
Chapter 6
Home Sweet Homepage :-)
“Hello Laura, it is nice to meet you. Please (producing a business card) visit our website and find out all about me or my company.” Or, in an email, “Can you believe this? See it here.” Or, “Look at their menu, I am very much looking forward to our dinner together.” These days, no serious professional or organization does not already have, or plans to have, a site on the World Wide Web (Web).
A website gives you your own domain name (BigBadWolf.com, for example). Then you’ll have email addresses in the form of [email protected]. Don’t forget to add your website and email address to your business card. You’ll be able to upload webpages and other information to your site for everyone to use. And that’s just the beginning of the advantages.
The Web service uses the client and server model, as explained in Section 5.9. Web servers and clients communicate with the HTTP (Hypertext Transfer Protocol) and HTTPS (Secure HTTP) application-level protocols (Figure 5.9), riding on top of TCP/IP. The Hypertext Markup Language (HTML) is used to author webpages. A resource available on the Web is retrieved by its Web address known as a URL (Universal Resource Locator). For example, the CT website is at http://computize.org.
The Web’s global impact has brought us numerous advantages, large and small. And it is transforming society at all levels as untold number of people actively blog, microblog, and otherwise express themselves with online media. It goes without saying that an understanding of the Web and how it works will be good for everyone.
6.1 What Is a Web Server?
A key factor for the Web’s great success is the low cost of putting information on it. You simply find a Web hosting service to upload files for your website. Any Internet host with a good Internet connection can provide Web hosting. A Web host provides space for websites to store webpages, pictures, audio and video files, and any programs that produce Web content on the fly. More importantly, the Web host also runs a Web server program through which the stored websites can be accessed on the Web.
There are a number of Web servers, but Apache™, the open source Web server from apache.org, is the most dominant. According to Web Technology From Computing to Computational Thinking Surveys (March 2015), market shares for major Web servers are Apache™ (58.4%), NGINX™ (23.3%), and Microsoft-IIS® (13.2%).
A Web server program listens to a specific networking port on the server host and follows the HTTP and HTTPS to receive requests and send responses. The standard HTTP port is 80, but can be some other designated port, such as 8080. The standard HTTPS port is 443.

FIGURE 6.1 Web Server Overview
In response to an incoming request, a server may return a static document from files stored on the server host, or it may return a document dynamically generated by a program, such as a PHP script, indicated by the request (Figure 6.1).
A single-thread server handles one incoming request at a time, while a multithread server can handle multiple concurrent requests. A server host may have multiple copies of a Web server running to improve the handling of requests.
On a server host, webpages and other files to be accessed from the Web must be placed in the Web server’s document space before they become available on the Web. The top folder of the document space is known as the server root. To further control access, files and folders inside the document space must also be given correct access permissions before the Web server can deliver them onto the Web.
6.2 Web Browsers
Another critical factor for the Web’s success is easy-to-use clients for browsing the Web.
We access the Web from anywhere on the Internet with desktops, laptops, tablets, and smartphones. Popular Web browsers (Figure 6.2) are:

FIGURE 6.2 Top Five Web Browsers
- Vendor proprietary—Google Chrome (all platforms), Internet Explorer (Microsoft Windows), Safari (Mac OS X and iOS)
- Open source for all platforms—Firefox, Opera, and others
In terms of popularity, you have Google Chrome and Firefox enjoying 56% and 30% of the market, 1 respectively.
Browsers make surfing the Web a great experience. They keep track of your browsing history, remember and organize your bookmarks, safely keep your user IDs and passwords for different sites, cache Web data for speed, supply multiple tabs (such a convenience), and allow a high degree of user customization, including browser home page (URL loaded automatically when the browser starts), fonts, colors, helper applications and more.
Accessing the Web on the go is important and fun. Android tablets and smartphones come with Google Chrome. Apple devices come with Safari. Windows phones come with IE Mobile. Businesses also provide dedicated mobile apps to access their information and services.
6.3 A Brief History of the Web
The Web got its start in the late 1980s. In 1989, Tim Berners-Lee at the European Laboratory for Particle Physics (CERN) started to develop a suite of technologies to make the Internet truly accessible and useful to people.
- URL—The Uniform Resource Locator
- HTML—The Hypertext Markup Language
- HTTP—The Hypertext Transfer Protocol
Berners-Lee also wrote the first Web browser and server.
The simplicity of HTML makes it easy to learn and publish webpages.
