
Chapter 10. Spark Streaming
Many applications benefit from acting on data as soon as it arrives. For example, an application might track statistics about page views in real time, train a machine learning model, or automatically detect anomalies. Spark Streaming is Spark’s module for such applications. It lets users write streaming applications using a very similar API to batch jobs, and thus reuse a lot of the skills and even code they built for those.
Much like Spark is built on the concept of RDDs, Spark Streaming provides an abstraction called DStreams, or discretized streams. A DStream is a sequence of data arriving over time. Internally, each DStream is represented as a sequence of RDDs arriving at each time step (hence the name “discretized”). DStreams can be created from various input sources, such as Flume, Kafka, or HDFS. Once built, they offer two types of operations: transformations, which yield a new DStream, and output operations, which write data to an external system. DStreams provide many of the same operations available on RDDs, plus new operations related to time, such as sliding windows.
Unlike batch programs, Spark Streaming applications need additional setup in order to operate 24/7. We will discuss checkpointing, the main mechanism Spark Streaming provides for this purpose, which lets it store data in a reliable file system such as HDFS. We will also discuss how to restart applications on failure or set them to be automatically restarted.
Finally, as of Spark 1.1, Spark Streaming is available only in Java and Scala. Experimental Python support was added in Spark 1.2, though it supports only text data. We will focus this chapter on Java and Scala to show the full API, but similar concepts apply in Python.
A Simple Example
Before we dive into the details of Spark Streaming, let’s consider a simple example. We will receive a stream of newline-delimited lines of text from a server running at port 7777, filter only the lines that contain the word error, and print them.
Spark Streaming programs are best run as standalone applications built using Maven or sbt. Spark Streaming, while part of Spark, ships as a separate Maven artifact and has some additional imports you will want to add to your project. These are shown in Examples 10-1 through 10-3.
Example 10-1. Maven coordinates for Spark Streaming
groupId = org.apache.spark artifactId = spark-streaming_2.10 version = 1.2.0
Example 10-2. Scala streaming imports
importorg.apache.spark.streaming.StreamingContextimportorg.apache.spark.streaming.StreamingContext._importorg.apache.spark.streaming.dstream.DStreamimportorg.apache.spark.streaming.Durationimportorg.apache.spark.streaming.Seconds
Example 10-3. Java streaming imports
importorg.apache.spark.streaming.api.java.JavaStreamingContext;importorg.apache.spark.streaming.api.java.JavaDStream;importorg.apache.spark.streaming.api.java.JavaPairDStream;importorg.apache.spark.streaming.Duration;importorg.apache.spark.streaming.Durations;
We will start by creating a StreamingContext, which is the main entry point for streaming functionality.
This also sets up an underlying SparkContext that it will use to process the data.
It takes as input a batch interval specifying how often to process new data, which we set to 1 second.
Next, we use socketTextStream() to create a DStream based on text data received on port 7777 of the
local machine. Then we transform the DStream with filter() to get only the lines that contain
error. Finally, we apply the output operation print() to print some of the filtered lines. (See Examples 10-4 and 10-5.)
Example 10-4. Streaming filter for printing lines containing “error” in Scala
// Create a StreamingContext with a 1-second batch size from a SparkConfvalssc=newStreamingContext(conf,Seconds(1))// Create a DStream using data received after connecting to port 7777 on the// local machinevallines=ssc.socketTextStream("localhost",7777)// Filter our DStream for lines with "error"valerrorLines=lines.filter(_.contains("error"))// Print out the lines with errorserrorLines.()
Example 10-5. Streaming filter for printing lines containing “error” in Java
// Create a StreamingContext with a 1-second batch size from a SparkConfJavaStreamingContextjssc=newJavaStreamingContext(conf,Durations.seconds(1));// Create a DStream from all the input on port 7777JavaDStream<String>lines=jssc.socketTextStream("localhost",7777);// Filter our DStream for lines with "error"JavaDStream<String>errorLines=lines.filter(newFunction<String,Boolean>(){publicBooleancall(Stringline){returnline.contains("error");}});// Print out the lines with errorserrorLines.();
This sets up only the computation that will be done when the system receives data. To start receiving
data, we must explicitly call start() on the StreamingContext. Then, Spark Streaming will start to schedule Spark jobs on the underlying SparkContext. This will occur in a separate thread, so to keep
our application from exiting, we also need to call awaitTermination to wait for the streaming
computation to finish. (See Examples 10-6 and 10-7.)
Example 10-6. Streaming filter for printing lines containing “error” in Scala
// Start our streaming context and wait for it to "finish"ssc.start()// Wait for the job to finishssc.awaitTermination()
Example 10-7. Streaming filter for printing lines containing “error” in Java
// Start our streaming context and wait for it to "finish"jssc.start();// Wait for the job to finishjssc.awaitTermination();
Note that a streaming context can be started only once, and must be started after we set up all the DStreams and output operations we want.
Now that we have our simple streaming application, we can go ahead and run it, as shown in Example 10-8.
Example 10-8. Running the streaming app and providing data on Linux/Mac
$spark-submit --class com.oreilly.learningsparkexamples.scala.StreamingLogInput$ASSEMBLY_JARlocal[4]$nc localhost7777# Lets you type input lines to send to the server<your input here>
Windows users can use the ncat command in place of the nc command. ncat is available as part of
nmap.
In the rest of this chapter, we’ll build on this example to process Apache logfiles.
If you’d like to generate some fake logs, you can run the script ./bin/fakelogs.sh or ./bin/fakelogs.cmd in this book’s Git repository to send logs to port 7777.
Architecture and Abstraction
Spark Streaming uses a “micro-batch” architecture, where the streaming computation is treated as a continuous series of batch computations on small batches of data. Spark Streaming receives data from various input sources and groups it into small batches. New batches are created at regular time intervals. At the beginning of each time interval a new batch is created, and any data that arrives during that interval gets added to that batch. At the end of the time interval the batch is done growing. The size of the time intervals is determined by a parameter called the batch interval. The batch interval is typically between 500 milliseconds and several seconds, as configured by the application developer. Each input batch forms an RDD, and is processed using Spark jobs to create other RDDs. The processed results can then be pushed out to external systems in batches. This high-level architecture is shown in Figure 10-1.
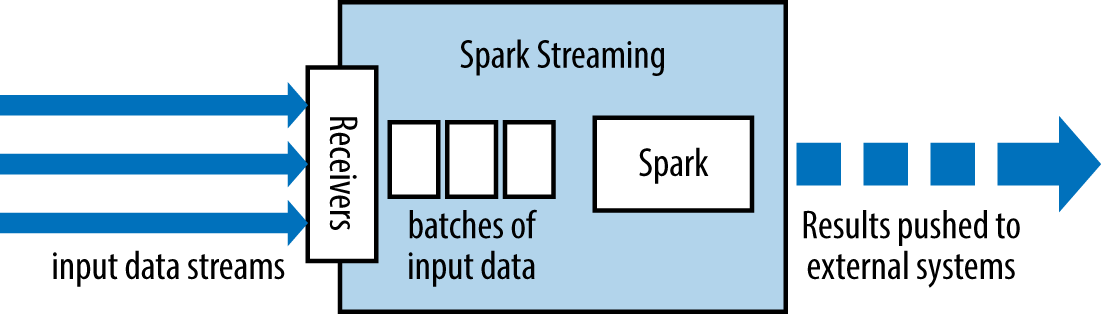
Figure 10-1. High-level architecture of Spark Streaming
As you’ve learned, the programming abstraction in Spark Streaming is a discretized stream or a DStream (shown in Figure 10-2), which is a sequence of RDDs, where each RDD has one time slice of the data in the stream.

Figure 10-2. DStream as a continuous series of RDDs
You can create DStreams either from external input sources, or by applying transformations to other DStreams. DStreams support many of the transformations that you saw on RDDs in Chapter 3. Additionally, DStreams also have new “stateful” transformations that can aggregate data across time. We will discuss these in the next section.
In our simple example, we created a DStream from data received through a socket, and then applied a filter() transformation to it. This internally creates RDDs as shown in Figure 10-3.
