
Chapter 8. Object References, Mutability, and Recycling
‘You are sad,’ the Knight said in an anxious tone: ‘let me sing you a song to comfort you. […] The name of the song is called “HADDOCKS’ EYES”.’
‘Oh, that’s the name of the song, is it?’ Alice said, trying to feel interested.
‘No, you don’t understand,’ the Knight said, looking a little vexed. ‘That’s what the name is CALLED. The name really IS “THE AGED AGED MAN."’ (adapted from Chapter VIII. ‘It’s my own Invention’).
Lewis Carroll, Through the Looking-Glass, and What Alice Found There
Alice and the Knight set the tone of what we will see in this chapter. The theme is the distinction between objects and their names. A name is not the object; a name is a separate thing.
We start the chapter by presenting a metaphor for variables in Python: variables are labels, not boxes. If reference variables are old news to you, the analogy may still be handy if you need to explain aliasing issues to others.
We then discuss the concepts of object identity, value, and aliasing. A surprising trait of tuples is revealed: they are immutable but their values may change. This leads to a discussion of shallow and deep copies. References and function parameters are our next theme: the problem with mutable parameter defaults and the safe handling of mutable arguments passed by clients of our functions.
The last sections of the chapter cover garbage collection, the del command, and how to use weak references to “remember” objects without keeping them alive.
This is a rather dry chapter, but its topics lie at the heart of many subtle bugs in real Python programs.
Let’s start by unlearning that a variable is like a box where you store data.
Variables Are Not Boxes
In 1997, I took a summer course on Java at MIT. The professor, Lynn Andrea Stein—an award-winning computer science educator who currently teaches at Olin College of Engineering—made the point that the usual “variables as boxes” metaphor actually hinders the understanding of reference variables in OO languages. Python variables are like reference variables in Java, so it’s better to think of them as labels attached to objects.
Example 8-1 is a simple interaction that the “variables as boxes” idea cannot explain. Figure 8-1 illustrates why the box metaphor is wrong for Python, while sticky notes provide a helpful picture of how variables actually work.
Example 8-1. Variables a and b hold references to the same list, not copies of the list
>>>a=[1,2,3]>>>b=a>>>a.append(4)>>>b[1, 2, 3, 4]
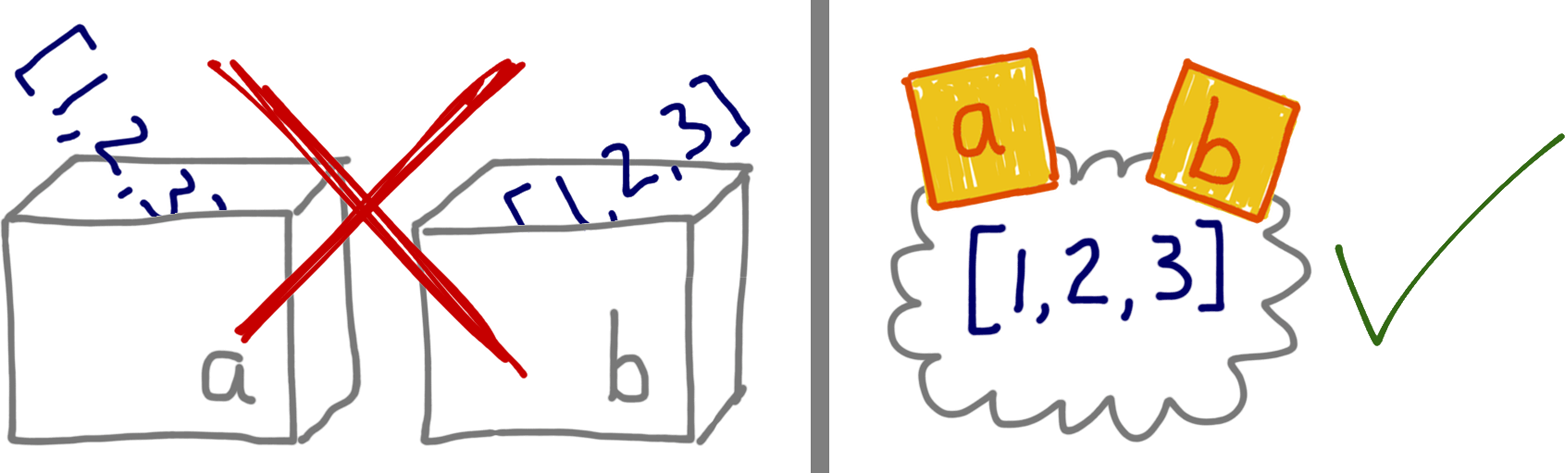
Figure 8-1. If you imagine variables are like boxes, you can’t make sense of assignment in Python; instead, think of variables as sticky notes—Example 8-1 then becomes easy to explain
Prof. Stein also spoke about assignment in a very deliberate way. For example, when talking about a seesaw object in a simulation, she would say: “Variable s is assigned to the seesaw,” but never “The seesaw is assigned to variable s.” With reference variables, it makes much more sense to say that the variable is assigned to an object, and not the other way around. After all, the object is created before the assignment. Example 8-2 proves that the righthand side of an assignment happens first.