It caught on. In 1992-1993, a group at NCSA (National Center for Supercomputing Applications, US) developed the Mosaic visual/graphical browser (Figure 6.3). Mosaic added support for images, nested lists, and fill-in forms, and it fueled the explosive growth of the Web. Several people from the Mosaic project helped start Netscape (Figure 6.3) in 1994. At the same time, the W3

FIGURE 6.3 Mosaic and Netscape
Consortium (W3C) was formed and housed at MIT as an industry-supported organization for the standardization and development of the Web.
6.4 URLs
The Web uses Uniform Resource Locators (URLs) to identify (locate) many kinds of resources available on the Internet. URLs are used by Web browsers to request and retrieve information. We know URLs can locate webpages. But they can also identify pictures/images and audio and video media, as well as Internet/Web services.
A URL usually has the form scheme ://serverhost : port/pathname? query_string that consists of several parts. Let’s break the URL down.
- The scheme part indicates the information service type and therefore the protocol. Common schemes include http (Web service), ftp (file transfer service), file (local file system), https (secure Web service), and sftp (secure file transfer service). Many other schemes can be found at http://www.w3.org/addressing/schemes. Because http is the default scheme, it, together with the trailing :// can sometimes be omitted.
- The serverhost part, separated from the scheme by ://, is a domain name or IP address that identifies a server host.
- The port number is optional. It is a number given with a : prefix to identify a networking channel on the host. Standard Internet services are assigned default ports (for example, 80 for HTTP and 443 for HTTPS). The port number is needed only if the server program does not use its default port.
- The pathname part is optional. If omitted, the URL brings up the homepage (site entry) of a website. The pathname is a filename, with a / prefix, relative to the server root folder on the server host. If this pathname has a trailing / character, it represents a directory rather than a data file.
- The query string part is optional. When the pathname leads to an executable program that dynamically produces an HTML or other valid file to return (Section 6.8), a query string, given after a ?, can provide input values to that program. A query string takes the form of name=value pairs separated by &.
Here are some examples,
| http://www.kent.edu | (Ket State U. homepage) |
| http://w3.org/ | (W3C site) |
| https://chase.com | (Chase Bank secure site) |
| http://computize.org/example.html | (CT site example page) |
| https://amazon.com/.../home?ie=UTF8 | (amazon.com after login) |
| ftp://webtong.com | (Public FTP webtong.com) |
| file:///C:/Users/pwang/Desktop/a.jpg | (Picture on local Desktop) |
URLs are critical in Web operations. You can enter any valid URL into the Location box of any Web browser to reach the target resource. When a URL specifies a directory, a Web server usually returns an index file, typically named index.html, for that directory. Otherwise, it may return a list of the filenames in that directory. Thus, for example, the URL http://cnn.com is the same as http://cnn.com/index.html.
URLs are also used in webpages to link to other webpages and resources, inside or outside a particular website. The cross-links among webpages globally form a worldwide web structure. Because of its importance, many applications, including email readers, PDF readers, text/document editors, presentation tools, and shell windows, recognize the http URL and, when you click on it, will launch the default Web browser.
Relative URLs
Within an HTML document, you can link to another document served by the same Web server by giving only the pathname part of the URL. Such links are examples of relative URLs.
- A relative URL with a leading / (for example, /file_xyz.html) refers to a file under the server root, the top-level directory controlled by the Web server.
- A relative URL without a leading / points to a file relative to the location of the document that contains the URL in question. Thus, a simple file_abc.html refers to that file in the same directory as the current document.
CT: BE AWARE OF THE IMPLICIT CONTEXT
Be aware of the implicit context. It can bring convenience and efficiency or confusion and misunderstanding.
Implicit contexts are everywhere and happen all the time. When dialing a local phone number we may skip the country code and sometimes even the area code. When addressing a domestic letter, we do not have to indicate the country. When mentioning an address to a friend, we save our breath on the country, state, or even city. On the Internet, inside the domain cs.kent.edu, we can refer to the host tiger.cs.kent.edu as simply tiger.
When building a website, it is advisable to code webpages using URLs relative to the current page as much as possible. This makes it easy to reorganize the file/folder structures of a website and to move the entire website to another location on the local file system or to a different server host.
When communicating, the parties must use the “same implicit context” or misunderstandings can happen. For example, “You should be honest” can be stating a principle (editorial “you”) or an accusation. A day of the week is relative to the week. Therefore, people must pay attention to the sent date and time when reading email or text messages (CT: PAY ATTENTION TO DETAILS, Section 4.6.1). But why depend on others being careful? Instead of terms such as “Saturday,” “yesterday,” “tomorrow,” or “next week”, we should always state a specific date and time in our messages.
