides a client services that may change over time or with the needs of the client. A client can register with the framework, an interceptor that can intercept incoming events from the client and reroute them to the intended receiver, such as a client-specific version of a service. This way, a client can transparently update services provided by a framework and access them via the interceptors. An example of this pattern can be experienced with how the US Post Office delivers mail. A customer (client) can instruct the post office (framework) to stop the mail delivery (service) for a predetermined length of time. A postal worker (interceptor) can intercept the mail intended for the customer and hold the mail (modified service) for the instructed length of time.
4.3.5 Language Extension View
A system is viewed as a part that is native to its environment and another part that is not. Patterns under this view offer an abstraction layer to the system that translates the nonnative part into the native environment. Figure 4.7 shows patterns based on this perspective.
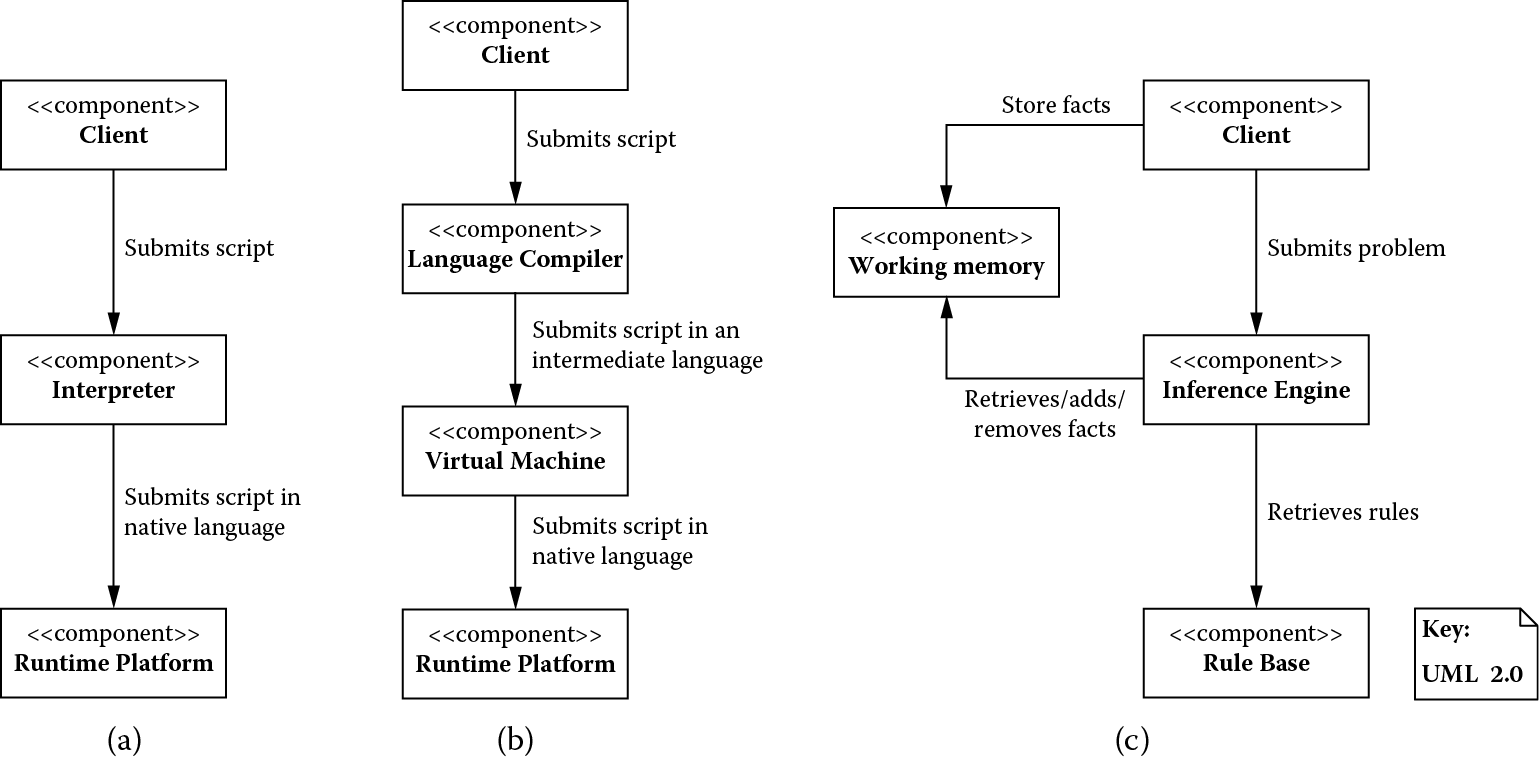
Architectural patterns based on a language extension view: (a) interpreter, (b) virtual machine, and (c) rule-based system.
Figure 4.7 is the interpreter pattern where the nonnative part of a system may be in the form of scripts or a language which is an interpreter translates into a language native to a given runtime platform or execution environment. For instance, the United Nations may draft a resolution in English that the interpreters may translate into various languages native to the dignitaries or representatives from various participating nations.
Figure 4.7 is a variation of the interpreter pattern; the virtual machine in this variation defines a simple architecture on which an intermediate form of a language can be executed. The translation of an original script (in a language not native to the system) to an intermediate language is handled by a language compiler. The virtual machine itself can then translate the intermediate language into a language native to a given runtime platform or execution environment.
Figure 4.7 shows a rule-based system used for expressing logical problems in a system and consists of facts and rules and an engine that acts on them. Facts are stored in a working memory and condition-action rules in a rule base. A client may wish to know if a fact is implied by the existing rule base and already known facts or if any new facts can be derived from the existing rule base and already known facts. It submits this query (or problem) to an inference engine. The inference engine collects rules whose conditions match facts in the working memory and performs actions indicated by the rules. The actions involve adding new facts to or deleting existing facts from the working memory. The inference engine continues to do this until the problem is solved. This pattern is widely used in expert systems.
