
Chapter 13. Replication patterns
The previous chapter introduced powerful architectural and implementation patterns for breaking down a larger system into simple components that are isolated from each other while encapsulating failures. One aspect that we did not cover is how to distribute the functionality of a component such that it can withstand hardware and infrastructure outages without loss of availability. This topic is large enough by itself to be treated in a separate chapter. In particular, in this chapter you will learn about the following:
- The Active–Passive Replication pattern, for cases where explicit failover is acceptable or desirable
- Three different Multiple-Master Replication patterns that allow clients to contact any replica of their choosing
- The Active–Active Replication pattern, which specializes in zero downtime for a selected class of failures
Note
This chapter presents some deep treatment of replication with its pitfalls and limitations. Unfortunately, for this topic, the devil is in the details, and some surprising semantics result from seemingly insignificant properties of the underlying implementation. Therefore, it may be adequate to only skim this chapter upon reading this book for the first time and come back to it when necessary or when your experience with building Reactive systems inspires a wish to deepen your knowledge of these aspects.
13.1. The Active–Passive Replication pattern
Keep multiple copies of the service running in different locations, but only accept modifications to the state in one location at any given time.
This pattern is also sometimes referred to as failover or master–slave replication. You have already seen one particular form of failover: the ability to restart a component means that after a failure, a new instance is created and takes over functionality, like passing the baton from one runner to the next. For a stateful service, the new instance accesses the same persistent storage location as the previously failed one, recovering the state before the crash and continuing from there. This works only as long as the persistent storage is intact; if that fails, then restarting is not possible—the service will forget all of its previous state and start from scratch. Imagine your web shop forgetting about all registered users—that would be a catastrophe!
We use the term active–passive replication to more precisely denote that in order to be able to recover even when one service instance fails completely—including loss of its persistent storage—you distribute its functionality and its full dataset across several physical locations. The need for such measures was discussed in section 2.4: replication means not putting all of your eggs in one basket.
Replicating and thereby distributing a piece of functionality requires a certain amount of coordination, in particular considering operations that change the persistent state. The goal of active–passive replication is to ensure that at any given time, only one of the replicas has the right to perform modifications. This allows individual modifications to be made without requiring consensus about them, as long as there is consensus about what the currently active party is, just as electing a mayor serves the purpose of simplifying the process of coordination within a city.
13.1.1. The problem setting
In the batch service example, the most important component used by all the other components is the storage module. Restarting this component after a failure allows it to recover from many issues, but you must take care to protect its data from being lost. This means storing the data in multiple places and allowing the other components to retrieve the data from any of them.
In order to visualize what this means, we will consider an incoming request that arrives at the client interface. Because the storage component is now spread across multiple locations, the client interface will need to know multiple addresses in order to talk to it. Assume that there is a service registry via which all components can obtain the addresses of their communication partners. When the storage component starts up, it will register all of its locations and their addresses in the registry, where the client interface can retrieve them. This allows new replicas to be added and old ones to be replaced at runtime. A static list of addresses might be sufficient in some cases, but it is in general desirable to be able to change addresses, especially in a cloud computing environment.
Which replica is the active one will change over time. There are several options for routing requests to it:
- The storage component can inform its clients via the service registry regarding which address belongs to the currently active replica. This simplifies the implementation of the client but also leads to additional lag for picking up a change of replica after a failure.
- The internal consensus mechanism for electing the active replica can be made accessible to the clients, allowing them to follow changes by listening in on the election protocol. This provides timely updates but couples the implementation of client and service by requiring them to share a larger protocol.
- All replicas can offer the service of forwarding requests to the currently active replica. This frees clients from having to track replica changes closely while avoiding downtime or close coupling. A possible downside of this approach is that requests sent via different replicas may arrive with substantially different delays, thereby making the ordering of request processing less deterministic.
The task: Your mission is to implement active–passive replication for a key–value store (represented by an in-memory map) using Akka Cluster, with the location of the active replica being managed by the Cluster Singleton feature. An important property of the implementation is that once the service replies with a confirmation, the request must have been processed and its results persisted to disk such that after a subsequent failure, the new active replica will behave correctly.
13.1.2. Applying the pattern
Basing this illustration on Akka Cluster allows us to focus on the replication logic and delegate the election of the active replica to the Cluster Singleton feature that is offered by this library. A cluster singleton is an actor that is spawned on the oldest cluster member with a given role. The Akka implementation ensures that there cannot be conflicting information about which member is the oldest within the same cluster, which means there cannot be two instances of the cluster singleton running simultaneously. This guarantee relies on the proper configuration of the cluster: during a network partition, each of the isolated parts will have to decide whether to continue operation or shut itself down; and if the rules are formulated such that two parts can continue running, then a singleton will be elected within each of these parts. Where this is not desired, a strict quorum must be employed that is larger than half the total number of nodes in the cluster—with the consequence that during a three-way split, the entire cluster may shut down. Further discussion of these topics can be found in chapter 17; for now, it is sufficient to know that the Cluster Singleton mechanism ensures that there will be only one active replica running at any time.
As a first step, you implement the actor that controls the active replica. This actor will be instantiated by the Cluster Singleton mechanism as a cluster-wide singleton, as just explained. Its role is to accept and answer requests from clients as well as to disseminate updates to all passive replicas. To keep things simple, you will implement a generic key–value store that associates JSON values and uses text strings as keys. This will save you the trouble of defining the required data types for your batch service operation—which is not central to the application of this pattern, in any case. The full source code for this example can be found at www.manning.com/books/reactive-design-patterns and in the book’s GitHub repository at https://github.com/ReactiveDesignPatterns.
Before we begin, here are the protocol messages by which clients interact with the replicated storage:
case class Put(key: String, value: JsValue, replyTo: ActorRef) case class PutConfirmed(key: String, value: JsValue) case class PutRejected(key: String, value: JsValue) case class Get(key: String, replyTo: ActorRef) case class GetResult(key: String, value: Option[JsValue])
In response to a Put command, you expect either a confirmation or rejection reply, whereas the result of a Get command will always indicate the currently bound value for the given key (which may optionally be empty). A command may be rejected in case of replication failures or service overload, as you will see later. The type JsValue represents an arbitrary JSON value in the play-json library, but the choice of serialization library is not essential here.
When the singleton actor starts up, it must first contact a passive replica to obtain the current starting state. It is most efficient to ask the replica within the same actor system (that is, on the same network host), because doing so avoids serializing the entire data store and sending it over the network. In the following implementation, the address of the local replica is provided to the actor via its constructor.
Listing 13.1. Singleton taking over as the active replica

While the actor is waiting for the initial state message, it needs to ignore all incoming requests. Instead of dropping them or making up fake replies, you stash them within the actor, to be answered as soon as you have the necessary data. Akka directly supports this usage by mixing in the Stash trait. In the running state, the actor will use the data store and the sequence-number generator, but it will need several more data structures to organize its behavior, as follows.
Listing 13.2. Active replica disseminating replication requests


The actor keeps a queue of items to be replicated, called toReplicate, plus a queue of replication requests that are currently in flight. The latter—replicating—is implemented as an ordered map because you need direct access to its elements as replication requests complete. Whenever the actor receives a Put request, it checks whether there is still room in the queue of items to be replicated. If the queue is full, the client is immediately informed that the request is rejected; otherwise, a new Replicate object is enqueued that describes the update to be performed, and then the replicate() method is invoked. This method transfers updates from the toReplicate queue to the replicating queue if there is space. The purpose of this setup is to place a limit on the number of currently outstanding replication requests so that clients can be informed when the replication mechanism cannot keep up with the update load.
