
Chapter 2. A (Graphical) Grammar for Reputation
The phrase reputation system describes a wide array of practices, technologies, and user-interface elements. In this chapter, we’ll build a visual “grammar” to describe the attributes, processes, and presentation of reputation systems. We’ll use this grammar throughout subsequent chapters to describe existing reputation systems and define new ones. Furthermore, you should be able to use this grammar as well—both to understand and diagram common reputation systems, and to design systems of your own.
Meta-modeling: A formalized specification of domain-specific notations…following a strict rule set.
Much reputation-related terminology is inconsistent, confusing, and even contradictory, depending on what site you visit or which expert opinion you read. Over the last 30 years, we’ve evaluated and developed scores of online and offline reputation systems and identified many concepts and attributes common to them all; enough similarity that we propose a common lexicon and a “graphical grammar”—the common concepts, attributes, and methods involved—to build a foundation for a shared understanding of reputation systems.
Why propose a graphical grammar? Reputation is an abstract concept, and deploying it usually requires the participation of many people. In practice, we’ve consistently seen that having a two-dimensional drawing of the reputation model facilitates the design and implementation phases of the project. Capturing the relationships between the inputs, messages, processes, and outputs in a compact, simple, and accessible format is indispensable. Think of it like a screen mock, but for a critical, normally invisible part of the application.
In describing this grammar, we’ll borrow a metaphor from basic chemistry: atoms (reputation statements) and their constituent particles (sources, claims, and targets) are bound with forces (messages and processes) to make up molecules (reputation models), which constitute the core useful substances in the universe. Sometimes different molecules are mixed in solutions (reputation systems) to catalyze the creation of stronger, lighter, or otherwise more useful compounds.
Note
The graphical grammar of reputation systems is continually evolving as the result of changing markets and technologies. Visit this book’s companion wiki at http://buildingreputation.com for up-to-date information and to participate in this grammar’s evolution.
The Reputation Statement and Its Components
As we proceed with our grammar, you’ll notice that reputation systems compute many different reputation values that turn out to possess a single common element: the reputation statement. In practice, most input to a reputation model is either already in the form of reputation statements or is quickly transformed into them for easy processing.
Just as matter is made up of atoms, reputation is made up of reputation statements.
Like atoms, reputation statements always have the same basic components, but they vary in specific details. Some are about people, and some are about products. Some are numeric, some are votes, some are comments. Many are created directly by users, but a surprising number is created by software.
Any single atom always has certain particles (protons, neutrons, and electrons). The configurations and numbers of those particles determine the specific properties of an element when it occurs en masse in nature. For example, an element may be stable or volatile, gaseous or solid, and radioactive or inert, but every object with mass is made up of atoms.
The reputation statement is like an atom in that it too has constituent particles: a source, a claim, and a target (see Figure 2-1). The exact characteristics (type and value) of each particle determine what type of element it is and its use in your application.
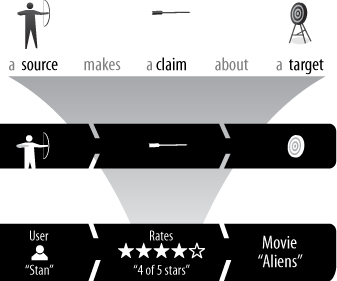
Reputation Sources: Who or What Is Making a Claim?
Every reputation statement is made by someone or something. A claim whose author is unknown is impossible to evaluate: the statement “Some people say product X is great” is meaningless. Who are “some people”? Are they like me? Do they work for the company that makes product X? Without knowing something about who or what made a claim, you can make little use of it.
We start building our grammar from the ground up, and so we need a few primitive objects:
- Entity
An entity is any object that can be the source or target of reputation claims. It must always have a unique identifier and is often a database key from an external database. Everything is for or about entities.
- Source
A source is an entity that has made a reputation claim. Though sources are often users, there are several other common sources: input from other reputation models, customer care agents, log crawlers, antispam filters, page scrapers, third-party feeds, recommendation engines, and other reputation roll-ups (see the description of roll-ups in the section Messages and Processes).
