
Writing T-SQL code that is manageable is a worthwhile goal to build upon a solid foundation of understandable and maintainable code. Chapter 3 discussed how you can standardize your T-SQL code. This continued in Chapter 9 with the concept of implementing SQL Coding Standards. The purpose of this foundation was to create a consistent code base for your database. While developing a consistent code base can help improve code quality, this effect is diminished if you are unable to maintain your T-SQL code.
Developing manageable T-SQL code covers many different aspects of writing database code. The previous chapter focused on coding standards as a way to help guide you and others to writing T-SQL code that performs well. Having database code that performs well and is easy to read can not only help your applications but also your development process. The next step in that path is to consider how you are storing your code.
One option is to consider using source control to save T-SQL code associated with creating various database objects. You may be wondering why source control is important or what it can do to help make T-SQL code development better. Knowing that you want to implement source control is different from defining a process for managing source control. Setting up guidelines on how source control can be handled puts you in a good place to begin creating your first database project in source control.
Why Use Source Control
There are several aspects to having maintainable code. This includes making sure that you can find the T-SQL code for any database object. You also want to know that you are modifying the correct version of the code. Serious issues can occur when the wrong version of T-SQL code is modified and deployed. It will also help you to know what version of code needs to be deployed at any point in time. All of these items can benefit from incorporating source control for your databases.
Keeping T-SQL code together in a way that can be easily accessed can be a challenge. Source control can help keep all your T-SQL code together and organized. While you may think that source control is only something software developers should use, that is no longer the case. One of the easiest ways to get development teams working together with database administrators is to adopt similar processes. There are additional tools available when your T-SQL code is saved in source control. These tools can help streamline your coding and script reviews by automatically rejecting code that does not meet T-SQL formatting or coding standards.
There are other issues that can happen when writing T-SQL code. You may have times where multiple people or teams need to change the same database objects. Depending on how your company handles deploying code, you may end up with some database objects that have multiple layers of changes. Source control can help manage those changes and make sure they are implemented correctly. Source control can allow you to work from the most up-to-date code.
When you are making changes to database code, you have the option to make those changes locally. If you choose to use SQL Server Data Tools and keep all your database code in the same project, you can build your code to verify that the code will execute. This is an advantage over deploying code manually to SQL Server. As part of the build process, the database project will verify that the fields in your views, functions, stored procedures, or other custom objects exist within the database.
Some changes to T-SQL code can be complex and involved, other times you may be working with database objects or code that is critical to running your company. To start working on changing code, you will want to make sure you are working with the most up-to-date code. Prior to source control, I would pull the code that was in Production. However, this object I am reviewing may have been altered as part of a user story since the last Production deployment. What is worse is that this code may not have been deployed to the development environment or may still be awaiting a script review. Using source control allows me to get the most recent version of the T-SQL code consistently.
When you make those changes, you may want a place where you can go through the process of changing code, testing code, and repeating this process until you get to the desired output. Source control can pull the most recently saved T-SQL code down to your local machine. You can then work on making your modifications to the T-SQL code on your local desktop. When you are ready to save that work, you can save your changes to the centralized location. This centralized repository becomes your source of record for all database changes.
If you keep all your databases in the same solution, you can add references between databases if there are dependencies. This ensures that if you make any changes to the underlying database object, you will receive an alert if any of the dependent objects no longer function. This can be especially useful when you are adding or removing columns, or you are changing column names. There may come a time when you want to re-factor a table or some other database object. If your applications and databases are saved in the same solution, you will have the option to automatically re-factor the code. This can help in situations where your applications have SQL code saved directly in the application.
Another benefit of using source control is that it is easier to quickly find what T-SQL code has changed. Prior to using source control, I would have to manually review an entire database object to confirm what changed. The best process I found was to visually compare the current Production stored procedure to the new version of the stored procedure. While this was somewhat effective, it was also possible for me to easily miss something. I would also review all the T-SQL code from top to bottom to make sure I understood every line.
Prior to performing a script review, I will read through the associated user story to see what the code is expected to do. I may have been tempted to only script review the lines of code that seemed to be explicitly related to the current user story. After getting the database added into source control, I could easily see all code that had changed as part of the script review. This allowed me to quickly see all T-SQL code that changed. This can be especially helpful if you work in an environment where fixing technical debt is not officially condoned, but developers have some freedom to fix technical debt while working on a user story that affects the same database code.
I could also use source control to easily compare T-SQL code to previous versions. As part of the comparison, sections of the code that had been modified were highlighted. Even more helpful was that code that was added vs. modified or removed was highlighted in two different colors. One drawback of source control is that I no longer reviewed the whole script. Any pre-existing issues with the T-SQL code that were not modified did not have a chance to be corrected. This applies to both formatting standards and also to coding standards.
Having access to your T-SQL code can make it easier to get scripts together for deployments. Source control also helps protect unapproved T-SQL code from getting deployed in error. Without source control for T-SQL, getting ready for a deployment can be a hassle. I have worked with various companies that handle deployments differently. I have experienced deployments where scripts were copied from tickets and added to a release page. I have been on deployments where the SQL scripts were bundled and prepped by the development team. Both methods will work, and every method has its downfall.
For the first method, I had one deployment where the same stored procedure was changed in three different user stories. When it came time to deploy the code, neither I nor the developers knew for certain which version should get deployed. In the second method, the actual deployment time was much shorter, and there was error logging. However, for both methods there was not a single source of truth when it came to database code. In either scenario, if I needed to undo a deployment that was several months old, it would take time to sift through deployment scripts to find which version of the T-SQL code needed to be deployed for the rollback.
You will need to be able to access scripts for different databases and deployments but also keep track of changes over time. You may change some T-SQL code for applications or reporting that may get overwritten with newer code. However, the business may decide they want to go back to the original code. When that code is saved in source control, it is much easier to search through the versions of the specific database object and find the specific occurrence. There are other times where an issue may get reported from Production several deployments after the original change went out. After I have determined the specific T-SQL code that is causing the bug, I may need to report to management the effects of this issue over time. With source control I can save time by finding when the change was implemented.
Another advantage of source control is allowing you to have one more tool to help in the case of disaster recovery. If you were to lose all your hardware and backups, how would it take you to get your business up and running again? While you may know that your backups need to be tested on a regular basis, you may not have had the opportunity to test them lately. Depending on how your company has developed their disaster recovery plan and what happens when disaster strikes could mean you lose access to your current Production servers and all the associated data. If this unlikely situation happens, you may find yourself in a situation where you are wondering how you will get your applications running again. As a plan of last resort, if your databases are in source control along with the necessary data in your base tables, you have a chance of getting your company’s systems up and running.
How to Use Source Control
One of the things I found out when first implementing source control were the types of discussions that needed to happen internally prior to implementing source control. I found that the database team, the development teams, and the QA teams needed to come to an agreement as to how code would be managed going forward. Some of these discussions had to deal with how the different teams functioned. There are differences in how you want to manage your database code. This can include guidelines for when to use local vs. centralized repositories, how to save your changes to source control, how to resolve bugs that have been deployed, and what should be included with your database code.
Prior to using source control, you may have written T-SQL scripts and save them locally. When testing your T-SQL scripts, you may have executed them locally on the SQL Server machine. Up until this point, you have done most of your work locally. Afterward, you may have executed them once these scripts were ready to deploy to the development environment. You may haved then modified the objects in your development environment, a database schema in a more centralized location. While this is an easy place to start when writing code, it does create some risk. If the scripts were saved locally on your machine and your machine died, you may have lost any work associated with the scripts. There is also the possibility that when you deployed code to the development environment, it broke functionality somewhere else. In addition, if you and a fellow coworker were both working on the same database object, you may find your changes overwritten with your coworker’s code.
This is where the benefits of writing code locally and then saving those changes in a centralized repository can be helpful. To a large extent, that is the idea behind source control. Source control allows you to work with code locally on your machine. You can create database objects or change database objects, and when you build the code locally, you have an additional check that the database project can build successfully. Once you have tested and confirmed your database code, you can check it in a centralized server. This central repository can receive code changes from you and any other members of your team that are authorized to make changes to this database project. This allows a certain degree of separation between your work environment, your coworkers’ work environment, and the collection of all code changes together.