When an update is moved to the replicating queue, the disseminate function is called. Here, you implement the core piece of the algorithm: every update that is accepted by the active replica is sent to all passive replicas for persistent storage. Because you are using Akka Cluster, you can obtain a list of addresses for all replicas from the Cluster Extension, using the local replica ActorRef as a pattern into which each remote address is inserted in turn. The replicate function stores the update together with a required replication count into the replicating queue, indexed by the update’s sequence number. The update will stay in the queue until enough confirmations have been received in the form of Replicated messages, as can be seen in the definition of the running behavior in listing 13.1. Only when this count is reached is the update applied to the local storage and the confirmation sent back to the original client.
Update requests as well as confirmations may be lost on the way between network nodes. Therefore, the active replica schedules a periodic reminder upon which it will resend all updates that are currently in the replicating queue. This ensures that, eventually, all updates are received by enough passive replicas. It is not necessary for all replicas to receive the updates from the active one, as you will see when we look at the implementation of a passive replica. The reason for this design choice is that burdening the active replica with all the concerns of successful replication will make its implementation more complex and increase the latency for responding to requests.
Before we focus on the passive replica implementation, you need to enable it to persist data on disk and read the data back. For the purpose of this example, you use the following simple file storage. It should be obvious that this is not suitable for production systems; we will discuss persistence patterns in chapter 17.
Listing 13.3. Implementing persistence by writing a JSON file to the local disk


The following listing assumes an import of the Persistence object so that you can use the persist and readPersisted methods where needed.
Listing 13.4. Passive replicas tracking whether they are up to date


The passive replica serves two purposes: it ensures the persistent storage of all incoming updates, and it maintains the current state of the full database so the active replica can be initialized when required. When the passive replica starts up, it first reads the persistent state of the database into memory, including the sequence number of the latest applied update. As long as all updates are received in the correct order, only the third case of the up-to-date behavior will be invoked, applying the updates to the local store, persisting it, confirming successful replication, and changing behavior to expect the update with the following sequence number. Updates that are retransmitted by the active replica will have a sequence number that is less than the expected one and therefore will only be confirmed because they have already been applied. A TakeOver request from a newly initializing active replica can in this state be answered immediately.
But what happens when messages are lost? In addition to ordinary message loss, this could also be due to a replica being restarted: between the last successful persistence before the restart and the initialization afterward, any number of additional updates may have been sent by the active replica that were never delivered to this instance because it was inactive. Such losses can only be detected upon receiving a subsequent update. The size of the gap in updates can be determined by comparing the expected sequence number with the one contained in the update; if it is too large—as determined by the maxLag parameter—you consider this replica as having fallen behind; otherwise, it is merely missing some updates. The difference between these two lies in how you recover from the situation, as shown next.
Listing 13.5. Passive replica requesting a full update when it falls too far behind


When falling behind, you first ask a randomly selected replica for a full dump of the database and schedule a timer. Then you change behavior into a waiting state in which new updates are accumulated for later application, very old updates are immediately confirmed, and requests to take over are deferred. This state can only be left once an initial-state message has been received; at this point, you persist this newer state of the database, confirm all accumulated updates whose sequence number is smaller than the now-expected one, and try to apply all remaining updates by calling the consolidate function that is shown next.
Listing 13.6. Consolidation: applying updates that were held previously


The waiting parameter contains the accumulated updates ordered by their sequence number. You then take and apply as many sequential updates as you have. Because the updates are stored in an ordered map, you can do this by matching sequence numbers in the map against a simple integer sequence until there is a mismatch (gap) in the sequence. The length of that matching prefix is the number of updates to persist, confirm, and drop from the waiting list. If the list is now empty—which means all accumulated updates had consecutive sequence numbers—you conclude that you have caught up with the active replica and switch back into up-to-date mode. Otherwise, you again determine whether the knowledge gap that remains is too large or whether remaining holes can be filled individually. The latter is done by the behavior that is shown next.
Listing 13.7. Determining whether holes in updates can be filled individually


Here, you finally use the queue of applied updates that you previously maintained. When you conclude that you are missing some updates, you enter this state knowing the next expected consecutive sequence number and a collection of future updates that cannot yet be applied. You use this knowledge to first create a list of sequence numbers that you are missing—you have to ask the other replicas in order to obtain the corresponding updates. Again, you schedule a timer to ask, in case some updates are not received; to avoid asking for the same update repeatedly, you must maintain a list of outstanding sequence numbers that you already asked for. Asking is done by sending a GetSingle request to a configurable number of passive replicas. In this state, you install a behavior that will confirm known updates, defer initialization requests from an active replica, reply to requests for a full database dump, and, whenever possible, answer requests for specific updates from other replicas that are in the same situation. When a replication request is received, it may be either a new one from the active replica or one that you asked for. In any case, you merge this update into the waiting list and use the consolidate function to process all applicable updates and possibly switch back to up-to-date mode.
This concludes the implementation of both the active and passive replicas. In order to use them, you need to start a passive replica on every cluster node in addition to starting the Cluster Singleton manager. Client requests can be sent to the active replica by using the Cluster Singleton Proxy helper, an actor that keeps track of the current singleton location by listening to the cluster-membership change events. The full source code, including a runnable demo application, can be found at www.manning.com/books/reactive-design-patterns or https://github.com/ReactiveDesignPatterns.
13.1.3. The pattern, revisited
The implementation of this pattern consists of four parts:
- A cluster membership service that allows discovery and enumeration of all replica locations
- A Cluster Singleton mechanism that ensures that only one active replica is running at all times
- The active replica that accepts requests from clients, broadcasts updates to all passive replicas, and answers them after successful replication
- A number of passive replicas that persist state updates and help each other recover from message loss
For the first two, this example uses the facilities provided by Akka Cluster, because the implementation of a full cluster solution is complex and not usually done from scratch. Many other implementations can be used for this purpose; the only important qualities are listed here. The implementation of both types of replica is more likely to be customized and tailored to a specific purpose. We demonstrated the pattern with a use case that exhibits the minimal set of operations representative of a wide range of applications: the Get request stands for operations that do not modify the replicated state and that can therefore be executed immediately on the active replica, whereas the Put request characterizes operations whose effects must be replicated such that they are retained across failures.
The performance of this replication scheme is very good as long as no failures occur, because the active replica does not need to perform coordination tasks; all read requests can be served without requiring further communication, and write requests only need to be confirmed by a large enough subset of all replicas. This allows write performance to be balanced with reliability, in that a larger replication factor reduces the probability of data loss and a smaller replication factor reduces the impact of slow responses from some replicas—by requiring N responses, you are satisfied by the N currently fastest replicas.
