
You often need to know more than just the right data types to write T-SQL that performs quickly and uses hardware efficiently. Data types will help you determine how your data should be stored, but the next step will be to design the process to access that data. One of the largest benefits and drawbacks to using T-SQL is the number of options available to access data. The expectation is that you are already familiar with how to write T-SQL to read, insert, update, or delete data.
In this chapter, I will discuss various methods that can be used to interact with your data. There are objects that will allow you to consistently and quickly pull information together. You may also want a database object that performs small, quick actions and can reuse that code for multiple purposes. Some database objects can store information temporarily for reusability either within the same batch or connection. Other database objects can perform actions as result of activities on the server or database objects. While T-SQL performs best with set-based activities, you may also find yourself needing to loop through data one record at a time.
Depending on your purpose, there can be one or more database objects that meet your needs. While each of these database objects has their place, there are pros and cons for when and how to use each of these objects. Throughout this chapter, I will walk through various scenarios showing both the positive and negative consequences of using each of these database objects. First, I will start with discussing views in T-SQL.
Views
What is a view? Like the definition of the word view, a view in T-SQL is a means of taking several different items and putting them together to form one cohesive image. In this section, I will be discussing some of the options available when using views. As with any tool, there are advantages to using views, and there are risks associated with views if they are used incorrectly.
User-Defined Views
The term user-defined view is the full name for the basic version of a view. One of the results of a view is simplicity. It is one way for applications and users to access complex sets of information without needing to understand all the relationships in a database. There is some additional functionality for protection and security that is available when using views. I will go through examples of views that help performance as well as some situations where views may not be the right option.
For standard user-defined views, SQL Server does not store the actual data returned by a view physically. Therefore, each time a view is called, it will use the statement inside the view to pull back the data that currently exists. One of the advantages for this method is it allows users accessing these views to look at code that is cleaner and easier to read. Another feature of views is that users can be granted permission to the view but not the associated tables. This can allow users to have access to some but not all the data from the tables that make up the view.
Query for Analysis
Creating a View
Calling the View
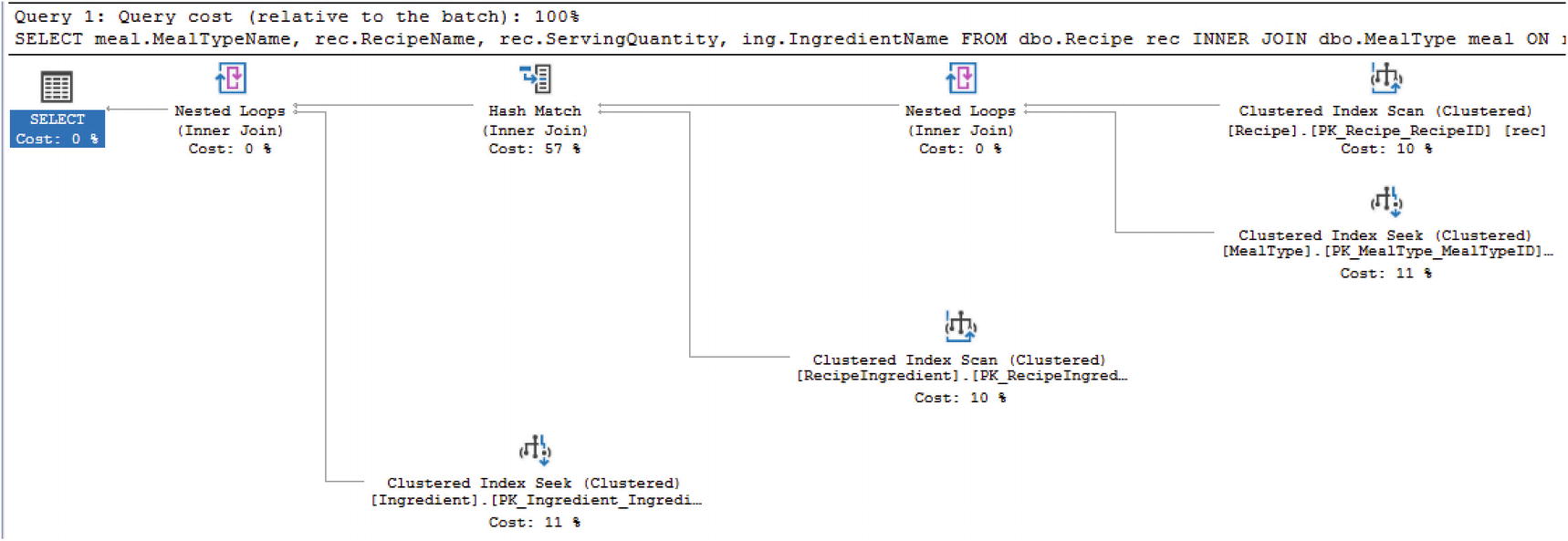
Ad Hoc Query Execution Plan
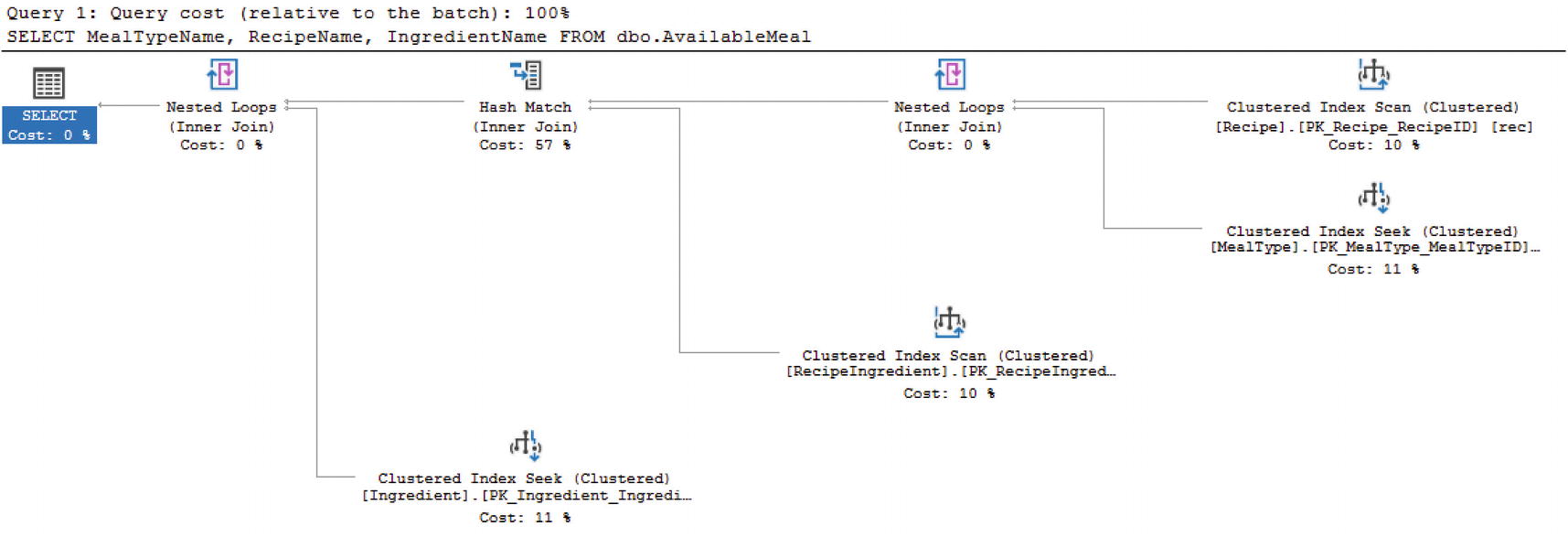
Execution Plan for View
Update Data in View
Insert Data Through a View
Create a View with Schema Binding
Remove Column in Schemabound View
Alter View to Change Column
Previously, I had a user that only had permission to access the data within the view dbo.AvailableMeal. My intention was to allow this user to only have access to the original columns in the view. This same user attempts to query the view at a later date, this same user is now able to see the data in the RecipeDescription column.
Throughout all these features, one of the largest issues remains around nested views. In typical software development, there is a desire to reuse the same software code in multiple scenarios. When creating views, it can become tempting to reuse those views to create other views. Unfortunately, this can create a situation where one view can start performing poorly. Once the view is performing poorly, it can take considerable effort to weave through the various layers of nested views to find the root cause.
Indexed View
I have covered how views can be used to simplify writing queries, to modify data, and to protect database schemas. I have also covered how reusing views to create other views can cause significant performance issues. As you saw in the previous section, views can help make T-SQL simpler, but the execution plan is the same for both the ad hoc query and the view. In some instances, there are joins that do not perform well either as a query or a view. There is the possibility of adding indexes to a view.
If you find yourself in a situation where you need to improve the performance of view, you have the option of adding indexes to a view. When adding indexes to a view, the view is then considered an indexed view. The first index added to a view must be a clustered index. After a clustered index has been added, non-clustered indexes can also be added to the view. However, there is a cost associated with adding indexes to a view. Each time data is modified, the indexes on any related table and the indexed view must also be updated.
