
Knowledge is a treasure, but practice is the key to it.
—Thomas Fuller
People often ask me about good resources for learning Python for data-centric applications. While there are many excellent Python language books, I am usually hesitant to recommend some of them as they are intended for a general audience rather than tailored for someone who wants to load in some data sets, do some computations, and plot some of the results. There are actually a couple of books on “scientific programming in Python”, but they are geared toward numerical computing and engineering applications: solving differential equations, computing integrals, doing Monte Carlo simulations, and various topics that are more mathematically-oriented rather than being about data analysis and statistics. As this is a book about becoming proficient at working with data in Python, I think it is valuable to spend some time highlighting the most important features of Python’s built-in data structures and libraries from the perspective of processing and manipulating structured and unstructured data. As such, I will only present roughly enough information to enable you to follow along with the rest of the book.
This chapter is not intended to be an exhaustive introduction to the Python language but rather a biased, no-frills overview of features which are used repeatedly throughout this book. For new Python programmers, I recommend that you supplement this chapter with the official Python tutorial (http://docs.python.org) and potentially one of the many excellent (and much longer) books on general purpose Python programming. In my opinion, it is not necessary to become proficient at building good software in Python to be able to productively do data analysis. I encourage you to use IPython to experiment with the code examples and to explore the documentation for the various types, functions, and methods. Note that some of the code used in the examples may not necessarily be fully-introduced at this point.
Much of this book focuses on high performance array-based computing tools for working with large data sets. In order to use those tools you must often first do some munging to corral messy data into a more nicely structured form. Fortunately, Python is one of the easiest-to-use languages for rapidly whipping your data into shape. The greater your facility with Python, the language, the easier it will be for you to prepare new data sets for analysis.
Python is an interpreted language. The Python
interpreter runs a program by executing one statement at a time. The
standard interactive Python interpreter can be invoked on the command line
with the python command:
$ python Python 2.7.2 (default, Oct 4 2011, 20:06:09) [GCC 4.6.1] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> a = 5 >>> print a 5
The >>> you see is
the prompt where you’ll type expressions. To exit the
Python interpreter and return to the command prompt, you can either type
exit() or press Ctrl-D.
Running Python programs is as simple as calling python with a .py file as its first
argument. Suppose we had created hello_world.py with these contents:
print 'Hello world'
This can be run from the terminal simply as:
$ python hello_world.py Hello world
While many Python programmers execute all of their Python code in
this way, many scientific Python programmers make use
of IPython, an enhanced interactive Python interpreter. Chapter 3 is dedicated to the IPython system. By using the
%run command, IPython
executes the code in the specified file in the same process, enabling you
to explore the results interactively when it’s done.
$ ipython Python 2.7.2 |EPD 7.1-2 (64-bit)| (default, Jul 3 2011, 15:17:51) Type "copyright", "credits" or "license" for more information. IPython 0.12 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: %run hello_world.py Hello world In [2]:
The default IPython prompt adopts the numbered In [2]: style compared with the standard
>>> prompt.
The Python language design is distinguished by its emphasis on readability, simplicity, and explicitness. Some people go so far as to liken it to “executable pseudocode”.
Python uses whitespace (tabs or spaces) to structure code instead of using braces as in many other languages like R, C++, Java, and Perl. Take the for loop in the above quicksort algorithm:
for x in array:
if x < pivot:
less.append(x)
else:
greater.append(x)A colon denotes the start of an indented code block after which all of the code must be indented by the same amount until the end of the block. In another language, you might instead have something like:
for x in array {
if x < pivot {
less.append(x)
} else {
greater.append(x)
}
}One major reason that whitespace matters is that it results in most Python code looking cosmetically similar, which means less cognitive dissonance when you read a piece of code that you didn’t write yourself (or wrote in a hurry a year ago!). In a language without significant whitespace, you might stumble on some differently formatted code like:
for x in array
{
if x < pivot
{
less.append(x)
}
else
{
greater.append(x)
}
}Love it or hate it, significant whitespace is a fact of life for Python programmers, and in my experience it helps make Python code a lot more readable than other languages I’ve used. While it may seem foreign at first, I suspect that it will grow on you after a while.
Note
I strongly recommend that you use 4 spaces to as your default indentation and that your editor replace tabs with 4 spaces. Many text editors have a setting that will replace tab stops with spaces automatically (do this!). Some people use tabs or a different number of spaces, with 2 spaces not being terribly uncommon. 4 spaces is by and large the standard adopted by the vast majority of Python programmers, so I recommend doing that in the absence of a compelling reason otherwise.
As you can see by now, Python statements also do not need to be terminated by semicolons. Semicolons can be used, however, to separate multiple statements on a single line:
a = 5; b = 6; c = 7
Putting multiple statements on one line is generally discouraged in Python as it often makes code less readable.
An important characteristic of the Python language is the consistency of its object model. Every number, string, data structure, function, class, module, and so on exists in the Python interpreter in its own “box” which is referred to as a Python object. Each object has an associated type (for example, string or function) and internal data. In practice this makes the language very flexible, as even functions can be treated just like any other object.
Any text preceded by the hash mark (pound sign)
# is ignored by the
Python interpreter. This is often used to add comments to code. At
times you may also want to exclude certain blocks of code without
deleting them. An easy solution is to comment out
the code:
results = []
for line in file_handle:
# keep the empty lines for now
# if len(line) == 0:
# continue
results.append(line.replace('foo', 'bar'))Functions are called using parentheses and passing zero or more arguments, optionally assigning the returned value to a variable:
result = f(x, y, z) g()
Almost every object in Python has attached functions, known as methods, that have access to the object’s internal contents. They can be called using the syntax:
obj.some_method(x, y, z)
Functions can take both positional and keyword arguments:
result = f(a, b, c, d=5, e='foo')
When assigning a variable (or name) in Python, you are creating a reference to the object on the right hand side of the equals sign. In practical terms, consider a list of integers:
In [241]: a = [1, 2, 3]
Suppose we assign a to a new
variable b:
In [242]: b = a
In some languages, this assignment would cause the data [1, 2, 3] to be copied. In Python, a and b
actually now refer to the same object, the original list [1, 2, 3] (see Figure A-1 for a mockup). You can prove this to
yourself by appending an element to a and then examining b:
In [243]: a.append(4) In [244]: b Out[244]: [1, 2, 3, 4]

Understanding the semantics of references in Python and when, how, and why data is copied is especially critical when working with larger data sets in Python.
Note
Assignment is also referred to as binding, as we are binding a name to an object. Variable names that have been assigned may occasionally be referred to as bound variables.
When you pass objects as arguments to a function, you are only passing references; no copying occurs. Thus, Python is said to pass by reference, whereas some other languages support both pass by value (creating copies) and pass by reference. This means that a function can mutate the internals of its arguments. Suppose we had the following function:
def append_element(some_list, element):
some_list.append(element)Then given what’s been said, this should not come as a surprise:
In [2]: data = [1, 2, 3] In [3]: append_element(data, 4) In [4]: data Out[4]: [1, 2, 3, 4]
In contrast with many compiled languages, such as Java and C++, object references in Python have no type associated with them. There is no problem with the following:
In [245]: a = 5 In [246]: type(a)
Out[246]: int
In [247]: a = 'foo' In [248]: type(a)
Out[248]: strVariables are names for objects within a particular namespace; the type information is stored in the object itself. Some observers might hastily conclude that Python is not a “typed language”. This is not true; consider this example:
In [249]: '5' + 5 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-249-f9dbf5f0b234> in <module>() ----> 1 '5' + 5 TypeError: cannot concatenate 'str' and 'int' objects
In some languages, such as Visual Basic, the string '5' might get implicitly converted (or
casted) to an integer, thus yielding 10. Yet in
other languages, such as JavaScript, the integer 5 might be casted to a string, yielding the
concatenated string '55'. In this
regard Python is considered a strongly-typed language, which
means that every object has a specific type (or
class), and implicit conversions will occur only
in certain obvious circumstances, such as the following:
In [250]: a = 4.5 In [251]: b = 2 # String formatting, to be visited later In [252]: print 'a is %s, b is %s' % (type(a), type(b)) a is <type 'float'>, b is <type 'int'> In [253]: a / b Out[253]: 2.25
Knowing the type of an object is important, and it’s
useful to be able to write functions that can handle many different
kinds of input. You can check that an object is an instance of a
particular type using the isinstance function:
In [254]: a = 5 In [255]: isinstance(a, int)
Out[255]: Trueisinstance can accept
a tuple of types if you want to check that an object’s type is among
those present in the tuple:
In [256]: a = 5; b = 4.5 In [257]: isinstance(a, (int, float)) In [258]: isinstance(b, (int, float)) Out[257]: True Out[258]: True
Objects in Python typically have both attributes, other
Python objects stored “inside” the object, and methods, functions
associated with an object which can have access to the object’s
internal data. Both of them are accessed via the syntax
obj.attribute_name:
In [1]: a = 'foo' In [2]: a.<Tab> a.capitalize a.format a.isupper a.rindex a.strip a.center a.index a.join a.rjust a.swapcase a.count a.isalnum a.ljust a.rpartition a.title a.decode a.isalpha a.lower a.rsplit a.translate a.encode a.isdigit a.lstrip a.rstrip a.upper a.endswith a.islower a.partition a.split a.zfill a.expandtabs a.isspace a.replace a.splitlines a.find a.istitle a.rfind a.startswith
Attributes and methods can also be accessed by name using the
getattr
function:
>>> getattr(a, 'split') <function split>
While we will not extensively use the functions getattr and related
functions hasattr and
setattr in this book,
they can be used very effectively to write generic, reusable
code.
