
Chapter 11. Image Processing and Text Recognition
From Google’s self-driving cars to vending machines that recognize counterfeit currency, machine vision is a huge field with far-reaching goals and implications. In this chapter, we will focus on one very small aspect of the field: text recognition, specifically how to recognize and use text-based images found online by using a variety of Python libraries.
Using an image in lieu of text is a common technique when you don’t want text to be found and read by bots. This is often seen on contact forms when an email address is partially or completely rendered as an image. Depending on how skillfully it is done, it might not even be noticeable to human viewers but bots have a very difficult time reading these images and the technique is enough to stop most spammers from acquiring your email address.
CAPTCHAs, of course, take advantage of the fact that users can read security images but most bots can’t. Some CAPTCHAs are more difficult than others, an issue we’ll tackle later in this book.
But CAPTCHAs aren’t the only place on the Web where scrapers need image-to-text translation assistance. Even in this day and age, many documents are simply scanned from hard copies and put on the Web, making these documents inaccessible as far as much of the Internet is concerned, although they are “hiding in plain sight.” Without image-to-text capabilities, the only way to make these documents accessible is for a human to type them up by hand—and nobody has time for that.
Translating images into text is called optical character recognition, or OCR. There are a few major libraries that are able to perform OCR, and many other libraries that support them or are built on top of them. This system of libraries can get fairly complicated at times, so I recommend you read the next section before attempting any of the exercises in this chapter.
Overview of Libraries
Python is a fantastic language for image processing and reading, image-based machine-learning, and even image creation. Although there are a large number of libraries that can be used for image processing, we will focus on two: Pillow and Tesseract.
Either can be installed by downloading from their websites and installing from source (http://bit.ly/1FVNpnq and http://bit.ly/1Fnm6yt) or by using a third-party Python installer such as pip and using the keywords “pillow” and “pytesseract,” respectively.
Pillow
Although Pillow might not be the most fully featured image-processing library, it has all of the features you are likely to need and then some unless you are doing research or rewriting Photoshop in Python, or something like that. It is also a very well-documented piece of code that is extremely easy to use.
Forked off the Python Imaging Library (PIL) for Python 2.x, Pillow adds support for Python 3.x. Like its predecessor, Pillow allows you to easily import and manipulate images with a variety of filters, masks, and even pixel-specific transformations:
fromPILimportImage,ImageFilterkitten=Image.open("kitten.jpg")blurryKitten=kitten.filter(ImageFilter.GaussianBlur)blurryKitten.save("kitten_blurred.jpg")blurryKitten.show()
In the preceding example, the image kitten.jpg will open in your default image viewer with a blur added to it and will also be saved in its blurrier state as kitten_blurred.jpg in the same directory.
We will use Pillow to perform preprocessing on images to make them more machine readable but as mentioned before, there are many other things you can do with the library aside from these simple manipulations. For more information, check out the Pillow documentation.
Tesseract
Tesseract is an OCR library. Sponsored by Google (a company obviously well known for its OCR and machine learning technologies), Tesseract is widely regarded to be the best, most accurate, open source OCR system available.
In addition to being accurate, it is also extremely flexible. It can be trained to recognize any number of fonts (as long as those fonts are relatively consistent within themselves, as we will see soon) and it can be expanded to recognize any Unicode character.
Unlike libraries we’ve used so far in this book, Tesseract is a command-line tool written in Python, rather than a library used with an import statement. After installation, it must be run with the tesseract command, from outside of Python.
Installing Tesseract
For Windows users there is a convenient executable installer. As of this writing, the current version is 3.02, although newer versions should be fine as well.
Linux users can install Tesseract with apt-get:
$sudoapt-gettesseract-ocr
Installing Tesseract on a Mac is slightly more complicated, although it can be done easily with many third-party installers such as Homebrew, which was used in Chapter 5 to install MySQL. For example, you can install Homebrew and use it to install Tesseract in two lines:
$ruby-e"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"$brewinstalltesseract
Tesseract also can be installed from the source, on the project’s download page.
To use some features of Tesseract, such as training the software to recognize new characters later in this section, you will also need to set a new environment variable, $TESSDATA_PREFIX, to let it know where data files are stored.
You can do this in most Linux system and on Mac OS X using:
$exportTESSDATA_PREFIX=/usr/local/share/
Note that /usr/local/share/ is the default data location for Tesseract, although you should check to make sure that this is the case for your own installation.
