
Authoring XML Schema
Now that you have been introduced to the type system of XML Schema in Chapter 5, we continue our tour de force in this chapter. The first section discusses the overall structure of schemata written with XML Schema and how namespaces are handled. The next two sections cover reuse mechanisms and schema composition. (Schema composition is a must if we want to define multi-namespace schemata.) The final section, “Usage Patterns,” discusses some best practices for authoring XML schemata with XML Schema.
6.1 NAMESPACES
XML Schema provides full support for XML namespaces (see Section 4.1), so much so that the whole concept of schemata is based on the concept of target namespaces. In addition, schemata can ask their instances to qualify elements and attributes with namespace declarations, and wildcards can be used to include content from foreign namespaces.
6.1.1 Target Namespace
The main mechanism for namespace support with XML Schema is the targetNamespace declaration. Each schema file that contains a targetNamespace declaration serves as a description of that particular namespace. A schema file may describe only a single namespace, but there can be several schema files for the same target namespace. For example:
![]()
As shown in Figure 6.1, the namespace serves as the connecting element between document instances and schemata. For each namespace declared in a document instance, an XML processor will try to find a corresponding schema definition. The document instance may help the XML processor in this process by specifying a schema location. But this is not required, and the XML processor is free to choose a different schema definition, for example, a built-in schema definition (see Section 6.3.2).
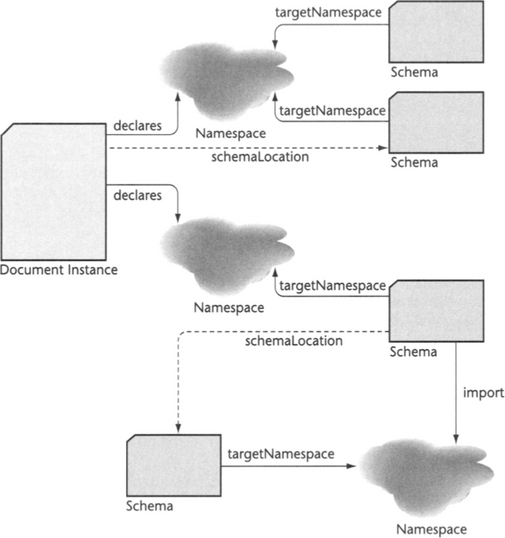
Figure 6.1 Schemata are connected to instances via namespaces. Optionally, an instance may specify a schema location. The same logic applies when a schema imports types from other schemata, as shown in the lower section of this diagram.
It is also possible to define schemata without a target namespace. These schemata can be used to describe unqualified elements (discussed next), or they can be assigned to a namespace when they are used—for example, when they are imported into another schema.
6.1.2 Qualified and Unqualified Names
A schema may ask that the local elements and attributes of its target namespace be specified in qualified or in unqualified form in document instances (see Section 4.1. A document instance has two ways to qualify element and attribute names:
A schema can ask for qualified names for each element or attribute individually, using the form=“qualified” attribute within element and attribute definitions. It can also specify elementFormDefault=“qualified” or attributeFormDefault=“qualified” as attributes of the <schema> clause. This will ask for qualification of all elements or attributes unless they are specified with form=“unqualified”.
Note that these declarations apply only to local elements and attributes, not to global elements (see Section 5.3.13). Global elements must always appear in qualified form in document instances, either qualified by prefix or by using a default namespace. The reason for this is that a processor must be able to locate the schema definition that belongs to an element’s namespace. Since local elements always have a global ancestor element, the processor is always able to determine the namespace, because the global ancestor element is always qualified.
However, this can lead to disturbing situations. The combination of elementFormDefault=“unqualified” and not providing a default namespace in a document instance can make the authoring of document instances difficult. Document authors need to know which elements are defined locally and which elements are defined globally—global elements must be specified with a namespace prefix, while local elements must not be specified with a namespace prefix.
The consequence is: Always use elementFormDefault=“qualified”. Either decorate both local and global elements consistently with namespace prefixes, or define a default namespace for the document instance and do not prefix local and global elements. Since attributes inherit their in-scope namespaces from their owner elements, it is fine to specify attributeFormDefault=“unqualified”.
6.1.3 Wildcards
