
Chapter 17. State management and persistence patterns
The previous chapter introduced the concepts of message rate, load, and time; previously, we had only considered the timeless relationship between different components. This chapter adds another orthogonal dimension to complete the picture: it is the purpose of almost all components to maintain state, and we have not yet discussed how this should be done. The patterns presented are closely related to each other and form a cohesive unit:
- The Domain Object pattern decouples business logic from communication machinery.
- The Sharding pattern allows you to store any number of domain objects on an elastic cluster.
- The Event-Sourcing pattern unifies change notifications and persistence by declaring the event log to be the sole source of truth.
- The Event Stream pattern uses this source of truth to derive and disseminate information.
This chapter can only serve as a basic introduction to these patterns. We hope it inspires you to delve into the rich literature and online resources on domain-driven design, event sourcing, and command-query responsibility separation (see the footnotes throughout the chapter for pointers).
17.1. The Domain Object pattern
Separate the business domain logic from communication and state management.
In chapter 6, we discussed the principle of divide and conquer; and in section 12.1, you learned how to apply this in the form of the Simple Component pattern. The resulting components have a clearly defined responsibility: they do one thing and do it in full. Often, this involves maintaining state that persists between invocations of these components. Although it may be intuitive to identify a component with its state—for example, by saying that a shopping cart in its entirety is implemented by an actor—this has notable downsides:
- The business logic becomes entangled with the communication protocols and with execution concerns.
- The only available mode of testing this component is through asynchronous integration tests—the implemented business behavior is accessible only via the externally defined protocols.
The Domain Object pattern describes how to maintain a clear boundary and separation between the different concerns of business logic, state management, and communication. This pattern is intuitively understandable without additional knowledge, but we highly recommended that you study domain-driven design,[1] because it provides more in-depth techniques for defining the ubiquitous language used within each bounded context. Bounded contexts typically correspond to components in your hierarchical system decomposition, and the ubiquitous language is the natural language in which domain experts describe the business function of the component.
See, for example, Eric Evans, Domain-Driven Design (Addison-Wesley, 2003); or Vaughn Vernon, Implementing Domain-Driven Design (Addison-Wesley, 2013).
17.1.1. The problem setting
In this chapter, we will use the example of implementing a shopping cart component. Although there may be a variety of facets to be covered in a real-world implementation, it is sufficient for the demonstration of the important aspects of these patterns to be able to associate an owner, add and remove items, and query the list of items in the shopping cart.
The task: Your mission is to implement a domain model for the shopping cart that contains only the business information and offers synchronous methods for performing business operations. Then, you will implement an actor that encapsulates a domain model instance and exposes the business operations as part of its communication protocol.
17.1.2. Applying the pattern
You will begin by defining how the shopping cart will be referenced and how it will reference its contained items and its owner:
case class ItemRef(id: URI) case class CustomerRef(id: URI) case class ShoppingCartRef(id: URI)
You use URIs to identify each of these objects and wrap them in named classes so that you can distinguish their purpose with their static type to avoid programming errors. With these preparations, a minimalistic shopping cart looks like the following listing.
Listing 17.1. A minimalistic shopping cart definition
case class ShoppingCart(items: Map[ItemRef, Int],
owner: Option[CustomerRef]) {
def setOwner(customer: CustomerRef): ShoppingCart = {
require(owner.isEmpty, "owner cannot be overwritten")
copy(owner = Some(customer))
}
def addItem(item: ItemRef, count: Int): ShoppingCart = {
require(count > 0,
s"count must be positive (trying to add $item with count $count)")
val currentCount = items.get(item).getOrElse(0)
copy(items = items.updated(item, currentCount + count))
}
def removeItem(item: ItemRef, count: Int): ShoppingCart = {
require(count > 0,
s"count must be positive (trying to remove $item with count $count)")
val currentCount = items.get(item).getOrElse(0)
val newCount = currentCount - count
if (newCount <= 0) copy(items = items - item)
else copy(items = items.updated(item, newCount))
}
}
object ShoppingCart {
val empty = ShoppingCart(Map.empty, None)
}
A shopping cart starts out empty, with no owner; through its class methods, it can obtain an owner and be filled with items. You can completely unit-test this class with synchronous and deterministic test cases, which should make you happy. It is also straightforward to discuss this class with the person in charge of the website’s commercial function, even if that person is not a programming expert. In fact, this class should be written not by a distributed systems expert but by a software engineer who is fluent in business rules and processes.
