
Machine learning is primarily oriented toward prediction, whereas much of economics is concerned with causality and equilibrium. While the two disciplines have a shared interest in forecasting, they often approach it with different preferences and objectives. The economics discipline tends to favor forecasting models that are explicable, parsimonious, and stable, whereas machine learning uses an empirical process for determining what is included in a model, prioritizing feature selection, regularization, and testing over intuition.
As a consequence of these seemingly intractable differences, the economics discipline was initially slow in adopting methods from machine learning. It has since become clear that economics can benefit from integrating the models, methods, and conventions of machine learning. In this chapter, we will examine work that has argued in favor of introducing elements of machine learning into economics and finance. This research not only identifies where machine learning can be fruitfully employed to solve problems in economics but also determines where there are genuine conflicts between the two disciplines that are unlikely to be reconcilable.
While this book centers around building, training, and testing models using TensorFlow, this chapter has a different objective: to build a strong conceptual understanding of the relationship between economics and machine learning. We will do this by stepping through the landmark papers in economics and finance that discuss machine learning and its role in the discipline.
“Big Data: New Tricks for Econometrics” (Varian 2014)
Varian (2014) made one of the earliest attempts to introduce methods from machine learning to economists in a paper entitled “Big Data: New Tricks for Econometrics.” Among other things, he argues that economists could benefit from developing a better understanding of ML’s approach to model uncertainty and validation.
He points out that economists typically use a single model that is assumed to be the “true” one, whereas machine learning scientists often average over many small models. With respect to validation, he explains how machine learning methods for cross-validation could be used. For instance, k-fold cross-validation, which is depicted in Figure 2-1, divides a dataset into k folds or subsets of equal size. It then uses a different fold as the validation set in each of k training iterations. He argues that k-fold validation and other ML cross-validation techniques could provide an alternative to goodness-of-fit measures, such as R2, which are commonly used in econometrics.
In addition to high-level insights, Varian (2014) also discusses common methods in machine learning that could be employed in econometrics. This includes the use of classification and regression trees; random forests; variable selection techniques, such as LASSO and spike-and-slab regression; and methods for combining models into ensembles, such as bagging, boosting, and bootstrapping.
Varian (2014) also provides a number of concrete examples of how machine learning could be used in economics. He applies tree-based estimators to measure the impact of racial discrimination on mortgage lending decisions, making use of the Home Mortgage Disclosure Act (HMDA) data . He argues that such estimators could provide an alternative to more commonly used methods for binary classification in economics, such as the logit and probit models.

A diagram of k-fold cross-validation for k = 5
“Prediction Policy Problems” (Kleinberg et al. 2015)
Kleinberg et al. (2015) discuss the concept of “prediction policy problems,” where the generation of accurate predictions is more important than a causal inference assessment. They argue that machine learning, which is organized around the generation of accurate predictions, has an advantage over traditional econometric methods in such applications.
Kleinberg et al. (2015) provide an illustrative comparison between two types of policy problems. In the first, a policymaker is confronted with a drought and is deciding whether to use a technology, such as cloud seeding, to increase rainfall. In the second, an individual is deciding whether to take an umbrella on a commute to work to avoid becoming wet if it rains. In the first case, the policymaker is concerned with causality, since the effectiveness of the policy will depend on whether cloud seeding causes rainfall. In the second case, the individual will only be concerned with predicting the likelihood of rain and will be uninterested in causal inference. In both cases, the intensity of the rainfall will affect the policy outcome of interest.
The authors summarize the policy prediction problem in general terms in Equation 2-1.
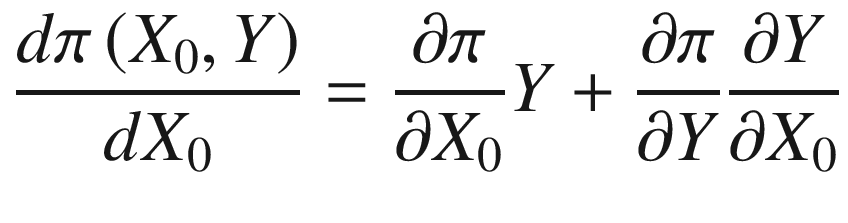
Here, π is the payoff function, X0 is the policy adopted, and Y is the outcome variable. In the umbrella choice example, π is the extent to which the person is wet after commuting, Y is the intensity with which it rained, and X0 is the policy adopted (umbrella or not). In the drought example, π measures the impact of the drought, Y is the intensity with which it rained, and X0 is the policy adopted (cloud seeding or not).
