
XML Schema
The XML Schema Working Draft was first published in May 1999, and the final recommendation was released in May 2001. It consists of three parts. Part Zero is a very readable (but non-normative) XML Schema primer, written by David C. Fallside (http://www.w3.org/TR/xmlschema-0). Part One specifies XML Schema structures (http://www.w3.org/TR/xmhchema-1), and Part Two specifies XML Schema data types (http://www.w3.org/TR/xmlschema-2). These parts are harder to read, sometimes resembling certain legal texts.
During their work, the XML Schema Working Group could include experiences with several other already existing schema languages, such as XSchema, DDML, XML-Data, XDR, and SOX. Now, with the XML Schema recommendation released, most XML communities are moving toward XML Schema.
This chapter gives a complete introduction to the type system of XML Schema. We begin with simple XML Schema data types—the most important advantage of XML Schema over DTDs apart from the support for namespaces. XML Schema data types have also been adopted by other schema languages such as Relax NG (see Chapter 7). The rest of the standard will be covered in Chapter 6.
5.1 AN APPETIZER
Although XML Schema is a complex standard, moving from a DTD to XML Schema is quite simple: Just feed your schema editor a DTD, and export it in XML Schema format. Things become more complicated when you move into advanced concepts: user-defined data types, for example, or modularized schemata with multiple namespaces. But these are things that you can’t do at all with DTDs.
Becoming an XML Schema expert requires some effort to master the language and exploit its full potential. Moving from DTD authoring to XML Schema authoring is like moving from a Model T Ford to a Porsche: If you can’t control it, you will easily drive it through the next fence. On the other hand, you don’t have to go uphill in reverse gear (for lack of a fuel pump in the Model T).
Just as an appetizer let’s look at a very small DTD:
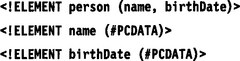
And here is the equivalent schema for a simple person element containing a name and birth date written in XML Schema:
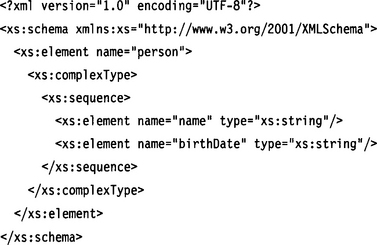
Well, that doesn’t look too difficult. Here, we define a document type with a root element named person. This root element has two child elements named name and birthDate. When we look at the schema diagram in Figure 5.1, the concept is even easier to grasp.
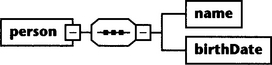
We see that XML Schema works quite differently from DTDs: Elements can be defined within the element definition of another element. One advantage is that the code (and also the diagram) displays the later tree structure of the document instances quite well. Global element definitions as in a DTD are possible, too, but we will deal with this later.
We also see that an element containing other elements is defined as a complex type element. Type declarations, type=“xs:string”, replace the (#PCDATA) declarations from the DTD. This brings us to one of the most outstanding features of XML Schema and—apart from its support for namespaces—its most important improvement over DTDs: its support for data types. We will therefore start with an extensive discussion of simple data types in XML Schema. Later sections discuss how data structures (that is, complex data types) can be defined and how namespaces are handled. Finally, we will have a look at XML Schema’s reuse mechanisms that allow the modularization of schemata and the construction of type libraries. We will see that XML Schema offers concepts like inheritance, generic types, and polymorphism that are similar to concepts found in object-oriented programming, yet at the same time are quite different.
In contrast to DTDs, XML Schema uses XML syntax for schema definition. The concepts throughout this chapter are explained using the following notation to document the features of a syntactical construct in XML Schema:

The Name column specifies the element name of the construct (the tag name). The Attributes column contains the attributes that this element may have. (The question mark denotes an optional attribute.) The Contains column defines the possible child elements.
The definition for simpleType given above would allow, for example, the following schema clause:

5.2 SIMPLE DATA TYPES
Simple data types in XML Schema are constructed by means of a few basic concepts: value space, lexical space, fundamental facets, constraining facets, and type extensions. The following sections discuss these basic concepts and then present the data types that are built into XML Schema.
5.2.1 Value Space
The type system of XML Schema makes a clear distinction between value space and lexical space. While the value space consists of an abstract collection of valid values for a data type, the lexical space contains the lexical representation of these values—that is, the tokens as they appear in the XML document. Take for example an integer. The value of integer 5 is always the same; the lexical representation, however, can differ: 5, 005, five, V, ***, and so on.
5.2.2 Lexical Representations and Canonical Representation
The XML Schema recommendation defines which lexical representations are valid for a given data type. In some cases, there is only one possible representation, but in many cases, various kinds of lexical representations are allowed. Take for example data type boolean: XML Schema allows the representation “true” and “false” but also the representation “1” (for “true”) and “0” (for “false”).
In such cases where XML Schema allows several lexical representations, one representation is designated as the canonical representation. For data type boolean this is the representation “true” or “false.” Canonical representations are important when we want to compare two document instances for equality: It is first necessary to convert both documents into the canonical form, before they can be compared by character string comparison. Section 4.3 already discussed the W3C recommendation “Canonical XML” [Boyer2001]. Because XML data types are not covered by this recommendation, the XML Schema specification explicitly defines the canonical formats of its own data types.
5.2.3 Fundamental Facets
XML Schema defines basic data types in a very systematic way. The properties of data types are classified in so-called facets. Each facet describes a specific aspect of a data type, such as equality, cardinality, and length. Again, these facets are classified into two categories:
![]() Fundamental facets define the basic value space properties of data types. They are used to declare the primitive data types that are built into the standard. They are not used to declare derived data types (built-in or user defined).
Fundamental facets define the basic value space properties of data types. They are used to declare the primitive data types that are built into the standard. They are not used to declare derived data types (built-in or user defined).
![]() Constraining facets are used, as the name says, to constrain the value space or lexical space of a data type. They are used to derive new data types from existing data types by restriction. This is discussed in detail in Section 5.2.7.
Constraining facets are used, as the name says, to constrain the value space or lexical space of a data type. They are used to derive new data types from existing data types by restriction. This is discussed in detail in Section 5.2.7.
XML Schema defines the following fundamental facets:
| Facet | Description |
| equal | Defines equality between values of a data type. For example, two items are equal if their values (not necessarily their string representations in the lexical space) are equal. Every value space in XML Schema supports the notion of equality, so this facet has the value “true” for every data type. |
| ordered | Defines order relations between values of a data type. The order relation can be total or partial. For example, numeric values are totally ordered, date values are partially ordered, and string values are not ordered at all. This may seem odd, but the ordering of strings depends on the localization context, and for date values it is impossible to determine an order relation between a date that specifies a time zone and one that comes without one. |
| bounded | Defines whether the values of a data type are restricted by an upper and/or lower bound. For example, float values are bounded (due to their IEEE 754-1985 representation), while decimal values are not bounded. |
| cardinality | Defines whether the value space of a data type is finite or countable infinite. (Uncountable infinite data types do not exist in the recommendation.) For example, enumerations are finite, and integer numbers are countable infinite. Float values are also finite due to their IEEE 754-1985 representation, although in mathematics real numbers are uncountable infinite. |
| numeric | Defines whether a data type is numeric or not. |
5.2.4 Built-in Primitive Data Types
Using fundamental facets, XML Schema defines a set of built-in primitive data types. Table 5.1 lists these data types with their respective lexical representations. Canonical representations are printed in bold, and the other representations are followed by the reason why they are not canonical. The table also lists which constraining facets may be applied to each data type in order to derive other data types from it (see Section 5.2.7).
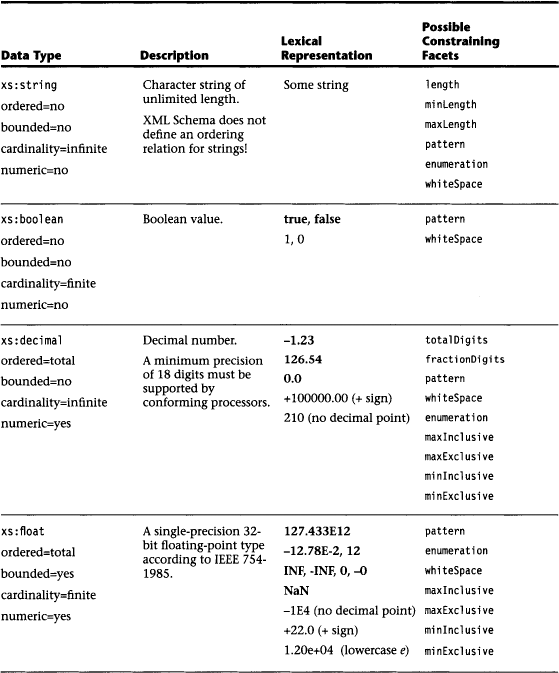
5.2.5 Constructed Types
XML Schema derives additional built-in data types from these primitive data types. This is done with a simpleType declaration.

XML Schema uses three methods for constructing built-in data types.1 These methods can also be employed by schema authors to construct their own data types.
![]() Restriction. The value space or the lexical space of the original data type is restricted by constraining facets. For example, the data type integer is derived from the primitive data type decimal by constraining the facet fractionDigits to 0. For details see Section 5.2.7.
Restriction. The value space or the lexical space of the original data type is restricted by constraining facets. For example, the data type integer is derived from the primitive data type decimal by constraining the facet fractionDigits to 0. For details see Section 5.2.7.
![]() Extension by list. This allows a sequence of values of the same simple data type. For example, the data type NMTOKENS is constructed from data type NMTOKEN by concatenating a list of NMTOKEN values. For details see the next section.
Extension by list. This allows a sequence of values of the same simple data type. For example, the data type NMTOKENS is constructed from data type NMTOKEN by concatenating a list of NMTOKEN values. For details see the next section.
![]() Extension by union. The value space of the new data type is a union of the value spaces of multiple existing simple data types. This extension method is not used to construct built-in data types but can be used to define user-defined data types. For details see Section 5.2.10.
Extension by union. The value space of the new data type is a union of the value spaces of multiple existing simple data types. This extension method is not used to construct built-in data types but can be used to define user-defined data types. For details see Section 5.2.10.
The application of these methods by XML Schema to the built-in data types results in a rather large hierarchy of built-in derived data types, which are listed in Section 5.2.8. In terms of the theory of regular types, restrictions create subtypes (see Section 1.7.4), while extensions create supertypes.
When defining user-defined types, users have the ability to inhibit further type construction. This is done with the final attribute, which can take one of the following values: #all, list, union, restriction. This allows inhibiting further construction by any method (#all) or by a specific method.
5.2.6 Extending Data Types by List
Most data types can be extended to a list of this base data type. Within an XML element or attribute instance, the values of a list are separated by whitespace. Therefore, this extension method can only be applied to data types that do not allow whitespace in the lexical representation. In particular, it is not possible to nest lists.
In contrast to the type system of Relax NG (see Chapter 7), XML Schema does not allow the construction of lists with members of different data types.

The following example shows how we can define a vector consisting of an arbitrary number of double-precision floating-point numbers:

A possible instance of such a type could look like the following:
![]()
Extension by list defines a supertype of the base data type. The value space of the base data type is just a subset of the value space of the list data type (list length = 1).
5.2.7 Restricted Data Types
In contrast, constructing a data type by applying constraints results in a subtype of the base data type, because the value space of the new data type is restricted; that is, it is a subset of the value space of the base data type.

