
Appendix A. The Reputation Framework
The reputation framework is the software that forms the execution environment for reputation models. This appendix takes a deeper and much more technical look at the framework. The first section is intended for software architects and technically minded product managers to generate appropriate requirements for implementation and possible reuse by other applications.
The second section of this appendix describes two different reputation frameworks with very different sets of requirements in detail: the Invisible Reputation Framework and the Yahoo! Reputation Platform.
This appendix talks about messaging systems, databases, performance, scale, reliability, etc., and you can safely skip it if you are not interested in such gory internals.
Reputation Framework Requirements
This section helps you identify the requirements for your reputation framework. As with all projects, the toughest requirements can be stated as a series of trade-offs. When selecting the requirements for your framework, be certain that they consider its total lifetime, meeting the needs at the beginning of your project and going forward, as your application grows and becomes successful.
Keep in mind that your first reputation model may be just one of several to utilize your reputation framework. Also, your reputation system is only a small part of an application…it shouldn’t be the only part.
Are your reputation calculations static or dynamic? Static means that you can compute your claim values on a go-forward basis, without having to access all previous inputs. Dynamic means the opposite…that each input and/or each query will regenerate the values from scratch.
What is the scale of your reputation system…small or huge? What is the rate of inputs per minute? How many times will reputation scores be accessed for display or use by your application?
How reliable must the reputation scores be…transactional or best-effort?
How portable is the data? Should the scores be shared with other applications or integrated with their native application only?
How complex is the reputation model…complicated or simple? If it is currently simple, will it stay that way?
Which is more important, getting the best possible response immediately, or a perfectly accurate response as soon as possible? Or, more technically phrased: What is the most appropriate messaging method…Optimistic/Fire-and-Forget or Request-Response/Call-Return?
Calculations: Static Versus Dynamic
There are significant trade-offs in the domain of performance and accuracy when considering how to record, calculate, store, and retrieve reputation events and scores. Some static models have scores that need to be continuous and real-time; they need to be as accurate as possible at any given moment. An example would be spammer IP reputation for industrial and scale email providers. Others may be calculated in batch-mode, because a large amount of data will be consulted for each score calculation.
Dynamic reputation models have constantly changing constraints:
- Variable contexts
The data considered for each calculation is constrained differently for each display context. This use is common in social applications, such as Zynga’s popular Texas HoldEmPoker, which displays friends-only leaderboards.
- Complex multielement relationships
The data calculations affect one another in a nonlinear way, such as search relevance calculations like Google’s PageRank. Recommender systems are also dynamic data models…typically a large portion of the data set is considered to put every element in a multidimensional space for nearest-neighbor determination. This allows the display of “People like you also bought…” entities.
Static: Performance, performance, performance
Very large applications require up-to-the-second reputation statements available to any reading applications at incredibly high rates. For example, a top email provider might need to know a spammer reputation for every IP address for email messages entering the service in real time! Even if that’s cached in memory, when that reputation changes state, say from nonspammer to spammer, instant notification is crucial. There’s just no time to use the traditional database method of recalculating the reputation over and over again from mostly unchanged data. By static we mean roll-forward calculations, in which every reputation input modifies the roll-ups in such a way that they contain the correct value at the moment and contain enough state to continue the process for the next input.
Dynamic: Reputation within social networks
Given the description of static, you might be tempted to select the dynamic requirement for a framework because it provides the greatest range of reputation models possible. There is a serious cost to this option…it increases the cost of implementing, testing, and most importantly scaling your framework. Static reputations are easier to understand, implement, and test, and they scale better. Look at the history of Twitter.com’s Fail Whale, a direct result of the requirement for a dynamic custom display of tweets for each and every user. Dynanism is costing them a fortune.
When possible, find ways to simplify your model, either by adding more specific contexts or by reducing dimensions through some clever math. This book won’t cover the many forms of dynamic systems in any depth, as many of the algorithms are well covered in academic literature. See Appendix B for pointers to various document archives.
Scale: Large Versus Small
Scale—or the number of inputs (and the database writes they ultimately generate) and reputation claim value reads—is probably the most important factor when considering any reputation system implementation.
Small scale is any transaction rate such that a single instance of a database can handle all reputation-related reads and writes without becoming overloaded and falling behind.
Large scale requires additional software services to support reading and storing reputation statements. At the point where your reputation system grows large enough to require multiple databases (or distributing the processing of inputs to multiple machines), then you probably need a distinct reputation framework. It becomes just too complicated for the high-level application to manage the reputation data model.
At a low enough volume, say less than thousands of reads per minute and only hundreds of writes, it is easy to think that simple database API calls mixed directly into the application code as needed would be the best approach for speed of development. Why bother adding a layer to isolate the reputation system access to the database? Consider that your application may not always stay small. What if it is a hit and suddenly you need multiple databases or more reputation frameworks to process all the inputs? This has happened to more than a few web databases over the years, and on occasion—such as when Ma.gnolia ended up losing all its users’ data—it can be fatal to the business.
So, even for small-scale applications, we recommend a clean, modular boundary between the application and the reputation system: all inputs should use a class or call a library that encapsulates the reputation process code and the database operations. That way, the calculations are centralized and the framework can be incrementally scaled. See the section The Invisible Reputation Framework: Fast, Cheap, and Out of Control for a specific example of this practice.
Reliability: Transactional Versus Best-Effort
Reputation claims are often critical to the success of an application, commercial or otherwise. So it would seem to follow naturally that it should be a requirement that the value of the claims should be 100% reliable. This means that every input’s effect on the reputation model should be reflected in the calculations. There’s nothing more valuable than the application’s contributions to the bottom line, right?