The wildcards <xs:any/> and <xs:anyAttribute/> are used to declare elements and attributes that can contain content from other namespaces (see Section 5.3.15). This namespace is defined with the attribute namespace.
Wildcards can be processed by an XML processor in three ways:
![]() processContents=“skip” indicates that there are no constraints regarding the content of the element or attribute. It is sufficient that the content is well formed. An XML processor will not check the content for validity.
processContents=“skip” indicates that there are no constraints regarding the content of the element or attribute. It is sufficient that the content is well formed. An XML processor will not check the content for validity.
![]() processContents=“lax” requires that the element or attribute is valid when it is declared. If the processor cannot obtain the corresponding schema definition, the content is not checked.
processContents=“lax” requires that the element or attribute is valid when it is declared. If the processor cannot obtain the corresponding schema definition, the content is not checked.
![]() processContents=“strict” requires that the element or attribute is declared in the specified namespace or in the document instance via an xsi:type declaration (see Section 6.2.4), and that it is valid. This instruction requires the XML processor to obtain the corresponding schema definition and to perform the necessary checks. This is the default value.
processContents=“strict” requires that the element or attribute is declared in the specified namespace or in the document instance via an xsi:type declaration (see Section 6.2.4), and that it is valid. This instruction requires the XML processor to obtain the corresponding schema definition and to perform the necessary checks. This is the default value.
The attribute namespace can be used to specify a list of namespace identifiers. This list can contain
![]() The string “##targetNamespace”. This specifies the target namespace of the current schema.
The string “##targetNamespace”. This specifies the target namespace of the current schema.
![]() The string “##local”. This specifies the namespace of the respective document instance.
The string “##local”. This specifies the namespace of the respective document instance.
As an alternative to a list, the following string values can be specified:
![]() “##any”. Any namespace. This is also the default value of the namespace attribute. This value is often used together with processContents=“skip”.
“##any”. Any namespace. This is also the default value of the namespace attribute. This value is often used together with processContents=“skip”.
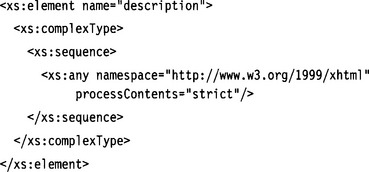
The following example defines an element description that must contain valid XHTML content:
6.1.4 Schema Default Namespace
Because a schema defined with XML Schema is an XML document, too, it is possible to define a default namespace for the schema itself. This default namespace applies to all elements and attributes used in the schema definition that are not decorated with a namespace prefix. This includes the XML Schema declarations such as <element>, <attribute>, <simpleType>, or <complexType>.
Basically, we have three options for assigning a default namespace:
![]() Use the target namespace as the default namespace. In this case we do not have to prefix the items that we define in the schema and that belong to the target namespace. Instead, we prefix all XML Schema declarations with an appropriate prefix such as xs:. This is the preferred method for using the default namespace because it makes schema composition easy: Unqualified definitions (those that do not belong to a namespace) from external schema parts that we include (see Section 6.3.3) are automatically added to the default namespace (which is the target namespace). This is the desired behavior. For example:
Use the target namespace as the default namespace. In this case we do not have to prefix the items that we define in the schema and that belong to the target namespace. Instead, we prefix all XML Schema declarations with an appropriate prefix such as xs:. This is the preferred method for using the default namespace because it makes schema composition easy: Unqualified definitions (those that do not belong to a namespace) from external schema parts that we include (see Section 6.3.3) are automatically added to the default namespace (which is the target namespace). This is the desired behavior. For example:

