
Chapter 9
Data everywhere
The world runs on data. This was true long before the introduction of modern computers. The very first programmable digital computer, the ENIAC (Electronic Numerical Integrator And Computer, 1946), was designed to do fast number crunching to solve numerical problems, such as projectile trajectory in ballistics. Later, in 1951, the first UNIVAC I (UNIVersal Automatic Computer I) was accepted by the United States Census Bureau to process census data.
We now live in an interconnected world of information technology (IT), where all sorts of data are created, stored, processed, analyzed, and applied to great benefits. Data is everywhere: contact lists on our smartphones, events on calendars, academic records in schools, inventories in stores, addresses and ZIP codes in the postal system, bar codes for products, QR (Quick Response) codes, accounting in companies, transaction records in finance, police records in crime fighting, maps and GPS data in navigation systems, medical records in health care, measurements in weather prediction, streaming and broadcasting contents, ancestries in genealogy, DNA structures in biology, orbits of near-earth objects in astronomy. And the list goes on.
In fact, all the pages on the Web form an ever-expanding and changing set of data that has revolutionized our lives. Understanding digital data and their processing can significantly inform computational thinking.
When you come right down to it, modern computers execute instructions that manipulate bit patterns. They are natural numerical machines able to crunch numbers at great speed and precision. To turn this ability loose on data, we must find clever ways to represent, structure, and organize all kinds of data in numerical forms (bit patterns).
For a program, the instructions constitute a certain procedure or algorithm. Data made available to a program become its input. And data produced by a program become its output. Thus, a program can be regarded as a well-defined transformation of input data to output data.
CT: GARBAGE IN, GARBAGE OUT
If the input is incorrect, then the output cannot be correct.

FIGURE 9.1 A Program
Obviously, no program can take incorrect input data and produce useful output data. We must make sure both the program and the input data are correct in order to obtain desirable output data.
In Chapter 2, we saw how bit patterns are used to represent numbers and characters. Now, we will see how more complicated data, such as images, audios, videos, employee records, and so on, are represented, processed, and stored.
In a real sense, programming consists of two main activities, designing and implementing algorithms and creating and manipulating data. The effectiveness and efficiency of a program depend on both its algorithms and its data structures/representations.
9.1 Digital Images
Modern displays, for HDTVs, computers, and smartphones, render images by illuminating individual pixels (picture elements) on the screen. The display screen consists of a rectangular array of pixels. Each row of the array contains the same number of pixels. A monitor with a denser pixel array gives higher resolution and the ability to display finer details. For example, a typical widescreen (16:9 aspect ratio) HD (high definition) monitor provides 1920 (column) x 1080 (row) of pixels.
Likewise, a digital camera also captures each image as an array of pixels. Typical resolutions include: 640 x 480, 1216 x 912 (1 Megapixels, MP), 1600 x 1200 (2 MP). And it goes much higher. Each individual pixel is specified by its color. Images so represented are known as raster images.
9.1.1 Representing Color
Let’s take a look at how colors are represented as data. Of course, we have names for various colors: red, green, blue, yellow, cyan, magenta, and so on. But color names are limited and hard to use in computing. For on-screen display, the RGB (red-green-blue) additive color model is widely used. With RGB, a color is specified by the amounts of the three primary colors it contains. By adding the specified red, green, and blue lights at a pixel location, a certain color can be produced on the monitor screen.
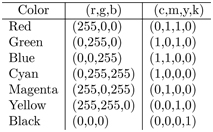
Usually, three bytes (R,G,B) are used (Table 9.1). The value (0–255) of each byte specifies the red, green, or blue component of a color, allowing for 2563 = 16, 777, 216 different colors (true color)1. For example, (255,0,0) is full red, (0,255,0) is full green, and (0,0,225) is full blue. And (0,0,0) is black, (255,255,255) is white. Often, each RGB byte is written down as two hex digits. For example, color=“#FFFFFF” sets the foreground color to white in a webpage (Section 6.6). For printing hard copies, the CMYK (cyan-magenta-yellow-black) subtractive color model is usually used. Ink used for printing absorbs specific colors while being transparent to other colors. Combining different inks takes out unwanted colors (from a white background) to reflect a desired color.
- Cyan ink—Absorbs red (no reflection of red from white background)
- Magenta ink—Absorbs green
- Yellow ink—Absorbs blue
- Black ink—Reduces light overall reflection to produce gray and black
TABLE 9.1 24-bit RGB Color Representation

When cyan, magenta, and yellow inks are mixed together at their full density, in theory, we should get black. But, this is usually not true in practice because the white paper can reflect some light through the semitransparent inks. Black ink is used to add the necessary ink density to produce darker colors. Only black ink is needed to produce black for printing. When an image represented in RGB is printed, it is usually automatically converted to CMYK, where the value of each component ranges from 0 (none) to 1 (full strength). Table 9.2 lists a few examples.
TABLE 9.2 RGB to CMYK Conversion
A color may also be given an alpha value indicating its opacity, a property that determines how much or how little of its background shows through. For alpha = 0, a color is completely transparent (invisible) and lets its background show through completely. For alpha = 1, a color is totally opaque and will not let any of its background show through. Transparency increases and opacity decreases as the alpha value varies from 1 to 0.
1The human eye can distinguish about 10 million different colors.