During failures, you will see two different modes of performance degradation. If a network node hosting a passive replica fails, then there will be increased network traffic after its restart in order to catch up with the latest state. If the network host running the active replica fails, there will be a period during which no active replica will be running: it takes a while for the cluster to determine that the node has failed and to disseminate the knowledge that a new singleton needs to be instantiated. These coordination tasks need to be performed carefully in order to be reasonably certain that the old singleton cannot interfere with future operations even if its node later becomes reachable again after a network partition. For typical cloud deployments, this process takes on the order of seconds; it is limited by fluctuations in network transmission latency and reliability.
While discussing failure modes, we must also consider edge cases that can lead to incorrect behavior. Imagine that the active replica fails after sending out an update, and the next elected active replica does not receive this message. In order to notice that some information was lost, the new active replica would need to receive an update with a higher sequence number—but with the presented algorithm, that will never happen. Therefore, when it accepts the first update after the failover, the new active replica will unknowingly reuse a sequence number that some other replicas have seen for a different update. This can be avoided by requiring all known replicas to confirm the highest-known sequence number after a failover, which of course adds to the downtime.
Another problem is to determine when to erase and when to retain the persistent storage after a restart. The safest option is to delete and repopulate the database in order to not introduce conflicting updates after a network partition that separated the active replica from the surviving part of the cluster. On the other hand, this will lead to a significant increase in network usage that is unnecessary in most cases, and it would be fatal if the entire cluster were shut down and restarted. This problem can be solved by maintaining an epoch counter that is increased for every failover so a replica can detect that it has outdated information after a restart—for this, the active replica will include its epoch and its starting sequence number in the replication protocol messages.
Depending on the use case, you must make a trade-off among reliable operation, performance, and implementation complexity. Note that it is impossible to implement a solution that works perfectly for all imaginable failure scenarios.
13.1.4. Applicability
Because active–passive replication requires consensus regarding the active replica, this scheme may lead to periods of unavailability during widespread outages or network partitions. This is unavoidable because the inability to establish a quorum with the currently reachable cluster members may mean there is a quorum among those that are unreachable—but electing two active replicas at the same time must be avoided in order to retain consistency for clients. Therefore, active–passive replication is not suitable where perfect availability is required.
13.2. Multiple-Master Replication patterns
Keep multiple copies of a service running in different locations, accept modifications everywhere, and disseminate all modifications among them.
With active–passive replication, the basic mode of operation is to have a relatively stable active replica that processes read and write requests without further coordination, keeping the nominal case as simple and efficient as possible, while requiring special action during failover. This means clients have to send their requests to the currently active replica, with uncertainty resulting in case of failure. Because the selection of the active replica is done until further notice instead of per request, the client will not know what happened in case of a failure: has the request been disseminated or not?
Allowing requests to be accepted at all replicas means the client can participate in the replication and thereby obtain more precise feedback about the execution of its requests. The collocation of the client and the replica does not necessarily mean both are running in the process; placing them in the same failure domain makes their communication more reliable and their shared failure model simpler, even if this just means running both on the same computer or even in the same computing center. The further distributed a system becomes, the more prominent are the problems inherent to distribution, exacerbated by increased communication latency and reduced transmission reliability.
There are several strategies for accepting requests at multiple active replicas, which differ mainly in how they handle requests that arrive during a network partition. In this section, we will look at three classes of strategies:
- The most consistent results are achieved by establishing consensus about the application of each single update at the cost of not processing requests while dealing with failures.
- Availability can be increased by accepting potentially conflicting updates during a partition and resolving the conflicts afterward, potentially discarding updates that were accepted at either side.
- Perfect availability without data losses can be achieved by restricting the data model such that concurrent updates are conflict-free by definition.
13.2.1. Consensus-based replication
Given a group of people, we have a basic understanding of what consensus means: within the group, all members agree on a proposal and acknowledge that this agreement is unanimous. From personal experience, we know that reaching consensus is a process that can take quite a bit of time and effort for coordination, especially if the matter starts out as being contentious—in other words, if initially there are multiple competing proposals, and the group must decide which single one to support.
In computer science, the term consensus[1] means roughly the same thing, but of course the definition is more precise: given a cluster of N nodes and a set of proposals P1 to Pm every nonfailing node will eventually decide on a single proposal Px without the possibility to revoke that decision. All nonfailing nodes will decide on the same Px. In the example of a key–value store, this means one node proposes to update a key’s value, and, after the consensus protocol is finished, there will be a consistent cluster-wide decision about whether the update was performed—or in which order, relative to other updates. During this process, some cluster nodes may fail; and if the number of failing nodes is less than the failure-tolerance threshold of the algorithm, then consensus can be reached. Otherwise, consensus is impossible; this is equivalent to requiring a quorum for Senate decisions in order to prevent an absent majority from reverting the decision in the next meeting.[2]
See, for example, https://en.wikipedia.org/wiki/Consensus_(computer_science) for an overview.
Incidentally, a similar analogy is used in the original description of the PAXOS consensus algorithms by Leslie Lamport in “The Part-Time Parliament,” ACM Transactions on Computer Systems16, no. 2 (May 1998): 133-169, http://research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf.
A distributed key–value store can be built by using the consensus algorithm to agree on a replicated log. Any incoming updates are put into numbered rows of a virtual ledger; and, because all nodes eventually agree about which update is in which row, all nodes can apply the updates to their own local storage in the same order, resulting in the same state once everything is said and done. Another way to look at this is that every node runs its own copy of a replicated state machine; based on the consensus algorithm, all individual state machines make the same transitions in the same order, as long as not too many of them fail along the way.
Applying the pattern
There are several consensus algorithms and even more implementations to choose from. In this section, we use an existing example from the CKite project,[3] in which a key–value store is written as simply as the following listing.
See https://github.com/pablosmedina/ckite for the implementation of the library and http://mng.bz/dLYZ for the full sample source code.
Listing 13.8. Using CKite to implement a key–value store
class KVStore extends StateMachine {
private var map = Map[String, String]()
private var lastIndex: Long = 0
def applyWrite = {
case (index, Put(key: String, value: String)) => {
map.put(key, value);
lastIndex = index
value
}
}
def applyRead = {
case Get(key) => map.get(key)
}
def getLastAppliedIndex: Long = lastIndex
def restoreSnapshot(byteBuffer: ByteBuffer) =
map =
Serializer.deserialize[Map[String, String]](byteBuffer.array())
def takeSnapshot(): ByteBuffer =
ByteBuffer.wrap(Serializer.serialize(map))
}
This class describes only the handling of Get and Put requests once they have been agreed on by the consensus algorithm, which is why this implementation is completely free from this concern. Applying a Put request means updating the Map that stores the key–value bindings and returning the written value, whereas applying a Get request will only return the currently bound value (or None if there is none).
Because applying all writes since the beginning of time can be a time-consuming process, there is also support for storing a snapshot of the current state, noting the last applied request’s index in the log file. This is done by the takeSnapshot() function, which is called by the CKite library at configurable intervals. Its inverse—the restoreSnapshot() function—turns the serialized snapshot back into a Map, in case the KVStore is restarted after a failure or maintenance downtime.
CKite uses the Raft consensus protocol (https://raft.github.io). In order to use the KVStore class, you need to instantiate it as a replicated state machine, as follows.