There’s another reason you’d like reputation roll-ups to be reliable, especially when users provide the claims that are combined to create them: sometimes users abuse the system, and often this abuse comes in great volume if the scores have financial value to the end users themselves. (See eBay Seller Feedback Karma.) If scores are reliable and tracked on a transactional basis, the effects of the abuse can be reversed. If a user is determined to abuse the reputation system, often the correct action is to reverse all of his inputs on every target that he ever evaluated. This is the Undo anything feature and requires a reputation framework that is optimized to support reversible inputs and a database that is indelible by source identifier only.
So, if it’s good for business and it’s good for abuse mitigation, why shouldn’t my reputation system require transactional-style reliability throughout? The answer: performance.
Every reversible input adds at least one additional database read-modify-write to store the event. If the database is locked for each input, high-transaction rate systems can create a severe bottleneck waiting for resources to become available. Not only that, it at least doubles the size of the database and messaging network load, and depending on the input-to-output ratio, may increase it by an order magnitude or more.
For some applications, say Ratings and Reviews (see the section User Reviews with Karma ), storing all the inputs is already a part of the application design, so these costs must be met. But when you look at top-100 website or online game transaction rates, you see that it quickly becomes cost-prohibitive to store everything everyone does in an indexed database. As Mammad Zadeh, chief architect of Yahoo!’s Reputation Platform, said about best-effort volume data inputs for spammer reputation:
Approximate can be good enough!
For applications that have continuous input, the reputation model can be designed to deal with best-effort message delivery. Yahoo!’s reputation model for identifying spammer IP addresses takes user inputs in the form of “This Is Spam” votes and also receives a continuous stream of volume data: the total email received per IP address per minute. There are hundreds of thousands of mail server IP addresses, and at any moment tens of thousands of them are sending mail to Yahoo! mailboxes. The user inputs are several orders of magnitude less common than the incoming traffic data.
It was clear immediately that the internal messaging infrastructure would quickly get overwhelmed if every reputation input message had to be sent with guaranteed delivery. Instead, the much lighter overhead and much quicker protocol was selected to make best-effort delivery for these messages, while the user actions were sent using a slower but more reliable channel. The model was designed so that it would keep a windowed history of traffic data for each target IP address and a floating average volume for calculations. This allowed the model to have a sense of time as well as make it insensitive to the occasional dropout of traffic data. Likewise, the inputs never had to be reversed, so were never stored in deployment. During the testing, tuning, and debugging phase, the traffic data was stored in order to verify the model’s results.
Why not just design all of the models to be compatible with best-effort delivery then? Because it becomes a much more difficult task with user inputs. In many applications, the user evaluations took considerable effort to construct (i.e., Reviews) or are a part of the user’s identity (i.e., Favorites) and can’t just disappear; if this ever approaches becoming a common occurrence, you risk driving the customer away. This is also true for roll-up reputation that is attached to users’ objects: their karma scores or ratings for their eBay shop or reviews of their favorite objects. People track their scores like hawks and get upset if ratings are incorrectly calculated.
Best-effort message delivery also makes reversible reputation math very messy…because of lost messages, counters can go negative; go out of range; and scores can get stuck with inappropriate values given the number of reported inputs, for example, “0 users say this movie is 5-stars!”
Finally, losing inputs in a time-critical application, such as the one described in Chapter 10, could increase operational costs.
There is a compromise: if you build a reputation framework that supports reversible transactions, and use that feature only judiciously in your models, you can have the best of both worlds.
Model Complexity: Complex Versus Simple
Reputation models often start out very simple: store a number, starting at 0, and periodically add 1 to it and update the record. It seems there is no need for a reputation framework in this case beyond that provided by the current application environment and that of the database.
In practice, however, reputation systems either evolve or fail. Reputation is used to increase the value of your entities. So, either the model succeeds at increasing value or it needs to be abandoned or changed to reflect the actual use pattern that will achieve this goal. This usually involves making the system more complex, for example, tweaking it to include a more subtle set of inputs. On the other hand, if it is successful, it may well become the target of manipulation by those who directly benefit from such actions. For instance, the business owners on Yelp formed collectives to cross-review each other’s businesses and increase their rankings (see “Merchants angry over getting yanked by Yelp” by Ellen Lee and Anastasia Ustinova in the July 4, 2008, edition of the San Francisco Chronicle). Even when successful, reputation models must constantly evolve.
So, whether a reputation model starts as complex or succeeds sufficiently to become complex, the reputation framework should be designed to assume that models may contain several, perhaps dozens of reputation processes—and more importantly that the model will change over time. This suggests that version control for both the framework and the models that execute within.
As the number of processes in a model increases, there are performance trade-offs based on other requirements on the framework. If the entire framework is transactional—say by wrapping a complex process chain with a database lock—though reliable, this will lead to increased lock contention and may significantly decrease throughput.
It may also be possible to do static graph analysis of reputation models to combine processes and parallelize execution, in effect reducing the complexity before execution to improve performance.
Data Portability: Shared Versus Integrated
Should reputation statements be kept separate on a per-application or per-context basis or be made more available for other uses? Intuitively, from both a simplified security view and an incremental development approach, the answer would be yes: isolate the data and integrate the reputation framework in-line with the application code, which has appropriate access to the database as well has a code-level understanding of the source and target objects. For single-application environments, data portability seems like a nice-to-have feature, something that the team will get to in version 1.x.
Although it is true that reputation claims are always most valuable in the context in which they were generated, sometimes the context stretches across multiple applications. For example, Yahoo! Shopping and Yahoo! Music both benefit from users evaluating new music releases, either at the time of purchase or even when listening to them via real-time stream.