- User [as Source]
Users are probably the most well-known source of reputation statements. A user represents a single person’s interaction with a reputation system. Users are always formal entities, and they may have reputations for which they are the source or of which they are the target.
- Aggregate Source
Reputation systems are all about collecting and combining or aggregating multiple reputation statements. The reputation statements that hold these collected claims are known as roll-ups and always use a special identifier: the aggregate source.
This sounds like a special exception, but it isn’t. This is the very nature of reputation systems, even in life: claims that a movie is number one at the box office don’t include a detailed list of everyone who bought a ticket, nor should they. That claim always comes with the name of an aggregation source, such as “according to Billboard Magazine.”
Reputation Claims: What Is the Target’s Value to the Source? On What Scale?
The claim is the value that the source assigned to the target in the reputation statement. Each claim is of a particular claim type and has a claim value. Figure 2-1 shows a claim with a 5-star rating claim type, and this particular reputation statement has a claim value of 4 (stars).

- Claim type
What type of evaluation is this claim? Is it quantitative (numeric) or qualitative (structured)? How should it be interpreted? What processes will be used to normalize, evaluate, store, and display this score? Figure 2-2 shows reputation statements with several different common claim types.
- Quantitative or numeric claims
Numeric or quantitative scores are what most people think of as reputation, even if they are displayed in a stylized format such as letter grades, thumbs, stars, or percentage bars. Since computers handle numbers easily, most of the complexity of reputation systems has to do with managing these score classes. Examples of common numerical score classes are accumulators, votes, segmented enumerations (that is, stars), and roll-ups such as averages and rankings.
- Qualitative claims
Any reputation information that can’t be readily parsed by software is called qualitative, but such information plays a critical role in helping people determine the value of the target. On a typical ratings-and-reviews site, the text comment and the demographics of the review’s author set important context for understanding the accompanying 5-star rating. Qualitative scores commonly appear as blocks of text, videos, URLs, photos, and author attributes.
- Raw score
The score is stored in raw form—as the source created it. Keeping the original value is desirable because normalization of the score may cause some loss of precision.
- Normalized score
Numeric scores should be converted to a normalized scale, such as 0.0 to 1.0, to make them easier to compare to each other. Normalized scores are also easier to transform into a claim type other than the one associated with input.
A normalized score is often easier to read than trying to guess what 3 stars means, since we’re trained to understand the 0–100 scale early in life and the transformation of a normalized number to 0–100 is trivial to do in one’s head. For example, if the community indicated that it was 0.9841 (normalized) in support of your product, you instantly know this is a very good thing.
Reputation Targets: What (or Who) Is the Focus of a Claim?
A reputation statement is always focused on some unique identifiable entity—the target of the claim. Reputations are assigned to targets, for example, a new eatery. Later, the application queries the reputation database supplying the same eatery’s entity identifier to retrieve its reputation for display: “Yahoo! users rated Chipotle Restaurant 4 out of 5 stars for service.” The target is left unspecified (or only partially specified) in database requests based on claims or sources: “What is the best Mexican restaurant near here?” or “What are the ratings that Lara gave for restaurants?”
- Target, aka reputable entity
Any entity that is the target of reputation claims. Examples of reputable entities are users, movies, products, blog posts, videos, tags, guilds, companies, and IP addresses. Even other reputation statements can be reputable entities if users make reputation claims about them—movie reviews, for example.
- User as target, aka karma
When a user is the reputable entity target of a claim, we call that karma. Karma has many uses. Most uses are simple and limited to corporate networks, but some of the more well-known uses, such as points incentive models and eBay feedback scores, are complex and public (see the section Karma for a detailed discussion).
- Reputation statement as target
Reputation statements themselves are commonly the targets of other reputation statements that refer to them explicitly. See Complex Behavior: Containers and Reputation Statements As Targets for a full discussion.