Often you may not care about the type of an object but
rather only whether it has certain methods or behavior. For example,
you can verify that an object is iterable if it implemented the
iterator protocol. For many objects, this means
it has a __iter__ “magic method”,
though an alternative and better way to check is to try using the
iter function:
def isiterable(obj):
try:
iter(obj)
return True
except TypeError: # not iterable
return FalseThis function would return True for strings as well as most Python
collection types:
In [260]: isiterable('a string') In [261]: isiterable([1, 2, 3])
Out[260]: True Out[261]: True
In [262]: isiterable(5)
Out[262]: FalseA place where I use this functionality all the time is to write functions that can accept multiple kinds of input. A common case is writing a function that can accept any kind of sequence (list, tuple, ndarray) or even an iterator. You can first check if the object is a list (or a NumPy array) and, if it is not, convert it to be one:
if not isinstance(x, list) and isiterable(x):
x = list(x)In Python a module is simply a .py file containing
function and variable definitions along with such things imported from
other .py files. Suppose
that we had the following module:
# some_module.py
PI = 3.14159
def f(x):
return x + 2
def g(a, b):
return a + bIf we wanted to access the variables and functions defined in
some_module.py, from another file
in the same directory we could do:
import some_module result = some_module.f(5) pi = some_module.PI
Or equivalently:
from some_module import f, g, PI result = g(5, PI)
By using the as keyword you can
give imports different variable names:
import some_module as sm from some_module import PI as pi, g as gf r1 = sm.f(pi) r2 = gf(6, pi)
Most of the binary math operations and comparisons are as you might expect:
In [263]: 5 - 7 In [264]: 12 + 21.5
Out[263]: -2 Out[264]: 33.5
In [265]: 5 <= 2
Out[265]: FalseSee Table A-1 for all of the available binary operators.
To check if two references refer to the same object, use the
is keyword. is not is also perfectly valid if you want
to check that two objects are not the same:
In [266]: a = [1, 2, 3] In [267]: b = a # Note, the list function always creates a new list In [268]: c = list(a) In [269]: a is b In [270]: a is not c Out[269]: True Out[270]: True
Note this is not the same thing is comparing with ==, because in this
case we have:
In [271]: a == c Out[271]: True
A very common use of is and
is not is to check if a variable is
None, since there is only one
instance of None:
In [272]: a = None In [273]: a is None Out[273]: True
Table A-1. Binary operators
| Operation | Description |
|---|---|
a + b | Add a and b |
a - b | Subtract b from
a |
a * b | Multiply a by
b |
a / b | Divide a by b |
a // b | Floor-divide a by
b, dropping any fractional
remainder |
a ** b | Raise a to the
b power |
a & b | True if both
a and b are True. For integers, take the bitwise
AND. |
a | b | True if either
a or b is True. For integers, take the bitwise
OR. |
a ^ b | For booleans, True
if a or b is True, but not both. For integers,
take the bitwise EXCLUSIVE-OR. |
a == b | True if a equals b |
a != b | True if a is not equal to b |
a <= b, a <
b | True if a is less than (less than or equal)
to b |
a > b, a >=
b | True if a is greater than (greater than or
equal) to b |
a is b | True if a and b reference same Python
object |
a is not b | True if a and b reference different Python
objects |
When using any programming language, it’s important to understand when expressions are evaluated. Consider the simple expression:
a = b = c = 5 d = a + b * c
In Python, once these statements are evaluated, the calculation
is immediately (or strictly) carried out, setting
the value of d to 30. In another
programming paradigm, such as in a pure functional programming
language like Haskell, the value of d might not be evaluated until it is
actually used elsewhere. The idea of deferring computations in this
way is commonly known as lazy evaluation. Python,
on the other hand, is a very strict (or eager) language. Nearly
all of the time, computations and expressions are evaluated
immediately. Even in the above simple expression, the result of
b * c is computed as a separate
step before adding it to a.
There are Python techniques, especially using iterators and generators, which can be used to achieve laziness. When performing very expensive computations which are only necessary some of the time, this can be an important technique in data-intensive applications.
Most objects in Python are mutable, such as lists, dicts, NumPy arrays, or most user-defined types (classes). This means that the object or values that they contain can be modified.
In [274]: a_list = ['foo', 2, [4, 5]] In [275]: a_list[2] = (3, 4) In [276]: a_list Out[276]: ['foo', 2, (3, 4)]
Others, like strings and tuples, are immutable:
In [277]: a_tuple = (3, 5, (4, 5)) In [278]: a_tuple[1] = 'four' --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-278-b7966a9ae0f1> in <module>() ----> 1 a_tuple[1] = 'four' TypeError: 'tuple' object does not support item assignment
Remember that just because you can mutate an object does not mean that you always should. Such actions are known in programming as side effects. For example, when writing a function, any side effects should be explicitly communicated to the user in the function’s documentation or comments. If possible, I recommend trying to avoid side effects and favor immutability, even though there may be mutable objects involved.
Python has a small set of built-in types for handling
numerical data, strings, boolean (True or False) values, and dates and time. See Table A-2 for a list of the main scalar
types. Date and time handling will be discussed separately as these are
provided by the datetime module in the
standard library.
Table A-2. Standard Python Scalar Types
The primary Python types for numbers are int and float. The size of
the integer which can be stored as an int is dependent on
your platform (whether 32 or 64-bit), but Python will transparently
convert a very large integer to long, which can store
arbitrarily large integers.
In [279]: ival = 17239871 In [280]: ival ** 6 Out[280]: 26254519291092456596965462913230729701102721L
Floating point numbers are represented with the Python
float type. Under the
hood each one is a double-precision (64 bits) value. They can also be
expressed using scientific notation:
In [281]: fval = 7.243 In [282]: fval2 = 6.78e-5
In Python 3, integer division not resulting in a whole number will always yield a floating point number:
In [284]: 3 / 2 Out[284]: 1.5
In Python 2.7 and below (which some readers will likely be using), you can enable this behavior by default by putting the following cryptic-looking statement at the top of your module:
from __future__ import division
Without this in place, you can always explicitly convert the denominator into a floating point number:
In [285]: 3 / float(2) Out[285]: 1.5
To get C-style integer division (which drops the fractional part
if the result is not a whole number), use the floor division operator
//:
In [286]: 3 // 2 Out[286]: 1
Complex numbers are written using j for the imaginary part:
In [287]: cval = 1 + 2j In [288]: cval * (1 - 2j) Out[288]: (5+0j)
Many people use Python for its powerful and flexible
built-in string processing capabilities. You can write
string literal using either single quotes
' or double quotes ":
a = 'one way of writing a string' b = "another way"
For multiline strings with line breaks, you can use triple
quotes, either ''' or """:
c = """ This is a longer string that spans multiple lines """
Python strings are immutable; you cannot modify a string without creating a new string:
In [289]: a = 'this is a string'
In [290]: a[10] = 'f'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-290-5ca625d1e504> in <module>()
----> 1 a[10] = 'f'
TypeError: 'str' object does not support item assignment
In [291]: b = a.replace('string', 'longer string')
In [292]: b
Out[292]: 'this is a longer string'Many Python objects can be converted to a string using the
str function:
In [293]: a = 5.6 In [294]: s = str(a)
In [295]: s
Out[295]: '5.6'Strings are a sequence of characters and therefore can be treated like other sequences, such as lists and tuples:
In [296]: s = 'python' In [297]: list(s)
Out[297]: ['p', 'y', 't', 'h', 'o', 'n']
In [298]: s[:3]
Out[298]: 'pyt'The backslash character is an
escape character, meaning that it is used to
specify special characters like newline
or unicode characters. To write a string
literal with backslashes, you need to escape them:
In [299]: s = '12\34' In [300]: print s 1234
If you have a string with a lot of backslashes and no special
characters, you might find this a bit annoying. Fortunately you can
preface the leading quote of the string with r which means that the characters should be
interpreted as is:
In [301]: s = r'thishas ospecialcharacters' In [302]: s Out[302]: 'this\has\no\special\characters'
Adding two strings together concatenates them and produces a new string:
In [303]: a = 'this is the first half ' In [304]: b = 'and this is the second half' In [305]: a + b Out[305]: 'this is the first half and this is the second half'
String templating or formatting is another important topic. The
number of ways to do so has expanded with the advent of Python 3, here
I will briefly describe the mechanics of one of the main interfaces.