4.3.6 User Interaction View
In a user interaction view, a system is seen as a part that represents a user interface and a part that represents system logic associated with that interface. Patterns under this view deal with decoupling the user interface from the system logic. Figure 4.8 shows patterns based on this perspective.
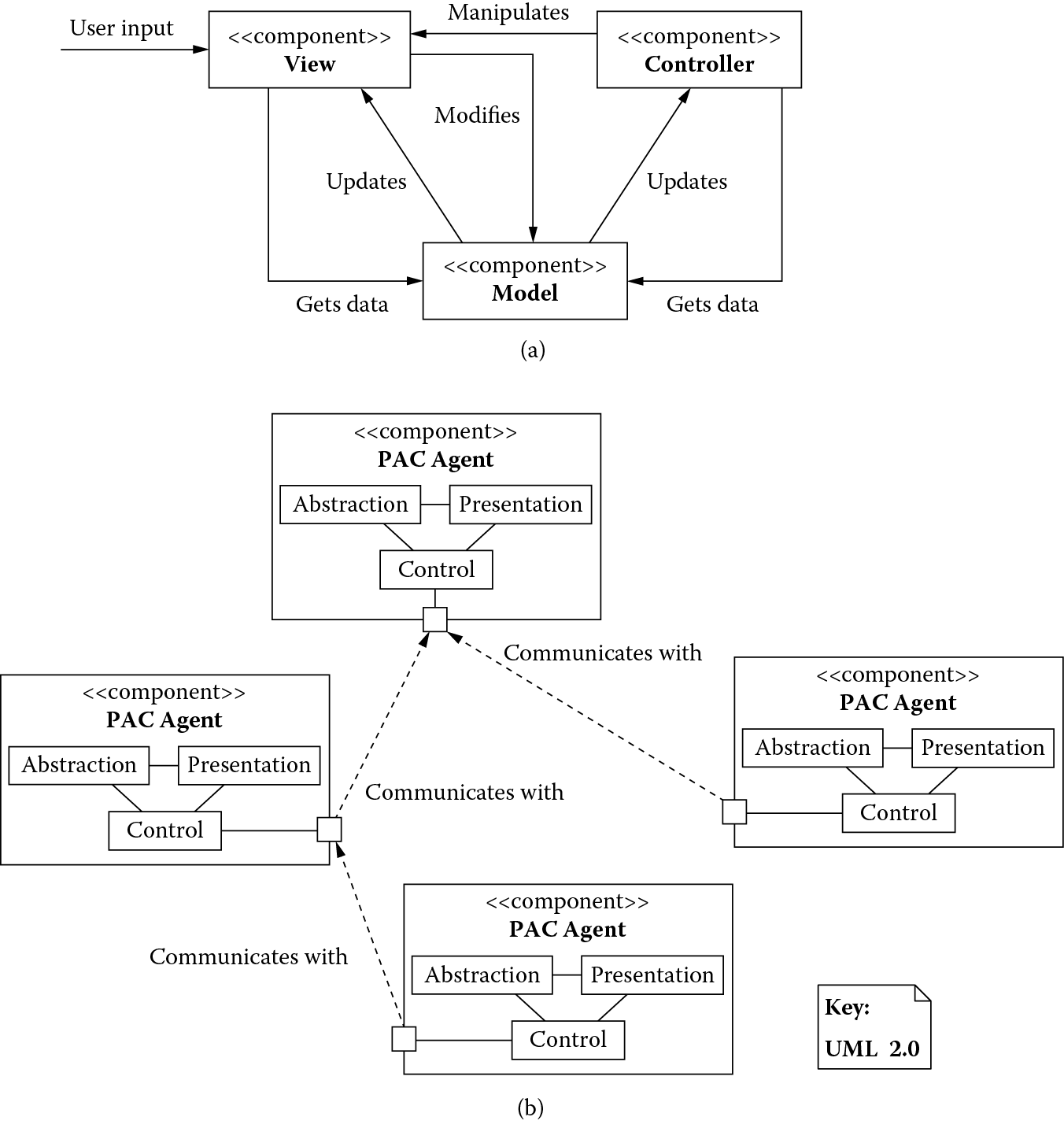
Architectural patterns based on a user interaction view: (a) model-view-controller and (b) presentation-abstraction-control.
Figure 4.8 shows the model-view-controller pattern in which the system offers multiple user interfaces. It is structured as a model that encapsulates its data along with the associated logic, one or more views that display portions of this data, and a controller associated with each view that translates any request from the view to a request for the model. View and controller together constitute a user interface. The users interact strictly through the user interface, and the model in turn notifies all its associated user interfaces so they accurately reflect all of its updates. An example of this pattern can be seen in an election year. National polls keep tally of vote counts (model) from different regions and display the total results (view) that reflect how each party is faring in the election. Whenever the vote tally (model) changes, the total results (view) are immediately updated to reflect that change.
Figure 4.8 shows the presentation-abstraction-control (PAC) pattern in which a system is structured as a hierarchy of multiple cooperating PAC agents that offer multiple diverse functionalities, each with its own user interface. These functionalities, however, need to communicate with each other. The system is therefore structured like a tree of agents: Leaf-level node agents represent the diverse functionalities, middle-level node agents combine the functionalities of the lower-level agents, and the top-level node agent orchestrates the middle-level node agents to offer their collective functionality. Each agent is structured as a presentation part that represents the user interface, the abstraction part that represents its data along with the associated logic, and the control part that mediates between the two and the controls of all other agents. In the election scenario, votes may be tallied by voting districts, states, and the nation as a whole. In this case, the leaf-level agents would correspond to the voting districts that tally the votes and display results of the local government elections. They, however, communicate with their respective states (middle-level agents), which aggregate votes for state representatives and display the results for the state. The states in turn communicate to the nation as a whole (top-level agent), with votes aggregated and displayed for the national government. Thus, details can be viewed at each level.