Similarly, on Windows, you can use the following to use the environment variable:
#setx TESSDATA_PREFIX C:Program FilesTesseract OCR
NumPy
Although NumPy is not required for straightforward OCR, you will need it if you want to train Tesseract to recognize additional character sets or fonts introduced later in this chapter. NumPy is a very powerful library used for linear algebra and other large-scale math applications. NumPy works well with Tesseract because of its ability to mathematically represent and manipulate images as large arrays of pixels.
As always, NumPy can be installed using any third-party Python installer such as pip:
$pipinstallnumpy
Processing Well-Formatted Text
With any luck, most of the text that you’ll need to process will be relatively clean and well formatted. Well-formatted text generally meets several requirements, although the line between what is “messy” and what is “well formatted” can be subjective.
In general, well-formatted text:
- Is written in one standard font (excluding handwriting fonts, cursive fonts, or excessively “decorative” fonts)
- If copied or photographed has extremely crisp lines, with no copying artifacts or dark spots
- Is well-aligned, without slanted letters
- Does not run off the image, nor is there cut-off text or margins on the edges of the image
Some of these things can be fixed in preprocessing. For instance, images can be converted to grayscale, brightness and contrast can be adjusted, and the image can be cropped and rotated as needed. However, there are some fundamental limitations that might require more extensive training. See “Reading CAPTCHAs and Training Tesseract”.
Figure 11-1 an ideal example of well-formatted text.

Figure 11-1. Sample text saved as a .tiff file, to be read by Tesseract
You can run Tesseract from the command line to read this file and write the results to a text file:
$tesseracttext.tiftextoutput|cattextoutput.txt
The output is a line of information about the Tesseract library to indicate that it is running, followed by the contents of the newly created textoutput.txt:
TesseractOpenSourceOCREnginev3.02.02withLeptonicaThisissometext,writteninArial,thatwillbereadbyTesseract.Herearesomesymbols:!@#$%"&‘()
You can see that the results are mostly accurate, although the symbols “^” and “*” were interpreted as a double quote and single quote, respectively. On the whole, though, this lets you read the text fairly comfortably.
After blurring the image text, creating some JPG compression artifacts, and adding a slight background gradient, the results get much worse (see Figure 11-2).

Figure 11-2. Unfortunately, many of the documents you will encounter on the Internet will look more like this than the previous example
Tesseract is not able to deal with this image nearly as well mainly due to the background gradient and produces the following output:
This is some text, written In Arlal, that" Tesseract. Here are some symbols: _
Notice that the text is cut off as soon as the background gradient makes the text more difficult to distinguish, and that the last character from each line is wrong as Tesseract tries futilely to make sense of it. In addition, the JPG artifacts and blurring make it difficult for Tesseract to distinguish between a lowercase “i” and an uppercase “I” and the number “1”.
This is where using a Python script to clean your images first comes in handy. Using the Pillow library, we can create a threshold filter to get rid of the gray in the background, bring out the text, and make the image clearer for Tesseract to read:
fromPILimportImageimportsubprocessdefcleanFile(filePath,newFilePath):image=Image.open(filePath)#Set a threshold value for the image, and saveimage=image.point(lambdax:0ifx<143else255)image.save(newFilePath)#call tesseract to do OCR on the newly created imagesubprocess.call(["tesseract",newFilePath,"output"])#Open and read the resulting data fileoutputFile=open("output.txt",'r')(outputFile.read())outputFile.close()cleanFile("text_2.png","text_2_clean.png")
The resulting image, automatically created as text_2_clean.png, is shown in Figure 11-3:
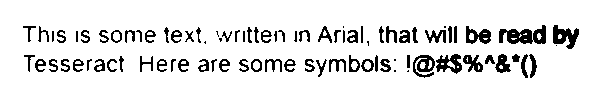
Figure 11-3. This image was created by passing the previous “messy” version of the image through a threshold filter
Apart from some barely legible or missing punctuation, the text is readable, at least to us. Tesseract gives it its best shot:
This us some text‘ written In Anal, that will be read by Tesseract Here are some symbols: !@#$%"&'()
The periods and commas, being extremely small, are the first victims of this image wrangling and nearly disappear, both from our view and Tesseract’s. There’s also the unfortunate misinterpretation of “Arial” as “Anal,” the result of Tesseract interpreting the “r” and the “i” as the single character “n.”
Still, it’s an improvement over the previous version in which nearly half of the text was cut off.