Example 8-2. Variables are assigned to objects only after the objects are created
>>>classGizmo:...def__init__(self):...('Gizmo id:%d'%id(self))...>>>x=Gizmo()Gizmo id: 4301489152>>>y=Gizmo()*10Gizmo id: 4301489432Traceback (most recent call last):File"<stdin>", line1, in<module>TypeError:unsupported operand type(s) for *: 'Gizmo' and 'int'>>>>>>dir()['Gizmo', '__builtins__', '__doc__', '__loader__', '__name__','__package__', '__spec__', 'x']

The output
Gizmo id: ...is a side effect of creating aGizmoinstance.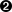
Multiplying a
Gizmoinstance will raise an exception.
Here is proof that a second
Gizmowas actually instantiated before the multiplication was attempted.
But variable
ywas never created, because the exception happened while the right-hand side of the assignment was being evaluated.
Tip
To understand an assignment in Python, always read the right-hand side first: that’s where the object is created or retrieved. After that, the variable on the left is bound to the object, like a label stuck to it. Just forget about the boxes.
Because variables are mere labels, nothing prevents an object from having several labels assigned to it. When that happens, you have aliasing, our next topic.
Identity, Equality, and Aliases
Lewis Carroll is the pen name of Prof. Charles Lutwidge Dodgson. Mr. Carroll is not only equal to Prof. Dodgson: they are one and the same. Example 8-3 expresses this idea in Python.
Example 8-3. charles and lewis refer to the same object
>>>charles={'name':'Charles L. Dodgson','born':1832}>>>lewis=charles>>>lewisischarlesTrue>>>id(charles),id(lewis)(4300473992, 4300473992)>>>lewis['balance']=950>>>charles{'name': 'Charles L. Dodgson', 'balance': 950, 'born': 1832}
lewisis an alias forcharles.The
isoperator and theidfunction confirm it.Adding an item to
lewisis the same as adding an item tocharles.
However, suppose an impostor—let’s call him Dr. Alexander Pedachenko—claims he is Charles L. Dodgson, born in 1832. His credentials may be the same, but Dr. Pedachenko is not Prof. Dodgson. Figure 8-2 illustrates this scenario.

Figure 8-2. charles and lewis are bound to the same object; alex is bound to a separate object of equal contents
Example 8-4 implements and tests the alex object depicted in Figure 8-2.
Example 8-4. alex and charles compare equal, but alex is not charles
>>>alex={'name':'Charles L. Dodgson','born':1832,'balance':950}>>>alex==charlesTrue>>>alexisnotcharlesTrue
alexrefers to an object that is a replica of the object assigned tocharles.The objects compare equal, because of the
__eq__implementation in thedictclass.But they are distinct objects. This is the Pythonic way of writing the negative identity comparison:
a is not b.
Example 8-3 is an example of aliasing. In that code, lewis and charles are aliases: two variables bound to the same object. On the other hand, alex is not an alias for charles: these variables are bound to distinct objects. The objects bound to alex and charles have the same value—that’s what == compares—but they have different identities.
In The Python Language Reference, “3.1. Objects, values and types” states:
Every object has an identity, a type and a value. An object’s identity never changes once it has been created; you may think of it as the object’s address in memory. The
isoperator compares the identity of two objects; theid()function returns an integer representing its identity.
The real meaning of an object’s ID is implementation-dependent. In CPython, id() returns the memory address of the object, but it may be something else in another Python interpreter. The key point is that the ID is guaranteed to be a unique numeric label, and it will never change during the life of the object.
In practice, we rarely use the id() function while programming. Identity checks are most often done with the is operator, and not by comparing IDs. Next, we’ll talk about is versus ==.
Choosing Between == and is
The == operator compares the values of objects (the data they hold), while is compares their identities.
We often care about values and not identities, so == appears more frequently than is in Python code.
However, if you are comparing a variable to a singleton, then it makes sense to use is. By far, the most common case is checking whether a variable is bound to None. This is the recommended way to do it:
xisNone
And the proper way to write its negation is:
xisnotNone
The is operator is faster than ==, because it cannot be overloaded, so Python does not have to find and invoke special methods to evaluate it, and computing is as simple as comparing two integer IDs. In contrast, a == b is syntactic sugar for a.__eq__(b). The __eq__ method inherited from object compares object IDs, so it produces the same result as is. But most built-in types override __eq__ with more meaningful implementations that actually take into account the values of the object attributes. Equality may involve a lot of processing—for example, when comparing large collections or deeply nested structures.
To wrap up this discussion of identity versus equality, we’ll see that the famously immutable tuple is not as rigid as you may expect.
The Relative Immutability of Tuples
Tuples, like most Python collections—lists, dicts, sets, etc.—hold references to objects.1 If the referenced items are mutable, they may change even if the tuple itself does not. In other words, the immutability of tuples really refers to the physical contents of the tuple data structure (i.e., the references it holds), and does not extend to the referenced objects.
Example 8-5 illustrates the situation in which the value of a tuple changes as result of changes to a mutable object referenced in it. What can never change in a tuple is the identity of the items it contains.