Add Clustered Index to a View
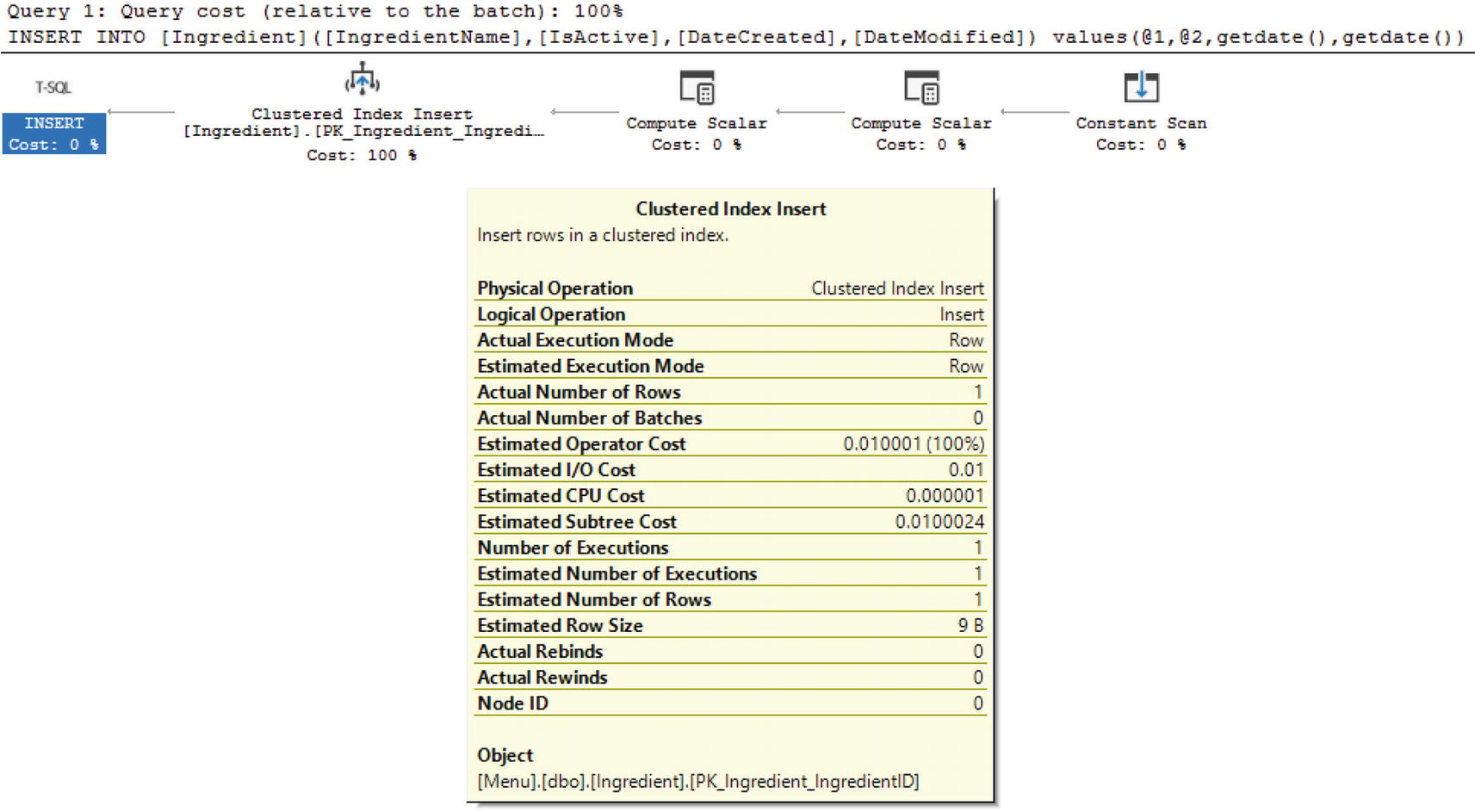
Execution Plan for Insert into Base Table
As you can see, there is an extra step where the index on the view is updated as part of the insert into the base table.
Functions
In many applications, there are core parts of the functionality that may be recalculated or reused several times. Sometimes you may want to write some simple piece of code once and reuse that code throughout various other database objects. There are other situations where you may want to take complex logic and create a database object that encompasses that logic and returns the required results. This could be done to make T-SQL code appear less complex and therefore less overwhelming. Either way, functions can help you simplify your T-SQL code.
Scalar Functions
You may find yourself in a situation where you need to rerun the same portion of code in many different scenarios. You may be looking up a configuration value, or you may want to rerun the same basic logic in many different parts of your code where only one value is returned. When there are times where you want to pass zero or more parameters and you only want to return a single value, you may be able to use a scalar function. However, you will want to consider what the potential cost on may be when using a scalar function.
Prior to SQL Server 2019, scalar functions worked very differently in SQL Server. Historically, SQL Server did not include cost-based optimization on scalar functions. This often meant that scalar functions were not included as part of the execution plan. Now that SQL Server 2019 has implemented additional features as part of the intelligent query processing, including scalar user-defined function (UDF) inlining, the performance of functions has improved.
An inline function is one that can be included as part of the execution plan. One of the largest advantages of inlining scalar UDFs is the significantly improved performance when it comes to using scalar UDFs. When wanting to simplify complex processes and reuse code, scalar UDFs are the ideal option when the function only needs to return one result.
Creating a Scalar UDF
Code to Execute Function
Change Database Compatibility Mode to Previous Version
Clear Execution Plan for Query from Listing 2-11
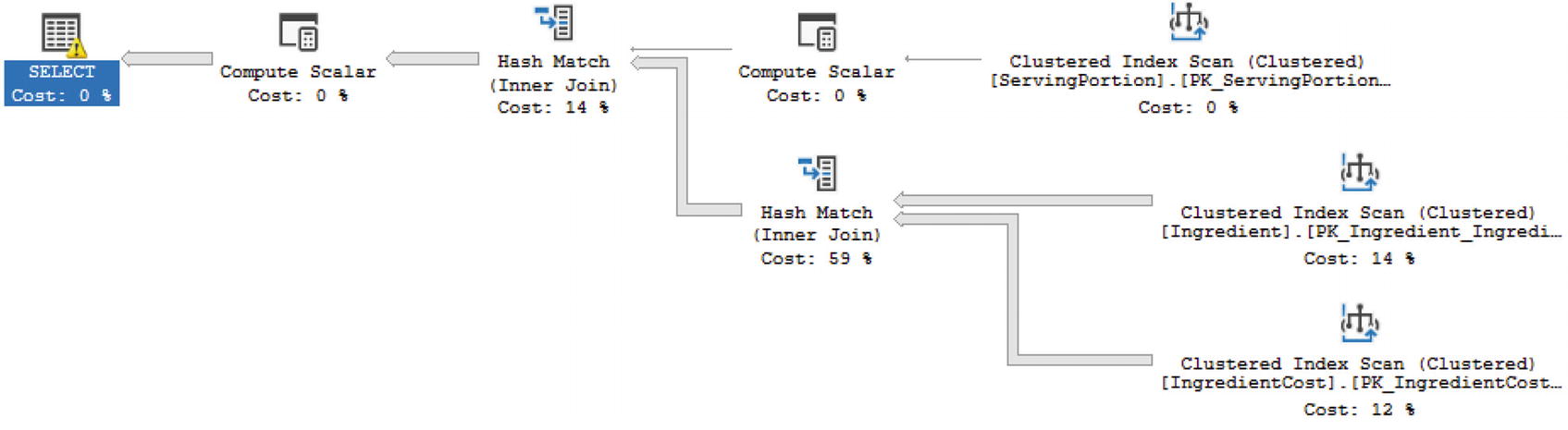
Execution Plan for Compatibility Mode 140
Execution Plan for Compatibility Mode 150
Elapsed and CPU Times for Query Execution
Compatibility Mode | CPU Time | Elapsed Time |
|---|---|---|
140 | 3438 milliseconds | 4768 milliseconds |
150 | 655 milliseconds | 1913 milliseconds |
As you can see, the function performs significantly better in compatibility mode 150 vs. 140.
Create Multi-Statement Scalar UDF
The multi-statement scalar UDF created in Listing 2-14 will benefit from the same scalar inlining as the scalar UDF created in Listing 2-10. Regardless of the scalar UDF you decide to use, SQL Server 2019 has been improved so that you can see improved performance with these functions.
Table-Valued Functions
There will be situations where you find yourself needing to perform complex logic, but you need to return more than one value. When these situations come up, you may want to consider using a table-valued function. Prior to SQL Server 2019, the only function that could run inline was a variation of table-valued functions.
Table-valued functions are useful for those times where you need a table as a result. This could be anything from one row with multiple columns to one column with the potential for multiple rows or many rows and many columns. No matter your purpose, if you want a reusable piece of code that can give you a table output, then table-valued functions may be what you want. Keep in mind that there are two main types of table-valued functions, and while the output can look the same, the performance of each of these types can be incredibly different.
Inline Table-Valued Functions
If you’re using a function to perform some complex logic, but you can survive only using a select statement, then you may want to learn more about how inline table-valued user-defined functions can work for you. It is important to note that you do not specifically indicate that a function is inline or multi-statement. It is how you create and declare the function that will determine which type of function you have created.
Like the inline scalar user-defined functions (UDFs) available in SQL Server 2019, table-valued functions can also be inlined. Also be aware that table-valued functions have been able to be inlined for quite some time, while inlining scalar UDFs is quite new. Either way, the advantage is clear. When a table-valued function can be run inline with the rest of the query, the optimizer can provide a better execution plan for the function and the T-SQL code overall.