XML Schema classifies the constraints that can restrict a data type into constraining facets. Each facet controls a different aspect of a data type, for example, the total number of digits or the number of fractional digits for a decimal data type. As shown earlier in Table 5.1, each primitive data type defines which constraining facet may be applied to it.
The following constraining facets are available in XML Schema:



5.2.8 Built-in Constructed Data Types
By applying the constraining facets explained above and by applying list extensions, XML Schema defines a hierarchy of built-in constructed data types (see Table 5.2 and Figure 5.2). Built-in data types belong to the XML Schema namespace, represented here with prefix “xs:”.
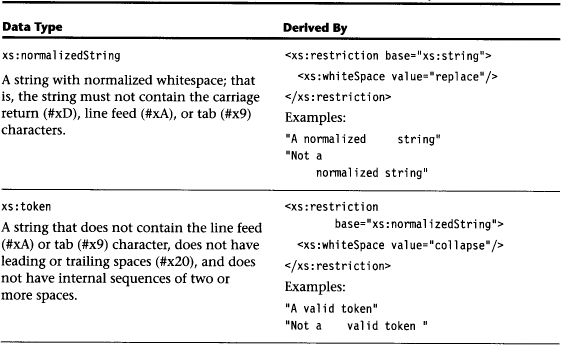
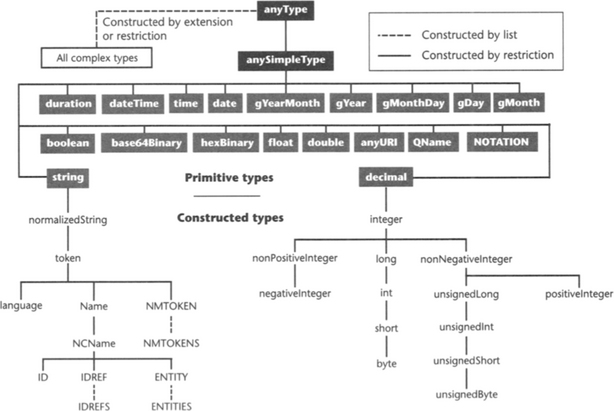
5.2.9 The Hierarchy of Built-in Primitive and Constructed Data Types
The built-in primitive data types listed in Section 5.2.4 and the built-in constructed data types listed in Section 5.2.8 establish a hierarchy of data types as shown in Figure 5.2. Constructed data types are obtained from primitive data types and other constructed data types by restriction and list extension. Please note that these operations do not establish a hierarchy in terms of subtype and supertype. While type restriction always results in a subtype of the base type, list extension always results in a supertype of the base type. This is the reason why we use the term constructed data type in contrast to derived data type as used in the XML Schema Recommendation, Part Two. The formal definition of derived in Part One of the recommendation does not allow for type extension by list or union.
5.2.10 Union Types
With the union operation, it is possible to combine disparate data types in a single data type. The new data type is a supertype to all the contributing member data types: Its value space is the union of the value spaces of all contributing member data types. The member data types can be either referenced by name in the memberTypes attribute or defined locally using simpleType declarations within the union element.

In the following schema fragment, a string data type tISBN is defined. The pattern facet restricts valid strings to the typical ISBN patterns, such as 0-646-27288-8. (For an explanation of the pattern syntax, see the appendix.) A second data type, tProductNo, is defined next, representing custom product numbers. These product numbers start with “9-” followed by two groups of three to five decimal characters, followed by a single decimal character, for example, 9-234-9393-0.
We can then use these two type definitions to construct a union type tISBNorProductNo allowing both patterns. We could use this combined data type for a catalog containing books and other products.

In this example the patterns of the two member types tISBN and tProductNo are chosen in such a way that their lexical value domains overlap. In such cases the sequence of the member types given in the union clause matters: An XML Schema-aware processor would first try to match an instance string to the tISBN pattern, and if that failed, to the tProductNo pattern. However, individual instances may enforce the usage of a specific member type via the xsi:type attribute (see Section 6.2.4).
5.2.11 User-Defined Data Types
As mentioned in Section 5.2.5, it is possible for users to construct their own data types from built-in data types. Let’s look at an example. We want to declare a schema for asset jazzMusician defined in Figure 3.5. We choose to represent the property kind as an attribute. Since only three values are allowed, we want to declare the attribute accordingly, restricting its value range to instrumentalist, jazzSinger, and jazzComposer. We can achieve this with the following definition:

What we do is declare a simple data type on the fly. This new anonymous data type is only used for the attribute with the name “kind” and is derived from the built-in data type xs:NMTOKEN by restriction. We then use three occurrences of the xs:enumeration facet to define the three possible values.
Similarly, we could define an element duration (for the duration property of asset track):


Here, we use a restricted form of the built-in data type xs:duration in that we only allow durations smaller or equal to 77 minutes.
5.3 STRUCTURE IN XML SCHEMA
As you can see in Figure 5.3 (page 140), the definition of a document structure with XML Schema is a rather complex undertaking. Understanding the interrelated concepts of XML Schema takes a while of reading forward and backward. Be patient. The best method is to learn the most basic constructs first and worry about advanced features such as global definitions and reuse mechanisms later:
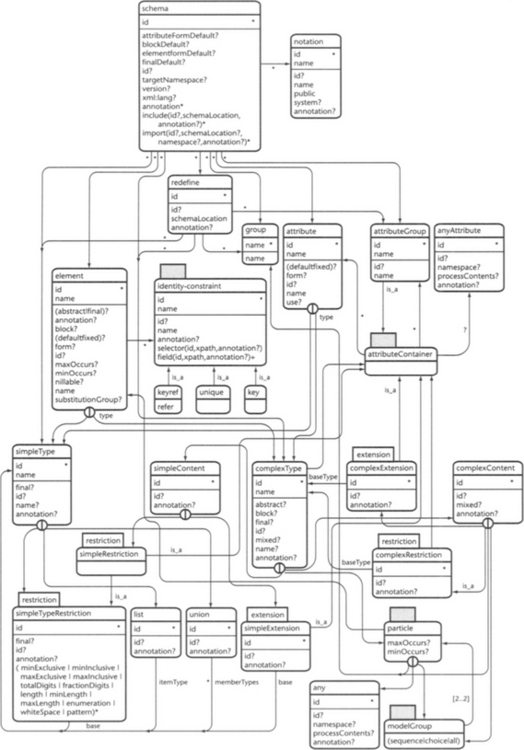
Figure 5.3 The XML Schema metamodel. The relationships between the different syntactical elements of a schema definition are complex, indeed.
1. The root element of a document is defined on the schema level via an element definition.
2. This root element has a complex type.
3. Complex type declarations combine other (global and local) elements that again may have a complex type, or otherwise have a simple type.
4. This combination is achieved via model groups consisting of sequences, choices, or bags.
5. Particles can further constrain model groups by introducing cardinality constraints.
5.3.1 Hierarchy
XML documents have a clear hierarchical structure. There is a root element that has child elements that in turn can have other child elements, and so on. Additionally, each element may be decorated with attributes.
On the schema level, two types of elements can be defined:
![]() The first element definition specifies the root element for all document instances.
The first element definition specifies the root element for all document instances.
![]() Subsequent element declarations on the schema level are used to specify global elements. They may or may not appear in instance documents, and will certainly not appear in root position. Instead, this set of element definitions acts as a kind of local library for element definitions.
Subsequent element declarations on the schema level are used to specify global elements. They may or may not appear in instance documents, and will certainly not appear in root position. Instead, this set of element definitions acts as a kind of local library for element definitions.
Readers will find this concept similar to the definition of a document structure with DTDs, where all element definitions happen on the global level. Typically, we define elements that occur in several places as global elements to avoid redundant local definitions. Also, global element definitions can be used to specify recursive element structures. Section 5.3.12 discusses global elements in more detail.
5.3.2 Elements and Complex Types
Elements are defined in XML Schema with the element clause:

All these attributes and child elements of the element clause will be discussed in the following sections. Let’s begin with the most basic ones. The required attribute name defines the name of the element (the tag):
![]()
Optionally, each element definition can include a type specification. This can be a simple type, as discussed in Section 5.2. The type attribute can refer to a built-in type or to a user-defined type. In the following example we refer to the built-in type normalizedStri ng. (The prefix xs: was defined as a prefix for the XML Schema namespace—see Section 6.1.)
![]()
Where there is a simple type there must also be a complex type. Indeed, the complexType declaration in XML Schema is used to aggregate several XML elements and attributes into a single data type. Consequently, each node in an XML document has a data type—whether explicitly defined or not. Leaf nodes—elements without child elements and attributes, and attributes—adhere to a simple data type, while all other nodes are of a complex type.

Complex types are always user-defined types with one notable exception: The built-in type xs:anyType is a generic complex type, to which all other complex types are subtypes. Complex types can be defined at a global level, or locally as implicit data types. Here is an example for such a local type definition:

Here is the equivalent DTD (ignoring type declarations):


In this example, the complex type consists of a particle—a complex structure containing child elements. (The next section will discuss particles in detail.) There are several content models for complex types:
![]() Particles define child element structures.
Particles define child element structures.
![]() Simple content relates to a simple data type that can be extended by local definitions.
Simple content relates to a simple data type that can be extended by local definitions.
![]() Complex content relates to an earlier defined complex data type or to the built-in data type xs:anyType. This complex type can then be restricted by local definitions.
Complex content relates to an earlier defined complex data type or to the built-in data type xs:anyType. This complex type can then be restricted by local definitions.
All of these content models can contain attribute definitions. Section 5.3.11 discusses the definition of attributes.
Even in the case when an element contains only a single child element, it must be defined via a complex type with a particle (see next section). Since particles are defined via connectors (sequence, choice, all), we have to define a rather meaningless connector—in this example xs:sequence. Semantically it does not matter which one you choose, but for reasons of style, select xs:sequence.

5.3.3 Particles and Model Groups
In the example above we defined a particle consisting of a sequence of elements. XML Schema defines a particle as one of the following:
In addition, particles can have a cardinality constraint (see Section 5.3.4) specified with minOccurs and maxOccurs.
Model Groups
Model groups are similar to DTD model groups, but the syntax is completely different and there is a new connector. Model groups can be constructed using three kinds of connectors:
The xs:sequence connector has the following child nodes:

This connector has the same semantics as the, connector in an XML DTD or the, operator in a regular expression (see Section 1.7. It specifies an ordered sequence of elements—that is, it requires that instance documents adhering to this schema always use elements in the prescribed sequence. Given the schema fragment

the following instance fragment is valid

The xs:all connector has the following child nodes:

This connector has no equivalent in the XML DTD, but it has the same semantics as the & connector in an SGML DTD or the & operator in a regular expression (see Section 1.7. It does not require a particular order of elements in the document instance—it specifies a bag of elements. Given the schema fragment

both of the following instance fragments are correct:
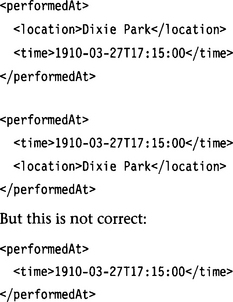
As you can see, XML Schema makes it easy to specify unordered sequences. With the DTD we had to resort to specifying alternatives of all possible permutations of the child elements, a quite laborious process.
Note: When nesting particles, there is one restriction with the xs:all connector. The xs:all connector cannot directly contain other connectors (but it may contain other complex elements constructed with other connectors). It also may not be a child element of other connectors. This is to avoid nondeterministic expressions and keep parsers simple (see also Sections 5.3.4 and 5.3.18).
The following example is invalid for two reasons: (1) The all connector is the child of an xs:sequence connector, and (2) the all connector contains an xs:choice connector.

The xs:choice connector has the following child nodes:

This connector has the same semantics as the | connector in an XML DTD or the | operator in a regular expression (see Section 1.7. It specifies alternatives of elements—that is, it requires that the instance documents use only one element out of the defined list. Given the schema fragment

the following instance fragments are possible:



The xs:sequence and xs:choice connectors can be nested to create complex element structures. For example:

Here is the equivalent DTD fragment (ignoring type declarations):

Here, we have defined an alternative that consists either of a sequence of from and to elements, or of a bag of location and time elements. Note that we have resolved the bag into two xs:sequence connectors, as it is not allowed to define an xs:all connector inside an xs:choice connector.
The following instance fragments would be possible:

Note: For a discussion of nondeterministic choice groups, see Section 5.3.18.
5.3.4 Cardinality Constraints
Cardinality constraints can be applied to particles. A particle is either an element, a wildcard (see Section 5.3.15), or a model group:
![]() minOccurs defines the minimum of occurrences of the particular element or particle.
minOccurs defines the minimum of occurrences of the particular element or particle.
![]() maxOccurs defines the maximum of occurrences of the particular element or particle.
maxOccurs defines the maximum of occurrences of the particular element or particle.
Obviously, the following constraints apply for the values of minOccurs and maxOccurs:

A special “unbounded” value for maxOccurs allows an unlimited number of occurrences. For both minOccurs and maxOccurs the default value is 1; so, if neither is specified, an element or particle has to appear once and only once. Compared to the cardinality operators available in DTDs (+, ?, *), the combination of minOccurs and maxOccurs offers advanced functionality (see Table 5.3).
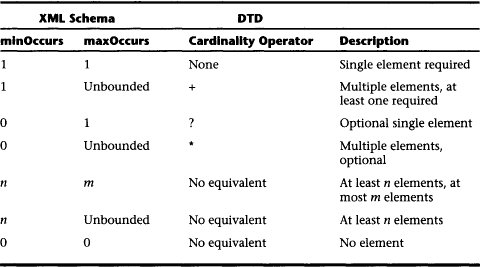
Note: A maxOccurs value greater than 1 is not allowed for elements that contain an xs:all connector, or for elements contained in an xs:all connector. This is to avoid nondeterministic expressions (see also Section 5.3.3).
For example, this album has exactly one title and one or several tracks:

Here is the equivalent DTD fragment:

5.3.5 Default Values and Fixed Values
DTDs allow us to define default values and fixed values for attributes. In contrast to DTDs, XML Schema allows us to define default values and fixed values for elements, too. This is done via the attributes default and fixed. For example:

Note that these schema declarations modify—just like the DTD default and fixed values—the content of the instance document. The content seen by a schema-aware application is different from the content seen by a non-schema-aware application parser.
5.3.6 Mixed Content
By default, an element of complex type must only contain attributes and child elements, but no other content, such as text. To allow mixed content—content consisting of child elements and text—we specify the attribute mixed=“true” in a complexType declaration. This method of declaring mixed content for an element is superior to the mixed content declaration in a DTD: We can control not only the number and types of child elements but also their sequence, with the help of an xs: sequence connector. If we do not want to control the sequence, we just use an xs:all connector instead. In fact, we may use an arbitrary complex particle consisting of several nested connectors in connection with the mixed declaration.
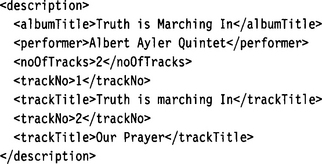
The following example instance document shows a typical mixed content element description:

We can define such an element type with the following specification:
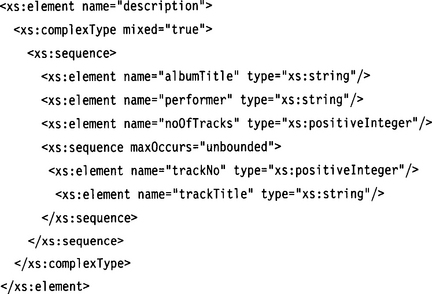
Here is the equivalent DTD fragment (ignoring type declarations):

In this example, we have defined a header consisting of album title, performer, and number of tracks, followed by a repeating group consisting of track number and track title. All the defined elements must appear in the prescribed order, but because we have specified mixed=“true”, arbitrary text may be interspersed between the elements. Without this declaration the document instance fragment would have to look like this:
5.3.7 Simple Content
Simple content definitions refer to existing simple data types, as discussed in Section 5.2 (built-in or user defined), via an extension or restriction clause. They are usually used to define leaf elements that may contain attributes (see Section 5.3.11).





Here is an example of a simple content definition:

5.3.8 Complex Content
Complex content definitions refer to existing complex data types (user defined or the only built-in complex data type, xs: anyType) via an extension or restriction clause. They are usually used to exploit existing complex type definitions (see also Section 6.2 and to define empty elements (see Section 5.3.10). A type extension can be used to add extra particles and/or attributes to a base type.



Note: The new definition describes a superset of instances compared to the base type only if the particles and attributes that are added (or all elements contained in those particles) are optional. In this case, the instances of the base type are represented by the new type definition, too. This means that not every extended type is a supertype of the base type.
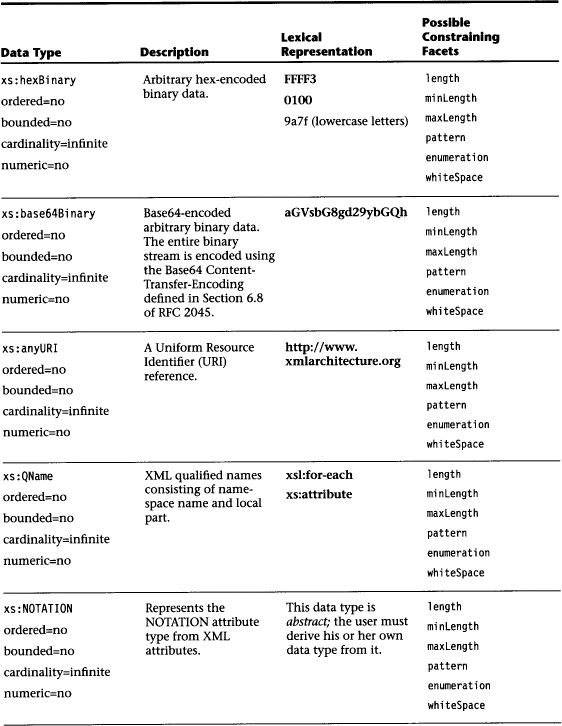
Given the following type definition,
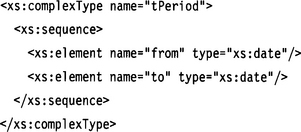
we add an optional mode element to the complex type definition named tPeriod:
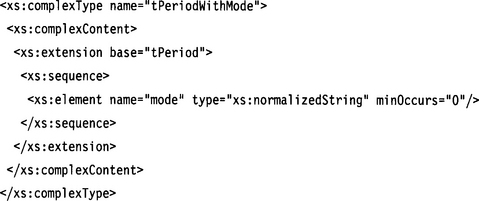
The result would be equivalent to the following type definition:

Because the new element is optional (minOccurs=“0”), the definition covers all instances of the original type tPeriod, too. If the new element were not defined as optional, the extension would not be a supertype, because the new instance set would not cover the instances of the original type definition.
Note that additional elements are always added at the end of a child element sequence. XML Schema does not provide a way to specify a particular position where a new element should be inserted.
In contrast, the restriction clause can be used to add constraints to a component. Given the original type definition,

the following definition describes a subset of the original instance set (only those names with a single first name and no middle name):
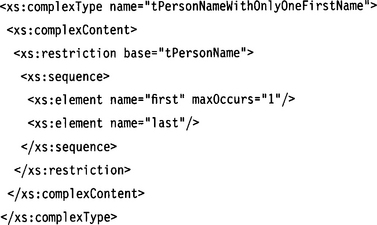
Here, the definition of maxOccurs=“1” is essential because we wish to override the maxOccurs=“unbounded” value.
Actually,the original type definition of

is only an abbreviated form of


Any complex type in XML Schema is a restriction of the only built-in complex type in XML Schema: xs: anyType.
5.3.9 Type Hierarchies
Extension and restriction applied on complex elements result in type definition hierarchies. This should not be misunderstood as a type hierarchy in terms of subtypes and supertypes. Although deriving a complex type A from another complex type B by restriction always results in a true type hierarchy (A being a subtype of B), this cannot be said for type extension. A type obtained by extension is a supertype of the original type only if the added features (elements and attributes) are optional (minOccurs=“0”). This is a must if we want to keep the extended schema compatible with existing document instances. Table 5.4 shows under which conditions a type derivation results in a subtype/supertype relation.

On the other hand, many supertypes cannot be derived by type extension. For example, it is not possible to insert an optional child element into a sequence of elements at any position other than the end of the sequence. It is also not possible to add alternatives to elements (that is, replace an element with a choice group).
5.3.10 Empty Elements
Unlike the DTD, XML Schema does not have an explicit notation for empty elements. Instead, the complex content clause can be used for that purpose:
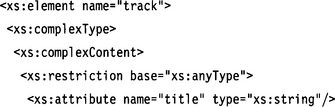

We use the built-in complex type xs: anyType as a base type. We restrict this generic base type to the two attributes title and duration. These definitions result in valid instance fragments such as
![]()
As we saw in Section 5.3.8, we can abbreviate this restriction to xs:anyType with the following, preferred construct:
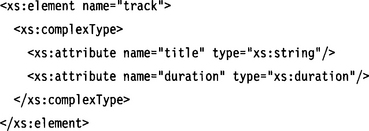
Here is the equivalent DTD (ignoring type declarations):

The same element without attributes
![]()
would have the following definition:


![]()
5.3.11 Attributes
Attributes can be added to all content models: particles, simple content, and complex content. Attributes are defined with the xs:attribute clause.

This clause always contains the definition of the attribute name. Optionally, it can define a type (simple types only) and can contain a use clause and a default or fixed value definition. The use clause can have the values required, optional, and prohibited.

Here is the equivalent DTD fragment (ignoring type declarations):

In this example, we have defined duration as an attribute of track. The type was set to the built-in type xs:duration and the use clause to required, meaning that this attribute must be specified in instance documents. A valid instance of this element would be
![]()
If a type has multiple attributes, the sequence of their definition does not matter, as the attribute nodes of an element form an unordered set (see Section 4.2.4).
Unlike elements, attributes cannot be placed into model groups. The consequence is that we do not have the ability to define elements with mutually exclusive attributes. For example, we might want to define an element person that either has an attribute age or an attribute birthDate. The only option is to define a choice group with two local person elements: one with the attribute age, the other with the attribute birthDate—or even better, to implement both birthDate and age as elements! In Chapter 7 we will see how Relax NG deals with this problem.
5.3.12 Global and Local Types
Both simple types and complex types can be defined on a global level, that is, on the schema level. Such types must be named. This makes it possible to refer to these type definitions when they are used locally. For example,

or

Typically, we define global types when these type definitions are used in several places. We can refer to such type definitions in element definitions and in extension and restriction clauses:
![]()

or

Global types can be defined as abstract using the clause abstract=“true”. Such types cannot be used for type designation in element definitions, but can only be used to derive other types via extension or restriction. This can be done either within the schema or in the document instance with an xsi:type declaration (see Section 6.2.4).
On the other hand, it is possible to declare a global type as final using the attribute final. This attribute may specify “restriction”, “extension”, or “#all” as a value. If “restriction” is specified, it is not possible to derive other types by restriction. Similarly, “extension” means it is not possible to derive other types by extension, and “#all”, to derive other types by any method.
5.3.13 Global Elements and Attributes
Similar to types, elements and attributes may also be defined on a global level. Global elements and attributes are defined on the schema level following the definition of the document root element. Again, the definition of global elements and attributes makes sense when we want to refer to this definition from several places.
In the following schema we define a global element title after the definition of root element jazzMusician:

When we want to reuse this definition we simply use an element reference like this:
![]()
Global definition is the only way to define an element in a DTD. This has drawbacks: It is impossible to define elements with the same name but of different types in different contexts.
5.3.14 Recursive Structures
Global definition of elements is one way in XML Schema to define recursive element structures. For example,

defines a recursive tree of part elements. Because the child element definition refers to the containing element, the containing element must be defined as a global element.
Here is the equivalent DTD fragment (ignoring type declarations):
![]()
This technique has a disadvantage: It is not possible to define context-specific recursive element structures. For example, if we want two different part trees—one allowing mixed content, the other not allowing mixed content—and we want to use them in the same document, we have a problem. However, it is relatively easy to define context-specific recursions by using the group construct, discussed in detail in Section 6.2.2. Groups are defined on a global level and can refer to themselves and thus establish recursive structures. Nothing stops us from defining several recursive groups with different layouts and referencing them from context-specific but equally named elements:


Here, we have defined two recursive groups gDetailedListPart and gShortListPart. Note that element productNo is defined as a global element because it has an identical definition in both groups. We can now set up a root element containing two different lists in different contexts, but both lists are constructed from elements with tag part (see Figure 5.4).
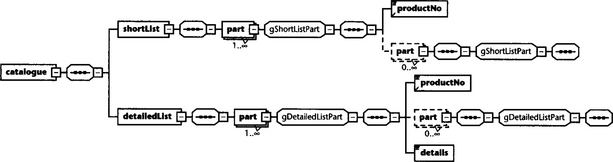