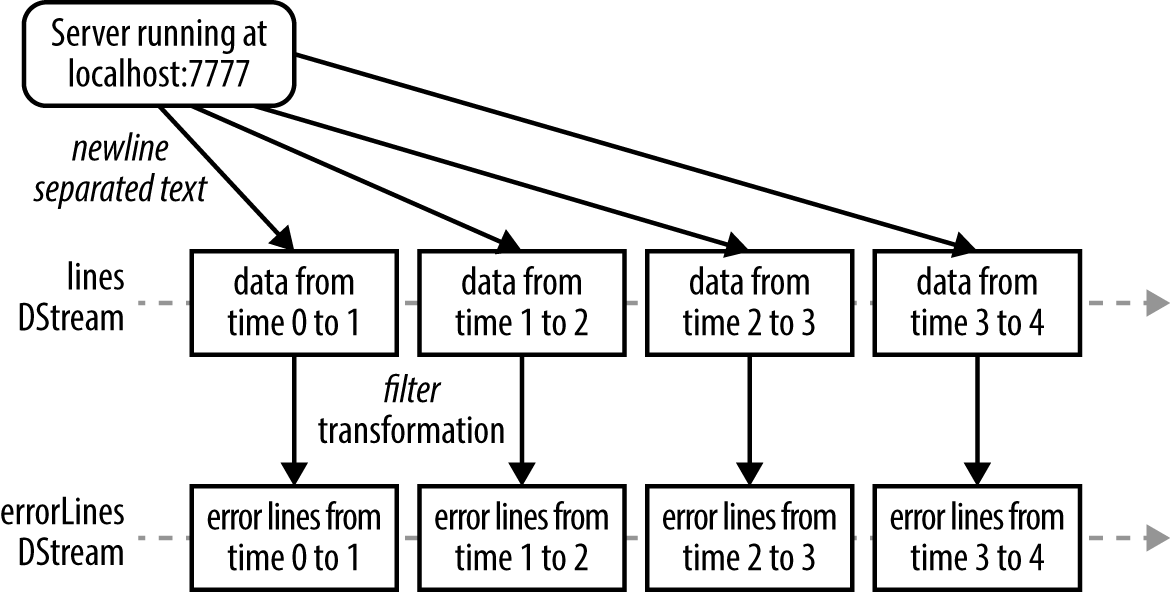
If you run Example 10-8, you should see something similar to the output in Example 10-9.
Example 10-9. Log output from running Example 10-8
------------------------------------------- Time: 1413833674000 ms ------------------------------------------- 71.19.157.174 - - [24/Sep/2014:22:26:12 +0000] "GET /error78978 HTTP/1.1" 404 505 ... ------------------------------------------- Time: 1413833675000 ms ------------------------------------------- 71.19.164.174 - - [24/Sep/2014:22:27:10 +0000] "GET /error78978 HTTP/1.1" 404 505 ...
This output nicely illustrates the micro-batch architecture of Spark Streaming. We can see the filtered logs being printed every second, since we set the batch interval to 1 second when we created the StreamingContext. The Spark UI also shows that Spark Streaming is running many small jobs, as you can see in Figure 10-4.
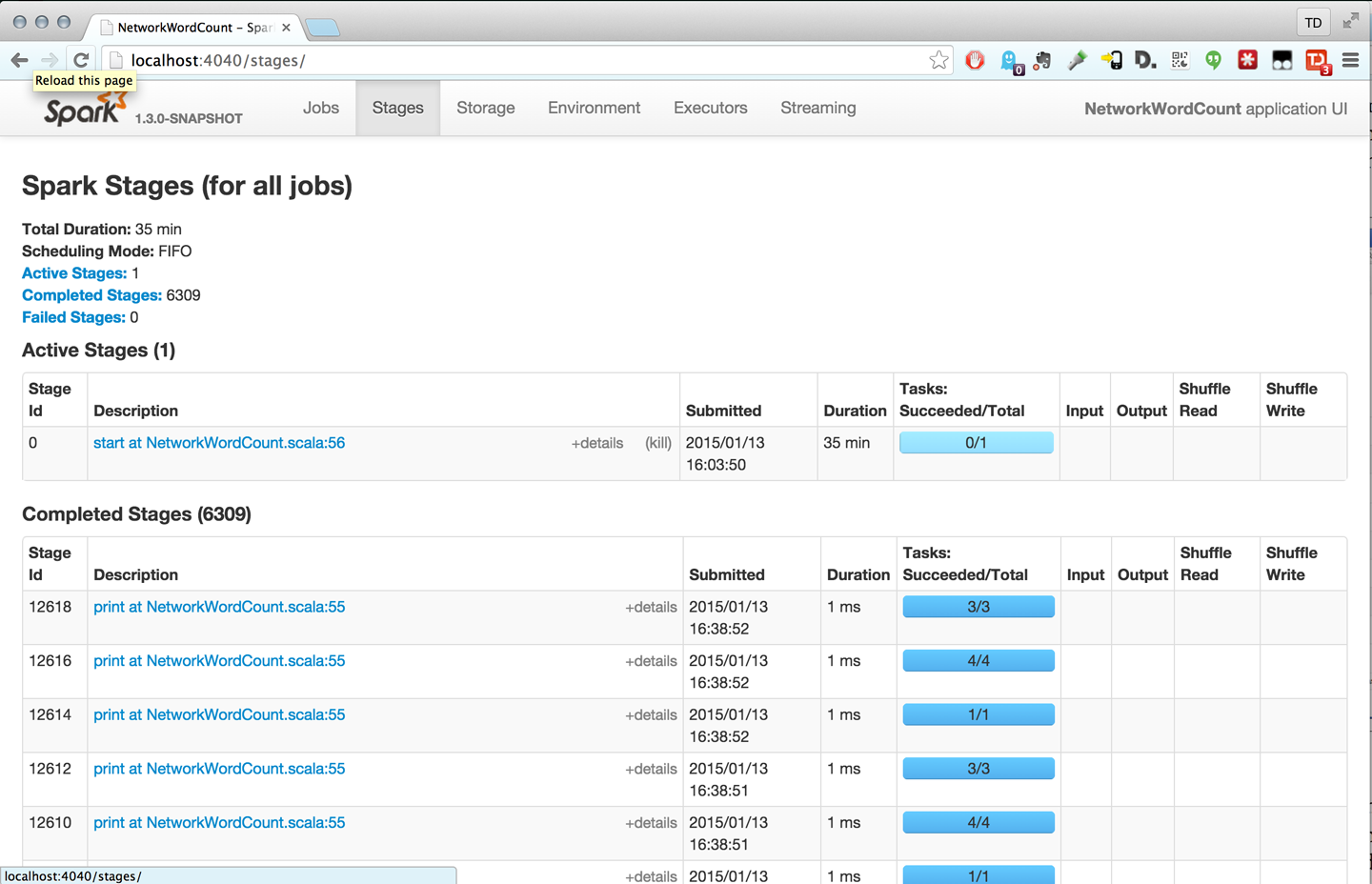
Figure 10-4. Spark application UI when running a streaming job
Apart from transformations, DStreams support output operations, such as the print() used in our example. Output operations are similar to RDD actions in that they write data to an external system, but in Spark Streaming they run periodically on each time step, producing output in batches.
The execution of Spark Streaming within Spark’s driver-worker components is shown in Figure 10-5 (see Figure 2-3 earlier in the book for the components of Spark). For each input source, Spark Streaming launches receivers, which are tasks running within the application’s executors that collect data from the input source and save it as RDDs. These receive the input data and replicate it (by default) to another executor for fault tolerance. This data is stored in the memory of the executors in the same way as cached RDDs.14 The StreamingContext in the driver program then periodically runs Spark jobs to process this data and combine it with RDDs from previous time steps.
