
Managing Software Development Projects
7.1 Project Life Cycles
So far, we have looked at the activities to build software (Chapter 2) and at the activities to manage software development processes (Chapter 3, Chapter 4 and Chapter 5). We paid less attention, however, to the way in which they integrate in a coherent process.
In this chapter, we look at the development processes that have been proposed to accommodate the needs of different types of software development. Some favor a more thorough definition of the problem and solution before moving to the implementation phase. Others embrace flexibility and start implementation with partial information. In some cases, processes also come with a set of best practices and prescriptions that explain how activities should be carried out. In all cases, these approaches influence the organization of work, the structure of teams, and also the typical documentation and paperwork that a project produces.
At a bare minimum, we can characterize processes along two main dimensions:
- The linearity of the process: the order in which the development of more elementary components of the project is organized
- The formality of the process: the amount of infrastructure a project requires.
Concerning linearity, we can distinguish sequential, cyclical, and parallel development. The first proceeds from specification to implementation, with little opportunities for backtracking. The second organizes development in different rounds, with each round delivering more or improved functionality. The third uses concurrent development: an initial activity organizes further development efforts, which are then carried out in independent and parallel tracks; a final activity integrates the contribution of the different tracks.
If we look at the formality of the process, authors distinguish among traditional, agile, and extreme project management.
The term traditional project management denotes highly structured frameworks, in which managers use the techniques described in Chapters 3 and 4 to plan and monitor projects. The underlying assumption is that efficiency can be achieved with a top-down and planned organization of work. Only with this approach, according to their advocates, it is possible to eliminate misunderstandings, errors, and rework, while at the same time promoting an efficient use of resources. To go back to our millefoglie example, traditional managers prefer a well-structured millefoglie, with each layer nicely laid out.
Agile project management, by contrast, focuses on efficiency and flexibility. For the supporters of agile methodologies, management is an infrastructure that adds unnecessary work and unnecessary rigidity to the process. According to their supporters, projects should exploit any opportunity to improve the quality of a product and the efficiency of its development. This cannot be achieved if the development process is highly structured and regulated. Agile thus favors people over processes and interaction over formality. Agile fans prefer a low-fat millefoglie.
Finally, high-risk and exploratory projects require even more flexibility than agile methodologies can provide. Extreme project management thus denotes a situation in which long-term planning is impossible: high speed, high change, and high uncertainty are the three conditions characterizing these projects. Extreme project managers do not know whether they will have a millefoglie for dessert.*
When starting a new software development project, managers are faced with the need to choose a management approach and a development process. There is no such thing as the best process. Factors such as the criticality of the application, uncertainty, and unpredictability of the project environment, organizations and people involved, and regulations and recommendations determine which is the most appropriate choice. Quoting McCracken and Jackson (1982), “To contend that a life cycle scheme, even with variations, can be applied to all system development is either to fly in the face of reality or to assume a life cycle so rudimentary as to be vacuous.”
The next sections therefore provide some more information to take more informed decisions. The processes we present compose the elementary activities that we have presented in Chapter 2, organizing them in different ways in order to adapt to different project conditions. The focus will be on the organization of the technical activities; the combination of a development process with a proper management framework will help ensure that all pieces fit together.
*Notice that extreme project management is different from extreme programming, which we will see in Section 7.3.1.
7.2 From Traditional to Agile
7.2.1 The Waterfall
The waterfall is traditionally the first process presented in books and courses, given its rationality and simplicity. We confirm the rule and start from the process defined by Royce in the 1970s.
Simplifying a bit, in the waterfall development activities proceed sequentially, from conceptualization of the problem to delivery of the final product. Each activity of the process takes as input the outputs produced by the previous activity of the chain, uses them to produce artifacts closer to the final product, and passes the outputs to the next activity in the chain (Royce, 1970).
A simplified version of the waterfall process is shown in Figure 7.1. (We changed the naming and number of activities, which are more articulated in the original definition.) The first activity is requirements, which outputs the requirements documents. This, in turn, is used to define the system architecture during the design phase. The phase produces a system architecture. This is the input for the next activity in the chain, namely, implementation, which produces the system to be tested. The last two phases in the process are testing, during which the system is checked for compliance with the requirements, and deployment, during which the system is installed in production.
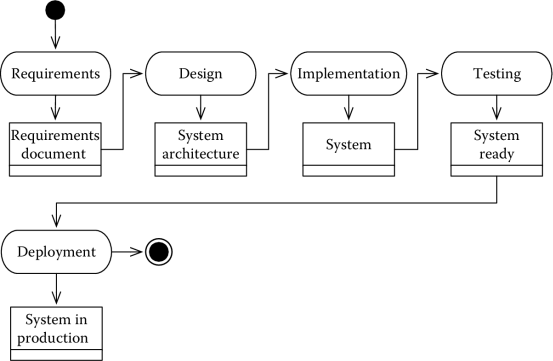
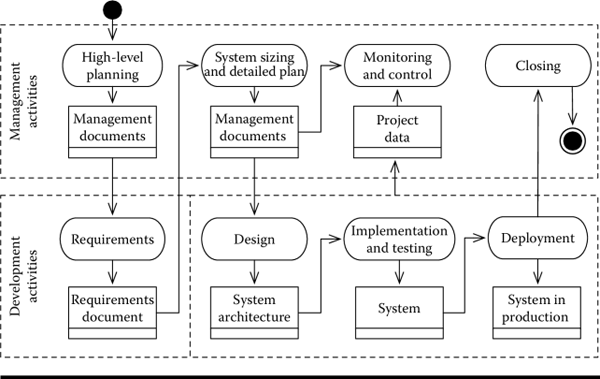
The model can be easily extended to accommodate project management activities. In its simplest extension, the process starts with a high-level planning activity to define the project scope, schedule, risk, and budget. If algorithmic estimation techniques are used, after the requirements phase, a second detailed planning takes place. This generates the plan for the subsequent development activities of the waterfall. A monitoring and control activity runs in parallel with the development activities. A final closing activity properly terminates the project. This is shown in Figure 7.2.
In the ideal case, the waterfall is a staged process in which quality control on the outputs of an activity determine the transition to the next activity, with no possibility of backtracking. In practice, lack of information, misunderstandings, mistakes, and changed conditions cause some backtracking. For instance, during the coding phase, it might become necessary to revise the system architecture to fix a conceptual and unanticipated issue that is making implementation cumbersome.
The rigidity of the waterfall is, at the same time, its main advantage and weakness. In projects where the requirements are very clear or in which a controlled development environment is very beneficial, the waterfall process shows its advantages. However, in many other cases, the rigidity of the waterfall can hinder, rather than speed up, development.
Different variations of the waterfall have been proposed in the literature to overcome some of its limitations. For instance, McConnell (1996) mentions the sashimi waterfall, where activities are allowed to overlap, the waterfall with subprojects, in which the implementation of different components defined by the architecture proceeds in parallel, and the waterfall with risk reduction, in which an initial risk analysis helps mitigate risks in the later phases of implementation.
The approaches just mentioned introduce some flexibility while retaining the waterfall’s main characteristics. In many situations, however, even these changes are not sufficient and a more radical approach is necessary. Abstracting a bit, these models variate on the waterfall model by
- Allowing for structural backtracking during the testing phase. In the V-cycle model, testing activities provide systematic ways to consolidate the implementation or backtrack to the most appropriate development activity. This is explained in more detail in Section 7.2.2.