Used in this way, groups work similarly to non-terminal symbols in grammars—their names do not appear in instance documents. Consequently, by using group constructs, we should be able to express any schema that can be described by a regular grammar. This is not possible with DTDs!
Here is a valid instance document. (For an explanation of the namespace attributes in the xs:schema clause, see Section 6.1.)
![]()

XML Schema wouldn’t be XML Schema if it did not offer at least two solutions to a problem. Another way to define recursive structures in XML Schema is via global complex types. We want to create two part lists—one containing part elements with mixed content, the other containing part elements without mixed content. To do so we define two different types tPart and tPartMixed that introduce part elements of different types locally. These part elements refer recursively to the previously defined type declarations.
Here is the definition of a recursive part structure without mixed content:
![]()

The definition for the recursive part structure with mixed content looks quite similar:

We can then use both type definitions to define local part elements that are recursive but have a different type (see Figure 5.5):
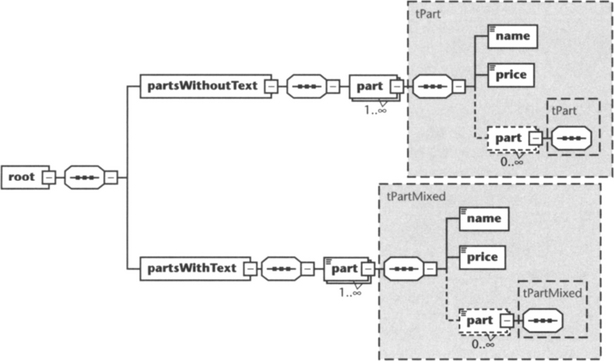


Now we can define a document instance that can contain both types of part elements nested in unlimited depth:

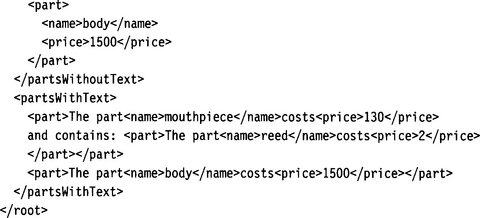
5.3.15 Wildcards
A wildcard (an element or attribute of no further specified content) can be declared with the XML Schema elements <xs:any/> or <xs:anyAttribute/>.


Using wildcards allows for the inclusion of elements and attributes from foreign schemata and namespaces (see Section 6.1.3). In this way, sections of XHTML, SVG, RDF, or other content could be included in a document. For example:

The attributes namespace and processContents will be explained in Section 6.1.3.
5.3.16 Nullability
DTDs only support the concept of optional elements: An element is either present or absent. Besides allowing optional elements (with minOccurs=“0”), XML Schema introduces a new concept. Instance elements can be set to “nil” by specifying the attribute xsi:nil=“true”. (Here, xsi: denotes the namespace prefix for XML Schema Instances http://www.w3.org/2001/XMLSchema-instance.) In the schema, the attribute
![]()
declares whether an element is nillable, or not (the default value is “false”). Nilled elements must not have any content, but they are allowed to have attributes!
With the following schema fragment,

we allow things like colored null values:

Note that a nilled element is a new concept: It is neither an absent element (defined via minOccurs=“0”) nor an empty element (see Section 5.3.10).
In my opinion, the concept of nilled elements is of limited value. It was introduced to improve the compatibility of XML with certain relational database products. However, mapping, for, example, a nullable SQL field to a nillable XML element may work for a specific application, but it is not a general solution. Traditionally, in many applications nullable database fields are already mapped to optional XML elements. So relational null values already have a defined representation in XML (an optional element or attribute). To represent the new nillable elements in object-oriented or relational data models would therefore require a new representation in these applications.
However, the concept makes sense if we wish to express different flavors of nothingness. A value may be absent for different reasons: It could be absent because it represents real nothingness (such as a person without a middle name), because the document author did not know the value (middle name exists, but is unknown), or it could be absent for some technical reasons (server breakdown, for example). These reasons could be coded into the attributes of a nilled element so that appropriate action can be taken.
5.3.17 Uniqueness, Keys, Reference
Similar to the DTDs, XML Schema provides built-in data types ID and IDREF for modeling cross-references between document elements. However, the main purpose of these data types is to provide backward compatibility with existing XML documents.
XML Schema introduces a more flexible concept for keys, key references, and uniqueness with the key, keyref, and unique clauses. These are not hampered by the inherent restrictions of the DTD key concept:
![]() DTDs do not allow keys to have a specific data type, as keys must be specified with the ID and IDREF data types.
DTDs do not allow keys to have a specific data type, as keys must be specified with the ID and IDREF data types.
![]() Elements cannot be declared as keys. Only attributes can be declared as keys with data type ID.
Elements cannot be declared as keys. Only attributes can be declared as keys with data type ID.
![]() The data type ID can only define keys that are global for the whole document instance, and therefore must be unique within the scope of the whole document instance.
The data type ID can only define keys that are global for the whole document instance, and therefore must be unique within the scope of the whole document instance.
![]() ID and IDREF cannot handle composite keys. This may be required when we want to represent relational structures in an XML document. XML Schema allows composite keys. However, it must be noted that using composite keys creates a problem for schema validators: In general, for schemata containing composite keys and key references, it is not possible to determine whether the schema has valid instances [Fan2001].
ID and IDREF cannot handle composite keys. This may be required when we want to represent relational structures in an XML document. XML Schema allows composite keys. However, it must be noted that using composite keys creates a problem for schema validators: In general, for schemata containing composite keys and key references, it is not possible to determine whether the schema has valid instances [Fan2001].
Unique
The unique clause allows us to define nodes or node combinations that must be unique within a specified scope. This scope is determined by the location where the unique clause is defined.







