
The heart of ITIL lies in operations. This is the phase of service management where value is essentially created or lost, customers are awed or move away, and organizations thrive or barely survive. There may be a phase when enhancements or new developments could pause (maybe due to economic slump) but operations continue as long as the product’s end of support exists or until the service that is offered to customers is active.
They say that you need to put your money where your mouth is. For a service provider, most of the action takes place during operations. Customers always tend to remember service operations over all other practices and activities, as their interactions mostly happen in this area. The service provider also bills the maximum amount of the total contract in the operations phase. Yet, this is not the best place to put your money, although the mouth is wide open. You will find out the reasons soon enough!
Operational activities deal with maintaining products and services that have been designed, built, and transitioned in the earlier activities of the service value chain. In this phase, no functional or nonfunctional modifications are performed to the service (any modifications performed will be done as an enhancement). A status quo is maintained, ensuring that the service runs as it was designed to. The operational practices run the longest in terms of timeline, are the biggest in terms of staff strength, and, most importantly, the customer generally forms a perception of the service provider through the operational phase achievements.
If the strategy is innovative, the design is sound, and the transition is perfect, then you can expect service operations to be less noisy and probably peaceful. In reality though, this never happens. Strategies are bound to change over time, designs have flaws, either manmade or limitations owing to technology, and transitions are rarely event free. Technological innovations and advancements bring in changes to products and services. These changes are designed, built, and transitioned through the change control practice; after the transition, the modified specs of the product or service are maintained by the operational practices. With the advent of DevOps, product and service maintenance is far easier. Otherwise, there usually exists a period of transition and training of the support staff. In that case, since the support staff is new to the changes, you can expect support glitches and compounding problems for the customer. DevOps methodology has ensured that operations is a no-brainer and it is business as usual in the life of a DevOps team that builds and manages products and services.
I have worked in service operations for a good portion of my career, and it is not something that I would like to focus my memory cells on. The usual run-of-the-mill day included taking calls on the fly, sleeping when the customer is sleeping, and juggling vacation plans in sync with peers. Now the good part: service operations hire the most people in the service management industry. ITIL practitioners have job security as long as they are able to adjust to the flexibility needs of organizations. Remember that not all service provider organizations work in a DevOps mode, so there’s plenty of work to be done in the next decade or so.
With DevOps, a service operations professional is expected to manage more than just service operations—like managing some of the CI-CD tools or getting your hands dirty with coding. But one thing is clear: you cannot expect to survive the IT industry as a one-trick pony. You need to be able to do multiple forms of activities. That is the way the future is shaping up, and it’s an immediate trend that I am seeing in the industry today.
Monitoring and event management
Incident management
Problem management
The monitoring and event management’s expectations from an examination perspective are a basic understanding requirement, while the incident and problem management practices have to be well understood. This is an important chapter from two angles: (1) as I mentioned earlier, operations are at the heart of ITIL and the chapter therefore demands maximum focus; and (2) a number of other practices interlink to these practices, so it is imperative that you get to the bottom of operational practices.
Practices for managing operations is an important topic from the ITIL Foundation exam perspective. If you need to answer questions correctly, you need more than a cursory understanding of the topics. You can expect six to seven questions to appear from this chapter.
Monitoring and Event Management
ITIL Definition of Monitoring and Event Management Practice
The purpose of the monitoring and event management practice is to systematically observe services and service components, and record and report selected changes of state identified as events.
The job of monitoring and event management practice is to ensure that a finger is placed on the pulse at all times. The objective is to notice abnormal behaviors at the earliest possible time in order to bring help. Think about it! The earlier you detect a problem, the sooner you can fix it, which translates to service outages staying at a minimum.
Some of the typical CIs that are monitored include infrastructure, applications, IT security, services, and business processes. A typical service could have thousands of CIs behind it. So, it doesn’t make sense to monitor every single one of them. Typically, the critical CIs that will contribute directly to the workings of a service are monitored. If a server has an auto failover established (high availability architecture) through another server, the frequency of monitoring may be limited. Not-so-critical applications may not be monitored at the same breakneck speed as an Internet banking application. The idea behind this is to prioritize the services and CIs that need to be monitored and the subsequent actions that have to be taken in case of a failure. In the same example, if the Internet banking application is down, alarm bells could start ringing for the major incident management staff to pool technical resources to fix the problem at a rapid pace. Technical staff may be woken up from their sleep to jump into the issue. Now suppose internal time management software goes down; the downtime is probably identified when a staff reports it, and it may be fixed at its own pace. Clearly and considerably, the Internet banking application is prioritized over the time management software. It all depends on the impact and urgency to get the application up and running.
Types of Events
ITIL Definition of an Event
Any change of state that has significance for the management of a service or other configuration item (CI).
An event is a change of state. My daughter going from hungry to full after a meal is also a change of state. So is the server not being accessible anymore. An event by itself is not a game changer but the significance behind an event is critical. What are the types of events that we possibly want to keep an eye out for? A user logging into an application successfully is an event that can be ignored, but an application used by security agencies registering a login from North Korea is worth taking note of and confirming.
The definition of an event is one of the frequently asked questions on the ITIL foundation exam. The question will center on identifying the right definition from a list of choices. So, it is prudent for you to understand and memorize the definition verbatim.
All events are not the same. Most are informational and some indicate failures or about to fail conditions. Based on the application, events are broadly categorized as follows.
Exception Events
Exception events signify errors. They indicate a condition where the monitored subject is not performing as it should—in other words, there is possibly something wrong with a component or a service. They require the most attention. Therefore, they are classified in the topmost tier and normally require urgent action.
Server is unreachable
Hard disk space has exceeded the threshold limits
Administrator has tried to log in with an incorrect password
PC scan reveals malware
The definition of which events are exceptions and which are not is a decision of the organization in agreement with the customer. There is no universal categorization based on illustration of events.
Warning Events
You might have heard of the end of days apocalyptic events, wherein prophecies are foretold about the end of the world as we know it. The world has not ended yet but there is a warning ahead of time. The warning is meant to accelerate caution and take a corrective course before something bad sets in.
Similar warning events are defined in the monitoring and event management practice, and these events exist to warn about an impending exception. They throw out a warning stating that things will soon take a wrong turn if not dealt with quickly. They are important because they help an IT organization to be proactive and prevent exceptions/downtimes. The end of times may be a fantasy but warning events aren’t. They have a high probability of materializing. Therefore, it is imperative that a service provides the same kind of urgency as for exception events.
Memory usage is hovering close to the acceptable threshold.
An application is running slower than normal.
Turnaround time for a certain transaction is not within the optimized limits.
Temperature in the datacenter is not at the ideal level.
Informational Events
If you are big on online shopping, you get those emails and messages when the package has been dispatched or when it is out for delivery. They don’t mean much in terms of our response. I don’t get ready to receive a package as soon as I receive an email in the morning informing that it is out for delivery. But I would definitely feel jittery if I didn’t get this message.
In short, informational events convey information, particularly the information about a change of state—not necessarily an abnormal change or status or anomaly. These events do not call for urgent action from IT staff and are generally recorded and retained for compliance and audit purposes.
User has logged in to a server
New folder created on a SharePoint drive
Application has processed a batch job
Hardware technician has entered the datacenter
Note A service provider organization must spend considerable time and effort in designing the events and the event conditions. They wouldn’t like to get an event rather late in the day and they definitely don’t want to spend additional time processing an informational event.
Key Activities
In the erstwhile ITIL framework, event management was a minor process. Although monitoring was a part of the event management, it wasn’t explicitly called out. Although critical, it was considered minor because the scope and management of it was limited to few activities and most of it was driven through toolsets. ITIL 4 doesn’t make such a distinction, and the practice has been called out to perform several activities in the service management group.
Monitoring Strategy
Monitoring is an activity carried out by the tools. Yet, it does not give organizations the freedom to monitor every CI and every node, for the simple reasons that it costs money to procure licenses and management of them will be nothing short of a nightmare.
There is a need for a strategy to be put in place to set the record straight and to provide direction and leadership to the management of events. The strategy puts down conditions on what CIs and services will be monitored, which will in turn be based on service criticality and the business impact.
