
XML Basics
In this part of the book we will implement the conceptual models that we have developed in Part I as XML schemata in three ways—in the form of DTDs, in XML Schema, and in Relax NG. But before we do so, an overview of the concepts and facilities of all three schema languages is presented.
This chapter deals with the DTD as it is defined in the XML 1.0 specification [Bray2000]. But before we go into the DTD details, we will look at some advanced XML topics, such as XML namespaces, the XML information model, and canonical XML. A good understanding of namespaces and the XML Information Set is essential for appreciating the various features in XML Schema definition languages.
This discussion assumes that you are already familiar with the XML syntax. If not, there are many excellent books that provide an introduction to XML.
4.1 NAMESPACES
XML namespaces are defined in [Bray1999]. Namespaces are important for schema composition. Using namespaces helps to avoid name conflicts. Take for example a document that includes parts described by different document standards, such as XHTML, SVG, SMIL, SOAP, and your own schema definitions. Without namespaces it would be almost impossible to avoid name clashes. For this reason I recommend that you always define a target namespace with a schema, and I discourage the use of DTDs for schema definition.
Namespaces must be declared in an XML document instance with the help of the xmlns attribute or an attribute with the prefix xmlns:. The first defines the default namespace; the second defines namespaces that are associated with a namespace prefix. For example:
![]()
defines the XML Schema namespace as the default namespace. In contrast,
![]()
associates the XML Schema namespace with the prefix xs:.
The scope of such a namespace definition is the element where it is defined plus all child elements (unless a child element overrides it with another namespace declaration). So, if we declare namespaces in the root element of a document, their scope is usually the whole document.
We say that the name of an element is qualified if the element is within the scope of a default namespace declaration, or if its name is specified with a namespace prefix. Attributes are qualified if they are specified with a namespace prefix. (Default namespaces do not apply to attributes.) For example:
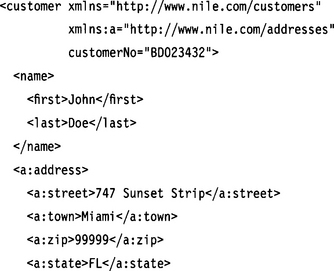

In this example all elements are qualified. The ones without a prefix belong to namespace http://www.nile.com/customers, and the ones with prefix a: belong to namespace http://www.nile.com/addresses. The attribute customerNo is not qualified.
Care must be taken if documents are composed from multiple entities (see Section 4.4.6). If namespace declarations were contained in an unexpanded entity (see Section 4.2.6), they would not be visible and the whole document would not be processed correctly.
4.2 THE XML INFORMATION MODEL
The principal information model of XML is defined in a W3C recommendation called the “XML Information Set” [Cowan2001]. The XML Information Set is independent of the actual representation of a document; the document may exist in the serialized form of an XML text file, in the form of a DOM tree, in the form of Java objects, and others. So, for the discussion of the XML information model, the concrete XML syntax is irrelevant.
In its current state this recommendation describes the abstract data model of the XML 1.0 recommendation [Bray2000], including XML namespaces [Bray1999], but does not cover new features introduced with XML Schema. In particular, it does not support type definitions for elements. For attributes, only those types that can be defined with a DTD are featured. Also, there is no support for the advanced integrity constraints that can be defined with XML Schema such as the key, keyref, and unique clauses (see Section 5.3.17).
4.2.1 Overview
Table 4.1 (page 92) lists all the information items that constitute the XML Information Set, with examples in serialized XML form. The XML Information Set has a tree structure, with the nodes of the tree made up of the information items in Table 4.1. Figure 4.1 (page 94)shows the structure of the XML Information Set using the AOM modeling language defined in Chapter 2.