Next, you will define the interface between this domain class and the message-driven execution engine that will manage and run it. This includes commands and their resulting events as well as queries and their results, as shown in the next listing.
Listing 17.2. Messages for communication with a shopping cart object
trait ShoppingCartMessage {
def shoppingCart: ShoppingCartRef
}
sealed trait Command extends ShoppingCartMessage
case class SetOwner(shoppingCart: ShoppingCartRef, owner: CustomerRef)
extends Command
case class AddItem(shoppingCart: ShoppingCartRef, item: ItemRef, count: Int)
extends Command
case class RemoveItem(shoppingCart: ShoppingCartRef, item: ItemRef, count: Int)
extends Command
sealed trait Query extends ShoppingCartMessage
case class GetItems(shoppingCart: ShoppingCartRef) extends Query
sealed trait Event extends ShoppingCartMessage
case class OwnerChanged(shoppingCart: ShoppingCartRef, owner: CustomerRef)
extends Event
case class ItemAdded(shoppingCart: ShoppingCartRef, item: ItemRef, count: Int)
extends Event
case class ItemRemoved(shoppingCart: ShoppingCartRef, item: ItemRef, count: Int)
extends Event
sealed trait Result extends ShoppingCartMessage
case class GetItemsResult(shoppingCart: ShoppingCartRef, items: Map[ItemRef, Int])
4 extends Result
A command is a message that expresses the intent to make a modification; if successful, it results in an event, which is an immutable fact about the past. A query, on the other hand, is a message that expresses the desire to obtain information and that may be answered by a result that describes an aspect of the domain object at the point in time when the query was processed. With these business-level definitions, you are ready to declare an actor and its communication protocol, which allows clients to perform commands and queries, as in the following listing.
Listing 17.3. A shopping cart manager actor
case class ManagerCommand(cmd: Command, id: Long, replyTo: ActorRef)
case class ManagerEvent(id: Long, event: Event)
case class ManagerQuery(cmd: Query, id: Long, replyTo: ActorRef)
case class ManagerResult(id: Long, result: Result)
case class ManagerRejection(id: Long, reason: String)
class Manager(var shoppingCart: ShoppingCart) extends Actor {
/*
* this is the usual constructor, the above allows priming with
* previously persisted state.
*/
def this() = this(ShoppingCart.empty)
def receive = {
case ManagerCommand(cmd, id, replyTo) =>
try {
val event = cmd match {
case SetOwner(cart, owner) =>
shoppingCart = shoppingCart.setOwner(owner)
OwnerChanged(cart, owner)
case AddItem(cart, item, count) =>
shoppingCart = shoppingCart.addItem(item, count)
ItemAdded(cart, item, count)
case RemoveItem(cart, item, count) =>
shoppingCart = shoppingCart.removeItem(item, count)
ItemRemoved(cart, item, count)
}
replyTo ! ManagerEvent(id, event)
} catch {
case ex: IllegalArgumentException =>
replyTo ! ManagerRejection(id, ex.getMessage)
}
case ManagerQuery(cmd, id, replyTo) =>
try {
val result = cmd match {
case GetItems(cart) =>
GetItemsResult(cart, shoppingCart.items)
}
replyTo ! ManagerResult(id, result)
} catch {
case ex: IllegalArgumentException =>
replyTo ! ManagerRejection(id, ex.getMessage)
}
}
}
The pattern here is regular: for every command, you determine the appropriate event and send it back as a response. The same goes for queries and results. Validation errors will be raised by the ShoppingCart domain object as IllegalArgumentExceptions and turned into ManagerRejection messages. This is a case where catching exceptions within an actor is appropriate: this actor manages the domain object and handles a specific part of failures emanating from it.
