
Reality Check
The World Is Object-Oriented
Except in environments dominated by the documentation aspect, XML and XML schemata do not exist in isolation but have to integrate with other core technologies of enterprise IT, such as relational databases and object-oriented programming. This is probably the most important difference between SGML and XML. SGML flourished in documentation scenarios. XML, in contrast, intrudes into many traditional areas of enterprise technology: data storage, data integration, and message exchange. It is therefore essential that we get a clear understanding not only of the synergy effects between these existing technologies and XML but also of the “impedance mismatch” between these technologies and XML.
This chapter discusses XML Schema in context with object-oriented technologies; Chapter 11 deals with relational environments. The first part of this chapter explains some basic concepts of the object-oriented model and then compares it with the XML data model. We will see that both models follow concepts that are in parts alien, even opposed to each other. That will cause some problems when it comes time to implement integrated solutions in which object-oriented and document-related techniques are “married.” What makes this marriage so important is that object-oriented languages are the primary language used to combine processing logic with XML documents, despite the fact that functional languages such as Haskell are better suited to emulate the complex type system of XML. Java, especially, has strong XML support, followed by C++ and C#, but other 00 languages such as SmallTalk or Eiffel provide XML access layers, too.
10.1 OBJECT-ORIENTED IMPLEMENTATIONS OF THE XML DATA MODEL
The most precise mapping of the XML Information Set onto object-oriented structures is the Document Object Model (DOM). The DOM defines a full application programming interface for XML documents on a generic level. It provides access to the various nodes of a document such as document, element, and attribute, and to node lists. By doing so, it allows clients not only to navigate within XML documents but also to retrieve, add, modify, or delete elements and content. To provide a language-independent specification, DOM uses the OMG IDL (Object Management Group Interface Description Language) as defined in the CORBA 2.2 specification. DOM bindings are defined for many languages, such as Java, C++, ECMAScript (JavaScript), and others.
There are currently three DOM API levels: Level 1, Level 2, Level 3 [LeHors 2002]. Apart from other improvements, DOM Level 2 adds an event model to the DOM specification, while DOM Level 3 adds an XML Content Model, load and save, document validation with DTD or XML Schema, better namespace handling, and optional support for XPath. I will not go into the details of DOM API programming, as these are usually well covered in the many excellent textbooks about XML with Java.
Section 9.4.1 gave an example for using the DOM API with Java. We saw how constraints can be checked using standard DOM Level 2 access methods or using the new XPath access methods defined as an add-on to DOM Level 3. What is discussed here is not a physical mapping of XML structures onto object-oriented structures as the DOM does, but a semantic mapping of conceptual structures onto both XML structures and object-oriented structures. In an OO application we want to be able to deal with jazzMusician, band, album, customer, and purchaseOrder objects instead of having to deal with Document, Element, Node, and NodeList objects. And, we want to be able to map existing OO class hierarchies onto XML structures.
So, what we need is a binding between XML structures and OO structures on the semantic level. Needless to say, there is no standard method to achieve that. In fact, it must be possible to customize such a binding according to the requirements of the application. And we want to keep the OO class hierarchy as similar as possible to the type inheritance hierarchy in the XML Schema.
Several products, such as Sun’s JAXB (java.sun.com/xml/jaxb), Enhydra’s Zeus (zeus.enhydra.org), and Breeze XML Studio (www.breezefactor.com), provide a framework to define such bindings. Other products are Castor (www.castor.org) and JaxMe (jaxme.sourceforge.net).
![]() JAXB is currently only available in an early access release supporting only DTDs. The final draft of JAXB v1.0, which supports XML Schema, should be available when this book publishes and will set the standard for Java-XML data binding. JAXB 1.0 will only support a subset of XML Schema, not covering wildcards, keys and key references, and NOTATION types.
JAXB is currently only available in an early access release supporting only DTDs. The final draft of JAXB v1.0, which supports XML Schema, should be available when this book publishes and will set the standard for Java-XML data binding. JAXB 1.0 will only support a subset of XML Schema, not covering wildcards, keys and key references, and NOTATION types.
![]() Zeus is an open source development currently in beta status. It supports XML Schema.
Zeus is an open source development currently in beta status. It supports XML Schema.