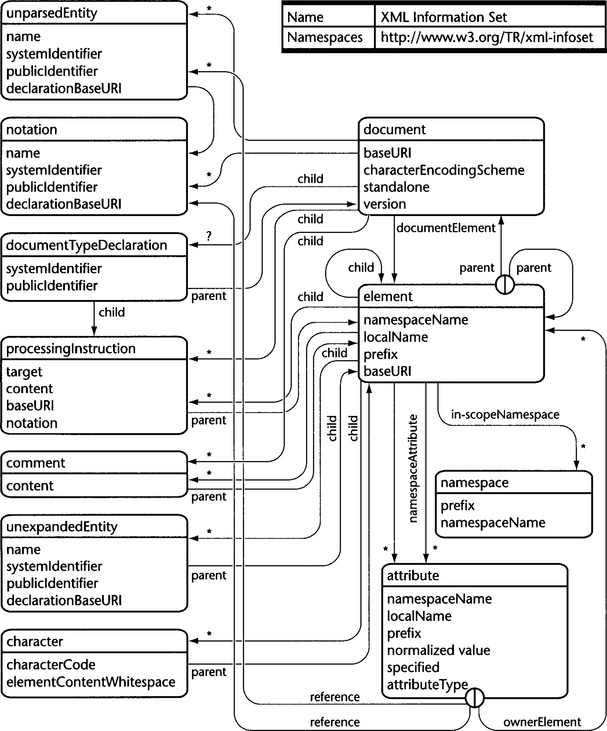
Note that the information set of a document instance defined under a DTD changes when a DTD-aware parser processes the document. Default and fixed values declared in the DTD may change the value of attributes in the document instance. Attributes declared in the DTD may be added to the attribute set of a document element in the document instance. Notations and unparsed entities declared in the DTD are added to the document node of the document instance. If this additional information is contained in an external DTD subset and the parser chooses to use this information (nonvalidating parsers are free to make use of an external DTD or not), the information set of the document instances changes.
Similarly, a schema defined with XML Schema may change the information set of a document instance: Default and fixed values declared in the DTD may change the value of attributes and elements in the document instance. Attributes declared in the DTD may be added to the attribute set of a document element in the document instance.
The following sections discuss each of these information items in detail.
4.2.2 Document Node
An XML document is defined as a document node in its own right. This node has the following properties:
![]() Children. A document node can own exactly one element node—the root element, also called document element. Besides this element, a document node can contain other child nodes: processing instructions, comments, and a document type declaration. Processing instructions and comments defined in the Document Type Definition (DTD) are not included in the information set of the document node. (Processing instructions defined in the Document Type Definition are child nodes of the document type declaration node, discussed in Section 4.2.9.)
Children. A document node can own exactly one element node—the root element, also called document element. Besides this element, a document node can contain other child nodes: processing instructions, comments, and a document type declaration. Processing instructions and comments defined in the Document Type Definition (DTD) are not included in the information set of the document node. (Processing instructions defined in the Document Type Definition are child nodes of the document type declaration node, discussed in Section 4.2.9.)
![]() Document element. The root element of the document. This element contains all other document elements as children, grandchildren, and further descendants.
Document element. The root element of the document. This element contains all other document elements as children, grandchildren, and further descendants.
![]() Notations. An unordered set of notation information items, one for each notation declared in the DTD (see Section 4.2.11).
Notations. An unordered set of notation information items, one for each notation declared in the DTD (see Section 4.2.11).
![]() Unparsed entities. An unordered set of unparsed entity information items (see Section 4.2.10), one for each unparsed entity declared in the DTD.
Unparsed entities. An unordered set of unparsed entity information items (see Section 4.2.10), one for each unparsed entity declared in the DTD.
![]() Base URI. The base URI of the document entity. Base URIs can be specified explicitly with the xml:base attribute as defined in the “XML Base” recommendation [Marsh2001].
Base URI. The base URI of the document entity. Base URIs can be specified explicitly with the xml:base attribute as defined in the “XML Base” recommendation [Marsh2001].
![]() Character encoding scheme. The code system used for this document. By default, XML uses the UTF-8 code system for character encoding. However, it is possible to declare other code systems such as UTF-16 for a document. In an XML file this is done with an encoding declaration in the document prolog:
Character encoding scheme. The code system used for this document. By default, XML uses the UTF-8 code system for character encoding. However, it is possible to declare other code systems such as UTF-16 for a document. In an XML file this is done with an encoding declaration in the document prolog:
![]()
![]() Standalone. An indication of the standalone status of the document. The value “true” indicates that a document does not rely on external markup definitions such as default values or entity declarations.
Standalone. An indication of the standalone status of the document. The value “true” indicates that a document does not rely on external markup definitions such as default values or entity declarations.
4.2.3 Elements
Element nodes may have one or several child nodes. They can be other elements, attributes, processing instructions, comments, character data, unparsed and unexpanded entities, and in-scope namespaces. Elements can repeat within a context, except the document element, which must occur exactly once.
An element has the following properties:
![]() Namespace name. The name of the namespace of the respective element type. The chosen namespace name should be globally unique.
Namespace name. The name of the namespace of the respective element type. The chosen namespace name should be globally unique.
![]() Local name. The local part of the element type name (excluding namespace prefix).
Local name. The local part of the element type name (excluding namespace prefix).
![]() Prefix. The namespace prefix in the element type name. This prefix serves as a shorthand notation for the element’s namespace.
Prefix. The namespace prefix in the element type name. This prefix serves as a shorthand notation for the element’s namespace.
![]() Children. An ordered list of child nodes. This can be other elements, processing instructions, unexpanded entities, characters, and comments.
Children. An ordered list of child nodes. This can be other elements, processing instructions, unexpanded entities, characters, and comments.
![]() Attributes. An unordered set of attribute information items, one for each attribute (either specified in the document instance or defaulted from the DTD).
Attributes. An unordered set of attribute information items, one for each attribute (either specified in the document instance or defaulted from the DTD).
![]() Namespace attributes. An unordered set of attribute information items, one for each namespace declaration (specified or defaulted from the DTD). Namespace attributes are declared by using the prefix xmlns:. For example,
Namespace attributes. An unordered set of attribute information items, one for each namespace declaration (specified or defaulted from the DTD). Namespace attributes are declared by using the prefix xmlns:. For example,
![]()
defines a namespace attribute for the XML Schema namespace. This attribute is owned by the <xs:schema> element.
In addition, a declaration of the form xmlns=“”, which undeclares the default namespace, counts as a namespace attribute.
![]() In-scope namespaces. An unordered set of namespace information items, one for each of the namespaces in effect for this element. These are not only namespaces that have been declared with this element but also namespaces that have been declared with parent elements, or the default namespace. In addition, XML’s own namespace, http://www.w3.org/XML/1998/namespace, with the prefix xml, belongs to the in-scope namespaces.
In-scope namespaces. An unordered set of namespace information items, one for each of the namespaces in effect for this element. These are not only namespaces that have been declared with this element but also namespaces that have been declared with parent elements, or the default namespace. In addition, XML’s own namespace, http://www.w3.org/XML/1998/namespace, with the prefix xml, belongs to the in-scope namespaces.
![]() Base URI. The base URI of the element. Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
Base URI. The base URI of the element. Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
![]() Parent. A reference to the parent node, either the document node or an element node.
Parent. A reference to the parent node, either the document node or an element node.
4.2.4 Attributes
The attribute nodes of an element always form an unordered list—that is, it is not possible to make statements about the order in which the attributes of an element occur. Attributes are always leaf nodes; they do not have child nodes. Each attribute has a local name and can have a namespace identifier. The local name (also, the combination of local name and namespace identifier) is not required to be unique within a document: Attributes with the same name may appear in different contexts in a document (under different owner elements). Attributes must not repeat within a context.
Attributes have the following properties:
![]() Namespace name. The name of the namespace of the respective attribute type.
Namespace name. The name of the namespace of the respective attribute type.
![]() Local name. The local part of the attribute type name (excluding namespace prefix).
Local name. The local part of the attribute type name (excluding namespace prefix).
![]() Prefix. The namespace prefix in the attribute type name.
