
The first, and sometimes hardest part of doing any data analysis is acquiring the data from which you hope to extract information. Whether you want to look at your personal spending habits, calculate your next trade in fantasy baseball, or compare a politician’s investment returns to your own, the data you need is usually there on the web with some sense of order to it, but it’s probably not in a form that’s very useful for analysis. If this is the case, you’ll need to either manually gather the data or write a script to collect the data for you.
The granddaddy of all data formats is the data table, with a column
for each attribute and a row for each observation. You’ve seen this if
you’ve ever used Microsoft Excel, relational databases, or R’s data.frame object.
Table 5-1. An example data table
| Date | Blog | Posts |
|---|---|---|
2012-01-01 | adamlaiacano | 2 |
2012-01-01 | david | 4 |
2012-01-01 | dallas | 6 |
2012-01-02 | adamlaiacano | 0 |
2012-01-02 | david | 4 |
2012-01-02 | dallas | 6 |
Most websites store their data behind the scenes in tables within relational databases, and if those tables were accessible to the computing public, this chapter of Bad Data Handbook wouldn’t need to exist. However, it’s a web designer’s job to make this information visually appealing and interpretable, which usually means they’ll only present the reader with a relevant subset of the dataset, such as a single company’s stock price over a specific date range, or recent status updates from a single user’s social connections. Even online “database” websites are vastly different from a programmer’s version of a database. On web database websites such as LexisNexis or Yahoo! Finance, there are page dividers, text formatting, and other pieces of code to make the page look prettier and easier to interpret. To a programmer, a database is a complete collection of clean, organized data that is easily extracted and transformed into the form you see on the web. So now it’s your job to reverse-engineer the many different pages and put the data back to a form that resembles the original database form.
The process of gathering the data you want consists of two main steps. First is a web crawler that can find the page with the appropriate data, which sometimes requires submitting form information and following specific links on the web page. The second part is to “scrape” the data off of the page and onto your hard drive. Sometimes these steps are both straightforward, often one is much trickier than the other, and then there is the all too common case where both steps are tricky.
In this chapter, I’ll cover how and when you can gather data from the web, give an example of a simple scraper script, and provide some pitfalls to watch out for.
Writing the code to crawl a website and gather data should be your last resort. It’s a very expensive undertaking, both in terms of developer salary and the opportunity cost of what you could be doing with the data once it’s acquired. Before writing any web scraping code, I would consider some of the following actions.
First off, see if somebody else already did this work and made the data available. There are websites such as the Infochimps Data Marketplace and ScraperWiki that contain many useful datasets either for free or for a fee. There are also several government websites that put their data in common, easy to use formats with a searchable interface. Some good examples are www.data.gov.uk and nycopendata.socrata.com.
Also see if the data you want is available through an API (Application Programming Interface). You’ll still have to extract the data programmatically, but you can request specific pieces of information, such as all of a certain user’s Twitter followers or all of the posts on a certain Tumblr blog. Most major social networks offer an API and deliver the information in a standard format (JSON or XML) so there’s no need to try to scrape data off of the rendered web pages.
In some cases, you can try contacting the website and tell them what you want. Maybe they’ll sell you the data, or just send you a database dump if they’re really nice. My colleagues and I were once able to acquire several months worth of Taxi and Limousine Commission (TLC) data for New York City via the Freedom of Information Law (FOIL). The folks at the TLC were very nice and mailed us a DVD with three months of pick up, drop off, fare, and other information about every taxi ride in the five boroughs.
Database architects spend a lot of time optimizing the ETL (Extract,
Transform, Load) flow to take data out of a database and put it on a
webpage as efficiently as possible. This involves making sure that you
index the right columns, keep relevant data in the same table so that you
don’t have to do expensive JOIN
operations, and many other factors.