Monitoring Design
We discussed the event types in the earlier section. During the monitoring design activity, a definite shape to each of these types of events is carved out. It essentially identifies the type of events that will go into each of the buckets.
Further, the thresholds for firing warning and exception events have to be defined. For example, if you are going to produce a warning event of hard disk capacity at 95 percent, it may not give the operations team sufficient time to work on the capacity issue at hand. Rather, giving a warning at 70 percent will provide ample time and enable prudent decisions by the operations team. Such thresholds are identified for different types of CIs: a warning event for a server will have separate conditions compared with a warning event for an application.
Solution architects employ empirical methods and trend analyses to determine thresholds and other design parameters. The monitoring tools as well are determined by them.
Policy Management
Now that the events have been designed, the next item on the list is the management of them. What are the policies that drive the management of these events? That is the essence of this activity.
Every type of event that is designed is supplemented with a policy and a process for its management. If there is a warning of a hard disk capacity of a server, what should be done? Should an alert be raised to the server team, or should an incident with low priority be created and assigned automatically? What should be the priority for exception events? Do all exception events have the same incident priority tagged to them? The answers to these questions are an outcome of this activity.
Implementation of Monitoring Tools
With the monitoring designs in place, the monitoring tools are implemented. Tools such as AppDynamics and Splunk rule the monitoring tool space, and this activity ensures that they are set up against the CIs, nodes, and services as per the design.
There are two types of monitoring that we normally employ: passive monitoring and active monitoring.
Passive monitoring is the native monitoring capability built into a CI; for example, a firewall has its own monitoring capability. When something doesn’t work as it should, then its monitoring picks up the signal and takes appropriate action.
Active monitoring is a nonnative entity that performs monitoring. Nagios, AppDynamics, and Splunk provide active monitoring. These are featureful compared with passive monitoring, as they proactively monitor various parameters of a CI and a service. Say, for example, Splunk pings a server every minute and if there is no response back after certain number of pings, it raises an exception event. Let’s say, in this case, the network is down. A server’s passive monitoring tool does not come into play, as the loss of network does not give it a fair chance to create events.
Implementation of Processes
Processes are defined to manage events and the subsequent activities. Not only this, processes provide a framework for the maintenance of monitoring tools and the process efficiencies around them.
The event management processes are defined through the policy activity and get implemented through this activity. Event management even provides guidance to the implementation of automation, the threshold conditions, and the automation actions.
The activity is also responsible for identifying the process roles and their responsibilities. Their accesses must be sorted out. To perform their roles, they are tightly aligned with the defined policies and processes.
Automation Enablement
Most practices in ITIL are role and people focused. Automation is used in repetitive jobs and to generate efficiency. Monitoring and event management practice is the lone practice that bucks the trend. Its processes employ automation for its normal operations; without tools and automation, the practice fails to deliver. In other words, tools and automation form the backbone of the monitoring and event management practice.
Automation can be a part of the CIs through the passive monitoring feature that is built in to them. It can perform limited sets of activities and can come in handy in identifying configurational level changes. On the other hand, active monitoring tools employ automation to poll the CIs and to take necessary actions based on the response. Also, the changes identified in passive monitoring can be fed into the active monitoring tools for further processing such as raising alerts and incidents.
Engagement with Service Value Chain
Incident Management Practice
Incident management is one of the most popular ITIL practices, from the perspective of the number of jobs the process creates. Quite naturally, most ITIL professionals are aware of the principles that the practice lives by.
In addition, the practice runs the longest, and with maximum touch points with various stakeholders across the service value chain. The incident management practice is primarily responsible for customer satisfaction and the agility with which service interruptions are handled.
I have worked a number of years in the incident management practice area, some as an incident manager and mostly as the incident management practice owner. The incident management process is lively, and you always end up learning something new every time a new situation comes up. You cannot get bored with the process, as every situation is different; even in two similar situations, the potential responses could vary. It is also the process that has kept me up all night on certain days and has kept the senior management of the customer organization at the edge of their seats throughout.
If you need to be exact about the incident management practice, you can state that it is a reactive process with no proactive side to it. And I would agree. It reacts to situations, and its efficiency depends on how quickly and efficiently the service outage is managed. The customer does not get upset if there are service outages, but the customer would definitely become disgruntled when the restoration goes beyond the expectations set.
It is a general habit or a practice to begin either the design or implementation of ITIL practices in an organization from the incident management practice. Whether this is the best practice to start with or not, I will reserve my comment for now. However, its popularity owing from break fixes that are the norms in the service or product industry has made the practice an essential part of every industry, including non-IT ones.
ITIL Definition of Incident
An unplanned interruption to a service or reduction in the quality of a service.
Customers enjoy services, which provide value. If there is a disruption to the service, then the value that comes through the service is no longer there. Think about a salon in your area. You go there to get a haircut, which is a service. The value is good looks coming from well-groomed hair. If the salon closes down due to a water leakage, then the service gets interrupted. As a customer, you can no longer enjoy the service until the water leak is taken care of.
The disruption to the service is an incident. If the water leak is planned (I cannot imagine it can be, but for argument sake let’s say it is), then it is no longer an incident.
The second criterion for an incident is subpar quality of service. If the barber in the salon gives you a haircut that’s uneven and asymmetrical, then although you are getting the service, you are no longer deriving the benefits from it. You will be far from having good looks from a bad haircut. Such cases are considered as incidents as well.
Some IT examples could be buffering Netflix videos, unable to send emails, and hard drive failure on a laptop. In all these cases, the service is either completely unavailable or is of bad quality. Such disruptions are referred to as incidents.
If you are a betting person, you should place your bets on the definition of an incident appearing on the ITIL foundation exam. The question will center on identifying the right definition from a list of choices. So, it is prudent for you to understand and memorize the definition verbatim.
ITIL Definition of Incident Management Practice
The purpose of the incident management practice is to minimize the negative impact of incidents by restoring normal service operation as quickly as possible.
We know what an incident is: a disruption to a service. Incidents, although common, are bad. In our respective projects and organizations, we too don’t want to have incidents on our plates. The management of incidents is all about keeping the incident rate at the lowest and ensuring that the lifespan of an incident is as short as possible. This minimizes the loss of a service and increases customer satisfaction.
Looking specifically at the definition, the incident management practice exists to reduce the impact of an incident, which is possible by quick resolution of incidents.
Considering the examples that I stated earlier, as a customer you would be happier if Netflix stops buffering and starts playing the movie—at the soonest possible timescale. We don’t appreciate loss of a service even for a minute but when we compare, we would be happier to see services restored in 10 minutes rather than in 20 minutes. The essence is time. The faster the resolution, the more effective the incident management practice.
Leaders may say proactiveness is the way forward and the future. However, when it comes to the incident management practice, it is highly (or completely) reactive and the most looked after process in the service management industry.
Good Practices of Incident Management
- 1.
Find a fix (cure) so that the downtime (sickness) does not last long.
- 2.
Find a preventive fix (immunity) so for the majority of causes, you remain protected from incidents (sicknesses).
Yet, you may get the occasional incident (common cold) where an application freeze (flu) can only be resolved through a server restart (paracetamol).
The trick is to manage incidents in a way that the downtime is minimal. It is difficult to define minimal downtime, as every user and every service has its own limits of withstanding downtimes. Most importantly, improvements that are put in the Improve activity of the SVC find opportunities that could potentially prevent incidents, like scheduling an auto-reindexing job of the database to prevent data search slowness.
Next up, incidents come in all shapes, colors and sizes. So the management of incidents must be able to pinpoint the area of concern and get the right team involved. For example, the team that manages servers is separate from the team that manages databases. And the team that manages applications is separate from the team that manages integrations. For all we know, these teams could be sitting in different business units and be a part of different organizations.
- 1.
Log all the incidents, including those identified by the internal IT staff.
- 2.
Self-help is a great aid for organizations in hands-free operations. Activities like password reset should be carried out without human intervention.
- 3.
Have an able service desk as a first point of contact for users and other stakeholders. Let them not be just a mouthpiece but rather be the first line of defense for the incident management practice.