Example 8-5. t1 and t2 initially compare equal, but changing a mutable item inside tuple t1 makes it different
>>>t1=(1,2,[30,40])>>>t2=(1,2,[30,40])>>>t1==t2True>>>id(t1[-1])4302515784>>>t1[-1].append(99)>>>t1(1, 2, [30, 40, 99])>>>id(t1[-1])4302515784>>>t1==t2False
t1is immutable, butt1[-1]is mutable.Build a tuple
t2whose items are equal to those oft1.Although distinct objects,
t1andt2compare equal, as expected.Inspect the identity of the list at
t1[-1].
Modify the
t1[-1]list in place.
The identity of
t1[-1]has not changed, only its value.
t1andt2are now different.
This relative immutability of tuples is behind the riddle “A += Assignment Puzzler”. It’s also the reason why some tuples are unhashable, as we’ve seen in “What Is Hashable?”.
The distinction between equality and identity has further implications when you need to copy an object. A copy is an equal object with a different ID. But if an object contains other objects, should the copy also duplicate the inner objects, or is it OK to share them? There’s no single answer. Read on for a discussion.
Copies Are Shallow by Default
The easiest way to copy a list (or most built-in mutable collections) is to use the built-in constructor for the type itself. For example:
>>>l1=[3,[55,44],(7,8,9)]>>>l2=list(l1)>>>l2[3, [55, 44], (7, 8, 9)]>>>l2==l1True>>>l2isl1False
list(l1)creates a copy ofl1.The copies are equal.
But refer to two different objects.
For lists and other mutable sequences, the shortcut l2 = l1[:] also makes a copy.
However, using the constructor or [:] produces a shallow copy (i.e., the outermost container is duplicated, but the copy is filled with references to the same items held by the original container). This saves memory and causes no problems if all the items are immutable. But if there are mutable items, this may lead to unpleasant surprises.
In Example 8-6, we create a shallow copy of a list containing another list and a tuple, and then make changes to see how they affect the referenced objects.
Tip
If you have a connected computer on hand, I highly recommend watching the interactive animation for Example 8-6 at the Online Python Tutor. As I write this, direct linking to a prepared example at pythontutor.com is not working reliably, but the tool is awesome, so taking the time to copy and paste the code is worthwhile.
Example 8-6. Making a shallow copy of a list containing another list; copy and paste this code to see it animated at the Online Python Tutor
l1=[3,[66,55,44],(7,8,9)]l2=list(l1)l1.append(100)l1[1].remove(55)('l1:',l1)('l2:',l2)l2[1]+=[33,22]l2[2]+=(10,11)('l1:',l1)('l2:',l2)
l2is a shallow copy ofl1. This state is depicted in Figure 8-3.Appending
100tol1has no effect onl2.Here we remove
55from the inner listl1[1]. This affectsl2becausel2[1]is bound to the same list asl1[1].For a mutable object like the list referred by
l2[1], the operator+=changes the list in place. This change is visible atl1[1], which is an alias forl2[1].+=on a tuple creates a new tuple and rebinds the variablel2[2]here. This is the same as doingl2[2] = l2[2] + (10, 11). Now the tuples in the last position ofl1andl2are no longer the same object. See Figure 8-4.
The output of Example 8-6 is Example 8-7, and the final state of the objects is depicted in Figure 8-4.
Example 8-7. Output of Example 8-6
l1:[3,[66,44],(7,8,9),100]l2:[3,[66,44],(7,8,9)]l1:[3,[66,44,33,22],(7,8,9),100]l2:[3,[66,44,33,22],(7,8,9,10,11)]
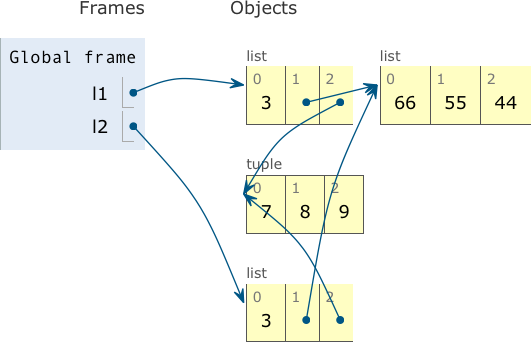
Figure 8-3. Program state immediately after the assignment l2 = list(l1) in Example 8-6. l1 and l2 refer to distinct lists, but the lists share references to the same inner list object [66, 55, 44] and tuple (7, 8, 9). (Diagram generated by the Online Python Tutor.)
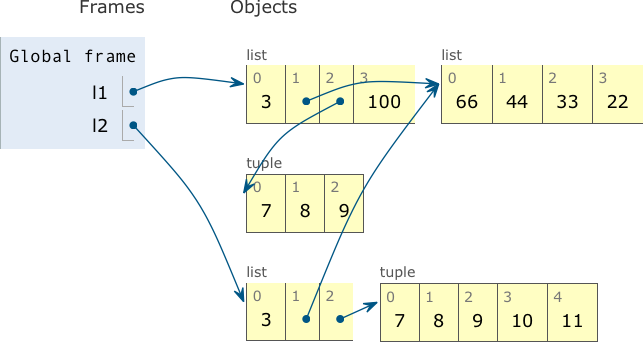
Figure 8-4. Final state of l1 and l2: they still share references to the same list object, now containing [66, 44, 33, 22], but the operation l2[2] += (10, 11) created a new tuple with content (7, 8, 9, 10, 11), unrelated to the tuple (7, 8, 9) referenced by l1[2]. (Diagram generated by the Online Python Tutor.)