If we select the umbrella as our policy option, then we know that ∂Y/∂X0 = 0, since the umbrella does not stop the rain from falling. This reduces the problem to an evaluation of ∂π/∂X0 and Y, that is, the impact of the umbrella on the payoff function and the intensity of rainfall. Since the impact of the umbrella on preventing wetness is known, we only need to predict Y. Thus, the policy problem itself reduces to a prediction problem.
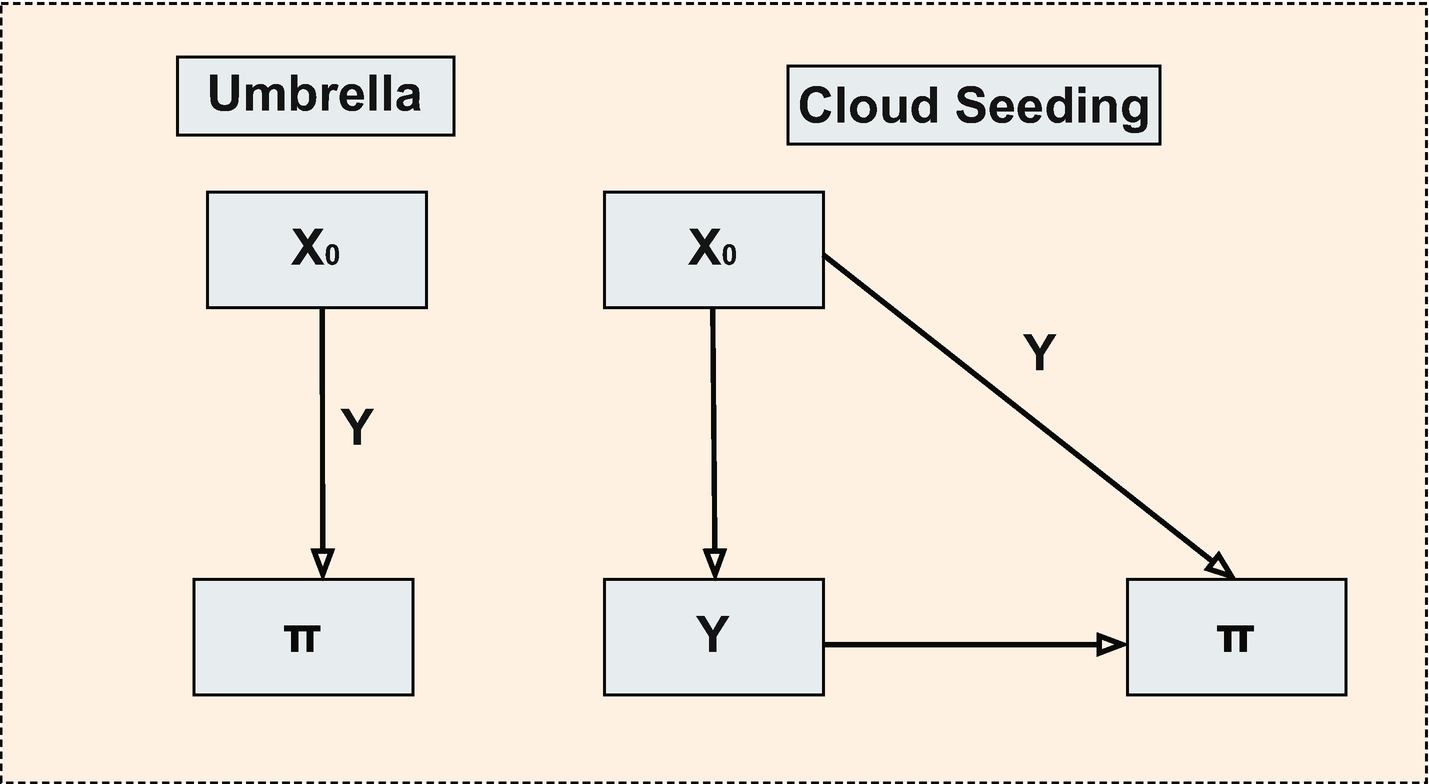
Illustration of policy prediction problems from Kleinberg et al. (2017)
Kleinberg et al. (2015) suggest that important policy problems can sometimes be resolved by predicting Y itself, rather than performing causal inference. This opened up a subfield of problems in economics for which machine learning is particularly well-suited to solve. This also has useful implications for practitioners, including public and private sector economists: identifying problems where a policy can be determined purely through prediction allows you to use off-the-shelf ML techniques without further modification.1
“Machine Learning: An Applied Econometric Approach” (Mullainathan and Spiess 2017)
Mullainathan and Spiess (2017) examine how supervised machine learning methods could be applied to economics. They argue that problems in economics are typically centered around recovering estimates of model parameters, ߈, whereas problems in machine learning are typically centered around the recovery of fitted values or model predictions, yˆ.