![]() Use the XML Schema namespace as the default namespace. In this case we do not have to prefix the XML Schema declarations, but we have to prefix the elements, types, and attributes that we define in the schema. This method is less flexible than the previous method: Unqualified definitions from included schemata would be added to the XML Schema namespace, which is not desired. For example:
Use the XML Schema namespace as the default namespace. In this case we do not have to prefix the XML Schema declarations, but we have to prefix the elements, types, and attributes that we define in the schema. This method is less flexible than the previous method: Unqualified definitions from included schemata would be added to the XML Schema namespace, which is not desired. For example:

![]() Use no default namespace at all. In this case we have to prefix XML Schema declarations, and the elements, types, and attributes that we define in the schema. Again, this method causes trouble when unqualified definitions are included from external schemata. These definitions would not belong to any namespace, which results in an error when the schema is used. For example:
Use no default namespace at all. In this case we have to prefix XML Schema declarations, and the elements, types, and attributes that we define in the schema. Again, this method causes trouble when unqualified definitions are included from external schemata. These definitions would not belong to any namespace, which results in an error when the schema is used. For example:

Clearly, the first option (using the target namespace as the default namespace) is the way to go.
6.2 REUSE MECHANISMS
XML Schema provides various mechanisms for elements reusing existing declarations, in particular global elements and types and various group constructs.
6.2.1 Global Elements and Global Types
Sections 5.3.12 and 5.3.13 discussed the definition of global elements and global types. The question for the schema author is: When should I use global elements, and when is it better to define a global type?
The answer is easy: Types are much more flexible constructs than elements. In almost all cases, it is better to define a global type instead of a global element. Global types can be used for element declaration, but it is also possible to derive other types from them via restriction and extension. In addition, we can build separate type libraries and import them with the import statement (see Section 6.3.5). In contrast, a global element can only be referred to, and that’s it (almost).
There are two exceptions where a global element is more appropriate:
![]() Defining recursive structures is only possible by reference, and reference requires global elements (see Section 5.3.14). Using global elements is not the only way to define recursive structures, but it is the simplest.
Defining recursive structures is only possible by reference, and reference requires global elements (see Section 5.3.14). Using global elements is not the only way to define recursive structures, but it is the simplest.
![]() Elements that are subject to substitution (see Section 6.2.5) must be defined as global elements.
Elements that are subject to substitution (see Section 6.2.5) must be defined as global elements.
Of course, nothing stops us from using global elements and global types in combination. A global element can always refer to a global type definition. This solution provides the most flexibility. We can easily redefine types and use type libraries, while allowing other schemas that are importing our schema to apply substitution mechanisms to the globally defined elements.
6.2.2 Groups
A group definition can furnish a model group with a name. Groups can only be defined globally on the schema level. In Section 5.3.14 we used groups to define context-specific recursive structures. Groups are the most flexible construct for defining complex document structures.

For example, we define a group:

This group can now be referenced by name instead of explicitly specifying a model group:

6.2.3 Attribute Groups
Similar to groups, attribute groups can combine several attribute definitions into a single named group. Attribute groups can only be defined globally on the schema level.

For example, we define the attribute group:

The whole group can then be referenced by specifying the group name instead of specifying each individual attribute.

6.2.4 Instance Type Overriding
XML Schema allows document instances to override the type of elements (but not of attributes) locally with another type definition. This can be done with the xsi:type attribute, “xsi:” is the prefix for the namespace http://www.w3.org/2001/XMLSchema-instance and must be declared in the document instance. This namespace contains all XML Schema declarations that may appear in document instances.
The new type can be a built-in type or a type defined globally in the schema, but must be a type that is derived1 from the original type of the element. In the following example from Section 5.2.10, we use an xsi:type definition in the document instance to select a specific member element from a union type:

![]()
In a particular document instance, we can ensure that the tProductNo type definition is used by an XML processor by overriding the type definition of its productNo element via xsi:type=“tProductNo”:

This is possible because tProductNo is a member type of tISBNorProductNo, and consequently is regarded as derived from tISBNorProductNo. Without this overriding, the content of this productNo instance would be interpreted as of type tISBN because tISBN is specified first in the union clause, and “0-646-27288-8” satisfies the tISBN pattern.
Of course, the discrimination between tISBN and tProductNo does not make much sense if we only want to validate a document. But for other XML processors, different types might imply different semantics; in such cases, type overriding would enforce different behavior.
Overriding schema type definitions in a document instance is, of course, also possible for complex types, provided the complex type definition was not decorated with a block attribute. The block attribute can take the values #all, restriction, extension, or combinations of restriction and extension. It is therefore possible to inhibit selectively the restriction or the extension of a complex type in document instances, or to inhibit both. (The block attribute is not allowed for simple type definitions. However, we can inhibit the overriding of simple types by using the block attribute in the definition of elements.)
Typical use cases for instance type overriding are
![]() The type defined in the schema is abstract. The instance must specify a concrete derived type.
The type defined in the schema is abstract. The instance must specify a concrete derived type.
![]() The document schema is fairly generic and does not define the type of elements but leaves this task to document instances. One application that heavily uses this technique is SOAP.
The document schema is fairly generic and does not define the type of elements but leaves this task to document instances. One application that heavily uses this technique is SOAP.
![]() We want to convey meta-information to the application as in the example given above.
We want to convey meta-information to the application as in the example given above.
6.2.5 Substitution Groups
Substitution groups are a kind of alias mechanism for elements. An element is called substitutable if it specifies a so-called head element via the substitutionGroup attribute. The element referring to the head element must be of a type that can be derived2 (via extension or restriction) from the type of the head element, and both the head element and the referring element must be defined globally.
Since head elements and referring elements can belong to different namespaces, substitution groups are a great way to cross namespace borders. For example, when we include or import definitions (see Sections 6.3.3 and 6.3.5) from another schema file, there are always cases when we might not want to use the defined element names but would like to rename. This can be done with substitution groups, as long as the elements were defined globally. Substitution groups allow mediating between different namespaces and different schema parts.
Let’s assume we have a schema file with target namespace http://www.jazz.org/generic and that this file contains the definition for an element instrument:
![]()
This element is not intended to appear in instance documents, as we have defined it as abstract. We now want to define another schema with target namespace http://www.myMusicShop.com/instruments in which we import the above definition. However, we do not want to keep the name instrument but would prefer to use specific instruments like saxophone and trombone. We can achieve this with a substitution group:

