
Step back, look at your Oracle database from all angles including: (1) the database functionality itself, (2) calling database functionality from within the database, (3) calling database functionality from outside (client, middle-tier, etc), and (4) calling external system/functionality from within the database. Far from being exhaustive, the case studies presented here will give you a broader, 360-degree view of how you can program the database using Java, JDBC, SQLJ, JPublisher, and Web services. Here are synopses of the case studies in question:
TECSIS Systems: This case study describes how TECSIS Systems reduced its costs by integrating its platform using Java in the database, JDBC, PL/SQL, AQ, RMI Call-out, SAP Java Connector, JDBC Call-out, and Oracle XDK. The platform comprises SAP systems, custom applications, SQL Server, Natural Adabas, AS400 RPG-DB, and Tandem COBOL.
Oracle inter Media: This is an Oracle database component that enables you to store, manage, and retrieve images, audio, video, or other heterogeneous media data in an integrated fashion with other enterprise information. This case study describes how Oracle inter-Media built a server-side media parser and an in-database image processor using Java in the database.
British Columbia, Online Corporate Registration: This case study describes how the British Columiba Corporate and Personal Registries have put legal filings online, as part of their Online e-Government Applications, using Java in the database, database Web services, XML DB, JMS/AQ, and Message-Driven Beans in OC4J.
Information Retrieval Using Oracle Text, XML DB Framework, and Java in the Database: This case study describes the design and implementation of a search engine for a controlled environment, such as a text warehouse or a corporate intranet.
Database-driven Content Management System (DBPrism CMS): This is an open-source and database-oriented content management system (CMS), using Java in the database, XML DB framework, and the Apache Cocoon framework.
This case study has been presented and demonstrated at Oracle World in San Francisco, California, and is reproduced here with the authorization and courtesy of my good friend Esteban Capoccetti, System Architect at TECSIS and the mastermind behind this architecture.
Tenaris, the world leader in tubular technologies, represents eight established manufacturers of steel tubes: AlgomaTubes, Confab, Dalmine, NKKTubes, Siat, Siderca, Tamsa, and Tavsa. Tenaris is a leading supplier of tubular goods and services to the global energy and mechanical industries, with a combined production capacity of 3 million tons of seamless and 850,000 tons of welded steel tubes, annual sales of $3 billion, and 13,000 employees on five continents. Our market share is about 30% of world trade in OCTG seamless products and 13% of total world seamless tube production.The main goal of TECSIS, the System Technology division of Tenaris, is to validate and disseminate technology throughout the companies within the Tenaris group. This case study describes their experience of using Java in the Oracle database and how it solved our integration requirements.
For the last three years, our company has been using Oracle database, not just as a database, but also as an integration infrastructure. We started by implementing the business rules, using PL/SQL stored procedures, which gave us many advantages. With the Java virtual machine embedded in the database (OracleJVM), we extended the capabilities of our database and turned it into a data integration hub.
Our business requirements made it necessary to integrate online information from different platforms, including SAP, AS400, ADABAS/NATURAL, and COBOL Tandem. Our PL/SQL-based business rules needed to send and get data from these platforms. Existing legacy systems, as well as new intranet/Internet-based development, required cross-platform integration. Our main goal was cost savings through reuse of software, systems, and skills.
We needed to integrate the following platforms: Oracle PL/SQL Stored Procedures, SAP R3, Natural/Adabas, RPG/DB400, COBOL Tandem, COM Components, and non-Oracle databases (Adabas-D, MSSQL Server). We tried different RPC technologies to integrate legacy systems, but we were unhappy with their degree of integration. By that time, it became crucial for us to reach information available online on other platforms, from existing PL/SQL packages.
In summary, our most important requirements were to:
Simplify cross-platform integration.
Save costs: Instead of adding a new integration layer, we decided to leverage existing components and use each of these components to the best of its capacity.
Avoid the explosion of communication that would be generated by point-to-point integration.
We choose to leverage OracleJVM and its ability to run Java libraries in the database, because all existing ERP systems, as well as non-Oracle databases, furnish either a Java-based Remote Procedure Call (RPC) software or a pure Java JDBC driver that can be loaded into the Oracle JVM. PL/SQL wrappers make these mechanisms available to the SQL world as Java stored procedures. Existing or new PL/SQL-based business rules can easily interact with other systems. By centralizing our business rules in the Oracle database, along with transformation rules and making the whole thing accessible by both Web clients and batch jobs, the Oracle database became our integration engine.
All of our new systems are based on Web pages that call stored procedures, which access the business rules. Existing batch jobs, as well as client applications, share the same business rules. We have also been able to standardize the way in which we call the procedures, using XML-based IN and OUT parameters. These XML parameters are parsed or generated using Oracle XDK.
The fact that the system became operational in a few days, without costly retraining of our PL/SQL programmers, is the best illustration of the simplicity of the solution. In addition, we accomplished the integration of batch jobs through three-line SQL* Plus scripts.
Using a traditional Enterprise Application Integration (EAI) product would have been more complex and expensive. Instead, employing Java in the database not only simplified our integration process, but it also saved us money.
This section describes our use cases and the two pillars of our architecture, which are Java stored procedures calling out external components from within the database and external systems calling in Java stored procedures.
We had three use cases: (1) Code Validation, system A (COBOL Tandem) needs to check whether a specific code value exists in system B (Oracle Database); (2) Pop-Up Lists, system A (AS400 screen) needs to display a list of values using content from system B (Natural Adabas); and (3) Cross-Platform Modifications, a new product is added to system A (Oracle Database), and the same product must also be added to system B (Natural Adabas).
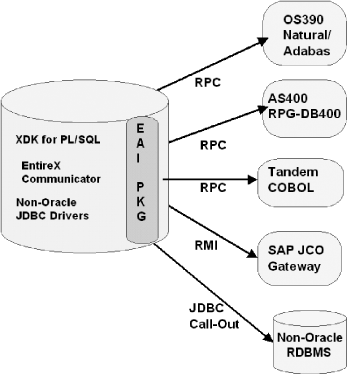
We selected the Software AG EntireX Communicator (formerly EntireX broker) to make remote calls to Natural/Adabas programs (OS/390), RPG programs (AS400), and Tandem COBOL programs.
Although SAP Java connector (SAP JCO) is distributed as a JAR file, it is not 100% Java based because it uses several .sl (libraries). For security reasons, OracleJVM does not allow Java classes to use external .sl libraries (i.e., JNI calls). We worked around this restriction by running the SAP JCO as an external RMI server. Doing this allows us to issue RMI calls to the SAP JCO from within Java stored procedures (See SAP Call-Out in Part I).
We loaded third-party pure Java JDBC drivers into the database for interaction between Java stored procedures and non-Oracle databases (JDBC Call-out is described in Part I). If we needed to interact with a remote Oracle database, we would just use the pure Java server-side Oracle JDBC-Thin driver, from within the database. Then we created standard PL/SQL wrappers, called EAI_PKG, for each loaded module to allow uniform invocation from the PL/SQL-based business rules. Finally, we distributed an application integration guide internally to all PL/SQL programmers. In a few days, they were able to build procedures that interact with other platforms.
By centralizing the business rules, and adding integration and transformation rules, we created a complete data integration framework. These business, integration, and transformation rules all interact with external systems through Java stored procedures, using the EAI_PKG. Our new system comprises a Web-based presentation layer, as well as batch jobs (SQL*PLUS scripts). We use Oracle Object for OLE (OO4O) to execute Oracle procedures from our presentation layer (.asp). Both the presentation layer and the batch jobs use this same integration framework.
Figure 17.1 illustrates this architecture. Although the concept of the Oracle Advanced Queuing system does not appear in Figure 17.1, which illustrates how to call external systems from within the database, the EAI_PKG furnishes a queue corresponding to every remote system. If a remote system is down or unreachable, the EAI_PKG package automatically enqueues the message in the corresponding queue. An internal DBMS_JOB job is associated with every queue and is scheduled to run at a determined frequency. This job dequeues the pending messages and attempts to process them until the target system becomes available. Compared with Java stored procedures, traditional EAI products do not offer the same level of ease of use.
After we were able to call all our external systems from Java stored procedures, the next step was enabling external systems to call Java stored procedures, as illustrated by Figure 17.2. To accomplish this second step, we reused both the EntireX Communication and the SAP Java connector. Natural Adabas, AS400, and COBOL Tandem place a call against EntireX, which, in turn, invokes a Java stored procedure. The response from the Java stored procedure is sent back to the legacy system.
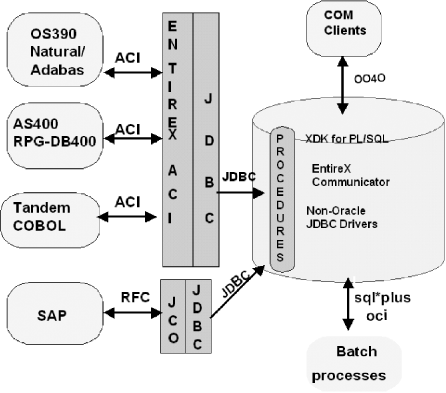
Similarly, SAP/ABAP applications call the SAP Java connector, which, in turn, calls the Oracle stored procedure. The response from the stored procedure is returned to the ABAP application.
As Figure 17.3 illustrates, by using the Oracle database as a central point of communication, we enabled any system to talk to any other system, while avoiding point-to-point communication.
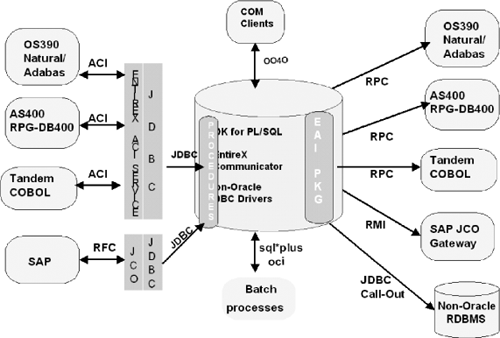
The entire framework is monitored by an Oracle stored procedure, which, at a determined frequency, performs a call to each target system as well as the EntireX and SAP connector.
If one of the monitored systems returns an error, the procedure sends a notification email. Our next step will be to send SNMP traps to a central console. We are currently working on this.
We were able to implement a complete, easy-to-use integration framework employing Java and PL/SQL procedures. PL/SQL procedures were easy to create and maintain, and we were able to use the existing skills of our programmers. We do not see Java as a replacement for PL/SQL but, rather, as an enabling technology to extend and improve PL/SQL usage.
By using Java in the Oracle database to its full capacity, we were able to turn the database into an online integration broker. In addition, we were able to shield our developers from the underlying complexity of our platform, thereby simplifying the integration process.
This use case has been kindly provided by the head of the interMedia development (she will recognize herself).
As explained previously, Java in the database is more than just an alternative to proprietary stored procedure languages; the combination of the RDBMS and Java enables the implementation of complete database-resident products and component such as Oracle interMedia.
interMedia is an Oracle database component that enables you to store, manage, and retrieve images, audio, video, or other heterogeneous media data in an integrated fashion with other enterprise information. It makes native format understanding available for popular image, audio, and video formats, such as JPEG, TIFF, ASF, and MP3.
interMedia provides methods for metadata extraction, making the metadata embedded in popular image, audio, and video formats available for database searching and indexing. interMedia provides methods for embedding metadata into images, making it possible to encapsulate metadata and image data together into the same binary image. Methods are also provided for image processing, such as format conversion and thumbnail generation.
interMedia supports popular streaming technologies, allowing audio and video data stored in Oracle database to be streamed using Windows Media and Real Networks Streaming Servers. interMedia also integrates with JDeveloper ADF components (previously known as BC4J) and UIX (i.e., a framework for building Web applications) and Oracle Application Server Portal, allowing for rapid development of media-rich applications using these tools.
To support multimedia data in the database, interMedia defines a set of new database media data types to handle image, audio, video, or other heterogeneous media data.
ORDAudio is the data type defined to hold digital audio. It includes a source attribute that points to the media data, defines audio-specific attributes such as mimeType and duration, and methods such as setProperties to extract embedded metadata.
ORDImage is the data type defined to hold digital images. It includes a source attribute that points to the media data, defines image-specific attributes such as mimeType, height, and width, and methods such as setProperties to extract metadata and processCopy to copy the image and generate an image thumbnail.
ORDVideo is the data type defined to hold digital video. It includes a source attribute, defines video-specific attributes such as mimeType, duration, height, and width, and methods such as setProperties.
ORDDoc is the data type defined to hold any type of media. If a column can hold mixed media (i.e., image, audio, or video data) in a single column, it should be defined to be of type ORDDoc. It includes a source attribute, defines attributes that are common to all types of media, such as mimeType and format, and methods such as setProperties.
For applications that already have large volumes of media data stored in database BLOBs or BFILEs, interMedia provides a relational interface that makes the services of interMedia available without requiring an interMedia object type to be instantiated. With the relational interface, the application manages the BLOB or BFILE and metadata columns, and calls object static methods for metadata extraction, image processing, and so on.
While the relational interface is a standard and supported part of Oracle interMedia, the recommended way of storing media in Oracle is the inter-Media object interface. The interMedia object types are recommended because they are self-describing and easy for applications and other Oracle tools such as JDeveloper ADF Components and Oracle Application Server Portal to understand. If you use BLOBs in your application instead of inter-Media object types, the knowledge of what is in the BLOB must be hard-coded into the application.
Many considerations drive interMedia adoption, including synchronization with related relational information, robustness, reliability, availability, security, scalability, integrated administration, search/query capabilities, integrated transactionality, simplicity, and cost reduction.
The media data stored in the database can be directly linked with corresponding relational data. Related information is kept in sync. If media are stored in a file system, it is possible for external processes to delete or modify the data, causing it to be orphaned or to lose synchronicity with its corresponding relational data.
Oracle interMedia extends Oracle database’s robustness, reliability, availability, and scalability to multimedia content in traditional, Internet, electronic commerce, and media-rich applications.
The database allows for fine-grained (row-level and column-level) security. The same security mechanisms are used for both media data and corresponding relational data. When using many file systems, directory services do not allow fine-grained levels of access control. It may not be possible to restrict access to individual users; in many systems, enabling a user to access any content in the directory gives access to all content in the directory. Oracle also makes it possible to attach timeouts to the content, to include check-in/check-out capabilities, to audit who accesses the content, and to enable exclusive access to the content.
Oracle provides a single administrative environment for managing, tuning, administering, backing up, and recovering the content. The media data is treated operationally in exactly the same manner as all other content. It can be partitioned, placed in transportable tablespaces, incrementally backed up, and recovered to the last committed transaction.