In sly advertisements, clever manipulation of the implicit context is often used to mislead. No wonder why legal documents are so lengthy, repetitive, and formal.
6.4.1 URL Encoding
According to the URL specification (RFC1738), only the following characters may be included directly within a URL.
- Reserved characters: ! * ‘ (); : @ & = + $, / ? # [ ] used for their reserved purposes (supporting the URL syntax)
- Unreserved characters: 0–9, a–z, A–Z, and $ – _ . ~
Other characters (such as SPACE, NEWLINE, , “, and so on), reserved characters not used for URL syntax, and non-ASCII (Section 2.6.1) UNICODE characters (Chinese characters, for example) may cause problems (unsafe) if used directly in a URL. To include such a character, it should be encoded following percent encoding rules.
- To percent encode an unsafe ASCII character, replace it with a three- character sequence %hh (percent encoding), where hh is the character’s byte code in hexadecimal. For example, ~ is %7E and SPACE is %20. Thus, a relative URL to the file “chapter one.html” becomes
- chapter%20one.html
- and a relative URL to the strangely-named document file Indeed?.pdf becomes
- Indeed%3F.pdf
- It is clear why. The ? character unencoded would make .pdf a query string, not part of the file name.
- To percent encode a non-ASCII character, UTF-8 encode (Section 2.6.2) the character into two or more bytes, then percent encode each byte. For example
| U+738B | Έ | %E7%8E%8B |
| U+58eb | i | %E5%A3%AB |
| U+5f18 | & | %E5%BC%98 |
See Demo: PercentEncode on the CT website for an interactive tool.
CT: WEAR DIFFERENT HATS
Realize and provide a clear indication when the same entity is to perform a different function.
It is not unusual for a person to have multiple roles to play. For example, a policeman can be on or off duty. A door can be an entrance or an exit. A road can be oneway or twoway. Often, the distinction is important to avoid confusion, and we use different hats, labels, signs, or uniforms as indications. In case of the one-way street, the sign may mean life or death.
In computing, characters often must do multiple duties. This is simply because there are not enough characters on the keyboard to satisfy all the varied needs in different situations. For example, in many programming languages, character strings are enclosed in double quotes (“). But that begs the question: “What if a double quote is part of a string?” The problem is caused by “ performing double duty as delimiters of strings and as just a character. And the solution? Place a in front of “ to escape it from being treated as terminating a string. The JavaScript code
str_a = “The double quote (”) character.”;
is an example. Now, the BACKSLASH () doubles as an escape character, itself must then be escaped in a string:
str_b = “The backslash (\) character.”;
The escape character performs the same function as a hat or a label for the next character in a string. The URL percent encoding is basically the same story—the % character escapes a 2-character sequence that represents an arbitrary byte. And, again, the character % must itself be percent encoded (%25) to be part of a URL.
6.5 HTML and HTML5
HTML (the Hypertext Markup Language) is used to structure webpage contents for easy handling by Web clients on the receiving end. From its simple start in 1989, HTML has been constantly evolving and maturing. Beginning with HTML 4.0, the language has become standardized under the auspices of the W3C (World Wide Web Consortium), the industry wide open standards organization for the Web. Subsequently, by making HTML 4.0 compatible with XML (eXtensible Markup Language Section 9.7.1), XHTML became a widely used new standard. Today, the Web is moving toward HTML5, the next-generation HTML standard, which brings many new features and APIs (application programming interfaces). HTML5 makes it easier to provide dynamic user interactions and promises to transform the Web into an even more useful and powerful tool.
A document written in HTML contains ordinary text interspersed with markup tags and uses the .html filename extension. The tags mark portions of the page as heading, section, paragraph, quotation, image, audio, video, link, and so on. Thus, an HTML file consists of two kinds of information: contents and HTML tags. The HTML code provide webpage organization and structure information to make automatic processing of the contents easier. An HTML tag takes the form <tag>. A begin tag such as <h1> (level-one section header) is paired with an end tag, </h1> in this case, to mark content in between. Table 6.1 lists some frequently used tags.
TABLE 6.1 Some HTML Tags

The following is a sample HTML5 page (Demo: Sports):


Figure 6.4 shows the Big on Sports page displayed by Firefox.

FIGURE 6.4 A Sample Webpage
CT: MARK IT UP
Organize information in a document by identifying and delimiting its parts. Marked-up documents are easier to use, exchange, and process mechanically.