9.2 Raster Image Encoding
Data for raster images specify colors of a grid of pixels. The finer the grid, the better the resolution. The more bits per pixel, the truer the color. The total memory size required for this raw image data would be (number of pixels) x (number of bits per pixel). For example, a 13 MP image may take (4208 x 3120) x 24 = 315095040 bits or about 37.56 MB of memory.
9.2.1 Raster Image Formats
A raster image usually does not need to record each and every pixel individually. Compression methods can significantly reduce the image data size. There are a number of standard image compression formats in common usage. They employ different compression and decompression (codec) schemes (Section 9.8). The whole codec process may (lossy compression) or may not (lossless compression) lose some details or quality contained in the raw image data.
Widely used image compression formats include:
- Graphics Interchange Format (GIF)—A raster format suitable for icons, logos, cartoons, and line drawings. GIF images can have up to 256 colors (8-bit). GIF files use the .gif file name suffix.
- Portable Network Graphics (PNG) format—A format designed to replace GIF. PNG really has three main advantages over GIF: alpha channels (color transparency), gamma correction (cross-platform control of image brightness;), and two-dimensional interlacing (a method of progressive display). PNG files use the .png file name suffix.
- Joint Photographic Experts Group (JPEG) format—A lossy raster format widely used for color and black-and-white photographs that usually have continuously changing color tones. JPEG images can store up to 24-bit RGB color and achieve good compression ratio. But it does not support transparency. JPEG files use the .jpg or .jpeg file name suffix.
- Tagged Image File Format (TIFF)—A lossless format widely used primarily in printing, often using the CMYK color space. It also supports transparency. Images created by a scanner or digital camera are usually stored in TIFF. TIFF files use the .tif file name suffix.
Even with JPEG compression, a typical digital photograph takes about 2.5 MB storage. Such a large file is more expensive to transmit, store, and process. And the large size is usually not necessary for most purposes.
CT: SMALL IS BEAUTIFUL
Reduce the camera resolution when taking pictures to share online.
People often take pictures with their smartphones or digital cameras to be shared with others by email or texting. In such cases, there is no need for the full resolution, 8–20 MP or better available on most devices, which can result in large picture files. Instead, the camera image resolution should be set to 2 MP or less. In fact, a 640 x 480 photo (about 0.3 MP), at less than 300 KB, can do well for most email, texting, and on-Web sharing.
The higher MP settings should be used only to take pictures to be printed or enlarged.
9.2.2 Vector Graphics
Not all pictures are represented as raster images. Vector graphics uses coordinates and formulas to record points, lines, curves and other geometric objects to represent an image.
Vector image encoding avoids representing every pixel. Hence, vector images are usually smaller and easier to scale up or down. Also, geometric information can be combined with raster information to represent a complete image. Display software must understand the geometric information to render vector graphics files.
9.2.3 Scalable Vector Graphics
The Web supports vector graphics well. For example, HTML5 allows Scalable Vector Graphics (SVG), and JavaScript provides vector graphics programming. Also, the widely used Adobe Flash™supports vector graphics.
As an example, Figure 9.2 shows the company logo of webtong.com, which simply consists of a red triangle and two blue triangles. The box and coordinates shown are not part of the logo.
The SVG code for this logo is
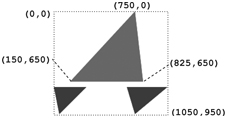
FIGURE 9. 2 Sample SVG Graphic

where the the triangles are drawn in a rectangular display area whose upper left corner is at (0,0) and lower right corner at (1050,950) (line A). The red triangle starts at (750,0), to (150,650), then to (825,650), and finally returns to the starting point (line B). A 210 x 190 PNG image of the same logo is 3503 bytes, whereas the SVG version is only 274 bytes, independent of image size. See Demo: SVGDemo and Demo: WebtongLogo for an interactive experience with SVG graphics.
9.3 Audio and Video
9.3.1 Digital Audio
Audio and video form a big part of the Web and Internet. Technically, audio refers to sound within the human hearing range. An audio signal is naturally a continuous oscillating wave representing amplitudes. Analog audio must be digitized for processing and playback on computing devices.
An analog audio signal is digitized by sampling and quantization. Sound is caused by vibration. A sound wave represents the amplitude (volume) and frequency (pitch) of sound. The continuous sound wave is sampled at regular time intervals, and the amplitude value at each sampling point is quantized to the nearest discrete level (Figure 9. 3). The resulting data are stored in binary format as a digital audio file. The higher the sample rate and the greater the bit depth (number of quantization levels), the higher the sound fidelity and the larger the file size. The same sampling and quantization process takes place in digitizing an image into an array of pixels.
Let F be the highest frequency of an audio signal. The sampling rate must be at least 2F to represent the signal well. This is the so-called sampling theorem. Human hearing is limited to a range of 20 Hz to 20K Hz (cycles per second). Thus, the CD-quality sampling rate is often 44.1K Hz. Human speech is limited from 20 Hz to 3K Hz. An 8K Hz sampling frequency is high enough for telephony-quality audio.