Tesseract’s greatest weakness seems to be backgrounds with varying brightness. Tesseract’s algorithms attempt to adjust the contrast of the image automatically before reading the text, but you can probably get better results doing this yourself with a tool like the Pillow library.
Images you should definitely fix before submitting to Tesseract are those that are tilted, have large areas of non-text, or have other problems.
Scraping Text from Images on Websites
Using Tesseract to read text from an image on your hard drive might not seem all that exciting, but it can be a very powerful tool when used with a web scraper. Images can inadvertently obfuscate text on websites (as with the JPG copy of a menu on a local restaurant site), but they can also purposefully hide the text, as I’ll show in the next example.
Although Amazon’s robots.txt file allows scraping of the site’s product pages, book previews typically don’t get picked up by passing bots. That’s because the book previews are loaded via user-triggered Ajax scripts, and the images are carefully hidden under layers of divs; in fact, to the average site visitor they probably look more like a flash presentation than image files. Of course, even if we could get to the images, there’s the not-so-small matter of reading them as text.
The following script accomplishes just this feat: it navigates to the large-print edition1 of Tolstoy’s War and Peace, opens the reader, collects image URLs, and then systematically downloads, reads, and prints the text from each one. Because this is relatively complex code that draws on multiple concepts from previous chapters, I’ve added comments throughout to make it a little easier to understand what’s going on:
importtimefromurllib.requestimporturlretrieveimportsubprocessfromseleniumimportwebdriver#Create new Selenium driverdriver=webdriver.PhantomJS(executable_path='<Path to Phantom JS>')driver.get("http://www.amazon.com/War-Peace-Leo-Nikolayevich-Tolstoy/dp/1427030200")time.sleep(2)#Click on the book preview buttondriver.find_element_by_id("sitbLogoImg").click()imageList=set()#Wait for the page to loadtime.sleep(5)#While the right arrow is available for clicking, turn through pageswhile"pointer"indriver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"):driver.find_element_by_id("sitbReaderRightPageTurner").click()time.sleep(2)#Get any new pages that have loaded (multiple pages can load at once,#but duplicates will not be added to a set)pages=driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")forpageinpages:image=page.get_attribute("src")imageList.add(image)driver.quit()#Start processing the images we've collected URLs for with Tesseractforimageinsorted(imageList):urlretrieve(image,"page.jpg")p=subprocess.Popen(["tesseract","page.jpg","page"],stdout=subprocess.PIPE,stderr=subprocess.PIPE)p.wait()f=open("page.txt","r")(f.read())
As we have experienced with the Tesseract reader before, this prints many long passages of the book perfectly, as seen in the preview of page 6:
6 “A word of friendly advice, mon cher. Be off as soon as you can, that's all I have to tell you. Happy he who has ears to hear. Good-by, my dear fellow. Oh, by the by!” he shouted through the doorway after Pierre, “is it true that the countess has fallen into the clutches of the holy fathers of the Society of je- sus?” Pierre did not answer and left Ros- topchin's room more sullen and an- gry than he had ever before shown himself.
However, when the text appears on a colored background on the front and back covers of the book, it becomes incomprehensible:
WEI‘ nrrd Peace Len Nlkelayevldu Iolfluy Readmg shmdd be ax wlnvame asnossxble Wenfler an mm m our cram: Llhvary — Leo Tmsloy was a Russian rwovelwst I and moval phflmopher med lur A ms Ideas 01 nonviolenx reswslance m 5 We range 0, “and”
Of course, you can use the Pillow library to selectively clean images, but this can be extremely labor intensive for a process that was designed to be as human-free as possible.
The next section discusses another approach to solving the problem of mangled text, particularly if you don’t mind investing a little time up front in training Tesseract. By providing Tesseract with a large collection of text images with known values, Tesseract can be “taught” to recognize the same font in the future with far greater precision and accuracy, even despite occasional background and positioning problems in the text.
Reading CAPTCHAs and Training Tesseract
Although the word “CAPTCHA” is familiar to most, far fewer people know what it stands for: Computer Automated Public Turing test to tell Computers and Humans Apart. Its unwieldy acronym hints at its rather unwieldy role in obstructing otherwise perfectly usable web interfaces, as both humans and nonhuman robots often struggle to solve CAPTCHA tests.