The idea is hardly new or surprising. Take this textbook, for example; we organized it into chapters, sections, and subsections. It has a table of contents, and an index, among other things. The organization is achieved through headers, page formats, and other visual conventions.
For textual documents, such as webpages, markup elements or tags are used to indicate the start and end of parts, such as headings, paragraphs, tables, images, quotations, links, and so on. A marked-up document can be easily transmitted and processed by applications on receiving host computers.
6.6 Webpage Styling
While HTML takes care of page structure, the way information is actually presented (visually or otherwise) to the end user is controlled by the Web browser, user-defined styling preferences, and styling rules that come with the webpage.
Styling rules are coded in Cascading style sheets (CSS) and attached to different parts of a webpage. Style rules are usually placed in files separate from the webpage. Isolating page styling from page structure makes it easy for Web designers to reuse styling rules in different pages and to enforce consistent visual styling over an entire website.
For example, if we want to make all level-one headers dark blue, we can use this CSS rule:
hl { color: darkblue }
Thus, HTML makes webpages easy to read by programs, while CSS makes them easy to read by humans.
CSS has also evolved through the years to provide more features and functions for various styling needs. The current standard is CSS3. Experiment with HTML and CSS with the Demo: CodeTester at the CT site.
6.7 Web Hosting
Web hosting is a service for individuals and organizations to place their websites on the Web. Hence, publishing on the Web involves:
- Designing and constructing the pages and writing the programs for a website
- Placing the completed site with a hosting service
Colleges and universities host personal and educational sites for students and faculty without charge. Web hosting companies provide the service for a fee.
Commercial Web hosting can provide secure data centers (buildings), fast and reliable Internet connections, specially tuned Web hosting computers, server programs and utilities, network and system security, regularly scheduled backup, and technical support. Each hosting account provides an amount of disk space, a monthly network traffic allowance, email accounts, Web-based site management and maintenance tools, and other access, such as FTP and SSH/SFTP.
CT: REALLY USE YOUR WEBSITE
Put your website to serious use. Manage it appropriately. Update it diligently. Make it an integral part of your organization.
A website is far more than a static online advertisement. It is a window to the world. Take advantage of all that the Web can do to make your organization more effective and efficient. Integrate the access, modification, and management of your site into your business operations. Always make sure information on the site is up-to-date.
To host a site under a given domain name, a hosting service associates that domain name to an IP number assigned to the hosted site. The domain- to-IP association is made through DNS servers and Web server configurations managed by the hosting service.
CT: BE CAREFUL WITH ONLINE INFORMATION
Be critical; don’t believe everything online. Avoid spreading untruth.
Easy online sharing is a powerful and positive force in the digital age. With all kinds of information available on the Web, Internet, and by email, we must also be keenly aware of an unpleasant fact, that not all such information is accurate or even true. The good news is, by digging a little deeper (a few Web searches, for example), you can usually find out. Too many have unwittingly sent onward to friends rumors, falsehoods, or baseless claims, even causing bad information to go viral sometimes. Let’s not participate in such silliness.
6.8 Dynamic Generation of Webpages
Webpages are usually prepared and set in advance to supply some predetermined content. These fixed pages are static. A Web server can also deliver dynamic pages that are generated on the fly by programming on the server side. Dynamic pages bring many advantages, including:
- Managing user login and controlling interactive sessions
- Customizing a document depending on when, from where, by whom, and with what program it is retrieved
- Collecting user input (with HTML forms), processing such input data, and providing responses to the incoming information
- Retrieving and updating information in databases from the Web
- Directing incoming requests to appropriate pages; redirection to mobile sites is an example
- Enforcing certain policies for outgoing documents
Dynamic webpages are not magic. Instead of retrieving a fixed file, a Web server calls another program to compute the document to be returned and perhaps perform other functions. As you may have guessed, not every program can be used by a Web server in this manner.
A Web server invokes a server-side program by calling it and passing arguments to it and receiving the results thus generated. Such a program must conform to the Common Gateway Interface (CGI) specifications governing how the Web server and the invoked program interact (Figure 6.5).
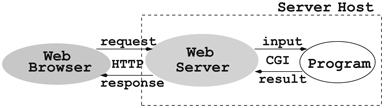
FIGURE 6.5 Common Gateway Interface
A CGI program can be written in any programming language as long as it follows the CGI specification and can be invoked by the Web server. The Web server and a CGI program may run as independent processes and interact through interprocess communication. Or, the external program can be loaded into the server and run as a plug-in module.