- 4.
Identify a functional escalation matrix where, starting from the service desk, an incident gets escalated through various teams for its resolution.
- 5.
Keep a matrix of teams that are responsible for different categories of incidents. This is handy for quick handover followed by faster resolution of incidents.
- 6.
Remember that all the stakeholders who support the service value chain can potentially resolve incidents— including suppliers who provide necessary enablers to a service.
- 7.
Remember the commandos who are specially trained units helicoptered in for special missions. Build a team such as the commandos who can be relied upon when the impact and urgency is of utmost importance.
- 8.
Use techniques such as swarming, where all stakeholders get together during the initial stages of resolution. Once they are able to identify which stakeholder needs to take it forward, others disperse and the stakeholder in charge continues to the end.
- 9.
Some incidents could give rise to service continuity management practice (which is not covered as a part of this book), where the disaster recovery plans are invoked for a speedy resolution (or workaround) to be put in place.
- 10.
Remember that all stakeholders are bound by a single principle: to keep all the updates recorded on an incident register. Without this discipline in place, it is impossible to realize the benefits of the other good practices that I have mentioned here.
The good practices I have stated here are just the tip of the iceberg and definitely not comprehensive, but I believe they should get you started in recording the good practices that work for you and your organization.
Service continuity management comes into play when there is a disaster. Examples could be the COVID situation, floods, earthquakes, and riots. The practice ensures that the service endures in the wake of disasters. Some techniques employed could be replication of data in real time to a server in a different part of the world, and flying out people to different parts of the geography to work as normally as possible. While this is reactive in nature, proactively the practice will work on building resilience into services by ensuring that second and third lines of defense will come into the arena if the services were to come under the effects of a disaster.
Incident Management Life Cycle
Monitoring and Event Management in SVC
SVC Activity | Involvement | Details |
|---|---|---|
Plan | None | There is no engagement of the practice in the plan activity due to its transactional and operational nature. |
Design and Transition | Medium | The data coming from monitoring CIs and services can influence designs. |
Obtain/Build | Low | During environment development, its respective environments could come under the purview of the monitoring and event management practice. |
Engage | Low | Based on the monitoring outputs, third parties could be engaged. |
Deliver and Support | High | The crux of the monitoring and event practice performs in the Deliver and Support activity – which is the operational activity of the service value chain. Identifying anomalies and raising incidents are examples of its engagement. |
Improve | Medium | The monitoring and event management practice keeps its ears close to the ground and is in an excellent position to provide data points for improvements. |
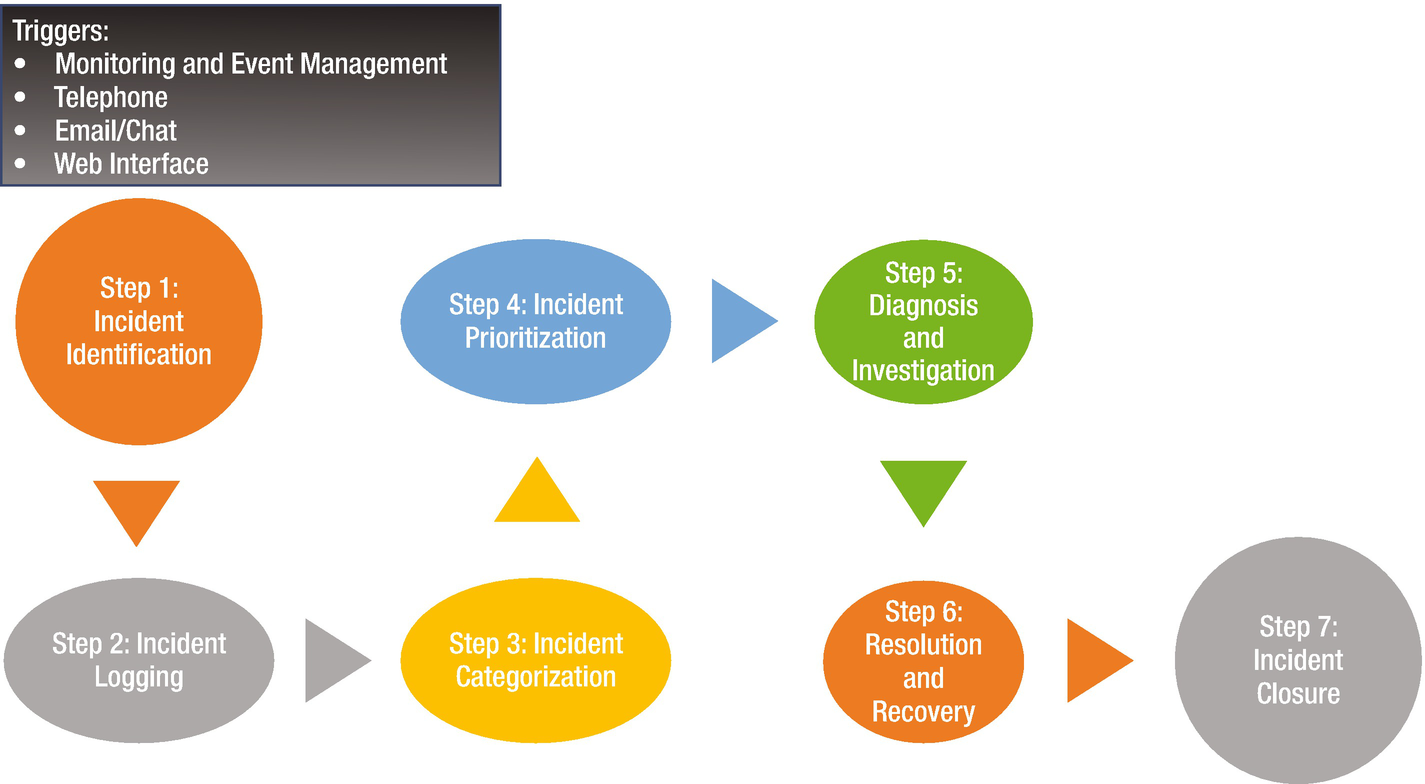
Incident management life cycle
Incident Management Practice in SVC
SVC Activity | Involvement | Details |
|---|---|---|
Plan | None | The planning activity and the incident management practice do not necessarily have to work with each other. |
Design and Transition | Medium | During transition (system tests and user acceptance tests), incidents do occur (depending on the definition set forth). Resolving them quickly will help in releasing the end product as per the planned scheduled. |
Obtain/Build | Medium | Just as in having incidents in the test environment, they could happen in the development environment as well. Resolving them quickly will help in releasing the end product as per the planned scheduled. |
Engage | High | Much of incident management is communication to stakeholders. They can be customers, users, or suppliers. It is a good practice to keep the statuses transparent, to build trust with the stakeholder community by setting the right expectations and obtaining confirmations upon resolution. |
Deliver and Support | High | Incident management operates in the operate space, and the union between the practice and the service value chain is significant. |
Improve | Medium | Improvement ideas are often generated on the back of incidents. Depending on the number of incidents and their impact, improvements are prioritized and delivered as well. |
The steps showcased in this section may or may not appear on the ITIL Foundation exam. If you want to jump ahead, feel free to skip this section. However, if you are keen to understand how the process is laid out and what activities are performed and in which order, read on!
Step 1: Incident Identification
Monitoring and event management: Through the monitoring and event management practice, incidents are identified; and through integration between the monitoring tools and incident logging tool, incidents can be automatically logged.
For example, a server that goes down raises an exception with an event management tool. The tool is designed to poll the server every minute; when it does not receive a response three consecutive times, an exception event is raised, which in turn logs an incident ticket.
Telephone: One of the oldest forms of raising complaints is to pick up the phone and complain about a disrupted service. To raise an incident, users have the option of calling the service desk. The trigger in this case is the phone call by the users. It is also possible that IT staff could find a fault in one of the systems and call the service desk.
Email/chat: Instead of calling in, users can opt for a passive form of communication through email or real-time chat. They would still be interacting with the service desk and getting them to raise an incident on their behalf. This form is quite popular at the time of writing of this book, and it lets service providers cater to multiple users through a single service desk agent.