Molecules: Constructing Reputation Models Using Messages and Processes
Just as molecules are often made up of many different atoms in various combinations to produce materials with unique and valuable qualities, what makes reputation models so powerful is that they aggregate reputation statements from many sources and often statements of different types. Instead of concerning ourselves with valence and Van der Waals forces, in reputation models we bind the atomic units—the reputation statements—together with messages and processes.
In the simple reputation model presented in Figure 2-3, messages are represented by arrows and flow in the direction indicated. The boxes are the processes and contain descriptions of the processes that interpret the activating message to update a reputation statement and/or send one or more messages onto other processes. As in chemistry, the entire process is simultaneous; messages may come in at any time, and multiple messages may take different paths through a complex reputation model at the same time.
People often become confused about the limited scope of reputation, and where to draw the lines between multiple reputations, so we need a couple of definitions:
- Reputation model
A reputation model describes all of the reputation statements, events, and processes for a particular context. Usually a model focuses on a single type of reputable entity.
Yahoo! Local, Travel, Movies, TV, etc. are all examples of ratings-and-reviews reputation models. eBay’s Seller Feedback model, in which users’ ratings of transactions are reflected in sellers’ profiles, is a karma reputation model. The example in Figure 2-3 is one of the simplest possible models and was inspired by the Digg it vote-to-promote reputation model (see Chapter 6) made popular by Digg.com.
- Reputation Context
A reputation context is the relevant category for a specific reputation. By definition, the reputation’s reuse is limited to related contexts. A high ranking for a user of Yahoo! Chess doesn’t really tell you whether you should buy something from that user on eBay, but it might tell you something about how committed the user is to board gaming tournaments. See the sections Reputation Takes Place Within a Context and FICO: A Study in Global Reputation and Its Challenges for a deeper consideration of the limiting effects of context.
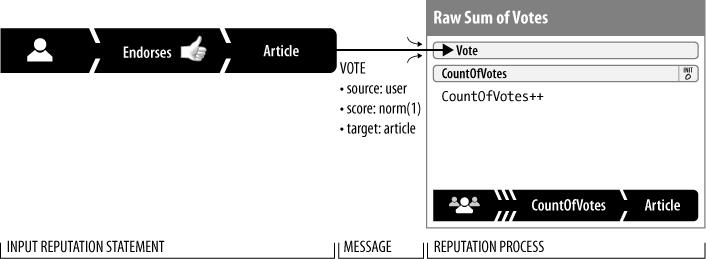
Messages and Processes
Again, look at the simplest reputation model diagram shown in Figure 2-3. The input reputation statement appears on the left and is delivered as a message to the reputation process box. Messages and processes make up the working mechanics of the reputation model:
- Reputation message
Reputation messages, represented by the flow lines in reputation model diagrams, are information supplied to a reputation process for some sort of computational action. In this example, the input is a reputation statement delivered as a message to the Raw Sum of Votes process. These messages may come from other processes, explicit user action, or external autonomous software. Don’t confuse the party sending the messages with the reputation source; they are usually unrelated. For example, even when the source of a reputation input is a user, the message usually comes from an application—allowing the reputation system to take different actions based on the sender’s identity.
- Input event (reputation message)
In this book, we call initial messages—those that start the execution flow of a reputation model—input events; we show them at the start of a model diagram. Input events are said to be transient when the reputation message does not need to be undone or referenced in the future. Transient input events are not stored.
If, on the other hand, an event may need to be displayed or reversed in the future (e.g., if a user abuses the reputation model), it is said to be reversible and must be stored either in an external file such as a log or as a reputation statement. Most rating-and-review models have reversible inputs. But for very large-scale systems, such as IP address reputations that identify mail spammers, it’s too costly to store a separate input event for every email received. For those reputation models, the transient input method is appropriate.
- Reputation process
The large boxes represent one or more reputation processes. Using the message parameters, these processes normalize, transform, store, decide how to route new messages, or, most often, calculate a value. Although this book describes several common process types, the logic in these processes is usually customized to the application’s requirements for more engineering-level detail about a specific implementation example, see Appendix A.