The name attribute identifies the unique constraint. It can be referenced in a keyref clause (discussed shortly).
The selector element defines in its xpath attribute the document element to which the unique constraint applies. This is done with an XPath expression relative to the location where the unique clause was defined.
Similarly, the field elements (there can be several) define in their xpath attributes which combination of fields constitutes a unique value. Nodes within such a combination may have various data types, such as string, decimal, float, and so on. Here, the XPath expression is relative to the element specified in the selector clause.
The XPath syntax is described fully in [Clark1999]. However, for our purposes, it is sufficient to know that document node hierarchies are expressed by the node names separated by slashes, that attribute names are prefixed with the @ character, that . denotes the current node, and that the choice operator | separates alternative paths.
Let’s assume we have a document with a root element album. This root element contains child element track, which in turn contains title elements. We want to make sure that each track has a different title. We must therefore declare the title element as unique. We do so by placing a unique clause into the definition of element track:


Here we declare the element title as unique within the context of album. That is achieved by placing the xs:unique clause into the scope of element album and by selecting the track element in the xs:selector element of the xs:unique clause. The xpath specification in the field element locates the attribute title relative to the context specified in the xs:selector element.
Key
The key clause allows us to define nodes or node combinations as a primary key within a specified scope. Keys must be unique, too, but they must also be present within the scope where the key clause is defined. Therefore, it does not make sense to define an element that has been declared as a key as optional (minOccurs=“0”), nor to define it as nillable.

The name attribute identifies the key constraint. It can be referenced in a keyref clause (see next section). The syntax of the selector and key clauses is the same as for the unique specification.
Let’s assume we want to refer to track elements by their trackNo attribute. We place the key clause into the scope of the root element album:
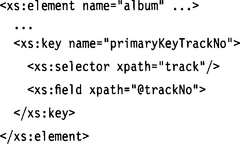
Keyref
The keyref clause allows us to define nodes or node combinations as a foreign key within a specified scope.

Again, the syntax of the selector and key clauses is the same as for the unique specification. The name attribute is optional and has no defined function.
The attribute refer identifies the corresponding key or unique definition. Yes, you can refer to a unique clause! Contrary to a key clause, however, the unique clause does not guarantee that the reference can be resolved (it allows dangling references).
The type of the keyref node (or the combination of types) must match the type (or combination of types) of the corresponding key or unique definition.
If a document instance contains those nodes that make up a foreign key, it must also contain the document nodes to which the foreign key relates. Otherwise the document would not be valid.
Let’s assume our album contains a second list, sample, where each item refers to an item in the track list via its attribute trackRef. We could establish a cross-reference between these two lists in the following way:


Finally, let’s look at a more advanced example. We’ll assume our sample element is constructed from a choice group consisting of elements goodSample, badSample, and uglySample. Each of these elements has an attribute trackRef.
How do we construct a foreign key for a choice group? We make use of the XPath choice connector and specify alternate paths in the selector clause. In the following listing we define the complete schema for our album documents. The root element album has two child elements: sample (defined as a global element) and track. The root element also contains a definition for a primary key pkTrack with the selector track and the key field @trackNo. The foreign key is defined with fkSample with the selector sample/goodSample | sample/badSample | sample/uglySample and the key field trackRef.



The following code shows a valid document instance of the schema defined above:
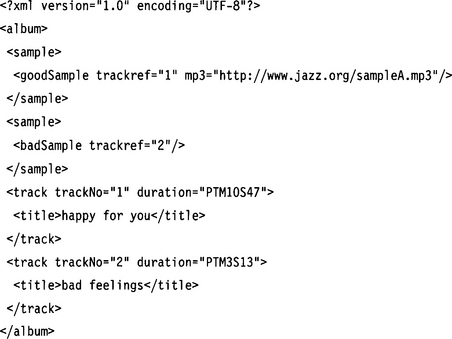
Note: This schema could not be expressed as a DTD. The ID/IDREF construct used in DTDs to establish cross-references requires ID and IDREF attributes to have NMTOKEN values. NMTOKEN values, however, must start with a letter. This does not fit with our integer track numbers. In addition, DTDs do not have a unique construct.
5.3.18 Deterministic Types
Appendix E of the second edition of the XML 1.0 Recommendation notes that content models should be deterministic (unambiguous). This requirement exists for the purpose of compatibility with SGML. SGML parsers may flag a nondeterministic schema as ambiguous. XML Schema also requires content models such as choice groups and all groups to be deterministic (Unique Particle Attribution).
A content model is deterministic if all particles defined in the model can be reduced to a deterministic regular expression (see Section 1.7.6). A regular expression is deterministic if at each choice point it is possible to decide which branch to take without having to look ahead. Let’s look at an example:
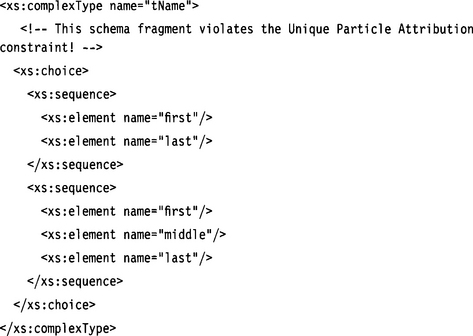
This type definition is not deterministic because both choice branches begin with the same elements. However, the same type can be easily expressed in a deterministic (and more compact) way:

The Unique Particle Attribution is subject to an ongoing debate. The question is: What is more desirable, efficient parsers or easier schema authoring? Arguably, if somebody should suffer, it should be the machine and not the human. But nondeterminism can cause the parser to suffer very much, indeed, as a look-ahead may stretch across several megabytes. And then it is the end user who suffers because of unacceptable response times.
It is not always possible to make a definition deterministic. The following schema was written to describe a small orchestra consisting of either seven saxophone players or three guitarists. It violates the Element Declarations Consistent constraint:

This structure is nondeterministic because both branches begin with a musician tag. There is no way we could refactor this structure into an equivalent nondeterministic structure. In XML Schema, the above schema is illegal: Using an element (musician) with different type declarations within the same choice clause is not allowed. In such cases we are required to change the document structure, for example, to rename the musician elements as saxophonist and guitarist, or to use a different namespace for each musician element.
1.The XML Schema Recommendation Part Two uses the term “derived” instead of “constructed” in this context. Since this terminology clashes with the semantics defined for “derived” in Part One of the recommendation, we use the term “constructed.”