
Chapter 5. The Challenge of Reusable Client Apps
“Everything does go in a circle.”
Cyndi Lauper
The challenge of building client applications is that we often start with a solution in mind. That might seem like a good thing, but sometimes it is not. Sometimes, it is more important to start with the problem in mind; more specifically, the problem domain.
This notion of starting with the problem domain has some important implications. Instead of using the problem itself as the design model, we’ll need something else. This is usually referred to as the interaction model. At this level, the interaction model becomes one of the first-class aspects of the application design. There are a handful of different ways to model interaction and we’ll explore two of them in this chapter along with coming up with a model of our own that we can use when implementing our hypermedia clients.
Finally, using information from the interaction models, we’ll be able to identify one of the key differences between hypermedia clients (what I’ll be calling map-style clients) and non-hypermedia clients (path-style clients). Hypermedia clients have a key aspect of the interaction model (the ability to understand action details and interpret the structure of responses) missing from the code. Instead of being hardcoded in the client, these details are supplied by the messages sent from the service. When you can build a client that doesn’t have to memorize the solution ahead of time (e.g., have all the possible actions and workflow baked into the code), you can start building clients that can solve previously unknown problems and who are “smart” enough to adapt to new possible actions as the service presents them.
How can you build “smarter” client apps by teaching them less about how to solve a particular problem? Well, that depends on what problem you are trying to solve in the first place. And that’s where we’ll start this chapter on creating general-use client applications.
What Problem Are You Solving?
Thinking about the general problem space gives us a chance to consider a wide range of solutions to the same problem. It also gives us a chance to think up lots of related problems. In fact, if we’re not careful, we can rush to come up with a solution to the wrong problem. When working on a design, it is important to make sure you understand the “real” problem to solve. In his book The Design of Everyday Things, Donald Norman, one of the leading thinkers in the human–computer interaction (HCI) space, put it this way:
Good designers never start out by trying to solve the problem given to them: they start by trying to understand what the real issues are.
A similar approach is part of the Toyota Way and is called “The Five Whys.” In his 1988 book, Toyota Production System (Productivity Press) Taiichi Ohno states:
By asking why five times and answering each time, the real cause of a problem can be discovered.
Double Diamond Model of Design
The act of taking a single problem and expanding the problem space even larger is a common technique for designers. This is sometimes referred to as the Double Diamond Model of Design (see Figure 5-1). Created by the UK Design Council in 2005, the Double Diamond illustrates the four-part process of DISCOVER, DEFINE, DEVELOP, and DELIVER. The DISCOVER and DEVELOP phases aim to expand the area of consideration in order to explore alternatives, and the DEFINE and DELIVER phases aim to narrow the list of options to find the best available solution.
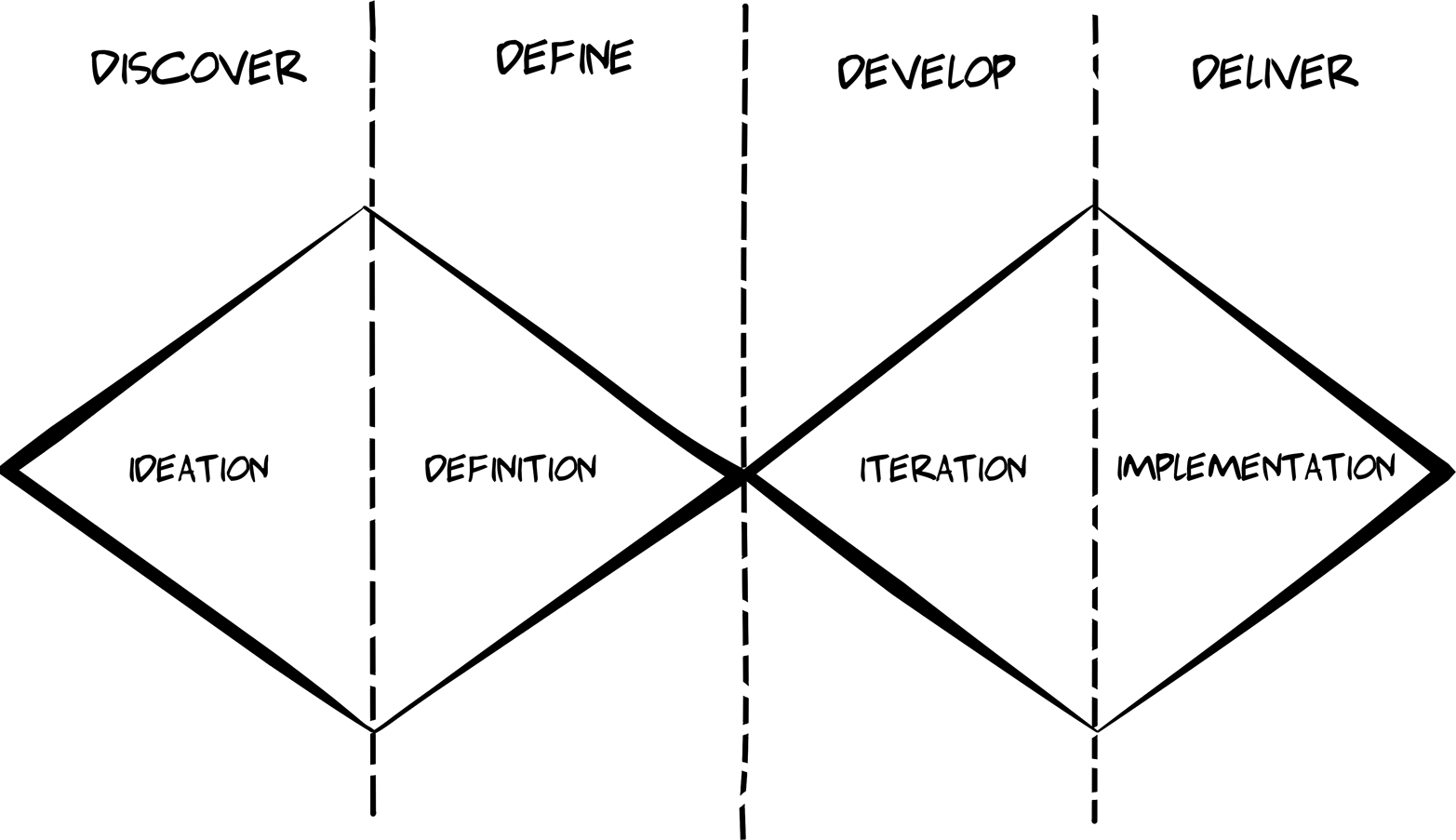
Figure 5-1. The UK Design Council’s Double Diamond Model of Design
So, being ready to explore the problem more in depth is important. But how can we go about doing that?