![]() Breeze Studio is a commercial product supporting XML Schema with the commitment to integrate JAXB when the standard becomes available.
Breeze Studio is a commercial product supporting XML Schema with the commitment to integrate JAXB when the standard becomes available.
Binding involves five phases—two phases when creating the application and three when running the application. The two phases during creation are
![]() Definition of the binding by the programmer. The programmer has to describe how elements and attributes defined in the schema are mapped to Java classes and fields.
Definition of the binding by the programmer. The programmer has to describe how elements and attributes defined in the schema are mapped to Java classes and fields.
![]() Generation of the classes. This step is performed by the binding framework.
Generation of the classes. This step is performed by the binding framework.
The three phases when running the application are
![]() The unmarshaling process reads a document into fields of class instances. This involves the parsing of the document.
The unmarshaling process reads a document into fields of class instances. This involves the parsing of the document.
![]() In the modification process the client code modifies these fields via get… and set… methods.
In the modification process the client code modifies these fields via get… and set… methods.
![]() The marshaling process converts the instance fields back into an XML document.
The marshaling process converts the instance fields back into an XML document.
Before describing these steps in detail, let’s look at the similarities and differences between the object-oriented data model and the XML data model.
10.2 ENCAPSULATION AND BEHAVIOR
The term “object-oriented” gives a clear hint about the concept of OO languages. Similar to real-world objects, software objects expose only their exterior to the client. The internal structure is of no concern to the client. This is called encapsulation. The object encapsulates its internal mechanism. Its functionality is offered to the client via an interface. Take for example an electric lamp. The lamp has an internal structure: wiring, electric contacts, and so forth. What is exposed to the client is the switch with which to turn the lamp on or off. Taking a screwdriver and trying to switch on the lamp by connecting internal wires would be both inconvenient and dangerous. The same applies to software objects.
Objects also expose a behavior. Our lamp, for example, changes its state when I press the switch. Press the switch once, and the lamp is lit. Press the switch twice, and the lamp is switched off again. The lamp, it seems, has an internal state that influences the reaction that is caused by the press on the button. The behavior of each object can be described by stimulus-response patterns. Each stimulus (each client action at the object’s interface) generates a certain response that can be observed by the client via the interface. This response depends on the stimulus and, of course, on the internal state. Or looked at another way, the internal state may be modified by a stimulus.
This sounds very much like an automaton, and, in fact, an object can be described as a finite state automaton. Its behavior can be completely described by a finite number of finite sequences of stimulus-response patterns. For software objects, the stimuli consist of messages that are sent to the object, and, similarly, the responses are messages that are sent back to the client. While some object-oriented languages (for example, SmallTalk) use this message metaphor, other object-oriented languages, such as Java and C++, have packaged the message concept into method calls. A method call consists of a method name, parameters, and a return value. Both name and parameters constitute the stimulus message that is sent to the object, while the return value contains the response message. In languages such as C++ and Java, methods are not classified by their name but by their signature. The method signature consists of the message name, the number of parameters, and the data types of all these parameters. For example, the method switch (boolean) is different from the method switch (float).
Some OO languages support the concept of public object variables, allowing clients to access these variables. This may seem to violate the principle of encapsulation, but it does not. Object variables that are published at the object’s interface are simply an abbreviation: The compiler translates read accesses to such a variable into a get… () method and write accesses into a set… () method. So, under the surface, the stimulus-response mechanism is still at work.
When we compare these object-oriented concepts of encapsulation and behavior with the document-centric model, we see that both models are in opposition. First, a document does not expose behavior. Second, a document is not encapsulated. Everything in a document is public. The contents may be encrypted, but they are still publicly visible.
10.3 CLASS, INSTANCE, TYPE