- Stored Reputation Value
A stored reputation value is simply a reputation statement that may be read as part of a reputation process that calculates a new claim value for itself or another reputation statement.
Many reputation processes use message input to transform a reputation statement. In our example in Figure 2-3, when a user clicks “I Digg this URL,” the application sends the input event to a reputation process that is a simple counter:
CountOfVotes. This counter is a stored reputation value that is read for its current value, then incremented by one, and then is stored again. This brings the reputation database up to date and the application may use the target identifier (in Digg’s case, a URL) to get the claim value.- Roll-ups
A roll-up is a specific kind of stored reputation value—any aggregated reputation score that incorporates multiple inputs over time or from multiple processes. Simple average and simple accumulator are examples of roll-ups.
Reputation Model Explained: Vote to Promote
Figure 2-3 is the first of many reputation model diagrams in this book. We follow each diagram with a detailed explanation.
This model is the simple accumulator: It counts votes for a target object. It can count clickthroughs or thumbs-ups, or it can mark an item as a favorite.
Even though most models allow multiple input messages, for clarity we’re presenting a simplified model that has only one, in the form of a single reputation statement:
Likewise, whereas models typically have many processes, this example has only one:
Raw Sum of Votes: When vote messages arrive, the
CountOfVotescounter is incremented and stored in a reputation statement of the claim typeCounter, set to the value ofCountOfVotesand with the same target as the originating vote. The source of this statement is said to be aggregate because it is a roll-up—the product of many inputs from many different sources.
See Chapter 3 for a detailed list of common reputation process patterns, and see Chapters 6 and 7 for a discussion of the effects of various score classes on a user interface.
Building on the Simplest Model
Figure 2-4 shows a fuller representation of a Digg.com-like vote-to-promote reputation model. This example adds a new element to determining community interest in an article: adding a reputation for the level of user activity, measured by comments left on the target entity. These two are weighted and combined to produce a rating.
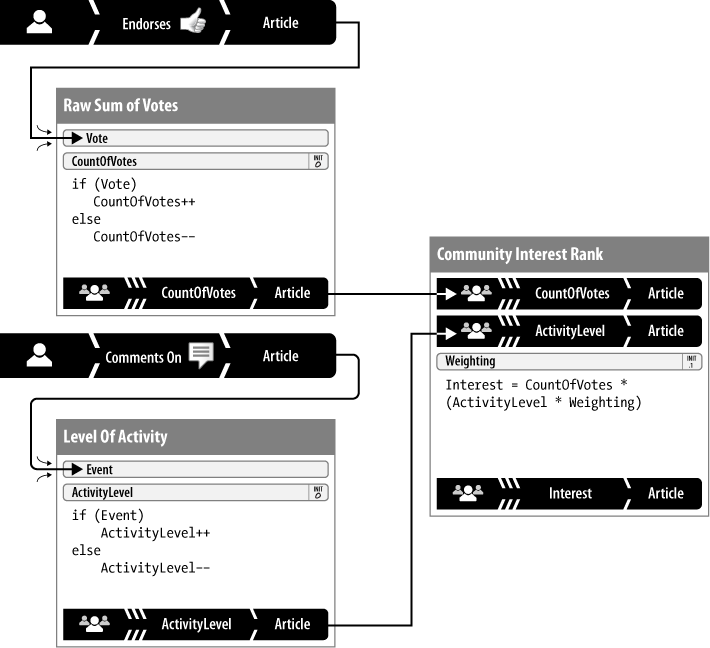
The input messages take the form of two reputation statements:
When a user endorses an article, the thumbs-up vote is represented as a 1.0 and sent as a message to the Raw Sum of Votes process. If a previous thumbs-up vote is withdrawn, a score of 0.0 is sent instead.
When a user comments on an article, it is counted as activity and represented as a 1.0 and sent as a message to the Level of Activity process. If the comment is later deleted by the user, a score of 0.0 is sent to undo the earlier vote.