Closed Solution Versus Open Solution
One way you can get beyond writing a bespoke application for each and every problem is to rethink how you design the client itself. Most web client applications are crafted and tailored to solve a single problem or a small set of closely related problems. These apps are what I call closed-solution apps. The problems they are designed to solve (and the solutions) are known ahead of time—before the app is built. In these cases, programmers are there to translate the predetermined solution into code and deploy the results for use.
But there is a class of applications that are designed to allow users to solve their own problems. These apps are what I call open-solution apps. The solution is not defined ahead of time and supplied by the code. Instead, the app is created in order to allow users to define and solve problems that the app designer/programmer may have never imagined. Easy examples of this class of apps are spreadsheets, word processors, drawing tools, and the like. It is this second class of apps—the open-solution apps—that can be the most valuable over time and the most challenging to implement.
What separates open-solution app designs form more typical single-use client apps? One way to think about it is that closed-solution apps are usually designed to provide a single, static path through a domain space—a path that leads from the start of the problem to the completed solution. Think of a wizard-style interface that leads the user through a series of steps until the job is complete. That’s a path-style application.
For example, here’s some pseudo-code for a path-style application:
START COLLECT userProfile THEN COLLECT productToBuy THEN COLLECT shoppingCart THEN COLLECT shippingInfo THEN COLLECT paymentInfo THEN FINALIZE checkOut END
The advantage of “closed-solution” apps is that they are often very easy for users to navigate and are relatively easy to implement and deploy. They solve a narrow-focused problem like a fixed set of steps or workflow through a problem domain (e.g., online retail sales). The downside is that any changes to the workflow mean the current app is “broken” and needs to be recoded and redeployed. For example, if the workflow was changed so that it no longer requires users to identify themselves (COLLECT userProfile) before shopping (COLLECT productToBuy) then this app would need to be rewritten. The same would happen if the service was able to use a default shipping service, thus skipping the COLLECT shippingInfo step. And the list goes on…
However, in an open-solution style app, there is no direct path from start to finish. Instead, there are a series of possible actions that may (or may not) be needed. The user (or sometimes another service) helps determine which actions to take depending on what is being accomplished and the “state of things” at any point in time.
Here’s how we might recode the shopping client as more of an open-solution style app:
WHILE NOT EXIT IF-NEEDED COLLECT userProfile OR IF-NEEDED COLLECT productToBuy OR IF-NEEDED COLLECT shoppingCart OR IF-NEEDED COLLECT shippingInfo OR IF-NEEDED COLLECT paymentInfo OR IF-ALLOWED FINALIZE checkOut OR IF-REQUESTED EXIT WHILE-END
As you can see from the second example, the app is designed as a continuous loop, and within that loop a number of things could possibly happen based on a check of the “state of things” (IF-NEEDED, IF-ALLOWED) at any time along the way. And this loop continues until the job is completed (FINALIZE checkout and IF-REQUESTED EXIT). This kind of implementation doesn’t look like a path through the problem domain. Instead, it looks more like a list or map of interesting possibilities (locations) within the problem domain (the map). Just looking at this imaginary code, you can see that the app is now something that allows for solving all sorts of problems within the online retail sales domain, such as:
-
Creating/updating a user profile
-
Selecting products to purchase
-
Loading and managing a shopping cart
-
Managing shipping details
-
Managing payment information
-
Authorizing and completing a purchase
And, most important, the order in which these are done is not very important. There is certainly a check (IF-ALLOWED) to see that all things are supplied before allowing the user to complete the checkOut action. In a nontrivial app, this “if allowed” pattern would occur often and cover things like the status of the logged-in user (IF-ALLOWED delete user), the state of content on the server (IF-INSTOCK selectForPurchase), or the user’s account (IF-AUTHORIZED purchaseOnConsignment).