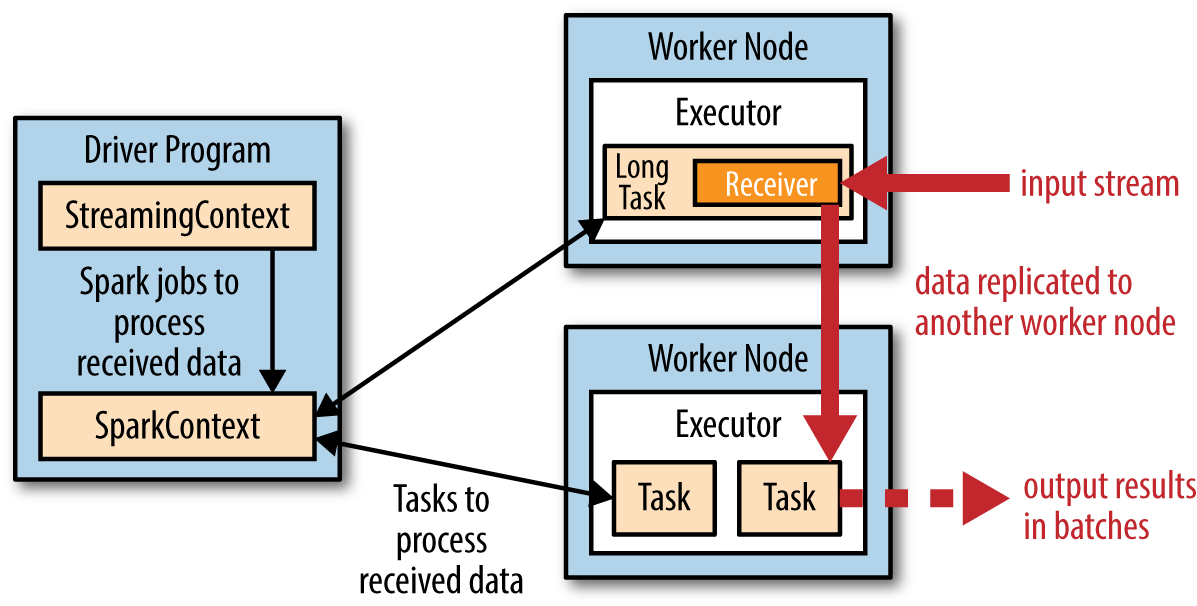
Figure 10-5. Execution of Spark Streaming within Spark’s components
Spark Streaming offers the same fault-tolerance properties for DStreams as Spark has for RDDs: as long as a copy of the input data is still available, it can recompute any state derived from it using the lineage of the RDDs (i.e., by rerunning the operations used to process it). By default, received data is replicated across two nodes, as mentioned, so Spark Streaming can tolerate single worker failures. Using just lineage, however, recomputation could take a long time for data that has been built up since the beginning of the program. Thus, Spark Streaming also includes a mechanism called checkpointing that saves state periodically to a reliable filesystem (e.g., HDFS or S3). Typically, you might set up checkpointing every 5–10 batches of data. When recovering lost data, Spark Streaming needs only to go back to the last checkpoint.
In the rest of this chapter, we will explore the transformations, output operations, and input sources in Spark Streaming in detail. We will then return to fault tolerance and checkpointing to explain how to configure programs for 24/7 operation.
Transformations
Transformations on DStreams can be grouped into either stateless or stateful:
-
In stateless transformations the processing of each batch does not depend on the data of its previous batches. They include the common RDD transformations we have seen in Chapters 3 and 4, like
map(),filter(), andreduceByKey(). -
Stateful transformations, in contrast, use data or intermediate results from previous batches to compute the results of the current batch. They include transformations based on sliding windows and on tracking state across time.
Stateless Transformations
Stateless transformations, some of which are listed in Table 10-1, are simple RDD transformations being applied on every batch—that is, every RDD in a DStream. We have already seen filter() in Figure 10-3. Many of the RDD transformations discussed in Chapters 3 and 4 are also available on DStreams. Note that key/value DStream transformations like reduceByKey() are made available in Scala by
import StreamingContext._. In Java, as with RDDs, it is necessary to create a JavaPairDStream using mapToPair().
| Function name | Purpose | Scala example | Signature of user-supplied function on DStream[T] |
|---|---|---|---|
|
Apply a function to each element in the DStream and return a DStream of the result. |
|
|
|
Apply a function to each element in the DStream and return a DStream of the contents of the iterators returned. |
|
|
|
Return a DStream consisting of only elements that pass the condition passed to filter. |
|
|
|
Change the number of partitions of the DStream. |
|
N/A |
|
Combine values with the same key in each batch. |
|
|
|
Group values with the same key in each batch. |
|
N/A |
Keep in mind that although these functions look like they’re applying to the whole stream, internally each DStream is composed of multiple RDDs (batches), and each stateless transformation applies separately to each RDD. For example, reduceByKey() will reduce data within each time step, but not across time steps. The stateful transformations we cover later allow combining data across time.
As an example, in our log processing program from earlier, we could use map() and reduceByKey() to count log events by IP address in each time step, as shown in Examples 10-10 and 10-11.
Example 10-10. map() and reduceByKey() on DStream in Scala
// Assumes ApacheAccessLog is a utility class for parsing entries from Apache logsvalaccessLogDStream=logData.map(line=>ApacheAccessLog.parseFromLogLine(line))valipDStream=accessLogsDStream.map(entry=>(entry.getIpAddress(),1))valipCountsDStream=ipDStream.reduceByKey((x,y)=>x+y)
Example 10-11. map() and reduceByKey() on DStream in Java
// Assumes ApacheAccessLog is a utility class for parsing entries from Apache logsstaticfinalclassIpTupleimplementsPairFunction<ApacheAccessLog,String,Long>{publicTuple2<String,Long>call(ApacheAccessLoglog){returnnewTuple2<>(log.getIpAddress(),1L);}}JavaDStream<ApacheAccessLog>accessLogsDStream=logData.map(newParseFromLogLine());JavaPairDStream<String,Long>ipDStream=accessLogsDStream.mapToPair(newIpTuple());JavaPairDStream<String,Long>ipCountsDStream=ipDStream.reduceByKey(newLongSumReducer());
Stateless transformations can also combine data from multiple DStreams, again within each time step. For example, key/value DStreams have the same join-related transformations as RDDs—namely, cogroup(), join(),
leftOuterJoin(), and so on (see “Joins”).
We can use these operations on DStreams to perform the underlying RDD operations separately on each batch.
Let us consider a join between two DStreams. In Examples 10-12 and 10-13, we have data keyed by IP address, and we join the request count against the bytes transferred.
Example 10-12. Joining two DStreams in Scala
valipBytesDStream=accessLogsDStream.map(entry=>(entry.getIpAddress(),entry.getContentSize()))valipBytesSumDStream=ipBytesDStream.reduceByKey((x,y)=>x+y)valipBytesRequestCountDStream=ipCountsDStream.join(ipBytesSumDStream)
Example 10-13. Joining two DStreams in Java
JavaPairDStream<String,Long>ipBytesDStream=accessLogsDStream.mapToPair(newIpContentTuple());JavaPairDStream<String,Long>ipBytesSumDStream=ipBytesDStream.reduceByKey(newLongSumReducer());JavaPairDStream<String,Tuple2<Long,Long>>ipBytesRequestCountDStream=ipCountsDStream.join(ipBytesSumDStream);
We can also merge the contents of two different DStreams using the union() operator as in regular Spark, or using StreamingContext.union() for multiple streams.
Finally, if these stateless transformations are insufficient, DStreams provide an advanced operator called transform() that lets you operate directly on the RDDs inside them. The transform() operation lets you provide any arbitrary RDD-to-RDD function to act on the DStream. This function gets called on each batch of data in the stream to produce a new stream.
A common application of transform() is to reuse batch processing code you had written on RDDs. For example, if you had a function, extractOutliers(), that acted on an RDD of log lines to produce an RDD of outliers (perhaps after running some statistics on the messages), you could reuse it within a transform(), as shown in Examples 10-14 and 10-15.