Web interface: In today’s world of cutbacks, the service desk is often replaced by self-help mechanisms. ITSM (IT Service Management) ticketing tools provide the front end for users to raise their own tickets without the aid of the service desk. In a way, it is good that precious resources can be used elsewhere. But it could also lead to a good number of misidentified incidents that could add to the flab that you don’t like to see.
Most organizations also allow users to create their own incidents through a web interface by building a wrapper around the ITSM ticketing tool. For the user, the form they fill out would be simple without the complications of an ITSM tool.
Step 2: Incident Logging
All incidents that are identified should be logged, with a timestamp that is unalterable. Incidents are generally logged directly into the tool by the user if there is a web interface.
And the event management tools can also create incidents, based on the threshold levels and the designed algorithms. The service desk raises incidents on behalf of end users when they call, email, or chat about their issues.
There are several ITSM ticketing tools that are employed to log incidents. Popular ones include ServiceNow, BMC Remedy, and CA IT Service Management. ServiceNow is far ahead of its competitors. Its seamless integrations with other tools and flexibility to implement and run on optimized infrastructure make it an easy choice for organizations. Essentially, ITSM tools log different types of tickets, be it incidents, changes, or problems, among others. They also host CIs and CMDBs and knowledge databases. When an incident is raised, it can be mapped to the CI and, based on the incident summary, the knowledge base often pulls knowledge articles that could help with the resolution.
Incident number (unique)
End user name
End user team name
Incident logger name
Time of logging the incident
Incident medium (phone/chat/web/email)
Impact
Urgency
Priority
Category
Related CI
Incident summary
Incident description
Assigned resolver group
Assigned engineer
Status
Resolution code
Time of resolution/closure
Step 3: Incident Categorization
Not all incidents fall into the same bucket. Some incidents are server based, some network, and some application/software. It is very important to identify which bucket the incident falls into, as the incident categories determine which resolver group gets assigned to resolve it.
For example, if there is an incident logged for the loss of Internet, you need the network team in charge of handling network issues to work on it. If this incident gets categorized incorrectly, say applications, the incident will be assigned to a resolver group that specializes in software troubleshooting and code fixes. They will not be able to resolve the incident. They are required to recategorize and assign it to the right group. But the effect of wrong categorization is that the resolution takes longer, and this defeats the purpose of the incident management process. So, it is absolutely imperative that the team that is logging the incident is specialized in identifying the incident types and categorizing them correctly.
In cases of autologged incidents, event management tools are designed to select a predetermined category that does not falter. User-raised incidents are automatically categorized based on the keywords mentioned in the incident summary and description. It is quite possible that the incident could be categorized incorrectly in this scenario, but in the interests of automation, this is the price we have to pay .
Step 4: Incident Prioritization
Consider a real-life scenario of a company that employs 100,000 employees and there is a support team of about 100 technicians. At any given time, around 1 percent of the employees raise incidents for issues faced by them—1,000 tickets. So you have 100 IT staff to handle 1,000 incidents. They cannot handle them all at the same time. They need to pick and choose which ones to work on first and follow up with the rest. How do they pick and choose? The answer is in prioritization of incidents .
Not all incidents carry the same weight in terms of their impact and urgency. Some are more urgent, some cause more impact than others, some may not be urgent, and some are neither grossly affecting nor urgent.
A finance application at the end of the month will cause a major impact and it needs to be fixed urgently.
A finance application in the middle of a month will cause major impact but it may not be urgent.
The PDF viewer not displaying in the right format for a single user is low impact and not urgent.
Network connectivity for an entire floor of business users causes a great impact and is urgent.
The email application not working for a VIP user is low impact but is very high on the urgency list.
Incident Priority = Impact × Urgency
Financial losses
Productivity losses
Loss of reputation
Regulatory or legislative breaches
Urgency is a measure of how quickly or how swiftly the incident needs to be resolved. It may demand a majority of the staff be dedicated to a particular incident immediately or indicate resolution when IT resources become available.
Problem Management Practice in SVC
SVC Activity | Involvement | Details |
|---|---|---|
Plan | None | The planning activity and the problem management practice do not necessarily have to work with each other. |
Design and Transition | Low | Problem management inputs may be used during testing, and knowledge transfer activities during transitions. |
Obtain/Build | Low | The output of problem management might lead to detection of product defects, which is fed back to the Obtain/Build activity for providing the fixes. |
Engage | Medium | Problems are fewer but may not be limited to the IT community alone. Long-standing problems could be made visible to customers and end users who may like to be a part of the problem resolution process. The supplier likewise may be involved if the problem could be caused due to them or if they have a role to play in its resolution. |
Deliver and Support | High | Problem management has the highest play in the Deliver and Support activity—through the activities involving incident reduction and problem resolution. |
Improve | High | Problem management is the other side of the improvement activity. Both the Improve activity and problem management practice are set out to make the product/service more stable and incident free (read incident reduction). |
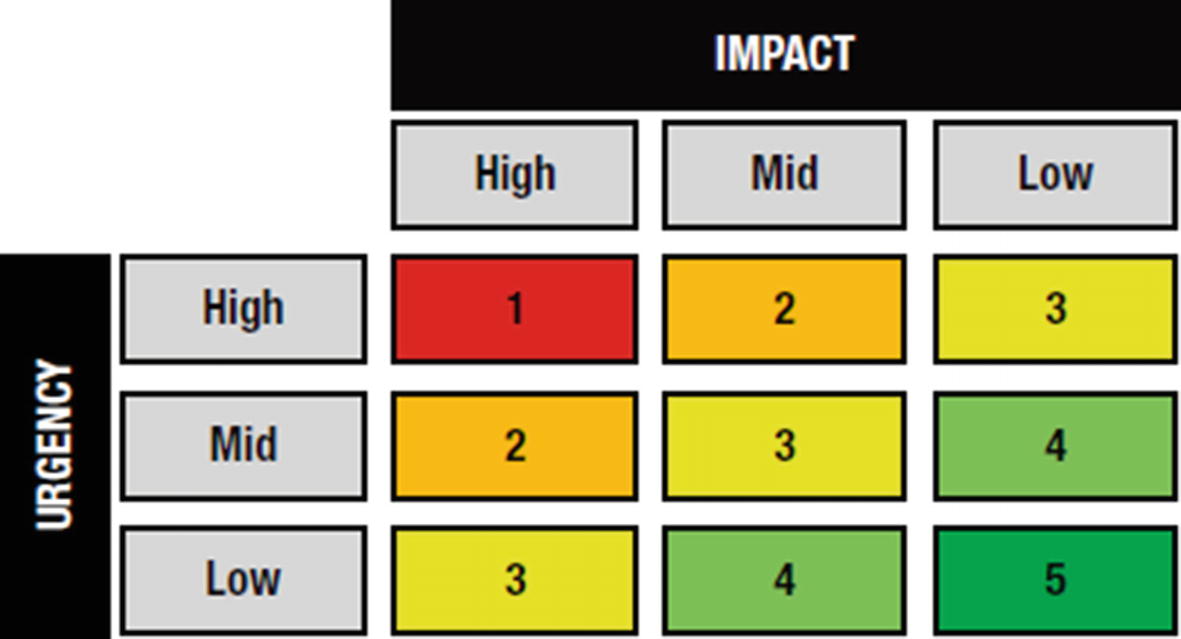
Incident priority matrix
As per the matrix, a high impact and a high urgency incident would be classified as priority 1. A medium impact and urgency incident is prioritized as 2, and so on. The matrix shown here is too simple to be used in the real world. There are far too many permutations and combinations to consider in rating the priority of an incident, but the principle is the same.
Response SLA is the target set for technicians to respond to incidents, say by acknowledging and accepting the incident in their respective queues. For example, an incident was logged at 10 a.m. and the defined response SLA is 30 minutes. In this case, the technician is expected to accept the incident before 10:30 a.m.
Resolution SLA is the target set for technicians to resolve incidents. For example, an incident was logged at 10 a.m. and the defined resolution SLA is one hour. In this case, the technician is expected to resolve the incident before 11 a.m.