The Turing test was first described by Alan Turing in his 1950 paper, “Computing Machinery and Intelligence.” In the paper, he described a setup in which a human being could communicate with both humans and artificial intelligence programs through a computer terminal. If the human was unable to distinguish the humans from the AI programs during a casual conversation, the AI programs would be considered to have passed the Turing test, and the artificial intelligence, Turing reasoned, would be genuinely “thinking” for all intents and purposes.
It’s ironic that in the last 60 years we’ve gone from using these tests to test machines to using them to test ourselves, with mixed results. Google’s notoriously difficult reCAPTCHA, currently the most popular among security-conscious websites, blocks as many as 25% of legitimate human users from accessing a site.2
Most other CAPTCHAs are somewhat easier. Drupal, a popular PHP-based content management system, for example, has a popular CAPTCHA module, that can generate CAPTCHA images of varying difficulty. The default image looks like Figure 11-4.
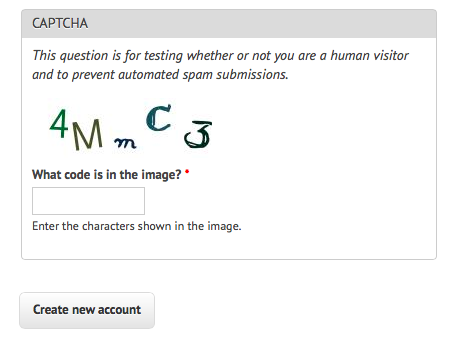
Figure 11-4. An example of the default text CAPTCHA for Drupal’s CAPTCHA project
What makes this CAPTCHA so easy for both humans and machines to read, compared to other CAPTCHAs?
- Characters do not overlap each other, nor do they cross into each other’s space horizontally. That is, it is possible to draw a neat rectangle around each character without overlapping any other character.
- There are no background images, lines, or other distracting garbage that could confuse an OCR program.
- It is not obvious from this image, but there are few variations on the font that the CAPTCHA uses. It alternates between a clean sans-serif font (as seen in the characters “4” and “M”) and a handwriting-style font, (as seen in the characters “m,” “C,” and “3”).
- There is a high contrast between the white background and the dark-colored characters.
This CAPTCHA does throw a few curves, though, that make it challenging for OCR programs to read:
- Both letters and numbers are used, increasing the number of potential characters.
- The randomized tilt of the letters might confuse OCR software, but remains very easy for humans to read.
- The relatively strange handwriting font presents particular challenges, with extra lines in the “C” and “3” and an unusually small lowercase “m” requiring extra training for computers to get the hang of.
When we run Tesseract over this image using the command:
$tesseractcaptchaExample.pngoutput
we get this output.txt file:
4N,,,C<3
It got the 4, C, and 3 right, but it’s clearly not going to be able to fill out a CAPTCHA-protected field any time soon.
Training Tesseract
In order to train Tesseract to recognize writing, whether it’s an obscure and difficult-to-read font or a CAPTCHA, you need to give it multiple examples of each character.
This is the part where you might want to queue up a good podcast or movie because it’s going to be a couple of hours of fairly boring work. The first step is to download multiple examples of your CAPTCHA into a single directory. The number of examples you compile will depend on the complexity of the CAPTCHA; I used 100 sample files (a total of 500 characters, or about 8 examples per symbol, on average) for my CAPTCHA training, and that seems to work fairly well.
Tip: I recommend naming the image after the CAPTCHA solution it represents (i.e., 4MmC3.jpg). I’ve found that this helps to do quick error-checking across large numbers of files at once—you can view all files as thumbnails and compare the image against its image name easily. This helps greatly in error checking in subsequent steps, as well.
The second step is to tell Tesseract exactly what each character is and where it is in the image. This involves creating box files, one for every CAPTCHA image. A box file looks like this:
4 15 26 33 55 0 M 38 13 67 45 0 m 79 15 101 26 0 C 111 33 136 60 0 3 147 17 176 45 0
The first symbol is the character represented, the next four numbers represent coordinates for a rectangular box outlining the image, and the last number is a “page number” used for training with multipage documents (0 for us).
Obviously, these box files are not fun to create by hand, but there are a variety of tools to help you out. I like the online tool Tesseract OCR Chopper because it requires no installation or additional libraries, runs on any machine that has a browser, and is relatively easy to use: upload the image, click the “add” button at the bottom if you need additional boxes, adjust the size of the boxes if necessary, and copy and paste your new box file text into a new file.