6.8.1 Active Server Pages
The dynamic generation of pages is made simpler and more integrated with webpage design and structure by allowing a webpage to contain active parts (Figure 6.6) that are treated by the Web server and transformed into desired content on the fly as the page is retrieved and returned to a client browser.

FIGURE 6.6 An Active Page
The dynamic (active) parts in a page are written in some kind of notation to distinguish them from the fixed parts of a page. The ASP (Active Server Pages), JSP (Java Server Pages), and the popular PHP (Hypertext Preprocessor) are examples. With PHP, the active parts are enclosed inside the bracket <?php ... ?> and embedded directly in an HTML page or other types of Web document. For example, inside an active page, code such as
<p>Today’s date is: <?php echo(date(“l M. d, Y”)); ?><p>
may appear. The date is dynamically computed and inserted in the HTML paragraph. Here is a result line the code would generate:
Today’s date is: Wednesday Sep. 2, 2015
When active pages are treated by modules loaded into the Web server, the processing is faster and more efficient, compared to external CGI programs. PHP usually runs as an Apache module and can provide excellent server-side programming and support.
6.8.2 Database Access
Dynamic webpages are often generated from information stored in databases (Section 9.10). A database is an efficiently organized collection of data for a specific purpose. Database systems use the standard SQL (Structured Query Language; Section 9.10.2) for access and update of information in databases (Figure 6.7).
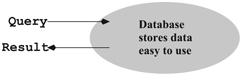
FIGURE 6.7 Database Function
Examples of databases abound: employee database, membership database, customer account database, airline (hotel) reservation database, user feedback database, inventory database, supplier or subcontractor database, and so on.
Relational database systems (RDBMS; Section 9.10.1) support the management and concurrent access of relational databases. A relational database is one that uses tables to store, organize, and retrieve data.
In today’s fast-moving world, online access to databases is increasingly important for businesses and organizations. Using a Web interface to provide such online access has become the norm. In addition to providing access to databases, many websites also employ databases for their own purposes, such as user accounts, product inventory, blogging and forum support, just to name a few.
6.9 Client-Side Scripting
Modern browsers make the Web useful for everyone by providing a convenient user interface that usually supports keyboard, mouse, and touch screen interactions as well as video and audio presentations.
The actions of a Web browser can be defined and controlled by programming within a webpage. Such programming can supply customized user experiences and make webpages more responsive and useful for end users. The programs execute within the browser, which runs on the client host, the computer used to access the Web. For all major browsers, JavaScript is the standardized scripting language for client-side programming. Because the JavaScript language standard has been developed and maintained by the ECMA (European Computer Manufacturer Association), the language is also known as ECMAScript (ecma-international.org).
With JavaScript, a webpage can define reactions to user interface events (Section 4.6.2), verify correctness/completeness of user input, exchange information with the page’s server while displaying a page, change/update and otherwise manipulate the page display, and much more. Because JavaScript runs on the client, it takes advantage of the processing power of the client host and can potentially lessen the load on the Web server.
6.10 Hypertext Transfer Protocol
As we have mentioned, Web browsers and Web servers communicate following HTTP, the Hypertext Transfer Protocol. It does not matter which browser is contacting what server; as long as both sides use the same protocol, everything will work.
In the early 1990s, HTTP gave the Web its start. HTTP/1.0 was standardized in the first part of 1996. Important improvements and new features have been introduced in HTTP/1.1, and it is now the stable version.
HTTP is an application layer (Figure 5.9) protocol that sits on top of TCP/IP, which provides reliable two-way connection between the Web client and Web server. We don’t need all the details to understand the basics of HTTP.
- A Web client, usually a browser but can be any user agent (UA), sends an HTTP query to a server.
- A Web server, upon receiving a query, sends back an HTTP response.
A query and a response form an HTTP transaction. Each transaction stands alone and has no protocol-provided means to be correlated with any other transaction. Figure 6.8 illustrates an HTTP transaction.

FIGURE 6.8 An HTTP Transaction
A simple HTTP transaction goes as follows:
- Connection—A browser (client) opens a connection to a server.
- Query—The client requests a resource controlled by the server.
- Processing—The server receives and processes the request.
- Response—The server sends the requested resource, or an error, back to the client.
- Termination—The transaction is finished, and the connection is closed unless it is kept open for another request immediately from the client on the other end of the connection.
HTTP governs the format of the query and response messages (Figure 6.9). Basically, each query or request consists of an initial line, one or more header lines and an optional body. The initial line and header lines are textual (ISO-8859-1). Each line should end in RETURN and NEWLINE, but it may end in just NEWLINE.