Prefix. The namespace prefix in the attribute type name.
![]() Normalized value. The normalized attribute value, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
Normalized value. The normalized attribute value, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
![]() Specified indicator. Indicates whether this attribute was actually specified in the start tag of its element, or if it was defaulted from the DTD.
Specified indicator. Indicates whether this attribute was actually specified in the start tag of its element, or if it was defaulted from the DTD.
![]() Attribute type. An indication of the type declared for this attribute in the DTD. Legitimate values are ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS, NOTATION, CDATA, and ENUMERATION (see Section 4.4.3).
Attribute type. An indication of the type declared for this attribute in the DTD. Legitimate values are ID, IDREF, IDREFS, ENTITY, ENTITIES, NMTOKEN, NMTOKENS, NOTATION, CDATA, and ENUMERATION (see Section 4.4.3).
![]() References. An attribute may refer to another document item depending on its type:
References. An attribute may refer to another document item depending on its type:
Attributes of type IDREF and IDREFS refer to elements.
Attributes of type ENTITY, ENTITIES refer to unparsed entities.
![]() Owner element. A reference to the element that owns the attribute.
Owner element. A reference to the element that owns the attribute.
4.2.5 Processing Instructions
Processing instructions are evaluated by XML processors. For example, a processing instruction can cause a web browser to invoke an XSLT processor to convert the document into HTML:
![]()
A processing instruction information item has the following properties:
![]() Target. A string representing the target part of the processing instruction. In the example above, this is xml:Stylesheet.
Target. A string representing the target part of the processing instruction. In the example above, this is xml:Stylesheet.
![]() Content. A string representing the content of the processing instruction. In the example, href=“convert.xsl” type=“text/xsl”.
Content. A string representing the content of the processing instruction. In the example, href=“convert.xsl” type=“text/xsl”.
![]() Base URI. The base URI of the processing instruction. Base URIs can be specified explicitly with the xml: base attribute, as defined in the “XML Base” recommendation [Marsh2001].
Base URI. The base URI of the processing instruction. Base URIs can be specified explicitly with the xml: base attribute, as defined in the “XML Base” recommendation [Marsh2001].
![]() Notation. The notation information item named by the target (see Section 4.2.11).
Notation. The notation information item named by the target (see Section 4.2.11).
![]() Parent. A reference to the element that contains the processing instruction.
Parent. A reference to the element that contains the processing instruction.
4.2.6 Unexpanded Entity Reference
Normally, the information set describes an XML document with all parsed entities expanded. However, there may be cases when a processor chooses not to expand an entity, for example, when the entity definition is not accessible. In this case, the entity is represented by an unexpanded entity information item with the following properties:
![]() Name. The name of the entity referenced.
Name. The name of the entity referenced.
![]() System identifier. The system identifier of the entity.
System identifier. The system identifier of the entity.
![]() Public identifier. The public identifier of the entity, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
Public identifier. The public identifier of the entity, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
![]() Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
![]() Parent. A reference to the element that contains the unexpanded entity reference.
Parent. A reference to the element that contains the unexpanded entity reference.
4.2.7 Character
There is a character information item for each data character that appears in the document, whether literally, as a character reference, or within a CDATA section. A character information item has the following properties:
![]() Character code. The ISO 10646 (Universal Multiple-Octet Coded Character Set (UCS)) character code. The character code ranges from 0 to #x10FFFF, though not every value in this range is a legal XML character code:
Character code. The ISO 10646 (Universal Multiple-Octet Coded Character Set (UCS)) character code. The character code ranges from 0 to #x10FFFF, though not every value in this range is a legal XML character code:
![]()
This is the complete range of Unicode characters except xFFFE and xFFFF.
![]() Element content whitespace. A Boolean indicating whether the character is whitespace appearing within element content.
Element content whitespace. A Boolean indicating whether the character is whitespace appearing within element content.
![]() Parent. A reference to the element that contains the character.
Parent. A reference to the element that contains the character.
The XML Information Set specification does not specify how these character information items are aggregated in text nodes. This has resulted in various incompatible text node implementations. For example, XPath combines all characters within a node in a text child node, while DOM allows several text fragment child nodes. (DOM Level 3 remedies this situation by introducing an additional attribute, wholeText.)
4.2.9 Document Type Declaration
If the XML document has a document type declaration, then the information set contains a single document type declaration information item, which has the following properties:
![]() System identifier. The system identifier of the external DTD subset.
System identifier. The system identifier of the external DTD subset.
![]() Public identifier. The public identifier of the external DTD subset, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
Public identifier. The public identifier of the external DTD subset, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
![]() Children. An ordered list of processing instruction information items representing processing instructions appearing in the DTD.
Children. An ordered list of processing instruction information items representing processing instructions appearing in the DTD.
![]() Parent. A reference to the document node that contains the document type declaration.
Parent. A reference to the document node that contains the document type declaration.
4.2.10 Unparsed Entity
There is an unparsed entity information item for each unparsed general entity declared in the DTD. Unparsed entities are non-XML entities, such as images, audio files, and binaries. An unparsed entity information item has the following properties:
![]() System identifier. The system identifier of the external subset.
System identifier. The system identifier of the external subset.
![]() Public identifier. The public identifier of the external subset, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
Public identifier. The public identifier of the external subset, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
![]() Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml: base attribute, as defined in the “XML Base” recommendation [Marsh2001].
Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml: base attribute, as defined in the “XML Base” recommendation [Marsh2001].
![]() Notation. The notation information item named by the notation name (see next section).
Notation. The notation information item named by the notation name (see next section).
4.2.11 Notation
There is a notation information item for each notation declared in the DTD. Notations are used to identify the format of unparsed entities, the format of attributes declared with type NOTATION, and the processor for a processing instruction. A notation information item has the following properties:
![]() Name. The internal name of the entity.
Name. The internal name of the entity.
![]() System identifier. The system identifier of the referenced entity.
System identifier. The system identifier of the referenced entity.
![]() Public identifier. The public identifier of the referenced entity, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
Public identifier. The public identifier of the referenced entity, consisting of a normalized character string. A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.
![]() Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
Declaration base URI. The base URI relative to which the system identifier should be resolved (that is, the base URI of the resource within which the entity declaration occurs). Base URIs can be specified explicitly with the xml:base attribute, as defined in the “XML Base” recommendation [Marsh2001].
4.2.12 Namespace
Each element in the document has a namespace information item for each namespace that is in scope for that element (see Section 4.2.3). A namespace information item has the following properties:
4.2.13 An Example
For the following (very small) XML document, let’s discuss the XML Information Set.