The state management you implement here is that the actor maintains a reference to the current snapshot of the shopping cart’s state. In addition to keeping it in memory, you could also write it to a database upon every change or dump it to a file; the plethora of ways to do this are not shown here because they are not necessary for demonstrating the point that the actor controls this aspect as well as the external communication. The full source code is available with this book’s downloads, including an example conversation between a client and this manager actor.
17.1.3. The pattern, revisited
You have disentangled the domain logic from the state management and communication aspects by starting out from the domain expert’s view. First, you defined what a shopping cart contains and which operations it offers, and you codified this as a class. Then, you defined message representations for all commands and queries as well as their corresponding events and results. Only as the last step did you create a message-driven component that serves as a shell for the domain object and mediates between the messages and the methods offered by the domain object.
One noteworthy, deliberate aspect is a clear separation of domain object, commands, events, queries, and results on the one hand and the actor’s protocol on the other. The former reference only domain concepts, whereas the latter references what is needed for communication (the ActorRef type, in this Akka-based example, as well as message IDs that could be used for deduplication). Having to include message-related types in source files that define domain objects is a signal that the concerns have not been separated cleanly.
17.2. The Sharding pattern
Scale out the management of a large number of domain objects by grouping them into shards based on unique and stable object properties.
The Domain Object pattern gives you the ability to wrap the domain’s state in small components that can, in principle, be distributed easily across a cluster of network nodes in order to provide the resources for representing even very large domains that cannot be held in memory by a single machine. The difficulty then becomes how to address the individual domain objects without having to maintain a directory that lists every object’s location—such a directory could easily reach a size that is impractical to hold in memory.
The Sharding pattern places an upper bound on the size of the directory by grouping the domain objects into a configurable number of shards—the domain is fractured algorithmically into pieces of manageable size. The term algorithmically means the association between objects and shards is determined by a fixed formula that can be evaluated whenever an object needs to be located.
17.2.1. The problem setting
Coming back to this chapter’s running example, suppose you need to store a huge number of shopping carts—imagine writing the back end for a huge retail website on the internet, with millions of customers creating billions of shopping carts every day. Rather than manually creating the manager actors, you need to employ a sharding strategy that can effectively and efficiently distribute this dataset over an elastic cluster of machines.
The task: Your mission is to change the minimalistic Domain Actor pattern example in the book’s downloads such that the manager actors are created on a cluster of nodes according to a sharding algorithm based on 256 shards.
17.2.2. Applying the pattern
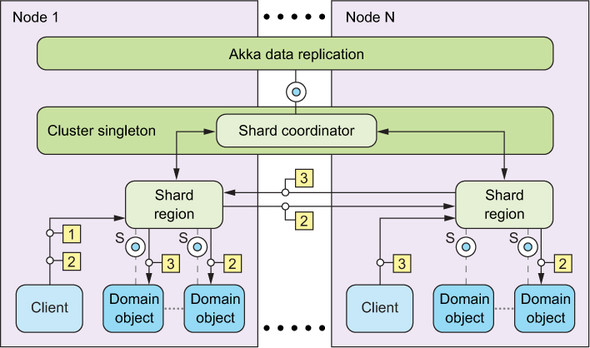
Because you are already using Akka, you can concentrate on the essence of the problem by using the akka-cluster-sharding module, which implements low-level sharding mechanics. An overview of how these mechanics work is given in figure 17.1.
Figure 17.1. Sharding requires that a ShardRegion is started on all participating nodes and registers itself with the ShardCoordinator. When a message is to be sent from a client to one of the managed domain objects—called an entity here—it will be sent via the local ShardRegion, which will consult the coordinator cluster singleton as to where the shard that contains the domain object should be located. The shard will be created on demand if it does not yet exist. The shard is maintained by an actor situated between the region and the entities (not shown here for the sake of simplicity). The allocation of shards to regions is replicated in memory among all nodes using the Data Replication module (see section 13.2.3 on CRDTs).