For the element trombone, we have restricted the type to xs:normalizedString. This is possible, since instrument was defined with xs:string, and xs:normalizedString is a restriction of xs:string. However, if instrument was defined with type xs:token, then the definition of trombone would be invalid because xs:normalizedString is not derived from xs:token (see Section 5.2.9).
It is possible to protect an element against the definition of substitution groups by defining it as final. The final attribute can take the values #all, restriction, and extension, or a combination of restriction and extension. It is therefore possible to protect an element against specific substitution methods.
Similarly, it is possible to protect an element against the application of substitution groups in document instances by decorating it with a block attribute. This attribute can take the value #all, the values restriction, extension, substitution, or combinations thereof.
For an application of substitution groups in a larger example, please see Section 6.4.2.
6.3 SCHEMA COMPOSITION
A schema does not necessarily consist of a single file but may consist of several components, may refer to type libraries, and so forth. This section discusses the various possibilities, such as include, import, and redefine, for composing schemata within the same namespace and across namespaces.
Theoretically, these mechanisms allow for construction of very deep inclusion and redefinition hierarchies. (COBOL copy code experts will be delighted.) However, it is good practice to keep these hierarchies as flat as possible. This improves readability and avoids cyclic inclusions and contradicting redefinitions.
6.3.1 The Schema Clause
The schema clause is the root element of any schema file.
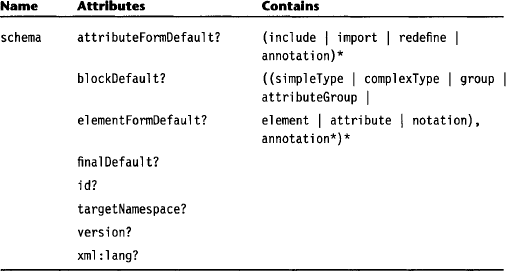
The schema clause defines the default values for the form attributes in attribute definitions, form attributes in element definitions, block attributes, and final attributes. As child elements, it contains definitions that must be made on the schema level such as global types, global elements and attributes, groups and attribute groups, and notation declarations. The schema clause may also be decorated with one or several annotations.
6.3.2 Locating Schemata
XML instances may specify the schemata that can be used for validation of the instance via the xsi:schemalLocation attribute. Because this declaration is located in the document instance, it must be qualified with the namespace for XML Schema instances that must be declared in the document instance, too.

The schemaLocation attribute contains one or several pairs of URIs. The first URI in each pair identifies the namespace, while the second URI in each pair specifies the location of the corresponding schema. Note that the latter is only a hint from the document author to the XML processor about where to find the schema. It is up to the processor to use this schema reference or not. For example, an SVG processor or a SMIL processor may discard this reference and use its built-in schema definition for the SVG or SMIL namespace. The location of schemata that do not have a namespace can be specified with the attribute noNamespaceSchemaLocation.
6.3.3 Include
The mechanisms for inclusion, redefinition, and import allow us to establish and use type libraries. Type libraries are useful because they help to standardize type definitions within a corporation or across corporations.
A schema definition can include any number of external schema files. However, there is a condition: An included external schema file must have the same target namespace definition as the including file, or no target namespace definition at all. In the latter case, the definitions in the included schema are adapted to the target namespace of the including schema.
The include, redefine (Section 6.3.4), and import (Section 6.3.5 clauses must always be located at the beginning of a schema clause.