Shared context is the primary reason reputation frameworks should treat targets as foreign keys: identifiers in an external database. But it also means that the reputation statement store should be accessible by multiple applications. This exact situation comes up more often than you might think, and one-off solutions for sharing or duplicating data across applications quickly become cost prohibitive. When Yahoo! Local and Yahoo! Travel decided that they should share their hotel and restaurant reviews between the applications, they incurred a large cost to merge the data, since they each used different target identifiers for the same real-world business.
Tip
Even if you don’t yet have multiple applications in development, plan for success. Create sharable object identifiers that new applications can use, and make the schema portable. It doesn’t take any longer and keeps your options open.
Even with shared source and target identifiers, you might be tempted to think that the reputation framework should be developed all in-line with the initial application. For example, you might presume that a master application would be the only one that would want to calculate the reputations and store them; all ancillary apps would be read-only. Many systems are structured this way. This sounds great, but it creates a dependency on the master application development team whenever the reputation model needs to change to accommodate a new input or new interim score or to retune based on anomalous behavior perhaps introduced as the result of a new use pattern.
In the section Generating inferred karma, we discussed the pattern of inferred karma, where reputation is borrowed from other contexts to create an interim reputation that can be used in the case where no context-specific claim is available or yet trustworthy. As detailed in Chapter 10, when Yahoo! Answers borrowed membership reputation, IP reputation, and browser cookie reputation to use as a reason to trust someone’s report of abusive content, the creators of those component reputations had no inkling that they’d be used this way.
This mixing of external scores may seem to be a contradiction of the “reputation is always in context” rule, but it doesn’t have to be, as long as each reuse maintains all, or most, of the original context’s meaning. The fact that a Yahoo! account is months or years old has more reputation value when compared to one created today. The same thing goes for the age of a browser cookie, or abuse history on an IP address. None of these components is reliable alone, nor should any of them be used to make serious decisions about the reliability of a user, but combined they might just give you enough information to make the user’s experience a little better.
Caution
A reputation framework that allows multiple applications to read and write reputation statements to each other’s contexts can lead to serious data problems; a bug in one model can damage the execution of another. For such environments, a security model and/or a disciplined development process is strongly suggested.
See the detailed example in The Yahoo! Reputation Platform: Shared, Reliable Reputation at Scale for a description of a specific implementation.
Optimistic Messaging Versus Request-Reply
The reputation framework really has only two interfaces to the application environment: a channel for routing inputs to an executing model and a method for sending a signal that something interesting happened in the model. In the vast majority of cases, reputation scores are not output in the classical sense, but they are stored for the application code to retrieve later.
This approach means that the reputation framework can be isolated from the application for performance and security reasons. One way to think of it is like a special database preprocessor for turning inputs into database records.
Given the narrow input channel, the framework implementor may choose between several messaging models. Certainly programmers are most familiar with request-reply messaging—most everything works that way: programs call functions that return results when complete, and even the Web can make your computer wait up to a minute for the server to reply to a HTTP GET request. It seems logical for an application to send a reputation input, such as a star-rating for a movie to the reputation model, and wait for confirmation of the new average score to return. Why bother with any other messaging model?
Performance at scale
Many inputs, especially those that are not reflected back to the user, should be sent without waiting for acknowledgment. This is called optimistic (or asynchronous) messaging, colloquially known as fire-and-forget. This makes the application much faster, as the application no longer has to wait for network round trip plus all of the database accesses required by the reputation model. The load instead shifts the burden to the messaging infrastructure and the machines that process the messages. This is how large-scale applications work: send messages into a cloud of computers that can be expanded and reconfigured to handle increasing traffic.
Note that request-reply can be added as a lightweight library on top of an optimistic messaging service: pass a callback handle to the model, which will get triggered when the result is complete. Application developers would use this wrapper sparingly, only when they needed an immediate new result. Generally, this is rare. For example, when a user writes a review for a hair dryer, he doesn’t see the effects on the roll-up score immediately; instead he’s looking at the review he just submitted. In fact, delaying the display of the roll-up might be a good idea for abuse mitigation reasons.
Even if it seems that you will never need optimistic messaging
because you’ll never have that many inputs, we urge that your
reputation framework (even if it is just a local library) provide the
semantics of messaging (i.e.,
SendReputationEvent() and SendReputationEventAndWait()), even if it
is implemented as a straightforward function call underneath. This is
low cost and will allow your applications to run even if you
significantly change the operational characteristics of your
framework.
Framework Designs
Each trade-off made when selecting framework design requirements has implementation impacts for the framework itself and constrains the reputation models and applications that utilize it. In order to more clearly illustrate the costs and benefits of various configurations, we now present two reputation sandbox designs: the minimalist Invisible Framework and the full-scalable Yahoo! Reputation Platform. Table A-1 shows the framework requirements for each.
| Framework design | Calculations | Scale | Reliability | Portability | Messaging | Model complexity |
| Invisible Reputation Framework | Dynamic (option) | Small | Best-effort | Embedded | Request-reply | Simple |
| Yahoo! Reputation Platform | Static | Huge | Transactional (option) | Shared | Optimistic | Complex |
The Invisible Reputation Framework: Fast, Cheap, and Out of Control
When most applications start implementing social media, including the gathering of user evaluations or reputation, they just place all input, processing, and output as code in-line with their application. Need a thumbs-up? Just add it to the page, create a votes table to store an entry for everyone who votes, and do a database query to count the number of entries at display time. It is quick and easy. Then they start using a score like this for ranking search results, and they quickly realize that they can’t afford to do that many queries dynamically, so they create a background or timed process to recalculate the reputation for each entity and attach it to that entities record.
And so it goes, feature after feature, one new-use optimization after another, until either the application becomes too successful and scaling breaks or the cost-benefit of another integration exceeds the business pain threshold.
