
Chapter 7. Principled failure handling
You have seen that resilience requires distributing and compartmentalizing systems. Distribution is the only way to avoid being knocked out by a single failure, be that hardware, software, or human; and compartmentalization isolates the distributed units from each other such that the failure of one of them does not spread to the others. The conclusion was that in order to restore proper function after a failure, you need to delegate the responsibility of reacting to this event to a supervisor.
The importance of ownership appeared already within the decomposition of a system according to divide et regna, expressed as the difference between a descendant module and a dependency. Descendants own a piece of the parent’s functionality, but foreign functions are incorporated only by reference. The resulting hierarchy gives the supervision structure for the modules.
7.1. Ownership means commitment
In the previous chapter, you saw an analogy between a system hierarchy and a corporate organization. Imagine yourself for the moment to be a customer in a store belonging to one of these organizations. If you are talking to a sales clerk about buying a shirt and that person tells you that they do not like their job and wanders off midconversation, it is not your responsibility to resolve the situation. It is the responsibility of the store manager to handle it. This seems obvious and perhaps even humorous, but consider the situation with software. It is not at all uncommon for software to tell callers about internal problems it is having, by throwing exceptions.
This does not make much sense.
The caller is rarely in a position to do something useful about the failure. If the failing module has been properly encapsulated, the caller must be completely insulated from the implementation details, but those implementation details are often exposed in the exception. For example, suppose a simple lookup function is implemented using a database query. The caller might implement some handling for a SQLException to cover the more common database failures. Now, suppose the database-based lookup function is replaced by a microservice making HTTP calls: depending on how the exceptions were declared, the complete system may or may not compile. It has certainly broken backward compatibility with existing callers. The system may appear to work as long as the new implementation is running correctly, but whatever was put in place to handle database exceptions most likely is completely unprepared to handle network exceptions due to HTTP failures.[1]
The FreeBSD fortune command may sometimes respond with “Steinbach’s Guideline for Systems Programming: Never test for an error condition you don’t know how to handle.” This turns out to be better advice than it might seem at first glance.
It is worth remembering that validation errors are part of the normal operation protocol between modules, but failures are those cases in which the normal protocol cannot be executed any longer and the supervision channel is needed. Validation goes to the user of a service, whereas failure is handled by the owner of the service. The sales clerk asking what size and style of shirt you want is validation. The sales clerk who wanders off midconversation is a failure condition.
If a certain piece of the problem is owned by a module, that means this module needs to solve that part and provide the corresponding functionality. No other module will do so in its stead. Dependent modules will rely on this fact and will not operate correctly or to their full feature set when the module that is supposed to offer these functions is not operational. In other words, ownership of a part of the problem implies a commitment to provide the solution, because the rest of the application will depend on this.
Every function of an application is implemented by a module that owns it; and, according to the hierarchical decomposition performed in the previous chapter, this module has a chain of ancestors reaching all the way up to the top level. That one corresponds to the high-level overall mission statement for the full system design as well as its top-most implementation module, which is typically an application bundle or a deployment configuration manager for large distributed applications.
This ancestor chain is necessary because we know that failures will happen, and by failures we mean incidents where a module cannot perform its function any longer (for example, because the hardware it was running on stopped working). In the example of the Gmail contacts service, the low-latency search module can be deployed on several network nodes, and if one of them fails, then the capacity of the system will be reduced unintentionally. The search service is the next owner in the ancestor chain, the supervisor. It is responsible for monitoring the health of its descendant modules and initiating the start of new ones in case of failure. Only when that does not work—for whatever reason—does it signal this problem to its own supervisor. This process is illustrated in figure 7.1.
Figure 7.1. A failure is detected and handled within the search part of the contacts module’s hierarchy. The search supervisor creates a new instance of the low-latency search that has previously failed—for whatever reason.

The rationale for this setup is that other parts of the application will depend on the search service and all the services it offers for public consumption; therefore, this module needs to ensure that its submodules function properly at all times. Responsibility is delegated downward in the hierarchy to rest close to the point where each function is implemented. The unpredictable nature of failure makes it necessary to delegate failure-handling upward when lower-level modules cannot cope with a given situation. This works exactly as in an idealized (properly working) corporate structure, assuming that failure is treated as an expected fact of life and not swept under the carpet, and is in contrast to the traditional method of throwing exceptions back to the calling module. Even on small systems, expecting the caller to handle faults creates problems with system cohesion. This is greatly compounded when the system is distributed and location of the failing module may not be known to the caller.