Because media data may have different characteristics than related relational data (e.g., multimedia content tends to be very large and not often updated), it can be treated differently using the same infrastructure. For example, older content can be placed on inexpensive disks with slower retrieval properties, storage areas can be excluded from nightly backups, and so on.
Zero data-loss configurations are also possible. Unlike configurations where attribute information is stored in the database with pointers to media data in files, only a single recovery procedure is required in the event of failure.
interMedia extracts embedded metadata (information about the content) from the media data and makes it available for indexing and querying purposes. Using the specialized media object types enables the database to have knowledge of the data types, their behavior, and permitted operators (over and above BLOBs). In numerous domains, there is a rapidly increasing trend toward embedding much more searchable metadata within commonly used formats. For example, in medical imaging, patient data, modality (equipment) settings, physician data, and diagnostic information are being included as metadata in the DICOM format.
Unlike file system–based media products, storing media data in the database enables transaction-based, programmatic access through SQL and Java to this data, integrated with other database attributes, in a secure environment.
Oracle interMedia provides SQL language extensions, PL/SQL and Java APIs, and JSP Tag Libraries, which simplify the development of multimedia applications. The applications have much less code than applications that do not use these language extensions, resulting in substantial productivity. In addition, interMedia adds algorithms that perform common or valuable operations through built-in operators (see next item).
Much of customers’ motivation to use Oracle’s support for media data comes from the power of the built-in functions and operators. By including operators that perform format conversion or thumbnail generation of images, the database reduces the need for application logic.
The foundation for interMedia is the extensibility framework of Oracle database, a set of unique services that enable application developers to model complex logic and extend the core database services (e.g., optimization, indexing, type system, SQL language) to meet the specific needs of an application. The Oracle database holds rich content in tables along with traditional data. Media data can be held in separate audio, image, or video columns or together in one column (ORDDoc). Oracle used these unique services to provide a consistent architecture for the rich data types supported by interMedia.
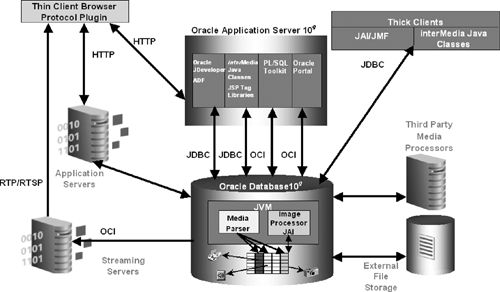
Using Java in the database, Oracle interMedia built a server-side media parser and an in-database image processor. These features were implemented using more than 1,000 Java classes in the database, most of which are natively compiled for faster execution performance. As illustrated by Figure 17.4, the main Java enablers are the media parser and the Image Processor (JAI).
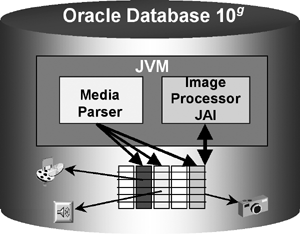
The database-resident, Java-based media parser supports image, audio, and video data formats and application metadata extraction; it can be extended to support additional formats.
Using the embedded OracleJVM allowed interMedia to take advantage of the Sun Microsystem Java Advanced Imaging (JAI) package. The JAI API furnishes a set of object-oriented interfaces that enable developers to easily perform complex digital imaging operations. The image processor provides operations such as thumbnail generation and image format conversion.
Embedded image metadata can be extracted and returned as a collection of schema valid XML documents that can be stored in Oracle database, indexed, searched, and made available to applications using XML DB and standard mechanisms of Oracle database.
Metadata, which has been formatted into XML format, can be stored into popular binary image formats, allowing metadata and image data to be encapsulated and shared and exchanged reliably as a unit.
Embedded audio and video metadata is stored as XML in a CLOB column of the interMedia data types and is available for indexing and searching using standard mechanisms of Oracle database.
Oracle interMedia provides a set of image processing operators for server-side image processing. Taken together, the scale and crop operators provide efficient and flexible thumbnail generation capability. Other image processing operations include arbitrary image rotate, flip, mirror, gamma correction, contrast enhancement, quantization methods, page selection, and alpha channel. Most applications only use a subset of the large set of different image formats. Oracle interMedia provides format-to-format conversion (transcoding) on demand.
interMedia Java Classes enable Java applications on any tier (client, application server, or database) to manipulate and modify audio, image, and video data, or heterogeneous media data stored in a database. Oracle interMedia Java Classes make it possible for Java database connectivity (JDBC) result sets to include both traditional relational data and interMedia media objects. This support enables applications to easily select and operate on a result set that contains sets of interMedia columns plus other relational data. These classes also enable access to object attributes and invocation of object methods.
interMedia allows applications to take advantage of all the features of Java Advanced Imaging by allowing client-side JAI applications to access images stored in the database. The inter Media Java Classes provide APIs for three types of stream objects, which let you read data from BLOBs and BFILEs and write to BLOBs from your JAI applications. interMedia allows applications to take advantage of all the features of JAI by allowing client-side JAI applications to access images stored in the database. The interMedia Java Classes provide APIs for three types of stream objects, which let you read data from BLOBs and BFILEs and write to BLOBs from your JAI applications.
These methods include the following:
BfileInputStream: A
SeekableStreamthat reads data from an Oracle BFILE associated with the streamBlobInputStream: A
SeekableStreamthat reads data from an Oracle BLOB associated with the streamBlobOutputStream: An
OutputStreamthat writes buffered data to an Oracle BLOB associated with the stream
These stream objects are not meant to replace the input and output stream objects provided by Sun Microsystems; these objects are included to provide an interface to image data stored in BLOBs and BFILEs in OrdImage objects that can be used by JAI without loss in performance.
We have seen the core interMedia framework, so how do you develop inter-Media applications using the provided APIs? Figure 17.5 captures the big picture. This section describes the steps necessary to build PL/SQL and Java applications that exploit interMedia.
The following is a set of simple PL/SQL examples that upload, store, manipulate, and export image data inside a database using interMedia. We assume that only Oracle Database Release 10g with Oracle interMedia is installed (the default configuration provided by Oracle Universal Installer). Although this example uses the ORDImage object type, the ORDAudio, ORDDoc, and ORDVideo object types are similar, with the exception of processing, which is supported for ORDImage only.
Note: Access to an administrative account is required in order to grant necessary file system privileges. In the following examples, you should change the command connect / as sysdba to the appropriate connect username/password as sysdba for your site. The following examples also connect to the database using connect scott/tiger, which you should change to an actual username and password on your system. You should also modify the definition of IMAGEDIR to point to the directory where you have downloaded the sample image files goats.gif and flowers.jpg. The sample image files and these examples can be found here: www.oracle.com/technology/sample_code/products/intermedia/ index.html.
First, we create a simple table with two columns: a numeric identifier (id) and an ORDSYS.ORDImage object (image). Note that all interMedia objects and procedures are defined in the ORDSYS schema.
connect scott/tiger create table image_table (id number primary key, image ordsys.ordimage);
This section shows how to bring images from the file system into the newly created table named image_table.
Create a directory object within the database that points to the file system directory that contains the sample image files. This is the directory where you saved the image files mentioned previously.
connect / as sysdba create or replace directory imagedir as '/home/alamb/ quickstart/'; -- For windows: create or replace directory imagedir as 'c:quickstart'; grant read on directory imagedir to scott;
Create a PL/SQL procedure
image_import()that inserts a new row intoimage_tableand then imports the image data in file name into the newly created ORDImage object.create or replace procedure image_import(dest_id number, filename varchar2) is img ordsys.ordimage; ctx raw(64) := null; begin delete from image_table where id = dest_id; insert into image_table (id, image) values (dest_id, ordsys.ordimage.init()) returning image into img; img.importFrom(ctx, 'file', 'IMAGEDIR', filename); update image_table set image=img where id=dest_id; end; /Call the newly created procedure to import two sample image files.
call image_import(1,"flowers.jpg"); call image_import(2,"goats.gif");
Note: The directory object is named IMAGEDIR (in uppercase letters) even if it was created with upper or lowercase letters. Thus, the command img.importFrom(ctx, 'file', 'imagedir', filename); will not work and the following error is returned:
ORA-22285: non-existent directory or file for FILEOPEN operation error.
Note: If the image you are importing is not one of interMedia’s supported formats (e.g., JPEG2000), the following error is returned:
ORA-29400: data cartridge error IMG-00705: unsupported or corrupted input format
Once image_table has been populated, you can access image attributes using SQL queries. In the following example, we demonstrate how to select some information from the imported images:
Note:The ORDImage import() and importFrom() methods automatically invoke the ORDImage setProperties() method to extract image properties from the imported image. For the ORDAudio, ORDDoc, and ORDVideo data types, the setProperties() method is not implicitly called by import() and importFrom(). It must be explicitly called by your application to extract properties from the media after import.
connect scott/tiger
select id,
t.image.getheight(),
t.image.getwidth()
from image_table t;
select id,
t.image.getfileformat(),
t.image.getcompressionformat()
from image_table t;
select id,
t.image.getcontentformat(),
t.image.getcontentlength()
from image_table t;The resulting output looks like the following:
id height width
---------- ---------- ----------
1 600 800
2 375 500
id fileformat compression
---------- ------------------------------ -----------------------
1 JFIF JPEG
2 GIFF GIFLZW
id contentformat length
---------- ------------------------------ ----------
1 24BITRGB 66580
2 8BITLUTRGBT 189337We next illustrate some image processing operations that can be invoked within the database. To generate a new ORDImage object from an existing one, the programmer describes the desired properties of the new image.
For example, the following description generates a JPEG thumbnail image of size 75×100 pixels: ‘fileformat=jfif fixedscale=75 100’.
Note:Process operations are only available for the ORDImage object type.
The following example defines image_processCopy(), which adds a new row to image_table with identifier dest_id and generates an ORDImage in the new row by processCopying of the ORDImage in the source row.
connect scott/tiger
create or replace procedure image_processCopy(source_id number,
dest_id number, verb varchar2) is
imgSrc ordsys.ordimage;
imgDst ordsys.ordimage;
begin
delete from image_table where id = dest_id;
insert into image_table (id, image)
values (dest_id, ordsys.ordimage.init());
select image into imgSrc from image_table where id = source_id;
select image into imgDst from image_table where id = dest_id for
update;
imgSrc.processCopy(verb, imgDst);
update image_table set image = imgDst where id = dest_id;
end;
/
-- Scale flowers.jpg to 10% into row with id=3
call image_processcopy(1,3,'scale=.1');
-- convert goats.gif to grayscale jpeg thumbnail into row with id=4
call image_processcopy(2,4,'fileformat=jfif contentformat=8bitgray
maxscale=100 100');
-- look at our handiwork
column t.image.getfileformat() format A20;
select id, t.image.getWidth(), t.image.getHeight(),
t.image.getFileFormat() from image_table t;The preceding example generates the following output:
ID T.IMAGE.GETWIDTH() T.IMAGE.GETHEIGHT() T.IMAGE.GETFILEFORMA
---------- ------------------ ------------------- --------------------
1 800 600 JFIF
2 500 375 GIFF
3 80 60 JFIF
4 100 75 JFIFExporting image data from the database with interMedia’s export method requires that the database write to the file system. Writing to the file system requires granting Java permissions to your user (scott in the examples) andto the ORDSYS schema, as shown in the following example:
connect / as sysdba
create or replace directory imagedir as '/home/quickstart';
-- For windows:
--create or replace directory imagedir as 'c:quickstart';
grant read on directory imagedir to scott;
call dbms_java.grant_permission('SCOTT','java.io.FilePermission',
'/home/alamb/quickstart/*','WRITE');
call dbms_java.grant_permission('ORDSYS','java.io.FilePermission',
'/home/alamb/quickstart/*','WRITE');
-For windows:
--call dbms_java.grant_permission('SCOTT','java.io.FilePermission',
-- 'c:quickstart*','WRITE');
--call dbms_java.grant_permission('ORDSYS','java.io.FilePermission',
-- 'c:quickstart*','WRITE');
connect scott/tiger
-- Writes the image data from ORDImage with id=<source_id>
-- in image_table
-- to the file named <filename> in the IMAGEDIR directory
create or replace procedure image_export (source_id number,
filename varchar2) as imgSrc ordsys.ordimage;
ctx raw(64) := null;
begin
select image into imgSrc from image_table where id = source_id;
imgSrc.export(ctx, 'FILE', 'IMAGEDIR', filename);
end;
/
call image_export(3, 'flowers_thumbnail.jpg');
call image_export(4, 'goats_grayscale.jpg');The following is a set of simple Java client examples that establish a connection, upload, set properties, get and display properties, manipulate, and download image data inside a database using interMedia. We assume that only Oracle Database Release 10g with Oracle interMedia is installed (the default configuration provided by Oracle Universal Installer). Although this example uses the ORDImage Java Class, the ORDAudio, ORDDoc, and OrdVideo Java Classes are similar, with the exception of processing, which is supported for ORDImage only.
Note: This example assumes the user account has access to the Sample Schema.