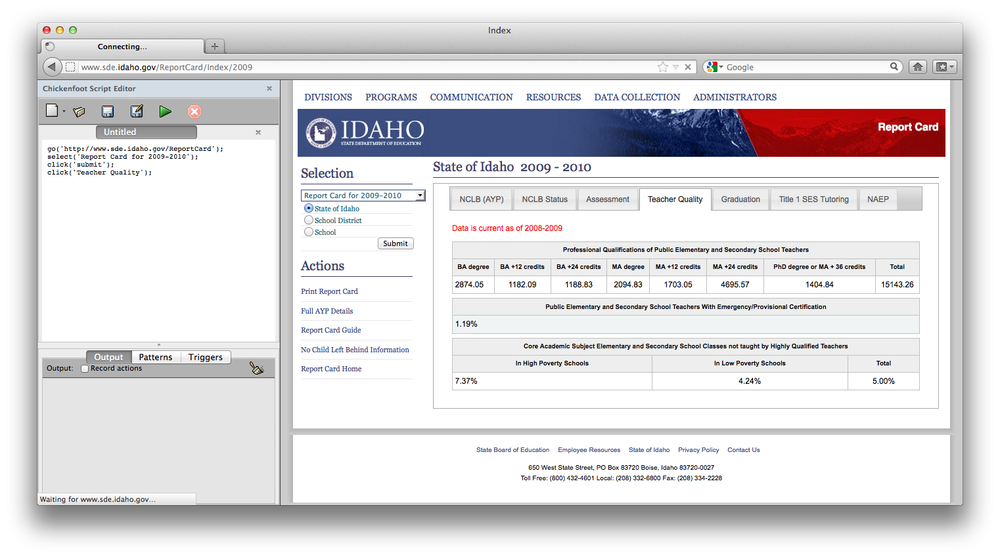
To scrape the data off a webpage, there is a similar workflow. I’ll work through an example of scraping No Child Left Behind teacher quality data from the Idaho state website. No Child Left Behind[5] requires an annual assessment of all schools that receive federal funding, and also requires the results to be made available to the public. You can easily find these results on each state’s website. The URL for Idaho is http://www.sde.idaho.gov/ReportCard. The site is very useful if you want to see how your specific school district is performing, but as data scientists, we need to see how all of the schools are performing so that we can search for trends and outliers.
In this chapter, we’ll be gathering the Teacher Quality for each of the school districts in Idaho for the year 2009. An example page that we’ll be scraping is http://bit.ly/XdPENa, pictured below. This example is written entirely in Python, though there are tools in pretty much all major scripting languages for screen scraping such as this. Just because we are used to viewing this information in a web browser doesn’t mean that’s the only way to access it. The further you can stay from an actual web browser when writing a web scraper, the better. You’ll have more tools available to you, and you can likely perform the whole process of finding, gathering, and cleaning data in fewer steps.
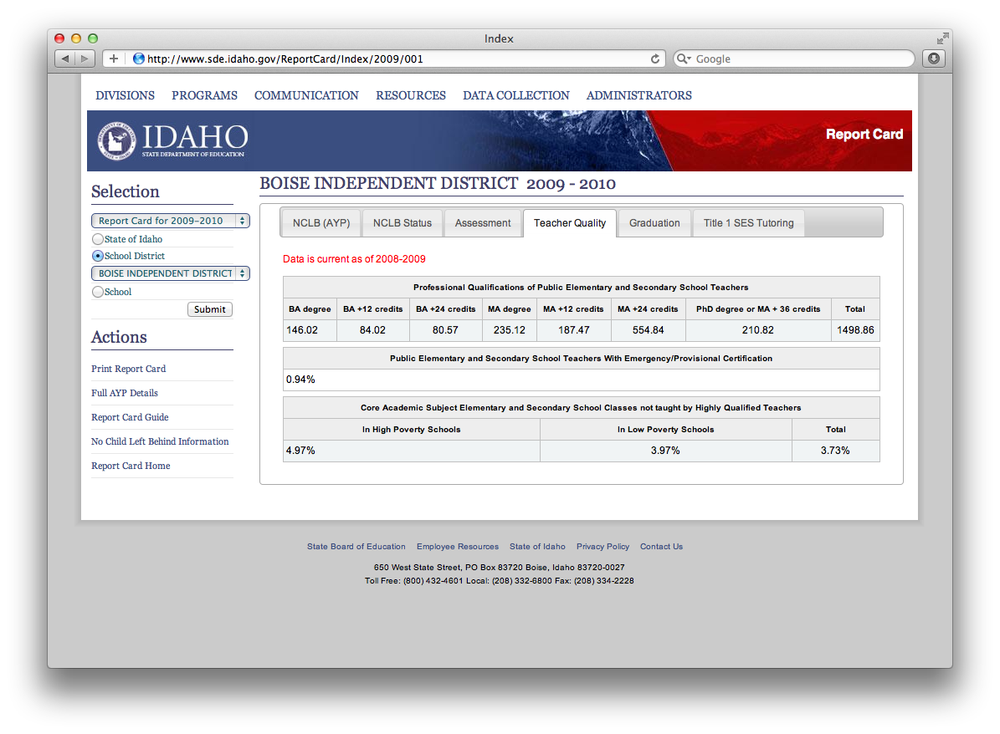
Figure 5-1. Example table to be gathered. There is an identical table for each school district in Idaho.
Extracting the data on all of these schools is a multistep process.
Find a pattern in the URLs for the different school districts
Store a copy of the web page’s HTML source code locally whenever possible
Parse web pages into clean datasets
Append new data to an existing dataset
The entire data extraction and cleaning process should be as close to fully automated as possible. This way you can re-acquire the entire dataset should it become lost or corrupted, and you can re-run the script again with minimal changes if more data becomes available.