7.2. Ownership implies lifecycle control
The scheme of failure handling developed in the previous section implies that a module will need to create all submodules that it owns. The reason is that the ability to re-create them in case of a failure depends on more than just the spiritual ownership of the problem space: the supervisor must literally own the lifecycle of its submodules. That is its responsibility. Imagine some other module creating the low-latency search module and then handing it out to contacts as a dependency, by reference. The contacts module would have to ask that other module to create a new low-latency search when it needed one, because that other module might not realize that the old instance had failed. Replacing a failed instance includes clearing out all associated state, such as removing it from routing tables and in general dropping all references to it so the runtime can then reclaim the memory and other resources that the failed module occupied.
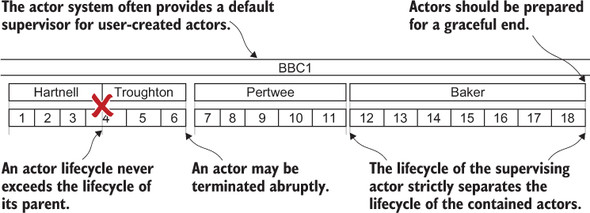
This has an interesting consequence in that the lifecycle of descendant modules is strictly bounded by its supervisor’s lifecycle: the supervisor creates it, and without a supervisor it cannot continue to exist. Figure 7.2 illustrates this bounding. An actor system, BBC1, is required to have an actor available to fulfill a particular role. As with our sales clerk previously, actors do not last forever in the role. When Hartnell leaves, he is replaced successively by Troughton, Pertwee, and Baker. In each case, the actor may have spawned further actors to accomplish additional tasks. When the actor is terminated, its spawned actors are terminated as well. There is no mechanism to hand off actors from one supervisor to the next. Attempting to do so would require a level of coordination that would impose severe design limitations on the actor system in the best of circumstances. In addition, there would be risks even if the hand-off were successful, because the reason the parent actor is being shut down is that something is irreparably wrong. It would not be safe to assume that all child actors are healthy and that the problem is limited to the parent.
Figure 7.2. The lifecycle of each actor is bounded by the lifecycle of its supervisor. The supervisor is therefore responsible for creating supervised actors and for terminating them if necessary.
Dependencies are not restricted in this fashion. In traditional dependency injection, it is customary to create the dependencies first such that they are available when dependent modules are started up. Similarly, they are terminated only after all dependents have stopped using them. That can create dependencies that are untenable. If the customer depends on the sales clerk, the sales clerk cannot be replaced until the customer activity is complete. That is convenient in theory but could put the system in an unstable state if the sales clerk fails in the midst of a customer interaction. With dynamic composition, as described in chapter 5 on location transparency, this coupling becomes optional. Dependencies can come and go at arbitrary points in time, changing the wiring between modules at runtime.
Considering the lifecycle relationship between modules therefore also helps in developing and validating the hierarchical decomposition of an application. Ownership implies a lifecycle bound, whereas inclusion by reference allows independent lifecycles. The latter requires location transparency in order to enable references to dependencies to be acquired dynamically.
7.3. Resilience on all levels
The way you deal with failure is inherently hierarchical; this is true in our society as well as in programming. The most common way to express failure in a computer program is to raise an exception, which is then propagated up the call stack by the runtime and delivered to the innermost enclosing exception handler that declares itself responsible. The same principle is expressed in pure functional programming by the return type of a called function in that it models either a successful result or an error condition (or a list thereof, especially for functions that validate input to the program). In both cases, the responsibility of handling failure is delegated upward; but in contrast to the Reactive approach described in this chapter, these techniques conflate the usage hierarchy with supervision—the user of a service gets to handle its failures as well.
The principled approach to handling failure described in this chapter adds one more facet to the module hierarchy: every module is a unit of resilience. This is enabled by the encapsulation afforded by message passing and by the flexibility inherent in location transparency. A module can fail and be restored to proper function without its dependents needing to take action. The supervisor will handle this for everyone else’s benefit.
This is true at all levels of the application hierarchy, although obviously the amount of work to be done during a restart depends on the fraction of the application that has failed. Therefore, it is important to isolate failure as early as possible, keeping the units small and the cost of recovery low, which will be discussed in detail as the Error Kernel pattern in section 12.2. Even in those cases where more drastic action is needed, the restart of the complete contacts service of the example Gmail application will leave most of the mail functionality intact (searching, viewing, and sorting mail does not depend critically on it; only convenience may suffer). Consequently, resilience can be achieved at all levels of granularity, and a Reactive design will naturally lend itself well to this goal.
7.4. Summary
In this chapter, we used the hierarchical component structure to determine a principled way of handling failure. The parent component is responsible for the functionality of its descendants, so it is logical to delegate the handling of such failures that cannot be dealt with locally to that same parent. This pattern allows the construction of software that is robust even in unforeseen cases, and it is the cornerstone for implementing resilience.
The next chapter investigates another aspect of building distributed components: consistency comes at a price. Once again, we will split the problem into a hierarchy of independent components.