It should be clear now that shallow copies are easy to make, but they may or may not be what you want. How to make deep copies is our next topic.
Deep and Shallow Copies of Arbitrary Objects
Working with shallow copies is not always a problem, but sometimes you need to make deep copies (i.e., duplicates that do not share references of embedded objects). The copy module provides the deepcopy and copy functions that return deep and shallow copies of arbitrary objects.
To illustrate the use of copy() and deepcopy(), Example 8-8 defines a simple class, Bus, representing a school bus that is loaded with passengers and then picks up or drops off passengers on its route.
Example 8-8. Bus picks up and drops off passengers
classBus:def__init__(self,passengers=None):ifpassengersisNone:self.passengers=[]else:self.passengers=list(passengers)defpick(self,name):self.passengers.append(name)defdrop(self,name):self.passengers.remove(name)
Now in the interactive Example 8-9 we will create a bus object (bus1) and two clones—a shallow copy (bus2) and a deep copy (bus3)—to observe what happens as bus1 drops off a student.
Example 8-9. Effects of using copy versus deepcopy
>>>importcopy>>>bus1=Bus(['Alice','Bill','Claire','David'])>>>bus2=copy.copy(bus1)>>>bus3=copy.deepcopy(bus1)>>>id(bus1),id(bus2),id(bus3)(4301498296, 4301499416, 4301499752)>>>bus1.drop('Bill')>>>bus2.passengers['Alice', 'Claire', 'David']>>>id(bus1.passengers),id(bus2.passengers),id(bus3.passengers)(4302658568, 4302658568, 4302657800)>>>bus3.passengers['Alice', 'Bill', 'Claire', 'David']
Using
copyanddeepcopy, we create three distinctBusinstances.After
bus1drops'Bill', he is also missing frombus2.Inspection of the
passengersatributes shows thatbus1andbus2share the same list object, becausebus2is a shallow copy ofbus1.bus3is a deep copy ofbus1, so itspassengersattribute refers to another list.
Note that making deep copies is not a simple matter in the general case. Objects may have cyclic references that would cause a naïve algorithm to enter an infinite loop. The deepcopy function remembers the objects already copied to handle cyclic references gracefully. This is demonstrated in Example 8-10.
Example 8-10. Cyclic references: b refers to a, and then is appended to a; deepcopy still manages to copy a
>>>a=[10,20]>>>b=[a,30]>>>a.append(b)>>>a[10, 20, [[...], 30]]>>>fromcopyimportdeepcopy>>>c=deepcopy(a)>>>c[10, 20, [[...], 30]]
Also, a deep copy may be too deep in some cases. For example, objects may refer to external resources or singletons that should not be copied. You can control the behavior of both copy and deepcopy by implementing the __copy__() and __deepcopy__() special methods as described in the copy module documentation.
The sharing of objects through aliases also explains how parameter passing works in Python, and the problem of using mutable types as parameter defaults. These issues will be covered next.
Function Parameters as References
The only mode of parameter passing in Python is call by sharing. That is the same mode used in most OO languages, including Ruby, SmallTalk, and Java (this applies to Java reference types; primitive types use call by value). Call by sharing means that each formal parameter of the function gets a copy of each reference in the arguments. In other words, the parameters inside the function become aliases of the actual arguments.
The result of this scheme is that a function may change any mutable object passed as a parameter, but it cannot change the identity of those objects (i.e., it cannot altogether replace an object with another). Example 8-11 shows a simple function using += on one of its parameters. As we pass numbers, lists, and tuples to the function, the actual arguments passed are affected in different ways.
Example 8-11. A function may change any mutable object it receives
>>>deff(a,b):...a+=b...returna...>>>x=1>>>y=2>>>f(x,y)3>>>x,y(1, 2)>>>a=[1,2]>>>b=[3,4]>>>f(a,b)[1, 2, 3, 4]>>>a,b([1, 2, 3, 4], [3, 4])>>>t=(10,20)>>>u=(30,40)>>>f(t,u)(10, 20, 30, 40)>>>t,u((10, 20), (30, 40))
The number
xis unchanged.The list
ais changed.The tuple
tis unchanged.
Another issue related to function parameters is the use of mutable values for defaults, as discussed next.
Mutable Types as Parameter Defaults: Bad Idea
Optional parameters with default values are a great feature of Python function definitions, allowing our APIs to evolve while remaining backward-compatible. However, you should avoid mutable objects as default values for parameters.
To illustrate this point, in Example 8-12, we take the Bus class from Example 8-8 and change its __init__ method to create HauntedBus. Here we tried to be clever and instead of having a default value of passengers=None, we have passengers=[], thus avoiding the if in the previous __init__. This “cleverness” gets us into trouble.
Example 8-12. A simple class to illustrate the danger of a mutable default
classHauntedBus:"""A bus model haunted by ghost passengers"""def__init__(self,passengers=[]):self.passengers=passengersdefpick(self,name):self.passengers.append(name)defdrop(self,name):self.passengers.remove(name)
When the
passengersargument is not passed, this parameter is bound to the default list object, which is initially empty.This assignment makes
self.passengersan alias forpassengers, which is itself an alias for the default list, when nopassengersargument is given.When the methods
.remove()and.append()are used withself.passengerswe are actually mutating the default list, which is an attribute of the function object.