The only remaining pieces needed to enlist the sharding module’s support are as follows:
- A recipe for how to create entities when they are first referenced
- A formula that extracts the unique entity ID from a command or query
- A formula that extracts the shard number from a command or query
The first will be a Props object, and the latter two will be functions. The shard extraction guides the message to the correct shard region, and the shard actor then uses the entity ID to find the correct domain object manager among its child actors. You group these two functions together with an identifier for the shopping cart sharding system, as follows.
Listing 17.4. Defining sharding algorithms for a shopping cart

With this preparation, you can start the cluster nodes and try it, as shown next.
Listing 17.5. Starting up a cluster to host the shards
val sys1 = ActorSystem("ShardingExample", node1Config.withFallback(clusterConfig))
val seed = Cluster(sys1).selfAddress
def startNode(sys: ActorSystem): Unit = {
Cluster(sys).join(seed)
ClusterSharding(sys).start(
typeName = ShardSupport.RegionName,
entityProps = Props(new Manager),
settings = ClusterShardingSettings(sys1),
extractEntityId = ShardSupport.extractEntityId,
extractShardId = ShardSupport.extractShardId)
}
startNode(sys1)
val sys2 = ActorSystem("ShardingExample", clusterConfig)
startNode(sys2)
From this point on, you can talk to the sharded shopping carts via the shard region, which acts as a local mediator that sends commands to the correct node:
val shardRegion = ClusterSharding(sys1).shardRegion(ShardSupport.RegionName)
For the other configuration settings that are necessary to enable clustering and sharding, please refer to the full source code available with the book’s downloads.
17.2.3. The pattern, revisited
You have used Akka’s Cluster Sharding support to partition shopping carts across an elastic cluster—the underlying mechanics allocate shards to network nodes in a fashion that maintains an approximately balanced placement of shards, even when cluster nodes are added or removed. In order to use this module, you had to provide a recipe for creating a domain object manager actor and two functions: one for extracting the target shard ID from a command or query message and one for extracting the domain object’s unique ID, which is used to locate it within its shard.
Implementing the basic mechanics of clustering and sharding is a complex endeavor that is best left to supporting frameworks or tool kits. Akka is not the only one supporting this pattern natively: another example on the .NET platform is Microsoft’s Orleans framework.[2]
17.2.4. Important caveat
One important restriction of this scheme in Akka is that in the case of elastic shard reallocations, the existing actors will be terminated on their old home node and re-created at their new home node. If the actor only keeps its state in memory (as demonstrated in the examples so far), then its state is lost after such a transition—which usually is not desired.
Orleans avoids this caveat by automatically making all Grains (the Orleans concept corresponding to Actors) persistent by default, taking snapshots of their state after every processed message. A better solution is to consider persistence explicitly, as we will do in the following section; Orleans also allows this behavior to be customized in the same fashion.
17.3. The Event-Sourcing pattern
Perform state changes only by applying events. Make them durable by storing the events in a log.
Looking at the Domain Object pattern example, you can see that all state changes the manager actor performs are coupled to an event that is sent back to the client that requested this change. Because these events contain the full history of how the state of the domain object evolved, you may as well use it for the purpose of making the state changes persistent—this, in turn, makes the state of the domain object persistent. This pattern was described in 2005 by Martin Fowler[3] and picked up by Microsoft Research,[4] and it has shaped the design of the Akka Persistence module.[5]
See https://msdn.microsoft.com/en-us/library/dn589792.aspx and https://msdn.microsoft.com/en-us/library/jj591559.aspx.
17.3.1. The problem setting
You want your domain objects to retain their state across system failures as well as cluster shard–rebalancing events, and toward this end you must make them persistent. As noted earlier, you could do this by always updating a database row or a file, but these solutions involve more coordination than is needed. The state changes for different domain objects are managed by different shell components and are naturally serialized—when you persist these changes, you could conceptually write to one separate database per object, because there are no consistency constraints to be upheld between them.