In this chapter we want to analyze how the type hierarchies in XML Schema relate to object-oriented type hierarchies. But before we do this, we must get a clear understanding of how type hierarchies in object-oriented languages are established, as we can identify three different concepts of hierarchy in these languages: class hierarchies, type hierarchies based on behavior, and type hierarchies based on syntax.
When taking a peek into the interior of an object, we can differentiate between the procedures that process incoming messages and the variables that hold state information. We say that objects belong to the same class if they have the same procedures. The individual objects of such a class, the class instances, differ only in the state they are currently in. If we regard objects as finite state automatons, we can say that two objects belong to the same class if they have the same state transition table. The actual state may differ for these two objects, but the state transition table is identical.
10.3.1 Class Hierarchies
Subclasses are classes that can be derived from a parent class by adding some functionality, such as new object variables or new methods. In terms of automaton theory, a subclass adds new states and new rows to the state transition table. However, most OO languages also allow us to derive subclasses from parent classes by overriding (modifying) existing functionality. By using inheritance mechanisms between parent class and subclass, it is only necessary to specify the new or modified functionality when implementing a class. The purpose of class hierarchies is to establish a mechanism for software reuse, not to establish an order relation between objects.
10.3.2 Type Hierarchies Based on Behavior
In contrast to class hierarchies, type hierarchies classify objects by behavior. Behavior in this sense means behavior at the interface: The same sequence of stimuli must generate the same sequence of responses. At this point we are not interested in side effects (writing to a file, drawing a window on the screen, playing a sound, etc.). Using stimulus response sequences, we can establish a subtype/supertype relation. A subtype must expose the same behavior as the parent type to all messages accepted by the object of the parent type but may expose additional behavior to other messages. The consequence is that we can substitute a parent type with a subtype without the client noticing (as long as the client is only looking at the interface). This is called polymorphism. Objects of the same type may belong to different classes as long as they expose the same behavior. These objects have a different implementation, but the functionality is identical.
Again, the object-oriented concept of types is opposed to the concept used in XML. In XML a type is defined by a set of structural constraints, while in object-oriented terms a type is a set of behavioral constraints.
10.3.3 Type Hierarchies Based on Syntax
Practical OO implementation, however, does not use this behavioral concept to establish a type hierarchy. This is because in order to support polymorphism, the compiler would have to know the exact behavior of a type. This is not always possible, as the implementation may not be available, and determining a behavioral type from an implementation is far from trivial. In terms of computational theory it is not decidable if two behavioral types are equal. Existing OO languages, therefore, use a different, syntactical notion of type. For example, a Java interface describes the methods that must be supported by a given type. It also can declare public variables, but we may ignore this here, as public variables are only an abbreviation for get… and set… methods. All methods are just described with their signature (name plus parameter types) and the return type.
Classes implement one or several interfaces. The type of a class instance, an object, is determined by the interfaces that the class implements. In fact, an object can belong to several types if the class implements several interfaces, and the object can be used in all places where such a type is expected. If, for example, the class MusicTeacher implements both interfaces Musician and Teacher, then an instance of MusicTeacher can be used in the role of type Musician and in the role of type Teacher.
Subtypes can be derived from parent types by adding method calls (or public variables) to the interface definition. This, of course, can also be achieved by combining several interface definitions. For example, we could define an interface MusicTeacher by combining Musician and Teacher. Consequently, MusicTeacher is a subtype of both Musician and Teacher. Subtypes can substitute a parent type in any occasion where the parent type is used, without violating type-safety. However, because this type concept is not based on behavior, this substitution can cause a complete change of the program’s behavior.
10.3.4 Object-Oriented Types vs. XML Types
It is this notion of substitutability that establishes a type hierarchy in the OO world. In contrast, the notion of subtypes in XML is based on set theory. A document type A is a subtype of document type B if every instance of A is also an instance of B. The consequence is that the relationship between subtype and parent type is not maintained when we map XML structures on OO structures and vice versa.
Let’s look at an example. The following XML type,