Example 8-13 shows the eerie behavior of the HauntedBus.
Example 8-13. Buses haunted by ghost passengers
>>>bus1=HauntedBus(['Alice','Bill'])>>>bus1.passengers['Alice', 'Bill']>>>bus1.pick('Charlie')>>>bus1.drop('Alice')>>>bus1.passengers['Bill', 'Charlie']>>>bus2=HauntedBus()>>>bus2.pick('Carrie')>>>bus2.passengers['Carrie']>>>bus3=HauntedBus()>>>bus3.passengers['Carrie']>>>bus3.pick('Dave')>>>bus2.passengers['Carrie', 'Dave']>>>bus2.passengersisbus3.passengersTrue>>>bus1.passengers['Bill', 'Charlie']
So far, so good: no surprises with
bus1.bus2starts empty, so the default empty list is assigned toself.passengers.bus3also starts empty, again the default list is assigned.The default is no longer empty!
Now
Dave, picked bybus3, appears inbus2.The problem:
bus2.passengersandbus3.passengersrefer to the same list.But
bus1.passengersis a distinct list.
The problem is that HauntedBus instances that don’t get an initial passenger list end up sharing the same passenger list among themselves.
Such bugs may be subtle. As Example 8-13 demonstrates, when a HauntedBus is instantiated with passengers, it works as expected. Strange things happen only when a HauntedBus starts empty, because then self.passengers becomes an alias for the default value of the passengers parameter. The problem is that each default value is evaluated when the function is defined—i.e., usually when the module is loaded—and the default values become attributes of the function object. So if a default value is a mutable object, and you change it, the change will affect every future call of the function.
After running the lines in Example 8-13, you can inspect the HauntedBus.__init__ object and see the ghost students haunting its __defaults__ attribute:
>>>dir(HauntedBus.__init__)# doctest: +ELLIPSIS['__annotations__', '__call__', ..., '__defaults__', ...]>>>HauntedBus.__init__.__defaults__(['Carrie', 'Dave'],)
Finally, we can verify that bus2.passengers is an alias bound to the first element of the HauntedBus.__init__.__defaults__ attribute:
>>>HauntedBus.__init__.__defaults__[0]isbus2.passengersTrue
The issue with mutable defaults explains why None is often used as the default value for parameters that may receive mutable values. In Example 8-8, __init__ checks whether the passengers argument is None, and assigns a new empty list to self.passengers. As explained in the following section, if passengers is not None, the correct implementation assigns a copy of it to self.passengers. Let’s now take a closer look.
Defensive Programming with Mutable Parameters
When you are coding a function that receives a mutable parameter, you should carefully consider whether the caller expects the argument passed to be changed.
For example, if your function receives a dict and needs to modify it while processing it, should this side effect be visible outside of the function or not? Actually it depends on the context. It’s really a matter of aligning the expectation of the coder of the function and that of the caller.
The last bus example in this chapter shows how a TwilightBus breaks expectations by sharing its passenger list with its clients. Before studying the implementation, see in Example 8-14 how the TwilightBus class works from the perspective of a client of the class.
Example 8-14. Passengers disappear when dropped by a TwilightBus
>>>basketball_team=['Sue','Tina','Maya','Diana','Pat']>>>bus=TwilightBus(basketball_team)>>>bus.drop('Tina')>>>bus.drop('Pat')>>>basketball_team['Sue', 'Maya', 'Diana']
basketball_teamholds five student names.A
TwilightBusis loaded with the team.The
busdrops one student, then another.The dropped passengers vanished from the basketball team!
TwilightBus violates the “Principle of least astonishment,” a best practice of interface design. It surely is astonishing that when the bus drops a student, her name is removed from the basketball team roster.
Example 8-15 is the implementation TwilightBus and an explanation of the problem.
Example 8-15. A simple class to show the perils of mutating received arguments
classTwilightBus:"""A bus model that makes passengers vanish"""def__init__(self,passengers=None):ifpassengersisNone:self.passengers=[]else:self.passengers=passengersdefpick(self,name):self.passengers.append(name)defdrop(self,name):self.passengers.remove(name)
Here we are careful to create a new empty list when
passengersisNone.However, this assignment makes
self.passengersan alias forpassengers, which is itself an alias for the actual argument passed to__init__(i.e.,basketball_teamin Example 8-14).When the methods
.remove()and.append()are used withself.passengers, we are actually mutating the original list received as argument to the constructor.
The problem here is that the bus is aliasing the list that is passed to the constructor. Instead, it should keep its own passenger list. The fix is simple: in __init__, when the passengers parameter is provided, self.passengers should be initialized with a copy of it, as we did correctly in Example 8-8 (“Deep and Shallow Copies of Arbitrary Objects”):
def__init__(self,passengers=None):ifpassengersisNone:self.passengers=[]else:self.passengers=list(passengers)
Make a copy of the
passengerslist, or convert it to alistif it’s not one.
Now our internal handling of the passenger list will not affect the argument used to initialize the bus. As a bonus, this solution is more flexible: now the argument passed to the passengers parameter may be a tuple or any other iterable, like a set or even database results, because the list constructor accepts any iterable. As we create our own list to manage, we ensure that it supports the necessary .remove() and .append() operations we use in the .pick() and .drop() methods.