It turns out this repeated loop style of apps is quite common. Most computer games use loops to manage user interaction. All windowing software uses loops and events to handle user interaction, and advanced robotics uses loops to sense the surroundings and continually act accordingly to adjust to external inputs.
So, one way to avoid falling into the trap of making every client app a bespoke or custom affair is to start thinking of clients as applications that enable users to explore a domain space. And an important way to do that is to think carefully about whether you want your application to offer a fixed path from start to finish or a detailed map of the general domain space itself. Path-style implementations get us to a predetermined destination quickly. Map-style implementations offer many possible ways to get similar results.
Whether you are implementing path-finders or map-makers, you need some model that underpins these general explorer applications. And that means we need to learn a little bit about modeling interaction before we make our ultimate decision.
Modeling Interaction
The process of modeling interaction can help provide a high-level guidance to designers and developers. The phrase interaction design was first coined in the 1980s, but thinking about how machines and humans would interact in the electronic age goes back further than that—at least as far as the 1960s for teachers at the School of Design in Ulm, Germany. And before that, the field of industrial design (from eighteenth-century England) established many of the principles used in interaction design today.
Multiple Views of Interaction Modeling
There’s a great ACM article from 2009, “What Is Interaction? Are There Different Types?”, that covers the topic in more depth than I can do in this book. It also introduces the notion of varying views of interaction modeling such as Design-Theory, HCI, and Systems-Theory views. If you want to explore this topic further, that article is a great place to start.
When thinking about the features of a general-use hypermedia client, it is important to get a feel for the field of interaction design and the models that have dominated the space over the last half-century. To that end, I’ve selected two individuals (and their models) to review:
-
Tomás Maldonado’s “Ulm Model”
-
Bill Verplank’s DO-FEEL-KNOW
Maldonado’s Mechanisms
One early example of thinking about how humans and machines interact comes from the German Ulm School for Design (Hochschule für Gestaltung, or HfG). In 1964, a paper (Science and Design by Maldonado & Bonsiepe) was published in the school’s journal. It included the notion of human–machine interface. The model assumes a relationship between Humans and Mechanisms mediated by Controls and Displays.
Argentine painter, designer, and philosopher Tomás Maldonado was a major force at the cutting-edge Ulm School of Design in the 1950s and 1960s, and the Ulm Model (see Figure 5-2) described in his 1964 paper is one of the lasting legacies of his work there. The work of Maldonado and his German colleague Gui Bonsiepe are, to this day, thought of as the standard of design theory.
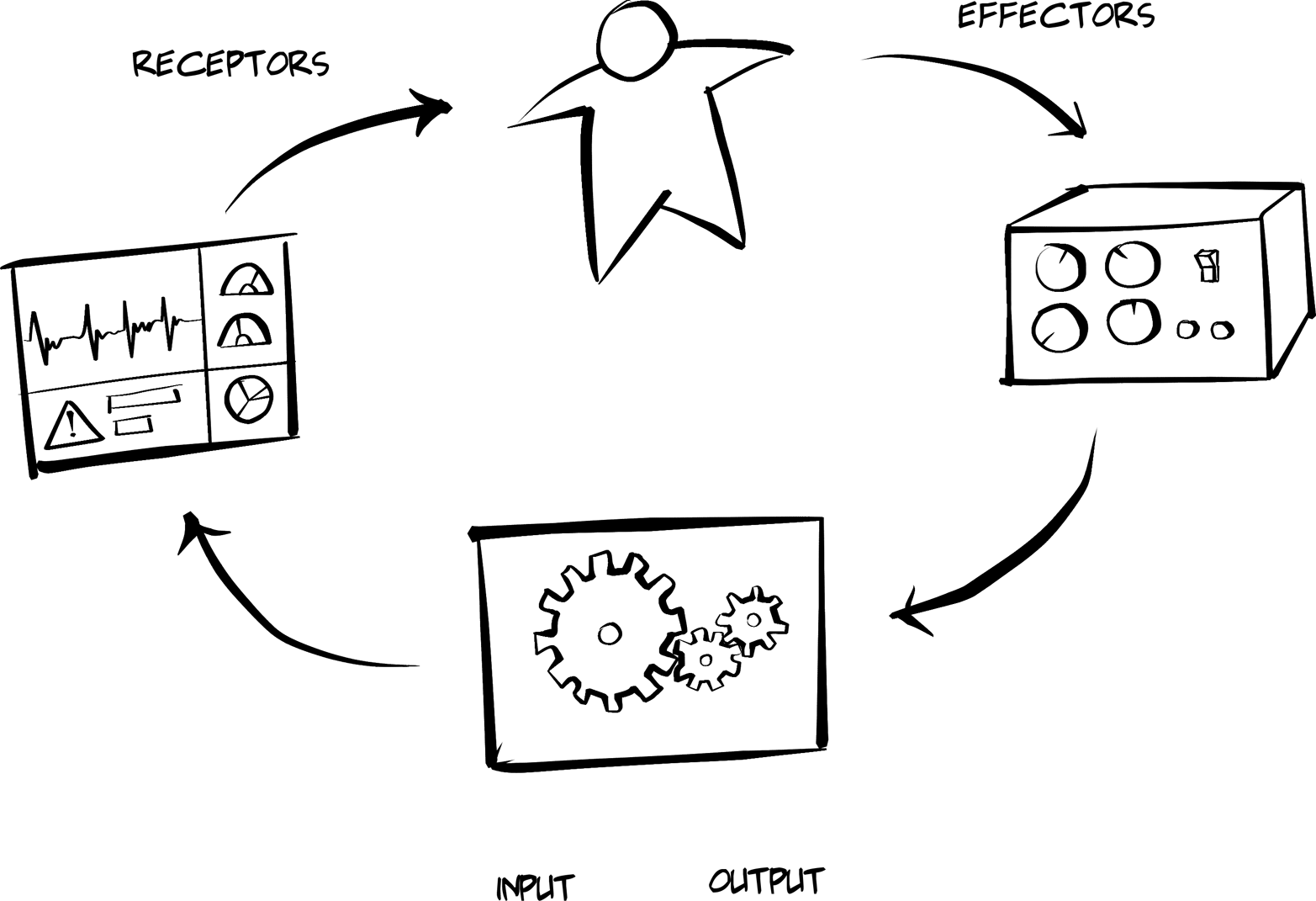
Figure 5-2. The Ulm Model of Human–Machine Interaction
As you can see from the diagram:
-
Humans can manipulate…
-
Controls, which produce inputs for…
-
Mechanisms, which produce outputs that may appear on…
-
Displays, which are viewed by Humans (and the loop continues).