Strings with a % followed by one or
more format characters is a target for inserting a value into that
string (this is quite similar to the printf function in C). As an example,
consider this string:
In [306]: template = '%.2f %s are worth $%d'
In this string, %s means to format an
argument as a string, %.2f a number
with 2 decimal places, and %d an integer. To
substitute arguments for these format parameters, use the binary
operator % with a tuple of
values:
In [307]: template % (4.5560, 'Argentine Pesos', 1) Out[307]: '4.56 Argentine Pesos are worth $1'
String formatting is a broad topic; there are multiple methods and numerous options and tweaks available to control how values are formatted in the resulting string. To learn more, I recommend you seek out more information on the web.
I discuss general string processing as it relates to data analysis in more detail in Chapter 7.
The two boolean values in Python are written as True and False. Comparisons and other conditional
expressions evaluate to either True
or False. Boolean values are
combined with the and and or keywords:
In [308]: True and True Out[308]: True In [309]: False or True Out[309]: True
Almost all built-in Python tops and any class defining the
__nonzero__ magic method have a
True or False interpretation in an if statement:
In [310]: a = [1, 2, 3] .....: if a: .....: print 'I found something!' .....: I found something! In [311]: b = [] .....: if not b: .....: print 'Empty!' .....: Empty!
Most objects in Python have a notion of true- or falseness. For
example, empty sequences (lists, dicts, tuples, etc.) are treated as
False if used in control flow (as
above with the empty list b). You
can see exactly what boolean value an object coerces to by invoking
bool on it:
In [312]: bool([]), bool([1, 2, 3])
Out[312]: (False, True)
In [313]: bool('Hello world!'), bool('')
Out[313]: (True, False)
In [314]: bool(0), bool(1)
Out[314]: (False, True)The str, bool, int and float types are also
functions which can be used to cast values to those types:
In [315]: s = '3.14159'
In [316]: fval = float(s) In [317]: type(fval)
Out[317]: float
In [318]: int(fval) In [319]: bool(fval) In [320]: bool(0)
Out[318]: 3 Out[319]: True Out[320]: FalseNone is the Python
null value type. If a function does not explicitly return a value, it
implicitly returns None.
In [321]: a = None In [322]: a is None
Out[322]: True
In [323]: b = 5 In [324]: b is not None
Out[324]: TrueNone is also a common
default value for optional function arguments:
def add_and_maybe_multiply(a, b, c=None): result = a + b if c is not None: result = result * c return result
While a technical point, it’s worth bearing in mind that
None is not a
reserved keyword but rather a unique instance of NoneType.
The built-in Python datetime module
provides datetime, date, and time types. The datetime type as you may imagine combines
the information stored in date and
time and is the most commonly
used:
In [325]: from datetime import datetime, date, time In [326]: dt = datetime(2011, 10, 29, 20, 30, 21) In [327]: dt.day In [328]: dt.minute Out[327]: 29 Out[328]: 30
Given a datetime instance,
you can extract the equivalent date
and time objects by calling methods
on the datetime of the same
name:
In [329]: dt.date() In [330]: dt.time() Out[329]: datetime.date(2011, 10, 29) Out[330]: datetime.time(20, 30, 21)
The strftime method
formats a datetime as a string:
In [331]: dt.strftime('%m/%d/%Y %H:%M')
Out[331]: '10/29/2011 20:30'Strings can be converted (parsed) into datetime objects using
the strptime
function:
In [332]: datetime.strptime('20091031', '%Y%m%d')
Out[332]: datetime.datetime(2009, 10, 31, 0, 0)See Table 10-2 for a full list of format specifications.
When aggregating or otherwise grouping time series data, it will occasionally be useful to replace fields of a series of datetimes, for example replacing the minute and second fields with zero, producing a new object:
In [333]: dt.replace(minute=0, second=0) Out[333]: datetime.datetime(2011, 10, 29, 20, 0)
The difference of two datetime objects produces a datetime.timedelta type:
In [334]: dt2 = datetime(2011, 11, 15, 22, 30) In [335]: delta = dt2 - dt In [336]: delta In [337]: type(delta) Out[336]: datetime.timedelta(17, 7179) Out[337]: datetime.timedelta
Adding a timedelta to a
datetime produces a new shifted
datetime:
In [338]: dt Out[338]: datetime.datetime(2011, 10, 29, 20, 30, 21) In [339]: dt + delta Out[339]: datetime.datetime(2011, 11, 15, 22, 30)
The if statement is
one of the most well-known control flow statement types. It checks a
condition which, if True, evaluates
the code in the block that follows:
if x < 0:
print 'It's negative'An if statement can be
optionally followed by one or more elif blocks and a catch-all else block if all of the conditions are
False:
if x < 0:
print 'It's negative'
elif x == 0:
print 'Equal to zero'
elif 0 < x < 5:
print 'Positive but smaller than 5'
else:
print 'Positive and larger than or equal to 5'If any of the conditions is True, no further elif or else blocks will be reached. With a compound
condition using and or or, conditions are
evaluated left-to-right and will short circuit:
In [340]: a = 5; b = 7 In [341]: c = 8; d = 4 In [342]: if a < b or c > d: .....: print 'Made it' Made it
In this example, the comparison c >
d never gets evaluated because the first comparison was
True.
for loops are for
iterating over a collection (like a list or tuple) or an iterater. The
standard syntax for a for loop
is:
for value in collection:
# do something with valueA for loop can be advanced to
the next iteration, skipping the remainder of the block, using the
continue keyword.
Consider this code which sums up integers in a list and skips None values:
sequence = [1, 2, None, 4, None, 5]
total = 0
for value in sequence:
if value is None:
continue
total += valueA for loop can be exited
altogether using the break keyword. This
code sums elements of the list until a 5 is reached:
sequence = [1, 2, 0, 4, 6, 5, 2, 1]
total_until_5 = 0
for value in sequence:
if value == 5:
break
total_until_5 += valueAs we will see in more detail, if the elements in the collection
or iterator are sequences (tuples or lists, say), they can be
conveniently unpacked into variables in the
for loop statement:
for a, b, c in iterator:
# do somethingA while loop specifies
a condition and a block of code that is to be executed until the
condition evaluates to False or the
loop is explicitly ended with break:
x = 256
total = 0
while x > 0:
if total > 500:
break
total += x
x = x // 2pass is the “no-op”
statement in Python. It can be used in blocks where no action is to be
taken; it is only required because Python uses whitespace to delimit
blocks:
if x < 0:
print 'negative!'