- Allowing for an iterative and evolutionary development of the system. All the phases are repeated various times to deliver increasingly refined versions of the system. This is explained in more detail in Section 7.2.4.
- Blurring the boundaries between activities. By further pushing the sashimi model, processes organize the development in stages in which different activities run in parallel with different levels of intensity. This is explained in more detail in Section 7.2.3.
- Embracing flexibility and change. By reducing management and paperwork in favor of flexibility and efficiency, software development becomes more efficient. This is explained in more detail in Section 7.3.
In the following paragraph, we present the different processes using a similarity approach, in which we slowly move away from the waterfall model, rather than a chronological approach, which would favor a historical presentation of the methods. One of the motivations is that older, in this context, does not mean obsolete. The waterfall is still applied in many development projects.
7.2.2 The V-Model
The V-Model is a process adopted by the German Federal Government that emphasizes the verification and validation of a system. As pointed out by IABG (2013), the model has undergone various revisions since its first definition in 1992, and it has been elaborated in different versions. Some of these versions focus on the development phases, while others propose a broader framework that includes technical, support, and managerial activities. We will focus on the technical activities only, pointing the reader to Testing (2013) and Christie (2008) for a discussion about some of the variations of the model.
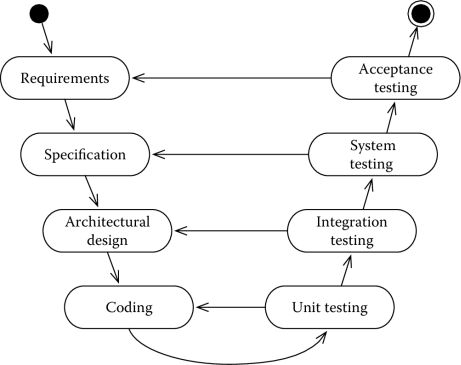
As we have seen in Section 2.4.1, testing can be organized in different activities, according to their scope. The V-Model, in particular, distinguishes four types of testing:
- Unit testing, which focuses on each component
- Integration testing, which focuses on the integration of components
- System testing, which evaluates the compliance of a system with its specified requirements
- Acceptance testing, which is meant to evaluate that a system meets its customer’s specification.
As we move from unit testing to acceptance testing, we increase the scope of the activity. The impact of bugs increases similarly. Bugs discovered during unit testing require local changes, while bugs discovered during acceptance testing require a more thorough analysis of the overall process. Consider the following two cases: a bug discovered during unit testing and a bug discovered during acceptance testing. The first is caused by an incorrect implementation of a module and it will be fixed by modifying the code of the module under test. A bug discovered during acceptance testing, however, has more far-reaching implications. The bug, in fact, could have originated during the system specification phase, when analysts incorrectly captured a customer requirement. The fix, in general, will require a revision of all choices taken after the error was made. This is the only way, in fact, to ensure that the correct fix is applied.
The V-Model accommodates such differences by having different testing activities causing backtracking at different depths in the process. The organization of core development activities foreseen by the V-Model is presented in Figure 7.3. The left side of Figure 7.3 shows the development/construction activities. The process proceeds from the specification of the requirements to coding in a way similar to the waterfall. The process differs when testing activities start, as shown on the right side of Figure 7.3. More specifically, the V-Model organizes testing in the four activities we presented above. Bugs discovered in each testing phase will cause the process to restart from the first development activity that might have originated them. Thus, for instance, unit testing has two possible outcomes. If all tests pass, the process moves to the next phase, namely, integration testing. However, if some unit test fails, the process is restarted from the first development activity that might have caused the problem, namely, coding. Similar is the case for the other activities.
7.2.3 The Rational Unified Process
The rational unified process (RUP) is a framework designed by Rational Software, the company also behind the definition of the Unified Modeling Language.* RUP is a very articulated framework that aims at supporting a wide range of software development projects. Its application typically requires one to select which activities are relevant and to tailor the process to the needs at hand.
The specification of RUP is based on best practices and on process specification, which describes how to organize activities while taking advantage of tool automation.
There are six main practices behind RUP:
- Develop software iteratively. The goal is to allow increasing understanding of the system to be developed, similar to the spiral model.
- Manage requirements. The goal is to provide adequate support to communicate with the customer, to evaluate different alternatives, and to manage changes.
- Use component-based architectures. The goal is to support an incremental approach to development by building robust components that can be integrated.
- Visually model software. The goal is to simplify communication and to use a simple and unambiguous representation to build a shared vision.
- Verify software quality. The goal is to ensure adequate quality of the final product.
- Control changes to the software. The goal is to provide adequate change management practices that support iterative development.
See Sommerville (2007) and Rational Software (2011) for more details.
RUP recognizes that during software development, different activities run in parallel and overlap, rather than being neatly separated like in the waterfall. The process is thus presented according to two dimensions, one that takes into account time and development phases and the other that takes into account development activities.
RUP organizes development activities in nine workflows. Seven of the workflows correspond to those we have already seen in Chapter 3.
They are
- Business modeling
- Requirements
- Analysis and design
- Implementation
- Testing
- Configuration and change management
- Deployment.
RUP adds two additional workflows. A project management workflow includes all activities related to managing a system, while an environment workflow is concerned with making the proper tools available for development.
Workflows run throughout a project. However, as development progresses, concern and focus change and we can distinguish different phases. Thus, RUP organizes four development phases. These are
- Inception, during which the main ideas and operating requirements of a system are identified
- Elaboration, during which the requirements are used to define the system architecture
- Construction, during which the system is actually built
- Transition, during which the system is deployed and the next phase is planned for.
Each phase terminates with a well-defined milestone, during which the team verifies that key goals of the phase have been achieved. If necessary, each phase can be further organized into iterations to break the complexity of system development in more manageable chunks.
As mentioned earlier, all workflows are active during all phases of development, with different levels of intensity. Thus, for instance, the main effort during inception will be spent on business modeling. However, the team will also engage in some requirements elicitation. If necessary, some analysis and design will allow the team to analyze some of the issues that could emerge in later phases of development, thus minimizing the risks. Similar is the case for the other phases.
One of the advantages of RUP is that it comes with a step-by-step guide and a set of templates that can be used to kick-start a project. This simplifies a bit its application and the costs related to its adoption. On the other hand, as mentioned earlier, the process and templates are very elaborate (see Table 7.1 for some data). Its efficient and effective implementation therefore requires a customization step.
Some Data about the RUP 2000 Model Definition
Discipline |
Number of Deliverables |
|---|---|
Business modeling |
8 |
Requirements |
7 |
Analysis and design |
2 |
Test |
2 |
Management |
11 |
Configuration and change management |
1 |
Deployment |
3 |
Implementation |
1 |
Environment |
7 |
Total |
42 |
To overcome the problem, variations of the process have been proposed, among which are OpenUP More information about RUP can be found in Kroll and Kruchten (2003), Kruchten (2004), and Rational Software (2011).
*Rational Software is now a division of IBM.
7.2.4 The Spiral
The spiral process was first proposed by Boehm (1988) and the process was first used for the production of the TRW Software Productivity System, an integrated environment for software engineering systems.