Create Inline Table-Valued Function
Query to Call Inline Table-Valued Function
Inline Table-Valued Function Execution Plan
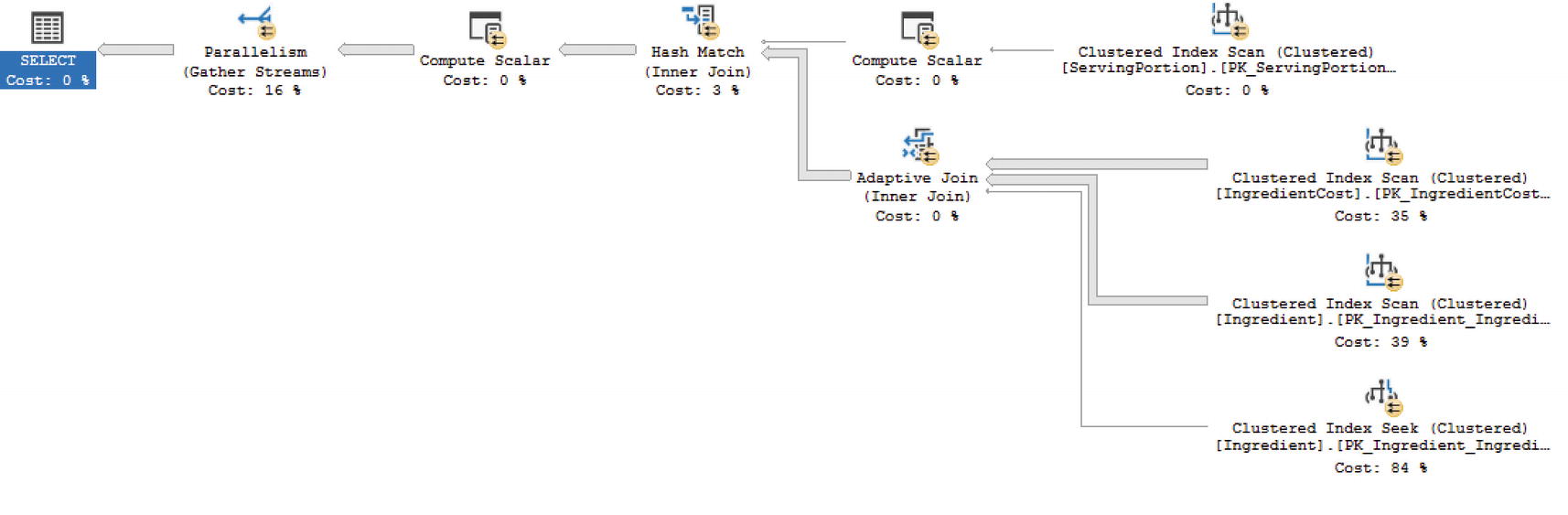
As you can see, the function appears directly in the execution plan. The optimizer is aware of this inline table-valued function. While inline table-valued UDFs can be used like tables and can accept parameters, there are still limitations associated with using inline table-valued UDFs. These types of functions can only allow for one select statement and one result set. In addition, the data that is returned in these functions cannot be modified in the database. However, data returned from an inline table-valued UDF that is displayed in a select statement can be modified. This is a change to the data that is cosmetic and does not affect the data that is stored in the database.
Multi-statement Table-Valued Functions
When there are times that you must have both code reuse and the ability to update SQL Server, then it may be time to consider using multi-statement table-valued functions. I would caution you to carefully consider whether this approach is necessary as these types of functions can end up having a tremendous performance impact.
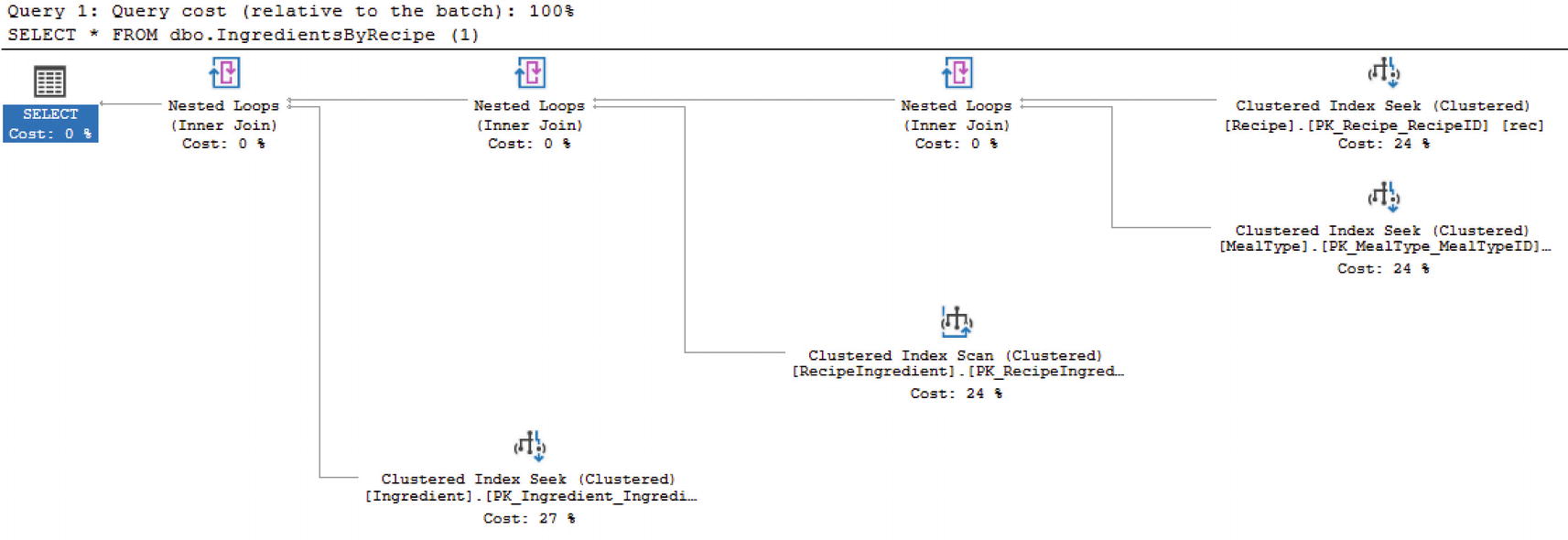
Multi-statement table-valued functions are not just inline table-valued functions that can do more. They also cannot be inlined with the query execution. This signifies that the query optimizer does not attempt a best guess when using these types of functions. As a matter of fact, prior to SQL Server 2014, multi-statement table-valued functions were estimated to have one row. For SQL Server 2014 and SQL Server 2016, the estimated number of rows was 100. However, as of SQL Server 2017, there is a possibility that SQL Server will get a proper estimate for the rows returned by using interleaved execution.
What will happen is that the optimization process will pause to allow execution so that the cardinality estimator can determine the actual number of rows that should be returned by the multi-statement table-valued function. While interleaved execution is part of the new adaptive query processing, there are some limitations to keep in mind. If there is a CROSS APPLY used in conjunction with a multi-statement table-valued function, then the interleaved functionality will not work. It has also been reported that if there is a WHERE clause inside the multi-statement table-valued function that depends on an input parameter, then interleaved execution may also not apply.
Multi-statement Table-Valued Function
Code to Execute Function

Execution Plan for Compatibility Mode 110
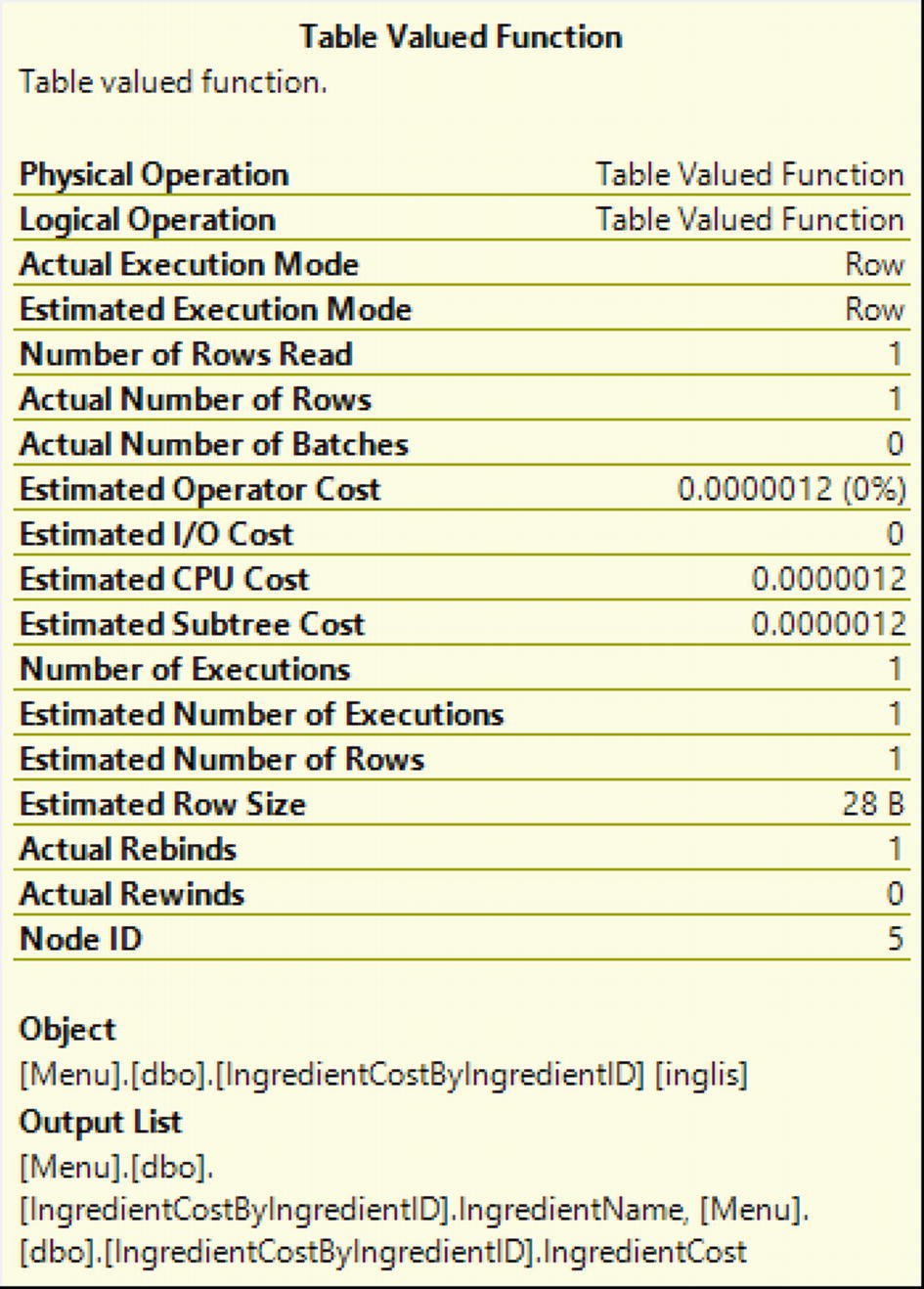
Properties for Table-Valued Function in Compatibility Mode 110

Execution Plan for Compatibility Mode 140
Comparing Execution Time for Multi-statement Table-Valued Function with Compatibility Modes 110 and 140
Compatibility Mode | CPU Time | Elapsed Time |
|---|---|---|
110 | 1172 milliseconds | 1529 milliseconds |
140 | 1140 milliseconds | 1523 milliseconds |

Properties for Table-Valued Function in Compatibility Mode 140
You can see that the estimated number rows in Figure 2-10 is 100. This is different from the estimated number of rows shown in Figure 2-8. You can also see that the estimated operator cost and estimated subtree cost have all changed slightly.

