
Chapter 11. Tagging and Structure
Structured PDF
As you’ve seen in all the previous chapters, PDF provides the ability to draw text, vectors, raster images, and even video and 3D onto a page that can be displayed or printed. However, the content is just that: a series of drawing instructions. It has no semantic or structural context. There is nothing that delineates one paragraph from another or one image from another. In fact, there isn’t even a concept of a paragraph or a word—just a bunch of glyphs and their associated encoding.
This limitation is addressed by a feature of PDF called logical structure. It enables associating a hierarchical grouping of objects, called structure elements, with the various graphic objects on the page and any additional attributes needed to sufficiently describe those objects. This is quite similar in concept to markup languages such as HTML or XML, but in PDF that structure and content are in separate logical areas of the PDF rather than being intermixed (as they are in HTML, for example). This separation allows the ordering and nesting of logical elements to be entirely independent of the order and location of graphic objects on the document’s pages.
While there is a series of predefined types of structure elements that enable the organization of a document into chapters and sections or the identification of special elements such as figures, tables, and footnotes, the facilities provided by PDF are quite extensible. This extensibility allows writers to choose what structural information to include and how to represent it, while enabling processors to navigate the file without knowing the specific structural conventions.

The Structure Tree
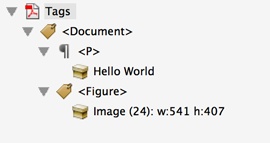
As previously mentioned, the structural elements are arranged in a hierarchical structure called the StructTree, or structure tree. At the root of the tree is the structure tree root, a dictionary whose Type key has a value of StructTreeRoot (see Example 11-1). There are two other things that are required to be present in the root: the first of the children in the tree and a grouping of structure elements by page (see Figure 11-1 and its result, Figure 11-2).
The K key in the root points to the first structural element in the structure tree. Its value can either be a single structure element dictionary or an array of structure element dictionaries. Most tagged PDFs will have a single entry, which is a structure element of type Document.
The ParentTree key is a number tree that groups all structural elements on a page together with an associated number/index. While it is more logical to have the ordinal page number represent the number/index in the number tree, that is not required, as we will see when we learn how to associate structure with a page (in Associating Structure to Content).
Structure Elements
Each structural element is represented by a dictionary whose Type key has a value of StructElem. The specific type of structural element that it represents is specified as the value of the S key. That value is a name object and can be anything, though it is recommended to stick to the values discussed in Standard structure types.
Note
If you choose to use your own name for a structure element, be sure to use a role map (see Role Mapping) to map it to the closest standard structure type.
The P key in the structure element dictionary has as its value the parent element in the tree, so that it is possible for a processor to navigate the tree in all directions. In the case of the first child, the parent will be the StructTreeRoot.
As with the StructTreeRoot, the children of each element can be found as the value of the K key. The value of K can be a structure element, an array of structure elements, or an integer that represents the marked content ID (MCID) on the target page for the content. In addition, it is possible to have a reference to an annotation or an XObject if you are referring to the entire object as the content of that particular structure element.
Note
While it is possible to have a direct reference to an XObject, it is more common to simply include the XObject inside of a marked content sequence (see Marked Content Operators).
Although it’s not required, it is common to have a Pg key present in the structure element’s dictionary whose value is the page dictionary where the content representing the element is displayed.
One other common key in the structure element’s dictionary is the Lang key, which can be used to clearly identify the natural language applicable to a given structure element (and its children, unless otherwise overridden). The value of this key is a standard RFC 3066 code. Example 11-2 demonstrates a few sample structure elements.
2 0 obj
<<
/K [ 3 0 R 4 0 R ] % there are two children to the document
/Lang (en-US)
/P 1 0 R % back to the struct root
/S /Document
/Type /StructElem
>>
endobj
3 0 obj
<<
/K 0 % this is MCID 0 on the page
/P 2 0 R
/Pg 5 0 R % and here is the page
/S /P % P(aragraph)
/Type /StructElem
>>
endobj
4 0 obj
<<
/K 1 % MCID 1
/P 2 0 R
/Pg 5 0 R % and here is the page
/S /Figure
/Type /StructElem
>>
endobjStandard structure types
By defining a standard for the types—that is, the value of the S key in a structure element dictionary—PDF provides for a common vocabulary that PDF writers can use to ensure that processors are able to understand the incorporated semantics. These types are categorized into grouping elements, block-level structural elements (BLSEs), and inline-level structural elements (ILSEs), depending on whether the element refers to actual content and how that content would normally be laid out on a page.
Grouping elements
Grouping elements have no presentation concepts, but serve strictly to group other sets of elements together. Document, for example, will be the single root structural element for most PDFs. Other common grouping elements are similar to those found in other markup systems, such as Sect, Div, and BlockQuote.
Block-level structural elements
A block-level structure element is any region of text or other content that is laid out in the block progression direction, such as a paragraph, heading, list item, or footnote. Table 11-1 lists some of these types of content and their related structure elements.
| Structure type | Description |
| (Heading) A label for a subdivision of a document’s content. |
| Headings with specific levels. |
| (Paragraph) A low-level division of text. |
| (List) A sequence of items of like meaning and importance. Its immediate children will be list items ( |
| (List item) An individual member of a list. |
| (Label) A name or number that distinguishes a given item from others in the same list or other group of like items. For example, in a dictionary list, it contains the term being defined; in a bulleted or numbered list, it contains the bullet character or the number of the list item and any associated punctuation. |
| (List body) The descriptive content of a list item. For example, in a dictionary list, it contains the definition of the term. |
| (Table) A two-dimensional layout of rectangular data cells, possibly having a complex substructure. It contains either one or more table rows ( |
| (Table row) A row of headings or data in a table. |
| (Table header cell) A table cell containing header text describing one or more rows or columns of the table. |
| (Table data cell) A table cell containing data that is part of the table’s content. |
| (Table header row group) A group of rows that constitute the header of a table. |
TBody | (Table body row group) A group of rows that constitute the main body portion of a table. |
| (Table footer row group) A group of rows that constitute the footer of a table. |
All other standard structure types will either be treated as ILSEs or appear as artifacts (see Artifacts).