Box files must be saved in plain text, with the .box file extension. As with the image files, it’s handy to name the box files by the CAPTCHA solutions they represent (e.g., 4MmC3.box). Again, this makes it easy to double-check the contents of the .box file text against the name of the file, and then again against the image file it is paired with if you sort all of the files in your data directory by their filename.
Again, you’ll need to create about 100 of these files to ensure that you have enough data. Also, Tesseract does occasionally discard files as being unreadable, so you might want some buffer room on top of that. If you find that your OCR results aren’t quite as good as you’d like, or Tesseract is stumbling over certain characters, it’s a good debugging step to create additional training data and try again.
After creating a data folder full of .box files and image files, copy this data into a backup folder before doing any further manipulation on it. Although running training scripts over the data is unlikely to delete anything, it’s better safe than sorry when hours’ worth of work put into .box file creation is involved. Additionally, it’s good to be able to scrap a messy directory full of compiled data and try again.
There are half a dozen steps to performing all the data analysis and creating the training files required for Tesseract. There are tools that do this for you given corresponding source image and .box files, but none at the moment for Tesseract 3.02, unfortunately.
I’ve written a solution in Python that operates over a file containing both image and box files and creates all necessary training files automatically.
The main settings and steps that this program takes can be seen in its main and runAll methods:
defmain(self):languageName="eng"fontName="captchaFont"directory="<path to images>"defrunAll(self):self.createFontFile()self.cleanImages()self.renameFiles()self.extractUnicode()self.runShapeClustering()self.runMfTraining()self.runCnTraining()self.createTessData()
The only three variables you’ll need to set here are fairly straightforward:
languageName- The three-letter language code that Tesseract uses to understand which language it’s looking at. In most cases, you’ll probably want to use “eng” for English.
fontName- The name for your chosen font. This can be anything, but must be a single word without spaces.
- The directory containing all of your image and box files
- I recommend you make this an absolute path, but if you use a relative path, it will need to be relative to where you are running the Python code from. If it is absolute, you can run the code from anywhere on your machine.
Let’s take a look at the individual functions used.
createFontFile creates a required file, font_properties, that lets Tesseract know about the new font we are creating:
captchaFont 0 0 0 0 0
This file consists of the name of the font, followed by 1s and 0s indicating whether italic, bold, or other versions of the font should be considered (training fonts with these properties is an interesting exercise, but unfortunately outside the scope of this book).
cleanImages creates higher-contrast versions of all image files found, converts them to grayscale, and performs other operations that make the image files easier to read by OCR programs. If you are dealing with CAPTCHA images with visual garbage that might be easy to filter out in post-processing, here would be the place to add that additional processing.
renameFiles renames all of your .box files and their corresponding image files with the names required by Tesseract (the file numbers here are sequential digits to keep multiple files separate):
- <languageName>.<fontName>.exp<fileNumber>.box
- <languageName>.<fontName>.exp<fileNumber>.tiff
extractUnicode looks at all of the created .box files and determines the total set of characters available to be trained. The resulting Unicode file will tell you how many different characters you’ve found, and could be a good way to quickly see if you’re missing anything.
The next three functions, runShapeClustering, runMfTraining, and runCtTraining, create the files shapetable, pfftable, and normproto, respectively. These all provide information about the geometry and shape of each character, as well as provide statistical information that Tesseract uses to calculate the probability that a given character is one type or another.
Finally, Tesseract renames each of the compiled data folders to be prepended by the required language name (e.g., shapetable is renamed to eng.shapetable) and compiles all of those files into the final training data file eng.traineddata.
The only step you have to perform manually is move the created eng.traineddata file to your tessdata root folder by using the following commands on Linux and Mac:
$cp/path/to/data/eng.traineddata$TESSDATA_PREFIX/tessdata
Following these steps, you should have no problem solving CAPTCHAs of the type that Tesseract has now been trained for. Now when I ask Tesseract to read the example image, I get the correct response:
$ tesseract captchaExample.png output;cat output.txt 4MmC3
Success! A significant improvement over the previous interpretation of the image as “4N,,,C<3”
This is just a quick overview of the full power of Tesseract’s font training and recognition capabilities. If you are interested in extensively training Tesseract, perhaps starting your own personal library of CAPTCHA training files, or sharing new font recognition capabilities with the world, I recommend checking out the documentation.
Retrieving CAPTCHAs and Submitting Solutions
Many popular content management systems are frequently spammed with registrations by bots that are preprogrammed with the well-known location of these user registration pages. On http://pythonscraping.com, for instance, even a CAPTCHA (admittedly, weak) does little to put a damper on the influx of registrations.