This is essentially the way the web browser operates. Humans manipulate the interface (e.g., they supply a URL and press Enter). Then the browser uses its own internal Mechanisms (code) to execute the request, parse the response, and Display it on the screen. The screen typically contains some level of information (data and context) and usually includes additional Controls (links and forms). The Human reviews the Displays and determines which Controls (if any) need to be manipulated to continue the process.
The good news is that all this work is done in modern software today by the web browser without any need for additional coding. The only required element is the HTML response provided by servers. Of course, the downside is that this important interaction model is hidden from us and difficult to observe directly. It didn’t take long before this changed with the introduction of client-side scripting for browsers.
Paying Attention to the Man Behind the Curtain
Much like the character Dorothy in the movie The Wizard of Oz, web developers were not content with keeping the Mechanisms of the web browser hidden. Not long after the release of web browsers, added support for client scripting allowed developers to use local code to improve the user interaction experience. Soon (around the year 2000) programmers gained access to the HTTP request/response interactions with the XMLHttpRequest object. By the 2010s, there was a movement to gain access to much more of the web browser’s internal mechanisms with the Extensible Web Manifesto movement.
A simple pseudo-code example of what the Ulm Model might look look like is:
WHILE
WAIT-FOR CONTROLS("user-action")
THEN EXECUTE MECHANISM(input:"user-action", output:"service-response")
THEN DISPLAY("service-response")
END-WHILE
Note that the preceding sample doesn’t have any domain-specific information. There is nothing about user access management or accounting, and so on. At this level, the general interaction is the focus, not some specific problem that needs to be addressed. Writing general-purpose applications often means focusing first on the interaction model.
This simple interaction model from 1964 is not the only one to consider. In fact, when Maldonado and Bonsiepe published the Ulm Model, there was no notion of interaction design as we know it.
Verplank’s Humans
It was Bill Verplank (along with William Moggridge) who coined the term interaction design in the 1980s. Much like the work of Maldonado and Bonsiepe at the Ulm School, Verplank and Moggridge codeveloped important theories on how humans and machine interactions are described and designed (see Figure 5-3). From Verplank’s point of view, interaction designers should ask three key questions:
-
How do you Do?
-
How do you Feel?
-
How do you Know?
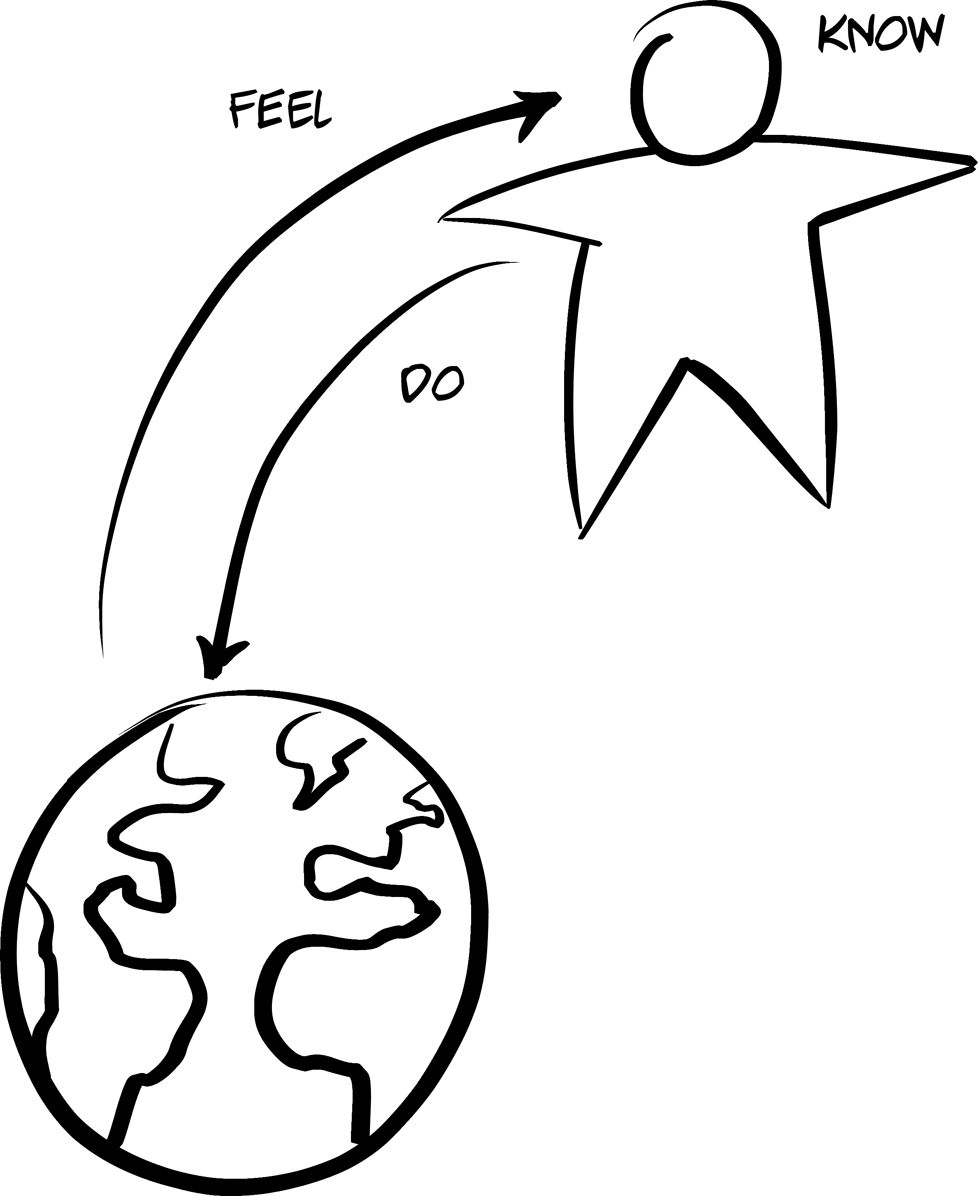
Figure 5-3. Verplank’s Do-Feel-Know Interaction Model
In Interaction Design Sketchbook, he offers a simple example of this interaction model by referring to the act of manipulating the light switch in a room:
Even the simplest appliance requires doing, feeling, and knowing. What I Do is flip a light switch and see (Feel?) the light come on; what I need to Know is the mapping from switch to light.
