
CONGRATULATIONS! YOU HAVE (ALMOST) no more bugs to fix, you’ve built a product that your trusted testers love, and your team is proud of what they built. You have the system instrumented so you’ll know when you’re doing well. You even have a rough cut of a blog post from way back when you first defined the product.
It’s time to launch, and launching is more complicated than uploading files to a server. There are several major launch steps you can follow to ensure a quality launch:
Just say no.
Start a war room.
Instill a sense of urgency in the team.
Complete the launch checklist.
Write the blog post.
Roll the software out.
Verify the software yourself.
Respond to the positive and negative effects of your launch.
When you’re driving to launch, you must say no as often as possible to features, to bugs, and to changes in the user experience. If you don’t say no, you’ll never finish your software and you’ll never ship. There’s an industry aphorism that goes, “You launch the software you have, not the software you want.” This aphorism is sticky within the software industry because it’s true—sometimes you just have to ship your product, even when it’s not perfect, because shipping something good is better than not shipping something perfect. Most of us can agree that this statement is true, but it’s hard to enforce because the definition of “good” is arbitrary.
To remove some of the arbitrariness from this stage of the project, I check to ensure that the team feels proud. Your team must be proud of the software they build, and the bugs you have in the product shouldn’t embarrass you. Beyond those caveats, you have to be willing to live with the decisions that you made months and weeks ago. One way to enable the team to say no is to create a list of things to change “immediately post-launch” (IPL). By enabling the team to understand that some changes shouldn’t block the launch but are the first things to change after you ship, you’ll help the team feel better about the product because they know their concerns will be addressed soon.
Another major reason you should say no to late-breaking changes is that almost any change to your code—aptly termed code motion—risks introducing new bugs or reintroducing old bugs. Reopening old bugs or having functionality that used to work fail is considered a regression. Teams frequently cope with avoiding regressions and continuing to move forward by creating a release branch. The release branch is a version of your software that you intend to ship, and you add code to this branch only if that code fixes critical problems. Development of new features can continue on a development branch. This process works well but adds overhead, because the engineering team must make changes to both the release branch and the development branch. While the engineering effort to maintain these branches is not double, it is a significant additional cost, so defer to your development lead when it comes to defining your branches.
I push very hard to maintain a release branch, for the simple reason that it gives my teams a way to cope with crisis. Because a release branch isn’t supposed to change after release, if you discover a major failure, such as a security, privacy, or major performance problem, you can apply that single “hotfix” to the release branch. The tests you need to perform on the release branch are therefore small and quick, because the change is isolated and nothing else has changed. Since your change and your tests were completed quickly, you can release the hotfix very soon after you discover the problem.
As you get close to launch, your meetings must change. Your weekly meetings are now unnecessary because everyone is aligned with the mission and moving quickly. At this point, you can rely on standup meetings and relax the rule that participants must take all issues offline. Moving quickly is critical if you’re going to make the launch, and some issues are best resolved quickly even if resolving them means that half the team is standing around idly. Standup meetings help you make rapid decisions and help communicate a sense of urgency to the team.
Because these standups are a bit more involved, they become more like a war room, in which people huddle together in a closet to work out emerging issues. The reality of your software release is that systems are so complicated and prone to fussy little failures that sometimes a war room is a great way to force coordination and eliminate downtime between hand-offs. If the people who need to hand off are sitting next to each other, the hand-off time is effectively zero.
One could argue that you’ve failed to manage your project well if you’re in the late stages of a project and there is a heightened sense of urgency. It does seem to follow that a well-organized and planned project should come in right on time. Real software projects don’t follow theory, though, and all projects seem to expand to fit the time allotted and end in a sprint. I’ve never seen it work otherwise, so embrace it, and remember that the time to maintain your cool is when others are losing theirs!