Document Node
The document node has only one child node: the element j:album. This is also the document element. There are no notations or unparsed entities. There is no explicit base URI specification, so the base URI defaults to the actual location of the document that we assume at http://www.jazz.org/albums/. There is also no explicit XML prolog, so the default values apply for the XML version, the encoding scheme, and the standalone attribute: “1.0,” “UTF-8,” and “yes.”
Elements
Element j:album has several child nodes: the namespace attribute xmlns:j, the attribute productNo, the child element j:publisher, and several whitespace characters. j:album has the namespace name of “http://www.jazz.org/encyclopedia,” the local name is “album,” the prefix is “j.” There is a single in-scope namespace “http://www.jazz.org/encyclopedia.” There is no explicit base URI specification, so the base URI is inherited from the parent node that is the document node.
Element j:publisher has 25 child nodes: the characters of “http://www.ecmrecords.com.” j:publisher has the namespace name of “http://www.jazz.org/encyclopedia,” the local name is “publisher,” the prefix is “j.” There is a single in-scope namespace “http://www.jazz.org/encyclopedia.” There is no explicit base URI specification, so the base URI is inherited from the parent node, which is the element j:album.
Attributes
The attribute productNo has the namespace name “http://www.jazz.org/encyclopedia,” which it has inherited from its owner element j:album. The local name is “productNo,” but there is no namespace prefix. The normalized value is “1064,” the specified indicator is “true,” the attribute type has no value. The attribute does not refer to other document items.
Characters
There are 25 non-whitespace character nodes and several whitespace characters (line feeds, carriage returns, and blanks) contained in the document. Each character is coded under ISO 10646. The whitespace characters all belong to parent element j:album, while the non-whitespace characters belong to parent element j:publisher. For the whitespace characters, the whitespace indicator is set to true.
Namespaces
There is one namespace defined in this document—“j” is the prefix, and “http://www.jazz.org/encyclopedia” is the namespace name.
4.3 XML CANONICAL FORM
The XML Information Set as discussed above represents XML documents in an abstract form. The lexical form of an XML document allows many variations for the same content. For example, attributes may appear in arbitrary order, redundant namespace declarations are possible, character content may be expressed with or without CDATA, and so on. This makes it difficult for humans and machines to determine whether two given XML documents are equivalent— not identical by the letter but equivalent by content. And this is not the only problem. Cryptographic methods used by message digests and digital signatures rely on the textual representation of a document. With different text representations, equivalent documents would, for example, have different digital signatures. The proposed W3C recommendation “XML-Signature Syntax and Processing” [Eastlake2002] therefore relies on the existing methods for producing canonical XML.
The W3C recommendation “Canonical XML” [Boyer2001] defines a canonical form for XML documents, a syntactical form that allows simple character string comparison of two XML documents. However, this recommendation does not cover the new features introduced with XML Schema, such as the canonical form for the various new data types. Therefore, XML Schema itself defines a canonical form for the lexical representation of all built-in data types defined in XML Schema.
4.3.1 Canonical Text
Acceptable forms of text in XML documents meet the following requirements:
![]() Canonical XML documents are always encoded in UTF-8.
Canonical XML documents are always encoded in UTF-8.
![]() All line breaks are normalized to #xA.
All line breaks are normalized to #xA.
![]() Character entity references are resolved—that is, they are replaced by the referenced entities. Here, the character entity euro is replaced with its definition in the ENTITY clause:
Character entity references are resolved—that is, they are replaced by the referenced entities. Here, the character entity euro is replaced with its definition in the ENTITY clause:
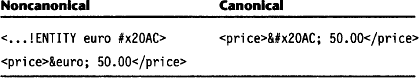
![]() Canonical text does not contain the characters &, <,>, nor the carriage return character (#xD). These characters are replaced by &, <, >, and 
.
Canonical text does not contain the characters &, <,>, nor the carriage return character (#xD). These characters are replaced by &, <, >, and 
.
![]() CDATA sections are replaced with their character content. Here, the CDATA wrapping around the if instruction is removed. By doing so, the unparsed character data becomes parsed character data, so we have to replace < with<.
CDATA sections are replaced with their character content. Here, the CDATA wrapping around the if instruction is removed. By doing so, the unparsed character data becomes parsed character data, so we have to replace < with<.