could be mapped on the following Java interface definition:

We can now create a subtype of CD:

The corresponding XML Schema definition,
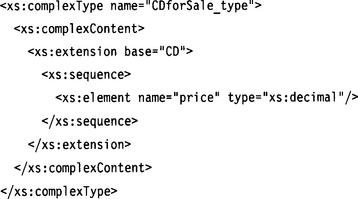
is by no means a subtype of CD; the instances of CDforSale are not instances of the XML type CD because they contain an additional element.
Note that there is a slight inaccuracy in our mapping. Since all Java interface variables can contain the null value, too, our XML type definitions should have a minOccurs=“0” with each child element:

In this case, the XML type CDforSale is a supertype of XML type CD (while the Java type CDforSale is a subtype of Java type CD)!
Conclusion: An XML Schema type DX constructed by extension from another XML Schema type TX can always be mapped onto a subtype SO of the corresponding OO supertype TO (see Figure 10.1). The same is true for derivation by restriction (because an OO subtype can override features of its supertype).
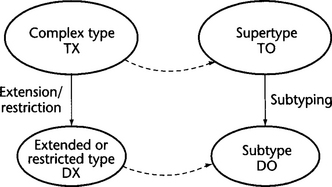
Figure 10.1 Hierarchical relationships between types can always be maintained when mapping XML Schema types onto object-oriented types.
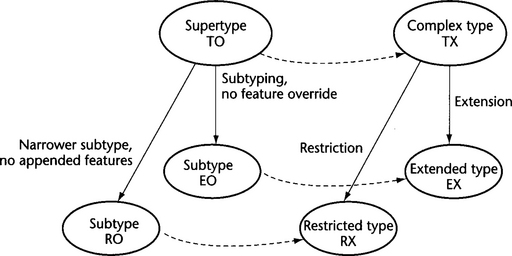
On the other hand, an OO subtype EO of an OO type TO can be mapped onto an extension EX of the corresponding XML Schema supertype TX only if the OO subtype SO does not override features of its supertype TO (see Figure 10.2). An OO subtype RO of OO type TO can be mapped onto a restriction RX of the corresponding XML Schema supertype TX only if the OO subtype TO overrides features of its supertype TO by narrowing them (making the set of instances smaller), and refrains from appending additional features.
10.4 SIMPLE TYPES
This section discusses how the simple types defined in XML Schema can be mapped onto types in OO languages. Some OO languages such as C++ and Java implement primitive types (types that are not objects). Java, for example, provides the following primitive types: byte, short, int, long, char, float, double, boolean.1 Other languages such as SmallTalk do not have primitive types. In such languages every type consists of objects—in OO lingo, of first-class citizens.
10.4.1 String Data Types
The primitive data type string as defined in XML Schema is based on the Unicode character set and is of unlimited length. In object-oriented languages the character set used depends on the particular language: While Java supports Unicode, most other OO languages support only ASCII. Most OO languages support strings of virtually unlimited length; some older languages such as Simula or object-oriented dialects of Pascal limit strings to a length of 255 characters. Java, for example, implements strings as first-class citizens in the form of the java.lang.String class, allowing a maximum number of characters of 2,147,483,647 (because the implementation stores the number of characters in an int variable).
XML Schema data types derived from string, such as normalizedString or token, are not supported as built-in data types in OO languages. However, it would be possible to implement such types in the form of user-defined classes. On the other hand, it is possible to define XML Schema data types derived from string that match the characteristics of a particular programming language, and to use these data types consistently when authoring XML schemata.
10.4.2 Binary Data Types
Since XML is text based, it does not support binary data in native format. Instead, XML Schema offers two encoded binary formats: hexBinary and base64Binary. Both formats support binary data of unlimited length.
Most OO languages do not provide an explicit concept for binary data. In Java, for example, binary data would be stored in arrays of data type byte.
10.4.3 The Boolean Data Type
XML Schema supports Boolean values with the data type boolean. Most OO languages implement a Boolean data type. Java, for example, has a built-in data type boolean.
10.4.4 Exact Numeric Types
The only primitive exact numeric data type in XML Schema is decimal. All other exact data types, such as integer, long, int, short, are derived from this data type by restriction. XML Schema does not restrict the upper and lower bounds of decimal but requires processors to support at least 18 decimal digits.
Most OO languages (except perhaps COBOL++) don’t have built-in support for decimal data types but may provide appropriate support via class libraries. For example, Java 2 provides a decimal data type in the library java.math. The class java.math.BigDecimal supports decimal numbers with an unlimited number of decimal and fractional digits.
The integer data type is found as a built-in data type in most OO languages (except in those that don’t have built-in data types at all, such as SmallTalk). In Java, for example, we find the following integer data types:
| XML | Java | Range |
| integer | java.math.BigInteger | unlimited |
| long | long | –9,223,372,036,854,775,808 9,223,372,036,854,775,807 |
| int | int | –2,147,483,648 2,147,483,647 |
| short | short | –32,768 32,767 |
| unsignedShort | char | 0 65,535 |
| byte | byte | –128 127 |
10.4.5 Approximate Numeric Types
XML Schema supports the approximate numeric types float and double for single and double precision floating-point numbers according to IEEE 754-1985. With these data types we find the highest compatibility with OO languages, as IEEE 754-1985 has been adopted by practically all OO languages.
10.4.6 Date and Time