Depending on the type of software you use for source control will determine how you manage writing and updating your T-SQL code. When I first started working with databases in source control, Git had not become the primary software used for source control. I started with Team Foundation Server (TFS) . In the company where I worked, we typically did not work with multiple branches. The database project is the first place we implemented branching. At the time of implementation, all of development fell under the same reporting structure and deployment cycle.
You can make changes to your source control. Each time you save these changes to central repository, it is called a check-in. When checking in code, you can add comments to the check-in. In my company, we usually indicate the user story number and a brief comment about what has changed. When you begin working on code in source control, you can have the code automatically checked out. This will allow others to know that you are making changes to the code.
Like a check-in in TFS, you can commit code in Git. Both actions save the changes that have been made to the branch you are currently using. While the functionality appears the same, these can work differently depending on what version control software you are using and what tool you are using with the software. Git and GitHub allow you to save changes before they are committed permanently to the repository. Staging changes is the term for when you save changes that are not immediately committed to the repository. Staging changes for your commit can be done through the command line.
When we discussed how to manage checking in code and managing branches, the design was based on our internal development process, script review process, and deployment cycle. We wanted to allow developers to be able to check in T-SQL code frequently and have that code available in their development environment. We also wanted to make sure that the database administrators had time to review code before the code was deployed to the QA environment. We wanted to make sure that QA did not spend time testing T-SQL code that had not been approved.
Due to this break between development and QA, we opted to create a branch specifically for code that had been script-reviewed and approved. As part of the script review process, the database administrators were responsible for merging the code. There were challenges with this process. Even though all code was meant to be deployed in the same sprint, there were times that items were merged out of order from how they were created in the development branch. This led to files getting overwritten. All of this became even more difficult to manage after the teams were split up and the development cycles became staggered.
With the desire for more companies to move to any combination of Agile, Kanban, Scrum, Continuous Integration, or Continuous Delivery, it has become increasingly important to have a source control solution that is more flexible. This new solution needed to allow for multiple different teams to simultaneously work on the same code base without negatively affecting deployments. That is where the popularity of Git originates.
The concept of using Git is that there is more control over how and when your code is merged. In my company, each team is rarely working on the same application as another team, so there are few conflicts when it comes to managing code. However, almost every application relies on shared databases. In addition, the database team is frequently working on the same databases. There are also different deployment cycles across the various teams. That is where you can see the power of Git.
Unfortunately, there are still challenges with using source control. These challenges exist for either TFS, Git, or any other versioning control software. Using version control is not something that has historically been common for data professionals. While there are benefits to making that change, there is also a learning curve when it comes to using and managing source control. As with many things the happy path works well, but when it comes to more complex scenarios, source control can become overwhelming.
There are features available in Git that require more training than using TFS. These same features are also what help make Git’s source control more flexible. As is the case, while the increased functionality is nice to have, it can also make using the software more complex. There is a main repository where a group of code can be saved together. If you are using SQL Server Data Tools, this is where you have the option of choosing if each database project will have its own repository, all databases will share the same repository, or all applications and databases will share the same repository. These decisions are not only based on preference and desired functionality. As you will see in Chapter 12, how you organize your repository will also determine how your code is deployed.
Inside of the repository, there is the concept of one or more branches. There is one branch that should be the main branch. Think of it similarly to what set of code would you regularly go to if you needed to deploy these changes. This branch is called the master. Any time you want to make changes to the master branch, it is generally best to create a new branch to write your T-SQL code. This allows the main branch to remain unaffected by code that is in development and is not ready to be deployed. In this way, the master branch can match the code that is currently deployed to Production.
When you create a branch, this takes a copy of the current repository. You can work with this copy and make any changes necessary. When using Git, you may decide that each person will work off their own branch. This helps everyone develop their code individually without being affected by someone else’s code. While this is a benefit for development and testing a specific piece of functionality, this is also where source control can get complicated.
As these check-ins happen per branch, you may find yourself in a situation where you need to deploy two different branches during the same deployment. This is where you will want to try to combine this code. In order to combine this code together, you want to take the changes in the branch and add the changes back to the master branch. To combine a feature branch to the master branch is called a merge. One aspect that can happen as part of this merge is called the conflict. This can happen when many people have been working on the same database object over the same period of time or there has been a delay in merging a previous feature branch with the master branch. Make sure to work with your development teams to get a better understanding of how to avoid merge conflicts and how they can be resolved.
One thing that happens more often than some of us would like to admit is when code is deployed and then does not work as intended. I have been in situations where those bugs were found during the deployment. Other times those bugs are not found until days, weeks, or months after a deployment. In either scenario, the key is to figure out how to quickly restore the database to a more functional state. One of the discussions I had with developers and QA was how to handle this on deployment night. A bug can be manually fixed by a T-SQL script. Depending on how you manage your database code deployments, it is possible that this bug fix can be undone in a future deployment. If you put the bug fix into source control, you can make sure this bug fix will not be undone going forward.
As a result, we concluded to adopt what we called a rollforward strategy . If we could quickly find and resolve the issue, then we would check those changes into source control and deploy them up through the environments. This rollforward strategy was only permitted on the night of the deployment. When we adopted the strategy, the concept was that we were going to deploy all code that had been merged to a master branch. If you choose to deploy a different version of the database project than the most recent version, you will not be able to use this method.
We also adopted a method to use a hotfix. These were changes that were needed as soon as possible due to a critical loss in functionality of an application. As there may be various items in development, we could not go ahead and just deploy the most recent database code. In these cases, I would still check the modified T-SQL code into source control. That code may have been deployed to development and tested in our QA environment, but the code would be manually deployed to production. The concept being that the next time the database code was deployed, this database object would already exist.
Designing how to save database code also involves conversations with the development, QA, and release management teams. There are pros and cons to the various methods that exist. You can save all of your database projects in the same solution with all of your application code. While this may take longer for your projects to build, if you create the right relationships, you can be certain that changes in your database will not affect functionality of your applications. Depending on the number of applications that exist in your company, this may be a difficult task. There is also the option of having all your databases saved in the same solution. If you have crossed database dependencies, this method will help protect your databases. This is particularly helpful when you make changes to one database object, and you are not certain if these changes will break functionality in a different database. The final option is to create one solution per database. The advantage of this method is that you can develop each database independently. The downside is that you may make changes to a database that breaks functionality for another database.
Prior to setting up your first database in source control, I would recommend discussing the topics in this section with the other teams at your company. You will want to make sure everyone is in agreement when it comes to writing, testing, and saving changes to your database code. Get others on board when it comes to how to fix database code once it has been deployed. Also consider how you want your database projects to interact with one another and your applications. Once you take all of this under consideration, you are ready to create a database project.
Setting Up Source Control
You are ready to set up source control now that you decided you would like to implement source control for your database, and you figured out some general guidelines on how you want to set up your database projects. One of the first things to do is get whatever IDE you are using to connect to source control. Once you are connected to version control, you will want to create a way to store the source control for your databases. You will want to figure out how to make and save changes to your database code after you have a place for your database source control.