First, we establish a connection to the database. Note when using interMedia, auto-commit must be set to false if updating LOBs, since they require selecting for update and then changing before a commit. Note that with a connection, the user can select either auto-commit after every transaction or manual commit.
public OracleConnection connect(String user, String
password)
throws Exception
{
String connectString;
DriverManager.registerDriver(new
oracle.jdbc.OracleDriver());
connectString = "jdbc:oracle:oci:@";
OracleConnection conn = (OracleConnection)
DriverManager.getConnection(connectString, user,
password);
conn.setAutoCommit(false);
return conn;
}This section shows how to upload a media file from a local disk file into a media row in the database table. Oracle callable statements are used to make it easy to bind parameters to the SQL involved and to allow return of a client-side object. A new row is inserted into the PM.Online_Media table with an empty ORDImage object, and the newly inserted ORDImage object is returned on insert. Next, image data is loaded from a local disk file into the ORDImage object, and the online_media table is updated.
public void upload(OracleConnection conn, String fileName,
int productId) throws Exception
{
OracleCallableStatement cstmt = null;
String queryInit = new String(
"begin insert into pm.online_media " +
" (product_id, product_photo, product_thumbnail) " +
" values(?, ORDSYS.ORDImage.init(), ORDSYS.ORDImage.init())"
+ " returning product_photo into ?; end; ");
cstmt = (OracleCallableStatement) conn.prepareCall(queryInit);
cstmt.setInt(1, productId);
cstmt.registerOutParameter(2, OrdImage._SQL_TYPECODE,
OrdImage._SQL_NAME);
cstmt.execute();
OrdImage img = (OrdImage)cstmt.getORAData(2,
OrdImage.getORADataFactory());
cstmt.close();
img.loadDataFromFile(fileName);
String queryUpload = new String(
"update pm.online_media set product_photo = ?
where product_id = ?");
OraclePreparedStatement pstmt =
(OraclePreparedStatement)conn.prepareStatement(queryUpload);
pstmt.setORAData(1, img);
pstmt.setInt(2, productId);
pstmt.execute();
pstmt.close();
conn.commit();
} The interMedia setProperties method causes interMedia to examine the media object, determine its type (e.g., JPEG), and parse out both format and application metadata. In the following example, an image is queried for update, a proxy image is retrieved to the client, the setProperties() method is executed on the server, metadata attributes are parsed out of the media and then populated into the image object, and finally the image object is updated in the database.
public void setPhotoProperties(OracleConnection conn, int productId)
throws Exception
{
String querySelect = new String(
"select product_photo from pm.online_media where product_id = ? for
update");
OraclePreparedStatement pstmt =
(OraclePreparedStatement)conn.prepareStatement(querySelect);
pstmt.setInt(1, productId);
OracleResultSet rs = (OracleResultSet)pstmt.executeQuery();
OrdImage img = null;
if (rs.next() == true)
{
img = (OrdImage)rs.getORAData(1, OrdImage.getORADataFactory());
}
else
throw new Exception("No row found for the product " + productId);
rs.close();
pstmt.close();
img.setProperties();
String queryUpdate = new String(
"update pm.online_media set product_photo = ?
where product_id = ?");
pstmt = (OraclePreparedStatement)conn.prepareStatement(queryUpdate);
pstmt.setORAData(1, img);
pstmt.setInt(2, productId);
pstmt.execute();
pstmt.close();
conn.commit();
}interMedia provides a set of getter methods for accessing the format metadata from a client-side proxy object, which has had the setProperties() method performed on it. In the following example, an image is queried from a database table and then bound to a local image variable. Various image attributes are then accessed using getter methods and output to the command line.
public void getPhotoProperties(OracleConnection conn, int
productId)
throws Exception
{
String querySelect = new String(
"select product_photo from pm.online_media
where product_id = ? for update");
OraclePreparedStatement pstmt =
(OraclePreparedStatement)conn.prepareStatement(querySelect);
pstmt.setInt(1, productId);
OracleResultSet rs = (OracleResultSet)pstmt.executeQuery();
OrdImage img = null;
if (rs.next() == true)
{
img = (OrdImage)rs.getORAData(1, OrdImage.getORADataFactory());
}
else
throw new Exception("No row found for the product "
+ productId);
rs.close();
pstmt.close();
System.out.println("MIME Type: " + img.getMimeType());
System.out.println("Height: " + img.getHeight());
System.out.println("Width: " + img.getWidth());
System.out.println("Content Length: " + img.getContentLength());
}In the following example, we illustrate some image processing operations that can be invoked within the database. This example copies an image and scales the copy, making a thumbnail and changing its format to GIFF.
Note: Process operations are only available for the ORDImage object type.
public void generateThumbnail(OracleConnection conn, int productId)
throws Exception
{
String queryGetThumb = new String(
"select product_photo, product_thumbnail from pm.online_media
" +
" where product_id = ? for update");
OraclePreparedStatement pstmt =
(OraclePreparedStatement)conn.prepareStatement(queryGetThumb);
pstmt.setInt(1, productId);
OracleResultSet rs = (OracleResultSet)pstmt.executeQuery();
OrdImage img = null;
OrdImage imgThumb = null;
if (rs.next() == true)
{
img = (OrdImage)rs.getORAData(1, OrdImage.getORADataFactory());
imgThumb = (OrdImage)rs.getORAData(2,
OrdImage.getORADataFactory());
}
else
throw new Exception("No row found for the product " +
productId);
rs.close();
pstmt.close();
img.processCopy("maxScale=64 64, fileFormat=GIFF", imgThumb);
String queryUpdate = new String(
"update pm.online_media set product_thumbnail = ?
where product_id = ?");
pstmt =
(OraclePreparedStatement)conn.prepareStatement(queryUpdate);
pstmt.setORAData(1, imgThumb);
pstmt.setInt(2, productId);
pstmt.execute();
pstmt.close();
conn.commit();
}In the following example, we query an image from the online_media table, bind the image to a client-side image proxy object, download the image from the database, and then write the image to a local disk file.
public void downloadThumbnail(OracleConnection conn, int productId,
String fileName)
throws Exception
{
String queryGetThumb = new String(
"select product_thumbnail from pm.online_media where
product_id = ?");
OraclePreparedStatement pstmt =
(OraclePreparedStatement)conn.prepareStatement(queryGetThumb);
pstmt.setInt(1, productId);
OracleResultSet rs = (OracleResultSet)pstmt.executeQuery();
OrdImage imgThumb = null;
if (rs.next() == true)
{
imgThumb = (OrdImage)rs.getORAData(1,
OrdImage.getORADataFactory());
}
else
throw new Exception("No row found for the product " +
productId);
rs.close();
pstmt.close();
boolean isSuc = OrdMediaUtil.getDataInFile(fileName,
imgThumb.getContent());
if (isSuc)
System.out.println("Download thumbnail for product
" + productId +
" is successful");
else
System.out.println("Download thumbnail for product "
+ productId + " is unsuccessful");
}This case study has been presented and demonstrated at Oracle World; it is reproduced here with the authorization and courtesy of my longtime friend Thor Heinrichs-Wolpert, System Architect at Lunartek, and the mastermind behind this architecture. The first time I met Thor, he and his associate Jeff wanted to implement Jini/JavaSpace services in the database, using the OracleJVM. I thought he was crazy, but when you think about it, the JavaSpace object state information is currently captured in a file system, so, when it comes to capturing millions of performance metrics in large ISP/ASP environments, the Oracle Database, RAC, and OracleJVM are definitely more robust, reliable, and scalable than file systems. But I suspect the Jini/Javaspace thing is at rest—at least for now—as Thor has been recently working on the award-winning[1] Corporate Online project for the British Columbia Corporate and Personal Registries.
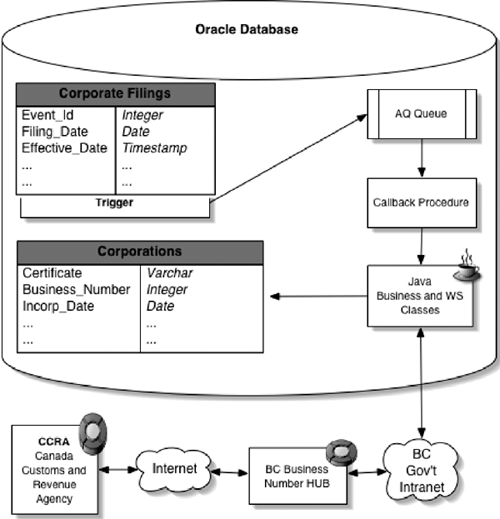
The legal records of corporations are usually filed on paper. Lunartek and the British Columbia Corporate Registry have developed and deployed in production a new application that stores and maintains the legal records of corporations electronically in an Oracle Database 10g, using Java in the database, PL/SQL, database Web services, XMLDB, and Oracle JMS over Streams/AQ. Prior to Corporate Online, companies had to wait several weeks or more to get their business number. With this application, the Corporate Registry issues the business number and sends it to the company within a few days.
The Corporate Registry database communicates incorporations or changes in a company to its partners and legacy systems via a set of Streams/AQ Queues, Java stored procedures, and Web service call-out, using XML documents stored in Oracle’s XMLDB. Simple database triggers place small messages into the queues that only propagate upon commits. Callbacks within the database receive the messages and generate the XML documents, which are then passed to Java Stored Procedures for delivery by regular Web service mechanisms. The latest release of Corporate Online also uses XMLDB and stored procedures to generate XML summaries and client receipts, which are transformed into PDFs in the middle tier.
In all of these instances, the Oracle database does the real heavy lifting of ensuring that a legal transaction has completed, that any future dated filings have come to pass, and that the appropriate XML documents are then delivered.
Figure 17.6 depicts the key database components that participate in the implementation of the application.
The mainline business system must be able to complete its business transaction without delay. Partners must be notified of any business change they are registered for, once the mainline business transaction has fully completed. But how to submit changes to the hub only if these were committed?
Ideally, the change or addition is monitored by a trigger on a table in the database, so that any application effecting a change has that change propagated. The problem with triggers is that they “fire” during a transaction and either execute a procedure as part of the transaction or out-of-band, but they do not fire after a commit has completed. Using Streams AQ, the messages are posted in queues that only propagate upon commits. To accomplish this task, we must use queues to propagate the event after completing a transaction in one system and then notifying the next.
First, create a type that will hold our message:
CREATE or REPLACE TYPE event_message_t AS OBJECT (
event_id NUMBER
,effective_dt DATE
);
/We’ll also create a log table to easily watch the status of our message:
Create table bn_message_log
(event_id NUMBER
,msg event_message_t
,msg_q_handle RAW(16)
,status CHAR(1)
,transaction_id VARCHAR2(4000)
,error_msg VARCHAR2(4000)
);This will hold our event and the date on which it should be processed. Next, we create the queue, the procedure to add a message to the queue, and the trigger to “fire” off the event:
prompt creating CREATE_QUEUE_TABLE
begin
DBMS_AQADM.CREATE_QUEUE_TABLE
( queue_table => 'event_qt'
,queue_payload_type => 'event_message_t'
,multiple_consumers => TRUE );
end;
/
prompt creating CREATE_QUEUE
begin
DBMS_AQADM.CREATE_QUEUE
( queue_name => 'eventqueue'
,queue_table => 'event_qt' );
end;
/
prompt creating START_QUEUE
begin
DBMS_AQADM.START_QUEUE
( queue_name => 'eventqueue' );
end;
/
prompt creating enqueue_event_msg
create or replace procedure enqueue_event_msg( p_msg in
event_message_t
,effective_dt in DATE )
as
enqueue_options dbms_aq.enqueue_options_t;
message_properties dbms_aq.message_properties_t;
message_handle RAW(16);
message event_message_t;
delay integer;
begin
-- we can delay the message so that the queue
-- will deliver this message sometime in the future
delay := (24*60*60)*(effective_dt - sysdate);
–- no delay for dates in the past
if ( delay > 1 ) then
message_properties.delay := delay;
end if;
-- only send our message if the transaction commits!!!
enqueue_options.visibility := dbms_aq.ON_COMMIT;
dbms_aq.enqueue( queue_name => 'eventqueue'
,enqueue_options => enqueue_options
,message_properties => message_properties
,payload => p_msg
,msgid => message_handle );
insert into message_log
( event_id
,msg
,msg_q_handle
,status
,transaction_id
,error_msg)
values ( p_msg.event_id
,p_msg
,message_handle
,'P'
,null
,null );
end;
/Let's create our EVENT table, which we’ll use to propagate a message from:
Create table EVENT ( event_id NUMBER
CONSTRAINT event_pk PRIMARY
KEY
,event_type VARCHAR2(25)
,effective_dt DATE
,note VARCHAR2(4000)
);
create or replace trigger event_propagate_trg after insert on
event
for each row
declare
flag CHAR(1) := 'Y';
begin
-- are we propagating?
-- This would be a bigger function in a real app
if ( flag = 'Y' ) then
enqueue_event_msg( event_message_t( :new.EVENT_ID
,:new.EFFECTIVE_DT
)
,:new.EFFECTIVE_DT );
end if;
end;
/We also use the ability of AQ to tag an effective time on a message, to allow filing to have future effective dates. We can make the determination if a filing is immediately active or if it is to take effect in the future.
This is pretty good so far, but what happens to the message in the queue? Callbacks within the database receive the Streams/AQ messages and generate the XML documents, which are then passed to Java stored procedures (as database trigger), which initiate the delivery using Web service mechanisms. In this sample, we’ll create a callback that will execute once a message is ready to be processed from the queue.
prompt creating queueCallBack
create or replace procedure queueCallBack ( context raw
,reginfo sys.aq$_reg_info
,descr sys.aq$_descriptor
,payload raw
,payloadl number)
as
dequeue_options dbms_aq.dequeue_options_t;
message_properties dbms_aq.message_properties_t;
message_handle RAW(16);
message event_message_t;
xml_view VARCHAR2(30); -- we'll use this later
err_msg VARCHAR2(4000) := null;
withdrawn NUMBER := null;
my_code NUMBER;
my_errm VARCHAR2(4000);
begin
dbms_output.put_line( 'about to process queue event' );
dequeue_options.msgid := descr.msg_id;
dequeue_options.consumer_name := descr.consumer_name;
DBMS_AQ.DEQUEUE( queue_name => descr.queue_name
,dequeue_options => dequeue_options
,message_properties => message_properties
,payload => message
,msgid => message_handle);
BEGIN
update message_log
set status = 'R'
where event_id = message.event_id;
EXCEPTION
when OTHERS then
my_errm := substr( SQLERRM, 1, 4000 );
ROLLBACK;
END;
if (my_errm is not null) then
update message_log
set status = 'E'
,error_msg = my_errm
where event_id = message.event_id;
end if;
commit;
end;
/Database Web services were covered earlier. We’re doing Web services directly from the database to move critical program information to/from our Oracle database from/to our leagcy IMS/CICS/DB2 mainframe. We are exchanging information between these older systems directly from the database via a set of Web services that are initiated by database triggers. We went with Web services directly from the database rather than from the application server, because many processes interact with the data and create items of interest for the mainframe systems. (See Figure 17.7.)
The SOAP wrappers can be generated by the Web services client stack, but because we are running in the database, we choose to use XMLDB to create the content of the SOAP message, using the following steps:
Create message types:
CREATE or REPLACE TYPE header_message_t AS OBJECT ( event_id NUMBER ,priority NUMBER(1) ,effective_dt DATE ); / CREATE or REPLACE TYPE body_message_t AS OBJECT ( message VARCHAR2(400) ,note VARCHAR2(50) ); / CREATE or REPLACE TYPE propagated_message_t AS OBJECT ( header header_message_t ,body body_message_t ); /Create an object_view on propagated_message type:
CREATE OR REPLACE VIEW propagated_message_ov OF propagated_message_t WITH OBJECT ID (header.event_id) AS SELECT header_message_t ( e.event_id ,1 -- priority ,e.effective_dt -- effective_dt ) ,body_message_t ( 'the message body' -- message ,'note to the partner' – note ) from event e /Generate a schema for the XML message:
SELECT DBMS_XMLSCHEMA.generateschema('SCOTT','PROPAGATED_MESSA GE_T') FROM DUAL;Edit and load the view as appropriate.