Execution Plan for Compatibility Mode 150
Comparing Execution Time for Multi-statement Table-Valued Function with Compatibility Modes 110, 140, and 150
Compatibility Mode | CPU Time | Elapsed Time |
|---|---|---|
110 | 1172 milliseconds | 1529 milliseconds |
140 | 1140 milliseconds | 1523 milliseconds |
150 | 391 milliseconds | 644 milliseconds |
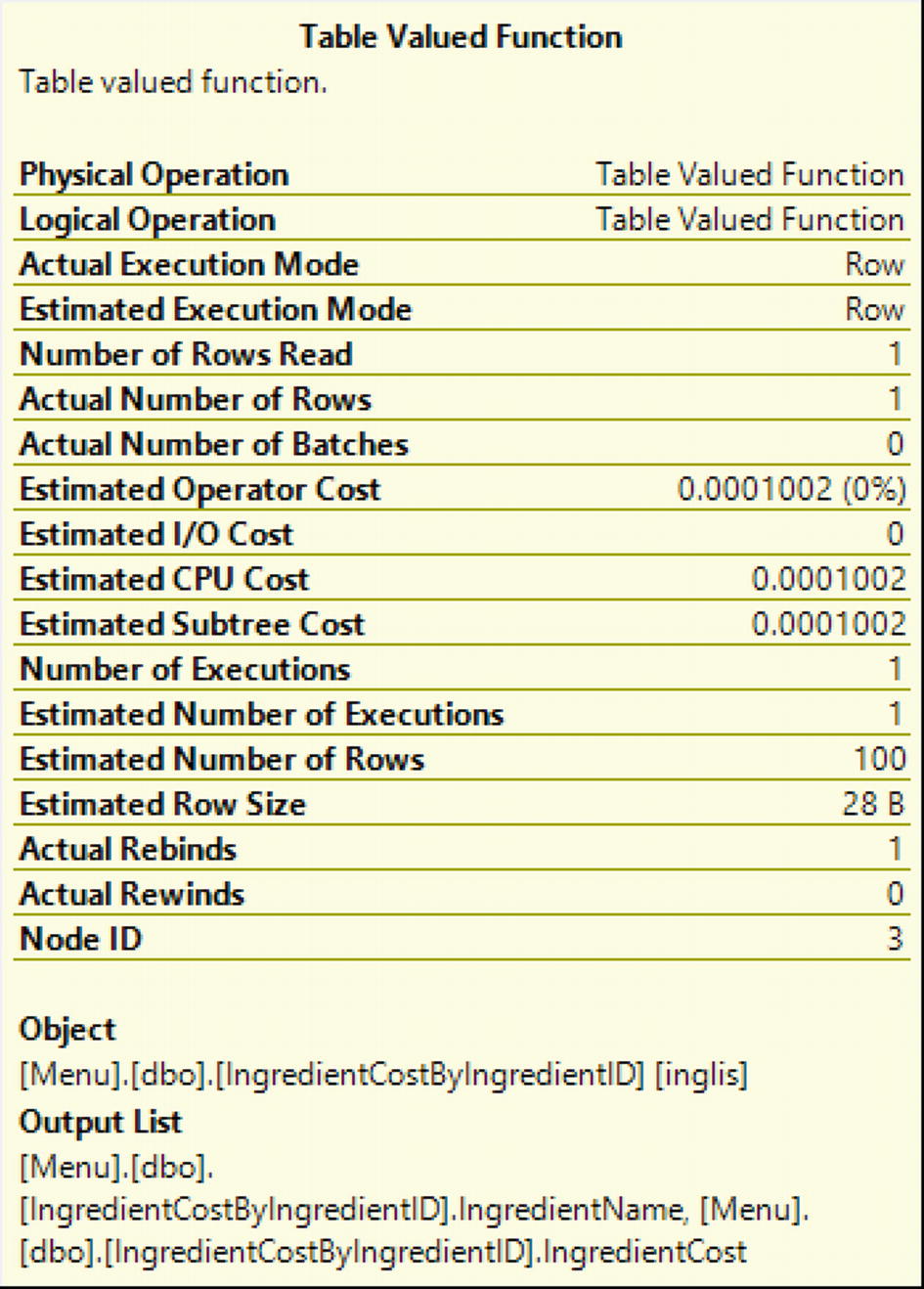
Properties for Table-Valued Function in Compatibility Mode 150
Looking at the values in Figure 2-12, there are several values that match those of Figure 2-10. This includes the more accurate estimated number of rows in both Figure 2-10 and Figure 2-12. The estimated operator cost, estimated CPU cost, and estimated subtree cost are also the same in both Figure 2-10 and Figure 2-12.
The performance of the multi-statement table-valued function improves in the newer versions of SQL Server. In addition, you can see that both SQL Server 2017 and SQL Server 2019 have the most accurate estimated and actual rows returned in the execution plan. While there still are performance concerns to keep in mind with multi-statement table-valued functions, there are scenarios where the performance is improved enough that it may be beneficial to use these functions starting with SQL Server 2017.
Other User-Defined Objects
There are many ways of working with complex data and breaking data up into sections that can be easily managed and analyzed. In some cases, data can be saved to temporary tables or table variables. However, there are other options available depending on your needs. One type of feature in SQL Server is using table-valued parameters. This allows for similar performance as temporary table, but it also works similarly to table variables. There is also a method where a temporary result set is created for use in the next statement in a batch.
User-Defined Table Types
Code to Create User-Defined Table Type
Once a user-defined table type has been created, it can be used as a parameter for a stored procedure or be used for variable declaration. The reusability and consistency that is created with user-defined table types comes with a cost. As the stored procedures now use a single parameter to represent all of the columns and rows stored in this object, it becomes difficult to determine what parameters in a stored procedure represent a single value and what parameters represent a user-defined table type. This object can make code easier to read; it can also make it harder to troubleshoot performance issues in the future.
Table-Valued Parameters
A high percentage of stored procedures can be used to insert, update, or delete data from tables. In some cases, the application may need to send one parameter per column of a table to various stored procedures. While using one parameter per field is straightforward and easy to debug, some can contend that it would be cleaner and simpler to send multiple fields in one parameter. I can understand wanting to simplify the code, but I also believe that too much simplification can make it difficult to troubleshoot code in the future.
However, you may want to use an array type format in a stored procedure or other code. In this case, it would be beneficial to use this data to perform a set-based operation. When doing so, you will need to remember that the user-defined table type that is passed in as a parameter cannot be modified. When this parameter is passed in, the data passed can be treated like a temporary table and used to join to the base table and make any necessary modifications.
As SQL Server is designed to perform best for set-based operations, you may get to the point where you want to take advantage of SQL Server’s inherent ability to work best with sets. You may want to consider using table-valued parameters if you are wanting to pass in a table to a stored procedure and use that table relationally with other tables within the same stored procedure.