I believe that a single sprint to the finish is not bad. A sprint that lasts less than a month is tolerable by most teams and families, particularly since you’ll give the team time to rest on the other side. A death march is when the sprint starts long before the release and continues after it. Death marches are evil. They destroy teams, they create bad software, and they’re no fun. Do not ask your team to sprint for more than a month, or maybe two at the outside. If your date is unrealistic and you need to push it, it’s your job to grit your teeth and take the message upstairs, even though you know you are coming back down the stairs with a s#!@ sandwich (see Chapter 12). Send the message now, before your team starts to sprint.
If you know this sprint is the real deal, the best thing you can do during your final sprint is ensure that your dependencies and supporting teams share your sense of urgency. Less experienced engineers are generally hesitant to escalate to other teams or ask for help. They are afraid of having people find out what they don’t know. This reticence makes psychological sense, because admitting you don’t know what to do requires some maturity; generally, the people who know the most are the first to admit they don’t know how to fix a problem. Make sure your development lead is paying attention to your less experienced engineers.
One way of instilling a sense of urgency in your dependencies is by calling them on the phone and brokering discussions between your team and their team. The conversation is likely to be a negotiation, so agree on goals first, and then work to come up with a creative solution (see Chapter 11 for tips on how to negotiate). Also remember that your job is not to solve the problem, but rather to facilitate the development of a solution to the problem. When you do get people on the phone together, make sure they’re speaking the same language and communicate your own sense of urgency to your dependencies.
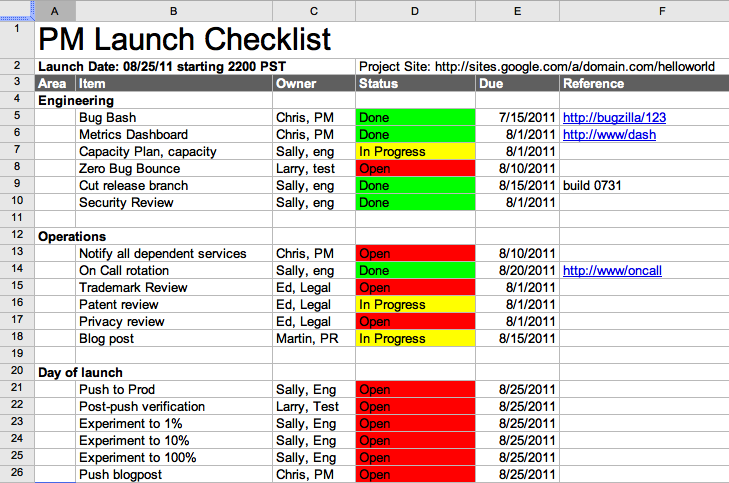
A great launch needs a launch checklist. The goal of the checklist is to ensure that all of the moving pieces of your software launch are aligned and scripted. The launch checklist also facilitates communication across the different functions of your team. Checklists are incredibly powerful when used properly; every single commercial pilot goes through a checklist on every single commercial airplane flight—that’s how powerful and important checklists are.
Each of your leads, from design to test, will have items in the checklist. There’s no perfect checklist for every project (each plane has its own, after all) and each subteam—such as legal, test, or marketing—may have its own subchecklists. But do your best and add items you know you need to track. A simple example checklist is shown in Figure 7-1 and is available for download at http://www.shippinggreatness.com.
If you’ve followed the detailed product development process, you’ve already written your blog post—or at least written the press release, which has the same objective. Your goal for the blog post is to state your mission, the customer to whom you’re speaking, and what problem you are solving. This is your “lede” in the classic journalism sense. For example, here is a great example from the beginning of the Google+ launch blog post:
Among the most basic of human needs is the need to connect with others. With a smile, a laugh, a whisper or a cheer, we connect with others every single day.
Today, the connections between people increasingly happen online. Yet the subtlety and substance of real-world interactions are lost in the rigidness of our online tools.
In this basic, human way, online sharing is awkward. Even broken. And we aim to fix it.
Google targets a clear group of people: those who want to share online. It has identified a problem: online sharing is “rigid” and “awkward.” And in the subsequent paragraphs, it drills into the four unique ways in which it will solve this awkwardness. If Google can do this with the launch of a product that was not all that different from one that already existed, imagine what you can do!
