
Knowing how to design T-SQL is part of the foundation for writing professional code. Once you can write T-SQL code that can be easily understood, you can start to focus on improving the performance of your T-SQL code. If you learned T-SQL informally as part of your job or your primary function is writing code for software applications, you may not consciously consider set-based design when writing your T-SQL code. You may be an experienced database developer and want to learn more about set-based design.
In this chapter, I want to discuss how to work with your data. The first step is to get familiar with the various ways to interact with your data. Once you understand the different ways you can interact with your data, you want to start thinking about how to put the data in the best format for your queries. Then you should be able to write those queries in a way that takes advantages of SQL Server’s natural strengths.
Introduction to Set-Based Design
We live in a world where data is everywhere. Almost anything we do can generate data that needs to be saved. The first challenge in collecting data is determining how to store data. The second challenge is accessing that data. One of the reasons you will use SQL Server is to take advantage of the relationships between data. This is because SQL Server is a relational database management system (RDBMS). While our focus is writing T-SQL, it is important to also understand how the data is stored in SQL Server.
Name
Cost
Ingredients
Number of Servings
Preparation Time
Cooking Time
Type of Cuisine
Cooking Method
Type of Meal
General Attributes for Ingredients
Recipe | Ingredient | Cooking Method |
|---|---|---|
Name | Name | Name |
Cuisine | Unit of Measure | |
Number of Servings | Cost | |
Ingredients | ||
Quantity of Ingredient |
General Ingredient Information
Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|
Diced Tomatoes | 28 | Ounces | $1.84 |
Tomato Paste | 10 | Tablespoon | $0.79 |
Tomato Sauce | 8 | Ounces | $0.55 |
Minced Garlic | 60 | Tablespoon | $5.99 |
The data organized in the table is a data set. Looking at the data in the first column, Ingredient Name, there are three records that contain the word tomato. There are also two rows that are measured in ounces.
One of the things that can be difficult when working with SQL Server is the use of set-based transactions. People come to SQL Server from other fields and professions. These include software development, networking, system administration, or general business operations. In each of these cases, a person may not have developed the skill set for thinking in set-based operations.
Ingredients by Individual Row
Ingredient Name | |
|---|---|
Diced Tomatoes |
Ingredient Name | |
|---|---|
Tomato Paste |
Ingredient Name | |
|---|---|
Tomato Sauce |
Ingredient Name | |
|---|---|
Minced Garlic |
Ingredients as One Data Set
Ingredient Name |
|---|
Diced Tomatoes |
Tomato Paste |
Tomato Sauce |
Minced Garlic |
Viewing the data like this allows you to also see the similarities between the data.
You are trying to figure out how to handle implementing a process or a task with multiple rows at the same time. You want to consider doing the same thing to all those rows at the same time. In the preceding example, I can quickly determine which records have the word tomato in common. The data is giving us a hint that if we want to look at or change something about ingredients with tomatoes, there may be more than one way to accomplish this goal. This type of scenario may indicate your logic should be structured in a way that it can function correctly by using algebraic logic instead of hard-coded values.
Procedural code is described as not only telling a system what to do but how to do it. In many companies the software developers or software engineers are the ones responsible for writing the T-SQL code. One of the things I have found is when writing application code, this code is designed to work best procedurally. Much of the code performs well when interacting with data iteratively. The cost of context switching between procedural application code and database T-SQL code can be significant. Overall the process of writing set-based code causes a very different thought process than dealing with the code iteratively.