XML Schema provides a rich set of date and time data types based on ISO 8601. dateTime specifies a precise instant in time (a combination of date and time), date specifies a Gregorian calendar date, and time specifies a time of day. All three types can be specified with or without a time zone. The data type duration specifies an interval in years, months, days, hours, minutes, and seconds, and allows negative intervals, too.
Not all OO languages provide built-in support for date and time. Java provides support for date and time in class library java.util: The classes java.util.Date, java.util.Calendar, and java.util.GregorianCalendar provide extensive support for date and time arithmetic. java.util.Date is almost equivalent to the XML Schema type dateTime with a resolution of milliseconds.2
Section 9.4.1 showed a conversion routine from the XML Schema xs:date and xs:dateTime formats into java.util.Date objects.
Most OO languages (including Java) do not provide built-in support for intervals. However, such a data type can easily be implemented as a specific class.
10.4.7 Other Data Types
XML Schema supports URIs with the data type anyURI. Java supports URLs (a subtype of URIs) with the class java.net.URL. Java 1.4 improves the support for URIs by adding class java.net.URI.
The QName data type in XML Schema specifies qualified names. It consists of a local part and a namespace part. It is relatively easy to represent such a qualified name in OO languages: It can be implemented as a tuple consisting of a namespace URI and the local name (string).
10.4.8 Type Restrictions
XML Schema provides a rich set of constraining facets to derive user-defined simple data types from built-in data types. Object-oriented languages allow us to implement user-defined data types that are directly or indirectly derived from built-in data types. The additional constraints can be implemented within the access method belonging to objects of these types.
10.4.9 Type Extensions
Restriction is not the only way in XML Schema to derive user-defined types. Type extensions such as type union and type extension by list are possible, too. In most OO languages there is no construct like a type union. (C++ recognizes the construct of a variant, which it inherited from C.) One solution is to use a type of the least common denominator, but some type-safety may be lost. In the worst case the most general type must be used, such as Object in Java.
Extension by list can easily be simulated in object-oriented languages through an appropriate collection type object such as java.util.List in Java. Some languages such as Eiffel support parameterized types, allowing the implementation of type-specific lists, such as a list of integers, a list of strings, and so on. Other languages such as Java must resort to a collection of general objects. (Java will support parameterized types with version 1.5.) This less type-safe solution requires casting a list element back into its specific data type when it is retrieved from the list.
10.4.10 Null Values
In OO languages, null values are possible when a data type is implemented as a class, and usually not possible when a data type is primitive. In Java, for example, the data types such as int, short, char, float, or double do not allow null values. For this purpose, Java provides wrapper classes: java.lang.Integer, java.lang.Float, or java.lang.Double.
Traditionally, OO null values are used to signal the absence of an XML element or attribute when an element or attribute is optional. This leaves us with the question of what to do when an element was defined as nillable (see Section 5.3.16). The answer is simple: It is in general not possible to represent a nilled element by a null value. The element may, for example, contain other attributes, so it must be represented by an object. Instead, the attribute xsi:nil=“true” must be represented by a Boolean field within the object.
10.4.11 Implementing a Type Hierarchy
A consistent approach to mapping the XML Schema type system onto an OO language is not to map directly to built-in primitive types, but to implement a hierarchy of classes that closely matches the XML hierarchy of built-in types. A generic class XMLObject could be at the top of such a hierarchy. This class could provide some features that are common to all XML objects, such as marshaling and unmarshaling. Derived from this generic class, we would find classes such as XMLAnyType, XMLAnySimpleType, XMLString, XMLNormalizedString, XMLToken, XMLNMTOKEN, and so on. These classes could implement the specific constraints for each built-in XML Schema data type. User-defined types could be derived from these classes, too.
10.5 COMPLEX TYPES
This section shows how the various constructs found in XML schemata, such as hierarchy, sequence, choice, and so on, can be mapped onto OO constructs. Java has been chosen as the implementation language.
10.5.1 Hierarchy
Leaf elements (elements that do not contain child elements) of a cardinality <= 1 and attributes can be implemented as simple fields of the data types shown in the previous section. Note that in Java it is not possible to express on a field level that an element is optional or not. However, it would be possible to add the necessary checks to the set… () access routines of a field. If an element is optional, it must be implemented as an object (reference) type and not as a primitive type (for example, as java.lang.Integer or our own XMLInteger instead of int) to allow for null values.
The following example shows how leaf elements can be translated into Java.