Your goal is to build the same quality blog post. Leverage your draft press release, veer away from the details while still using specific examples, and work with marketing to make it great. This is your chance to add sizzle, but do it in keeping with your corporate tone.
The blog post is your script for your demo. Plan to include a one-and-a-half to three-minute video following the post, so that users who don’t have access to your product or the patience to try it can still experience the great software you built.
The best way to roll out a feature is through an experimental framework. Experiments are great because both the old code and the new code live on your production servers at the same time, which enables you to flip back and forth between version 1 and version 2 extremely quickly and without having to restart servers. The investment to build an experimental framework almost always pays off longer term.
If you’ve watched major sites like Google and Amazon change, you may have noticed that some users get a different experience than others, because both are using experiments to deploy and test features. Amazon calls these releases Weblabs, because they measure how the new software impacts users, compared to the group of users who don’t have the new software. Yes, some of your users will have a different experience than the majority of your users, but that’s OK. It turns out that users don’t mind. And if they do mind, roll back and thank your lucky stars you planned to roll back!
Google has free systems in Google Analytics you can use to build your own Weblab-like releases. I’ve used them and they’re great. One team I led ran a series of experiments through Google Analytics and we increased conversion by 65%—Google Analytics provided us with that data.
There can be challenges to implementing this experimental approach, though. When your service has underlying data model changes, you may be unable to roll back, or you may have disjointed data sets. These are tricky problems, and it’s always best if you can avoid them entirely by making your data models backward compatible. Easier said than done, I know, but the benefit of being able to roll back without losing user data is a big win.
No matter how hard you try, it’s very challenging to get a launch right the first time. Building in a mechanism that enables you to ensure that you got everything connected and configured before millions of users see your product is incredibly valuable.
A word on timing: don’t launch on Friday or right before the holidays. Not only do you miss the press cycle, but also the last thing you want to do is roll out a bunch of software and then desperately page people all weekend. I once foolishly agreed to roll out some software on December 18 to take advantage of holiday PC buyers, only to find that my pager went off when our service started to fail and I had to call engineers around the country at dinnertime on Christmas Eve. No joke.
After you’ve pushed all your services to production, you want to verify the push in two ways. First, your test lead should orchestrate a verification pass, also known as a build verification test (BVT), which is typically run after doing a build of your software. By doing this, your test lead ensures that the right version of software was pushed to your production servers and that all the configuration was also pushed and set up correctly. It’s easy to miss little details, even if they’re simple, like making sure http://domain.com can handle traffic, not just http://www.domain.com!
Second, you need to personally go through the experience as a new user and ensure that all the major functions are working. Things that typically fail are signup processes, any form of data upload (like images), searching, and form submissions. These items tend to fail because they rely on subsystems and are sometimes configured to point to the wrong servers. These types of failures happen all the time. Your team should wait to roll out to a larger percentage of users until you, your test lead, and your development lead all sign off. This may seem like a lot of process, but it’s really just three people connected on IM, so it’s not bad.
If you’ve signed off on your verification pass, then congratulations—you’ve done a great job and your software has launched! But there are a few things remaining before you can consider your great software to have shipped. You need to deal with any crises that emerge, announce the product to the world, and celebrate with your team. Here are the five post-launch tasks you’ll need to complete:
Handle any rollbacks.
Cope with production crises.
Demo the product.
Handle the press.
Celebrate your launch.
Successful rollback is not failure. This bears repeating: successful rollback is not failure. A rollback is when you revert your software to its prelaunch state. Rollbacks are more common than you might think. I’ve seen releases take five attempts or more at both Amazon and Google. Large software systems have so many complicated interfaces and dependencies that it’s nearly impossible to test and validate every possible permutation before you launch. If you roll back and there was no significant customer damage, you haven’t been successful, but you haven’t failed yet. Therefore, in the end, the best defense is a well-planned retreat.