Example 10-14. transform() on a DStream in Scala
valoutlierDStream=accessLogsDStream.transform{rdd=>extractOutliers(rdd)}
Example 10-15. transform() on a DStream in Java
JavaPairDStream<String,Long>ipRawDStream=accessLogsDStream.transform(newFunction<JavaRDD<ApacheAccessLog>,JavaRDD<ApacheAccessLog>>(){publicJavaPairRDD<ApacheAccessLog>call(JavaRDD<ApacheAccessLog>rdd){returnextractOutliers(rdd);}});
You can also combine and transform data from multiple DStreams together using StreamingContext.transform or DStream.transformWith(otherStream, func).
Stateful Transformations
Stateful transformations are operations on DStreams that track data across time; that is, some data from previous batches is used to generate the results for a new batch. The two main types are windowed operations, which act over a sliding window of time periods, and updateStateByKey(), which is used to track state across events for each key (e.g., to build up an object representing each user session).
Stateful transformations require checkpointing to be enabled in your StreamingContext for fault tolerance. We will discuss checkpointing in more detail in “24/7 Operation”, but for now, you can enable it by passing a directory to ssc.checkpoint(), as shown in Example 10-16.
Example 10-16. Setting up checkpointing
ssc.checkpoint("hdfs://...")
For local development, you can also use a local path (e.g., /tmp) instead of HDFS.
Windowed transformations
Windowed operations compute results across a longer time period than the StreamingContext’s batch interval, by combining results from multiple batches. In this section, we’ll show how to use them to keep track of the most common response codes, content sizes, and clients in a web server access log.
All windowed operations need two parameters, window duration and sliding duration, both of which must be a multiple of the
StreamingContext’s batch interval.
The window duration controls how many previous batches of data are considered, namely the last windowDuration/batchInterval.
If we had a source DStream with a batch interval of 10 seconds and wanted to create a sliding window of the last 30 seconds (or last 3 batches) we would set the windowDuration to 30 seconds.
The sliding duration, which defaults to the batch interval, controls how frequently the new DStream computes results.
If we had the source DStream with a batch interval of 10 seconds and wanted to compute our window only on every second batch,
we would set our sliding interval to 20 seconds. Figure 10-6 shows an example.
The simplest window operation we can do on a DStream is window(), which returns a new DStream with the data
for the requested window. In other words, each RDD in the DStream resulting from window() will contain data from multiple batches, which we can then process with count(), transform(), and so on. (See Examples 10-17 and 10-18.)
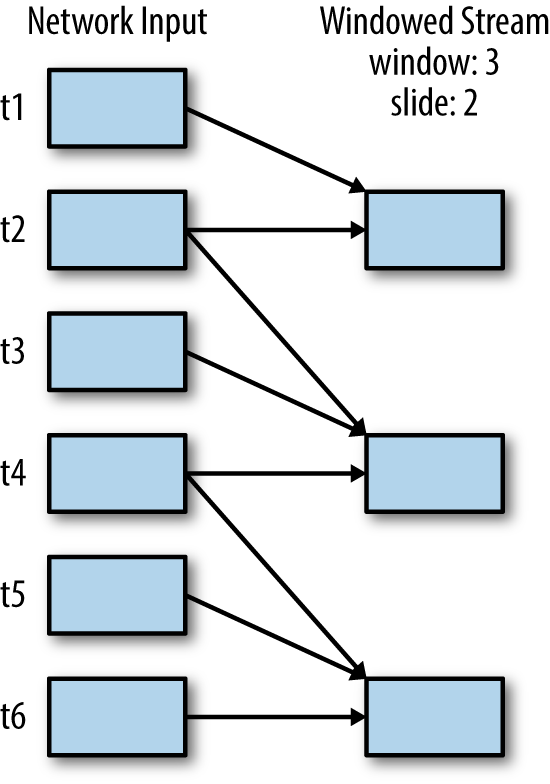
Figure 10-6. A windowed stream with a window duration of 3 batches and a slide duration of 2 batches; every two time steps, we compute a result over the previous 3 time steps
Example 10-17. How to use window() to count data over a window in Scala
valaccessLogsWindow=accessLogsDStream.window(Seconds(30),Seconds(10))valwindowCounts=accessLogsWindow.count()
Example 10-18. How to use window() to count data over a window in Java
JavaDStream<ApacheAccessLog>accessLogsWindow=accessLogsDStream.window(Durations.seconds(30),Durations.seconds(10));JavaDStream<Integer>windowCounts=accessLogsWindow.count();
While we can build all other windowed operations on top of window(), Spark Streaming provides
a number of other windowed operations for efficiency and convenience. First, reduceByWindow() and
reduceByKeyAndWindow() allow us to perform reductions on each window more efficiently.
They take a single reduce function to run on the whole window, such as +.
In addition, they have a special form that allows Spark to compute the reduction incrementally, by
considering only which data is coming into the window and which data is going out. This special form requires an inverse of the reduce function, such as - for +. It is much more efficient for large windows if your function has an inverse (see Figure 10-7).
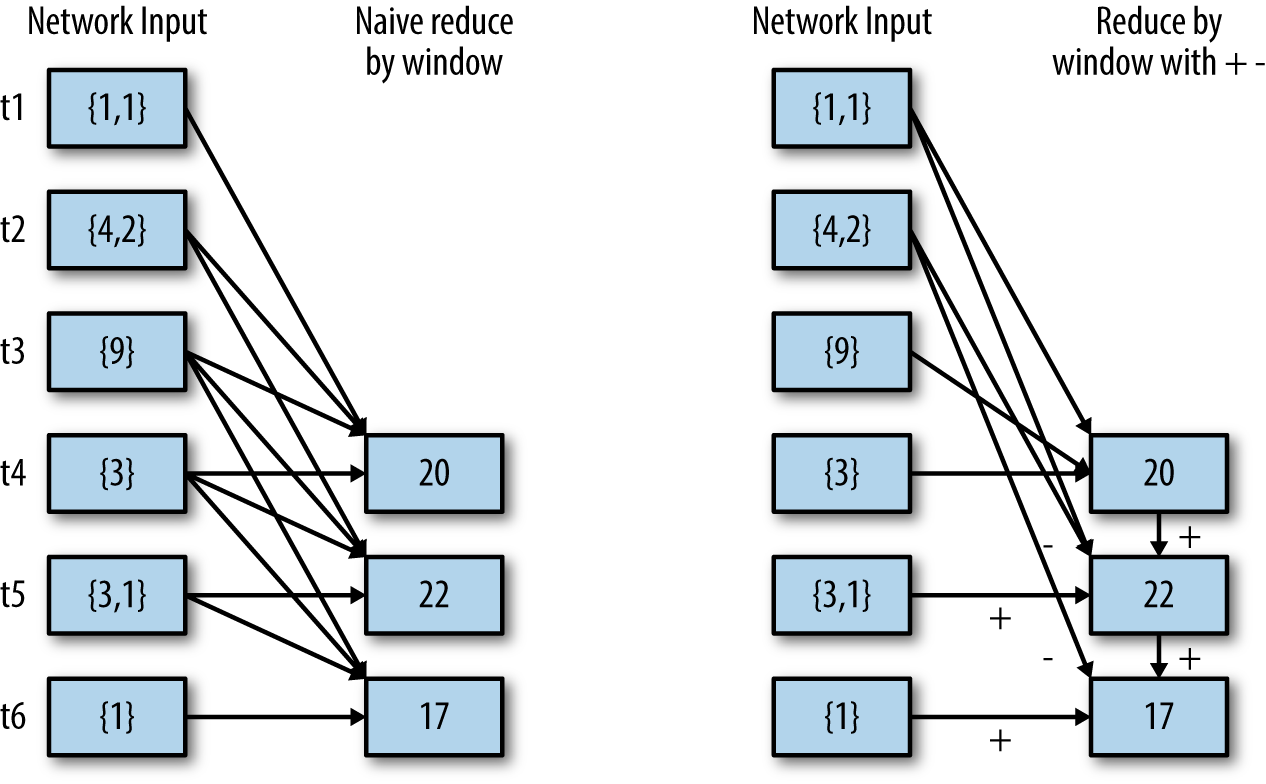
Figure 10-7. Difference between naive reduceByWindow() and incremental reduceByWindow(), using an inverse function
In our log processing example, we can use these two functions to count visits by each IP address more efficiently, as you can see in Examples 10-19 and 10-20.