FIGURE 6.9 HTTP Query and Response Formats
The initial line identifies the message as a query or a response.
- A query line has three parts separated by spaces: a query method name, a local path of the requested resource, and an HTTP version number. For example,
GET /path/to/file/index.html HTTP/1.1
HOST: domain_name
or
POST /path/script.php HTTP/1.1
HOST: domain_name
The GET method requests the specified resource and does not allow a message body. A GET method can invoke a server-side program by specifying the CGI or active-page path, a question mark, and then a query string:
GET /CT_join.php?name=value1&email=value2 HTTP/1.1
HOST: computize.org
Unlike GET, the POST method allows a message body and is designed to work with HTML forms for collecting input from Web users. The POST message body transmits name-value pairs just like a query string. - A response (or status) line also has three parts separated by spaces: an HTTP version number, a status code, and a textual description of the status. Typical status lines are
HTTP/1.1 200 OK
for a successful query or
HTTP/1.1 404 Not Found
when the requested resource cannot be found. - When the HTTP response contains a message body, the Content-Type and Content-Length headers are set so the client will know how to process it.
The Web borrowed the content type designations from the Internet email system and uses the same MIME (Multipurpose Internet Mail Extensions) defined content types. Hundreds of standard MIME content types are listed at the IANA site (iana.org/assignments/media-types/media-types.xhtml).
The content type information allows browsers to decide how to process the incoming content. HTML, text, images, audio, and video may be handled by the browser directly. Other types, such as PDF and Flash, are usually handled by plug-ins or external helper programs.
When using a browser to access the Web, the HTTP messages between it and the Web servers are kept behind the scenes. But it is possible to expose these messages and gain real experience with HTTP. See Demo: Http at the CT website.
While HTTP transmits information in the open, HTTPS (HTTP Secure) is a secure protocol that simply applies HTTP over a secure transport layer protocol Transport Layer Security (TLS 1.2) that is derived from the earlier Secure Sockets Layer (SSL). See Section 7.2 for more information on how this security feature works.
6.10.1 HTTP Caching
An important improvement of HTTP 1.1 over HTTP 1.0 is the introduction of caching for HTTP responses. On the Web, a great deal of contents are not changing often with time. These include static webpages, images, graphics, styling code, scripts, and so on. Saving a copy of such data can avoid a lot of unnecessary work of requesting and retrieving the same data over and over again from origin servers. Browsers (user agents) and caching proxy servers are able to serve data from their cache when they know or can verify that the data are still current and unchanged on the servers where they originated.
A caching proxy server accelerates requests by providing contents from its cache. Caching proxies keep local copies of popular resources so large organizations can greatly reduces their Internet usage and costs, while significantly enhance performance. Most ISPs and large businesses employ caching proxies.
The HTTP caching scheme significantly cuts down round-trip Web traffic to origin servers and reduce response time to users. This explains why it is slower the first time you visit a website. Then it is lightning fast when you visit again.
CT: CACHE FOR SPEED
Use cache to increase efficiency and speed. In many situations, significant improvement may result from storing the right items in a cache.
Take phone numbers for example. You remember certain frequently used numbers in your head (the cache) but have to consult your phone list, or even the white pages for other numbers. You have your favorite pots and pans handy in the kitchen and many others stored in the basement. You have important items in your wallet/purse, and many other things you don’t carry with you. And we already know that computer memory is organized into on-chip cache, RAM, and hard disk, a multilevel caching scheme.
Toward the end of 2013, when a team of super coders were helping to rescue and fix the healthcare.gov site, one immediate technique they used was introducing a database cache so that frequent queries could be separated from other queries into the huge database. The database cache reduced congestion, and they were able to lower the average page access time from 8 seconds to about 2 seconds. Later, with continued improvements, the access time was reduced to below 0.35 seconds. The rescue work may well have saved the Affordable Care Act from disaster.
6.11 Website Development
The simplicity of HTML makes it seem deceptively easy to create websites. Well, that may be true for very simple webpages with basic information. But, an inviting, attractive, and effective website requires much more effort and expertise.
A website is often a combination of online advertisement, product and service information, sales, shipping, and customer service, as well as other business functions, such as recruiting and investor relations.
CT: DEVELOP FOR USERS
Walk in the shoes of users of your product. Let user-centered thinking guide product design and development.
Make sure your users will not say: “These people seem to have never used their own product!”