There are times when you can’t roll back or when rollbacks are so expensive that doing so isn’t justifiable. In situations where you can’t roll back, your best bet is to make sure that you have the team capacity to keep moving forward very quickly for a couple of days, because it may take you that long to find and fix your problems—and as you’re fixing them, customers are having a bad day. On the other hand, if rollback is possible, you can turn off the changes, fix things at a leisurely pace, and try again.
Sometimes the world explodes. Maybe you got slashdotted. Or maybe there was a security hole, privacy violation, or pricing mishap. Or maybe an intern redirected the production website to his or her desktop instead of the datacenter (true story!). In cases like these, there’s a good script you can follow. And like all good reactive measures, it’s inspired by the Boy Scouts: you start by being prepared.
Part of being prepared means having an on-call rotation and pagers. I still haven’t seen cell phones work as reliably as pagers, but I also haven’t found a reliable way of forcing engineers outside of Amazon to carry pagers. Have the cell phone numbers of every engineer in your team on your phone or in your pocket.
A well-prepared product has software switches that can easily turn off or rate-limit your service. Remember to launch experimentally or with flags to disable your feature if at all possible. Remember, successful rollback is not failure!
You can prepare for disaster well ahead of time by having great design review meetings. In your reviews, you want to ensure that the engineering team designs for failure. You can do this by building logic that limits requests to overloaded servers. You’ll want this backoff to escalate exponentially, and always have a random modifier in the amount you back off so that the act of backing off doesn’t create further mayhem. The random modifier is no joke—I’ve seen the backoff mechanism take down more systems than the original problem did. Make sure that the backoff mechanism exists before you ship.
You’ll be better prepared if you know how to get in touch with a server genius even if you don’t have one on your team. Even better, maintain, publish, and know your emergency contacts. Create an internal wiki with your PR, legal, and cross-functional team contacts. There’s little more frustrating than trying to figure out whom in PR you need to talk to when your feature is suddenly behaving badly to a specific ethnic group for no apparent reason. And yes, this happened to me.
Establishing good communication paths in advance works the other way too: build a <service>[email protected] alias so the right people can get involved. This alias should probably include PR, customer support, you, your engineering and production leads, and essential cross-functional owners. Also subscribe your team alias to this list, because escalations are a great teaching device!
If there’s an ongoing risk (e.g., a launch), make sure all relevant parties know that there could be a problem. You must be willing to bother people to ask for help, but if the crisis is large you probably won’t have a hard time admitting that your pants are on fire.
The final thing you need to do to be prepared is print out the next two sections, tape them to your wall, and work through them like a playbook for when s#!@ hits the fan.
Don’t panic.
This is harder than it looks. If your boss is on the phone, the odds are good that he or she is panicking. It doesn’t seem to matter how much the bosses are paid or how experienced they are. Get them off the phone as fast as possible so you can go back to not panicking.
Verify that there’s an emergency and assess the extent of the damage.
You want to assess the percentage of your user base that’s affected and how severely. If you’re lucky, it’s not that big of a deal. Since you’re reading this book, and you work in software, it’s unlikely that you’re lucky, so read on.
Make sure it’s not just you.
Sometimes your computer or your account can end up in a strange state. The last thing you want to do is run around with your pants on fire when the only problem was that you cleared your cookies. You also want to make sure the problem is not specific to internal users within your company or a “dogfood” artifact. In addition to verifying with external accounts, you probably want to check for external customer reports in discussion forums, Twitter, eHarmony—whatever you use. You’re looking for a corroborating customer.
If the problem is a big deal, treat it like it’s a big deal. Don’t work too hard to convince yourself it’s not a big deal and that not that many customers are affected. Convincing yourself that it’s all going to be fine when really the situation is a disaster is not going to help. You can understand that you’re going to get fired and still not panic. Sure, that’s counterintuitive, but if you haven’t been there, you will be.
Set up a conference call.