Using a Table-Valued Parameter
Code to Execute Stored Procedure with Table-Valued Parameter
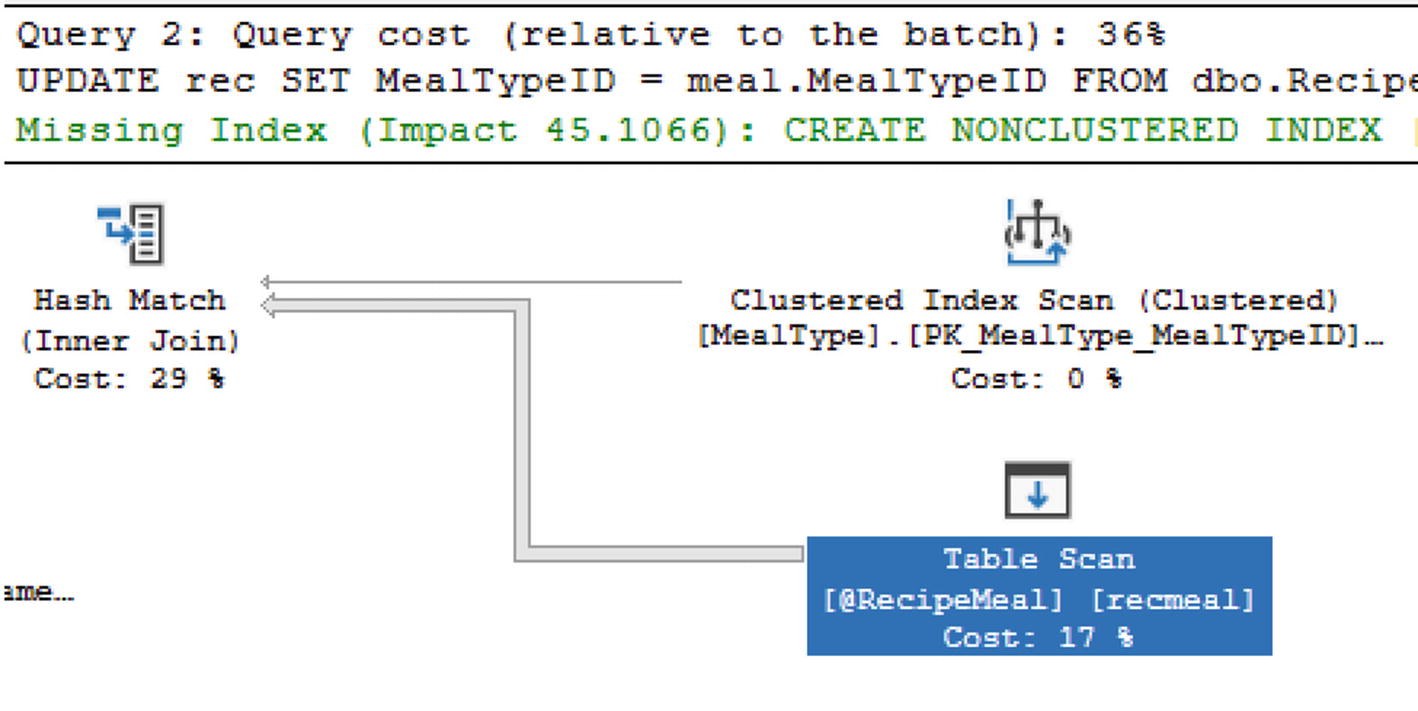
Execution Plan for Stored Procedure with Table-Valued Parameter
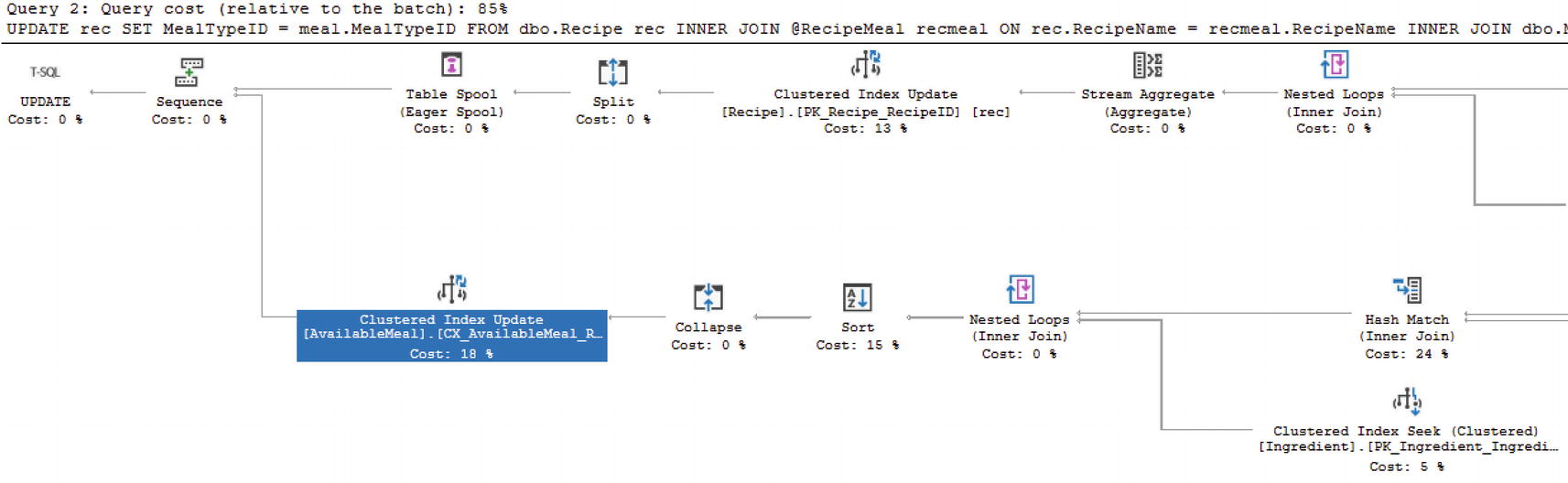
Execution Plan for Table-Valued Parameter with an Indexed View
While table-valued parameters can streamline your code, keep in mind that there can be a hidden performance impact. One of the best practices when developing new code is to check the execution plan and confirm that SQL Server is processing the code in a method that aligns with the shape of the data.
Common Table Expressions
While this is not a user-defined database object, I have included common table expressions in this section as they are often used for similar purposes as temporary tables, table variables, and table-valued parameters. Their purpose is to help break up complex logic or get a subset of data to be used later in the T-SQL code, batch, or stored procedure.
Create a Basic Common Table Expression
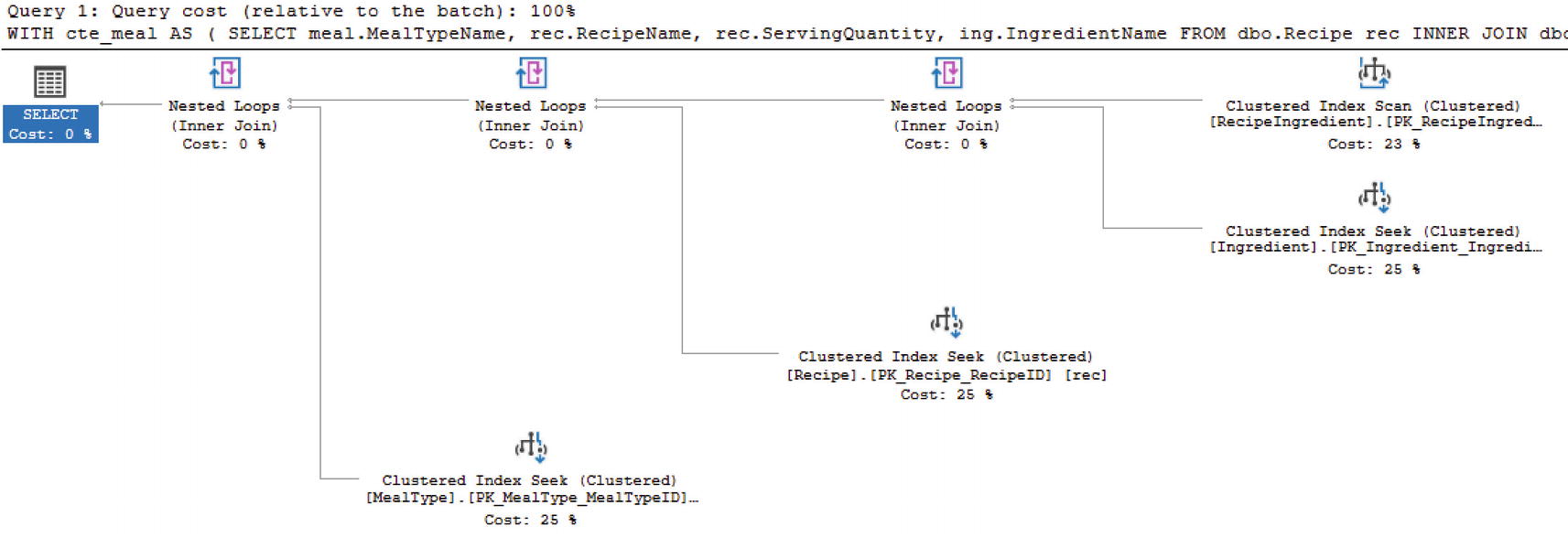
Execution Plan for Basic Common Table Expression
Using Joins with Common Table Expressions
Recursive CTE to Find All Required Recipes
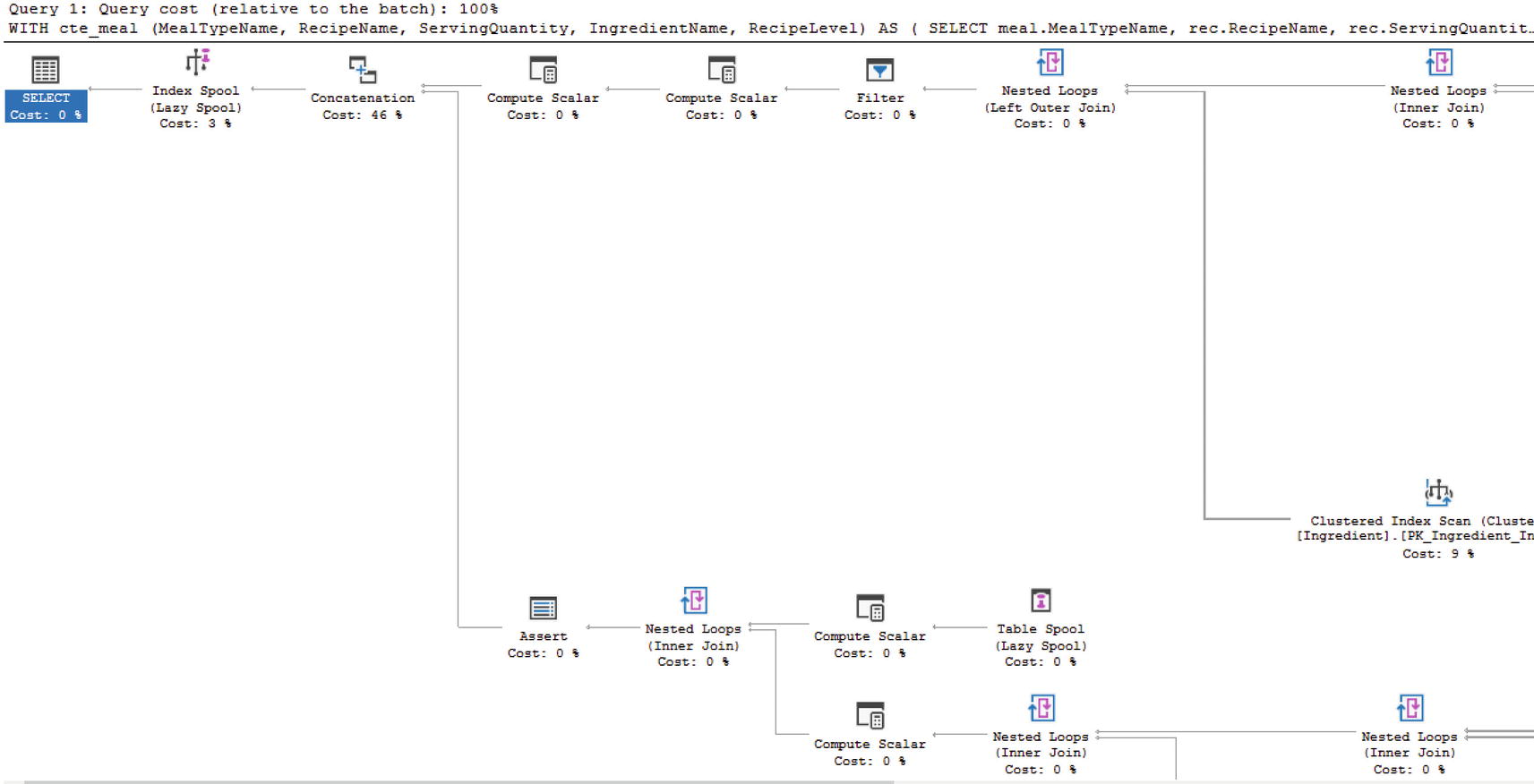
Partial Execution Plan for Recursive CTE
I have found very few times where I have needed to absolutely use a recursive CTE. However, when I have had to use a common table expression, I have found them very helpful.
Temporary Objects
You may find yourself in a situation where you need to create an object but only for a short period of time. Sometimes these objects are created so that you can work with a subset of data when dealing with complex logic. Other times it is easier to break some of the code out to create a temporary object to improve readability or make it easier for others to understand what you are doing. Regardless of the scenario, there is the possibility to create temporary objects in SQL Server.
Temporary Tables
Temporary tables are exactly what they sound like. They take the same shape as tables where they have columns and data types and stored data. The main difference is that temporary tables do not hang around indefinitely. Depending on what you want to do with your temporary tables and how long you need them to last will determine which type of temporary table you would end up creating.
There are other advantages to using temporary tables. These include the ability to use primary keys and indexes for improved performance. Statistics can also be created on temporary tables further improving their performance. One thing to consider is that statistics may not be automatically updated on the temporary table if additional modifications are performed after the temporary table is first created.
Local Temporary Tables
If you find yourself needing to put data aside for additional analysis or processing, then you may have considered using a local temporary table. This type of temporary table can also be useful inside of stored procedures. Local temporary tables are only available within the same session or connection as they were created. Once the session is closed or the connection is terminated, you are unable to access the local temporary table.
While local temporary tables can be used for many different scenarios, it is often recommended to not use temporary tables as the first option when needing to store data temporarily. There is nothing inherently wrong with local temporary tables, but you may find other objects can store data temporarily with less potential performance impact. As with all things related to SQL Server, it is best to implement a solution and test your solution including load testing before pushing the T-SQL code to Production.
Create a Temporary Table
Populate the Temporary Table