BEGIN
dbms_xmlschema.deleteSchema('http://www.lunartek.com/
schema/v1/PartnerMessage.xsd', 4);
END;
/
BEGIN
dbms_xmlschema.registerSchema('http://
www.lunartek.com/schema/v1/PartnerMessage.xsd',
'<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/
XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-
instance" xmlns:xdb="http://xmlns.oracle.com/xdb"
xsi:schemaLocation="http://xmlns.oracle.com/xdb http://
xmlns.oracle.com/xdb/XDBSchema.xsd">
<xsd:element name="PartnerMessage"
type="PROPAGATED_MESSAGE_TType"
xdb:SQLType="PROPAGATED_MESSAGE_T"
xdb:SQLSchema="SCOTT"/>
<xsd:complexType name="PROPAGATED_MESSAGE_TType"
xdb:SQLType="PROPAGATED_MESSAGE_T"
xdb:SQLSchema="SCOTT" xdb:maintainDOM="false">
<xsd:sequence>
<xsd:element name="header"
type="HEADER_MESSAGE_TType" xdb:SQLName="HEADER"
xdb:SQLSchema="SCOTT" xdb:SQLType="HEADER_MESSAGE_T"/>
<xsd:element name="body" type="BODY_MESSAGE_TType"
xdb:SQLName="BODY" xdb:SQLSchema="SCOTT"
xdb:SQLType="BODY_MESSAGE_T"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="HEADER_MESSAGE_TType"
xdb:SQLType="HEADER_MESSAGE_T" xdb:SQLSchema="SCOTT"
xdb:maintainDOM="false">
<xsd:sequence>
<xsd:element name="event" type="xsd:double"
xdb:SQLName="EVENT_ID" xdb:SQLType="NUMBER"/>
<xsd:element name="priority" type="xsd:double"
xdb:SQLName="PRIORITY" xdb:SQLType="NUMBER"/>
<xsd:element name="messageDate" type="xsd:date"
xdb:SQLName="EFFECTIVE_DT" xdb:SQLType="DATE"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="BODY_MESSAGE_TType"
xdb:SQLType="BODY_MESSAGE_T" xdb:SQLSchema="SBNDB"
xdb:maintainDOM="false">
<xsd:sequence>
<xsd:element name="message" xdb:SQLName="MESSAGE"
xdb:SQLType="VARCHAR2">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:maxLength value="400"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name="note" xdb:SQLName="NOTE"
xdb:SQLType="VARCHAR2">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:maxLength value="50"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>', TRUE, FALSE, FALSE);
END;
/Test out the schema and see what we get!
SELECT SYS_XMLGEN (value(s), xmlformat.createformat( 'PartnerMessage', 'USE_GIVEN_SCHEMA', 'http://www.lunartek.com/schema/v1/ PartnerMessage.xsd')).getclobval() FROM propagated_message_ov s WHERE s.header.event_id = 2;
It should output something like this:
<PartnerMessage>
<header>
<event>2</event>
<priority>1</priority>
<messageDate>2005-09-27</messageDate>
</header>
<body>
<message>the message body</message>
<note>note to the partner</note>
</body>
</PartnerMessage>Notice the mixed case and altered tags .... very cool!
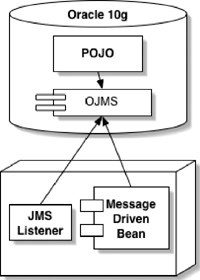
What if one of the partners was using some specific security toolkit—different from the standard JCE stack—that you couldn’t use from within the database? The current implementation of JCE in OracleJVM does not yet allow any JCE provider other than the Sun-provided one (part of J2SE). The Streams/AQ system once again came to the rescue, because it can be used as a transport for JMS messages. As depicted by Figure 17.8, we can forward the message using JMS/AQ and have a J2EE message bean accept the message and process it using the specific partner requirements! You may also use messaging across tiers to partition the workload between the middle tier and the database.
First, set up the JMS Queue.
Note: This example uses the default JMS queue setup within OC4J as the J2EE container.
BEGIN DBMS_AQADM.CREATE_QUEUE_TABLE( Queue_table => 'demoQTab', Queue_payload_type => 'SYS.AQ$_JMS_MESSAGE', sort_list => 'PRIORITY,ENQ_TIME', multiple_consumers => false, compatible => '8.1.5'); DBMS_AQADM.CREATE_QUEUE( Queue_name => 'demoQueue', Queue_table => 'demoQTab'); DBMS_AQADM.START_QUEUE( queue_name => 'demoQueue'); END; /Load the Java source in the database (Listing 17.1):
import oracle.jms.AQjmsQueueConnectionFactory; import oracle.jms.AQjmsSession; import oracle.jdbc.driver.OracleDriver; import javax.jms.*; public class JMSSender { public static void send( String msgBody ) { OracleDriver oraDriver = null; java.sql.Connection dbConnection = null; // Variables for the sender QueueConnection senderQueueConn = null; QueueSession senderQueueSession = null; QueueSender sender = null; Queue senderQueue = null; TextMessage sendMsg = null; try { // get database connection oraDriver = new OracleDriver(); dbConnection = oraDriver.defaultConnection(); // setup sender senderQueueConn = AQjmsQueueConnectionFactory.createQueueConnection( dbConnection ); senderQueueConn.start(); senderQueueSession = senderQueueConn.createQueueSession( true, Session.CLIENT_ACKNOWLEDGE ); senderQueue = ((AQjmsSession) senderQueueSession).getQueue( "scott", "demoQueue" ); sender = senderQueueSession.createSender( senderQueue ); System.out.println( "sender created" ); // create message sendMsg = senderQueueSession.createTextMessage( msgBody ); sendMsg.setStringProperty ( "RECIPIENT", "MDB" ); sendMsg.setJMSReplyTo( senderQueue ); System.out.println( "message created" ); // send message sender.send( sendMsg ); senderQueueSession.commit(); System.out.println( "message sent" ); // cleanup senderQueueSession.close(); senderQueueConn.close(); } catch (java.sql.SQLException ex) { ex.printStackTrace(); } catch (JMSException e) { e.printStackTrace(); } finally { try{ dbConnection.close } catch (Exception x) ; } } }Wrap it with a package.
Note
You don’t have to wrap it, but it’s nice to bundle all of the calls you need into a single package.
create or replace package jmsPartner as procedure sendJMSMessage(msg VARCHAR2); end jmsPartner; / create or replace package body jmsPartner as procedure sendJMSMessage(msg VARCHAR2) is language java name 'JMSSender.send (java.lang.String)'; end jmsPartner; /
Now, in the QueueCallBack procedure we can change the code:
BEGIN
update message_log
set status = 'R'
where event_id = message.event_id;
EXCEPTION to the following:
BEGIN
SELECT jmsPartner.sendJMSMessage(
SYS_XMLGEN (value(s), xmlformat.createformat(
'PartnerMessage'
,'USE_GIVEN_SCHEMA','http://www.lunartek.com/schema/
v1/PartnerMessage.xsd')).getstringval()
FROM propagated_message_ov s
WHERE s.header.event_id = message.event_id;
update message_log
set status = 'R'
where event_id = message.event_id;
EXCEPTION We’re almost there. The last step consists of creating a message-driven Bean in OC4J that will listen on the JMS/AQ for the incoming message!
public void onMessage(Message msg)
{
System.out.println( "Entering the onMessage call" );
try
{
String txnId = sendMessage( ((TextMessage)msg).getText() );
} catch ( Exception e ) {
e.printStackTrace();
mdc.setRollbackOnly();
}
}Future developments may also improve the turnaround time and issue the business number at the end of the filing transaction. We will be adding in Web service interactions with partner systems via a WebMethods Broker, but our connection to the hub will again be initiated by the database, because it is the central point where things can converge and we can inescapably control the data management in one place.
Similar to the TECSIS use case, this real-life use case makes use of many components of the Oracle database, including SQL, PL/SQL, Java in the Database, XDB, Streams-AQ, and OJMS. Furthermore it straddles the Oracle database and Oracle application server (messaging across tiers), which is another example of cooperation between database applications and middle-tier applications.
This case study was demonstrated at the last Oracle World by my good friend Omar Alonso, who works in Oracle’s Secure Enterprise Search group. Like many visitors, I was so impressed that I asked him to write this section for the book. Despite the tight schedule for submitting the manuscript, he busted his back, and here you are with a descriptrion of the design and implementation of a search engine for a controlled environment such as a text warehouse or corporate Intranet.
This section will briefly introduce the main technical features of Oracle Text, the rationale for using Java in the database, and the types of applications that you can build with the existing API. It then presents the built-in capabilities of the database for text searching, and finally you will learn how to build and experience Yapa, the nice demo, which prompted the writing of this case study.
Oracle Text is an Oracle database component that lets you build general-purpose information retrieval applications.[2] Oracle Text provides specialized text indexes for textual content search or traditional full-text retrieval, such as:
Intranet and extranet searches
Web-based e-business catalogs
Document archives and text warehouses
CRM and other document-oriented applications
Oracle Text can filter and extract content from different document formats. It supports several document formats, including popular ones such as Microsoft Office file formats, Adobe PDF, HTML, and XML.
It offers a complete set of multilingual features, supporting search across documents in Western languages (e.g., English, French, Spanish, German), Japanese, Korean, and traditional and simplified Chinese. The technology also supports the combination of different lexical analyzers (lexers), as well as the ability to define your own lexer for particular languages.
As part of the Oracle database, Oracle Text transparently integrates with and benefits from a number of key enterprise features, such as data partitioning, RAC, query optimization, tools and development environments, administration and manageability, and integrated security. Oracle Text is included with both the Oracle 10g Database Standard and Enterprise Editions.
Let’s take a quick look at how it works. First, we have to create a table and populate with some data—for example, a product table where we want to search product descriptions:
create table products ( id numeric, name varchar2(100), description varchar2(200)); insert into products values(1,'VT21','Monitor with high resolution'); insert into products values(2,'VT100','Flat panel. Color monitor'); commit;
Then create an index type called context that allows us to use the contains clause in SQL for text searching:
create index desc_idx on products(description) indextype is ctxsys.context;
Finally, with SQL we retrieve the product’s name where the description contains monitor and is near to the term resolution.
select name from products where contains(description,'monitor near resolution') > 0 NAME –––––––––––––––––––– VT21
The Oracle database furnishes an embedded Java run time, which can be used by database components such as XDB, interMedia, Spatial, Text, XQuery, and so on. Oracle Text leverages the XML DB framework, which includes a protocol server and a specialized Java Servlet runner, all running within the database. I need to clarify here that the J2EE stack has been discontinued from the database since Oracle 9i Release 2. This Servlet runner is by no means a reintroduction of J2EE in the database; it is not a full-fledged and general-purpose Servlet container; it’s sole purpose is to support the XDB framework. The servlets are configured using the /xdbconfig.xml file in the XDB Repository. The protocol server supports FTP, HTTP 1.1, and WebDAV. We describe the XDB repository and the configuration in the case study section later.
From development and deployment perspectives, there are some advantages of running Java in the database:
Simplified all-in-one environment in which you only need a Java-enabled database, no external JDK, no external Web Listener.
Easy to test and debug: no need to recycle a Web server or container.
The database does the heavy lifting, including the processing of SQL, XML, PL/SQL, and Java operations. Moving data across tables and data-intensive computations are better handled directly within the database.[3]
In this section, we present a high-level technical overview of the main features. The YAPA demo complements this section with more details and source code.
Oracle Text provides three types of indexes that cover all text search needs: standard, catalog, and classification.
Standard index type: For traditional full-text retrieval over documents and Web pages. The
contextindex type provides a rich set of text search capabilities for finding the content you need, without returning pages of spurious results. The first example showed this index type in action.Catalog index type: The first text index designed specifically for eBusiness catalogs. The
ctxcatcatalog index type provides flexible searching and sorting features. For example, a catalog index on a table that contains auction items:create index auctionx on auction(item_desc) indextype is ctxsys.ctxcat;
Once the
ctxcatindex is created, you use thecatsearchoperator for queries:select item_desc from auction where catsearch(item_desc, 'oracle', null)>0;
Classification index type: for building classification or routing applications. The
ctxruleindex type is created on a table of queries, where the queries define the classification or routing criteria. For example, a rule index for classifying incoming news:create index newscats_idx on news(categories) indextype is ctxsys.ctxrule;
Once the
ctxruleindex is created, you use thematchesoperator for queries:select message from news where matches(categories,'Soccer and football news")>0
Oracle Text also provides substring and prefix indexes. Substring indexing improves performance for left-truncated or double-truncated wildcard queries. Prefix indexing improves performance for right-truncated wildcard queries.
Oracle Text can intelligently process search queries using several strategies:
Keyword searching. Searching for keywords in a document. User enters one or more keywords that best describe the query.
Context queries. Searching for words in a given context. User searches for text that contains words near to each other.
Boolean operations. Combining keywords with Boolean operations. User can express a query connecting Boolean operations to the keywords.
Linguistic features. Using fuzzy and other natural language processing techniques. User searches for text that is about something.
Pattern matching. Retrieval of text that contains a certain property. User searches for text that contains words that contain a string.
A document service is any ad hoc operation on a particular document. Oracle Text provides the following document services: highlighting, markup, snippet, themes, and gist. These types of services can be very useful for browsing strategies and for document presentation. The PL/SQL CTX_DOC package exposes all document services.
The highlighting service takes a query string, fetches the document contents, and shows you which words in the document cause it to match the query.
Markup takes the highlighting service one step further and produces a text version of the document with the matching words marked up.
This procedure returns text fragments containing keywords found in documents. This format enables you to see the keywords in their surrounding text, providing context for them.
A “theme” provides a snapshot that describes what the document is about. The procedure returns a list of themes for a document with their associated weight.
A document classification application is one that classifies an incoming stream of documents based on their content. These applications are also known as document routing or filtering applications. For example, an online news agency might need to classify its incoming stream of articles as they arrive into categories such as politics, economy, or sports.
Oracle Text enables you to build such applications with the ctxrule index type. This index type indexes the rules (queries) that define classifications or routing criteria. When documents arrive, the matches operator can be used to categorize each document. The CTX_CLS PL/SQL package enables you to perform classification and clustering.
We can summarize the following steps to set up a basic document classification application:
Group related sample documents together.
For each group, write rules that explain why the documents belong in the group.
Using the rule set, classify incoming documents into appropriate groups.