elif x == 0:
# TODO: put something smart here
pass
else:
print 'positive!'It’s common to use pass as a
place-holder in code while working on a new piece of
functionality:
def f(x, y, z):
# TODO: implement this function!
passHandling Python errors or exceptions gracefully is an
important part of building robust programs. In data analysis
applications, many functions only work on certain kinds of input. As
an example, Python’s float function is
capable of casting a string to a floating point number, but fails with
ValueError on
improper inputs:
In [343]: float('1.2345')
Out[343]: 1.2345
In [344]: float('something')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-344-439904410854> in <module>()
----> 1 float('something')
ValueError: could not convert string to float: somethingSuppose we wanted a version of float that fails gracefully, returning the
input argument. We can do this by writing a function that encloses the
call to float in a try/except
block:
def attempt_float(x):
try:
return float(x)
except:
return xThe code in the except part of the
block will only be executed if float(x) raises an exception:
In [346]: attempt_float('1.2345')
Out[346]: 1.2345
In [347]: attempt_float('something')
Out[347]: 'something'You might notice that float
can raise exceptions other than ValueError:
In [348]: float((1, 2)) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-348-842079ebb635> in <module>() ----> 1 float((1, 2)) TypeError: float() argument must be a string or a number
You might want to only suppress ValueError, since a
TypeError (the input
was not a string or numeric value) might indicate a legitimate bug in
your program. To do that, write the exception type after except:
def attempt_float(x):
try:
return float(x)
except ValueError:
return xWe have then:
In [350]: attempt_float((1, 2))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-350-9bdfd730cead> in <module>()
----> 1 attempt_float((1, 2))
<ipython-input-349-3e06b8379b6b> in attempt_float(x)
1 def attempt_float(x):
2 try:
----> 3 return float(x)
4 except ValueError:
5 return x
TypeError: float() argument must be a string or a numberYou can catch multiple exception types by writing a tuple of exception types instead (the parentheses are required):
def attempt_float(x):
try:
return float(x)
except (TypeError, ValueError):
return xIn some cases, you may not want to suppress an exception, but
you want some code to be executed regardless of whether the code in
the try block succeeds or
not. To do this, use finally:
f = open(path, 'w')
try:
write_to_file(f)
finally:
f.close()Here, the file handle f will
always get closed. Similarly, you can have code
that executes only if the try:
block succeeds using else:
f = open(path, 'w')
try:
write_to_file(f)
except:
print 'Failed'
else:
print 'Succeeded'
finally:
f.close()The range function
produces a list of evenly-spaced integers:
In [352]: range(10) Out[352]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Both a start, end, and step can be given:
In [353]: range(0, 20, 2) Out[353]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
As you can see, range
produces integers up to but not including the endpoint. A common use
of range is for iterating through
sequences by index:
seq = [1, 2, 3, 4]
for i in range(len(seq)):
val = seq[i]For very long ranges, it’s recommended to use xrange, which takes the same arguments as
range but returns an iterator that
generates integers one by one rather than generating all of them
up-front and storing them in a (potentially very large) list. This
snippet sums all numbers from 0 to 9999 that are multiples of 3 or
5:
sum = 0
for i in xrange(10000):
# % is the modulo operator
if i % 3 == 0 or i % 5 == 0:
sum += iA ternary expression in Python
allows you combine an if-else block
which produces a value into a single line or expression. The syntax
for this in Python is
value =true-exprif condition elsefalse-expr
Here, true-expr and
false-expr can be any Python expressions.
It has the identical effect as the more verbose
ifcondition: value =true-exprelse: value =false-expr
This is a more concrete example:
In [354]: x = 5 In [355]: 'Non-negative' if x >= 0 else 'Negative' Out[355]: 'Non-negative'
As with if-else blocks, only
one of the expressions will be evaluated. While it may be tempting to
always use ternary expressions to condense your code, realize that you
may sacrifice readability if the condition as well and the true and
false expressions are very complex.
Python’s data structures are simple, but powerful. Mastering their use is a critical part of becoming a proficient Python programmer.
A tuple is a one-dimensional, fixed-length, immutable sequence of Python objects. The easiest way to create one is with a comma-separated sequence of values:
In [356]: tup = 4, 5, 6 In [357]: tup Out[357]: (4, 5, 6)
When defining tuples in more complicated expressions, it’s often necessary to enclose the values in parentheses, as in this example of creating a tuple of tuples:
In [358]: nested_tup = (4, 5, 6), (7, 8) In [359]: nested_tup Out[359]: ((4, 5, 6), (7, 8))
Any sequence or iterator can be converted to a tuple by invoking
tuple:
In [360]: tuple([4, 0, 2])
Out[360]: (4, 0, 2)
In [361]: tup = tuple('string')
In [362]: tup
Out[362]: ('s', 't', 'r', 'i', 'n', 'g')Elements can be accessed with square brackets [] as with most other
sequence types. Like C, C++, Java, and many other languages, sequences
are 0-indexed in Python:
In [363]: tup[0] Out[363]: 's'
While the objects stored in a tuple may be mutable themselves, once created it’s not possible to modify which object is stored in each slot:
In [364]: tup = tuple(['foo', [1, 2], True])
In [365]: tup[2] = False
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-365-c7308343b841> in <module>()
----> 1 tup[2] = False
TypeError: 'tuple' object does not support item assignment
# however
In [366]: tup[1].append(3)
In [367]: tup
Out[367]: ('foo', [1, 2, 3], True)Tuples can be concatenated using the + operator to produce
longer tuples:
In [368]: (4, None, 'foo') + (6, 0) + ('bar',)
Out[368]: (4, None, 'foo', 6, 0, 'bar')Multiplying a tuple by an integer, as with lists, has the effect of concatenating together that many copies of the tuple.
In [369]: ('foo', 'bar') * 4
Out[369]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')Note that the objects themselves are not copied, only the references to them.
If you try to assign to a tuple-like expression of variables, Python will attempt to unpack the value on the right-hand side of the equals sign:
In [370]: tup = (4, 5, 6) In [371]: a, b, c = tup In [372]: b Out[372]: 5
Even sequences with nested tuples can be unpacked:
In [373]: tup = 4, 5, (6, 7) In [374]: a, b, (c, d) = tup In [375]: d Out[375]: 7
Using this functionality it’s easy to swap variable names, a task which in many languages might look like:
tmp = a a = b b = tmp
b, a = a, b
One of the most common uses of variable unpacking when iterating over sequences of tuples or lists:
seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
for a, b, c in seq:
passAnother common use is for returning multiple values from a function. More on this later.
In contrast with tuples, lists are variable-length and
their contents can be modified. They can be defined using square
brackets [] or using the
list type
function:
In [378]: a_list = [2, 3, 7, None]
In [379]: tup = ('foo', 'bar', 'baz')
In [380]: b_list = list(tup) In [381]: b_list
Out[381]: ['foo', 'bar', 'baz']
In [382]: b_list[1] = 'peekaboo' In [383]: b_list
Out[383]: ['foo', 'peekaboo', 'baz']Lists and tuples are semantically similar as one-dimensional sequences of objects and thus can be used interchangeably in many functions.
Elements can be appended to the end of the list with the
append method:
In [384]: b_list.append('dwarf')
In [385]: b_list
Out[385]: ['foo', 'peekaboo', 'baz', 'dwarf']Using insert you can insert
an element at a specific location in the list:
In [386]: b_list.insert(1, 'red') In [387]: b_list Out[387]: ['foo', 'red', 'peekaboo', 'baz', 'dwarf']
Warning
insert is
computationally expensive compared with append as
references to subsequent elements have to be shifted internally to
make room for the new element.
The inverse operation to insert is pop, which removes
and returns an element at a particular index:
In [388]: b_list.pop(2) Out[388]: 'peekaboo' In [389]: b_list Out[389]: ['foo', 'red', 'baz', 'dwarf']
Elements can be removed by value using remove, which locates
the first such value and removes it from the last:
In [390]: b_list.append('foo')
In [391]: b_list.remove('foo')
In [392]: b_list
Out[392]: ['red', 'baz', 'dwarf', 'foo']If performance is not a concern, by using append and remove, a Python list can be used as a
perfectly suitable “multi-set” data structure.
You can check if a list contains a value using the in keyword:
In [393]: 'dwarf' in b_list Out[393]: True
Note that checking whether a list contains a value is a lot slower than dicts and sets as Python makes a linear scan across the values of the list, whereas the others (based on hash tables) can make the check in constant time.