While this difference may initially seem trivial, it turns out to be quite important for two reasons. First, it leads to a different orientation in model building and estimation that typically results in inconsistent parameter estimates in machine learning. That is, as the sample size grows, the parameter estimates, ߈, won’t necessarily converge in probability to the true parameter values, ß, in machine learning models. And second, it is often difficult or impossible to construct a standard error for any individual parameter in a machine learning model.
- 1.
Measuring economic activity: This could be done, for instance, using image or text datasets. Model parameters do not need to be consistently estimated, as long as the model returns an accurate prediction of economic activity.
- 2.
Inference tasks that have a prediction step: Certain inference tasks, such as instrumental variables (IV) regression, involve intermediate steps where fitted values are generated. Since biases in parameter estimates arise from overfitting in the intermediate steps, making use of machine learning techniques, such as regularization, could reduce bias in IV estimates. Figure 2-3 illustrates the case where we have a regressor of interest, X; a confounder, C; a dependent variable, Y; and a set of instruments, Z. We then use ML to transform Z into fitted values for X.
- 3.
Policy applications: The objective of policy work in economics is ultimately to offer recommendations to policymakers. For instance, a school may be deciding whether to hire an additional teacher or a criminal justice system may be deciding when to give bail to those who have been arrested. Making a recommendation ultimately involves making a prediction. Machine learning models are better suited to this task than simple linear models.

Illustration of instrumental variables regression using ML
Mullainathan and Spiess (2017) also conduct an empirical application in the paper to evaluate the usefulness of machine learning in improving fit. The exercise involves the prediction of the natural logarithm of house prices from a random sample of 10,000 houses drawn from the American Housing Survey. They make use of 150 features and evaluate the results using R2. Comparing OLS, a regression tree, LASSO regression, a random forest, and an ensemble of models, they find that ML methods are, in general, able to deliver improvements in R2 over OLS. Furthermore, there is heterogeneity in those improvements: for certain house price quintiles, the gains are large, whereas they are small or even negative in other quintiles.
Finally, Mullainathan and Spiess (2017) argue that ML offers value added to economics along two additional dimensions. First, it provides an alternative process for estimating or training models, which is centered around regularization to prevent overfitting and tuning based on empirical feedback. And second, it can be used to test theories about predictability. The Efficient Markets Hypothesis (EMH), for instance, implies that risk-adjusted excess returns should not be predictable. Consequently, using ML models to demonstrate predictability has implications for the theory, even if all parameters used in the prediction are inconsistently estimated.
“The Impact of Machine Learning on Economics” (Athey 2019)
Similar to Mullainathan and Spiess (2017), Athey (2019) reviews the impact of machine learning on economics and makes predictions about likely future developments. Her work centers on a comparison between machine learning and traditional econometric methods, an evaluation of off-the-shelf machine learning routines for use in economics, and a review of policy prediction problems of the variety discussed in Kleinberg et al. (2015).
Machine Learning and Traditional Econometric Methods
Athey (2019) argues that machine learning tools are not suitable for performing causal inference, which is the objective of most econometric exercises. They are, however, useful for improving semi-parametric methods and do enable researchers to make use of a large number of covariates. Given the parsimony of econometric models and the increasing availability of “big data,” it seems likely that there will be substantial value in adopting methods and models from machine learning, which are generally better suited to processing and modeling large volumes of data.
Another area of strength Athey identifies is the use of flexible functional forms. The econometrics literature has broadly specialized around producing tools for a single narrow task: performing causal inference in a linear regression model. In many cases, however, there are good reasons to believe that such models fail to capture important non-linearities. Machine learning offers a rich variety of models that allow for non-linearities between features, and between features and the target, something that is usually absent from econometric models.