Everyone starts this way. It is completely normal.
Requirements
“Time to market is everything…we need reputation (ratings, reviews, or karma) and we need it now. We can fix it later.” This summarizes the typical implementation plan for legions of application developers. Get something—anything—working, ship alpha-quality code, and promise yourself you will fix it later. This is a surprisingly tight constraint on the design of the invisible reputation framework, which is actually no framework at all!
- Mostly dynamic calculations with static results cache as optimization
When first implementing a reputation system, it seems obvious and trivial: store some ratings and when you need to display the roll-up, do a database query to calculate the average just in time. This is the dynamic calculation method, and it allows for some interesting reputation scores, such as Your Friends Rated this 4.5 Stars. When reputation gets used for things such as influencing the search rank of entities, this approach becomes too expensive. Running hundreds of just-in-time averages against the database when only the top 10 results are going to be displayed 90% of the time is cost-prohibitive. The typical approach is a dynamic-static hybrid: at a fixed interval, say daily, calculate a dynamic database average for each and every entity and store the roll-up value in a search index for speedy searches tomorrow. When you need a new index for some new calculation, repeat the process. Clearly this can quickly become unwieldy.
- Small Scale: 100 transactions/minute or less
At a small scale, no more than one transaction per second or so, the database is not a bottleneck, and even if it becomes one, many commercial scaling solutions are available.
- Best-effort reliability with ad-hoc cleanup
Reliability is a secondary consideration when time to market is the main driver. Code developed in Internet time will be buggy and revised often. It’s simply impractical to consider that reputation would be completely accurate. This requires that reputation models themselves will be built to auto-correct obvious errors, such as a roll-up going negative or out-of range, since it will happen.
- Application bound reputation data
The temptation will be to store reputation statements as claim values as closely bound to the target data records as possible. After all, it will make it easier for search ranking and other similar uses. Only one application will read and write the reputation, so there is no need to be worried about future uses, right?
- Request-reply messaging direct to database
When coding in a hurry, why introduce a new and potentially unfamiliar optimistic messaging system? It adds cognitive, implementation, and messaging overhead. The invisible reputation framework trusts the engineer to code up the database action in-line in the application: the SQL Query requests are sent using the vendor-supplied interface, and the application waits dutifully for the reply. This is most familiar and easiest to understand, even if it is the has poor performance characteristics.
- Simple or ad-hoc model support
Model? What model? There is no execution environment for the reputation model, which is broken into little pieces and spread throughout the application. Of course, this makes the model code much harder to maintain because future coders will have to search through the source to find all the places the model is implemented. If the programmers think ahead, they might break the common functions out into a library for reuse, but only if time allows.
Implementation details
A typical invisible reputation framework is implemented as in-line code. Taking a typical LAMP (Linux, Apache, MySQL, PHP/Perl/Python) installation as an example, this means that the data schema in the reputable entities tables are extended to include reputation claim values, such as average rating or karma points, and a new table is set up to contain any stored/reversible user created reputation statements. The database calls are made directly by the application through a standard PHP MySQL library, such as the MySQLi class.
With this approach, simple ratings and review systems can be created and deployed in a few days, if not hours. It doesn’t get any quicker than that.
Lessons learned
Assuming your application succeeds and grows, taking the absolutely quickest and cheapest route to reputation will always come back to bite you in the end.
Most likely, the first thing to cause trouble will be the database; as the transaction rate increases, there will be lock contention on writes and general traffic jams on reads. For a while the commercial solutions will help, but ultimately decoupling the application code from the reputation framework functionality will be required, both for reading and for writing statements.
Another set of challenges—tuning the model, adding more reputation uses, and attendant debugging—become cost-prohibitive as your application grows, causing time to market to suffer significantly. Not planning ahead will make you slower than your competition. Again, a little investment in compartmentalizing the reputation framework, such isolating the execution of the model into a library, ends up being a great cost-benefit trade-off in the medium- to long-term.
Whatever you do, compartmentalize!
Tip
If the development time budget allows only one best-practice recommendation to be applied to the implementation of a reputation framework, we recommend this above all others: compartmentalize the framework! By that we mean the reputation model, the database code, and the data tables. Yes, you can count that as three things if you must. They are listed in priority order.
The Yahoo! Reputation Platform: Shared, Reliable Reputation at Scale
Yahoo! is a collection of diverse web applications that make it collectively the website with the largest audience in the world. Over a half-billion different people use a Yahoo! application each month. In a single day, Yahoo! gathers millions of user evaluations, explicit and implicit, of reputable entities spread over dozens of topic areas and hundreds of applications. And almost none of it is shared across similar topics or applications. We’ve already mentioned that it was only a few years ago that Yahoo! Travel and Yahoo! Local started to share hotel and restaurant reviews, and that one-off integration provided no technical or operational assistance to Yahoo! Music and Yahoo! Shopping when they similarly wanted to share information about user DVD ratings.
Yahoo! requirements
Outrageously large scaling requirements and sharing were the driving requirements for the Yahoo! Reputation Platform. The following are Yahoo! Reputation Platform requirements in force-ranked order:
- Huge scale: 10,000,000,000 transactions/year
When Yahoo! started its efforts at building a common reputation infrastructure in the form of a standard platform, the current rate of user ratings entering the Yahoo! Music Experience, their real-time music streaming service, had reached one billion ratings per year. This was more than half of the total explicit user ratings it was gathering at the time across all of its sites. The executives were excited by the possibility of this project and how it might be used in the future, when cellphones would become the predominant device for accessing social data, and therefore suggested that the minimum input rate should exceed that seen by Yahoo ! Music by at least a factor of 10×—or ten billion transactions per year. That’s an average of about 350 transactions per second, but traffic is never that smooth…common peaks would exceed 1,000 per second.