The main motivation behind the spiral is to reconcile the rigidity of the waterfall with the uncertainties and flexibility required by software development projects. In its original formulation, in fact, the waterfall leaves little opportunities to analyze and assess risks. Even in its risk-driven variance, the process is still sequential, with no opportunities to take into considerations the risks identified and occurring during system development.
The spiral changes this approach by organizing development into a risk-driven, iterative process. Each iteration builds on the results achieved at the previous one. In the words of Boehm: “the model reflects the underlying concept that each cycle involves a progression that addresses the same sequence of steps, for each portion of the product and for each of its levels of elaboration, from an overall concept of operation document down to the coding of each individual program.”
All iterations have the same structure, organized in four main activities:
- Determine objectives, during which the team puts together the following information: the objectives to be achieved for the current portion of development, that is, the current loop of the spiral; the constraints that need to be satisfied (e.g., costs, time); the potential alternatives that could achieve the goals, while satisfying the constraints.
- Evaluate alternatives and risks, during which the team identifies and resolves the main risks. During this phase, the alternatives identified at the previous step are evaluated to understand which solution fits the objectives and constraints better. The risk resolution phase includes a wide set of activities, such as prototyping, simulation, interviews, and modeling.
- Develop, during which the team produces the outputs determined by the information gathered at the previous step. During the first cycles of the spiral, these outputs will consist of software concepts, specifications, and designs. Later stages will produce an implementation of the system.
- Plan the next iteration, during which the team plans the next cycle of the spiral that is planned. Starting from the outputs of the other phases, a critical review of the results, and an analysis of the main objectives, the project manager and the team plan and prioritize the next activities.
7.2.5 Prototyping/Evolutionary
One big concern in software development is to bridge the communication gap between the customer and the development team, in order to facilitate the comprehension of the customer’s needs, explain the main constraints posed by the existing technologies, and come out with a system that satisfies the customer’s needs while respecting the cost and quality constraints. Any approach that facilitates such communication is therefore beneficial (McCracken and Jackson, 1982).
In the prototyping or evolutionary approach, the team builds one or more prototypes of the system, in order to verify various project assumptions about the system being built. The prototypes are incomplete versions of a system, demonstrating some of its functions. The simplest prototypes are mockups, which mimic the behavior of the system, using different technologies, and demonstrate to the customer how the system could work or behave.
Two types of system development are possible when using the prototype approach using throwaway prototypes or adopting an evolutionary model.
Throwaways are prototypes built to demonstrate a function or test a specific approach. For instance, a throwaway prototype could be defined to show how a user interface could behave or to verify whether certain nonfunctional constraints can be met, given the current requirements (e.g., performances). The prototype ceases to be useful when it has proven (or disproved) what it was built for.
Remark
Throwaway prototyping is a practice that can be easily embedded in many development processes. When it becomes necessary to verify a specific project assumption, the team starts the development of a throwaway prototype, in parallel to the other standard development activities. When the throwaway prototype has had its use, the prototyping activity terminates and the process proceeds as usual. Thus, for instance, a manager could extend the requirements phase of a waterfall process to include the construction of a prototype of the GUI. Short of the extra activity to build the prototype, the process will exactly follow the waterfall model.
Evolutionary prototypes, by contrast, evolve to the final product through successive refinements. This requires an iterative process. Each iteration ends with the production of a prototype, which is used as the basis for the next cycle. At the end of each cycle, the customer might be asked to validate the prototype, in order to steer development and take into account the customer’s needs. As one can imagine, evolutionary development considerably limits the amount of time and effort dedicated to requirements and design, favoring coding instead.
For instance, McConnell (1996) highlights a process composed of the following four steps:
- Initial concept, whose goal is to highlight the most evident characteristics of a system
- Design and implement the initial prototype, whose goal is to sketch the system architecture and build an initial prototype
- Refine the prototype till acceptable, whose goal is to progressively refine a system through different iterations
- Complete and release the prototype, whose goal is to complete the last prototype so that it can be deployed
The evolutionary model is particularly suited for the development of new technologies or new ideas. Consider, for instance, a scenario in which a first cycle allows one to build a simplified prototype that explores a new concept in user interaction. The prototype is tested with some users and the information then used to develop the prototype into a fully functional system.
Some of the disadvantages include increased costs and delivery time.
The prototype model also has its difficulties, as can easily be imagined. As pointed out in Boehm (1988), it is difficult to plan system development. Moreover, premature (and wrong) choices made on early prototypes might make their evolution into the final product cumbersome and difficult. Finally, Boehm argues that it might be difficult to identify a good sequence of evolutionary prototypes to apply to a poorly structured and large legacy system, making the use of the evolutionary approach ineffective in such scenarios.
7.2.6 Cleanroom Software Engineering
Cleanroom software engineering is a development process based on formal methods and statistical testing, whose goal is to achieve zero-defect software (Linger, 1993). The process was tested on various systems in the 1990s, many of whom were safety-critical applications. Linger (1993) reports that the smallest system was an automated documentation system of about 1.8 KLOC, while the biggest was a control system for a NASA satellite of about 170 KLOC.
The zero-defect goal is achieved by a controlled, iterative process in which a pipeline of software increments accumulates to achieve the final product. The increments are developed and certified by small, independent teams, with teams of teams for large projects, a characteristic we also find in agile processes.
Formal verification techniques and statistical testing are used for the certification.
Figure 7.4 illustrates the process. Starting from the customer requirements, a specification of the system behavior, formalized with a functional specification and a usage specification, defines the basis for further development. These two documents, the first of which is used for development and the second for testing, allow the team to define the system components and to plan the development and testing increments (increments planning in Figure 7.4). The implementation of each system increment is the responsibility of two independent teams. The development team develops the components, using formal methods (formal design and implementation), while the testing team is responsible for verifying the behavior of the components. This is achieved with statistical methods; the corresponding activities in the diagram are random test case generation, to generate test cases, and statistical testing, to perform the tests. A final quality certification activity produces an estimation of the mean time to failure (MTTF) and suggestions to improve results in the next increment.
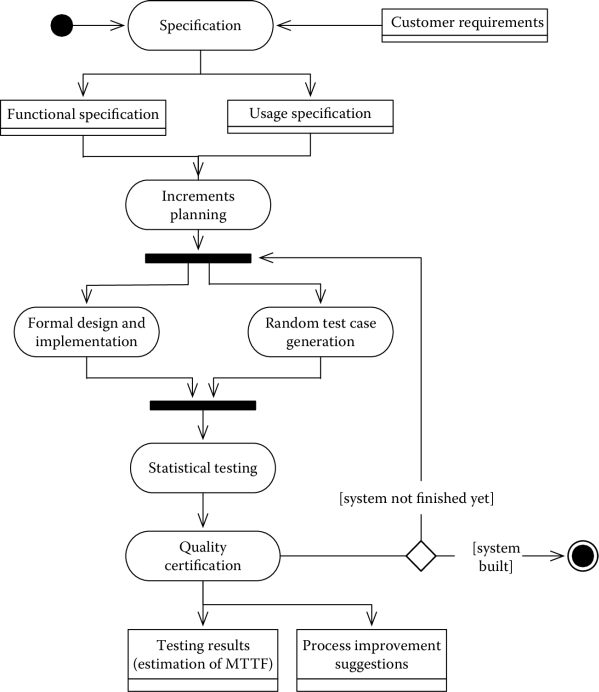
An important remark is that the philosophy behind the process is quick and clean, rather than quick and dirty. As mentioned in Linger (1993), “Team correctness verification takes the place of unit testing and debugging, and software enters system testing directly, with no execution by the development team. All errors are accounted for from first execution on, with no private debugging permitted.”