In addition to causal inference, Athey also compares the processes for performing empirical analysis, selecting a model, and computing confidence intervals on parameter values. The conclusions she reaches about machine learning are covered in the following subsections.
Empirical Analysis
Athey (2019) highlights an important contrast between economics and machine learning, which is most visible in their differing approach to empirical analysis. Economists typically select a model using some set of principles and determine its functional form through the use of theory. They then estimate the model once.
Machine learning takes a different approach to empirical analysis – namely, an iterative one. Rather than starting with a model determined by principles and theory, machine learning starts with a standard model architecture and/or set of hyperparameters. It then trains the model, evaluates performance using a form of cross-validation, and then tunes the hyperparameters and model architecture to improve performance. The training process is then repeated.
Athey argues that tuning and cross-validation are some of the most useful tools that machine learning offers to econometricians. Reorienting empirical analysis in economics around an iterative and empirical process could lead to substantial improvements in explaining variation in the data.
Model Selection

Illustration of model evaluation process in machine learning
What we can’t do, however, is measure “causality” and train our models to maximize it. This is a serious challenge, whether we are using econometric tools or machine learning tools; however, it is particularly important to point it out for machine learning tools, since this is a reason to believe that they will not help us to improve along the causality dimension.
Confidence Intervals
One drawback of using machine learning methods in economics is that such models typically do not produce valid confidence intervals. In fact, confidence intervals are not usually an object of interest in machine learning, since models often contain thousands of parameters. Athey (2019) argues that this is a challenge for research in economics, which typically involves hypothesis testing that is centered around the statistical significance of individual parameters. It is, however, possible to overcome this restriction in certain settings, but it requires the use of advanced, recently developed methods in economics and statistics, which are not typically available with off-the-shelf ML routines .
Off-the-Shelf ML Routines
Athey (2019) evaluates a broad set of off-the-shelf routines to consider how they would perform if applied to tasks in economics and finance. She argues that unsupervised machine learning methods, such as clustering algorithms and topic modeling, could play a valuable role in economics. They have the benefit of not generating spurious relationships, since there is no dependent variable, and can, themselves, be used to generate a dependent variable.
She then evaluates supervised machine learning methods, classifying such methods according to their widespread adoption in the social sciences. Neural networks, for instance, have been used in various applications in the social sciences in the past, but have only recently gained widespread use and acceptance. As such, Athey (2019) would classify such models as “machine learning models.” The same cannot be said, for instance, for OLS or the logit model, which have long been used in economics and finance.
Athey (2019) identifies the following models which can be classified as “machine learning models” under this scheme: regularized regression, including LASSO, ridge, and elastic net; random forests and regression trees; support vector machine (SVM) models; neural networks; and matrix averaging.
The standard trade-off inherent in using such models, as originally argued by Mullainathan and Spiess (2017), is expressiveness versus overfitting. Using more features, allowing for more flexible functional forms, and reducing regularization penalties come at the cost of a higher probability of overfitting.
Athey argues that this approach has many advantages in settings where there are a high number of covariates. It is, however, necessary to employ non-standard routines to compute confidence intervals. It is also important to evaluate whether results are spurious.
Policy Analysis
In addition to causal inference, economics is also concerned with prediction for its own sake. An accurate economic forecasting model, for instance, will still be useful for planning purposes, even if the accuracy arises as a result of non-causal associations between variables. As discussed previously in the review of Kleinberg et al. (2015), this concept also applies to policy problems. Governments and organizations trying to decide whether to take a specific action will often do so under two different sets of circumstances. In the first set of circumstances, there is uncertainty about the efficacy of the policy they will adopt. In the second, the uncertainty is about some external event.
Consider, for instance, a small bank deciding whether or not to build a larger capital buffer to prepare for a financial crisis. They might construct a model that indicates the targeted size of their buffer conditional on the state of the world. This would involve constructing and estimating a model that produces a policy prediction. Importantly, causality is irrelevant in this model, since the small bank does not influence the state of the financial sector to any appreciable extent. Rather, it simply needs to be able to predict a crisis in advance, so it can adopt the correct policy.
- 1.
Model interpretability: Economic models tend to be simple and interpretable, making the origin of the policy prescription understandable. This is not the case for many ML models.
- 2.
Fairness and non-discrimination: The complexity of machine learning models often makes it difficult to determine the origin of unfair or discriminative policy prescriptions. As such, transitioning to ML models will necessitate an evaluation of how fairness and non-discrimination can be preserved.