So how do these bots do it? We’ve successfully solved CAPTCHAs in images sitting around on our hard drive, but how do we make a fully functioning bot? This section ties together many techniques covered in previous chapters. If you haven’t already, you should at least skim the chapters on submitting forms and downloading files.
Most image-based CAPTCHAs have several properties:
- They are dynamically generated images, created by a server-side program. They might have image sources that do not look like traditional images, such as
<img src="WebForm.aspx?id=8AP85CQKE9TJ">, but can be downloaded and manipulated like any other image. - The solution to the image is stored in a server-side database.
- Many CAPTCHAs time out if you take too long to solve them. This usually isn’t a problem for bots, but queuing CAPTCHA solutions for later use, or other practices that may delay the time between when the CAPTCHA was requested, and when the solution is submitted, may not be successful.
The general approach to this is to download the CAPTCHA image file to your hard drive, clean it, use Tesseract to parse the image, and return the solution under the appropriate form parameter.
I’ve created a page at http://pythonscraping.com/humans-only with a CAPTCHA-protected comment form for the purpose of writing a bot to defeat. The bot looks like the following:
fromurllib.requestimporturlretrievefromurllib.requestimporturlopenfrombs4importBeautifulSoupimportsubprocessimportrequestsfromPILimportImagefromPILimportImageOpsdefcleanImage(imagePath):image=Image.open(imagePath)image=image.point(lambdax:0ifx<143else255)borderImage=ImageOps.expand(image,border=20,fill='white')borderImage.save(imagePath)html=urlopen("http://www.pythonscraping.com/humans-only")bsObj=BeautifulSoup(html)#Gather prepopulated form valuesimageLocation=bsObj.find("img",{"title":"Image CAPTCHA"})["src"]formBuildId=bsObj.find("input",{"name":"form_build_id"})["value"]captchaSid=bsObj.find("input",{"name":"captcha_sid"})["value"]captchaToken=bsObj.find("input",{"name":"captcha_token"})["value"]captchaUrl="http://pythonscraping.com"+imageLocationurlretrieve(captchaUrl,"captcha.jpg")cleanImage("captcha.jpg")p=subprocess.Popen(["tesseract","captcha.jpg","captcha"],stdout=subprocess.PIPE,stderr=subprocess.PIPE)p.wait()f=open("captcha.txt","r")#Clean any whitespace characterscaptchaResponse=f.read().replace(" ","").replace("","")("Captcha solution attempt: "+captchaResponse)iflen(captchaResponse)==5:params={"captcha_token":captchaToken,"captcha_sid":captchaSid,"form_id":"comment_node_page_form","form_build_id":formBuildId,"captcha_response":captchaResponse,"name":"Ryan Mitchell","subject":"I come to seek the Grail","comment_body[und][0][value]":"...and I am definitely not a bot"}r=requests.post("http://www.pythonscraping.com/comment/reply/10",data=params)responseObj=BeautifulSoup(r.text)ifresponseObj.find("div",{"class":"messages"})isnotNone:(responseObj.find("div",{"class":"messages"}).get_text())else:("There was a problem reading the CAPTCHA correctly!")
Note there are two conditions on which this script fails: if Tesseract did not extract exactly five characters from the image (because we know that all valid solutions to this CAPTCHA must have five characters), or if it submits the form but the CAPTCHA was solved incorrectly. The first case happens approximately 50% of the time, at which point it does not bother submitting the form and fails with an error message. The second case happens approximately 20% of the time, for a total accuracy rate of about 30% (or about 80% accuracy for each character encountered, over 5 characters).
Although this may seem low, keep in mind that there is usually no limit placed on the number of times users are allowed to make CAPTCHA attempts, and that most of these incorrect attempts can be aborted without needing to actually send the form. When a form is actually sent, the CAPTCHA is accurate most of the time. If that doesn’t convince you, also keep in mind that simple guessing would give you an accuracy rate of .0000001%. Running a program three or four times rather than guessing 900 million times is quite the time saver!
1 When it comes to processing text it hasn’t been trained on, Tesseract fares much better with large-format editions of books, especially if the images are small. In the next section we’ll discuss how to train Tesseract on different fonts, which can help it read much smaller font sizes, including previews for non-large print book editions!
2 See http://bit.ly/1HGTbGf.