7.3 Agile Methodologies
The waterfall process and the other traditional software development processes structure the process to limit variability and changes. Each artifact and each step of the process consolidate and fix constraints, increasing one’s confidence in the stability of artifacts that are easy to modify and, more important, that might not capture the actual needs. This approach draws from other engineering disciplines. Take, for instance, bridge construction. In the early phases, when the design of the bridge is blueprinted, the changes are relatively easy. As we move with development, however, making changes becomes increasingly costly and difficult, since we are constrained by the physical artifacts we have already built.
If the analogy promotes a vision of software that is as solid as a bridge, at the same time it fails to recognize its unique flexibility. Changes in software are not always costly. Thus, imposing rigidity with a process where or when it is not needed makes it impossible to exploit opportunities for building a better system, when these opportunities arise and are convenient to implement. In other words, the process should exploit, rather than limit, the unique characteristics of software and the opportunities it offers to make its development more efficient.
Agile methodologies start out of the frustration of practitioners with traditional techniques. The Agile Manifesto, written in 2001 during a gathering in the mountains of Utah, lists four main principles that differentiate agile development from traditional practices (Manifesto for agile software development, 2001; Highsmith and Fowler, 2001).
These are
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan.
A set of software development methodologies and processes is based on the Manifestos principles, and agile development has gained a lot of popularity in recent years. Today, the adoption of agile methodologies is comparable to that of traditional techniques. According to Geracie et al. (2012), who report on a survey conducted in 2012, when asked about the methods used to produce software, 18% of the respondents declared using agile or Kanban; another 18% declared using the waterfall model; and 53% declared using both.
7.3.1 Extreme Programming
Extreme Programming (XP) is an agile methodology designed by Kent Beck, Ward Cunningham, and others while working on the C3 project at Chrysler (Copeland, 2001; Wells, 2009). XP introduces various interesting concepts, which can improve the way in which software is developed, even when the method is not fully adopted.
XP starts from the consideration that change is an integral part of software development and that a sound software development process should embrace change rather than discourage it altogether. However, since resources are not infinite, appropriate practices and mechanisms must be in place to evaluate the importance and cost of changes so that choices are made, reasonable goals set, and work prioritized. Thus, XP ensures that the cost of change is constant throughout the development life of a product, rather than increasing as we move along the development process (Chromatic, 2003).
The XP process is characterized by the following three main elements:
- Values , which define the inspirational principles that guide any XP project
- Practices, which describe the techniques applied in XP projects
- Process, which describes how activities are organized, what roles are identified, and what artifacts are to be produced.
The XP values are open and honest communication, honest feedback, simplicity, and courage.
The first value is open and honest communication. This is essential to reduce friction between the different stakeholders participating in a project and their different goals/interests. XP, in particular, has customers and developers speaking directly. So, rather than having a marketing department passing every customer’s request to the developers as they come and irrespective of the complexity, XP favors an approach in which priorities are set and the work to be done discussed and chosen together by the customer and by the developers.
The second value is honest feedback, which is essential to build a shared view about the system and the project. For this reason, XP favors rapid feedback. The closer the feedback is to what is being commented on, in fact, the simpler it is to give it and to learn from it, as well as to adapt activities to changed conditions. As mentioned in Chromatic (2003), “rapid feedback reduces the investment of time and resources in ideas with little payoff. Failures are found as soon as possible, within days or weeks, rather than months or years.”
The third value is simplicity, namely, keeping a system as simple as it can be, but not any simpler than that. The XP design philosophy is inspired to the KISS design principle, an acronym that stands for keep it simple, Stupid.
The fourth value is the courage to take difficult decisions, be they technical or managerial. If a system does not work, it has to be fixed, even if the work required might be significant and delay the actual delivery. If a project is late, it is better to tell the customer.
XP also prescribes a set of rules (Wells, 1999). Some of these rules are easier to implement than others and might also be the reason other agile processes, such as Scrum, have become more popular. Among the most interesting and controversial rules, we mention:
- Make small and frequent releases.
- Give the team an open workspace.
- Stand-up meetings are organized every day.
- People are moved around to facilitate communication.
- Prototypes are created to reduce risk related to planning.
- The customer is always available.
- Unit tests are written before the code.
- All code is pair programmed.
- Ownership of the code is collective.
- When a bug is found, tests are created.
Figure 7.5 shows a simplified version of the XP process. The process is based on an iterative development that favors small releases and continuous feedback, at different levels of granularity. Each iteration is a complete development cycle, which starts with an estimation and a selection of user requirements, written in the form of stories, and ends with a release.
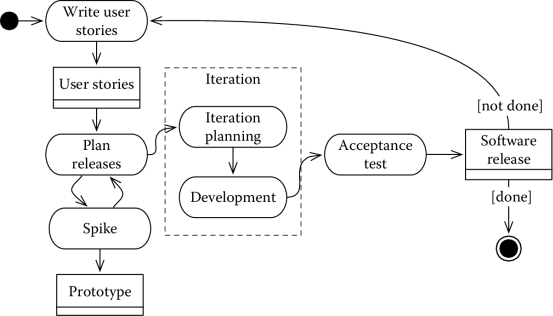
We distinguish, in particular:
- Write user stories, which outputs the requirements of the system to be developed, in the form of user stories.
- Plan releases, which takes as input the user stories and outputs the overall project plan. Information, such as the number of ideal hours* required for each user story and the team velocity (number of ideal hours actually completed in a given time period), can be used to determine a rough plan for the project. An important aspect of the estimation is that, different from traditional techniques, it is performed by the developers.
- Development is structured in iterations, lasting between 1 and 3 weeks. The iteration starts with an iteration planning activity, during which the team selects the user stories to implement, according to priority, effort, and other constraints. Development then starts, using a test-driven approach, in which tests are written before the code is written, and pair programming. Daily stand-up meetings, moving people around, and promoting collective ownership of the code allow one to create a shared view on the system.
Iterations end with a release, that is, working software delivering some functions to the customer. The process is then iterated at the most appropriate level by adding user stories (if necessary), revising the release plan (if necessary), and starting the next iteration.
*An ideal hour is an hour fully dedicated to the development of a user story. No interruptions, no phone calls, no extra tasks—that is an ideal hour!
7.3.2 Dynamic System Development Method
The Dynamic system development method (DSDM) was first introduced by the DSDM Consortium, starting from the experience of RAD (rapid application development) and from three considerations: people are key to project success, change is inevitable, and no software is perfect the first time it is released. It is an agile methodology embracing the considerations of the Agile Manifesto, which would be published various years after DSDM.
The method has undergone various revisions; the current version was released in 2007 and is named DSDM Atern, after a bird, the “Arctic Tern.”
Figure 7.6 shows the DSDM development process, which is iterative and organized in seven phases.