4.3.7 Component Interaction View
In the component interaction view, a system is viewed as a collection of independent components that interact with each other in the context of the system. Patterns under this view focus on how individual components exchange messages while retaining their autonomy. Figure 4.9 shows patterns based on this perspective.

Architectural patterns based on a component interaction view: (a) explicit invocation and (b) implicit invocation.
Figure 4.9 shows the explicit invocation pattern; a client component explicitly invokes the services of a server component either synchronously or asynchronously. The client must know about the location of the server, the name of the service being invoked, and its parameters. The client-server pattern is a variant of explicit invocation, by which the server needs to scale because of requests coming from multiple clients. Together, the clients and server must implement tasks such as session, security, and transaction management. As an example, customers (clients) can call in to a department store (server) to order products. They need to know the 800 number (location) to call; the product and the department from which it is to be ordered (service); and the details of the product and their shipping and billing information (parameters). The department store needs to understand how many client calls are to be handled on a given day (scalability needs) and provide enough associates to take these calls. The store must ensure the security of the transaction and guarantee the handling of the transaction (order fulfillment and shipping) or no money will be charged to the clients.
Another variant of explicit invocation is the peer-to-peer pattern in which there is no distinction between client and server components. They can serve both roles and request services of each other. For example, in peer-to-peer marketplaces, people can purchase goods from others offering them for sale. Those who sell these goods can in turn purchase items offered for sale by the very people who bought from them. So, anyone can play a role of a client or a server in this scenario.
In the implicit invocation pattern, a client component implicitly invokes the services of a server component. The client and server are decoupled because the invocation happens indirectly. Figure 4.9 shows the publish-subscribe pattern, which is a variant of implicit invocation; in this variant, clients (event consumers) subscribe to specific events, and servers (event producers) publish specific events. The publishing of an event triggers a callback mechanism that notifies the subscribers or consumers of that event. Auctioning is a good example of this pattern. An auctioneer (event manager) broadcasts, from a current bidder (publisher), the bid for an item being auctioned to the other bidders (subscribers). If one of the bidders accepts this bid, then he or she becomes the current bidder (publisher) and the auctioneer (event manager) publishes his or her new bid to the other bidders (subscribers).
4.3.8 Distribution View
A system is viewed as a collection of components that are distributed among different network nodes or processes. Patterns under this view deal with interactions among distributed components. Figure 4.10 shows patterns based on this perspective.
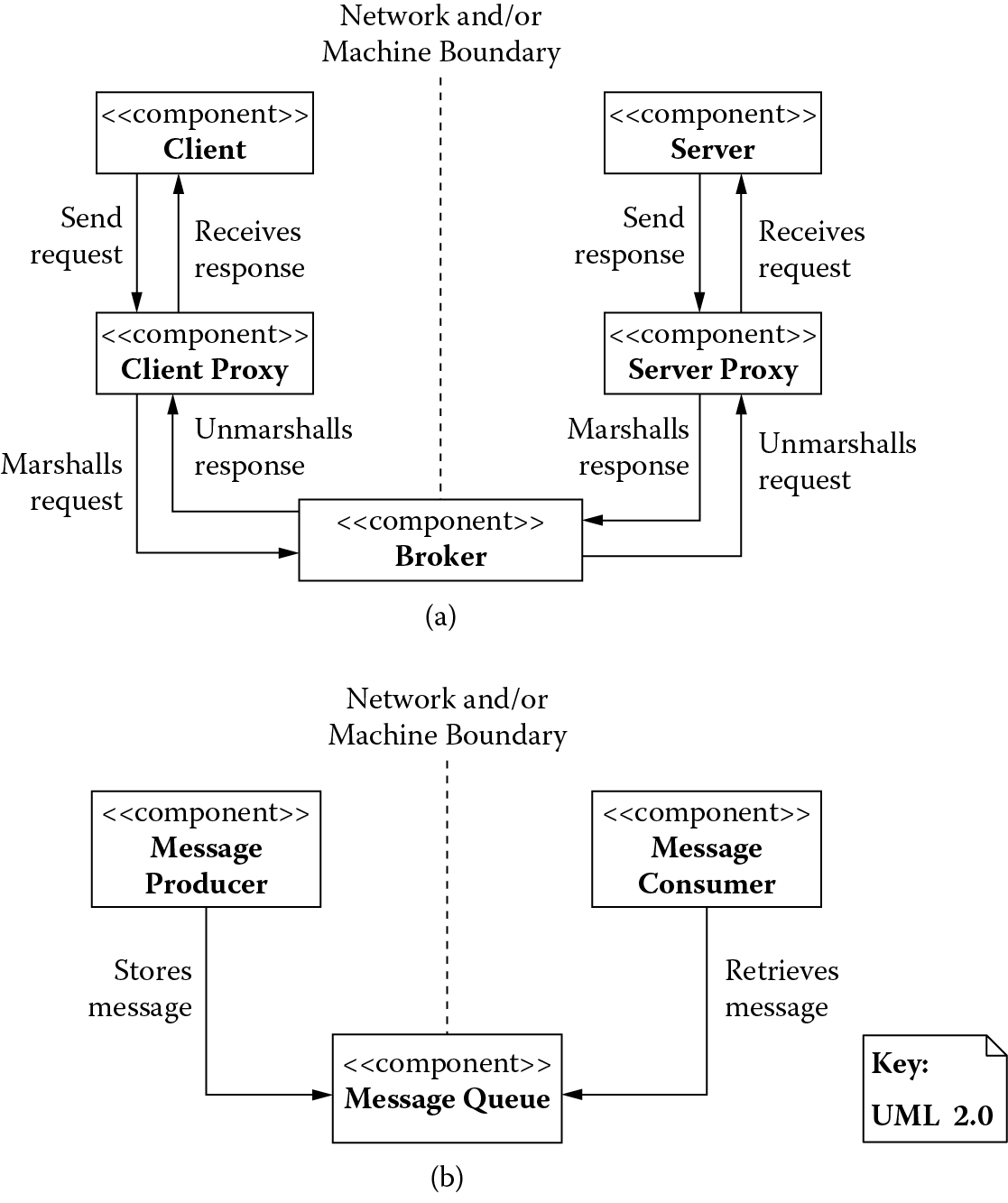
Architectural patterns based on a distribution view: (a) broker and (c) message queuing.