The ctxrule index type automates step 3 of the process, but the user has to write the rules. The CTX_CLS package automates step 2 by generating ctxrule query rules for a set of documents. The user has to supply a training set consisting of categorized documents, and each document must belong to one or more categories. The package generates the queries that define the categories and then writes the results to a table.
Contrary to classification, clustering is the unsupervised classification of patterns into groups. As part of CTX_CLS, the clustering procedure automatically clusters a set of documents according to their semantic meanings. The document in a cluster is believed to be more similar with each other inside the cluster than with outside documents.
Oracle Text’s knowledge base contains more than 400,000 concepts from very broad domains classified into 2,000 major categories. These categories are organized hierarchically under six top terms: business and economics, science and technology, geography, government and military, social environment, and abstract ideas and concepts. Users can extend and customize this knowledge base by adding new terms or redefining existing ones.
Oracle Database 10g provides an extensibility framework[4] that enables developers to extend the data types understood by the database kernel. Oracle Text uses this framework to fully integrate the text indexes with the standard Oracle query engine. This means the user has:
A single repository for all data (text and structured). This is easy to maintain, back up, and so on.
A single API for developing applications.
Optimizer integration.
The advantages of integration:
Cost-effective solution. Oracle Text is part of all editions of the Oracle Database 10g (Enterprise and Standard Editions). There are no separate products to buy or integrate.
Efficient. The database will choose the fastest plan to execute queries that involve both text and structure content.
High integrity. Because text is stored in the database, it inherits all of the integrity benefits (e.g., any update to the database can be reflected to the text search functionality), which means users can get an integrated, holistic view of all their data.
Low complexity. Text is treated just like structured data, which makes it easy to develop and integrate search applications with existing systems.
Manageable. Oracle Text can be managed by DBAs, using standard enterprise management tools.
In this section, you will build and play with Yapa;[5] it demonstrates the main features of Oracle Text. Although it runs entirely in the database, it has two constituents: the back end and the user interface handler.
The back end consists of the following components: the search component, the browser, the clusterer, and the query logger. The search component consists of a text index for traditional information retrieval queries and a classification index for categorizing the documents. The text index type provides a rich set of text search capabilities for finding content, without returning pages of spurious results. The classification index type is the inverse of the usual text index. The index is created on a table of queries, where the queries define the classification or routing criteria.
The user interface is based on a two-view model, where the left side shows structure and the right side shows content. The left view presents the results in the following structures: list, categories, and clusters. The right view shows content and operations. The operations are documents with highlighted query terms, document themes, document summary, and document gist.
As we mentioned earlier, Yapa runs within an Oracle Database 10g with no extra components, such as external Web Listener or external Java VM. The architecture consists of SQL scripts (for the schema preparation) and a Java code (for the search application). The scripts perform the schema and index creation, along with the classification and clustering of the document collection. The Java code leverages a specialized and embedded XDB Servlet engine, which provides methods for searching, browsing, query logs manipulation, and document services. All that is available in the context of a two-view interface model. (See Figure 17.9)
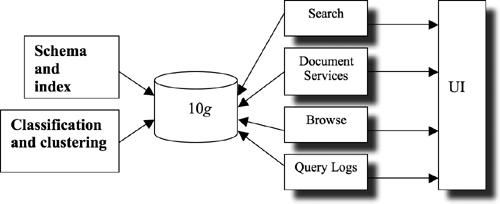
In this implementation, we decided to store the document in a regular database table using the LOB (Large Object) data type for the actual text. In case you don’t want to store the documents in the database, you can store them in the file system or on the Web. The context index type creates the text index on that LOB column. There is a second table, which contains the categories for the collection. The ctxrule index type creates a classification index on the categories column. This index type indexes the rules (queries) that define classifications or routing criteria. When documents arrive, the matches operator can be used to categorize each document. The following SQL script fragment shows the tables and indexes creation:
-- Enable theme indexing
exec ctx_ddl.create_preference('mylex','BASIC_LEXER');
exec ctx_ddl.set_attribute('mylex','MIXED_CASE','NO');
exec ctx_ddl.set_attribute('mylex','THEME_LANGUAGE','ENGLISH');
exec ctx_ddl.set_attribute('mylex','index_themes','YES');
exec ctx_ddl.set_attribute('mylex','index_text','YES');
-- Create HTML sections for searching within tags
exec ctx_ddl.create_section_group('htmlgroup','html_section_group');
exec ctx_ddl.add_zone_section('htmlgroup','title','TITLE');
exec ctx_ddl.add_zone_section('htmlgroup','heading','H2');
exec ctx_ddl.add_zone_section('htmlgroup','body','BODY');
-- Create index for documents
create index med_idx on med_table(text)
indextype is ctxsys.context
parameters('lexer mylex filter ctxsys.null_filter section group
htmlgroup');
-- Create index for categories
create index mesh_cat_idx on mesh_cats(query)
indextype is ctxsys.ctxrule;In this particular example, we have created a simple batch classifier. This classifier is rudimentary and is intended to show how the basis works. For real production classifiers, you should look at the decision tree approach or Support Vector Machines (SVM). Both are supported in 10g.
for doc in (select tk, text from med_table)
loop
v_document := doc.text;
v_doc := doc.tk;
for c in (select queryid, category
from mesh_cats
where matches(query, v_document) > 0 )
loop
insert into med_doc_cat values (doc.tk, c.queryod);
end loop;
update med_table set category = v_categories where
tk=doc.tk;
end loop;Once the index has been created, we just run a script that computes clustering on the entire collection. The CTX_CLS package has a number of parameters in case you want to tune the quality of the output.
exec
ctx_ddl.create_preference('ycluster','KMEAN_CLUSTERING');
exec ctx_ddl.set_attribute('ycluster','THEME_ON','YES');
exec ctx_ddl.set_attribute('ycluster','TOKEN_ON','YES');
exec ctx_ddl.set_attribute('ycluster','CLUSTER_NUM',12);
exec
ctx_cls.clustering('med_idx','tk','clu_restab','clu_clusters'
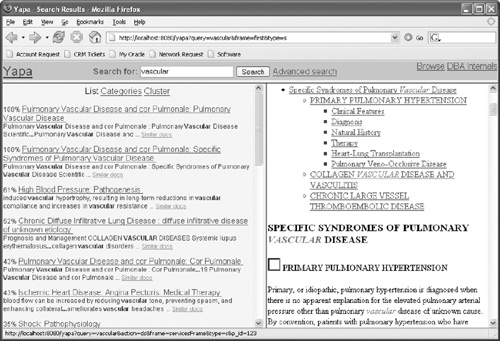
,'ycluster');The user interface is HTML-based, entirely generated and rendered from within the database. A Web page is divided into three parts: the search panel, the structure view, and the content view. The top frame consists of the search box for simple and advanced search. The left frame presents search results in three views: list, categories, and cluster. The traditional search results are presented in a list. For the categories view, the interface presents folders as categories. You can click on a category and present the documents. The cluster view presents a description of each cluster and its set of documents. The right frame presents the document content and its operations (e.g., the document with highlighted terms). The number of operations is implemented as tabs, allowing you to apply different services to the same document. Figure 17.10 shows the two-view interface.
The panel presents two options for search: simple search and advanced search. The latter provides the ability to search within the structure of the document (e.g., within tags of HTML/XML documents). The following code snippet shows the main search block:
...
Connection conn = null;
try
{
String stateT = "select /*+ FIRST_ROWS */ rowid, tk,
title, " + " category, score(1) scr," +
"ctx_doc.snippet('med_idx',tk,'"+query+"') snippet " +
"from med_table " + "where contains(text,'" + query + "',1) >
0 " + "order by ctxsys.score(1) desc ";
// text search is performed using the contains clause
// score returns the relevance for a returned document in
// a query
// ctx_doc.snippet returns the keyword in context for a
// query
OracleDriver ora = new OracleDriver();
conn = ora.defaultConnection();
OracleCallableStatement state =
(OracleCallableStatement)
conn.prepareCall(stateT);
state.execute(stateT);
ResultSet rs = state.executeQuery(stateT);
int items = 0;
while(rs.next() && items < 20) {
items++;
String tk = rs.getString(2);
String title = rs.getString(3);
String category = rs.getString(4);
String score = rs.getString(5);
out.println("<p class=OraCrumbs>");
out.println(score+ "% ");
out.println("<a class=OraLine href=
"yapa?query="+query+"&action=ds&frame=servicesFrame&type=s&p_
id=" + tk +"" target="servicesFrame">");
out.println(title);
out.println("</a><br>");
String kwic = rs.getString(6);
out.println(kwic+ " ... ");
}
rs.close();
conn.close();
state.close();
}
catch(SQLException e) {
out.println("SQLException: " + e.getMessage() + "<B>");
}The list of views (list, categories, clusters) is presented as tabs. The default view for a search is the list view, which presents the results sorted by score. The categories view presents the results as a folder (category), where the user can expand the folder to see the list of documents. The cluster view presents a list of a cluster and its description (usually themes). The user can expand the cluster folder to see all the documents.
The traditional search results are presented as a list of documents sorted by score. For each document, the view displays the title and its metadata (e.g., URL, data, size). The metadata and the number of items per page can be set in the settings area. Figure 17.10 shows the result set for a search using the list view on the left and displays a highlighted version of the document on the right frame. The list view also presents the document snippet (also know as kwic) using the ctx_doc.snippet package, as presented in the previous code sample.
For the categories view, the interface presents search results arranged by folders (categories). The user can click on the category to show all the documents. Figure 17.11 shows an example using a collection of medical documents where the categories are based on the MeSH taxonomy.[6]

The cluster package calculates the clusters plus other information and returns the data set in a couple of tables. The cluster view displays the description of the clusters with the option to display the documents that belong to that particular cluster. The cluster package is useful for implementing features such as “more similar documents.” Figure 17.12 shows the search results by clusters.

At any point, and independently of a particular view that the user has selected, it is possible to operate on a document. The basic operation of a document is to click on it and display its content in HTML on the right frame. The number of operations is implemented as tabs, allowing the user to apply different services to the same document in context. We will describe the implementation of the highlighting and theme services.
This operation displays the document with highlighted query terms in a particular format. The following Java snippet shows how the highlighting method is implemented. The service executes the CTX_DOC.MARKUP procedure that returns an in-memory LOB structure with the content. To display the document, we read by chunks from the data structure and print to the Web browser.
...
Connection conn = null;
String highlightQuery = "begin"
+" ctx_doc.markup(index_name=>'med_idx',"
+" textkey=>?,"
+" text_query=>?,"
+" restab=>?,"
+" starttag=> '<font color=red>',"
+" endtag=> '</font>' "
+" ); "
+"end; ";
try {
OracleDriver ora = new OracleDriver();
conn = ora.defaultConnection();
conn.createStatement().execute("begin
ctx_doc.set_key_type('PRIMARY_KEY'); end;");
OracleCallableStatement stmt =
(OracleCallableStatement)conn.prepareCall(highlightQuery);
// get paramters
stmt.setString(1,doc_id);
stmt.setString(2,query);
stmt.registerOutParameter(3, OracleTypes.CLOB);
stmt.execute();
oracle.sql.CLOB text_clob = null;
text_clob = ((OracleCallableStatement)stmt).getCLOB(3);
int chunk_size = text_clob.getChunkSize();
Reader char_stream = text_clob.getCharacterStream();
char[] char_array = new char[chunk_size];
for (int n = char_stream.read(char_array); n >0;
n = char_stream.read(char_array)) {
out.print(char_array);
}
} catch (SQLException e)
{
out.println("SQLException: " + e.getMessage() +
"<B>");
}
...Sometimes, searching for content is not enough, and users would like to browse or navigate the collection. In our example, you can browse by categories (based on MeSH) or by clusters.
We use an information visualization metaphor to present information in ways other than hit lists or folders. Visualization can show relationships across items in addition to satisfying query results. Figure 17.13 shows a stretch viewer visualization to browse the collection by categories. By issuing a double-click on the title of a document, you can view the content on the right frame.
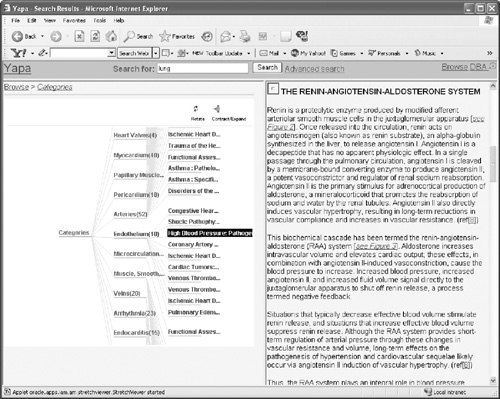
The visualization involves two steps. The first one is to generate the necessary HTML code on the fly that contains the following snippet. As we can see, apart from the usual code directory, we need to specify where the data comes from.
<object classid="clsid:8AD9C840-044E-11D1-B3E9-00805F499D93"
width="100%" height="500" align="baseline"
codebase="http://java.sun.com/products/plugin/1.3/
jinstall-13-win32.cab#Version=1,3,0,0">
<param name="code"
value="oracle.apps.iam.am.stretchviewer.StretchViewer.class"/
>
<param name="ImageDirectory" value="images/"/>
<param name="codebase" value="http://localhost:8080/
classes_g/"/>
<param name="DATA" value="http://localhost:8080/
yapacats?p_format=sv"/>
<param name="DATALENGTH" value="66308"/>
<param name="MODE" value="horizontal"/>
<param name="BACKGROUND" value="white"/>
<param name="STICKCOLOR" value="lightGray"/>
<param name="AUTOEXPAND" value="true"/>
<param name="CONTRACTABLE" value="true"/>
<param name="TARGET" value="servicesFrame"/>
</object>The generation of the categories involves a SQL query that returns all the necessary data.
select med_table.tk, title from med_table, med_doc_cat
where med_doc_cat.category_id = v_category
and med_table.tk=med_doc_cat.tkHere, we are going to configure the Servlet, compile it, and test it. First, we need to start the Web server and ftp server from the command line. Connected as sys, you have to run:
SQL> call dbms_xdb.setHttpPort(8080); Call completed. SQL> call dbms_xdb.setFtpPort(2100); Call completed.