![]()
This clause has basically the same effect as pasting the content of http://www.jazzstore.com/cd.xsd into the current schema file.
6.3.4 Redefine
The redefine clause works similarly to the include clause. A redefined external schema file must have the same target namespace definition as the including file, or no target namespace definition at all. What is different from the include clause is that redefine allows modification of the included definitions. For example, simple types can be restricted, and complex types can be extended or restricted.
The include, import, and redefine clauses must always be located at the beginning of a schema clause.

Given the following schema in file tName.xsd,

we can now include this type definition in another schema and at the same time redefine it:


Note that the name of the redefined complex type and the name of the base type are identical (tName)! This is required by the redefinition mechanism. It is possible to redefine all or only some of the included types.
It is also possible to redefine groups and attribute groups. Given the following schema in file gName.xsd,

we can now extend this group via a redefinition:

Again, the redefined group has the same name as the group to which it refers.
6.3.5 Import
In contrast to include, the import clause can combine several schemata from different target namespaces. This is important since a single schema definition only supports a single target namespace. Multi-namespace schemata or instances must therefore be composed from several schema files.
The include, import, and redefine clauses must always be located at the beginning of a schema clause.

A multi-namespace schema defines the namespaces used with their prefixes via a standard namespace declaration in the schema element. Directly after the schema element, the necessary import statements are specified to import the foreign namespaces.
Optionally, the import statement may specify the schema location in order to help the XML processor to locate the schema file that defines that namespace. However, for the XML processor, this is only one possible source of information. Document instances may specify schema locations for the various namespaces, too, and the processor is free to use built-in namespace definitions for particular namespaces (see Section 6.3.2).
The following schema imports the XHTML namespace and assigns the prefix html:to it. We can then, for example, refer to the XHTML blockquote element definition.


6.3.6 Notation
The notation element supports the simple abstract type NOTATION and provides the functionality known from the XML 1.0 NOTATION declarations (see Section 4.2.11). Its purpose is to provide compatibility for the translation of DTDs into XML Schema.
The following example includes a jpeg image in a document and defines application viewer.exe as its processor.
![]()
6.3.7 Annotations
Any element of an XML Schema definition can contain one or several annotations. Annotations can contain both appinfo elements and documentation elements as child elements. appinfo elements contain user-defined information for machine consumption, while documentation elements contain information for human readers.
| Name | Attributes | Contains |
| annotation | (appinfo | documentation)* |
Here is an example of using appinfo to describe physical properties of a schema element to a native XML database (Software AG’s Tamino, see also Section 11.11.1):

Note that XHTML is used to mark up the documentation text. This should be adopted as a best practice. (Similarly, HTML is consistently used to mark up documentation in Java source code and JavaDocs.)
6.4 USAGE PATTERNS
The following sections discuss some advanced techniques that exploit the modularity and reuse mechanism of XML Schema. These patterns also qualify as best practices recommendations.
6.4.1 Chameleon Components and Type Libraries
Reusing XML Schema components requires some consideration. It requires that we design the single components with their possible reuse purposes in mind. One aspect of this is how we treat namespaces.
When furnishing a generic schema component such as a type library with a fixed target namespace, we have already restricted the possible reuse scenarios. We have removed one point of variation (one degree of freedom)—the component has lost some flexibility. It now contains type definitions that belong to a dedicated namespace; we cannot use it in other scenarios where other namespaces are in effect.
So, it is a good idea not to equip generic components with a target namespace. Such components are called chameleon components. They can easily be inserted into other schema files that do have a target namespace, and of course, we want them to blend into that target namespace. This is in fact the case: XML adds included components that do not have a target namespace to the target namespace of the including schema.
Let’s look at an example. We define a small type library named customer.xsd (see Figure 6.2) with just a single type tCustomer:
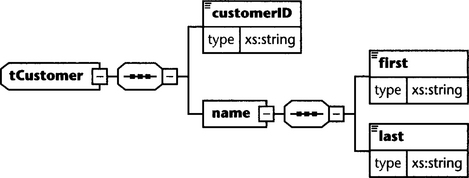
We can use this type definition in a schema such as the following invoice schema (see Figure 6.3):
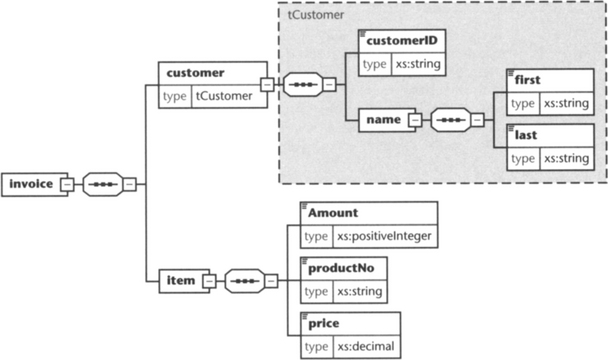