What’s compelling about Verplank’s model is that the human aspects of Feel (the ability to perceive change in the world) and Know (the information needed to act accordingly) is accounted for directly. This leads to an important aspect of creating client-side applications that is rarely discussed in the API world—human understanding. Although quite a bit of interesting and powerful programming can be written into client applications, these applications are still often standing in as user-agents for humans. It is the humans that know the ultimate goal (e.g., “I wonder if that bicycle is still on sale?”) and it is the humans who have the power to interpret responses and decide which step(s) are still needed to accomplish the goal.
Hypermedia Clients are Dumb
One comment I hear when talking to people about hypermedia goes like this: “It doesn’t make sense to include hypermedia links and forms in responses because hypermedia clients won’t know what to do with them anyway.” This is, of course, true. Just sending links and forms in responses does not magically make client applications smart enough to understand goals or make choices that lead to them. But including hypermedia controls makes it possible for humans to make choices. That’s the first role of hypermedia—to allow humans the opportunity to make their own choices about what happens next. Hypermedia is not there to take the place of human understanding and choice; it is there to enable it.
So, with Verplank’s model, we can isolate parts of the interaction loop where humans play a role (Feel and Know) and where machines play a role (Do). Similar to the Ulm Model, humans are an important feature of the interaction loop. But, with Verplank, the contributions humans make are more specific than in the Ulm Model. That gives developers a chance to approach the process of implementing client applications with a clear separation of concerns. This is a well-known concept that is discussed in computing, too.
The Origin of Separation of Concerns
The phrase separation of concerns is thought to have been coined by E. W. Dijkstra in his 1974 essay “On the Role of Scientific Thought."” Initially, he was discussing the importance of taking differing points of view when evaluating the same program (correctness, efficiency, etc.). Later the phrase was used to describe programs that kept various aspects of the work clearly separated (e.g., algorithms, user input, memory management, etc.).
Again, what would an application’s interaction approach look like if it followed Verplank’s DO-FEEL-KNOW model? Probably something like this:
WHILE
WITH-USER:
FEEL(previously-rendered-display)
KNOW(select-action)
WITH-MACHINE:
DO(RUN selected-action on TARGET website and RENDER)
END-WHILE
Here we can see that the HUMAN is responsible for scanning the display for information (Feel) and then deciding what action to take (Know). Once that happens, the MACHINE will Do the selected action and render the results before starting the loop again.
When human and machine roles are separated, it’s possible to see that client applications do not need to be designed to solve a particular problem (shopping for bicycles). Instead, they can be designed to provide a set of capabilities (finding stores that sell bicycles, filtering a list of bicycles within a store, ordering a bicycle, etc.). This makes it possible to allow machines to Do what they know how to do based on humans’ ability to Feel and Know.