Instead of transforming the state-changing events into updates of a single storage location, you can turn things around and make the events themselves the source of truth for your persistent domain objects—hence, the name event-sourcing. The source of truth needs to be persistent, and because events are generated in strictly sequential order, you merely need an append-only log data structure to fulfill this requirement.
The task: Your mission is to transform the manager actor from the Domain Object pattern into a PersistentActor whose state is restored upon restart.
17.3.2. Applying the pattern
You saw the PersistentActor trait in action in section 15.7.2 when you implemented at-least-once delivery to attempt to keep this promise even across system failures. With the preparations from the previous sections, it is straightforward to recognize the events you need to make persistent and how to apply them. First, you need to lift the association between events and domain-object methods from the manager actor into the business domain—this is where they belong, because both the object and the events are part of the same business domain. Therefore, the domain object should know how the relevant domain events affect its state, as shown in the following listing.
Listing 17.6. Adding the domain events to the business logic
case class ShoppingCart(items: Map[ItemRef, Int], owner: Option[CustomerRef]) {
...
def applyEvent(event: Event): ShoppingCart = event match {
case OwnerChanged(_, owner) => setOwner(owner)
case ItemAdded(_, item, count) => addItem(item, count)
case ItemRemoved(_, item, count) => removeItem(item, count)
}
}
With this in place, you can formulate the persistent object manager actor in terms of commands, events, queries, results, and one in-memory snapshot of the current domain object state. This ensemble is shown in the next listing.
Listing 17.7. Persisting an event-sourced domain object
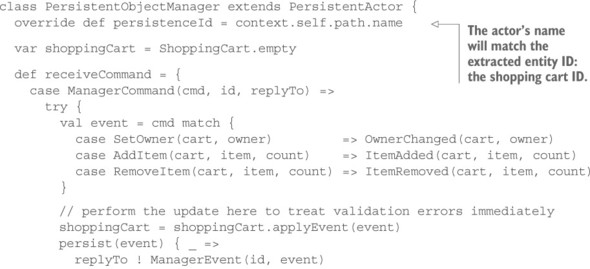

Instead of invoking business operations directly on the ShoppingCart object, you perform a mapping from commands to events and ask the shopping cart to apply the events to itself. In case of validation errors, this will still result in an IllegalArgument-Exception that you turn into a rejection message; otherwise, you first persist the event before replying to the client that you have performed the change—this scheme interoperates smoothly with the Reliable Delivery pattern presented in section 15.7.
The biggest change is that instead of defining a single receive behavior, you declare the live behavior as receiveCommand and add a receiveRecover behavior as well. This second behavior is not invoked for actor messages: it only receives the persisted events as they are read from the event log (also called a journal) right after the actor is created and before it processes its first message. The only thing you need to do here is apply the events to the shopping cart snapshot to get it up to date. The full source code is available in the book’s downloads, together with an example application that demonstrates the persistent nature of this actor.
17.3.3. The pattern, revisited
You have taken the events the domain object manager sent in its replies to clients and repurposed them as representations of the state changes the domain object goes through. In the case we discussed, every command corresponds to exactly one event; but sometimes, in addition to confirmation events being sent back to clients, internal state changes occur as well—these will have to be lifted into events and persisted like the others.
It is important to note that the events that describe state changes of domain objects are part of the business domain as well: they have business meaning outside the technical context of the program code. With this in mind, it may be appropriate to choose a smaller granularity for the events than would be the case by following the derivation from the Domain Object pattern followed here—this path is more useful as a learning guide and should not be taken to be a definition. Please refer to the event-sourcing literature for an in-depth treatment of how to design and evolve events.
17.3.4. Applicability
This pattern is applicable where the durability of an object’s state history is practical and potentially interesting (you will hear more about this last part in the following section). A shopping cart may see some fluctuation before checkout, payment, and delivery, but the total number of events within it should not exceed hundreds—these correspond to manual user actions, after all. The state of a token bucket filter within a network router, on the other hand, changes constantly, goes back and forth through the same states, and may, most important, see trillions of changes within relatively short periods of time; it is therefore not likely to be practically persistable, let alone by using event sourcing.