Similar to tuples, adding two lists together with
+ concatenates
them:
In [394]: [4, None, 'foo'] + [7, 8, (2, 3)] Out[394]: [4, None, 'foo', 7, 8, (2, 3)]
If you have a list already defined, you can append multiple
elements to it using the extend method:
In [395]: x = [4, None, 'foo'] In [396]: x.extend([7, 8, (2, 3)]) In [397]: x Out[397]: [4, None, 'foo', 7, 8, (2, 3)]
Note that list concatenation is a compartively expensive
operation since a new list must be created and the objects copied
over. Using extend to append
elements to an existing list, especially if you are building up a
large list, is usually preferable. Thus,
everything = []
for chunk in list_of_lists:
everything.extend(chunk)is faster than than the concatenative alternative
everything = []
for chunk in list_of_lists:
everything = everything + chunkA list can be sorted in-place (without creating a new
object) by calling its sort function:
In [398]: a = [7, 2, 5, 1, 3] In [399]: a.sort() In [400]: a Out[400]: [1, 2, 3, 5, 7]
sort has a few options that
will occasionally come in handy. One is the ability to pass a
secondary sort key, i.e. a function that produces
a value to use to sort the objects. For example, we could sort a
collection of strings by their lengths:
In [401]: b = ['saw', 'small', 'He', 'foxes', 'six'] In [402]: b.sort(key=len) In [403]: b Out[403]: ['He', 'saw', 'six', 'small', 'foxes']
The built-in bisect module
implements binary-search and insertion into a sorted list. bisect.bisect finds the location where an
element should be inserted to keep it sorted, while bisect.insort
actually inserts the element into that location:
In [404]: import bisect
In [405]: c = [1, 2, 2, 2, 3, 4, 7]
In [406]: bisect.bisect(c, 2) In [407]: bisect.bisect(c, 5)
Out[406]: 4 Out[407]: 6
In [408]: bisect.insort(c, 6)
In [409]: c
Out[409]: [1, 2, 2, 2, 3, 4, 6, 7]You can select sections of list-like types (arrays,
tuples, NumPy arrays) by using slice notation, which in its basic form
consists of start:stop passed to
the indexing operator []:
In [410]: seq = [7, 2, 3, 7, 5, 6, 0, 1] In [411]: seq[1:5] Out[411]: [2, 3, 7, 5]
Slices can also be assigned to with a sequence:
In [412]: seq[3:4] = [6, 3] In [413]: seq Out[413]: [7, 2, 3, 6, 3, 5, 6, 0, 1]
While element at the start index is
included, the stop index is not
included, so that the number of elements in the result is stop - start.
Either the start or stop can be omitted
in which case they default to the start of the sequence and the end of
the sequence, respectively:
In [414]: seq[:5] In [415]: seq[3:] Out[414]: [7, 2, 3, 6, 3] Out[415]: [6, 3, 5, 6, 0, 1]
Negative indices slice the sequence relative to the end:
In [416]: seq[-4:] In [417]: seq[-6:-2] Out[416]: [5, 6, 0, 1] Out[417]: [6, 3, 5, 6]
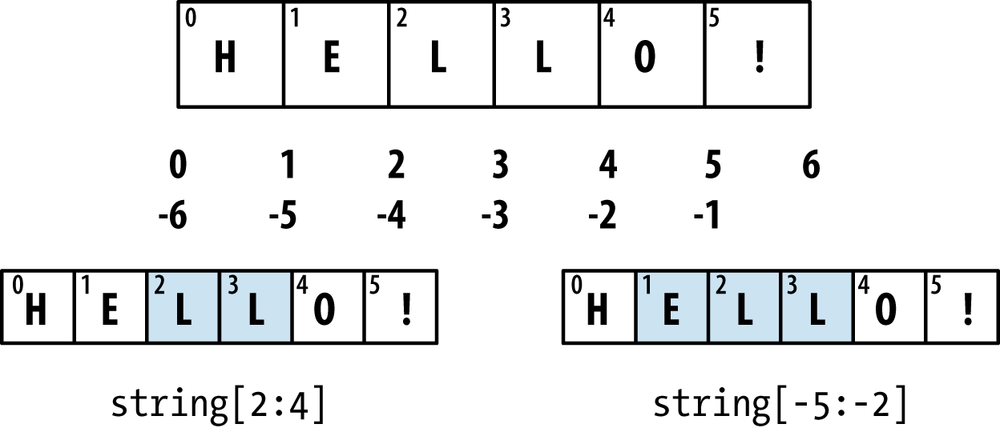
Slicing semantics takes a bit of getting used to, especially if you’re coming from R or MATLAB. See Figure A-2 for a helpful illustrating of slicing with positive and negative integers.
A step can also be used
after a second colon to, say, take every other element:
In [418]: seq[::2] Out[418]: [7, 3, 3, 6, 1]
A clever use of this is to pass -1 which has the useful effect of reversing
a list or tuple:
In [419]: seq[::-1] Out[419]: [1, 0, 6, 5, 3, 6, 3, 2, 7]
Python has a handful of useful sequence functions that you should familiarize yourself with and use at any opportunity.
It’s common when iterating over a sequence to want to keep track of the index of the current item. A do-it-yourself approach would look like:
i = 0 for value in collection: # do something with value i += 1
Since this is so common, Python has a built-in function enumerate which returns a sequence of
(i, value) tuples:
for i, value in enumerate(collection): # do something with value
When indexing data, a useful pattern that uses enumerate is computing a dict mapping the values of a sequence (which
are assumed to be unique) to their locations in the
sequence:
In [420]: some_list = ['foo', 'bar', 'baz']
In [421]: mapping = dict((v, i) for i, v in enumerate(some_list))
In [422]: mapping
Out[422]: {'bar': 1, 'baz': 2, 'foo': 0}The sorted function
returns a new sorted list from the elements of any sequence:
In [423]: sorted([7, 1, 2, 6, 0, 3, 2])
Out[423]: [0, 1, 2, 2, 3, 6, 7]
In [424]: sorted('horse race')
Out[424]: [' ', 'a', 'c', 'e', 'e', 'h', 'o', 'r', 'r', 's']A common pattern for getting a sorted list of the unique
elements in a sequence is to combine sorted with set:
In [425]: sorted(set('this is just some string'))
Out[425]: [' ', 'e', 'g', 'h', 'i', 'j', 'm', 'n', 'o', 'r', 's', 't', 'u']zip “pairs” up the
elements of a number of lists, tuples, or other sequences, to create a
list of tuples:
In [426]: seq1 = ['foo', 'bar', 'baz']
In [427]: seq2 = ['one', 'two', 'three']
In [428]: zip(seq1, seq2)
Out[428]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]zip can take an arbitrary
number of sequences, and the number of elements it produces is
determined by the shortest sequence:
In [429]: seq3 = [False, True]
In [430]: zip(seq1, seq2, seq3)
Out[430]: [('foo', 'one', False), ('bar', 'two', True)]A very common use of zip is
for simultaneously iterating over multiple sequences, possibly also
combined with enumerate:
In [431]: for i, (a, b) in enumerate(zip(seq1, seq2)):
.....: print('%d: %s, %s' % (i, a, b))
.....:
0: foo, one
1: bar, two
2: baz, threeGiven a “zipped” sequence, zip can be applied in a clever way to
“unzip” the sequence. Another way to think about this is converting a
list of rows into a list of
columns. The syntax, which looks a bit magical,
is:
In [432]: pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'),
.....: ('Schilling', 'Curt')]
In [433]: first_names, last_names = zip(*pitchers)
In [434]: first_names
Out[434]: ('Nolan', 'Roger', 'Schilling')
In [435]: last_names
Out[435]: ('Ryan', 'Clemens', 'Curt')We’ll look in more detail at the use of * in a function call. It is equivalent to
the following:
zip(seq[0], seq[1], ..., seq[len(seq) - 1])
dict is likely the most
important built-in Python data structure. A more common name for it is
hash map or associative array.
It is a flexibly-sized collection of key-value pairs, where
key and value are Python
objects. One way to create one is by using curly braces {} and using colons to
separate keys and values:
In [437]: empty_dict = {}
In [438]: d1 = {'a' : 'some value', 'b' : [1, 2, 3, 4]}
In [439]: d1
Out[439]: {'a': 'some value', 'b': [1, 2, 3, 4]}Elements can be accessed and inserted or set using the same syntax as accessing elements of a list or tuple:
In [440]: d1[7] = 'an integer'
In [441]: d1
Out[441]: {7: 'an integer', 'a': 'some value', 'b': [1, 2, 3, 4]}
In [442]: d1['b']
Out[442]: [1, 2, 3, 4]You can check if a dict contains a key using the same syntax as with checking whether a list or tuple contains a value:
In [443]: 'b' in d1 Out[443]: True
Values can be deleted either using the del keyword or the
pop method (which
simultaneously returns the value and deletes the key):
In [444]: d1[5] = 'some value'
In [445]: d1['dummy'] = 'another value'
In [446]: del d1[5]
In [447]: ret = d1.pop('dummy') In [448]: ret
Out[448]: 'another value'The keys and values method give you
lists of the keys and values, respectively. While the key-value pairs
are not in any particular order, these functions output the keys and
values in the same order:
In [449]: d1.keys() In [450]: d1.values() Out[449]: ['a', 'b', 7] Out[450]: ['some value', [1, 2, 3, 4], 'an integer']
One dict can be merged into another using the update method:
In [451]: d1.update({'b' : 'foo', 'c' : 12})
In [452]: d1
Out[452]: {7: 'an integer', 'a': 'some value', 'b': 'foo', 'c': 12}It’s common to occasionally end up with two sequences that you want to pair up element-wise in a dict. As a first cut, you might write code like this:
mapping = {}
for key, value in zip(key_list, value_list):
mapping[key] = valueSince a dict is essentially a collection of 2-tuples, it should
be no shock that the dict type
function accepts a list of 2-tuples:
In [453]: mapping = dict(zip(range(5), reversed(range(5))))
In [454]: mapping
Out[454]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}In a later section we’ll talk about dict comprehensions, another elegant way to construct dicts.