Now, via FTP or WebDAV, we need to edit the /xdbconfig.xml file by inserting the following XML element tree in the <servlet-list> element:
<servlet>
<servlet-name>Yapa</servlet-name>
<servlet-language>Java</servlet-language>
<display-name>Yapa Servlet</display-name>
<servlet-class>Yapa</servlet-class>
<servlet-schema>med</servlet-schema>
</servlet>We also have to add the following element tree in the <servlet-mappings> element:
<servlet-mapping>
<servlet-pattern>/yapa</servlet-pattern>
<servlet-name> com.oracle.demo.yapa.Yapa </servlet-
name>
</servlet-mapping>To install the Servlet, compile it, and load it into the Oracle database, you need to issue the following command:
>loadjava -grant public -u med/med -r Yapa.class
To launch the demo, open the search.html file or just edit a different one adding the following code that calls the servlet. As usual, replace the hostname and port number as appropriate:
<form action="http://localhost:8080/yapa" target="_top"> <center>Search for: <input type="text" name="query" size=20> <input type="hidden" name="frame" value="first"> <input type="hidden" name="type" value="s"> <input type="submit" value="Search" > </center> </form>
The home page is shown in Figure 17.14.
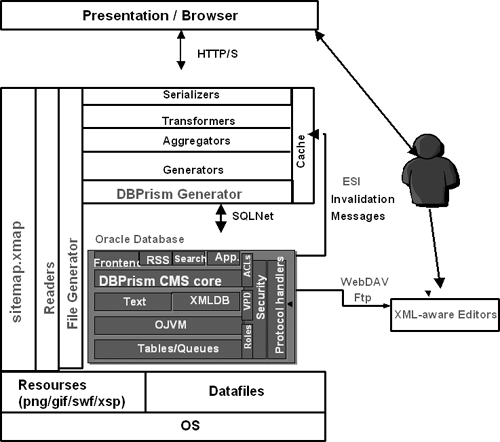
Oracle Text provides a complete API for building any type of information retrieval application. We also demonstrated that with Java in the database and XML in the database (XDB), the database becomes a content repository and also a full development and deployment platform. We presented Yapa, a demo system that combines search, classification, and clustering, as well as an integrated user interface based on a two-view model. We also demonstrated that it is possible to build and/or integrate visualization metaphors on top of the existing API. The complete source code is available from the book’s Web site as well as from the Oracle Technology Network (OTN) Web site.
This innovative and open-source based case study has been provided by my new friend Marcelo Ochoa.
DBPrism CMS is the first open source database-oriented CMS using Java inside the database and XMLDB repository. It takes all the benefits from Oracle XML Enable Database and the Apache Cocoon Framework for CMS functionalities.
The following list describes the functionalities of DBPrism CMS:
Simple and Compact. Unlike other CMS systems, the core functionality of DBPrism CMS is only 962 lines of Java code, which runs as Oracle Java Stored Procedure.
Powerful. It is built on powerful capabilities such as XML, Oracle Text indexing and portal content aggregation functionality from Cocoon such as My Yahoo (TM).
Dynamic content. It furnishes simple services written in Java or PL/SQL for producing dynamic content.
Multilanguage support. It includes attributes inside its document schema definition to provide multilanguage support.
Secure. It runs as a Java Stored Procedure, hence it inherits all the security mechanisms of Java in the database (described in Part I), as well as XMLDB repository ACLs.
Concurrency control. All the assets are stored in database tables, which are controlled by the concurrency features of the database.
Performance. It uses ESI invalidation protocol to provide a cache coherence between the Cocoon internal cache system and the database assets (i.e., the user can edit content into the database, and immediately after the page is updated an XML ESI invalidation message is sent by the database to the Cocoon to invalidate the cached pages).
Separation of layout and content. Presentation concerns are responsibilities of Web designers; content authors don’t deal with presentation concern, but they write a neutral XML document that will be rendered to HTML or PDF documents by Cocoon. In addition to this, a Web look and feel could be changed in seconds, and it will be applicable to all the Web pages of the Web site.
Scheduling system. Using the database DBMS_SCHEDULER package, it is possible to invoke any CMS task at any specific time or periodically; pages can be programmed to be public at a specific date or time.
Enterprise support. Oracle Java Stored Procedures are ready-to-use enterprise services such as Web services, so it is possible to easily integrate other applications into the CMS as a dynamic service.
Native XML support. DBPrism CMS uses XML documents complying with Apache’s
documentv20.dtd, images in SVG format, and i18n support.Editing tools. It is possible to use any XML-aware editor with WebDAV support, such as XMLSpy or Oracle JDeveloper. In addition, the CMS front-end application furnishes a simple WYSIWYG HTML editor, which supports basic CML functionalities such as creating, deleting, updating, and publishing pages and directories.
Workflow. A simple workflow of two stages can be used to maintain private and public pages. It means that the user can edit private pages located under the XMLDB
/homedirectory and publish them with the front-end application to the/publicdirectory, which is used by Cocoon for the public Web site. An N-state workflow can be implemented using multiples CMS users, in which case pages move into a sequence of steps (schema) waiting for the approval of the owners.Everything is a URL. Cocoon provides a powerful rewrite engine to transform plain URLs to everything else, so you don’t deal with cryptic URLs like
/portal//index.jsp?&pName=products2col&path=membership&file=coa.xml&xsl=generic.xsl. These types of URLs will frustrate users who read them on a printed page. In addition to this, by using plain URLs, it is possible to store the Web site in a CDROM or other media using wget, for example.Support for Creative Commons digital signatures. The user can choose these licenses for every page, and CMS will put the RDF header for search engines and extensions such as mozcc.
The DBPrism CMS has several components, as illustrated by Figure 17.15.
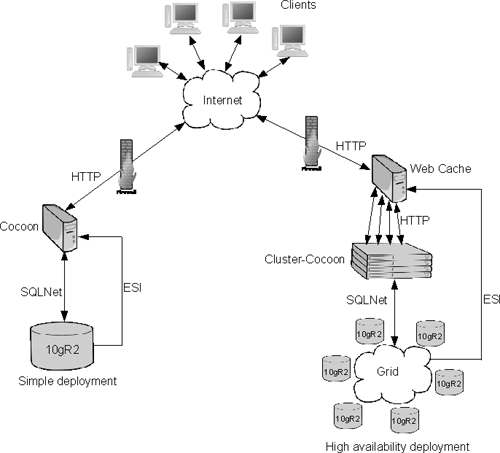
The main components are:
Browser: Users can interact using regular Web browsers such as Explorer or Firefox.
Cocoon: Represented by the components in dark blue. This framework provides many architectural components to DBPrism CMS and is a proven technology used by CMS products such as Apache Lenya or Forrest. Cocoon separates the XML content, the style, the logic, and management functions of a Web site.
sitemap.xmap: A configuration file, which controls all the behavior of the Cocoon framework.
Serializers: Used to render an input XML structure into some other format (not necessarily XML, e.g., HML Serializer, Text Serializer, XML Serializer).
Transformers: Used to map an input XML structure into another XML structure (e.g., XSLT Transformer, Log Transformer, SQL Transformer, I18N Transformer).
Aggregators: Compound new documents by the aggregation of different parts or subdocuments; in DBPrism CMS every page consists of the content asset and the RSS of the site, but the site administrator can modify this configuration according to preferences.
Generators: Used to create an XML structure from an input source (file, directory, stream, DBPrism). DBPrism Generator generates the dynamic XML inside the database by executing a Stored Procedure. It also provides parallel content generation, which means that during the setup stage of an aggregated document, multiple requests will be started to the database for execution, and the result will be collected in a serialized form.
Readers: The starting and endpoints of an XML pipeline. They collapse the features of a generator, transformer, and serializer. Readers are useful for delivering binary content-like images; more general readers deliver content as is.
Cocoon cache system: Responsible for caching every component through the execution pipeline. This cache system evaluates for changes in every part of the CMS document; parts are the content assets, RSS channels, style sheets, files, and so on. DBPrism adds a new cache component to Cocoon, which provides an external cache invalidation system, so the content is considered valid until an ESI invalidation message arrives to the system. This message is sent using HTTP, and in that case it is thrown by a database trigger.
DBPrism CMS core: Basically a set of Java Stored Procedures and some PL/SQL utilities. This Java code will be explained in more detail in the following sections.
Front end/RSS/Search/App: Components running using the CMS core components. They use some common functionalities, such as metadata of the documents, static resources, and so on.
XMLDB: Another key component of DBPrism CMS, it provides all the repository metaphor for the CMS; up to release 2.0, DBPrism CMS uses regular Oracle tables with CLOB columns for storing the content assets. Now, with the addition of XMLDB DBPrism, CMS stores the content assets using native XMLType data types, obtaining good performance, security through ACLs, and support for external access to the repository using FTP or WebDAV.
Oracle Text: Used to index the content assets to provide full searching facilities on the site using AltaVista syntax for writing queries.
OJVM: The core code of DBPrism CMS is written in Java, and it runs inside the Oracle Database as a Java Stored Procedure. The availability of Java inside the database simplifies the code of DBPrism CMS, because working with XML is simple and all APIs working with XML are native.
Security: DBPrism CMS inherits the security system of the database, including authentication, authorization, access control on database resources, and WebDAV ACLs on the content assets.
The XMLDB protocols server: Furnishes an alternative access to the XMLDB repository with protocols other than SQLNet, including HTTP(s), FTP, and WebDAV. Users can access the repository, and insert, delete, and update CMS content assets using external and third-party editors and tools.
OS level resources: These resources, handled by the operating system, are the static resources of the Web site, such as graphics files in
png,gif, andswfformats and the database data files, log files, and so on.
DBPrism CMS typically is deployed in two servers, one for the application server (e.g., OC4J) and one for the database server.
A scalable architecture can be implemented using a cluster installation for the application servers. It means Cocoon replicated N times behind an Oracle Web Cache, in that case the ESI invalidation messages will be routed directly to it instead of to the cache of Cocoon. Also, an Oracle RAC installation can be used for scaling up the database counterpart. Figure 17.16 shows a simple deployment and a high availability deployment.
This section is a bit advanced and might be intimidating.
The simplified execution flow of a CMS is illustrated in Figure 17.17.
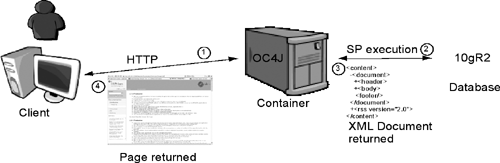
A client browser sends an HTTP request asking for a CMS page (e.g.,
/demo/doc/Documentation/Distribution/index.html).The HTTP Listener will route this request to Cocoon, which will execute a stored procedure on the database using DBPrism Generator.
The execution of the stored procedure will return an XML page using the client credentials and other HTTP information. This XML page has a
contentdocument root node with aheader, body,andfootersubnodes.With the XML document returned by the database, Cocoon will apply a set of preconfigured steps, such as extraction, transformation, and serialization, to generate the HTML page for the browser.
The complete execution steps involved for every page loaded from the CMS is depicted in Figure 17.18.
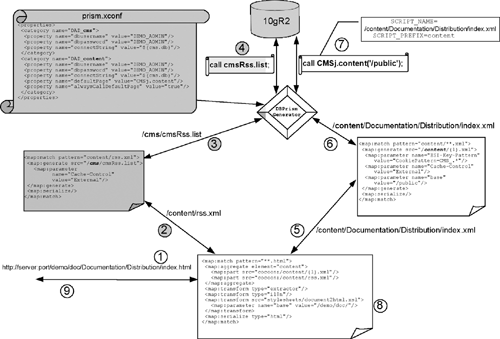
A CMS user asks for the page http://server:port/demo/doc/
Documentation/Distribution/index.html. This URL matchs with thesitemap.xmap pattern“**.html”. The configuration values tell the Cocoon engine that the document will be generated by the aggregation of two new subdocuments,/content/ rss.xmland/content/Documentation/Distribution/ index.html, the path components demo and doc were extracted by the Servlet Container, and the mount point was defined on the Cocoon installation, respectively.The component
/content/rss.xmlis generated byDBPrism-Generator,which is the default generator in this configuration.The generation involves the URL
/cms/cmsRss.list. DBPrism uses the same mechanism as Oraclemod_plsql, extracting the first part of URL as DAD key, so the Database Access Descriptorcmsis used to find the username, password, and connect string for the target database into the prism.xconf configuration file.DBPrism will execute at the database side the stored procedure
cmsRss.listconnected as DEMO_ADMIN user. This stored procedure will return the RSS XML shown in the next section, and the content will be cached by the Cocoon Cache system, because the Cache-Control parameter is given with the value External.The component
/content/Documentation/Distribution/ index.xmlis evaluated at this branch.Unlike the previous branch, the used DAD is content, and due to the parameters
defaultPageandalwaysCallDefaultPage,the stored procedure CMSj.content will be used irrespective of the URL evaluated. The parameter ESI-Key-Pattern is used to designate the cookies CMS_* as a discrimination pattern for storing pages. This configuration is required because the same URL for one page will be different if theCMS_LANGcookie is es or en.The stored procedure
CMSj.content('/public')is executed using the DEMO_ADMIN user to get the document content shown in the next section. This stored procedure will use the CGI environment variablesSCRIPT_NAMEandSCRIPT_PREFIXto know which CMS page is returned.Once the two components are returned (document and rss), Cocoon will apply the extractor transformer to extract SVG images into the document. Then it will transform the document, analyzing the i18N tags, and finally the XML document is transformed into HTML using the XSL style sheet
document2html.xsl.The HTML page is returned to the browser.
The previous section shows that the aggregation configuration of the Cocoon sitemap will consist of an XML document with a root node content and two subnodes, document and rss.
Here is a simplified version of this document, which will help clarify the Java code used in the next sections:
<?xml version="1.0" encoding="UTF-8"?>
<content>
<document xmlns:i18n="http://apache.org/cocoon/i18n/2.0">
<header xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!-- WebDAV Metadata tags here-->
<!-- other metadata information about the page such as owner, last
modifier, etc.>
<title>Distribution</title>
<subtitle>Distribution Section</subtitle>
<rdf:RDF xmlns="http://web.resource.org/cc/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!-- CreativeCommons license tags -->
</rdf:RDF>
<categories/>
<map>
<!-- Information about the two first level of the web site-->
</map>
<path>
<!-- path information from the root directory to the current page -->
</topics>
</header>
<body>
<section>
<title>Distribution Section</title>
</section>
</body>
<footer/>
</document>
<rss version="2.0">
<channel name="OTN News">
<!-- RSS chanel 2.0 content -->
.....
</channel>
</rss>
<!-- Toolkit version 2.0.0.3 Author: Marcelo F. Ochoa "[email protected]" -
->
</content>CMS contents are compounded by
documentandrsschannels.Document is divided into
header, body,andfooter.Header includes WebDAV, CMS, and Apache
document-v2.0.dtdheader tags.Footer includeds
Creative Commonslicense links.Finally, a
RSS 2.0channel is included.