Listing 13.9. Instantiating KVStore as a replicated state machine
object KVStoreBootstrap extends App {
val ckite =
CKiteBuilder()
.stateMachine(new KVStore())
.rpc(FinagleThriftRpc)
.build
ckite.start()
HttpServer(ckite).start()
}
The HttpServer class starts an HttpService in which HTTP requests are mapped into requests to the key–value store, supporting consistent reads (which are applied via the distributed log), local reads that just return the currently applied updates at the local node (which may be missing updates that are currently in flight), and writes (as discussed). The API for this library is straightforward in this regard:
val consistentRead = ckite.read(Get(key)) val possiblyStaleRead = ckite.readLocal(Get(key)) val write = ckite.write(Put(key, value))
The pattern, revisited
Writing your own consensus algorithm is almost never a good idea. There are so many pitfalls and edge cases to be considered that using one of the sound, proven ones is a very good default. Due to the nature of separating a replicated log from the state machine that processes the log entries, it is easy to get started with existing solutions, as demonstrated by the minimal amount of code necessary to implement the KVStore example. The only parts that need to be written are the generation of the requests to be replicated and the state machine that processes them at all replica locations.
The advantage of consensus-based replication is that it is guaranteed to result in all replicas agreeing on the sequence of events and thereby on the state of the replicated data. It is therefore straightforward to reason about the correctness of the distributed program, in the sense that it will not get into an inconsistent state.
The price for this peace of mind is that in order to avoid mistakes, the algorithm must be conservative: it cannot boldly make progress in the face of arbitrary failures like network partitions and node crashes. Requiring a majority of the nodes to agree on an update before progressing to the next one not only takes time but also can fail altogether during network partitions, such as a three-way split where none of the parts represents a majority.
13.2.2. Replication with conflict detection and resolution
If you want to change your replication scheme such that it can continue to operate during a transient network partition, then you will have to make some compromises. Obviously, it is impossible to reach consensus without communication, so if all cluster nodes are to make progress in accepting and processing requests at all times, conflicting actions may be performed.
Consider the example of the storage component within your batch service that stores the execution status of some computing job. When the job is submitted, it is recorded as “new”; then it becomes “scheduled,” “executing,” and finally “finished” (ignoring failures and retries for the sake of simplicity here). But another possibility is that the client that submitted the job decides to cancel its execution because the computation is no longer needed, perhaps because parameters have changed and a new job has been submitted. The client will attempt to change the job status to “canceled,” with further possible consequences, depending on the current job status—it may be taken out of the scheduled queue, or it may need to be aborted if it is currently executing.
Assuming that you want to make the storage component as highly available as possible, you may let it accept job-status updates even during a network partition that separates the storage cluster into two halves and renders it unable to successfully apply a consensus protocol until communication is restored. If the client interface sends the write of the “canceled” status to one half while the execution service starts running the job and therefore sets the “executing” status on the other half, then the two parts of the storage component have accepted conflicting information. When the network partition is repaired and communication is possible again, the replication protocol will need to figure out that this has occurred and react accordingly.
Applying the pattern
The most prominent tool for detecting whether cluster nodes have performed conflicting updates is called a version vector.[4] With this, each replica can keep track of who updated the job status since the last successful replication, by incrementing a counter:
In particular, you do not need a vector clock: see Carlos Baquero, “Version Vectors Are Not Vector Clocks,” HASlab, July 8, 2011, https://haslab.wordpress.com/2011/07/08/version-vectors-are-not-vector-clocks for a discussion (in short: you only need to track whether updates were performed by a replica, not how many were performed). See also Nuno Preguiça et al., “Dotted Version Vectors,” November 2010, http://arxiv.org/abs/1011.5808 for a description.
- The status starts out as “scheduled” with an empty version vector on both nodes A and B.
- When the client interface updates the status on node A, the replica will register it as “canceled” with a version vector of <A:1> (all nodes that are not mentioned are assumed to have version zero).
- When the executor updates the status on node B, it will be registered as “executing” with the version vector <B:1>.
- When replicas A and B compare notes after the partition has been repaired, the status will be both “canceled” and “executing,” with version vectors <A:1> and <B:1>; and because neither fully includes the other, a conflict will be detected.
The conflict will then have to be resolved one way or another. A SQL database will decide based on a fixed or configurable policy: for example, storing a timestamp together with each value and picking the latest update. In this case, there is nothing to code, because the conflict resolution happens within the database; the user code can be written just like in the nonreplicated case.
Another possibility is implemented by the Riak database (http://mdocs.basho.com/riak/latest/theory/concepts/Replication), which presents both values to any client that subsequently reads the key affected by the conflict, requiring the client to figure out how to proceed and bring the data store back into a consistent state by issuing an explicit write request with the merged value; this is called read repair. An example of how this is done is part of the Riak documentation.[5]
In the batch service example, you could employ domain-specific knowledge within your implementation of the storage component: after a partition was repaired, all replicas would exchange version information for all intermediately changed keys. When this conflict was noticed, it would be clear that the client wished to abort the now-executing job—the repair procedure would automatically change the job status to “canceled” (with a version vector of <A:1,B:1> to document that this included both updates) and ask the executor to terminate the execution of this job. One possibility for implementing this scheme would be to use a data store like Riak and perform read repair at the application level together with the separately stored knowledge about which keys were written to during the partition.
The pattern, revisited
We have introduced conflict detection and resolution at the level of a key–value store or database where the concern of state replication is encapsulated by an existing solution in the form of a relational database management system or other data store. In this case, the pattern consists of recording all actions as changes to the stored data such that the storage product can detect and handle conflicts that arise from accepting updates during network partitions or other times of partial system unavailability.
When using server-side conflict resolution (as is done by popular SQL database products), the application code is freed from this concern at the cost of potentially losing updates during the repair process—choosing the most recent update means discarding all others. Client-side conflict resolution allows tailored reactions that may benefit from domain-specific knowledge; but, on the other hand, it makes application code more complex to write, because all read accesses to a data store managed in this fashion must be able to deal with receiving multiple equally valid answers to a single query.
13.2.3. Conflict-free replicated data types
In the previous section, you achieved perfect availability of the batch service’s storage component—where perfect means “it works as long as one replica is reachable”—at the cost of either losing updates or having to care about manual conflict resolution. You can improve on this even further, but unfortunately at another cost: it is not possible to avoid conflicts while maintaining perfect availability without restricting the data types that can be expressed.
As an example, consider a counter that should be replicated. Conflict freedom would be achieved by making sure an increment registered at any replica would eventually be visible (effective) at all replicas independent of other concurrent increments. Clearly it is not enough to replicate the counter value: if an increment of 3 is accepted by node A, whereas an increment of 5 is accepted at node B, then the value after replication will either signal a conflict or miss one of the updates, as discussed in the previous section. Therefore, you split the counter into individual per-node subcounters, where each node only ever modifies its own subcounter. Reading the counter then means summing up all the per-node subcounters.[6] In this fashion, both increments of 3 and 5 will be effective, because the per-node values cannot see conflicting updates. And after the replication is complete, the total sum will have been incremented by 8.
An implementation in the context of Akka Distributed Data can be studied at http://mng.bz/rf2V. This type of counter can only grow, hence its name: GCounter.
With this example, it becomes clear that it is possible to create a data structure that fulfills the goal, but the necessary steps in the implementation of this replicated counter are tailored to this particular use case and cannot be used in general—in particular, it relies upon the fact that summing all subcounters correctly expresses the overall counter behavior. This is possible for a wide range of data types, including sets and maps, but it fails wherever global invariants cannot be translated to local ones. For a set, it is easy to avoid duplicates because duplicate checking can be done on each insertion, but constructing a counter whose value must stay within a given range requires coordination again.