I also can’t stress enough that you should separate these steps as much as possible within your code, especially if you’re executing your script daily/weekly/monthly to append new data. I once had a web scraping script running for several days when it suddenly started throwing errors. The problem was that the website had been completely redesigned. Fortunately, I only had to rewrite the one function that parses the HTML tables. As we make our way through the No Child Left Behind example, keep in mind that we’re only gathering data for 2009, and what would be required to modify the program to collect data on a different year. Ideally, it would only be a line or two of code to make this change.
Nearly every website has a robots.txt file that tells web crawlers (that’s you) which directories it can crawl, how often it can visit them, and so on. The rules outlined in robots.txt are not legally binding, but have been respected since the mid-1990s. You should also check the website’s terms of service, which are certainly legally binding.
Here is an example robots.txt file from App Annie, which is a website that gathers and reports the reviews for your apps in the iOS App Store.
User-agent: * Crawl-delay: 5 Sitemap: http://www.appannie.com/media/sitemaps/sitemapindex.xml Disallow: /top/*date= Disallow: /matrix/*date= Disallow: /search/* Disallow: /search_ac/ Disallow: */ranking_table/ Disallow: /top-table/* Disallow: /matrix-table/* Disallow: */ranking/history/ Disallow: */ranking/history/chart_data/
Let’s break these down one section at a time.
User-agent: *The following rules apply to everybody. Sometimes a site will allow or block specific web crawlers such as Google’s indexer.
Crawl-delay: 5Crawlers need to wait five seconds between each page load.
Sitemap: http://www.appannie.com/media/sitemaps/sitemapindex.xmlDefines which pages a web crawler should visit and how often they should be indexed. It’s a good way to help search engines index your site.
Disallow:Specifies which pages the bots are not allowed to visit. The
*acts as the familiar wildcard character.
Robots.txt should be respected even for public data, such as in our example. Even though the data is public, the servers hosting and serving the traffic may be privately owned. Fortunately, there isn’t actually a file at http://www.sde.idaho.gov/robots.txt, so we’re all set to go.
Note
For more specifics on how to interpret the rules of a robots.txt file, check out its Wikipedia page.
We first need to figure out how to navigate to the page that
contains the data. In our example, we want to loop over school
districts. If we visit http://www.sde.idaho.gov/reportcard,
we’ll see a select object with each
of the school districts.