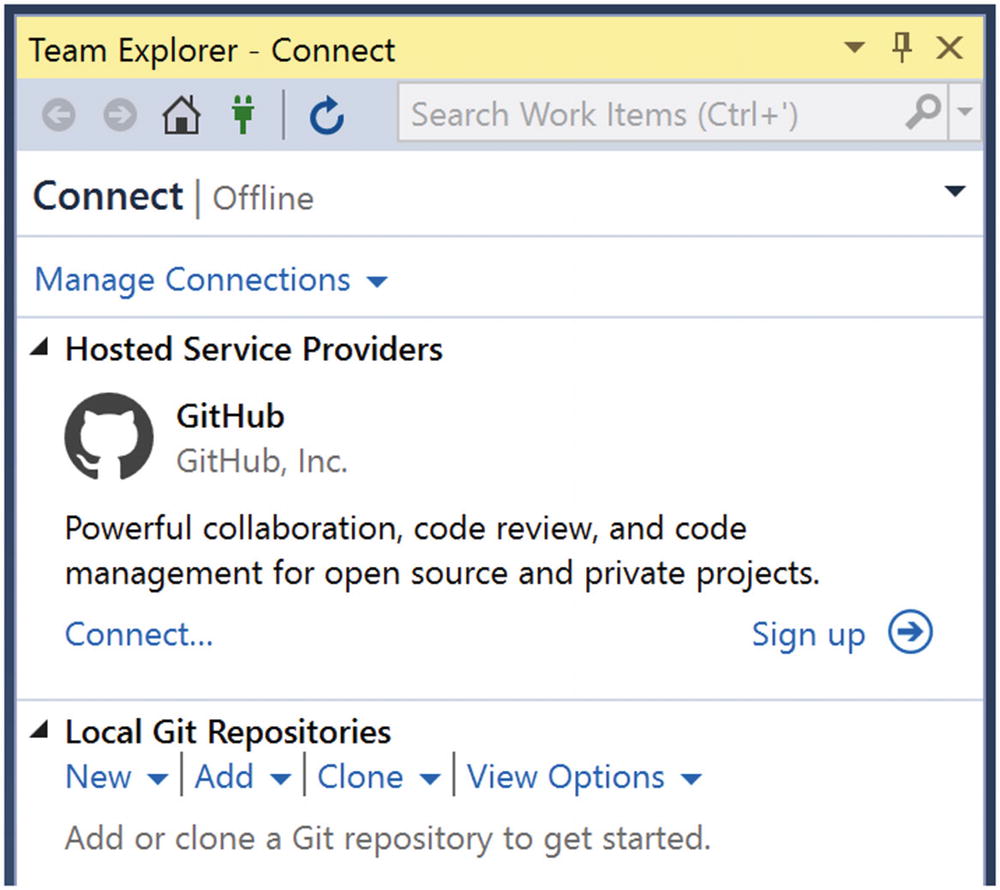
Connect Visual Studio to Version Control
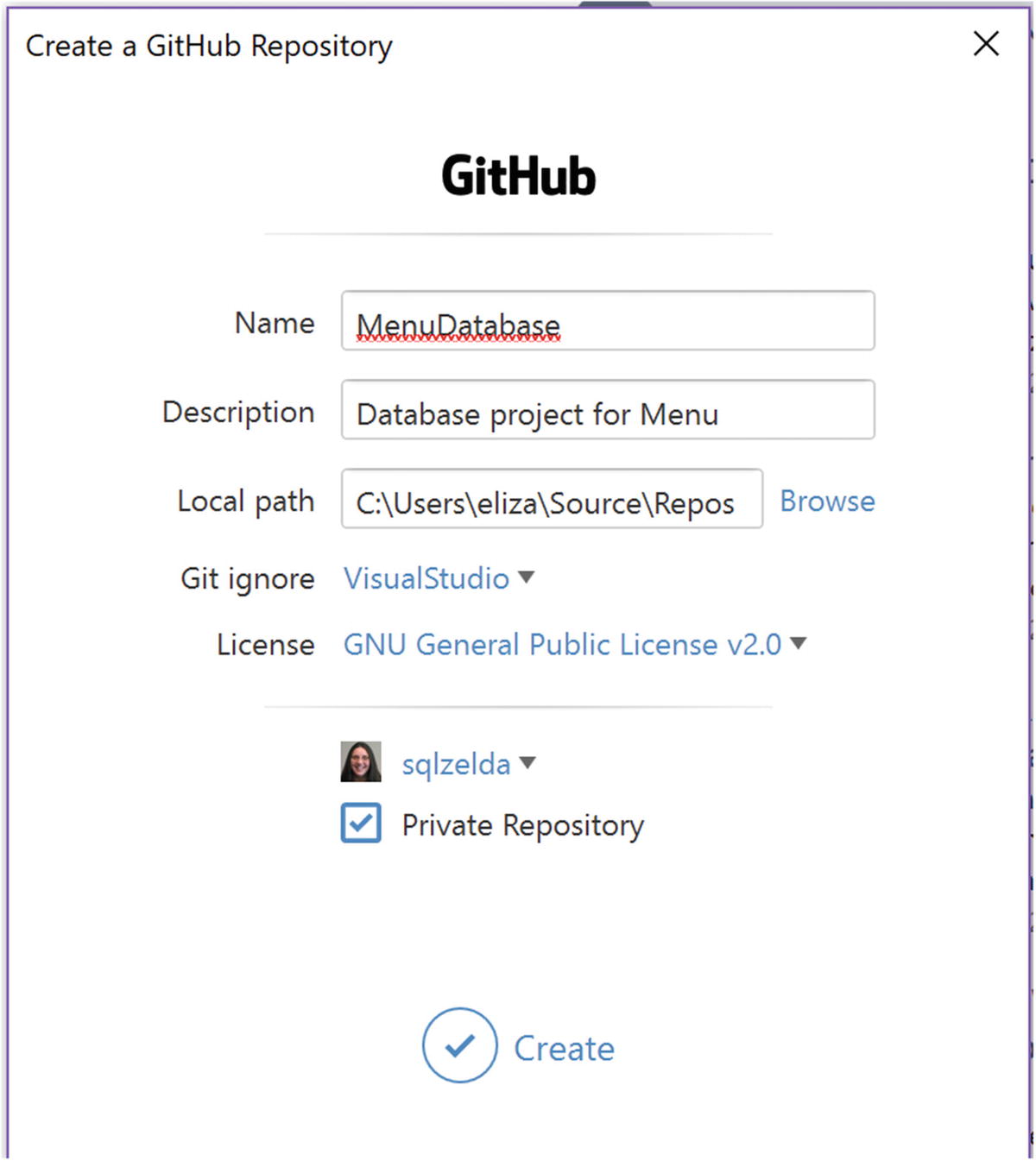
Create Git Repository
In this step, I am creating a Git repository and connecting it to my GitHub account. I have decided to name the repository MenuDatabase. I have given the repository the description of Database project for Menu. I also specified a local path where my local code repository should be saved. I have selected the default for Git ignore of Visual Studio. I’ve also selected a license of GNU General Public License v2.0. It is beyond the scope of this book to go into detail regarding Git ignore or the available licensing options. The last part I specified is a private repository. The main difference between a public and private repository is whether you would like others to be able to access, download, and make suggestions regarding your code.