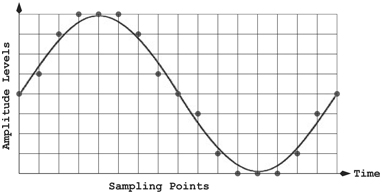
FIGURE 9. 3 Sampling and Quantization
9.3.2 Audio Encoding Formats
Advances in digital audio bring increasingly sophisticated compression schemes to reduce the size of audio files while preserving sound quality. For example, the widely used MP3 is the audio compression standard ISO-MPEG Audio Layer-3 (IS 11172-3 and IS 13818-3).
In 1987, the Fraunhofer Institute (Germany), in cooperation with the University of Erlangen, devised an audio compression algorithm based on perceptual audio, sounds that can be perceived by the human ear. Basically, MP3 compression eliminates sound data beyond human hearing. By exploiting stereo effects (data duplication between the stereo channels) and by limiting the audio bandwidth, audio files can be further compressed. The effort resulted in the MP3 standard. For stereo sound, a CD requires 1.4 Mbps (megabits per second). MP3 achieves CD-quality stereo at 112–128 Kbps, near CD-quality stereo at 96 Kbps, and FM radio-quality stereo at 56-64 Kbps. In all international listening tests, MPEG Layer-3 impressively proved its superior performance, maintaining the original sound quality at a data rate of around 64 Kbps per audio channel.
MP3 is part of the MPEG audio/video compression standards. MPEG is the Moving Pictures Experts Group, under the joint sponsorship of the International Organization for Standardization (ISO) and the International Electro-Technical Commission (IEC). MPEG works on standards for the encoding of moving pictures and audio. See the MPEG home page (mpeg.org) for further information.
More recently, Ogg Vorbis (xiph.org) offers a fully open, nonproprietary, patent-and-royalty-free, general-purpose audio format that is preferred by many over MP3. Table 9.3 lists common audio formats.
TABLE 9.3 Audio Formats
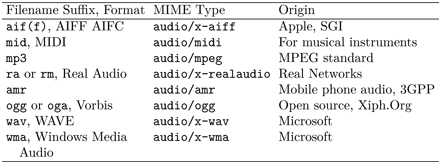
Actually, Ogg is a media container format (Section 9.4.1) rather than a single codec format.
Format converters are freely available to rewrite audio/video files from one format to another.
9.4 Digital Video
A video is a sequence of images displayed in rapid succession that is usually also played in synchrony with a sound stream. For smooth motion, a sufficient frame rate, about 30 frames per second (fps), is needed. There are many digital video formats for different purposes, including DVD, Blu-ray™, HDTV, DVCPRO/HD, DVCAM/HDCAM, and so on.
A video file usually supplies video tracks, audio tracks, and metadata. Tracks in a video file can also be organized into chapters that can be accessed and played directly. Such files are known as video containers, and they follow well-designed container formats, which govern the internal organization of a video file.
9.4.1 Video Containers
Widely used video container formats include:
- MPEG 4—A suite of standard audio and video compression formats from the Moving Pictures Experts Group (content type video/mp4; file suffix mp4, mpg4).
- Mobile phone video—A 3GPP-defined container format used for video for mobile phones (content type video/3gpp; file suffix 3pg).
- Flash Video—A proprietary format used by Adobe Flash Player (content type video/x-flv; file suffix flv).
- Ogg—A free and completely open standard from the Xiph.Org Foundation. The Ogg video container is called Theora (content type video/ogg; file suffix ogv). The Ogg audio container is called Vorbis (content type audio/ogg; file suffix ogg).
- WebM—A new standard developed by webmproject.org and announced in mid-2010. The format, free and completely open, is used exclusively with the VP8 video codec and Vorbis audio codec. It is supported by, among others, Adobe, Google, Mozilla, and Opera. Google offers a WebM plug-in component for IE9. WebM is a new media container designed for the Web and is recommended for use with the audio and video elements of HTML.
- AVI—Audio Video Interleaved format from Microsoft (content type video/x-msvideo; file suffix avi).
- RealVideo—An audio and video format by Real Networks. For historical reasons, it uses the seemingly incorrect content type audio/x-pn-realaudio and the file suffix rm.
9.4.2 Video Codecs
The video and audio tracks in a container are delivered with well-established compression methods. A video player must decompress the tracks before playing the data. Many compression-decompression algorithms exist. Generally speaking, video compression uses various ways to eliminate redundant data within one frame and between frames.
The most important video codecs for the Web include H.264, Theora, and VP8.
- H.264—A widely used standard from MPEG providing different encoding profiles to suit devices from smartphones to high-powered desktops. Also known as MPEG-4 Advanced Video Coding, the standard enjoys good hardware and software support.
- HEVC—High Efficiency Video Coding, jointly developed by ISO and MPEG, HEVC can double the compression ratio of H.264/MPEG-4 AVC while maintaining the same level of video quality.
- Theora—A completely free standard from Xiph.Org Foundation providing a modern codec that can be embedded in any container. But, it is usually delivered in an Ogg container. Theora is supported on all major Linux distributions, Windows, and Mac OS X.
- VP8—A very modern and efficient standard from On2 (part of Google) giving everyone an open source and royalty-free codec for the Web. VP8 is usually delivered inside the WebM container.
- WMV—Windows Media Video, a family of proprietary video codecs, including WMV 7, WMV 8, WMV 9, and VC-1.