This model involves the following reputation processes:
- Raw Sum of Votes
This process either increments (if the input is 1.0) or decrements a roll-up reputation statement containing a simple accumulator called
CountOfVotes. The process stores the new value and sends it in a message to another process, Community Interest Rank.- Level of Activity
This process either increments (if the input is 1.0) or decrements a roll-up reputation statement containing a simple accumulator called
ActivityLevel. It stores the new value back into the statement and sends it in a message to another process, Community Interest Rank.- Community Interest Rank
This process always recalculates a roll-up reputation statement containing a weighted sum called interest, which is the value that the application uses to rank the target article in search results and in other page displays. The calculation uses a local constant—
Weighting—to combine the values ofCountOfVotesandActivityLevelscores disproportionately; in this example, an endorsement is worth 10 times the interest score of a single comment. The resultingInterestscore is stored in a typical roll-up reputation statement: aggregate source, numeric score, and target shared by all of the inputs.
Complex Behavior: Containers and Reputation Statements As Targets
Just as there exist some interesting-looking molecules in nature, and much like hydrogen bonds are especially strong, certain types of reputation statements called containers join multiple closely related statements into one super-statement. Most websites with user-generated ratings and comments for products or services provide examples of this kind of reputation statement: they clump together different star ratings with a text comment into an object formally called a review. See Figure 2-5 for a typical example, restaurant reviews.

Containers are useful devices for determining the order of reputation statements. Although it’s technically true that each individual component of a container could be represented and addressed as a statement of its own, that arrangement would be semantically sloppy and lead to unnecessary complexity in your model. The container model maps well to real life. For example, you probably wouldn’t think of the series of statements about Dessert Hut made by user Zary22 as a rapid-fire stream of individual opinions; you’d more likely consider them related and influenced by one another. Taken as a whole, the statements express Zary22’s experience at Dessert Hut.
Note
A container is a compound reputation statement with multiple claims for the same source and target.
Once a reputation statement exists in your system, consider how you might make it a reputable entity itself, as in Figure 2-6. This indirection provides for subtle yet powerful feedback. For example, people regularly form their own opinions about the opinions of others based on some external criteria or context. (“Jack hated The Dark Knight, but he and I never see eye to eye anyway.”)
Another feature of review-based reputation systems is that they often incorporate a form of built-in user feedback about reviews written by other users. We’ll call this feature the Was This Helpful? pattern. (See Figure 2-7.) When a user indicates whether a review was helpful, the target is a review (container) written earlier by a different user.
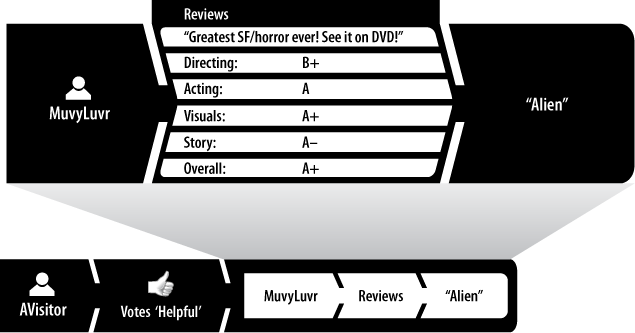
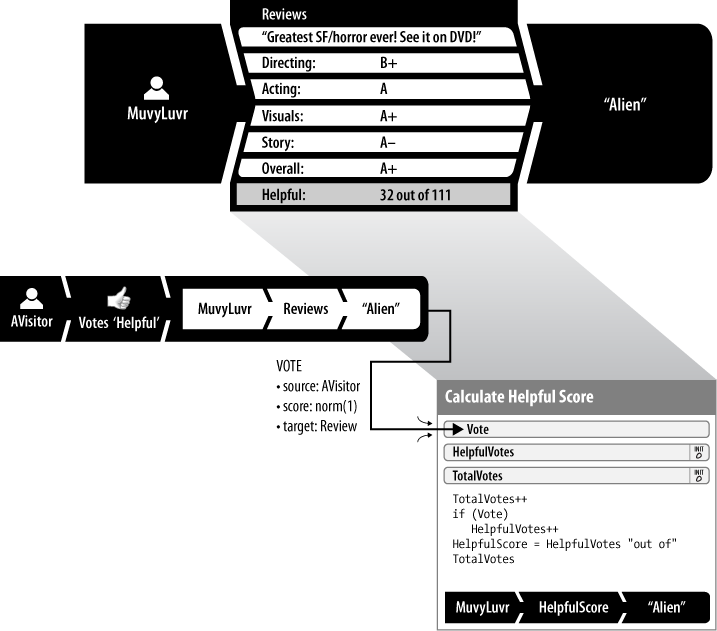
The input message takes the form of a single reputation statement:
A user votes on the quality of another reputation statement, in this case a review: a thumbs-up vote is represented by a 1.0 value, and a thumbs-down vote by a 0.0 value.