Java Interface

The last four instructions define the string constants that represent the tag names associated with this interface. These constants are used during the marshaling and unmarshaling process.
Java Implementation

Complex elements with a cardinality of <= 1 are implemented in the same way, except that the child elements are represented by fields with the type of the child node.

Java Interface

The representation of repeating elements requires some more effort. Such an element must be represented as a collection data type (List, ArrayList, LinkedList, Vector). These data types have their own interface, which makes it possible to iterate through the list, access list elements, and modify the list. Elements contained in a list always have the data type Object (the most general data type in Java). When retrieving an element from the list it is necessary to cast it into the appropriate type.


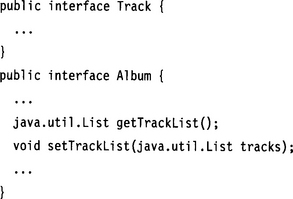
Client Code
![]()
Alternatively, we could implement a type-safe access layer around such a collection type, replicating all its access methods. Languages such as Eiffel or Pizza allow us to use generics (parameterized types) to specify collection types such as a list of track elements. Again, control for cardinality constraints could be built into the implementation of setTrackList().
10.5.2 Sequence
Maintaining sequence information is normally not a big problem when translating XML schemata into OO interfaces, as access is always performed field by field and by name. Also, the sequence in repeating elements is maintained: List items are ordered and can be accessed by an index.
However, there is one case that causes a problem. Let’s assume that a schema constructs a complex element by using an all connector. The consequence is that a sequence of elements in the document instance may arrive in a different order than the one defined in the schema. That does not really matter, as we normally access elements by name. But if we want to access an element by position, we are in trouble (XPath, for example, allows such things). We cannot determine the name of the element in question from the schema, because the instance may have a different element order. The relationship between tag and position is determined by the document instance.



Java Interface


Once converted to Java, the relationship between tag and position is lost. We are not able to ask: Was time given before or after location?
The problem also affects marshaling. Unmarshaling instance 2 into our Java structure should not cause problems: The unmarshaling process receives a tag and maps the element in the correct field. But when this data structure is marshaled again into XML, the information of the original sequence is no longer present, and the resulting XML will look like instance 1. This is, of course, unacceptable. The <xs: all> connector does not mean that the sequence of elements in an instance does not matter, it only means that all sequences are valid. (The XML Information Set [Cowan2001] (see Section 4.2 defines the child elements of a document as an ordered set.)
To solve this problem, it would be necessary to resolve the all connector into a choice of all possible permutations of the all list. However, this can result in a rather large amount of interface definitions. Section 10.9 discusses an alternate approach to this problem.
10.5.3 Repetition
One more point about sequences requires consideration: repeating sequences. Repetitions are mapped onto collection types such as List, ArrayList, and so on. The elements of such a collection type now do not contain an XML element but an XML model group (a sequence of elements). We represent such a model group with its own object type (LocationAndDate).
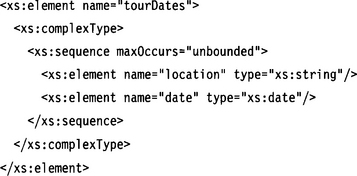
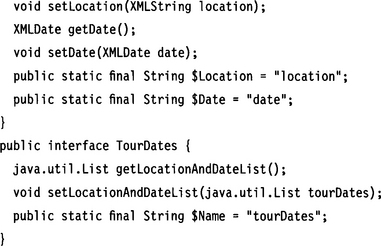

10.5.4 Choice
There is not much choice when we want to map a choice group onto OO structures: We have to implement it as a sequence (except in C++, where we might exploit the antediluvian variant construct), but with the additional constraint that only one of these fields in this sequence is not null. If we want to enforce this constraint, we have to provide an access method that sets all branches of the choice model group in a single step.


Java Interface

Sequences within a choice group must be implemented as their own object type, as shown with QuantityAndUnit. The method setAmountOrQuantityAndUnit is used to set both branches of the choice group in one step. Thus, the implementation of this method can check if only one parameter is not null.
The implementation of repeating choice groups is similar to the implementation of repeating sequences. If the choice group in the example above were to repeat, we would implement it as a list of AmountOrQuantityAndUnit objects.
10.5.5 Recursion
Recursion is relatively easy to model. The recursive element is implemented as its own object type. This type contains fields that hold objects that refer recursively (directly or indirectly) to it.

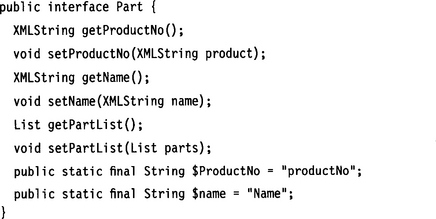
10.5.6 Global and Local Elements
The mapping shown above works well for elements defined globally. However, in the case of complex elements that are defined locally, we may run into name clashes. Remember that elements defined locally with the same tag names may have different types. So far, we have derived the interface names directly from the tag names by capitalizing the first letter.
As a matter of fact, this problem is easy to solve. We just name interfaces for locally defined elements differently, preferably by using the full path name. Using such a naming convention for a locally defined element performedAt (as child of jamSession), we would arrive at the following interface:
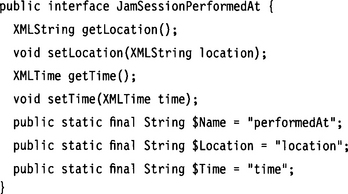
The constant $Name for the tag name, however, stays the same.
10.6 GLOBAL TYPES
Global XML Schema types can be mapped onto OO structures in much the same way as XML elements. The only difference is that no tag name is declared for the type structure.