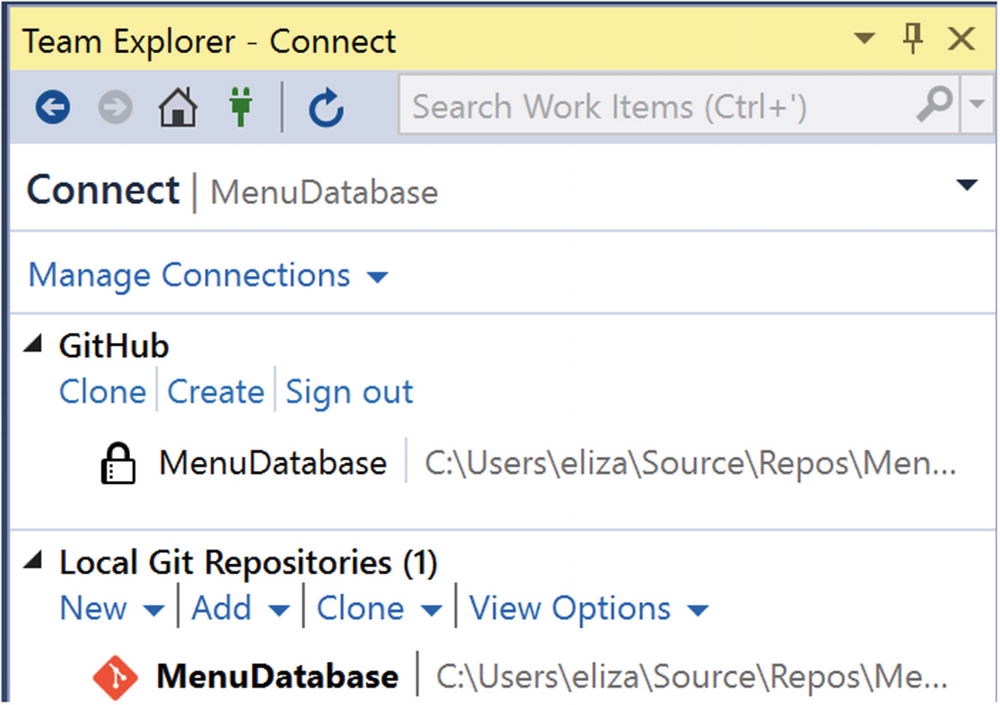
Repository in Team Explorer
Install Third-Party Tools for GitHub
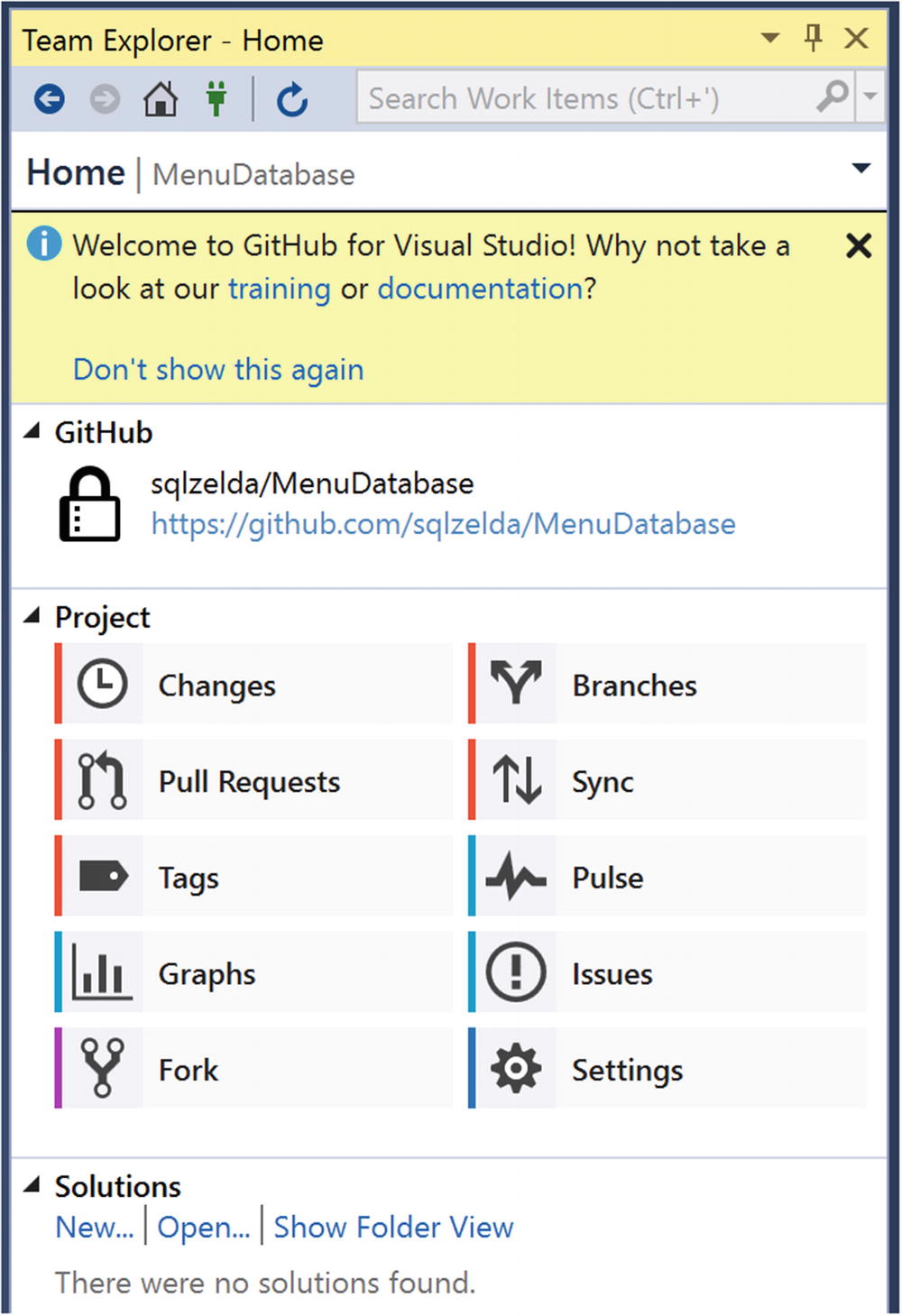
GitHub Action Menu
The actions available include changes, branches, pull request, and syncing, to name a few.
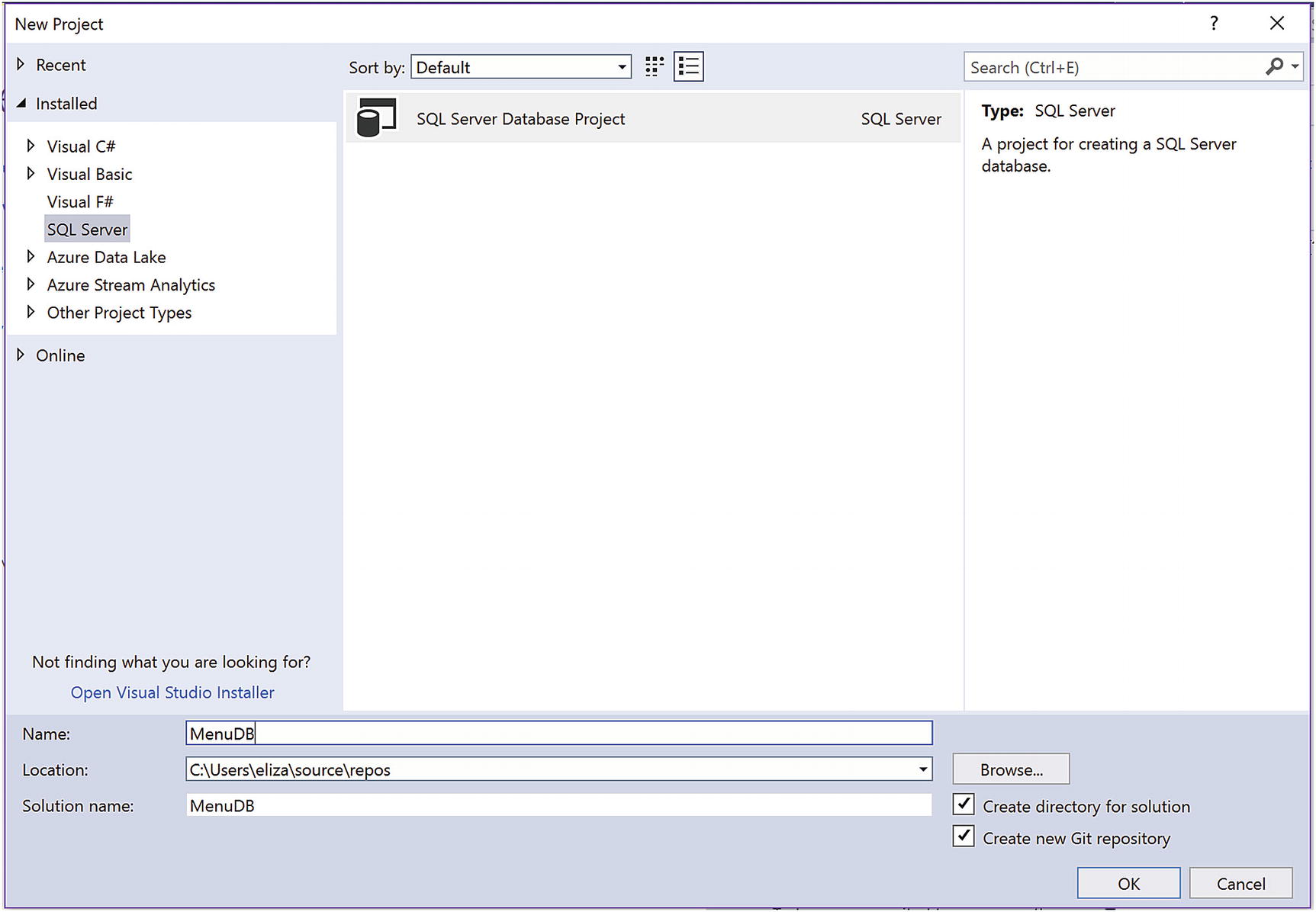
Create New Project in Source Control
Solution for Database Project
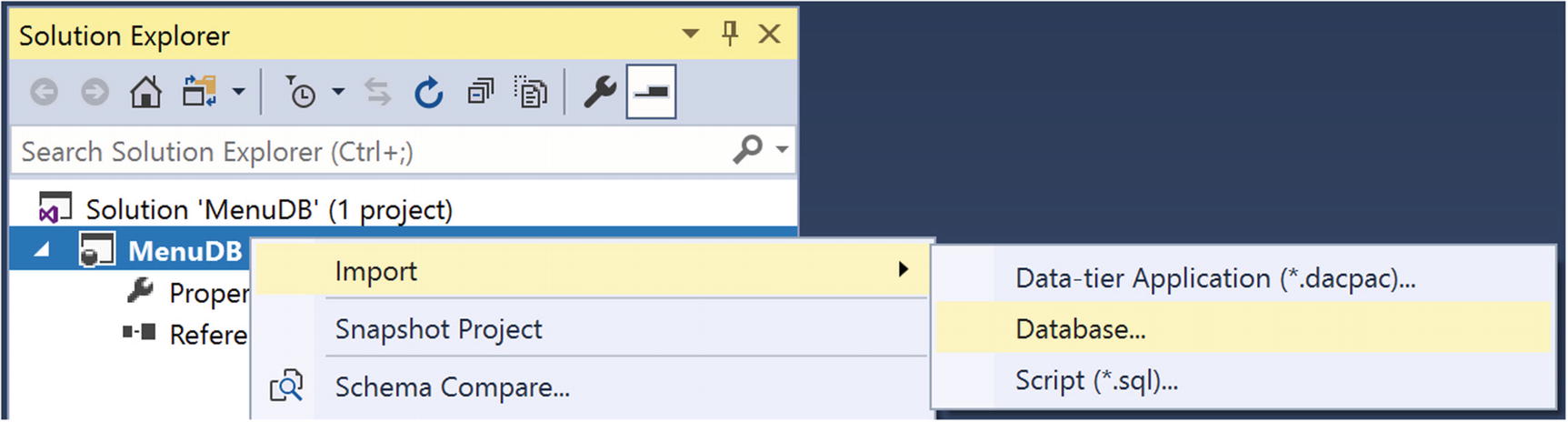
Add Database to the Project