Figure 4.10 shows a broker that separates and hides the communication functionality from the rest of the system and mediates all communication among its distributed components. For instance, when planning travel, a customer may use a travel agency for booking services such as air, hotel, and car. The customer (client) may use the travel agency system (client-side proxy) for making arrangements for these services, and the travel agency (broker) may use a reservation system (server-side proxy) for booking these services (server).
Figure 4.10 shows a message queuing pattern in which messages between components of a system are exchanged through message queues. The sender of a message simply deposits a message in a queue and the receivers monitor the queue, picking up the messages they are interested in when they arrive. For instance, waiters (message producers) in a restaurant place orders from their customers in a queue (message queue), and the bartenders or chefs (message consumers) can monitor these queues and pick up the orders to be filled. They in turn can play the role of message producers, marking the orders filled and placing them in a queue (message queue) that waiters (message consumers) monitor, picking up filled orders to be delivered to their customers.
Patterns provide well-known solutions to recurring design problems that arise in a given context.
4.4 What Is a Tactic?
Patterns are composed from fundamental design decisions known as tactics. Tactics, therefore, are the building blocks of design from which architectural patterns are created. For instance, when thinking of the layer pattern introduced previously, we notice that it entails several design decisions. It uses the following:
- Semantic coherence to assign to each layer those responsibilities that work closely together without excessive reliance on other layers. This increases cohesion within a layer and minimizes its coupling to other layers, with the goal of localizing the impact when modifications are made to a given layer (things that work together are likely to change together).
- Hide information to make services of a layer available through interfaces keeping internal details of how these services are provided by the layer private with the goal of preventing changes made to a given layer from propagating to the other layers (things that are not publicly visible can change and evolve independently).
- Limit exposure by placing layers as intermediaries. The intermediaries can thus decouple higher-level layers from lower-level layers, limiting the exposure of some critical design decisions (limiting the exposure of security-critical functions can prevent them from becoming a target of attack).
Semantic coherence, hide information, and limit exposure are tactics that together yield the layer pattern. This example also illustrates that a given tactic is targeted; it focuses on a design concern related to a single quality attribute: Semantic coherence addresses the modifiability concern related to localizing the impact of change; information hiding addresses the modifiability concern related to preventing the ripple effect of a change; and limit exposure addresses the security concern related to resisting/preventing attacks. A pattern, on the other hand, can address multiple concerns related to multiple quality attributes at the same time; the layers pattern addresses multiple design concerns related to modifiability and security.
In the following sections, a subset of tactics based on the work of Bass et al. (2013) is described. These tactics address design concerns related to some predominant quality attributes and Bass et al. (2013) provide a more complete catalog of these tactics.
4.4.1 Tactics for Availability
The availability quality attribute is concerned with managing systems faults. If left unmanaged, system faults can cause failures that may compromise the system’s ability to deliver certain services (some of which may be safety critical and could lead to loss of life) or render the system completely unusable. Availability, therefore, is concerned with managing faults such that system services continue to operate as expected, making a system more reliable, secure, and safe. It is measured in terms of the length of time for which a system continues to operate without experiencing any downtime that results from a failure, referred to as mean time between failures or MTBF, and the length of time it takes to recover should a system experience a failure, referred to as mean time to repair or MTTR. The ratio (MTBF/(MTBF + MTTR)) yields the availability percentage of a system. The system is 100% available if MTTR is 0 (it takes no time to recover or, more important, faults never become failures). A system that has availability of 99.999% experiences a downtime of a little over 5 min each year as a result of failures.
Tactics for availability are concerned with adding capabilities to a system for handling faults. Table 4.2 provides a subset of these tactics categorized by the availability design concerns they address.
Tactics for Addressing Availability Design Concerns
|
Design Concern |
Tactic |
|
Detect the occurrence of a fault |
|
|
Recover from a fault |
|
|
Prevent the occurrence of a fault |
|
For handling faults, an important design concern is the ability to detect the occurrence of a fault. The monitor tactic uses a process that continuously monitors the status of different elements of a system. The monitoring process may use an additional tactic called ping/echo to periodically ping an element for its status and could receive an echo back from the element indicating it was operating normally. Alternatively, the monitoring process may use a heartbeat tactic; it waits for a periodic status update from the monitored element, and if this update does not arrive, it assumes a fault has occurred. The periodic status update may simply be the monitoring process observing messages flowing back and forth from the element being observed and assuming a fault if the element has been inactive for some predetermined amount of time. An element can also use an exception tactic and throw an exception to let the monitoring process know an exception has occurred.