Tip
Unless a method is explicitly intended to mutate an object received as argument, you should think twice before aliasing the argument object by simply assigning it to an instance variable in your class. If in doubt, make a copy. Your clients will often be happier.
del and Garbage Collection
Objects are never explicitly destroyed; however, when they become unreachable they may be garbage-collected.
Data Model, chapter of The Python Language Reference
The del statement deletes names, not objects. An object may be garbage collected as result of a del command, but only if the variable deleted holds the last reference to the object, or if the object becomes unreachable.2 Rebinding a variable may also cause the number of references to an object to reach zero, causing its destruction.
Warning
There is a __del__ special method, but it does not cause the disposal of the instance, and should not be called by your code. __del__ is invoked by the Python interpreter when the instance is about to be destroyed to give it a chance to release external resources. You will seldom need to implement __del__ in your own code, yet some Python beginners spend time coding it for no good reason. The proper use of __del__ is rather tricky. See the __del__ special method documentation in the “Data Model” chapter of The Python Language Reference.
In CPython, the primary algorithm for garbage collection is reference counting. Essentially, each object keeps count of how many references point to it. As soon as that refcount reaches zero, the object is immediately destroyed: CPython calls the __del__ method on the object (if defined) and then frees the memory allocated to the object. In CPython 2.0, a generational garbage collection algorithm was added to detect groups of objects involved in reference cycles—which may be unreachable even with outstanding references to them, when all the mutual references are contained within the group. Other implementations of Python have more sophisticated garbage collectors that do not rely on reference counting, which means the __del__ method may not be called immediately when there are no more references to the object. See “PyPy, Garbage Collection, and a Deadlock” by A. Jesse Jiryu Davis for discussion of improper and proper use of __del__.
To demonstrate the end of an object’s life, Example 8-16 uses weakref.finalize to register a callback function to be called when an object is destroyed.
Example 8-16. Watching the end of an object when no more references point to it
>>>importweakref>>>s1={1,2,3}>>>s2=s1>>>defbye():...('Gone with the wind...')...>>>ender=weakref.finalize(s1,bye)>>>ender.aliveTrue>>>dels1>>>ender.aliveTrue>>>s2='spam'Gone with the wind...>>>ender.aliveFalse
s1ands2are aliases referring to the same set,{1, 2, 3}.This function must not be a bound method of the object about to be destroyed or otherwise hold a reference to it.
Register the
byecallback on the object referred bys1.The
.aliveattribute isTruebefore thefinalizeobject is called.As discussed,
deldoes not delete an object, just a reference to it.Rebinding the last reference,
s2, makes{1, 2, 3}unreachable. It is destroyed, thebyecallback is invoked, andender.alivebecomesFalse.
The point of Example 8-16 is to make explicit that del does not delete objects, but objects may be deleted as a consequence of being unreachable after del is used.
You may be wondering why the {1, 2, 3} object was destroyed in Example 8-16. After all, the s1 reference was passed to the finalize function, which must have held on to it in order to monitor the object and invoke the callback. This works because finalize holds a weak reference to {1, 2, 3}, as explained in the next section.
Weak References
The presence of references is what keeps an object alive in memory. When the reference count of an object reaches zero, the garbage collector disposes of it. But sometimes it is useful to have a reference to an object that does not keep it around longer than necessary. A common use case is a cache.
Weak references to an object do not increase its reference count. The object that is the target of a reference is called the referent. Therefore, we say that a weak reference does not prevent the referent from being garbage collected.
Weak references are useful in caching applications because you don’t want the cached objects to be kept alive just because they are referenced by the cache.
Example 8-17 shows how a weakref.ref instance can be called to reach its referent. If the object is alive, calling the weak reference returns it, otherwise None is returned.
Tip
Example 8-17 is a console session, and the Python console automatically binds the _ variable to the result of expressions that are not None. This interfered with my intended demonstration but also highlights a practical matter: when trying to micro-manage memory we are often surprised by hidden, implicit assignments that create new references to our objects. The _ console variable is one example. Traceback objects are another common source of unexpected references.
Example 8-17. A weak reference is a callable that returns the referenced object or None if the referent is no more
>>>importweakref>>>a_set={0,1}>>>wref=weakref.ref(a_set)>>>wref<weakref at 0x100637598; to 'set' at 0x100636748>>>>wref(){0, 1}>>>a_set={2,3,4}>>>wref(){0, 1}>>>wref()isNoneFalse>>>wref()isNoneTrue
The
wrefweak reference object is created and inspected in the next line.Invoking
wref()returns the referenced object,{0, 1}. Because this is a console session, the result{0, 1}is bound to the_variable.a_setno longer refers to the{0, 1}set, so its reference count is decreased. But the_variable still refers to it.Calling
wref()still returns{0, 1}.When this expression is evaluated,
{0, 1}lives, thereforewref()is notNone. But_is then bound to the resulting value,False. Now there are no more strong references to{0, 1}.Because the
{0, 1}object is now gone, this last call towref()returnsNone.