So, how can we apply this knowledge to our hypermedia client implementations? What we need is our own model for creating general-use hypermedia clients—our own interaction loop.
A Hypermedia Interaction Loop
The client applications in this book deal mostly with Verplank’s Do level. They are focused on executing the actions specified by humans and reflecting the results of those actions back to the human user. This gets us close to the map-style implementations that can have a long shelf life and support a wide range of solutions in more than one problem domain space.
Using the previous interaction models as a guide, I’ll describe a simple model that can help when building hypermedia client applications—what I call the RPW model. This model is used as an implementation pattern for all the hypermedia clients we’ll see in this book.
The Request, Parse, Wait Loop
From a programmatic standpoint, a very straightforward interaction model is that of the web browser:
-
Wait for some input (e.g., a URL or field inputs, etc.).
-
Execute the request (using the inputs supplied).
-
Parse and render the response (text, images, etc.).
-
Go back to step 1.
This pattern is at the heart of all user-centric web applications, too, and is shown in Figure 5-4. Get some inputs, make a request, and render the results. Starting from the request step, I call this the Request, Parse, and Wait loop (RPW).
Sometimes it is easy to see the pattern, but sometimes it is hidden or muddled behind lots of code or multiple interaction modules. For example, in event-based client implementations, there are dozens of isolated RPW interactions happening throughout the life of the client application. Some of the RPWs are initiated by the client, but many of them are simple reactions to incoming messages from the service. In those cases the, “R” of RPW (the request) exists in the form of a subscription—a general request made by the client one time that says “Please send me any notifications related to the User object” or some other similar statement. There are a number of programming frameworks that adopt this style of RPW including React, Meteor, AngularJS, and others.
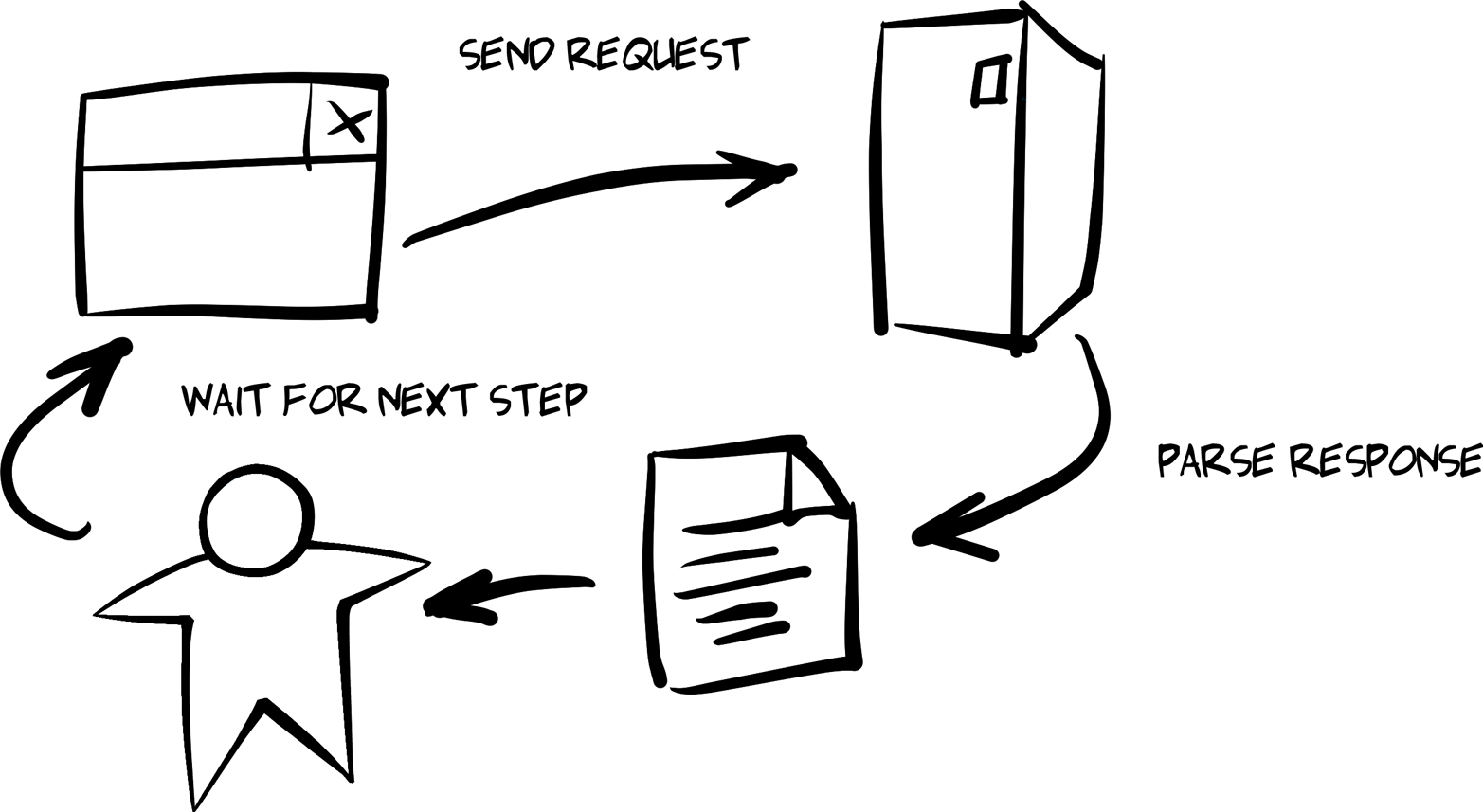
Figure 5-4. The Request, Parse, and Wait model
Another form of the RPW loop exists for asynchronous implementations. A client might initiate a request and not expect to parse the response immediately. In asynchronous clients, multiple requests may be sent before any of the responses need to be parsed. The RPW loops are stretched out over time and sometimes overlap with each other. JavaScript is based on support for async operations. This is essentially how NodeJS works, too. When using NodeJS to write API consumer code, you can fire off one or more requests, register callback functions for each, and assemble the results once all calls have been resolved.