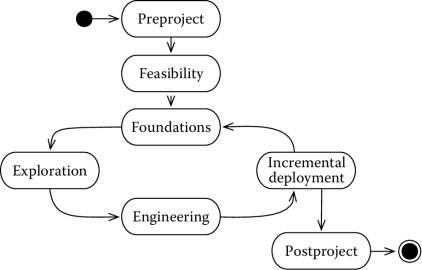
The preproject phase is where a project starts and all the activities necessary to set up a project are performed. The next two phases are feasibility, where the team investigates whether the goals are achievable with the given constraints, and foundations, where the business value of the proposed project is analyzed, requirements are prioritized using the MoSCoW approach, and the baseline architecture is sketched. The iterative process starts at the end of this activity.
Iterations are organized in three steps of fixed duration (time-boxed). The exploration step produces a prototype, which is used to refine requirements and priorities with the client, to identify nonfunctional requirements and to define an operational plan for the next activity.
The engineering step is where the nonfunctional requirements are added to the prototype and the prototype is made fit for delivery.
The incremental deployment step is where the results of the current increment are released.
Finally, a postproject phase hands over the final solution to the client and manages product maintenance.
The method is well documented and various resources are available on the Internet, including the official page of the DSDM consortium, which makes available, with certain restrictions, material and templates for practitioners and teachers alike (DSDM Consortium, 2013).
Another characteristic of the DSDM method is that it has been integrated with the PRINCE2® management framework, adding a sound management framework to the development practices proposed by the method. See, for instance, DSDM Consortium (2000, 2007).
7.3.3 Scrum
Scrum was first proposed in Takeuchi and Nonaka (1986) as a way to overcome the limitations of the traditional product development practices and achieve more speed and flexibility. The analogy is with the sport of rugby, where all players move together toward a goal, setting a rhythm and adapting quickly to variations in the external conditions.
The approach is based on six principles, which fit together like a jigsaw and are all essential in order to achieve results:
- Built-in instability, achieved by giving teams broad goals and general strategic directions
- Self-organizing project teams, achieved by allowing teams to self-organize roles, tasks, and work
- Overlapping development phases, achieved by having different production phases overlap (similar to RUP), so that bottlenecks can be better dealt with
- Multilearning, so that the team can learn both from internal and external sources and adapt quickly to changing conditions and environments
- Subtle control, by providing the right steering to the project without interfering too much (e.g., selecting the right people for the job, creating an open environment, tolerating, and anticipating mistakes)
- Organizational transfer of learning, by ensuring that the know-how acquired in a project is transferred and reused in other projects.
Jeff Sutherland and Ken Schwaber adapted the metaphor to software development in Sutherland (1995). Today, Scrum is probably the most popular agile methodology. According to VersionOne (2013), in fact, Scrum or Scrum variants account for 72% of agile projects.
The process is very simple and based on three roles (which we have already seen in Section 5.2.4), three main artifacts (the product backlog, the Scrum board, and a potentially shippable product (PSP)), and an iterative development process that proceeds in time-boxed sprints typically lasting between 2 and 4 weeks each.
Figure 7.7 shows the process. Similar to XP, the development in Scrum projects is driven by user stories (see Chapter 2). Simplifying a bit, user stories are the planning chunks, which define the work items of the project.*
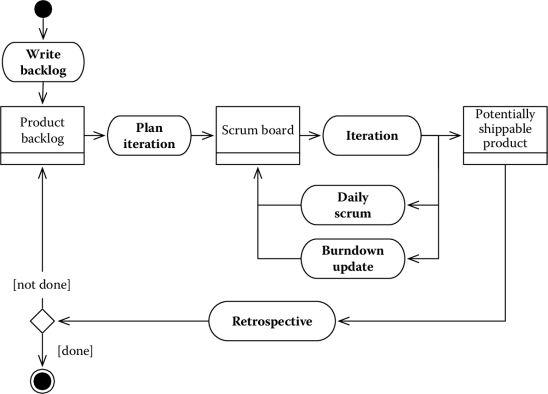
The product owner labels user stories with a priority in which the team assigns each a weight, called story points. The priority represents the importance for the customer, while the weight measures the difficulty of implementing a user story. Different from traditional planning techniques, story points do not measure the effort, but rather they are an abstract measure of complexity. This measure is also team-dependent, since the same number might represent two different weights for two different teams. See Section 5.3.3.4 for a description of how teams assign story points to user stories.
Iterations start with a planning phase, during which the team selects the user stories to implement according to priority and (story) points. The number of stories allocated to each sprint depends upon the team velocity, namely, the number of story points that the team can develop during a sprint. Note that since velocity is an essential planning measure and since its value depends on the actual time the team dedicates to a project, Scrum requires to use people full time on Scrum project.
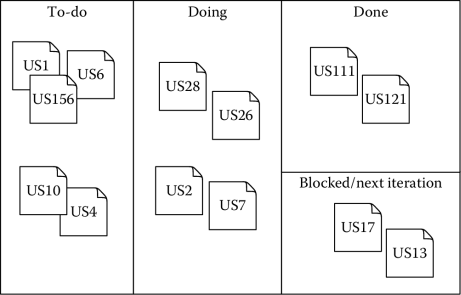
The story allocated to a current sprint are collected in a scrum board, which is the basis for monitoring and control. The Scrum board is organized in columns. Each column corresponds to a specific status of a work item, such as, for instance, to-do, doing, done. A special area of the board might be dedicated to those user stories that are blocked, namely, have been allocated, but cannot be implemented in the current iteration. User stories are represented by post-it that are put on the Scrum board according to their status. Thus, during an iteration, they move from the left-hand side of the board to the right-hand side, as work proceeds.* Team members self-allocate work by choosing user stories and moving them on the board. The Scrum board thus also becomes a tool to quickly report on the project status. Figure 7.8 shows an example of a Scrum board, with different user stories (work items) in different states.
The Scrum master monitors the overall progress updating the burndown chart and taking other quantitative measures. See Sections 3.9.5 and 3.9.6 for more details.
One important characteristic of sprints is that they are shielded from external influences. No change to the planned work can occur during a sprint, allowing the team to focus on the user stories selected at the beginning of the sprint.
During a sprint, daily stand-up meetings, called scrum meetings, are held. During these meetings, each team member answers three questions:
- What have I done yesterday?
- What will I do today?
- What impediments do I have?
The daily meeting allows members to commit to the work to be done, while at the same time highlighting the main impediments which hinder work.
During the sprint, on a daily basis, the scrum master updates the burndown chart to monitor progress and measure the sprint velocity. See Section 3.9.5 for the details.
The sprint ends when the time has passed, independent of the stories actually implemented. The number of points actually implemented is used to determine the velocity achieved during the sprint. The stories allocated to the sprint, but not implemented, return to the product backlog.
At the end of a sprint, a PSP is released, that is, a product that the customer can use. The PSP is presented during a sprint review, during which the team demos what it has accomplished. While the method focuses on working software, it also allows for mockups and other products to be shipped. This makes the method also usable in complex projects, where a sprint might not be sufficient to start building software.
Finally, a retrospective about the sprint allows the team to analyze what has worked and what problems it has encountered during the sprint, so that the process can be improved in the next cycle.
*In practice, user stories are split into more elementary tasks, which are closer to actual implementation. This allows one to optimize work by identifying software elements that are common to different user stories; tasks can also be used for nonfunctional requirements, which are difficult to represent as user stories.
*When user stories are split in tasks, the whiteboard can also be organized in lines, with each line allocated to a specific user story and containing all the tasks necessary to implement the user story.