That may seem huge, but consider how the database transaction rate might become inflated by another factor of 2× to 10×, depending on the nature of the reputation model’s complexity. Each stored roll-up could add a (lock)-read-modify-write-(unlock) cycle. Also, using and/or displaying reputation (aka capturing the value) multiplies the number of reads by a significant amount, say 5× in lieu of a concrete example. So by the time things get down to the database, for a typical model, we could see 100 billion reads and 20 or 30 billion writes!
Clearly scale is the requirement that will impose the most challenges on the framework implementation team.
- Reputation events sharable across applications and contexts
Why bother building a gigantic reputation platform? One of the driving requirements was that reputation information be shared across applications and Yahoo! sites. Travel, Local, Maps, and other sites should be able to access and contribute user evaluations to the reputable entities—businesses and services—they all have in common. Shopping, Tech, Coupons, and others all have users interacting with products and merchants.
It was clear that the segmentation of Yahoo! applications and sites were not the best contexts for reputation. The properties of the entities themselves—what kind of thing they were, where they were located, and who was interacting with them—these are the real reputation contexts. A common platform was a great way to create a neutral, shared environment for collecting and distributing the users’ contributions.
- Transaction-level reliability used by most models
Reputation is a critical component of Yahoo!’s overall value and is used throughout the service: from web search to finding a good hotel to identifying the songs you never want to hear on your personal web-radio station.
This value is so important that it creates the incentive for significant reputation abuse. For example, there is a billion-dollar industry, complete with an acronym, for capitalizing on design flaws in search algorithms: SEO, or search engine optimization. Likewise, the reputation models that execute in this framework are subject to similar abuse. In fact, for many applications, there are so many targets that the number of user evaluations for each is very small, making the abusive manipulation of roll-ups accessible to small groups or even dedicated individuals (see Commercial incentives).
Generally, it is not technically possible for software to detect small-scale reputation abuse. Instead, social mechanisms are used, typically in the form of a Report Abuse button. The community polices reputation in these cases. Unfortunately, this method can be very expensive, as each report requires a formal review by customer care staff to decide whether the reputation has been manipulated. And each abuser typically generates dozens if not hundreds of abusive reputation contributions. The math is pretty straightforward: even if abuse is reported for 1 in a 100 product reviews, at Yahoo! scale it is not cost-efficient to have humans screen everything.
After identifying a user account or browser cookie or IP address that is abusing the reputation system, there is a requirement that customer care can remove all of the related reputation created by the user. Nothing they created can be trusted and everything is presumed to be damaging, perhaps event multiple entities.
This adds a transactional requirement to the framework: every explicit user input and its roll-ups that were also affected must be reversible. It is not enough to just delete the user and the specific event; the reputation model must be executed to undo the damage.
Note that this requirement is very expensive and is used only on reputation models that require it. For example, in tracking the user’s personal ratings for songs, Yahoo! Music Engine may not require reversibility, because charging a subscription fee is considered sufficient deterrent to reputation abuse.
Also, large-volume models that do not surface roll-up reputation to the users may not be transactional. A good example is the Yahoo! Mail IP Spammer reputation model, as described in the patent application, which does not keep a transactional history of individual IP address but does keep the This Is (Not) Spam votes on a per-user basis for abuse management as described earlier.
- Complex and interconnected model support
Between Yahoo!’s existing understanding of reputation abuse in its current systems as well as the strong requirement to share data between applications, it was clear that the reputation models that would execute on this platform would be more complex than simply counting and averaging a bunch of numeric scores.
There was also an original requirement for modular reuse of hypothetical reputation model components in order to speed up the development and deployment of new applications integrating reputation.
- Static calculations
As a result of the performance constraints imposed by the scaling requirements, it was immediately clear that models running in the framework should execute with linear, O(n), performance characteristics, which precluded considering dynamic computation. There is no time to grab multiple items from the database to recalculate a custom value for every model execution. All calculations would be limited to roll-forward computation: a roll-up must be updatable using a fixed number of repository reads, usually exactly one. This means that the platform will not support per-user reputation contexts, such as Your Friends Rated This Entity 4.5. Time-limited contexts, such as Last Year, Last Month, etc., could still be implemented as specific static reputation calculations. (See the discussion of windowing decay systems in Freshness and decay.)
- Optimistic messaging system
Given that we can anticipate that the database is going to be the choke point for this platform, a request-reply protocol to the reputation system would be unable to deliver on a reliable service level. There are just too many inputs coming into too many complex model instances to be sure how long it will take for the model to run.
Performance demands an asynchronous, optimistic messaging backbone, where messages are delivered by a load-balancing queue manager to multiple reputation framework instances to be processed on a first-come, first-served basis.
Applications that read reputation claim values directly from the database, not via the framework, will always get the best result possible at that moment.
The application developer that is collecting explicit user reputation events, such as ratings, is offered several choices to deal with the immediate-reply nature of the optimistic messaging system:
If possible (not displaying a roll-up) assume success and echo the user’s input directly back to him as though it had been returned by the platform.
Implement a callback in the reputation model, and wrap the asynchronous call with one that waits. Don’t forget a timeout in best-effort message delivery environments.
Get whatever the current result is from the database and explain to the user, if needed, that it might take a bit longer for his result to be reflected in the roll-up.