10.7 INHERITANCE
Section 10.3 already covered type hierarchies in OO languages. We found that object-oriented languages such as Java allow us to derive a subtype from a parent type by extending the definition of the parent type, and that the subtype inherits features from the parent type. This is very much in sync with derivation by extension in XML Schema. This inheritance mechanism should therefore be relatively easy to map between both data models. For example, if we want to extend the above CD_type with a price element, we can use the existing CD type interface and extend it, too.

Java Interface

XML Schema can also derive types by restriction, for example, by excluding optional child elements or attributes from the definition of a complex type. Within an OO implementation, such restricting constraints can easily be added by sharpening the constraints defined in the access method implementations (or by adding new constraints). For example, if we want to exclude an optional (minOccurs=“0”) element from a restricted type, we simply override its access methods with methods that throw an exception when they are used.
10.8 POLYMORPHISM
In object-oriented languages, the term polymorphism denotes the ability to use instances of a given type in the role of another type, usually instances of a subtype in the role of the supertype (substitutability). For example, given the above parent type CD_type and the subtype CDforSale_type, we can use CDforSale_type anywhere CD_type is used.
XML Schema has a similar concept. We can use a type that has been derived from a parent type anywhere the parent type is used.
![]() This applies, for example, to substitution groups. Elements that belong to a substitution group can replace the head element anywhere the head element is specified. Remember that the type of a substitution group element must be a type that is derived from the type of the head element.
This applies, for example, to substitution groups. Elements that belong to a substitution group can replace the head element anywhere the head element is specified. Remember that the type of a substitution group element must be a type that is derived from the type of the head element.
![]() Similarly, document instances may explicitly declare a type (via xsi:type) for an element or attribute used in the document instance. The condition is that this type is derived from the type under which the element or attribute was declared in the schema.
Similarly, document instances may explicitly declare a type (via xsi:type) for an element or attribute used in the document instance. The condition is that this type is derived from the type under which the element or attribute was declared in the schema.
Since the subtyping characteristic in Java and XML Schema is equivalent, as pointed out in the previous section, we can implement a Java binding of a given schema and trust that this binding can handle all documents with types derived from the original schema.
10.9 DYNAMIC MARSHALING
This section presents a proposal for how to solve the sequence problem with the <xs:all> connector (see Section 10.5. Two new fields are included in the interface definition: an integer field first and an integer array next:

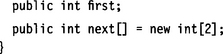
These two fields are filled by the unmarshaling process, which records the sequence of elements found in the document instance. For example, if the document is
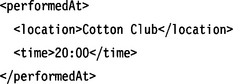
the content of first is 0, the content of next[0] is 1, and the content of next[1] is −1. If the instance is
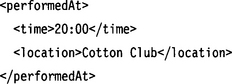
the content of first is 1, the content of next[0] is −1, and the content of −next [1] is 0.
Now the marshaling process, instead of just writing out the elements in the sequence of their definition, can use the information in −first and −nextand write the elements in this sequence. The elements in the output document will have the same order as in the original document. The content of −first and −next could also be used to address elements by position.
10.10 CONSTRAINTS
As mentioned earlier, the object-oriented data model is based on encapsulation. The data within an object can only be accessed via methods. This makes it possible to implement all kinds of constraints in these access methods, including the constraints defined in an XML Schema.
10.10.1 Simple Types
The simplest constraints are those implied by simple types. These constraints are defined in XML Schema in the form of constraining facets such as minInclusive, maxExclusive, fractionDigits, pattern, and so on. Facets such as minInclusive or fractionDigits are easy to implement in very few instructions; pattern, however, can require serious programming in some OO languages. Fortunately, Java 1.4 comes with a regex class that provides exactly the functionality to implement the pattern facet.
10.10.2 Cross-References
Cross-references that are defined in XML Schema via ID, IDREF, key, and keyref can, of course, also be checked. For example, a set… method for a list could check the list for duplicates and thus establish that the list elements are unique. Or, it could check if the list elements can be found in another specified list, and are thus suitable as references.
10.10.3 When to Check
Should we check constraints within access methods? Or would it be better to postpone the constraint validation until the final XML document is created (marshaled)? The problem with the first method is that constraints can get in the way when we want to modify content, especially if a constraint affects several fields. Also, a constraint can be checked more than once, which degrades performance.
However, the second method also has drawbacks. First, it is more difficult to identify the client code that caused the constraint violation. Second, if the document modification happens in an interactive environment—for example, when filling out a form—it is not very friendly to end users to tell them about a wrong field located at the beginning of the form after they have completed the whole form.
A good compromise is to implement constraints that affect a single field only in their respective access methods, and to test cross-field constraints in a separate step that can be invoked before the XML document is marshaled.
10.10.4 Conceptual Constraints
Conceptual models define additional constraints, in particular constraints that span multiple fields and multiple documents. Section 9.2.2 discussed such constraints that cannot be modeled with XML Schema. Section 9.4 showed how to check such constraints with application code, XSLT, and Schematron.
Section 9.4.1 showed an implementation of the constraint
![]()
for document type jamSession. There, we relied on the DOM API to access document nodes. The listing below shows an implementation based on an XML binding as outlined in the previous sections. Note that we deal with two document types: jamSession and jazzMusician. The binding for document type jazzMusician has been put into a separate Java package named jazzMusician to avoid name clashes.