If you are running the concall, do not try to solve the problem. I emphasized this advice on purpose. It is very hard not to solve the problem when you know a lot about your systems and care passionately about your customers. However, your job on the concall is to facilitate the conversation, not solve the problem. If you try to solve the problem, you’ll only add confusion. I know this sounds counterintuitive, but many managers have learned this. If you want to try to learn it yourself, go ahead…
Open a bug.
You’ll use this bug to record changes that you make to your systems. When engineers get log snippets, they can add them to the bug. People can add themselves to the bug if they want to listen in on the technical conversation. This bug will be very useful when you write the postmortem because it will have timestamps and good documentation on what you did right and what you did wrong.
Notify your escalation alias.
Send email to the email list you set up in advance and engage the first person on the escalation path, whether that’s PR, engineering, or someone at the network operations center. Make sure you get a positive acknowledgment, either by the phone, pager, or email. It’s not enough to leave a voicemail.
Ask, “Can we roll it back?”
The best way to fix any substantial crisis is to undo the change that caused it. “Rolling forward” requires more code, more testing, and therefore more time. It’s best to avoid writing code under extreme pressure, so try to roll back first.
Postpone any planned PR.
Frequently, but not always, you’ll encounter a problem when you launch. If you have marketing, PR, or other plans that would draw additional traffic to your now-defunct product, make sure you put those operations on hold.
Let your dependent services know you are having a problem.
Don’t assume that you’re the only one having a problem—make sure that your outage isn’t hurting someone else. If you’re hurting others, tell them so that they can work through the checklist themselves. They might have marketing plans too! Similarly, you want to make sure that you aren’t being hurt by some other service. Occasionally, a major shared subsystem, like your backend storage, will go down and wreak havoc. In situations like these, the good news is that there’s nothing you can do. The bad news is that there’s nothing you can do, so add yourself to their bug (assuming they are following our process!) and watch it closely.
Notify your community.
If you have a community forum or any way you typically communicate with your customers, you may want to let your customers know that “There seems to be a problem with X. We’re actively investigating and will have more information/solution by time T.” Google’s Apps Status dashboard (http://www.google.com/appsstatus) is a great example of how to do this well. Use your PR/customer support team to help draft this note, so that you don’t reveal something sensitive or overly frightening. It is, however, OK to admit that you had a problem. Customers appreciate honesty.
Keep your bug updated.
Remember, people from other teams are looking for updates, and engineers are watching the bug to get additional background information. It’s hard to tell when a small update will have substantial impact on your ability to make progress; be generous with your updates to the bug.
Find and introduce experts to consult with the team.
Some problems are difficult to solve. Your team will probably solve any issue with enough time, but if your problem is directly impacting customers on an ongoing basis, you may not be willing to wait for your team to figure out the problem. Consider bringing in an expert from another team to help. You’ll want to be careful as you do this, since you don’t want to undermine or randomize your engineering team, but a very experienced engineer will generally know how to work well with your beleaguered team.
Inform your management.
At this point your team knows what’s going on, since you sent a note to your escalation alias. But your bosses don’t know, and they need to know because they don’t want their bosses to send a nastygram for which they are unprepared. So put your manager’s email on the To: line, fill out the following MadLib, and hit Send.

Sometimes a crisis is going to last longer than a few hours. This is when you turn to your second in command and repeat what my first boss at Amazon told me: “This is going to suck for a while, but then it’s going to be OK.” After you’ve made this proud, bold, managerial statement, you need to move into long-term mode and start fixing things again. At this point, there are no quick and easy checklists. Rather, there are things you must do every day, including:
Send status updates regularly and when you said you will. If people are asking for updates, you’re not sending them often enough. Delivering status reports on time will help reassure your bosses that the problem is being solved well.
Don’t keep customers hanging. Set expectations about the problem and keep them informed. Try to underpromise and overproduce, because you get relatively few chances to make good with customers.
Keep working the issue. People naturally get tired of working on just one thing, particularly when it’s a firefighting project. Without your sense of urgency, your team could lose focus.
Make sure that the people who are working on it have what they need—get them food, servers, support from other teams, etc.