4.3.2 Canonical Whitespace
Acceptable forms for whitespace in canonical XML documents meet the following requirements:
![]() Whitespace outside of the document element and within start and end tags is normalized. (A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.)
Whitespace outside of the document element and within start and end tags is normalized. (A character string is normalized by reducing whitespace within the string to a single whitespace character and by removing any whitespace from the beginning and end of the string.)
![]() Attribute values are normalized; that is, whitespace within the attribute value string is reduced to a single whitespace character, and whitespace at the beginning and end of the string is removed.
Attribute values are normalized; that is, whitespace within the attribute value string is reduced to a single whitespace character, and whitespace at the beginning and end of the string is removed.
![]() All whitespace in character content is retained (excluding characters removed during line feed normalization—see above). Here, all whitespace within tags, and within the value of attribute ref, is normalized:
All whitespace in character content is retained (excluding characters removed during line feed normalization—see above). Here, all whitespace within tags, and within the value of attribute ref, is normalized:

4.3.3 Resolved References
The resolution of parsed entity references involves the following steps:
![]() Parsed entity references are replaced by the referenced entities.
Parsed entity references are replaced by the referenced entities.
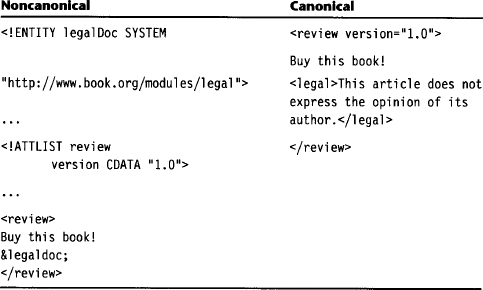
![]() Default attributes and fixed attributes are added to each element if not already present. Here, we have resolved entity legalDoc with the content of the file http://www.book.org/modules/legal to which it refers. We have also included the default value of attribute review in the document content.
Default attributes and fixed attributes are added to each element if not already present. Here, we have resolved entity legalDoc with the content of the file http://www.book.org/modules/legal to which it refers. We have also included the default value of attribute review in the document content.
4.3.4 Removal of Redundant Nodes
In canonical XML, the XML declaration and Document Type Definition (DTD) are removed. The XML declaration is no longer necessary since the canonical document is always a standalone document in UTF-8 code. The DTD is no longer necessary, as all default and fixed values and all referenced entities have been resolved.
Redundant namespace nodes are also removed. An element’s namespace node is redundant when the nearest parent element has a namespace node in the node-set with the same local name and value. Here, we have removed the namespace declaration in element title because the parent element book already declared the same namespace. We have also removed the XML declaration and the DOCTYPE declaration.

4.3.5 Canonical Elements
The child nodes of an element (elements, attributes, processing instructions, comments, character data, unparsed and unexpanded entities, and in-scope namespaces) are ordered in the following sequence:
2. Namespaces: Namespaces are ordered in lexical sequence.
3. Attributes: The attribute nodes are sorted lexicographically, with the namespace URI as the primary sort criterion and the local name as the secondary sort criterion.
Empty elements are expanded to start-end tag pairs. Here, we have brought namespace declarations and attributes into the correct order. We have also expanded the empty element <isPayed/> to a start tag and end tag.