Whether your user-centric client implements the client–server model (e.g., classic HTML-only apps), an event-based model (AngularJS, etc.), or an asynchronous model (NodeJS-style callbacks), at the heart of all the interactions between the client and the target service is some form of the RPW loop. This RPW-style loop exists outside of computer programming, too. Consider calling ahead for a dinner reservation and then traveling to the restaurant to retrieve your table. Or telling your friend to call you the minute they get home and then going about your business until the call arrives. Or using a thermostat to adjust the temperature of an overheated office and then waiting for the air conditioner to turn on to start cooling the room. These are all examples of RPW-type loops.
So what does this look like in code?
Implementing RPW in Code
In Chapter 2, JSON Clients, we saw that the initial entry point for the single-page app (SPA) was the act of passing an initial URL to the client library:
window.onload=function(){varpg=jsonClient();pg.init("http://localhost:8181/","TPS");}
After validating the initial call, this URL is used to make the first request:
// init library and startfunctioninit(url){if(!url||url===''){alert('*** ERROR: MUST pass starting URL to the library');}else{httpRequest(url,"get");}}
And, when the response comes back, it is parsed and rendered in the browser:
// primary loopfunctionparseMsg(){processTitle();processItems();processActions();}
Once the parsing is completed, the application Waits for the user to activate a link or fill in a form. When that happens, another Request is made and the response is Parsed. This repeats until the application is closed by the user.
The Request and Parse steps correspond closely to the Do step of Verplank’s model. The Wait step in our model is the part where the human steps in. The application simply waits for the human to do all the other work—in this case, Verplank’s Feel step.
But it turns out something is missing from the RPW model. What about Verplank’s Know step? Once a human reacts to the rendered response, gets the Feeling that what is needed is adding a new user to the database, fills in the proper inputs, and presses the Enter key, how does the client application Know how to turn those inputs into a valid action to Do?
The answer to this question goes to the primary differences between path-style and map-style client applications. And this difference is what sets hypermedia client applications apart from others.
Handling Verplank’s KNOW Step
We saw in the JSON client application built in Chapter 2, JSON Clients that it relies on a simple loop. But what we glossed over is that there is another level of functionality baked into the JSON client app—the functionality that Knows how to construct and execute network requests. This changes the nature of the JSON client as it relates to Verplank’s Know level. The app has code that predefines all the possible behaviors so that it knows how to handle all the operations ahead of time. In this way, I (as the programmer of that app) have narrowed the app’s ability to solve problems. It can only Do the things it Knows in advance.
Most of the Know content of the example JSON client from Chapter 2 is kept in two locations:
global.actionsobject collection-
This contains the rules that let the app Know which behaviors are possible and how to perform the specified actions at runtime (e.g.,
addTask,assignUser, etc.). processItems()function-
This function Knows how to interpret the responses in order to find all the objects and their properties and how to render this information on the screen.
For example, near the top of the JSON client source code file, you can see the collection actions:
// all URLs and action detailsg.actions.task={tasks:{target:"app",func:httpGet,href:"/task/",prompt:"Tasks"},active:{target:"list",func:httpGet,href:"/task/?completeFlag=false",prompt:"Active Tasks"},closed:{target:"list",func:httpGet,href:"/task/?completeFlag=true",prompt:"Completed Tasks"},byTitle:{target:"list",func:jsonForm,href:"/task",prompt:"By Title",method:"GET",args:{title:{value:"",prompt:"Title",required:true}}},add:{target:"list",func:jsonForm,href:"/task/",prompt:"Add Task",method:"POST",args:{title:{value:"",prompt:"Title",required:true},tags:{value:"",prompt:"Tags"},completeFlag:{value:"",prompt:"completeFlag"}}},item:{target:"item",func:httpGet,href:"/task/{id}",prompt:"Item"},edit:{target:"single",func:jsonForm,href:"/task/{id}",prompt:"Edit",method:"PUT",args:{id:{value:"{id}",prompt:"Id",readOnly:true},title:{value:"{title}",prompt:"Title",required:true},tags:{value:"{tags}",prompt:"Tags"},completeFlag:{value:"{completeFlag}",prompt:"completeFlag"}}},delete:{target:"single",func:httpDelete,href:"/task/{id}",prompt:"Delete",method:"DELETE",args:{}},};
Each action element in the preceding code set contains all the information needed to fully describe one of the possible domain actions. These are the static set of paths the client Knows about. They are fixed within the client source code and the list cannot be updated without also updating and redeploying the client app itself.