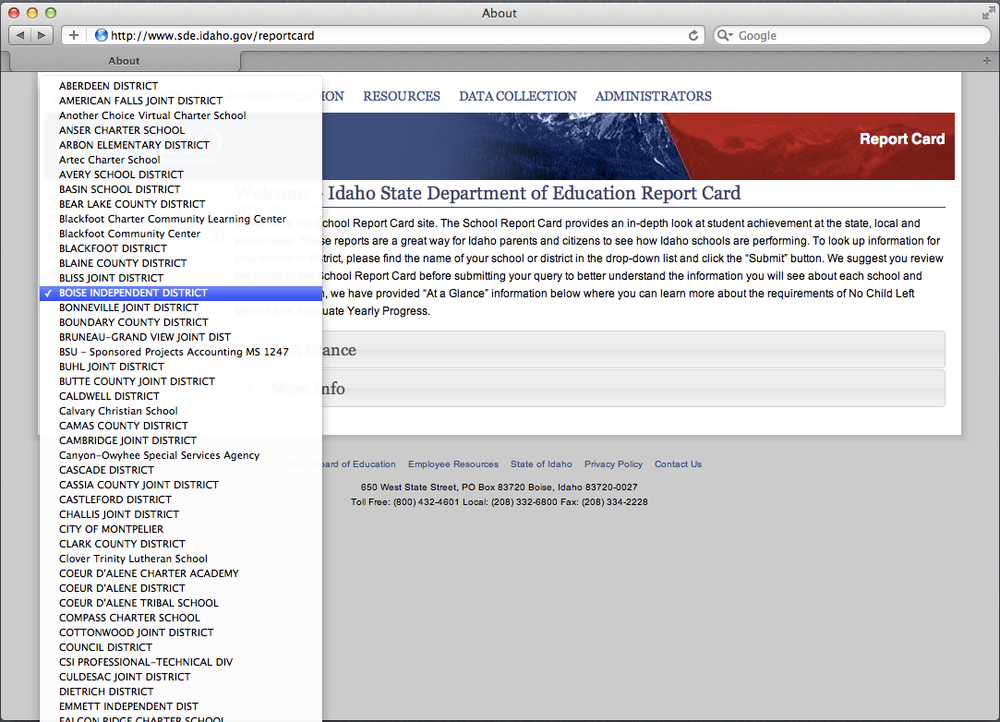
Clicking on each of these options will bring us to a page with the
pattern http://www.sde.idaho.gov/ReportCard/Index/2009/<id
number>. So all we have to do is obtain the list of
districts and their ID numbers and we can begin looping through the
pages to extract their source HTML code. If we view the HTML for http://www.sde.idaho.gov/reportcard
and find the select element with the
school districts listed, we’ll see that it will provide us with all of
the information we need:
<select id="LEA" name="LEA">
<option value="058">ABERDEEN DISTRICT</option>
<option value="381">AMERICAN FALLS JOINT DISTRICT</option>
<option value="476">Another Choice Virtual Charter School</option>
<option value="492">ANSER CHARTER SCHOOL</option>
<option value="383">ARBON ELEMENTARY DISTRICT</option>
<option value="796">Artec Charter School</option>
<option value="394">AVERY SCHOOL DISTRICT</option>
...more districts...
</select>We’ll be interested in the value attribute, which will appear in the URL
pattern for the individual district pages, and of course we’ll need the
district name itself. We can extract a list of these values with the
following function. We use the BeautifulSoup
package[6] for Python, which makes it simple to parse and navigate
HTML files.
def get_district_pages(index_url):
"""
Takes a URL string and returns a list of tuples with page IDs and district
names from the 'LEA' drop-down menu.