9.5 Format of Data and Files
Data and application programs are usually intimately related. Often, an application receives input data, processes the data, and produces output data. Such data are typically saved in files for later use or sharing with others. There are many different types of files to satisfy various kinds of application and intended purposes.
Typically, the first thing when processing a file is to determine its file type. Only the correct application programs can process files of certain types. Imagine what would happen if a music-playing application is given a spreadsheet file to process! The sound must be awful, if it works at all.
Files fall in two broad categories: text file and binary file. The former contains only characters in ASCII or UNICODE (Section 2.6), the latter a sequence of arbitrary bytes. PNG images, MP3 songs, and compiled programs, for example, are stored in binary files. Emails, Web pages, and Shell scripts, in addition to plaintext notes, are in text files. Text files have the advantage of being easily readable by humans and modifiable using simple text editors. Binary files require specific applications but are usually more compact and efficient.
CT: INTERPRETING DATA
Each file or content type defines its own data format, structure, and encoding.
Without knowing the type, data cannot be interpreted correctly. Ways to indicate the file/data type have been evolving together with advancements in operating systems, networking, and the Internet. In addition to file name suffix and standard MIME content types, as we have seen in Section 4.8, in-file metadata can also be used to specify the file type as well as other properties of a file. Such files follow a well-defined file format that governs the file’s internal organization such as the file header structure, any magic number, and other metadata.
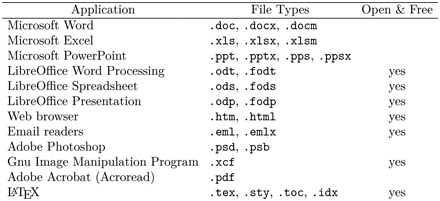
Table 9.4 lists some common file formats associated with well-known applications. A file format can be proprietary (.psd, for example), open but may require a license (.doc, .xls, .ppt, and .mp3, for example), or open and free (.html and LibreOffice formats, for example).
TABLE 9.4 Application and Data
CT: DATA IS APPLICATION DEPENDENT
Data and files are usually represented differently for different applications.
The PDF file type is worth noting. It has become the defacto standard for sharing documents online across all platforms. Putting a PDF file online or in an email is the best way to avoid printing and/or faxing. Besides, contents of a PDF file can be searched automatically.
CT: SAVE TREES WITH PDF
Never print or fax a document if you can save/send it as PDF.
Applications use their own native file/data formats for effectiveness, efficiency, and sometimes proprietary reasons. Use the file->save option to save any changes and overwrite the original version, use file->save as to save it under a different name, use file->export to save it into some other format. Application can usually also work with non-native format files by first importing them, converting to them to the native format.
Programs are often available to convert files between comparable formats. Freely available audio and video converters are examples.
9.6 Data Sharing
Using data from others is one thing, supplying data you created to others is another. It is not unusual for an individual to want to share pictures, music, audio, video, and other types of documents either publicly or privately. Here are a number of ways to do it.
- Email—Send the files as email attachments. Beware that email systems have limitations to the size of attachments. Generally, if they total under 10MB, you should be OK.
- Website—Upload the files to your own website and send their URLs to others to share. Beware that Web access is public unless the files are placed in a protected realm (requiring login).
- The Cloud—Don’t have a Website? Upload the files to the Cloud to share, using such online services as Dropbox™, Facebook™, Google Drive™, Picassa™ (pictures), YouTube™ (videos), and Spotify™ (music).
- FTP—Upload files to an FTP server to share with others.
- Bittorrent—Prepare a torrent for the files and folders you wish to share via Bittorrent. A torrent is a file that contains meta data about the contents to be shared, how they are cut into pieces, and other useful information. Upload the contents and the torrent to a Bittorrent site for others to download.
- Physical media—Store the files on a Flash drive or a CD/DVD and send it to someone.
When you have a group of files to share, consider using compression formats, such as .zip, .tgz, or .rar (Section 9.8).
9.7 Document Markup
Treating textual documents as data items is an important aspect of information technology. An effective way to organize complicated textual documents for easy automated processing is to delineate the role or meaning of pieces and parts contained inside the document. To make such delineations is to markup the document. For example, we have seen how HTML tags are used to markup Web pages (Section 6.5). The HTML tags are key for Web browsers and JavaScript programs to process, display, and otherwise manipulate Web pages and their constituent parts.
HTML is a markup language for organizing Web pages. But what about other documents, such as tax returns, employee records, product catalogs, and so on? Well, XML, the extensible Markup Language, is a technology that provides a way for anyone to invent and design a set of markup tags for any desired type of document.
Markup makes documents easy to communicate among heterogeneous platforms and efficient to process by programs.
9.7.1 What Is XML?
XML is not a markup language with a set of tags specific to structuring a certain kind of document. In fact, XML defines no tags at all. Instead, XML is a set of rules by which you can invent your own set of tags to organize and structure any specific type of textual documents you wish. Each organizational unit, usually bracketed by begin and end tags, is called an element. Thus, XML is a way to define your own markup language. Each XML-defined markup language is known as an XML application. Documents so marked up are called XML documents. XML is also a Web standard and there are many tools, mostly free, to create, process, and display XML documents.
SVG (Section 9.2.3) is just one of a large number of XML applications. For example, RSS (Rich Site Summary) and Atom (Atom Syndication Format) are standard Web news syndication formats based on XML (Section 9.7.3). Figure 9. 4 shows the two familiar news syndication icons.