The data types we are talking about here are called conflict-free replicated data types (CRDTs)[7] and are currently being introduced in a number of distributed systems libraries and data stores. In order to define such a data type, you need to formulate a rule about how to merge two of its values into a new resulting value. Instead of detecting and handling conflicts, such a data type knows how to merge concurrent updates so that no conflict occurs.
See M. Shapiro et al., “A Comprehensive Study of Convergent and Commutative Replicated Data Types,” 2011, https://hal.inria.fr/inria-00555588 for an overview; and C. Baquero, “Specification of Convergent Abstract Data Types for Autonomous Mobile Computing,” 1997, http://haslab.uminho.pt/cbm/publications/specification-convergent-abstract-data-types-autonomous-mobile-computing for early ground work.
The most important properties of the merge function are that it is symmetric and monotonic: it must not matter whether you merge value1 with value2 or value2 with value1; and after having merged two values into a third one, future merges must not ever go back to a previous state (example: if v1 and v2 were merged to v2, then any merge of v2 with another value must not ever result in v1—you can picture this as the values following some order and merging only ever goes forward in this order, never backward).
Applying the pattern
Coming back to the example of updating the status of a batch job, we will now demonstrate how a CRDT works. First, you define all possible status values and their merge order, as shown in figure 13.1—such a graphical representation is the easiest way to get started when designing a CRDT with a small number of values. When merging two statuses, there are three cases:
- If both statuses are the same, then obviously you just pick that status.
- If one of them is reachable from the other by walking in the direction of the arrows, then you pick the one toward which the arrows are pointing; as an example, merging “new” and “executing” will result in “executing.”
- If that is not the case, then you need to find a new status that is reachable from both by walking in the direction of the arrows, but you want to find the closest such status (otherwise, “finished” would always be a solution, but not a useful one). There is only one example in this graph, which is merging “executing” and “canceled,” in which case you choose “aborted”—choosing “finished” would technically be possible and consistent, but that choice would lose information (you want to retain both pieces of knowledge that are represented by “executing” and “canceled”).
Figure 13.1. Batch job status values as CRDTs with their merge ordering indicated by state progression arrows: walking in the direction of the arrows goes from predecessor to successor in the merge order.

The next step is to cast this logic into code. This example prepares the use of the resulting status representation with the Akka Distributed Data module that takes care of the replication and merging of CRDT values. All that is needed is the merge function, which is the only abstract method on the ReplicatedData interface.
Listing 13.10. Code representation of the graph in figure 13.1

This is a trivial transcription of the graph from figure 13.1, where each node in the status graph is represented by a Scala object with two sets of nodes describing the incoming and outgoing arrows, respectively: an arrow always goes from predecessor to successor (for example, Scheduled is a successor of New, and New is a predecessor of Scheduled). We could have chosen a more compact representation where each arrow is encoded only once: for example, if we had provided only the successor information, then after construction of all statuses, a second pass would have filled in the predecessor sets automatically. Here, we opted to be more explicit and save the code for the post-processing step. Now it is time to look at the merge logic in the following listing.
Listing 13.11. Merging two statuses to produce a third, merged status
def mergeStatus(left: Status, right: Status): Status = {
/*
* Keep the left Status in hand and determine whether it is a
* predecessor of the candidate, moving on to the candidate's
* successor if not successful. The list of exclusions is used to
* avoid performing already determined unsuccessful comparisons
* again.
*/
def innerLoop(candidate: Status, exclude: Set[Status]): Status =
if (isSuccessor(candidate, left, exclude)) {
candidate
} else {
val nextExclude = exclude + candidate
val branches =
candidate.successors.map(succ => innerLoop(succ, nextExclude))
branches.reduce((l, r) =>
if (isSuccessor(l, r, nextExclude)) r else l)
}
def isSuccessor(candidate: Status, fixed: Status,
exclude: Set[Status]): Boolean =
if (candidate == fixed) true
else {
val toSearch = candidate.predecessors -- exclude
toSearch.exists(pred => isSuccessor(pred, fixed, exclude))
}
innerLoop(right, Set.empty)
}
In this algorithm, you merge two statuses, one called left and one called right. You keep the left value constant during the entire process and consider right a candidate that you may need to move in the direction of the arrows. As an illustration, consider merging New and Canceled:
- If New is taken as the left argument, then you will enter the inner loop with Canceled as the candidate, and the first conditional will call isSuccessor, with the first two arguments being Canceled and New. These are not equal, so the else branch of isSuccessor will search all predecessors of Canceled (New and Scheduled) to determine whether one of them is a successor of New; this now satisfies the condition of candidate == fixed, so isSuccessor returns true and the candidate in innerLoop (Canceled) will be returned as the merge result.
- If New is taken as the right argument, then the first isSuccessor call will yield false. You enter the other branch in which both successors of the candidate New will be examined; trying Scheduled will be equally fruitless, escalating to Executing and Canceled as its successors. Abbreviating the story a little, you will eventually find that the merge result for the Executing candidate will be Aborted, whereas for Canceled it is Canceled itself. These branches are then reduced into a single value by pairwise comparison and picking the predecessor, which is Canceled in the case of trying Scheduled just now. Returning to the outermost loop invocation, you thus twice get the same result of Canceled for the two branches, which is also the end result.
This procedure is somewhat complicated by the fact that you have allowed the two statuses of Executing and Canceled to be unrelated to each other, necessitating the ability to find a common descendant. We will come back to why this is needed in the example, but first we will look at how this CRDT is used by a hypothetical (and vastly oversimplified) client interface. In order to instantiate the CRDT, you need to define a key that identifies it across the cluster:
object StorageComponent extends Key[ORMap[Status]]("StorageComponent")
You need to associate a Status with each batch job, and the most fitting predefined CRDT for this purpose is an observed-remove map (ORMap). The name stems from the fact that only keys whose presence has previously been observed can be removed from the map. Removal is a difficult operation because you have seen that CRDTs need a monotonic, forward-moving merge function—removing a key at one node and replicating the new map would mean only that the other nodes would add it right back during merges, because that is the mechanism by which the key is spread across the cluster initially.[8]
For details of how this is implemented, see Annette Bieniusa et al., “An Optimized Conflict-Free Replicated Set,” October 2012, https://hal.inria.fr/hal-00738680.
One thing to note here is that CRDTs can be composed as shown earlier: the ORMap uses Strings as keys (this is fixed by the Akka Distributed Data implementation) and some other CRDTs as values. Instead of using the custom Status type, you could use an observed-remove set (ORSet) of PNCounters if you needed sets of counters to begin with, just to name one possibility. This makes it possible to create container data types with well-behaved replication semantics that are reusable in different contexts. Within the client interface—represented as a vastly oversimplified actor in the following listing—you can use the status map by referencing the StorageComponent key.
Listing 13.12. Using Akka Distributed Data to disseminate state changes
class ClientInterface
extends Actor with ActorLogging {
val replicator = DistributedData(context.system).replicator
implicit val cluster = Cluster(context.system)
def receive = {
case Submit(job) =>
log.info("submitting job {}", job)
replicator !