- 3.
Stability: Given the complexity of machine learning models, it is not clear whether relationships estimated for one population will tend to hold for others. Additional work will be needed to evaluate the generalizability of results.
- 4.
Manipulability: The size and complexity of ML models, along with their low level of interpretability, opens up the possibility of manipulation. This is already a problem in economic models, but it is compounded by the complexity and black-box nature of many ML models.
These remain both interesting topics of research and also important considerations for practitioners. Both public and private sector economists will need to evaluate the interpretability, fairness, stability, and manipulability of the predictions that arise from the use of ML models in economics .
Active Research and Predictions
Athey (2019) concludes with an exhaustive review of active lines of ML research in economics, as well as predictions for the future. Interested readers should refer to the manuscript itself for details. We will, however, highlight some of the areas of active research and predictions about future developments.
Active lines of research include (1) the use of ML to estimate average treatment effects,2 (2) the estimation of optimal policy under heterogeneous treatment effects,3 (3) the use of ML to perform supplementary analyses that evaluate the extent of the confoundedness problem in causal inference,4 and (4) the use of ML in panel and difference-in-difference methods.5
Athey includes an extensive list of predictions for ML’s adoption and spread within economics, starting with increased use of off-the-shelf methods, initially employed for their intended purpose within ML. From there, ML is likely to be localized to perform tasks that are of particular interest to economists and social scientists. She predicts that the impact on causal inference in economics will be small, but the overall impact will be large, necessitating increased interdisciplinary work, coordination with private businesses, and a revival of stale literatures focused on economic measurement.
“Machine Learning Methods Economists Should Know About” (Athey and Imbens 2019)
Separately, Athey and Imbens made substantial contributions to the advancement of machine learning methods in economics through multiple works. In Athey and Imbens (2019), they provide an overview of methods in machine learning that are useful for economists.
They start with a discussion of the integration of ML into economics, the initial resistance it faced, and the reasons underlying that resistance. The most serious initial objection was that ML models failed to produce valid confidence intervals off the shelf. While not important for ML itself, this was a substantial hindrance for the use of ML in traditional problems in economics.
Athey and Imbens (2019) explain that the literature has since approached this problem by producing modified versions of machine learning models. In particular, they argue that it is often necessary to modify ML models to exploit the structure of specific economic problems. This might include issues related to causality, endogeneity, monotonicity of demand, or theoretically motivated restrictions.
- 1.
Local linear forests
- 2.
Neural networks
- 3.
Boosting
- 4.
Classification trees and forests
- 5.
Unsupervised learning with k-means clustering and GANs
- 6.
Average treatment effects under the confoundedness assumption
- 7.
Orthogonalization and cross-fitting
- 8.
Heterogeneous treatment effects
- 9.
Experimental design and reinforcement learning
- 10.
Matrix completion and recommender systems
- 11.
Synthetic control methods
- 12.
Text analysis
Interested readers should consult Athey and Imbens (2019) for the details of how each method can be integrated into economic analysis. We will return to some of these methods in detail later in the book and will delay a detailed discussion to those chapters.
“Text as Data” (Gentzkow et al. 2019)
In contrast to the other surveys we have covered, Gentzkow et al. (2019) are narrowly focused on a single topic: text analysis. They provide a comprehensive survey of text analysis methods used in economics, as well as an introduction to methods that are not currently used in economics, but which they argue would be useful if adopted.
The paper is divided into three sections: (1) representing text as data, (2) statistical methods, and (3) applications. Since we will cover text analysis in Chapter 6, including extended coverage of Gentzkow et al. (2019), we will limit ourselves to a brief overview here.
Representing Text As Data
The paper starts with an extended discussion of standard pre-processing routines for text datasets. For most economists, such routines will be unfamiliar, but learning how to perform them is essential for conducting text analysis. These routines involve the transformation of text documents into a numerical format that is usable in models. This usually starts with a cleaning process, followed by a feature selection process. Common features include words and phrases. We will cover this process in detail in Chapter 6.
Statistical Methods
The authors point out that most text analysis done in economics makes use of dictionary-based methods. Dictionary-based methods fall into the category of unsupervised learning methods. Rather than training a model to learn the relationship between features and a target, you instead specify a dictionary in advance, which is then applied to a document, yielding a measure of some feature of the text.