Data Retrieval from a Single Query
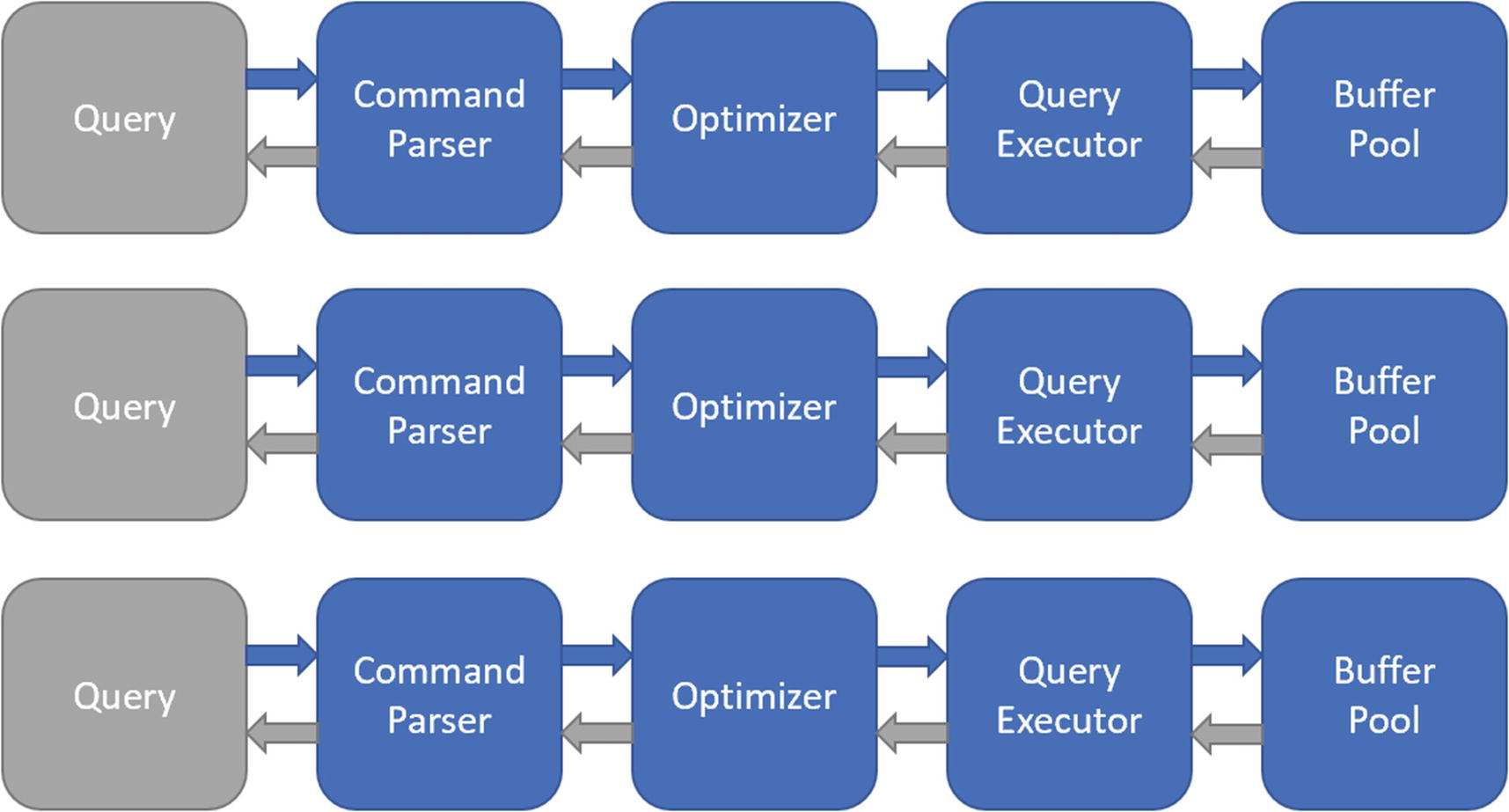
Data Retrieval when Query Retrieves One Row at a Time

Data Retrieval from Disk to the Buffer Cache
When the query is executed, that data may not even be in the buffer cache at that point in time. SQL Server must go to the subsystem disk I/O to find that data. Once that data is found, that data is stored in the buffer cache.
If each row is pulled individually, that call to the disk I/O will have to happen individually for each record. Pulling data from the buffer cache is not instantaneous. Getting data from the disk I/O and putting it in the buffer cache to then be retrieved by the query is even more resource intensive. Ultimately this creates a scenario where you want to focus on set-based design to have the best possible performance for the queries that you are executing.
Thinking in Data Sets
Now that I have discussed what data sets are, I want you to be comfortable thinking about data in a way that embraces data sets. Before you start writing T-SQL code, it may save you time and energy by first understanding what information is stored, how the data is stored, and selecting or using that data in groups of similar characteristics. Working with data sets is also easier to accomplish when the underlying tables are designed to work best with data sets.
Ingredient Data
Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|
Diced Tomatoes | 28 | Ounces | $1.85 |
Tomato Paste | 10 | Tablespoons | $0.79 |
Tomato Sauce | 8 | Ounces | $0.55 |
Minced Garlic | 60 | Tablespoon | $5.99 |
This is a list of possible ingredients for a recipe along with the number of units, the unit of measure, and the cost per unit. By looking at the preceding data, I can find similarities between the data in some of the columns.