What is important here is how we define the default schema namespace. As you can see, the default schema namespace is the same as the target namespace, while the XML Schema namespace is linked with the prefix xs:. Consequently, we have to decorate each XML Schema term, such as sequence or complexType, with the prefix xs:, while—and this is important—the elements of invoice do not need a qualifying prefix. If we had chosen to define the default schema namespace differently, we would need to qualify all elements of invoice with a prefix because they belong to the target namespace. This would also apply to the elements included from the type library customer.xsd. This, of course, is not possible, as customer.xsd is defined without a namespace.
So, the golden rule for schema design is
target namespace = default schema namespace
With this policy and with chameleon components, we can easily create type libraries that can be included in schemata of different target namespaces.
Note that we can also apply this technique on the document instance level. We can include chameleon components into document instances using the noNamespaceSchemaLocation declaration, as discussed in Section 6.3.2. The component will be added to the default namespace of the document.
6.4.2 Defining Schema Families
A common problem, especially in electronic businesses, is adapting schemata to national, regional, or cultural standards and customs. For example, the address element of an invoice looks different in Europe and in the United States. We would rather not have to provide an extra document schema for each local context. One way to achieve this is to define an abstract master schema. This schema defines the basic structure of the document but leaves the details to the various localized schema extensions.
Using Substitution Groups
An elegant way to define such a master schema and later extend it is to make use of substitution groups (see Section 6.2.5). Remember, a substitution group allows us to use the members of a substitution group in lieu of the head element to which each member of the substitution group refers.
The strategy we use is to define the master schema in such a way that any document node where we need variability can act as the head element for a substitution group. We define such head elements as global elements (a requirement for substitution groups), and we define them as abstract elements. This ensures that we cannot create document instances before we have actually substituted all head elements with a concrete implementation.
Here is an example for an invoice master schema (see also Figure 6.4):
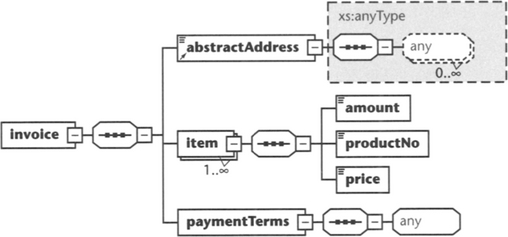


Here, we have included the element abstractAddress as a point of variability. This element is defined as a global element and is referred to in the definition of the root element invoice. We have declared element abstractAddress as abstract.
We have also declared the type as xs:anyType. This is the only built-in complex type in XML Schema, and it is a type from which all other complex types can be derived. Remember that the member of the substitution group that will later replace element abstractAddress must have a type that can be derived from the type of abstractAddress. xs:anyType gives us the most flexibility. The only limitation is that we cannot replace abstractAddress with an element of a simple type.
Of course, we could define head element abstractAddress with a specific complex type, if we wish to restrict the possible replacements for this element. However, as we cannot foresee the future, we may at some time be faced with an address format that cannot be derived from the type of abstractAddress. For this reason we have chosen xs:anyType, which allows us any address format, even if it is an address on Mars.
Now, let’s see how we can instantiate this abstract master schema with a concrete address definition (see Figure 6.5).
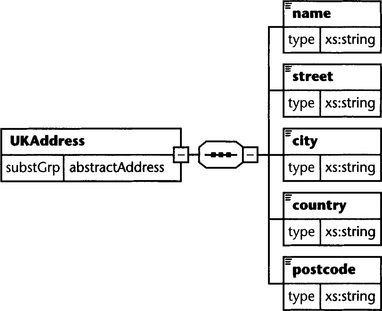


Here, we have defined a complete localized invoice schema for the United Kingdom. First, we have included our master schema. Then we have defined a global element UKAddress and have declared it as a member of the substitution group abstractAddress. Because abstractAddress was defined with type xs:anyType, we can now furnish UKAddress with any complex type definition of our choice.
Based on this schema definition we can now create a document instance:

This instance is a valid instance of schema UKInvoice.xsd. Note that we must use element UKAddress instead of element abstractAddress because abstractAddress was defined as abstract. In the same way, we could define invoice schemata for the United States, Germany, France, Italy, and so on, all based on invoiceMaster.xsd.
Substitution groups are a good way to achieve variability in a single namespace, but they also have drawbacks:
![]() All variable elements and their substitutions must be defined as global elements, so it is not possible to define context-specific (local) elements here.
All variable elements and their substitutions must be defined as global elements, so it is not possible to define context-specific (local) elements here.
![]() Things get out of hand when there are several context drivers. For example, the address of an invoice may depend on the location, the layout of the items in the invoice may depend on the industry sector, and the layout of the payment terms may depend on the target audience (corporate, consumer). As these context drivers may appear in various combinations, the number of possible concrete schemata can become quite large.
Things get out of hand when there are several context drivers. For example, the address of an invoice may depend on the location, the layout of the items in the invoice may depend on the industry sector, and the layout of the payment terms may depend on the target audience (corporate, consumer). As these context drivers may appear in various combinations, the number of possible concrete schemata can become quite large.
Using Type Substitution
Another technique to allow variability in schemata is to use abstract types. When a particular schema instance is written, concrete types substitute for these abstract types. The schema supplies these concrete types in the form of a type library, so that instance authors may select the types they need from that library. The library can be defined in the same schema, or it can be defined in a separate file that is then included in the schema file.
The following example illustrates this technique. Again, we have implemented an invoice schema (see Figures 6.6 and 6.7). This time all elements (except the root element) are defined as local elements, but they refer to abstract types that are defined globally.
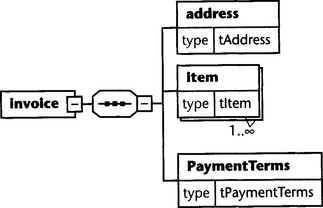
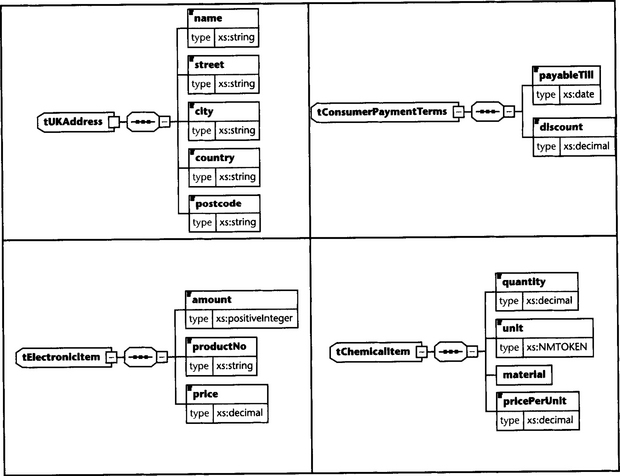


Also in this case, the concrete types that substitute for the abstract types must have been derived from the corresponding abstract types. We see that, for example, tConsumerPaymentTerms was defined with a base type tPaymentTerms. It can, therefore, substitute for tPaymentTerms in any occurrence that specifies tPaymentTerms.
We have also defined the abstract types with the most general complex type (xs:anyType). This allows us maximum flexibility for the types in the respective type libraries.
Applying this technique requires a bit more work on the part of document authors. The document author has to specify which type is used with which element:

The concrete types for address, item, and paymentTerms elements are determined within the document instance. This allows a wide variety of document flavors without the need to create a huge number of schemata. Context-specific (local) elements are also possible.
Once again, this approach has a few drawbacks:
![]() It requires more effort from document authors.
It requires more effort from document authors.
![]() It cannot be used to extend a schema from the “outside.” The master schema must define or include a library containing all valid types.
It cannot be used to extend a schema from the “outside.” The master schema must define or include a library containing all valid types.
![]() It may allow the document author too much freedom. For example, a certain industry sector may only want items of a specific type used in an invoice, but document authors are free to mix item types at their discretion. For instance, in this example we mixed electronic items and chemical items in one invoice.
It may allow the document author too much freedom. For example, a certain industry sector may only want items of a specific type used in an invoice, but document authors are free to mix item types at their discretion. For instance, in this example we mixed electronic items and chemical items in one invoice.
Using Dangling Type Definitions
Our final technique is based on multiple namespaces. We use the fact that the definition of a schema location in the import directive is optional, and that a document instance may specify schema locations for namespaces used in the document. Note that the declaration of a schema location is only a hint to the XML processor about where a schema for that namespace may be found (see Section 6.3.5).
In the master schema we simply avoid declaring types that we want to keep variable. Instead, we import the namespaces that contain these type definitions but don’t tell the processor where to find these namespaces.
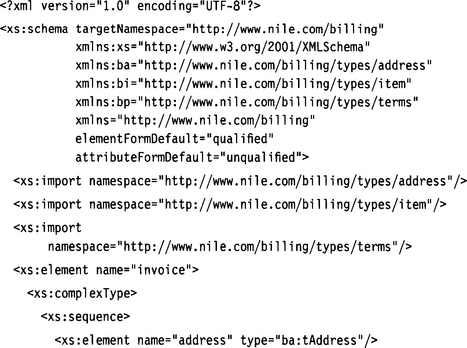