Application of general sentiment dictionary to FOMC statement
The authors argue that Baker et al. (2016) is an ideal use of dictionary-based methods in economics. First, the feature they want to extract, uncertainty about economic policy, is unlikely to emerge from a topic model applied to newspaper articles. And second, the dictionary they used to extract the feature was tested against human readers and produced similar results. In such cases, a dictionary-based method is likely to be ideal. A plot of the EPU indices for selected countries is shown in Figure 2-6.7

EPU indices for US, UK, Germany, and Japan
Their coverage includes text-based regression, penalized linear regression, dimensionality reduction, and non-linear text regression, including regression trees, deep learning, Bayesian regression methods, and support vector machines.
Finally, they also cover word embeddings, which are arguably underused in text analysis applications within economics. Word embeddings provide an alternative means of expressing features in text, which are continuous and retain the information content of words. This contrasts with commonly used approaches in economics, which typically involve treating words as one-hot encoded vectors, all of which are orthogonal to each other.
Applications
Gentzkow et al. (2019) end with an expansive literature review of text analysis methods in economics. Such applications include authorship identification, stock price prediction, central bank communication, nowcasting, policy uncertainty measurement, and media slant quantification. We will return to this literature and the details of the applications in question in Chapter 6.
“How is Machine Learning Useful for Macroeconomic Forecasting” (Coulombe et al. 2019)
Both the reviews of machine learning in economics and the methods that have been developed for machine learning in economics tend to neglect the field of macroeconomics. This is, perhaps, because macroeconomists typically work with nonstationary time series datasets, which contain relatively few observations. Consequently, macroeconomics is often seen as a poor candidate for benefitting from the adoption of machine learning methods, even though prediction (forecasting) is a common task among private and public sector macroeconomists.
- 1.
Non-linearities: Macroeconomics is inherently non-linear. Unemployment tends to decline slowly during economic expansions, only to spike suddenly when a recession occurs. Furthermore, if a downturn affects the financial sector, leading to a credit contraction, a recession might become considerably more severe and prolonged. Capturing such elements could be critical for producing accurate macroeconomic forecasts. At least in principle, ML provides a toolset that allows for flexible functional forms, including non-linearities, which could be used for such a purpose.
- 2.
Regularization: In the era of big data, there are now many time series available for use in macroeconomic forecasting models. The St. Louis Federal Reserve Bank’s FRED system, for instance, currently includes more than 700,000 time series. Given the low frequency of commonly forecasted series, such as GDP and inflation, traditional models will have too few observations to make use of the high number of covariates without overfitting. ML suggests that such problems can be resolved by the application of regularization techniques, which penalize the inclusion of additional variables.
- 3.
Cross-validation: As with ML, the test of a good forecast model is its out-of-sample performance. However, unlike ML, this is not typically the only test of a good model. As such, less emphasis is placed on cross-validation techniques, which are generally better developed in the ML literature. It is possible that economics and finance could benefit by adopting both techniques and best practices.
- 4.
Alternative loss functions: The uniformity of methods used in economics has resulted in the widespread adoption of the same loss functions for all problems. It is possible, however, that not all prediction errors should be weighted using the same scheme; and thus, there may be something to gain from examining the ML literature, where it is common to train models with exotic loss functions .
- 1.
Having more data and exploiting non-linearities improve forecasting at long time horizons for real variables.
- 2.
Factor models, which are already commonly in use in macroeconomics, are a suitable source of regularization.
- 3.
K-fold cross-validation is as useful in evaluating overfitting as the Bayesian Information Criterion (BIC).
- 4.
The L2 loss function, which is already common in macroeconomics, proved sufficient for their forecasting exercise.
Overall, the authors find that ML methods can improve macroeconomic forecasts; however, the gains, as we may have expected, might be small relative to other categories of problems within economics. Time series forecasts for financial series, for instance, might benefit considerably more than macroeconomic forecasts, since the data is often available at considerably higher frequencies .
Summary
- 1.
Off-the-shelf machine learning methods, if applied to policy prediction problems or economic forecasting, can generate improvements over existing econometric methods.
- 2.
Off-the-shelf ML methods are unlikely to be useful for causal inference. Modifying ML algorithms to localize them for use in economics will be necessary.
- 3.
Unlike economics models, ML models don’t typically yield valid confidence intervals for individual parameter values.
- 4.
Whereas economics uses a theory-driven approach to modeling and performs estimation only once, ML is grounded in empirics and iterative improvement via tuning.