The same is true for the code that represents the client’s ability to parse the response and render it on the screen:
// the only fields to processglobal.fields=["id","title","tags","dateCreated","dateUpate","assignedUser"];for(varitemofitemCollection){li=domHelp.node("li");dl=domHelp.node("dl");dt=domHelp.node("dt");// emit item-level actionsdt=processitemActions(dt,item,(itemCollection.length===1));// emit the data elementsdd=d.node("dd");for(varfofglobal.fields){p=domHelp.data({className:"item "+f,text:f,value:item[f]+" "});domHelp.push(p,dd);}domHelp.push(dt,dl,dd,li,ul);}
In the function that handles each item in the response (just shown), we can see the code that filters through the list of item properties and only shows the ones that are in the client’s global.fields array (![]() ). This client already Knows which data elements to display and parses the response in order to find and render them.
). This client already Knows which data elements to display and parses the response in order to find and render them.
There is also code in the preceding example that parses the response to emit additional actions (![]() ) to expose to the human user. That routine (
) to expose to the human user. That routine (processItemActions) looks like this:
// handle item-level actionsfunctionprocessItemActions(dt,item,single){vara,link;// item linklink=global.actions.item;a=domHelp.anchor({href:link.href.replace(/{id}/,item.id),rel:"item",className:"item action",text:link.prompt});a.onclick=httpGet;domHelp.push(a,dt);// only show these for single item rendersif(single===true){// edit linklink=global.actions.edit;a=domHelp.anchor({href:link.href.replace(/{id}/,item.id),rel:"edit",className:"item action",text:link.prompt});a.onclick=jsonForm;a.setAttribute("method",link.method);a.setAttribute("args",JSON.stringify(link.args));domHelp.push(a,dt);// delete linklink=global.actions.remove;a=domHelp.anchor({href:link.href.replace(/{id}/,item.id),rel:"remove",className:"item action",text:link.prompt});a.onclick=httpDelete;domHelp.push(a,dt);}returndt;}
Note that the JSON client not only knows how to construct valid URLs (![]() ). It also knows when selected actions will be valid (
). It also knows when selected actions will be valid (![]() ). Again, this kind of knowledge (URL rules for each action and when an action is possible) are now hardcoded into the app. Changes in these rules will invalidate the app itself.
). Again, this kind of knowledge (URL rules for each action and when an action is possible) are now hardcoded into the app. Changes in these rules will invalidate the app itself.
We can now see that the JSON client app contains code that covers not just the ability to Do actions and parse the results. It also has a set of rules baked into the code to handle all the possible actions—the capability to Know how each action is constructed and understand the semantic content of responses.
In hypermedia-style clients, this information is left out of the client completely. All the information that describes how to formulate requests and parse responses is part of the message itself. And hypermedia clients have additional skills to recognize this descriptive information, giving them the ability to execute actions that do not appear in the source code. These clients are able to read the map supplied by the message instead of just following a predetermined path.
For example, the HAL client we covered in Chapter 4 has the ability to understand the _link elements in each response in order to compose (Do) simple requests. It is important to note that we also decided to implement the HAL-FORMS extension in order to help the client app Know how deal with additional information on formulating requests.
And that’s what we’re focusing on as we build our hypermedia-style clients. We are exploring ways to allow client apps to improve their ability interact with API services based on their ability to Know the interaction information (LINKS and FORMS) contained in responses and use this information to Do things on behalf of the user.
Essentially, we’re creating adaptable map-makers instead of just static path-finders.
Summary
In this chapter, we looked at the challenges of implementing general-use API clients. We learned about the difference between path-style and map-style app designs. We also explored the background interactive design through the works of Tomás Maldonado (the Ulm Model) and Bill Verplank (Do-Feel-Know). From that exploration, we came up with our own interaction model (RPW) to use as a guide for implementing our client applications.
Finally, we reviewed the JSON client app from Chapter 2 and saw how that implementation illustrates the path-style approach. And we noted that hypermedia client apps, such as the HAL client app discussed in Chapter 4, get their action information from the messages they receive instead of from the source code itself. This RPW model will also act as a guide as we explore other client implementations in future chapters like the ones that support the Siren format (Chapter 6) and the Collection+JSON format (Chapter 8).
References
-
The Design of Everyday Things, Revised and Expanded Edition is the 2013 update of Donald Norman’s classic 1988 book on usability and interaction design.
-
A short paper from 1978 with the title “The Toyota Production System” is available online. This is dated ten years before the 1988 release of the book with the same name.
-
Peter Merholz has a nice blog post about the UK Design Council’s Double Diamond Design Model.
-
The article “What Is Interaction? Are There Different Types?” was published in the January 2009 issue of Interactions magazine.
-
The Ulm Model and the Ulm School of Design has a colorful history and it is well worth exploring.
-
You can learn more about the Extensible Web movement by visiting their website and reading their Manifesto.
-
Bill Verplank has a unique presentation style that includes sketching as he speaks. There are a number of videos online where you can see this in action. He also released a short pamphlet online called Interaction Design Sketchbook.
-
Moggridge’s book Designing Interactions is a collection of interviews with many important figures in the history of interaction design.
-
Dijkstra’s 1974 essay, “On the role of scientific thought,” is available online.