Yahoo! implementation details
The architecture of the Yahoo! Reputation Platform is detailed in two recently published patent applications:
U.S. Patent Application 11/774,460:“Detecting Spam Messages Using Rapid Sender Reputation Feedback Analysis,” Libbey, Miles; Farmer, F. Randall; Mohsenzadeh, Mohammad; Morningstar, Chip; Sample, Neal
U.S. Patent Application 11/945,911:“Real-Time Asynchronous Event Aggregation Systems,” Farmer, F. Randall; Mohsenzadeh, Mohammad; Morningstar, Chip; Sample, Neal
The implementation details we describe here for the platform are derived primarily from these documents, interviews with the development teams, and our personal experience setting the platform’s design requirements.
High-level architecture
Figure A-1 renders the Yahoo! reputation framework architectural stack using a traditional layer cake model. Though the onerous scaling requirements make the specifics of this implementation very specialized, at this level of abstraction, most reputation framework models are the same: they each need message dispatching services; a reputation model execution engine with an interface reputation statement relational database service; a method to activate or signal external processes; and a separate high-performance, query-only interface to the data for application display and other uses, such as search result ranking.
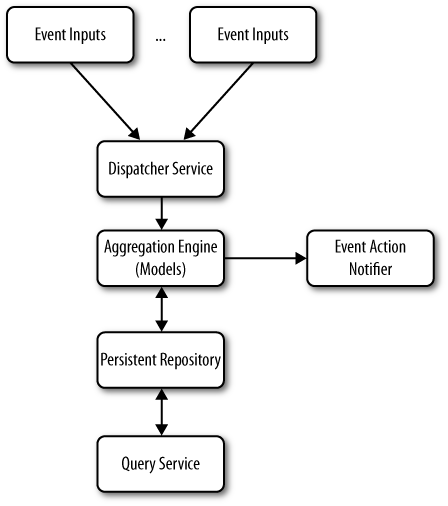
The following sections describe in detail the specific choices that the Yahoo! Reputation Platform team made for implementing each layer.
Messaging dispatcher
Figure A-2 shows the top architectural layer of the framework, a message dispatcher whose job it is to accept inputs, usually in the form of reputation statements (source, claim, and target), transform them to standard-format messages and sending them on to one of many model execution engines to be processed.
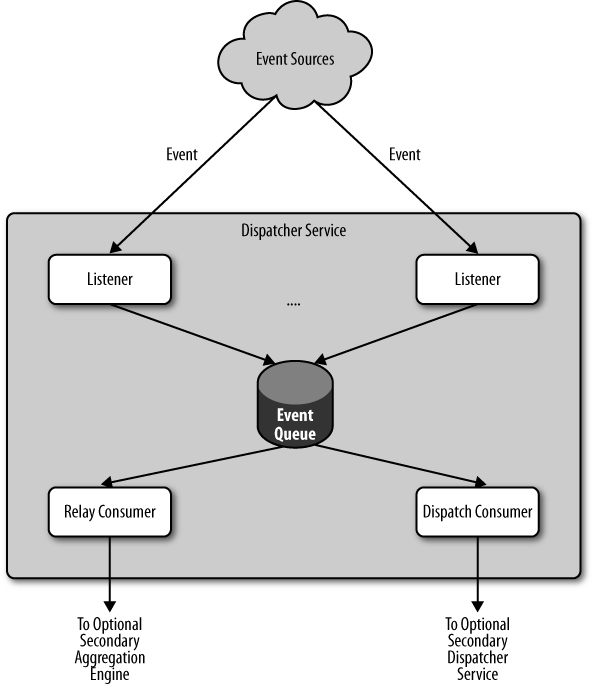
There are three main components of this subsystem: a set of input listeners, a single message event queue, and message consumers, of which there are two subtypes—dispatch consumers and relay consumers.
- Input listeners
This is the compatibility layer for messaging. Different listeners can have different semantics. For example, some listeners can be implemented to understand asynchronous messages of different data formats, such as XML or JSON. They may be hand-coded function calls to do last-moment data transformations, such as turning a source or target identifier from one context into an identifier from another context. Another common listener enhancement is to add a timestamp to, and/or to write a log of, each message to aide in abuse mitigation or model testing and tuning.
Tip
It is important to note that when reputation models interact with one another across contexts, as is often the case with karma systems, the first model will send a message via this message dispatching service instead of making a direct call to a hardcoded entry point in the second model.
Once normalized into a common format, the messages are then handed off to the message event queue for first-in, first-in processing.
- Message event queue
The message event queue holds all of the input messages waiting for processing. This process is tightly optimized and can do load-balancing and other throughput optimizations, not detailed here. There are many books and papers on these methods.
- Message consumers
Each message will be fetched by a consumer process, typically to be forwarded somewhere else. There can be several types, each with its own semantics, but the main two kinds are:
- Dispatch consumer
The dispatch consumer delivers messages to the model execution engines. Typically there is one dispatch consumer for every known model execution engine. In self-scaling systems, where more resources are brought online automatically, when a new model execution engine starts up, it might register with a dispatcher, which would start a dispatch consumer to start forwarding messages.
- Relay consumer
When more than one message dispatcher is running, it is often desirable to separate message traffic, and by extension the ability to modify reputation, by context. This provides data modification isolation, limiting possible damage from context-external applications. But, there are specific cases where cross-context modification is desirable, with karma being the typical example: multiple contexts contribute reputation to the user-profile context.
In order to allow this cross-context, cross-model, and cross-dispatcher messaging, certain predetermined messages are consumed by the relay consumer and passed onto other dispatchers, in effect stacking dispatchers as needed. This way the Yahoo! Movies ratings and review system can send a message to the Yahoo! Profiles karma model without knowing the address for the dispatcher; it can just send a message to the one for its own framework and know that the message will get relayed to the appropriate servers.
Note that a registration service, such as the one described for the dispatch consumer, is required to support this functionality.