The weakref module documentation makes the point that the weakref.ref class is actually a low-level interface intended for advanced uses, and that most programs are better served by the use of the weakref collections and finalize. In other words, consider using WeakKeyDictionary, WeakValueDictionary, WeakSet, and finalize (which use weak references internally) instead of creating and handling your own weakref.ref instances by hand. We just did that in Example 8-17 in the hope that showing a single weakref.ref in action could take away some of the mystery around them. But in practice, most of the time Python programs use the weakref collections.
The next subsection briefly discusses the weakref collections.
The WeakValueDictionary Skit
The class WeakValueDictionary implements a mutable mapping where the values are weak references to objects. When a referred object is garbage collected elsewhere in the program, the corresponding key is automatically removed from WeakValueDictionary. This is commonly used for caching.
Our demonstration of a WeakValueDictionary is inspired by the classic Cheese Shop skit by Monty Python, in which a customer asks for more than 40 kinds of cheese, including cheddar and mozzarella, but none are in stock.3
Example 8-18 implements a trivial class to represent each kind of cheese.
Example 8-18. Cheese has a kind attribute and a standard representation
classCheese:def__init__(self,kind):self.kind=kinddef__repr__(self):return'Cheese(%r)'%self.kind
In Example 8-19, each cheese is loaded from a catalog to a stock implemented as a WeakValueDictionary. However, all but one disappear from the stock as soon as the catalog is deleted. Can you explain why the Parmesan cheese lasts longer than the others?4 The tip after the code has the answer.
Example 8-19. Customer: “Have you in fact got any cheese here at all?”
>>>importweakref>>>stock=weakref.WeakValueDictionary()>>>catalog=[Cheese('Red Leicester'),Cheese('Tilsit'),...Cheese('Brie'),Cheese('Parmesan')]...>>>forcheeseincatalog:...stock[cheese.kind]=cheese...>>>sorted(stock.keys())['Brie', 'Parmesan', 'Red Leicester', 'Tilsit']>>>delcatalog>>>sorted(stock.keys())['Parmesan']>>>delcheese>>>sorted(stock.keys())[]
stockis aWeakValueDictionary.The
stockmaps the name of the cheese to a weak reference to the cheese instance in thecatalog.The
stockis complete.After the
catalogis deleted, most cheeses are gone from thestock, as expected inWeakValueDictionary. Why not all, in this case?
Tip
A temporary variable may cause an object to last longer than expected by holding a reference to it. This is usually not a problem with local variables: they are destroyed when the function returns. But in Example 8-19, the for loop variable cheese is a global variable and will never go away unless explicitly deleted.
A counterpart to the WeakValueDictionary is the WeakKeyDictionary in which the keys are weak references. The weakref.WeakKeyDictionary documentation hints on possible uses:
[A
WeakKeyDictionary] can be used to associate additional data with an object owned by other parts of an application without adding attributes to those objects. This can be especially useful with objects that override attribute accesses.
The weakref module also provides a WeakSet, simply described in the docs as “Set class that keeps weak references to its elements. An element will be discarded when no strong reference to it exists any more.” If you need to build a class that is aware of every one of its instances, a good solution is to create a class attribute with a WeakSet to hold the references to the instances. Otherwise, if a regular set was used, the instances would never be garbage collected, because the class itself would have strong references to them, and classes live as long as the Python process unless you deliberately delete them.
These collections, and weak references in general, are limited in the kinds of objects they can handle. The next section explains.
Limitations of Weak References
Not every Python object may be the target, or referent, of a weak reference. Basic list and dict instances may not be referents, but a plain subclass of either can solve this problem easily:
classMyList(list):"""list subclass whose instances may be weakly referenced"""a_list=MyList(range(10))# a_list can be the target of a weak referencewref_to_a_list=weakref.ref(a_list)
A set instance can be a referent, and that’s why a set was used in Example 8-17. User-defined types also pose no problem, which explains why the silly Cheese class was needed in Example 8-19. But int and tuple instances cannot be targets of weak references, even if subclasses of those types are created.
Most of these limitations are implementation details of CPython that may not apply to other Python interpreters. They are the result of internal optimizations, some of which are discussed in the following (highly optional) section.
Tricks Python Plays with Immutables
Note
You may safely skip this section. It discusses some Python implementation details that are not really important for users of Python. They are shortcuts and optimizations done by the CPython core developers, which should not bother you when using the language, and that may not apply to other Python implementations or even future versions of CPython. Nevertheless, while experimenting with aliases and copies you may stumble upon these tricks, so I felt they were worth mentioning.
I was surprised to learn that, for a tuple t, t[:] does not make a copy, but returns a reference to the same object. You also get a reference to the same tuple if you write tuple(t).5 Example 8-20 proves it.
Example 8-20. A tuple built from another is actually the same exact tuple
>>>t1=(1,2,3)>>>t2=tuple(t1)>>>t2ist1True>>>t3=t1[:]>>>t3ist1True
t1andt2are bound to the same object.And so is
t3.
The same behavior can be observed with instances of str, bytes, and frozenset. Note that a frozenset is not a sequence, so fs[:] does not work if fs is a frozenset. But fs.copy() has the same effect: it cheats and returns a reference to the same object, and not a copy at all, as Example 8-21 shows.6
Example 8-21. String literals may create shared objects
>>>t1=(1,2,3)>>>t3=(1,2,3)>>>t3ist1False>>>s1='ABC'>>>s2='ABC'>>>s2iss1True
Creating a new tuple from scratch.
t1andt3are equal, but not the same object.Creating a second
strfrom scratch.Surprise:
aandbrefer to the samestr!