Basically, the header information is used by Cocoon to render some contextual information of the Web site, such as the menu of the first and second depth of the hierarchy, title, license tags for the search engine, and so on.
As mentioned previously, the execution of a stored procedure leads to the generation of the XML structure shown in the previous paragraph. The code is located on the package com.prism.cms.core and is named www.Index.java; it has some static entry point for the PL/SQL wrapper defined on the package CMSj. The main entry point is the static method content(String user, String base).
public static void content(String user, String base)
throws SQLException {
String source = Jowa.GETCGIVAR("SCRIPT_NAME");
if (source==null) // provides a default page
source = Jowa.GETCGIVAR("SCRIPT_PREFIX")+"/index.html";
source = source.substring(source.indexOf('/',
Jowa.GETCGIVAR("SCRIPT_PREFIX").length())); // removes
// DAD info
wwwIndex thisPage = new wwwIndex(user,source,base);
Jxtp.tagOpen("document","xmlns:i18n='http://apache.org/
cocoon/i18n/2.0'");
if (thisPage.showMetaData()) {
Jxtp.tagOpen("body");
thisPage.showContent();
Jxtp.tagClose("body");
Jxtp.tagOpen("footer");
thisPage.showFooter();
Jxtp.tagClose("footer");
} else
return;
Jxtp.tagClose("document");
}This code creates an instance of wwwIndex class using the source value extracted from the HTTP header attribute SCRIPT_PREFIX without the DAD information. Following the example of Figure 17.18, user is provided by the PL/SQL wrapper, base is hard-coded on the sitemap.xmap to ‘/public’, and the SCRIPT_NAME is /Documentation/Distribution/ index.html. This object, then, is used to get the metadata, content, body, and footer. The Stored Procedure cmsRss.list, which generates the RSS information, is not shown here. The class constructor is shown as follows:
public wwwIndex(String cmsUser, String p_info, String base)
throws SQLException {
this();
// Override cms user
user = cmsUser;
path = Util.getPath(p_info);
name = Util.getName(p_info);
ext = Util.getExt(p_info);
OraclePreparedStatement stmt = null;
ResultSet rset = null;
try {
baseUrl = base+"/"+user+"/cms/"+lang;
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"SELECT extract(res,'/Resource/Contents/*');res FROM
resource_view "+ "WHERE equals_path(res, ? ) = 1");
stmt.setString(1,baseUrl+path+name+".xml");
rset = stmt.executeQuery();
if (rset.next()) {
doc = (XMLType)rset.getObject(1);
xdbresource = (XMLType)((OracleResultSet)rset).getObject(2);
} else if (directoryScan) {
// default page not found try to generate a directory listing.
directoryListing();
} else { // Shows Page Not Found
rset.close();
rset = null;
stmt.close();
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"SELECT extract(res,'/Resource/Contents/*');res FROM
resource_view "+ "WHERE equals_path(res, ? ) = 1");
stmt.setString(1,baseUrl+NotFoundUrl);
rset = stmt.executeQuery();
rset.next();
doc = (XMLType)rset.getObject(1);
xdbresource = (XMLType)rset.getObject(2);
}
} catch (SQLException e) {
throw new SQLException(".wwwIndex - SQLException on: "
+e.getLocalizedMessage());
} catch (Exception e) {
StringWriter sw = new StringWriter();
e.printStackTrace(new PrintWriter(sw));
throw new SQLException(".wwwIndex - Exception on: "
+sw.getBuffer().toString());
} finally {
....
}
}The code starts creating some auxiliary variables and then gets from the XMLDB repository, using the resource_view, the XML document requested by the user. That is, for the original request /Documentation/ Distribution/index.html, it instantiates an XMLType object doc for the document stored at /public/DEMO_ADMIN/cms/en/Documentation/ Distribution/index.xml and its WebDAV metadata in xdbresource. If the document is not on the repository, the content will be replaced by a directory listing, if it was enabled at installation time, or replaced by the content of the document notFound.xml.
Then, the method showMetaData() is called. The code of this method is shown as follows:
public void metaData() throws SQLException {
// WebDAV Properties from resource_view
Jxtp.tag("DisplayName",Util.getResourceAttribute(xdbresource,"Display
Name"));
Jxtp.tag("Language",Util.getResourceAttribute(xdbresource,"Language")
);
Jxtp.tag("CharacterSet",Util.getResourceAttribute(xdbresource,"Charac
terSet"));
Jxtp.tag("VCRUID",""+Util.getResourceAttribute(xdbresource,"VCRUID"))
;
Jxtp.tag("ModificationDate",Util.getResourceAttribute(xdbresource,"Mo
dificationDate"));
Jxtp.tag("LastModifier",Util.getResourceAttribute(xdbresource,"LastMo
difier"));
// page context properties
Jxtp.tag("urlname",this.name);
Jxtp.tag("urlpath",this.path);
Jxtp.tag("urlext",this.ext);
Jxtp.tag("lang",this.lang);
Jxtp.tag("country",this.country);
Jxtp.tag("user",this.user);
Jxtp.tag("time",DateFormat.getDateTimeInstance(DateFormat.SHORT,
DateFormat.SHORT, new Locale(Actions.getLang(),
Actions.getCountry())).format(newDate(System.currentTimeMillis())));
// document-v20.xsd header information
XMLType title = ((doc==null) ? null : doc.extract("/document/
header/title",""));
Jxtp.p(""+((title==null) ? Jxtf.tag("title",
Util.getResourceAttribute(xdbresource,"DisplayName")) :
title.getStringVal()));
XMLType subtitle = (doc==null) ? null : doc.extract("/document/
header/subtitle","");
Jxtp.p(""+((subtitle==null) ? Jxtf.tag("subtitle","") :
subtitle.getStringVal()));
XMLType license = (doc==null) ? null
: doc.extract("/document/footer/legal/a/@href","");
String sLicense = (license==null) ? "http://creativecommons.org/
licenses/by/2.0/" : license.getStringVal() ;
Jxtp.tagOpen("Work","rdf:about=''");
Jxtp.tag("license","","rdf:resource='"+sLicense+"'");
Jxtp.tagClose("Work");
Jxtp.tagOpen("License","rdf:about='"+sLicense+"'");
licenseTags(sLicense);
Jxtp.tagClose("License");
Jxtp.tag("categories",Util.getResourceAttribute(xdbresource,"ResExtra
/Categories"));
}showMetadata() makes all the XML nodes of the header part (i.e., WebDAV metadata) as other document-related information. Following this information, the CMS contextual information of the document is placed—that is, all the directories at levels 1 and 2 of depth into the Web site (showMapInfo) to make the menu information of the site, the path to the page in the hierarchy to make go back links (showPath), and finally related topics (relatedTopics), pages that are neighbors of the current page or linked using the CMS table cms_related, which provides many-to-many relations.
Here is the Java code:
public void showMapInfo() throws SQLException {
OraclePreparedStatement stmt = null;
ResultSet rset = null;
Jxtp.tagOpen("map");
try {
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"select depth(1),path(1),res "+
"from resource_view "+
"where under_path(res,2,?,1)=1 and "+
"extractValue(res,'/Resource/@Container')='true'");
stmt.setString(1,baseUrl);
rset = stmt.executeQuery();
while(rset.next()) {
int depth = rset.getInt(1);
String link = rset.getString(2);
String name = Util.getName(link);
XMLType res = (XMLType)rset.getObject(3);
Jxtp.tagOpen("linkmap","level='"+depth+"' name='"+name+"'
DisplayName='"+
((res==null) ? name :
Util.getResourceAttribute(res,"DisplayName") )+
"' href='"+((link.endsWith(".xml")) ?
link.substring(0,link.length()-4)+".html" : link+"/" )+"'");
Jxtp.tagClose("linkmap");
}
} catch (SQLException e) {
throw new SQLException(".showMapInfo - SQLException: "
+e.getLocalizedMessage());
} finally {
.....
Jxtp.tagClose("map");
}
}
public void showPath() throws SQLException {
OraclePreparedStatement stmt = null;
ResultSet rset = null;
int level = 1;
Jxtp.tagOpen("path");
try {
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"SELECT path(1),res "+
"FROM resource_view "+
"where under_path(res,?,1)=1 and ? like
any_path||'/%'");
stmt.setString(1,baseUrl);
stmt.setString(2,baseUrl+path+name);
rset = stmt.executeQuery();
while(rset.next()) {
String link = rset.getString(1);
String name = Util.getName(link);
XMLType res = (XMLType)rset.getObject(2);
Jxtp.tagOpen("linkmap","level='"+level+"' name='"+name+
"' DisplayName='"+((res==null) ? name :
Util.getResourceAttribute(res,"DisplayName"))+
"' href='/"+link+"/'");
Jxtp.tagClose("linkmap");
level++;
}
} catch (SQLException e) {
throw new SQLException(".showPath - SQLException: "
+e.getLocalizedMessage());
} finally {
.....
Jxtp.tagClose("path");
}
}
public void relatedTopics()
throws SQLException {
Jxtp.tagOpen("topics");
OraclePreparedStatement stmt = null;
ResultSet rset = null;
try {
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"SELECT '/'||path(1) link, '1', "+
"r.res "+
"FROM cms_related,resource_view r "+
"WHERE owner = ? and page_from = ? and "+
"under_path(r.res,?,1)=1 and "+
"equals_path(r.res, ?||page_to ) = 1 "+
"UNION ALL "+
"SELECT ?||path(2) link, '0', "+
"rv.res "+
"FROM resource_view rv "+
"WHERE under_path(rv.res,1,?,2)=1");
stmt.setString(1,user);
stmt.setString(2,path+name+".xml");
stmt.setString(3,baseUrl);
stmt.setString(4,baseUrl);
stmt.setString(5,path);
stmt.setString(6,baseUrl+path);
rset = stmt.executeQuery();
while(rset.next()) {
String link = rset.getString(1);
String name = Util.getName(link);
String level = rset.getString(2);
XMLType res = (XMLType)rset.getObject(3);
link = (link.endsWith(".xml")) ?
link.substring(0,link.length()-3)+"html" : link+"/" ;
Jxtp.tagOpen("linkmap","level='"+level+"' name='"+name+"'
DisplayName='"+
((res==null) ? name :
Util.getResourceAttribute(res,"DisplayName") )+
"' href='"+link+"'");
Jxtp.tagClose("linkmap");
}
} catch (SQLException e) {
throw new SQLException(".relatedTopics - SQLException:
"+e.getLocalizedMessage());
} finally {
.....
Jxtp.tagClose("topics");
}
}Finally, the body and the footer are placed into the content nodes. These operations only copy the content as is, extracted from the XMLType doc variable using the native implementations of the operation extract.
public void showContent()
throws SQLException {
try {
if (doc==null) {
Jxtp.p(defaultDoc);
return;
}
XMLType podoc = doc.extract("/document/body/*","");
if (podoc==null) {
Jxtp.tag("s2","/document/body is null");
return;
}
Jxtp.p(podoc.getStringVal());
} catch (Exception e) {
Jxtp.tag("s2","Exception type: "+e.getClass().toString());
Jxtp.tagOpen("s3");
Jxtp.tagOpen("source");
Jxtp.p("<![CDATA[");
e.printStackTrace(new PrintWriter(Jxtp.getWriter()));
Jxtp.p("]]>");
Jxtp.tagClose("source");
Jxtp.tagClose("s3");
}
}
public void showFooter()
throws SQLException {
try {
if (doc==null)
return;
XMLType legal = doc.extract("/document/footer/*","");
if (legal!=null)
Jxtp.p(legal.getStringVal());
} catch (Exception e) {
Jxtp.tagOpen("legal");
Jxtp.tag("em","Exception type: "+e.getClass().toString());
Jxtp.tagOpen("code");
Jxtp.p("<![CDATA[");
e.printStackTrace(new PrintWriter(Jxtp.getWriter()));
Jxtp.p("]]>");
Jxtp.tagClose("code");
Jxtp.tagClose("legal");
}
}In addition to the plain core CMS capabilities, the following features are made possible by the power of the Oracle database and its embedded XML (also known as XML DB).
The following code shows how to compare nonpublic documents on the private area of the CMS. Remember that the CMS uses a workflow of two stages for publishing, meaning that only pages copied to the directory /public/ USER/cms/[en|es] will be visible at the Web site.
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"select * from (select rownum as ntop_pos, q.* from ("+
"select ?||path(1) p from resource_view e "+
"where under_path(e.res,HOME_PATH,1)=1 "+
"and instr(e.any_path,HOME_LIVE_DIR)=0 "+
"and extractValue(e.res,'/Resource/
@Container')='false' "+
"minus "+
"select ?||path(2) p from path_view f "+
"where under_path(f.res,PUBLIC_PATH,2)=1 "+
"and extractValue(f.res,'/Resource/
@Container')='false'"+
") q) where ntop_pos>=? and ntop_pos<?");This code fragment is part of the com.prism.cms.frontend.Reports source, and is part of the CMS front-end application. In order to get nonpublic pages, it’s necessary to select all the resources under the home directory of the user (HOME_PATH), except the resources under the public area (PUBLIC_PATH), and that’s all; the outside query is Top-N query for pagination purpose.
Looking for updated pages is a task similar to the previous example. The goal is to locate pages under the public area that have a modification date older than the private area. The following JDBC statement and SQL query are used:
stmt =
(OraclePreparedStatement) conn.prepareStatement(
"select * from (select rownum as ntop_pos, q.* from ("+
"select substr(e.any_path,?) p, e.res "+
"from resource_view e,resource_view f "+
"where under_path(e.res,HOME_PATH,1)=1 "+
"and instr(e.any_path,HOME_LIVE_DIR)=0 "+
"and extractValue(e.res,'/Resource/
@Container')='false' "+
"and equals_path(f.res,PUBLIC_PATH||'/
'||path(1))=1 "+
"and extractValue(e.res,'/Resource/
ModificationDate')> "+
"extractValue(f.res,'/Resource/
ModificationDate')"+
") q) where ntop_pos>=? and ntop_pos<?");This code is also part of the Reports.java source of the CMS front-end application. It looks for pages under the private area that have their WebDAV modification date greater than the same document on the public side. It also excludes documents under the /home/USER/cms/[en|es]/ live directory because these are part of the CMS front end.