Ingredients with Measurement of Tablespoon
Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|
Tomato Paste | 10 | Tablespoons | $0.79 |
Minced Garlic | 60 | Tablespoon | $5.99 |
Ingredients with a Cost Less Than $1.00
Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|
Tomato Paste | 10 | Tablespoons | $0.79 |
Tomato Sauce | 8 | Ounces | $0.55 |
Calculated Value for Cost per Unit of an Ingredient
Ingredient Name | Cost per Unit |
|---|---|
Tomato Paste | $0.08 per tablespoon |
Tomato Sauce | $0.07 per ounce |
One of the greatest challenges working with SQL Server is learning how to think in data sets. The simplest way to think of data sets is to view the process of retrieving data as performing an action on a column or a subset of a column. If you can find some sort of pattern on how to perform that action on a subset of the data, then you are thinking in terms of data sets.
General Listing of Ingredients
IngredientID | Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|---|
1 | Diced Tomatoes | 28 | Ounces | $1.85 |
2 | Tomato Paste | 10 | Tablespoons | $0.79 |
3 | Tomato Sauce | 8 | Ounces | $0.55 |
4 | Minced Garlic | 60 | Tablespoon | $5.99 |
Ingredients Containing the Work Tomato
IngredientID | Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|---|
1 | Diced Tomatoes | 28 | Ounces | $1.85 |
2 | Tomato Paste | 10 | Tablespoons | $0.79 |
3 | Tomato Sauce | 8 | Ounces | $0.55 |
Adding Tomato Soup to Ingredients
IngredientID | Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|---|
1 | Diced Tomatoes | 28 | Ounces | $1.85 |
2 | Tomato Paste | 10 | Tablespoons | $0.79 |
3 | Tomato Sauce | 8 | Ounces | $0.55 |
4 | Minced Garlic | 60 | Tablespoon | $5.99 |
5 | Tomato Soup | 10.75 | Ounces | $1.58 |
Ingredients with Tomato Using Hard-Coded IngredientID
IngredientID | Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|---|
1 | Diced Tomatoes | 28 | Ounces | $1.85 |
2 | Tomato Paste | 10 | Tablespoons | $0.79 |
3 | Tomato Sauce | 8 | Ounces | $0.55 |
Ingredients with Tomato Searching on the Ingredient Name
IngredientID | Ingredient Name | Unit(s) | Measurement | Cost |
|---|---|---|---|---|
1 | Diced Tomatoes | 28 | Ounces | $1.85 |
2 | Tomato Paste | 10 | Tablespoons | $0.79 |
3 | Tomato Sauce | 8 | Ounces | $0.55 |
5 | Tomato Soup | 10.75 | Ounces | $1.58 |
In that case, I would want to run a query where the ingredient name was like tomato. As you can see in this example, there are not only limitations with regard to data sets that affect performance but can also affect functionality.
One of the largest challenges in using data sets has to do with inserting data records. In most cases, when you insert a data record, you are inserting a single record at a time. This can cause it to become a habit to only deal with inserting one individual record at a time. When you are designing new table or moving data, you may have situations where you can think of an insert in terms of a data set. This will often happen when you are creating a query to insert data into another table.
While it does not seem like these situations will come up very often, I am frequently using data sets when I am populating temporary tables, table variables, and common table expressions.
Ingredients in a Recipe by Each Record
RecipeID | IngredientID | IsActive |
|---|---|---|
Spaghetti | Diced Tomatoes | True |
RecipeID | IngredientID | IsActive |
|---|---|---|
Spaghetti | Tomato Paste | True |
RecipeID | IngredientID | IsActive |
|---|---|---|
Spaghetti | Tomato Sauce | True |
RecipeID | IngredientID | IsActive |
|---|---|---|
Spaghetti | Minced Garlic | True |
Ingredients in a Recipe as a Data Set
RecipeID | IngredientID | IsActive |
|---|---|---|
Spaghetti | Diced Tomatoes | True |
Spaghetti | Tomato Paste | True |
Spaghetti | Tomato Sauce | True |
Spaghetti | Minced Garlic | True |
Another scenario where I have found using bulk inserts into temporary objects is when those records may require additional modifications by joining to other queries that include multiple table joins.
If you are changing how your application code works and inserting new tables or changing how the value should be populated, you may find yourself needing to perform bulk updates. While you can perform bulk updates by updating one record at a time with hard-coded values, you will want to see if there is a way to update all the records in the data set by using the same code logic. However, this can be where data sets really help you out.
You can write one query to find all the records that you need to update and systematically perform all those updates. In addition to the advantages in terms of performance and functionality, this type of process also ensures that your data is being handled consistently.