Once a fault is detected, the monitoring process may need to repair the system so that the fault does not manifest itself as a failure. This is especially true when dealing with safety-critical systems, for which a failure could lead to a catastrophic loss. So, an important design concern for building highly available systems is to recover from a fault. An active redundancy tactic suggests introducing a redundant copy of a safety-critical element into the system. Both the safety-critical element (called the primary) and its redundant copy (called the secondary) actively process their inputs, but the system utilizes the output of the primary only. When a fault occurs, the monitoring process detects the fault, promotes the secondary to the primary, and reconfigures the system to start using the new primary. The monitoring process then initiates the recovery of the failed primary and on successful recovery reintroduces it into the system as a secondary. The passive redundancy tactic is similar to active redundancy except only the primary element actively processes all input while the secondary lies dormant. When the primary fails, the monitoring process must do the following:
- Activate the secondary, which brings itself into a state consistent with the primary before the primary had failed.
- To achieve this, the primary must use a checkpoint tactic to periodically save its current state, and the secondary can use a state resynchronization tactic to read the primary’s checkpoint state, bringing itself into a state consistent with that of the primary before the primary had failed.
- Promote the secondary element to be the new primary and reconfigure the system to start using the new primary.
- Run recovery for the failed primary and reintroduce it as a secondary into the system after its recovery is completed successfully.
When redundant elements are identical copies of each other, there is a distinct possibility that the cause that led to the failure of the primary may also cause the secondary to fail. To avoid such common-cause failures, functional redundancy or analytic redundancy is used. In functional redundancy, the redundant elements process the same inputs and produce the same outputs, but they do so using different processing algorithms (for instance, a set of linear equations can be solved using different mathematical techniques, such as substitution or elimination). In analytic redundancy, the redundant elements process different inputs using different processing algorithms and produce different outputs (for instance, an aircraft can determine its altitude using a barometer or radar). When using such diverse inputs, processing algorithms, and outputs, a more sophisticated tactic called voting is used to determine if a component has failed. An element called a voter monitors the output of all redundant components and uses a sophisticated (domain-specific) algorithm to identify and overcome failures.
When a fault is detected, action must also be taken such that the fault does not propagate to other parts of the system. Therefore, another availability design concern is to prevent the occurrence of a fault. A tactic such as removal from service simply removes a failed element from service to prevent any cascading effect of its failure. Another tactic called transactions bundles together several tasks into a unit of work called a transaction and ensures that either the entire transaction completes or any effects of partial completion (which may leave a system in an inconsistent state) are completely undone.
4.4.2 Tactics for Interoperability
The interoperability quality attribute concerns itself with the ability of two or more systems to work together to achieve some given purpose. Often, these systems may not be under a centralized control and may have been developed without envisioning any interoperability scenarios. Under these circumstances, mechanisms have to be put in place such that a system can discover the services it needs from another system and can use these services to have a meaningful exchange. Tactics for interoperability are designed to make this possible. Table 4.3 provides a subset of these tactics categorized by the interoperability design concerns they address.
Tactics for Addressing Interoperability Design Concerns
|
Design Concern |
Tactic |
|
Locate a service |
|
|
Manage interfaces to a service |
|
Before a system can use one or more services offered by another system, it must know about their location. This locate-a-service interoperability design concern is addressed via the discover service tactic, which suggests putting in place a directory that systems can use to register the services they provide and that other systems can query to discover the systems that provide the needed services. Once the services have been discovered, they have to be invoked via some interface so the work needed is done. This manage-interfaces-to-a-service design concern can be addressed using two different tactics. The orchestrate tactic suggests having a mechanism to compose the invocation of a diverse set of services (perhaps across multiple different systems) into a workflow, and the tailor service tactic suggests having an ability to adapt the interface of the invoked services to conform to a given need.
Having a standardized location, orchestration and adaption mechanisms create location and platform transparency that can significantly reduce the effort required to bring together a diverse set of systems possibly distributed across machine and network boundaries and perhaps running on multiple different platforms.
4.4.3 Tactics for Modifiability
Modifiability is a quality attribute concerned with the ease of making a change to a system. Systems that are easier to modify are more maintainable, easy to extend, and easy to port to multiple different platforms and offer greater opportunity for reuse. Improved modifiability leads to a more modular system, increasing its adaptive capacity. A system’s adaptive capacity is important for its ability to evolve gracefully and has immense economic value (Parnas, 1972; Baldwin and Clark, 2000; Sullivan et al., 2001).
Tactics for modifiability deal with minimizing the effort required for making changes to a given system. Table 4.4 provides a subset of such tactics categorized by the modifiability design concerns they address.
Tactics for Addressing Modifiability Design Concerns
|
Design Concern |
Tactic |
|
Limit the impact of a change |
|
|
Limit the ripple effect of a change |
|
|
Defer the binding time of a change |
|
The foremost modifiability design concern is limiting the impact of a change made to a system; that is, designers strive to localize a change to one and only one place in a given system so that its impact is limited. The tactic to maintain semantic coherence suggests that system elements that are used together should belong together because elements that are used together are likely to change together. Therefore, bundling such elements into a single module not only makes the system semantically coherent (easier to understand) but also localizes any changes made to these elements, making such a change more manageable. In the same vein, the tactic to abstract common services suggests factoring into common services the aspects that are similar across multiple elements of a system. By abstracting these common services into their own modules, changes to these services are again localized to these modules rather than distributed across multiple elements. The tactic generalize module advocates increasing the ability of a module to handle a much broader set of inputs, thus eliminating the need for having several specialized modules to handle subsets of these inputs. The tactic to anticipate expected changes suggests we should determine in advance the changes that are likely to be made to a given system in the foreseeable future so that we can prepare the system for such changes. Stated another way, we do not have to make each and every thing within the system more modifiable, only those that are likely to change.