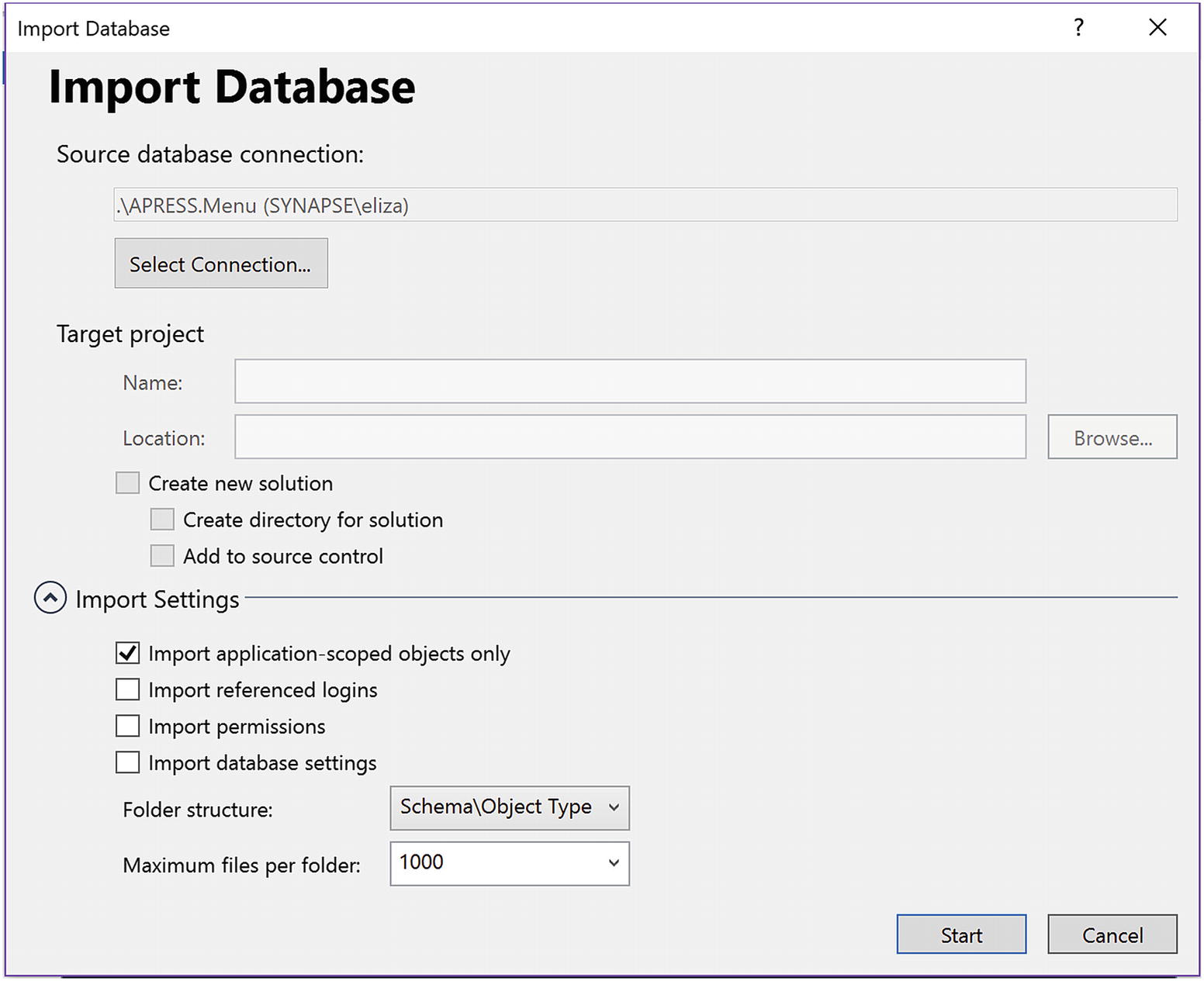
Connect to SQL Server, Select Database, and Configure Settings
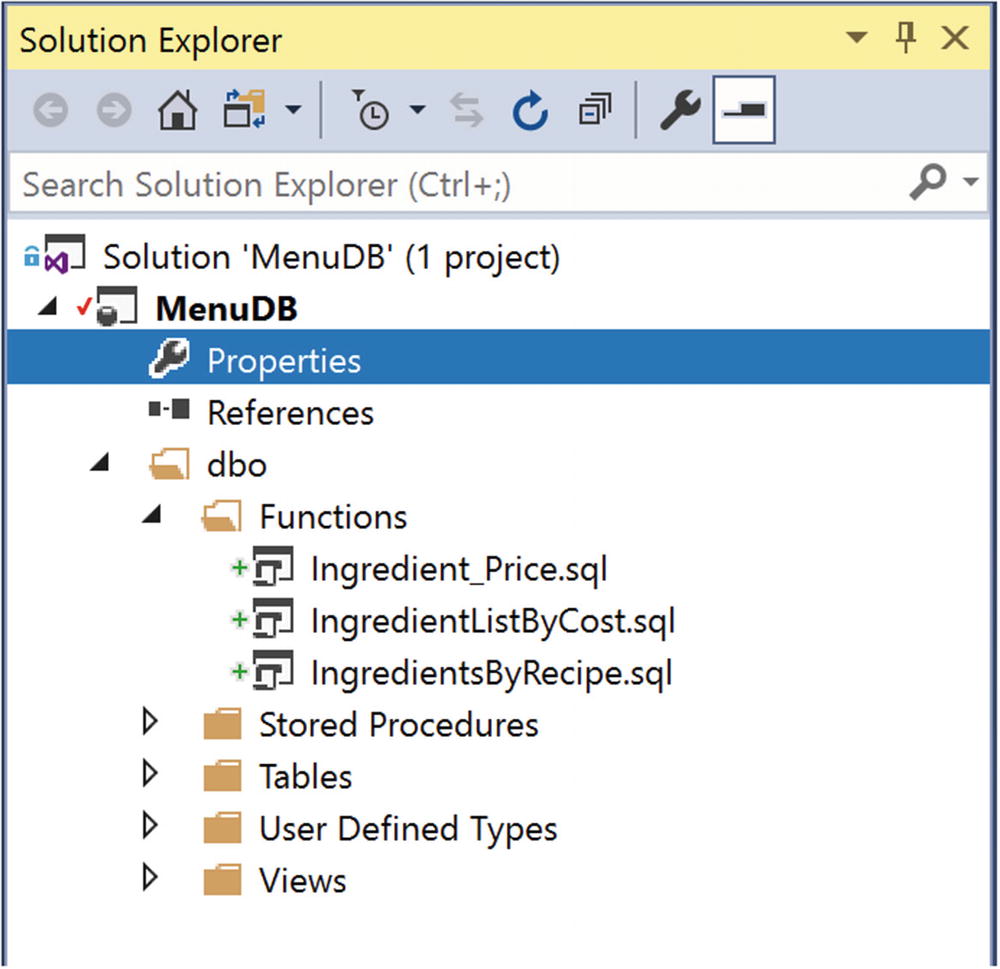
Database Project After Importing a Database
The plus signs next to the functions indicate items that have been newly added. These items did not exist in the database project before. The red check next to the project name MenuDB indicates that there have been changes to the project.