For domain objects that may accumulate state over a longer time period, and where the event reply during recovery may eventually take longer than is affordable, there is a workaround, but it should be used with care. From time to time, the domain object’s snapshot state may be persisted together with the event sequence number it is based on; then, recovery can start from this snapshot instead of having to go back to the beginning of time. The problem with this approach is that changes to the domain logic (bug fixes) can easily invalidate the snapshots, which fact must be recognized and considered. The underlying issue is that although the events have meaning in the business domain, the snapshot does not—it is just a projection of the implementation details of the domain object logic.
Event sourcing generally is not applicable in cases where it would be desirable to delete events from the log. Not only is the entire concept built on the notion of representing immutable facts, but this desire usually arises when the persisted state does not have meaning in the business domain—for example, when using a PersistentActor as a durable message queue. There are much more performant solutions to this problem that are also easier to use: see, for example, Kafka (http://kafka.apache.org) and other distributed queues.
17.4. The Event Stream pattern
Publish the events emitted by a component so that the rest of the system can derive knowledge from them.
The events that a component stores in its log represent the sum of all the knowledge it has ever possessed. This is a treasure trove for the rest of the system to delve into: although the shopping cart system is only interested in maintaining the current state of customer activity, other concerns are tangential to it, such as tracking the popularity of various products. This secondary concern does not need to be updated in a guaranteed fashion in real time; it does not matter if it lags behind the most current information by a few seconds (individual humans usually would not be able to notice even a delay of hours in this information). Therefore, it would be an unnecessary burden to have the shopping cart component provide this summary information, and it would also violate the Simple Component pattern by introducing a second responsibility.
The first dedicated event log that specializes in supporting use cases like this is Greg Young’s Event Store.[6] Akka offers the Persistence Query module[7] as a generic implementation framework for this pattern.
See https://geteventstore.com and Greg’s presentation at React 2014 in London: https://www.youtube.com/watch?v=DWhQggR13u8.
17.4.1. The problem setting
You have previously implemented a PersistentObjectManager actor that uses event sourcing to persist its state. The events are written by Akka Persistence into the configured event log (also called a journal). Now you want to use this information to feed another component, whose function will be to keep track of the popularity of different items put into shopping carts. You want to keep this information updated and make it available to the rest of the system via a query protocol.
The task: Your mission is to implement an actor that uses a persistence query to obtain and analyze the AddItem events of all shopping carts, keeping up-to-date status information available for other components to query. You will need to add tagging for the events as they are sent to the journal, to enable the query.
17.4.2. Applying the pattern
By default, the events persisted by Akka Persistence journals are only categorized in terms of their persistenceId for later playback during recovery. All other queries may need further preparation, because keeping additional information has an extra cost—for example, database table indexes or duplication into secondary logs. Therefore, you must add the categorization along other axes in the form of an event adapter, as shown next.
Listing 17.8. Tagging events while writing to the journal
class ShoppingCartTagging(system: ExtendedActorSystem)
extends WriteEventAdapter {
def manifest(event: Any): String = "" // no additional manifest needed
def toJournal(event: Any): Any =
event match {
case s: ShoppingCartMessage => Tagged(event, Set("shoppingCart"))
case other => other
}
}
The tags are simple strings, and every event can have zero or more of them. You use this facility to mark all ShoppingCartMessage types—this will be useful for further experiments that look into correlations between addition and removal of the same item relating to the same shopping cart, an exercise that will be left for you. With this preparation, you can write the popularity-tracking actor.