Set up a shift so that you don’t have one developer working 24 hours. During one crisis at Amazon, I had an engineer say to me, “It’s 3 a.m. and I don’t think I can write any bug-free code right now.” I appreciate that kind of honesty.
Start building workarounds and contingency plans. Specifically, find ways to replace the failing systems with something else temporarily. For example, at Google we hit a capacity problem with our download servers at one point. We fixed this problem temporarily by shunting download traffic to Akamai’s content delivery network.
Pat yourself on the back—you’ve fixed the problem, and the bosses are probably not going to fire you until tomorrow morning when they start reading their email. So get out your thumb drive, start copying your music, and follow the next steps:
Monitor your fix. Be double-sure that you fixed the problem; it’s never good to be in a place where your team’s judgment is questioned and you say, “We’re 100% sure we fixed the problem,” only to find out that you should have said “99% sure.” Just like when you verify software yourself before you launch it, verify the fixes personally.
Prepare a blog post if you or your PR team thinks outward communication is warranted.
Build the action items into your team roadmap and update your business’s stakeholders with their progress.
Write a postmortem.
A postmortem is a data-based apology for your management. A good postmortem is pretty easy to write, because you can structure it like you structured your third grade papers: What, Who, When, Why, and How. These questions are in this order to make it easier for your execs to get the answers they want in the order in which they tend to ask questions. Your bosses are likely to ask these questions as follows:
- What happened?
To answer this question, lay out the condensed timetable that describes when the issue first occurred, when it was discovered, when your team engaged, when it was fixed, and any other relevant milestones.
- Whom did this affect?
You want to be as specific as possible when talking about your customers. You want to say how many of them were affected, which subset of customers was affected, and anything else you know about them that might be relevant.
- When did it start; when did it end?
You should provide a basic timeline for the crisis.
- Why did this happen?
The “Why” section is where you explain the root cause. If you don’t have a root cause, keep asking “why?” until you do (see Chapter 10’s discussion of fishbone diagrams for some tips on this). You don’t necessarily need to build out the discussion, as I do in the upcoming sidebar, but it may help explain why you reached the conclusions in the postmortem.
- How will you prevent this type of problem in the future?
If you have one great fix, that’s fantastic (albeit unlikely). But if you’re writing a postmortem, you probably have many things your team could do differently, so call them all out. To make sure that one or more of these changes happen, ensure that a single individual takes ownership for the change.
A hypothetical postmortem, also known as a “Cause Of Error” (COE) report, appears in the sidebar Sample COE Report
We’re back to the fun stuff, where your launch is going smoothly and now you need to show it off with a demo. Your demo should be straightforward; the goal of the demo is to tell the story from the blog post and reinforce your message at every step. It must be brief, probably less than 10 minutes, in order to hold the audience’s attention. Your video on the blog post can’t be a 10-minute video, however; videos need to be 90 seconds or less to hold someone’s attention.
In the same way you wrote your blog post, the demo must be on-message. Start your demo with the problem statement and your message. Continually stating your message may feel repetitive, but it works. Start your demo by explaining why people should care about it.
Next, use your demo to tell a customer story. Great presentations use stories to draw listeners in and make the ideas real (more in Chapter 10 on presentations). Start your demo with a customer story and use that story to walk through your demo. Statements like “Imagine if…” and “People have a problem…” will help you tell the story and hook the audience. As you go through your demo, don’t worry about the details of what you are trying to show. If some small thing goes wrong, skip over it and use the distraction as an opportunity to reiterate your core message.
While you can certainly skip over small defects in your presentation, the best cure for problems is to not have them. The best demos take weeks of preparation. Steve Jobs was notorious for demanding in-depth rehearsals, and it shows in the output of Apple’s keynotes. In addition, Apple always thinks about how it can reduce the points of failure in a demo.
Microsoft product managers think the same way and routinely have three laptops: their personal laptop, their demo laptop, and their backup demo laptop. This approach gives them multiple backup strategies and ensures a stable demo environment. Personally, when I need to show something online, I bring hotspots from two different wireless providers and always try to use a wired connection when I can.