For Web development, in addition to carefully preparing the text, image, and multimedia contents, a well-designed website must:
- Identify the target audiences and anticipate their needs
- Have a logical and attractive user interface design
- Make finding information and doing business on the site fast and easy
- Ensure a pleasant and rewarding browsing experience
- Provide for easy update, revision, and management
To achieve these goals, it takes expertise in usability, visual communication design, site architecture and navigation, and copy editing, as well as programming techniques. And it takes time and effort to test, debug, and deploy. In other words, great websites need professional help and cooperation on the part of the site owner. Sometimes, even development professionals can mess up. The infamous healthcare.gov website launch debacle in October 2013 is an example.
6.12 Web Search Engines
The Web is so easy to access and contains so much information that the answer to almost any question is just a Web search away.
Many search engines are available, but Google remains predominant (Figure 6.10; source: netmarketshare.com).
A search engine makes finding information on the Web easy by working hard to gather data about what’s where online and organize the collected data into indexes for efficient search. Because data online change constantly, the job of a search engine is never done. It must roam the Web continuously to update its indexes. The equipment, algorithms, and the exact ways a search engine works are closely guarded secrets.
Generally, search engines use automated robots and/or manual submissions to collect indexing information. A robot or crawler is software that visits webpages and follows links in them to recursively visit connected pages. Meta information about visited pages, together with manually submitted data, are organized and deposited in databases. When a user enters a search request, the search is conducted in the databases, not on the open Web.
CT: GOOGLE IT
The answer is “Google.”
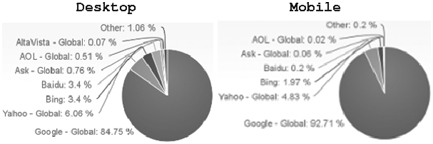
FIGURE 6.10 Search Engine Market Shares (05/2015)
Doing research, curious about something, or just playing trivia? Don’t bother, just Google it first.
When doing a search, try to be precise about what you are looking for. Start with the information type such as “sports,” “science,” “finance,” “health,” “entertainment,” “politics,” and so on. If you are looking for something local, be sure to add the location such as “Ohio” or “Kent, Ohio.” Follow that with specific keywords for the search. Often, you’ll get what you want in the first try. If not, you can refine your search accordingly. Getting desired information immediately online and determining the reliability of such information is a skill everyone needs to develop.
CT: BELIEVE IT OR NOT
The Internet and Web are open. Therefore, not all information is correct or accurate.
So, don’t believe everything you see or read on the net. Use common sense. Double check. You’ll soon get the correct information.
6.13 Web Services
Most people think of the Web as a vast collection of webpages ready to be visited. That is certainly true. But the Web is more than that. It is also widely used to make computing powers available to remote clients via HTTP. Such computational services are known as Web services.
A Web service is a resource or program on the Web that can be invoked with an HTTP request. A Web service usually computes a result based on the request input and sends back a result in a well-defined format. The most widely used Web service result formats are XML and JSON (JavaScript Object Notation). A Web service is like a remote procedure, it runs on a remote computer and provides specific results useful for clients. But, unlike remote procedures, Web services will always use HTTP for request and response (Figure 6.11).

FIGURE 6.11 Web Service Overview
In the early days of Web services, the SOAP (Simple Object Access Protocol) was widely used. Contemporary Web service and client developers prefer REST 2 (REpresentational State Transfer), which is an academic term for URLs, query strings, and request/response bodies used in HTTP. In other words, REST-based Web services receive HTTP POST/GET requests and send back results, often in XML or JSON, in an HTTP response body.
Application programs running on a computer connected to the Internet can easily make requests to Web services and obtain results to be used in the application. For example, a news reader application can obtain news feeds (the simplest kind of Web service) via HTTP requests and then use the results (RSS 3 documents in XML) for displaying and retrieving news articles. On a Web host, we can use a server-side script, in PHP for example, to dynamically obtain information from Web services. Such server-side scripts can also be invoked by webpages, originating from the same server, via AJAX from the client side 4 . This way, a webpage can access indirectly any Web services available.
Example Web Services
There are many Web services throughout the world. Here are some examples:
- Amazon Web services—for Amazon vendors and for providing cloud computing.
- Google Maps API Web services—for requesting Maps API data to be used in your own Maps applications; available to registered users.
- PayPal Web services—for automating various aspects of PayPal payment processing; available for PayPal account holders.
- National Oceanic and Atmospheric Administration’s National Weather Service Web service—for hourly updated weather forecasts, watches, warnings, and advisories; available to the public.
- FAA airport status Web service—for US airport status, delays, and airport weather; available to the public. See Demo: FAA on the CT site.