Replicator.Update(StorageComponent, ORMap.empty[Status],
Replicator.WriteMajority(5.seconds))
(map => map + (job -> New))
case Cancel(job) =>
log.info("cancelling job {}", job)
replicator !
Replicator.Update(StorageComponent, ORMap.empty[Status],
Replicator.WriteMajority(5.seconds))
(map => map + (job -> Canceled))
case r: Replicator.UpdateResponse[_] =>
log.info("received update result: {}", r)
case PrintStatus =>
replicator ! Replicator.Get(StorageComponent,
Replicator.ReadMajority(5.seconds))
case g: Replicator.GetSuccess[_] =>
log.info("overall status: {}", g.get(StorageComponent))
}
}
The Replicator is the actor provided by the Akka Distributed Data module that is responsible for running the replication protocol between cluster nodes. Most generic CRDTs like ORMap need to identify the originator of a given update, and for that the Cluster extension is implicitly used—here it is needed by both function literals that modify the map during the handing of Submit and Cancel requests.
With the Update command, you include the StorageComponent key, the initial value (if the CRDT was not referenced before), and a replication-factor setting. This setting determines the point at which the confirmation of a successful update will be sent back to the ClientInterface actor: you choose to wait until the majority of cluster nodes have been notified, but you could just as well demand that all nodes have been updated, or you could be satisfied once the local node has the new value and starts to disseminate it. The latter is the least reliable but is perfectly available (assuming that a local failure implies that the ClientInterface is affected as well); waiting for all nodes is most reliable for retaining the stored data but can easily fail at storage. Using the majority is a good compromise that works well in many situations—just as for legislative purposes.
The modifications performed by the client interface do not care about the previous job status. They create a New entry or overwrite an existing one with Canceled. The executor component demonstrates more interesting usage, as shown next.
Listing 13.13. Introducing a request identifier for the job
class Executor extends Actor with ActorLogging {
val replicator = DistributedData(context.system).replicator
implicit val cluster = Cluster(context.system)
var lastState = Map.empty[String, Status]
replicator ! Replicator.Subscribe(StorageComponent, self)
def receive = {
case Execute(job) =>
log.info("executing job {}", job)
replicator !
Replicator.Update(StorageComponent, ORMap.empty[Status],
Replicator.WriteMajority(5.seconds),
Some(job))
{ map =>
require(map.get(job) == Some(New))
map + (job -> Executing)
}
case Finish(job) =>
log.info("job {} finished", job)
replicator !
Replicator.Update(StorageComponent, ORMap.empty[Status],
Replicator.WriteMajority(5.seconds))
(map => map + (job -> Finished))
case Replicator.UpdateSuccess(StorageComponent, Some(job)) =>
log.info("starting job {}", job)
case r: Replicator.UpdateResponse[_] =>
log.info("received update result: {}", r)
case ch: Replicator.Changed[_] =>
val current = ch.get(StorageComponent).entries
for {
(job, status) <- current.iterator
if (status == Aborted)
if (lastState.get(job) != Some(Aborted))
} log.info("aborting job {}", job)
lastState = current
}
}
When it is time to execute a batch job, the update request for the CRDT includes a request identifier (Some(job)) that has so far been left out: this value will be included in the success or failure message that the replicator sends back. The provided update function now checks a precondition: that the currently known status of the given batch job is still New. Otherwise, the update will be aborted with an exception. Only upon receiving the UpdateSuccess message with this job name will the actual execution begin; otherwise, a ModifyFailure will be logged (which is a subtype of Update-Response).
Finally, the executor should abort batch jobs that were canceled after being started. This is implemented by subscribing to change events from the replicator for the StorageComponent CRDT. Whenever there is a change, the replicator will take note of it; and as soon as the (configurable) notification interval elapses, a Replicator.Changed message will be sent with the current state of the CRDT. The executor keeps track of the previously received state and can therefore determine which jobs have newly become Aborted. In this example, you log this; in a real implementation, the Worker instance(s) for this job would be asked to terminate. The full example, including the necessary cluster setup, can be found in the source code archives for this chapter.
The pattern, revisited
Conflict-free replication allows perfect availability but requires the problem to be cast in terms of special data types (CRDTs). The first step is to determine which semantics are needed. In this case, you needed a tailor-made data type, but a number of generically useful ones are readily available. Once the data type has been defined, a replication mechanism must be used or developed that will disseminate all state changes and invoke the merge function wherever necessary. This could be a library, as in the example shown in listing 13.12, or an off-the-shelf data store based on CRDTs.
Although it is easy to get started like this, note that this solution cannot offer strong consistency: updates can occur truly concurrently across the entire system, making the value history of a given key nonlinearizable (which means different clients can see conflicting value histories that are eventually reconciled). This may present a challenge in environments that are most familiar with and used to transactional behavior of a central authority—the centrality of this approach is precisely the limitation in terms of resilience and elasticity that conflict-free replication overcomes, at the cost of offering at most eventual consistency.
13.3. The Active–Active Replication pattern
Keep multiple copies of a service running in different locations, and perform all modifications at all of them.
In the previous patterns, you achieved resilience for the storage subsystem of the example batch job processing facility by replicating it across different locations (data centers, availability zones, and so on). You saw that you can achieve strong consistency only when implementing a failover mechanism; both CRDT-based replication and conflict detection avoid this at the cost of not guaranteeing full consistency. One property of failover is that it takes some time: first, you need to detect that there is trouble, and then, you must establish consensus about how to fix it—for example, by switching to another replica. Both activities require communication and therefore cannot be completed instantaneously. Where this is not tolerable, you need a different strategy, but because there is no magic bullet, you must expect different restrictions.
Instead of failing over as a consequence of detecting problems, you can assume that failures occur and therefore hedge your bets: rather than contacting only one replica, always perform the desired operation on all of them. If a replica does not respond correctly, then you conclude that it has failed and refrain from contacting it again. A new replica will be added based on monitoring and supervision.
In computer science, the first description of active–active replication was offered by Leslie Lamport,[9] who proposed that distributed state machines can be synchronized by using the fact that time passes in a sufficiently similar fashion for all of them. His description yields a more generic framework for replication than is presented in this section. The definition of active–active replication used here[10] is inspired by the space industry, where, for example, measurements are performed using multiple sensors at all times and hardware-based voting mechanisms select the prevalent observation among them, discarding minority deviations by presuming them to be the result of failures. As an example, the main bus voltage of a satellite may be monitored by a regulator that decides whether to drain the batteries or charge them with excess power coming from the solar panels; making the wrong decision in this regard will ultimately destroy the satellite, and therefore three such regulators are taken together and their signals are fed into a majority voting circuit to obtain the final decision.
Leslie Lamport, “Using Time Instead of Timeout for Fault-Tolerant Distributed Systems,” ACM Transactions on Programming Languages and Systems 6, no. 2 (April 1984): 254-280.
Note that database vendors sometimes use active–active replication to mean conflict detection and resolution as described in the previous section.
The drawback of this scheme is that you must assume that the inputs to all replicas are the same, so that the responses will also be the same; all replicas internally go through the same state changes together. In contrast to the concrete bus voltage that is measured in the satellite example—the one source of truth—having multiple clients contact three replicas of a stateful service means there must be a central point that ensures that requests are delivered to all replicas in the same order. This will either be a single choke point (concerning both failures and throughput) or require costly coordination again. But instead of theorizing, we will look at a concrete example.