Despite all these warnings, if you’re doing a demo at a live event, no amount of backup is sufficient. You must have screenshots or video for every part of your demo, because you can never fully predict what will go wrong. The launch of GoogleTV was riddled with technical problems and was painful to watch. In contrast, Apple’s launch of the iPad 2 had similar problems but cut away to screenshots while the team forcibly disabled all WiFi access for attendees to the event, thereby remedying the problem. You want to be as prepared as Apple was, not as prepared as Google was.
If you have the good fortune to be contacted by the press or bloggers (it’s good to remember that bloggers prefer to be thought of as press), you can make the most of it by engaging deeply. Take the calls and do demos. Respond quickly because most of the writers are on a deadline. If a writer posts something that is factually incorrect, reach out with a courteous correction—reporters may publish a correction. However, by the time the content is published it’s usually too late for the reporter to do anything about it.
It is not too late, however, to respond online. First, you can respond directly to articles that are published online through their existing comment systems. Be clear and factual, and attribute the comments directly to you so that you’re transparent and others can reach out to you. In the past I’ve published my email address directly in these forums in order to respond to contentious issues, and I’ve rarely been disappointed by the reaction I’ve encountered.
Second, you can respond to comments that others make, particularly if you have a user group. One of the most valuable ways you can spend your time immediately after launch is handling support requests and conversing with users in groups online. Users will tell you what you’ve done wrong, what’s not working (even if you think it is), and what you need to add. If you listen closely in the weeks immediately after you launch, you’ll be able to adjust your roadmap based on real customer input, and that will lead you to a very successful second version of your product.
Every significant product release is enabled by many small (or sometimes large) sacrifices, and it’s critical that you acknowledge what your team gave. Post-launch high-fives of any kind are basically free and can help readjust your team’s point of view. For example, after working on Google’s “Google Apps Sync for Microsoft Outlook” project for two years, I put together some basic metrics on early adoption that I shared with the team. I was able to use those metrics to pat the team on the back and get them some exposure to the senior leadership, and in turn the team was able to use those numbers to make their promotion cases. Your team will like you more if you get them promoted.
With teams at Amazon I brought in champagne for each launch, and the team signed the bottle. We put each bottle on a shelf in the office, creating a memento that stood as a reminder for the office of how great it is to ship.
Ideally, you want to celebrate your launch as close as possible to the time you launch. Keeping the timing of the celebration close to the sacrifices helps tie rewards and thanks to the actual sacrifices and accomplishments. But please, don’t have a party during the launch. This guidance may be counterintuitive, but I once saw a program manager at Amazon have a launch party with food, beer, and paper plates (high-end for Amazon!) as his product rolled out. I asked him, “How’s it going?” and he said, “Good!” thinking I meant the party. I was actually asking about the launch.
I went down the hall and most of his engineering team was sitting in their cubes, watching server health. It’s really demoralizing when your team members can’t go to their own party. The other dimension of this is that you don’t want to celebrate too early. Frequently, you’ll need to roll back a launch or sprint for another couple of days to fix emergent production problems. Ideally, you want your team to get past that panic and then celebrate and thank them for their effort.
Individual accolades are critical as well, but it can be both dangerous and helpful to compliment specific members of the team very publicly. Before you do so, have a good reason for why you want to make a public statement. Because everything is a teaching opportunity, I sometimes use stellar successes as a way of pointing out to the team what greatness looks like, so they know what to shoot for.
Be careful with public accolades. A Google VP once defended a generous perk he gave his team by saying, “They’ve worked really hard and I wanted to do something nice for them.” This was broadly interpreted by Googlers-at-large as, “My team works harder than you, blah blah blah.” Foot, meet bullet. He would have been much better served to associate that perk with a specific accomplishment. Also, when a single person does something truly unique and is OK with being singled out, go for it. But if there’s any question, take that person to lunch and thank him or her oneon-one. You don’t want to embarrass your teammates.