Execution Plan to Create Temporary Table
Query the Temporary Table

Query the Temporary Table
While this query used a Table Scan, it is possible to add indexes to a temporary table.
Global Temporary Tables
You may find yourself wanting to create a temporary table that exists for a longer period than just the current session or active database connection. Maybe you want a temporary table that can be accessed by more than one user. In this case, you may want to create a global temporary table. This global temporary table would exist even if the original session or connection that created the global temporary table is still available.
Create Global Temporary Table
The only change between creating a local and global temporary table is with the table name used during creation. Comparing the code in Listing 2-26 for a local temporary table and Listing 2-28 for a global temporary table, you can see the difference in the table names. In Listing 2-26, the table name is #TempAvailableMeal, while the temporary table name is ##TempAvailableMeal in Listing 2-28. The addition of the second # character at the beginning of the table name indicates that this temporary table is a global temporary table. In addition, global temporary tables operate similarly to local temporary tables. One of the key differences is global temporary tables can be accessed outside of the specific connection that created the temporary table.
Persistent Temporary Table
Create Persistent Temporary Table
Create Stored Procedure for Global Temporary Tables
Update Stored Procedure to Execute on Startup
If you find yourself in the situation where you are considering a persistent temporary table, consider your environment and what potential difficulty is being added in terms of maintenance and knowledge sharing so that everyone is aware a mission critical table may exist on the tempdb database.
Table Variables
There are instances where you want to store data locally, but you know that the number of records you will be storing is limited. If you do not need to have the data available to other connections and it is acceptable to only have the data persist within the batch, then you may want to try out using table variables. When it comes to using table variables, you also have the option to reuse the table variable as many times as you would like if you are willing to keep everything in the same batch.
Prior to SQL Server 2019, the estimated number of rows for a table variable was one record. Like other objects discussed previously in this chapter, SQL Server has made significant strides to improve general performance related to table variable. SQL Server is now capable of generating a more accurate estimated number of rows when it comes to using table variables. Now that SQL Server is estimating the number of rows more accurately, it is also saving that logic in the execution plan.
If you find yourself in a situation where the data that will be pulled back with the table variable can be highly skewed, you may find that the T-SQL code will perform inconsistently. Now that the information about the table variable is getting stored in the execution plan, there is a higher probability of coming across parameter sniffing. While this may be troublesome, remember that SQL Server is also generating an execution plan that can be highly efficient for at least some data values.
Declare and Populate a Table Variable
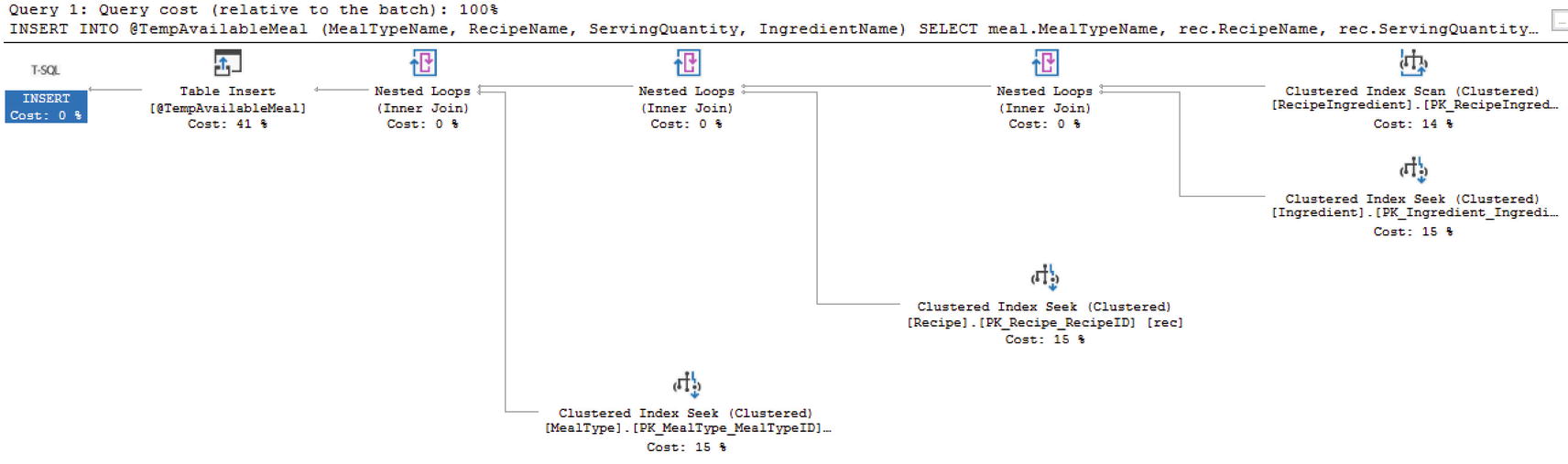
Populating the Table Variable
Now that SQL Server 2019 has been updated to allow for better estimates when using table variables, I expect the execution plans to match often. However, I would double-check the query performance especially if you are planning on adding large quantities of data to the table variable.