13.3.1. The problem setting
Again, you will apply this replication scheme to the key–value store that represents the storage component of the batch job service. The two involved subcomponents—a coordinator and a replica—are represented as vastly simplified Actors, concentrating on the basic working principle. The idea behind the pattern is that all replicas go through the same state changes in lockstep without coordinating their actions and while running fully asynchronously. Because coordination is necessary nevertheless, you need to control the requests that are sent to the replicas by introducing a middleman that also acts as bookkeeper and supervisor.
13.3.2. Applying the pattern
The starting point for implementing this solution is the replicas, which, due to the lack of coordination, can be kept simple.
Listing 13.14. Starting active–active replication with an uncoordinated implementation


First, you define sequenced command and result wrappers for the communication between the coordinator and the replicas as well as initialization messages to be sent between replicas. The replica starts out in a mode where it waits for a message containing the initial state to begin from—you must be able to bring new replicas online in the running system. Once the initialization data have been received, the replica switches to its initialized behavior and replays all previously stashed commands. In addition to Put and Get requests, it also understands a command to send the current contents of the key–value store to another replica in order to initialize that replica.
As noted, in the code, we have left out all sequence-number tracking and resend logic (the same is true in the coordinator actor discussed in listing 13.15) in order to concentrate on the essence of this pattern. Because we already solved reliable delivery of updates for active–passive replication, we consider this part of the problem solved; please refer back to section 13.1. In contrast to having the replicas exchange missing updates among each other, you, in this case, establish the resend protocol only between the coordinator and each replica individually.
Assuming that all replicas perform their duties if they are fed the same requests in the same order, you now need to fulfill that condition: it is the responsibility of the coordinator to broadcast the commands, handle and aggregate the replies, and manage possible failures and inconsistencies. In order to nicely formulate this, you need to create an appropriate data type that represents the coordinator’s knowledge about the processing status of a single client request, as follows.
Listing 13.15. Encapsulating knowledge about the status of a single client request


ReplyState tracks when the time limit for a client response expires; whether the reply value is already known; which replica’s response deviated from the prevalent one; and which replica’s response is still outstanding. When a new request is made, you begin with an Unknown reply state containing an empty set of replies and a set of missing replica ActorRefs that contains all current replicas. As responses from replicas are received, your knowledge grows, as represented by the add() function: the response is added to the set of replies, and as soon as the required quorum of replicas has responded with a consistent answer, ReplyState switches to Known (taking note of the replica ActorRefs from which the wrong answer was received). If, after receiving the last expected response, no answer has reached a quorum, one of the answers must be selected in order to make progress; in this case, you use a simple majority as implemented in the fromUnknown function. Within the Known state, you still keep track of arriving responses so that corrupted replicas can be detected. Before we dive into this aspect, the following listing shows the overall structure of the Coordinator.
Listing 13.16. Managing replicas as child actors


In this simplified code, Coordinator directly creates the replicas as child actors; a real implementation would typically request the infrastructure to provision and start replica nodes that would then register themselves with Coordinator once Replica is running on them. Coordinator also registers for lifecycle monitoring of all replicas using context.watch(), in order to be able to react to permanent failures that are detected by the infrastructure—in the case of Akka, this service is implicitly provided by the Cluster module. Another thing to note is that, in this example, Coordinator is the parent actor of the replicas and therefore also their supervisor. Because failures escalated to Coordinator usually imply that messages have been lost, and this simplified example assumes reliable delivery, you install a supervisor strategy that will terminate any failing child actor; this will eventually lead to the reception of a Terminated message, upon which a new replica will replace the previously terminated one.
The flow of messages through the coordinator is depicted in figure 13.2. Whereas the external client sends commands and expects returned results, looping the requests through the replicas requires some additional information; hence, the messages are wrapped as SeqCommand and SeqResult, respectively. The name signifies that these are properly sequenced, although, as discussed, we omit the implementation of reliable delivery that would normally be based on the contained sequence numbers. The only sequencing aspect modeled is that the external client sees the results in the same order in which their corresponding commands were delivered; this is the reason for the nextReply variable that is used by the following implementation of sendReplies().
Figure 13.2. Flow of messages in the Active–Active Replication pattern

Listing 13.17. Sending replies in sequence
@tailrec private def sendReplies(): Unit =
replies.get(nextReply) match {
case Some(k @ Known(_, reply, _, _)) =>
reply.replyTo ! reply.res
nextReply += 1
sendReplies()
case _ =>
}
If the next reply to be sent has a “known” value, then you send it back to the client and move on to the next one. This method is called after every handled message in order to flush replies to the clients whenever they are ready. The overall flow of replies through the coordinator’s response-tracking queue (implemented by a TreeMap indexed by command sequence) is shown in figure 13.3.
Figure 13.3. The movement of replies through the status tracking within the coordinator: new entries are generated whenever a command is received, and they move from “unknown” to “known” status either by receiving SeqResult messages or due to timeout. Consecutive “known” results are sent back to the external client, and replies where no more replica responses are expected are evicted from the queue.
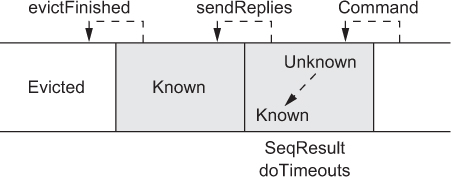
You have seen the handling of SeqResult messages already in the coordinator’s behavior definition, leaving the following doTimeouts() function as the other possibility through which an “unknown” reply status can be transformed into a “known” reply.
Listing 13.18. Upon timeout, forcing “missing” replies to “known” replies
private def doTimeouts(): Unit = {
val now = Deadline.now
val expired = replies.iterator.takeWhile(_._2.deadline <= now)
for ((seq, state) <- expired) {
state match {
case Unknown(deadline, received, _, _) =>
val forced = Known.fromUnknown(deadline, received)
replies += seq -> forced
case Known(deadline, reply, wrong, missing) =>
replies += seq -> Known(deadline, reply, wrong, Set.empty)
}
}
}
Because sequence numbers are allocated in strictly ascending order and all commands have the same timeout, replies will also time out in the same order. Therefore, you can obtain all currently expired replies by computing the prefix of the replies queue for which the expiry deadline lies in the past. You turn each of these entries into a “known” one for which no more responses are expected—even wrong replies that come in late are discarded. Notice the corrupted replicas during one of the subsequent requests. If no result has been determined yet for a command, you again use the fromUnknown function to select a result with simple majority, noting which replicas responded with a different answer (which is wrong by definition). The last remaining step is similar to a debriefing: for every command that you responded to, you must check for deviating responses and replace their originating replicas immediately.