This query is a bit complex and is used to search for broken links after renaming or moving operations on the CMS pages. It uses the Oracle Text index for checking link tags; these tags are <a href="/path/page.html" title="title of the link"/>, and the query will produce a report of the CMS pages with possible broken links.
stmt = (OraclePreparedStatement) conn.prepareStatement ( "select substr(any_path,?) path,r.res," + "c.object_value.transform(XMLType(xdbURIType( '/home/USER/cms/en/live/stylesheets/ brokenlinks.xsl').getClob())," + "'base="''../..'||substr(any_path,?,instr(any_path,'/ ',-1)-?)|| '''" file="''test.html''"').getStringVal() " + "from cms_docs c,resource_view r " + "where contains(c.object_value,'test.html within a@href')>1 and " + "sys_op_r2o(extractValue(r.res,'/Resource/ XMLRef'))=c.object_id and" + "under_path(r.res,?)=1");
This query will search for pages that have test.html within the attribute href of the tag a, using the Oracle Text operator CONTAINS on the table CMS_DOCS. The CMS_DOCS table is the object relational table that stores all the CMS documents associated with the schema “http://www.dbprism.com.ar/xsd/document-v20.xsd.” XMLDB automatically detects XML documents with this signature and stores the content in the object relational storage of the CMS_DOCS table.
Once the document is located, this object is joined to the resource_view using the XMLRef value, which is a pointer to the content stored outside this view to get the path of the page. With this path, an XSLT transformation is made inside the database for making a report of the possible broken links, the style sheet that makes the report looks like this:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/
Transform">
<xsl:output method="xml" indent="yes"/>
<xsl:param name="base"/>
<xsl:param name="file"/>
<xsl:template match="a">
<xsl:if test="contains(@href,$file)">
<xsl:choose>
<xsl:when test="starts-with(@href,'/')">
<a href="{@href}" title="{@title}">
<xsl:copy-of select="*|text()"/>
</a>
</xsl:when>
<xsl:when test="starts-with(@href,'http://')">
<a href="{@href}" title="{@title}">
<xsl:copy-of select="*|text()"/>
</a>
</xsl:when>
<xsl:when test="starts-with(@href,'ftp://')">
<a href="{@href}" title="{@title}">
<xsl:copy-of select="*|text()"/>
</a>
</xsl:when>
<xsl:when test="starts-with(@href,'mailto://')">
<a href="{@href}" title="{@title}">
<xsl:copy-of select="*|text()"/>
</a>
</xsl:when>
<xsl:otherwise>
<a title="{@title}">
<xsl:attribute name="href">
<xsl:value-of select="concat($base,@href)"/>
</xsl:attribute>
<xsl:copy-of select="*|text()"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
</xsl:if>
</xsl:template>
<xsl:template match="text()">
<!-- ignore -->
</xsl:template>
</xsl:stylesheet>The style sheet receives as parameters a base directory of the page that has broken links and a file name that was renamed or moved; base is used to produce a correct link to the target page on the report. Note that the style sheet is also stored on the CMS repository and is accessed using xdbUriType object.
Obviously, the previous query is executed in seconds within the OracleJVM, so this report is automatically displayed to the user with options for correcting the links. Management of broken links is usually a nightmare for CMS implementers, but when using the correct tools it’s quite simple.
A key feature of CMS is the ability to search the content repository. Newspapers on the Web use public search engines such as Google or Yahoo, but these engines use a crawler tool for indexing the content. So for recent news, your query will return no hits because of the latency between index update (inherent to the batch nature of the crawler).
On DBPrism CMS, the content repository is indexed using the Oracle Text engine. The following Java code shows the query using this index:
stmt = (OraclePreparedStatement) conn.prepareStatement(
"select * from (select rownum as ntop_pos, q.* from ("+
"select score(1) rank,"+
"extract(c.object_value,'/document/header/*');"+
"substr(r.any_path,?) "+
"from cms_docs c,resource_view r "+
"where under_path(r.res,PUBLIC_DIR,2)=1 and "+
"sys_op_r2o(extractValue(r.res,'/Resource/
XMLRef'))=c.object_id "+
"and contains(c.object_value,QUERY_STRING,1)>1 "+
"order by rank desc "+
") q) where ntop_pos>=? and ntop_pos<?");The outside query is the Top-N pagination. The inner query first limits the rows where the search is made to only the pages under the public directory of the user, and then the operator contains is used to query the content assets.
Reindex operations on Oracle Text indexes are not expensive in time consumption, so they can be executed after insert or update table actions or at a fixed time (e.g., 5 minutes). The collateral action of this task is that the user is always querying on the up-to-date content.
The code at com.prism.cms.ext.AvQuery class also includes a transform method, which takes the Alta Vista query syntax and transforms it into Oracle Text syntax; this code can be found in the OTN Samples section. Also, the Oracle Text index is configured to recognize documents in different languages, so the user can define the language of the content asset, providing the attribute lang on the root node. Here is an example for a Spanish document:
<?xml version="1.0" encoding="UTF-8"?>
<document lang="es"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://www.dbprism.com.ar/xsd/
document-v20.xsd">
...
</document>English documents are configured as the default language, so the attribute can be ignored.
This section covers the minimal steps to get DBPrism CMS up and running with a demo Web site. DBPrism CMS can be downloaded from the SourceForge Web site at the URL http://prdownloads.sourceforge.net/dbprism/cms-2.1.0-production.zip?download and was tested against these dependencies:
Apache Ant 1.6.2+ plus the extension for using FTP (jakarta-oro, commons-net)
Oracle 10g R2 with Oracle Text installed
OC4J 10g, Tomcat 4.1.12
Red Hat Linux Advanced Server 4.0 on the database server, and Linux Mandrake 10.2 on the OC4J/Tomcat container
Note
The Apache Cocoon framework requires some related libraries to run; these libraries can be downloaded from the SourceForge Web site at the URL http://prdownloads.sourceforge.net/dbprism/cms-2.1.0-applibproduction.zip?download; these JARS can be extracted in a common place of the Container (e.g., the applib directory of an OC4J 10g).
As mentioned in the previous paragraph, all of the CMS components are installed using the Apache Ant utility, so you need to check the availability of this tool by executing the following command:
#ant -v Apache Ant version 1.6.2 compiled on July 16 2004
Common deployment settings are placed into the common.xml file located under the root directory of the distribution. This file has parameters such as the following:
<property name="database" value="devel"/>
<property name="db.host" value="reptil"/>
<property name="db.port" value="1521"/>
<property name="db.sid" value="devel"/>
<property name="thin_string"
value="${db.host}:${db.port}:${db.sid}"/>
<property name="jdbc_string"
value="jdbc:oracle:thin:@${thin_string}"/>These parameters define the connect string of the SQLNet and JDBC for the target database. The user can check it using the tnspingutility:
# tnsping devel TNS Ping Utility for Linux: Version 9.2.0.4.0 - Production on 18-JUL-2005 09:56:42 Copyright (c) 1997 Oracle Corporation. All rights reserved. Used parameter files: /u01/app/oracle/product/9.2.0/network/admin/sqlnet.ora Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = reptil)(PORT = 1521))) (CONNECT_DATA = (SERVICE_NAME = devel.mochoa.dyndns.org))) OK (0 msec)
A DBA database username and password of the target database:
<property name="dba_user" value="sys"/>
<property name="dba_pass" value="change_on_install"/>
<!-- Database Schema used for storing CMS code -->
<property name="cms.owner.user" value="CMS_CODE"/>
<property name="cms.owner.pass" value="CMS_CODE"/>
<!-- Database Schema used for CMS primary user (owner of
cms_docs table)-->
<property name="cms.admin.user" value="CMS_DATA"/>
<property name="cms.admin.pass" value="CMS_DATA"/>dba_user will be used to create the CMS_CODE and the CMS_DATA on this example. Note that the installation scripts will first delete this schema.
Network-related settings:
<property name="proxy.host" value="null" /> <property name="proxy.port" value="null" />
If the database is behind a proxy firewall, change these values with the host and port values; if not, leave them with “null” string.
<property name="web.host" value="p1"/> <property name="web.port" value="8888"/> <property name="admin.port" value="23791"/> <property name="admin.user" value="admin"/> <property name="admin.pass" value="admin"/>
The hostname and the port of the container define where Cocoon will run. If you deploy the CMS behind an Apache server, leave these values to the container values, because they will be used by ESI invalidation triggers to send the messages.
The other three values are used for a remote deployment using the OC4J administrative interface, so you can easily deploy DBPrism CMS application using Ant.
Finally, check some environment variables used by an administrative tool:
<property name="env" environment="env" value="env"/>
<property name="ORACLE_HOME" value="${env.ORACLE_HOME}"/> ORACLE_HOME needs to point to a valid Oracle Home installation; if you are installing DBPrism CMS remotely, this Oracle Home could be a minimum 9.2.0. If you are using Oracle JDeveloper, you can set ORACLE_HOME to the directory where JDeveloper was uncompressed, create a network/admin and bin directories on it, and move the SQLPlus utility under the bin directory. These parameters are common to all the sites that DBPrism will manage within a unique Oracle database instance. You can find a sample Web site on the directory sites/www.mycompany.com/; this directory could be used as a skeleton for any other custom installation.
The site environment settings of the build.xml file are described as follows:
<property name="cms.esi.user" value="dbprisminvalidator"/>
<property name="cms.esi.pass" value="dbprism259"/>
<property name="cms.rep.user" value="DEMO_ADMIN"/>
<property name="cms.rep.pass" value="DEMO_ADMIN"/>
<property name="project.web" value="demo" />
<property name="project.app" value="demo" />
<property name="project.base.web" value="/${project.web}/
doc/" />
<property name="project.base.live" value="/${project.web}/
ldoc/" />ESI username and password are used by Cocoon to validate the access of incoming invalidation messages. These values are sent as part of the HTTP authorization header by the database triggers.
Repository username and password are the database schema used to validate site access to the content authors. The username will be the owner of the XML pages stored on the XMLDB repository. For the example shown previously, the private content assets will be stored on /home/ DEMO_ADMIN/cms/[en|es] directories. Once the page becomes public, a copy of it will be in the XMLDB directory /public/DEMO_ADMIN/cms/ [en|es]. project.web and project.app are values used to name the .war and .ear files during the application deployment. project.base.web and project.base.live are directories of the static resources on the container space; these resources are JPG and GIF images, css, Java Script files, and so on. During the deployment task, Ant will use these constants to rewrite some paths on the files located under the sites/sitename/etc directory.
Install the required JARS on the database. This step is executed one time, because these JARS are uploaded to sys schema and granted to public access. These libraries are in binary format and are the DBPrism Jxtp toolkit (a toolkit similar to Oracle mod_plsql HTP toolkit but written in Java) and the HTML parsing utility Jtidy, used to process documents edited with the WYSIWYG HTML editor of the front-end application.
# cd sites/www.mycompany.com # ant pre-install Buildfile: build.xml Ant output goes here...... BUILD SUCCESSFUL Total time: 35 seconds
Install the CMS code and data. This step is executed one time; the task will delete and create the database schema, which holds the code and the data of the CMS. These code and data are shared by all the CMS sites and users.
# ant install-cms Buildfile: build.xml Ant output goes here......
Add the CMS user and upload the initial content. This step is run for each CMS user on the system. Unlike the previous task, the
add-cms-usertask does not drop an existing database user; if you need to do this, execute first ant del-cms-user to drop the schema and XMLDB folders associated with it.# ant add-cms-user Buildfile: build.xml Ant output goes here...... # and demo-web-install Buildfile: build.xml demo-web-install: upload-demo-docs: [ftp] sending files [ftp] transferring /home/oracle8i/jdevhome/mywork/ cms-2.1/sites/www.mycomp any.com/cms/en/About/Credits.xml ..... [exec] Trigger altered. [exec] Disconnected from Oracle Database 10g Enterprise Edition Release 10. 2.0.1.0 - Production [exec] With the Partitioning, OLAP and Data Mining options BUILD SUCCESSFUL Total time: 1 minute 47 seconds
Deploy static resources to the container. This task will create a
war/ earfile and deploy them to an OC4J, which is up and running. If you are using Tomcat, execute theant cms-wartask, and it makes a{project.web}.warfile for manual deployment.
# ant deploy-app Buildfile: build.xml Ant output goes here...... # ant deploy-web Ant output goes here...... # ant demo-doc-ldoc-app Ant output goes here...... # cd /usr/local/JDev10g/j2ee/home/applications/demo/ demo # unzip /home/oracle8i/jdevhome/mywork/cms-2.1/deploy/ demo-doc-app.zip # unzip /home/oracle8i/jdevhome/mywork/cms-2.1/deploy/ demo-ldoc-app.zip
Once these steps are completed, you can test the CMS at URL http:// localhost:8888/demo/ldoc/. The CMS will prompt for a valid CMS user; log in using demo_admin/demo_admin as user name and password, and you will get the screen pictured in Figure 17.19.

From its Release 1.0, which was based on Cocoon 1.x architecture to the latest release, which uptakes Oracle Database 10g Release 2, DBPrism CMS is continually enhanced with new capabilities. It currently provides a linear versioning system based on the archived_cms_docs table, which backs up every page modified by users. XMLDB provides a Versioning API, but only for resources stored inside the resource_view (i.e., documents based on registered schema cannot be versioned). The challenge for the next release of DBPrism CMS will be to unify XMLDB versioning with the linear versioning. An object-oriented API for XML resource access such as JSR 170[7] or JNDI will be implemented, instead of using queries on the resource_view. A simpler import and export mechanism of the XML content and metadata using ZIP files will be added to the front-end application; these operations are currently manual using FTP clients and SQLPlus. Last, but not least, a shopping cart application will demo how to use XForms with CMS.
This case study shows how a complete database-oriented CMS can be implemented with a few lines of Java code. I also walked you through the architecture and the motivations behind our design choices. Java is a natural language for processing XML; a corresponding PL/SQL code implementing the same functionality would be too complex and incomplete, because some operations would not be possible. Using Java, we could perform all the data-intensive processing in the database and only return the XML to Cocoon. By doing so, we eliminate unnecessary information transfer between the database and the middle-tier container and avoid unnecessary JDBC roundtrips. The XML DB abstraction layer and its protocol server greatly simplify the development of DBPrism CMS. The Cocoon presentation framework is a crucial component of the CMS, which provides caching, transformation, and many other features.
[1] International Association of Commercial Administrators in the category of”government to government.”
[2] The Oracle Text home page is http://www.oracle.com/technology/products/text/index.html.
[3] In Part I, you have experienced that SQL-intensive JDBC applications run faster in the database.
[4] The interMedia case study, highlighted the importance of the extensibility framework.
[5] Yapa is a South American Spanish word, which means “a little bit more for free.”
[7] Content Repository for JavaTM Technology API.