Example 10-19. Scala visit counts per IP address
valipDStream=accessLogsDStream.map(logEntry=>(logEntry.getIpAddress(),1))valipCountDStream=ipDStream.reduceByKeyAndWindow({(x,y)=>x+y},// Adding elements in the new batches entering the window{(x,y)=>x-y},// Removing elements from the oldest batches exiting the windowSeconds(30),// Window durationSeconds(10))// Slide duration
Example 10-20. Java visit counts per IP address
classExtractIpextendsPairFunction<ApacheAccessLog,String,Long>{publicTuple2<String,Long>call(ApacheAccessLogentry){returnnewTuple2(entry.getIpAddress(),1L);}}classAddLongsextendsFunction2<Long,Long,Long>(){publicLongcall(Longv1,Longv2){returnv1+v2;}}classSubtractLongsextendsFunction2<Long,Long,Long>(){publicLongcall(Longv1,Longv2){returnv1-v2;}}JavaPairDStream<String,Long>ipAddressPairDStream=accessLogsDStream.mapToPair(newExtractIp());JavaPairDStream<String,Long>ipCountDStream=ipAddressPairDStream.reduceByKeyAndWindow(newAddLongs(),// Adding elements in the new batches entering the windownewSubtractLongs()// Removing elements from the oldest batches exiting the windowDurations.seconds(30),// Window durationDurations.seconds(10));// Slide duration
Finally, for counting data, DStreams offer countByWindow() and countByValueAndWindow() as shorthands.
countByWindow() gives us a DStream representing the number of elements in each window.
countByValueAndWindow() gives us a DStream with the counts for each value. See Examples 10-21 and 10-22.
Example 10-21. Windowed count operations in Scala
valipDStream=accessLogsDStream.map{entry=>entry.getIpAddress()}valipAddressRequestCount=ipDStream.countByValueAndWindow(Seconds(30),Seconds(10))valrequestCount=accessLogsDStream.countByWindow(Seconds(30),Seconds(10))
Example 10-22. Windowed count operations in Java
JavaDStream<String>ip=accessLogsDStream.map(newFunction<ApacheAccessLog,String>(){publicStringcall(ApacheAccessLogentry){returnentry.getIpAddress();}});JavaDStream<Long>requestCount=accessLogsDStream.countByWindow(Dirations.seconds(30),Durations.seconds(10));JavaPairDStream<String,Long>ipAddressRequestCount=ip.countByValueAndWindow(Dirations.seconds(30),Durations.seconds(10));
UpdateStateByKey transformation
Sometimes it’s useful to maintain state across the batches in a DStream (e.g., to track sessions as users visit a site). updateStateByKey() enables this by providing access to a state variable for DStreams of key/value pairs. Given a DStream of (key, event) pairs, it lets you construct a new DStream of (key, state) pairs by taking a function that specifies how to update the state for each key given new events.
For example, in a web server log, our events might be visits to the site, where the key is the user ID.
Using updateStateByKey(), we could track the last 10 pages each user visited. This list would be our “state” object, and we’d update it as each event arrives.
To use updateStateByKey(), we provide a function update(events, oldState) that takes in the events that have arrived for a key and its previous state, and returns a newState to store for it.
This function’s signature is as follows:
-
eventsis a list of events that arrived in the current batch (may be empty). -
oldStateis an optional state object, stored within anOption; it might be missing if there was no previous state for the key. -
newState, returned by the function, is also anOption; we can return an emptyOptionto specify that we want to delete the state.
The result of updateStateByKey() will be a new DStream that contains an RDD of (key, state) pairs on each time step.
As a simple example, we’ll use updateStateByKey() to keep a running count of the number of log messages with each HTTP response code. Our keys here are the response codes, our state is an integer representing each count, and our events are page views. Note that unlike our window examples earlier, Examples 10-23 and 10-24 keep an “infinitely growing” count since the beginning of the program.
Example 10-23. Running count of response codes using updateStateByKey() in Scala
defupdateRunningSum(values:Seq[Long],state:Option[Long])={Some(state.getOrElse(0L)+values.size)}valresponseCodeDStream=accessLogsDStream.map(log=>(log.getResponseCode(),1L))valresponseCodeCountDStream=responseCodeDStream.updateStateByKey(updateRunningSum_)
Example 10-24. Running count of response codes using updateStateByKey() in Java
classUpdateRunningSumimplementsFunction2<List<Long>,Optional<Long>,Optional<Long>>{publicOptional<Long>call(List<Long>nums,Optional<Long>current){longsum=current.or(0L);returnOptional.of(sum+nums.size());}};JavaPairDStream<Integer,Long>responseCodeCountDStream=accessLogsDStream.mapToPair(newPairFunction<ApacheAccessLog,Integer,Long>(){publicTuple2<Integer,Long>call(ApacheAccessLoglog){returnnewTuple2(log.getResponseCode(),1L);}}).updateStateByKey(newUpdateRunningSum());
Output Operations
Output operations specify what needs to be done with the final transformed data in a stream (e.g., pushing it to an external database or printing it to the screen).
Tip
Much like lazy evaluation in RDDs, if no output operation is applied on a DStream and any of its descendants, then those DStreams will not be evaluated. And if there are no output operations set in a StreamingContext, then the context will not start.
A common debugging output operation that we have used already is print(). This grabs the
first 10 elements from each batch of the DStream and prints the results.
Once we’ve debugged our program, we can also use output operations to save results. Spark Streaming has similar save() operations for DStreams, each of which takes a directory to save files into and an optional suffix. The results of each batch are saved as subdirectories in the given directory, with the time and the suffix in the filename. For instance, we can save our IP address counts as shown in Example 10-25.
Example 10-25. Saving DStream to text files in Scala
ipAddressRequestCount.saveAsTextFiles("outputDir","txt")
The more general saveAsHadoopFiles() takes a Hadoop OutputFormat. For instance, Spark Streaming doesn’t have
a built-in saveAsSequenceFile() function, but we can save SequenceFiles as shown in Examples 10-26 and 10-27.
Example 10-26. Saving SequenceFiles from a DStream in Scala
valwritableIpAddressRequestCount=ipAddressRequestCount.map{(ip,count)=>(newText(ip),newLongWritable(count))}writableIpAddressRequestCount.saveAsHadoopFiles[SequenceFileOutputFormat[Text,LongWritable]]("outputDir","txt")
Example 10-27. Saving SequenceFiles from a DStream in Java
JavaPairDStream<Text,LongWritable>writableDStream=ipDStream.mapToPair(newPairFunction<Tuple2<String,Long>,Text,LongWritable>(){publicTuple2<Text,LongWritable>call(Tuple2<String,Long>e){returnnewTuple2(newText(e._1()),newLongWritable(e._2()));}});classOutFormatextendsSequenceFileOutputFormat<Text,LongWritable>{};writableDStream.saveAsHadoopFiles("outputDir","txt",Text.class,LongWritable.class,OutFormat.class);
Finally, foreachRDD() is a generic output operation that lets us run arbitrary computations on the RDDs
on the DStream. It is similar to transform() in that it gives you access to each RDD.
Within foreachRDD(), we can reuse all the actions we have in Spark.
For example, a common use case is to write data to an external database such as MySQL, where Spark
may not have a saveAs() function, but we might use for eachPartition() on the RDD to write it out.
For convenience, foreachRDD() can also give us the time of the current batch, allowing us to output
each time period to a different location. See Example 10-28.
Example 10-28. Saving data to external systems with foreachRDD() in Scala
ipAddressRequestCount.foreachRDD{rdd=>rdd.foreachPartition{partition=>// Open connection to storage system (e.g. a database connection)partition.foreach{item=>// Use connection to push item to system}// Close connection}}
Input Sources
Spark Streaming has built-in support for a number of different data sources. Some “core” sources are built into the Spark Streaming Maven artifact, while others are available through additional artifacts, such as spark-streaming-kafka.