7.3.4 Kanban
Lean manufacturing is a management practice mainly derived from the experience of the Toyota Production System, which starts from the consideration that everything that does not add value to the customer is waste and needs to be eliminated. Although the original definition had seven different sources of waste, three basic categories can be identified: muda (nonvalue-adding activities), mura (variations in production), and muri (overburden) (Ikonen et al., 2010).
Kanban is a lean-management practice that eliminates waste by using a just-in-time, pull-based production system. The system was first applied to the factory floor as a way to limit inventory levels. In the traditional process, production pushes products to the market independent of actual demand; if the production is higher than the actual demand, inventory builds up. Kanban reverts the process by creating a pull system, in which work is processed through being signaled, rather than being scheduled. Every time someone in the production chain has the need of a product upstream, he or she picks it, actually pulling an item from the chain and moving the demand upstream. The analogy is similar to that of supermarkets, where clients get what they need and shelves are filled based on the actual demand of customers.
Kanban means signboard in Japanese and the name derives from the fact that a signboard is used to monitor the pulling process. The signboard is organized in different areas, each corresponding to a different step of the production chain. Cards are used to represent different work items, with each card representing a different item being assembled in the production line. As work items are pulled into line, so do cards move on the billboard, allowing for a simple way to monitor progress and needs.
Kanban is becoming a popular technique for software development. According to Ikonen et al. (2010), in fact, various sources of waste can be identified in software development. Among them are partially done work, which ties up resources, unnecessary paperwork and gold plating, which consume resources without adding value, task switching, which consumes resources and delays delivery* waiting, which keeps resources idle, and defects, which require extra work to be fixed.
The analogy between factory floor and software development is that software development can be thought of as a production pipeline, with feature requests entering on one end of the pipe and working software exiting on the other end (Peterson, 2009). The software pipeline is composed of different and distinct steps, as we have seen when presenting the waterfall model. The equivalent of inventory build-up are software features getting stuck during one development phase. Kanban thus tries to reduce the number of features being worked on in parallel. There are, in fact, various advantages in reducing the amount of work in progress, or “in process,” using the terminology of Scotland (2010) including focusing and delivering early (earlier).
According to Peterson (2009), the implementation of a Kanban system for software production can proceed as follows:
- Define the development process, which allows one to identify where features come from and what steps they go through. For instance, it could be that each feature goes through the following steps: analysis, design, implementation, and testing.
- Define the entry and exit points of the process, which allows one to identify where you have control on the process
- Agree with your team policies to pull items and to set priorities. Having an explicit specification of the selection process is, in fact, the only way to discuss about it and improve it.
- Get started and empirically adjust. Empirical adjustment is based on creating effective feedback loops and creating an environment in which the team is willing to experiment and collaborates on improving the process.
One important aspect for the implementation of a Kanban system is that it requires a shift of mentality, since the method requires teams to improve their capacity to collaborate, for instance, to reduce buildup of work (Scotland, 2010).
Figure 7.9 depicts the process by showing a Kanban board. Four steps have been identified in the development process, “analysis,” “design,” “implementation,” and “testing.” Various feature requests, represented by cards in the board, are being worked on. For instance, three features are in the analysis phase, two in the design phase, and two in the implementation phase. Some features are done and ready to be pulled to the next step: see, in particular, C4, C10, and C11.
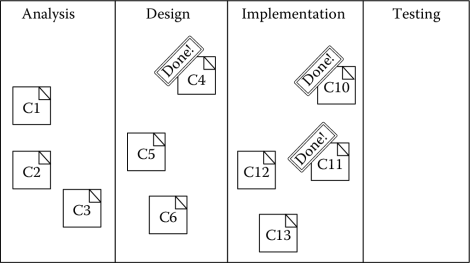
*If task A and task B require 5 man-days, if work is performed sequentially by one person, A will be delivered after 5 days and B after 10 days. However, if the person works on both items at the same time, both will be delivered in 10 days.
7.4 Open Source Development Practices
In Section 6.2.3, we introduced the concept of free software and discussed some revenue models. Here, we focus on the engineering aspects of the domain, highlighting the peculiarities and challenges. The analysis is interesting and useful also for projects that are not developed using an open source license.
7.4.1 Open Source Development Challenges
Open source software development is typically carried out by a geographically distributed community of volunteers under the steering of the owners of the project. Larger projects might also have companies behind, which tasks employees with the development or steering of the project.
The peculiar business model of the software being developed, together with the challenges posed by the team structure, requires one to pay particular attention to some steering, managerial, and technical activities.
Some challenges are related to maintaining a project healthy. This requires one to focus efforts on:
- Community building and growth, which include all the activities to have a large community of developers and users. The former, in fact, is necessary to develop and maintain the system. The latter is what makes a system useful and interesting to develop. Notice that some open source systems compete with commercial counterparts, backed by for-profit companies. For this reason, some projects have a specific marketing structure and evangelists to promote their software.
- Financing and sustainability. Even though open source software relies (mainly) on the work of volunteers, these projects incur various costs. We have seen some of the commercial models of open source software in Section 6.2.3.
Attention has also to be paid to development practices, since the methodologies we have seen so far do not cope very well with teams of volunteers. The impacts are at different levels and some of the concerns include
- Project steering. Adequate policies, means, and tools have to be defined for deciding on the evolution of a system. A system roadmap helps to keep a system coherent and functional, but at the same time, it might shift the interest of volunteers. A second aspect to consider is that many open source systems promote a collective ownership of the project, posing interesting questions on how the roadmap is formed in the first place.
- Assignment of work. Since contributions to open source systems are mainly based on the work of volunteers, tasks are often self-assigned. Completion time is more difficult (if not impossible) to control.
- Maintain the system structure coherent. Since contributions come from people with different background and experience, style, approach, and coding standards differ quite a bit. To keep the system maintainable, it becomes essential to enforce vision over a systems architecture, define a design philosophy, and enforce coding standards.
- Quality control. For the reasons mentioned above, effective quality control practices have to be in place to ensure that contributions do not introduce bugs.
- User documentation. Work in open source projects focuses on the fun parts, which is coding for many. As a result, finding volunteers for other important activities, such as writing user documentation, can be difficult.
7.4.2 An Open Source Development Process
Figure 7.10 shows a development process for open source systems. An open source software project rarely starts from scratch. More frequently, a project starts with an initial release performed by the person or team making a system available as open source. Together with the first release of a system, the team prepares the technical infrastructure to make the software artifacts available to the community.
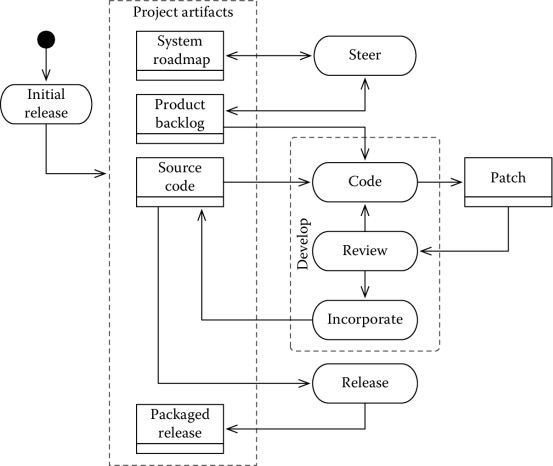
The process then continues with a set of activities that are loosely interconnected:
- Steer, shown in the upper part of Figure 7.10, includes the activities to decide the roadmap of an open source system.