Incident management SLAs
In the example, the highest priority, P1, has a response SLA of 15 minutes and resolution SLA of 2 hours. This requires the technical team to acknowledge the incident within 15 minutes (start working on the resolution), and the P1 incident is required to be resolved before 2 hours. Say, for example, a very sensitive banking application that allows foreign exchanges to transact is down. This outage will cost the bank a significant amount of financial loss and the bank will lose customer perception. Also, it could face the government’s wrath as well owing to regulatory norms. To ensure that such a scenario is contained, a P1 priority with stringent timelines will allow the maximum resources to be allocated at the earliest possible time to resolve the incident.
Incident priorities and parameters for setting the priority are different for every customer. The service provider is expected to adhere to the requirements put forth by the customer and charge them accordingly, based on the number of resources and assets utilized in fulfilling the service obligations.
The service desk measures the urgency and impact and sets the incident priority. Event management tools have the ability to set the right priority based on an algorithm. User-created incidents are normally assigned a default priority, and the resolver group changes the priority once it begins resolving the incident.
Incident priorities are not set in stone. They can be changed throughout the life cycle of an incident. It is possible that the end user has hyped the impact of the incident and could have gotten a higher priority incident raised. During the resolution process, the resolver group validates the impact and urgency and alters the priority as needed. Some critical incidents are monitored after resolution. The observation period could see the priority pushed down until closure.
Step 5: Diagnosis and Investigation
The service desk performs the initial diagnosis of an incident by understanding the symptoms of the incident. The service desk tries to understand exactly what is not working and then tries to take the user through some basic troubleshooting steps to resolve the incident. This is a key substep, as it provides the necessary data points for further investigation on the incident. It is analogous to a doctor asking you about the symptoms you have: Do you have throat pain? Do you have a cough? Do you have a cold?
Do you have a headache? You get the drift. Likewise, the service desk is expected to ask a series of questions to provide the necessary information to resolve the incident quickly, which is the objective of the incident management process.
Not all incidents can be resolved by the service desk. They get functionally escalated to the next level of support, generally referred to as level 2, or L2. The L2 group is normally a part of an expert group, such as the server group, network group, storage group, or software group.
The resolver group diagnoses the incident with the available information, and if needed, calls the user to obtain more information. It is possible that the service desk’s line of questioning could be on the wrong path, and perhaps the resolver group must start all over again by asking the right set of questions.
What is the user expecting to obtain through the incident?
What has gone wrong?
What is the sequence of steps that led to the incident?
Who is impacted? Is it localized or global?
Were there changes performed in the environment that might have upset the system?
Are there any similar incidents logged previously? Are there any KEDB articles available to assist?
Step 6: Resolution and Recovery
Based on the investigation, resolutions can be applied. For example, if the resolver group determines that a particular incident is not localized, there is no reason for it to resolve the incidents on the user’s PC, but rather it starts troubleshooting in the server or network. Or perhaps it brings in the experts who deal with global issues.
The success of resolution rides on the right path of investigation. If the doctor you are seeing prescribes the wrong medicines because the line of investigation was way off, the chances of recovery are close to nil, aren’t they?
For incidents that are widespread in nature (affecting multiple users), once the resolution is applied, various tests have to be conducted by the resolver group to be absolutely sure that the incident has been resolved. There is generally a recovery period to observe the incident and be on the lookout if anything were to go wrong again.
In some of the accounts that I have handled in major incident management, it was a regular practice to keep major incidents open for at least a week. This was done to observe, and to hold daily/hourly meetings with stakeholders to check the pulse and keep tabs on things that could go wayward.
Step 7: Incident Closure
When an incident is resolved, it is normal practice to confirm with the user before closing the incident ticket. The confirmation is generally made by the service desk, not the resolver group. So the process for postresolution of an incident is that the incident gets assigned to the service desk for confirmation and closure of the incident.
Some organizations feel that this step adds too much overhead to the service desk and prefer to forgo this confirmation. They keep the incident in resolved status for maybe three days. An email is shot out to the user informing him that the incident has been resolved, and if they feel otherwise, they are expected to inform back or to reopen the incident. If there is no response within 3 days, the incident would be autoclosed. I like doing this and have been a proponent of the autoclosure system, as confirmation can be overbearing; and, from a user’s standpoint, it is irritating to the customer to receive calls just to ask for confirmation.
After an incident has been closed, a user satisfaction survey goes out asking for feedback on the timeliness of the resolution, the ease of logging incidents, and whether the user was kept informed of the incident status throughout the life cycle.
Major Incident Management
Major incidents, as the name suggests, are severely impacting incidents that have the potential to cause irreparable damage to the business. So the ITIL service management suggests that major incidents be dealt with through a different lens. This can be done by having a separate process, a more stringent one of course, with stricter timelines and multiple lines of communication. Many organizations institute a separate team to look into major incidents and hire those with specialized skill sets to be exposed to the pressure that this job inherits.
The people who work solely on major incidents are called major incident managers. They have all the privileged powers to mobilize teams and summon management representatives at any time of the day (or night). They run the show when there is a major incident and become completely accountable for the resolution of the incident. The pressure on them is immense, and it calls for nerves of steel to withstand the pressure from the customer, service provider senior management, and all other interested parties.
I once worked as a major incident manager and was heading a major incident management team not too long ago. The job entailed keeping the boat floating at all times, and any delays from my end could potentially jeopardize the lives of miners across the globe. During a major incident, there could have been two or three phones buzzing with action, emails flying daggers into my inbox, and chat boxes flashing and roaring. It was a good experience when I think about it in hindsight, and a time I will cherish.
In a typical organization, you will have the service desk working on low-priority incident resolution. I will discuss the service desk later in this chapter. To track, manage, and chase incident-related activities, there are incident managers who keep tabs on all occurrences. When a major incident hits the queue, none of these groups take responsibility, but they call in the experts (major incident managers) to manage the situation. In some cases, the service desk and incident managers might validate the incident priority before calling the major incident line.
It is a good practice to let the whole service provider team and the customer organization know that a major incident is in progress, to make sure that everybody knows that certain services are down and to avoid users calling the service desk to report on the same incident. A few good practices in this regard include sending out emails at the start and end of major incidents, flashing messages on office portals and on ticket logging pages, and playing an interactive voice response (IVR) message when users call the service desk.
Engagement with Service Value Chain
Problem Management Practice
Incident management is the first line of defense in providing immediate relief against the disruption of services and eventual downtimes. However, by no means does the incident management process get into the nitty-gritty of putting an end to the cause behind the incidents. Its purpose is to bring the services back up, even if the solution is a nonpermanent one.
The second ring of process governance ensuring permanence to solutions is the problem management practice. This is a process that deep dives into the cause of incidents and follows the problem to its root, ensuring that incidents related to the particular cause do not repeat.
To summarize, the incident management practice deals with correction, while the problem management practice focuses on prevention.
The problem management practice in the service management practices is critical for the product and the service to thrive. Incident management is good, but at the end of the day, the more incidents, the more downtime, and the more efforts required to bring the services back up. The customer gains zilch from the process, as it’s trying to keep the support above water at all times but not really taking it to new places. There is a dire need to bring value to services, and value can be brought about only if stability is assured. One of the pillars for ensuring service stability is the problem management practice.
The problem management practice is academic in nature. It does not believe in happenstance and does not (in effect) try to resolve world hunger in one swooping move. There is a definite method to the madness around laying tombstones on top of the problems. I represent the problem management practice as the investigation unit of the IT service provider organization.
You might have seen the popular TV series CSI, where crimes are solved by following the leads and taking down the culprits. The problem management process is the CSI of IT service management, and you can compare incident management to the police squad.
Let’s consider an example involving an application that crashes frequently when certain actions are performed simultaneously. An incident is raised. The incident is diagnosed, and the resolution is identified to be a complex one. But incident management focuses on helping users move on with their day-to-day activities involving services. Therefore, an incident analyst recommends a workaround whereby the user can perform actions on the application in a sequential manner rather than in parallel. The user’s immediate issue is solved, but the impending problem exists. A problem is raised, and an investigation into the problem begins. The problem is recreated, the codebase is examined, and all the relevant logs are studied to debug the underlying cause. The investigation pays off, and the cause is identified and subsequently fixed. All the investigative activities are done under the auspices of problem management to identify the problem and find a permanent solution.