Temporary Stored Procedures
If a stored procedure is created in the tempdb database, then this stored procedure is a temporary stored procedure. SQL Server may have made this functionality possible, but keep in mind how developers and applications would interact with this database object. At the very least, having a temporary stored procedure in the tempdb database would make it more difficult to troubleshoot or maintain code related to these stored procedures.
Triggers
SQL Server provides the ability to have specific actions occur as a result of some other activity. The reactions can occur in result to a user logging into the system. There are other reactions that can happen after or prevent changes to the existing database. When dealing with applications and data, the most common type of reaction is in response to changing data in the database. Regardless of the reason, these reactions are defined as triggers. Triggers are a special type of stored procedure that responds to a specific action on the server, database(s), or table(s).
Logon Triggers
When users log onto the server , you may want to record that specific activity. Or in other instances, you may want to limit user activity upon login or implement additional security functionality as a result of a server login. The logon trigger gives you the ability to allow SQL Server to initiate reactions in response to some or all logins onto the server.
There are not many scenarios where logon triggers will be needed for application development. However, there are some things that can be done with logon triggers that could help protect your application. A logon trigger can limit the number of connections allowed by a login. In the case of a breach, this could make sure the database does not get flooded with excess connections. Conversely, limiting the number of connections allowed per login can also limit scalability and futureproofing. The number of acceptable connections today may be much lower than the number of logins needed in the future.
Data Definition Language (DDL) Triggers
When applications or users change the overall database schema, they are using data definition language. In the case of SQL Server, it is possible to react to specific scenarios resulting from changes to the database. While I do not expect this to be a standard part of application development, it may be helpful to be aware of this type of trigger.
If you are concerned about SQL injection causing issues on your server, data definition language triggers can help mitigate the damage. There are options to prevent all sorts of database objects from being dropped. In addition, it is possible to log or record when database objects are created or altered. While you may want to use triggers to set up all sorts of triggers to monitor every activity on the server and the databases, there can be better options available. There are other alternatives available for tracking this type of behavior. This includes SQL Server Audit for both server and database activity. Typically, applications are not concerned with logging changes to the server or database schemas.
Data Manipulation Language (DML) Triggers
If you find yourself needing to implement auditing or logging as a part of your application development, you may find using data manipulation triggers quite helpful. These triggers have several options and respond to a variety of actions based on changes to the actual data in the database. In some cases, you may just want to record when the change happened and what changed. In other instances, it may be more important to change or verify the functionality of the request.
Create After Insert DML Trigger
Query to Insert Record into IngredientCost
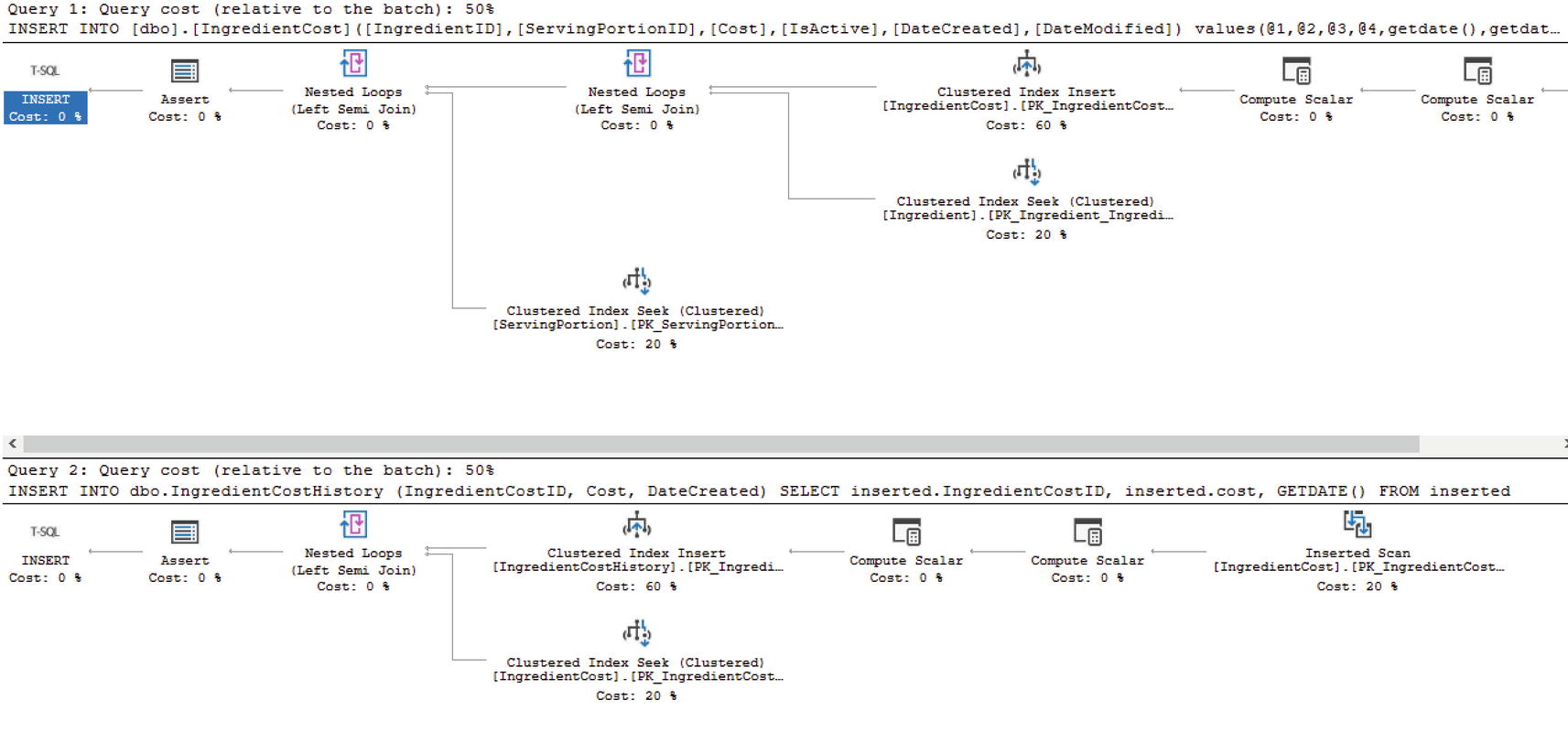
Execution Plan to Insert Record with Trigger
Update Statement that Will Not Update Any Records

Execution Plan Where No Records Are Updated
Instead of Trigger
As you can see, there is more than one option available when using DML triggers in SQL Server. There is also the possibility of having multiple triggers per database object. You can have up to one INSTEAD OF trigger per INSERT, UPDATE, and DELETE. You can have multiple AFTER triggers on the same table or view as well. Due to the number of triggers allowed, you can also specify which trigger should be run first and last per INSERT, UPDATE, or DELETE. If you have more than one type of AFTER trigger per action type, any of the triggers will be run in a random order.
Since there can be so many layers of triggers on a given database object, testing the functionality of these triggers is important. Like many other concepts discussed in this chapter, understanding how triggers will perform under load helps prepare for how the application will perform.
Cursors
In order to use relational databases effectively, it is often critical to think of processes and data in large chunks, or sets. The goal in almost all scenarios is to write T-SQL that takes advantage of this set-based logic. While this is the ideal method, you may find yourself in a situation where you feel handling data in large sections is not possible. In some of these scenarios, it may mean that it is time to handle the data by each row individually.
If you consider this route, it is imperative to acknowledge that SQL Server is designed to perform best when dealing with one large section of data vs. dealing with lots of individual records one at a time. In some cases where it is tempting to use something that handles row-by-row logic, it may be time to look for another tool to handle your needs better. Such is the case when creating a cursor to connect to several instances of SQL Server one at a time and perform a task. While it is outside the scope of this book, this specific situation may be best resolved by creating an SQL Server Integration Services (SSIS) package to handle connecting to the various SQL Server instances.
There are other times where you may need to use T-SQL to generate a result set where the data returned is the same, but the data must be segmented by location or vendor information. In this example, SQL Server Reporting Services (SSRS) could be used to achieve the same goal. However, your business may decide not to use SSRS. Therefore, using a cursor may be the right choice. I have also seen situations where data needed to be updated with a calculation using a specific, calculated value per record. In this case, it was almost impossible to perform the updates using set-based logic. While SQL Server was able to handle this task, it would have been preferable for the application to handle these changes.
Cursors can help make a repeatable process that touches one record at a time. While cursors can be used to address a variety of issues, it is important to remember that many times there may be a different way to achieve the same outcome without using cursors. If you have decided that you must really use a cursor, the next step is determining which type of cursor to use. While the concept of a cursor is the same regardless of which type is used, the type of cursor will determine the functionality and accessibility of the data within the cursor.
When choosing the right type of cursor for your needs, choose the one with the least amount of functionality that will meet your needs. This will help reduce negative performance as compared to cursor types with more functionality. Whenever you are handling records in SQL Server one at a time, they will almost always perform worse than handling data in groups.