"""
index_page = urllib2.urlopen(index_url).read()
soup = BeautifulSoup(index_page)
drop_down = soup.find(attrs={'id':'LEA'}) #  school_districts = []
for district in drop_down.findAll('option'): #
school_districts = []
for district in drop_down.findAll('option'): #  if district.text.strip() != "" and district['value'].strip() != "":
school_districts.append(
(str((district['value'])), str(district.text.lower()))
)
return school_districts
districts = get_district_pages('http://www.sde.idaho.gov/reportcard')
if district.text.strip() != "" and district['value'].strip() != "":
school_districts.append(
(str((district['value'])), str(district.text.lower()))
)
return school_districts
districts = get_district_pages('http://www.sde.idaho.gov/reportcard')-
This finds HTML elements of any type that have the
id="LEA"attribute. In this case, it is the<select>object containing our list.-
Once we have extracted the
LEAobject, we loop through all<option>sub-elements and extract their values.
The result will be a list of tuples, with the district ID and name. The first few elements will look like this:
[('381', 'american falls joint district'),
('476', 'another choice virtual charter school'),
('492', 'anser charter school'),
('383', 'arbon elementary district'),
('796', 'artec charter school'),
...
]Now we can create a function to convert this (id, name) tuple to a URL. This is a simple
one-line function, but it’s important to use a function here in case the
URL pattern changes when the site is updated.
def build_url(district_tuple):
return 'http://www.sde.idaho.gov/ReportCard/Index/2009/%s' % district_tuple[0]Now that we have the URLs generated, we can loop through and save an offline version of each. I highly recommend doing this because most websites don’t like having their data scraped (whether it’s public information or not) and some detect bots like this. As you debug the function to parse the actual page, you will probably have to run the script several times, and it’s much faster and easier to load a local version of the file than to download it from the Web again. Additionally, if you’re gathering data from a page that changes daily (such as the front page of a media website), you will probably want to keep a history of the pages you’ve scraped in case you find a bug or decide you want more information at a later date.
Here’s a function to load a web page and save the source in flat
files with a simple id_name.html
naming convention.
def cache_page(district, cache_dir):
"""
Takes the given district tuple and saves a copy of the source code locally.
This way we don't have to wait for pages to load and don't bother the website
with requests.
"""
url = build_url(district)
# Create the cache directory if it doesn't already exist
if not cache_dir in os.listdir('.'):
os.mkdir(cache_dir)
source = urllib2.urlopen(url).read()
dest_file = os.path.join(cache_dir, "%s_%s.html" % district)
open(dest_file, 'wb').write(source)The last step is of course to parse the page contents and get
the information we want. It turns out that the Teacher Quality table
that we’ll scrape in is contained in a div tag with three total tables. The structure
looks like this:
<div id="TeacherQuality">
<p><font color="red">Data is current as of 2008-2009</font></p>
<table>
<thead>
<tr>
<th colspan="8">
Professional Qualifications of Public Elementary and Secondary
School Teachers
</th>
</tr>
<tr>
<th>BA degree</th>
<th>BA +12 credits</th>
...
</tr>
</thead>
<tbody>
<tr>
<td>58.45</td>
<td>30.94</td>
...
</tr>
</tbody>
</table>
<table>
...
</table>
<table>
...
</table>
</div>Fortunately, BeautifulSoup will let
us jump right to that div tag and
then iterate through the table
elements within it. I’m also taking a couple of other precautions here:
first, I’m checking the local cache directory for a local copy of the
source code before loading the page from the web. Second, I’m logging
any errors to a log file. If any connection is lost or there is an
anomaly on a specific web page that causes an error in the script, I can
easily revisit those pages in a second pass.
def scrape_teacher_quality(district, cache_dir=None):
"""
Takes a district id and name as a tuple and scrapes the relevant page.