ITIL Definition of Problem
A cause, or potential cause, of one or more incidents.
There are unresolved incidents where the fix is yet to be determined. The resolution of these incidents is not possible until the root cause of the incident is known. Yes, one can shoot in the dark trying to do a hundred things, hoping that something sticks, like restarting the server as soon as the server goes down. But it’s not always that simple. The resolution of incidents must be surgical. A problem comes into the play only when there are incidents where the root cause is unknown.
This is similar to a doctor prescribing medicines. If the doctor does not know the cause of certain symptoms, then the doctor will not be able to prescribe medicines. Well, he/she might guess, assume, and hope certain medicines work. When they don’t, the doctor might prescribe another set. Through problem management, we want to avoid this behavior; as I mentioned earlier, it has to be surgical. In the medical analogy, the cause of the disease must be found and the right medicines prescribed. If it requires MRI scans, blood tests, and swabs, so be it. The thing that matters is to find out what is wrong and to find an apt solution.
In IT organizations too, to resolve incidents, the technical resolver groups must know the root cause of the problems. If they do not know the root cause, they start to guess by asking users to restart machines, uninstall and reinstall software, and other “fiddles” that may amount to a waste of time and resources. But, if the principles of problem management are applied and the root cause identified, the solution to follow will be a matter of routine.
A problem gets raised when the root cause of an incident is unknown. Or a bunch of incidents with a common thread is unable to be resolved, as the underlying root cause is yet to be identified.
The definition of a problem is a must learn, not just from the perspective of the ITIL Foundation exam but also to get a better footing in the ITIL framework. On the exam though, you should expect to see a question asking you to identify the right definition from a list of choices. So, it is prudent for you to understand and memorize the definition verbatim.
Incidents vs. Problems
It is my experience that many IT professionals in the IT service management industry use the terms incident and problem interchangeably. This does more harm than good, especially if you are working in an organization that takes shape after ITIL and especially if you are preparing for the ITIL foundation exam. In this section, I will differentiate the two terms with examples, so as we move forward toward the process and other key terminologies, there shouldn’t be any speck of doubt between incidents and problems.
Incidents are raised due to loss or degradation of services. They are raised by users, IT staff, or event management tools. When incident resolution is not possible, because the underlying root cause is unknown, the IT team will raise a problem. Remember that users and event management tools don’t raise problems; generally speaking, they can come only through the incident. However, in a mature IT environment, we can configure event management tools to look for specific patterns of events and subsequently raise problems. But, let’s keep this discussion out of the scope and restrict problems to be derived only on the back of incidents.
Let’s consider the example of a software application that crashes when it is initiated. The user raises an incident to fix this issue. The software resolution team tries to start the application in safe mode, uninstalls and reinstalls the application, and finally makes changes to the OS registry, to no avail. When all hopes fail, they provide a heads-up to the problem management to find the root cause and provide a permanent solution.
The problem management practice, aided by experts in the software architecture group, debug the application loading and run a series of tests to find the triggers and sparks for the crash. They find out that the root cause of the crash is because of a conflict with a hardware device driver. They recommend a solution to uninstall the hardware device driver and update it with the latest driver. The recommendation works like a charm, and the software application that used to crash loads nicely without any fuss.
This is the problem management practice in action, working on difficult problems that can cause irreparable damages to the customer organization if not dealt with on a timely basis.
Other Key Terminologies in Problem Management
Problem management digs deep, and the process brings a certain amount of complexity to the table. The complexity begins with a few terms that are used quite often during various stages of the process activities. It is important that you understand all the terminology that I put forth here. It helps you use better terms at work and most definitely bags a few more right answers on the ITIL Foundation exam.
Root Cause
The root cause is the fundamental reason for the occurrence of an incident. Let’s say that you are in a bank and the ATM does not disburse the money that you requested. The underlying cause or the root cause for the denial of service in this instance is attributed to a network failure in the bank. For every incident, there will be a root cause.
Only when you identify the root cause will you be able to resolve the incident. In the ATM instance, unless you know of the network failure, you cannot bring the ATM service back up.
Root-Cause Analysis
Identifying the root cause of an incident is no menial task. At times the root cause may reveal itself, but many times it will become challenging to identify the root causes of complex incidents. You are required to analyze the root cause by using techniques that commonly fall under the activity called root-cause analysis (RCA).
Remember that the outcome of RCA may not always result in identifying the root cause of an incident. In such cases, RCA must be performed using complex techniques and with experts pertaining to related fields of technology and management.
Known Error
ITIL Definition of Known Error
A problem that has been analyzed but has not been resolved.
There could be various reasons why solutions cannot be implemented. Commonly, permanent solutions come with an expensive price tag. Most organizations are price conscious these days and may not approve the excess expenditure. Other reasons could include a lack of experts or people resources to implement the permanent solution, or governance or legislation controls that could prevent implementation.
The definition of a known error is important from the ITIL Foundation exam point of view. On the exam though, you should expect to see a question asking you to identify the right definition from a list of choices. So, it is prudent for you to understand and memorize the definition verbatim.
Known Error Database
Known errors are documented and are stored in a repository called a known error database (KEDB). The KEDB consists of various known errors, their identified root causes, and the workarounds that can be applied. The known error records are not permanent members of a KEDB. Known errors will cease to exist in this repository when the permanent solution is implemented.
Workaround
ITIL Definition of Workaround
A solution that reduces or eliminates the impact of an incident or problem for which a full resolution is not yet available. Some workarounds reduce the likelihood of incidents.
For example, say a printer on your floor is not working and you cannot wait until the technician can get to it. A classic workaround, in this case, is to print from a printer on a different floor. The workaround will solve your problem temporarily by providing a way out, but it may not be a permanent solution because you may find it inconvenient to run down to the next floor every time. Another workaround could be that you don’t print the document but instead send the soft copy to the intended recipient.
A workaround exists to provide immediate or intermediate relief from the service disruption. In some cases, if a permanent solution is not found (due to technical or financial reasons, et al), then the workaround could possibly be considered as a final solution.
Permanent Solution
When the root cause of a problem is known, the follow-up activity in problem management process is to identify a permanent solution. This solution permanently resolves the problem, contributes toward a reduction in the incident count, and avoids future outages.
As I mentioned earlier, permanent solutions come at a cost, and organizations may not always be willing to shell out the required capital. In such cases, permanent solutions are known but not implemented.