This model includes only one reputation process:
Calculate Helpful Score: When the message arrives, load the
TotalVotesstored reputation value, increment, and store it. If the vote is not zero, the process incrementsHelpfulVotes. Finally, set theHelpfulScoreto a text representation of the score suitable for display: “HelpfulVotesout ofTotalVotes.” This representation is usually stored in the very same review container that the voter was judging (i.e., had targeted) as helpful. This configuration simplifies indexing and retrieval, e.g., “Retrieve a list of the most helpful movie reviews by MuvyLuvr” and “Sort the list of movie reviews of Aliens by helpful score.” Though the original review writer isn’t the author of his helpful votes, his review is responsible for them and should contain them.
You’ll see variations on this simple pattern of reputation-statements-as-targets repeated throughout this book. It makes it possible to build fairly advanced meta-moderation capabilities into a reputation system. Not only can you ask a community “What’s good?”; you can also ask “…and whom do you believe?”
Solutions: Mixing Models to Make Systems
In one more invocation of our chemistry metaphor, consider that physical materials are rarely made of a single type of molecule. Chemists combine molecules into solutions, compounds, and mixtures to get the exact properties they want. But not all substances mix well—oil and water, for example. The same is true in combining multiple reputation model contexts in a single reputation system. It’s important to combine only those models with compatible reputation contexts.
- Reputation system
A reputation system is a set of one or more interacting reputation models. An example is SlashDot.com, which combines two reputation models: an entity reputation model of users’ evaluations of individual message board postings and a karma reputation model for determining the number of moderation opportunities granted to users to evaluate posts. It is a “the best users have the most control” reputation system. See Figure 2-8.
- Reputation framework
The reputation framework is the execution environment for one or more reputation systems. It handles message routing, storing, and retrieving statements, and maintaining and executing the model processes. Appendix A describes an implementation of a reputation framework.
Figure 2-8 shows a simple abuse reporting system that integrates two different reputation models in a single weighted voting model that takes weights for the IP addresses of the abuse reporters from an external karma system. This example also illustrates an explicit output, common in many implementations. In this example, the output is an event sent to the application environment suggesting that the target comment be dealt with. In this case, the content would need to be reviewed and either hidden or destroyed. Many services also consider punitive action against the content creator’s account, such as suspension of access.