4.3.6 Canonical Attributes
The canonical form of an attribute consists of
![]() the attribute’s qualified name
the attribute’s qualified name
![]() the value as a canonical string with normalized whitespace (see Section 4.3.2)
the value as a canonical string with normalized whitespace (see Section 4.3.2)
Here, we have normalized the whitespace in the attribute value, removed whitespace between element name and attribute and between equality sign and quote, and replaced the single quotes with double quotes:

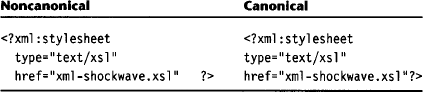
4.3.7 Canonical Processing Instructions
Processing instruction (PI) nodes consist of
![]() the PI target name of the node
the PI target name of the node
![]() a leading space and the string value if the string value is not empty
a leading space and the string value if the string value is not empty
![]() for PIs outside the document element, a separating #xA character between processing instruction and document element
for PIs outside the document element, a separating #xA character between processing instruction and document element
Here, we have removed unnecessary whitespace:
4.4 THE DOCUMENT TYPE DEFINITION (DTD)
In this section we move from the instance to the schema. As stated in Section 1.5, a schema defines a document type (or a class of documents) by imposing a set of constraints on the document instances. For example, we can postulate that documents of type book must start with an introduction, followed by a table of contents, followed by one or several chapters, followed by an index. This schema would clearly reject any document with the table of contents somewhere between the chapters.
Traditionally, document types are defined in XML with the help of a Document Type Definition (DTD). The DTD has its legacy in SGML. Because of its deficiencies (see Section 4.4.8), it has sparked a variety of alternate schema languages for XML, among them schema languages such as XDR, RELAX, Trex, or SOX. This has culminated in the definition of the W3C’s XML Schema, the now official way to define XML schemata.
However, DTDs are still popular. DTDs are much simpler than XML Schema. Schemata defined with a DTD are more compact than those defined with XML Schema. Tool support for XML Schema is still patchy but, fortunately, is quickly improving. Last but not least, there is a large pool of XML and SGML experts who are well versed in DTDs, while a similar skill pool for XML Schema has still to develop. Therefore, the rest of the chapter discusses how to define a document schema with a DTD.
4.4.1 Document
The first thing to know about a Document Type Definition is that a document instance does not necessarily need one. A document instance without a Document Type Definition is only constrained by the XML syntax—it must only be well formed, provided that no other schema definition exists for this document instance (through XML Schema, XDR, Relax NG, etc.). This well-formedness is sufficient for parsers and similar XML processors to process any XML document even if no DTD exists, or if the DTD cannot be accessed.
Note, however, that processing a document without the DTD can yield different results from processing with the DTD. A DTD can contain definitions that are relevant for the document content, such as default and fixed values and entity declarations. Only when a document is declared as standalone (see Section 4.2.2) is it semantically safe to process it without its DTD. When a DTD is specified and can be accessed, XML can validate the content of the document instance against the Document Type Definition. Since not all XML processors are able to do so, we differentiate between validating and nonvalidating XML processors.
The next important thing to know about a Document Type Definition is that it comes in parts. A DTD can consist of an internal and an external subset. The external subset exists as a separate physical entity, such as a file, and is referenced by a document instance via a DOCTYPE declaration with a SYSTEM identifier:

The SYSTEM identifier points via a URI to the physical entity containing the external DTD subset. The PUBLIC identifier identifies a publicly known document type such as a W3C standard. Such DTD subsets are usually built into the XML client, for example, into an XHTML browser. The document instance, however, may specify an additional URI after the public identifier to help the client to locate the DTD subset.
The internal subset of a DTD is specified within the document instance. In this case, too, a DOCTYPE declaration is used, but without the SYSTEM identifier. Instead, DTD components are specified locally.

Of course, it does not make much sense to define a document type for a single document instance. But the internal subset makes much more sense when it is combined with an external subset. It allows us to extend the definition of the external subset for individual document instances. For example, if we have a book that also has a glossary, we might append the definition for the glossary within the internal DTD subset of this document. The most common reason for internal subsets is to define, redefine, or extend entities—both character entities and the entities that define the structure of documents.
When we define both an external and internal DTD subset, we can combine both DOCTYPE declarations into one:

4.4.2 Elements
Now, let’s look at the components of a Document Type Definition. In a DTD, all XML elements are defined on a global level. This means that it is not possible to define identically named elements of different types in different contexts. For example, if we have a document
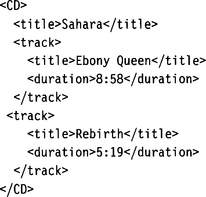
all title elements must have the same type definition. It would not be possible to have different element type definitions for CD/title and CD/track/title. This is fine in the above example, but a serious restriction in other cases.
The definition of elements in a DTD is very close to the definition of regular sets. In fact, we could see a DTD as a Hedge-Regular Grammar (HRG) (see Section 1.6.4). The ELEMENT and ATTLIST components of a DTD could be seen as production rules of such a grammar.
The following example could be a complete DTD for the document type book mentioned above:

The difference between a DTD and the definition of a regular grammar is that all non-terminal symbols are identical with the tag names in the document instances. This identity is the reason for the fact that DTDs do not allow us to define identically named elements of differing types in different contexts (which XML Schema and Relax NG allow). It is also responsible for the fact that DTDs are not equivalent with Hedge-Regular Grammars; they only define a subset of HRG languages.
But back to the basics. The DTD statement
![]()
can be seen as a grammar’s production rule because it describes the production of a <book>…</book> element. The <book> tags enclose the rest of the production consisting of (title+,authors). The production of the non-terminal symbols title and authors is defined in the following rules. Recursive definitions are possible, as in
![]()
The production stops when a terminal symbol is reached. The following terminal symbols are possible:
ANY Wildcard: The element can contain mixed content, including character data and child elements.
Denotes an empty element. The element contains parsed character data. (Parsed character data must not contain characters such as < or &.)Model Groups
If the right side of a production rule contains non-terminal symbols, then this is either a single non-terminal symbol or a model group. Basically, a model group is a regular expression (see Section 1.6.3) consisting of non-terminal and/or terminal symbols.
The following operators (also called connectors) can be used to combine these symbols:
| (child) | Single symbol, no operator required |
| (child1,child2,…,childn) | Sequence, elements separated by comma |
| (child1|child2|…|childn) | Choice, elements separated by the vertical bar |
| (child1,(child2|(child3,child4)),child5) | Parentheses are used to denote complex structures |
In addition, non-terminal symbols and expressions in parentheses can be postfixed with a modifier that denotes the cardinality of the symbol or expression:
| Symbol | Cardinality Constraint |
| No modifier | One occurrence, item is mandatory [1..1] |
| ? | One occurrence, item is optional [0..1] |
| + | Multiple occurrences, item is mandatory [1..n] |
| * | Multiple occurrences, item is optional [0..n] |
In the example given earlier we defined
![]()
because the element <authors> can contain multiple <author> elements, but must contain at least one of them. We defined
![]()
because the element <author> must contain the elements <firstName> and <lastName>, but may or may not contain the element <middleName>.
4.4.3 Attributes
Each non-terminal symbol (each tag name) may have a supplementary ATTLIST production rule for the definition of attributes. ATTLIST rules list all attributes of an element:

Here, ATTLIST defines the attributes for element author. These are author-id and role. Each single attribute definition consists of an attribute name, an attribute type, and a default value specification.
ATTLIST rules are always terminal because XML attributes cannot have a complex structure. The attribute types can be selected from a few built-in primitive types:

The following default value specifications can be used for attribute definitions:
| #IMPLIED | Attribute is neither required nor does it have a default value. |
| #REQUIRED | Attribute must be specified in document instance. |
| “yes” | Default value. An attribute with the specified default value is inserted into the document instance when the instance does not specify the attribute. |
| #FIXED “v1” | Fixed content. If the instance specifies the attribute, it must have this value. If not, the attribute with this value is inserted into the instance. |

defines that an author element must always specify an attribute author-id of type ID. If the attribute role is specified, it must have either the value “contributor” or “editor”. If this attribute is not specified, the default value role=“contributor” is inserted into the document. For example,
![]()
results in
![]()
4.4.4 Cross-References
The ID and IDREF attribute types can be used to establish cross-references between elements. This allows us to establish networklike document structures that cannot be captured in tree structures. In particular, it is possible to define documents that mimic relational tables by using the ID and IDREF constructs. Attributes of type ID act as primary keys, while attributes of type IDREF act as foreign keys. Most XML DOM implementations allow for locating elements by ID, too.
4.4.5 Extension Mechanisms
The NOTATION attribute type acts as a type extension mechanism for elements. A NOTATION type attribute refers to one or several NOTATION declarations. For example:

By referring to several NOTATION declarations, a NOTATION attribute can implement a type union. Each NOTATION declaration declares a specific data type. A custom XML processor can check this data type, possibly by using a helper application.
In practical applications, the NOTATION construct is rarely used, especially as there are now better ways to define data types for XML attributes and elements with XML Schema.
4.4.6 Document Composition
A DTD can declare user-defined entities. These entities can be used within the document text and are replaced in the document by the entity definition when the document is processed and when the entity definition is accessible. Locally defined entities are used to abbreviate frequently used terms and phrases or to introduce a symbolic notation for commonly needed constants. For example:
![]()
Externally defined entities are used to modularize schemata. For example,
![]()
includes the contents of file http://www.book.org/modules/legal in the document content.
Using external entities can modularize both the definition of schemata and document instances. This can be helpful when documents are very large and complex. External entities can contain references to other entities, so it’s possible to construct large entity trees. SGML authors, especially, have developed a high art of modularization with entities.
However, when external entities are used too extensively for modularization, the maintenance of schemata becomes difficult. In addition, the use of external entities in some application areas is not recommended. For example, if XML is used as a message format, external entities should be avoided; standalone documents are preferred. Also, XML database systems will usually resolve all external entities before they store a document. When the document is retrieved again, it looks different: The external entities are now included.
Both entity types discussed above are parsed entities (they contain XML content that can be parsed). In addition, XML recognizes unparsed entities—entities that contain non-XML data such as images, audio files, and video clips. An unparsed image entity, for example, can be referenced with
![]()
4.4.7 Schema Composition and Reuse Mechanisms
Parameter entities are only used within a DTD; they do not appear within the content of XML instances. A parameter entity is an abbreviation for a string that is used frequently within a DTD, thus allowing these strings to be factored out.
A parameter entity can be declared through
![]()
All occurrences of %entity-name within the DTD will be substituted with string-value. Because the string value may contain other references to parameter entities, the concept of parameter entities is quite powerful.
A parameter entity may not only relate to a simple string value but also to a public identifier or to a system identifier. This makes it possible to compose a DTD from several parts. Typically, a complex DTD consists only of a small root unit containing a set of parameter entity declarations referring to the various components that constitute the DTD. Our book DTD could look like this:

The file common.ent could, for example, contain the definitions

while the file author.ent would contain the definitions

However, this technique quickly reaches its limits. Document schemata made up of dozens of separate entity files are difficult to manage; because there is no namespace concept, name clashes are all too common.
One important application of parameter entities is to implement a schema extension mechanism. Take for example our book schema. A book instance may only consist of one or several title elements and one authors element. We are not allowed to add some detail information to specific instances, such as comments, a table of contents, or reviews.
If we want to allow arbitrary extensions to a document schema on the instance level, we can utilize parameter entities. First we define the external DTD subset in the following way:
![]()
Here, we define an empty parameter entity named details and append it to the definition of element book. So, this definition is equivalent to
![]()
But if we override the definition of entity details within the internal DTD subset, things look completely different:

![]()
is resolved to
![]()
and we can add a publishersReview element as a child element to the book element.
4.4.8 DTD Deficiencies
In the past, DTDs were the standard way to define a schema for an XML document type. This has changed with the release of the XML Schema Recommendation by the W3C. Compared to XML Schema, DTDs have several deficiencies:
![]() The syntax of a DTD is different from XML syntax. This inhibits the use of the vast array of XML tools for editing, validating, parsing, and transforming DTDs.
The syntax of a DTD is different from XML syntax. This inhibits the use of the vast array of XML tools for editing, validating, parsing, and transforming DTDs.
![]() DTDs do not support namespaces. Although DTDs allow the use of prefix: name combinations for element and attribute names, they interpret these combinations as simple names. This can lead to confusion.
DTDs do not support namespaces. Although DTDs allow the use of prefix: name combinations for element and attribute names, they interpret these combinations as simple names. This can lead to confusion.
![]() DTDs only recognize a small range of built-in data types that can only be applied to attributes. For example, we cannot define elements and attributes that must be numeric or integers. Thus, the content of elements and the value of attributes are always regarded as character data. This can have unpleasant effects when a processor wants to compare two elements containing numeric values. Because the processor does not know that the element content is numeric, 6 is regarded as greater than 139594; -1 is regarded as smaller than -5; the floating-point number 3.7e-10 is regarded as larger than 2.0e+16; and so on. Languages such as XPath, therefore, have explicit means of interpreting the content of an element or attribute as numeric.
DTDs only recognize a small range of built-in data types that can only be applied to attributes. For example, we cannot define elements and attributes that must be numeric or integers. Thus, the content of elements and the value of attributes are always regarded as character data. This can have unpleasant effects when a processor wants to compare two elements containing numeric values. Because the processor does not know that the element content is numeric, 6 is regarded as greater than 139594; -1 is regarded as smaller than -5; the floating-point number 3.7e-10 is regarded as larger than 2.0e+16; and so on. Languages such as XPath, therefore, have explicit means of interpreting the content of an element or attribute as numeric.
![]() There is no standard way to create user-defined data types. Type definitions with the NOTATION mechanism require custom extensions to XML processors and are rarely portable.
There is no standard way to create user-defined data types. Type definitions with the NOTATION mechanism require custom extensions to XML processors and are rarely portable.
![]() DTDs do not provide a special mechanism for specifying sequences of elements with no specified order. For a given model group (e1,e2,e3) the elements e1…e3 must appear in the document instance in the exact sequence as defined in the DTD. To simulate such an unordered sequence (a bag), all possible permutations must be given as alternatives: ((e1,e2,e3) | (e1,e3,e2) | (e2,e1,e3) | …). In contrast, SGML allows for specifying such sequences with (e1&e2&e3). We will see that XML Schema provides means for specifying bags, too.
DTDs do not provide a special mechanism for specifying sequences of elements with no specified order. For a given model group (e1,e2,e3) the elements e1…e3 must appear in the document instance in the exact sequence as defined in the DTD. To simulate such an unordered sequence (a bag), all possible permutations must be given as alternatives: ((e1,e2,e3) | (e1,e3,e2) | (e2,e1,e3) | …). In contrast, SGML allows for specifying such sequences with (e1&e2&e3). We will see that XML Schema provides means for specifying bags, too.
![]() The definition of general cardinality constraints such as [2:4] is not supported. Again we must enumerate all possible combinations: ((e,e), (e,e,e), (e,e,e,e)). When there is no upper bound, such as [4:*], we need to write this as (e,e,e,e+).
The definition of general cardinality constraints such as [2:4] is not supported. Again we must enumerate all possible combinations: ((e,e), (e,e,e), (e,e,e,e)). When there is no upper bound, such as [4:*], we need to write this as (e,e,e,e+).
![]() In DTDs all elements are defined on the global level. This makes it impossible to define context-sensitive elements—elements with the same name but different structures in different contexts.
In DTDs all elements are defined on the global level. This makes it impossible to define context-sensitive elements—elements with the same name but different structures in different contexts.
![]() DTDs do not allow the definition of multifield cross-reference keys, nor is it possible to use element values as keys (only attributes can be defined as type ID). Keys cannot be scoped, either; they are always defined on the global level. This can require document authors to construct rather complex key values to simulate multifield keys or scoped keys.
DTDs do not allow the definition of multifield cross-reference keys, nor is it possible to use element values as keys (only attributes can be defined as type ID). Keys cannot be scoped, either; they are always defined on the global level. This can require document authors to construct rather complex key values to simulate multifield keys or scoped keys.
Section 3.5 showed how to construct a composite key value. In a document where we want to index jazzMusician elements by name, for example, we have to construct a composite key value from the constituents of the name element, such as MingusCharles. If in the same document we also want to index jazz musicians by instrument, we must prefix the key values with a scope prefix in order to distinguish musician keys from instrument keys, for example, musician#MonkThelonious and instrument#piano.