"""
from BeautifulSoup import BeautifulSoup
# load data, either from web or cached directory
if cache_dir is None:
url = build_url(district)
try:
soup = BeautifulSoup(urllib2.urlopen(url).read())
except:
print "error loading url:", url
return
else:
try:
file_in = os.path.join(cache_dir, '%s_%s.html' % district)
soup = BeautifulSoup(open(file_in, 'r').read())
except:
print "file not found:", file_in
return
quality_div = soup.find('div', attrs={'id':'TeacherQuality'}) #
header = ['district_id', 'district_name']
data = list(district)
for i, table in enumerate(quality_div.findAll('table')):
header_prefix = 'table%s ' % i #
header_cells = table.findAll('th')
data_cells = table.findAll('td')
# some rows have an extra 'th' cell. If so, we need to skip it.
if len(header_cells) == len(data_cells) + 1:
header_cells = header_cells[1:]
header.extend([header_prefix + th.text.strip() for th in header_cells])
data.extend([td.text.strip() for td in data_cells])
return {
'header' : header,
'data' : data
}-
On this page, all of the different tabs are in
divtags with appropriate IDs, and all but the activedivare commented out.-
Since there are three tables and some have the same title, I’ll give the headers a prefix. In fact, headers here aren’t necessary if the data within the tables are always the same. I included them here as an example.
This code will often be very specific to the way that a web page has been coded. If a website gets redesigned, this function will probably have to be amended, so it should rely on the other functions as little as possible. You can also write functions to scrape the other tables pertaining to this school district such as NCLB Status and Adequate Yearly Progress (AYP) and execute them at the same time as this one.
Now that we have all of the pieces, we can put them all together
in the main() function. I will write
the results to a comma-delimited flat file, but you could just as easily
store them in a relational or NoSQL database, or any other kind of
datastore.
from BeautifulSoup import BeautifulSoup
import urllib2, os, csv
def main():
"""
Main funtion for crawling the data.
"""
district_pages = get_district_pages('http://www.sde.idaho.gov/reportcard')
errorlog = open('errors.log', 'wb')
for district in district_pages:
print district
try:
cache_page(district, 'data')
except:
url = build_url(district)
errorlog.write('Error loading page %s
' % url)
continue
fout = csv.writer(open('parsed_data.csv', 'wb')) #
# write the header
header = [
'district_id',
'district_name',
'ba_degree',
'ba_plus_12',
'ba_plus_24',
'ma_degree',
'ma_plus_12',
'ma_plus_24',
'phd_degree',
'degree_total',
'emergency_cert',
'poverty_high',
'poverty_low',
'poverty_total',
]
fout.writerow(header)
for district in district_pages:
parsed_dict = scrape_teacher_quality(district, cache_dir='data')
#
if parsed_dict is not None:
fout.writerow(parsed_dict['data'])
else:
errorlog.write('Error parsing district %s (%s)' % district)
del(fout)
del(errorlog)-
Python’s
csvpackage is excellent at handling escaped characters and any other annoyances that may creep up when working with flat files and is a much better option than writing strings directly.-
If you wanted to scrape other tables from the page, just drop the function call to the table’s parser function here.
I spent a few years as a full-time research assistant at a prominent business school. Part of my duties included gathering and cleaning datasets for research projects. I crawled many websites to reproduce the clean dataset that I knew sat behind the web pages. Here are a few of the more creative projects I came up against.
In my first web scraping application, I had to go through about 20GB of raw text files stored on an external website and do some simple text extraction that relied mostly on matching some regular expressions. I knew it would take a while to download all of the data, so I figured I would just process the files line-by-line as I download them.
The script I wrote was pretty simple. I used Python’s
urllib2 library to open a remote file
and scan through it line-by-line, the same way you would for a local
file. I let it run overnight and came in the next morning to find that I
couldn’t access the Internet at all. It turns out that requesting 20GB
of data a few hundred bytes at a time looks an awful lot like a college
student downloading movies through a torrent service. It was my third
day of a new job and I had already blacklisted myself. And that’s why
you always download a batch of data and parse it locally.
The structure of most of the websites that I encountered had a similar data retrieval pattern: fill out a form, reverse-engineer the results page to extract the meaningful data, repeat. One online database, however, had a more complex pattern:
Log in to the website.
Fill out a form with a company name and date range.