FIGURE 9. 4 News Syndication Icons
The list of publicly used XML applications is long (see the wikipedia). And then there are nonpublic markups used within organizations and even by individuals. XML makes it possible and easy for anyone to create a new markup language (CT: MARK IT UP, Section 6.5).
9.7.2 XML Document Format
As shown in Figure 9. 5, an XML document begins with processing instructions, followed by a root element that may contain other elements. The elements are defined by individual XML applications following rules given by XML.

FIGURE 9. 5 An XML Document
For example, here is a simple XML document:

The <?xml processing instruction (line 1) is required as the first line of any XML document. It provides the XML version and the character encoding used for the document. Other processing instructions follow the first line and can supply style sheets, definitions for the particular type of XML document, and other meta information for the document. Coming after the processing instructions is the root element that encloses the document content. The root element in this example is the address element (line 2), which constitutes the remainder of the XML document.
In Section 9.2.3, we have seen how SVG (an XML application) is used to markup a vector-based image.
9.7.3 XML for News Syndication
XML is used widely in practice. Perhaps the best-known example is news syndication on the Web. The Web standard RSS is an XML application for Web feeds, and frequently updated content, such as blog entries and news headlines. An RSS document can supply an abstract, author, organization, publishing dates, and a link to the full story or article. Using a Web browser or an RSS reader, end users can subscribe to RSS feeds and easily see the changing headlines.
Here is a simple RSS example, the books.rss file:
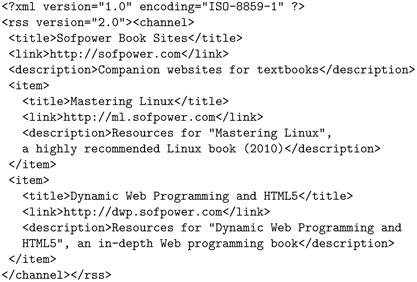
The file lists two information/news items, about books published recently by the author, from the sofpower.com (channel) each linking to a website.
Atom is another XML-based news syndication standard from the IETF
(Internet Engineering Task Force).
Web browsers and news reader applications understand RSS and Atom formats. Clicking on a link leading to an RSS or Atom file causes a Web browser to ask you if you wish to subscribe to the news feed. If you do subscribe, your browser will bookmark the feed and monitor any new headlines from the feed.
News feed links are usually marked by an orange-colored icon. See cnn.com/services/rss for RSS feeds from CNN, or hosted2.ap.org/APDEFAULT/APNewsFeeds for Atom feeds from AP.
The first step in processing the contents of a document is to discover its structure and the values for its various parts. This requires parsing, which may be difficult or even impossible for arbitrary documents. Markup tags change all that by making the document structure explicit.
CT: MARKUP FOR INTEROPERABILITY
Use XML to make data in your documents easily sharable and usable across heterogeneous computing systems.
9.8 Data Compression
It takes space to store data and time to transmit data. Data compression techniques can help reduce these requirements. With data compression (Figure 9. 6), a message (data file or stream) is deflated (reduced in size) before storage or transmission. A deflated message can later be inflated to recover the original message, either exactly (in lossless compression) or approximately (in lossy compression). Some compression algorithms, such as those used in JPEG, GIF, and PNG (Section 9.2.1), are application specific. Others are more general and will work for nearly all message types.

FIGURE 9. 6 Data Compression
A compression algorithm takes advantage of the nature of the target messages to reduce their size. Consider black-and-white, two-tone images, those from FAX machines, for example. The pixels can be represented as a sequence of pixels; each is either white or black. But we can compress such a message using a run-length scheme that reduces the message into a sequence of integers indicating the number of consecutive white or black pixels. This can work well for ordinary document pages that are mostly white with a few black pixels here and there. It won’t work at all if the whole page is filled with tiny black dots. For such a page, the run-length encoded message can become much larger. Compared to run-length, the actual algorithms used for JPEG, PNG, MP3, and so on are much more sophisticated.
Generally, a message, consisting of one or more files, can often be treated as a stream of characters or bytes. The LZ77 (by Abraham Lempel and Jacob Ziv, 1977) algorithm and the Huffman coding (David A. Huffman, 1952) for message deflation are very effective and employed by many popular compression applications (Table 9.5). It depends on the particular message, but these compression programs can often deflate a message to a third of its original size, or better.
TABLE 9.5 Lossless Data Compression Applications

While both data compression and data encryption (Section 7.4) transforms data into forms that must be unwound before being used, they serve very different purposes.
CT: COMPRESSION IS NOT ENCRYPTION
Compression reduces data size. Encryption secures data content.
An encrypted message cannot be decrypted unless the correct password is given. A compressed message, although not immediately readable, can be decompressed by anyone using readily available tools. No password is required.
9.8.1 LZ Deflation
LZ77 deflation replaces each repeated string in the source message by a reference to an earlier occurrence in the message. Such a reference is in the form of a length-distance pair
(len, d),
and it means “a sequence of len bytes, same as that d bytes earlier in the original message.” This is effective when the original message is lengthy and contains many repeated sequences of bytes. Such is the case with HTML, XML, and plaintext documents. Here are some examples:
Source message = teamwork, the way a team works
encoded message = teamwork, the way a (4,20) (4,21)s
Source message = bgfgfgfgbggb
encoded message = bgf(5,2)(2,8)gb
As you can see, an LZ77 deflated message basically consists of references and literals, single characters or bytes not represented by references. The literals and numbers in references can usually be further deflated using Huffman code.