Recipes with Servings and Meal Type
Recipe | Serving Quantity | Meal Type |
|---|---|---|
Spaghetti | 8 | Dinner |
Spinach Frittata | 6 | Breakfast |
Roasted Chicken | 4 | Dinner |
Dinner Rolls | 12 | Bread |
Recipes as Individual Records
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Spaghetti | 8 | Dinner | Meat |
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Spinach Frittata | 6 | Breakfast | Egg |
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Roasted Chicken | 4 | Dinner | Meat |
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Dinner Rolls | 12 | Bread | Grain |
Recipes as Data Sets by Meal Type
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Spaghetti | 8 | Dinner | Meat |
Roasted Chicken | 4 | Dinner | Meat |
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Spinach Frittata | 6 | Breakfast | Egg |
Recipe | Serving Portion | Original Meal Type | New Meal Type |
|---|---|---|---|
Dinner Rolls | 12 | Bread | Grain |
While these updates could be done in a with hard-coded values, there are times that it may be better to join the table you are updating to other related tables. This type of interaction between the tables may make it easier to perform your updates.
You could use the ingredients in the recipe to determine how to update the meal types on your recipes. It helps to think about the logic you would want to use. If you wanted to update the meal type to a generic category based upon the main ingredient per recipe, you would first need to figure out what the main ingredient was per recipe. You would also need to determine general categories for your meal type. In the preceding scenario, I might have Meat, Egg, Fruit, Vegetable, Grain, and Sugar. Once I have both pieces of information, I may create a temporary table to map the ingredients to a specific category, unless I have designed the ingredient table to record that specific category per ingredient.
In general, I found anytime that I am dealing with data one record of the time, I am often having to perform some type of manual interaction. I have found that manual interactions are the most likely to have issues or errors. I much prefer writing code in data sets, so that I can be more assured that my logic is being consistent.
Writing Code for Data Sets
Previously, I discussed how to start thinking about your data as data sets instead of individual records. I frequently use data sets when selecting, updating, or deleting data. While most application code may insert single records at a time, there are many common scenarios where inserting data as data set may also be helpful. In this next section, I will walk through various scenarios where you may want to think about your data as sets instead of individual records.
The most frequent use for data sets is when you want to view a portion of data. Ideally, these data sets are selected based upon specific criteria. This is not only good for performance but also can help make sure you are only looking at the specific data that you want. For most scenarios, it does not even make sense to retrieve and display one individual record at a time. Oftentimes, if you find yourself in a situation where you are selecting one record at a time, it is a good indication that you may want to see if that T-SQL code can be rewritten to use set-based logic.
Union of Two Queries
General Ingredients
IngredientID | IngredientName | Measurement | IsActive |
|---|---|---|---|
1 | Italian Sausage | Pound | 1 |
2 | Tomato Sauce | Tablespoon | 1 |
3 | Diced Tomatoes | Ounces | 1 |
4 | Tomato Paste | Ounces | 1 |
5 | Minced Garlic | Ounces | 1 |
Ingredients with Tomatoes
IngredientID | IngredientName |
|---|---|
2 | Tomato Sauce |
3 | Diced Tomatoes |
4 | Tomato Paste |
Ingredients Measured in Ounces
IngredientID | IngredientName |
|---|---|
3 | Diced Tomatoes |
4 | Tomato Paste |
5 | Minced Garlic |
Union All of Two Queries
As you can see, the UNION ALL would return two rows that were identical. There are times where each of these scenarios may be desirable.
Intersect of Two Queries
Except of Two Queries
Using an EXCEPT statement may not be the preferred method to exclude results from a data set, but it is the method that I am more accustomed to using. Therein lies the benefits and challenges of T-SQL code, for almost any scenario there is almost certainly more than one way to write T-SQL code. Depending on the reason you are writing database code will determine the level of flexibility you have in writing your code. If you are executing a query for a single time, you may be able to use a less efficient method to access this data. However, if you are writing your code for an application, you will want to balance how you write your T-SQL code to be both efficient and readable.
Inserting Data as a Set
Inserting Data Record by Record
As you can see, inserting data record by record takes up considerably more code and can be quite a bit more tedious.
Updating Data Record by Record
Updating Data as a Range
Updating Data as a Data Set
This query accomplishes two goals. It lets you update more than one record in a given query. This T-SQL code also uses the data set for all ingredients that contain the word tomato to determine which records should be updated.
Updating Data with Joins to Create a Data Set
Verifying the Data Set with a Select Statement
You can check the records and verify the record count. Before performing the update, I suggest wrapping the UPDATE statement in a BEGIN TRAN… ROLLBACK to verify the record count.
Just like working with updates, you can also use data sets when deleting data. I have found that deleting data using data sets can be significantly more efficient, but it can also be somewhat risky if the data is not verified prior to deleting.
One of the largest temptations overall in writing T-SQL code is not taking advantage of data sets. Often, this is a result of being more comfortable writing procedural code or not having developed the ability to think in terms of data sets. My goal throughout this next section is to guide you through various ways to write code that embraces using data sets.