This section walks through some of these sources. It assumes that you already have each input source set up, and is not intended to introduce the non-Spark-specific components of any of these systems. If you are designing a new application, we recommend trying HDFS or Kafka as simple input sources to get started with.
Core Sources
The methods to create DStream from the core sources are all available on the StreamingContext. We have already explored one of these sources in the example: sockets. Here we discuss two more, files and Akka actors.
Stream of files
Since Spark supports reading from any Hadoop-compatible filesystem, Spark Streaming naturally allows a stream to be created from files written in a directory of a Hadoop-compatible filesystem. This is a popular option due to its support of a wide variety of backends, especially for log data that we would copy to HDFS anyway. For Spark Streaming to work with the data, it needs to have a consistent date format for the directory names and the files have to be created atomically (e.g., by moving the file into the directory Spark is monitoring).15 We can change Examples 10-4 and 10-5 to handle new logfiles as they show up in a directory instead, as shown in Examples 10-29 and 10-30.
Example 10-29. Streaming text files written to a directory in Scala
vallogData=ssc.textFileStream(logDirectory)
Example 10-30. Streaming text files written to a directory in Java
JavaDStream<String>logData=jssc.textFileStream(logsDirectory);
We can use the provided ./bin/fakelogs_directory.sh script to fake the logs,
or if we have real log data we could replace the rotator with an mv command to rotate the logfiles into the directory we are monitoring.
In addition to text data, we can also read any Hadoop input format. As with “Hadoop Input and Output Formats”,
we simply need to provide Spark Streaming with the Key, Value, and InputFormat classes. If, for example, we
had a previous streaming job process the logs and save the bytes transferred at each time as a SequenceFile, we could read
the data as shown in Example 10-31.
Example 10-31. Streaming SequenceFiles written to a directory in Scala
ssc.fileStream[LongWritable,IntWritable,SequenceFileInputFormat[LongWritable,IntWritable]](inputDirectory).map{case(x,y)=>(x.get(),y.get())}
Akka actor stream
The second core receiver is actorStream, which allows using Akka actors as a source for streaming.
To construct an actor stream we create an Akka actor and implement the org.apache.spark.streaming.receiver.ActorHelper interface. To copy the input from our actor into Spark Streaming, we need
to call the store() function in our actor when we receive new data. Akka actor streams are less common
so we won’t go into detail, but you can look at the streaming documentation and the ActorWordCount example in Spark to see them in use.
Additional Sources
In addition to the core sources, additional receivers for well-known data ingestion systems
are packaged as separate components of Spark Streaming. These receivers are still part of Spark, but require extra
packages to be included in your build file. Some current receivers include Twitter, Apache Kafka, Amazon Kinesis, Apache Flume, and ZeroMQ. We can include these additional receivers by adding the Maven artifact spark-streaming-[projectname]_2.10 with the same version number as Spark.
Apache Kafka
Apache Kafka is popular input source due to its speed and resilience.
Using the native support for Kafka, we can easily process the messages for many topics. To use it, we have to include the Maven artifact spark-streaming-kafka_2.10 to our project.
The provided KafkaUtils
object works on StreamingContext and JavaStreamingContext to create a DStream of your Kafka messages.
Since it can subscribe to multiple topics, the DStream it creates consists of pairs of topic and message.
To create a stream, we will call the createStream() method with our streaming context,
a string containing comma-separated ZooKeeper hosts,
the name of our consumer group (a unique name),
and a map of topics to number of receiver threads to use for that topic (see Examples 10-32 and 10-33).
Example 10-32. Apache Kafka subscribing to Panda’s topic in Scala
importorg.apache.spark.streaming.kafka._...// Create a map of topics to number of receiver threads to usevaltopics=List(("pandas",1),("logs",1)).toMapvaltopicLines=KafkaUtils.createStream(ssc,zkQuorum,group,topics)StreamingLogInput.processLines(topicLines.map(_._2))
Example 10-33. Apache Kafka subscribing to Panda’s topic in Java
importorg.apache.spark.streaming.kafka.*;...// Create a map of topics to number of receiver threads to useMap<String,Integer>topics=newHashMap<String,Integer>();topics.put("pandas",1);topics.put("logs",1);JavaPairDStream<String,String>input=KafkaUtils.createStream(jssc,zkQuorum,group,topics);input.();
Apache Flume
Spark has two different receivers for use with Apache Flume (see Figure 10-8). They are as follows:
- Push-based receiver
-
The receiver acts as an Avro sink that Flume pushes data to.
- Pull-based receiver
-
The receiver can pull data from an intermediate custom sink, to which other processes are pushing data with Flume.
Both approaches require reconfiguring Flume and running the receiver on a node on a configured port (not your existing Spark or Flume ports). To use either of them, we have to include the Maven artifact spark-streaming-flume_2.10 in our project.

Figure 10-8. Flume receiver options
Push-based receiver
The push-based approach can be set up quickly but does not use transactions to receive data. In this approach, the receiver acts as an Avro sink, and we need to configure Flume to send the data to the Avro sink (Example 10-34).
The provided Flume Utils object sets up the receiver to be started on a specific worker’s hostname and port (Examples 10-35 and 10-36). These must match those in our Flume configuration.
Example 10-34. Flume configuration for Avro sink
a1.sinks = avroSinka1.sinks.avroSink.type = avroa1.sinks.avroSink.channel = memoryChannela1.sinks.avroSink.hostname = receiver-hostnamea1.sinks.avroSink.port = port-used-for-avro-sink-not-spark-port
Example 10-35. FlumeUtils agent in Scala
valevents=FlumeUtils.createStream(ssc,receiverHostname,receiverPort)
Example 10-36. FlumeUtils agent in Java
JavaDStream<SparkFlumeEvent>events=FlumeUtils.createStream(ssc,receiverHostname,receiverPort)
Despite its simplicity, the disadvantage of this approach is its lack of transactions. This increases the chance of losing small amounts of data in case of the failure of the worker node running the receiver. Furthermore, if the worker running the receiver fails, the system will try to launch the receiver at a different location, and Flume will need to be reconfigured to send to the new worker. This is often challenging to set up.
Pull-based receiver
The newer pull-based approach (added in Spark 1.1) is to set up a specialized Flume sink Spark Streaming will read from, and have the receiver pull the data from the sink. This approach is preferred for resiliency, as the data remains in the sink until Spark Streaming reads and replicates it and tells the sink via a transaction.
To get started, we will need to set up the custom sink as a third-party plug-in for Flume. The latest directions on installing plug-ins are in the Flume documentation. Since the plug-in is written in Scala we need to add both the plug-in and the Scala library to Flume’s plug-ins. For Spark 1.1, the Maven coordinates are shown in Example 10-37.
Example 10-37. Maven coordinates for Flume sink
groupId = org.apache.spark artifactId = spark-streaming-flume-sink_2.10 version = 1.2.0
groupId = org.scala-lang artifactId = scala-library version = 2.10.4
Once you have the custom flume sink added to a node, we need to configure Flume to push to the sink, as we do in Example 10-38.
Example 10-38. Flume configuration for custom sink
a1.sinks = sparka1.sinks.spark.type = org.apache.spark.streaming.flume.sink.SparkSinka1.sinks.spark.hostname = receiver-hostnamea1.sinks.spark.port = port-used-for-sync-not-spark-porta1.sinks.spark.channel = memoryChannel
With the data being buffered in the sink we can now use FlumeUtils to read it, as shown in Examples 10-39 and 10-40.
Example 10-39. FlumeUtils custom sink in Scala
valevents=FlumeUtils.createPollingStream(ssc,receiverHostname,receiverPort)
Example 10-40. FlumeUtils custom sink in Java
JavaDStream<SparkFlumeEvent>events=FlumeUtils.createPollingStream(ssc,receiverHostname,receiverPort)
In either case, the DStream is composed of SparkFlumeEvents. We can access the underlying AvroFlumeEvent through event. If our event body was UTF-8 strings we could get the contents as shown in Example 10-41.
Example 10-41. SparkFlumeEvent in Scala
// Assuming that our flume events are UTF-8 log linesvallines=events.map{e=>newString(e.event.getBody().array(),"UTF-8")}
Custom input sources
In addition to the provided sources, you can also implement your own receiver. This is described in Spark’s documentation in the Streaming Custom Receivers guide.