A cursor selects a set of data, fetches one record at a time, and then modifies the current record. Once the required actions have been taken, the next record can be fetched. This is where knowing the various types of cursors available will allow you to choose the correct type.
Forward-Only Cursors
Example of a Forward-Only Cursor
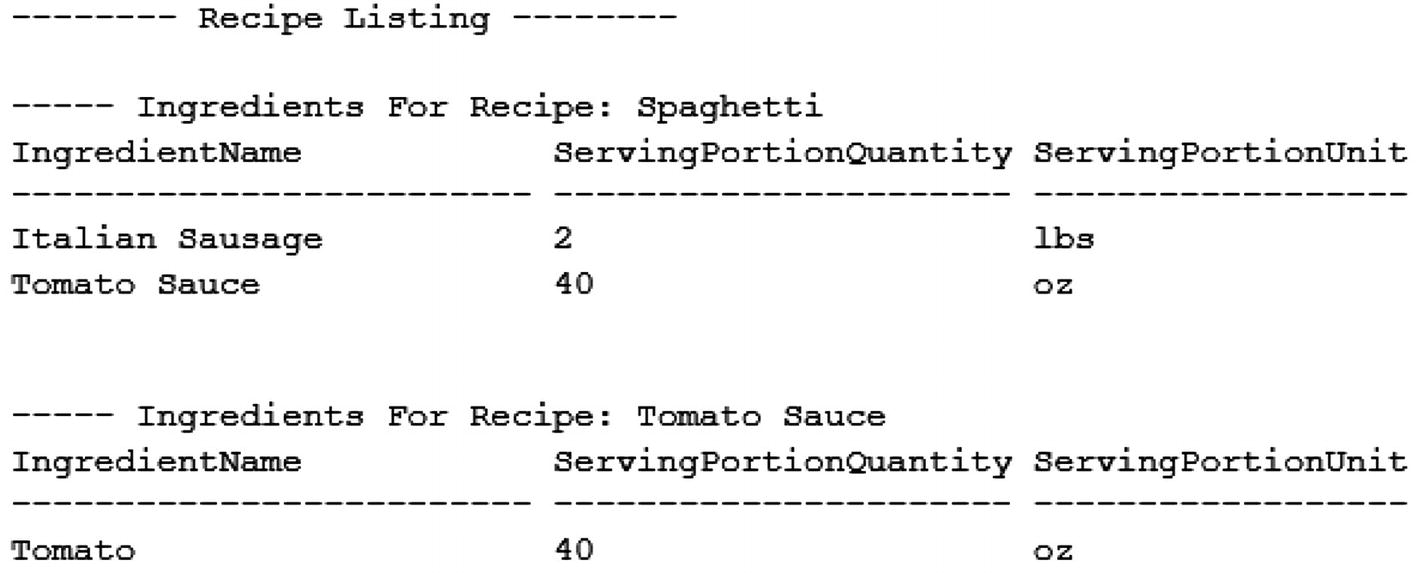
Output from the Forward-Only Cursor
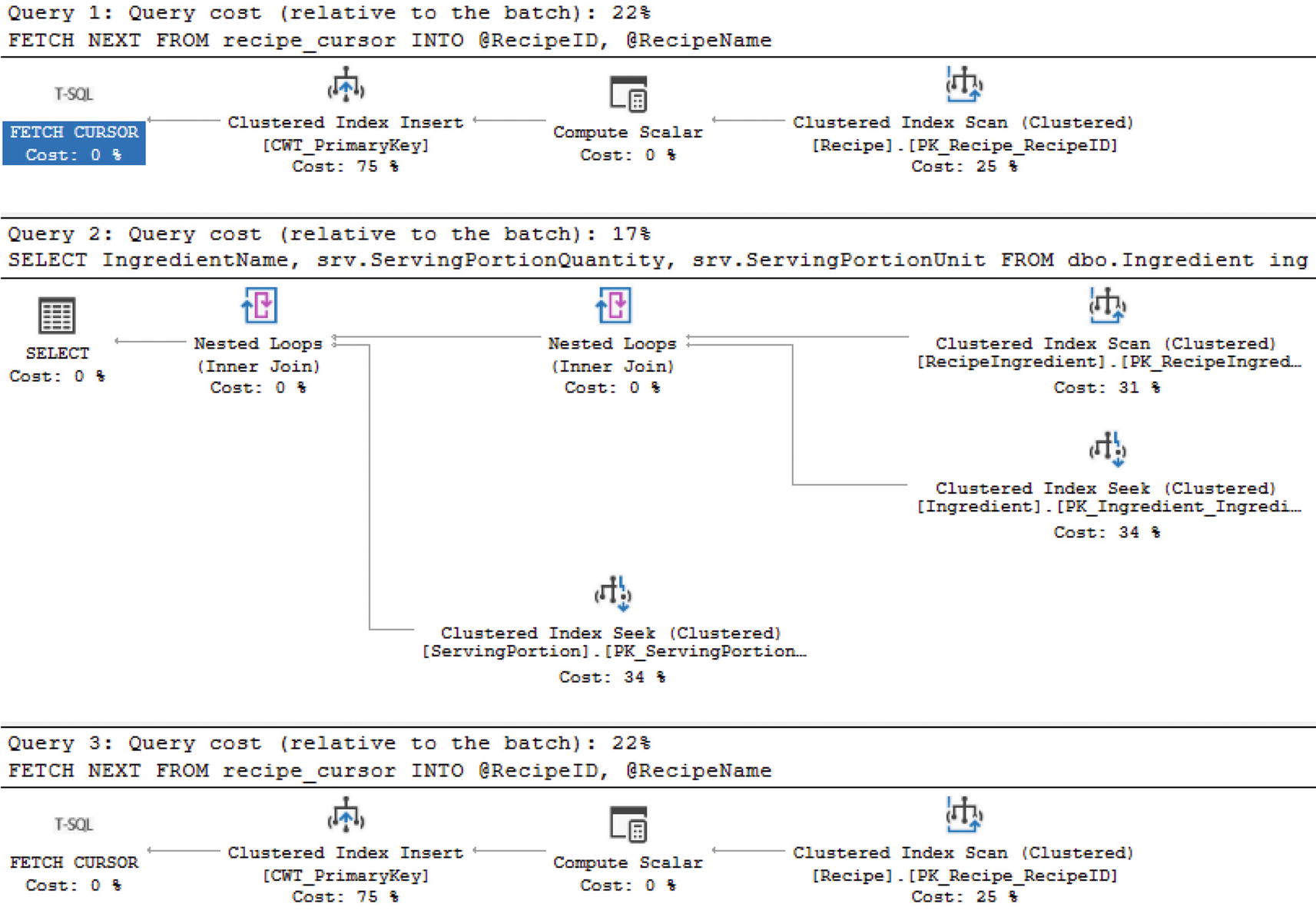
Execution Plan for a Forward-Only Cursor
It is important to remember that the second and third sections of this figure will rerun for each row processed in this cursor. When the underlying queries are quick and perform efficiently, that may not be an issue. However, if the queries inside of the cursor have any performance issues at all, a cursor can severely exacerbate any of these performance issues.
Static Cursors
Sometimes you will want to be able to move backward and forward when running the cursor. When using a static cursor, the available result set does not change from when the cursor is first opened. The static cursor has the option to be read only or allow reads and writes. When the cursor is read only, data cannot be modified. If the data is modified, there is no guarantee that the cursor will pull back the modified data.
Keyset Cursors
When defining a cursor, there may be a set of columns that create a unique entry. If that set of unique data can be found and you need to be able to interact with records that have changed, using the keyset cursor may be an option. The keyset is a set of keys from the unique set of columns. The cursor can move backward and forward, but the only way to detect changes to the order are the records that belong in the cursor to close and reopen the cursor.
Dynamic Cursors
If the other cursors may not work for your situation, there is a final type of cursor available. This type of cursor should be used as infrequently as possible due to the potential performance implications. The dynamic cursor allows you to move forward and backward through the result set. In addition, it will be aware of changes made to the data. While dealing with transaction levels is outside the scope of this book, there are some additional caveats for dynamic cursors when related to transaction levels. All changes from committed transactions will be visible. However, the only way uncommitted transactions can be seen is if the transaction level of the cursor is set to uncommitted.
Earlier in this section, I showed how to create a forward-only cursor. The interesting thing about creating cursors is that the code does not change significantly when switching between the various types of cursor. The largest difference between the cursor types is what data modifications each cursor can see and how the data is fetched. One of the largest temptations is that cursors work very similarly to application code. Instead of handling large quantities all at once, the cursors loop through data. In application code, this would be the preferred method of accessing data, which makes using cursors even more tempting.
Creating a Dynamic Cursor
Changing the cursor type from FORWARD_ONLY to DYNAMIC was as easy as swapping out the phrases for one another. The output of these cursors is also the same. The real difference that could have happened is behind the scenes. If a record had changed while the cursor was running, the forward-only cursor may not have been aware of that change, whereas the dynamic cursor may have been able to scroll to see that change or in certain scenarios the dynamic cursor may have seen the change before it was committed.
Throughout this chapter, I have covered several different types of database objects that are available to use when writing T-SQL. These objects can help make code more readable. While some of these database objects can improve performance in the right circumstances, none of these database objects are designed to resolve every technical challenge. There are situations where using the wrong database objects can have negative performance impact on the database and your application code. Now that you know when to use each database object, it is time to start considering the quality of code you write.