Problem Management Phases
Problem Identification
Problem Control
Error Control
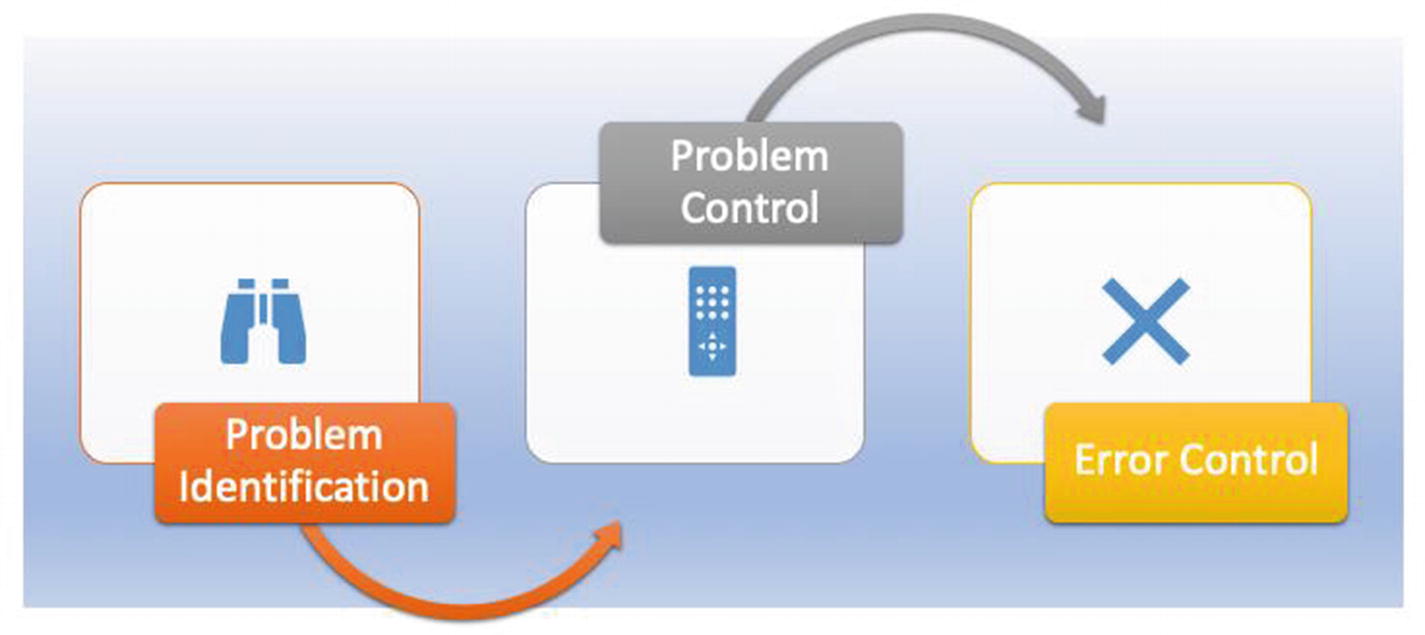
Problem management phases
Problem Identification
Incident records should be analyzed on a regular basis to identify common elements such as similar incidents like occasional Chrome browser crashing, or it could be a particular CI that is breaking down multiple times.
Through trend analysis of incidents, repetitive incidents can be identified, and the intel can be provided by users and IT staff as well.
Suppliers and other third parties could also potentially provide intel around problems.
All major incidents could be succeeded by the problem management process to ensure such incidents do not occur again.
During the development cycle, unresolved bugs could transform into problems during operations; the lead can be provided by testers and developers.
For COTS products, the software publisher could provide the list of potential problems .
Problem Control
Problem control typically analyzes the identified problem, and finds its root cause and a permanent solution if possible. If there are a handful of problems, then perhaps all problems can be analyzed. If there are several, an activity of prioritization is done to pit problems against each other in the order of impact and its probability, which is nothing but the risk it poses.
Brainstorming
The technique that has been used, misused, and underused at times is the power of using our brains to focus on areas of investigation. The brainstorming technique involves focused thinking without any inhibitions.
In the brainstorming technique, there are no bad thoughts. Every single thought must be weighed, and then a decision must be made. In other words, ideas are not tagged absurd or made fun of; everything is accepted, examined, and then acted upon based on the results of the examination. Let me explain brainstorming in the form of an example. If thinking is a car, then in this car I take out the brakes because I don’t want the thinking to stop or be impeded. There must be no action taken to stop the flow of thoughts. I use only the steering wheel to steer my thoughts toward the goal I want to achieve. The more thinking, with the right steering, the closer I will get to my destination.
Brainstorming can be done on your own or in a group. The more the merrier, right? Not always. It is possible through group brainstorming sessions that the clear thoughts in your mind could get defocused, so group brainstorming must be done with caution and with a process to keep it in a framework. Osborn says in his book that group brainstorming sessions are more effective than individual ones, as he firmly believes that quantity breeds quality. The assumption is that a greater number of ideas generated provide a better probability of striking gold .
Five-Why Technique
One of the most used and misused techniques in the problem management process is the five-why technique. It is used during the investigation of a problem, specifically during the root-cause determination stage. The technique is so commonly taught and retaught to problem management personnel that it has become a de facto standard in the activity of root-cause analysis.
The five-why technique involves asking the question “why?” to the problem on hand five times to arrive at the root cause. It was conceived by Japanese industrialist Sakichi Toyoda, the founder of Toyota Industries in 1930. But it wasn’t until the Toyota Production System became popular that the technique became more widespread in the 1970s. The technique’s principle relies on being on the ground to find out the reasons rather than in the comfort of an air conditioned office (a “go and see” philosophy).
- The part that makes the technique popular is that it is extremely simple to use and takes a short amount of time to process and execute. Figure 11-5 is an illustration of using the five-why technique for identifying the root cause of the problem.
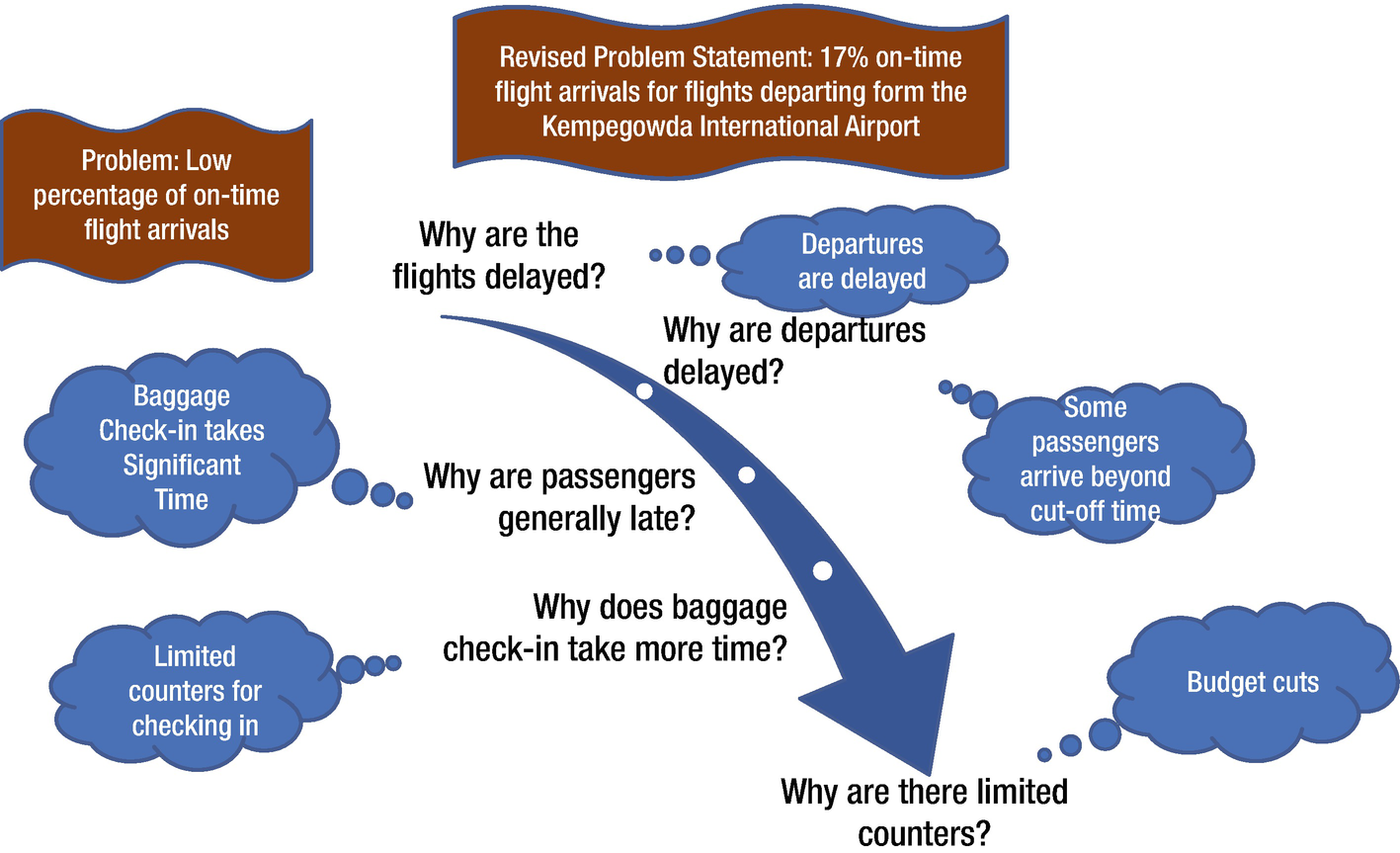 Figure 11-5
Figure 11-5Illustration of the five-why technique
Ishikawa
An Ishikawa diagram is known by multiple names such as fishbone diagram, fishikawa diagram, and herringbone diagram, among others. The diagram consists of a central spine that represents the problem. Several branches jut out of the spine to indicate possible causes. The arrangement of the spine and branches looks like a fishbone.