It’s very common to have logic like:
if key in some_dict:
value = some_dict[key]
else:
value = default_valueThus, the dict methods get and pop can take a default value to be returned,
so that the above if-else block can be
written simply as:
value = some_dict.get(key, default_value)
get by default will
return None if the key is not
present, while pop will raise an
exception. With setting values, a common case is
for the values in a dict to be other collections, like lists. For
example, you could imagine categorizing a list of words by their first
letters as a dict of lists:
In [455]: words = ['apple', 'bat', 'bar', 'atom', 'book']
In [456]: by_letter = {}
In [457]: for word in words:
.....: letter = word[0]
.....: if letter not in by_letter:
.....: by_letter[letter] = [word]
.....: else:
.....: by_letter[letter].append(word)
.....:
In [458]: by_letter
Out[458]: {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}The setdefault dict
method is for precisely this purpose. The if-else block above
can be rewritten as:
by_letter.setdefault(letter, []).append(word)
The built-in collections module
has a useful class, defaultdict,
which makes this even easier. One is created by passing a type or
function for generating the default value for each slot in the
dict:
from collections import defaultdict
by_letter = defaultdict(list)
for word in words:
by_letter[word[0]].append(word)The initializer to defaultdict only needs to be a callable
object (e.g. any function), not necessarily a type. Thus, if you
wanted the default value to be 4 you could pass a function returning
4
counts = defaultdict(lambda: 4)
While the values of a dict can be any Python object, the
keys have to be immutable objects like scalar types (int, float,
string) or tuples (all the objects in the tuple need to be immutable,
too). The technical term here is hashability. You can check whether
an object is hashable (can be used as a key in a dict) with the
hash function:
In [459]: hash('string')
Out[459]: -9167918882415130555
In [460]: hash((1, 2, (2, 3)))
Out[460]: 1097636502276347782
In [461]: hash((1, 2, [2, 3])) # fails because lists are mutable
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-461-800cd14ba8be> in <module>()
----> 1 hash((1, 2, [2, 3])) # fails because lists are mutable
TypeError: unhashable type: 'list'To use a list as a key, an easy fix is to convert it to a tuple:
In [462]: d = {}
In [463]: d[tuple([1, 2, 3])] = 5
In [464]: d
Out[464]: {(1, 2, 3): 5}A set is an unordered collection of unique elements. You
can think of them like dicts, but keys only, no values. A set can be
created in two ways: via the set function or using a
set literal with curly braces:
In [465]: set([2, 2, 2, 1, 3, 3])
Out[465]: set([1, 2, 3])
In [466]: {2, 2, 2, 1, 3, 3}
Out[466]: set([1, 2, 3])Sets support mathematical set operations like union, intersection, difference, and symmetric difference. See Table A-3 for a list of commonly used set methods.
In [467]: a = {1, 2, 3, 4, 5}
In [468]: b = {3, 4, 5, 6, 7, 8}
In [469]: a | b # union (or)
Out[469]: set([1, 2, 3, 4, 5, 6, 7, 8])
In [470]: a & b # intersection (and)
Out[470]: set([3, 4, 5])
In [471]: a - b # difference
Out[471]: set([1, 2])
In [472]: a ^ b # symmetric difference (xor)
Out[472]: set([1, 2, 6, 7, 8])You can also check if a set is a subset of (is contained in) or a superset of (contains all elements of) another set:
In [473]: a_set = {1, 2, 3, 4, 5}
In [474]: {1, 2, 3}.issubset(a_set)
Out[474]: True
In [475]: a_set.issuperset({1, 2, 3})
Out[475]: TrueAs you might guess, sets are equal if their contents are equal:
In [476]: {1, 2, 3} == {3, 2, 1}
Out[476]: TrueTable A-3. Python Set Operations
List comprehensions are one of the most-loved Python language features. They allow you to concisely form a new list by filtering the elements of a collection and transforming the elements passing the filter in one conscise expression. They take the basic form:
[exprfor val in collection ifcondition]
This is equivalent to the following for loop:
result = []
for val in collection:
if condition:
result.append(expr)The filter condition can be omitted, leaving only the expression. For example, given a list of strings, we could filter out strings with length 2 or less and also convert them to uppercase like this:
In [477]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python'] In [478]: [x.upper() for x in strings if len(x) > 2] Out[478]: ['BAT', 'CAR', 'DOVE', 'PYTHON']
Set and dict comprehensions are a natural extension, producing sets and dicts in a idiomatically similar way instead of lists. A dict comprehension looks like this:
dict_comp = {key-expr : value-expr for value in collection
if condition}A set comprehension looks like the equivalent list comprehension except with curly braces instead of square brackets:
set_comp = {expr for value in collection if condition}Like list comprehensions, set and dict comprehensions are just syntactic sugar, but they similarly can make code both easier to write and read. Consider the list of strings above. Suppose we wanted a set containing just the lengths of the strings contained in the collection; this could be easily computed using a set comprehension:
In [479]: unique_lengths = {len(x) for x in strings}
In [480]: unique_lengths
Out[480]: set([1, 2, 3, 4, 6])As a simple dict comprehension example, we could create a lookup map of these strings to their locations in the list:
In [481]: loc_mapping = {val : index for index, val in enumerate(strings)}
In [482]: loc_mapping
Out[482]: {'a': 0, 'as': 1, 'bat': 2, 'car': 3, 'dove': 4, 'python': 5}Note that this dict could be equivalently constructed by:
loc_mapping = dict((val, idx) for idx, val in enumerate(strings))
The dict comprehension version is shorter and cleaner in my opinion.
Note
Dict and set comprehensions were added to Python fairly recently in Python 2.7 and Python 3.1+.
Suppose we have a list of lists containing some boy and girl names:
In [483]: all_data = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], .....: ['Susie', 'Casey', 'Jill', 'Ana', 'Eva', 'Jennifer', 'Stephanie']]
You might have gotten these names from a couple of files and
decided to keep the boy and girl names separate. Now, suppose we
wanted to get a single list containing all names with two or more
e’s in them. We could certainly do
this with a simple for loop:
names_of_interest = []
for names in all_data:
enough_es = [name for name in names if name.count('e') >= 2]
names_of_interest.extend(enough_es)You can actually wrap this whole operation up in a single nested list comprehension, which will look like:
In [484]: result = [name for names in all_data for name in names
.....: if name.count('e') >= 2]
In [485]: result
Out[485]: ['Jefferson', 'Wesley', 'Steven', 'Jennifer', 'Stephanie']At first, nested list comprehensions are a bit hard to wrap your
head around. The for parts of the
list comprehension are arranged according to the order of nesting, and
any filter condition is put at the end as before. Here is another
example where we “flatten” a list of tuples of integers into a simple
list of integers:
In [486]: some_tuples = [(1, 2, 3), (4, 5, 6), (7, 8, 9)] In [487]: flattened = [x for tup in some_tuples for x in tup] In [488]: flattened Out[488]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Keep in mind that the order of the for expressions would be the same if you
wrote a nested for loop instead of
a list comprehension:
flattened = []
for tup in some_tuples:
for x in tup:
flattened.append(x)You can have arbitrarily many levels of nesting, though if you have more than two or three levels of nesting you should probably start to question your data structure design. It’s important to distinguish the above syntax from a list comprehension inside a list comprehension, which is also perfectly valid:
In [229]: [[x for x in tup] for tup in some_tuples]
Functions are the primary and most important method of code
organization and reuse in Python. There may not be such a thing as having
too many functions. In fact, I would argue that most programmers doing
data analysis don’t write enough functions! As you have likely inferred
from prior examples, functions are declared using the def keyword and returned
from using the return keyword:
def my_function(x, y, z=1.5):
if z > 1:
return z * (x + y)
else:
return z / (x + y)There is no issue with having multiple return statements. If the
end of a function is reached without encountering a return statement,
None is returned.