9.8.2 Huffman Code
In a particular message or type of messages, the frequencies of different symbols are certainly not equal. Some symbols happen more often than others and certain symbols hardly at all. For example, in a textual document, you would expect the letters r, s, t, as well as the vowels, to be more frequent than, say, x, y, and z; and characters such as ~ hardly at all. We can take advantage of such frequency differences to save space in representing characters. The basic idea of Huffman code is simple. Instead of using the same number of bits to represent each character (as in ASCII and UNICODE), we can use fewer bits for frequent characters and more bits for other characters.
The same goes for numbers. Instead of using, say, a 32-bit integer representation, we can use just a few bits for high-frequency numbers. In practice, you’ll find small numbers much more often.
To Huffman encode a message, we first find the frequencies of symbols to be encoded. Based on the frequencies, we can build a Huffman binary tree (CT: FORM TREE STRUCTURES, Section 8.8), which defines how these symbols will be encoded into bit strings of various lengths. The Huffman tree is stored as part of the deflated message because it is needed for inflation.
As an example, let’s apply Huffman coding to deflate a love poem by Nima Akbari (Demo: HuffCode), which begins
You’re my man, my mighty king,
And I’m the jewel in your crown,
You’re the sun so hot and bright,
I’m your light-rays shining down,
The plaintext file for the whole poem contains 545 bytes, including spaces and line breaks. The character frequencies are shown here in increasing frequency.

Note characters include uppercase and lowercase letters and punctuation marks, including SPACE (SP), and RETURN (CR).
A list, fq, of character-frequency pairs, ordered in increasing frequency, such as the above, is used in a simple recursive algorithm to build a Huffman tree. Basically, the algorithm builds a binary tree from the bottom up, by creating tree nodes with characters having the least frequencies first. Each recursive call huffmanTree(fq) passes a list fq that is smaller in size.
Algorithm huffmanTree(fq):
Input: Character-frequency list fq, in increasing frequency order
Output: Returns a Huffman binary tree
- If fq is empty, then return an empty binary tree node
- If fq has only one entry and that entry is a character, then return a leaf node with that character its child
- If fq has only one entry and that entry is a tree node, (node, frequency), then return node
- Remove the lowest frequency two entries x and y from fq; create a new binary node, node, with x and y as children
- Set fr = frequency(x) + frequency(y); insert a new entry (node, fr) into fq, making sure that the list fq stays ordered
- Return huffmanTree(fq)
In the algorithm, the word “character” means a single byte. The constructed Huffman tree is used to generate the Huffman code for each character/byte in the message to be deflated. Figure 9. 7 shows a Huffman tree constructed this way. Starting from the tree root and using 0 for the left branch and 1 for the right branch, we see the most frequent character (SPACE) can be represented with just 3 bits, 000.
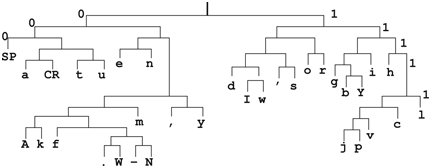
FIGURE 9. 7 An Example Huffman Code Tree
Following the code tree, we see the code for the first three characters (You)
is 110011101000111.
The resulting Huffman code for the entire poem is 2457 bits, as compared to the ASCII file, which is 545 x 8 = 4360 bits.
Of course, we also need to include the required Huffman tree as part of the deflated message so it can be inflated later. This costs no more than ((number of symbols) x (sz + 2) – 1) bits, where sz is usually 8 in ASCII code. For our example, the cost is 339 bits.
Applying the GZIP tool on this poem, we get a file 291 bytes long, which is still better than using Huffman code alone (Demo: TryGZIP).
CT: CUSTOMIZE FOR EFFICIENCY
One size does not fit all well. Custom solutions can examine and take advantage of properties in individual cases and become more efficient.
Representing a message as a stream of characters with ASCII/UNICODE encoding fits all. Yet, data compression schemes can examine individual messages and deflate each one using repeated patterns and character frequencies unique in the message.
Modern Web servers can automatically deflate specific types of documents, such as HTML, CSS, and JavaScript, just before sending, and Web browsers can automatically inflate them when received. This, working together with HTTP caching (Section 6.10.1), can significantly speed up loading of Web pages and reduce unnecessary Internet traffic.
9.9 Data Structures
As you may expect, a computer program must usually manipulate data to achieve its goals. An important task in any program is to organize and manipulate data correctly and efficiently.
The term data structures in computer science refers to well-known techniques to organize data often used in programming. These structures provide systematic ways to store and manipulate in-memory data.
For example, a tree structure, or tree for short, is useful for organizing data in a hierarchy. We have seen the file tree (Section 4.8), the solution tree (Figure 8.11), and, of course, the Huffman code tree in the previous section (Section 9.8.2).
Here is a list of common data structures:
- Array—A sequence of equal-size memory cells in consecutive memory locations. Each cell can be reached directly by an integer index, starting from zero. An array stores data items of the same type, an array of integers, characters, or names, for example (Section 3.5.2).