- United Parcel Service (UPS) Web services—for address verification, shipping rates, tracking, and other services; available for registered customers. See Demo: Address on the CT site.
Online listings and directories for Web services are available. The Web Services Directory at programmableweb.com is an example.
6.14 Standard Web Technologies
In summary, a number of technologies enable the Web to work as it does. These include networking protocols, data encoding formats, clients (browsers), servers, webpage markup and styling languages, and client-side and server-side programming.
The Web can deliver text, images, animation, audio, video, and other multimedia content. Standard and proprietary media formats, tools, and players are also part of the Web. The World Wide Web Consortium (W3C) is a nonprofit organization leading the way in developing open Web standards.
Core Web technologies recommended by the W3C include:
- HTTP/HTTPS—The Hypertext Transfer Protocol employed by the Web. The current version is HTTP 1.1.
- HTML5—The new standard markup language, and its associated technologies, for coding regular and mobile webpages.
- CSS3—The current Cascading Style Sheet standard, offering improved styling, transformation, animation, and styling subject to media conditions (media queries).
- JavaScript—A standard scripting language for browser control and user interaction.
- DOM—Document Object Model, an application programming interface (API) for accessing and manipulating in-memory webpage style and content.
- PHP—A widely used server-side active page programming language and tool that is open and free.
- MySQL—A relational database system that is freely available and used widely for online business and commerce.
- DHTML—Dynamic HTML, a technique for producing responsive and interactive webpages through client-side programming.
- SVG, MathML, and XML—Scalable Vector Graphics (for 2D graphics; Section 9.2.3) and Mathematics Markup Language are part of HTML5. They are important applications of XML, the Extensible Markup Language (Section 9.7.1).
- AJAX—Asynchronous JavaScript and XML providing client-side JavaScript-controlled access to the Web and Web services.
- Web Services—Combining HTTP and XML or JSON to serve data on the Web to other programs.
- HTML5-related APIs—JavaScript-based APIs introduced by HTML5 and other projects for a good number of useful purposes.
- LAMP—Industry standard Web hosts supported by Linux (OS), Apache (Web server), MySQL (database), and PHP (active page).
The items listed here represent open/industry standards and best practices that are not private or proprietary.
With the modern Web, you can get up-to-the-moment news, find answers to any questions, satisfy any curiosity, and air your views on forums, blogs, and social media. So, fire up your browser, get online, and enjoy the Web. Life is sweet!
Exercises
- 6.1 Explain the Web as an Internet service in terms of client, server, and protocols.
- 6.2 Give your own reasons why you think the Web is so successful.
- 6.3 What is universal about URLs?
- 6.4 How is the scheme of a URL related to the port number? Please explain.
- 6.5 Find the percent encoding for JLi, the Chinese name of Confucius.
- 6.6 Follow the address markup in Section 6.5 and invent a markup of your own.
- 6.7 What is client-side scripting? What standard language is used on modern browsers?
- 6.8 What is a database? How is the Web related to databases? Please explain.
- 6.9 HTTP is said to be stateless. Please explain.
- 6.10 Explain how Web search engines work and why we say, “The answer is Google.”
- 6.11 Computize: Give examples of your own of an entity doing double or multiple duties and the indications used to distinguish among its roles. (Hint: HTML)
- 6.12 Computize: You and your boss are working hard on a project, burning the midnight oil. Your boss said to you, “Let’s call it a day, but we need to finish this by the end of tomorrow.”
- 6.13 Computize: Critically discuss the notions “scroll up”, “scroll down” on Web browsers.
- 6.14 Computize: Name the ways you can personally contribute to the Web and make the world a little better.
- 6.15 Group discussion topic: Use of terms such as he, she, it, tomorrow, yesterday, and 9 o’clock in communication.
- 6.16 Group discussion topic: How things were done before the Web.
- 6.17 Group discussion topic: I want my own website.
- 6.18 Group discussion topic: The impact of the Web on newspapers and magazines.
- 6.19 Group discussion topic: The impact of the Web on teaching and learning.
- 6.20 Group discussion topic: The impact of the Web on science and technology.
- 6.21 Group discussion topic: The impact of the Web on government.
- 6.22 Group discussion topic: The impact of the Web on businesses.
- 6.23 Group discussion topic: The impact of the Web on individuals.
Footnote
1 2014 statistics by w3cschool.
2 See CT: CAPTURE THE STATE, Section 4.9.
3 Rich Site Summary
4 For security reasons, browsers only allow JavaScript to network back to its originating host.