- Develop, shown in the middle portion of Figure 7.10 (and organized in three distinct activities), includes all software development activities to improve a system.
- Release, shown in the lower portion of Figure 7.10, includes the activities to release a new version of an open source system.
7.4.2.1 Open Source Project Steering
Like any other software product, open source projects benefit from the definition of a clear vision and evolution roadmap. Often, but not always, the roadmap tends to focus on the technical aspects of development, such as the architectural choices and approaches that have to be preferred.
According to the community that has been built around an open source project, different models can be used to define a roadmap. Two popular models include the benevolent dictator model and the participatory model.
In the benevolent dictator model, one person or a restricted team is in charge of taking final decisions. As pointed out in Fogel (2009), the benevolent dictators of successful projects work more as facilitators and moderators, integrating comments and observations of expert programmers participating in the community. This has two reasons. First, it is unlikely that one person has enough expertise to cover all technical areas of a project, and second, obsessive control is not an excellent way to build a community. The benevolent dictator is often the project initiator, because of the credibility gained in the community and the technical proficiency in managing the view of a project. Personal and communication skills are a plus, although not all project owners are famous for their politeness and diplomacy.
Completely different is the participatory model, in which decisions are taken by consensus and, when consensus is not reached, by voting. One issue to address in this kind of model is who participates in the discussion and who has the right to vote. Some models prefer to involve volunteers with more seniority, who have contributed significantly or steadily to a project. This is the model adopted for the development of Mozilla Thunderbird, as described in Mozilla Foundation (2013c). Others prefer to involve a larger base, which includes all people who ever contributed to the system. While the latter method is simpler to implement, as it has a measurable access criteria, it also has risks related to equally weighting the opinion of people with quite a lot of different experience on the system being developed.
Concerning the value of the roadmap as a project guidance, in this case, also two different models are in place. When there is a strong community of regular contributors, work and tasks are assigned similar to what happens in other software development projects. In this scenario, the roadmap is implemented and the system evolves as planned. In other situations, this is not feasible. In these cases, the roadmap can be considered as a list of features or desiderata, which are made public and available to contributors. Features land into the software when someone volunteers and takes charge to implement them.
7.4.2.2 Open Source Development
As mentioned earlier, one important aspect of any open source project is maintaining a coherent vision of a system. This is vital, since a loosely controlled evolution can lead to a system that is difficult or impossible to maintain.
For the reasons mentioned above, open source software relies on two practices:
- The enforcement of coding guidelines, which describe good coding practices and standards and how to write code that is considered of high quality for the project at hand. Coding guidelines are documents that specify naming conventions, that is, how names are assigned to filenames, classes, variables, and constants; minimum requirements for comments, that is, how a specific method or class should be documented; source code structuring, for example, how the code should be indented or organized; other syntactic rules, like, for instance, what constructs to avoid; and other general guidance on how to write code. Several coding standards are available, some of which have been specifically devised for open source projects and some of which have been defined for specific programming language; see, for instance Free Software Foundation (2013), Batsov (2013), Oracle (1999), and Linux kernel coding style (2013e). Notice that coding standards devised for open source projects, such as Free Software Foundation (2013), are adopted and used in free and commercial development projects alike.
- The use of a version control system ensures, on the one hand, that all contributors have the possibility of assessing system resources and, on the other, that changes and modifications are controlled and can be reversed, if necessary. Notice that while read access to the version control system is granted to anyone, writing and committing is granted to a controlled and restricted set of people.
Open source contributions are often in the form of incremental/evolutionary patches to an existing and consolidated code base. System evolution tends to be regulated by the following three-step process, called patch contribution process in Sethanandha et al. (2010):
- Code is the process of creating a modification to an existing system. Coding is usually performed by a volunteer, either in response to a known problem or feature request in the product backlog or to follow up on a need or request originated by the volunteer. The coding process terminates with a publish and discover operation, to make the contribution available to the community. When a distributed versioning system is used, this operation takes the name of fork (the creation of a new branch in the code) and pull request (the request to include a particular contribution in the codebase of a system). Other methods used include distribution of patches to mailing lists.
- Review is the process of verifying that a patch complies with the quality and coding standards defined by the project. This is performed or managed by volunteers with seniority, who are either tasked with quality control or who have the overall responsibility over a module or over the whole system. If the proposed patch meets the quality criteria, it is added to the code base; otherwise, more coding takes place till the minimum quality requirements are met.
- Incorporate is the process of incorporating a patch into the codebase. An aspect during this step is to ensure that changes are well isolated. This is to ensure that they can be reversed, if need be and, more important, that it is possible to choose what changes are incorporated in the next release. See the next section for more details.
7.4.2.3 Open Source Releases
Releasing open source software requires one to address the following points:
- Deciding/controlling what features make it into the next version
- Deciding when to release.
To illustrate the issues, we will see the release process of the Firefox browser. According to the model, four different source code repositories (or branches) are made available to all contributors. Each repository is used to generate a version of the Firefox browser. The repositories are organized as a waterfall, with repositories that are downstream receiving changes from those upstream. In more detail:
- The mozilla-central repository is the topmost repository and it is used to incorporate all changes and contributions of the community. It generates nightly builds, that is, versions of the browser incorporating the most recent changes. Nightly builds can be unstable (since the changes have undergone little quality control) and are used by a relatively small community. Crash reports are used to perform some quality control on the features contributed by the community.
- The mozilla-aurora repository incorporates those changes of mozilla-central that are getting ready for production. The repository generates alpha builds, that is, versions of the browser that can be very unstable but are meant for a slightly larger user base.
- The mozilla-beta includes all those features from mozilla-aurora that will land in the next release of the browser. The branch generates beta releases, which are meant for an even wider audience. The build and the repository are used to discover and fix any issue found in the browser, so that the browser can get ready for release.
- Finally, the mozilla-release repository is used as a reference to keep track of the versions of Firefox that have been released.
For the sake of completeness, we remark that the Mozilla uses a fifth repository, called the shadow repository, for security fixes. The repository, however, is not public, to avoid publicizing ways in which a security bug could be exploited. The shadow repository merges into mozilla-central.
Development and fixes proceed in parallel on each repository, leading to a staggered development process. The approach has been chosen “to allow for continuous new feature development on mozilla-central, while the other channels are devoted to stabilizing features ready for a wider audience” (Mozilla Foundation, 2013a). The overall development cycle, from central to release, lasts about 16 weeks and is shown in Figure 7.11. Security, quality assurance, and other testing activities are conducted in parallel to development. The release process defines a specific procedure to decide whether to release the next version or not. The “go/no-go” decision is taken in a specific release activity. Compare activity 8 in the plan in Figure 7.11.
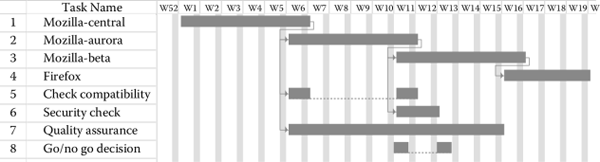
See Mozilla Foundation (2013a,b) for more details.