- Linked list—A sequence of data items where each item has a pointer to the next item. The last item has points to a special end symbol. A list makes it easy to splice in or cut out an item. Each item on a bidirectional list also has a pointer to the previous item.
- Queue—A specialized list or array where items are processed in a first- in-first-out order (FIFO).
- Stack—A specialized list or array where items are processed in a first-inlast-out order (FILO), like a stack of plates in the cafeteria (Figure 9. 8).
- Tree—A hierarchical structure with a root node pointing to child nodes that may point to their own child nodes. A node with no children is called a leaf node. Each node, except the root, has a unique parent node. The Huffman code tree is a binary tree (up to two child nodes).
- Buffer—A holding place for data items, where a producer program can deposit data and a consumer program can remove data.
- Table—A collection of key-value pairs, not unlike a dictionary. A table makes it easy to look up values by keys. A hash table is a particularly efficient way to store and retrieve items by computing hash codes for keys allowing direct access to items stored in the table without searching through the table.
- Graph—A structure with nodes connected by edges. Consider a graph as a generalized tree where any node can point to any other node, not just to child nodes. This structure is useful to represent connectivity in networking, transportation, and so on.
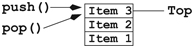
FIGURE 9. 8 A Stack
As you can see, each data structure provides two kinds of programming support: data organization and data manipulation. For example, a stack organizes data items in a linear sequence and then it provides push (onto the top), pop (off the top) and is-empty (test) procedures for using a stack. To protect the integrity of a stack, these are the only allowed operations.
CT: SYNTHESIZE AND SIMPLIFY
Synthesize lower-level details and operations into understandable higher- level objects and actions. They can simplify complicated tasks.
Such data structures help hide data and operational details and allow programmers to think about, for example, pushing and popping a stack instead of bit patterns, memory addresses, and other such details. This is a form of abstraction (CT: ABSTRACT AWAY, Section 1.2) known in computer science as data abstraction.
9.10 What Is a Database?
Large, complicated, and dynamically changing data, such as student records, store inventories, and airline reservations, can not be adequately handled in static files, such as spreadsheets. They require database systems.
A database is a collection of data efficiently organized in digital form to support specific applications. A database is normally intended to be shared and updated by multiple users.
A Database Management System (DBMS) is a software system that operates databases, providing storage, access, security, backup, and other facilities. A DBMS usually makes databases available to many users at the same time and handles user login, privileges (abilities to perform certain operations), and local or network access.
A Relational Database is one that uses relations or tables to organize data. Even though there are other ways to organize data, relational databases are by far the most popular and widely used in practice. Well-known relational DBMS (RDBMS) include IBM DB2, Oracle, MySQL, SQLite, Derby, and Microsoft Access.
9.10.1 Relational Databases
A relational database uses multiple tables, called relations in database theory, to efficiently organize data. A relation is a set of related attributes and their possible values. Figure 9.9 shows a typical database table.
Each table is defined by a schema that specifies
- The names of the attributes (column headings)
- The type of value allowed for each attribute
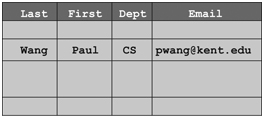
FIGURE 9. 9 A Simple Database Table
For example, the type of an attribute can be character string, date, integer, or decimal, and so on.
Each row in a table is a set of attribute values. A row is also called a record or a tuple, and no two records can be exactly the same in a table (the no duplicate row rule). The collection of all records in a table is called a table instance or relation instance. Immediately after a table is defined by its schema, it has no records. So the table instance is the empty set. As records are inserted into the table, the table instance grows. As records are removed from the table, the table instance shrinks. As data in table records are changed, the table instance changes. When dealing with database tables, it is important to keep in mind the difference between the table schema and the table instances.
Each database in an RDBMS is identified by a name. A relational database usually consists of multiple tables organized to efficiently represent and interrelate the data. The RDBMS also stores, in its own management database, information about which users can access what databases and what database operations are allowed. Usually, a user must first login to the RDBMS from designated hosts before access can be made. For example, if access is restricted to the localhost, then only access made by a program, running on the same host computer as the RDBMS, is allowed.
9.10.2 SQL: Structured Query Language
Of course, each RDBMS needs to provide a way for application programs to create, access, and manipulate databases, tables, records, and other database- related items. The Structured Query Language (SQL2) standardizes a programming language for this need. SQL, an ISO (International Organization for Standardization) and ANSI (American National Standards Institute) standard, is a declarative language that uses sentences and clauses to form queries that specify database actions. SQL consists of a Data Definition Language (DDL) to specify schemas, and a Data Manipulation Language (DML) for adding, removing, updating, retrieving, and manipulating data in databases.
Major RDBMSs are all SQL compliant to a great degree. Thus, programs coded in SQL can easily be made to work on different systems. However, there are still differences among different database systems. In this book, examples show SQL code for the MySQL system. The code can easily be repurposed for other RDBMSs.
2 SQL is pronounced by saying each of the three letters.
A database query, or simply a query, is a command written in SQL that instructs the RDBMS to perform a desired task on a database. A data retrieval query usually returns a resultset, which is a table of records. A data update query does not return a resultset.