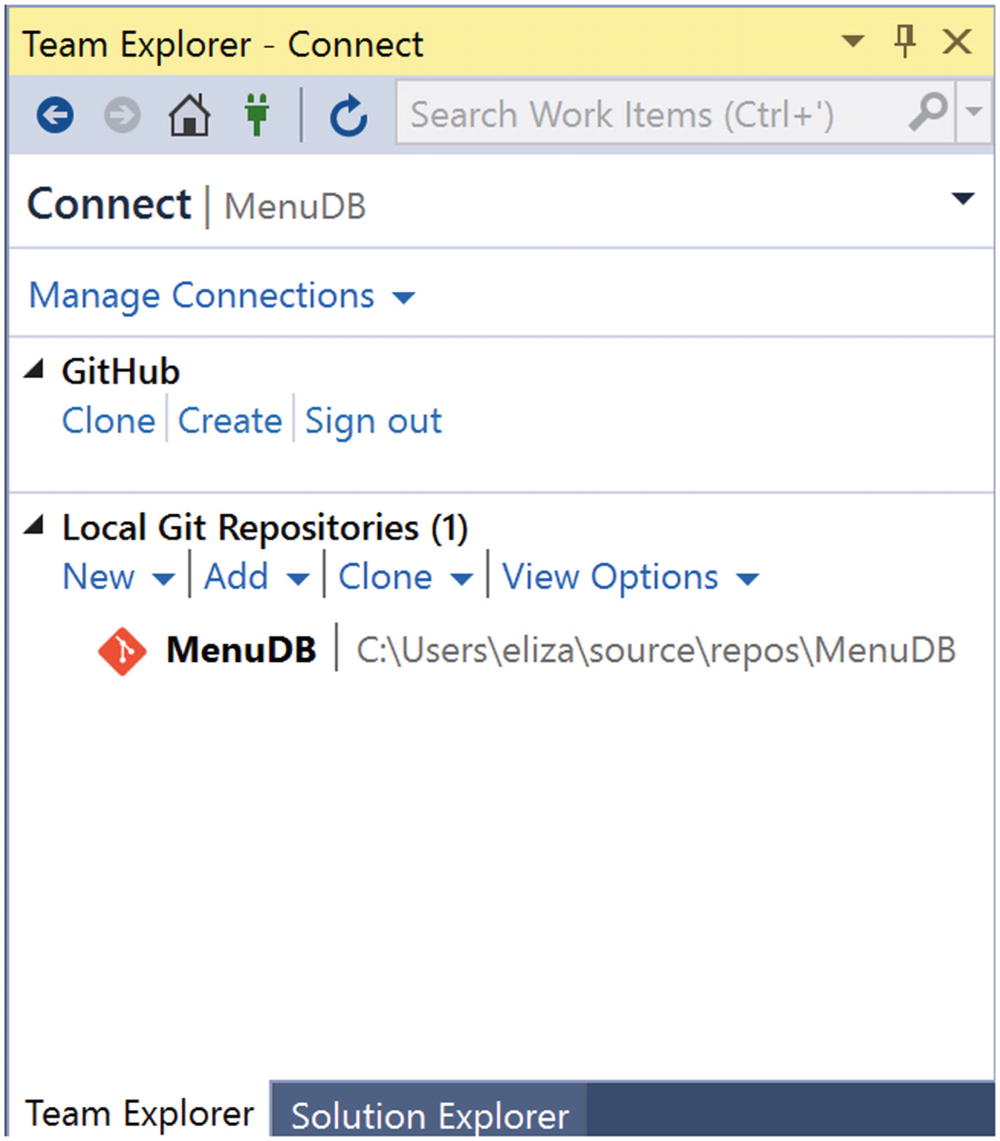
MenuDB as a Local Git Repository
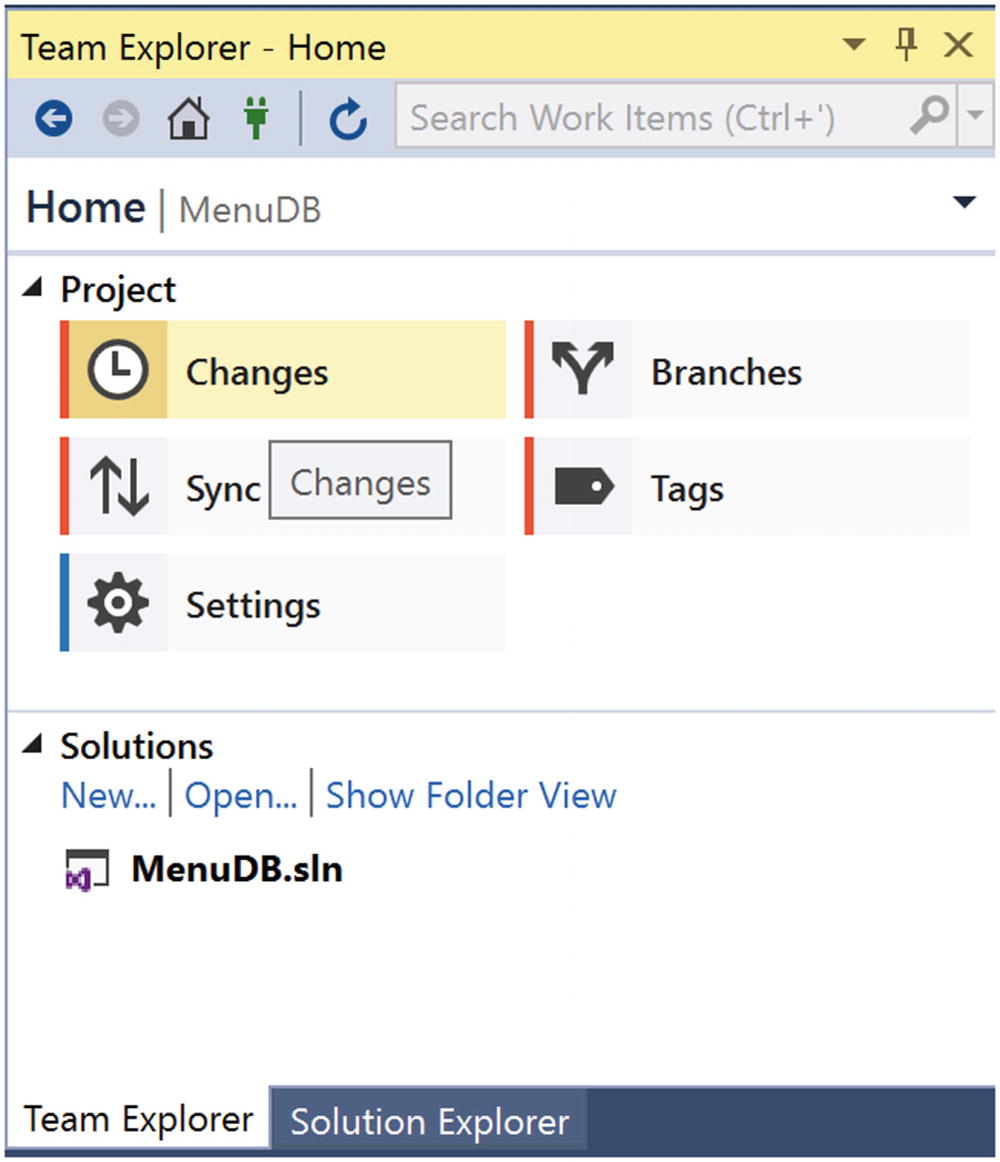
Access Changes to GitHub
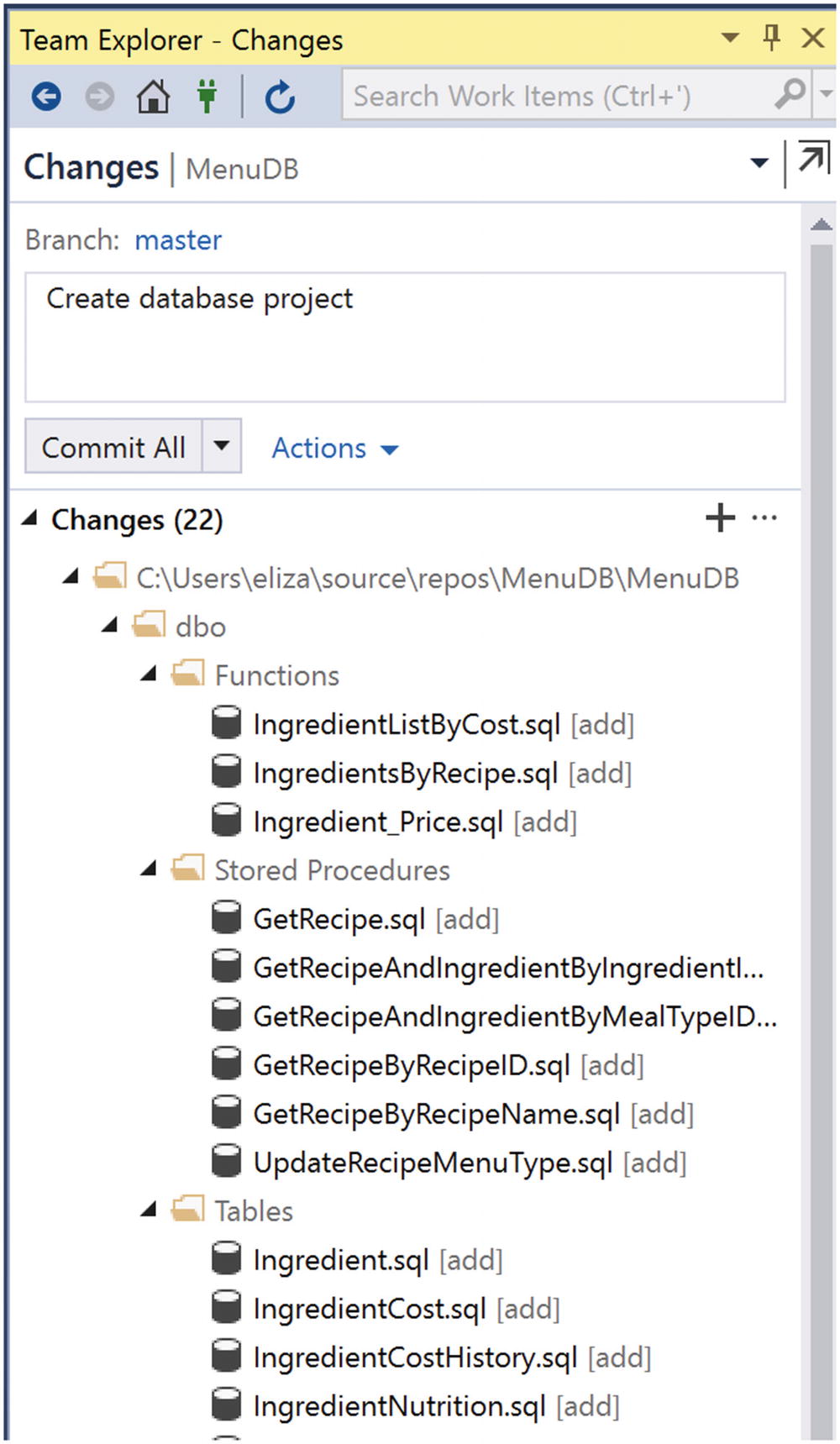
Changes Menu to Commit to Local Git Repository
I can choose to commit all or some of these changes. In this case, I am making a new project, and I would like all of the code that has been imported to