When an element within a system is changed, it is likely that other elements that depend on the one being changed are also affected. So, once anticipated changes to a system have been localized, the next design concern is limiting the ripple effect of a change. One tactic to achieve this is to restrict dependencies, which suggests designing a system in a way such that the number of elements depending on an element likely to change is minimized. Another tactic is to use an intermediary, which decouples an element likely to change from the rest of the system, and all access to this element is channeled through an intermediary. Therefore, in the likelihood that a change to the element does ripple, its effect would be muted by the intermediary. Because some elements must still depend on an element likely to change (a completely decoupled element would sit by itself and would serve no useful purpose for a system), the hide information tactic suggests that the changeable element must hide as much internal detail as possible from the external elements with which it interacts. These external elements should interact with the changeable element through interfaces that only make public the services that these elements need. Furthermore, the tactic to maintain existing interface suggests that these public interfaces should be stable so that external elements that depend on them are not affected.
Once the changes have been localized and their ripple effect contained, one has to worry about who will make the change and when. It is likely that a change is made by engineers during the development cycle of a system, or it is made by the installers at the time the system is being deployed, or the change is made by the technicians while the system is operational. Therefore, the next design concern is deferring the binding time of a change, that is, designing the architecture of a system so that it is capable of delaying when a change is made to the system. To make this possible, the polymorphism tactic can be used to make an element closed to modification but open to extension; that is, the element itself need not change (hence be closed to modification), but its capabilities can be enhanced through one or more extension points it provides (hence be open to extension). If these extensions need to be bootstrapped while a system is operation, then a combination tactic of runtime registration and configuration files can be used. When a new capability is added while the system is in operation, the system can detect this change and read an accompanying file that contains configuration parameters indicating to the system how to bootstrap this additional capability. The strategy to adhere to defined protocols suggests using a standard protocol, in which case the system can simply use a standard protocol for interacting with an extension when it detects this additional capability.
4.4.4 Tactics for Performance
The performance quality attribute is concerned with decreasing latency and increasing throughput. Latency is decreased if the system is responsive or can respond to a request rapidly. Throughput is increased if a system can process a high volume of requests without any perceptible decrease in its responsiveness. Addressing latency and throughput is important because it has an impact on how quickly end users can make a system process their individual requests. Responsive systems are not only scalable (can handle a high volume of requests) but also improve a system’s availability (by not choking in the face of a high volume of requests).
Tactics for performance deal with improving the responsiveness of a system. Table 4.5 provides a subset of these tactics categorized by the performance design concerns they address.
Tactics for Addressing Performance Design Concerns
|
Design Concern |
Tactic |
|
Manage demand for a resource |
|
|
Manage a resource |
|
The first design concern when improving performance of a system is to manage the demand for its resources. For software-intensive systems, this means demand for any shared resource such as central processing units (CPUs), memory, network, or data. The higher the demand for these resources, the more contention it will generate, affecting the overall responsiveness of a system. The tactic to increase resource efficiency suggests looking at the ways algorithms use a resource to process an event or input and optimizing them to reduce their processing time. Further, the tactic to reduce overhead suggests that if this processing is accomplished by multiple processing elements distributed across process, machine, or network boundaries, then colocating them within the same process or a machine would significantly reduce the processing overhead created by interelement communication. The prioritize events tactic recommends giving higher priority to highly important events or inputs and processing them ahead of low-priority events (which may be ignored or may wait an arbitrarily long time before being processed). The bound execution time tactic advocates, when possible, fixing the amount of time allocated to processing an event. This could compromise how accurate the processing result is and therefore can only be done when a less-than-accurate output is acceptable. If a system is becoming overwhelmed by the number of events it needs to process because it is sampling these events from its environment at a certain rate, then the tactic to manage sampling rate suggests the system can reduce this sampling rate and the limit event response tactic advocates setting a maximum event-processing rate after which events may be dropped or some policy crafted to handle the overflow.
If system performance continues to be an issue after having utilized all possible tactics to manage demand for a resource, then the next design concern to address would be to manage a resource itself. If cost is not a concern, the tactic to increase resources suggests simply adding more of a given resource, and the tactic to introduce concurrency recommends utilizing the capacity of a given resource by processing requests in parallel. The maintain multiple copies tactic advocates that contention for a shared resource can be decreased by having multiple copies of that resource. For instance, client-server architectures replicate services clients need across a cluster of servers and use a load balancer to distribute the requests from the clients across this cluster. The schedule resources tactic recommends using a scheduling policy (such as first in/first out, deadline monotonic, rate monotonic, round-robin, etc.) that assigns a priority to requests for a resource and dispatches these requests in priority order when the resource becomes available.
4.4.5 Tactics for Security
The security quality attribute concerns itself with preventing unauthorized access to a resource (for instance, information or a service). It explores ways in which a system can guarantee confidentiality (a resource can be accessed only by authorized users), integrity (a resource will not be altered by unauthorized users), and availability (continued access by authorized users) of resources.
Tactics for security are designed for making systems easy to secure. Table 4.6 provides a subset of these tactics categorized by the security design concerns they address.
Tactics for Addressing Security Design Concerns
|
Design Concern |
Tactic |
|
Resist attacks |
|
|
Detect attacks |
|
|
Recover from attacks |
|
Resisting attacks is an important security design concern, and tactics that address this concern prevent access to resources from unauthorized users. The authenticate users tactic is used for identifying users and guaranteeing that they are who they claim to be. The authorize users tactic ensures that authenticated users have access to only those resources that they are authorized to access. The encrypt data tactic recommends keeping information in an encrypted form such that only authorized users who hold the key to decrypt such information can manipulate it. This tactic is useful when an authorized user needs to transmit confidential information to another party over a network. The limit access tactic advocates limiting access to privileged resources by putting in place protection mechanisms (such as Demilitarized Zone and firewalls that protect an organization’s intranet). The limit exposure tactic suggests limiting the number of access points to resources, thereby limiting opportunities for unauthorized access.