Mozilla has chosen an approach to software release in which the goals are fixed and duration varies according to achievement. That is, the release process is about 16 weeks, but it could last more or less, according to how quickly development and testing proceed. This is very similar to what happens in traditional software development.
A different approach is preferred by other projects. LibreOffice, for instance, adopts a time-based release, an approach according to which releases are predetermined and fixed in the calendar. Each release cycle for a significant release lasts 6 months, with minor releases given to the public more often. What features actually land on each release depend on the maturity of their implementation as release time approaches: the schedule is fixed, but what functions are delivered is not. See Open Document Foundation (2013) for more details.
7.5 Questions and Topics for Discussion
- What are the main advantages and disadvantages of traditional project management?
- What are the main advantages and disadvantages of agile project management?
- Could an agile process be used for the development of safety-critical systems? Which could be the point of attention? What are the opportunities?
- Try and set up a Kanban board for the ticket tracking process described in Figure 2.5.
- Set up a Kanban board for your to-do list and try to use it for a couple of weeks. Then discuss the advantages and issues you have encountered.
- What are the similarities between Kanban and Scrum? What are the differences?
References
Batsov, B., 2013. Rails style guide. Available at BozhidarBatsov. Last retrieved May 25, 2013.
Boehm, B. W., 1988. A spiral model of software development and enhancement. IEEE Computer 21 (5), 61–72.
Christie, J., 2008. The seductive and dangerous v-model. Testing Experience, (4):73–77. Available at http://www.scribd.com/doc/53329390/Testing-Experience-Issue-04-Dec-2008. Last retrieved November 22, 2013.
Chromatic, 2003. Extreme Programming Pocket Guide. O’Reilly, Sebastopol, CA.
Copeland, L., 2001. Extreme programming. Available at http://www.computerworld.com/s/article/66192/Extreme_Programming. Last retrieved November 22, 2013.
DSDM Consortium, 1997. Integrating DSDM® into an existing PRINCE2 environment. White paper, DSDM Consortium.
DSDM Consortium, 2000. Using DSDM® with PRINCE2. White paper, DSDM Consortium. Available at http://leadinganswers.typepad.com/leading_answers/files/DSDM_Prince2_WP_10.pdf. Last retrieved June 8, 2013.
DSDM Consortium, 2013. DSDM® consortium. Available at http://www.dsdm.org. Last retrieved June 26, 2013.
Fogel, K., 2009. How to Run a Successful Free Software Project–Producing Open Source Software. CreateSpace, Paramount, CA. Also available at http://producingoss.com/en/index.html.
Free Software Foundation, 2013, April. GNU coding standards. Available at http://www.gnu.org/prep/standards/. Last retrieved May 1, 2013.
Geracie, G., D. Heidt, and S. Starke, 2012. Product team performance. Technical report, Actuation Consulting.
Highsmith, J. and M. Fowler, 2001. The agile manifesto. Software Development Magazine 9(8), 29–30.
IABG, 2013. Das v-modell®. Available at http://v-modell.iabg.de/index.php. Last retrieved June 26, 2013.
Ikonen, M., P. Kettunen, N. Oza, and P. Abrahamsson, 2010. Exploring the sources of waste in Kanban software development projects. In Proceedings of EUROMICRO Conference on Software Engineering and Advanced Applications, pp. 376–381, Lille, France.
Kroll, P. and P. Kruchten, 2003. The Rational Unified Process Made Easy: A Practitioner’s Guide to the RUP. The Addison-Wesley Object Technology Series. Addison-Wesley Publishing Company Incorporated, Boston, MA, USA.
Kruchten, P., 2004. The Rational Unified Process: An Introduction. The Addison-Wesley Object Technology Series. Addison-Wesley, Boston, MA, USA.
Linger, R. C, 1993. Cleanroom software engineering for zero-defect software. In ICSE, pp. 2–13.
Linux kernel coding style, 2013e. Available at https://www.kernel.org/doc/Documentation/CodingStyle. Last retrieved May 25, 2013.
Manifesto for agile software development, 2001. Available at http://agilemanifesto.org. Last retrieved May 19, 2013.
McConnell, S., 1996. Rapid Development—Taming Wild Software Schedules. O’Reilly, Sebastopol, CA, USA.
McCracken, D. D. and M. A. Jackson, 1982, April. Life cycle concept considered harmful. SIGSOFT Software Enginering Notes 7(2), 29–32.
Mozilla Foundation, 2013a. Mozilla firefox: Development process–draft. Available at http://mozilla.github.io/process-releases/draft/development_overview/. Last retrieved May 25, 2013.
Mozilla Foundation, 2013b. Mozilla firefox: Development specifics—draft version. Available at http://mozilla.github.io/process-releases/draft/development_specifics/. Last retrieved May 25, 2013.
Mozilla Foundation, 2013c. Thunderbird/new release and governance model. Available at https://wiki.mozilla.org/Thunderbird/New_Release_and_Governance_Model. Last retrieved June 28, 2013.
Open Document Foundation, 2013. Release plan. Available at https://wiki.documentfoundation.org/ReleasePlan. Last retrieved May 25, 2013.
Oracle, 1999. Code conventions for the java (™) programming language. Available at http://www.oracle.com/technetwork/java/javase/documentation/codeconvtoc-136057.html. Last retrieved May 25, 2013.
Peterson, D., 2009. What is Kanban. Available at http://www.kanbanblog.com/explained/. Last retrieved June 7, 2013.
Rational Software, 2011. Rational unified process—Best practices for software development teams. White Paper TP026B, Rev 11/01, Rational Software. Available at http://www.ibm.com/developerworks/rational/library/content/03July/1000/1251/1251_bestpractices_TP026B.pdf Last retrieved November 15, 2013.
Royce, W W, 1970. Managing the development of large software systems. In Proceedings of the Western Electronic Show and Convention (WESCON 1970), pp. 1–9. IEEE Computer Society. Reprinted in Proceedings of the 9th International Conference on Software Engineering, ACM Press, 1989, pp. 328–338, United States.
Scotland, K., 2010. Aspects of Kanban. Software Development Magazine. Available at http://www.methodsandtools.com/archive/archive.php?id=104. Last retrieved June 7, 2013.
Sethanandha, B., B. Massey, and W. Jones, 2010. Managing open source contributions for software project sustainability. In Technology Management for Global Economic Growth (PICMET), 2010 Proceedings of PICMET ’10, pp. 1–9, Phuket, Thailand.
Sommerville, I., 2007. Software Engineering (8th ed.). Addison-Wesley, Redwood City, CA.
Sutherland, J., 1995, October. Business object design and implementation workshop. SIGPLAN OOPS Messenger 6 (4), 170–175.
Takeuchi, H. and I. Nonaka, 1986. The new new product development game. Harvard Business Review (January–February).
Testing, C. 2013. The seductive and dangerous V-model. Available at http://www.clarotesting.com/page11.htm. Last retrieved November 22, 2013.
VersionOne, 2013. 7th annual state of agile development survey. Technical report, VersionOne. Last retrieved June 26, 2013.
Wells, D., 1999. The rules of extreme programming the rules of extreme programming. Available at http://www.extremeprogramming.org/rules.html. Last retrieved May 31, 2013.
Wells, D., 2009. Extreme programming. Available at http://www.extremeprogramming.org/donwells.html. Last retrieved November 22, 2013.