Multiple Sources and Cluster Sizing
As covered earlier, we can combine multiple DStreams using operations like union().
Through these operators, we can combine data from multiple input DStreams.
Sometimes multiple receivers are necessary to increase the aggregate throughput of
the ingestion (if a single receiver becomes the bottleneck). Other times different receivers are created on different sources to receive different kinds of data, which are then combined using joins or cogroups.
It is important to understand how the receivers are executed in the Spark cluster to use multiple ones. Each receiver runs as a long-running task within Spark’s executors, and hence occupies CPU cores allocated to the application. In addition, there need to be available cores for processing the data. This means that in order to run multiple receivers, you should have at least as many cores as the number of receivers, plus however many are needed to run your computation. For example, if we want to run 10 receivers in our streaming application, then we have to allocate at least 11 cores.
Tip
Do not run Spark Streaming programs locally with master configured as "local" or "local[1]". This allocates only one CPU for tasks and if a receiver is running on it, there is no resource left to process the received data. Use at least "local[2]" to have more cores.
24/7 Operation
One of the main advantages of Spark Streaming is that it provides strong fault tolerance guarantees. As long as the input data is stored reliably, Spark Streaming will always compute the correct result from it, offering “exactly once” semantics (i.e., as if all of the data was processed without any nodes failing), even if workers or the driver fail.
To run Spark Streaming applications 24/7, you need some special setup. The first step is setting up checkpointing to a reliable storage system, such as HDFS or Amazon S3.16 In addition, we need to worry about the fault tolerance of the driver program (which requires special setup code) and of unreliable input sources. This section covers how to perform this setup.
Checkpointing
Checkpointing is the main mechanism that needs to be set up for fault tolerance in Spark Streaming. It allows Spark Streaming to periodically save data about the application to a reliable storage system, such as HDFS or Amazon S3, for use in recovering. Specifically, checkpointing serves two purposes:
-
Limiting the state that must be recomputed on failure. As discussed in “Architecture and Abstraction”, Spark Streaming can recompute state using the lineage graph of transformations, but checkpointing controls how far back it must go.
-
Providing fault tolerance for the driver. If the driver program in a streaming application crashes, you can launch it again and tell it to recover from a checkpoint, in which case Spark Streaming will read how far the previous run of the program got in processing the data and take over from there.
For these reasons, checkpointing is important to set up in any production streaming application. You can set it by passing a path (either HDFS, S3, or local filesystem) to the ssc.checkpoint() method, as shown in Example 10-42.
Example 10-42. Setting up checkpointing
ssc.checkpoint("hdfs://...")
Note that even in local mode, Spark Streaming will complain if you try to run a stateful operation without checkpointing enabled. In that case, you can pass a local filesystem path for checkpointing. But in any production setting, you should use a replicated system such as HDFS, S3, or an NFS filer.
Driver Fault Tolerance
Tolerating failures of the driver node requires a special way of creating our StreamingContext,
which takes in the checkpoint directory. Instead of simply calling new StreamingContext,
we need to use the StreamingContext.getOrCreate() function. From our initial example we would
change our code as shown in Examples 10-43 and 10-44.
Example 10-43. Setting up a driver that can recover from failure in Scala
defcreateStreamingContext()={...valsc=newSparkContext(conf)// Create a StreamingContext with a 1 second batch sizevalssc=newStreamingContext(sc,Seconds(1))ssc.checkpoint(checkpointDir)}...valssc=StreamingContext.getOrCreate(checkpointDir,createStreamingContext_)
Example 10-44. Setting up a driver that can recover from failure in Java
JavaStreamingContextFactoryfact=newJavaStreamingContextFactory(){publicJavaStreamingContextcall(){...JavaSparkContextsc=newJavaSparkContext(conf);// Create a StreamingContext with a 1 second batch sizeJavaStreamingContextjssc=newJavaStreamingContext(sc,Durations.seconds(1));jssc.checkpoint(checkpointDir);returnjssc;}};JavaStreamingContextjssc=JavaStreamingContext.getOrCreate(checkpointDir,fact);
When this code is run the first time, assuming that the checkpoint directory does not yet exist, the StreamingContext will be created when you call the factory function (createStreamingContext() for Scala, and JavaStreamingContextFactory() for Java). In the factory, you should set the checkpoint directory. After the driver fails, if you restart it and run this code again, getOrCreate() will reinitialize a StreamingContext from the checkpoint directory and resume processing.
In addition to writing your initialization code using getOrCreate(), you will need to actually restart your driver program when it crashes.
On most cluster managers, Spark does not automatically relaunch the driver if it crashes, so you need to monitor it using a tool like monit and restart it. The best way to do this is probably specific to your environment.
One place where Spark provides more support is the Standalone cluster manager, which supports a --supervise flag when submitting your driver that lets Spark restart it. You will also need to pass --deploy-mode cluster to make the driver run within the cluster and not on your local machine, as shown in Example 10-45.
Example 10-45. Launching a driver in supervise mode
./bin/spark-submit --deploy-mode cluster --supervise --master spark://... App.jar
When using this option, you will also want the Spark Standalone master to be fault-tolerant. You can configure this using ZooKeeper, as described in the Spark documentation. With this setup, your application will have no single point of failure.
Finally, note that when the driver crashes, executors in Spark will also restart. This may be changed in future Spark versions, but it is expected behavior in 1.2 and earlier versions, as the executors are not able to continue processing data without a driver. Your relaunched driver will start new executors to pick up where it left off.
Worker Fault Tolerance
For failure of a worker node, Spark Streaming uses the same techniques as Spark for its fault tolerance. All the data received from external sources is replicated among the Spark workers. All RDDs created through transformations of this replicated input data are tolerant to failure of a worker node, as the RDD lineage allows the system to recompute the lost data all the way from the surviving replica of the input data.
Receiver Fault Tolerance
The fault tolerance of the workers running the receivers is another important consideration. In such a failure, Spark Streaming restarts the failed receivers on other nodes in the cluster. However, whether it loses any of the received data depends on the nature of the source (whether the source can resend data or not) and the implementation of the receiver (whether it updates the source about received data or not). For example, with Flume, one of the main differences between the two receivers is the data loss guarantees. With the receiver-pull-from-sink model, Spark removes the elements only once they have been replicated inside Spark. For the push-to-receiver model, if the receiver fails before the data is replicated some data can be lost. In general, for any receiver, you must also consider the fault-tolerance properties of the upstream source (transactional, or not) for ensuring zero data loss.
In general, receivers provide the following guarantees:
-
All data read from a reliable filesystem (e.g., with
StreamingContext.hadoopFiles) is reliable, because the underlying filesystem is replicated. Spark Streaming will remember which data it processed in its checkpoints and will pick up again where it left off if your application crashes. -
For unreliable sources such as Kafka, push-based Flume, or Twitter, Spark replicates the input data to other nodes, but it can briefly lose data if a receiver task is down. In Spark 1.1 and earlier, received data was replicated in-memory only to executors, so it could also be lost if the driver crashed (in which case all executors disconnect). In Spark 1.2, received data can be logged to a reliable filesystem like HDFS so that it is not lost on driver restart.
To summarize, therefore, the best way to ensure all data is processed is to use a reliable input source (e.g., HDFS or pull-based Flume). This is generally also a best practice if you need to process the data later in batch jobs: it ensures that your batch jobs and streaming jobs will see the same data and produce the same results.
Processing Guarantees
Due to Spark Streaming’s worker fault-tolerance guarantees, it can provide exactly-once semantics for all transformations—even if a worker fails and some data gets reprocessed, the final transformed result (that is, the transformed RDDs) will be the same as if the data were processed exactly once.
However, when the transformed result is to be pushed to external systems using output operations, the task pushing the result may get executed multiple times due to failures, and some data can get pushed multiple times. Since this involves external systems, it is up to the system-specific code to handle this case. We can either use transactions to push to external systems (that is, atomically push one RDD partition at a time), or design updates to be idempotent operations (such that multiple runs of an update still produce the same result). For example, Spark Streaming’s saveAs...File operations automatically make sure only one copy of each output file exists, by atomically moving a file to its final destination when it is complete.