- 5.
Big data, coupled with ML methods, such as regularization and cross-validation, is likely to have a substantial impact on which economic questions can be answered and how they are answered.
- 6.
Machine learning is likely to be useful for measuring economic activity, performing inference with models that have a prediction step, and solving policy prediction problems.
In the coming chapters, we will focus primarily on applying the methods and strategies discussed in this chapter to economic and financial problems using TensorFlow.
Bibliography
Athey, S. 2019. “The Impact of Machine Learning on Economics.” In The Economics of Artificial Intelligence: An Agenda, by Joshua gans, and Avi Goldfarb Ajay Agrawal. University of Chicago Press.
Athey, S., and G.W. Imbens. 2019. “Machine Learning Methods that Economists Should Know About.” Annual Review of Economics 11: 685–725.
Athey, S., and G.W. Imbens. 2017. “The State of Applied Econometrics: Causality and Policy Evaluation.” Journal of Economic Perspectives 31 (2): 3–32.
Athey, S., G.W. Imbens, and S. Wager. 2016. “Approximate Residual Balancing: De-Biased Inference of Average Treatment Effects in High Dimensions.” arXiv.
Athey, S., J. Tibshirani, and S. Wager. 2019. “Generalized random forests.” The Annals of Statistics 47 (2): 1148–1178.
Baker, S.R., N. Bloom, and S.J. and Davis. 2016. “Measuring Economic Policy Uncertainty.” The Quarterly Journal of Economics 131 (4): 1593–1636.
Chernozhukov, V., C. Hansen, and M. Spindler. 2015. “Post-Selection and Post-Regularization Inference in Linear Models with Many Controls and Instruments.” American Economic Review: Papers & Proceedings 105 (5): 486–490.
Chernozhukov, V., D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, W. Newey, and J. Robins. 2017. “Double/debiased machine learning for treatment and structural parameters.” The Econometrics Journal 21 (1).
Coulombe, P.G., M. Leroux, D. Stevanovic, and S. Surprenant. 2019. “How is Machine Learning Useful for Macroeconomic Forecasting?” CIRANO Working Papers.
Doudchenko, N., and G.W. Imbens. 2016. “Balancing, Regression, Difference-In-Difference and Synthetic Control Methods: A Synthesis.” NBER Working Papers 22791.
Friedberg, R., J. Tibshirani, S. Athey, and S. Wager. 2018. “Local Linear Forests.” arXiv.
Gentzkow, M., B. Kelly, and M. Taddy. 2019. “Text as Data.” Journal of Economic Literature 57 (3): 535–574.
Glaeser, E.L., A. Hillis, S.D. Kominers, and M. Luca. 2016. “Crowdsourcing City Government: Using Tournaments to Improve Inspection Accuracy.” American Economic Review: Papers & Proceedings 106 (5): 114–118.
Goodfellow, I., Y. Bengio, and A. Courville. 2016. Deep Learning. MIT Press.
Kleinberg, J, J. Ludwig, S. Mullainathan, and Z. Obermeyer. 2015. “Prediction Policy Problems.” American Economic Review: Papers & Proceedings 105 (5): 491–495.
Kleinberg, J., H. Lakkaraju, J. Leskovec, J. Ludwig, and S. Mullainathan. 2017. “Human Decisions and Machine Predictions.” The Quarterly Journal of Economics 133 (1): 237–293.
Mullainathan, S., and J. Spiess. 2017. “Machine Learning: An Applied Econometric Approach.” (Journal of Economic Perspectives) 31 (2): 87–106.
Perrault, R., Y. Shoham, E. Brynjolfsson, J. Clark, J. Etchemendy, B. Grosz, T. Lyons, J. Manyika, S. Mishra, and J.C. Niebles. 2019. The AI Index 2019 Annual Report. AI Index Steering Committee, Human-Centered AI Institute, Stanford, CA: Stanford University.
Sala-i-Martín, Xavier. 1997. “I Just Ran Two Million Regressions.” American Economic Review 87 (2): 178–183.
Varian, Hal R. 2014. “Big Data: New Tricks for Econometrics.” Journal of Economic Perspectives 28 (2): 3–28.
Wager, S., and S. Athey. 2018. “Estimation and Inference of Heterogeneous Treatment Effects using Random Forests.” Journal of the American Statistical Association 113 (532): 1228–1242.