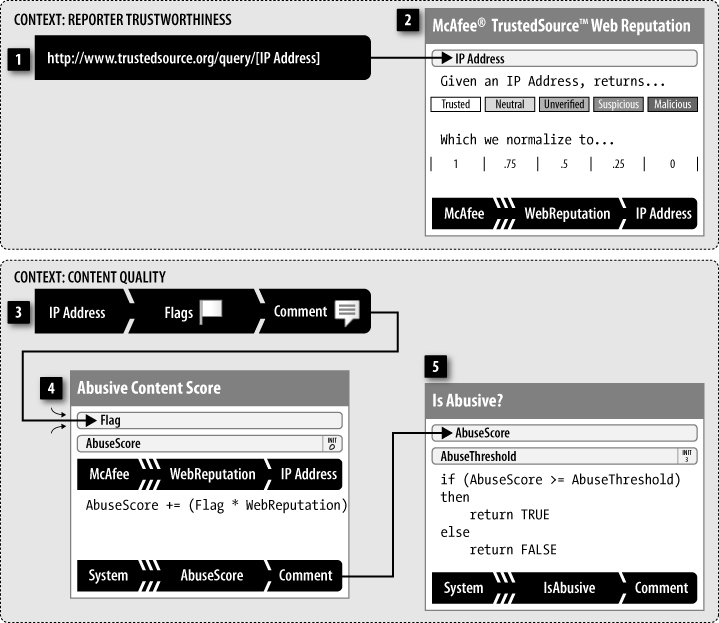
For the reporter trustworthiness context, the inputs and mechanism of this external reputation model are opaque—we don’t know how the model works—because it is on a foreign service, namely TrustedSource.org by McAfee, Inc. Its service provides us one input, and it is different from previous examples:
When a reputation system is prompted to request a new trust score for a particular IP address—perhaps by a periodic timer or on demand by external means—it retrieves the
TrustedSourceReputationas input using the web service API, represented here as a URL. The result is one of the following categories:Trusted,Neutral,Unverified,Suspicious, orMalicious, which the system passes to the McAfee TrustedSource Web Reputation process.
This message arrives at a reputation process that transforms the external IP reputation, in a published API format, into the reputation system’s normalized range:
McAfee TrustedSource Web Reputation: Using a transformation table, the system normalizes the
TrustedSourceReputationintoWebReputationwith a range from 0.0 (no trust) to 1.0 (maximum trust). The system stores the normalized score in a reputation statement with a source of TrustedSource.org, claim type simple karma, with the claim value equal to the normalizedWebReputation, and a target of the IP address being evaluated.
The main context of this reputation is content quality, which is designed to collect flags from users whenever they think that the comment in question violates the site’s terms of service. When enough users whose web providers have a high enough reputation flag the content, the reputation system sends out a special event. This reputation model is a weighted voting model.
This model has one input:
A user, connected using a specific IP address, flags a target comment as violating the site’s terms of service. The value of the flag is always 1.0 and is sent to the Abusive Content Score process.
This model involves two processes—one to accumulate the total abuse score, and another to decide when to alert the outer application:
The Abusive Content Score process uses one external variable:
WebReputation. This variable is stored in a reputation statement with the same target IP address as was provided with the flag input message. TheAbuseScorestarts at 0 and is increased by the value ofFlagmultiplied byWebReputation. The system stores the score in a reputation statement with an aggregate source, numeric score type, and the comment identifier as the target, then passes the statement in a message to the Is Abusive? process.Is Abusive? then tests the
AbuseScoreagainst an internal constant, calledAbuseThreshold, in order to determine whether to highlight the target comment for special attention by the application. In a simple (request-reply) framework implementation, this reputation system returns the result of the Is Abusive? process asTRUEorFALSEto indicate whether the comment is considered to be abusive. For high-performance asynchronous (fire-and-forget) reputation platforms such as the one described in Appendix A, an alert is triggered only when the result isTRUE.
From Reputation Grammar to…
This chapter defined the graphical reputation grammar, from bottom (reputation statements made of sources, claims, and targets) to top (models, systems, and frameworks). All members of any team defining a reputation-enhanced application should find this reference material helpful in understanding their reputation systems.
But at this point, readers with different team functional roles might want to look at different parts of the book next:
- Product managers, application designers
Chapter 3 expands the grammar with a comprehensive review of common source, claim, target, and process types that serve as the basis of most reputation models. Think of these as the building blocks that you would start with when thinking about designing your customized reputation model.
- Reputation framework engineers, software architects
If you’re interested in technical details and want to know more about implementing reputation systems and dealing with issues such as reliability, reversibility, and scale, look at Appendix A for a detailed discussion of reputation frameworks before proceeding.
- Reputation enthusiasts
If you’re considering skipping the detailed extension of the grammar provided in Chapter 3, be sure not to miss the section Practitioner’s Tips: Reputation Is Tricky for some detailed insights before skipping ahead to Chapter 4, which provides a detailed look at common deployed reputation systems.