Each function can have some number of
positional arguments and some number of keyword arguments. Keyword arguments
are most commonly used to specify default values or optional arguments. In
the above function, x and y are positional arguments while z is a keyword argument. This means that it can
be called in either of these equivalent ways:
my_function(5, 6, z=0.7) my_function(3.14, 7, 3.5)
The main restriction on function arguments is that the keyword arguments must follow the positional arguments (if any). You can specify keyword arguments in any order; this frees you from having to remember which order the function arguments were specified in and only what their names are.
Functions can access variables in two different scopes: global and local. An alternate and more descriptive name describing a variable scope in Python is a namespace. Any variables that are assigned within a function by default are assigned to the local namespace. The local namespace is created when the function is called and immediately populated by the function’s arguments. After the function is finished, the local namespace is destroyed (with some exceptions, see section on closures below). Consider the following function:
def func():
a = []
for i in range(5):
a.append(i)Upon calling func(), the empty
list a is created, 5 elements are
appended, then a is destroyed when
the function exits. Suppose instead we had declared a
a = []
def func():
for i in range(5):
a.append(i)Assigning global variables within a function is possible, but
those variables must be declared as global using the global keyword:
In [489]: a = None In [490]: def bind_a_variable(): .....: global a .....: a = [] .....: bind_a_variable() .....: In [491]: print a []
Caution
I generally discourage people from using the global keyword frequently. Typically global
variables are used to store some kind of state in a system. If you
find yourself using a lot of them, it’s probably a sign that some
object-oriented programming (using classes) is in order.
Functions can be declared anywhere, and there is no problem with having local functions that are dynamically created when a function is called:
def outer_function(x, y, z):
def inner_function(a, b, c):
pass
passIn the above code, the inner_function will not exist until outer_function is called. As soon as outer_function is done executing, the inner_function is destroyed.
Nested inner functions can access the local namespace of the enclosing function, but they cannot bind new variables in it. I’ll talk a bit more about this in the section on closures.
In a strict sense, all functions are local to some scope, that scope may just be the module level scope.
When I first programmed in Python after having programmed in Java and C++, one of my favorite features was the ability to return multiple values from a function. Here’s a simple example:
def f():
a = 5
b = 6
c = 7
return a, b, c
a, b, c = f()In data analysis and other scientific applications, you will likely find yourself doing this very often as many functions may have multiple outputs, whether those are data structures or other auxiliary data computed inside the function. If you think about tuple packing and unpacking from earlier in this chapter, you may realize that what’s happening here is that the function is actually just returning one object, namely a tuple, which is then being unpacked into the result variables. In the above example, we could have done instead:
return_value = f()
In this case, return_value
would be, as you may guess, a 3-tuple with the three returned variables.
A potentially attractive alternative to returning multiple values like
above might be to return a dict instead:
def f():
a = 5
b = 6
c = 7
return {'a' : a, 'b' : b, 'c' : c}Since Python functions are objects, many constructs can be easily expressed that are difficult to do in other languages. Suppose we were doing some data cleaning and needed to apply a bunch of transformations to the following list of strings:
states = [' Alabama ', 'Georgia!', 'Georgia', 'georgia', 'FlOrIda',
'south carolina##', 'West virginia?']Anyone who has ever worked with user-submitted survey data can expect messy results like these. Lots of things need to happen to make this list of strings uniform and ready for analysis: whitespace stripping, removing punctuation symbols, and proper capitalization. As a first pass, we might write some code like:
import re # Regular expression module
def clean_strings(strings):
result = []
for value in strings:
value = value.strip()
value = re.sub('[!#?]', '', value) # remove punctuation
value = value.title()
result.append(value)
return resultThe result looks like this:
In [15]: clean_strings(states) Out[15]: ['Alabama', 'Georgia', 'Georgia', 'Georgia', 'Florida', 'South Carolina', 'West Virginia']
An alternate approach that you may find useful is to make a list of the operations you want to apply to a particular set of strings:
def remove_punctuation(value):
return re.sub('[!#?]', '', value)
clean_ops = [str.strip, remove_punctuation, str.title]
def clean_strings(strings, ops):
result = []
for value in strings:
for function in ops:
value = function(value)
result.append(value)
return resultThen we have
In [22]: clean_strings(states, clean_ops) Out[22]: ['Alabama', 'Georgia', 'Georgia', 'Georgia', 'Florida', 'South Carolina', 'West Virginia']
A more functional pattern like this enables
you to easily modify how the strings are transformed at a very high
level. The clean_strings function is
also now more reusable!
You can naturally use functions as arguments to other functions
like the built-in map function, which
applies a function to a collection of some kind:
In [23]: map(remove_punctuation, states) Out[23]: [' Alabama ', 'Georgia', 'Georgia', 'georgia', 'FlOrIda', 'south carolina', 'West virginia']
Python has support for so-called
anonymous or lambda functions, which are really
just simple functions consisting of a single statement, the result of
which is the return value. They are defined using the lambda keyword, which
has no meaning other than “we are declaring an anonymous
function.”
def short_function(x):
return x * 2
equiv_anon = lambda x: x * 2I usually refer to these as lambda functions in the rest of the book. They are especially convenient in data analysis because, as you’ll see, there are many cases where data transformation functions will take functions as arguments. It’s often less typing (and clearer) to pass a lambda function as opposed to writing a full-out function declaration or even assigning the lambda function to a local variable. For example, consider this silly example:
def apply_to_list(some_list, f):
return [f(x) for x in some_list]
ints = [4, 0, 1, 5, 6]
apply_to_list(ints, lambda x: x * 2)You could also have written [x * 2 for x
in ints], but here we were able to succintly pass a custom
operator to the apply_to_list
function.
As another example, suppose you wanted to sort a collection of strings by the number of distinct letters in each string:
In [492]: strings = ['foo', 'card', 'bar', 'aaaa', 'abab']
Here we could pass a lambda function to the list’s sort method:
In [493]: strings.sort(key=lambda x: len(set(list(x)))) In [494]: strings Out[494]: ['aaaa', 'foo', 'abab', 'bar', 'card']
Closures are nothing to fear. They can actually be a very useful and powerful tool in the right circumstance! In a nutshell, a closure is any dynamically-generated function returned by another function. The key property is that the returned function has access to the variables in the local namespace where it was created. Here is a very simple example:
def make_closure(a):
def closure():
print('I know the secret: %d' % a)
return closure
closure = make_closure(5)The difference between a closure and a regular Python function is
that the closure continues to have access to the namespace (the
function) where it was created, even though that function is done
executing. So in the above case, the returned closure will always print
I know the secret: 5 whenever you
call it. While it’s common to create closures whose internal state (in
this example, only the value of a) is
static, you can just as easily have a mutable object like a dict, set,
or list that can be modified. For example, here’s a function that
returns a function that keeps track of arguments it has been called
with:
def make_watcher():
have_seen = {}
def has_been_seen(x):
if x in have_seen:
return True
else:
have_seen[x] = True
return False
return has_been_seenUsing this on a sequence of integers I obtain:
In [496]: watcher = make_watcher() In [497]: vals = [5, 6, 1, 5, 1, 6, 3, 5] In [498]: [watcher(x) for x in vals] Out[498]: [False, False, False, True, True, True, False, True]
However, one technical limitation to keep in mind is that while you can mutate any internal state objects (like adding key-value pairs to a dict), you cannot bind variables in the enclosing function scope. One way to work around this is to modify a dict or list rather than binding variables:
def make_counter():
count = [0]
def counter():
# increment and return the current count
count[0] += 1
return count[0]
return counter
counter = make_counter()You might be wondering why this is useful. In practice, you can write very general functions with lots of options, then fabricate simpler, more specialized functions. Here’s an example of creating a string formatting function:
def format_and_pad(template, space):
def formatter(x):
return (template % x).rjust(space)
return formatterYou could then create a floating point formatter that always returns a length-15 string like so:
In [500]: fmt = format_and_pad('%.4f', 15)
In [501]: fmt(1.756)
Out[501]: ' 1.7560'If you learn more about object-oriented programming in Python, you might observe that these patterns also could be implemented (albeit more verbosely) using classes.