be saved with one commit. This will be the starting point for the repository going forward.
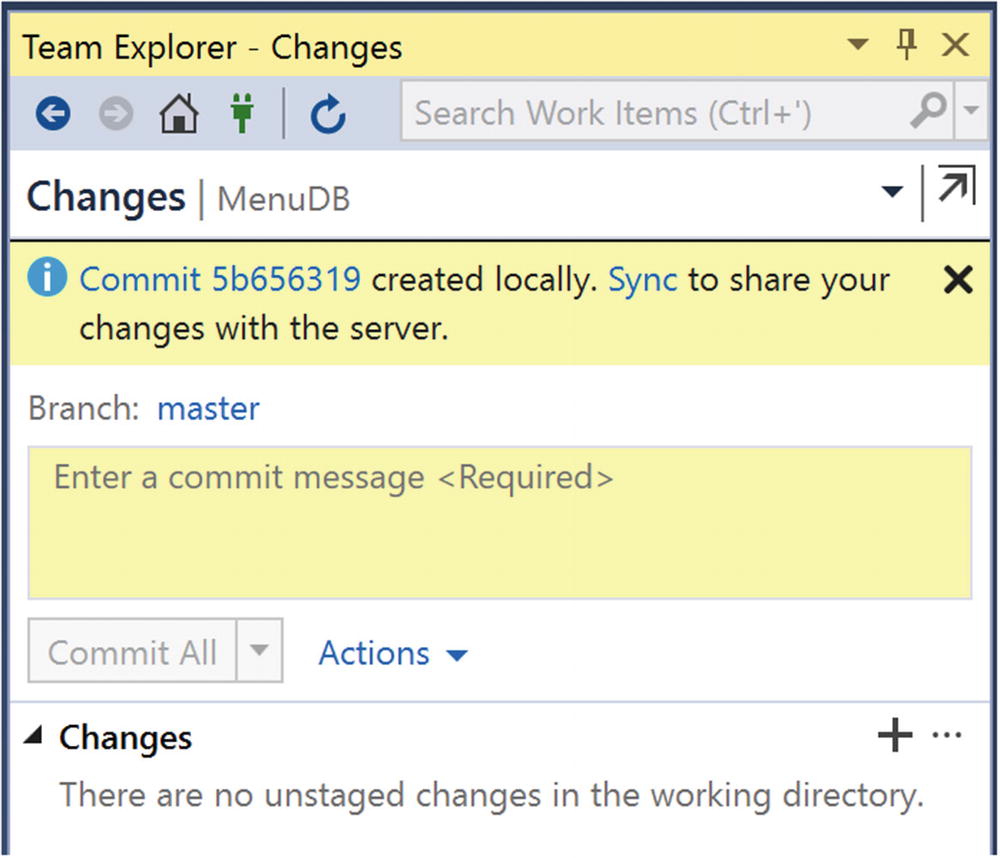
Confirmation Window for Successful Commit
Along with the commit, there is a message indicating that I can Sync my changes to the GitHub server. In Figure 10-15, you can see the window that appears after clicking the hyperlink to Sync these changes.