Despite putting in place tactics for resisting attacks, unauthorized users try to gain access to privileged resources by exploiting some system vulnerability. Therefore, another important security design concern is to detect attacks from unauthorized users. The detect intrusion tactic suggests monitoring traffic coming into a system against known patterns of attacks. The detect service denial is a tactic for detecting a special type of attack in which the system becomes overwhelmed with a flood of unauthorized access attempts and cannot do anything useful (other than just thwarting such attempts). The tactic to detect message delay detects a man-in-the-middle attack by which an unauthorized user may intercept a message and alter it (therefore introducing a delay) before it arrives at the system. The tactic to verify message integrity uses techniques (such as hash values and checksums) to ensure that a message (or any other privileged resource) has not been altered.
If unauthorized users are successful in compromising a system, then steps must be taken to recover from the attacks. Maintain audit trail is a tactic that keeps a trail of all activity on the system and can be used not only to identify and prosecute attackers but also to improve the security of the system in the future. If the system becomes compromised, then it can be restored by performing recovery using the availability tactics.
4.4.6 Tactics for Testability
Testability is a quality of a system that makes it easier to test. The ease of testing hinges on how much effort is required to understand or discover the cause for faulty system behavior. Tactics for testability are designed to reduce this effort. Table 4.7 provides a summary of these tactics.
To minimize the effort required to understand or discover the cause for faulty system behavior, the foremost design concern is the ability to control and observe system state. The specialized interface tactic recommends creating specialized testing interfaces that allow gaining access to the internal state of a system. The record/playback tactic suggests putting in place a mechanism that records any information that crosses a system interface. This information can then be used as an input for playback or exercising the same interface and therefore reproducing the (possibly faulty) behavior of the system. The built-in monitor tactic advocates that, to improve the testability of an element within a system, the element can have a built-in monitor that maintains and makes available its internal state, thus providing increased visibility of its internal operations.
4.4.7 Tactics for Usability
Usability is the quality of the system concerned with its ease of use. Improved usability makes systems easier to learn, navigate, and work with; systems can guide their users through the workflows, seeking their input at each step, providing feedback, and preventing them from making any errors. Usability tactics therefore are focused on reducing the effort needed in gaining proficiency in the use of such systems. Table 4.8 provides a summary of such tactics categorized by the usability design concern they address.
Tactics for Addressing Usability Design Concerns
|
Design Concern |
Tactic |
|
Support user initiative |
|
|
Support system initiative |
|
To make a system easier to use, one of the usability design concerns is supporting user initiative or allowing the user to initiate certain actions. For instance, after launching a particular task, users may change their mind (for various reasons, such as the task is taking too long to complete or the user simply made a mistake) and may want to abort the task. The cancel tactic suggests putting in place a mechanism within the system that allows a user to terminate a task. Terminating a task may not be as simple as just ending the task midstream; all the work the task performed before aborting may have caused side effects that could leave a system in an inconsistent state. The undo tactic recommends putting in place a mechanism that undoes these side effects. The pause/resume tactic advocates having an ability to pause a long-running task midstream and resume it at a later time (so that a user is not compelled to cancel it simply because it is taking too long).
After launching a task, it would also be nice for users to track its progress and receive guidance in successfully completing the task. Therefore, the next usability design concern is support system initiative or support for the ability of a system to provide periodic feedback to the user. The maintain system model tactic advocates creating a model that allows a system to determine its expected behavior and gives it the ability to predict the completion time (by displaying a progress bar, for instance) of a currently running task. The maintain task model tactic recommends having a model of the task itself so the system has a context of what a user is attempting to accomplish and can provide useful feedback by identifying any errors (by highlighting incorrect inputs or correcting them when possible) and can help navigating through the workflow (by going to the next logical step in the workflow where user input is needed). The maintain model of the user tactic suggests keeping a model of a user so that the system can provide guidance based on whether a user is a novice or an expert, for instance.
Patterns are composed of fundamental building blocks of design called tactics.
4.5 Summary
This chapter began to explore the shaded portion of ISO/IEC 42010 conceptual framework for system and software architecture shown in Figure 4.11.