10.10.5 Automatic Code Generation
The code above is much shorter than the code in Section 7.1.1, which is based on the DOM API. It is also more intuitive. However, it is not as short and compact as the original constraint specification:
![]()
This raises the question: Is there a way that we can automatically generate code like the above from the constraint specification given in the conceptual model? The answer is simple: not yet. The different implementations for binding XML Schema to object-oriented structures all generate different layouts, and many of these implementations have not yet reached a stable state. Once a standard binding method is established (this will probably be based on JAXB), the implementation of a constraint generator becomes an issue, too.
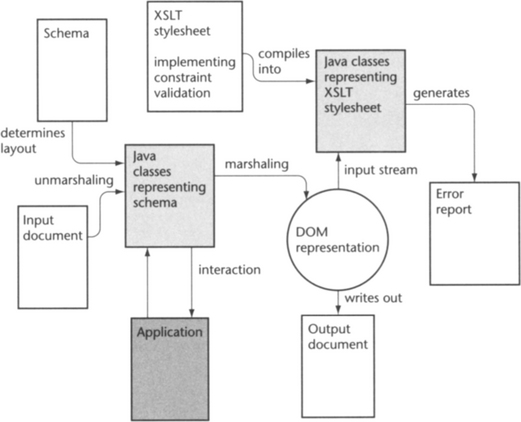
What is possible with current technology is shown in Figure 10.3. Instead of marshaling the Java data structures representing our input document to an output document file, we marshal it into a DOM representation. We can then use a suitable XPath processor (such as Jaxen) to apply the conceptual constraints formulated in XPath (see Section 9.3.
10.11 IDENTITY
The concept of keys (primary keys and foreign keys) is alien to the object-oriented concept. Instead, OO uses the concept of object identity. Objects are addressed by reference using an object identifier that is allocated whenever a new object is created. In contrast, relational databases (see Section 11.2 allow us to select table rows by content (XML databases also allow us to select XML documents by content, via XPath or XQuery).
This can create problems when we want to map several XML data types to OO structures and want to navigate within these structures. As discussed in Section 8.4.2, the XML documents may not contain the necessary navigation structures, and consequently the necessary object references in the OO implementation are missing. There are two ways to solve this:
![]() A map is created that describes the navigational model structure. Each map node points to the related map nodes and to the represented object.
A map is created that describes the navigational model structure. Each map node points to the related map nodes and to the represented object.
![]() Content-based addressing is implemented. This can be done again, for example, with maps. Primary and foreign keys of an asset are mapped to their owning object. This allows all necessary navigation to be performed within a larger structure.
Content-based addressing is implemented. This can be done again, for example, with maps. Primary and foreign keys of an asset are mapped to their owning object. This allows all necessary navigation to be performed within a larger structure.
10.12 VISIBILITY
Most object-oriented languages implement a concept of visibility. An object class and its features can be defined with various degrees of visibility. Private features are only visible for the class itself; public features are visible for everyone.
In Java, the default setting for the visibility of a class or feature is visibility within the same package. A package combines classes that are in some sense interrelated. The concept of packages can be compared with XML namespaces, as packages are used to avoid name clashes as well. When mapping XML schemata onto Java classes, we usually want to map each namespace onto a separate package. Since packages can be nested, we can even mimic the hierarchical organization of XML namespaces. For example, given the namespaces
![]()
andhttp://www.jazz.org/shopwe can map those onto the packagesorg.jazz.encyclopediaandorg.jazz.shopwhich are both contained in package jazz.
1.The Sun XML Datatypes Library (xsdlib) is one example of a Java implementation of the XML Schema type system.
2.However, these Java types always require the specification of a time zone, which is optional in XML Schema. Also, the date components (year, month, day, etc.) are restricted in size in Java, which is not the case in XML Schema.