Dismiss a dialog box (“Do you really want to submit this query?”).
Switch to the new tab that the results open in; extract the data.
Close the new tab, returning to the original form.
Repeat.
For this, I used my favorite last-resort tool: Chickenfoot[7], which is a Firefox plug-in that allows you to programmatically interact with a web page through the browser. From the web server’s perspective, all of the requests are as if a real person was submitting these queries through their browser. Here is a simple example that will load the Idaho NCLB page that we crawled and go to the first school’s “Teacher Quality” page.
go('http://www.sde.idaho.gov/ReportCard'),
select('Report Card for 2009-2010'),
click('submit'),
click('Teacher Quality'),Chickenfoot provides a few simple commands like click, select, and find, but also gives you full access to the
Javascript DOM for extracting data and fully controlling the webpage. It
is easy to make AJAX requests, modify and submit forms, and pretty much
anything else. The disadvantage is that it is slow since it runs in the
browser and has to render each page, and doesn’t always fail gracefully
if a page doesn’t load properly.
We went through an example of scraping data from the Idaho
No Child Left Behind report card website, but not all states are as easy
to scrape as that one. Some states actually provide the raw data in
.csv format, which is great, but
others are trickier to get data out of.
One particular state (I forget which one, unfortunately) decided that Adobe Flash would be the best way to display this data. Each school has its own web page with a Flash applet showing a green (excellent), yellow (proficient), or red (failing) light for each of the subjects on which it is evaluated. Adobe Flash is an incredibly powerful platform, and for better or worse, it is a brick wall when it comes to accessing the underlying source code. That means that we had to get creative when gathering this data.
My colleagues and I put this state aside while we gathered the NCLB data for the others. We had already built the list of URLs that we would have to navigate to for each shool, but had to figure out how to get the data out of Flash. Eventually, it came to us: AppleScript. AppleScript can be a helpful tool for automating high-level tasks in OSX such as opening and closing programs, accessing calendar information in iCal, and visiting web pages in the Safari web browser. We wrote an AppleScript to tell Safari to navigate to the correct URL, then tell OSX to take a screen shot of the page, saving it with an ID number in the file name. Then we could analyze the images afterwards and look at the color of specific pixels to determine the school’s performance.
It would have to run at night, because we needed the green/yellow/red circles to be equally aligned on every page. That meant the browser window had to be active and in the same place for each screen shot. Each morning, for about a week, we came into the office to find about 2GB of screenshot images.
We used a MATLAB script to loop through all of these results and
get the color of the pixels of interest. When MATLAB loads a .jpg image file that is N pixels tall and M pixels wide, it stores it as a
three-dimensional array with dimensions NxMx3. Each of the layers
holds the red, green, and blue color intensity for the relevant pixel
with a number between 0 and 255. Red pixels would have the value
[255, 0, 0], green pixels were
[0, 255, 0], and yellow pixels were
[255, 255, 0].
Sometimes you’re trying to get data from a site that doesn’t want to be crawled (even though you’ve confirmed that you’re allowed to crawl the pages, right?). If your crawler is detected, your IP address or API key will likely be blacklisted and you won’t be able to access the site. This once happened to a coworker of mine and the entire office was blocked from accessing an important website. If you’re writing a web crawler similar to the example in this chapter on a page that you suspect will block you, it’s best to insert pauses in the crawler so that your script is less likely to be detected. This way your page requests will look less programmatic and the frequency of the requests might be low enough that they don’t annoy the website’s administrators.
Any “screen scraping” program is subject to many factors that are beyond your control and which can make the program less reliable. Data changes as websites are updated, so saving an offline version of those pages is a priority over actually parsing and extracting the live data. Slow connections cause timeouts when loading pages, so your program has to fail gracefully and move on, keeping a history of what you were and were not able to save so that you can make a second (or third or fourth) pass to get more data. However, it is sometimes a fun challenge to reverse-engineer a website and figure out how they do things under the hood, notice common design approaches, and end up with some interesting data to work with in the end.