There can be many message dispatchers deployed, and this layer is a natural location to provide any context-based security that may be required. Since changes to the reputation database come only by sending messages to the reputation framework, limiting application access to the dispatcher that knows the names and addresses of the context-specific models makes sense. As a concrete example, only Yahoo! Travel and Local had the keys needed to contact, and therefore make changes to, the reputation framework that ran their shared model, but any other company property could read their ratings and reviews using the separate reputation query layer (see Reputation query interface).
The Yahoo! Reputation Platform’s dispatcher implementation was optimistic: all application API calls return immediately without waiting for model execution. The messages were stored with the dispatcher until they could be forwarded to a model execution engine.
The transport services used to move messages to the dispatcher varied by application, but most were proprietary high-performance services. A few models, such as Yahoo! Mail’s Spam IP reputation, accepted inputs on a best-effort basis, which uses the fastest available transport service.
Tip
The Yahoo! Reputation Platform high-level architectural layer cake shown in Figure A-1 contains all the required elements of a typical reputation framework. New framework designers would do well to start with that design and design/select implementations for each component to meet their requirements.
Model execution engine
Figure A-3 shows the heart of the reputation framework, the model execution engine, which manages the reputation model processes and their state. Messages from the dispatcher layer are passed into the appropriate model code for immediate execution. The model execution engine reads and writes its state, usually in the form of reputation statements via the reputation database layer. (See Reputation repository.) Model processes run to completion, and if cross-model execution or optimism is desired, may send messages to the dispatcher for future processing.
The diagram also shows that models may use the external event signaling system to notify applications of changes in state. See the section External signaling interface.
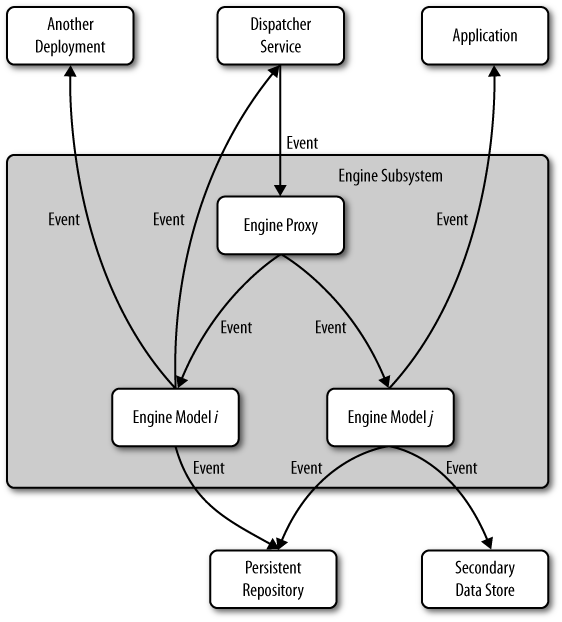
This platform gets much of its performance from parallel processing, and the Yahoo! Reputation Platform uses this approach by implementing an Engine Proxy that routes all incoming message traffic to the engine that is currently running the appropriate model in a concurrent process. This proxy is also in charge of loading and initializing any model that is not currently loaded or executing.
The Yahoo! Reputation Platform implemented models in PHP with many of the messaging lines within the model diagram implemented as function calls instead of higher-overhead messages. See Your Mileage May Vary for a discussion of the rationale. The team chose PHP mostly due to its members’ personal expertise and tastes (there was no particular technical requirement that drove this choice).
External signaling interface
In optimistic systems, such as the Yahoo! reputation platform, output happens passively: the application has no idea when a change happened or what the results were of any input event. Some unknown time after the input, a query to the database may or may not reflect a change. In high-volume applications, this is a very good thing because it is just impractical to wait for every side effect of every input to propagate across dozens of servers. But when something important (read valuable) happens, such as an IP address switching from good-actor to spammer, the application needs to be informed ASAP.
This is accomplished by using an external signaling interface. For smaller systems, this can just be hardcoded calls in the reputation model implementation. But larger environments normally have signalling services in place that typically log signal details and have mechanisms for executing processes that take actions, such as changing user access or contacting supervisory personnel.
Another kind of signaling interface can be used to provide a layer of request-reply semantics to an optimistic system: when the model is about to complete, a signal gets sent to a waiting thread that was created when the input was sent. The thread identifier is sent along as a parameter throughout the model as it executes.
Reputation repository
On the surface, the reputation repository layer looks like any other high-performance, partitioned, and redundant database. The specific features for the repository in the Yahoo! reputation platform are:
Like the other layers, the repositories may themselves be managed by a proxy manager for performance.
The reputation claim values may be normalized by the repository layer so that those reading the values via the query interface don’t have to know the input scale.
To improve performance, many read-modify-write operations, such as increment and addToSum, are implemented as stored procedures at the database level, instead of being code-level mathematic operations at the model execution layer. This significantly reduces interprocess message time as well as the duration of any lock contention on highly modified reputation statements.
The Yahoo! Reputation Platform also contains features to dynamically scale up by adding new repository partitions (nodes) and cope gracefully with data migrations. Though those solutions are proprietary, we mention them here for completeness and so that anyone contemplating such a framework can consider them.
Reputation query interface
The main purpose for all of this infrastructure is to provide speedy access to the best possible reputation statements for diverse display and other corporate use patterns. The reputation query interface provides this service. It is separated from the repository service because it provides read-only access, and the data access model is presumed to be less restrictive. For example, every Yahoo! application could read user karma scores, even if they could only modify it via their own context-restricted reputation model. Large-scale database query service architectures are well understood and well documented on the Web and in many books. Framework designers are reminded that the number of reputation queries in most applications is one or two orders of magnitude larger than the number of changes. Our short treatment of the subject here does not reflect the relative scale of the service.