- The causes are not arbitrary, as discussed in the five-why technique. There is a method to the madness in the Ishikawa process of the root cause of determination. Each branch is designated to a category of cause, and the thinking behind it is to follow the category lead to determine the root cause. One of the popular fishbone models used in the manufacturing industry is called the 6M model. The six categories of causes are modeled are as follows:
Material: causes related to the material used in the manufacturing process
Method: the process
Machine: the actual machinery, technology, and so on
Mother Nature: the environment
Measurement: the measurement techniques employed in deriving metrics
Man: the people involved
- There are other models as well, depending on the type of industry. Figure 11-6 is an illustration of the Ishikawa technique.
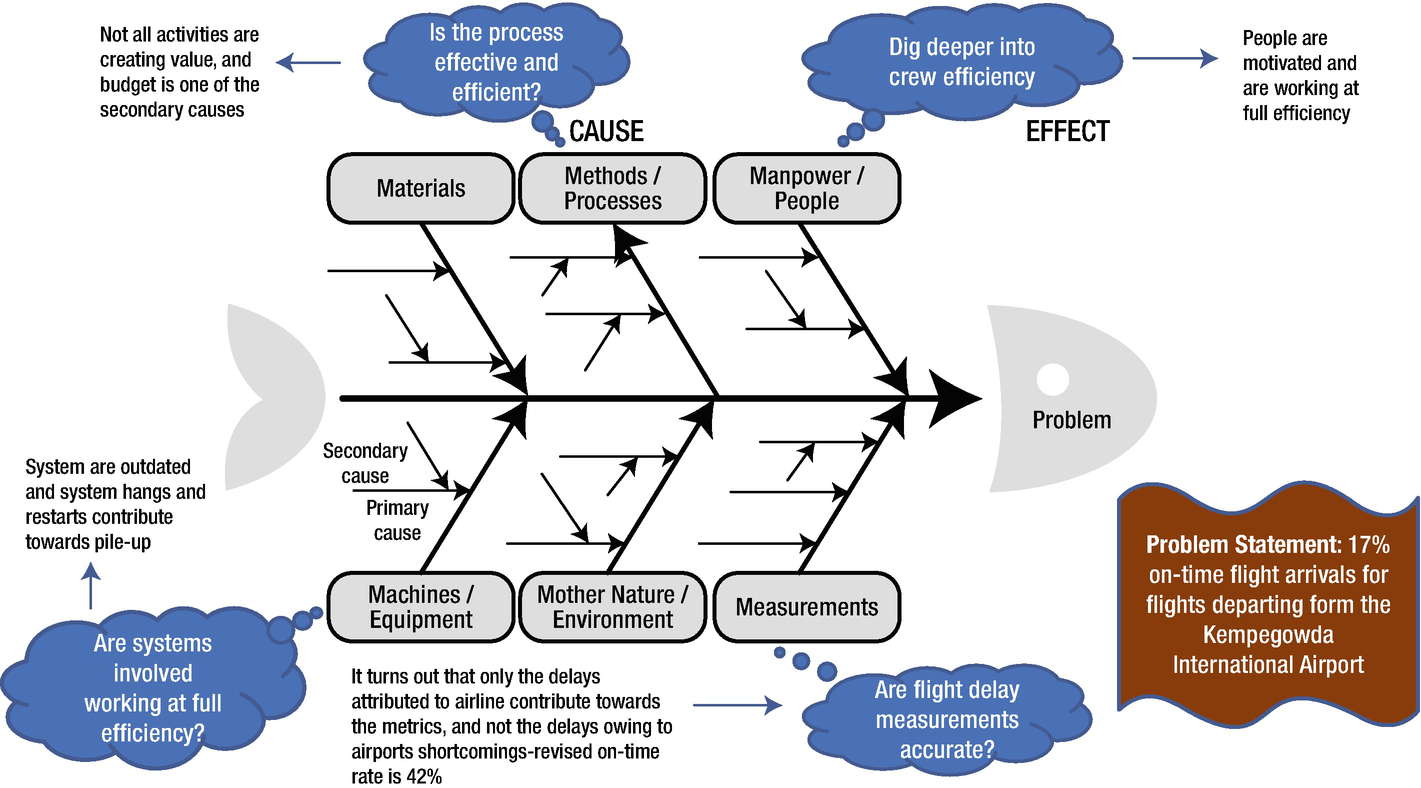 Figure 11-6
Figure 11-6Illustration of the Ishikawa technique
- The outcome of any of the techniques could result in the following options:
No root cause
Root cause and permanent solution known
Root cause known but no permanent solution
If the root cause is not determined, then the technique needs to be altered and reprocessed to identify the root cause. When the root cause and the permanent solution are known, then a determination needs to be done whether the permanent solution needs to be implemented or not. A number of factors could influence it: commercial, collateral risk, etc. If the root cause is known but not the permanent solution , the next best thing to do is identify a workaround that will hold the fort until the cavalry arrives (permanent solution).
Error Control
An error or a known error comes up if a permanent solution to a problem is not implemented. As I mentioned earlier, there could be several reasons why a permanent solution is not implemented: it may not be technically determined yet, it may be commercially unfeasible, or the collateral risks could outweigh the benefits.
Managing errors is done though a KEDB. The exercise involves regular assessments of the known error to identify potential permanent solutions and to ensure that the known errors are well socialized with the user and IT staff community. The assessment is done on the basis of impact to customers, the cost of implementing a permanent solution, effectiveness of the permanent solution, and the effectiveness of the workarounds identified .
Engagement with Service Value Chain
Knowledge Check
- 11-1.Which of the following is the correct event definition?
- A.
Any change of state that is significant for a service or product or related CI
- B.
Any change of state that triggers changes to the other operational processes
- C.
Any change of state for CIs that correlates risks and issues to the service and service management processes
- D.
Any change of state that has significance for the management of a service or other CI
- A.
- 11-2.Which of the following is the correct incident definition?
- A.
A problem that has been analyzed but has not been resolved
- B.
Interruptions to a service are referred to as an incident
- C.
An unplanned interruption to a service or reduction in the quality of a service
- D.
A method for overcoming a problem or limitation in a program or system
- A.
- 11-3.What kind of a tool should be used to log incidents?
- A.
A tool that is specialized for registering incidents, and carries attributes such as incident summary, incident description, priority, category, etc. Also, there must be room provided for customizing the fields.
- B.
A tool that provides access to all IT staff, users, and the service desk and that is available on demand
- C.
A tool that provides links to CIs, problems and known errors
- D.
A tool that can be used for self-healing of incidents and that can provide quick resolution
- A.
- 11-4.Which is the difference between a problem and a known error?
- A.
Problems are created to identify root cause of incidents; known errors are created when root cause of an incident is known but a permanent solution is yet to be implemented.
- B.
Problems are created to identify root cause of incidents; known errors are created to identify the product bugs that are released from the development cycle.
- C.
Problems are created to identify a permanent solution to an incident; known errors are created when the permanent solution to an incident is yet to be implemented.
- D.
Problems are created to identify a permanent solution to an incident; known errors are created to track and identify product bugs that come from the development cycle.
- A.
- 11-5.Which of these is not a valid problem identification technique?
- A.
Performing trend analysis of incidents
- B.
On the back of a major incident
- C.
Five-why analysis
- D.
Analyzing recurring issues
- A.
- 11-6.Which of the activities is a valid error control activity?
- A.
Applying workarounds to incidents
- B.
Identification of permanent solution
- C.
Analysis of root cause of known errors
- D.
Analyzing recurring issues
- A.