Listing 17.9. An actor listening to the event stream


First, you obtain a read-journal interface for the journal implementation you are using in this example—the LevelDb journal is simple to use for small trials that are purely local, but it does not support clustering or replication and is unsuitable for production use. You then construct a source of events using the eventsByTag query, selecting all previously tagged events starting at the journal’s beginning (marked by the zero argument). The resulting Akka Stream is then transformed to select only the ItemAdded events and group them in intervals spanning at most 1 second or 100,000 events, whichever occurs first. Then, you mark the grouped source you have constructed up to this point as having an asynchronous boundary around it—you want to inform Akka Streams that it should run these steps in an actor that is separate from what follows, because you do not want the analysis process to influence the time-based grouping. The last step is to create a histogram that assigns the addition frequency to each type of item. To avoid creating a lot of garbage objects in the process, you use an immutable map to hold mutable counters that are then updated in the foldLeft operation.
The resulting histograms are then sent to the actor wrapped in a TopProducts message at least once per second. The actor will store this information and allow others to retrieve it with a GetTopProducts inquiry. The book’s downloads include the full source, including a shopping cart simulator that creates enough activity to see this in action.
17.4.3. The pattern, revisited
You have added a common categorization for all shopping cart events to the persistence-journal configuration and used this from another actor that consumes the events to derive a secondary view from the data. This secondary view does not hold the same information; it removes the individual, fine-grained structure and introduces a time-based analysis into it—you have transformed one representation of information into a related but decoupled second representation of information.
In the example code above, the derived information is computed live, initially catching up from the beginning of the journal; but there are other approaches: you could make TopProductListener persistent, storing up to the offset at which the journal has already been analyzed and restarting at that point. You could also persist the computation results, aggregating the product-popularity history for yet another step of analysis by another component.
Another use case for this pattern is to use the events emitted by the authoritative source—the shopping cart’s business logic—to maintain another representation: for example, in a relational database, allowing extensive, flexible querying capabilities. This could also be described in other terms: the normal form of the data is kept in the place that accepts updates, whereas the information is asynchronously distributed to other places that hold the same data in denormalized form, optimized for retrieval and not updates. This explains why the Event Stream pattern is central to the idea of CQRS.
Event streams may also transport information across different components and thereby into foreign bounded contexts where a different business domain defines the ubiquitous language. In this case, the events need to be translated from one language to the other by a component at the boundary. This component will usually live within the bounded context that consumes the stream, in order to free the source of data from having to know all of its consumers.
17.4.4. Applicability
An important property of event streams is that they do not represent the current state of an object of the system: they only consist of immutable facts about the past that have already been committed to persistent storage. The components that emit these events may have progressed to newer states that will only be reflected later in the event stream. The delay between event emission and stream dissemination is a matter of journal-implementation quality, but the fact that there is a significant delay is inherent to this architecture and cannot be avoided.
This implies that all operations that must interact with the authoritative, current data must be done on the original domain objects and cannot be decoupled by the Event Stream pattern. For a more in-depth discussion, please refer back to chapter 8 on delimited consistency.
For all cases where time delay and consistency restrictions are not an issue, it is preferable to rely on this pattern instead of tightly coupling the source of changes with its consumers. The Event Stream pattern provides the reliable dissemination of information across the entire system, allowing all consumers to choose their desired reliability by maintaining read offsets and persisting their state where needed. The biggest benefit is that this places the source of truth firmly in a single place—the journal—and removes doubt as to the location from which different pieces of information may be derived.
17.5. Summary
With this chapter, we conclude the third and final part of this book. The patterns in the chapter provide guidance about how to structure the state management in Reactive systems and should be used in unison:
- The Domain Object pattern decouples the business domain representation from message-driven execution and allows domain experts to describe, specify, and test logic without having to care about distributed system concerns or asynchrony.
- The Sharding pattern allows the efficient storage of an arbitrary number of domain objects, given a cluster with sufficient resources.
- The Event-Sourcing pattern turns the destructive update of persistent state into a nondestructive accumulation of information by recognizing that the full history of an object’s state is represented by the change events it emits.
- The Event Stream pattern uses these persisted change events to implement reliable and scalable dissemination of information throughout the entire system without burdening the originating domain objects with this task. The emitted events can be distributed by the supporting infrastructure and consumed by any number of interested clients to derive new information from their combination or to maintain denormalized views onto the data that are optimized for queries.