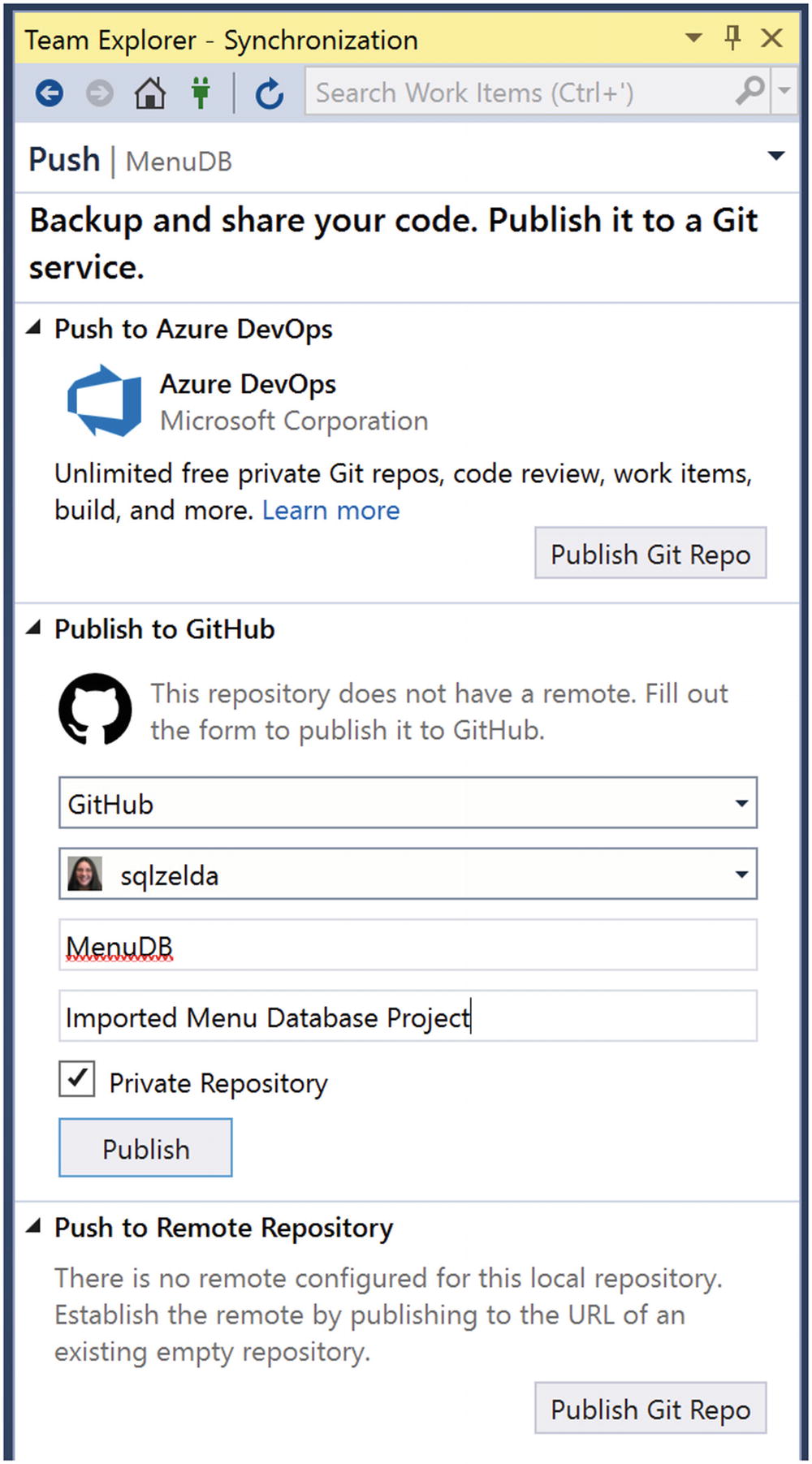
Select Where to Sync the Solution
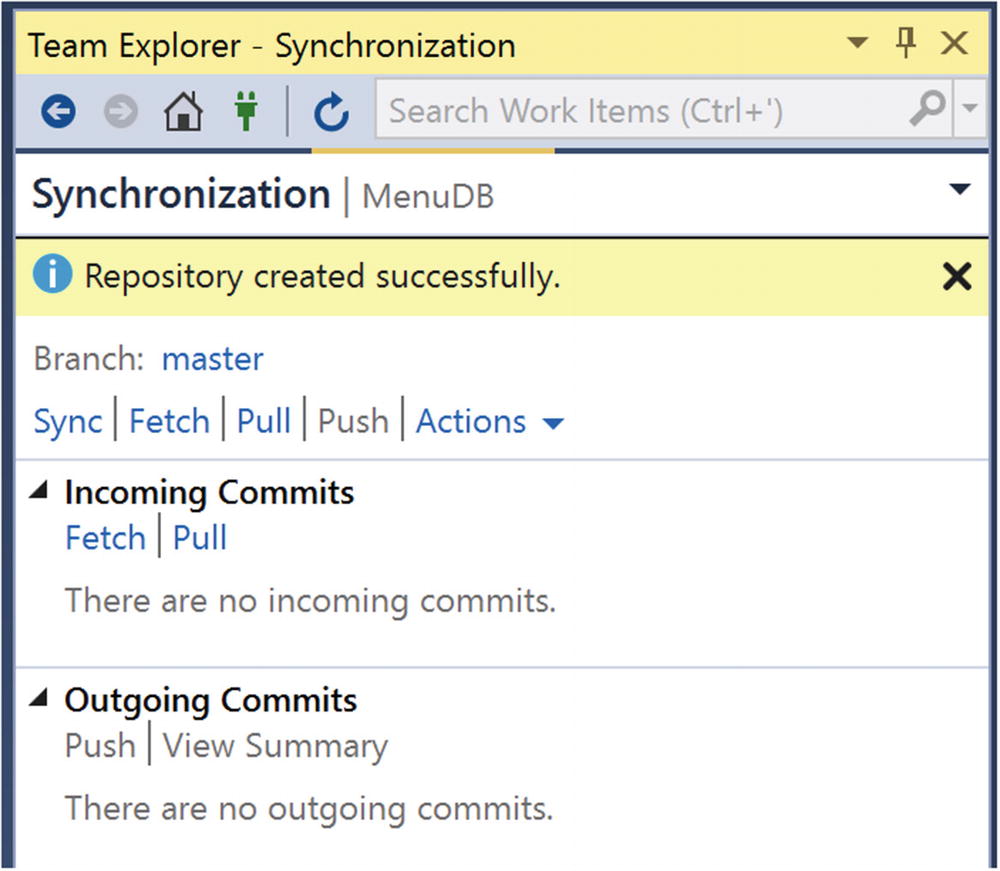
Database Project Has Been Added to GitHub Repository
You can see that the repository has been successfully created. This window also shows you that there are no incoming or outgoing commits for this project. Once you get the repository created, you will want to get accustomed to pulling incoming changes before you begin making changes to the database objects. Pulling changes down from the centralized Git repository will allow you to have the most updated code before you begin making changes. After pulling down incoming commits, you can then push outgoing commits. I am also unable to commit any changes as all changes have already been committed.
Database Project After Added to Source Control
Now that all items have been committed, you can see blue locks next to all the items. This signifies that all items have been properly checked into source control.
Implementing source control is a big step into getting your database projects to be more manageable. Knowing why source control can not only help you but help you convince others to help champion a source control initiative at your company. You are also ready to reach out to other departments and put procedures in place that ensure everyone feels comfortable implementing source control. I have also walked through the beginning steps of getting your database added to source control. This is the beginning of a journey that will have some hiccups but also save you time in the long run. Now that you have implemented source control, you are ready for the next steps in managing your T-SQL code. The next chapter will focus on the various methods you can use to test your T-SQL code and confirm that you are complying with various coding standards.