Listing 13.19. Terminating and replacing replicas that did not finish
@tailrec private def evictFinished(): Unit =
replies.headOption match {
case Some((seq, k @ Known(_, _, wrong, _))) if k.isFinished =>
wrong foreach (replaceReplica(_, terminate = true))
replies -= seq
evictFinished()
case _ =>
}
private def replaceReplica(r: ActorRef, terminate: Boolean): Unit =
if (replicas contains r) {
replicas -= r
if (terminate) r ! PoisonPill
val replica = newReplica()
replicas.head ! SendInitialData(replica)
replicas += replica
}
The evictFinished function checks whether the reply status of the oldest queued command is complete (no more responses are expected). If so, it initiates the replacement of all faulty replicas and removes the status from the queue, repeating this process until the queue is empty or an unfinished reply status is encountered. Replacing a replica would normally mean asking the infrastructure to terminate the corresponding machine and provision a new one, but in this simplified example you just terminate the child actor and create a new one.
In order to get the new replica up to speed, you need to provide it with the current replicated state. One simple possibility is to ask one of the remaining replicas to transfer its current state to the new replica. Because this message will be delivered after all currently outstanding commands and before any subsequent commands, this state will be exactly the one needed by the new replica to be included in the replica set for new commands right away—the stashing and replay of these commands within the Replica actor has exactly the correct semantics. In a real implementation, there would need to be a timeout-and-resend mechanism for this initialization, to cover cases where the replica that is supposed to transfer its state fails before it can complete the transmission. It is important to note that the faulty replica is excluded from being used as the source of the initialization data, just as the new replica is.
13.3.3. The pattern, revisited
The Active–Active Replication pattern emerged from a conversation with some software architects working at a financial institution. It solves a specific problem: how can you keep a service running in fault-tolerant fashion with fully replicated state while not suffering from costly consensus overhead and avoiding any downtime during failure—not even allowing a handful of milliseconds for failure detection and failover?
The solution consists of two parts: the replicas execute commands and generate results without regard to each other, and the coordinator ensures that all replicas receive the same sequence of commands. Faulty replicas are detected by comparing the responses received to each individual command and flagging deviations. In the example implementation, this was the only criterion; a variation might be to also replace replicas that are consistently failing to meet their deadlines.
A side effect of this pattern is that external responses can be generated as soon as there is agreement about what that response will be, which means requiring only three out of five replicas would shorten the usually long tail of the latency distribution. Assuming that slow responses are not correlated between the replicas (that is, they are not caused by the specific properties of the command or otherwise related), then the probability of more than two replicas exceeding their 99th percentile latency is only 0.001%, which naïvely means the individual 99th percentile is the cluster’s 99.999th percentile.[11]
This is of course too optimistic, because outliers in the latency distribution are usually caused by something that might well be correlated between machines. For example, garbage collection pauses for JVMs that were started at the same time, and executing the same program with the same inputs will tend to occur roughly at the same time as well.
13.3.4. The relation to virtual synchrony
This pattern is similar in some aspects to the virtual synchrony[12] work done by Ken Birman et al. in the 1980s. The goal of both is to allow replicated distributed processes to run as if synchronized and to make the same state transitions in the same order. Although our example restricts and simplifies the solution by requiring a central entry point—the coordinator—the virtual synchrony model postulates no such choke point. As we discussed in section 13.2, this would normally require a consensus protocol to be used to ensure that transitions occur only once all replicas have acknowledged that they will make the transition. Unfortunately, this approach is doomed to fail, as proven by Fischer, Lynch, and Paterson in what is usually referred to as the FLP[13] result. The practical probability for this kind of failure is vanishingly small, but it is enough to question the endeavor of trying to provide perfect ordering guarantees in a distributed system.
https://en.wikipedia.org/wiki/Virtual_synchrony. See Ken Birman, “A History of the Virtual Synchrony Replication Model,” https://www.cs.cornell.edu/ken/history.pdf for an introduction and historical discussion.
Michael Fischer, Nancy Lynch, and Michael Paterson, “Impossibility of Distributed Consensus with One Faulty Process,” ACM, April 1985, http://dl.acm.org/citation.cfm?id=214121.
Virtual synchrony avoids this limitation by noticing that, in most cases, the ordering of processing two requests from different sources is not important: if the effects of two requests A and B are commutative, then it does not matter whether they are applied in the order A, B or B, A, because the state of the replica will be identical in the end. This is similar to how CRDTs achieve perfect availability without conflicts: impossibility laws do not matter if the available data types and operations are restricted in a way that conflicts cannot arise.
Taking a step back and considering daily life, we usually think in terms of cause and effect: I (Roland) observe that my wife’s coffee mug is empty, fill it with coffee, and tell her about it, expecting that when she looks at the mug, she will be pleased because it is now full. By waiting to tell her until after my refill, I make sure the laws of physics—in particular, causality—will ensure the desired outcome (barring catastrophes). This kind of thinking is so ingrained that we like to think about everything in this fashion, including distributed systems. When using a transactional database, causality is ensured by the serializability of all transactions: they happen as if one were executed after the other, every transaction seeing the complete results of all previously executed transactions. Although this works great as a programming abstraction, it is stronger than needed; causality does not imply that things happen in one universal order. In fact, the laws of special relativity clearly describe which events can be causally related and which cannot—events that happen at remote locations are truly concurrent if you cannot fly from one to the other even at the speed of light.
This fact may serve to motivate the finding that causal consistency is the best you can implement in a distributed system.[14] Virtual synchrony achieves greater resilience and less coordination overhead than consensus-based replication by allowing messages that are not causally related to be delivered to the replicas in random order. In this way, it can achieve performance similar to the active–active replication described in this section, at the cost of carefully translating the desired program such that it relies only on causal ordering. If the program cannot be written in this fashion because, for example, some effects are not commutative, then at least for these operations the coordination cost of establishing consensus must be paid. In this sense, the coordinator represents a trade-off that introduces a single choke point in exchange for being able to run arbitrary algorithms in a replicated fashion without the need for adaptation.
Wyatt Lloyd et al., “Don’t Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS,” SOSP ’11, ACM 2011, http://dl.acm.org/citation.cfm?id=2043593.
13.4. Summary
In this chapter, we discussed various replication patterns that allow you to distribute systems in space so as to not put all of your eggs in one basket. When it comes to replication, you are presented with a choice: do you favor consistency, reliability, or availability? The answer depends on the requirements of the use case at hand and is rarely black and white—there is a continuous range between these extremes, and most patterns are tunable. The following list can be used for orientation:
- Active–passive replication is relatively simple to use, based on an existing cluster-singleton implementation. It is fast during normal operation, suffers downtime during fail-overs, and offers good consistency due to having a single active replica.
- Consensus-based replication enables greater resilience by allowing updates to be accepted by any replica. But in return for offering perfect consistency, it suffers from high coordination overhead and, consequently, low throughput. Preferring consistency entails unavailability during severe failures.
- Replication based on conflict detection and resolution allows the system to stay available during severe failure conditions, but this can lead to data losses or require manual conflict resolution.
- Conflict-free replicated data types are formulated such that conflicts cannot arise by construction. Therefore, this scheme can achieve perfect availability even during severe failures; the data types are restricted, requiring special adaptation of the program code as well as designing it for an eventual consistency model.
- Active–active replication addresses the concern of avoiding downtime during failures while maintaining a generic programming model. The cost is that all requests must be sent through a single choke point in order to guarantee consistent behavior of all replicas—alternatively, the program can be recast in terms of causal consistency to achieve high performance and high availability by employing virtual synchrony.
This summary is of course grossly simplified. Please refer back to the individual sections for a more complete discussion of the limitations of each approach.