Today, the Web and database systems are nearly inseparable (Section 6.8.2). The Web supercharges the power of databases by providing them with on-Web frontends (Figure 9.10). Any untrained user can fill forms in webpages to retrieve and update information in databases. At the same time, databases support various on-Web operations, such as user accounts, making them more functional and useful. As a result, you have online class registration, shopping, banking, ticketing, investing, and many other functions most of us can’t do without in our daily lives.
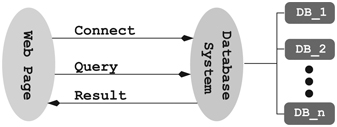
FIGURE 9. 10 Web Access to Databases
CT: COMBINE WEB AND DATABASE
Combine the Web and database systems. Form a powerful union much greater than its parts.
Modern technologies, such as space probes and telescopes, earth resource and observation satellites for example, generate tremendous amounts of data. It takes enormous computing power to digest and understand such data in order to discover knowledge from them. Database systems also play an important part in such efforts.
9.10.3 Big Data
Advances in digital and information technologies, especially in the sensing and gathering of data in many different areas, result in collections of data that are extremely large. It was estimated that, as of 2012, 2.5 exabytes (1018 bytes) of data were created every day! And the data collection rate has been increasing rapidly as well.
Basically, we have the ability to collect data on everyone, everything, everywhere. And we do it in many different fields including census, demographics, medicare, weather prediction, crime fighting, science, business, and finance. Very large databases are needed to store big data. Working with databases of such sizes requires parallel programs executing on hundreds or thousands of computers.
CT: DATA TO INSIGHT
Big data is big resource. Analyzing big data can reveal hidden relations and correlations, which can be invaluable in decision and policy making.
The breakthrough thinking is “We are not limited to sampling data and statistics. We have the abilities to collect, examine, and analyze, all the data.”
9.11 Protecting Personal Data
The widespread creation, collection, transmission, and access of data online have made the information age what it is. The benefit it brings is immense and indispensable.
However, we should also be aware of the drawbacks. Particularly, we need to prevent personal data from falling into the wrong hands or being misused. Examples of personal data are full name, date and place of birth, ID numbers, address, phone number, login information, screen name, account numbers, financial and credit information, medical records, health information, and so
on.
CT: GUARD PERSONAL DATA
Individuals and organizations must do their best to keep personal data confidential.
Generally, personal data is any information that can be identified with, is specific to, or can be connected to a living individual. Usually, personal data must be kept confidential by any individual or company that collects or retains the information. Many countries have regulations that define personal data and the responsibilities collectors and keepers have to protect such information.
Exercises
- 9.1 What is the resolution of an HD monitor?
- 9.2 If each pixel requires 24 bits, what is the storage size of a raw HD image?
- 9.3 Explain additive color and subtractive color models.
- 9.4 In printing, why do we need black ink when combining CMY inks can produce black?
- 9.5 In 24-bit RGB notation, what color is (255,0,255)? (100, 100, 100)? (500,400,600)?
- 9.6 Why do we want to reduce the resolution when taking pictures with our digital cameras or smartphones?
- 9.7 What is the difference between vector and raster graphics?
- 9.8 What is sampling? Quantization? How are they related to the final data size?
- 9.9 What is a codec?
- 9.10 In an application program, what is the usual meaning of these operations: save, save as, export, import.
- 9.11 What is document markup, and why is it useful?
- 9.12 What is data compression? Lossy and lossless compression?
- 9.13 Compress the SVG code for the webtong.com logo (Figure 9.2), in Section 9.2.3), using both GZIP and ZIP. Report how small the compressed files are.
- 9.14 What are the two main techniques to deflate a message?
- 9.15 Refer to Figure 9.7 and deduce the code word for each of these characters: b, Y, y, and f.
- 9.16 Continue from the previous exercise and write down the code words for all 34 characters.
- 9.17 Look at the result in the previous exercise. Do you see any code word that happens to be a prefix of some other code word? If not, please explain why this is always the case for Huffman code.
- 9.18 Consider the following bit encoding of a Huffman tree.
Algorithm treeEncode:
Input: Root node nd of tree to be encoded Output: Bit string to represent the tree
- If nd is leaf node, then output a 1-bit followed by the 8-bit charac- ter/byte and return.
- Output a 0-bit; call treeEncode(left child of nd); call treeEncode(right child of nd).
What is the bit length of this bit string? How would you decode this bit encoding back into a binary tree with characters at the leaves?
- 9.19 What is a database, a table, and a relation?
- 9.20 What is SQL, and who needs it?
- 9.21 Computize: Find out about the current state of digitizing the human smell, taste, and touch.
- 9.22 Computize: TV screens are going to 4K. What resolution is that? What implications are there for streaming shows in 4K?
- 9.23 Computize: Look into 3D printing, how it works, and how it relates to representing digital images.
- 9.24 Computize: If bit patterns are the only way to store information, how do you think executable programs are stored? How are they distinguished from non-executable files? And who cares?
- 9.25 Computize: Invent a personnel record markup. Give an example record in your markup.
- 9.26 Group discussion topic: QR codes and their uses.
- 9.27 Group discussion topic: My favorite search engine.
- 9.28 Group discussion topic: The way Google Translate works and improves through time.