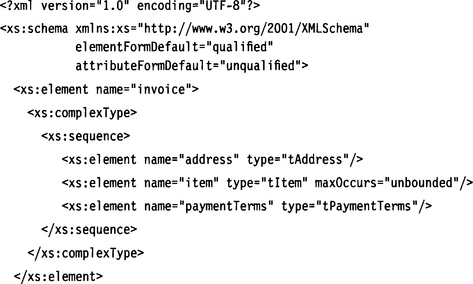
This approach is called “dangling types” because the types for the elements address, item, and paymentTerms are not declared in the schema (see Figure 6.8). Instead, we have put these types into namespaces of their own, which we import via corresponding import statements. Because these import statements do not have a schemaLocation attribute, it is still unclear where the type declaration resides.
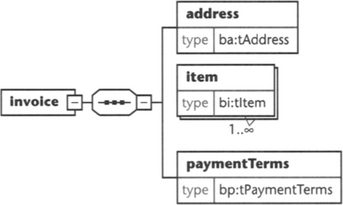
Three schema files containing the necessary type declarations are presented next.
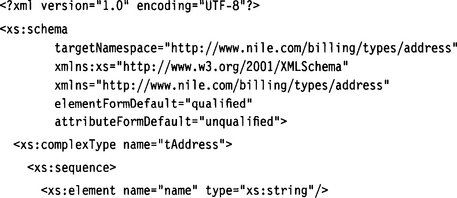


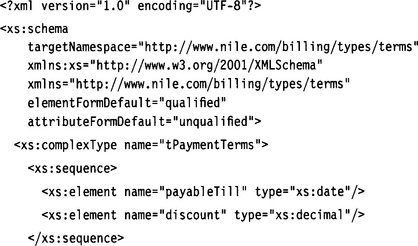
ConsumerPaymentTerms.xsd
![]()
We can now create a document instance. Within the document instance we connect the namespaces with the files that define the respective types. Other document instances may assign other document declaration files to the corresponding type namespaces, and so, can customize the schema.


This technique does not have the drawbacks of the previous method. In particular, it is possible to extend schemata from the “outside” simply by creating new type declaration files and using them in document instances. However, this method has a few disadvantages of its own:
![]() Documents are required to use multiple namespaces, basically one namespace for each variation point. When single-namespace documents or no-namespace documents are required, this technique cannot be used.
Documents are required to use multiple namespaces, basically one namespace for each variation point. When single-namespace documents or no-namespace documents are required, this technique cannot be used.
![]() It is not possible to validate the master schema in isolation because the referenced types are not declared. But even if we provide type declaration files, schema validators may not find them as long as we don’t supply schemaLocation attributes. With some parsers, we even witnessed problems with document instance validation. (Remember, the instance specifies the locations of the various schemata.)
It is not possible to validate the master schema in isolation because the referenced types are not declared. But even if we provide type declaration files, schema validators may not find them as long as we don’t supply schemaLocation attributes. With some parsers, we even witnessed problems with document instance validation. (Remember, the instance specifies the locations of the various schemata.)
So, the best advice is to treat this method cautiously but to keep it in mind as XML Schema–aware XML processors get more mature.
1.In the case of simple types, XML Schema uses the narrower definition of derived as defined in Part One of the XML Schema Recommendation. Derivation by list extension or union is not allowed for instance type overriding. However, the member types of a union or a list are valid derivations of the corresponding union or list type.
2.In the case of simple types, XML Schema uses a narrower definition of derived as defined in Part One of the XML Schema Recommendation. Derivation by list extension or union is not allowed for substitution groups. However, the member types of a union or list are valid derivations of the corresponding union or list type.