The sharing of string literals is an optimization technique called interning. CPython uses the same technique with small integers to avoid unnecessary duplication of “popular” numbers like 0, –1, and 42. Note that CPython does not intern all strings or integers, and the criteria it uses to do so is an undocumented implementation detail.
Warning
Never depend on str or int interning! Always use == and not is to compare them for equality. Interning is a feature for internal use of the Python interpreter.
The tricks discussed in this section, including the behavior of frozenset.copy(), are “white lies”; they save memory and make the interpreter faster. Do not worry about them, they should not give you any trouble because they only apply to immutable types. Probably the best use of these bits of trivia is to win bets with fellow Pythonistas.
Chapter Summary
Every Python object has an identity, a type, and a value. Only the value of an object changes over time.7
If two variables refer to immutable objects that have equal values (a == b is True), in practice it rarely matters if they refer to copies or are aliases referring to the same object because the value of an immutable object does not change, with one exception. The exception is immutable collections such as tuples and frozensets: if an immutable collection holds references to mutable items, then its value may actually change when the value of a mutable item changes. In practice, this scenario is not so common. What never changes in an immutable collection are the identities of the objects within.
The fact that variables hold references has many practical consequences in Python programming:
-
Simple assignment does not create copies.
-
Augmented assignment with
+=or*=creates new objects if the lefthand variable is bound to an immutable object, but may modify a mutable object in place. -
Assigning a new value to an existing variable does not change the object previously bound to it. This is called a rebinding: the variable is now bound to a different object. If that variable was the last reference to the previous object, that object will be garbage collected.
-
Function parameters are passed as aliases, which means the function may change any mutable object received as an argument. There is no way to prevent this, except making local copies or using immutable objects (e.g., passing a tuple instead of a list).
-
Using mutable objects as default values for function parameters is dangerous because if the parameters are changed in place, then the default is changed, affecting every future call that relies on the default.
In CPython, objects are discarded as soon as the number of references to them reaches zero. They may also be discarded if they form groups with cyclic references but no outside references. In some situations, it may be useful to hold a reference to an object that will not—by itself—keep an object alive. One example is a class that wants to keep track of all its current instances. This can be done with weak references, a low-level mechanism underlying the more useful collections WeakValueDictionary, WeakKeyDictionary, WeakSet, and the finalize function from the weakref module.
Further Reading
The “Data Model” chapter of The Python Language Reference starts with a clear explanation of object identities and values.
Wesley Chun, author of the Core Python series of books, made a great presentation about many of the topics covered in this chapter during OSCON 2013. You can download the slides from the “Python 103: Memory Model & Best Practices” talk page. There is also a YouTube video of a longer presentation Wesley gave at EuroPython 2011, covering not only the theme of this chapter but also the use of special methods.
Doug Hellmann wrote a long series of excellent blog posts titled Python Module of the Week, which became a book, The Python Standard Library by Example. His posts “copy – Duplicate Objects” and “weakref – Garbage-Collectable References to Objects” cover some of the topics we just discussed.
More information on the CPython generational garbage collector can be found in the gc module documentation, which starts with the sentence “This module provides an interface to the optional garbage collector.” The “optional” qualifier here may be surprising, but the “Data Model” chapter also states:
An implementation is allowed to postpone garbage collection or omit it altogether—it is a matter of implementation quality how garbage collection is implemented, as long as no objects are collected that are still reachable.
Fredrik Lundh—creator of key libraries like ElementTree, Tkinter, and the PIL image library—has a short post about the Python garbage collector titled “How Does Python Manage Memory?” He emphasizes that the garbage collector is an implementation feature that behaves differently across Python interpreters. For example, Jython uses the Java garbage collector.
The CPython 3.4 garbage collector improved handling of objects with a __del__ method, as described in PEP 442 — Safe object finalization.
Wikipedia has an article about string interning, mentioning the use of this technique in several languages, including Python.
1 On the other hand, single-type sequences like str, bytes, and array.array are flat: they don’t contain references but physically hold their data—characters, bytes, and numbers—in contiguous memory.
2 If two objects refer to each other, as in Example 8-10, they may be destroyed if the garbage collector determines that they are otherwise unreachable because their only references are their mutual references.
3 cheeseshop.python.org is also an alias for PyPI—the Python Package Index software repository—which started its life quite empty. At the time of this writing, the Python Cheese Shop has 41,426 packages. Not bad, but still far from the more than 131,000 modules available in CPAN—the Comprehensive Perl Archive Network—the envy of all dynamic language communities.
4 Parmesan cheese is aged at least a year at the factory, so it is more durable than fresh cheese, but this is not the answer we are looking for.
5 This is clearly documented. Type help(tuple) in the Python console to read: “If the argument is a tuple, the return value is the same object.” I thought I knew everything about tuples before writing this book.
6 The white lie of having the copy method not copying anything can be explained by interface compatibility: it makes frozenset more compatible with set. Anyway, it makes no difference to the end user whether two identical immutable objects are the same or are copies.
7 Actually the type of an object may be changed by merely assigning a different class to its __class__ attribute, but that is pure evil and I regret writing this footnote.