Inline-level structural elements
An inline-level structural element contains a portion of text or other content having specific styling characteristics or playing a specific role in the document. Within the containing BLSE, consecutive ILSEs (possibly intermixed with other content items) are considered to be laid out consecutively in the inline-progression direction (e.g., left to right in Western writing systems). An ILSE may also contain a BLSE. Table 11-2 lists some common types of inline-level structural elements.
| Structure type | Description |
| (Span) A generic inline portion of text having no particular inherent characteristics. |
| (Quotation) An inline portion of text attributed to someone other than the author of the surrounding text. |
| (Note) An item of explanatory text, such as a footnote or an endnote, that is referred to from within the body of the document. |
| (Reference) A citation to content elsewhere in the document. |
| (Bibliography entry) A reference identifying the external source of some cited content. |
| (Code) A fragment of computer program text. |
| (Link) An association between a portion of the ILSE’s content and a corresponding link annotation. |
| (Annotation) An association between a portion of the ILSE’s content and a corresponding annotation. |
Additional structure elements can be found in ISO 32000-1:2008, 14.8.
Artifacts
Artifacts are graphic objects that are added by the authoring system but don’t necessarily represent the author’s original content, such as page or Bates numbers or background images. Graphic objects that aren’t necessary to understand the author’s content, such as repeating headers or footnote rules, are also identified as artifacts.
An artifact is distinguished from real content by enclosing it in a marked content sequence with the tag Artifact. An example is shown in Example 11-3.
Role Mapping
When using custom values for a structure type, it is important to provide a role map dictionary to describe which of the standard structure types it most closely resembles. The role map dictionary is simply a list of keys corresponding to the custom types in use for each key, the value is the name of the standard structure type. This dictionary is specified as the value of the RoleMap key in the structure tree root. An example of RoleMap is shown in Example 11-4.
1 0 obj
<<
/K 3 0 R % the first structure element
/ParentTree 2 0 R % number tree of the elements
/Type /StructTreeRoot
/RoleMap 6 0 R % map the custom elements
>>
endobj
2 0 obj
<<
% a one-page document with two elements on it
/Nums [ 0 [4 0 R 5 0 R] ]
>>
endobj
3 0 obj
<<
/K [ 4 0 R 5 0 R ] % there are two children to the document
/Lang (en-US)
/P 1 0 R % back to the struct root
/S /Document
/Type /StructElem
>>
endobj
4 0 obj
<<
/K 0 % this is MCID 0 on the page
/P 3 0 R
/Pg 10 0 R % and here is the page
/S /Para % Para(graph)
/Type /StructElem
>>
endobj
5 0 obj
<<
/K 1 % MCID 1
/P 3 0 R
/Pg 10 0 R % and here is the page
/S /Chap % Chap(ter)
/Type /StructElem
>>
endobj
6 0 obj
<<
/Para /P
/Chap /Sect
>>
endobjAssociating Structure to Content
Identifying which graphics operators in a content steam are associated with a specific structure element is done by simply enclosing those elements in a pair of marked content operators—specifically BDC and EMC—and an associated property list. A simple example is presented in Example 11-5.
BT
/TT0 1 Tf
-0.018 Tw 60 0 0 60 158.1533 714.3984 Tm
/P <</MCID 0 >>BDC
[(Hello W)80.2(orld)]TJ
EMC
ET
/Figure <</MCID 1 >>BDC
q
541 0 0 407 36 189.4000244 cm
/Im0 Do
Q
EMCThis content refers to the structure elements from Example 11-2, which consisted of two numbered elements, 0 and 1, the numbers that are referenced by the MCID keys in the property lists.
Note
Although the name used in this example for the tag around the image is Figure, it could have been Foo or any other string. It is the value of the S key in the structure element dictionary that actually determines the structure type. Using the same name is a very good idea and is highly recommended!
Although applying structure to the graphics operators in the page’s content stream is the most common approach, it is also possible to apply structure inside other types of content streams, such as the one associated with a form XObject. In most cases, the entire form XObject represents a complete structure element and you can just enclose the Do operator inside of the marked content, as in the preceeding example. However, it is also possible to apply the same type of marked content operators to individual graphics operators inside of the XObject’s content stream.
Tagged PDFs
Although adding structure to a PDF can be quite useful, there are additional rules that can be applied during the writing of the PDF content to enable an even richer set of semantics in the final PDF. When these rules are applied, the PDF is called a tagged PDF.
A tagged PDF document conforms to the following rules:
- All text shall be represented in a form that can be converted to Unicode.
- Word breaks shall be represented explicitly.
- Actual content shall be distinguished from artifacts of layout and pagination.
- Content shall be given in an order related to its appearance on the page, as determined by the PDF writer.
- A basic layout model for describing the arrangement of structure elements on the page shall be applied.
- The set of standard structure types shall be used to define the meaning of structure elements.
Note
One of the most important purposes of these rules is to ensure that all of the text in the page content can be determined reliably.
A tagged PDF document will also contain a mark information dictionary with a value of true for the Marked key. The mark information dictionary is the value of the MarkInfo key in the document catalog dictionary.
What’s Next
In this chapter, you learned about how to add semantic richness to your PDF content through tagging and structure. Next you will see how to incorporate metadata into a PDF at the document as well as the object level.