Streaming UI
Spark Streaming provides a special UI page that lets us look at what applications are doing. This is available in a Streaming tab on the normal Spark UI (typically http://<driver>:4040). A sample screenshot is shown in Figure 10-9.
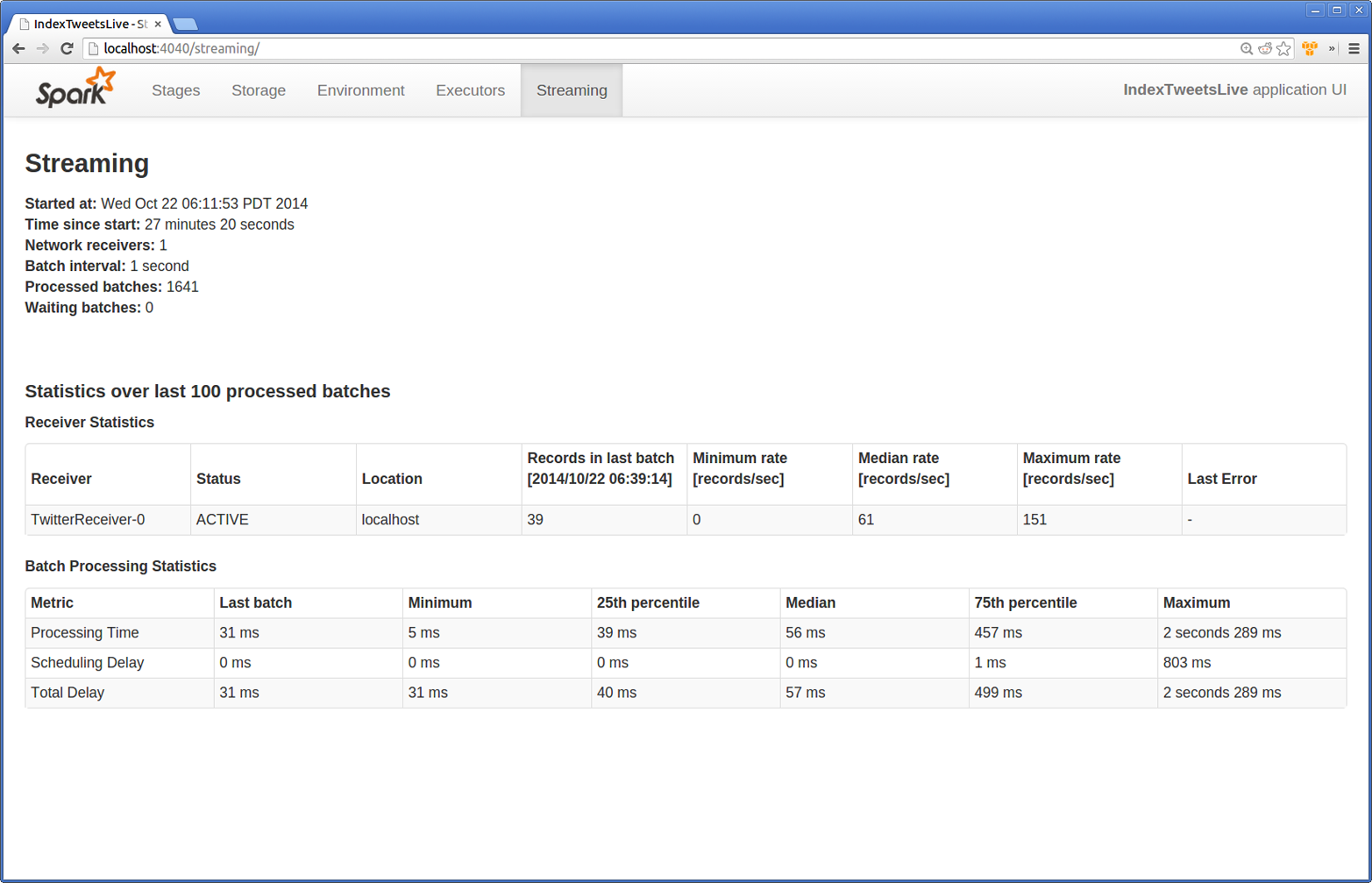
Figure 10-9. Streaming UI tab in the Spark UI
The Streaming UI exposes statistics for our batch processing and our receivers. In our example we have one network receiver, and we can see the message processing rates. If we were falling behind, we could see how many records each receiver is able to process. We can also see whether a receiver failed. The batch processing statistics show us how long our batches take and also break out the delay in scheduling the job. If a cluster experiences contention, then the scheduling delay may increase.
Performance Considerations
In addition to the existing performance considerations we have discussed in general Spark, Spark Streaming applications have a few specialized tuning options.
Batch and Window Sizes
The most common question is what minimum batch size Spark Streaming can use. In general, 500 milliseconds has proven to be a good minimum size for many applications. The best approach is to start with a larger batch size (around 10 seconds) and work your way down to a smaller batch size. If the processing times reported in the Streaming UI remain consistent, then you can continue to decrease the batch size, but if they are increasing you may have reached the limit for your application.
In a similar way, for windowed operations, the interval at which you compute a result (i.e., the slide interval) has a big impact on performance. Consider increasing this interval for expensive computations if it is a bottleneck.
Level of Parallelism
A common way to reduce the processing time of batches is to increase the parallelism. There are three ways to increase the parallelism:
- Increasing the number of receivers
-
Receivers can sometimes act as a bottleneck if there are too many records for a single machine to read in and distribute. You can add more receivers by creating multiple input DStreams (which creates multiple receivers), and then applying
unionto merge them into a single stream. - Explicitly repartitioning received data
-
If receivers cannot be increased anymore, you can further redistribute the received data by explicitly repartitioning the input stream (or the union of multiple streams) using
DStream.repartition. - Increasing parallelism in aggregation
-
For operations like
reduceByKey(), you can specify the parallelism as a second parameter, as already discussed for RDDs.
Garbage Collection and Memory Usage
Another aspect that can cause problems is Java’s garbage collection. You can minimize unpredictably large pauses due to GC by enabling Java’s Concurrent Mark-Sweep garbage collector. The Concurrent Mark-Sweep garbage collector does consume more resources overall, but introduces fewer pauses.
We can control the GC by adding -XX:+UseConcMarkSweepGC to the spark.executor.extraJavaOptions configuration parameter. Example 10-46 shows this with spark-submit.
Example 10-46. Enable the Concurrent Mark-Sweep GC
spark-submit --conf spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC App.jarIn addition to using a garbage collector less likely to introduce pauses, you can make a big difference by reducing GC pressure. Caching RDDs in serialized form (instead of as native objects) also reduces GC pressure, which is why, by default, RDDs generated by Spark Streaming are stored in serialized form. Using Kryo serialization further reduces the memory required for the in-memory representation of cached data.
Spark also allows us to control how cached/persisted RDDs are evicted from the cache.
By default Spark uses an LRU cache.
Spark will also explicitly evict RDDs older than a certain time period if you set spark.cleaner.ttl.
By preemptively evicting RDDs that we are unlikely to need from the
cache, we may be able to reduce the GC pressure.
Conclusion
In this chapter, we have seen how to work with streaming data using DStreams. Since DStreams are composed of RDDs, the techniques and knowledge you have gained from the earlier chapters remains applicable for streaming and real-time applications. In the next chapter, we will look at machine learning with Spark.
14 In Spark 1.2, receivers can also replicate data to HDFS. Also, some input sources, such as HDFS, are naturally replicated, so Spark Streaming does not replicate those again.
15 Atomically means that the entire operation happens at once. This is important here since if Spark Streaming were to start processing the file and then more data were to appear, it wouldn’t notice the additional data. In filesystems, the file rename operation is typically atomic.
16 We do not cover how to set up one of these filesystems, but they come in many Hadoop or cloud environments. When deploying on your own cluster, it is probably easiest to set up HDFS.