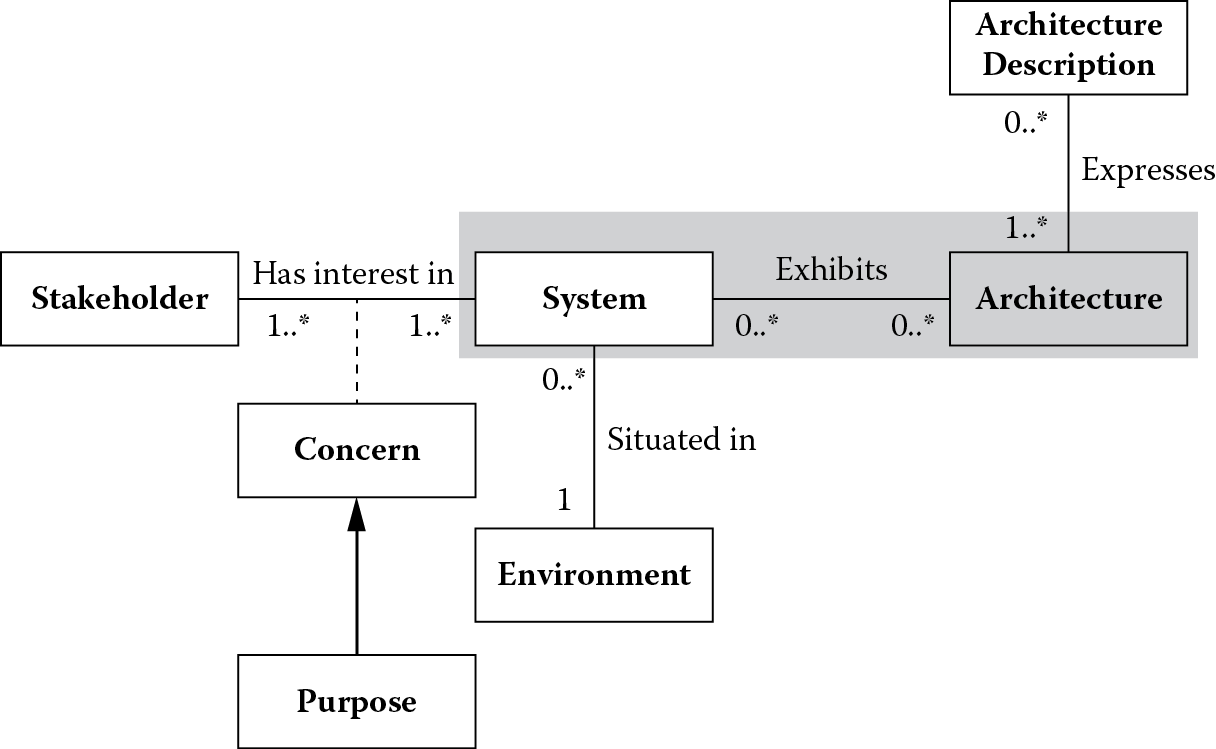
In particular, we discussed how the most significant architectural requirements that drive the design of a system architecture are distilled from its quality attribute scenarios and functional responsibilities and constraints with implied quality concerns. Their conflicting nature limits us to consider only a handful of these ASRs, which we refer to as architectural drivers.
Rather than designing a system architecture from scratch, architects use design patterns and tactics to satisfy the design concerns inherent in the architectural drivers. Design patterns are solutions to recurring design problems in a given context, and tactics are more fundamental design decisions that serve as building blocks for these patterns. This chapter explored a subset of these patterns and tactics.
4.6 Questions
- Can you think of additional constraints (related to organization, technology, or product) that may have a strong influence on the architecture of the building automation system?
- Consider the publish-subscribe pattern. What qualities might this pattern try to address? What tactics make up this pattern?
- Although the patterns and tactics listed in this chapter relate predominantly to software-intensive systems, can you find examples of other kinds of systems in which these have been or can be applied?
- Consider a warehouse management (WM) system that needs to communicate with an enterprise resource planning (ERP) system to control and optimize the material flow within a warehouse. The two systems are deployed across a computer network to meet their operational requirements. Consequently, there could be a machine boundary between the two.
- How can we shield the objects of the system from dealing with networking issues directly while supporting location-independent interaction between them? Consider the messaging or broker pattern described in the text when coming up with a solution. Clearly explain the trade-offs when making your choice.
- Present a sketch of your design.
- Identify the tactics used by the pattern of your choice.
References
P. Avgeriou and U. Zdun, Architectural patterns revisited—A pattern language. In Proceedings of 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Irsee, Germany, 2005, pp. 1–39.
C. Baldwin and K. Clark, Design Rules: The Power of Modularity, Volume 1. Cambridge, MA: MIT Press, 2000.
L. Bass, P. Clements, and R. Kazman, Software Architecture in Practice, third edition. Boston: Addison-Wesley, 2013.
F. Buschmann, K. Henney, and D. Schmidt,. Pattern-Oriented Software Architecture: A Pattern Language for Distributed Computing, Volume 4. New York: Wiley, 2007a.
F. Buschmann, K. Henney, and D. Schmidt, Pattern Oriented Software Architecture: On Patterns and Pattern Languages, Volume 5. New York: Wiley, 2007b.
F. Buschmann, R. Meunier, H. Rohnert, P. Sommerlad, and M. Stal, Pattern-Oriented Software Architecture: A System of Patterns, Volume 1. New York: Wiley, 1996.
M. Duell, J. Goodsen, and L. Rising, Non-software examples of software design patterns. In Addendum to the 1997 ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (Addendum) (OOPSLA ‘97). New York: ACM, 1997, pp. 120–124.
ISO/IEC/IEEE Systems and software engineering—Architecture description, ISO/IEC/IEEE 42010:2011(E) (Revision of ISO/IEC 42010:2007 and IEEE Std 1471-2000), pp. 1–46, 2011.
ISO/IEC JTC1, Information Technology—Open System Interconnection—OSI Reference Model: Part 1—Basic Reference Model, ISO/IEC 7498-1, 1994.
M. Kircher and P. Jain, Pattern-Oriented Software Architecture: Patterns for Resource Management, Volume 4. New York: Wiley, 2004.
National Aeronautics and Space Administration (NASA), Systems Engineering Handbook (NASA/SP-2007-6105 Rev1). Washington, DC: NASA Headquarters, December 2007.
D. Parnas, On the criteria to be used in decomposing systems into modules. Commun. ACM 15, 12 (December 1972), 1053–1058, 1972.
D. Schmidt, M. Stal, H. Rohnert, and F. Buschmann, Pattern-Oriented Software Architecture: Patterns for Concurrent and Networked Objects, second edition, Volume 2. New York: Wiley, 2000.
K. Sullivan, W. Griswold, Y. Cai, and B. Hallen, The structure and value of modularity in software design. In Proceedings of the 8th European Software Engineering Conference Held Jointly with 9th ACM SIGSOFT International Symposium on Foundations of Software Engineering (ESEC/FSE-9). New York: ACM, pp. 99–108.