The way that function arguments work under the hood in
Python is actually very simple. When you write func(a, b, c, d=some, e=value), the positional
and keyword arguments are actually packed up into a tuple and dict,
respectively. So the internal function receives a tuple args and dict kwargs and internally does the equivalent
of:
a, b, c = args
d = kwargs.get('d', d_default_value)
e = kwargs.get('e', e_default_value)This all happens nicely behind the scenes. Of course, it also does some error checking and allows you to specify some of the positional arguments as keywords also (even if they aren’t keyword in the function declaration!).
def say_hello_then_call_f(f, *args, **kwargs):
print 'args is', args
print 'kwargs is', kwargs
print("Hello! Now I'm going to call %s" % f)
return f(*args, **kwargs)
def g(x, y, z=1):
return (x + y) / zThen if we call g with say_hello_then_call_f we get:
In [8]: say_hello_then_call_f(g, 1, 2, z=5.)
args is (1, 2)
kwargs is {'z': 5.0}
Hello! Now I'm going to call <function g at 0x2dd5cf8>
Out[8]: 0.6Currying is a fun computer science term which means deriving new functions from existing ones by partial argument application. For example, suppose we had a trivial function that adds two numbers together:
def add_numbers(x, y):
return x + yUsing this function, we could derive a new function of one
variable, add_five, that adds 5 to
its argument:
add_five = lambda y: add_numbers(5, y)
The second argument to add_numbers is said to be
curried. There’s nothing very fancy here as we
really only have defined a new function that calls an existing function.
The built-in functools module can
simplify this process using the partial
function:
from functools import partial add_five = partial(add_numbers, 5)
When discussing pandas and time series data, we’ll use this technique to create specialized functions for transforming data series
# compute 60-day moving average of time series x ma60 = lambda x: pandas.rolling_mean(x, 60) # Take the 60-day moving average of all time series in data data.apply(ma60)
Having a consistent way to iterate over sequences, like objects in a list or lines in a file, is an important Python feature. This is accomplished by means of the iterator protocol, a generic way to make objects iterable. For example, iterating over a dict yields the dict keys:
In [502]: some_dict = {'a': 1, 'b': 2, 'c': 3}
In [503]: for key in some_dict:
.....: print key,
a c bWhen you write for key in
some_dict, the Python interpreter first attempts to create an
iterator out of some_dict:
In [504]: dict_iterator = iter(some_dict) In [505]: dict_iterator Out[505]: <dictionary-keyiterator at 0x10a0a1578>
Any iterator is any object that will yield objects to the Python
interpreter when used in a context like a for loop.
Most methods expecting a list or list-like object will also accept any
iterable object. This includes built-in methods such as min, max, and sum, and type
constructors like list and tuple:
In [506]: list(dict_iterator) Out[506]: ['a', 'c', 'b']
A generator is a simple way to
construct a new iterable object. Whereas normal functions execute and
return a single value, generators return a sequence of values lazily,
pausing after each one until the next one is requested. To create a
generator, use the yield keyword
instead of return in a
function:
def squares(n=10):
print 'Generating squares from 1 to %d' % (n ** 2)
for i in xrange(1, n + 1):
yield i ** 2When you actually call the generator, no code is immediately executed:
In [2]: gen = squares() In [3]: gen Out[3]: <generator object squares at 0x34c8280>
It is not until you request elements from the generator that it begins executing its code:
In [4]: for x in gen: ...: print x, ...: Generating squares from 0 to 100 1 4 9 16 25 36 49 64 81 100
As a less trivial example, suppose we wished to find all unique ways to make change for $1 (100 cents) using an arbitrary set of coins. You can probably think of various ways to implement this and how to store the unique combinations as you come up with them. One way is to write a generator that yields lists of coins (represented as integers):
def make_change(amount, coins=[1, 5, 10, 25], hand=None):
hand = [] if hand is None else hand
if amount == 0:
yield hand
for coin in coins:
# ensures we don't give too much change, and combinations are unique
if coin > amount or (len(hand) > 0 and hand[-1] < coin):
continue
for result in make_change(amount - coin, coins=coins,
hand=hand + [coin]):
yield resultThe details of the algorithm are not that important (can you think of a shorter way?). Then we can write:
In [508]: for way in make_change(100, coins=[10, 25, 50]): .....: print way [10, 10, 10, 10, 10, 10, 10, 10, 10, 10] [25, 25, 10, 10, 10, 10, 10] [25, 25, 25, 25] [50, 10, 10, 10, 10, 10] [50, 25, 25] [50, 50] In [509]: len(list(make_change(100))) Out[509]: 242
A simple way to make a generator is by using a generator expression. This is a generator analogue to list, dict and set comprehensions; to create one, enclose what would otherwise be a list comprehension with parenthesis instead of brackets:
In [510]: gen = (x ** 2 for x in xrange(100)) In [511]: gen Out[511]: <generator object <genexpr> at 0x10a0a31e0>
This is completely equivalent to the following more verbose generator:
def _make_gen():
for x in xrange(100):
yield x ** 2
gen = _make_gen()Generator expressions can be used inside any Python function that will accept a generator:
In [512]: sum(x ** 2 for x in xrange(100))
Out[512]: 328350
In [513]: dict((i, i **2) for i in xrange(5))
Out[513]: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}The standard library itertools module has
a collection of generators for many common data algorithms. For
example, groupby takes any
sequence and a function; this groups consecutive elements in the
sequence by return value of the function. Here’s an example:
In [514]: import itertools In [515]: first_letter = lambda x: x[0] In [516]: names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven'] In [517]: for letter, names in itertools.groupby(names, first_letter): .....: print letter, list(names) # names is a generator A ['Alan', 'Adam'] W ['Wes', 'Will'] A ['Albert'] S ['Steven']
See Table A-4 for a list of a few other itertools functions I’ve frequently found useful.
Table A-4. Some useful itertools functions
Most of this book uses high-level tools like pandas.read_csv to read
data files from disk into Python data structures. However, it’s important
to understand the basics of how to work with files in Python. Fortunately,
it’s very simple, which is part of why Python is so popular for text and
file munging.
To open a file for reading or writing, use the built-in open function with either
a relative or absolute file path:
In [518]: path = 'ch13/segismundo.txt' In [519]: f = open(path)
By default, the file is opened in read-only mode 'r'. We can then treat the file handle f like a list and iterate over the lines like
so
for line in f:
passThe lines come out of the file with the end-of-line (EOL) markers intact, so you’ll often see code to get an EOL-free list of lines in a file like
In [520]: lines = [x.rstrip() for x in open(path)] In [521]: lines Out[521]: ['Suexc3xb1a el rico en su riqueza,', 'que mxc3xa1s cuidados le ofrece;', '', 'suexc3xb1a el pobre que padece', 'su miseria y su pobreza;', '', 'suexc3xb1a el que a medrar empieza,', 'suexc3xb1a el que afana y pretende,', 'suexc3xb1a el que agravia y ofende,', '', 'y en el mundo, en conclusixc3xb3n,', 'todos suexc3xb1an lo que son,', 'aunque ninguno lo entiende.', '']
If we had typed f = open(path,
'w'), a new file at ch13/segismundo.txt would have been created,
overwriting any one in its place. See below for a list of all valid file
read/write modes.
Table A-5. Python file modes
To write text to a file, you can use either the file’s write or writelines methods. For
example, we could create a version of prof_mod.py with no blank lines like so:
In [522]: with open('tmp.txt', 'w') as handle:
.....: handle.writelines(x for x in open(path) if len(x) > 1)
In [523]: open('tmp.txt').readlines()
Out[523]:
['Suexc3xb1a el rico en su riqueza,
',
'que mxc3xa1s cuidados le ofrece;
',
'suexc3xb1a el pobre que padece
',
'su miseria y su pobreza;
',
'suexc3xb1a el que a medrar empieza,
',
'suexc3xb1a el que afana y pretende,
',
'suexc3xb1a el que agravia y ofende,
',
'y en el mundo, en conclusixc3xb3n,
',
'todos suexc3xb1an lo que son,
',
'aunque ninguno lo entiende.
']See Table A-6 for many of the most commonly-used file methods.
Table A-6. Important Python file methods or attributes