Yahoo! used context-specific entity identifiers (often in the
form of database foreign keys) as source and
target IDs. So, even though Yahoo! Movies might have permission to
ask the reputation query service for a user’s restaurant reviews, it
might do them no good without a separate service from Yahoo! Local
to map the reviews’ local-specific target ID back to a data record
describing the eatery. The format used is
context.foreignKeyValue; the reason for the
context. is to allow for context-specific wildcard
search (described later). There is always at least one special
context: user., which holds karma. In practice, there
is also a source-only context, roll-up., used for
claims that aggregate the input of many sources.
Claim type identifiers are of a specific
format—context.application.claim. An example is
YMovies.MovieReviews.OverallRating to hold the claim
value for a user’s overall rating for a movie.
Queries are of the form: Source: [SourceIDs], Claim:
[ClaimIDs], Target: [TargetIDs]. Besides the obvious use of
retrieving a specific reputation statement, the identifier design
used in this platform supports wildcard queries (*) to support
various multiple return results:
Source:*, Claim: [ClaimID], Target: [TargetID]Returns all of a specific type of claim for a particular target. e.g., all of the reviews for the movie Aliens.
Source: [SourceID], Claim: context.application.*, Target: *Returns all of the application-specific reputation statements for any targets by a source, e.g., all of Randy’s ratings, reviews, and helpful votes on other user reviews.
Source: *, Claim: [ClaimID], Target: [TargetID, TargetID, ...]Returns all reputation statements with a certain claim type of multiple targets. The application is the source of the list of targets, such as a list of otherwise qualified search results, e.g., What have users given as overall ratings for the movies that are currently in theaters near my house?
There are many more query patterns possible, and framework designers will need to predetermine exactly which wildcard searches will be supported, as appropriate indexes may need to be created and/or other optimizations might be required.
Yahoo! supports both RESTful interfaces and JSON protocol requests, but any reliable protocol would do. It also supports returning a paged window of results, reducing interprocess messaging to just the number of statements required.
Yahoo! lessons learned
During the development of the Yahoo! Reputation Platform, the team wandered down many dark alleys and false paths. Presented next are some of warning signs and insights gained. They aren’t intended as hard-and-fast rules, just friendly advice:
It is not practical to use prebuilt code blocks to build reputation models, because every context is different, so every model is also significantly different. Don’t try to create a reputation scripting language. Certainly there are common abstractions, as represented in the graphical grammar, but those should not be confused with actual executing code. To get the desired customization, scale, and performance, the reputation processes should be expressed directly in native code. The Yahoo! Reputation Platform expressed the reputation models directly in PHP. After the first few models were complete, common patterns were packaged and released as code libraries, which decreased the implementation time for each model.
Focus on building only on the core reputation framework itself, and use existing toolkits for messaging, resource management, and databases. No need to reinvent the wheel.
Go for the performance over slavishly copying the diagrams’ inferred modularity. For example, even the Simple Accumulator process is probably best implemented primarily in the database process as a stored procedure. Many of the patterns work out to be read-modify-write, so the main alternatives are stored procedures or deferring the database modifications as long as possible given your reliability requirements.
Creating a common platform is necessary, but not sufficient, to get applications to share data. In practice, it turned out that the problem of reconciling the entity identifiers between sites was a time-intensive task that often was deprioritized. Often merging two previously existing entity databases was not 100% automatic and required manual supervision. Even when the data was merged, it typically required each sharing application to modify existing user-facing application code, another expense. This latter problem can be somewhat mitigated in the short-term by writing backward-compatible interfaces for legacy application code.
Your Mileage May Vary
Given the number of variations on reputation framework requirements and your application’s technical environment, the two examples just presented represent extremes that don’t exactly apply to your situation. Our advice is to design in favor of adaptability, a constraint we intentionally left off the choice list.
It took three separate tries to implement the Yahoo! Reputation Platform.
Yahoo! first tried to do it on the cheap, with a database vendor creating a request-reply, all database-procedure-based implementation. That attempt surfaced an unacceptable performance/reliability trade-off and was abandoned.
The second attempt taught us about premature reputation model compilation and optimization and that we could loosen the strongly typed and compiled language requirement in order to make reputation model implementation more flexible and accessable to more programmers.
The third platform finally made it to deployment, and the lessons are reflected in the previous section. It is worth noting that though the platform delivers on the original requirements, the sharing requirement—listed as a primary driver for the project—is not yet in extensive use. Despite the repeated assertions by senior product management, the applications designers end up requiring orientation in the benefits of sharing their data as well as leveraging the shared reputations of other applications. Presently, only customer care looks at cross-property karma scores to help determine whether an account that might otherwise be automatically suspended should get additional, high-touch support instead.
Recommendations for All Reputation Frameworks
Reputation is a database. Reputation statements should be stored and indexed separately so that applications can continue to evolve new uses for the claims.
Though it is tempting to mix the reputation process code in with your application, don’t do it! You will be changing the model over time to either fix bugs, achieve the results you were originally looking for, or to mitigate abuse, and this will be all but impossible unless reputation remains a distinct module.
Sources and targets are foreign keys, and generally the reputation framework has little to no specific knowledge of the data objects indexed by those keys. Everything the reputation model needs to compute the claims should be passed in messages or remain directly accessible to each reputation process.
Discipline! The reputation framework manages nothing less than the code that sets the valuation of all user-generated and user-evaluated content in your application. As such, it deserves the effort of regular critical design and code reviews and full testing suites. Log and audit every input that is interesting, especially any claim overrides that are logged during operations. There have been many examples of employees manipulating reputation scores in return for status or favors.